
Abstract
The successful deployment of the Semantic Web of Things (SWoT) requires the adaptation of the Semantic Web principles and technologies to the constraints of the IoT domain, which is the challenging research direction we address here. In this context we promote distributed reasoning approaches in IoT systems by implementing a hybrid deployment of reasoning rules relying on the complementarity of Cloud and Fog computing. Our solution benefits from the complementarity between Cloud and Fog infrastructures. Indeed, remote powerful Cloud computation resources are essential to the deployment of scalable IoT applications, and locally distributed constrained Fog resources, close to data producers, enable low-latency decision making. Moreover, as IoT networks are open and evolutive, the computation should be dynamically distributed across Fog nodes according to the transformation of the network topology. For this purpose, we propose the Emergent Distributed Reasoning (EDR) approach, implementing a dynamic distributed deployment of reasoning rules in a Cloud–Fog IoT architecture. We elaborated mechanisms enabling the genericity and the dynamicity of EDR. We evaluated its scalability and applicability in a simulated smart factory use-case. The complementarity between Fog and Cloud in this context is assessed based on the experimentation conducted.
Introduction
The maturity of Internet of Things (IoT) communication technologies is fostering a wide variety of industrial and societal applications, including home automation and industry 4.0 scenarios. However, the heterogeneity of IoT data and use cases raises interoperability issues constituting hurdles for the development of cross-domain IoT service platforms, leading to isolated application silos. The Semantic Web (SW) technologies and principles constitute an interoperability enabler providing expressive vocabularies to describe data and manipulate information. The domain at the interface between the SW and the IoT is called the Semantic Web of Things (SWoT), and its emergence is not trivial. Even though the SWoT was envisioned as soon as the fundamental article of the SW [2] was published, where smart agents interact with devices in the user’s environment, practical SWoT achievements were proposed in recent years only [26]. In particular, a core challenge the SWoT is facing is the deployment of SW technologies, which are resource-consuming, into IoT networks, characterized by constrained devices.
The integration of the SW stack into an IoT architecture is often centered on remote and powerful machines as in [9] or [41]. IoT data is centralized on such machines before being processed using SW technologies, in a Cloud computing approach [22]. SWoT deployment architectures consider pervasively distributed devices, with potentially limited computation and communication capabilities. Transporting data from these local devices to remote Cloud servers relies on multiple middle nodes. It introduces a delay in data processing, and can degrade applications’ responsivity.
Distributing the SW stack among the multiple middle nodes between the Cloud servers and the IoT devices allows the SWoT architecture to avoid the drawbacks of a Cloud-centered processing. By doing so, the architectures evolve towards the Fog computing paradigm [4] that promotes data storage and processing at the edge of the network [24]. However, Fog computing is not introduced as a paradigm meant to replace Cloud computing: its limited computing capabilities, as well as the locality of the scale of its deployments, are not suited to support Cloud computing use cases. Cloud and Fog computing are two complementary approaches that, when associated, enable the deployment of complex SWoT applications [28].
In the scope on this paper, the purpose of semantic processing is, thanks to knowledge captured in ontologies, to process data in order to produce meaningful business information. One can suppose that knowledge about the deployed IoT system and its environment is modelled beforehand by the system administrators. However, business-specific knowledge needs may not have been identified when the IoT system is designed and might need to be injected into to reasoning system at runtime. Business-specific knowledge must therefore be modeled as self-contained bundles, and inserted into the system at runtime when needed. Moreover, when considering a distributed approach, all of the business knowledge might not be relevant in the context of all the nodes. If packaged into bundles that can be moved from node to node, business knowledge may be opportunistically distributed in the network. Inspired by the application bursting approach introduced in [5], we propose to consider modular applications to enable the distribution of some of their modules. Rules are a common way to capture business-level logic: a rule is a self-contained representation of a logical process.
Following these considerations, we consider in this paper rule-based reasoning: rules are used as representation of business logic, applied in a Knowledge base (KB) capturing the environment of the node. The proposed contribution is a generic approach to the dynamic distribution of rule-based reasoning into a Cloud–Fog IoT architecture, called Emergent Distributed Reasoning (EDR). EDR aims at harnessing scalability and latency issues by distributing reasoning rules among Fog nodes, while benefiting from the Cloud stability and permanent availability. Strategies for rule distribution are often application-dependent, with a wide variety of requirements due to the heterogeneity of IoT application domains. That is why EDR is a generic approach, that can be specialized depending on the desired rule distribution strategy. The work presented in this paper completes and extends two conference articles, [31] and [32], where some aspects of EDR and its refinements have been introduced. Novel work includes a more extensive presentation of related work, the detailed presentation of the vocabulary enabling the genericity of EDR and the description of the usage of the Linked Rules [16] principles. Complementary evaluations regarding the impact of distribution, and the impact of the execution of EDR on a constrained hardware are included, leading to a discussion analyzing the light shed by the obtained results on Cloud–Fog complementarity. The scientific challenge we faced considers three characteristics of the distributed reasoning system: scalability, responsiveness, and dynamicity. These characteristics are presented in detail in Section 2. In Section 3, existing work is introduced, to identify the added value of the present contribution. The core contribution is detailed in Section 4 and Section 5, and it is evaluated in Section 6. This paper is concluded in Section 7.
Desirable characteristics for the proposed solution
In order to capture the main characteristics of the contribution presented in Sections 4 and 5, an illustrative industry 4.0 use case is introduced, that will drive the evaluations in Section 6. Elements considered in the use case are then generalized into the main desirable characteristics for the proposed approach.
Illustrative smart factory use case

Fog-enabled smart factory.
Let us consider a production plant divided into two floors, processing different kinds of products, illustrated on Fig. 1. These floors are modular: the plant structure is subject to change in order to adapt to new productions. Each floor is equipped with conveyor belts carrying products from machine to machine for transformation. Devices are organized hierarchically: machines are connected to conveyors that are connected to the floor gateway that itself collects and delivers data to the factory datacenter. The factory is equipped with sensors in order to ensure the safety of workers: each floor is equipped with presence, luminosity, particle and temperature sensors, and the workers are equipped with wearables communicating with nearby conveyors. Observations from the different sensors are used in order to identify potentially harmful situations, and then notify the control center, where actions can be taken remotely. Unsafe situations are described with deduction rules, based on the semantic description of observations and of the environment. For instance, “The presence of a worker near an operating conveyor in a low luminosity environment is a personal security hazard” is a potential rule. Some rules are also dedicated to quality insurance: sensors available in the factory, such as temperature sensors, or sensors integrated to machines and to the conveyor, enable the continuous control of production quality. Some operations are temperature-sensitive, and a quality insurance rule is “The detection of a temperature above a certain threshold while machines are operating is a break in the cold chain”. As safety and quality insurance are time-sensitive applications, rule processing should be as fast as possible. Moreover, the mobility of some sensors (e.g., worker wearables), combined with the modularity of the factory floors, create a dynamic network topology that evolves over time.
Due to the modularity of the factory, the number of devices in the environment is not bounded a priori. In the specific industry 4.0 use case, this device count is unlikely to increase by multiple orders of magnitude, contrary to application domains of the IoT such as smart cities or connected vehicles, where large volumes of devices are involved.
Therefore, scalability is an important characteristic for a SWoT system, and the decentralization of reasoning is an enabler of such scalability [21]. However, the difference of computing power between Cloud and Fog nodes should not be neglected: the intrinsic capabilities of Cloud architectures enable a resource upscale impossible for Fog architectures. Moreover, Cloud infrastructures provide a stability that is complementary to the dynamic nature of Fog architectures. We propose therefore to leverage both the distributed nature of Fog computing and the permanent, powerful nature of Cloud computing by adopting a mixed approach.
Responsivity
In the proposed use case, the rules deployed in the system are used to detect potentially harmful situations, requiring the inferred notifications to be received by the control center as soon as possible. The proposed system should be able to reduce as much as possible the time from the appearance of an undesirable situation, and the moment where the control center is notified of such situation. Responsivity therefore is another desirable characteristic for our contribution.
Fog-enabled architectures trade computational power for proximity with data sources, which reduces the number of hops between data production and data processing. This reduces delays due to message delivery to distant Cloud nodes, and it is also interesting for situations where increasing the proximity with data sources decreases the complexity of reasoning. When decentralizing processing, the individual computational load is reduced for each node compared to a centralized approach, which can yield better performances [35]. Instead of funneling all the data towards the Cloud before inferring higher level information, combining Fog computing and direct communication between Fog nodes and applications should enable a faster notification delivery.
Dynamicity
IoT systems are dynamic by nature: they are open systems, where devices can appear and disappear, as well as move from one point to the other. In the smart factory use case we introduced, the modularity of the factory floors might lead to changes in the network. More frequently, failures might happen, disconnecting a device. For energy saving purposes, not all the machines might also be powered permanently. Moreover, some devices are attached to workers that are mobile: they will be connected to different machines over time, leading to a dynamic network topology.
As the placement of rules in the network should adapt to the evolution of the topology, the last characteristic that we want for EDR is dynamicity. Depending on the devices available at a given moment on a given node of the network, not all the applicative rules will necessarily be relevant to this node. If a rule requires observations from a sensor that disconnects, carrying on applying this rule is a waste of resources. Applications consuming IoT data are also subject to change, and adapting the rule distribution strategy depending on the applications is also an aspect of dynamicity we consider.
Related work for rule deployment in SWoT architectures
As the proposed approach sets out to deploy reasoning rules among Fog nodes to enable deducing application-dedicated information from IoT data, state-of-the-art work dealing with logical rules for the IoT, distributed reasoning and processing on constrained nodes is presented.
Rules for the SWoT
Rules are logical twofold elements, composed of preconditions and postconditions. Preconditions represent a state of the world such that the rule should be applied in order to generate its post conditions, which represent a new state of the world. In our literature search, we identified two main types of rules associated to the SWoT [3]:
Production rules, or deduction rules, in which preconditions are expressed as a logical expression, and postconditions are new knowledge which is the logical consequence of the preconditions.
Event-Condition-Action (ECA) rules, in which preconditions are the association of a logical expression and an event triggering its evaluation, and the postconditions are actions to be executed if the preconditions are matched. Such actions are not limited to knowledge inference: they can be instantiated by running a piece of code.
As production rules are explicit deduction representations, they have been considered in IoT networks to express and share the correlation between sensor observations and high-level symptoms since early work on the SWoT [34]. [33] lists numerous works using rules for context-awareness in the IoT.
With the goal of facilitating rule reuse, Linked Rules principles have been proposed [16]. They apply the basic principles of Linked Open Data and Linked Open Vocabularies to rules: rules are designated by dereferencable International Resource Identifier (IRI)s, expressed in W3C-compliant standards, and they can be linked to each other. Inspired from the Linked Rules, the Sensor-based Linked Open Rules (S-LOR) [9] is dedicated to rule re-usability for deductions based on sensor observations. Production rules are a mechanism similar to Complex Event Processing (CEP) approaches, used for instance in [19], but the rule representation shifts from an ad-hoc rule format in CEP to a unified format in the SWoT.
[37] proposes a classification of production rules for the IoT, in order to identify recurring patterns. The authors distinguish rules enabling deductions from relations between nodes, and from relations between events (i.e. changes of the environment). In our contribution, we go further than this distinction by manipulating hybrid rules: their preconditions may rely both on conditions expressed on the nodes of the network, or on their environment.
Centralizing rule processing on Cloud nodes
In most existing approaches, i.e. [9,19] or [42], production rules are handled by Cloud nodes. An example of Industrial IoT (IIoT) use case enabled by Cloud-based semantic rules processing is presented in [41]. This paper proposes a self-configuring smart factory: conveyors and machines produce data which is processed on a Cloud node where user rules are used to make reconfiguration decisions. Rules are expressed in SWRL. The same formalism is used in [27], where production rules are computed in a central Cloud node in order to dynamically reconfigure the communication network topology between devices and the Cloud node. The inferred deductions are converted into network reconfiguration actions by ad-hoc agents. A similar hybrid approach is used in [8]: rules are expressed as production rules, but their postconditions may include ad-hoc properties dedicated to the triggering of actions.
In [15], a multi-agent blackboard approach is chosen to dynamically manage rules in a smart home. Observations are published to a central node, the Domotic Status Board (DSB), where they are checked against rules in order to trigger inferences and reactions: the rules considered combine properties of production rules and ECA rules. Rules are expressed in the Jena formalism,1
Production rules are used for context-awareness in a smart user space in [11]. Location information is combined to business knowledge, and to observations of the state of the user’s environment, in order to make assumptions on the context. For instance, the following is a rule introduced by the authors: “IF the user is in an airport lounge with a low luminosity and the drapes closed THEN the user is sleeping”. Such deduction is then used by context-aware services to adapt their behavior, materialized by ECA rules. Data required for the deductions are gathered into a central hub before being processed, and deductions are then sent to remote nodes.
Rules are deported on Cloud nodes rather than executed in Fog nodes when used to achieve context-awareness, such as in [8] or [11], in order to obtain a global execution context. However, in [27] for instance, some reconfiguration decisions could be taken considering only a local context. In this case, rules could be executed directly on Fog nodes.
The centralized architecture of the previously described papers raises issues such as the cost of semantic reasoning that increases rapidly with the size of the KB [21]. Fog computing offers a low-latency, resilient alternative for rule processing, even though the constrained nature of Fog nodes (compared to Cloud nodes) must be taken into account: processing power or bandwidth are critical resources. Centralization also requires all the content collected by IoT devices to be processed in the same place, while Fog computing makes computing power available closer to IoT devices. Fog computing enables content to be processed with rules where it is produced, rather than requiring it to be transported to a remote node to be processed by Cloud computing. Rule placement in Fog architectures is thus a topic of interest for the SWoT
Most approaches for processing on constrained nodes focus on optimizations enabling such processing for a single node without considering the others. When considering a distributed execution composed of several Fog nodes, processing placement is not dynamic: all nodes execute the same rules, or each a predefined rule set statically assigned. For instance, even though it is not directly targeted at SWoT applications, the RETE algorithm proposed in [40] is dedicated to constrained nodes. RETE aims at reducing the memory requirements for production rule processing. This is a very interesting optimization, but it is dedicated to a single Fog node and does not consider distributed processing. [7] shows how gateways are Fog nodes capable of enriching data: observations are initially produced by legacy devices in ad-hoc formats. It is the gateway, communicating with devices using protocols adapted to constrained environments, such as CoAP, that enriches the data before forwarding it towards a Cloud node. Observations are therefore enriched on the edge of the network, and only the Fog nodes in direct contact with legacy devices have to perform data enrichment. [17] or [14] propose to execute ECA in Fog architectures, used to automate the response of the system to a stimulus. However, both authors only consider one gateway executing the rules, and the ad-hoc rule format is not suited for rule exchange. The contribution introduced in [6] uses ECA rules associated to SW formalisms, namely SWRL and SPARQL. The authors use the Wiselib RDF provider [10], as well as CoAP and 6LowPan communication, in order to enable semantic processing directly on constrained nodes. How rules are distributed in the network is not discussed.
Regarding processing distribution in existing work, the dynamic nature of IoT networks should be considered. The topology of a network evolves as devices connect, disconnect, or move geographically. Therefore, a viable distribution of rules at a given moment is not guaranteed to remain optimal in the future, and the distribution strategy should be adapted to the evolution of the network topology. [21] does not detail the mobility strategy used for its mobile nodes, and each node applies all the rules regardless of their relevance to the content it aggregates. In [35], rule placement is static, in either Cloud or Fog nodes. [39] focuses on resource placement in a Fog-enabled IoT. The authors compute optimal deployment of application modules based on the representation of available resources in the Fog architecture compared to requirements expressed by applications. Module positions are static, and computed at the time of deployment. Rules are deployed on gateways in an IIoT context in [14]. The rules themselves are not expressed using SW formalisms, but they are combined to a semantic engine proposed in [13] in order to consume enriched data. The placement of rules in the Fog architecture is not dynamic, however ad-hoc mechanisms enable rule update at runtime.
EDR differs from previous proposals by several aspects in order to comply with the requirements described in Section 2:
The locality of the knowledge involved in the rule deployment: each node only considers its own KB when propagating a rule. The dynamicity of rule deployment in the SWoT system at runtime, constantly adapting to the state of the topology in an event-driven behavior. The genericity of the approach, enabling its adaptation to various application-level strategies.
EDR, a generic approach to dynamically distributed rule-based reasoning
In this section, EDR, a generic approach to dynamically distributed rule-based reasoning supported by semantic Fog computing, is introduced. EDR is based on architectural assumptions that are presented in Section 4.1. EDR’s functional overview is depicted in Section 4.2, before presenting the vocabulary used to describe EDR core functionalities in Section 4.3. Modular rules are at the core of EDR, the formalisms used to represent them and the roles of their modules is described in Section 4.4.

EDR node-centric functional overview.
EDR is based on the hypothesis of a hierarchical network topology: nodes are organized in a tree-like structure, and only communicate with neighboring nodes, i.e. Cloud node and semantic-computing-enabled Fog nodes. The neighbours of a node are either its (unique) parent, or its children nodes. This assumption is made because such topologies are frequent in IoT networks, represented in studies such as [1,27,43] (based on the oneM2M standard), [38], or [35]. Based on this hypothesis, it can be assumed that there only is one path from any node to any of its ancestors, which simplifies our approach.
Applications are not deployed on a Cloud node belonging to the IoT topology: they are executed remotely on personal devices such as smartphones or laptops. Rules represent applicative needs: when deductions from sensor observations are required by an application, it injects the rule in the network in order to be provided directly with the deductions, instead of being forwarded raw data by the network and applying the rules itself.
It is therefore assumed that Fog nodes can communicate with applications directly. Rules are initially submitted by applications to the Cloud node, so it is the only node they know a priori. The Cloud infrastructure provides a unique permanent interface to the network, the dynamic Fog topology underneath is therefore transparent for applications.
We qualified the EDR approach as “dynamic”, because nodes constantly re-evaluate their past decisions (e.g. rule management or data propagation). Whenever an event occurs that may impact the current distribution of the rules in the network, each node locally recomputes the decision algorithm introduced in the remainder of this section. However, the proposed approach will adapt to the evolutions of the underlying topology based on the assumption that all events impacting the topology are considered by the appropriate nodes. In particular, the failure of a node must be captured by its parent, which must then propagate the consequences of this event on its own behavior to the rest of the network. Therefore, we consider failure management to be handled in the middleware layer, and it does not need to be explicitly handled in the scope of the applicative layer proposed in this contribution.
Overview of the EDR approach
In order to ensure decentralization, the algorithm of the EDR approach is executed in parallel on each node able to perform reasoning in the topology. EDR considers a neighbor-to-neighbor rule and data propagation, enabling a reduction the nodes’ knowledge of the topology to a limited subset of the complete deployment. Thus, consistency of the knowledge only has to be maintained with neighbors, which limits required knowledge-related exchanges between nodes, and improves scalability. Due to the potential mobility and variable availability of Fog nodes, EDR is meant to foster decision making in a local context for each node, leading at a large scale to the dynamic emergence of a desirable behavior.
A parent node propagates a rule to its child if the parent considers that the child is empowered to apply the rule. This decision is made by the parent based on a deployment strategy embedded in the rule, as well as on the knowledge it has of said child. The deployment strategy captures the criteria required for a node to process a rule, and therefore characterizes if a child node is suitable to be forwarded said rule. In order to enable rule deployment, nodes exchange messages describing their characteristics, e.g., their location, the type of data they observe, or the type of data they are interested in. To ensure the dynamicity of the rule deployment with respect to the evolving network topology, these messages are exchanged constantly, whenever nodes characteristics are modified. When a node makes a new deduction based on a rule, it sends the result to all the nodes it knows to be interested, including the application that submitted the rule.
The EDR approach itself is agnostic to the deployment strategy, which is defined by the rule implementer: that is why we qualify EDR as generic. The present Section 4 is dedicated to the EDR approach, which defines the characteristics of a deployment strategy without implementing them. Such implementation is described with a refinement of EDR,
A functional representation of an EDR node is provided in Fig. 2: each node has a local KB, where knowledge necessary to the execution of EDR is stored. This knowledge is used to drive the basic functionalities of the node, and rules are used by the inference engine to update the KB.
Featured knowledge includes:
the knowledge the node has of its own characteristics,
the knowledge it has about its neighbors,
the knowledge it has about the static organization of the environment such as the geographic or indoor location, or the relationship between the surrounding elements,
the value of the last observations depicting the current state of the dynamic features of the environment,
the rules that it has received from either applications or other nodes.
This knowledge is used to control the behavior of the node, composed of simple functionalities. A node is able to:
send a piece of data, typically a sensor observation, to a remote node,
propagate a rule to a remote node,
apply a rule on its knowledge base,
announce a description of its own characteristics to a remote node,
deliver a deduction obtained by processing a rule to a remote node.
How these node functionalities are related to the KB in the core EDR mechanism to enable the propagation of observations and rules is described in Section 4.3. The modular rule representation embedding the deployment strategy, and the updates of the KB they trigger, are detailed in Section 4.4. In this paper, the focus is on the propagation of rules, and on their execution, which leads to the production of new information. How this information may be used by the nodes to trigger real-world actions is not in the scope of this contribution. Using high-level deduction to trigger actions in an autonomic loop has been the topic of previous work [29].
A vocabulary driving the deployment mechanism
Node behavior is made quite simple on purpose, in order to decorrelate the rule-specific deployment strategy from the core algorithm on which EDR is based. Rule deployment strategies are dedicated to a particular purpose, e.g., response time reduction or privacy enforcement, while EDR is generic. In order to support the genericity of EDR with a knowledge-driven method, node functionalities are based on a dedicated vocabulary, used to describe knowledge in the node’s KB.
For instance, this vocabulary captures the hierarchical nature of the topology. Let the set of children of node n be referred to as
Namespaces are available in the Appendix (Table 8).
Individuals such as n and
A description of all the functionalities of the nodes, and of the vocabulary that drives them, is provided in Section 4.3.1. Further details about the announcement functionality are provided in Section 4.3.2, especially with regard to the consumption of data. Finally, the scope of the announcements is studied in Section 4.3.3.
Each functionality relies on dedicated triples, and a node implements its behavior based on the description held in its KB. How these triples are inferred from the deployment strategy is described in the next Section 4.4. Before detailing how the strategy triggers nodes functionalities, let us examine the vocabulary describing said node functionalities.
Announce self-description When a node connects, disconnects or changes characteristics, it notifies its neighbors of its self-representation. Since a notification is sent at each update of the node’s state, the perception of a node by its neighbors remains consistent with its evolution over time. Two mechanisms support this announcement:
a partial update, in which a node adds statements to its description already held by the target, a complete update, in which the representation of the node is completely erased by the target before being updated.
These mechanisms add information about a node by exchanging light messages containing partial representations, while removing outdated statements with the complete update. A particular node characteristic that is declared in the announcement functionality is the type of data in which a node is interested, captured with the predicate edrt:isInterestedIn, which is used in the data sending functionality. The announcement functionality is extended by the mechanisms described in Section 4.3.2 to control which characteristics of the node are propagated, and the scope of this propagation in Section 4.3.3.
Apply rules When a node n receives a new observation, either from its own sensors or children, n executes the rules r stored in its KB if the description of r contains ⟨r,edr:isRuleActive,true⟩.
Deliver deduction If the processing of an observation with rule r by node n leads to a deduction δ, δ is sent to each node belonging to
Send data When node n receives an observation of type
Propagate rule A node sends a rule to one of its neighbors if it considers that its target is capable of applying the rule, such a consideration being part of the rule deployment strategy. In the case where rule r should be propagated towards node
Controlling node characteristics propagation
The EDR algorithm depends on the exchanges between neighboring nodes of their mutual descriptions, enabled by the announcement functionality. However, presupposing node characteristics relevant to any deployment strategy that will be implemented to refine EDR is not possible. In order to remain agnostic to the deployment strategy, EDR relies on a dedicated vocabulary used to describe which of each node’s characteristics should be announced to its neighbors. A node has two types of neighbors: its parent, and its children, and since the parent is unique (according to our assumptions) while the children are potentially many, two approaches are devised.
Announcing characteristics to a node’s parent Let us consider a node n, with a characteristic represented by a property
Announcing characteristics to a node’s children The announcement mechanism from parent to children is quite similar to the one from children to parent, with the difference that children may be many. Therefore, the class edr:ChildrenAnnouncedProperty has two subclasses to distinguish two possible cases:
edr:AllChildrenAnnouncedProperty denotes a characteristic that is systematically announced to all the node’s children. edr:SomeChildrenAnnouncedProperty denotes a characteristic that should only be announced to a subset of the node’s children.
This distinction is made to give flexibility to the deployment strategy designers.
In the case of a characteristic captured by a predicate of type edr:SomeChildrenAnnouncedProperty, each child eligible to be proxied the new characteristic must be represented explicitly with the predicate edr:announceTo, which requires the reification of the announced characteristic. In order to be announced towards child node
The interest of a node for a type of data, denoted by the predicate edr:isInterestedIn, is managed as a node characteristic. Therefore, depending on the deployment strategy, the interest of nodes is classified as one of the subclasses of edr:ChildrenAnnouncedProperty. More details about this particular predicate are provided in Section 5, with the instantiation of a concrete deployment strategy.
Propagating knowledge beyond neighbors
EDR is designed for neighbor-to-neighbor rule and data propagation: a node n only communicates with
The proxying mechanism implemented in EDR is inspired from [23], where reasoning nodes act as proxy for the characteristics of legacy nodes unable to process enriched data. In EDR, each reasoning-enabled node has a similar role, and proxy characteristics of its neighbors. Such proxying is bidirectional: the characteristics of a node’s parent are proxied towards its children, and vice versa. Specifically, node n proxying a characteristics of
If a node n wants to be notified whenever a temperature observation is available, it notifies its children
Characteristics proxied from children to parent Let us assume that
Characteristics proxied from parent to children The proxying mechanism from parent to children is similar to the one from children to parent. Contrary to the announcement functionality, the multiplicity of children is not considered: all the children are proxied any received parent characteristic. Such policy is made necessary by the locality of decision-making enforced by EDR. On the one hand, a node n receiving a characteristic to proxy
It is possible that the proxying mechanism and the announcement mechanism lead to conflicting behaviors. In particular, a node may have chosen not to announce a characteristic of its own to some of its children, but be required to proxy the same characteristic instead of one of its ancestors. In this case, the proxying mechanism supersedes the announcement mechanism, and any proxied characteristic is processed as a edr:AllChildrenAnnouncedProperty. For instance, if a node n did not announce its interest for a data type
Rule representation and deployment
Rule modular structure
EDR rules are composed of several modules, as represented on Fig. 3. Each of these modules enables some node functionalities:
The Rule propagation module triggers the rule forwarding functionality.
The Result delivery module triggers the result delivery functionality.
The Activation module triggers the rule application, the data consumption and the result delivery functionalities.
The Rule core module contains the actual business logic of the rule.
The intelligence regarding rule deployment is located in the rules, and not hard-coded into EDR or statically attached to nodes. The behavior of the algorithm at a global scale can thus be parameterized at a fine granularity, for each rule. Rules are represented in SHACL, and the modules are based on the SHACL advanced functionality named “SHACL rules”. Each module is composed of two parts: a SHACL rule, that inserts deductions into the KB, and a SHACL shape that determines whether the rule is applied or not. An example rule, named

Rule modules.
In order to associate all the modules to a rule represented as a single individual in a node’s KB, we introduce the notion of rule envelope as a reification mechanism. The envelope of an EDR rule is an individual subject of triples whose predicates are edr:hasTransferShape, edr:hasApplyShape, edr:hasDeliveryShape and edr:hasDeductionShape. The rule envelope is especially useful in the rule deployment process, when all the modules of a given rule must be collected for the rule to be propagated to a remote node.
Core module The operational part of the rule, containing the application-dedicated inference, is referred to as the rule core module. The core module is based on a predicate logic rule used to deduce high-level information, similar to the rules introduced in the use case in Section 2.1. Let
Rule transfer module The rule transfer module determines on which remote nodes the rule may be deployed, according to a rule-specific deployment strategy. This condition is expressed as a SPARQL query embedded in the SHACL rule being the conditional part of the rule transfer module. The deduction part of the module infers the triple ⟨r,edr:transferableTo,
Rule activation module The activation module detects if the current node is suitable to apply the rule itself. If the conditional part of rule r activation module determines that the current node is suitable to apply r, the activation of rule r is made explicit by the triple ⟨r,edr:isRuleActive,true⟩. In the case where some node characteristics are conditionally proxied towards children (edr:SomeChildrenProxiedProperty), the rule activation module may infer reified statements as described in Section 4.3.3. This case is illustrated in more detail in Section 5.3. The activation module of a rule r is denoted
Result delivery module The result transfer module enables the forwarding of deductions to other nodes that are not the originator of the rule, such as the parent
Dynamically managing modules activation
The rule core must be computed each time a new observation is received by the node, in order to check if new deductions may be inferred. However, it is worth noting that the other rule modules only need to be evaluated when the rule is received, or when the topology evolves, e.g., with new productions by children, new consumptions by parent, or nodes connecting/disconnecting.
The SHACL standard is such that by default, when reasoning on a KB containing SHACL shapes and rules, all of them are considered.5
See Section 4.3 of the recommendation
The appropriate modules, i.e. all except the core module, are classified as edr:NodeSensitiveComponent (as opposed to what would be a “Content sensitive component”). Therefore, a unique query activates or deactivates rule modules related to deployment, for all the rules stored in a node’s KB.
Deployment module management is represented on Fig. 4, in an overview of the algorithm. When a rule is initially received, all of its modules are active. No activation is required when receiving a new rule, marker (1) on Fig. 4. The rule deployment update, marker (3) on Fig. 4, is performed by the reasoner. Since no other rule deployment module has been activated since the new rule has been received, and by default these modules are deactivated, only the deployment of the newly received rule is computed.
In the case where the node receives information about a topology update, such as the connection or disconnection of a node or the change of characteristics of a known node, it is possible that the rule deployment should be updated accordingly. For this reason, for all the rules stored in the node’s KB, the deployment modules are activated upon the reception of a topology update, as seen in marker (2) on Fig. 4. The received change is then integrated in the KB, and if necessary the new topology is propagated to parent nodes, before performing a reasoning step computing the deployment rule modules. If the placement rule needs to be updated due to the topology change, the new deployment is enforced by activating or propagating rules in compliance with the deductions and the EDR vocabulary, before deactivating the rule deployment modules, marker (4) on Fig. 4.
If the received message is an observation, no rule deployment update is required. The only active rule modules are the core modules for rules that the node should process, and they are used by the reasoner to test if new inferences are possible. The marking and propagation of deductions is discussed in Section 4.4.4.
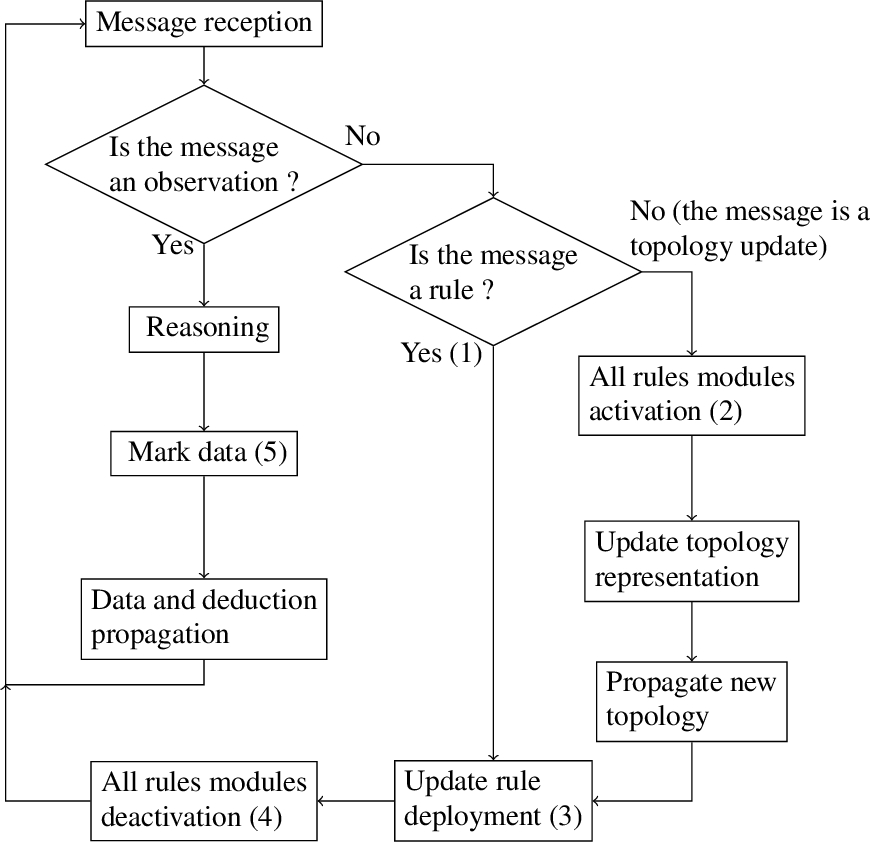
EDR algorithmic overview.
EDR rules are compliant with the Linked Rules principles [16], and in particular they are uniquely identified by an IRI. The identification of rules being shared among all nodes, provenance can be traced for a given deduction. Two purposes have been identified for this traceability: the avoidance of redundant computation, and the update of rules at runtime.
Preventing redundant computation With the rules being uniquely identified among all nodes, it is possible to mark observations when they have been processed with a rule, successfully leading to a deduction or not. After an observation o has been involved in a reasoning step with rule r, a new triple is added to the observation description: ⟨o,edr:usedForDeductionBy,r⟩. This marking prevents an observation being processed multiple times with the same rule when it is propagated from one node to another. Considering this marking or not is up to the rule implementers: for instance, the strategy presented in Section 5 takes it into account, so that each observation is at most processed once by each rule for performance issues. Depending on the propagation strategy, it may be necessary to process the same piece of data with the same rule in multiple contexts, in which case the marking may be ignored. The marking of observations with the edr:usedForDeductionBy property is shown on Fig. 4, marker (5).
If a rule is submitted by multiple applications to the topology, the uniqueness of the identifier also avoids redundant processing. In a node’s KB, each rule can be associated to several originators, indicating that the deduction should be sent to several applications. Expressed in an application-specific namespace, two identical rules would be applied twice, leading to a waste of resources.
Updating rules at runtime The use of a unique dereferencable identifier also incrementally modifies rules at runtime, so that the operation of the monitored system is not interrupted. Modifying rules allow applications to fine-tune their behavior according to a feedback loop that considers either previous responses to inputs, or external factors (e.g., seasonal change, or regulation evolution). When a rule r is received by a node n, if r’s IRI is already known by n, all the triples describing the rule are compared to the triples stored in the node’s KB.
If the newly received version of the rule is different from the version held by the node, then the rule representation is updated in the KB, and the rule is processed as if it were a new rule. All the modules of the rule are evaluated, and changed characteristics of the node, if there are any, are propagated to its neighbors as in any topology change. However, it is possible that the new representation of the rule is no longer applicable by children of the current node (or by their descendant in the case of proxying), to which the former version of the rule had been previously propagated. In the regular EDR algorithm, the rule would not be forwarded to such children, but in this case this is an issue: two different mutually exclusive versions of the rule are executed in the topology.
To tackle this issue, an object property is used: when a node n transfers a rule r to
This approach however leaves a consistency issue unsolved: during the propagation of the new rule version, the two mutually exclusive versions of the same rule are both active. There is no guarantee that the latest version of the rule has been propagated successfully at any point in time after its injection in the network. A way to solve this issue is to attach a version number to the rule with the owl:versioninfo annotation property. This version information is then attached to deductions made with the rule, so that applications are aware of the version of the rule that leads to any deduction.
Refining EDR with
As has been said in Section 4, EDR is a generic approach to rule deployment among semantic-enabled Fog nodes, agnostic to the criteria according to which rules are propagated in the topology. In order to demonstrate the applicability of EDR, the present section is dedicated to
After introducing the
Implementing a deployment strategy based on property types with
The purpose of
To manipulate these property types in the following sections, the
Let us consider
The deployment of
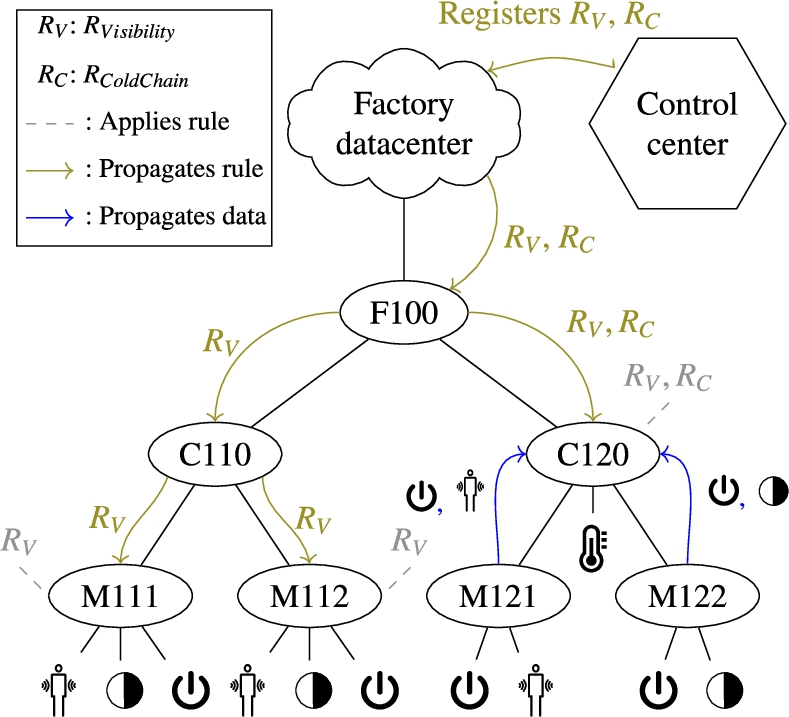
Example of
Node knowledge on itself
A node n has in its KB information about the property types of the data it produces, denoted by the predicate
Node knowledge on the topology
A node n knows its parent in the network tree-like hierarchy. On Fig. 5,
Announcing productions The transmission of rules among nodes organized by
In order to enable the propagation of rules towards nodes that are not direct neighbors, the proxying mechanism introduced in Section 4.3.3 is implemented for property types productions: ⟨edr:producesDataOn,rdf:type,edr:ParentProxiedProperty⟩.
To illustrate the proxying in more detail, let us define
Announcing consumptions As it has been discussed in Section 4.3.1, in order to limit unnecessary exchanges, data is exchanged lazily based on the node consumption announcement functionality. A node n has to explicitly advertise its interest for a property type
The interest of n for
Exploiting the contextual locality of IoT data
The rule deployment strategy supported by

Illustration of observations spatio-temporal context.
The relation between the spatio-temporal context and the topology is represented in Fig. 6, where each gray area represents the context of a Fog node. Our assumption is that, since both M111 and M112 contexts contain enough information to process rule
In the case of the C120 context, since neither M121 nor M122 produce the information necessary to process
As for context proximity, context inclusion is impacted by the hierarchy. A context A is considered included in a context B if the elements of context A are also available in context B. On Fig. 6, the C120 context includes the M121 and M122 contexts, since activity, presence and luminosity values are propagated to C120. Since C120 applies
If, as in our case, the scope of rules is not broader than the context in which they are applied, applying rules deeper in the hierarchy does not impact the completeness of the result. However, if the rules are not adapted to the topology in which they are deployed with
This behavior is adapted to rules supporting deductions for time-sensitive applications, which is the focus of the present contribution, and cannot be applied to aggregation rules, where time series or multiple instances of the same property types are considered. This choice is motivated by the assumption that aggregation rules are more likely to be used in applications supporting long-term reporting and decision support, where the time constraint is not strong, and thus outside the scope of this contribution. The EDR approach and its refinements (such as
To ensure decidability, only DL-safe rules are considered, and EDR is only suitable for stratified rule sets. Cyclic dependencies between rules are not resolved. When a node applies rule r, it is considered as producer of all
The behavior of a node implementing
The purpose of
This condition is expressed in Listing 1, an extract of the SHACL shape constituting

Since it is assumed that rules are initially submitted to the Cloud node, the neighbor-to-neighbor propagation is only considered downwards in the topology. Each node that handles the rule in the deployment process keeps its representation in its KB. It is not necessary to re-propagate a rule upwards: if a node ceases to be able to apply a rule, the change should be considered by the activation module of the rule held by its ancestors, as it is detailed in Section 5.4.
Incrementally, the rule r will converge toward nodes such that, for any node n of them:
n can no longer propagate r, i.e. n is able to apply the rule r, i.e.
These are the nodes able to apply the rule that are the closest to the original data producing: propagating the rule deeper in the hierarchy is not necessary. Such a node is represented on Fig. 5 with gray dashes connected to
In order to apply a rule r, a node n must be the lowest common ancestor to the producers of property types in the rule body. Such a node has a set

If the conditional part of module

In

Propagation of
Nodes executing the EDR algorithm maintain a coherent view of their neighborhood, and deploy rules with respect to this perception of their environment according to the strategy implemented by
When changing characteristics Sensors are the primary source of data for the network. The data they produce is collected by their reasoning-enabled parent. When semantic computing-enabled nodes start, they try to connect to their sensors children of which they have a priori knowledge. How nodes discover and gather information about sensors can be a process tightly related to the underlying technology, or hard-coded in the node KB.
Nodes connected to sensors announce the property types they (and potentially any
In the case when the node already held some rules, their placement might need to be updated according to the new topology denoted by the received message. In order to adjust the rule deployment accordingly, rule modules dedicated to such deployment, namely application, transfer and delivery modules, are activated, processed in a reasoning step, before being deactivated again as detailed in Fig. 4. The deductions yielded by this reasoning step, based on the edr vocabulary, are used to control the node behavior as described previously. The use of these modules is similar when a new rule is received, as it is described in the next section. A part of the propagation of
When receiving a rule When node n receives a new rule r, n evaluates whether it can apply r directly, and/or if it should propagate r to some of its children by performing a reasoning step with all modules of r activated. Based on the deductions produced by this reasoning step, some node functionalities are activated if necessary:
If the rule r is applicable by the current node, the productions of n are updated by
The rule r is propagated to child nodes marked suitable by the rule transfer module. Local metadata is added to rule r in order to keep track of the lower nodes to which it has been transmitted with the predicate edr:ruleTransmittedTo. Such metadata is not added by the rule transfer module, but by the node after the completion of the propagation to the target.
When receiving new data Different kinds of data can be received by node n:
raw observations directly produced by a sensor connected to n, enriched observation or deduction sent to n by node
If the received observation is raw, node n enriches it by annotating it with an ontology before its processing as a new enriched observation. If the piece of data is either an enriched observation or a deduction, it is directly integrated to its KB and processed.
The data, of property type
Experimentation
As EDR is a generic approach, it cannot be subjected to a quantitative evaluation by itself: it must be refined by a concrete approach implementing a deployment strategy. The evaluations presented in this section are dedicated to
In order to compare the proposed contribution to a panel of baselines, different delivery mechanisms are introduced in Section 6.1. By default,
The setup in which the evaluations were performed is described in Section 6.2, along with the references to the code used for running the experiments. Two characteristics of
Deduction delivery mechanisms
The purpose of the evaluations presented in this section is to compare the performances of centralized Cloud-based and decentralized Fog-based approaches to reasoning. It aims at distributing reasoning among Fog nodes in order to perform computation as close as possible to the sensors producing observations. The baseline to which
Unlike rule deployment strategies, deduction delivery mechanisms are decorrelated from the rules: they are variations of the “Deduction delivery” functionality described in Section 4.3.1. Therefore, the propagation of rules, the deductions they yielded and data is described as intended according to ad-hoc strategies (here,
Cloud-Indirect-Raw (CIR) is the baseline approach: the rules are only kept in the top Cloud node, and raw observations are forwarded neighbor-to-neighbor from the nodes that collect them toward the central node. The Cloud then delivers deductions to applications. Applications are notified by the Cloud node, and not by Fog nodes, in all delivery mechanisms except the last one.
Cloud-Direct-Raw (CDR) is also an approach where rules are not deployed, and only processed in the central Cloud node. In this configuration, the observation producers directly send raw observations to the Cloud node, where they are used for rule-based deductions. Such a delivery mechanism enables to measure the impact of transfer time on deduction delay when centralizing raw data for processing. To implement this configuration, the interest proxying mechanism presented in Section 5.2.2 is altered. Nodes that are not the upper node in the hierarchy propagate the interests they receive without proxying them.
Cloud-Indirect-Processed (CIP) is a hybrid delivery mechanism: rules are deployed among Fog nodes according to
Cloud-Direct-Processed (CDP) is another hybrid mechanism where rules are processed by Fog nodes, but deductions are delivered directly to the Cloud node instead of applications. It is the Cloud node that performs the delivery to applications. In this case, the purpose is to measure the impact of centralized delivery in a decentralized reasoning context. To implement CDP, when forwarding a rule it has received, the Cloud node declares itself as the originator instead of the application. Deductions can also be propagated among Fog nodes if a node explicitly expressed its interest.
Application-Direct-Processed (ADP) is the purely decentralized strategy that we propose for
The characteristics of the different delivery mechanisms are summarized in Table 1, where their important features are highlighted:
whether rules are propagated among Fog nodes or not,
whether deductions are propagated neighbor-to-neighbor or directly delivered,
whether Fog nodes communicate with the Cloud node or directly with applications.
Delivery mechanisms summary
Delivery mechanisms summary
All these characteristics are illustrated in an example and illustrated on Fig. 8, where the propagation of raw data and deductions according to the different delivery mechanisms is represented. In the case of deduction delivery, it is assumed for the sake of clarity that deductions are made in the lowest Fog nodes. The manipulation of the EDR behavior by implementing different delivery mechanisms enables the comparison of centralized (CIR and CDR) and distributed approaches (CIP, CDP, ADP), and the comparison of approaches based on direct (CDP, CDR) and indirect (CIR, CIP) communication with the Cloud node.

Delivery mechanisms.
Hardware setup
In order to assess the distributed nature of the approach, and its suitability for constrained Fog nodes, the experimental setup includes a Raspberry Pi 2 and a Raspberry Pi 3, a laptop and a server, described in Table 2.
Experimental setup
Experimental setup
In order to measure the tradeoff between decentralization and the loss of computing power when reasoning on Fog nodes, experiments are run twice, in two different environments:
In the first case, the complete topology is emulated on the same server, each node being run as an individual process. This environment is referred to as “single-host execution”. Such an execution environment makes testing more practical.
In the second case, the topology is distributed across different machines listed on Table 2. This environment is referred to as “multi-host execution”. Such execution environment is more realistic than single-host execution, since it includes constrained nodes. However, large scale experimentation on such decentralized environments is harder to achieve, since it requires multiple machines. Ideally, each node should be executed on a separate computing system, but this would require too many resources. We compromised by executing multiple nodes on a single constrained machine. The necessity to run the experiments on multiple machines at the same time also creates technical issues making the testing process more complex.
The use case topology is simulated for the experiments. Simulated nodes are organized in a tree-like hierarchy, with a Cloud node at the root, sensors at the leaves, and Fog nodes in between. Each physical machine running the simulation hosts multiple virtual nodes, composed of an HTTP server, a KB, a SPARQL engine, and a code base.7
The code is available at
Experiments are run by simulating a building setup with sensors generating raw data. To enable the deployment on multiple machines, each node is implemented as a standalone Java process, and inter-process communication is performed over HTTP. To enable scalable experiments, sensors are implemented as multiple threads of one process, otherwise the RAM overhead for having an HTTP stack deployed for each sensor prevents deploying large topologies. To enable replaying exactly the same sequence of observations, it would have been necessary to synchronize more than 400 threads since the order in which observations are received impacts the obtained result. We were not able to ensure such synchronization without reducing the rate at which observations are produced by sensors. All the results are therefore simulated by generating data. Each sensor pushes a random observation to its parent every two seconds, and each simulation is run for five minutes.
Two aspects of EDR have been evaluated:
the validity of our hypothesis, namely that the distribution of rules increases responsiveness,
the scalability of the proposed approach.
To measure the responsiveness of applications enabled by EDR, the delay between the moment observations are captured by sensors and the delivery of the deduction these observation triggered is measured. Precisely, the delay for the processing of a rule is characterized as the time difference between the moment when the most recent data used in the body of the rule is produced, and the moment when the rule head is received by the application. A dedicated timestamp is associated to each observation once it has been enriched, in order to avoid any impact of the enrichment process on the measure. For instance, if a luminosity observation observed at
Experimental measures showed that, for each simulation, the number of deductions is consistent between centralized and distributed approaches: there is no knowledge loss when applying
In order to analyze closely the cause for the increased delay, the journey of a message has been broken down in discrete timestamped events. The first event related to a message is its construction, either by enrichment of an observation or by achieving a deduction. In order to be propagated in the network, a message might be sent from a node n to another node
Multiple hops are registered, from the first node responsible for the message creation toward any node that is interested in the message content for deduction. When a message is received by a node n, n starts a reasoning step where it tries to make new deductions based on the rules in its knowledge base. Events are logged at the beginning and at the end of reasoning. In order to detail the delay for each deduction, the journey of the most recent observation leading to the deduction is reconstructed. This journey is built by identifying all consecutive events related to the piece of data leading to the deduction, from its initial enrichment to its processing leading to the deduction, and the delivery of said deduction to the application.
Three components of delay have been identified:
Transfer delays, measured between the emission and the reception of a message. This delay is both impacted by the quality of the network link between two nodes, but also by the processing speed of the recipient: the transfer is considered completed when the recipient declares the reception at the software level, and it is not measured at the network layer. When the message is transferred through multiple hops, the delays are summed. Reasoning delays, measured between the beginning and the end of a reasoning step. Reasoning delays are summed if the same message is processed with different rules across the topology. Idle delays, measured between the reception of a message and its processing, or between the reasoning step and the propagation of deductions.
The use case considered for the evaluation is the industry 4.0 scenario introduced in Section 2.1. Table 3 summarizes the rules driving the scenario. All the rules’ SHACL representations are available online.9
Safety and quality rules
As stated in Section 4.3.2, the EDR approach, and by extension
The complete query is available in the source code of EDR: node/queries/data/enrich_data.sparql.

Description of a node

Exchanged sensor observations

Enrichment query snippet
Simulation topologies
In order to assess the scalability of the proposed strategy for EDR, performances have been measured on three topologies, denoted s0, s1 and s2,14
Topology representations are available at
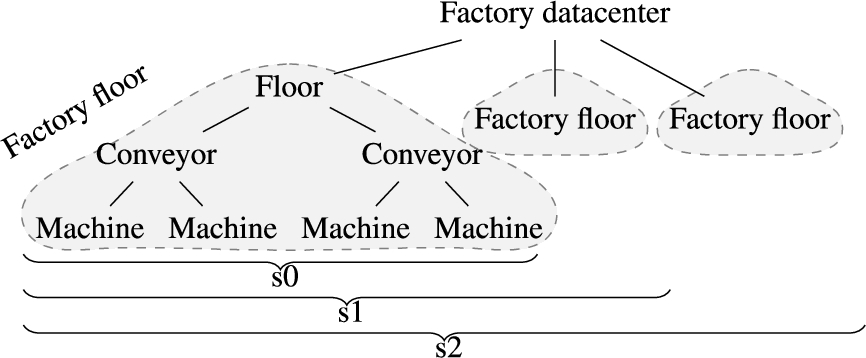
Simulation topology s*.
s* topologies
Machine hosts for scalability experiments

Scalability measures, single-host execution.
Due to scaling issues, results are separated in several figures:
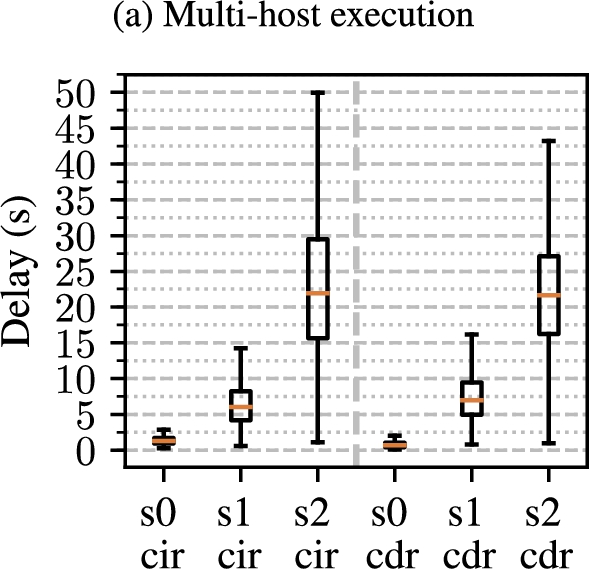
Results for centralized deduction delivery mechanisms (i.e. CIR and CDR) are shown on Fig. 10(a) for single-host execution, and on Fig. 11 for multi-host execution.
Results for distributed deduction delivery mechanisms (i.e. CIP, CDP and ADP), are shown on Fig. 10(b) for single-host execution, and on Fig. 12(a) and 12(b) for multi-host execution.
Scalability measures, centralized reasoning.
The gain in scalability provided by the decentralized approaches appears in the results. In topology s0, the discrepancy between delivery delay for distributed and centralized reasoning approaches is reduced, especially in the single-host execution setting, with a median around 0.65 s for CIR and CDR, and 0.065 s for CDP, CIP and ADP.

Scalability measures, decentralized reasoning.

Breakout of delays (normalized, multi-host execution).
However, in topologies s1 and s2, the gap between centralized and distributed approaches increases dramatically. The deduction time is multiplied by more than 20 from s0 to s2, while the relative share of reasoning time contributing to the delay decreases, as shown on Fig. 13. The transit times are those which increase relatively the most, which denotes a network overflow over a computing saturation on the centralized reasoning node.
A delay increase is also observed for distributed delivery strategies in the single-host execution environment, but it is much smaller, as seen on Fig. 10(b). In the multi-host execution environment, there is a performance difference between direct and indirect delivery mechanisms. Even though overall the increase in the number of nodes has little impact on the measured delays, the delays measured in the CIP configurations are much longer than in CDP or ADP.
An explanation for this observation is the fact that, due to their location, the Raspberry Pis are a bottleneck for communication only in this configuration. In CIP, they must both forward observations and deductions towards a Cloud node, as well as performing reasoning, while they only have to process rules with the CDP and ADP strategies. This conclusion is also strengthened by the fact that, if the Raspberry Pis 3 are replaced by Raspberry Pis 2, which have a lower computing power, that same profile is observed, with longer delays, as seen on Fig. 12(c) for CIP for instance. On Fig. 13, among the three decentralized delivery mechanisms, CIP has the shortest relative transfer time dedicated to reasoning. This is coherent with the fact that more deductions are forwarded by the constrained nodes rather than deduced directly by it, since it is at depth 1 in the topology, and it is only connected to a few sensors compared to conveyor or machine nodes.
Approaches promoting direct communication, i.e. CDR and CDP, perform better than their indirect counterparts, respectively CIR, CIP. This is an expected result, as direct communication reduces the number of hops required for a message (be it an observation or a deduction) to reach its target.
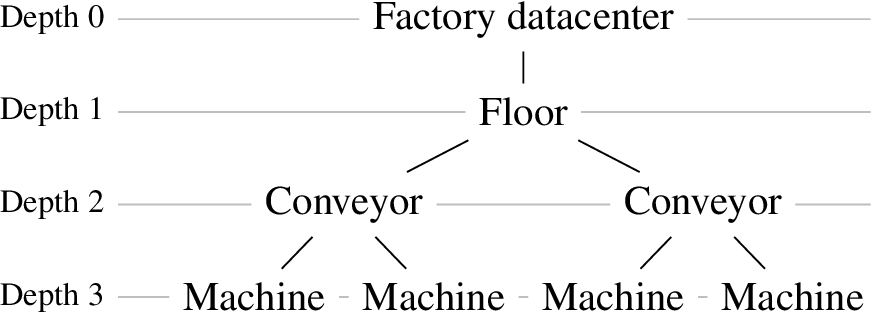
Reference topology for d*.

d* topologies.
A trend that can be observed in the breakout is the increase of the share of transfer time in centralized strategies compared to decentralized ones. An explanation for this phenomenon is the saturation of the network link, combined to an overhead on the central node induced by the necessity to perform all the reasoning. The central node has less CPU time available to declare reception of messages, and therefore the time between the emission event and the reception event is increased. Overall, the limited increase of delays and the balance of the delays breakdown in the distributed settings support our claim that
Simulation topology
To measure how distribution impacts responsiveness, four topologies were distinguished, labeled d1 to d4 and further on simply denoted d*, based on the blueprint shown on Fig. 14. Each of these topologies is composed of 42 identical nodes, and processes data according to four rules, r1 to r4. The difference between the four d* topologies is the location of sensors, as depicted in Fig. 15. Sensors producing data of the type
To assess the impact of distribution, the same sensors are deployed from topology d0 to d4, but they are not situated at the same level, enabling the control of the level at which rules are processed. Sensors are situated in d* topologies so that the rules are processed at the depths depicted in Table 6. The simulation topology is composed of 42 nodes in total (including sensors), hosted on the physical machines as detailed on Table 7. Figure 16 displays results for single-host approaches, and Fig. 17 for multi-host approaches, both showing centralized and distributed reasoning.
Results
Depth of rule processing for d*
Depth of rule processing for d*
Machines hosts for distribution experiments

Distribution experiments, single-host execution.
Distribution experiments, multi-host execution.
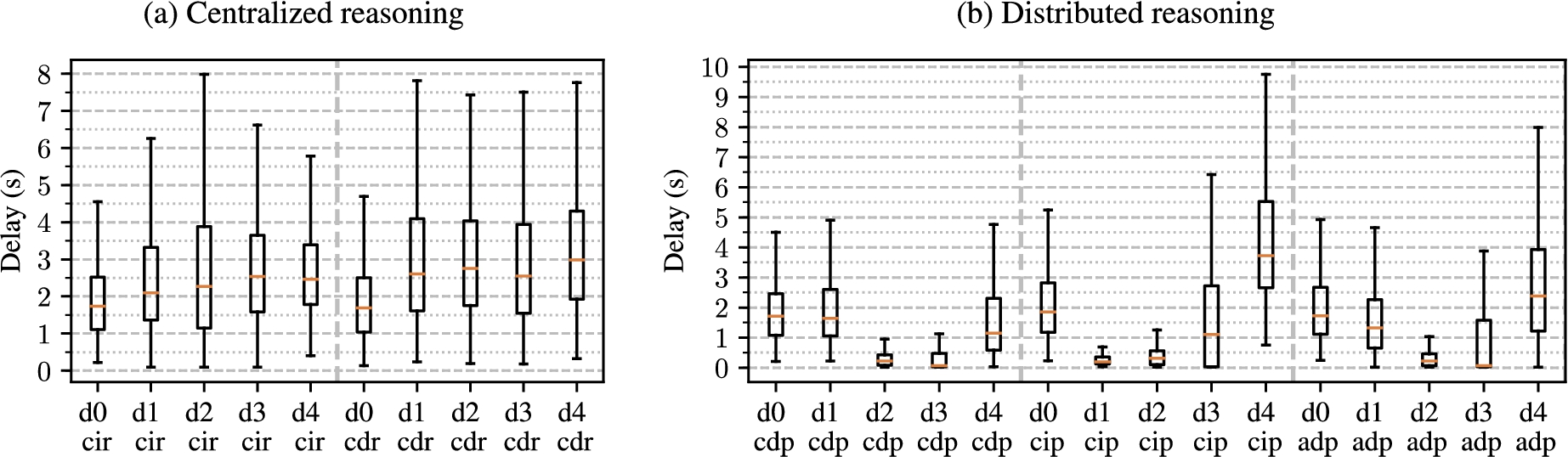
With the centralized reasoning delivery mechanisms, there is little impact of the distribution on performances as seen on Fig. 16(a). The best performances are measured in the most centralized topology, d0, when the sensors are directly connected to the reasoning node, thus minimizing the transit time, as shown on Fig. 16(a) and Fig. 17(a). Moreover, for this completely centralized topology, the delays measured with the decentralized delivery mechanisms (CDP, CIP, ADP) are comparable to the centralized ones (CIR, CDR), which is an expected result: since all the sensors are connected to a single node, there is no difference between rule deployments. It should also be noted that there are no significant differences between the centralized and decentralized executions. Since all reasoning, which is the most computing-intense process of the simulation, is located in both cases on the most powerful node, it is also an observation consistent with our expectations.
For the decentralized delivery mechanisms, where rules are propagated into the network according to the
Distribution experiments delays breakout (single-host execution).

Distribution experiments delays breakout (multi-host execution).
However, comparing Fig. 16 and 17 shows a discrepancy between the simulation in a single-host and a multi-host-host environment, the latter actually including constrained nodes. For ADP and CIP on Fig. 17(b), at the d3 topology, the third and fourth quartiles show an increase in the delays. The median delay is compliant with the expected decreasing trend for ADP, but it begins increasing for CIP. For the d4 topology on Fig. 17(b), where the distribution is maximal, there is an significant increase of delays for all decentralized delivery mechanisms, exceeding the delays measured even for d0. This is discussed in details in Section 6.6.
When increasing the distribution of rule execution in the multi-host experimentation environment, a degradation of the performances is observed. An explanation for this phenomenon is the saturation of the Fog node beyond a certain work load, the tipping point being crossed around d3 (see Fig. 17(b)). Rules executed deeper are processed by constrained Fog nodes, and beyond a certain load, the benefits of the distribution are compensated by the limitations of their processing capabilities.
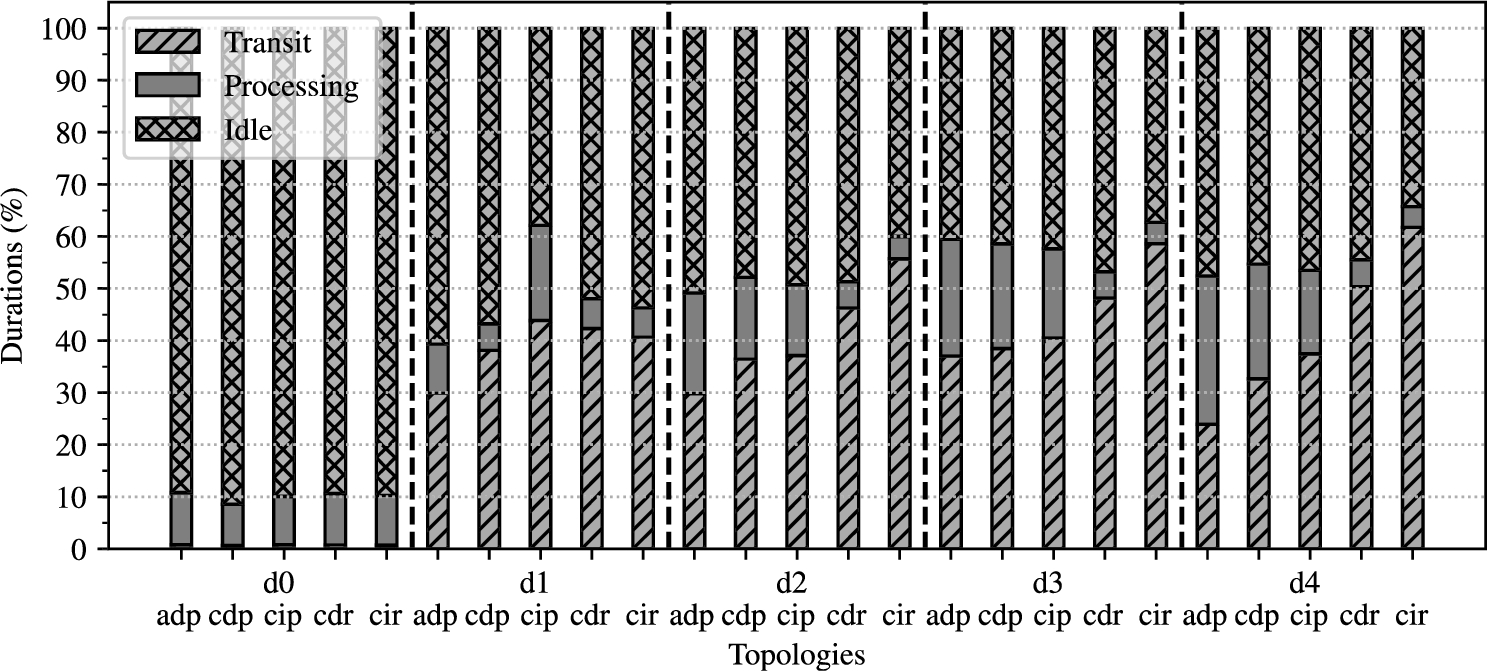
The progressive relative increase of idle time when increasing distribution, seen when comparing d3 an d4 on Fig. 18 and Fig. 19, supports this hypothesis. To this regard, the
The technological choices made for the implementation of
The HTTP framework used (Jersey16
The SHACL engine used in our experiments is described by its creators as “not really optimized for performance, just for correctness”.17
Knowledge is exchanged between nodes serialized in RDF Turtle. Other more compact RDF serializations exist [36], and switching to such a format would reduce the communication overhead when messages are exchanged.
Moreover, due to technical constraints, the experiments we conducted could not be performed at a large scale on constrained nodes. This introduces a bias in the measured results, since the simulated nodes ran on much more powerful machines than the Fog nodes should be. We are aware of this bias, and the experiments are designed in such way that it has as little impact as possible. For future experiments, we intend to set up a network of virtual machines, emulating the actual capabilities of physical nodes, rather than mere processes.
In this paper, we proposed EDR, a generic approach for dynamically distributed rule-based reasoning in a Cloud–Fog IoT architecture. In existing approaches to rule-based reasoning for the SWoT, computation is often performed on Cloud nodes only, potentially leading to a centralized bottleneck, and, by design, creating network communication overhead. In order to tackle these issues, decentralized approaches are proposed in the literature, taking advantage of the Fog computing paradigm. In such cases, computation is disseminated among Fog nodes in order to be brought closer to the IoT devices producing the data. However, these distributed reasoning approaches do not discuss rule placement: it is static, either computed at design time, or all the nodes execute the same set of rules.
With EDR, the contributions described in this paper, address these shortcomings by leveraging the complementarity between Cloud and Fog computing, in order to associate remote powerful nodes providing stability, and local, limited, opportunistically available computing resources. EDR is a generic approach to dynamically distributed rule-based reasoning, based on modular SHACL rules. The execution by Fog nodes of core EDR functionalities is controlled via a dedicated vocabulary describing knowledge in each node’s KB. This vocabulary is used by rule modules to implement deployment strategies enabling the propagation of rules neighbor-to-neighbor across the Fog tier of the Cloud–Fog–Device pattern. Rule deployment strategies aim at optimizing rule placement for customizable criteria, such as response time or energy consumption, based on the knowledge stored in each node’s KB. Such knowledge includes a description of its neighbors, the current state of the environment based on sensor observations, and background knowledge. Overall, EDR enables, in a purely decentralized and emergent manner, the deployment of rules, the propagation of data and the delivery of deductions inferred when applying the rules once they have been deployed. In order to enforce its genericity, EDR itself is made agnostic to individual deployment strategies. It has to be refined by injecting rules embedding their own deployment strategy, selected according to application-level requirements. The obtained genericity enables the implementation of several policies, however it requires from the developing team a full SWoT expertise, from the IoT to the SW. We hope that future adoption of the SWoT will support the generalization of such expertise.
To show the interest of our contribution, we proposed
The genericity and the dynamicity of the EDR approach are achieved by design, while its scalability and the improvement brought by distribution for responsiveness have been measured through experimentation. A simulated smart factory use case has been considered, executed on a powerful server or distributed across constrained nodes. Decentralized delivery mechanisms outperform centralized ones: Quality of Service (QoS) is less degraded when the number of nodes increase in a distributed reasoning setting. Enabling a more widespread distribution of rules by modifying sensor deployment does not improve QOS with a centralized delivery mechanism. The complementarity of Fog and Cloud paradigms is also supported by the results of our approach: there is an improvement of performances even in cases where deductions are forwarded to a Cloud node, and not directly to applications, compared to a centralized reasoning approach. Therefore, unloading the Cloud infrastructure by performing semantic Fog computing, while considering the Cloud node both as a computation resource and as a stable Web endpoint for applications enables scalable deployments for the SWoT.
However, not considering the resources available in the Fog showed limitations, and in future work we intend to develop distribution strategies able to perform load balancing between Cloud and Fog nodes based on node capabilities. The impact of the changes in the underlying network on the deployment is not evaluated in this paper. The dynamicity of EDR is shown by construction, but future work will include a detailed evaluation of the performances of this adaptation mechanism.
The genericity of the EDR approach enables such extensions to be developed without modifying the core algorithm. Likewise, future work will include the development of a privacy-aware deployment strategy for EDR. In the strategy implemented by
Footnotes
Namespaces
Namespaces referenced in this paper, and the associated prefixes
| Prefix | Namespace |
| ssn: |
|
| rdf: |
|
| owl: |
|
| lmu: |
|
| iotl: |
|
| ex: |
|
| edr: |
|
| edrt: |
|
| dul: |
|
| adr: |
|