
Abstract
Within manufacturing processes, faults and failures may cause severe economic loss. With the vision of Industry 4.0, artificial intelligence techniques such as data mining play a crucial role in automatic fault and failure prediction. However, due to the heterogeneous nature of industrial data, data mining results normally lack both machine and human-understandable representation and interpretation of knowledge. This may cause the semantic gap issue, which stands for the incoherence between the knowledge extracted from industrial data and the interpretation of the knowledge from a user. To address this issue, ontology-based approaches have been used to bridge the semantic gap between data mining results and users. However, only a few existing ontology-based approaches provide satisfactory knowledge modeling and representation for all the essential concepts in predictive maintenance. Moreover, most of the existing research works merely focus on the classification of operating conditions of machines, while lacking the extraction of specific temporal information of failure occurrence. This brings obstacles for users to perform maintenance actions with the consideration of temporal constraints.
To tackle these challenges, in this paper we introduce a novel hybrid approach to facilitate predictive maintenance tasks in manufacturing processes. The proposed approach is a combination of data mining and semantics, within which chronicle mining is used to predict the future failures of the monitored industrial machinery, and a Manufacturing Predictive Maintenance Ontology (MPMO) with its rule-based extension is used to predict temporal constraints of failures and to represent the predictive results formally. As a result, Semantic Web Rule Language (SWRL) rules are constructed for predicting the occurrence time of machinery failures in the future. The proposed rules provide explicit knowledge representation and semantic enrichment of failure prediction results, thus easing the understanding of the inferred knowledge. A case study on a semi-conductor manufacturing process is used to demonstrate our approach in detail. The evaluation of results shows that the MPMO ontology is free of bad practices in the structural, functional, and usability-profiling dimensions. The constructed SWRL rules posses more than 80% of True Positive Rate, Precision, and F-measure, which shows promising performance in failure prediction.
Introduction
Manufacturing processes are sets of structured operations to transform raw material or semi-finished product parts into further completed products. To ensure high productivity, availability and efficiency of manufacturing processes, the detection of harmful tendencies and conditions of production lines is a crucial issue for manufacturers. In general, anomaly detection on production lines is performed by analyzing data collected by sensors, which are located on machine components and also in production environments. The collected data record real-time situations and reflect the correctness of mechanical system conditions. When the tendency of a mechanical failure emerges, experienced operators in factories are able to take appropriate operations to prevent the outage situations of production systems. However, as the collected data become more heterogeneous and complex, it is conceivable that the operators may fail to respond to mechanical failures timely and accurately. In the context of Industry 4.0, advanced techniques such as the Industry Internet of Things (IIoT) and Cloud Computing enable machines and production systems in smart factories to be interconnected to exchange data continuously. This trend has brought opportunities to manufactures to effectively manage and use the collected big data and has triggered the demand of methodologies to detect anomalies on production lines automatically.

A predictive maintenance task based on a cyber-physical approach [8].
In the manufacturing domain, the detection of anomalies such as mechanical faults and failures enables the launching of predictive maintenance tasks, which aim to predict future faults, errors, and failures and also enable maintenance actions. Normally, a predictive maintenance task relies on the monitoring of a measurable system diagnostic parameter, which identifies the state of a system [21]. In this way, maintenance decisions, such as calling the intervention of a machine operator, are proposed based on the severity of anomalies, to prevent the halt of the production lines and to minimize economic loss. Several techniques have been used to detect wear and tear in mechanical units and to predict future machinery conditions, such as machine learning, data mining, statistics, and information theory [10].
With the trend of Industry 4.0, the predictive maintenance tasks are benefiting from a cyber-physical approach. Within cyber-physical systems (CPS), production facilities are able to exchange information with autonomy and intelligence, which enable manufacturers to optimize the production processes. Fig. 1 shows the architecture of a CPS designed for predictive maintenance tasks. Within a CPS, predictive maintenance of manufacturing entities is performed based on a three-layer collaboration between the cyber space and the physical space: 1). The Physical Space, where machine operating data is gathered using sensors located on the machines and machine components. Additional data is collected from the products, manufacturing environments, as well as the machine operators’ experience; 2). The Cyber-Physical Interface, where statistical techniques such as data mining and machine learning use the collected data to understand the manufacturing processes and to learn from operators’ experience; 3). The Cyber Space, where decision-making about machine failure prediction and maintenance are proposed. In this layer, machine degradation models, and knowledge base of machine health are employed to predict machine damage, quality loss or maintenance demands in the future.
In the second layer of the architecture, data mining is normally performed by obtaining and processing sensor data that contain measurements of physical signals of machinery, such as temperature, voltage, and vibration. By identifying events and patterns that are not consistent with the expected behavior, potential hazards in production systems, such as power outage of the systems, could be detected.
However, sometimes the knowledge extracted from data mining is presented in a complex structure, therefore formal knowledge representation methods are required to facilitate the understanding and exploitation of it [42]. Furthermore, there may exist the semantic gap issue, which stands for the incoherence between the knowledge extracted from industrial data and the interpretation of the knowledge from a user [15]. To overcome these issues, semantic technologies have been utilized in several research efforts to promote the interpretation and management of knowledge [8,15,42]. Also, since semantic technologies ensure the explicit representations of machine-interpretable domain semantics, they can support the semantic interoperability in a large heterogeneous environment of loosely coupled systems [35]. In the data mining domain, several stages can benefit from the involvement of formal semantics, such as data transformation, algorithm selection, and post-processing [15]. Moreover, the use of semantic technologies can also integrate the capitalization of domain experts’ experience. For example, in a predictive maintenance task of machine cutting tool, when data mining algorithms fail to identify the occurrence time of a future cutter failure, logic-based expert rules which capitalize experience of domain experts can be applied to propose predictive decisions.
In the context of predictive maintenance in smart factories, pattern mining has been widely used to discover frequently occurring temporally-constrained patterns, through which warning signals can be sent to humans for a timely intervention [16]. Among pattern mining techniques, chronicle mining has been applied to industrial data sets for extracting temporal information of events and to predict potential machinery failures [12]. However, even though chronicle mining results are expressive and interpretable representations of complex temporal information, domain knowledge is required for users to have a comprehensive understanding of the mined chronicles [39]. As the predictive maintenance domain is becoming more knowledge-intensive, tasks performed in this domain can often benefit from incorporating domain and contextual knowledge, by which the semantics of the chronicle mining results can be explicitly represented and clearly interpreted. This helps to reduce the semantic gap issue. However, to the best of our knowledge, no work has been proposed to combine chronicle mining, and semantics to facilitate the predictive maintenance of manufacturing processes. Also, most of the existing research works about predictive maintenance in the manufacturing domain merely focus on the classification of operating conditions of machines (e.g., normal operating condition, breakdown condition...), while lacking the extraction of specific temporal information of failure occurrence. This brings obstacles for users to perform maintenance actions with the consideration of temporal constraints.
The use of chronicles for predictive maintenance in Industry 4.0: A case study
In manufacturing factories, rotating machinery is a core and critical component of a variety of machines, machine tools, industrial plants, and ground transportation vehicles. During the operation time of rotating machinery, several elements produce vibrations when the machine or machine tool is partially or completely degraded [6]. The analysis of these vibration signals allows the setting up of condition-based monitoring of rotating machinery and to avoid the breakdown of the machine or machine tool. Inside a piece of rotating machinery, bearings are the most important components for identifying the working conditions. The defects of bearings can be categorized into cage defect, a ball, or an inner race or outer race. These bearing conditions are identified by the monitoring and analysis of the root mean square (RMS) and the crest factor of the vibration signal.
For a machine that constructed with a set of rotating machinery, the mining of machine historical data allows the extraction of a set of chronicles such as the one shown in Fig. 2. Inside this chronicle, vertices are set of events characterized by the values of RMS and crest factor. Edges are the time intervals among different events. The numbers are associated with the time intervals, representing the lower and upper bound of the time duration. G stands for the good condition of the bearing, which indicates the bearing works without defect. Dir is the condition that the bearing suffers inner race defect, and Dor indicates the bearing is with outer race defect. F represents a failure event, which means the breakdown of the machinery.

A chronicle extracted from the mining of machine history data, for the aim of condition-based monitoring of a rotating machinery.
By matching a set of chronicles with real data, normal and abnormal machine conditions can be identified. Also, the occurrence of future machinery failures and the temporal constraints of these failures can be predicted. This allows the monitoring system to detect anomalies at an appropriate time, and send alerts/alarms to humans for a timely intervention [33]. The prediction of temporal constraints of failures can be further used for identifying the criticality of the failures, thus enabling machine operators to schedule maintenance actions intelligently [9].
To address the challenges mentioned in Section 1.1, in this paper, we propose an ontology-based approach to represent chronicle mining results in a semantic rich format, which enhances the representation and reuse of knowledge. The proposed approach is based on a combined use of chronicle mining and semantic technologies. By specifying domain semantics and annotating industrial data with rich and formal semantics, ontologies with their rule-based extensions help to address the issues described in Section 1.1. In more detail, the contributions of this paper are as follows:
We present a domain ontology named Manufacturing Predictive Maintenance Ontology (MPMO), which is a Web Ontology Language (OWL) [32] based ontology designed to model the knowledge related to condition-based maintenance. The MPMO ontology provides the foundation to formally represent chronicles with their numerical time constraints, for the purpose of predictive maintenance.
We propose an algorithm to transform chronicles into Semantic Web Rule Language (SWRL) based logic rules, by which the predictive results are formalized, thus interpretable for both human and machines. The proposed transformation enables the automatic generation of SWRL rules from chronicle mining results, thus allowing an automatic semantic approach for machinery failure prediction.
We evaluate the feasibility and effectiveness of our approach by conducting experimentation on a real industrial data set. The performance of SWRL rule construction and the quality of failure prediction is evaluated against the aforementioned data set.
The rest of this paper is structured as follows. Section 2 provides a review of existing ontology-based models and systems developed for predictive maintenance. Section 3 introduces the foundations and basic notions of chronicle mining and semantics that are necessary for describing our approach. It contains formal definitions of chronicles and the Semantic Web Rule Language (SWRL). Sections 4 presents a hybrid semantic approach for automatic failure prediction. The approach includes the use of the MPMO ontology, which models necessary and principle knowledge related to chronicles. We introduce a real-world example scenario and use it to describe our approach in detail. Also, one algorithm for transforming chronicles to SWRL-based predictive rules is introduced. Section 5 evaluates our approach through a real industrial data set. Section 6 gives concluding remarks and outlines future research directions.
Related work
There are plentiful of works that deal with the predictive maintenance tasks in Industry 4.0. In this section, we analyze the related works according to two perspectives: 1). The common approaches for machinery failure prediction within manufacturing processes; 2). Existing ontologies and ontological models that are used by knowledge-based predictive maintenance systems.
Common approaches to predictive maintenance in Industry 4.0
The main objective of machinery failure prediction is to estimate the time of the occurrence of future failures. The prediction is normally based on the examination of the current condition of the machinery and the past operation profile. The estimation of remaining useful life (RUL) is the main approach that is used in predictive maintenance. The commonly used methods for RUL estimation can be classified into four categories [18]:
Knowledge-based Models. This type of models assess the similarity between an observed situation and a databank of previously defined failures and deduce the life expectancy from previous events [44]. Normally, a knowledge-based model contains a rule base that consists of a set of rules. The rules are formulated as IF-THEN statements, and they are often proposed based on heuristic facts acquired by domain experts. Knowledge-based models can be further classified into Expert Systems and Fuzzy Systems.
Life Expectancy Models. They determine the RUL of individual machine components with respect to the expected risk of deterioration under known operating conditions [44]. This type of models can be further grouped into Stochastic Models and Statistical Models.
Artificial Neural Networks. They compute an estimated output for the RUL of a piece of machinery, directly or indirectly, from a mathematical representation of the machinery derived from observation data rather than a physical understanding of the failure processes [44]. This type of models can be used for direct RUL forecasting or parametric estimation for other models.
Physical Models. They compute an estimated output for the RUL of a piece of machinery from a mathematical representation of the physical behaviour of the degradation processes [44]. By using physical models, users can obtain a thorough understanding of the system behaviour in response to different levels of stress and burden, at both macroscopic and microscopic levels.
In this work, we focus on the use of Knowledge-based Models in predictive maintenance. In the next subsection, we present the existing solutions, especially the ontology-based approaches that are applied to failure prediction tasks.
Existing knowledge-based models to predictive maintenance
In recent years, several knowledge-based models have been proposed to facilitate the failure prediction tasks in the predictive maintenance domain. Among them, the ontology-based approach is an effective and notable method that has drawn considerable attention from researchers. Ontologies are explicit specifications of conceptualizations, and they are comprehensive and reusable knowledge repositories in various domains [22]. In general, this type of approach uses ontologies to formally define the semantics of knowledge and data, and utilizes sets of logic rules to enable ontological reasoning, for inferring new knowledge. The available research works related to this approach can be categorized into two major fields, according to different purposes: i) using ontology-based approach to represent data mining results in a formal and structured way, to further enrich knowledge bases; ii) using ontology-based approach to facilitate knowledge formalization,sharing and reuse in the predictive maintenance domain.
To formalize the data mining results and to facilitate the interpretation of them, many researchers tried to incorporate explicit domain knowledge with using ontologies. The DAMON ontology [7] is developed as a data mining ontology to simplify the development of distributed knowledge discovery systems. The ontology is used as a knowledge reference model to help domain experts solve tasks. Also, the ontology enables users to search for data mining resources and software when they want to find solutions for a specific problem. The EXPO ontology [46] formalizes concepts about experimental design, methodologies and results representation in a general way. The ontology promotes the sharing of experimental results within and among different subjects, and it can reduce the information duplication and loss in the sharing process. The OntoDM-core ontology [38] is developed to formally describe core data mining entities. The ontology provides a framework to represent essential and basic data mining concepts, such as data sets, data mining tasks, algorithms, and constraints. The advantage of this ontology is its powerful representation of constraint-based data mining activities.
The use of an ontology-based approach can also facilitate knowledge formalization, sharing and reuse in the predictive maintenance domain. In the context of predictive maintenance, several ontologies and ontology-based intelligent systems are developed to achieve this goal. To enhance the expressiveness of these ontologies, several rule-based extensions were proposed to perform ontological reasoning, in order to facilitate maintenance decisions of users. We review existing ontologies according to two aspects: ontologies that model manufacturing processes and ontologies that model preventive maintenance tasks.
As indicated in the introduction, manufacturing processes are structured sets of operations that transform raw materials or semi-finished product segments into further completed product parts. Over the last decades, several ontologies have been developed to represent knowledge about manufacturing processes. The Process Specification Language (PSL) ontology [23] is one of the early-stage contributions. This ontology axiomatizes a set of semantic primitives that are essential for describing a wide range of manufacturing processes. The axioms defined in this ontology model the key elements of manufacturing processes, such as process scheduling, process modeling, production planning, and project management [23]. Another contribution in this subdomain is the Manufacturing Service Description Language (MSDL) ontology, which defines a well-defined framework for formal representation of manufacturing services [2]. This ontology formalizes manufacturing capabilities of manufacturing resources in different levels of abstraction, based on which a rule-based extension of the ontology is proposed to enable automatic supplier discovery. At last we mention the Manufacturing Reference Ontology (MRO) [48] that is developed to formalize a set of core concepts about the manufacturing in a high abstraction level. The ontology categorizes the manufacturing domain into eight general concepts: Realized Part, Part Version, Manufacturing Facility, Manufacturing Resource, Manufacturing Method, Manufacturing Process, Feature and Part Family. This categorization enables further development of more specific ontologies in the production domain.
Compared to ontologies that model manufacturing processes, ontologies for predictive maintenance are much less numerous. These type of ontologies normally focus on the issues of fault or failure prognostics and machine health monitoring. Among these ontologies, the OntoProg Ontology [34] addresses the failure prediction of machines in smart factories. The ontology is developed based on a set of international standards, and a classification for severity criteria, detection, diagnostics and prognostics of failure modes is provided. The ontology standardizes the concepts that are necessary for tackling machinery failure analysis tasks. As another most recent contribution, the Sensing System Ontology [31] is proposed to define the embedded sensing systems for industrial Product-Service Systems (PSSs). This ontology is used as the backbone of the PSS knowledge-based framework and it describes the sensors that are embedded on PSSs, for the aim of providing customized services for users.
A comparison between the proposed MPMO ontology and the existing ontologies with respect to their domain coverage
A comparison between the proposed MPMO ontology and the existing ontologies with respect to their domain coverage
We summarize the domain coverage of existing ontologies in Table 1. A comparison among existing ontologies with respect to the MPMO ontology is also presented. We evaluate the domain coverage and scopes of these ontologies by examining whether the key concepts required for describing the predictive maintenance domain are covered and formally described in existing ontologies. These key concepts can be categorized into three subdomains: Manufacturing, Context, and Condition Monitoring. For the Manufacturing subdomain, the key concepts are Product, Process and Resource. For the Context subdomain, the key concepts are Identity, Activity, Time, and Location. While for the Condition Monitoring subdomain, Anomaly, Fault, Failure, Severity, Prognostics, Diagnostics, Alarm, and Alert are the key concepts. These concepts form the columns of the Table 1, and the ontologies are enumerated by rows. If the concept is covered by the ontology, a check mark is placed in the table. Otherwise, a cross mark is assigned.
After reviewing the ontologies mentioned above, we recognize that none of them provides a satisfactory knowledge representation of the three subdomains. Some of these ontologies focus on a narrow field, such as manufacturing resource planning, and they do not formalize predictive maintenance-related concepts, e.g., machinery Failure and Fault. Also, none of the existing ontologies standardize the concepts related to chronicle mining. To jointly use chronicle mining with semantic technologies for a predictive maintenance task, the knowledge-based model should incorporate not only the machine-interpretable knowledge of manufacturing entities such as product and process but also the knowledge about chronicles within which the machinery failures are described in a structured way. To this end, an ontology that formally describes all the concepts in Table 1 is needed. This motivates us to propose the MPMO ontology. The MPMO ontology aims to formalize all the predictive maintenance-related concepts as well as relationships.
In this section, we introduce the foundations and basic notions of chronicle mining and semantics that are necessary for describing our approach. The foundations include a formal description of Sequential Pattern Mining (SPM) and chronicles, as well as an introduction to Semantic Web Rule Language (SWRL).
Foundations of sequential pattern mining
In industry, data collected for preventive maintenance tasks are normally represented as sets of sequences with time stamps [43]. To cope with this type of data sets, SPM is one important technique to extract frequently occurring patterns. SPM was first studied by [1], to analyze customer purchase behavior sequences. One SPM task could be described as follows: Given a data set containing a number of sequences, the goal of SPM is to find sequential patterns whose support exceed a predefined numeric support threshold.
This support threshold indicates the minimal number of occurrences of the sequential patterns, and the found patterns are called frequent sequential patterns. For the output of SPM algorithms, each frequent sequential pattern is a sequence which consists of a set of items in a certain order.
An example sequence data set
An example sequence data set
To give a formal description of sequential patterns, in this subsection we review the definitions of key concepts. A sequence S is a set of ordered itemsets, denoted by
Over the last decades, considerable contributions have been settled in the research field of SPM [19]. As a result, various SPM algorithms have been proposed to mine frequent sequential patterns. Based on these proposed SPM algorithms, a variety of approaches and experiments have been launched to improve the performance and efficiency of SPM tasks.
Even though sequential patterns contain information about the orders of items, the algorithms introduced in the previous section cannot specify the time intervals between elements and items. In real-world situations, the occurrences of events are often recorded with temporal information, such as time points and time intervals between events. Thus, several contributions have been proposed to obtain the time intervals between successive items in sequences. The notion of the time-interval sequential pattern is first presented by Yoshida et al. [51]. The authors name this kind of patterns as “delta patterns”. A delta pattern is an ordered list of itemsets with the time intervals between two neighboring itemsets. It can be represented as
With the introduction of delta patterns, a group of algorithms were proposed to facilitate the mining process in temporal sequence data sets. One significant contribution is the work by Hirate et al. [25]. In this work, the authors propose the Hirate–Yamana algorithm to mine all frequent time-extended sequences. To do this, the authors generalize SPM with item intervals. In the generalization, they define a set of time-extended sequences, denoted as
If the data sets contain time stamps, which indicate the transaction occurrences of items, then
If the data sets do not contain time stamps, then
The study on existing notions and algorithms help to capture the core concepts in the domain of time-interval SPM. These core concepts form the foundations of chronicle mining.
Foundations of chronicle mining
As introduced in the previous section, the temporal patterns we consider in this paper are chronicles. To give formal definition of chronicles, we start by introducing the concept of Event, given by [12].
(Event).
Let
A sequence contains a set of ordered events, which are timestamped. The events contained in a sequence appear according to their time of occurrences.
(Sequence).
Let
When the events are time-stamped, how to describe the quantitative time intervals among different events is vital important for the prediction of possible future events. To achieve this goal, we introduce the notion temporal constraints in the following definition. The definition of temporal constraints is adopted from the one introduced in [12].
(Temporal constraint).
A temporal constraint is a quadruplet
We say that
With obtaining introducing the events and temporal constraints among different events within a sequence, we are able to define the concept of chronicles [12].
(Chronicle).
A chronicle is a pair
In the chronicle discovery process, support is used as a measure to compute the frequency of a pattern inside a sequence. It can therefore be formalized by the definition below.
(Chronicle support).
An occurrence of a chronicle
The relevance of a chronicle is essentially based on the value of its support.
To illustrate these basic definitions, we give an example including a sequence and a chronicle extracted from it. Assuming a sequence S contains three events
A sequence representing three events.
In Fig. 3, time constraints that describe the pattern
After the generation of temporal constraints, these events can be represented as a graphical way, as shown in Fig. 4. In the figure, events are represented by the circles, and temporal constraints are displayed through arrows among events. The values above each arrow are quantitative numerical bounds of temproal constraints.
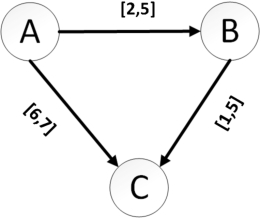
Example of a chronicle.

The procedure of the semantic approach for predictive maintenance.
In the domain of predictive maintenance, frequent chronicle mining has been used to detect machine anomalies in advance. To combine frequent chronicle mining and semantics for facilitating predictive maintenance tasks, a special type of chronicles, called failure chronicles is introduced [43].
For a chronicle
In [43], a new algorithm called CPM has been introduced to mine frequent failure chronicles. Based on their work, in this paper, we propose a novel algorithm to automatically generate SWRL rules from frequent failure chronicles. The generated SWRL rules aim to provide decision making for predictive maintenance in industry. The algorithm is introduced in Section 4.
Semantic web rule language
Semantic Web Rule Language (SWRL) is based on a combination of its sublanguages OWL DL and OWL Lite with the RuleMarkup Language. A SWRL rule is in the form of an implication between an antecedent (body) and consequent (head), which can be interpreted in a way that whenever the conditions specified in the antecedent hold, then the conditions specified in the consequent must also hold [28]. In SWRL, a rule has the syntax:
In this work, the reason we choose SWRL rules is two-fold. Firstly, SWRL provides model-theoretic semantics and has the advantage of its close association with OWL ontologies, which enables the definition of complex rules for reasoning about individuals in ontologies. Secondly, the use of SWRL to write rules is independent of rule implementation languages within rule engines, which has the advantage of the flexible selection of rule engines and inference platform.
To represent data mining results, especially chronicles, in a formal and structured way, we use ontologies as well as SWRL rules to propose predictive rules. The proposed rules describe events and temporal constraints within chronicles, and predict a special type of event (a machinery failure), with corresponding to temporal information.
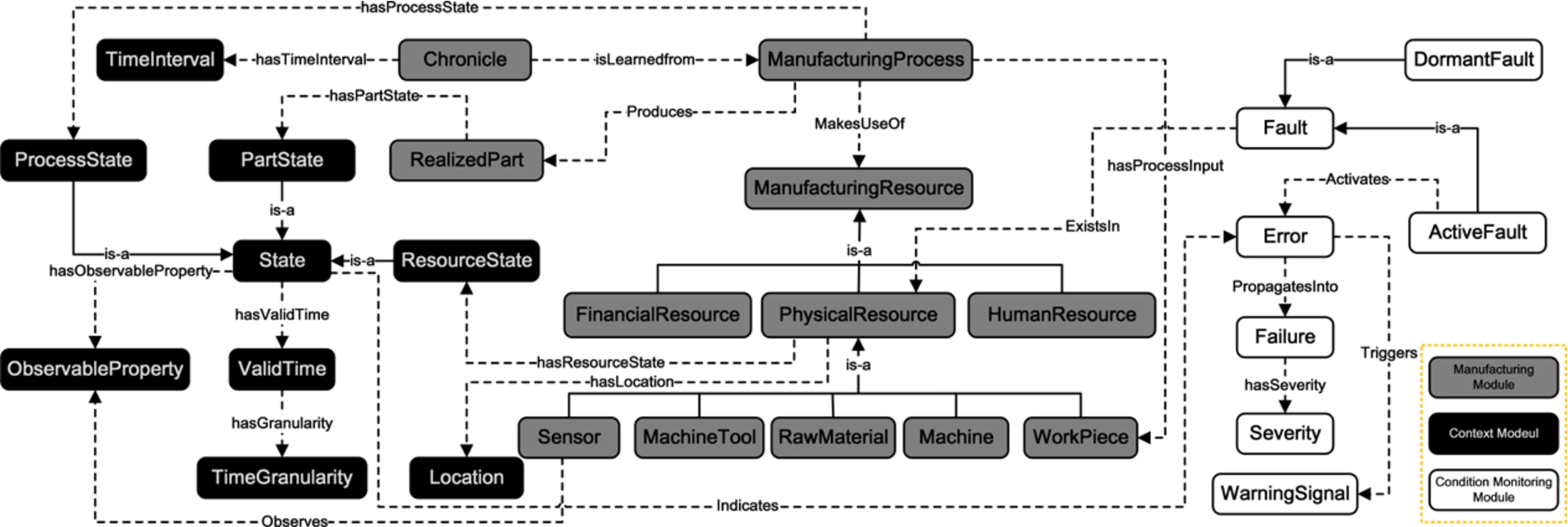
The global architecture of the MPMO ontology [8].
To propose the novel hybrid semantic approach for predictive maintenance, we jointly use data mining and semantic technologies, within which chronicle mining is used to predict the future failures of the monitored industrial machinery, and domain ontologies with their rule-based extension is used to predict temporal constraints of failures and to represent the predictive results formally. The procedure of the semantic approach is shown in Fig. 5. Firstly, data pre-processing is implemented on raw industry data sets to obtain sequences in the form of pairs (event, time stamp), where each sequence finishes with the failure event. Secondly, frequent chronicle mining algorithms mine the pre-processed data to discover frequent patterns that indicate machinery failures. Thirdly, based on the mined frequent patterns, semantic technologies are used to automate the generation of SWRL-based predictive rules. These rules enable ontological reasoning over individuals in ontologies, thus facilitating decision making.
Domain knowledge
Within an intelligent system, ontologies contain the domain knowledge to operate. In this work, the MPMO ontology is developed to describe the concepts and relationships within chronicles. The definitions of key concepts and relationships in the MPMO ontology are formalized based on the basic notions introduced in Section 3. To ensure the reusability of the MPMO ontology, we adopt the ontology modularization method during the development process [14]. As a result, the ontology is constructed with three small reusable modules: the Condition Monitoring Module, the Manufacturing Module, and the Context Module. In this way, other ontology engineers and ontologists can reuse a portion of the MPMO ontology when they need. This ensures the reusability of the MPMO ontology. Fig. 6 shows the global architecture of the ontology. In the figure, round rectangles stand for classes, solid lines stand for is-a or subsumption relationships, and dashed lines represent object properties. The classes with gray background belong to the Manufacturing Module, classes with black background are associated with the Context Module, and classes with white background belong to the Condition Monitoring Module. More detailed descriptions of the MPMO ontology can be found in our previous paper [8].
The original MPMO ontology is not capable of providing specific knowledge about different types of events (non-failure events, failure events) as well as their temporal information. This motivates us to develop a more specific domain ontology, which extends the MPMO ontology and focus on the modelling of essential knowledge for failure prediction. To enable failure prediction based on chronicles, we extend the MPMO ontology to describe different types of events and their temporal information. We use a UML notation where boxes stand for ontology classes, and arrows represent object properties. Data properties are indicated by class attributes. The UML diagram for describing the main classes is shown in Fig. 7. For the purpose of clarity, only a subset of the whole classes and relationships are presented.
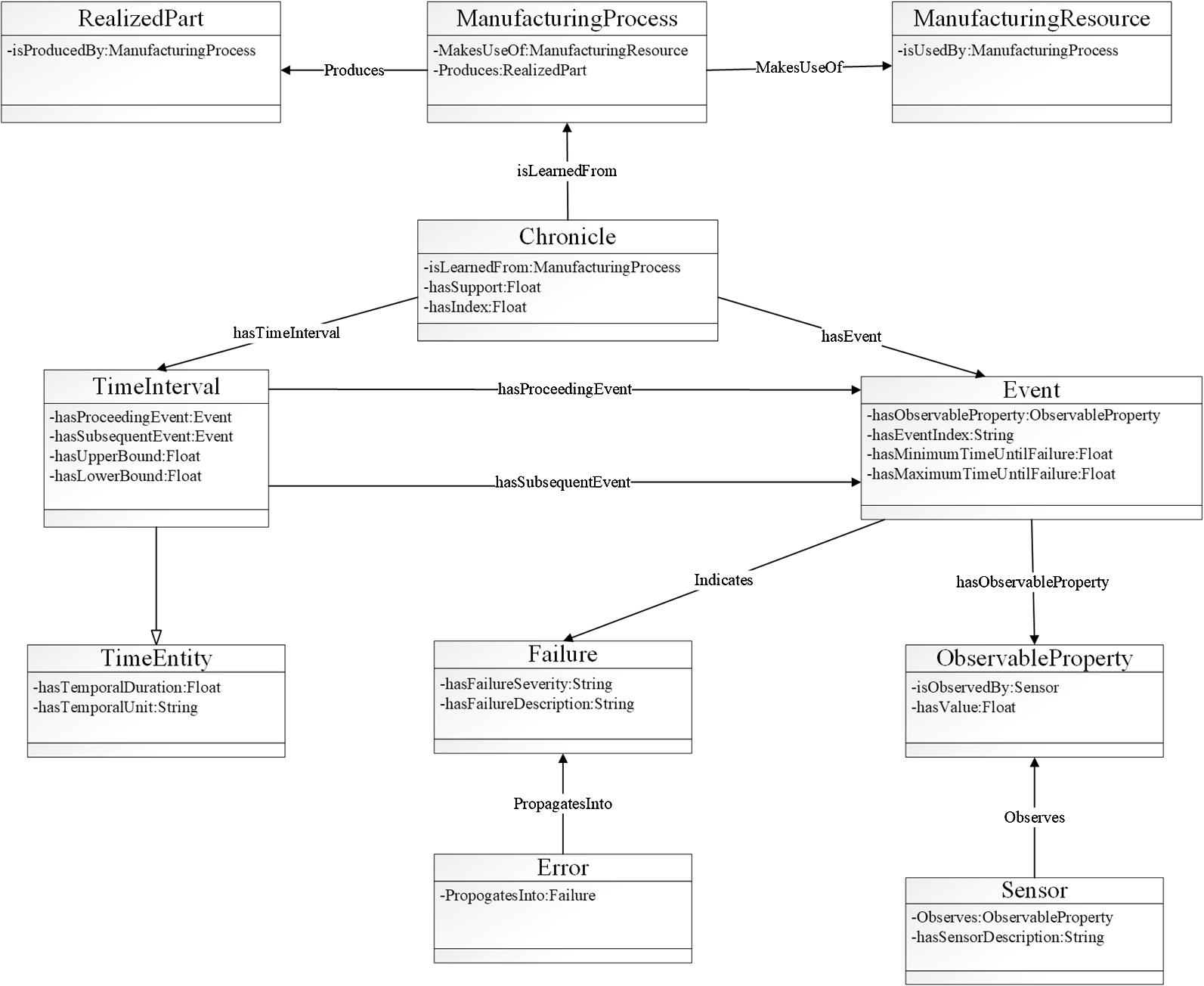
The main classes in the extended MPMO ontology.
We then give the axioms of the main classes in the MPMO ontology. The axioms defining the main classes are presented below using the description logic (DL) syntax [4].
ManufacturingResource: This class describes the resources that are used within manufacturing processes. It consists three subclasses: FinancialResource, HumanResource, and PhysicalResource. Among the three subclasses, PhysicalResource stands for a set of physical entities that the predictive maintenance tasks are performed upon, such as machine tools, workpieces, and final products. The definition of this class is extended from the class MASON: Resource, in the MASON ontology [30]. The DL axioms for defining this class and the PhysicalResource class are
ManufacturingProcess: It describes different types of structured sets of operations that transform raw materials or semi-finished product segments into further completed product parts [8]. The DL axioms for defining this class are
Chronicle: Chronicles are a special type of temporal patterns, in which temporal orders of events are quantified with numerical bounds [12]. To introduce this concept in the MPMO ontology, we use the following axiom.
Event:. In predictive maintenance tasks, an Event is generally associated with a set of ObservedProperties which indicate the correctness of the operation of a piece of machinery. In this context, the DL axioms for defining this class is
ObservedProperty: This is an attribute which represents some significant measurable characteristic of a monitored ManufacturingProcess, ManufacturingResource or RealizedPart. The value of an ObservedProperty is measured by sensors which are located at different components of the monitored entity. This class is also called Attribute. The DL axioms for defining this class are
Failure: This class represents the Failures that are indicated by Events. A Failure is the inability of an entity to perform one required function, and it can be the result of a propagation of a machinery error [3]. The following axiom is used to define this class:
TimeInterval: A temporal entity with an extent or duration. The definition of this class is adopted from the Time Ontology [26]. The axiom for describing this class is
By defining the common concepts and relationships in the predictive maintenance domain, the MPMO ontology can support semantic interoperability among different systems and system components. Also, the MPMO ontology provides rich representations of machine-interpretable semantics for knowledge-based predictive maintenance systems. This ensures the predictive maintenance systems can interoperate with shared semantics and a high level of semantic precision.
In the proposed semantic approach, different SWRL rules are used for predicting machinery failures. The launching of these rules allows reasoning over individuals contained in the MPMO ontology. In this subsection, we first introduce SWRL rules which are used to predict the time interval between a certain event and a future failure, and then introduce the algorithm developed for transforming chronicles into SWRL rules. The proposed rules and algorithm enable the semantic approach for automatic failure prediction in the predictive maintenance domain.
Failure time prediction rules
Chronicles provide not only the order of occurrence of events, but also the intervals of time they occur in. Fig. 8 gives an example failure chronicle within which the last event is a failure.

Example of a failure chronicle.

Example of a SWRL-based predictive rule, generated from the chronicle introduced in Fig. 8.
Inside the chronicle, A, B and C are different events. The three events are identified by their associated observed properties and quantitative values. The observed properties and quantitative values are obtained by a feature selection method, that determines the most relevant attributes in predicting the future failures. The last event C indicates a failure, and the time intervals among events A, B with event C gives the temporal information of a future failure (event C).
However, even though the chronicle in Fig. 8 is represented in a structured format, it lacks formal semantics and domain knowledge to be interpreted by humans and predictive maintenance systems. For example, the descriptions of events A, B, and C are missing, which may cause the semantic gap between chronicle mining results and users. To overcome this issue, we use ontologies with their rule-based extensions to represent chronicles in a semantic rich format, which helps the sharing and reuse of chronicle mining results.
As the mining of sequential data sets can generate frequent failure chronicles, SWRL rules can be proposed to reason about temporal information of machinery failures. Therefore, when a new sequence of times-tamped events arrive, SWRL rules can be launched to predict the time intervals among different events and future failures. As stated in Section 4.1, an event within a chronicle is determined by a set of observed properties (with their associated values). Based on this definition, we construct the antecedent of such a rule by describing quantitative values of observed properties (attributes) and the temporal constraints inside a chronicle. The consequent of such a rule comprises the lower and upper bounds of the time intervals among certain events and the failure.
Based on the chronicle in Fig. 8, a SWRL rule can be elicited. Fig. 9 demonstrates how the rule that describes different events and temporal constraints can be constructed from the chronicle in Fig. 8. Within the rule, Chronicle stands for the root class of all the chronicle individuals in the ontology. hasEvent is the object property that links individuals of the class Chronicle and those under the class Event. hasA1V, hasA2V, hasA3V, and hasA4V are data properties that assign quantitative values of attributes to the two individuals A and B under the Event class. TimeInterval corresponds to the root class of all individuals of time intervals. There are two object properties that link TimeInterval with Event: hasSubEvent and hasProEvent, among which hasSubEvent corresponds to the subsequent event of a time interval, and hasProEvent indicates the proceeding event of a time interval. In this case, event A is the proceeding event of the time interval between A and B, and event B is the subsequent event of this time interval. By describing the numerical values of different attributes and the time interval with its proceeding and subsequent events, temporal constraints among events A, B with the failure C are indicated. The temporal constraints comprise the minimum time duration between an event with the failure, described by the data property hasMinF, and the maximum time duration between an event with the failure, described by another data property hasMaxF.
To enable the automatic generation of a SWRL rule, in this work we propose an algorithm to transform chronicles into predictive SWRL rules. Algorithm 1 demonstrates the general idea of our rule transformation method. It runs in four major steps:
The function LastNonfailureEvent extracts the last non-failure event within a chronicle.
For each temporal constraint in a chronicle, the two functions ProceedingEvent and SubsequentEvent extract the proceeding and subsequent events of the time interval that is defined in this temporal constraint. Then the two events and this time interval forms different atoms in the antecedent of the rule, and they are treated as conjunctions.
For each last non-failure event before the failure (there could be multiple last events before the failure), extract the temporal constraint between this event and the failure. The extracted temporal constraint is treated as a conjunction with the last event, to form the consequent of the rule.
At last, a rule is constructed as an implication between the antecedent and the consequent.

Algorithm to transform a chronicle into a predictive SWRL rule
We then analyze the time complexity of Algorithm 1. The input of the algorithm is a chronicle
A sequence can be described by one or multiple chronicles. To improve the quality of failure prediction, we only keep the most relevant chronicles for the rule transformation. In this context, we take features of chronicles such as Chronicle Support as a reference measure, to select the most relevant chronicles.
We validate our approach by conducting experimentation on the SECOM data set [17], which contains measurements of features of semi-conductor productions within a semi-conductor manufacturing process. To evaluate the effectiveness of our approach, a software prototype is developed based on Java 10.0.2, Protégé 5.5.0 [20], OWL API [27] and SWRL API [36].1
The source codes for this paper can be found at: https://sites.google.com/view/combiningchronicleminingandsem/home.
In the SECOM data set, 1567 recordings and 590 attributes are collected, with each recording being characterized by a time stamp referring to the time that the data is recorded. Each recording is also associated with a label, which is either 1 or −1. The label of every recording explains the correctness of the event, with −1 corresponding to a non-failure event, and 1 refers to a failure. Timestamps are associated with all the records indicating the moment of each specific test point. In total, 104 pieces of records represent the failures of production. The data is stored in a raw text file, within which each line represents an individual example of recording with its timestamp. The features are separated by spaces.
However, the data contained in SECOM data set do not have the same types of attributes and values, that some of the information contained in the data is irrelevant to the failure prediction task thus is considered as noise. Moreover, due to the inter-dependency among individual features and the complex behavior of combined features, it is difficult to extract frequent patterns and rules based on analysis of all the 590 attributes. Thus, in this context, instead of going through the entire data set and use all 590 attributes for failure prediction, we use feature selection methods [24] to identify and select the most relevant attributes in predicting the failures. The selected attributes are subsequently used to extract the key factors and patterns that lead to machine failures. This reduces the data processing time and memory consumption.

Different steps used in the frequent failure chronicle mining approach, adapted from [43].
Extracted failure chronicles that have the highest 10 chronicle support
Extracted failure chronicles that have the highest 10 chronicle support
We aim to extract frequent failure chronicles and test the performance of Algorithm 1 on the SECOM data set. To obtain frequent failure chronicles, we use the frequent chronicle mining approach introduced in [43]. In [43], an industrial data pre-processing method is introduced, including data discretization and sequentialization. Figure 10 shows different steps within the data mining, especially the frequent chronicle mining approach. The steps presented in Fig. 10 elaborates the data mining procedure which is described in Fig. 5. The approach starts with the aforementioned feature selection, after which a feature subset of the SECOM data set is obtained while retaining a suitably high accuracy in representing the original data set. As a result, 10 most relevant attributes are selected as the optimal subset of all 590 attributes. After the feature selection, data discretization [41] is employed to discretize continuous values for obtaining nominal ones. Thereafter, data sequentialization is used to transform the data into the form of pairs (event, time stamp), where each sequence finishes with a failure. With obtaining sequences that contain failures, CloSpan algorithm [50] is applied to the pre-processed data set, to extract frequent sequential patterns. Also, the frequent chronicle mining algorithm introduced in [43] is used to extract the temporal constraints among these sequential patterns. Up to this step, we are able to obtain frequent failure chronicles that will be transformed into predictive rules.
As introduced in Section 4, to improve the quality of failure prediction, we take Chronicle Support as a reference measure, to select the most relevant failure chronicles for failure prediction. As a result, only a subset of all frequent chronicles are used for predictive rule transformation. Table 3 shows the failure chronicles that have the 10 highest chronicle support. We use these chronicles as examples to demonstrate the predictive rule generation approach. In Table 3, each failure chronicle is described by the number of events that it contains, the number of time intervals among events, all the observed properties (attributes) that characterize the failure chronicle, and the chronicle support. For the ease of demonstration, we label the 590 attributes as
Attributes with their numerical intervals within the failure chronicle

The SWRL-based predictive rule transformed from the failure Chronicle
For an event within a failure chronicle, it is not only identified by a set of attributes, but also the quantitative values of them. To obtain the corresponding quantitative attribute values for describing each event, data discretization has been applied to the SECOM data set. After data discretization, the quantitative data has been translated into qualitative data. Also, an association between each numerical value and a certain interval has been created. Taking the chronicle that is presented in Fig. 8 as an example, Table 4 shows the numerical intervals for describing the events within this failure chronicle. This chronicle is the failure chronicle
Based on the descriptions of the failure chronicle
Results evaluation
To evaluate the usefulness and effectiveness of our approach, we conduct results evaluation from two perspectives: i) the evaluation of the MPMO ontology; and ii) the evaluation of the SWRL rule-based failure prediction results. It should be noted that for evaluation we focus on the quality of semantic enrichment to the chronicle mining results, and the evaluation of the performance of the chronicle mining phase is out of the scope of this paper.
Evaluation of the MPMO ontology
Ontology evaluation enables users to assess the quality of ontologies. It is essential for the wide adoption of ontologies, since ontologies can be shared and reused by different users, and the quality of ontologies such as the consistency, completeness, and conciseness of taxonomies are key considerations when different users reuse ontologies in specific contexts. In this paper, to evaluate the quality of the proposed MPMO ontology, we use OOPS!, which is an online ontology evaluation tool [40]. The reason we choose this tool for ontology evaluation is two-fold. Firstly, OOPS! allows automatic detection of common pitfalls in ontologies, and the detection of pitfalls can be executed independently of the ontology development software and platforms. Secondly, it enlarges the list of errors that can be detected by most recent ontology evaluation tools, thus providing a broader scope of anomaly detection in ontologies [40].

Screenshot of the ontology evaluation result using OOPS! Online tool.
In OOPS!, ontology pitfalls are classified into three categories: structural, functional, and usability-profiling. Under each category, fine-grained classification criteria is provided to cope with specific types of anomalies. The MPMO ontology is examined according to the following three categories [40]:
Structural dimension: It focuses on anomaly detection on syntax and formal semantics. Since the MPMO ontology consists of logical axioms, the syntax and logical consistency can be evaluated and validated through anomaly detection within this category. To be more specific, This category is composed of five criteria: i) modeling decisions, which evaluates whether users use the ontology implementation language in a correct way; ii) real-world modeling or common sense, which evaluates the completeness of the domain knowledge formalized by the MPMO ontology; iii) no inference, which checks whether the desired knowledge can be inferred through ontology reasoning; iv) wrong inference, which refers to the detection of inference that lead to erroneous or invalid knowledge; and v) ontology language, which assesses the correctness of the ontology development language of the MPMO ontology.
Functional dimension: It considers the intended use and functionality of the MPMO ontology. Under this category, two specific criteria are used to evaluate the MPMO ontology: i) requirement completeness, which evaluates coverage of the domain knowledge that is formalized by the MPMO ontology; ii) application context, which evaluates the adequacy of the MPMO ontology for a given use case or application.
Usability-profiling dimension: It evaluates the level of ease of communication when different groups of users use the same ontology. Within this category, two specific criteria are applied for ontology evaluation: i) ontology understanding, which evaluates the quality of information or knowledge that is provided to users for easing the understanding of the ontology; ii) ontology clarity, which assesses the quality of ontology elements for being easily recognized and understood by users. These criteria is commonly used to check the quality of ontologies when users do not have sufficient domain knowledge.
To evaluate the MPMO ontology according to the aforementioned categories, we uploaded the ontology code to the OOPS! online tool. After loading the ontology code, the ontology pitfall scanner is used to check the pitfalls that exist in the MPMO ontology. Fig. 12 shows the evaluation result. The result shows that our ontology is free of bad practices in the structural, functional, and usability-profiling dimensions of evaluation. Moreover, the MPMO ontology is developed and formalized using OWL, which is a widely used language for knowledge representation and ontology development. This eases the reuse of the MPMO ontology in other contexts and also simplifies the integration of the MPMO ontology with other knowledge components that are developed with the same language.
To evaluate the quality of the SWRL rule-based failure prediction results, we apply the SWRL rules on the sequences in the SECOM data set, and three measures are used to assess the quality of these rules: the True Positive Rate (TPR), the Precision of failure prediction, and the F-measure. The equations for computing these three measures are shown in Equation (1), (2) and (3).
Among them, TPR measures the proportion of positive examples that are correctly identified after a classification approach. In our experimentation, TPR aims to measure the percentage of positive sequences that have been correctly classified. In Equation (1),
True positive rate, precision and F-measure of failure prediction based on SWRL rules
True positive rate, precision and F-measure of failure prediction based on SWRL rules
Precision is the fraction of relevant training examples among the total number of positive examples. In our case, Precision of failure prediction measures the percentage of sequences based on which the SWRL rules are constructed correctly. For a given sequence, failure chronicles are extracted through chronicle mining and SWRL rules are constructed for failure prediction. After applying the SWRL rules, if the predicted failure temporal constraints are out of the range of the failure occurrence time intervals in the sequence, then it indicates that the SWRL rules could not predict the temporal constraints of the failure in this sequence. Thus, the failure is classified as False Positive. In Equation (2),
With obtaining the above two measures, we can compute the F-measure according to the Equation (3). F-measure a measurement of a test’s accuracy. It considers both the TPR and the Precision of a rule to compute the value.
Table 5 shows the experimental results of the three measures. The three measures are computed according to different frequency thresholds of sequences in the data set. We use
We can see from Table 5 that all computed values for the three measures are above 80%, which shows the results are encouraging. As the minimum frequency threshold
Since the SWRL rules are generated from chronicle mining results, the quality of their prediction exclusively depend on the mined frequent chronicles. In this context, the 10-fold cross validation principle [47] is used to evaluate the quality of failure prediction. To apply the 10-fold cross validation principle, the SECOM data set is partitioned into two parts: the training set and the test set. Firstly, chronicles are extracted from the training sequences in the training set. Then, for the test set, we check for each sequence, its membership in at least one chronicle among those extracted. The number of sequences validated by the chronicles is computed to estimate its percentage with respect to the sequence set. This procedure is repeated 10 times to validate all the sequences of the database.
The launching of such a set of SWRL-based predictive rules enables the prediction of temporal constraints of future machinery failures. This allows users to take further maintenance actions, such as the replacement of the machine tools used on the production line. The performance of failure prediction could be enhanced by considering a new set of rules that reason about the severity levels of failures. We are currently applying machine learning techniques to classify the severity levels of failures, according to the temporal constraints among the failures and other events.
This paper demonstrates a novel hybrid approach for implementing predictive maintenance in industry. The proposed hybrid approach is a combination of frequent chronicle mining and semantics, within which chronicle mining is used to extract frequent chronicles based on industrial data sets, and a knowledge-based structure is used to automate the SWRL rule generation process and to formalize the predictive maintenance results.
The contributions of this paper are three-fold. Firstly, chronicles are formally represented with the use of ontologies, by which the main concepts and relationships for describing chronicles are formalized, then easing the knowledge representation and interpretation of frequent chronicle mining results. Secondly, a novel algorithm for transforming chronicles into SWRL-based predictive rules is introduced. The novel algorithm allows the automatic generation of SWRL rules based on the mined frequent chronicles, thus enabling an automatic semantic approach for predictive maintenance. Thirdly, the reasoning about temporal constraints of future machinery failures is enabled by the joint use of data mining and semantics, which allows the implementation of maintenance actions such as alarm launching.
However, there exists several limitations of the proposed approach. In general, there are three major problems need to be solved. The first problem is the partition method of numerical values. Since the rules we proposed in Section 5 are based on crisp logic, when the numeric values of attributes collected by sensors are considerably close to partition thresholds, the rules proposed in Section 5 may fail to partition these numeric values into correct categories. To deal with such kind of uncertainty situations, the use of fuzzy logic should be considered and a fuzzy semantic approach needs to be implemented. This approach will use machine learning techniques to automatically derive membership functions and fuzzy if-then rules from data sets. The fuzzy rules aim to enhance the representation of imprecise severity level of machinery failures. For example, an identification of failure will be associated with a fuzzy index, indicating the grade of its membership to a “low” or “high” level of failure. The fuzzy approach will be applied to tackle the challenge of symbol anchoring problem [11].
The second problem is the evolution of the ontology and the rule base. Since the manufacturing domain is highly-dynamic, the predictive maintenance system should be able to adapt itself to dynamic situations over time, for example, the change of context. Also, when the system fails to provide satisfactory results through launching the rules, it is required to consult domain experts for decisions about failure prediction and maintenance. In this situation, the domain experts use their expertise and experience to assess the current state of the system and provide appropriate decisions. For example, when the temperature measured by a sensor located at a cutting tool exceeds its threshold and no rule in the rule base is able to warn about his abnormal condition, domain experts can use their experience and expertise to identify this abnormal condition and provide possible solutions in order to avoid the production line to produce unqualified products. In this way, new rules which capitalize experts’ experience needs to be proposed to update the initial set of rules in the rule base, in order to facilitate the quality of failure prediction. In this context, when the next time a similar situation needs to be addressed, the rule which capitalizes domain experts’ experience will be launched together with the initial rules to identify potential failures and to make predictions. This requires the ontology and the rule base to be capable of coping with the dynamic change of knowledge. To deal with this issue, knowledge base evolution solutions should be proposed: The ontology should be able to adapt itself efficiently to the changes with using ontology evolution techniques, and the rule base should be updated according to the change of context, by implementing contextual reasoning.
The third problem is the handling of real-time data. Since the manufacturing domain is highly-dynamic, how to process real-time and heterogeneous data streams is a crucial concern to manufactures. However, the proposed approach uses the classical ontology reasoning techniques, which cannot deal with highly dynamic data in a timely fashion. To cope with this issue, stream reasoning techniques should be adopted to reason upon a variety of highly dynamic data [13]. In stream reasoning, rich query languages are provided by stream reasoners to continuously query data streams. In this way, predictive maintenance systems are able to detect and predict machinery failures in real-time.
Footnotes
Acknowledgements
This work has received funding from INTERREG Upper Rhine (European Regional Development Fund) and the Ministries for Research of Baden-Württemberg, Rheinland-Pfalz (Germany) and from the Grand Est French Region in the framework of the Science Offensive Upper Rhine HALFBACK project.