
Abstract
Searching for similar documents and exploring major themes covered across groups of documents are common activities when browsing collections of scientific papers. This manual knowledge-intensive task can become less tedious and even lead to unexpected relevant findings if unsupervised algorithms are applied to help researchers. Most text mining algorithms represent documents in a common feature space that abstract them away from the specific sequence of words used in them. Probabilistic Topic Models reduce that feature space by annotating documents with thematic information. Over this low-dimensional latent space some locality-sensitive hashing algorithms have been proposed to perform document similarity search. However, thematic information gets hidden behind hash codes, preventing thematic exploration and limiting the explanatory capability of topics to justify content-based similarities. This paper presents a novel hashing algorithm based on approximate nearest-neighbor techniques that uses hierarchical sets of topics as hash codes. It not only performs efficient similarity searches, but also allows extending those queries with thematic restrictions explaining the similarity score from the most relevant topics. Extensive evaluations on both scientific and industrial text datasets validate the proposed algorithm in terms of accuracy and efficiency.
Introduction
Huge amounts of documents are publicly available on the Web offering the possibility of extracting knowledge from them (e.g. scientific papers in digital journals). Document similarity comparisons in many information retrieval (IR) and natural language processing (NLP) areas are too costly to be performed in such huge collections of data and require more efficient approaches than having to calculate all pairwise similarities.
In this paper we address the problem of programmatically generating annotations for each of the items inside big collections of textual documents, in a way that is computationally affordable and enables a semantic-aware exploration of the knowledge inside it that state-of-the-art methods relying on topic models are not able to materialize.
Most text mining algorithms represent documents in a common feature space that abstracts the specific sequence of words used in each document and, with appropriate representations, facilitate the analysis of relationships between documents even when written using different vocabularies. Although a sparse word or n-gram vectors are popular representational choices, some researchers have explored other representations to manage these vast amounts of information. Latent Semantic Indexing (LSI) [12], Probabilistic Latent Semantic Indexing (PLSI) [20] and more recently, Latent Dirichlet Allocation (LDA) [8], which is the simplest probabilistic topic model (PTM) [7], are algorithms focused on reducing feature space by annotating documents with thematic information. PLSI and PTM also allow a better understanding of the corpus through the topics discovered, since they use probability distributions over the complete vocabulary to describe them. However, only PTM’s are able to identify topics in previously unseen texts.
One of the greatest advantages of using PTM in large document collections is the ability to represent documents as probability distributions over a small number of topics, thereby mapping documents into a low-dimensional latent space (the K-dimensional probability simplex, where K is the number of topics). A document, represented as a point in this simplex, is said to have a particular topic distribution. This brings a lot of potential when applied over different IR tasks, as evidenced by recent works in different domains such as scholarly [14,18], health [30,36], legal [15,33], news [19] and social networks [10,35]. This low-dimensional feature space could also be suitable for document similarity tasks, especially on big real-world data sets, since topic distributions are continuous and not as sparse as discrete-term feature vectors.
Exact similarity computations for most topic distributions require to have complexity
However, the smaller space created by existing hashing methods loses the exploratory capabilities of topics to support document similarity. The notion of topics is lost and therefore the ability to make thematic explorations of documents. Moreover, metrics in simplex space are difficult to interpret and the ability to explain the similarity score on the basis of the topics involved in the exploration can be helpful. While other models based on vector representations of documents are simply agnostic to the human concept of themes, topic models can help finding the reasons why two documents are similar.
Semantic knowledge can be thought of as knowledge about relations among several types of elements, including words, concepts, and percepts [17]. Since topic models create latent themes from word co-occurrence statistics in corpus, a topic (i.e. latent theme) reflects the knowledge about the word-word relations it contains. This abstraction can be extended to cover the knowledge derived from sets of topics. The topics obtained via state-of-the art methods (LDA) are hierarchically divided into groups with different degrees of semantic specificity in a document. Documents can then be annotated with the semantic inferred from the topics detected, and from their relation between topics inside each hierarchy level. Let’s look at a practical example to clarify this idea. A topic model is created from texts labeled with Eurovoc1
Thus, in this paper, we propose a hashing algorithm that (1) groups similar documents, (2) preserves their topic distributions, and (3) works over unseen documents. Therefore our contributions are:
a novel hashing algorithm based on topic models that not only performs efficient searches, but also introduces semantic in the hierarchy of concepts as a way to restrict those queries and provide explanatory information an optimized and easily customizable open-source implementation of the algorithm [6] data-sets and pre-trained models to facilitate other researchers to replicate our experiments and validate and test their own ideas [6].
In the probability simplex space created from topic models, documents are represented as vectors containing topic distributions. Distance metrics based on vector-type data such as Euclidean distance (
He distance is also symmetric and, along with JS divergence, are usually used in various fields where a comparison between two probability distributions is required. However, all these metrics are not well-defined distance metrics, that is, they do not satisfy triangle inequality [9]. This inequality considers
S2JSDwas introduced by [13] to satisfy the triangle inequality. It is the square root of two times the JS divergence:
However, making sense out of the similarity score is not easy. As shown in Figs 1 to 4, given a set of pairs of documents, their similarity scores vary according to the number of topics. So the distances between those pairs fluctuate from being more to less distant when changing the number of topics.
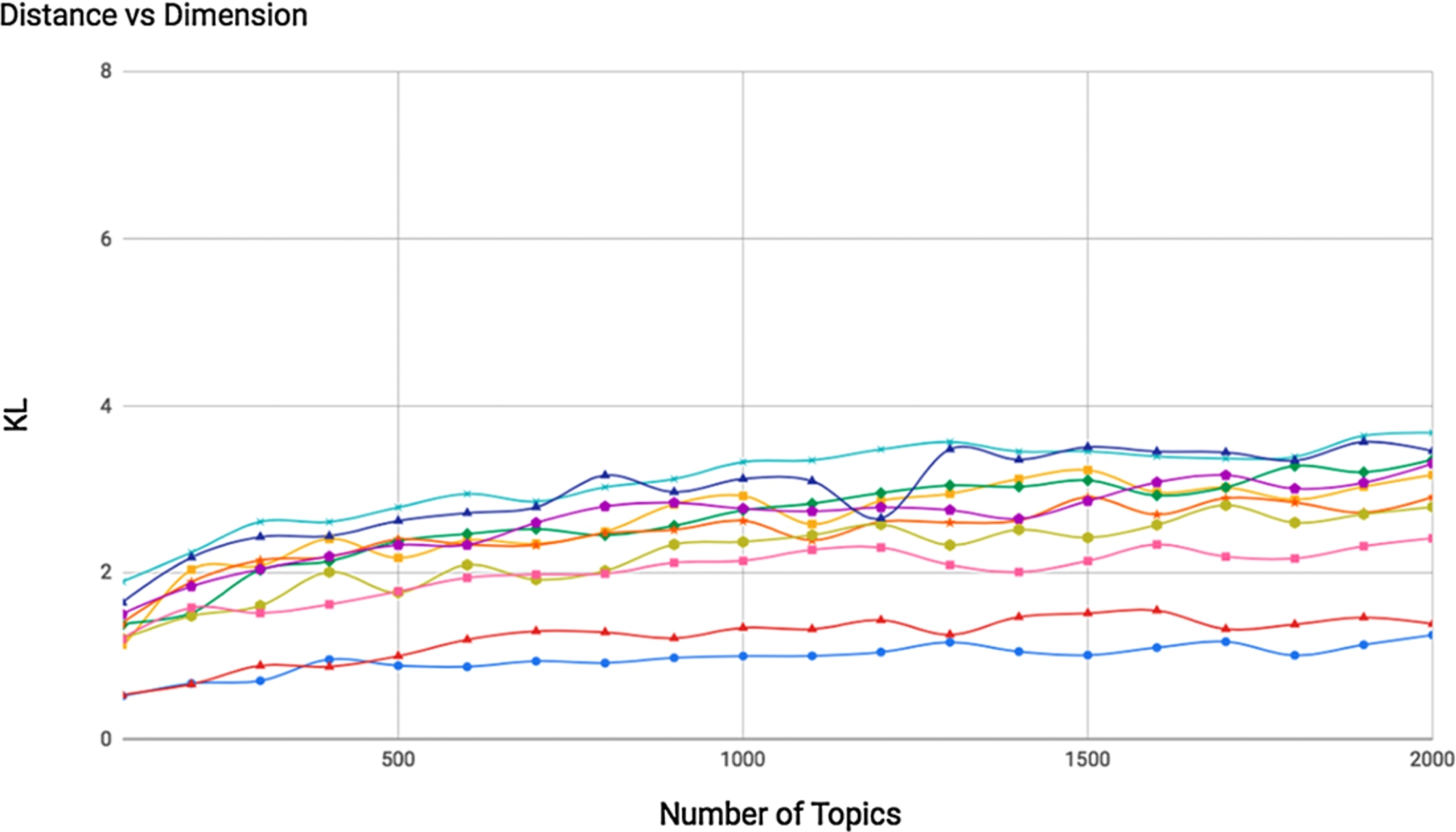
Distance values based on KL-divergence between 10 pair of documents from topic models with 100-to-2000 dimensions.

Distance values based on JS-divergence between 10 pair of documents from topic models with 100-to-2000 dimensions.
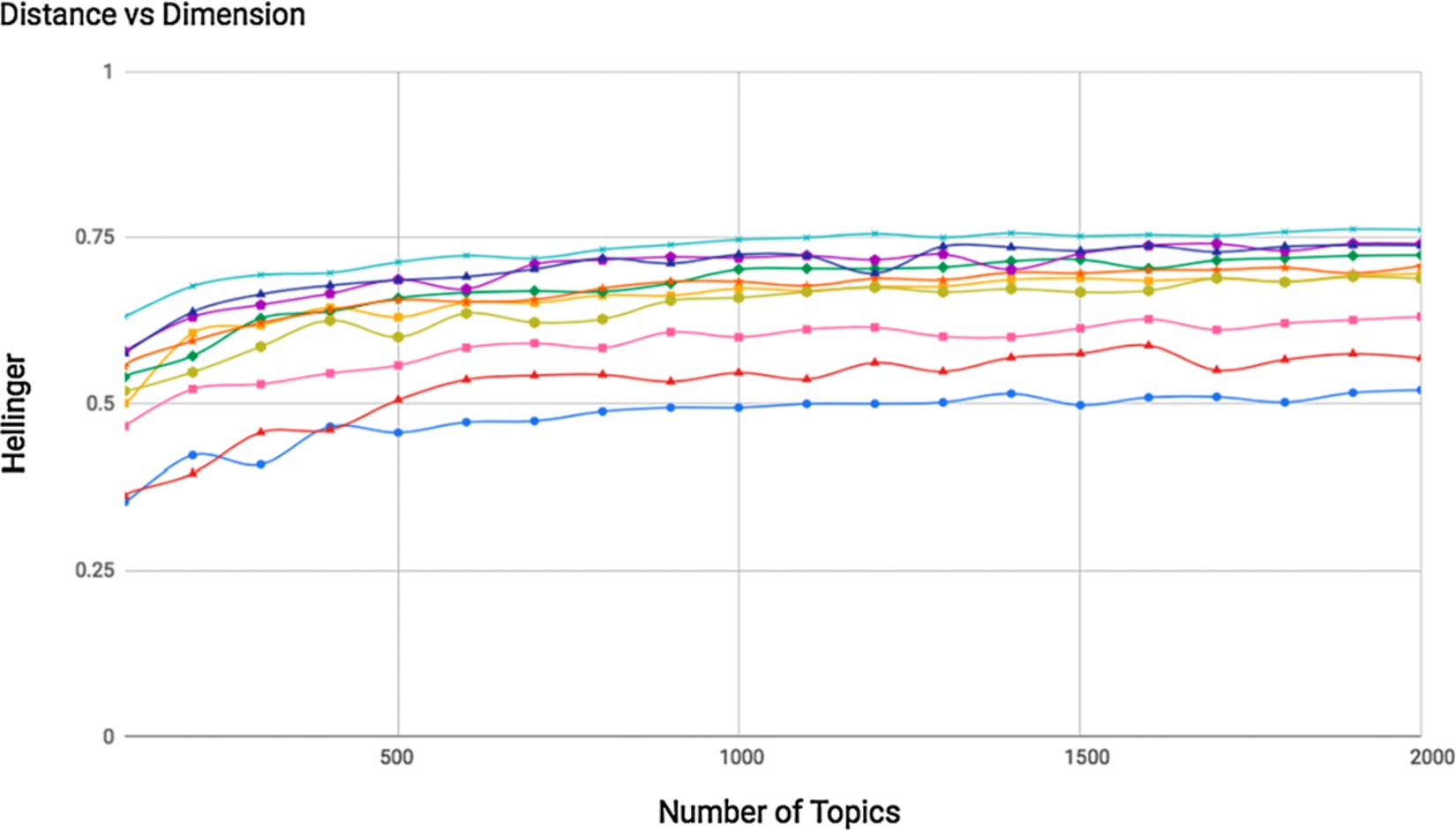
Distance values based on He-divergence between 10 pair of documents from topic models with 100-to-2000 dimensions.

Distance values based on S2JSD between 10 pair of documents from topic models with 100-to-2000 dimensions.
Distances between documents generally increase as the number of dimensions of the space increases. This is due to the fact that as the number of topics describing the model increases, the more specific the topics will be. Topics shared by a pair of documents can be broken down into more specific topics that are not shared by those documents. Thus, similarity between pairs of documents is dependent on the model used to represent them when considering this type of metrics. We know that absolute distances between documents vary when we tune hyperparameters differently [5], but in this study we also see that “relative distances” also change: e.g. for model M1, A is closer to B than C, but according to a M2 trained in the same corpora with different parameters, A is closer to C than B (cross-lines in Figs 1–4). This behaviour highlights the difficulty of establishing absolute similarity thresholds and the complexity to measure distances taking into account all dimensions. Distance thresholds should be model-dependent rather than general and metrics flexible enough to handle dimensional changes. These challenges are tackled through the proposed hashing algorithms by means of clusters of topics to measure similarity, instead of directly using their weights.
Hashing methods transform the data points from the original feature space into a binary-code Hamming space, where the similarities in the original space are preserved. They can learn hash functions (data-dependent) or use projections (data-independent) from the training data [41]. Data-independent methods unlike data-dependent ones do not need to be re-calculated when data changes, i.e. adding or removing documents to the collection. Taking large-scale scenarios into account (e.g. Document clustering, Content-based Recommendation, Duplicate Detection), this is a key feature along with the ability to infer hash codes individually (for each document) rather than on a set of documents.
Data-independent hashing methods depend on two key elements: (1) data type and (2) distance metric. For vector-type data, as introduced in Section 2, based on

Hash method based on hierarchical set of topics from a given topic distribution.
All of them have demonstrated efficiency in the search for similar documents, but none of them allows the search for documents (1) by thematic areas or (2) by similarity levels, nor they offer (3) an explanation about the similarity obtained beyond the vectors used to calculate it. Binary-hash codes drop a very precious information: the topic relevance.
A new hierarchical set-type data is proposed. Each level of the hierarchy indicates the importance of the topic according to its distribution. Level 0 contains the topics with the highest score. Level 1 contains the topics with highest score once the first ones have been eliminated, and so on (Fig. 5). From a vector of components, where each of the components is the score of topic t, a vector containing set of topics is proposed, where each of the dimensions means a topic relevance. Thus, for the topic distribution
A traditional approach to text representation usually requires encoding of documents into numerical vectors. Words are extracted from a corpus as feature candidates and based on a certain criterion they are assigned values to describe the documents: term-frequency, TF-IDF, information gain, and chi-square are typical measures. But this causes two main problems: huge number of dimensions and sparse distribution. The use of topics as feature space has been extended to mapping documents into low-dimensional vectors. However, as shown in Figs 1 to 4, the distance metrics based on probability densities vary according to the dimensions of the model and reveal the difficulty of calculating the similarity values using the vectors with the topic distributions.
Since hashing techniques can transform both vector and set-based data [23,31] into a new space where the similarity (i.e. closeness of points) in the original feature space is preserved, a new set-based data structure is proposed in this paper. It is created from clusters of topics organized by relevance levels and it aims to extend the ability of building queries with topic-based restrictions over the searching space while maintaining high level of accuracy.
The new hierarchical set-type data describes each document as a sequence of sets of topics sorted by relevance. Each level of the hierarchy expresses how important those topics are in that document. In the first level (i.e. level 0) are the topics with the highest score. In the second level (i.e. level 1) are the topics with the highest score once the first ones have been removed, and so on. In this work, several clustering approaches have been considered to assign topics to each level.
In a feature space created from a PTM with eight topics, for example, each data point p is described by a eight-dimensional vector with the topic distributions:
Domain-specific features such as vocabulary, writing style, or speech type, have a major influence on the topic models, but not in the hashing algorithms described in this article. The methods for creating hash codes are agnostic of these particularities since they are only based on the topic distributions generated by the models.
Distance metric
Since documents are described by set-type data, the proposed distance metric is based on the Jaccard coefficient. This metric computes the similarity of sets by looking at the relative size of their intersection as follows:
More specifically,
The proposed distance measure
Hash function
The hash function clusters topics based on relevance levels. Three approaches are proposed depending on the criteria used to group topics: threshold-based, centroid-based and density-based.
Threshold-based hierarchical hashing method
This approach is just an initial and naive way of grouping topics by threshold values into each relevance level. They can be manually defined or automatically generated by thresholds dividing the topic distributions as follows:
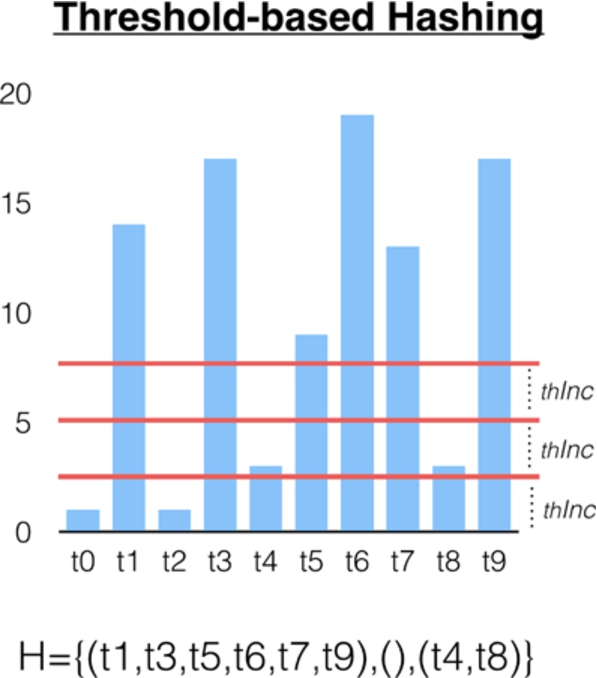
Threshold-based hierarchical hash (
If
Then, a threshold-based hierarchical hash
This approach assumes topic distributions can be partitioned into k clusters where each topic belongs to the cluster with the nearest mean score. It is based on the k-Means clustering algorithm, where k is obtained by adding 1 to the number of hierarchy levels. Unlike the previous method, threshold values used to define the hierarchy levels may vary between documents, i.e. for each topic distribution, since they are calculated for each distribution separately.

Centroid-based hierarchical hash (
Following the previous example, if
This approach also considers relative hierarchical thresholds for each relevance level. Now, a topic distribution is described by points in a single dimension. In this space, topics closely packed together are grouped together. This approach does not require a fixed number of groups. It only requires a maximum distance (
Following the above example, if
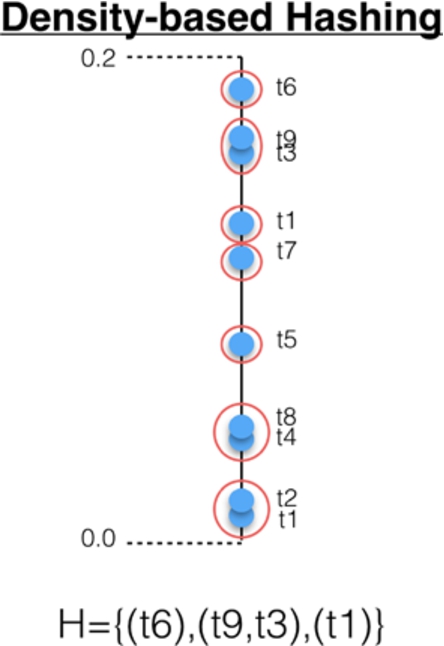
Density-based hierarchical hash (
Hashing methods are batch-mode learning models that require huge data for learning an optimal model and cannot handle unseen data. Recent work address online mode by learning algorithms [21] that get hashing model accommodate to each new pair of data. But these approaches require the hashing model to be updated during each round based on the new pairs of data.
Our methods rely on topic models to build hash codes. These models do not require to be updated to make inferences about data not seen during training. In this way, the proposed hashing algorithms can work on large-scale and real-time data, as the size and the novelty of the collection does not influence the annotation process.
Experiments
As mentioned above (Section 2), it is difficult to interpret the similarity score calculated by metrics in a probability space. Since all of them are based on adding the distance between each dimension of the model (Eq. (1), (2) and (3)), distributions that share a fair amount of the less representative topics may still get higher similarity values than those that share the most representative ones specially if the model has a high number of dimensions.

Topic distribution of two documents. Similarity score, based on JSD, is equals to 0.74.

Topic distribution of two documents. Similarity score, based on JSD, is equals to 0.71.
Figures 9 and 10 show overlapped topic distributions of two pairs of documents. In the first case (Fig. 9), none of the most representative topics of each document is shared between them. However, the similarity score calculated from divergence-based metrics (Eq. (2)) is higher than in the second case (Fig. 10), where the most representative topic is shared (topic 26). This behavior is due to the sum of the distances between the less representative topics (i.e. topics with a low weight value) being greater than the sum of the distances between the most representative ones (i.e. topic with a high weight value). In high-dimensional models, that sum may be more representative than the one obtained with the most relevant topics, which are fewer in number than the less relevant ones.
The following experiments aim to validate that hash codes based on hierarchical set of topics not only make it possible to search for similar documents with high accuracy, but also to extend queries with new restrictions and to offer information that helps explaining why two documents are similar.
Three datasets [6] are used to validate the proposed approach. The OPEN-RESEARCH4
Experiments use JS divergence as an information-theoretically motivated metric in the probabilistic space created by topic models. Since it is a smoothed and symmetric alternative to the KL divergence, which is a standard measure for comparing distributions [39], it has been extensively used as state-of-the-art metric over topic distributions in literature [1,31,38]. Our upper bound is created from the brute-force comparison of the reference documents with all documents in the collection to obtain the list of similar documents.
In this scenario the goal is to minimize the accuracy loss introduced by hashing algorithms. Since this is a large-scale problem and an accuracy-oriented task, recall is not a good measure to be considered and precision is only relevant for sets much smaller than the total size of data (between 3–5 candidates).
All the experimental results are averaged over random training/set partitions. For each topic space, 100 documents are selected as references, and the remaining documents as search space. As noted above, only p@5 will be used to report the results of the experiments.
It is challenging to create an exhaustive gold standard, given the significant amount of human labour that is required to get a comprehensive view of the subjects being covered in it. In order to overcome this problem, the list of similar documents to a given one is obtained after comparing the document with all the documents of the repository and sorting the result. We have observed that different distance functions perform similarly in this scenario (Figs 1 to 4), so we have decided to use only the JS divergence (Eq. (2)) in our experiments.
Only the top N documents obtained from this method are used as reference set to measure the performance of the algorithms proposed in this paper. The value of N is equals to 0.5% of the corpus size (i.e. if the corpus size is equal to 1000 elements, only the top 5 most similar documents are considered relevant for a given document). This value has been considered after reviewing datasets used in similar experiments [25,31]. In those experiments, the reference data is obtained from existing categories, and the minimum average between corpus size and categorized documents is around 0.5%.
Once the reference list of documents similar to a given one is defined, the most similar documents through the proposed methods (i.e. threshold-based hierarchical hashing method (thhm), centroid-based hierarchical hashing method (chhm) and density-based hierarchical hashing method (dhhm)) are also obtained. An inverted index has been implemented by using Apache Lucene7
Let’s look at an example to better understand the procedure. We want to measure the accuracy and data size ratio used to identify the top5 similar documents to a new document
The representational model for this example only considers 8 topics, that is, a document is described by a vector with 8 dimensions where each dimension corresponds to a topic (i.e.
According to methods described at Section 3.3, there are 3 ways to create the hierarchical hash codes for documents:
Precision at 5 (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on open research dataset using a model with 100 topics. LEVEL column indicates the number of hierarchies used
Precision at 5 (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on open research dataset using a model with 500 topics. LEVEL column indicates the number of hierarchies used
Precision at 5 (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on CORDIS dataset using a model with 70 topics. LEVEL column indicates the number of hierarchies used
As it can be seen in Tables 1 to 6, the mean and median of precision are calculated to compare the performance of the methods. In this assessment environment, the variance is not robust-enough because score values don’t follow a normal distribution. We consider the result obtained as significant, based on the fact that mean and median values are fairly close. The centroid-based method (chhm) and the density-based method (dhhm) show a similar behaviour to the one offered by the use of brute force by means of JS divergence.
Precision at 5 (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on CORDIS dataset using a model with 150 topics. LEVEL column indicates the number of hierarchies used
Precision at 5 (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on patents dataset using a model with 250 topics. LEVEL column indicates the number of hierarchies used
Precision at 5 (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on patents dataset using a model with 750 topics. LEVEL column indicates the number of hierarchies used
Data size ratio used (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on open research dataset and 100 topics
Data size ratio used (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on open research dataset and 500 topics
Data size ratio used (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on CORDIS dataset and 70 topics
In terms of efficiency, we consider the times to compare pairs of topic distributions constant, and we focus on the number of comparisons needed. Thus, algorithms with larger candidate spaces will be less efficient than others when the accuracy in both is the same. Tables 7–12 show the percentage of the corpus used by each of the algorithms to discover similar documents. Tables 1–6 show the accuracy of each algorithm for each of these scenarios. Density-based algorithm (dhhm) shows better balance between accuracy and volume of information (efficiency). It uses smaller samples (i.e. lower ratio size) than others in all tests and even when it only uses a subset that is a
Data size ratio used (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on CORDIS dataset and 150 topics
Data size ratio used (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on patents dataset and 250 topics
Data size ratio used (mean and median) of threshold-based (THHM), centroid-based (CHHM) and density-based (DHHM) hierarchical hashing methods on patents dataset and 750 topics
The precision achieved by the algorithm based on density (dhhm), which is much more restrictive than the others, suggests that few topics are required to represent a document in order to obtain similar ones. In addition, the number of topics does not seem to influence the performance of the algorithms, since their precision values are similar among the datasets of the same corpus. This shows that hashing methods based on hierarchical set of topics are robust to models with different dimensions.

Precision at 5 (mean) of threshold-based hashing method when number of topics varies in CORDIS dataset.
The behavior of the algorithms have also been analyzed when the number of topics in the model varies. Models with 100, 200, 300, 400, 500, 600, 700, 800, 900 and 1000 topics were created from the CORDIS corpus. For each model, the p@5 of the hashing methods is calculated taking into account the hierarchy levels: 2, 3, 4, 5 and 6. Figures 11 to 13 show the results obtained for each algorithm. It can be seen how the performance, i.e. precision, of each of the algorithms is not influenced by the dimensions of the model.

Precision at 5 (mean) of centroid-based hashing method when number of topics varies in CORDIS dataset.
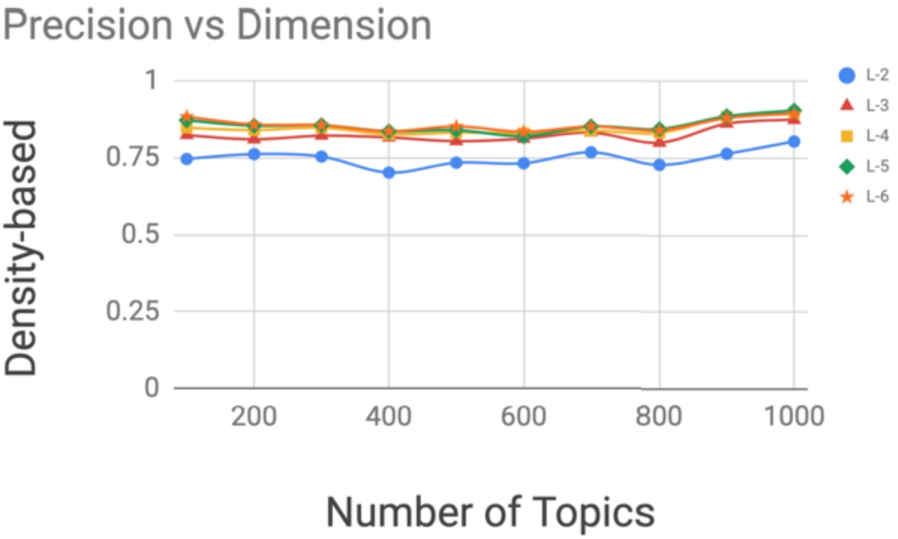
Precision at 5 (mean) of density-based hashing method when number of topics varies in CORDIS dataset.
In a certain domain, we may want to retrieve similar documents to one given. For example, searching for articles in the Biomedical domain that are similar to an article about Semantic Web. In terms of topics this kind of search requires to narrow down the initial search space to a subset with only documents that contain the topics that better describe the queried domain.
Existing hashing techniques based on a binary-code Hamming space do not allow to customize the search query beyond the reference document itself. However, the algorithms proposed in this work allow adding new restrictions to the initial query based on the reference document, since they use a hierarchy of set of topics as hash codes.
Through the following example we describe the workflow to enable such retrieval operations. For simplicity we consider hash expressions with only two hierarchy levels. The reference document
The first query,
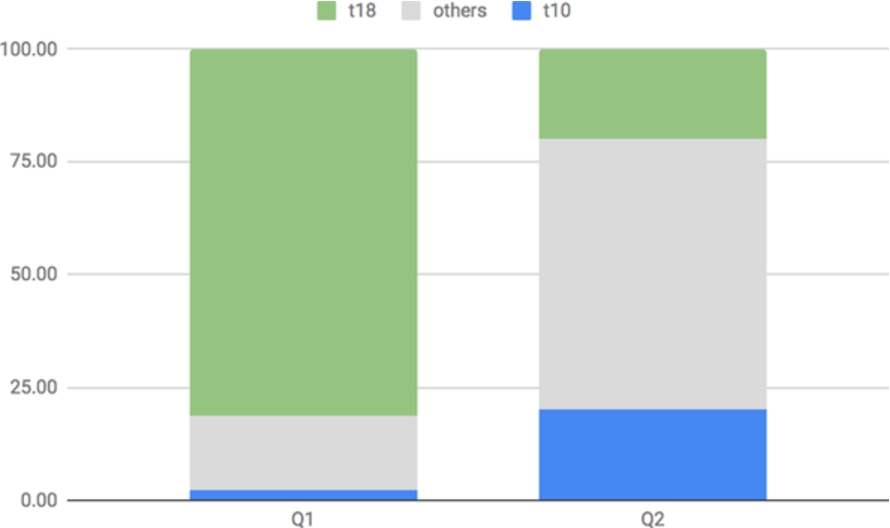
Most relevant topics in similar documents from using a document as query (Q1) and setting topic t10 as mandatory (Q2).
But if we were only interested in similar documents to
This type of restrictions based on the semantics offered by topics in the hash expression get enabled thanks to the methods proposed in this work.
Number of documents similar to a given one (q1) and also in a specific domain (q2) for threshold-based (thhm), centroid-based (chhm) and density-based (dhhm) hierarchical hashing methods
The usefulness of topics created by probabilistic models when exploring collections of scientific articles on large-scale has been widely studied in the literature. Each document in the corpus is described by probability distributions that measure the presence of those topics in their content. These vectors can also be used to measure the similarity between documents by using metrics such as Jensen–Shannon divergence. But with large amounts of items in the collection, discovering the entire set of nearest neighbors to a given document would be infeasible. Due to the low storage cost and fast retrieval speed, hashing is one of the popular solutions for approximate nearest neighbors. However, existing hashing methods for probability distributions only focus on the efficiency of searches from a given document, without handling complex queries or offering hints about why one document is considered more similar than another. A new data structure is proposed to represent hash codes, based on topic hierarchies created from the topic distributions. This approach has proven to obtain high-precision results and can accommodate additional query restriction. This way of encoding documents can also help to understand why two documents are similar, based on the intersection of topics at hierarchies of relevance.
In this paper we have focused on (1) comparing the performance of topic-based hashing methods with respect to the distance metrics based on probability distributions (e.g. JS divergence), (2) their ability to support more complex queries based on topic-based filters and (3) the expressiveness of their annotations (topics hierarchically divided into groups with different degrees of semantic specificity) to justify the relations obtained.
A manually annotated corpus with content similarity relations would further confirm the ability of the metrics proposed in this paper to reflect similarity as humans perceive it. Ongoing work on this line includes the creation of questionnaires8
The next steps in our research are to extend the metric proposed in this paper from the point of view of the perception of similarity that a human makes, and to perform a more in-depth investigation about the meaning of the topics grouped by levels of relevance.
Footnotes
Acknowledgements
This research was supported by the Spanish Ministerio de Economía, Industria y Competitividad and EU FEDER funds under the DATOS 4.0: RETOS Y SOLUCIONES – UPM Spanish national project (TIN2016-78011-C4-4-R)