
Abstract
Ontology Design Patterns (ODPs) have become an established and recognised practice for guaranteeing good quality ontology engineering. There are several ODP repositories where ODPs are shared as well as ontology design methodologies recommending their reuse. Performing rigorous testing is recommended as well for supporting ontology maintenance and validating the resulting resource against its motivating requirements. Nevertheless, it is less than straightforward to find guidelines on how to apply such methodologies for developing domain-specific knowledge graphs. ArCo is the knowledge graph of Italian Cultural Heritage and has been developed by using eXtreme Design (XD), an ODP- and test-driven methodology. During its development, XD has been adapted to the need of the CH domain e.g. gathering requirements from an open, diverse community of consumers, a new ODP has been defined and many have been specialised to address specific CH requirements. This paper presents ArCo and describes how to apply XD to the development and validation of a CH knowledge graph, also detailing the (intellectual) process implemented for matching the encountered modelling problems to ODPs. Relevant contributions also include a novel web tool for supporting unit-testing of knowledge graphs, a rigorous evaluation of ArCo, and a discussion of methodological lessons learned during ArCo’s development.
Keywords
Introduction
Museums, libraries, archives, private collections and other cultural institutions have the essential mission to preserve the cultural objects they collect. Hence, data about these objects is of utmost importance, since it allows to keep memory of them, their life cycle as well as their artistic, social, and historical context. If data are shared, they can be used as a means of enhancing cultural properties, by spreading knowledge on cultural heritage, and widening its potential consumers. Cultural Heritage (CH) data can have various types of consumers such as citizens, students, scholars, scientists, managers, public administrations and companies. Consequently, it can impact different domains such as tourism, research, management, teaching, etc. Moreover, cultural institutions and research organisations can mutually benefit from the data they publish, especially by creating connections between their knowledge bases. The Linked Data paradigm has shown its effectiveness in supporting this practice [2], and its adoption in the Cultural Heritage domain is leading to a significant transformation in the management of CH data [14,16,18,39,41].
The Italian Cultural Heritage is an important part of the world’s CH,1
According to UNESCO, Italy is the country with the highest heritage sites in the world [9].
Architecture of Knowledge, from Italian Architettura della Conoscenza.
ArCo KG (composed of ArCo ontology network and LOD data) is available at the MiBAC’s official SPARQL endpoint.3
Created with
LODE:
Besides the relevance of the produced resource, described in [9], ArCo’s project contributes to push the state of the art in knowledge graph engineering, with special focus on the CH domain, by sharing its “behind the scenes”, i.e. the intellectual and methodological processes performed, the adopted design principles and the lessons learned, all of which constitute the main focus of this paper. ArCo KG development follows a pattern-based ontology design methodology named eXtreme Design (XD) [4,6], and has contributed to extend and improve it, as discussed in Section 3.
ArCo KG is an evolving creature, so is the methodology it follows i.e. XD. New requirements are continuously collected, incremental versions are regularly released, and its methodological approach is discussed with the community, and possibly refined and evolved.10
ArCo’s implementation of XD is discussed on a dedicated
mailing list
There are several, valuable existing models for representing Cultural Heritage data and publishing them as LOD. The Europeana Data Model (EDM) [41] and CIDOC Conceptual Reference Model (CRM) [19] are two prominent examples. EDM defines a basic set of classes and properties for describing cultural objects, which are used to aggregate CH data into the Europeana portal.14
As compared to EDM and CIDOC CRM, ArCo KG aims at modelling the Cultural Heritage universe of discourse with a much finer grain and by addressing a wider variety of concepts, ranging from cultural properties’ metadata (e.g. authors, creation date, current location, style) to research findings and theories (e.g. scientific processes performed for analysing a cultural property, theories and foundations about possible former settlements in an archaeological site).
By formalising cultural properties, the events they participate in, the types of places they are located in, the processes they are involved in, etc. ArCo KG provides the CH and the Semantic Web communities with a set of ontology patterns to encode CH knowledge graphs. The ultimate goal is to enable researchers and scholars to make new findings about cultural entities, and to develop new theories based on observations performed on knowledge graphs modelled by means of ArCo ontologies.
ArCo ontologies are aligned to EDM and CIDOC CRM, in order to facilitate linking and reuse by aggregators. Alignment and differences between ArCo ontologies, EDM and CIDOC CRM are discussed in detail in Section 4 and in Section 8.1. Nevertheless ArCo ontologies take a different foundational commitment than CIDOC CRM and EDM. The foundations of ArCo KG are: (i) the theory of Constructive Descriptions and Situations (cDnS) [23] and (ii) the reflection of an epistemological perspective on cultural properties. These are discussed in detail in Section 4 and Section 5. Informally, ArCo KG is situation-centric, meaning that all facts in its universe of discourse are modelled as situations: occurrences of relational contexts involving objects, that can be temporally and spatially indexed (e.g. where a cultural property is located, why and when; which author is attributed to a cultural property, based on which criteria, and when). The epistemological stance substantiates in distinguishing facts (e.g. the creation date of a cultural property, the author of a cultural property) from interpretations (e.g. dating estimation, authorship attribution) about a cultural property as well as from entities that document them (e.g. catalogue records) along with their evolving content (e.g. catalogue record versions).
Contribution This paper extends [9] by providing an in-depth analysis of ArCo KG (including examples) and its development context. Novel contributions can be summarised as follows:
an extension of the eXtreme Design methodology for dealing with Cultural Heritage ontology projects (or for knowledge domains with characteristics similar to CH)
an architectural ontology pattern for implementing large ontology networks
a detailed explanation of the foundations of ArCo ontologies
a detailed description of the main modelling issues addressed by ArCo and the related implemented ODPs
a formal evaluation of ArCo ontologies based on both established structural metrics [13,27,44,49,58,63,66], and XD-based unit testing
a tool (TESTaLOD) for supporting XD-based regression tests
a thorough description of the experience in applying XD to the development of ArCo KG.
After Section 2, which describes the General Catalogue of Italian Cultural Heritage, Section 3 explains the eXtreme Design methodology and discusses how we applied and extended it in the context of the ArCo project. Section 4 provides details about the foundations of ArCo ontologies and poses the basis to discuss, in Section 5, the main modelling issues addressed in ArCo ontologies and how they have been matched to existing Ontology Design Patterns. Section 6 evaluates ArCo knowledge graph. Section 7 summarises the lessons learned from the experience of developing ArCo, so far, and Section 8 discusses relevant related work. Finally, Section 9 wraps up the paper and points out some ongoing and future work.
Building a knowledge graph and its reference ontology network requires to understand the domain and the ontological commitment that its conceptualisation conveys, and to transform the available data into linked entities that comply with the resulting ontologies. There may be different scenarios in terms of what is available at the beginning of a knowledge graph project, but one of the most common situations is having a (set of) database(s) where the data are stored and maintained. Along with a continuous interaction with the administrators of the databases and the domain experts, these resources are to be analysed in order to extract the (often implicit) conceptual model of the domain that they encode. ArCo KG main datasources have been an XML database of catalogue records and a set of pdf documents describing catalogue standards.
Cataloguing cultural heritage is the process of identifying and describing, through metadata, entities that are considered cultural properties, by virtue of their historic, artistic, archaeological and ethnoanthropological interest. In Italy, the Italian Ministry of Cultural Heritage and Activities (footnote 12) (MiBAC), regions and local agencies are in charge of cooperatively cataloguing Italian cultural heritage they own, aiming at safeguarding, enhancing and making publicly available data on cultural heritage.
The General Catalogue of Italian Cultural Heritage
ICCD coordinates these cataloguing activities by maintaining the General Catalogue of Italian Cultural Heritage (footnote 11) (GC), which is the official institutional database of Italian cultural heritage, promoting integrated management of data coming from all over Italy and from diverse institutions and local contexts.
The General Catalogue is built upon a collaborative platform, named SIGECweb (footnote 13), to which national or regional, public or private, institutional organisations that administer cultural properties can submit their catalogue records, i.e. files containing data on cultural properties and compliant with predetermined standards and guidelines (see Section 2.2). Only users from institutions that are formally authorised by ICCD can access and contribute to SIGECweb, with specific profiles (e.g. administrator, cataloguer). The highly reliable provenance of the database is guaranteed by (i) an accreditation process that allows only authorised entities to contribute to the platform, (ii) a data validation phase performed by heritage protection agencies that assess the scientific quality of catalogue records, and (iii) an automatic data validation phase based on compliance with specific cataloguing standards (see Fig. 1). Based on its authoritativeness, it is assumed as a high-quality database, in terms of accuracy and completeness.
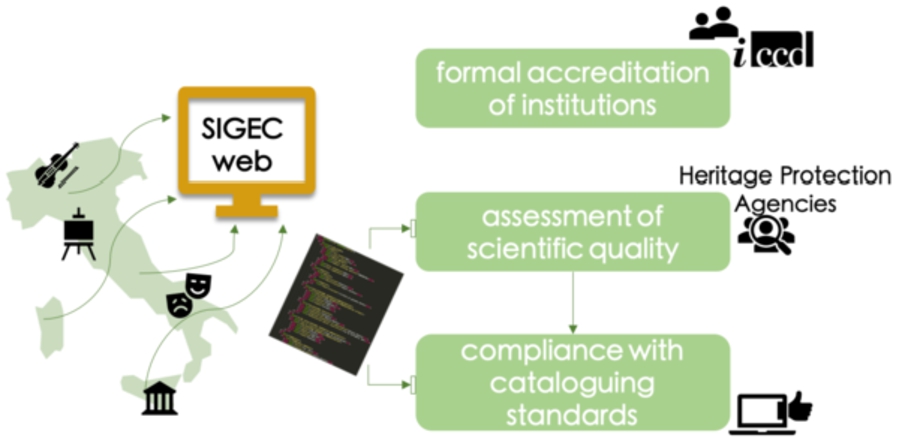
Accreditation and validation process for contributing to SIGECweb.
SIGECweb currently contains 2,735,343 catalogue records, 831,114 of which are publicly accessible through the General Catalogue. The privacy level associated with the remaining records prevents them to be openly published, since they refer to properties either private, or being at stake (e.g. items in unguarded buildings), or still requiring a scientific assessment by accounted institutions.
In order to guarantee high quality, consistency and interoperability between data accessible through the General Catalogue, ICCD defines a set of standards (normative) (footnote 9) for encoding catalogue records (schede di catalogo), which provides a template for collecting and organising data on different types of cultural properties and a methodological base for cataloguing. Thus, these standards are part of ArCo KG input, along with data contained in the GC catalogue records.
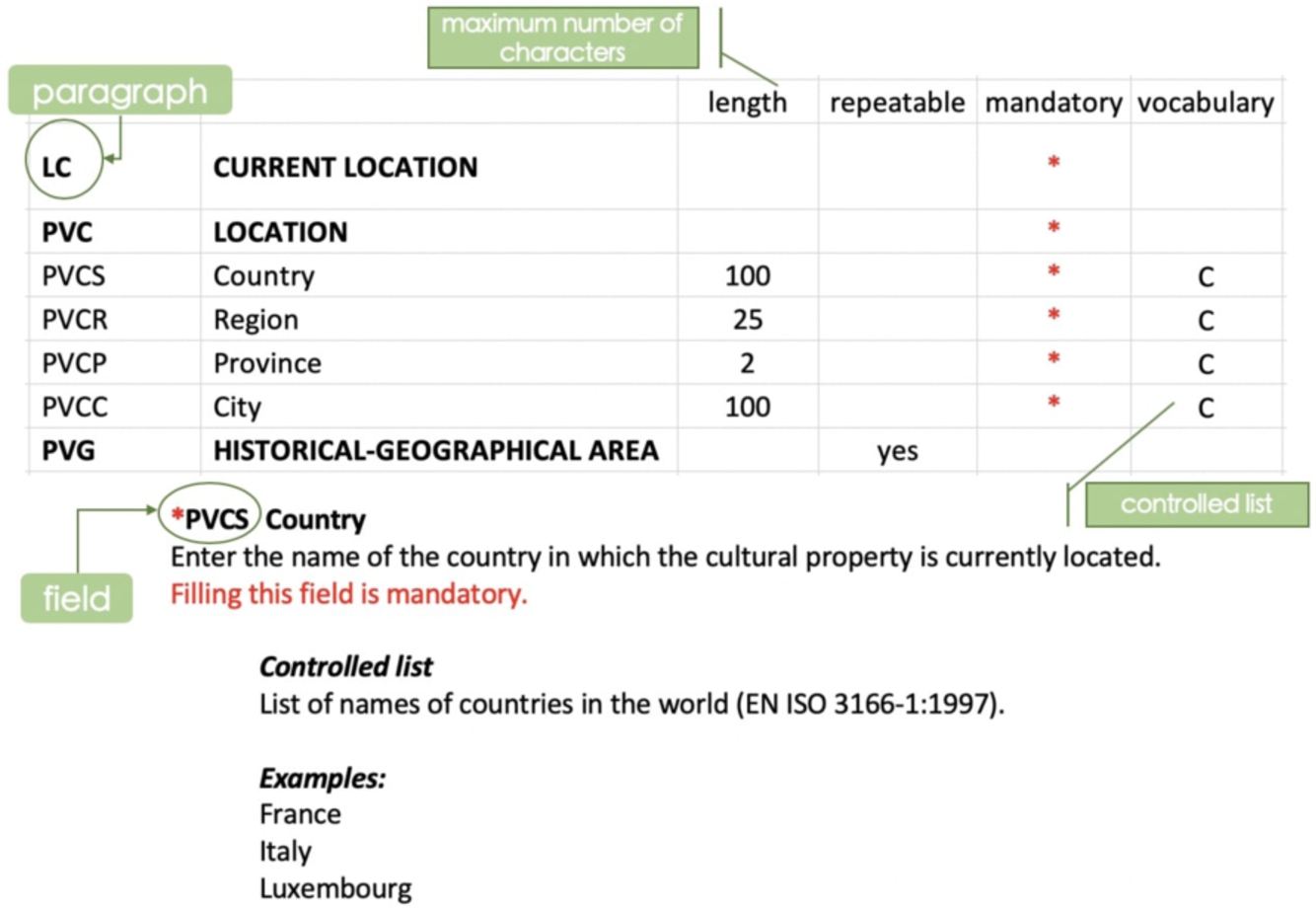
An example of the structure of an ICCD cataloguing standard.
Each cataloguing standard consists of a PDF document15
These standards are gradually being published also in XML Schema Definition (XSD) format.
ICCD collects catalogue records about 9 categories of cultural properties, which
generalise over 30 different more specific types: archaeological, architectural and
landscape, demo-ethno-anthropological, photographic, musical, natural, numismatic,
scientific and technological, historical and artistic properties. For each of the 30
types, a specific cataloguing standard has been defined, while a cross
cataloguing standard (Normativa Trasversale) groups and defines the
field common to all kinds of cultural property. Nevertheless, the particular features of
each cultural property type require specific standards for defining additional
paragraphs and fields, e.g. a paragraph for describing possible accessories, such as the
instrument case, of a musical instrument. Moreover, some fields are associated with
controlled lists, i.e. lists of non-overlapping terms used to control terminology. In
many cases, these controlled lists differ, partially or completely, depending on the
cultural property that is being catalogued: for example, according to the standard for
photographs, the list associated with the field type of measurement
contains values such as “
Currently, an effort is being made by ICCD in publishing on GitHub16
ICCD has been sharing cataloguing standards since 1990: they have undergone changes and updates, regarding both their structure and rules for compilation.17
Previous and current versions include: 1.00 and 2.00 (1990–2000), 3.00 (2002–2004), 3.01 (2005–2010), 4.00 (since 2015).
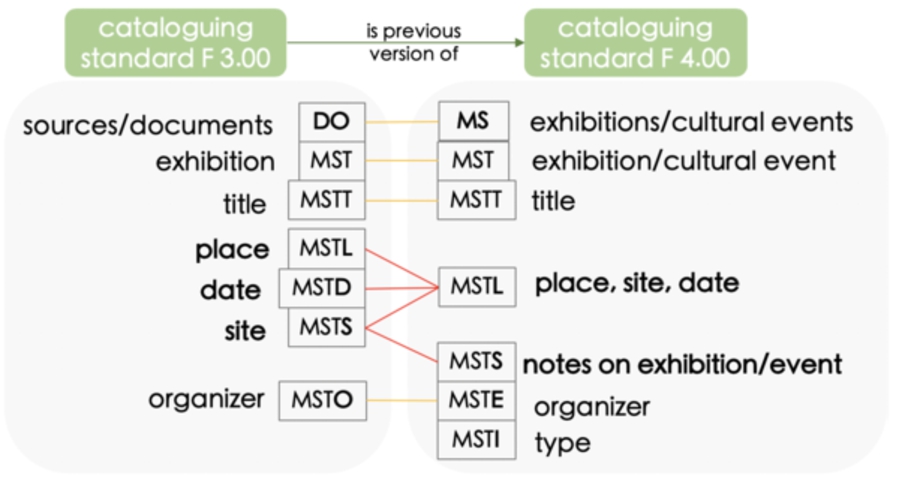
The ICCD cataloguing standard F for photographs: difference and mapping between version 3.00 and version 4.00.
Although catalogue records submitted to SIGECweb are subject to a validation process, being collaborative in nature means that catalogue records are not error-free. There are cases of: mandatory fields that are not properly filled, thus producing an error code; catalogue records containing values alternative to those provided by controlled lists, hence undermining data homogeneity; use of non-standard formats (e.g. for dates); minor bugs and typing errors. ICCD is continuously working for improving the collecting process, in order to minimise these situations.
Moreover, catalogue standards themselves could be improved in their structure, in order to maximise data mining from catalogue records: there are still many fields allowing for long descriptive texts, from which structured high-quality information could be derived and extracted.
Applying eXtreme Design principles to model the Cultural Heritage domain
In order to develop ArCo ontologies, which cope with a huge and complex domain such as Cultural Heritage’s, we use ontology design patterns (ODPs) [30,36]. Ontology patterns provide solutions to recurrent modelling issues. Their adoption guarantees a high level of the overall ontology quality, and favour its re-usability [3].
The use of design patterns in ontology engineering is less evident than in software engineering. Software design patterns are such a standard practice that many programming languages have built-in types implementing, or inspired by, them e.g. Observer in Java and Iterable both in Java and in Python. ODPs instead, although recognised as good practices in general, are yet distant to achieve a clear standard reference in the knowledge engineering community, and very far to be common practice in the Linked Data community. Their introduction in the Semantic Web is relatively recent [22] and to date there is still a lack of tooling to ease their adoption. A very recent and promising contribution to fill this gap is CoModIDE [59], a Protégé18
At the time of ArCo development the tool was not available, we plan to test and use it in future developments.
XD is an ontology design methodology that puts the reuse of ODPs at its core both as a principle and as an explicit activity. It provides guidelines for such an activity. Experiments have demonstrated its positive impact on ontology engineering and ontology quality [6,59].
XD is inspired by eXtreme Programming (XP) [60], an agile software development methodology that aims at minimising the impact of changes at any stage of the development, and producing incremental releases based on customer requirements and their prioritisation. Although the two approaches share the same principles and general guidelines, they in practice diverge towards different focuses, mainly due to the core differences between software systems and ontologies. XD is test-driven, and applies the divide-and-conquer approach as well as XP does. Also, XD adopts pair design (as opposed to pair programming). The intensive use of ODPs, modular design, and collaborative approach are the main characterising principles of the method. Further details on the relation between XP and XD, and a thorough description of XD, are given in [52].

The XD methodology as implemented for the ArCo knowledge graph.
As depicted in Fig. 4, after the project initiation, XD is
executed by iterating a set of steps, each involving one or more teams:
a customer team, which elicits
the requirements that guide the design and testing
process; a design team, which is in
charge of identifying and implementing the ODPs that best address the given
requirements; a testing team, which
performs testing and validation of the produced ontology
components; an integration team, which
takes care of integrating the different components.
In XD,
the design team works in parallel and interactively with the testing team: the same
requirements are used as input by the design team, for producing the ontology, and by the
testing team, for translating them into unit tests.
Figure 5 depicts a simple example that will be used to illustrate the main steps of the methodology.

An example of a user story translated into CQs, and of the matching between a CQ and an ODP.
Requirements engineering A fundamental step is to collect requirements and to engineer them. Requirements are collected in the form of user stories, which are provided by the customer team. A user story is a set of sentences, which describe by example the kind of facts that the resulting knowledge graph is required to encode. The length of a user story is limited to favour keeping them focused; its maximum length is decided by the design team. The customer team is instructed to break possible complex stories into smaller and simpler ones. An example of a simple user story is (cf. Fig. 5): “Leonardo da Vinci was an artist, a philosopher and an engineer”. User stories may be associated with a priority level, a title, and an ID.20
Each ontology project will define its own conventions.
Competency Questions One or more competency questions (CQs) [34] are derived from a generalisation of the user stories. CQs are the natural language counterpart of structured queries that we want to enable against the resulting knowledge graph. Generalising a user story means to identify the main concepts that it exemplifies. This generalisation is carried out by the design team, in collaboration with the customer team. For example, considering the previous user story, two CQs may be derived from it: “Which are the roles played by an artist?” and “Which artists played a certain role?” (cf. Fig. 5). The design and customer teams have identified that “Leonardo da Vinci” is an example of Artist, which is a relevant concept in the domain, and that “artist”, “philosopher”, and “engineer” are examples of Roles that an artist can play, another relevant concept to include in the ontology.
In addition to deriving CQs, the design team interacts with the customer team in order to identify possible general constraints that may accompany them. General constraints express possible inferences or other rules that apply to the concepts that the story involves. In the example of Fig. 5, the following general constraints can be drawn: “An artist is a person” and “A person cannot be a role”. General constraints are the natural language counterpart of axioms that will be formalised in the ontology. The CQs and the general constraints define the ontology requirements, hence contributing to assess the ontological commitment, as far as the ontology domain tasks and scope are concerned. From the XD perspective, the ontological commitment includes both meta-level aspects such as adopting a 3d or 4d view, as well as functional/application aspects which draw the boundaries of the scope of the ontology. ArCo ontological foundations are discussed in Section 4.
Matching CQs to ODPs CQs guide the selection of ODPs: a key process in XD, and in general in pattern-based design, is to match CQs to ODPs. At each iteration, a coherent set of CQs is selected, i.e. CQs dealing with the same modelling issues (e.g. roles played by agents). Possible existing solutions (ODPs) are analysed in order to find the most suitable one to be implemented in the ontology. This is a complex cognitive task that, currently, lacks proper tool support. Hence, it is better performed by whom has previous knowledge about existing ODPs. Nevertheless, if one is not familiar with ODPs, they can be found on catalogues, such as the catalogue maintained by the University of Manchester21
Testing and integration XD is test-driven and follows a unit testing approach as described in [7,52]. The CQs and general constraints defined by the design team are shared with the testing team. While the design team uses them for producing a piece of the ontology, the testing team uses them for designing unit tests: CQs are translated into possible SPARQL queries, while general constraints are used to create sample triples, based on the user stories, that are expected to provoke either consistency/coherence errors or inferences. The testing team will use a draft terminology based on the CQs. In other words, unit tests are sample OWL/RDF files (encoding the user story) and SPARQL queries, annotated with their corresponding expected results. When the testing team receives an ontology piece from the design team, it firstly attempts to replace the corresponding unit test (draft) terminology with the provided ontology vocabulary. At this stage possible missing concepts can be spotted, which would make the test positive25
A positive test means that some error has been raised.
Performing regression testing means re-running all previously defined unit tests and integration tests to check whether the ontology performs the same after a change, and to appropriately fix it, if it is not the case.
Challenges of XD methodology So far, we have described eXtreme Design
(XD) according to [4,6,52]. In the context of
the ArCo’s project we faced a number of challenges that are not explicitly tackled by XD,
hence we contributed to extend it. Specifically, one challenge concerns how to design the
architecture of an ontology network. As we deal with a wide and complex domain such as
Cultural Heritage, we would have benefit from clear guidelines. There is some preliminary
work described in [30] about architectural
patterns for ontologies, defined as patterns that [...] affect the overall
shape of the ontology, and dictate ‘how the ontology should look like’. [...] An
ontology that has a simple modular architecture is composed of a set of ontologies,
called modules, plus one ontology that imports all the modules.
Another challenge concerns the collection of requirements. Cultural heritage data are relevant for potentially many diverse consumers and applications. Our primary source of data is a catalogue, however our ultimate goal is to conceptualise the Cultural Heritage domain at large, going far beyond the cataloguing perspective. This means that ArCo needs to draw its requirements by a plethora of diverse potential consumers, which can enter the process at any time, posing new requirements. XD is adequate to support evolving requirements, but how to gather requirements from an evolving community is unclear.
A third challenge concerns testing. In this case, given the dimension and complexity of ArCo ontologies we soon realised that systematic testing, as recommended by XD, needed proper tool support, which was unavailable to the best of our knowledge. We have developed TESTaLOD to serve this purpose, which is presented in Section 6.1.
When the project started, its main customer was ICCD, i.e. the institute in charge of collecting and preserving the data of the General Catalogue, and of releasing updated cataloguing standards. ICCD domain experts formed the customer team and provided indications to the design team for the selection and prioritisation of requirements. They also supported the design team in gaining a good comprehension of the cataloguing standards. ArCo ontologies reflect (hence are compatible to) ICCD standards. However, they are not committed exclusively to their interpretation of the Cultural Heritage domain, which is limited to the point of view of cataloguing practices. The situation we faced is that ICCD wanted to address the need of diverse communities of potential consumers of CH data, while keeping an institutional management of the development process. We opted for a twofold approach: (i) we handled the requirements collection as an open process by involving external actors, and (ii) we have launched an “Early Adoption Program” aimed at engaging a number of representatives of potential consumers, who would provide both requirements and validation. This approach has favoured a relatively quick creation of an open community as well as widening the scope of the collected requirements. Early Adopters (EAs) are given assistance and support, and the fulfillment of their issues and requirements are put high in priority. In order to guarantee a lively interaction within the project community, regular meetings (e.g. webinars or meetups) are held and issues are discussed in an open mailing list. Furthermore, proposals for improvement and bugs can be submitted as GitHub issues.27
With this approach, the customer team became an evolving creature, which over time will extend by involving all representatives of potential producers and consumers of CH data. At the moment, ArCo is collecting requirements from private companies, public administrations, researchers and creative developers. These requirements are collected in the form of small stories (according to XD). A story is a non-structured text, exemplifying some scenario or reporting real use cases. They are submitted by the customer team to a Google Form, with a maximum of 250 characters.28
Requirements coming from user stories, as well those extracted from ICCD standards, are translated into Competency Questions. All CQs, and related SPARQL queries, that so far guided ArCo KG design and testing are available online.29
As an example, we report one of the stories collected through the Google form:
Type: Linking my data to ArCo
data
Title: Cultural heritage and residential
property
Story: I am looking for a residential property to
buy, and I want to filter the results based on the type of cultural heritage
nearby.
This story requires to address the following CQs: “What are the types of cultural properties located in a certain area?”, “Which is the current location of a cultural property?”, “Which are the geographic coordinates of the current location of a cultural property?”, “Which is the type of a cultural property?”. Other examples of stories concerned: linking cultural properties to multimedia resources, such as photographic documentation; describing specific attributes of drawings or music heritage; tracking over time the availability of cultural properties that have been confiscated from organised crime; relating catalogue records to heritage protection agencies.
Handling large ontologies is a non-trivial challenge for ontology engineers, reasoners and users. A modular approach, as opposed to a monolithic design, i.e. one ontology module addressing all CQs, favours readability, reusability and maintainability of an ontology [50,61]. Ontology modules are meant to identify conceptually coherent subparts of the domain. In this respect, XD lacks explicit guidelines on how to approach a modular design of potentially large, networked ontologies. Based on our experience in designing the architecture of the ArCo ontology network, we provide a set of guidelines as well as an architectural pattern that can be applied in other contexts with similar characteristics as the ArCo’s project.
The root-thematic-foundations architectural pattern
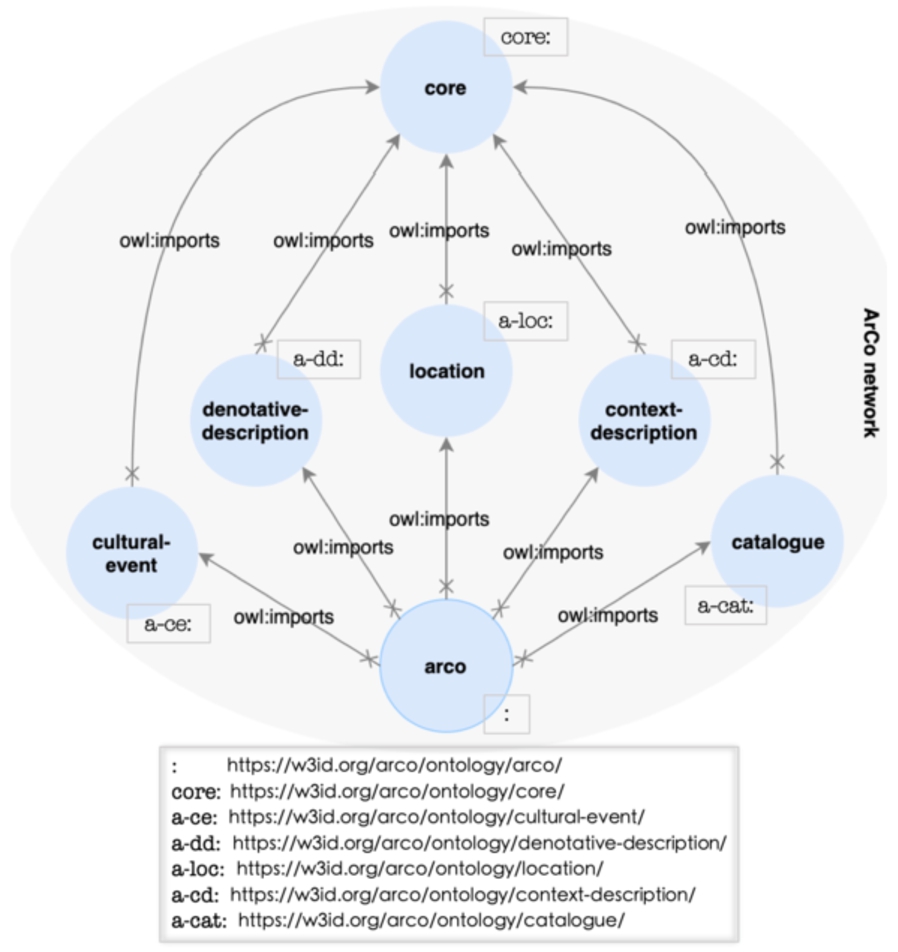
ArCo ontology network, currently including seven modules: arco is the root node of the network, while core is reused by all other modules, where concepts related to cultural properties and catalogue records are represented.
We name the architectural pattern implemented by the ArCo ontology network root-thematic-foundations (Fig. 6). It can be described as follows:
a root module acts as the entry point of the network, i.e. it causes
the whole network to be loaded by importing all main thematic
modules. In ArCo this is the arco module, and it also
contains the ontology top-level hierarchy of classes, with
a second layer of the network is composed of the main thematic modules, which are all imported by the root module. These modules may import, in turn, secondary thematic modules, that depend on them (which may form additional layers in the network). ArCo ontology network currently contains five main thematic modules: cultural-event, denotative-description, location, context-description, and catalogue.
a leaf module contains foundational concepts such as the part-whole relation, agent, physical object, role, etc. i.e. which are not domain-specific. This module is imported by all main thematic modules. In ArCo this is the core module.
The implementation of the root-thematic-foundations pattern requires a conceptual organisation of the domain into separate coherent subdomains. This can be achieved by clustering the requirements, based on thematic areas. The criteria for identifying thematic areas, and their granularity, can vary depending on the project’s commitment, design choices and the size of the domain. As ontologies are evolving objects, new (main) thematic modules may be added over time in case future requirements identify new subdomains.
In the context of ArCo, at a very early stage of development, we could leverage and analyse the ICCD catalogue, its data and standards, as well as the user stories provided by the customer team. In agreement with ICCD domain experts, we first focused on the cross cataloguing standard and related user stories, which address concepts that are relevant for all types of cultural properties. Our hypothesis is that the cross standard can give us a plausible overview of the CH domain. In all cataloguing standards, metadata are grouped into paragraphs, each containing different fields. We performed a manual clustering of these fields. This activity allowed us to identify five topics that could characterise the main thematic modules of the ArCo ontology network.
A first observation is that catalogue records contain: (i) data directly describing a cultural property and its contexts (e.g. techniques and materials, related exhibitions, surveys); (ii) data about catalogue records themselves (e.g. when they were created, by whom, their version, etc.); (iii) data about other entities referring to cultural properties (e.g. inventories, documentation, bibliography). Based on this observation, a main thematic module (catalogue30
Cultural properties, which are the main subjects of study of the CH domain, are described by means of measurable, intrinsic aspects such as length, weight, materials, conservation status, as well as properties deriving from an interpretation process, such as authorship attribution, dating. This conceptual distinction suggested us to define two additional thematic modules of the network: denotative description31
as for capturing descriptions of the first type, and context description32
Finally, it results fairly evident that the locations associated with a cultural property and the cultural events in which it participates in, are two major components of its lifecycle. As a consequence, the ArCo ontology network includes the two thematic modules location33
The foundational concepts captured by the core35
Finally, the arco36
Competency Questions Each module of the ontology network addresses a subset of the Competency Questions elicited by the customer team. Table 1 lists some representative CQs for each module, except the core module, which is specialised by the other modules.
Representative competency questions answered by ArCo ontology network
Ontology Design Patterns (ODPs) are established solutions to modelling problems (i.e. requirements) that emerge from, and evolve through, applied and theoretical results. ODPs can have relations among them, including subsumption, overlap, merge, etc. (cf. [30]). ODP subsumption is at the core of many formal ontology issues concerning the usefulness of foundational ontologies [22,28]. For example, the competency question Where is a cultural property currently located? could be subsumed by a general one: What is the location of something at some time?, and if a solution is not available for the specific requirement, we can reuse one that is good for the general requirement. In practice, when all the predicates from a requirement are stripped out of specificity, we get a foundational requirement, and if that requirement has a known solution (e.g. the Time Indexed Location ODP), we can apply it directly, by specialising the predicates as expressed in the specific requirement (cultural property, current).
When dealing with an ontology project as complex as ArCo, we need a good deal of generalisation that provides a shared modeling style to its data. The details of the ontological choices made against requirements are presented in Section 5.
Foundational commitment in ArCo: DOLCE-Zero
The ODPs implemented in ArCo ontologies are mostly taken from a set of interrelated foundational ODPs, inspired by DOLCE UltraLite+DnS (DUL)37
DUL is a commonly used foundational ontology that commits to (i) DOLCE [28] distinctions: objects vs. events vs. qualities (specific attributes of objects and events) vs. qualia (dimensional representations of qualities), and to (ii) D&S (Descriptions and Situations) [23,47] distinctions for entities including situations vs. descriptions vs. concepts (see Section 4.2 for details), e.g. types, topics, roles, tasks, quality types, parameters, reified relations and classes, etc.
DOLCE-Zero contains a small set of classes on top of DUL, relaxing ambiguity resolution
when needed. In particular, it introduces four “union classes”:
DOLCE Zero unions are formalised as follows:
However, DOLCE (and its OWL implementation in DUL) has disjoint classes for physical vs. social objects vs. spatial regions, since the authors wanted to pursue a multiplicative approach, i.e. ideally we would need to introduce an entity in the universe of discourse for each distinct entity, e.g. Uffizi-as-building, Uffizi-as-museum, Uffizi-as-organisation. However, refactoring existing datasets in order to enforce multiplicativism is not simple in practice, since we do not always know the context allowing for establishing the distinction. In addition, the co-predicative nature of certain entities is built in the cognitive intentionality of speakers or data modellers, and it would be very difficult to change the data. The result of those pragmatic issues is that it would be dangerous to choose one particular meaning (e.g. Uffizi-as-building), because that choice might induce an inconsistency if data refer e.g. to the director of Uffizi (i.e. Uffizi-as-museum).
As a matter of fact, those distinctions are seldom represented in lightweight ontologies and natural language lexicons: trying to push multiplicativism would lead to debatable inconsistencies, as argued in [51], which reports a large-scale experiment that uses DOLCE-Zero to detect millions of inconsistencies in the DBpedia knowledge graph. In that experiment DOLCE-Zero union classes have avoided a much larger amount of inconsistencies, which cannot be fixed. Of course, for integrity checking, we could resort at anytime to data analytics that test multiplicativism for e.g. a fragment of the DBpedia or ArCo knowledge graphs.
ArCo foundational distinctions have a similar foundational commitment as DOLCE-Zero, so using more specific DUL’s distinctions only when necessary. This commitment is implemented in Level 0,40
A cluster of foundational requirements in ArCo is about events, states, actions, and
their expressions, types and interpretations. Literature on these notions is heterogeneous
[12], applying pragmatical, logical, and
philosophical criteria, often mingled, to draw distinctions. As an example of the
underlying problems, we can distinguish (i) a restoration event
e on a cultural property c, (ii) the
restored state s of c, (iii) their
types or categorizations (e.g. procedures, phases, tasks, roles)
A related problem is that ArCo requirements (as most ontology design projects for the
Semantic Web) need to represent n-ary relations (with
Cf. the
W3C Working Group Note at
While this is a representation problem, rather than an ontological one, there is ample evidence (see e.g. [15,24,31,33]) that similar cognitive constructions (intensions, logically speaking) apply to events, states, actions, event types, action schemas, frames (in the sense of [21]), and relations as first-order objects.
Based on this assumption, a useful generalisation can be applied, treating those entities as either (i) reified (extensional) relationships, e.g. the situation of Canova’s Venus Victrix being located at Galleria Borghese in Rome since 1838, or (ii) reified (intensional) relations, e.g. the Attribution frame representing the authorship attribution to cultural properties, as made by an interpreter based on some criteria.
That generalisation is applied quite often in ontology design. ODPs such as situation, description, descriptionsituation, planexecution, etc. (cf. [53]), inspired by the theory of Constructive Descriptions and Situations (cDnS) [23], provide a framework to systematically relate frames (a.k.a. intensional relations, schemas, descriptions), and frame occurrences (a.k.a. extensional relations, situations, states of affairs).
The generalisation implements the cognitive assumption of extensional relations in the world being “framed” or “schematised” through observation, interpretation, diagnosis, norm, expectation, etc. In other words, framing applies a conceptual construction to a set of sensory perceptions, given data, reported facts, etc. The correspondence between frames and their occurrences leads to assigning contextual roles to participants (e.g. being a restored object in a Restoration frame occurrence), tasks/types to actions (e.g. being a completion phase in a Restoration frame occurrence), parameters to data values (e.g. being a reliable dating in an occurrence of a frame for evaluating the reliability of Carbon-14 dating of an archaeological object). Application of those ODPs can be found in multiple domains [23,25,26,32,48,57].
ArCo adopts the framing patterns to the representation of cultural properties, using the
class
While situations allow to generalise over any relational concept, regardless of their
arity, semantic web practices sometimes prefer binary predicates (called
object or datatype properties) whenever useful. In
order to accommodate the constructive stance of ArCo, which requires graphs including
multiple triples for each relation, with the practical benefit of having simpler graphs
with one triple representing each relationship, the same relational concepts are
represented as both
For instance, agencies related to a cultural property (e.g. a cataloguing
agency) can be represented in ArCo as either (i) a situation class
(
Other foundational event-like notions
Other event-like notions in foundational and cultural ontologies can be aligned as
subclasses of
CIDOC CRM E5 Event, subclass of E4 Period, is defined as ... changes of states in
cultural, social or physical systems, regardless of scale, brought about by a series or
group of coherent physical, cultural, technological or legal phenomena ... The
distinction between an E5 Event and an E4 Period is partly a question of the scale of
observation. Viewed at a coarse level of detail, an E5 Event is an ‘instantaneous’
change of state. CIDOC events are then considered as a granularity (or
“aspectual”) distinction within the larger class of periods, which seem to encompass also
other spatio-temporal phenomena, except E3 Condition State, which is defined as a
particular state of an entity. Both E4 Period and E3 Condition State are subclasses of E2
Temporal Entity, which “encompasses all phenomena”. Orthogonally, ArCo situations focus on
the role structure of event-, state-, and relation-like entities. All CIDOC temporal
entities can be considered situations in ArCo, while their aspectual distinctions are not
directly addressed in ArCo, since they could be defined as subclasses of
As a second example, DOLCE [28] notion of Event (a.k.a. Perdurant or Occurrent) is defined axiomatically as the class of entities that “happen in time”, i.e. some of their proper parts/phases may not be present at each time they are present (extreme cases include instantaneous and stationary states). Participation is defined in DOLCE for all events. An extension of DOLCE [47] axiomatises also intensional relations (called descriptions) as schemas, with proper roles, for events or other entities. The notion of frame/description/intensional relation used in ArCo is compatible with that of description in [47], while ArCo situations do not commit to the distinction between objects and events as applied in DOLCE (and CIDOC CRM), since a situation is defined as the occurrence of a description as observed, diagnosed, aggregated, invented, etc. In this sense, the constructive approach inherited from cDnS [23] departs from other foundational ontologies, which focus on the 3D/4D distinction as primary to declare their commitments. That constructive stance prioritises the dependence of an event-like entity on its framing, so that a requirement for ontology design can be directly matched by a frame. For example, an iconological interpretation for an iconographical element can be represented as a framing: an art historian like Erwin Panofsky with a requirement to find iconographical elements that match marriage iconology would interpret several iconographical elements in the Arnolfini Portrait by van Eyck as the occurrence of a marriage contract.
This stance, besides cognitive results, is also inspired by Davidson [15], which provides a solid ground to events as first-order entities, corresponding to (reified) relationships.
Finally, as discussed in Section 4.5, a constructive stance is immediately applicable to the interpreted nature of cultural entities: historical, anthropological or archaeological events are always dependent on some interpretation for their cultural identity to be established, and cultural properties may change their meaning when interpretation conditions change.
Epistemological stance in ArCo
Related to the previous section, ArCo applies a distinction between three epistemological levels: factual, interpretation, and reporting situations, which constitute the core of cultural data dynamics.
For example, having physical size, constitution, unique qualities, or authorship are factual situations for a cultural property c, while establishing constitution via Carbon-14 or attributing authorship for c are interpretation situations. This distinction allows the modeller to distinguish factual data from interpretation data, when they exist (e.g. only rarely we have data describing the criteria used to establish the material of a statue). Finally, providing data and content about c is a reporting situation. The cultural heritage scientist typically establishes factual situations based both on direct or sensor-based observation data, and on documented evidence, mediated by interpretation activities. Data provided by cultural agencies, researchers or citizens do not necessarily contain the full story of how facts have been exactly established/reported, extended causal chains. In ArCo, we need to live with incomplete epistemological foundations, trying to associate situations with their epistemological level.
The epistemological stance in ArCo involves the distinction between: (i) catalogue versions, e.g. when someone adds data in a catalog record, (ii) interpretations, e.g. when a catalogue record reports an attribution, and (iii) current factual data, e.g. the authoritative data for a cultural property at the current state of the art. When the catalogue record is the only source for a knowledge graph, we depend on its versions to reconstruct the epistemological trajectory of c, with its interpretations, updates, and the current state of its factual data. Section 5.1 describes the predicates used for relating cultural property situations and where they are reported e.g. catalogue records.
However, the vision of ArCo goes well beyond reengineering traditional catalogues, and its epistemological stance accommodates for a more complex knowledge graph hosting interpretations with different provenance and reliability, different reporting sources, and potentially conflicting factual data, so enabling cultural knowledge graphs as investigation tools for researchers.
ArCo top level hierarchy and distinctions
The most general Cultural Heritage concept modelled in ArCo is
The root of ArCo’s hierarchy (depicted in Fig. 7) is the
class

The taxonomy of cultural properties.
The ICCD standards extensively address different aspects of the cultural heritage domain in order to define the structure and content of catalogue records. Catalogue records can describe 30 types of cultural properties (cf. Section 2), each showing distinguishing features. ArCo’s further specialisations in the top level hierarchy are inspired by these distinctions.44
We plan to reflect additional classifications as provided by official national or international standards.
We report the definitions for the specific classes, according to ICCD standards.
In this section, we: (i) illustrate some of the main modelling issues that have emerged from ArCo’s requirements, along with the modelling solutions adopted for addressing them; (ii) use (i) as driving examples to describe the process of matching requirements to Ontology Design Patterns (ODPs), introduced in Section 3, as part of the XD methodology.
Figure 8 shows all the prefixes used in the next diagrams, designed according to Graffoo notation.45
Prefixes used in the next figures.
Dynamic concepts, such as situations that change over time, are present in almost every domain. There are different patterns that model dynamic situations: in this subsection, we exemplify ArCo approach to dynamicity with catalogue records and cultural property locations, which may both evolve over time.
A catalogue record as a fluent information object A catalogue record is an entity that contains metadata about a cultural property. As it describes a real-world object, it can be defined as an information object, i.e. a piece of information, independent from how it is concretely realised, describing something in the real world. This concept is defined in several ODPs, including Information Realization46
A catalogue record is then a fluent entity, an information object that changes as the description of its denoted cultural property changes.47
Cf. Section 4.5 about the difference between factual and reporting situations.
Every change of a catalogue record produces an information object, which is a new version of the catalogue record, including the reporting of a new situation involving a same persistent entity. Nevertheless, the catalogue record finds its persistence in describing the same real-world object, i.e. the same cultural property, independently from different versions of the content and the reported entity changes over time. Thus, the catalogue record is represented as a persistent information object, and is related to its versions, which are information objects reflecting changes of its content over time.

Information Realization and Sequence ODPs reused for modeling catalogue records.
The Time Interval ODP is used to represent the temporal validity of each version, and the pattern Sequence48
Figure 9a depicts catalogue record modeling with the reused
ODPs. A catalogue record is represented by the class
In Fig. 9b we can see an instance of this model. The
Multiple time-indexed and typed locations for one cultural property A tangible cultural property, i.e. a physical object, is located in a physical place, which can be defined by a set of components: country, region, city, address, etc. For an immovable cultural property (e.g. a monumental park), this place overlaps with the area occupied by the cultural property, and to which it is fixed. Instead, for a movable cultural property (e.g. a photograph), data about the address and the coordinates is referred to the building in which it is situated and preserved, and the related cultural institute. While an immovable cultural property, precisely because of its nature, will be related to a unique geographical place during its whole life cycle, a movable cultural property can be moved from a place to another. Different locations of a cultural property will hold in different time intervals. As a consequence, the temporal indexing of the locations associated with a cultural property is represented, also promoting the reconstruction of the spatial trajectory of the cultural property over time. During its life cycle, a movable cultural property is involved at least in as many situations as the places in which it has been located, and each situation is associated with a time interval. The Time Indexed Situation52

Time indexed situation ODP implemented for modelling different types of locations of a cultural property.
Figure 10a shows the class
Figure 10b depicts one of the time-indexed typed locations of a balsarium glass from the Imperial Roman age:53
A cultural property can be involved in many different situations during its life: it can be commissioned, bought or obtained, used (e.g. a garment wore by one person), it can be part of a collection, photographic or numismatic series, can change its availability as a result of theft, destruction or rescue, etc. Each situation defines a contextual relation between the cultural property and the other entities involved. The Situation54
For example, when a coin is issued, many entities play a role in such context: the
cultural property itself, the issuer, the issuing State, the mint and the minter. The
“coin issuance” is a situation representing the relation that keeps together all these
entities for that purpose. Figure 11 shows how we model the
coin issuance (
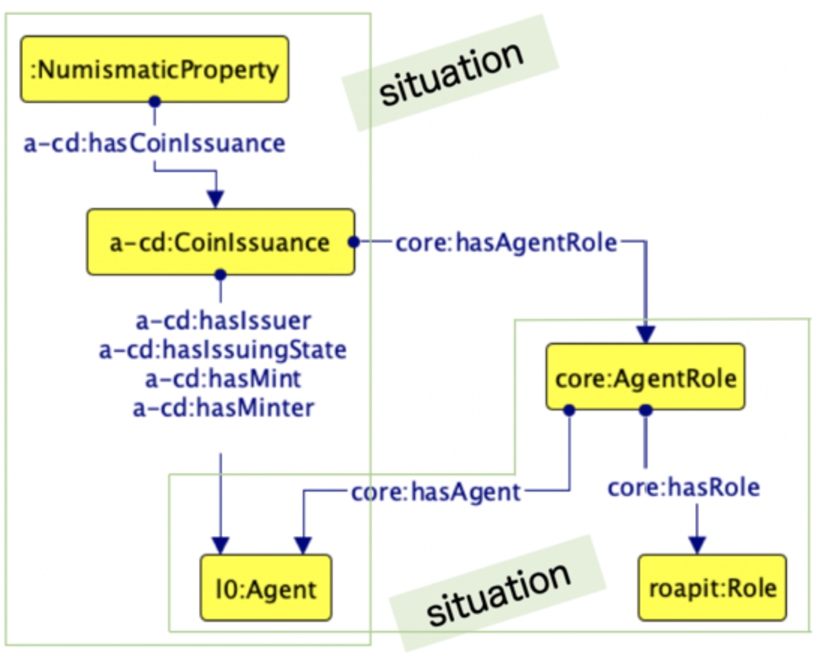
Situation ODP reused for representing the coin issuance.
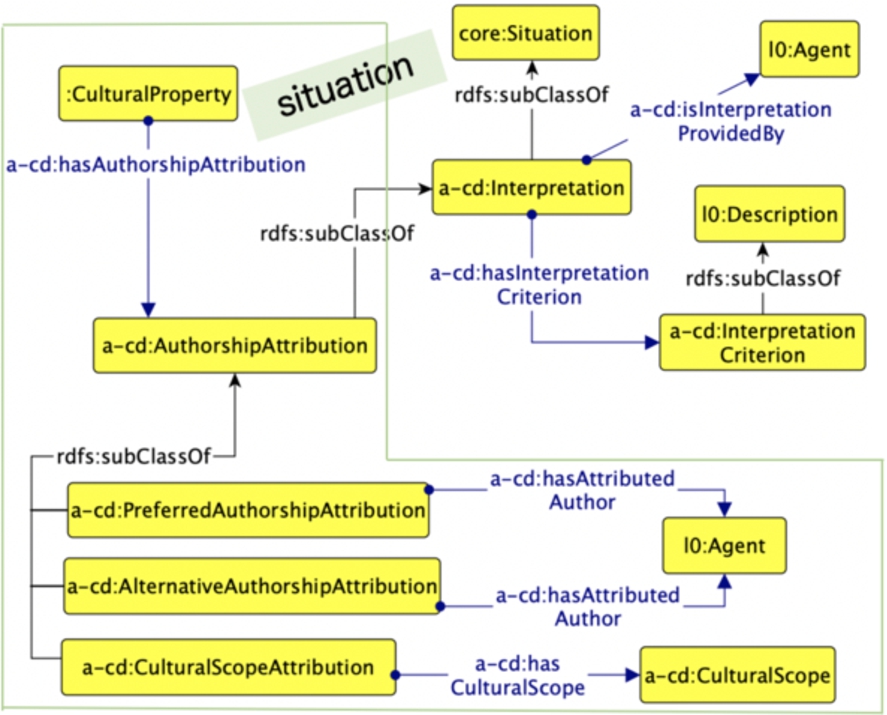
Situation ODP reused for the authorship attribution.
A central situation in which a cultural property can be involved is the authorship
attribution, a specific type of
Let us take as an example a coin55

The technical status of a cultural property Another example of situation involving a cultural property is its technical status. In this case, a cultural property is related to a set of technical characteristics, intended as its technical aspects, attributes or qualities. For instance, “the archaeological cultural property realised with pottery material and cylindrical in shape”. Technical status refers to physical features, since it involves characteristics of entities that are either physical objects or physical realisations of information objects. These characteristics can change over time, thus modifying the technical status of the cultural property: for example, a new survey on an archaeological monument may discover new materials used for its foundations. The temporal validity of a technical status refers to the moment when the characteristics were observed (and recorded in the catalogue record), until when a new condition occurs.
Different technical characteristics of a cultural property can be specified, in order to describe its technical status: the constituting materials (e.g. wood, clay), the employed techniques (e.g. oil-painting, melting), the shape (e.g. square, octagon), the file format for a digital photograph (e.g. “.gif”, “.jpeg”), the prevalent colour of a garment, etc. All these concepts (i.e. material, technique, shape) classify the corresponding technical characteristics (i.e. wood, oil-painting, square). The Classification56
A specific set of technical concepts classifying the technical characteristics of a cultural property type (e.g. an artwork) represents a way to conceptualise the technical status of a cultural property, hence they constitute a technical description (cf. Section 4.2 for the foundational description pattern reused here). For example, an artwork technical description may be defined as the relation between constituting material, employed technique, and shape. We say that such technical description uses these concepts. The technical status of artwork A1 could be wood, oil-painting, and square, while the technical status of artwork A2 could be clay, melting, and octagon. Both technical statuses are expressed according to the artwork technical description: we say that they satisfy it. The Description and Situation57

The D&S pattern reused and specialised for modelling technical descriptions and status of a cultural entity.
Figure 14a shows how we model the
Let us take a compass by an Italian workshop of the 19th century58
The involvement of a cultural property in an exhibition during its life cycle would be referred to, in everyday language, as a cultural event. When we informally refer to the repetition of a cultural event (e.g. different editions of an annual painting award), we use the term recurrent event as we are talking about an event that occurs more than once. Actually, we are implicitly referring to a series of conceptually unified situations: for example, the Art Biennale59
As these particular series of situations unfold, we can recognise a pattern in their iteration: an exhibition that has different editions over years usually follows a pattern in planning consecutive editions at regular time intervals (e.g. one edition per year). Moreover, it is possible to identify attributes that give all occurrences a unity: a general topic that does not change i.e. contemporary art, a place that hosts the situation i.e. Venice, etc.
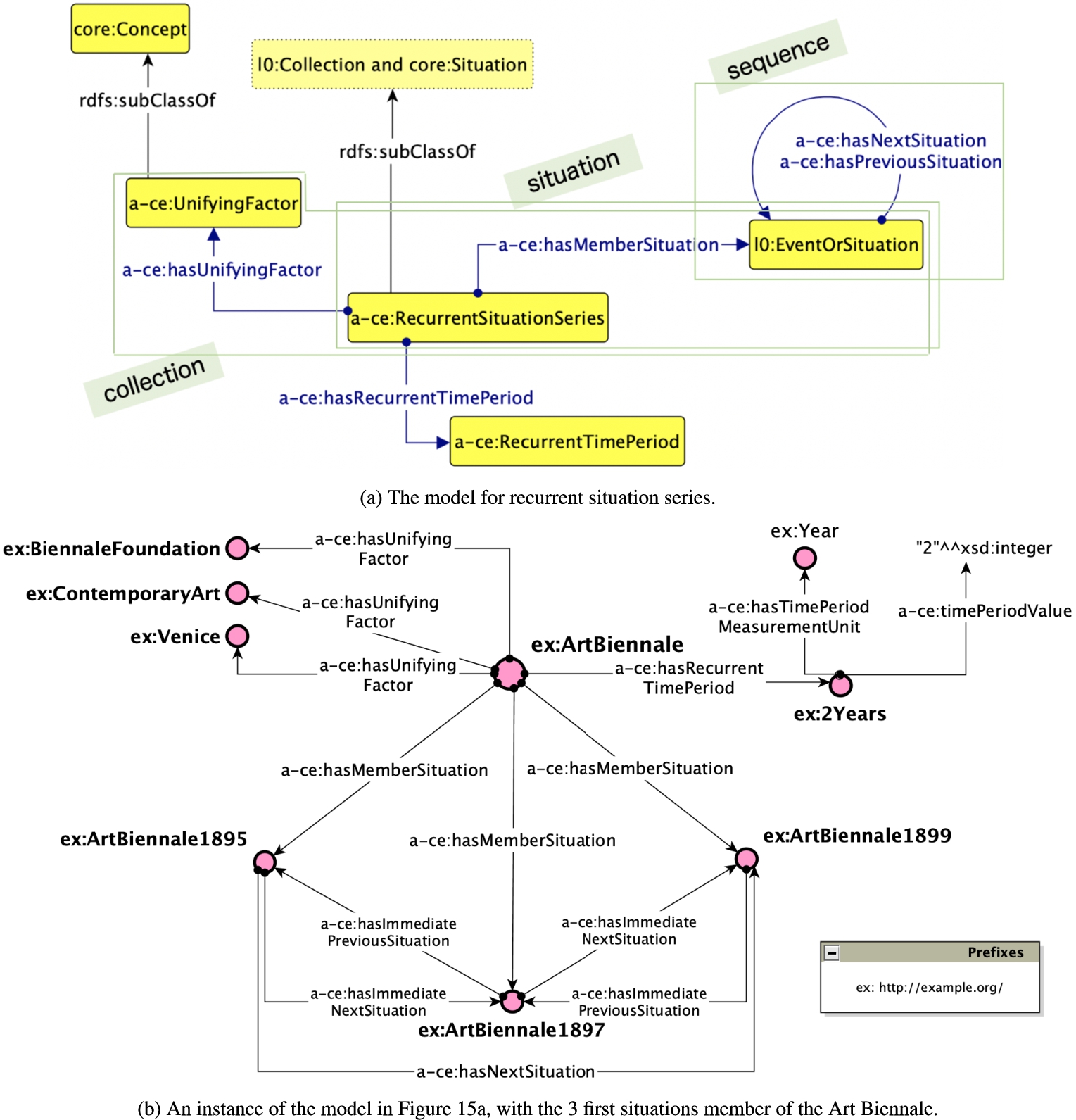
The new pattern Recurrent Situation Series as implemented in ArCo.
Recurrent situations are usually modelled as a special type of events (cf. Wikidata60
We represent, as depicted in Fig. 15a, recurrent situation
series (
In Fig. 15b we can see an instance of this pattern. The
Reusing ontologies and ODPs can be done by following two main different approaches, depending on the conditions and requirements of a project: direct and indirect reuse [54].
Direct reuse This approach consists in directly embedding individual entities or importing implementations of ODPs or other ontologies in the local ontology, thus making it highly dependent on them. This may jeopardise the stability of the ontology if the evolution of the imported ontologies is outside the control or monitoring of the team/organisation that is reusing them: even small changes in the reused ontologies could introduce inconsistencies in the local one, contrary to its original requirements. For this reason, ArCo directly reuses only two ontologies that are considered reference standards by the Italian Government and the evolving process of which is relatively slow and systematised, and involves ArCo’s team. These ontologies are Cultural-ON,63
Indirect reuse In this approach, relevant entities and patterns from
external ontologies are used as templates, by reproducing them in the
local ontology and providing possible extensions. Alignment axioms (such as
Annotating reused patterns supports the identification of ontology alignments, which is a tedious, non-trivial task. In fact, ODP annotations may ease the process to understand and explore an ontology. These assumptions have driven the development of the simple Ontology Pattern Language annotation (OPLa)66
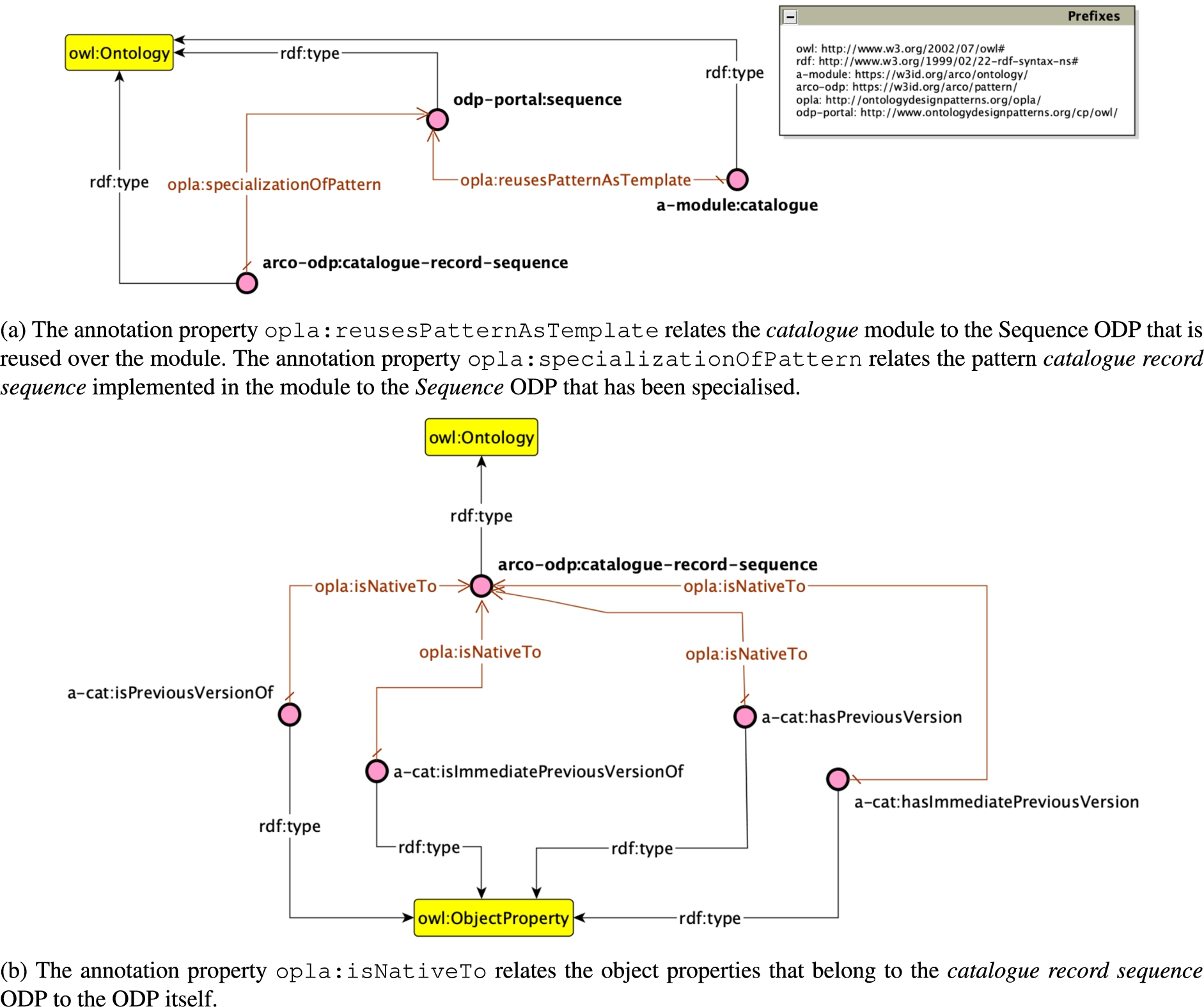
An example of a reused ODP annotated with OPLa ontology.
ArCo is evaluated along different dimensions: functional, logical, and structural dimensions as identified by [27]. The functional dimension is related to the intended use of a given knowledge graph (KG) and of its components, i.e. their function in a context. It is a core dimension for ontology testing. In fact, it allows ontology designers to assess the ability of an ontology to address requirements and cover the domain. The logical dimension measures whether an ontology can be successfully processed by a reasoner (inference engine, classifier, etc.). Finally, the structural dimension of a KG69
The authors of [27] refer to ontologies in their analysis. In the scope of this paper we generalise their results to knowledge graphs, since we also compute the distribution of the instances across classes.
CQ verification, inference verification and error provocation The logical dimension is addressed by running a reasoner on ArCo KG. This is a necessary step, but not sufficient. We regularly run a reasoner, but we perform additional tests at each iteration of the design methodology, i.e. every time new requirements are selected to be addressed. In doing so, we adopt the testing methodology described in [7]. This methodology focuses on evaluating the appropriateness of an ontology against its requirements intended as the ontological commitment expressed by means of CQs and domain constraints, i.e. functional dimension. User stories are translated into one or more CQs and general constraints during the design phase. To each CQ and to each constraint corresponds a unit test, which contributes, when run, to validate the ontology. Thus, the core element of each unit test is either a CQ or a general constraint (e.g. disjointness axiom). Accordingly, three different approaches are followed in the testing activity: CQ verification, inference verification, error provocation.
CQ verification This approach consists in testing whether the ontology vocabulary allows to convert a CQ, reflecting an ontology requirement, to a SPARQL query. Let us consider the CQ “When was a cultural property created, and which is the interpretation criterion which the dating is based on?”, which ArCo ontologies should answer, based on the collected requirements. The testing team starts verifying the completeness of the ontologies by translating this question from natural language to SPARQL, using classes and properties defined in ArCo ontologies (e.g. the entities defined for representing the date of creation of a cultural property). This step allows to detect any missing concept or gap in the vocabulary, e.g. whether the concept of interpretation criterion has been modeled. If the CQ can be successfully converted, the testers run the resulting SPARQL query over the actual RDF data or, when missing, over artificial data generated for testing purposes using Fuseki,70
Inference verification This step focuses on checking the inferences over
the ontologies, by comparing the expected inferences to the actual ones. Let us consider a
complex cultural property, which is a cultural property with one or more components, as
proper parts. If a
Error provocation This third testing activity is intended to stress the knowledge graph by injecting inconsistent data that violate our requirements.
For instance, the entities representing the concepts of dating and attributing an author
to a cultural property should be disjoint, since there can be no individuals that are
dating and authorship attributions at the same time. For validating the ontology regarding
this requirement, the testers inject in the KG an individual belonging to both
Refactoring and integration Problems spotted during the testing phase are passed back to the design team as issues. The design team refactors the modules and updates the ontology after performing a consistency checking. The result of this step is validated again by the testing team before including the model in the next release.
Evaluation tool We rely on TESTaLOD [11] for dealing with testing activities associated with CQ verification, inference verification, error provocation. TESTaLOD is a tool designed and implemented in the context of ArCo’s project for supporting not only the testing team of ArCo KG, but in general any testing team of projects adopting XD methodology or other test-driven methodologies. TESTaLOD is developed as a Web application71
Demo:
Source code:
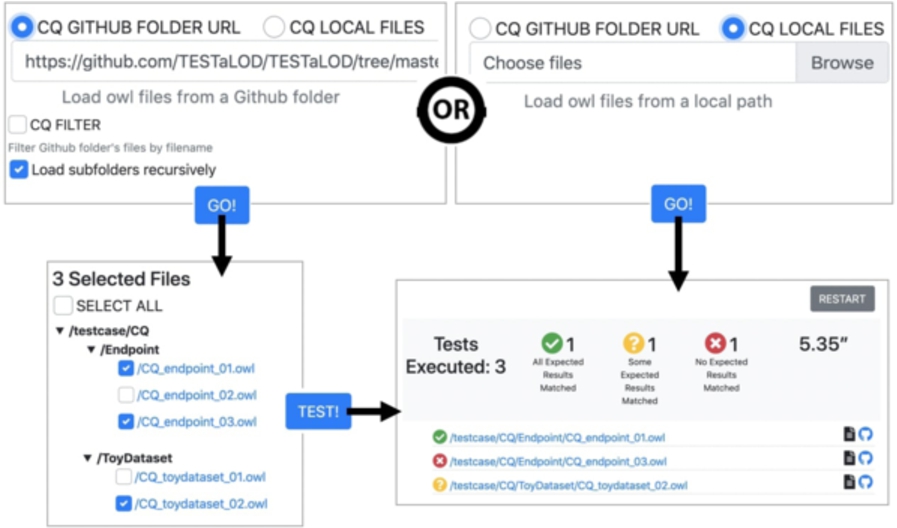
Workflow implemented by TESTaLOD based on the user interface.
Let us consider as an example the competency question “Which archival set (fonds, series, subseries) a cultural property is member of?”, and that we want to verify if our ontology models information on membership of cultural properties to archival record sets. The test case for running this test will be an OWL file, annotated with the following properties:72
In order to allow TESTaLOD to automatically run this test, two new annotation properties73
Terminological coverage Additionally, we further analyse the functional dimension by setting up an experiment aimed at assessing ArCo ontologies with regards to their ability in capturing and conveying domain-specific terminology. Inasmuch as only measuring the terminological coverage for ArCo ontologies might not be informative, we set up this experiment as a comparative analysis. For the comparison we select EDM74
Experiments execution and results The results recorded are the following.
Inference and CQ verification, and error provocation We define 18 test cases for inference verification, 29 test cases for error provocation, and 55 test cases for competency question verification. Each test case is publicly available on GitHub77
Terminological coverage The ontology alignment is computed with Silk [65] by using the substring metric with 0.5 as threshold. The alignment with the vocabulary is executed three times, i.e. once for each ontology involved in the comparison. The configuration files provided as input to Silk are available on FigShare.79
The link specification files for ArCo, CIDOC
CRM, and EDM are published with the DOIs

The terminological coverage as recorded for ArCo, EDM, and CIDOC CRM.
For assessing the structural dimension of ArCo KG we use different metrics that have been defined and used in literature [13,27,44,49,58,63,66]. First, we compute base metrics that record quantitative aspects of ArCo knowledge graph: classes and their instances, properties, axioms, etc. Then, we compute schema and graph metrics aimed at assessing (i) the richness, width, depth, and inheritance at the schema level and (ii) the cohesion, coupling, multihierarchical degree, and extensional coverage of the ontologies. Those parameters are used for understanding the quality of ArCo expressed in terms of (i) flexibility, (ii) transparency, (iii) cognitive ergonomics, and (iv) compliance to expertise. These quality properties have been defined in [27]: (i) flexibility is the property of an ontology to be easily adapted to multiple views; (ii) transparency is the property of an ontology to be analysed in detail, with a rich formalisation of conceptual choices and motivation; (iii) cognitive ergonomics is the property of an ontology to be easily understood, manipulated, and exploited by its consumers; and (iv) compliance to expertise is the property of an ontology to be compliant with the knowledge it is supposed to model.
The number of triples and individuals for EDM
were retrieved by querying the SPARQL endpoint of Europeana (i.e.
We use the CIDOC CRM v6.2.1 and EDM v5.2.4.
Available at
Available at
Available at
Comparison of base knowledge graph metrics as computed for ArCo v0.1, ArCo v0.5, ArCo v1.0, CIDOC CRM, and EDM, respectively. ArCo v1.0 is the latest release of the knowledge graph
Schema and graph metrics with corresponding quality properties addressed and values recorded. Values are reported for ArCo v0.1, ArCo v0.5, ArCo v1.0, CIDOC CRM, and EDM. ArCo v1.0 is the latest release of the knowledge graph
We focus on ArCo KG v1.0, which counts 20,030,941 individuals, for analysing the distribution of those individuals across classes. Such an analysis allows us to understand how individuals are organised in the knowledge graph with respect to concepts. This suggests possible compliance to expertise. In fact, it provides an indication about the recall of classes over the entities of the domain (i.e. the individuals). In this case the recall is meant as extensional coverage computed as the average number of entities captured by ontology classes. It is worth saying that compliance to expertise has a strong functional characterisation that we investigate further by analysing the functional dimension. Notwithstanding, the distribution of the instances across classes is a fair structural metric as it provides us a tool for empirically validating if dense areas (most populated parts of the ontology) correspond to ontology design patterns. The use of patterns is among the indicators suggested by [27] for measuring the quality properties of transparency and cognitive ergonomics. Figure 19 shows the top-50 ranked classes based on the number of individuals they have in the knowledge graph. The ranking including all the classes can be retrieved by querying the knowledge graph.86
The result set with
the ranking of all classes is available at

Top-50 ranked classes according to the number of individuals they have in the knowledge graph.
A high degree of modularity in an ontology is an indicator of transparency and flexibility. ArCo ontology network is highly modularised, however addressing transparency and flexibility meaningfully requires appropriate design of ontology modules. We compute the following metrics to assess the quality of ArCo modules.
Atomic size: the average size of a group of interdependent axioms in a module;
Appropriateness of module size: computed with the Schlicht and Stuckenschmidt function [58] that determines the appropriateness of an ontology module. The appropriateness value ranges from 0 (i.e. no appropriateness) to 1 (i.e. fully appropriateness). According to the Schlicht and Stuckenschmidt function a module size is as much more appropriate as the number of axioms defined in such a module is close to 250;
Encapsulation: the measure of knowledge preservation within the given module computed as defined by [44]. Encapsulation values range from 0 (poor encapsulation) to 1 (good encapsulation);
Coupling: the measure of the degree of interdependence of a module computed as proposed by [44]. Possible values range from 0 (high interdependence) to 1 (low interdependence).
Results of the module metrics
Table 4 reports the values recorded for the aforementioned module metrics computed for each ontology module of ArCo. Module metrics are obtained by using the Tool for Ontology Module Metrics87
The specific version of the tool we used can
be downloaded from
In the context of ArCo’s project, performing the testing activities initially resulted in a significant manual effort, for both annotating and running the unit tests. For this reason, TESTaLOD has been designed and implemented. The successful execution of inference verification, error provocation, and competency question verification is an indicator of (i) computational integrity and efficiency, and (ii) compliance to expertise. The former suggests that the ontology can be successfully processed by a reasoner. The latter suggests that ArCo KG is compliant with its collected requirements. Finally, the terminological coverage measured for ArCo (i.e. 0.72) shows very good results. In fact, the comparison with the results obtained for the Europeana Data Model (EDM) (i.e. 0.07) and for CIDOC CRM (i.e. 0.2) supports the claim that the expressiveness provided by such existing reference ontologies is not completely suitable for addressing ArCo’s requirements.
The analysis of the structural dimension shows that ArCo KG provides a larger terminological component than CIDOC CRM and EDM with 3,416 logical axioms, 340 classes, etc. ArCo is a massive knowledge graph counting of 172,580,211 triples describing 20,030,941 individuals. Nevertheless, ArCo is smaller than Europeana, which in turns counts of 2,836,270,332 triples describing 415,410,190 individuals. This finding is fair, first because ArCo is much younger than Europeana. Additionally, we remark that ArCo organises knowledge about Italian cultural properties only; on the contrary, Europeana contains structured knowledge about digital artifacts provided by 28 EU countries. Then, if we analyse the indicators obtained, we record that they suggest good transparency. In fact, we record:
39.55 axioms per class (i.e. axiom/class ratio), which is similar to that recorded for CIDOC CRM (41.7) and much higher than the number recorded for EDM (7.3);
an inheritance richness (2.48) comparable to CIDOC CRM (1.17) and EDM (0.32). This is a good indication of how well knowledge is grouped into different categories and subcategories in the ontology. Hence, it suggests a deep (or vertical) ontology, which, in turns, may indicate that the ontology covers a specific domain in a detailed manner;
a higher NoC (i.e. number of external classes) value for ArCo (38) than for CIDOC CRM (0) and EDM (3). However, this result should be contextualised with respect to the total number of classes (340, 84, and 41 for ArCo, CIDOC CRM, and EDM, respectively). Accordingly, we record 0.1, 0 and 0.07 external classes on average for ArCo, CIDOC CRM and EDM. This indicator suggests, besides transparency, low coupling;
a high degree of relatedness among the different classes, i.e. strong cohesion. In
fact, the classes are organised in a hierarchy with (i) a low depth (i.e.
Low coupling (i.e. NoC) and high cohesion (NoR, NoL, and ADIT-LN) also suggest flexibility, i.e. the property of adapting or changing the ontology with limited side-effects. The property of cognitive ergonomics (i.e. property of a knowledge graph to be easily understood, manipulated, and exploited by final users) is suggested by:
a lower class/property ratio for ArCo 0.44 (on a scale ranging from 0 to 1) than for CIDOC CRM (0.74) and EDM (0.84);
a low depth and breadth of the inheritance tree (i.e. 3.93 as ADIT-LN, 5 as max depth, 5.75 as average breadth, and 34 as max breadth). According to these indicators ArCo has a similar inheritance tree as EDM. Instead, the inheritance tree of CIDOC CRM is slightly different as it results in higher values for depth and lower for breadth. This means that ArCo has a more compact inheritance tree than CIDOC CRM;
a moderate tangledness (i.e. 0.56 on a scale ranging from 0 to 1) if compared to CIDOC CRM (0.18) and EDM (0.07). This suggests that the inheritance tree is more complex (a number of classes have multiple superclasses) than that of CIDOC CRM and EDM. We remind that this moderate complexity is only structural and derived from functional requirements. Nevertheless, the high number of annotation axioms (8,374) facilitates user readability. This value is much higher than (i) the total number of classes and properties in the ontology and (ii) that recorded for CIDOC CRM (2,589) and EDM (125);
the use of patterns. With regards to this it is worth noticing that patterns identify
dense areas within the knowledge graph. In fact, most of the top-ranked classes among
the most instantiated (cf. Fig. 19) identifies
patterns, such as those described in Section 5.
Significant examples are
With respect to the evolution of ArCo KG during the design process, we record a
significant growth of the knowledge graph from v0.1 to v0.5. For example the number of
axioms, classes, and object properties changes from 715, 54, and 38 to 9,564, 329, and
332, for v0.1 and v0.5, respectively. This observation is confirmed by the fact the
knowledge graph counts
Module metrics suggest that all modules are modelled by following a similar design
principle: identifying small and highly cohesive partitions as basic building blocks for
ontology design. This result is fully compliant with the pattern-based approach adopted
for modelling ArCo. As a matter of fact, the atomic size values we record are low and they
differ only slightly from one module to another, i.e. ranging from 4.85 (core module) to
6.63 (context description module). The appropriateness values recorded are optimal
(
Developing a KG using XD: Lessons learned
This project led us to reflect on both strong and weak points of the methodology applied, thus suggesting possible improvements for the future. In particular, in this section we want to focus on two key aspects of eXtreme Design methodology: (re)using patterns and test-driven design. Finally, we discuss how involving the community let us collect a wider set of requirements.
Reusing existing ontologies and patterns
eXtreme Design is a methodology that encourages the reuse of Ontology Design Patterns (ODPs), as common modelling solutions to classes of problems recurring in ontology design. Patterns to be reused can be both selected from dedicated catalogues (such as the ODP Portal (footnote 67)) and extracted from state-of-the-art ontologies. In Section 5.4 we briefly explained the two main practices for ontology reuse: direct and indirect [54].
Even if ODP catalogues represent a relevant support for pattern-based ontology design, there is a lack of well-documented and well-maintained high-quality ontology design patterns, as well as of tools for supporting ODP-driven ontology-engineering [5], which could guide the user in the selection of ODPs, e.g. by recommending possible ODPs to be reused for a certain modelling requirement. Additionally, using available ontologies as input to generate new ontologies is a difficult process, far from being automated [8,42,64], and can be hampered by scarcely documented ontologies, ontologies big in size and with a high number of classes, properties and axioms. Moreover, there is a need to carefully (thus time-consuming) consider the context, intended usage and semantic meaning of the ontology entities. Issues in reusing existing ontologies seem to be confirmed by [1], which observes a lack of explicit alignments between ontological entities in Linked Open Data, while the high number of top level classes may suggest a high number of conceptual duplicates.
Ontology reuse would benefit from annotations about the ODPs implemented by ontologies: [37] proposes a simple representation language for ontology design patterns (OPLa ontology), which makes use of OWL annotation properties for documenting ODPs. OPLa certainly contributes to fill a gap but its expressiveness requires an improvement. ArCo ontologies have been annotated with OPLa, but we soon realised that we were missing many relevant attributes of, and relations between, patterns that could be annotated and therefore possibly later detected from other parties.
As described in Section 5, during ArCo KG development we incrementally selected CQs from the available list and then match them with one or more existing ODPs. In this process, we also inspected state-of-the-art ontologies, such as CIDOC CRM (footnote 75), EDM (footnote 74), BIBFRAME,88
Testing an ontology network, which is periodically released in unstable and incremental versions, can be a time-consuming and repetitive activity, and, if performed manually, error-prone. Tests need to be run in order to validate our ontology, by translating competency questions into SPARQL queries, verifying expected inferences and provoking expected errors. Each time there are changes over the ontologies (e.g. a new version which models new information), new tests are created, and all previous tests must be executed again and, if needed, updated, in order to identify new possible bugs.
While performing testing in the context of ArCo KG, we realised that tools automatising it would have been of great support for the testing team. Building TESTaLOD (described in Section 6.1) helped us executing tests over new versions of the ontology network, allowing for automatic regression tests. At the moment TESTaLOD only addresses CQs-based testing and their corresponding SPARQL queries. Tests for inference verification and error provocation are executed externally. Moreover, the creation and annotation of test cases is not automatised. We believe that developing tools supporting (semi-) automatic creation of unit tests is of paramount importance to push the overall quality of released knowledge graphs. TESTaLOD is just a scratch on the surface of a possible tool suite for automatising many activities of ODP-based and test-driven methodologies such as XD.
Extended customer team for Cultural Heritage LOD projects
In ontology engineering methodologies, domain experts are the main actor and input source of requirements and validation tests: they give a crucial contribution, especially in defining domain and task requirements that guide the ontology design and testing phases [46]. User stories (then translated into Competency Questions) were used as a lingua franca for making communication effective between ontology designers and ICCD domain experts, during the development of ArCo KG.
Whilst not denying the key role played by ICCD domain experts in eliciting requirements, by means of both cataloguing standards, catalogue records and discussions on specific topics and issues, we believe that the Cultural Heritage (CH) domain has a specificity in its users: the community interested in CH data for different purposes is wide and diverse, involving domain experts, researchers, art critics, students, simple citizens, institutions and companies owning and managing CH data or data on related domains (e.g. tourism), public administrations and private companies offering services related to the CH domain, etc.
Cultural Heritage is usually managed with a top-down approach, where professionals and data owners (Galleries, Libraries, Archives, Museums, etc.) are in charge of defining standards and means for describing, representing and making available data on cultural heritage. More rarely, end-users are involved in this process. Instead, institutions aiming at enhancing cultural heritage would benefit from a bottom-up approach, alongside a top-down one, for collecting requirements from the community that consumes their data.
Linked Open Data projects can help in getting domain experts closer to their potential wide and diverse audience, and in promoting interactions between them. In carrying out the ArCo’s project, considering the characteristics of the CH domain and CH users, we involved a wider community in the requirements and feedback collection phase. Launching an Early Adoption Program, and involving the community in the unstable and incremental phases of the project, allowed us to capture a wider range of perspectives and requirements. For example, Synapta,90
With ArCo’s EAP, we experimented the involvement of private and public organisations, and extended XD to this purpose by identifying a set of tools (web forms, mailing lists, GitHub issue tracker), and practices that could support collecting requirements from such a diverse community (webinars, meetups). We believe that collecting requirements from a very diverse community is relevant for the CH domain but can apply also to other contexts, hence methodologies and possible supporting tools shall consider this aspect, so far neglected to the best of our knowledge, among their key requirements.
The Semantic Web and LOD principles have changed how cultural institutions manage and publish their data, how machines and users can access linked and enriched data on Cultural Heritage (CH), and have widened the possibility of reuse and generation of new knowledge starting from existing data. Ontologies make it possible to go beyond traditional CH data production and publication, providing users with new, more intelligent and eventually personalised Web applications and services, and with more and richer data [39].
LOD and ontologies for Cultural Heritage
Projects such as LODLAM92
Publishing and interconnecting data is leading to the creation of international CH portals [39], such as Europeana,99
Along with the publication of LOD collections, ontologies representing the CH domain are being developed, and some of them are becoming widely adopted standards, e.g. the Europeana Data Model (footnote 74) (EDM) [41] and CIDOC Conceptual Reference Model (CRM) (footnote 75) [19]. In addition to them, many other ontologies model specific domains that can be relevant to CH (e.g. the PRO ontology101
ArCo substantially contributes to the existing LOD CH cloud with a huge amount of invaluable data of Italian cultural properties, and an ontology network tackling overlooked modelling issues.
There is quite a variety of knowledge associated with works of art and their dynamics, including their dating, authorship attribution, history, maintenance, symbolic and cultural interpretation, catalog reporting, etc. The design of CH knowledge dynamics requires then sufficient flexibility, which ArCo gathers from its constructive stance, described in Sections 4.2 and 4.5.
We provide here some cases, where ArCo supplies modelling solutions that are not easily obtained in other widely adopted CH ontologies (see also some related foundational differences in Section 4.4).
As an example, the painting “Woman Portrait” by Caspar Netscher (17th century) is associated with several types of locations: it is now located at the Uffizi in Florence, it was stored in 1942 at Poppi Castle, it was involved (hence temporarily moved) in an exhibition at Pitti Palace in Florence in 1773 (cf. Fig. 20).

The painting “Woman Portrait” by Caspar Netscher (17th century) and the different (types of) locations it is associated with.
CIDOC CRM allows us to encode the data about all these locations by means of a “move” event that is both temporally and geographically indexed. This representation lacks the means to express (i) the knowledge about the type or motivation of a specific location, e.g. production, exhibition, storage, etc.; (ii) the temporal validity of that location, which is different from the time at which a moving event occurs; (iii) in addition, location types can be further characterised by other data or entities specific to them. In ArCo it is possible to represent the moving event with its temporal and spatial indexing, as well as the (functional) type of its locations with their own temporal validity, and their specificities. We also remark that CIDOC CRM events are defined as state changes, hence they should not be applicable to generalised situations or eventualities. However, CIDOC CRM condition states, which should cover the rest of phenomena (cf. Section 4.4), are not supposed to have participants. While in principle one could possibly extend CIDOC CRM to supply missing modelling solutions, in ArCo we stress the importance of having an explicit constructive stance (Section 4.2) providing patterns for joint modelling of events, situations, interpretations, etc.
Other examples of ArCo design patterns motivated by its constructive stance include: the modelling of catalogue records as entities of the CH domain representing interpretative perspectives on cultural properties, the recurrence of cultural events such as periodic festivals, as well as other situations in which cultural properties are involved (observations, issuances, etc).
Denotation, cataloguing, interpretation When modelling the CH domain, there are at least three levels of representation that might need to be investigated and modelled: (i) the cultural property as such, with its inherent attributes, (ii) the process of systematically gathering and recording pieces of information related to the cultural property, (iii) the process of interpreting these pieces of information in order to extract knowledge about the cultural property. These levels are separate, but interrelated. Cataloguing is a preliminary step for being able to get the attributes of a cultural property into the universe of discourse: for example, a tangible cultural property is made of a certain material, but without observing it, and collecting and recording data about the material of that specific cultural property, this information may be lost: this activity is essential for preserving cultural heritage. Moreover, cataloguing supports interpretations over cultural properties and their history, and interpretations can be in turn recorded by cataloguers.
We will call the first of these levels denotation, as the set of attributes of a cultural property that refer specifically and “literally” to that cultural property, without considering its context and the associated meanings that these attributes can have. The second level, cataloguing, is based on the observation and recording of the directly observable attributes of the cultural property, while the interpretation level discovers new knowledge on the cultural property by interpreting the meaning of one or more attributes within the context, e.g. the observable style of an artwork, or a bibliographic resource about it, can reveal its author.
ArCo distinguishes these three levels (cf. Section 4.5),
by providing models for: the denotative representation of a cultural property (materials,
conservation status, inscriptions, measurements, etc.); the process of cataloguing
(catalogue records as documents describing cultural properties, cataloguing agents, etc.);
the interpretation process, with agents involved and criteria guiding it
(
Both EDM and CIDOC CRM distinguish between the cultural object and possible information
resources related to it:
High-level vs. specific ArCo’s requirements are primarily based on the ICCD cataloguing standards: as explained in Section 2, catalogue records can describe 30 different types of cultural properties, each one with distinguishing features, not shared with other types. Specificity is therefore a key characteristic of ArCo ontologies, which provide cultural property-specific models to be reused, extending by specialisation the taxonomy offered by EDM and CIDOC CRM. As explained in [17], EDM has been developed for integrating and making interoperable various metadata standards from a multitude of Galleries, Libraries, Archives and Museums (GLAM) across Europe, as a “common denominator” model to use for the Europeana portal. Therefore, it is by design that EDM does not invest into a fine level of granularity or rich axiomatisation. It provides a basic set of classes and properties, which also includes many Dublin Core104
For example, a musical instrument would be of type
Specific types of cultural properties share some features (e.g. location, dating, author), but ArCo also needs to satisfy more modelling issues, overlooked by other ontologies so far, related to specific cultural properties, such as the diagnosis of a paleopathology and the interpretation of sex and age of death in anthropological material, other types of surveys on archaeological objects (e.g. laboratory tests), the coin issuance, the Hornbostel-Sachs classification of musical instruments, musicians and musical ensemble, recurrent art exhibitions, etc.
For example, let us take a modelling problem that a cultural institution publishing data
on anthropological materials may need to address: it has been estimated that discovered
anthropological materials (teeth, mandible and radius) are from a female individual dead
at young age. The assignments of the attributes “female” and “young age” would be modelled
in CIDOC as
Even in the case of features shared by most cultural properties, in many cases CIDOC
lacks the expressiveness needed for modelling ArCo data without missing information. For
example, according to CIDOC, changes of the physical location of a cultural property are
represented by move events, and we can only know from and to where the cultural property
was moved, and when the move happened, while there is no means to express e.g. the role
that a specific location played during a time interval, with respect to a specific
cultural property. EDM specialises
Alignments ArCo is aligned to both EDM and CIDOC CRM.108
For each module
of ArCo, a separate file stores its alignments, e.g.
Other alignments include: BIBFRAME (footnote 88), FRBR (footnote 89), FaBiO109
As discussed in [17], when building a knowledge graph (KG) for publishing its data, a cultural institution makes a first relevant choice: it can publish Linked Open Data by building and using its own infrastructure, give its data to a cultural heritage data aggregator such as Europeana, or invest in infrastructure for publishing its data as well as in the whole process for producing them, by using the ontology model of an aggregator. In making this choice, a cultural heritage administrator is influenced by different aspects both political, economical and technical.
An aggregator provides a single point of access to different collections from many cultural institutions, giving visibility and guaranteeing respective enrichment and interoperability. Nevertheless, the adopted ontologies only capture a subset and a simplified encoding of the available information about a cultural property because they prefer a lightweight modelling i.e. based on binary relations, as opposed to more complex predicates, e.g. n-ary relations. Many existing CH institutions provide data to Europeana and/or use Europeana Data Model, along with Dublin Core, for representing their collections, such as the Rijksmuseum dataset [18], possibly extending it, as in the case of the VVV ontology [20]. In each of these projects, the institution intentionally chooses to publish only a subset of all the features characterising cultural properties, which are instead present in the original dataset, in order to reuse EDM and avoid a more significant effort in mapping between the input data and the ontology model.
In our opinion, when possible, it is preferable for an institution to carry out the whole process of data production and publication and to release as much rich data as possible, while guaranteeing the interoperability with and the publication (of simplified or subsets of its data) through aggregators: this is the approach followed by ArCo. This choice allows a cultural institution to clearly define its requirements regardless of which data is possible to publish through an aggregator, and by using which ontology. Moreover, such an approach better supports an open requirements collection, not limiting the commitment of the developed ontologies to the institutional guidelines. Having full control on the ontological commitment minimises loss of information contained in input data, for reaching a wide audience of diverse users.
Conclusion
This paper presents how ArCo, a knowledge graph of Italian Cultural Heritage, has been designed, following the principles of the XD methodology. There are other valuable LOD resources containing and describing the Italian CH. Nevertheless, ArCo KG has a prominent role in this domain, not only because it injects in LOD a huge amount of high-quality data, extracted from the official institutional database of Italian Cultural Heritage (General Catalogue), but also because the expressiveness of its ontologies facilitates the adoption of its LOD by scholars and researchers in humanities and beyond, to make discoveries and find new patterns. The expected impact of ArCo KG on the general CH domain is motivated by a set of new requirements, addressed by its ontologies, which have been overlooked so far. These requirements emerged both from the richness of details provided by the General Catalogue records as well as from a growing community of consumers and producers of CH LOD.
ArCo KG can have an impact on the general Semantic Web community as well, since it is designed by following a robust methodology, based on the reuse of ontology design patterns, including extensive testing, detailed documentation and tutorial material, and formal evaluation: thus, it is a well-documented case study of the application of a methodology of ontology engineering (eXtreme Design), and can be used as a reference example by other researchers that are approaching knowledge graph engineering.
ArCo KG is still evolving and growing, and can be further improved and enriched. We plan to extend our ontologies, in order to model other aspects not addressed by the current version, e.g. some specific characteristics of naturalistic heritage, like slides and phials associated to an herbarium, the optical properties of a stone, etc. Being ArCo KG developed in the context of an evolving project, we keep encouraging our community to give us new requirements, in addition to continuous feedback, that we aim at addressing in the future. Moreover, in future requirement collection iterations, we want to extend our customer team to interested citizens, and further investigate how to best capture requirements from such a diverse audience.
ArCo KG will be enriched by extracting structured data from many textual metadata contained in the catalogue records (e.g. generic narrative descriptions of the cultural properties, historical biographical data about authors, etc.), using NLP techniques. Additional effort is being put to complete the translation of the data to other languages, starting from English, with an automated bootstrap to be refined by the community. Finally, ArCo’s project has highlighted the need for tools for facilitating reuse and testing, in general but also specific to the CH domain.