
Abstract
In the context of the Semantic Web regarded as a Web of Data, research efforts have been devoted to improving the quality of the ontologies that are used as vocabularies to enable complex services based on automated reasoning. From various surveys it emerges that many domains would require better ontologies that include non-negligible constraints for properly conveying the intended semantics. In this respect, disjointness axioms are representative of this general problem: these axioms are essential for making the negative knowledge about the domain of interest explicit yet they are often overlooked during the modeling process (thus affecting the efficacy of the reasoning services). To tackle this problem, automated methods for discovering these axioms can be used as a tool for supporting knowledge engineers in modeling new ontologies or evolving existing ones. The current solutions, either based on statistical correlations or relying on external corpora, often do not fully exploit the terminology. Stemming from this consideration, we have been investigating on alternative methods to elicit disjointness axioms from existing ontologies based on the induction of terminological cluster trees, which are logic trees in which each node stands for a cluster of individuals which emerges as a sub-concept. The growth of such trees relies on a divide-and-conquer procedure that assigns, for the cluster representing the root node, one of the concept descriptions generated via a refinement operator and selected according to a heuristic based on the minimization of the risk of overlap between the candidate sub-clusters (quantified in terms of the distance between two prototypical individuals). Preliminary works have showed some shortcomings that are tackled in this paper. To tackle the task of disjointness axioms discovery we have extended the terminological cluster tree induction framework with various contributions: 1) the adoption of different distance measures for clustering the individuals of a knowledge base; 2) the adoption of different heuristics for selecting the most promising concept descriptions; 3) a modified version of the refinement operator to prevent the introduction of inconsistency during the elicitation of the new axioms. A wide empirical evaluation showed the feasibility of the proposed extensions and the improvement with respect to alternative approaches.
Introduction
In the perspective of the Semantic Web (SW) as a Web of Data, a plethora of datasets are constantly published and connected to others in the form of Linked Data, along a standard data model and based on schemata formalized as Web ontologies [16]. In this scenario, many important services have been devised and deployed for exploiting and enriching these knowledge bases in a variety of tasks, such as classification, query answering, population and enrichment, reconciliation (instance matching), and consistency checking.
The effectiveness of the inference services that implement these tasks as well as further services that can be built upon them (e.g. statistical inference) is strictly dependent on the quality of the ontologies, namely on how precisely (and exhaustively) their axioms convey the intended semantics of the underlying domains. As ontologies are represented through standard languages ultimately based on Description Logics (DLs) [2], an open-world semantics is generally adopted as suitable for such a Web-scale scenario, opposed to the complete knowledge assumption backing the semantics of other contexts (e.g. relational databases and logic programs). Checking disjointness is one of the key reasoning tasks for DL knowledge bases together with satisfiability, subsumption, equivalence tests (they can be reduced to one another). Reasoning under open-world semantics, with tasks involving individuals, e.g. instance checking and retrieval queries, it may often happen that the truth of assertions cannot be ascertained, owing to the inherent incompleteness of the knowledge bases (for technical details see [2], Ch. 2). This issue affects also the other services mentioned above that are built upon them. For example, in tasks aimed at enriching knowledge bases, detecting the possible introduction of conflicting assertions (e.g. cases of inconsistency) is very important, as this might trigger further repair-actions to reconcile the possible causes. Hence disjointness axioms are essential to detect such cases.
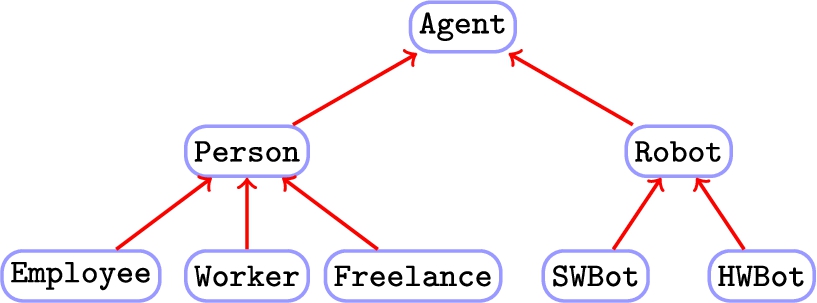
A simple concept hierarchy modeling the agents in a corporate domain.
To clarify this point, let us consider the case of a simple corporate knowledge base fragment (whose hierarchy is depicted in Fig. 1) with two sibling subconcepts, namely
However, in the design of various popular ontologies currently in use, the introduction of disjointness axioms as required by concept modeling methodologies (see [2], Ch. 10) has been neglected. As a result, they provide only a rather approximate representation of the domains, failing to capture all of the underlying constraints or making a complete knowledge assumption that distorts the intended semantics by admitting unintuitive cases. This lack of modeling accuracy was testified by a survey [30] in which only 97 out of a total of 1275 considered ontologies was found to include disjointness axioms. A possible reason for such an issue may be the inexperience with the language constructs, often leading users to overlook disjointness during the definition of domain axiomatizations [29]. As a result, while a growing number of datasets have been published joining the Linked Data cloud over the years, this issue is still ignored: at the time of writing this article, only 7 out of 9960 knowledge bases (0.7%) include this kind of axioms.1
This can be checked at
Another cause for this issue may lie in the context-dependent nature of the notion of disjointness which is consequently perceived in different ways [27]. For instance, considering the previous case, it may be assumed that the same individual cannot be both a
Noticeably, various works have shown how to exploit association rule mining for statistical schema induction [27,28]. The proposed methods often depend on the availability of heterogeneous external resources (corpora) for their elicitation for relying on lexical features. Conversely, the interplay between extensional and intensional knowledge (i.e. assertions regarding the individuals and terminological axioms) was only marginally taken into account. Most of the current approaches move from the assumption that two (or more) concepts may be mutually disjoint when the sets of their known instances, which should be representative for their extensions [2], do not overlap [14,29]. Moving from these considerations, a data-driven approach could be devised with the goal of finding partitions of similar individuals of the knowledge base according to a criterion that maximize the homogeneity of the individuals in each partition, i.e. emerging concepts, while minimizing their mutual overlap. Evidently, this boils down to a clustering problem [1] which is a classic topic in machine learning. It has also been taken into account in the context of ontology learning as a preliminary step for concept induction [19] or for automated solutions to concept drift or novelty detection problems [10]. Such problems have been tackled through extensions of basic clustering methods, such as (fuzzy)

A fragment of a TCT.
TCTs (see an example in Fig. 2) are quite similar to terminological decision trees [12,22]: they are grown through divide-and-conquer strategy and can be thought to form hierarchies of concepts that are built exploiting refinement operators for DLs [19,21]. The latter are essentially binary decision trees, induced by supervised methods exploiting information-based heuristics; they are meant for the classification of the individuals through the logical tests in their inner nodes and classes associated with the leaves. The former (with a similar structure except for the leaves) are trees induced through unsupervised learning methods aimed at eliciting types from the partitions of similar individuals. The concepts to be installed at inner nodes are defined by progressively refining the one at the parent node (or its complement for right-children): possible specializations of such a concept are computed by a refinement operator, and the best one is selected based on the quality of the (bi)partitions of individuals that would be routed to either children. This quality is measured in terms of their membership w.r.t. the candidate refinement. Suitable specific metrics for the underlying representation are required to derive a notion of cluster prototype [10]. Noticeably, the method is able to detect dense data regions in the underlying instance space, hence the number of clusters – which has a strong impact on the quality of the clustering structure – need not to be required as a parameter. As in many partitional clustering method [1] the cohesion of the clusters (e.g. measured as the similarity of the members w.r.t. the prototype) determines the stop condition: further partitioning of coherent clusters should be prevented to preserve the quality of the structure. Once the TCT is grown, the concepts in the tree are extracted to form candidate disjointness axioms. They are intended to be validated by a domain expert/ontology engineer and may be involved in a subsequent debugging process for eliciting future cases of inconsistency (i.e. newly available individuals found to belong to disjoint concepts as shown in the previous example). Despite the potential benefits deriving from the induction of TCTs, there are some issues that were not investigated in preliminary works [24], and whose solution can further improve the framework.
Firstly, we tackle the issue of possible inconsistency cases that may be introduced by some axioms (out of a potentially large number of candidates) elicited by the data-driven method. Due to the context-dependent nature of disjointness, it may be hard to determine if a case of inconsistency indicates a truly erroneous axiom or a special case for the domain represented by the ontology. As an example, let us consider the concepts
Summarizing, we further extend our framework for disjointness axiom discovery based on TCTs with:
a new version of the refinement operator that is able to prevent cases of inconsistency introduced by concepts installed in the tree nodes; the adoption of different versions of the distance measures between the individuals; a different heuristic aiming at maximizing the distances between the closest elements of two clusters instead of their medoid;
A new and more comprehensive empirical evaluation was designed and carried out aiming at assessing the effectiveness of the method based on the TCTs also in comparison with other related methods.
The paper is organized as follows: in Section 2, the disjointness axiom discovery problem is formalized in terms of a clustering problem of individuals of an ontological knowledge base. In Section 3, the details of the enhanced methods for inducing TDTs used for solving the targeted problem are illustrated. The comparative experimental evaluation of the new implementation on a testbed of common ontologies is presented in Section 4. In Section 5 related works are discussed. Section 6 concludes this work with further research directions.
In this section, we formalize the problem of discovering concept disjointness axioms from ontological knowledge bases in terms of a clustering task. We will borrow notation and terminology from Description Logics, being the theoretical foundation of the standard representation languages for the SW. Hence, we will use the terms concept (description) and role as synonyms of class and property respectively. DL constructors will be used for defining concept descriptions. Logic entailment, subsumption and equivalence for complex axioms will be denoted with the usual symbols ⊧, ⊑, and ≡, respectively. A knowledge base (KB)
Clustering is an unsupervised learning task aiming at grouping a collection of objects into subsets, named clusters, such that those within each cluster are more closely related/similar to one another than the objects assigned to different clusters [1]. In cluster analysis, the quality of the clusters is assessed using indices that take into account measures of cohesion, i.e. total reciprocal similarity, among the objects within a cluster, and of separation, i.e. total reciprocal dissimilarity, among different clusters. In a general setting, an object is usually described in terms of features from a selected set
A further interesting class of methods is represented by conceptual clustering approaches [26] which generate also an intensional description (defining the membership property) for each cluster (e.g. a conjunction of propositional atoms). Beyond vectorial or, equivalently, propositional representations, more expressive richer logic languages may be adopted, such as the mentioned DLs. Differently from other methods, conceptual clustering algorithms for such representations may exploit available (schema-level) background knowledge for building descriptions for each cluster, i.e. axioms defining new concepts. Expressive representations require the support of suitable metrics for upgrading clustering methods.
A necessary condition for the disjointness of two (or more) concepts to hold is that their extensions do not overlap. Then the task of discovering disjointness axioms may be regarded as an unsupervised conceptual clustering problem aimed at finding separate partitions of individuals in the KB (such that each cluster consists of similar individuals, according to a given criterion) and producing intensional descriptions for them.
The problem is defined as follows:
(disjointness axiom discovery problem).
a knowledge base a set of individuals
a partition Π of for each
Hence
Note that, differently from other settings, the number of clusters (say
In the context of the corporate domain introduced in Section 1, let us consider the agents in a company KB (humans and machines). A concept description should be assigned to each cluster of a partition produced by a suitable method. As a result, a disjointness axiom may be discovered involving e.g. the clusters corresponding to the concepts
Note that the formalization in Def. 1 is language-independent and it is aimed at a simple flat partitioning structure, yet it can be generalized to target hierarchical structures. In the next section, a solution to such a more complex form of clustering is presented.
The proposed approach is grounded on a two-step process. In the first step, given a knowledge base, clusters and the related concepts that describe them are discovered and organized in a tree structure. In the second step, the induced structure is exploited for learning a set of candidate disjointness axioms.
The model is formally defined as follows:
(terminological cluster tree).
Given a knowledge base each node, which stands for a cluster each edge departing from an internal node corresponds to a partition of Noticeable difference with concept hierarchies: for each node in the TCT, its cluster, composed by instances of the concept in the parent node (ideally ⊤ for the root), is bi-partitioned according to the membership w.r.t. the concept in the current node.
A tree-node is represented by a quadruple

A fragment of TCT whose nodes are also decorated with the size of the respective cluster of individuals
Figure 3 illustrates an example of TCT resulting from the fragment of the corporate KB introduced in previous examples. In this tree, each concept installed into inner nodes is used to split a cluster of individuals
The construction of a TCT combines elements of logical decision trees induction [4,12] (recursive partitioning and refinement operators for specializing concept descriptions) and of instance-based learning (a distance measure over the instance space). The details of the algorithms for (a) growing a TCT and (b) deriving intensional definitions of candidate disjoint concept descriptions are reported in the sequel.
A TCT is induced by a recursive strategy (see Algo. 1), which follows the schema proposed for growing terminological decision trees (TDTs) [12,22] solving the instance classification problem. The ultimate goal is to find a partition of pure clusters in terms of cohesion. The main routine

Main routine for growing TCTs and stop condition test
In the inductive step, which occurs when the stop condition does not hold, the current (parent) concept description C has to be specialized using a refinement operator (ρ) that spans over a search space of concepts subsumed by C. A set of candidate specializations
The proposed approach relies on a downward refinement operator ρ [12,21] that must be able to generate satisfiable concepts – in terms of the models of the KB – performing a specialization process. It can be defined by cases in terms of ancillary sub-functions. Given the a concept description C (or its complement) to be specialized, the operator ρ computes specializations of C in one of the following forms:
by adding a concept atom (or its complement) as a conjunct: by adding a general existential restriction (or its complement) as a conjunct: by adding a general universal restriction (or its complement) as a conjunct: by replacing a sub-description by replacing a sub-description
Note that the cases of
Given the TCT in Fig. 3, starting from
The refinement operator ρ performs a sort of random sampling over a DL concept space. It is to be remarked that it does not satisfy all of the properties required for ideality, i.e. finiteness (for any concept the set of specializations is finite), completeness (for all concepts C and D, such that
Instead of aiming at the definition of a theoretical operator endowed with these properties, which would be intended for a use with a generic generate-and-test algorithm, we decided to devise a more complex yet effective data-driven specialization procedure, capable of leveraging on the situation of the tree under construction. Algo. 2 illustrates the resulting procedure
the resulting specialization D is satisfiable w.r.t.
it does not overlap with the concepts

The specialization routines employed for inducing TCTs
The specializations D are produced by adding a new (complex) description via the auxiliary function
Let us suppose that
As previously mentioned, the specializations returned by ρ are required to be satisfiable. This does not ensure that instances of such concepts are actually represented in the training sets. It is important to avoid the generation of satisfiable concept descriptions for which the training individuals exhibit a neutral membership (neither positive nor negative examples): installing one of these concepts in a node would end up with all the individuals in the current node to be sorted to a single branch, thus undermining the divisive value of the node tests and increasing the complexity of the trees (in terms of number of nodes) with no evident advantage. To avoid these refinements, the algorithm verifies if a non-null number of positive and negative instances can be found for D, i.e. both the intersection between
Let us suppose that the function
The algorithms for growing TCTs and TDTs share a common structure but differ on the criterion for selecting the test concepts to be installed in the nodes: while the latter adopts a scoring function based on the classic notion of information gain, the separation measure to be maximized in the procedure for the TCTs relies on a distance defined over the individuals occurring in the KB. Specifically, the heuristic for selecting the best refinement of the parent concept is defined as follows:
The score for each candidate E is determined quantifying the risk of overlap between two clusters according to the distance between the closest individuals belonging to
Non uniform values for the vector of weights
An alternative distance measure proposed in other works [7] is the following:
Stop conditions
The growth of a TCT can be stopped if one of the following conditions are satisfied (see Algo. 1):
the set of individuals is too small to be partitioned: this is made testing if
The concept C to be specialized is different from ⊤:in this case the algorithm finds the positive and negative instances of C and exploits a threshold
To avoid trivial clusters, the Boolean function
Extraction of disjointness axioms from TCTs
The procedure for discovering/extracting disjointness axioms requires a TCT as its input. Its details are reported in Algo. 3.

Derivation of disjointness axioms from TCTs
Function
The set of collected concept descriptions
Note that the hierarchical nature of the approach may allow for a further generalization of this function, controlling with a further parameter the maximum depth of the inner nodes to be visited during the traversal. This would likely produce fewer and more general axioms with respect to the specification of the function reported in Algo. 3.
Given the TCT in Fig. 3, the following set of concepts can be built using the routine
The following candidates axioms can be derived:
The algorithm to elicit candidate axioms from TCTs provides an approximation of the missing axiom described in Ex 1. Additionally, it was also able to generate axioms involving other concepts, e.g.
In this section, the design and the outcomes of a comparative empirical evaluation of the proposed model and related methods are reported. The experiments were aimed at assessing the performance of the revised version4
Code and testbed of ontologies are publicly available at:
Ontologies
In the experiments, we considered a variety of freely available Web ontologies describing various domains, namely:
Ontologies employed in the experiments
Ontologies employed in the experiments
The experiments had two main goals:
assessing the ability of the proposed approach to (re-)discover target axioms originally defined as the result of a knowledge engineering process; assessing the number and quality of the new axioms discovered preserving the KB consistency in comparison with related methods.
In order to automate the test of the axioms produced we decided to bypass the intervention of domain experts which is hardly available and may compromise the repeatability of the experiments. To cope with the lack of target disjointness axioms in the considered KBs which would offer a natural gold standard (ground truth) for the tests, we considered modified versions of the ontologies reported in Table 1, which were produced through the artificial introduction of new disjointness axioms involving sibling concepts in the subsumption hierarchy, according to the SDA, yet preserving the consistency of the ontologies. For each ontology, a fraction f of disjointness axioms was randomly removed. To have performance indices unbiased by the specific selection of axioms, this procedure was repeated 10 times per ontology and also increasing f: 20%, 50%, 70%.
The effectiveness of the methods was evaluated in terms of
the average number of original axioms rediscovered (the larger the better) that can be considered as a sort of recall measure the average number of inconsistencies in the knowledge base (the less the better) and the average number of axioms elicited, which is an indicator of the precision of the tested methods.
Set-up of the implemented algorithms
In the evaluation we tested various configurations of the overall discovery process based on the TCT learning algorithm that can be summarized as follows:
v.1: first release of the TCT learning algorithm [24] combined with the heuristics (1) and (2) and the distance measures (4) and (6) (both entropic – denoted by e – and uniform weights – denoted by u – have been considered); v.2: new version of TCT learning algorithm exploiting the heuristics (1) and (2) and the distance measures (4) and (6) (with and without entropic weights) v.3: same as v.2 but with the consistency check described in Algo. 2.
The distance measure
As previously mentioned we tested the various configurations of the procedure based on TCTs against other approaches proposed in the related literature (see Section 5), in particular those based on Pearson’s correlation coefficient (PCC) and negative association rules (NAR) [27]. As for the latter, rules were mined using
Experimental results: Presentation and analysis
For the sake of readability Tables 2–7 report some outcomes of the empirical evaluation while the complete results are listed in Appendix A.
Rediscovering disjointness axioms
Average rates (and standard deviations) of original axioms re-discovered. Configurations v.1 and v.2 – scoring function 1
Average rates (and standard deviations) of original axioms re-discovered. Configurations v.1 and v.2 – scoring function 1
Throughout the experiments, we noted that the algorithm based on the TCTs was able to re-discover most of the disjointness axioms that had been previously removed to test this ability. The limited number of cases where the algorithm did not manage to re-discover the axioms depended on the choice for the threshold ν: the lower its values the less recursive calls are required for completing the induction of a TCT. Anticipating the termination, along with the inherent incompleteness of the refinement operator, may be one of the reasons for not getting the exact concepts involved in the original axioms. Further aspects that may have affected the outcomes are the choice of the distance measure and the heuristic adopted to select the concepts to be installed in the nodes. As regards the former, we noted that, adopting function (6), the rate of rediscovered axioms was lower than the one obtained with function (4). The resulting trees showed a less complex structure (less nodes) using (6) instead of (4). Besides, higher values were generally returned by the first measure. This makes homogeneous clusters of individuals (that determine the stopping condition for the tree growth) harder to find. In this perspective, also the choice of the vector of weights has had some influence: while the easier choice of uniform weights tended to flatten the distance measures, especially in the cases with large contexts of features, entropic weights resulted in a sort of preliminary feature selection that tended to discard many unrelated concepts of the context.
In this sense, the experiments with
Similar improvements were observed in the experiments with
In the evaluation, we also tested the effectiveness of the alternative heuristic (2). In this case very small or no changes were observed in the rate of rediscovered axioms although different tree structures were produced. Furthermore, in the experiments with TCT v.3, we observed an evident decrease of the performance (see the results with
A further aspect to consider is the availability of individuals that are instances of the concepts involved in disjointness axioms. In the elicitation of the target axioms, the larger the number of individuals in a given cluster, the more likely it is to find sub-clusters whose distance is maximized. Specifically, in the experiments we noted that it was hard to rediscover axioms involving concepts with less than 10–15 available instances: in such cases, the limited number of individuals in the clusters did not allow to maximize the distance of the candidate sub-clusters. Consequently, the scores computed via both heuristics (1) and (2) were quite low and the concepts were ignored. For instance, in the experiments on
Experimental comparison of the various approaches: average numbers of cases of inconsistency (#inc.) and total numbers of discovered axioms (#ax’s) for PCC and NAR
As regards the overall number of discovered axioms (see Tables 5–7) generally it can be observed that it decreased with larger fractions of axioms removed since the resulting trees showed a less complex structure. Moreover, we noted that, in the case of smallest ontologies (in terms of number of individuals), there was a non-negligible impact on the effectiveness coming from a proper tuning of the threshold ν. Conversely, the differences among the results are small in the experiments with largest ontologies such as
Concerning the distance measures used in the experiments, we noted that this was an important factor for the number of the elicited disjointness axioms. Plugging the distance measure (4) in the TCT-based algorithm had as a consequence the induction of taller trees with a larger number of nodes, owing to the selection of concepts that required many splits of the sub-clusters sorted to the (negative) right branches of the trees. Moreover, in some cases, TCTs with clusters containing few individuals were produced. This was due to the distributions of the instances w.r.t. the various concepts: for example concepts with few instances are frequent in
As regards the choice of the heuristic for selecting the most promising candidates, while this aspect did not affect the ability to rediscover the target axioms, it influenced the ability to induce new axioms avoiding the introduction of inconsistency: the scoring function (2) allowed to select concepts that determined sub-clusters whose distance was larger compared to those produced adopting function (1). As expected, this meant that the new heuristic was able to reduce the problematic cases of individuals of a sub-cluster that were close to those belonging to the sibling sub-cluster (which the heuristic (1) is less sensitive to), improving the homogeneity of the resulting sub-groups (and reducing also the number of the induced axioms). In particular, we noted that no inconsistency cases were introduced in the experiments with Eq. 1: for most candidate axioms involving concepts, say C and D, it seldom occurred that the number of individuals that were instances of
Experimental comparison of the various approaches: average numbers of cases of inconsistency (#inc.) and total numbers of discovered axioms (#ax’s) using TCT v.1 and v.2 – scoring function (1)
Experimental comparison of the various approaches: average numbers of cases of inconsistency (#inc.) and total numbers of discovered axioms (#ax’s) using TCT v.1 and v.2 – scoring function (1)
Experimental comparison of the various approaches: average numbers of cases of inconsistency (#inc.) and total numbers of discovered axioms (#ax’s) using TCT v.1 and v.2 – scoring function (2)
Experimental comparison of the various approaches: average numbers of cases of inconsistency (#inc.) and total numbers of discovered axioms (#ax’s) using TCT v.3 – scoring function (2)
Comparative experiments It is worthwhile to note that throughout the experiments, the number of axioms induced through TCTs was larger than the number of axioms induced through the methods based on PCC and NAR (see Table 4). This was due to the fact the, via one of the refinement operators, the TCT-based method performs a search in a larger space than the one considered by the other methods as they focus on the mere combination of concept names selected from the KB signature.
The outcomes reported in Tables 4, 5, 6 and 7 show that, in absolute terms, more axioms were generally discovered using the proposed method (for all three choices of threshold ν selected for the experiments) compared with the two other methods and yet the number of inconsistencies introduced (in case of direct addition of the axioms to the KB) was quite limited in proportion to the overall number of axioms produced: for example, with
As regards the performance of PCC and NAR, we noted that they had a more stable behavior with respect to the fractions of removed axioms f because, as previously mentioned, they could discover axioms involving exclusively named concepts of the KB signature whose instances are more likely to be available. Moreover, a weak correlation between two concepts is unlikely to depend on the presence of a disjointness axiom involving them. This led them also not to introduce further inconsistencies.
For a more complete evaluation covering also the qualitative viewpoint, we report some examples of the axioms that could be discovered through the various methods. As previously mentioned, one of the advantages deriving from the employment of the TCTs is related to the kind of axioms that can be elicited. Purely statistical methods focus on the KB signature and merely make pairwise comparisons in order to discover the concepts that are weakly correlated. Conversely, the TCT-based algorithm performs a sort of search that allows to elicit axioms that involve alternative versions of the targeted concepts, i.e. concept descriptions that are candidate to be equivalent to those considered in the target.
For instance, in the case of
An interesting (not previously existing) disjointness axiom elicited using the TCTs involved more complex concepts like
In the experiments with
In the experiments with
Efficiency of the refinement operators

Efficiency (ms) of the refinement operator.
The task of specialization generation is one of the major bottlenecks of the overall TCT induction method. Thus we carried out various tests for assessing the efficiency of the algorithm that is ultimately based on the refinement operator ρ.
The tests have been repeated on increasing sizes of the beam of candidates: 100, 300, 400, 500, 600, 1000. Also, the entire sets of individuals in each KB were considered to test the stop condition in the procedures. Additionally, we repeated the experiments considering both the original ontologies and the derived versions obtained applying the SDA.
Figure 4 illustrates the outcomes (execution time) using the ρ under SDA; similar trends were observed in the experiments on the original KBs. We noted that using ρ in most of the cases the time grew linearly w.r.t. the number of specializations, e.g. see the case of the experiments with
As a consequence the stop condition was satisfied earlier w.r.t. the case of concepts involving existential and universal restrictions. Indeed, instances of concept descriptions obtained as a conjunction of concept names are generally easier to find than for concepts involving universal and existential restrictions, due to the sparseness of assertional knowledge concerning roles observed in the KBs.
A final remark concerns the line of experiments in which the SDA was not made: they showed that the two operators behave similarly to the cases in which the SDA was made. Even if ρ showed a linear increase of the time as larger beams were considered, the lack of disjointness axioms of the original KBs makes hard to find individuals with a definite membership for each specialization, thus delaying the satisfaction of the stop condition. However, it should be clarified that this problem depends on the specific reasoner adopted to make the inferences required by the algorithms.
The problem of discovering the disjointness axioms to enrich and improve the quality of ontological knowledge bases has been receiving a growing attention. In early works the mentioned strong disjointness assumption [5], which states that the children of a common parent in the subsumption hierarchy should be considered as disjoint, has been exploited in a pinpointing algorithm for semantic clarification (i.e. the process of automatically enriching ontologies with appropriate disjointness statements [25].
Focusing on text and successively on RDF datasets, an unsupervised method for mining axioms, including disjointness axioms, has been proposed [15,29]. The main limitation of this approach is the loose use of any form of background knowledge which, on the contrary, can decisively help to increase the number of discovered axioms while preventing unnecessary/wrong axioms.
Moreover, both relational learning methods and techniques based on formal concept analysis have been proposed to the purpose [3,18], but no specific assessment of the induced axioms quality is made. This limit has been pointed out also by Volker et al. [28], where an approach based on association rule mining has been introduced. Additional approaches, relying on association rules have been proposed by Fleischacker et al. [14] and Volker et al. [27].
The focus of these works was studying the correlation between classes comparatively. Specifically, association rules, negative association rules and correlation coefficient have been considered. Also in these cases, background knowledge and reasoning was exploited in a limited extent.
Lehman et al. [18] proposed a tool for repairing various types of ontology modeling errors: it uses supervised methods from the
Our solution is based on an unsupervised approach, deriving from previous works on concept learning and inductive classification [12]. Specifically, we propose a hierarchical conceptual clustering method that, in addition, is able to provide intensional cluster descriptions, and that exploits a novel form of a family of semi-distances over the individuals in an ontological knowledge base [23] which can take into account the available background knowledge. The method is grounded on the notion of medoid as cluster prototypes since clustering algorithms adopting medoids have been introduced to overcome known limits such as the lack of algebraical structure of the representation of the instance space [1]. The hierarchical approach proposed in this paper is related to classic clustering algorithms such as
Specifically, the method proposed in this paper relies on logic tree models [4] which essentially adopt a divide-and-conquer strategy to derive a hierarchical structure. The learning method can work both in supervised and unsupervised mode, depending on the availability of information about the instance classification to be exploited for separating sub-groups of instances. Terminological decision trees were derived [12,22] in the former case to classify individuals w.r.t. an unknown target concept (assigning a class label at each leaf node), while for the latter case, First-order logic clustering trees [8] were proposed to induce concepts for the clusters expressed in the context of clausal logic theories. The
Conclusions
In this work, we have cast the task of discovering disjointness axioms as a clustering problem that was solved exploiting terminological cluster trees, an extension of terminological decision trees [12] (proposed to solve supervised learning problems). Moving from our previous work [24], we extended the framework for inducing terminological cluster trees along various directions to aim at improving both its effectiveness and efficiency. Specifically, we aimed at improving the quality of the resulting axioms using: 1) different distance measures; 2) different heuristic for selecting the concepts to be installed into tree nodes; 3) a modified version of the refinement operator to generate concepts enabling the elicitation of axioms that do not introduce inconsistency in the KB.
In the empirical evaluation, various experiments have been performed with the goal of assessing the effectiveness of the new methodology. Compared to related unsupervised approaches, ours proved to be able to discover disjointness axioms involving complex concept descriptions exploiting the underlying ontology as a source of background knowledge, unlike the other methods based on the statistical correlation between instances. The evaluation showed also that cases of inconsistency introduced in the KBs by the elicited axioms can be drastically lessened resorting to a different heuristic: candidate concepts are selected according to the farthest distance between the elements of a sub-cluster to the medoid of the sibling resulting from the split of the parent cluster. Additionally, the aforementioned cases can be totally avoided by checking the overlap between the concept installed into the current node and those installed into the tree up to that moment. We noted that the time required by the refinement operator increases linearly w.r.t. the number of specializations.
Various extensions may be envisaged for this work. The TCT induction algorithm can be further improved by introducing a post-pruning step for better tackling the problem of empty clusters. New metrics for evaluating the performance of such methods could also be proposed. Finally, it may be interesting to integrate the methodology within ontology engineering frameworks based on machine learning, such as
Footnotes
Detailed results of the experiments with TCTs
We report in the following the outcomes of further experiments with the TCTs produced by the various versions of the algorithm.