
Abstract
This article surveys existing vocabularies, ontologies and policy languages that can be used to represent informational items referenced in GDPR rights and obligations, such as the ‘notification of a data breach’, the ‘controller’s identity’ or a ‘DPIA’. Rights and obligations in GDPR are analyzed in terms of information flows between different stakeholders, and a complete collection of 57 different informational items that are mentioned by GDPR is described. 13 privacy-related policy languages and 9 data protection vocabularies and ontologies are studied in relation to this list of informational items. ODRL and LegalRuleML emerge as the languages that can respond positively to a greater number of the defined comparison criteria if complemented with DPV and GDPRtEXT, since 39 out of the 57 informational items can be modelled. Online supplementary material is provided, including a simple search application and a taxonomy of the identified entities.
Introduction
Westin [96] shaped the way we define online privacy before the web existed at all. One of his two major postulates was that individuals should be able to determine to what extent information about them is communicated to others. The second of these postulates was that technological artifacts could be used to achieve this goal. His books in the late sixties and the seventies exerted significant influence on the privacy legislation that was enacted in the following years, and even today, the European General Data Protection Regulation (GDPR), which came into full effect on May 25th of 2018, owes much to his work. Any information system has data representational needs, and privacy and data protection related information systems will have to represent ideas such as ‘consent’ or ‘the right to erasure’. If these applications are to interoperate, then the need for standard formats is clear, and the adoption of semantic-web enabled technologies that facilitate privacy-related data exchange is advantageous such as in data portability.
Machine-readable policy languages have been on the scene for some decades. Policy languages allow us to represent the will of an individual or organization to grant access to a certain resource, and they govern the operation of actual systems over actual data. They seem perfectly aligned with Alan Westin’s vision and indeed several privacy-related policy languages have been defined and used in real scenarios. On the other hand, computers can also help in other privacy and data protection tasks different from enforcing access to personal data, and policy languages are not enough to cover every representational need. Thus, in the last few years, vocabularies and computer ontologies have appeared to formalize concepts and rules in the domain that can be used either to simply represent information as RDF, or to govern ontology-based information systems. Not all of them, however, had the GDPR specifically as their framework of reference.
This paper surveys existing policy languages, vocabularies and ontologies in the domain of privacy and data protection, and it analyses their adequacy to support GDPR-related applications. These GDPR-related applications may either support individuals to manage their personal information or to support data controllers, data processors and other stakeholders to better manage compliance with the GDPR. This joint analysis of needs (individual-oriented and company-oriented) is based on the claim that these tools may converge in a near future, and that having common vocabulary elements and common data models to refer to GDPR rights and obligations and to denote specific GDPR concepts would permit heterogeneous applications to speak in the same terms and interoperate. Taking into account this rationale, we focus on the above motivations to address the following research question:
Moreover, the main contributions of this paper are:
a study of GDPR in terms of flows of information in different deontic modalities, systematized in Fig. 1, and further specified in Table 1 where the informational elements necessary for the management of each GDPR right and obligation are specified;
a survey of 22 existing vocabularies, ontologies and policy languages and their analysis in relation to that informational model; and
an online portal1
with additional resources for the reviewed works, a REST API service to find references to specific concepts and also a lightweight ontology, the GDPR Information Flows (GDPRIF), specified to model the relationships triggered by the study on GDPR information flows.The paper is organized as follows: Section 2 describes in detail the types of information that have to be shared between data subjects, controllers and other interested parties, as well as the main rights and obligations found in the GDPR that may be represented. Section 3 identifies related work and Section 4 systematically reviews the existing privacy-related policy languages first, and then the most salient vocabularies and ontologies in the domain. Section 5 provides an analysis of the solutions in the light of GDPR, following a systematic comparison framework, and the description of the supplementary webpage which has been published with additional resources about the reviewed solutions, a REST API service to look for specific concepts and a vocabulary with the concepts identified in Section 2. Finally, the last section synthesizes our conclusions, explicitly identifying the recommendations and possible representational needs that have to be covered.
In the light of the established GDPR rights and obligations, a set of information flows, related to the information that needs to be exchanged between stakeholders, can be identified. These stakeholders can be classified as a (DS) data subject, a (DC) data controller, a (DP) data processor, a (Rp) recipient, a (SA) supervisory authority or a (DPO) data protection officer.
In this context, an information flow refers to the information that has to be transmitted from one stakeholder to another so that a right or obligation can be invoked and granted. For instance, if a data subject invokes its right to erasure, along with the request, there is the need to represent information related to the grounds on which the request is based, and the controller needs to transmit this information to the other controllers processing the same personal data.
Figure 1 shows a diagram of the information flows that represent the transfer of information foreseen by GDPR’s rights and obligations regarding data subjects, controllers and other stakeholders. This chart is derived from an analysis of Chapter’s III and IV (‘Rights of the data subject’2
and ‘Controller and processor’,3 respectively) of the GDPR. Each article in both chapters was manually studied to search for interactions between the aforementioned stakeholders and, when a flow of information was identified between more than one stakeholder, the respective interaction was recorded in the diagram.
GDPR’s rights and obligations as information flows. The bidirectional arrows represent a right or obligation in which a request for information and respective response is expected (the open arrowhead, ➜, represents the entity waiting for the response and the closed arrowhead, ➡, the entity being requested), while the unidirectional arrows represent only a request or notification and no reply is expected (with the closed arrowhead, ➡, representing the entity being requested or notified).
Therefore, in this section, the GDPR rights and obligations that were classified as an information flow between GDPR’s stakeholders are studied with the purpose of assessing which informational elements need to be represented in order to support this stream of information. A methodical study of these elements of information was manually performed for each identified information flow and systematised in Table 1. In addition, for each described item, a list of GDPR’s articles where they are mentioned is also presented for readers to be able to refer to the regulation. From this list, it was therefore possible to establish mappings between each right or obligation and the respective specified informational items, which are presented in Tables 2 and 3, related to the rights of the data subject and to the responsibilities of the controllers and processors, respectively.
In particular, we shall emphasize the need to support Articles 13 and 14 of the GDPR, which describe the so-called ‘right to be informed’. According to these articles, whether personal data is collected directly from the data subject or obtained through other data sources, data controllers need to inform data subjects about any processing of personal data so that their activities are legal, fair and transparent. These articles, and the others that make up Chapter III of the GDPR, are studied here in order to understand what information data subjects are entitled to receive in the exercise of their rights and, correspondingly, what information data controllers need to disclose to be compatible with the GDPR. Sections 2.1 and 2.2 briefly describe these rights, as well as the informational items that may need to be represented.
The rights and obligations of controllers and processors, described in GDPR’s Chapter IV, are also analyzed here for the same purpose of identifying which pieces of information need to be represented in order for these stakeholders to be in compliance with the GDPR. Section 2.3 details the informational elements and respective rights and obligations that may need to be modeled.
Moreover, this study of rights and informational items will serve as a basis for the analysis of privacy-related policy languages to understand which rights and obligations can already be fully or partially formalized and for the comparison of privacy and data protection vocabularies and ontologies to perceive which can be used and extended to represent the informational items described in Table 1.
Chapter III of the GDPR establishes nine fundamental rights of the data subject when it comes to the lawful processing of their personal data.
In particular, Articles 13 and 14 detail the ‘Information to be provided where personal data are collected from the data subject’ (RI1) and the ‘Information to be provided where personal data have not been obtained from the data subject’ (RI2), respectively. According to them, for the processing of personal data to be lawful, fair and transparent, a certain set of informational items must be provided, namely items I1 to I19 described in Table 1.
Informational items to be represented and respective identifiers (I*), which will be used to specify the informational elements necessary for the management of each right and obligation represented in Fig. 1. The GDPR articles that mention these items are also specified
Informational items to be represented and respective identifiers (I*), which will be used to specify the informational elements necessary for the management of each right and obligation represented in Fig. 1. The GDPR articles that mention these items are also specified
This information, and any other communications provided in the context of the provision of data subjects’ rights, should be given in a concise, transparent and clear language and in an easily accessible manner. This information may also be provided with standardized icons for a more visible and intelligible overview of the intended processing.
The data controller has the obligation to support the exercise of the data subject’s rights and needs to reply with information to any requests related to the exercising of such rights within a month upon receiving the request. This period can be extended by a further two months if the data subject’s request is too complex or in the case of a large number of requests. The information should be freely provided and by electronic means, unless the data subject states otherwise.
Apart from the ‘right to be informed’, already described in the previous section, the data subject is entitled to the following rights:
the ‘right of access’ to the personal data being processed: data subjects have the right to receive confirmation that their data is being processed and a copy of the data in a common electronic format, as well as information about the purposes for processing, categories of the concerned personal data, their source, if not directly collected from the data subject, the recipients, the storage period, the existence of the data subject’s rights as well as the right to lodge a complaint with a DPA, details of the existence of automated decision making and the security measures applied where personal data is transferred to a third party.
the ‘right to rectification’: the data subject has the right to obtain from the data controller the amendment of inaccurate personal data and, where the data is incomplete, the right to have personal data completed.
the ‘right to erasure’ or ‘right to be forgotten’: the data controller has the obligation to delete personal data when it is no longer needed for the purposes which it was collected; when the data subject withdraws consent and there is no other legal basis for the processing; when the data subject objects to the processing; when said processing is unlawful; when it has to be erased to comply with a legal obligation; or when the data was collected for the provision of information society services.4
In GDPR’s Article 4.25, ‘information society service’ refers to “a service as defined in point (b) of Article 1.1 of Directive (EU) 2015/1535 of the European Parliament and of the Council”, meaning any service normally provided for remuneration, at a distance, by electronic means and at the individual request of a recipient of services.
the ‘right to restriction of processing’ of personal data: the data subject has the right to request the ceasing of the processing when the accuracy of the data is being contested; when the processing is unlawful and the data subject does not wish to erase the data; when the purposes stated by the controller are no longer valid but the data subject needs it for any legal claims; or when the data subject objects to the processing.
the ‘right to be notified’ about the rectification, erasure or restriction of processing: the data controller has the obligation of notifying the data subject and the recipients to whom the data was disclosed, as well to disclose these recipients to the data subject.
the ‘right to data portability’: the data subject has the right to receive its data in a commonly used and machine-readable format and has the right to request that its data be transferred directly from one controller to another.
the ‘right to object’ to any processing, including profiling.
the ‘right to not be subjected to automated decision-making’, including profiling.
The informational items to be granted to the data subject in function of the established GDPR rights are represented in Table 2.
Informational items (I*) to be provided to the data subject, according to the rights (R*) defined under Chapter III of the GDPR
Data controllers must be ready to demonstrate that their processing activities are in accordance with the GDPR and that they have in place the appropriate security measures to ensure people’s right to privacy and data protection. These measures must take into account the nature, context and risks associated with each processing activity and should be embedded by design and by default in the data controllers’ services.
The following rights and obligations must be observed by the data controllers and processors so that they can comply with the regulation:
the ‘joint controllers’ responsibilities: in the case where there are two or more controllers determining the purposes and means of processing, they are joint controllers. They must determine the responsibilities of each controller in relation to the obligations generated by the data subject’s rights and this information should be communicated to the data subjects.
contract with ‘processors’: the controller can establish contracts with processors, that have in place the appropriate security measures, for the processing to be carried out on behalf of them. This processing must be governed by a contract between controller and processor, that establishes the subject-matter, duration, nature and purpose of processing, as well as the personal data types, categories of data subjects and the rights of obligations of both the data controller and the data processor. The processor can only hire a sub-processor with the authorization of the controllers.
‘records of processing activities’ of data controllers: each controller and its representative should keep a record of the processing activities under their responsibility, which must be available to the supervisory authorities when requested.
the ‘records of processing activities’ of data processors: each processor and its representative should keep a record of the processing activities carried out on behalf of a controller, which must be available to the supervisory authorities when requested.
the ‘notification of a data breach’ to the supervisory authority: the data controller has 72 hours to notify the competent supervisory authority that a personal data breach has occurred. The processor should inform the controller without delay as soon as it is aware of the breach.
the ‘communication of a data breach’ to the data subject: the data subjects have the right to be informed about any data breach that results in a high risk to their rights and freedoms. This communication should contain at least the nature of the breach and the measures that are being taken to mitigate it.
the ‘data protection impact assessment’: in the case where the data controllers are going to perform an extensive evaluation of personal data based on automated processing, processing activities over special categories of data or criminal data or a systematic monitoring on a large scale, the controller should draft an assessment of the impact of the processing activities, and respective risks to the protection of personal data, with the guidance of the data protection officer.
the ‘prior consultation’ right: the controller has the right to consult the supervisory authority, prior to the processing, when the DPIA illustrates that the processing activities will result in a high risk to the privacy of the data subjects if the proper measures to mitigate risks are not implemented.
The informational items that must be represented, in function of the rights and obligations of the data controllers and processors, are represented in Table 3.
Informational items (I*) to be modelled, according to the rights and obligations of the controllers and processors, defined under Chapter IV of the GDPR
Informational items (I*) to be modelled, according to the rights and obligations of the controllers and processors, defined under Chapter IV of the GDPR
Some articles review the existing privacy-related policy languages, however, for the most part, they were published before the GDPR was enacted.
Kumaraguru et al. [59] provided a literature review on available privacy policy languages with the goal of developing a framework with metrics for their analysis. This framework classified languages based on the situations in which they could be used, also considering whether the policy language was user-centered or company-centered.
In 2007, Duma et al. [33] offered a scenario-based comparison of six policy languages focused on user privacy. The adopted evaluation criteria targeted the languages abilities to classify the sensitiveness of the information, to deal with resource granularity, to address access control, to support the principle of minimal information disclosure and more. Furthermore, it provides example implementations based on specific scenarios created to evaluate each specific criterion.
Moreover, Kasem-Madani and Meier [52] produced a survey focused on security and privacy policy languages. The survey’s goal is to present an overview of the existing solutions as well as providing a categorization framework to facilitate the adoption of policy languages. The main categories of the framework to classify the languages are the scope, syntax, extensability, context, type (focused on issues such as security, privacy or accountability), intention of use (user-centred, enterprise-centred or both) and usability (language oriented to humans or machines).
Zhao et al. [99] produced a review focused on existing policy languages that can be used to express user’s privacy preferences. The identified languages were analysed against a set of three features: the purpose of the language, i.e., if it is user or company-focused, the existence of user-friendly interface tools, and interoperability, however existing legislation on the privacy domain was not considered.
More recently, in 2018, Peixoto and Silva [84] present a framework for analyzing goal-oriented modelling languages in the context of representing requirements extracted from the GDPR, the ISO 29100 standard [49], the OECD Guidelines on the Protection of Privacy and Transborder Flows of Personal Data [73], and other privacy-related sources. The authors focused on three particular modelling languages, i* 2.0 [32], NFR-Framework [27] and Secure-Tropos [68], that were analysed against the fourteen (extracted) privacy requirements, e.g., capability to model different types of actors, capability to model different types of personal information, or capability to model consent.
The most recent review work on privacy languages, by Leicht and Heisel [61], intends to provide a survey on languages in the context of privacy policies that can help users to easily understand them and that are compatible with data protection legislations such as the GDPR. Therefore, this framework identifies the criteria to compare the languages through the GDPR legislation. The identified criteria are system obligations, time constraints and formalization of the language.
Other review works related to the privacy and data protection domain have been published, namely overviews of access control frameworks, rights expression languages or other semantic approaches related to the representation of consent.
Kirrane et al. [56] provide an overview of access control models, such as the Mandatory Access Control (MAC), the Discretionary Access Control (DAC) and the Role Based Access Control (RBAC) models, and other RDF-based standards and policy languages frameworks. A collection of access control requirements is proposed and are used to categorize the described frameworks accordingly.
Pellegrini et al. [85] produced a preliminary survey on Rights Expression Languages (RELs). RELs are used to define machine-readable permissions, obligations and prohibitions, and are an essential component of any Digital Rights Management (DRM) system. This work also proposed a framework to classify RELs according to their application area in the DRM domain, namely for the purpose of specifying access and trust policies, license policies and contract policies.
Pandit [78] PhD thesis describes and analyses state-of-the-art semantic-based technologies used to support and assess GDPR compliance, including privacy policy solutions, consent-related approaches and other solutions developed in the context of data privacy and data protection projects. The solutions are compared according to a set of categories, such as the representation of GDPR concepts, consent-related information or personal data handling activities, evaluation of GDPR compliance or resource accessibility.
Privacy and data protection languages and ontologies: A survey
In this Section, the results of the survey on privacy-related policy languages and data protection ontologies and vocabularies are described in detail. Furthermore, Section 4.1 details the methodology followed to perform the survey and Sections 4.2 and 4.3 provide a systematic description of each identified solution.
Methodology
There has been a large number of works being published on the methodologies for conducting a literature review [58,92,95]. Specifically, in 2019, Snyder [92] published an overview of different categories of reviews and provided guidelines on how to conduct and evaluate them. Three types of review methodologies are presented, namely, systematic, semi-systematic and integrative approaches, which should be chosen according with the purpose, research questions or the types of work being reviewed. In the context of this review, an integrative approach [97] was used as it is the most suitable for the purpose of discussing and synthesizing different privacy-related policy languages and data protection vocabularies in a qualitative manner and also quantitatively in the case of the discussed vocabularies. Following this approach, the search for academic publications to be included in this review, and other published documentation as this is a distinctive feature of an integrative review, was performed according to the snowballing procedure [98]. We started by researching existing survey articles connected to privacy-related policy languages and data protection vocabularies, and then performed additional research based on citation analysis, using both backward and forward snowballing methodologies, that were first introduced by Webster and Watson [95]. First, a backward snowballing approach, i.e., review the reference list of the articles to identify new papers that should be considered, was performed and then a forward approach, i.e., target new articles that cite the papers already being considered.
The collected results were reviewed and, if relevant for this analysis, included in this article. The following criteria was used to analyse and evaluate the found documentation:
Availability of a publication to analyse.
Only publications in English were contemplated.
Publications only focused on access control or rights expression were left out of the review process.
Existence of online material was not considered a prerequisite, however it allows for a better understanding of the structure and information provided by the reviewed solution.
In the cases where the found data protection vocabularies and ontologies include access to the specification, solutions can be quantified in terms of the core classes that they implement.
Both Pre- and Post-GDPR works are considered.
Moreover, in the cases where the identified solutions were found to be developed within the framework of a project, the main goals and research directions of said project are described through information gathered on the project’s website.
Privacy-related policy languages
In this subsection, we aim to identify privacy-related policy languages, describing the structure and information provided by each language as well as identify its compatibility with the GDPR to describe not only rights, but also obligations. For each solution, there is an introductory summary of the language complemented by a description of its main contributions, followed by a description of the core elements of the language. When available, specific examples of use cases using the language are mentioned, as well as implementations derived from it, including details on any available reasoners that use the work. The dependencies of the solutions in previously existing works are also documented when described in the literature. In addition, if developed in the framework of a project, its main goals are briefly described. In Table 4, there is a brief description of the policy languages specified in the subsequent subsections, 4.2.1 to 4.2.13, including information about the creators of the resources, version, date of publication and date of the last known update. These solutions are analysed in chronological order in relation to the date of publication and then in relation to the date of the last update. In Fig. 2, a dependency graph, that captures the relations between languages and its dependencies and follow-up works, is presented. The described solutions were evaluated and compared according with the following criteria:
Brief description of the resources described in Section 4.2
Brief description of the resources described in Section 4.2
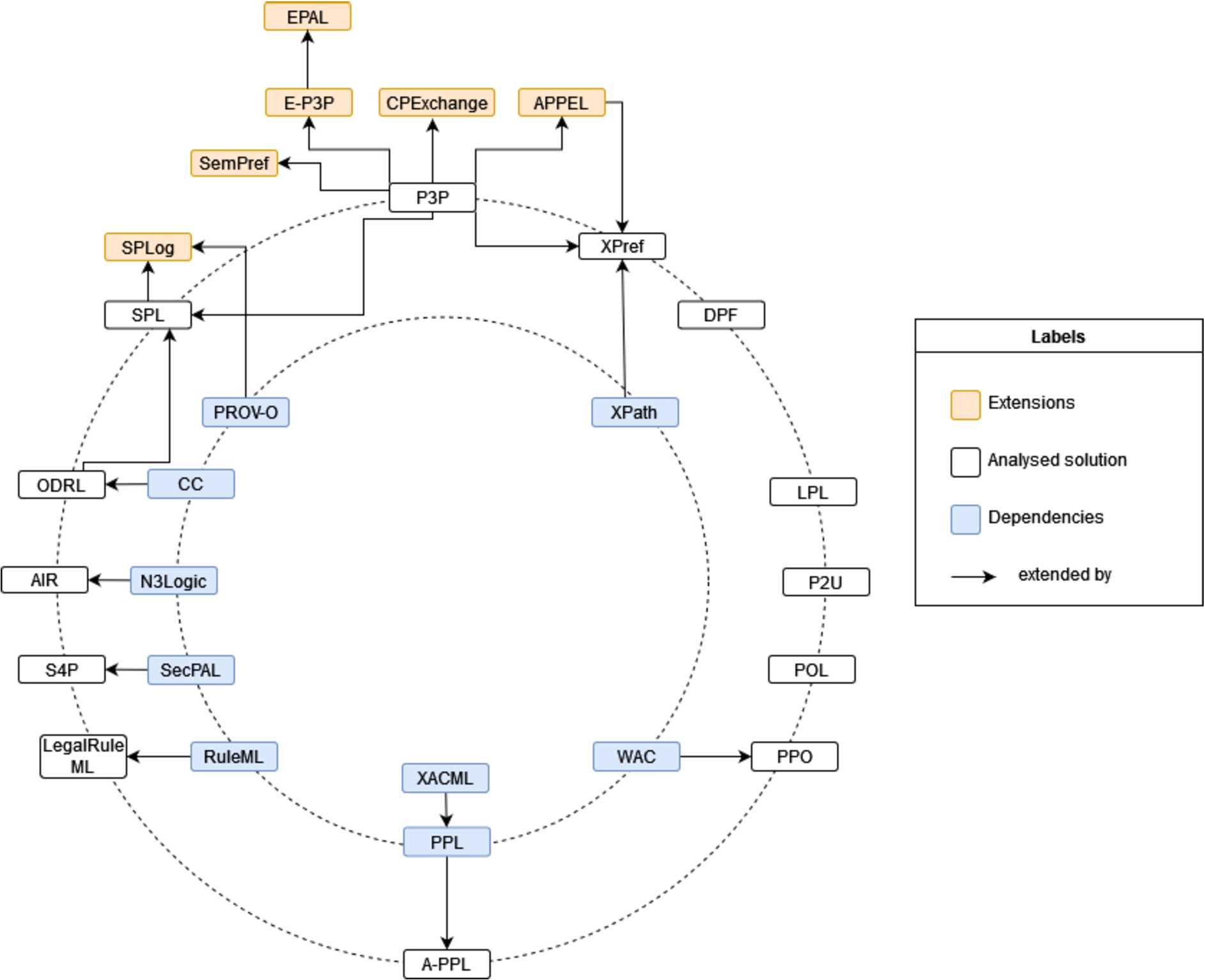
Privacy-related policy languages dependency chart.
Does it model deontic concepts (e.g., permissions, obligations)?
Can it be used to model GDPR concepts, such as the informational items in Table 1?
Does it provide any taxonomies of terms to populate the identified information flows?
Does it implement any mechanisms to assist with compliance?
Does it continue to be maintained? Are new improvements being developed?
Are the resources available in an open and accessible platform?
The results and discussion of this comparison are presented in Section 5.1 and systematised on Table 6.
P3P, implemented by Cranor et al. [30], emerged as a specification for websites to disclose privacy protocols in a machine-readable format so that web user agents could easily interpret them and notify the users about the decisions based on these practices. However, these mechanisms, that allow the user to be informed about the websites’ privacy policies in relation to its respective data collection, do not mean that the sites are actually implementing these policies since P3P does not provide a way to enforce them. Thus, the P3P vocabulary was not built to comply with a specific regulation but rather to specify the practices of each website.
The main contributions of the P3P specification are a P3P-based data schema for the data that the website intends to collect, a standard group of purposes, data categories and recipients and a XML standard to define privacy policies. The P3P policies are made up of general assertions and specific ones, called statements, that are related only to certain types of data. General assertions are constituted by the legal
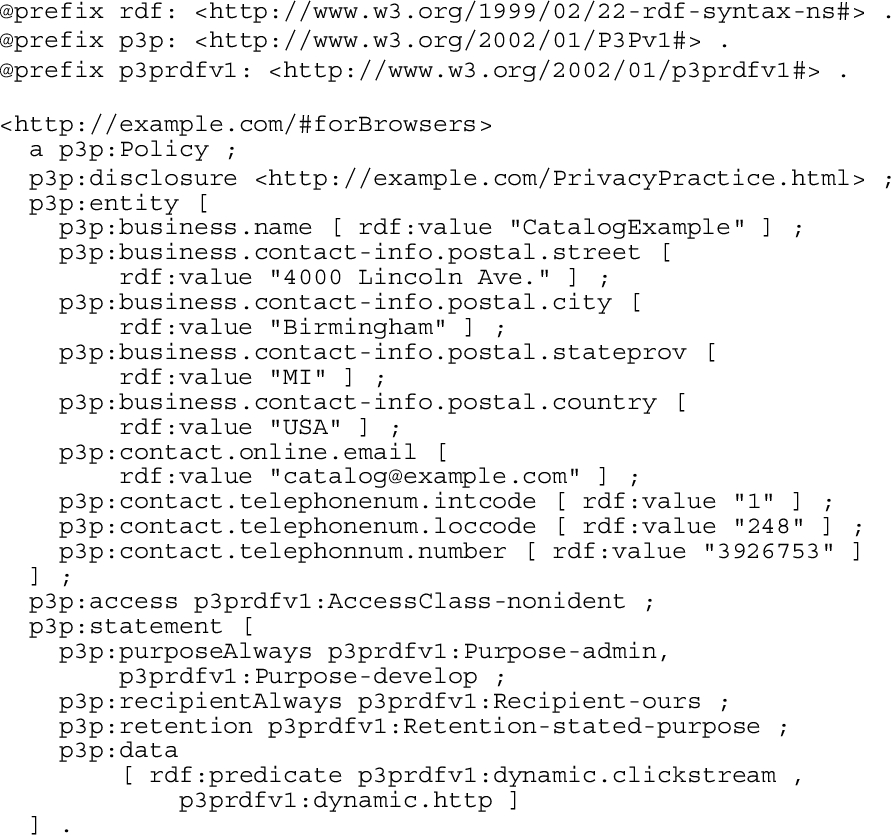
P3P policy adapted from Example 3.1 of the P3P specification [30], which specifies the privacy policy of CatalogExample for Browsers.
As P3P was designed to express web services policies, A P3P Preferences Exchange Language (APPEL) by Cranor et al. [29] was developed as an extension of P3P so that users can express their preferences. Therefore both languages should be used in order to match the user’s privacy preferences with the services’ privacy policies. In addition, in 2000, Bohrer and Holland [18] developed the Customer Profile Exchange (CPExchange) language, an XML specification for the transfer of customer data among enterprise services, which implements P3P privacy policies applicable to the data that is being exchanged. Similarly, IBM Research’s5
Enterprise Privacy Authorization Language (EPAL) [3], and its predecessor Platform for Enterprise Privacy Practices (E-P3P) [4], were also built using P3P statements to match enterprises’ privacy policies with the users’ preferences. In 2006, Li et al. [62] proposed a declarative data-centric semantics and a concise and clear syntax for P3P policies to represent the association of the different P3P elements. The main objective of this language is to declare policies that can be interpreted and represented in the same manner by different user agents. Building upon this semantics, the authors proposed a preference language, SemPref, that takes into account the meaning of the privacy policy instead of its syntactical representation.The P3P 1.0 Specification became a World Wide Web Consortium (W3C) recommendation on April 16, 2002. However, it has had a limited implementation, since its use needs to be adopted by both Web services and users and, in addition, no protocol has been implemented for these P3P policies to reflect the actual privacy practices of the sites. Its status has turned to W3C obsolete recommendation on August 30, 2018 and thereby future implementations are not recommended.
Although this specification became a W3C recommendation, its lack of adoption made it obsolete in 2018, as previously mentioned. However, the influence of P3P cannot be underestimated, as its development and implementation was the first major effort made in the area of machine-readable privacy languages. The main lessons brought by this language are therefore related to the need of having a formal semantics, to describe both the data subject and controller policies that reflect their data preferences and practices, respectively, and the need to have tools that actually enforce the policies described by the languages.
The ODRL Vocabulary & Expression 2.2 [48] is a W3C recommendation since February 2018, published by the Permissions & Obligations Expression (POE) Working Group (WG), being that its first version was released in 2001. The aim of this vocabulary is to define a language that can translate natural language policies to machine-readable formats, providing information about permissions, prohibitions and duties related to an asset. This vocabulary is based on the merge of the previous work performed by the ODRL Community Group (CG), the ODRL V2.1 Common Vocabulary, the ODRL V2.1 XML Encoding, the ODRL V2.1 Ontology and the ODRL V2.1 JSON Encoding. ODRL is currently supported and maintained by the ODRL CG.
Two vocabularies are used to describe ODRL: the ODRL Core Vocabulary and the ODRL Common Vocabulary. ODRL’s Core Vocabulary main class is the

ODRL privacy policy between Company A and Beatriz, regarding the Asset http://example.com/beatriz:contacts, which allows the assigner to use it under the pre-condition they obtain consent from Beatriz. If the assigner does not fulfil the duty, then the consequence will be that they will have to delete the asset.
The representational power of ODRL has a few shortcomings, as described by Kebede et al. [53], specially when it comes to the representation of delegation, the different semantics to represent duties or the handling of conflicts. However, there are works [39,40] on the way to formalise and harmonise the semantics of ODRL policies and constraints.
ODRL has already been used in several contexts, for instance by the working groups on Open Mobile Alliance SpecWorks7
and by the International Press Telecommunications Council (IPTC) Rights Expressions WG for the RightsML Standard, a rights expression language for the media industry.8Agrawal et al. [1] established XPref as an alternative to APPEL, which only allows for the definition of P3P policies that are unacceptable for the user. XPref resorts to XPath (XML Path Language) 1.0 and 2.0 expressions to replace APPEL rules, making the preferences formulation more precise and less error prone. XPath 1.0, by Clark and DeRose [28], and XPath 2.0, by Berglund et al. [14], are W3C Recommendations since November 16th, 1999, and December 14th, 2010, respectively, although no further maintenance will be performed to these specifications since later versions exist and have achieved the Recommendation statute. XPath’s main goal is to provide a way to navigate through the hierarchical elements present in a XML document. To accomplish this task, XPath treats a XML document as a tree of nodes and a XPath expression, when applied to the document, establishes the ordered sequence of the nodes to produce a compact path notation. The path is then comprised of expressions that return nodes, such as root, element, text, attribute, name-space, processing instruction or comment nodes.
XPref was designed so that its rules cannot only identify combinations of P3P elements which make a policy unacceptable, according to the user’s preferences, but also to verify that the presented elements are specified as acceptable. XPref manages these goals maintaining the APPEL syntax and semantics and its top classes,
Accountability in RDF (AIR)
Khandelwal et al. [54] implemented AIR, a declarative language to make assertions of facts and addition of rules, based on N3Logic [15], that supports rule nesting, rule reuse, and automated explanations of rule-based actions performed by the AIR reasoner. These explanations are customizable and, since they can be a source of sensitive information such as Personally Identifiable Information (PII), can be used to provide privacy, for instance, to hide actions performed under certain rules.
N3Logic is an extension of the RDF data model that aims at expressing logic rules in the web, so that the same language is used for data and logic.
AIR builds on N3Logic’s built-in functions, nested graphs and contextualized reasoning, allowing the AIR rules to adopt the usage of graphs as literal values, universally or existentially quantified variables in graphs and built-in functions or operators expressed as RDF properties.
Each rule has a unique Internationalized Resource Identifier (IRI), an HTTP Uniform Resource Identifier (URI), so that it is part of the linked data cloud and can be reused. These rules are defined using the following structure:
S4P
S4P (SecPAL for Privacy), developed by Becker et al. [10,11], is a language framework to express user’s privacy preferences and web services data handling policies. This language was developed by Microsoft Research9
and it is an extension of the company’s previous work, SecPAL, to define the handling of PII.SecPAL [9] is an extensible and decentralized authorization language, developed to express policies and better disclose expressiveness features such as delegation, domain-specific constraints, and negation. An authorization policy is composed of a group of assertions that have an issuer, that vouches for the assertion, the collection of conditional facts and constraints related to times, dates or addresses. Then, when requesting access to the service, this request is transformed into a series of queries, which are checked against the clauses defined to represent the system’s policy, so that the decision is made. S4P extends SecPAL to treat granted rights and required obligations as assertions and queries and, based on these, a satisfaction checking algorithm is defined for the disclosure of PII between users and data collecting services. Therefore, services express data-handling policies as SecPAL queries, defining what is going to be their behaviour in relation to the users’ PII, and the users express their preferences as SecPAL assertions, making precise what the services are permitted to do and what their obligations are towards the users’ PII. The satisfaction algorithm then checks if the services data collecting activities match the behaviours permitted by the users and if the obligations defined on the users’ preferences are respected by the services’ policies. If the outcome of this algorithm is positive, meaning the service’s policy satisfies the preferences of the user, the service can proceed with its data collecting activities. S4P also defines a data disclosure protocol to ensure that the users’ preferences are regarded when their data is provided to third parties. This protocol only allows the disclosure of the user’s PII if the service’s policies satisfy the preferences of the user while allowing the disclosure and if the policies of the third parties are aligned with the preferences of the user.
In addition to having an XML schema for implementations, S4P has a human-readable and unambiguous syntax that allows it to be used in other applications. Listing 3 presents S4P syntax through an example where the user, Alice, specifies her privacy preferences regarding the collection of her email address. Alice allows eBooking services to use her email address for sending confirmations and newsletters, and for statistical purposes. Alice also allows the booking services to forward her email address to trusted partners, which they can define for themselves, and she is only considering using registered services which will delete her email address within a month.

S4P example adapted from [10], which specifies the privacy preferences of Alice regarding the collection of her email address by eBooking services.
POL was developed by Berthold [17] in order to define privacy contracts between data controllers and data subjects, based on the concepts of financial option contracts and respective data disclosure agreements. Its framework applies the data minimization principle by automatically transforming privacy contracts into a canonical form. This canonical form allows the differences among contract compositions to be normalized and so contracts have a similar semantic structure.
In POL, each privacy contract is focused on defining the rights and obligations regarding data disclosure. As this language emerged in the financial context, contract formulations are mainly based on obligations, unless there is no trivial formulation of them. To implement these formulations, POL resorts to several modules that can also be extended. The main components defined by the language are the

POL contract examples adapted from [16].
This language was developed on the PETWeb II project, with the main goal of addressing societal questions in the domain of electronic identifiers. The online documentation provides application scenarios for the usage of POL.
As privacy is one of the challenges of the open data era, it is of the utmost importance to define who has access to what, specially in the context of the web. In this light, the PPO [90] proposes to represent users’ privacy preferences for the restriction or permission of access to specific RDF data within a RDF document. This ontology extends the Web Access Control (WAC) vocabulary [87], a taxonomy for detailing access control privileges that uses Access Control Lists (ACL) to determine which data users have access to. Its fundamental concepts are the
PPO’s restriction abilities apply to particular statements, to groups of statements (such as RDF graphs) and to resources, that can be particular subjects or objects within statements. The type of restriction must also be defined, as the user can either have read, write or both privileges to the data. Through the defined hasCondition property, certain conditions can be set to define privacy preferences in relation to specific resources, instances of particular classes or properties or even to specific values of properties. The access space should also be defined so that the requirements are met by the users to access certain resources. These requirements can be verified through a SPARQL ASK query that contains all attributes and properties that must be met by the users.
Particularly, the same authors focused in developing a specific tool for the semantic web domain, a privacy preference manager [89] based on PPO with the target of providing users with a way to specify their particular privacy choices and regulate the access to their data depending on profile characteristics such as relationships, interests or other common features. This ontology can be used to cover any social data that is modeled on RDF format or through RDF wrappers that can be applied to any major website through their API.
LegalRuleML
LegalRuleML is a rule interchange language applied to the legal domain, defined by the OASIS LegalRuleML Technical Committee, which achieved the OASIS Standard status in August 2021 [76]. It is a XML-schema specification that reuses and extends RuleML concepts and syntax – RuleML is an XML language for rule representation [19] – with formal features to represent and reason over legal norms, guidelines and policies. LegalRuleML’s main features include the use of multiple semantic annotations to represent different legal interpretations, the modeling of deontic operators, the temporal management of rules, the authorial tracking of rules and a mapping to RDF triples.
Thus, the core elements of a LegalRuleML document are the
Particularly, in 2018, Palmirani and Governatori proposed a framework which uses LegalRuleML, Akoma Ntoso and the PrOnto ontology (described in Section 4.3.5) to model GDPR rules and check for compliance [75]. Listing 5 presents an extract of LegalRuleML’s formalisation of GDPR,10
The formalisation of GDPR’s provisions in LegalRuleML is at https://raw.githubusercontent.com/dapreco/daprecokb/master/gdpr/rioKB_GDPR.xml.

Extract of LegalRuleML formalisation of GDPR’s Article 19.
The A-PPL language, implemented by Azraoui et al. [5], has its origin on the A4Cloud11
project, with the objective of applying accountability requirements to the representation of privacy policies. To accomplish this goal, the A-PPL expands PrimeLife Policy Language (PPL) by taking into account guidelines on notification, data location and retention, and auditability. PPL by Ardagna et al. [2] is an extensible privacy policy language designed within the context of the PrimeLife12 project, based on the eXtensible Access Control Markup Language (XACML) [83], an OASIS13Non profit organization focused on open standards for cloud, security and other areas, https://www.oasis-open.org/.
A-PPL introduced a role attribute identifier and added the data protection authority role to the ones already modeled by PPL, the data subject, data controller and data processor. Also, two new triggers to allow or prohibit access to personal data were included. Duration and region attributes related with a particular data processing purpose are used to enforce data retention and location rules. A-PPL further extends the PPL notification system to define the recipient and the type of notification to be sent in relation to a particular action. For auditing purposes, A-PPL added a trigger to monitor the data controller and collect evidence of data-related events which are logged with parameters such as the purpose of the action, the time-stamp or the executed action on the data. Listing 6 presents an example of an A-PPL obligation to notify a data subject in case of a breach. A-PPL’s

A-PPL example extracted from [5].
P2U, by Iyilade and Vassileva [51], has taken inspiration from P3P to build a policy language for the sharing of user information across different services and data consumers, resting on the principle of purpose of use. Its main focus is to provide a language for the secondary sharing and usage of data, making sure that the user’s privacy is maintained. It is designed to combine information about the data sharing purpose, its retention time and, in the case the user wants to sell it, the selling price and simultaneously allows the data consumers to negotiate prices and retention periods.
This policy framework involves the interaction of the users (the owners of the data), the data consumers (services that need the data), the data providers (services that collect and share the data) and the data brokers (services that monitor the consumers’ and providers’ activities and execute the negotiations, among other tasks). The main elements of P2U are the

P2U example extracted from [51].
An application scenario where a user allows the data sharing between several mobile applications is further specified in an additional publication by the same authors [50]. However this implementation does not enforce compliance of the data consumers with the policies defined by the users and does not specify any special treatment for cases dealing with sensitive data.
The EU H2020 SPECIAL (Scalable Policy-awarE linked data arChitecture For prIvacy, trAnsparency and compLiance) project aimed to develop technology that supports today’s on-going struggle between privacy and Big Data innovation, providing tools, for data subjects, controllers and processors, that facilitate the management and transparent usage of such data. Two vocabularies were produced as outcomes of this project: the SPECIAL Usage Policy Language (SPL) and the SPECIAL Policy Log Vocabulary (SPLog) [55].
A usage policy represents a set of lawful activities that can be performed in accordance with the data subject’s consent. To specify these in formal terms in compliance with the GDPR, the SPL establishes five core elements: the

SPL general usage policy extracted from [20].
SPLog was designed to provide a record of the processing events related to the consent actions given by the data owners. This vocabulary builds upon
The SPECIAL framework was implemented in various use-cases in distinct sectors: to build personalized touristic recommendations in collaboration with Proximus;20
for traffic alert notifications with Deutsche Telekom;21 with Thomson Reuters Limited22 to support anti-money laundering requirements.DPF [65,66] is being developed by an established team under the Defense Advanced Research Projects Agency (DARPA) Brandeis programme23
with the main goal of providing a privacy policy framework based on ontology engineering and a formal shareability theory. DPF’s policy engine builds on the ontology to define policy objects which are used in the development of User Interfaces (UIs). These UIs allow non-technical users to create, validate and manage privacy policies without the need to burden them with technical formalisms of a policy language. DPF’s engine can also be integrated into systems supporting the management of data requests and other Privacy Enhancing Technologies (PETs).Therefore, DPF uses a defined ontology as a common data model to specify a particular domain in order to support the definition of permissive and restrictive privacy policies. Each policy rule corresponds to an allow or disallow statement that should have an identifier and a description, a Policy Authority (PA), the data requesters to whom the policy applies, and also the affected data and effectiveness time imposed by the policy. Optionally, in the case of a permissive statement, there is the possibility to define a set of constraints to establish the conditions under which the data can be shared. The PA evaluates whether a certain data request complies with the defined policies. Hence, each data request must include, in addition to the data being requested, the PA that will be consulted to grant or refuse access, and the time of the request. Then the request follows the policy engine pipeline and if there is a matching rule the engine returns the decision, the identifier and description of the analogous rule and, in the case the request is authorized, the valid conditions in which it is allowed. Since a single request can trigger multiple policy rules, the engine must be equipped to deal with conflicting decisions. To achieve this, DPF implements baselines policies and then exceptions are created to define policy rules with higher priority in relation to the data that is being shared. With this mechanism in place, this privacy framework can override decisions based on detailed constraints.
The ontologies are defined in OWL and can be translated to Flora,24
an object-oriented reasoning system which can be used to reason with policies. To illustrate this framework, the authors provide a pandemic use-case where nation and community PAs implement data sharing policies about their residents and respective health status to monitor the disease’s outbreak. Listing 9 presents an example DPF policy rule based on this use-case, where any national policy authority,
DPF constrained policy rule extracted from [66].
LPL [43], implemented by Gerl et al., is a human and machine-readable privacy language which aims to promote the expression and enforcement of GDPR’s legal requirements related to data subject’s consent, personal data provenance and retention and also to implement privacy-preserving processing activities based on the application of state-of-the-art anonymization techniques. Further work by Gerl and Pohl [45] focused on improving LPL to be able to fully represent the requirements derived from Articles 12 to 14 of the GDPR, the so-called data subject’s ‘Right to be informed’.
LPL’s policy structure is

LPL policy adapted from [43].
Gerl and Meier [44] validate this language against an actual privacy policy use-case scenario in the complex healthcare domain to demonstrate its capabilities and limitations in relation to GDPR compliance. In addition, further work extends LPL with machine-readable privacy icons [42] to assess its impact on the speed and accuracy of understanding privacy policies and introduces a LPL Personal Privacy Policy User Interface [46]. This UI has the main goal of representing information related to the contents of privacy policies in order to support data subjects to give free and informed consent, which includes a policy header with a link to the human-readable policy and an overview of the purposes for processing using the aforementioned privacy icons, and a purpose section with an overview of all the purposes mentioned in the privacy policy and details regarding the identity of the controllers, data recipients, retention period and anonymisation methods.
In this subsection, for each solution, we describe the data protection vocabularies and ontologies, the core classes they implement and, when available, information about use cases where their resources are applied. In addition, the dependencies of the solutions in previously existing works are also documented, when described in the literature, and, if developed in the context of a specific project, its main objectives are briefly specified. Pre-GDPR ontologies are mentioned since they can be useful to identify missing concepts and relations between terms.
In Table 5, there is a brief description of the ontologies specified in the subsequent subsections, 4.3.1 to 4.3.8 and 4.4, including information about the creators of the resources, version, date of publication and date of the last known update. These solutions are analysed in chronological order in relation to the date of publication and the results of comparing the solutions in light of their ability to represent the identified informational items are discussed in Section 5.1 and systematised on Tables 7 and 8. In Fig. 3, a dependency graph, that captures the relations between the reviewed vocabularies and its dependencies, is presented.
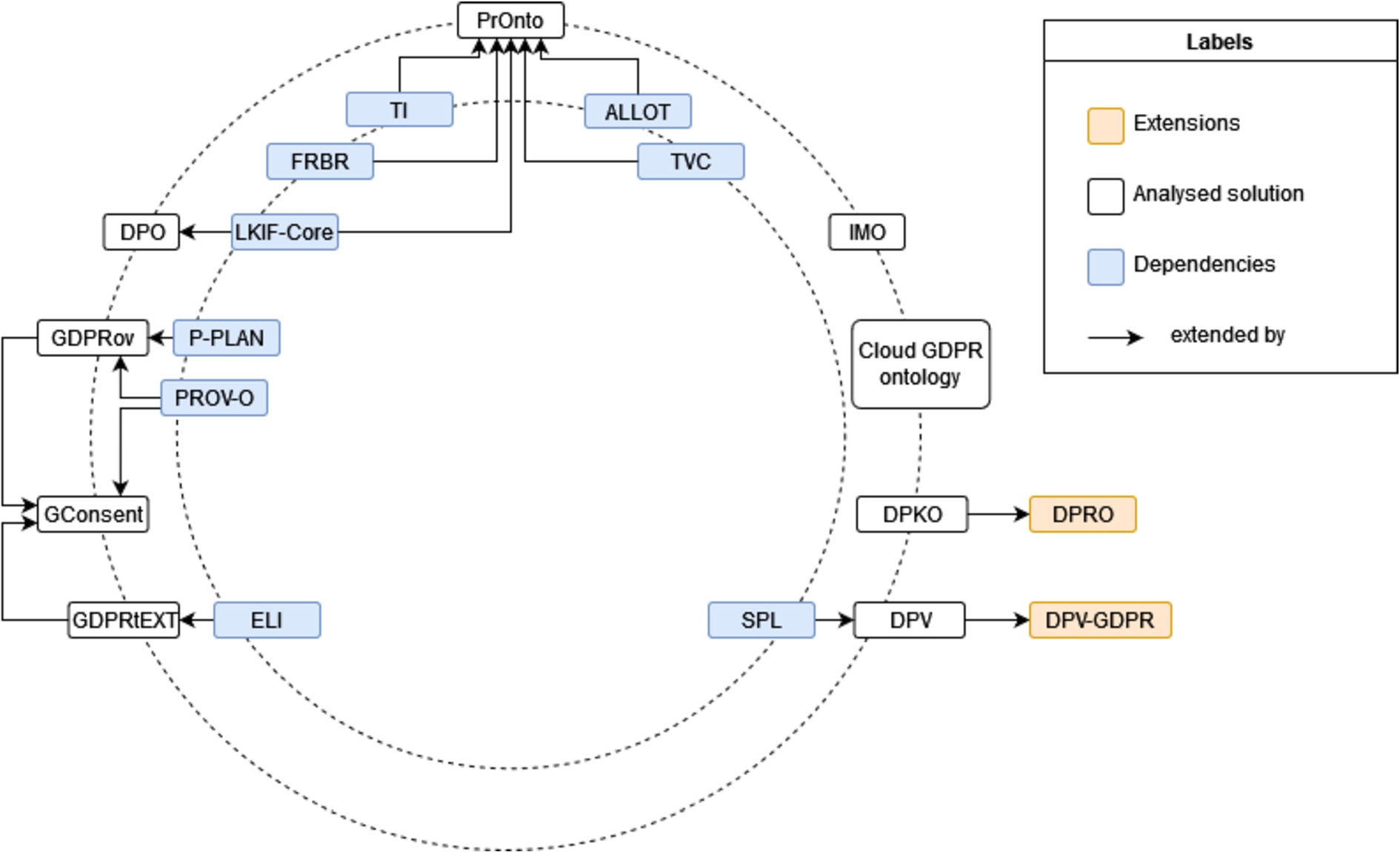
Data protection vocabularies and ontologies dependency chart.
Developed by S21SEC25
and IDT-UAB,26 the main focus of the NEURONA project [26] is the correctness of files containing personal data information and the measures of protection applied to them. Its legal basis was the Spanish protection of personal data regulation that was in effect prior to the GDPR enforcement in all Europe.The core classes implemented are the
These concepts constitute the core ontology of the project, the Data Protection Knowledge Ontology, from which the Data Protection Reasoning Ontology derives with the goal of classifying files based on its compliance with the legislation. Therefore, the NEURONA ontologies could prove useful in the context of companies that deal with great amounts of data stored in files, however, they are not publicly available for usage.
Bartolini and Muthuri [7] and Bartolini et al. [8] developed an ontology to deal with the new personal data rights and obligations stated by the GDPR, prior to its implementation in May 2018, using an early version of the regulation. The ontology was built focusing on the obligations of the data controller and corresponding rights of the data subject. Therefore the foundations of the ontology are the data protection principles defined in the GDPR, such as the purpose limitation, data quality or data minimization principles.
The ontology was created following the established METHONTOLOGY guide, by Fernández et al. [38], and it is based on the concepts collected from the GDPR, Data Protection Directive (DPD) and the Handbook on European data protection law [35], reusing concepts defined on the Legal Knowledge Interchange Format (LKIF) Core [47] and Simple Knowledge Organization System (SKOS) [67] ontologies. The core classes are the
The ontology has been used to extend the Business Process Model and Notation (BPMN), a language to model business processes [71], with the objective of applying data protection concepts that a data controller must follow so that its activity is GDPR compliant.
GDPR Provenance Ontology (GDPRov)
Based on the
For queries to be GDPR compliant, provenance information on consent, third party sharing, data collection, usage and storage, anonymisation of personal data and additional rights must be available. Under the GDPR, consent must be given in an explicit and unambiguous way, so that the user knows the purpose to which its data is being processed and which entities are involved in the data life cycle workflow. GDPRov implements this through the ConsentAgreementTemplate class, a common template regarding consent permissions presented to the users that models how the consent is obtained. Therefore, to ensure compliance, a record must be maintained on how the consent was obtained, which processing activities were approved and in the cases where the state of the consent changes, for instance in the case of consent withdrawal, the previous consents should be recorded. Also, data collected for a specific purpose must not be used in other contexts unless the user explicitly consents to it and should only be stored as long as it is necessary. Furthermore, references to third parties with which the data is shared must be detailed to the users, along with specifications on the nature of the data that is being shared, its purpose and information about the entity and its role in the workflow. To do so, provenance meta-data on the origin, use, storage and sharing of the data must be recorded. In the cases where the data was transformed or archived, a version control system must be in place so that the provenance of the data can be tracked. As GDPR authorizes the processing of personal data without consent in the cases where the data cannot be de-anonymised, GDPRov also provides the degree of anonymisation, based on Schwartz and Solove [91]’s work, a property that can have four states: completely anonymous, pseudo-anonymous that cannot be de-anonymised by the organization with which the data was shared, pseudo-anonymous but can be de-anonymised by the organization, and not anonymous. Provenance data on the execution of rights and obligations from users and data handlers is also kept, so that the records can be checked as proof of compliance. Therefore, for each right or obligation, a plan is defined to reflect the steps involving data or consent that need to be executed when the user wants to exercise a particular right.
Cloud GDPR ontology
Elluri and Joshi [36] developed a GDPR compliant ontology focusing on cloud services to express the obligations of both the cloud data consumers and the cloud data providers, also taking into account the respective Cloud Security Alliance (CSA) controls defined on the Code of Conduct for GDPR Compliance [25].
The
This work was extended by Elluri et al. [37] to automate the implementation of both the GDPR and the Payment Card Industry Data Security Standard (PCI DSS) guidelines [74] to compliance. The PCI DSS legislation deals with financial data, such as the credit card number or card-holder’s name. Therefore, building and maintaining a secure network, protecting card-holder’s data and implementing access control measures are a few of the main requirements of the PCI DSS. As it covers a narrower scope in comparison with the GDPR, a data breach in PCI DSS automatically results in one in GDPR. Thus, the cloud-related PCI DSS requirements were used to enrich this compliance ontology and its validation was done using privacy policies from five major companies that deal with card-holder’s data and PII. The ontology was also extended to include the rights of consumers, providers and end users.
Privacy ontology for legal reasoning – PrOnto
Palmirani et al. [77] presented in 2018 the first draft of PrOnto, a privacy ontology with the purpose to model the relationships between agents, processing activities, data categories and deontic specifications present on the GDPR. With the goal to support legal reasoning and compliance with the GDPR and other future regulations, PrOnto takes advantage of various other ontologies previously developed. The
The
XML vocabulary with the primary objective of providing information about the top level classes (person, event, locations,…) in legal or legislative documents.
PrOnto was built upon five core modules:
This ontology was tested on several use-cases: eGovernment services in the cloud, school services and also in the MIREL project28
and DAPRECO29 [88] projects.In the Article 6 of the GDPR, the legal basis for the lawful processing of personal data are settled, consent being one of them that should be freely given in a specific, informed and unambiguous way. Information about the consent must be collected and stored, as well as maintaining a log of any changes that may be requested over time, and should be available for all parties involved – data subject, data controller and processor and the authorities.
In this context, Pandit et al. [79] created the GConsent ontology based on the guidelines defined by Noy and McGuinness [69]. The GDPR was the main source adopted to collect information about consent, though other legal authorities’ guidelines and reports were used, such as the guidelines on consent published by the European Data Protection Board [34]. However, this ontology only conceptualizes consent in the domain within Article 4.11 of the GDPR, so special cases where other forms of consent are allowed, such as children’s personal data or scientific research, are not covered by this model. As GConsent aims at not only capturing the concept of consent, but also to represent its state, context and provenance, existing vocabularies on this subject, such as PROV-O [60], GDPRov [81] and GDPRtEXT [80], are reused.
The core classes are the
BPR4GDPR – compliance ontology
The BPR4GDPR (Business Process Re-engineering and functional toolkit for GDPR compliance) project started at May of 2018 and was running until April 2021. It is a European Union’s H2020 innovation programme with the main goal of providing a framework to reinforce the implementation of GDPR-compliant measures inside organizations at diverse scales and in several domains [23].
The Compliance Ontology, described on BPR4GDPR’s deliverable D3.1 by Lioudakis and Cascone [63], is based on the BPR4GDPR’s Information model, that aims to define the entities and respective roles that are involved in the organization processes’ life-cycles. Its core classes are the
Using this ontology, BPR4GDPR defines a policy instantiating its purpose, context, action, pre-action and pos-action. The action reflects the activity permitted, prohibited or obliged by the policy, while the pre-action and pos-action indicate the actions that must take place before and after the main action. In turn, each action is specified by the user’s role, data, operation and the organization where it takes place.
BPR4GDPR is implementing services in three use-cases: for governmental services in the social security and healthcare domains with IDIKA S.A.;30
for automotive management with CAS Software AG;31 and for cloud-supported real state agencies with Innovazioni Tecnologiche.32The Data Privacy Vocabulary (DPV) was introduced by the W3C Data Privacy Vocabularies and Controls Community Group (DPVCG)33
in 2018 when the GDPR came into force. This W3C CG was one of the first outputs from a W3C workshop on data privacy controls, that took place in Vienna in April 2018, with the objective of defining priorities for the standardization of this domain [21]. Initially, the group searched for relevant vocabularies that attempted to address data privacy and, in particular, the GDPR. From this state-of-the-art review, a few conclusions emerged: there is a need for vocabularies to describe personal data and the purposes for the processing of said data, as well as vocabularies to coordinate privacy legislations. The methodology used to develop the vocabulary was based on theThe personal data categories are split into top level classes such as financial or social data, which are further specified, and classes for sensitive and derived data are also present as required by the GDPR. The top level categories are adapted from the
The CG also developed a GDPR extension for DPV, the DVP-GDPR vocabulary.35
DVP-GDPR covers all the legal bases specified on the GDPR Articles 6 and 9 for the processing of personal data and also the legal bases for the transfer of personal data to third countries defined on Articles 45, 46 and 49. This vocabulary also models 12 GDPR rights of the data subjects.The work to improve and extend the DPV vocabularies, as well as to provide more examples of application scenarios, is ongoing at time of writing.
Pandit et al. [80] developed
The main terms represented in this ontology are the specific
GDPRtEXT’s documentation also contains two example use-cases where it was used for GDPR compliance reports and also to link obligation concepts with the previous data protection regulation, the DPD.
Discussion
Analysis of existing resources
Comparison of the analysed privacy policy languages according to the defined criteria, described on Section 4.2
Comparison of the analysed privacy policy languages according to the defined criteria, described on Section 4.2
Representation of the informational items I1 to I57 in the DPKO, DPO, GDPRov, Cloud and PrOnto ontologies. The names of the classes which can be used to specify a particular item are depicted in the table, as well as their respective number of sub-classes. The informational items which cannot be fully represented by the current ontology terms are illustrated with an asterisk
Representation of the informational items I1 to I57 in the GConsent, IMO, DPV and GDPRtEXT ontologies. The names of the classes which can be used to specify a particular item are depicted in the table, as well as their respective number of sub-classes. The informational items which cannot be fully represented by the current ontology terms are illustrated with an asterisk
Using Table 6 as a reference, it is possible to compare the policy languages described in Section 4.2 in relation to their capacity of assisting with the representation of the rights and obligations described in Section 2. In this Table, the languages are sorted in descending order by the number of supported criteria, then alphabetically, if necessary, to improve readability.
Although these languages do not specifically mention the rights and obligations discussed in Section 2, they can be used to represent a few of the items of information mentioned by them, which is why they are classified as capable of partially representing GDPR concepts and principles (Q2 criterion in Table 6). Therefore, most of the analysed languages can be used to partially model the GDPR representational needs identified in Section 2, apart from AIR, PPO and XPref. Listings 1 to 10 provide examples of how to encode a particular privacy policy aspect for each language identified as capable of partially representing concepts present in the rights and obligations described in Section 2.
However, only ODRL, SPL and P3P provide taxonomies to populate the identified information flows and solely LegalRuleML, ODRL, A-PPL and DPF model deontic concepts such as permissions or obligations. LegalRuleML, SPL, A-PPL, DPF, AIR, LPL and S4P also mention in their literature the existence of reasoning mechanisms or other tools, which are based on the implemented languages, to assist with compliance, and in some cases access to such tools are provided. From the described languages, solely LegalRuleML and ODRL continue to be actively maintained and developed, and only LegalRuleML, ODRL, SPL, P3P and AIR have the resources available for reuse on the Web.
In particular, LegalRuleML and ODRL stand out from other languages as they have resources to respond positively to a greater number of the established comparison criteria.
Since the majority of the policy languages were developed before the GDPR came into full effect, they do not model concepts such as the legal basis for processing or the rights of the data subject. In this context, the ontologies and vocabularies in the domain of privacy and data protection as well as the GDPRtEXT ontology, described in the previous sections and compared in Tables 7 and 8, are of particular interest to cover these gaps on the representation of informational items. When available, the name of the class that can be used to model the respective informational item is detailed, as well as the number of sub-classes which can be used to more specifically define the term. The cases in which there is still no specific concept to represent the informational item, yet there are terms that can be extended to accomplish it, are marked with an asterisk. Informational items I15, I19, I24, I26, I28 to I30, I33, I34, I46 to I48, I51, I52 and I54 to I56 are not represented in either Table 7 or 8 since they are not modeled by any of the analyzed ontologies.
DPO, GDPRov, PrOnto, DPV and GDPRtEXT can be used to partially populate a great deal of the informational items required by the ‘right to be informed’ (RI1 and RI2) and the other GDPR rights and obligations. However, we must highlight DPV and GDPRtEXT since they represent, at least partially, 31 and 25 informational items, respectively, out of the 57 described in Table 1. Furthermore, these vocabularies are the ones that have the largest number of sub-classes to specifically define the respective informational items.
Most of the ontologies and vocabularies presented are obsolete or without new developments in recent years, with BPR4GDPR’s IMO, GDPRov, GConsent, DPV and GDPRtEXT being the only ones that continue to be improved. Moreover, of all the covered vocabularies, only DPKO, IMO and PrOnto do not have open and accessible resources.
Taking into account the performed analysis, it can be concluded that LegalRuleML, ODRL, DPV and GDPRtEXT are resources that can be easily extended to support the discussed representational needs of GDPR rights and obligations. As an example, Listing 11 combines ODRL, DPV and GDPRtEXT with a few new terms to describe a communication of a data breach (CDB) obligation. This example describes the need of a certain controller to inform a specific data subject in the case of a personal data breach event. A data controller keeping these obligations in this structured form can more easily fulfill them if the event actually happens.

Communication of a personal data breach to a data subject.
In order to complement the description of privacy languages, ontologies and vocabularies presented on Section 4 of this paper, an online portal36
has been published with additional resources. For each solution, there is a brief description of the language or ontology and also links to additional documentation and available RDF serializations. There is more information about the authors of the solutions, when it was first created and last updated, about the projects or the research groups where it was developed and, when available, examples of implementations that are using it. The webpage’s source code is also preserved as a Zenodo resource, at https://doi.org/10.5281/zenodo.5148947 , and its public repository can be accessed by the community at https://github.com/besteves4/SotAResources for further development.This webpage also includes a REST API service to find references to specific concepts in the collection of ontologies and languages that have been identified in the context of this paper. The main objective of this service is to give users a platform where they can search for ontologies that model processing activities such as ‘derive’ or ‘disclose’ or a language that can be used to represent the ‘right to erasure’.
Furthermore, we specify a lightweight ontology, the GDPR Information Flows (GDPRIF),37
in order to model the relationships between GDPR stakeholders, informational items, GDPR rights and obligations and also to specify information about the flows of information and about the events that trigger the rights and obligations. GDPRIF’s documentation is also stored in a public repository.38There is a strong need to develop technologies to support individuals to manage their personal information and at the same time there is a need to support companies to better manage compliance. Having common vocabulary elements and common data models to refer to these rights and to denote specific GDPR concepts would favor data subjects and data controllers to speak in the same terms, and would ease the interoperability between different types of tools. Not only companies may have information systems to manage the individuals’ consent and abide the law: other software systems can also help individuals to manage the consent they are constantly giving. In particular: data subjects can control the access to their personal data in distributed stores; as recommended by the Opinion 9/2016 of the European Data Protection Supervisor on Personal Information Management Systems (PIMS). Conversely, data controllers can make sure they have complied with their obligations about (i) informing the data subjects and (ii) responding to the data subjects’ requests. For example, having a categorization of the types of information that an individual should receive would enable automatic labeling tools analyzing existing text communications. Aligning ontologies and vocabularies with the GDPR (or other equivalent norms in other territories) would greatly favor interoperability of the privacy-related tools both on the side of the individuals and on the side of the companies.
This paper has analyzed the value of existing policy languages, vocabularies and ontologies to support these interoperability needs, and has concluded that LegalRuleML, ODRL, DPV and GDPRtEXT are mature resources, ready to be used for representing privacy-related rights and obligations, with an explicit link to the current version of the GDPR text. Points in favor of these solutions are the fact that they are open access, have good documentation and, in the case of ODRL and LegalRuleML, they are a W3C recommendation for digital rights management and a OASIS Standard for representing legal rules, respectively. In the specific case of DPV and GDPRtEXT, together they already allow representing, at least partially, most of the informational items necessary to adequately represent both rights and obligations, so these solutions prove to be the most appropriate options to be extended to cover all representational needs. Furthermore, beyond maturity, these solutions can formalise the highest number of information flows and can represent the most informational items required by the GDPR. An example of using these resources to specify the obligation to report a data breach is given to support this conclusion. In terms of future work, we intend to create ODRL-DPV-GDPRtEXT rules for each of the rights and obligations found in GDPR, as this exceeds the ambitions of this paper, but would favor its quick adoption.
Footnotes
Acknowledgements
This research has been supported by European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 813497 (PROTECT).