
Abstract
Large scale cultural heritage datasets and computational methods for the Humanities research framework are the two pillars of Digital Humanities (DH), a research field aiming to expand Humanities studies beyond specific sources and periods to address macro-scale research questions on broad human phenomena. In this regard, the development of machine-readable semantically enriched data models based on a cross-disciplinary “language” of phenomena is critical for achieving the interoperability of research data. This paper reports on, documents, and discusses the development of a model for the study of reading experiences as part of the EU JPI-CH project Reading Europe Advanced Data Investigation Tool (READ-IT). Through the discussion of the READ-IT ontology of reading experience, this contribution will highlight and address three challenges emerging from the development of a conceptual model for the support of research on cultural heritage. Firstly, this contribution addresses modelling for multi-disciplinary research. Secondly, this work describes the development of an ontology of reading experience, under the light of the experience of previous projects, and of ongoing and future research developments. Lastly, this contribution addresses the validation of a conceptual model in the context of ongoing research, the lack of a consolidated set of theories and of a consensus of domain experts.
Keywords
Introduction
The combination of digital sources and computational methods is at the centre of a change of paradigm and of research breakthroughs on cultural heritage. Firstly, the discoverability of sources described and enriched through the Semantic Web enables the construction of integrated datasets of sources based on different archives. Secondly, data integration, as well as quantitative and qualitative studies, complement the in-depth analysis of individual sources. The use of large-scale datasets and computational methods applied within a Humanities research framework is the pillar of the revolution of the Digital Humanities (DH).
The current challenge for the Digital Humanities is how to scale up from the established paradigm of focused studies of specific sources and periods, to macro-scale research addressing broad human phenomena over the longue durée, as represented in cultural heritage [29]. While the humanistic research of the past has focused on scarce and hence exceptional case studies, the radical digital reconstruction of the cultural heritage archive permits for the first time the study of more extensive contexts or ideas [41]. In this vision, the systematic study of data generated by research case studies that focus on the human phenomenon of reading (see Section 2) could unlock advancements on macro-scale questions related to understanding the human condition through time [36]. To realise this vision, a crucial issue to be addressed is the development of a shared “language” for the formalisation of the phenomenon of reading to be used in the production of computable research data [19]. Lastly, to enable the use of computational methods of the Digital Humanities, research data must be usable outside the contexts of a single case study (interoperability) through alignment with established standards, such as ontologies for the description of cultural heritage artefacts, possibly by automatic means, so that contextual knowledge about these artefacts can be retained [44].
The importance of books and reading is unquestionable in modern European societies from the 18th century to the present. In the last 40 years, Humanities scholars have begun to study how changes to readers (e.g., greater literacy rates), reading media (e.g. the reduction in price of books and magazines during the 19th century) and reading processes (e.g. reading aloud, alone, outside, on digital devices and more) interact to enable the circulation of books and other media and therefore of the ideas they convey. A greater understanding of the “communications circuit” of authors, publishers and readers would allow scholars to identify certain of the factors that may facilitate or impede the reception of such ideas in different cultural groups [14]. However, the full impact of reading in our history and in our societies is not yet understood in full. This is due to the significant fragmentation of studies on reading, which are conducted on a plurality of sources from different historical periods, having different languages and formats and being approached through multiple disciplines, such as Book History, Media Studies, Cognitive Psychology, Aesthetics, Creative Writing, and Information Science. All of these disciplines, historical periods and approaches employ different definitions of reading, which make it difficult to compare different studies and to combine them in macro-scale questions. For example, scholars are investigating the reading experiences of 20th-century Czech schoolchildren by studying their reading diaries, but lack the framework for integrating this study with those of other times or places. Previous research on reading has not yet developed systematic approaches and tools to study the experience of reading (what readers read, where and how), the motivations for reading (why readers read) and the effects on readers and their lives (what happens to readers after reading) [51].
This paper reports on, documents and discusses the development of a model that enables the study of reading at micro and macroscopic level by supporting interoperable research data from multi-disciplinary case studies, developed within the framework of the EU JPI CH READ-IT project (see Section 2). The model presented is grounded on the study of the theory of reading, and has been encoded as an RDF/OWL ontology, used and validated through the READ-IT annotation tool.
Furthermore, this article will provide a discussion of the challenges related to the development of a semantic model in the framework of the Digital Humanities with the focus on a complex phenomenon such as reading. Specifically, this contribution will address:
the approach to conceptual modelling in a multidisciplinary framework
the modelling of the reading experience phenomenon in the light of previous projects and existing standards
the strategy for the validation of the conceptual model aimed at supporting the generation of new data and the development of new tools for supporting research activities.
Through the discussion of READ-IT, the authors will highlight three orders of challenges emerging from the development of a conceptual model for the support of research on cultural heritage. The first order of challenges arises from the limitations of existing research data and is grounded on the specific research framework of individual case studies. The second order of challenges is related to the presence of a vast landscape of disciplinary theories addressing specific aspects of the reading phenomenon. The third order of challenges concerns the requirements deriving from research activities. Based on the discussion of the emerging challenges, this contribution documents the rationale behind the methodology developed, the specific modelling choices and the validation of the model of reading experience.
The rest of the paper is structured as follows: Section 2 discusses the background to the study of reading, previous projects on reading and related ontologies. Section 3 describes the approach to ontology development and the modelling lifecycle. Section 4 explains the ontology requirements; while Section 5 details which ontologies were reused and why. Section 6 describes the Reading Experience Ontology developed by the project. Section 7 explains the ontology validation process. Finally, Section 8 discusses current and future implementations of the Reading Experience Ontology.
Background & state of the art
The study of reading has grown in importance since the 1980s. Scholars such as Darnton [14] and Chartier [10] defined the disciplinary area of Book History and realised the crucial role of readers within the “communications circuit”. Historians such as Vincent and Rose gathered documentary evidence of the reading practices of working-class readers [45,52]. Literary and cultural scholars such as Flint and Jack have studied how reading interacts with gender identity [20,32]. Scholars such as Mangen and Kuzmičová research cognitive and experiential aspects of reading such as reader immersion and cognitive engagement, especially within new digital media [35,38]. The case studies conducted by these and other scholars interrogate cultural heritage at the micro scale, often with extremely insightful results. However, because of lack of a common framework defining the activity of reading, these outcomes cannot be used to ask transversal macro-level questions such as the influence of media change (from manuscript to print to digital) over the centuries or whether the location of reading (e.g. indoors, outdoors, while travelling) influences the sentiment of the reader.
In regard to bridging the different research angles on reading, Mangen and van der Weel propose an “integrative framework for reading research” [37]. The authors provide a structure, connecting the different phases – preparation of reading, the act of reading and the effects of reading – with the different themes, such as text, reader environment, social and personal effects of reading. This framework highlights the potential convergences and collaborations between different research areas, but does not provide a common theoretical description of the reading phenomenon.
Reading and the reading experience have so far been addressed not as an overall phenomenon but as a wide range of specific facets. For instance, Eco addresses the active role of the reader as “performer” co-creating or staging the content [18]. Gerrig and Calvino reflect on reading as a form of “transport” of the reader in the narrative world [9,22]. Iser and Davies address the nature and conditions of “aesthetic response” to literature [15,31].
By contrast, READ-IT focuses on the reader’s experience as a whole with the aim to support the integration of results concerning the different facets of the reading phenomenon. The study of reading is framed as a DH interdisciplinary research programme combining micro-scale research use cases [51], and a macro-scale programme addressing questions concerning the identity of the European reader [51].
In this frame, the micro-scale research should be carried out through a common toolbox of digital tools generating interoperable research data. The READ-IT digital toolbox includes (a) an annotation tool for researchers, (b) a crowdsourcing tool of reading experiences and (c) algorithms for automated annotation of text sources. The envisaged applicative scenario of the READ-IT toolbox (see Section 4.1) is the systematic standardized computer-supported annotation of reading experiences. The toolbox aims to support the re-use of use case data; therefore the macro-scale research programme of READ-IT provides a large pool of data including evidence about different places, times and readers across Europe, see Fig. 1.
The rest of the section presents, in order, (a) related previous projects and (b) related ontologies. In addition, a summary of methods for validating conceptual models is included. Finally, we describe at the end of this section some notions that will help to define the READ-IT model of reading.

The READ-IT database is going to collect sources and annotations produced through case studies (outcomes) and their reuse in the development of new case studies. The READ-IT database will provide a large pool of evidence from different types of reading and readers in Europe, supporting the macroscale READ-IT research programme.
The design of the READ-IT ontology is based on the experience and limitations of previous projects focused on cataloguing experience recorded in literature. In this section, we present and discuss the case of the UK Reading Experience Database (UK-RED) and the Listening Experience Database (LED). We consider these two specific projects as they share their focus on the experience of contents (text or music performances) and the overall methodology grounded on the analysis and annotation of sources of experience. Furthermore, these two projects represent two significant steps towards finding a common operational definition of experience for supporting interdisciplinary and multidisciplinary research.
UK-RED
The UK-RED1
The RED ontology2
The RED ontology is supported by 10 years of use. One of the earliest crowdsourcing projects in the field, RED was based on sources collected directly by researchers and stored in its database. Thus, RED does not have connections with external repositories. Furthermore, the conceptualisation of Experience was scoped on the few objective facts related to experience: reader (agent), document (object of reading), time and location of reading. On the one hand, the simplicity of the RED model of reading allowed the accumulation in RED of a heterogeneous collection of sources and research data. On the other hand, the simple schema encoding the research data limits the reuse of RED content as a repository of sources about reading experience, rather than as a repository of research data about reading experience.
Similarly to UK-RED, the aim of the LED5
The LED ontologies (led) revolve around the concept of (listening) experience as “a documented engagement of an individual in an event of one or more pieces of music being performed” [1]. In this regard, LED core connects four main notions: Listening Experience, Source, Agent and Music. LED considers the listening experiences as events and, therefore, it uses an event ontology existing in literature.6
As an evolution of RED, LED structures include a formal description of the curation process of sources as part of the database and approaches the representation of the experiences as an abstraction of external repositories (result of the curation process), not limited to first-hand collected sources. Although LED does provide an enriched description of the facts related to the experience, it still does not describe their phenomenology.
In the field of cultural heritage, it is worth mentioning the LAWD (Linking Ancient World Data) Ontology.9
In addition to LAWD, the RED ontology is used in datasets that represent the history of reading in Britain from 1450 to 1945. This ontology, described in Section 2.1.2, represents knowledge about reading tastes and habits.
Reading can imply a direct consequence in the reader related to a severe and temporary mood disturbance, pleasant or painful. This effect is known as emotion and is central to reading experiences [43]. In order to represent emotions, the Emotion Ontology (EMO)10
From the perspective of ontologies in computing, the validation of conceptual models has enjoyed a great amount of research from which a series of key guidelines have emerged. These in turn are implemented across methodologies. Although no holistic validation methodology is in place, there has been an attempt to frame existing criteria, principles and strategies under a semiotic lens and a grouping of criteria into structural, functional and usability-oriented [21]. A recent survey by Degbelo [17] has analysed the merits of ontology validation from an operational as well as a theoretical perspective. Degbelo does not argue that a systematic mapping between validation criteria and strategies should exist – despite still acknowledging bindings between some of these, such as the unsuitability of empirical approaches for the computational efficiency of a model. A strict dependency between validation criteria and development phases does however emerge from the survey.
Some studies introduce the notion of internal and external validity of a model that we have assumed in this work. Guizzardi argues that these notions may loosely correspond to the “domain appropriateness” and “comprehensibility appropriateness” of language [27], a distinction which Kehagias et al. implement in terms of measuring the cognitive adequacy of an ontology versus its community uptake [33]. Aspects of technical validation, such as ensuring the description logic consistency of the entire ontology network resulting from the model being validated, can be regarded as elements of, or preconditions to, internal validity. Computational expressiveness is an internal validity factor, when addressing the decidability or tractability of querying domain data modelled after the ontology.
Further on the internal validity of the ontology, it is worth mentioning the OntoClean methodology for validating taxonomical relationships of ontologies [26]. The OntoClean approach is based on the systematic analysis of meta-properties of classes, e.g., rigidity, identity and unity, and the consistency of the propagation of the subsumption between classes, e.g., a group of people is also a group. There is limited applicability of OntoClean to this work, as the core concepts and their corresponding taxonomic relationships are imported from CIDOC CRM.11
As for external validity, comprehensibility is one aspect of a more general appropriability of the language which is acquired and transformed by the users who define its pragmatics. Indeed, while comprehensibility is an intrinsic property of the language, its adoption is the result of external factors such as documentation, training and tools. Thus, the evaluation of the ontology can and should take into account its actual use, by means of both machine learning and tools, all contextualised in the domain being defined where possible.
Even under an internal/external lens, however, the partitioning of evaluation criteria along this dimension is not absolute. In particular, the ability of a model to answer competency questions (CQs) transcends this notion. For one thing, it addresses domain expressiveness as opposed to computational expressiveness. However, CQs can also be considered as criteria for technical validation as much as conceptual, if regarded as having the same role as unit tests for software. Lastly, the ability to translate CQs into formal queries is a crucial factor to an ontology’s potential for community adoption, therefore a case can be made for them as external validity factors. The manifold validity of CQs and their adoption as a tool across several methodologies were influential in the decision to incorporate them in the validation of our model.
With the progressive growth of the Web of Data, methods for validating ontologies against datasets and text corpora, as originally introduced by Brewster et al. [8], have also been gaining continued attention. These methods attempt to respond to a need for objective measures of ontology quality beyond those mandated by the underlying logical framework. The idea behind data-driven ontology evaluation is “to determine how appropriate [an ontology] is for the representation of the knowledge of the domain represented by the texts” [8], although it has been argued that such evaluation metrics would not be exempt from at least temporal or category bias [30]. Although instances of data-driven ontology evaluation methods still form a checkered pattern, some insightful implementations have attempted to compare the model of an ontology to the features extracted from corpora using machine learning and text mining [34]. Though still in its infancy as a proper validation methodology, a corpus-driven approach provides several elements of interest for the domain at hand. However this aspect is deferred upon completion of the READ-IT dataset construction.
It should be noted that, although a collection of sources provides an outline of the reading phenomenon, it cannot be guaranteed to offer a complete representation. Thus, the ontological commitment of a model should at least express all dynamics emerging from the sources considered, but not be limited to it. Our design choices privileged a focus on addressing false negative examples, rather than constraining the ontology to strictly fit the examples collected. The ability of the ontology to generate scenarios beyond the examples provided was used to verify the validity of the model with the researchers. Indeed, the engagement of researchers highlighted both anti-examples and positive examples, not grounded on the available sources but supported by the current knowledge of the reading phenomenon.
Previous projects paved the way for READ-IT. On the one hand, UK-RED defined the approach for a systemic annotation supported by both projects and volunteer work of students and experts. A strong limitation of UK-RED we addressed is the lack of depth concerning the description of the experience, e.g., motivation for reading, expectation and emotions.
On the other hand, LED set a best practice concerning the integration of datasources: providing a significant example about repurposing data and enabling research through integration. As is the case with UK-RED, if for different reasons, LED lacks depth about the definition of experience. It frames an experience as a one-time isolated event, while dedicating a significant part of its ontology to the description of collaborative annotation. In READ-IT we focused on enabling collaborative annotation by defining a methodology that would, at the same time, dig into the concept of experience, thus enabling research, and achieve a cross-disciplinary consensus between the project partners.
On the one hand, previous projects did not provide data about reading experience with the level of details required by READ-IT. On the other hand, theories of reading address specific aspects of reading, by genre (e.g., narrative), type (e.g., skimming, poaching), response or reception. However, there is not a theory of reading experience that connects the different aspects of reading, from the cognitive and physical interaction with medium and content, to the effect during reading and beyond, on personal life and on society. Therefore, the development of the ontology has been backed up by a conceptual work aimed at reconciling and integrating the different perspectives in a shared view, documented in a public deliverable “The Model of Reading: Modelling principles, Definitions, Schema, Alignments” [5].

The main phases of the modelling life cycle and interactions with research and development work strands.
Concerning the role of existing theories in the development of the ontology, the authors consulted directly and indirectly (supported by the rest of the partners) a wide range of literature, listed in the “READ-IT Model of Reading” technical report [5]. Still, the level of detail of the literature was, in general, too specific and not adequate for the purpose of developing a broad model that could be used by experts of different disciplines or by volunteers. As a result, the literature was mostly used to narrow down or check the consistency of the model in the mainstream.
Lastly, READ-IT is still consistent with the overall approach outlined by UK-RED and LED. Specifically, READ-IT aims to collect structured individual experiences (responses) that, as a whole, could be used for reception studies at societal scale. Indeed, a limitation of this approach is that the model focused on individuals, therefore it does not support the encoding of evidence at societal scale.
Concerning the theoretical framework of the project, we could not rely on a consensus theory of reading experience that integrated the perspectives of the different research groups. Indeed, the literature about reading is wide and deep. In this regard, it is worth mentioning the important contribution of Mangen and Van der Weel proposing an integrative framework for the study of reading [37], but not of the reading phenomenon as a whole.
On a different note, the modelling of the reading experience had to take into consideration retrocompatibility with legacy data, the data collection for a wide range of disciplinary and interdisciplinary case studies, and the concurrent development of new tools.
In this scenario, we developed a specific modelling methodology motivated by sources, informed by theory, validated through case studies, iterative, incremental and engaged with the different project partners. Specifically, the modelling lifecycle was structured in four main phases, see Fig. 2. These phases are as follows: (1) analysis of sources, (2) analysis of theory and development of the model, (3) validation and testing, and (4) consolidation and documentation.
Furthermore, we revised the management of the ontology by including reuse, e.g., the W3C Web Annotation Model, the engagement with communities working on similar topics, e.g., the CIDOC CRM working group, and adopting tools such as GitHub, OntoMe12
The analysis of the sources used to ground the concepts of the model is based on the experiences of reading documented in the sources. The sources are provided by researchers involved in READ-IT and represent a significant set of the different types of sources and reading experiences. This phase is used to define concepts and functional requirements to feed into the development phase.
An emblematic type of source are interview transcriptions, such as the following extract from Memories of fiction:14
Extract from Memories of fiction, Ferelith H. interview part 2,
The study of theories about reading, experience and action is used to guide the integration of concepts and to fill the gaps in the examples included in the sources. In this phase, we considered theories from different fields, specific to reading (see Section 2), but also theories of experience, action, language and mind [6,7,16,23,24,39,42,54]. The development of the model, informed by the theory, addresses the formalisation of concepts and structures [4]. The development takes into account the functional requirements defined during the analysis of sources and the non-functional requirements emerging from the design and development of the tools. The development phase aims to produce a candidate model for the next phase, and its goals are the identification of issues and hypotheses that will be assessed with the help of researchers, and the consolidation of the project’s working definitions.
An emblematic example of the role of theory is related to the arguments against considering listening as a form of reading. Eco points out the importance of the role of reader as “performer” [18], while Gerrig pushes this metaphor referring to the performance [22] as described by Stanislavski [46]. These positions provide a strong argument against including listening as a type of reading experience, as the performance is mostly or exclusively carried out by the reader that provides interpretation and voice to a content (as a voice actor). As a result, the initial expressivity of the ontology was restricted to exclude the representation of listeners as readers accessing a content via a reader (acting as a medium).
Validation & testing
The validity of the model is defined as the ability to encode the relevant facets of the reading experience in the sources and to provide and support the data-related research (see Section 7 – Validation). In this regard, the validation is performed through the engagement of researchers on reading and development teams. The engagement of researchers addresses the details of their case studies, the use cases and the annotation of new sources. The engagement of technical partners involves the discussion of the tasks related to the tools which are relevant for the model, the testing of tools and the discussion of data-related issues. The outputs of this phase are new tasks for the backlog related to anti-examples (i.e. documented unwanted ontological commitments) and examples that are yet to be addressed (e.g. related to the test sources). The validation process is described in Section 7, where we discuss how the model addresses a list of competence questions.
An emblematic outcome of the validation is the capability to represent readers’ cumulative experiences, concerning multiple readings. This requirement emerged during the first iteration and specifically during an internal workshop testing the capabilities of the ontology against new sources.
Consolidation & documentation
The consolidation phase will address the open issues, generate documentation including examples and design patterns, and highlight the issues that can be addressed only as hypotheses or that require a contribution from the research strand of work.
Lastly, the engagement with the research groups and the project’s scientific lead provided an opportunity to reflect on the scope of the model and the assumptions emerging from the analysis of sources. For instance, during the consolidation phase, the ontology had been willingly limited in the ability to describe the cognitive and physical processes of reading (e.g., skimming reading), also through excluding collective reading and restricting the definition of reading to human reading.

READ-IT general architecture. The model of reading guides the design of the database, the systematic annotation of the curated sources and the analysis of the community-generated content, and it is an important factor in the design of the user interface.
READ-IT builds on the experience and limitations of previous projects. These include, for example, their limited geographical range and their lack of integration of multimodal digital sources of evidence (images, texts, audio sources, and computer-mediated communications). An additional limitation is the focus of their data models on the context of experience (e.g., who, where, when, and how), with only partial attention paid to its mental aspects (why and with what result). The READ-IT information architecture, see Fig. 3, is an evolution of previous projects, taking into account their limitations and the new requirements related to the envisioned interoperability of research data and scaling up of Digital Humanities research.
In the READ-IT framework, the model of reading has the role of informing the design of 1) the database that should integrate research data produced through case studies and 2) the tools that will support research activities (e.g., annotation algorithms, annotation tools, and crowdsourcing tools). Last but not least, the model of reading will be the main resource to guide the reuse of research data, thus providing a common language about the phenomenon of reading and guiding the use of the database, see Fig. 1.
Non-functional requirements
Another resulting set of requirements is related to the direct role of the model in the READ-IT architecture and its indirect role in the READ-IT research activities.
Types of sources
The primary sources of reading experiences are textual and visual sources drawn from cultural heritage repositories, such as diaries, letters, and portraits, which mention reading. However, future research strands on digital reading will also focus on hypertext, social media, e-readers, web-novels, webcomics, podcasts, and new emerging media.
In this frame and this stage, we considered primarily text-based sources (material or digital) and images (e.g., portraits and paintings of reading scenes), which constitute the vast majority of the available sources of reading experience. For instance, we considered interview transcripts from the “Reading Communities” project,15

A READ-IT crowdsourcing postcard from a contributor.
The potential focus of research on reading is a wide landscape, ranging from classical reception, narrative reception, expert reading, interaction with text, cognitive effects, history of reading to digital reading. The research initiatives addressing reading follow a wide range of methodologies producing data about different aspects of the reading experience. Regardless of the specifics of research activities, we consider exclusively annotations of reports of experiences of reading (Research Data).
Use of the ontology
As with different research initiatives, the research data about different aspects of reading experiences may represent a specific facet of the reading experience. In this regard, we must consider a partial use of the ontology in the annotation of sources, as well as allowing flexibility in the model design.
Data integration
Research data produced by different case studies and research initiatives will focus on different facets of the reading phenomenon (partial data). Research datasets only partially representing the phenomenon of reading could be difficult to reuse outside the same research framework. Thus, the ontology should support the reconstruction of the phenomenon of reading as a whole and the integration of partial datasets about specific aspects of reading.
Training set
An ongoing research strand is the investigation of the use of human annotations as training sets for Machine Learning algorithms and machine-supported annotation. To be used as training sets, the research data will be integrated by making explicit derivable facts and incorporating validation of annotations by experts to differentiate them from automatic annotations. In this regard, the use of the W3C Web Annotation Data Model16
Through the support of the researchers involved in READ-IT, we collected a sample of sources about reading experiences. The source samples were selected to be representative of the different types of sources, e.g., transcripts of interviews and diaries, and to highlight the richness and complexity in terms of the description of the reading experience, e.g., comparative reading, multiple readers, re-reading.
The functional requirements had been identified primarily through the analysis of sources, and secondarily through the direct engagement of the Humanities researchers involved in READ-IT. The analysis of sources aimed to identify the core concepts emerging from the descriptions of the experience of reading. The engagement of researchers on reading had the aim of discovering gaps in the identified concepts. The analysis was conducted in two cycles during the first six months of the project, in the course of which the following clusters of requirements were identified.
Reading activity
Readers identify an aspect of the activity of reading as causing a specific effect they experienced, e.g., an emotion, a memory, or a judgement. The analysis of the different cases showed that the effects of reading are related to: 1) a moment, e.g., a twist in the story or setting, related to a specific segment of the content 2) an episode of reading, e.g., on a train, a bedtime story, related to its contingency, and 3) a whole reading, e.g., reading of War and Peace, related to the interaction between reader and content. Summarising, the articulation of the reading activity is of relevance for the description of cause-effect relations between reading and readers’ conditions. Indeed, evidence of reading includes general considerations about a whole reading, a specific session or a passage acting as a trigger (experience).
It is worth highlighting that, by activity of reading, we mean the combination of physical and cognitive interactions between the reader and the medium and the reader and the content (through the medium). Thus, both material manipulation and sense-making are encoded with the general concept of reading process, which is characterised by a level of engagement, e.g., representing a focused or distracted reader.
Readers’ conditions
The description of the readers’ conditions includes information about 1) the human/social situation of reading and 2) their personal mental state. In the description of the situation, the focus is mostly on the social sphere, e.g., “on the train coming back from my grandmother, outside Oxford”. The details about place, time and material conditions of reading are characteristics of a socially relevant event, e.g., “visit to grandmother”, or “vacation with family”. This first set of conditions are represented through the concept of event. (Event) Secondly, readers describe specific aspects of their mental state triggered by reading. The readers’ descriptions focus on the changes of a single specific aspect of their mental conditions, e.g., “I felt excited”, or “I was swallowed by the reading”. This second set of conditions is represented through the concept of state of mind (State_of_Mind). Summarising, readers’ conditions are related to the social context of reading, in which the reader can have either a passive role (e.g., climatic event) or an active role (e.g., vacation), and to the specific aspects of their mental state that change in reaction to reading. Both types of conditions are indeed interrelated. Thus, the variety of interrelations, between events and the reader’s state of mind, was addressed by introducing a set of causal, correlation and temporal relations.
Effects of reading
The analysis of the collection of reading experiences outlines a landscape of facts, ideas, concepts, emotions, and judgements that readers use, refer to and consider. In the readers’ narrative, reading (and its cumulative effects) takes the role of baseline for the description of the effects of other readers, e.g., “unlike in the first book, in the second book the authors fail to address the condition of women”. This landscape is the result of incremental and cumulative effects of reading. Readers report about the evolution of their evaluation of contents, in relation to re-reading or time to think and re-think about it. Summarising, the effects of reading can be: a) a direct consequence of a specific aspect of the reading activity, b) a cumulative result of multiple readings or c) an incremental result of further reflection outside the scope of the reading activity. These cases are addressed by introducing the general concept of state of mind (State_of_Mind) and an open list of specialisations, such as emotion, aim, judgement, remembrance, to mention some of them. Furthermore, the causal relations between state of mind and reading activity are encoded through specific relations: premise of (:premiseOf), when a state of mind informs about a reading, and effect of (:effectOf), in case a reading is the source of a specific state of mind.
Approach to reading
Readers describe their standpoints in approaching reading from two main perspectives. Firstly, readers ground their stance on their experience and personal or social condition, e.g., previous judgements about topics, authors, and contents. We call this first type premises to reading. Secondly, readers refer to their stance in terms of developed reading habits, e.g., how often, where, when, why, and what they read. We refer to this second type as disposition (Disposition) of the reader. In the first case, the readers’ perspective is oriented toward a specific reading, e.g., about what they like or dislike, what they wish to accomplish or expect and the activities in which they are involved. In the second case, readers refer to their behavioural patterns, e.g., “this is always present in the books I like”, or “I read it every day to my kids”. Summarising, the description of the readers’ approach to reading is an important component in the description of the experience. Readers can provide a perspective on the frame of mind in which they approach reading, or the background of their typical readings. In both cases, the approach to reading is entangled with the contingent condition of the reader at the time of reading, e.g., “I was sixty-six”, or “I was in second grade”.
Reused ontologies
Ontology reuse has traditionally been considered a basic activity and a best practice in Ontology Engineering. In the context of the NeOn Methodology [48,49], prescriptive methodological guidelines for reusing ontologies have been proposed. These guidelines cover the following activities: (1) searching repositories for candidate ontologies that could satisfy the needs of the ontology to be developed; (2) assessing whether the candidate ontologies are useful for building the ontology; (3) selecting the best candidate ontologies for developing the ontology on the basis of a set of criteria; and (4) integrating the selected ontologies into the one being built.
Following this approach and based on the analysis of the ontology requirements (see Section 4), we assessed existing related ontologies. The criteria used concerned 1) the management of annotations and sources and 2) the description of the content of sources, with special focus on human agents and creative contents.
The existence of official or de facto standards was considered the most relevant criterion for deciding in favor of engaging with existing ontologies, specifically the W3C and CIDOC CRM ecosystem.
W3C web annotation data model
The W3C Web Annotation Data Model17
“The CIDOC Conceptual Reference Model (CRM) provides definitions and a formal structure for describing the implicit and explicit concepts and relationships used in cultural heritage documentation” [12]. CIDOC-CRM is an official standard, ISO 21127:2006, and therefore the reference vocabulary for digital representation of cultural heritage. CIDOC CRM is a core ontology for a family of specialist ontologies, such as FRBRoo18
The CIDOC CRM core provides the conceptual backbone of the READ-IT ontology of reading experience. Indeed, CIDOC CRM concepts of E2 Temporal Entity, E5 Event, E3 Condition State and E7 Activity are at the core of the ontology. For instance, the structure of the reading process is built exploiting the features of Activity, Event and Temporal Entity to describe the process of reading. This process is articulated in multiple sessions of different duration occurring in different places, involving the participation of multiple people, and interconnected in a progression.
FRBRoo
The Functional Requirements for Bibliographic Records model (FRBR) is a conceptual model of bibliographic contents. FRBR provides a conceptualisation of the life-cycle of creative contents: author’s Work (e.g., a romance), the different forms of Expression of a Work (e.g., a version of the romance), the Manifestation of an Expression of a Work (e.g., the material prototype of a book) and lastly several Items which are instances of a specific Manifestation (e.g., book copies).
FRBRoo is an ontology of the CIDOC CRM ecosystem that encodes the concepts of FRBR.
CRMsoc
“CRM Social is a domain ontology extending CIDOC CRM aimed to support and capture social documentation” [13]. CRMsoc has not been released yet, but we still take it into account for future-proofing.
CRMsoc (socE) is expected to provide a standard solution to the representation of concepts, such as social status, political stance, and gender, which are of great relevance for the description of the reader but outside the scope of the research on reading.
On the other hand, the socE Mental Attitude class overlaps with the READ-IT class State_of_Mind. The socE Mental Attitude represents the intention related to a plan and reading is indeed a specific type of an activity, implementation of a plan, supported by the reader’s intentionality.
At the current stage of socE, socE Mental Attitude as its definition is still an open issue. In the current documentation, socE Mental Attitude is described as “conscious maintaining of an intellectual attitude towards matters of knowing, believing or guiding actions and reactions to social and other environmental situations, such as, besides others, beliefs about laws governing nature or intentions to carry out actions” [11]. Therefore, in the READ-IT domain, socE Mental Attitude is close to the role of State_of_Mind as premise of (:premiseOf) Reading and to the reader’s Disposition toward reading, medium or content.
The class socE Intention to Apply, a specialisation of scoE Mental Attitude, represents the intentionality of E39 Actor toward a socE Activity Plan. In this framing, socE Intention to Apply could be a specialisation of State_of_Mind and :premiseOf a Reading_Process.

The three main conceptual areas addressed by the READ-IT ontology of reading experience, main concepts, relations and properties.
Friend-of-a-Friend (FOAF) is an ontology addressing the digital representation of people and the relations between people and web contents. FOAF is used to describe the reader and participants involved directly or indirectly in the situation of reading. The choice of FOAF is related to its wide adoption and existing alignments of FOAF with other vocabularies.
Reading experience ontology
The design of the READ-IT ontology focuses on addressing the description of the human experience of reading. The aim of the ontology is to provide the common language to structure and share research data addressing aspects related to three main conceptual areas (see Fig. 5):
the reading agent (Reading_Agent), who is reading, why and what are their conditions approaching a reading;
the reading resource (Reading_Resource), what is being read, what is the type and condition of the medium of reading; and
the process of reading (Reading_Process), where and when reading takes place, in which material and social conditions and how a reading is carried out.
The ontology will address the situated interactions between reader, medium and content, and the effects of reading during and after reading.
In the following section, the concepts of the READ-IT ontology are described using local names, e.g., Reader, Medium, and as prefixed QNames, e.g., foaf:Person, and with terms from other third-party ontologies, specifically: Friend-of-a-Friend (foaf), CIDOC CRM (cdc) and FRBRoo (frbr). The diagrams follow the RDF graph notation.
Source and annotation
The Reading Experience Ontology is aimed at supporting the encoding of annotations, of a wide variety of sources, produced through different approaches (e.g., trained annotators or volunteer-based work). In READ-IT, we represent the annotation process by using the W3C Web Annotation Data Model (WADM). This model connects a graph (wadm:body) to the metadata describing the annotation process (wadm:annotation), e.g., annotation agent with the source of the annotation, wadm:target.

Relationship between W3C web annotation data model and reading experience ontology graphs.
The findings about a reading experience in a source, i.e., the body of an annotation, is a sub-graph generated using the Reading Experience Ontology, see Fig. 6. Thus, a research dataset is a collection of WADM graphs, annotation, body and target, and relative graphs about reading experience.
The rest of the article addresses the value of the wadm:body and how to structure the reading experience, while it omits information about the source and the annotation.
The analysis of sources highlighted a set of requirements and concepts related to reading experience. As argued, concepts and requirements report about different aspects of reading in a fragmented view of the phenomenon. In this scenario, modelling the reading experience required the integration of different aspects of reading. These gaps were addressed through the analysis of existing theories about reading, action and experience.
The analysis of theories of reading indicated the existence of underlying dynamics connecting the different aspects of reading. Specifically, the modelling of the reading experience was grounded on the following assumptions: 1) a reading process triggers a process of sense-making defining, as a result, the reading in the reader’s mind (from an ongoing process to a concluded event); and 2) reading is grounded on the experience of the reader, in terms of previous reading and in general events, see Fig. 7.

Connections between activity, experience and event.
The analysis of sources guided the identification of the core concepts of the ontology. Similarly to LED and RED, the concepts emerging from the analysis of sources refer to the agent, the resource or the process of reading. In the READ-IT ontology we do not reuse RED or LED terms, but we adopt concepts from the CIDOC CRM (cdc) family of ontologies and Friend-of-a-Friend (foaf).
Reading agent
The agent is a human (foaf:Person). The description of the agent is at the time of reading, outlining a specific state in terms of physical, social and cognitive conditions. Thus, Reader represents the states of the agent, aggregation of variable properties describing the agent, a :descriptionOf a foaf:Person, see Fig. 8.

Reader:r1 of age 12 is a :descriptionOf a person foaf:p1.
As a description of a state of the Person, the Reader is characterised by properties addressing their education, social status, occupation, political stance, religion, age, nationality, and gender identity. The question of how to model these concepts is of relevance but falls outside the scope of this specific work. In this regard, the ontology will be revised to include the upcoming module of CIDOC CRM for social documentation, CRMsoc, as soon as it is officially released, as well as specific classes developed by READ-IT.
On the other hand, in strict relation with reading, readers often report their reading habits at the time of reading. Habit is addressed as a class and related to the Reader through the property :habit. The characterisation of Habit is one of the open questions that future research on reading should clarify, providing input for further extension of the ontology.
It is worth highlighting that the content of the testimonies of reading experience do not always provide sufficient information to discriminate between the concepts of Work, Expression, Manifestation and Item provided by FRBR. In this regard, the READ-IT concepts of Medium and Content act as an intermediate structure abstracting the FRBRoo implementation of the FRBR concepts.
The Reading_Resource is represented as a disjoint union of Medium and Content, respectively the material and immaterial components of the resource.20
The definitions of Medium and Content can be better captured by referring to the specific FRBR concepts of which Content and Medium are generalisation of, Work and Expression, and Manifestation and Item.
The description of experiences could include information about the status of the Medium at the time of reading, e.g., “the book was covered in brown paper”. An Alteration is a :partOf a state of the resource, specifically of the medium. State_of_Medium is a subclass of cdc:E3_Condition_State, and it represents a state of an instance of Medium (:stateOfMedium).
An Alteration can be related to the medium (:relatedToMedium) and/or to the content (:relatedToContent), e.g., “brown paper covering the book” and a note, Fig. 9.

A State_of_Medium,:somed1 is composed of two instances of Alteration,:a1 and:a2, respectively related to instances of the Medium:m1 and Content:c1, e.g “brown paper covering the book and a note.
Reading, in the sense of human activity, is represented with the concept of Reading_Process. Reading_Process is a subclass of cdc:E2_Temporal_Entity. The articulation of a Reading_Process is represented through the concepts of:
Reading, the full process of reading, from beginning to end, including both active reading and pauses.
Session, a continuous segment of active reading :partOf Reading.
Experience, a specific moment of active reading :partOf Session.
Reading_Process is a subclass of cdc:E7_Activity (and therefore of cdc:E2_Temporal_Entity). Reading, Session and Experience are subclasses of Reading_Process (abstract class, not meant to be instantiated).
The Reading_Process is characterised by the literal engagement with range “high”, “medium” and “low”. The engagement represents the level of involvement of the reader in reading, i.e., a spectrum between focus and distraction. Engagement refers to both physical and cognitive engagement and therefore with both Content and Medium. With transportation (specialisation of engagement) we refer to the specific cognitive engagement with a Content, e.g. story or arguments. See example in Fig. 10.

Reading instance:read1 includes two sessions,:s1 and:s2. The reader reports two experiences in session:s1, while about:s2 provides indication of “Low”:transportation but “High” engagement, e.g., “I was swallowed”, “I did not identify with the characters or the story”.
Subsequently, Reading_Process implies the existence of at least a Reading_Resource and a Reader. Thus, we define the properties:
:involving, a Reading_Process involves a Reading_Resource, and
:engagedIn, a Reader is engaged in a Reading_Process.
Lastly, a Reading_Process can be a cause of (:causeOfAlteration) an Alteration of the Medium, with Alteration :partOf the State_of_Medium, e.g., taking notes, underline. cause of alteration. See example in Fig. 11.
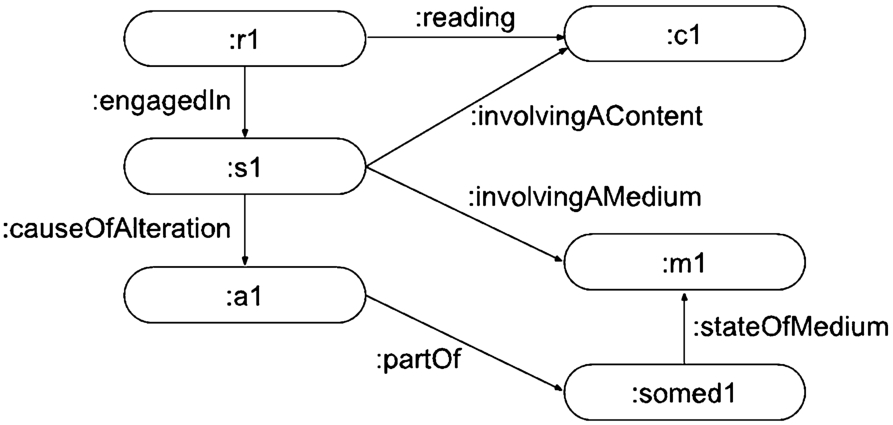
A reader:r1 is engaged in a session:s1, reading a content:c1. The session:s1 involves the content:c1 and medium:m1. Session:s1 is :causeOfAlteration :a1, which is :partOf the State_of_Medium :somed1, describing the state :stateOfMedium of the Medium :m1. The relations :involvingAContent and :involvingAMedium are sub-properties of :involving. For readability, we omitted relations such as:m1 :providingAccessTo:c1.
It is worth highlighting that each reading activity implies at least one instance of Reading and one of Session. Reading, for instance a book, requires at least one session (e.g., a short pamphlet). Thus, sessions are always situated in a reading. Furthermore, experiences always occur during a session, e.g., when the book is open and we are actively reading. In practical terms, every experience should be instantiated along with a session and a reading, even though there is no direct evidence or qualifying information in testimonies. Lastly, experiences are defined as triggers of changes in the reader’s state of mind, but the evidence of a state of mind is not always related to an experience. Indeed, states of mind that result from reading and co-occur during a reading are to be related with an experience, but premises (before reading) and outcomes (after reading) are not to be confused as results of experiences. To summarise, a state of mind can be the effect of an experience (during a reading or session) and the effect of a session or reading (after a reading or session) or premise of a reading (before a reading or a session).
In contrast to RED and LED, the experience is represented as a change of the reader’s mental state, State_of_Mind, related to the different phases and states of the process of reading, Reading_Process. The core of the reading experience is represented by the:effectOf relation between a reader’s State_of_Mind and Reading_Process.
State_of_Mind represents a revision of the mental state of the reader. State_of_Mind is a partial description of the new state in terms of the new or revised “facts” belonging to the reader’s mind. As such, State_of_Mind is:partOf Reader (description of the state of the agent).
State_of_Mind is described by the literal :orientation, with range:
“External”, description of a change related to the perception of external entities, e.g., objects, activities, or people, and
“Internal”, description of a change related to the self-perception of the reader, e.g., emotions
From a temporal perspective, State_of_Mind can occur before (:precedes), during (:coOccurringWith) or after (:follows) a Reading_Process. Specifically, there is a major distinction between the State_of_Mind occurring within the scope of a Reading_Process and the ones occurring outside, before or after.
Following the definition of Reading, Session and Experience, we characterise the Reading_Frame as the union of Reading and Session, an abstract class not meant to be instantiated. It is used to specify that only Reading and Session can have premises and outcomes (state of minds) as “framing” an activity, while Experience is limited to represent triggers of change in a state of mind (co-occurring during a session and reading).
State_of_Mind can have two different relations with respect to the Reading_Process: an effect of or a premise to reading. Among effects of reading, we distinguish between State_of_Mind occurring during (:coOccurringWith) an active reading and effects occurring after an active reading (in a pause between Sessions or after the end of Reading). In the first case, in accordance with the definition of Reading, Session and Experience, a State_of_Mind is evidence of experiences occurring during the Reading_Process. In the second case, a State_of_Mind is an outcome of a Reading or Session. Thus, we define the properties of:
:isEffectOf, a State_of_Mind occurring during a reading providing information about the effects of a Reading_Process
:isOutcomeOf, a State_of_Mind occurring after the end of a Reading or Session.
Lastly, we define the property:
:isPremiseOf, a State_of_Mind preceding and providing information about a Reading or Session.
Summarising, instances of state of mind co-occurring during a Session or Reading should be connected with an instance of Experience, while this is not the case if it follows or precedes an instance of Session or Reading, see Fig. 12.

A State_of_Mind:somind1 is a premise of a Session:s1 while:somind2 is an effect of an Experience:e1, part of:s1.
From the analysis of sources, we identified a non-limited list of facets of reader’s mind, encoded as subclass of State_of_Mind:
Self-reflection, reader’s self-assessment about the reading and its effects
Emotion, reader’s emotion related to reading process or resource
Achievement, a deliberation or result related to reader’s activities
Aim, expectations concerning the implications or effects of reading on the reader’s activities
Remembrance, reader’s memories about reading process or resources21
The upcoming next version of the ontology will support encoding memories, not strictly related to reading.
Disposition, reader’s stance toward a reading process or resource. Disposition is specialised as follows
Aesthetic_Disposition, disposition grounded on aesthetic arguments, e.g., genre preferences
Ethic_Disposition, disposition grounded on ethical arguments, e.g., disposition towards feminist positions
Group_Disposition, disposition grounded on the belonging to a social group or population segment, e.g., teenager, early career, left-wing voter
Skill_Disposition, disposition grounded on the physical or cognitive skills of the reader, e.g., French proficiency, first-grade education.
The dispositions of the reader are not effects of the reading experience, but a type of state of mind oriented toward content, medium or an upcoming reading. A disposition can be related toward a reading resource (:towardInteractingWith) and directed toward an instance of Reading_Frame (:inApproaching), see Fig. 13.
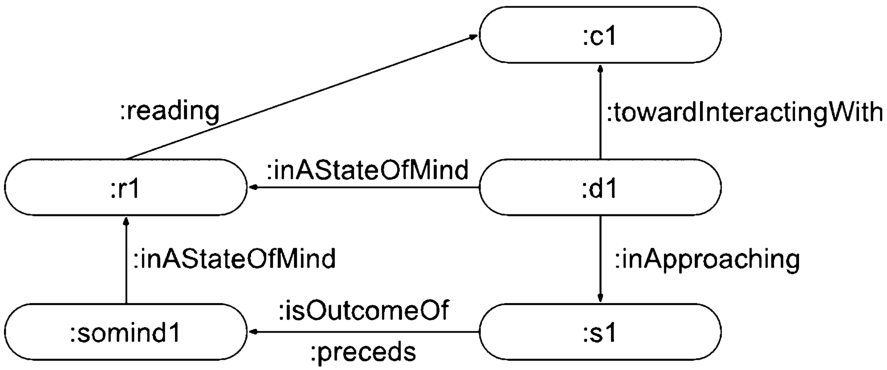
A reader:read1 reports a state of mind:somind1 outcome of a session:s1, and a disposition:d1 in approaching:s1 toward interacting with a content:c1.
The characterisation of the effects of reading on the reader’s mind is one of the major aims of the current research within the READ-IT project. Therefore, state of mind and its specialisations are yet to be fully described.
It is worth noting that we consider a reader as having a global state of mind (a stratification of reader’s experiences and knowledge), which we can only partially describe through the evidence found in the testimonies, e.g., an emerging emotion. In this framing, each state of mind is the result of a revision of the overall state of mind of the reader, but not necessarily related to reading (i.e., there is always a source for any state of mind, even though not reported). Thus, with State_of_Mind we encode these fragments, part of the reader, reported as result of reading (effects of), overall related to a specific reading (premises and outcomes) or in general to reading (dispositions), see Fig. 14.
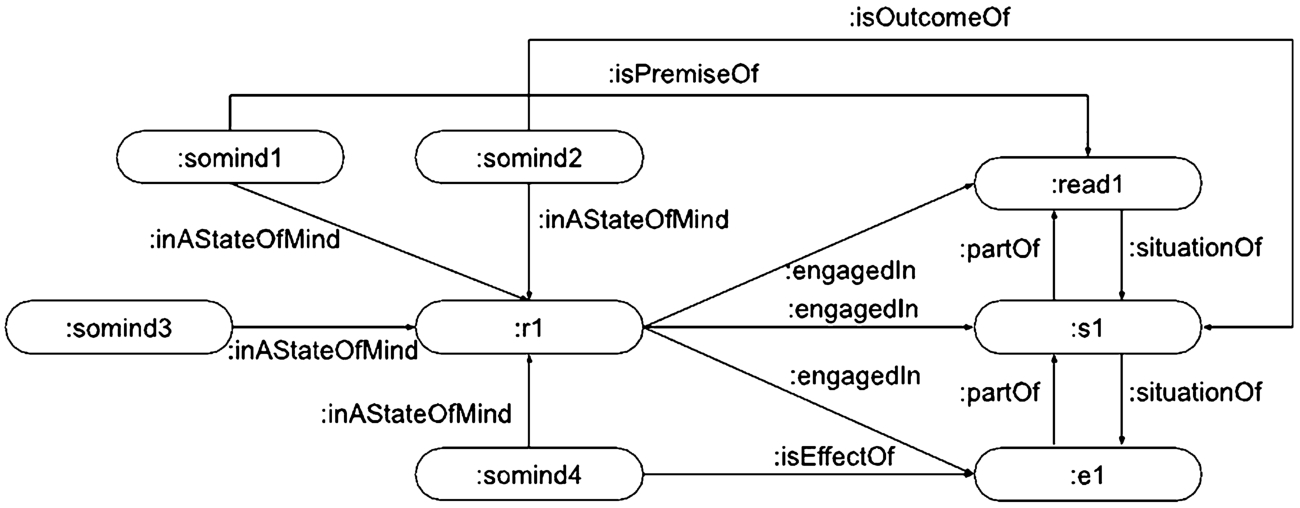
A Reader:r1 engaged in a Reading:read1, Session:s1 and Experience:e with several instances of State of Mind acting as premise of reading:somind1, outcome of a session:somind2, disposition:somind3 and effect of an experience:somind4.
Reports of reading experiences often include descriptions of co-occurring events or as the situation in which the reading occurs. Events can have a direct or indirect relation with reading. In the first case, reading is embedded in a situation, while, in the second case, an event is used to make sense of a reading, e.g., by comparison. We represent the situation of reading with the concept of cdc:E5_Event.
In CIDOC CRM, cdc:E5_Event “comprised distinct, delimited and coherent processes and interactions of a material nature, in cultural, social or physical systems involving and affecting instances of E77 Persistent Item in a way characteristic of the kind of process” [11]. This definition addresses the first case, direct relation between event and reading. Indeed, Person and Reading Resource are material entities which are embodied in a social / physical system, e.g., reading a paper in order to compile a survey, borrowing a book from the library, or reading to “kill time” during a flight.
Note that Reading_Process is also a type of event. Person and Reading Resource are involved in a Reading_Process, specialisation of cdc:E7_Activity and therefore of cdc:E5_Event. Thus, for instance, a Reading is the situation during which Sessions and Experience occur.
We represent the relations between events and reading introducing the property :situationOf, with domain and range cdc:E5_Event. For instance, an upcoming examination in English literature is :situationOf reading a textbook, a degree in Modern Literature is :situationOf all examinations and therefore of all reading related to them, e.g. see Fig. 15.
In this frame, the articulation of the Reading_Process in Reading, Session and Experience can be used to represent the implicit hierarchy of reading activity: a Reading instance is the situation of all instances of Session, while an instance of Session acts as the situation of the instances of Experience co-occurring during that instance of Session. In general, as a subclass of E2_Temporal_Entity, temporal properties apply to cdc:E5_Event and therefore events can co-occur, follow or precede other events.
In the case of indirect relations, reading and events are related to each other by the reader. Indeed, there is not a process of interaction of “material nature” outside the reader’s mind, but it is the reader’s deduction, knowledge, experience that creates the interaction at conceptual level. We address this case introducing a set of comparative properties with domain and range cdc:E5_Event (and therefore cdc:E7_Activity, Reading, Session and Experience):
:referredBy, an event B is being related to an event A
:comparableWith, an event A can be compared with an event B
:betterThan, an event A is evaluated as being better than an event B
:worseThan, inverse of :betterThan
In this frame, instances of the reading process can be compared to each other, e.g., “despite me getting the same score, reading about the industrial revolution was much better than reading about Roman history”, see Fig. 16.
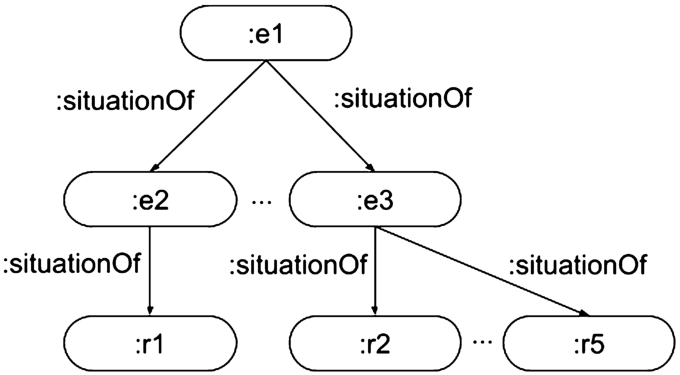
Event:e1, Bachelor in English Studies, is a situation of multiple exams, e2, e3, which are situation of multiple readings (of textbooks), r1-r5.
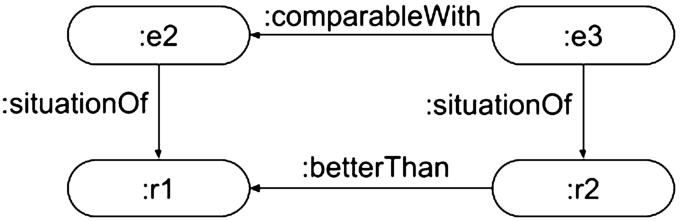
Event e2, exam on Roman history, is comparable with e3, exam on Modern history, while the reading r2, book History of the Industrial Revolution, was a better reading than the reading r1, The Gallic War.
It is worth highlighting that the ontology does not provide metrics for comparability between events, but the expressivity necessary to encode the comparisons expressed by readers. Explanations about the rationale provided by the reader can be encoded using a single instance of State_of_Mind, related to multiple instances of Reading, Session or Experience.
The validation process was led by the modelling team and carried out by engaging researchers both within the READ-IT project and outside.
The ontology was assessed in relation to its internal and external validity [40]. Internal validity was assessed in terms of a) rigour of the modelling process, and b) adherence to the phenomenon of reading reported in the sources of reading experiences. The rigour of the modelling was partially addressed in the description of the modelling lifecycle. In the subsection Formal Validity (Section 7.1), we report on the tests performed on the RDF and/or OWL encoding of the ontology.22
It is worth considering that reading is a phenomenon that can only be partially observed, thus the research on reading can rely only on indirect sources documenting reading experiences. In this scenario, the adherence of the ontology is assessed as the ability to represent the information content of sources and questions from research use cases [51]. The functional requirements extracted from the sources guided the development of the ontology while the requirements concerning the research use cases are discussed in Section 7.2 (Conceptual Validity).
Lastly, the external validity of the ontology is assessed in relation to the READ-IT project. Specifically, we discuss the non-functional requirements concerning the project architecture (System Requirements) and the research activities (Research Requirements).
The technical underpinnings of ontology validation are indicated in the literature as means to automatically test the soundness of an ontology with regard to (1) the underlying logical language used, and (2) from an engineering-oriented perspective, the ability to answer queries both domain-specific and cross-domain. Both are reported on in the following.
Description logic consistency
A basic metric for the validity of any ontology is its consistency with respect to the more expressive description logic (DL) by which it can be interpreted. This includes, at the terminological (TBox) level, whether it defines classes that subsume both the top (owl:Thing) and bottom concept (owl:Nothing), or at the level of facts (ABox), whether it defines individuals that are instances of disjoint classes or violate cardinality restrictions or property domain/range definitions. Assessing consistency requires that disjointness axioms be present, therefore class disjointness was formally defined between all sibling classes in the READ-IT model. The DL consistency of the READ-IT data model was verified by running the HermiT 1.4.3 reasoner23
Functional ontology requirements are written in the form of competency questions (CQs) [25]. These are defined as questions that the ontology being built should be able to answer. CQs and their answers play the role of a type of requirement specifications against which the ontology can be evaluated. The idea behind these questions is to ensure that the ontology being developed is committed to the reality being modelled, enough to respond to queries that may be posed to a system that uses the ontology. Thus, CQs also act as a unit test suite for the ontology.
The activity of checking whether the developed ontology is in compliance with a set of modelling requirements is called ontology verification [49]. One approach to performing this activity is (a) to transform (semi-)automatically CQs into SPARQL queries and (b) to check which and how many SPARQL queries obtain a sound response from the ontology.
This activity requires a set of instances covering the whole TBox of the ontology. Such instances can be used to encode the sample response of SPARQL queries. When such a dataset is not available, requirements are normally checked in a manual way, by analysing whether the concepts and relations in the ontology are describing nouns and verbs in the requirements written as competency questions. This approach is explained in Section 7.2.
Conceptual validity
The requirements concern specific aspects of the ontology. They emerge from the research questions behind the specific use cases or from a specific type of source. In the following, we address the questions and issues expressed by READ-IT researchers concerning the reader, situation and process of reading, and experience of reading, highlighting the type of source when applicable.
Representation of the reader
How to represent that a reader was in her youth (letters and diaries)?
How to represent the changes to the reader’s socio-economic status (letters)?
Is the reader’s writing habit within the scope of the model?
Who are the people who choose to report their emotions (interviews)?
How can I specify if a reader is an expert?
In reader psychology, there are theories about links between types of reader and reader response, but the models are built on small studies; e.g., readers from lower socio-educational backgrounds relate a read book to their personal experience, but is this the case when using larger samples (interviews)?
These questions concern the characterisation of the status of the reader at the time of reading. The ontology provides the class Reader to aggregate the properties concerning age, occupation, nationality, reading habits, gender identity, region, political stand, and social status. The collection of the statements of the reader about these aspects of their condition outline a profile of the reader. The characterisation of habit will be addressed in a later stage of the project, as part of the development of case studies and collection of research data in the READ-IT database. About occupation and social status, UK-RED and LED provide two different characterisations of these concepts. In READ-IT, we did not address concepts concerning the social and personal sphere of the person, but we reuse the upcoming CIDOC CRM module for social structures and social relations, CRMsoc,24
How do we represent multiple locations of reading (letters)?
Is there a link between the physical environment and different kinds of reading (interviews)?
What do you read where and why? Are mobile devices changing the way we read (interviews)?
Reading aloud: to whom (letters)?
How do we represent different types of reading, e.g., reading for pleasure or reading for work/study (letters)?
How can I specify if the reader is reading as part of his/her professional activities?
These questions concern the modalities of reading, e.g., at home on a book, standing on a tram on a smartphone, during a lunch break on an e-reader. Modalities of reading are combinations of place, time, duration and medium. The ontology addresses these aspects through the classes Medium and cdc:E7_Activity. Medium is defined as union of frbr:F3_Manifestation_Product, frbr:F4_Manfestation_Singleton and frbr:F5_Item addressing both physical and digital manifestation of works (e.g. manuscript, eBook) and multiple types of carriers (e.g. printed book, DVDs). The cdc:E7_Activity is a specialisation of cdc:E5_Event and therefore of cdc:E2_Temporal_Entity. As such it addresses temporal aspects, location and participants and properties related to the performance, influences and motivation of the activity. In this frame, the ontology can be used to describe and keep a distinction between 1) the motivation of the activity and the aim of the reader (State of Mind), 2) the objects involved in the activity and the medium used by the reader, and 3) the reading and the activity involving the reading, e.g., class lesson and reading during the class lesson.
My evidence reports of reading social media, blog posts or other contents which are not books: how should that be encoded in the data model (web contents)?
In case reading is between multiple contents connected through hyperlink, how do we represent references between content (web contents)?
How do we encode experiences in which we have information about fragments of text, but information about the title is missing (letters)?
These questions concern the object of reading. Indeed, today, reading is a multi-modality activity (e.g., beginning on a laptop and then switching to a smartphone) that can involve a wide range of types and combination of physical and digital contents, e.g., blog posts, web novels, comics, social media comments. The ontology provides the flexibility to represent complex situations in which the reader’s experience is related to multiple reading or reading involves multiple media or content. Furthermore, as previously discussed, the types of content and medium are not limited to printed books or periodicals.
What if the experience is about an incomplete reading or an attempt to read?
How to represent something that will be read in the future (letters)?
These questions concern the quality of the interaction between reader and content, specifically about the necessary conditions for considering an interaction as evidence of a reading experience. A future reading or partial reading implies that a reader is aware of the content that they intend or tried to read. This awareness can be the result of reading the title, the back cover, a review, a summary or upon receipt of a simple suggestion. Aside from suggestions and reviews, all other cases require a direct interaction with the medium and or the content, and a “first impression”. A first impression can be considered as a reading experience with a legitimate outcome, e.g. “I wish to read it” or “I don’t like it” in which the fragment of the content is the title, the back cover or a blurb. Suggestions (in written form) and reviews are not considered part of the content, but contents on their own (about other contents).
How can I quantify the reader’s engagement?
This question addresses the evolution of the reader’s level of engagement in the activity of reading. The engagement in reading can be on multiple levels: physical in relation to the interaction with the medium; and cognitive or emotional in relation with the analysis of the content (e.g. arguments, narrative, story or characters). The ontology introduces the class Reading_Process, specialisation of cdc:E7_Activity, to support the characterisation of the engagement. At the current stage, the ontology includes the data properties “engagement” and “transportation” to indicate a level of engagement with, respectively, the process in general or the content.
The representation of the experience
Given different kinds of entries, where do people mention their subjective experience (interviews)?
In a testimony of reading, how do readers refer to their personal experience, memories, aspirations, identification with character etc. (interviews)?
These questions concern the presentation of the evidence of reading effects in the sources of the reading experience. In this regard, the ontology addresses the encoding of the annotation body, while the W3C Web Annotation Data Model addresses the reference to the portion of source target of the annotation body. The presentation of the experience in the different types of sources can be answered through the study of the fragment of sources annotated as State of Mind and the metadata about the position and structure of these fragments of their target.
This reader’s experiences are expressed by comparison. Does the model support comparison between experiences?
This question concerns the reader’s habit of defining experience by comparison. The ontology provides a set of comparative properties, e.g., better than, and relational properties, e.g., about, to support the description of comparison between reading.
If the reader does not indicate dates but just emotions, how do we represent the experience (letters)?
What to do when the reader is comparing one book with others, but it is not clear which ones (letters)?
Not all reading events are transformative (for the reader), reading evidence or indicators of an experience alone. Which is the minimum set of information required to have a reading experience entry?
These questions concern the minimum set of information required for structuring a representation of reading experience. In general, the lack of information about the effect of reading on the reader is a legitimate piece of information, for instance for the study of how readers report their reading experiences. The ontology can be used to represent an interaction without specific effects or effects of reading without details about the reader, the content or the process.
In the evidence, the reader is describing emotional aspects of the content and not of their personal reading experience. Is this information in the scope of the READ-IT data model (interviews)?
This question points out that the content of a reported experience could be personal or impersonal and states an ambiguity about the content of the experience. In a broader sense, the ontology represents the orientation of a state of mind, e.g., an emotion, which could be oriented toward the self, internal, or other entities and activities. Furthermore, an emotion could be encoded as “emotion” if concerning the response of the reader, or as a “remembrance” if quoting the content.
Ontology and system requirements
The ontology was evaluated under a new set of requirements emerging from the engagement of research and technology partners.
Types of sources
The ontology can address annotations on multiple types of sources of reading experience, such as social media, diaries, books, recordings, paintings, video and pictures. The management of annotation is addressed by the concept of “target” of the W3C Web Annotation Data Model (WADM). Specifically, a target can be any resource that can be identified by an IRI (Internationalized Resource Identifier). The description of the target includes information concerning the source (IRI), the style and system of rendering (e.g., software for PDF), selection of the resource (e.g., start and end character counter) and status of the resource at time of annotation (e.g., version). The W3C WADM can represent multiple types of media, individually or as collections.
Research data
As previously argued, the W3C WADM supports a wide range of different types of sources, while the ontology supports the encoding of the annotations of the different types of reading experience (emerging from the sampling of sources). About the different types of research activities, we rely on the development of different tools, making use of the ontology, designed for supporting specific tasks. In this regard, in READ-IT we consider the following types of tasks.
Crowdsourcing of sources of reading experience, including metadata and licensing through a webtool (as showcased at the SHARP 2019 conference25
The new collected sources will be in the scope of the ontology only when annotated
Manual Annotation of sources by researchers, scholars, students and volunteers.
In this regard, a prototype tool for text annotation is currently being tested. As a result of the first annotation sessions, we identified a subset of concepts of the ontology that will be available through the interfaces of the annotation tool documented in the annotation guide. The data generated through the annotation tool will be integrated through automatic reasoning.
Machine learning and automatic annotation of sources.
The data generated from the manual annotation tool and the construction of a training set requires enriching the data with the aim of making the implicit knowledge explicitly encoded. In this regard, the ontology provides an extensive set of properties aimed at the explicit representation of indirect relations, e.g., “reader A reading content B, reading through medium C” can be enriched by stating explicitly that the medium C provides access to content B. Furthermore, the annotation of images and paintings about reading rely on specific visual cues, e.g., an opened book or reading to a group of people. In this regard, we introduced the class of State_of_Medium, and the properties Participants (to an Event) and ListeningTo.
The ontology can support the production of data in the frame of research use cases, and the interoperability of research data beyond the single use cases. The ontology is able to represent the different types of research experiences included in the sources considered in the case studies.
Data integration
The ontology can support the integration and querying across partial research data. For instance, we consider two applicative scenarios about integration and transversal querying of data about research on an author reading: Example 1 – How to study the reading experiences of Italian poet Ugo Foscolo (1778–1827) in relation to his location; and Example 2 – Reading in the Italian Peninsula and during the Italian unification.
Example 1 – studies on Ugo Foscolo’s reading Italian poet Ugo Foscolo lived and worked in several countries during the early 19th century, undergoing changes of social status, political outlook and language during the course of his life.
Sources: letters and critical works
Studies: Foscolo’s reading in
different countries
different languages
different socio/economic conditions
different political stans
The ontology allows the integration of these different outputs through the concept of Person, the contextualisation of specific reading Events and the analysis of his States of Mind. We can thus query whether at a given time the location of Foscolo’s reading experience, his socio-economic situation or the motivation of his reading influenced his evaluations of an author or work and compare his experiences with those of other contemporary readers.
Example 2 – reading in the Italian Peninsula
Reading had a central role in the emergence of an Italian national identity during the 19th century
Sources: diaries and letters
Studies: Italian readers from multiple locations in the Italian Peninsula during the 19th century
While analysing the diaries and letters of Italian readers from multiple locations, we can query, for example, whether reading the classics of medieval and Renaissance Italian literature or contemporary political outputs was more common within one of the eight states in which Italy was subdivided after 1815, and whether the creation of the new Italian state in 1861 changed reading preferences, for example through national school curricula.
Supporting research
The management and use of sources in case studies is mostly addressed by the W3C Web Annotation Data Model (WADM). The issues concerning the use of sources are related to their veracity and the reliability of the annotations. Furthermore, researchers point out more conceptual issues related to the aim of the descriptions of reading experience and the social context in which reading and documenting the experience are embedded.
Is there a distinction between fiction and non-fiction content of sources?
How can we know if annotations are reliable?
These questions concern the value of the information of sources and annotations.
A source can report real or fictional experiences of reading, e.g., a diary is supposed to be a source of real experience while a novel is supposed to be fictional. In general, evaluating the veracity of the reading experience is grounded on both the type of source and its content. For example, a novel may be fictional but include the real experience of the author, whereas a diary can report third-party comments. In both cases, the evaluation of the annotator should be reflected on the annotations but not as source metadata.
The reliability of annotations is addressed by the annotation concept of the W3C WADM. Specifically, the W3C WADM addresses the agent creating the annotation (human creator and software generator), and the intended purpose and motivation. Quoting the W3C WADM “The creator of the Annotation is also useful for determining the trustworthiness of the Annotation. The software used to create ... the Annotation ... is useful for both advertising and debugging issues” [53].
Summarising, the W3C WADM provides the information and references to assess the source (target) and the agent responsible for the annotation (body) but does not provide a structure to report an evaluation as part of the annotation model.
Can we include anonymised data from reader focus groups? (interviews)
The anonymised or pseudo-anonymised transcripts retain the relation between subjects and content. Therefore, transcripts of group meetings can be encoded using the concepts of Person and Reader. For instance, a group including two people each reporting about their readings can be encoded as in Fig. 17.

During an event cdc:e1 (focus group), two people, foaf:p1 and foaf:p2, report about being readers in reading situations:r1,:r2 and reading situation:r3.
Can we represent the historical and social context of sources relevant for their correct interpretation and study (diaries)?
In case the evidence of reading is meant for someone, e.g., the author, how could this information be represented (letters, diaries, periodicals)?
In case the experience uses different languages, depending on the addressee, how can it be represented (letters)?
These questions concern the relevance of the evaluation of the context in the study of sources. Understanding the context of sources is critical for the annotation process and for making use of the annotation in research. For instance, the social context can be the source of emerging patterns about the reading, for instance, specific authors or content subject to censorship or a strong social pressure. This information is outside the scope of the model of reading experience, but is partially taken into account by the W3C WADM through the concept of scope of the source (IRI), e.g., a Wikipedia page or essay. Indeed, a future development of the project (or a future project) should address the design and development of a repository about the context of sources that could be linked as scope.
The development of the READ-IT ontology provides a valuable opportunity to reflect on the role of modelling in the context of research projects, and on how a modelling process can contribute to the creation of new knowledge.
Modelling in the case of the READ-IT ontology moves beyond the encoding of the consolidated domain knowledge of a specific discipline (in this case, history of reading) into facilitating the integration of different disciplinary perspectives and enabling the convergence of knowledge. In particular, the READ-IT ontology transcends the limitations of earlier projects on the history of reading such as UK RED, by modelling reading as a human phenomenon rather than as a collection of sources. This approach allows the READ-IT ontology to model the aim of the research process of the project (to gain greater understanding of the role of reading in Europe from 1700 to the present), as well as its starting point (cultural heritage documents that contain evidence of reading). The READ-IT model then enables generative research through the formulation of new, reasoned hypotheses on the experience of reading.
The approach to modelling of the READ-IT ontology supports researchers by establishing a common framework of enquiry. For example, by defining reading agent and reading resource (consisting of medium and content) as two fundamental elements of reading, the model enables Humanities researchers to compare findings and hypotheses even if they are based on data that spans significant temporal and linguistic diversity. The modelling process also highlights questions that are still open for debate, for example those that pertain to the state of mind of the reader, helping to focus current and future research.
With the READ-IT ontology, modelling transcends the encoding of the consolidated domain knowledge of a specific discipline and enables the convergence of knowledge from different disciplinary perspectives. The ontology provides a common framework that can be applied beyond the isolated case studies that constitute the norm in Humanities research, to analyse issues that are still under debate and allow the definition of a common object of study.
From a technical perspective, the READ-IT project and the development of its technological ecosystem required rethinking the role of the ontology. In READ-IT, the ontology facilitates the creation of new data sets, addressing limitations of data models used in previous projects. Furthermore, the ontology is used as a reference for the design and development of tools for supporting research activities, such as crowdsourcing reading experience and annotation of sources. The fulfilment of these roles emerged as a precondition for the assessment of the value of the ontology in relation to data and within the project framework.
Use of the ontology
The ontology and the conceptual model value is two-fold. Firstly, the conceptual model is used to support the framing of research case studies, such as authors’ libraries, diaries and correspondences [2], and new reading practices [3]. Furthermore, the ontology had been used in the implementation of the READ-IT annotation tool in a series of collaborative annotation campaigns.
In regard to the use of the ontology for annotation, a challenge worth mentioning concerned the “appropriability” of the ontology by researchers. The complexity of the ontology appeared as an impeding factor for it. Furthermore, the design of a web-based tool for annotation based on the ontology would not have reduced its complexity and could have resulted in discouraging students and volunteers. Indeed, we faced a situation in which the ontology’s expressiveness was considered correct and appropriate but also an issue.
In this regard, we worked on identifying a subset of concepts of the ontology, a simplified version, which could be easily translated in the annotation tool and be of immediate use for annotators. This solution required a compromise in having a tool generating data on a fragment of the ontology and creating the need to develop an ad hoc reasoner to enrich and complete this type of data source. This solution will enable the creation of new data in a common format without sacrificing the expressiveness of the ontology, which will be of use in the development of other tools and algorithms.
In this scenario, ontology reasoning should aim to integrate the description of the partial annotations, exploiting a set of rules encoding the hidden assumptions encoded in the annotation tool. For instance, the annotation tool provides the concept of Session but not of Reading, but the fragmentation of sources allows the assumption that each instance of Session should be connected to an instance of Reading, not explicit annotated but implicit in the definition of the fragment to annotate, as a testimony of a single reading. This use of the ontology will be explored in the future development of the project.
Challenge of legacy
A second challenge concerns the conversion of legacy data from UK-RED (Reading Experience Database). In contrast to what was expected, the data collected during the approximately ten years of UK-RED related to reading experience could not be used to validate the ontology. Indeed, the UK-RED data concern concepts and relations almost exclusively related to the reused ontologies (CIDOC-CRM and FOAF). Thus, rather than providing a validation set for READ-IT ontology, UK-RED data actually provides a challenge in terms of preserving the value of a legacy project within a new theoretical and technological framework that is yet to be addressed.
Limitations and future development
To summarise, the limitations of this work are strongly dependent on the challenge it addresses: broadening the scope within the core of research activities; supporting multiple purposes and activities within a yet-to-be-defined technological ecosystem; supporting both disciplinary, multidisciplinary and interdisciplinary research, and current and future research activities; and anticipating and facilitating the production of new research data. In this regard, during the next two years of the project, the development of research case studies, technologies and the production of data will provide the opportunity to re-assess the validity of the ontology under the light of first-hand experience and extend or reframe its most controversial concepts.
Footnotes
Acknowledgements
This work was partially supported by Reading Europe – Advanced Data Investigation Tool (READ-IT), a project funded by the JPI Cultural Heritage under the European Union Horizon 2020 Research and Innovation programme (grant agreement No 699523).
This research work has been partially funded by the Agence Nationale de la Recherche (ANR-17-JPCH-0001-01).
This research work has been partially funded by (a) the Research, Development and Innovation Program from the Universidad Politéctinca de Madrid (UPM) (Programa Propio de I+D+i de la UPM) and (b) the project entitled “System for Evaluating and Adapting Learning Materials to the Easy-to-Read Methodology”, approved by the XIX UPM Call for Actions to contribute to the achievement of the Sustainable Development Goals.
The authors would like to thank the READ-IT consortium and associate partners![]()