
Abstract
In the last decade, ontologies have become widely adopted in a variety of fields ranging from biomedicine, to finance, engineering, law, and cultural heritage. The ontology engineering field has been strengthened by the adoption of several standards pertaining to ontologies, by the development or extension of ontology building tools, and by a wider recognition of the importance of standardized vocabularies and formalized semantics. Research into ontology engineering has also produced methods and tools that are used more and more in production settings. Despite all these advancements, ontology engineering is still a difficult process, and many challenges still remain to be solved. This paper gives an overview of how the ontology engineering field has evolved in the last decade and discusses some of the unsolved issues and opportunities for future research.
Ontologies make an impact
The research on ontologies in computer science started in the early 1990s. Ontologies were proposed as a way to enable people and software agents to seamlessly share information about a domain of interest. An ontology was defined as a conceptual representation of the entities, their properties and relationships in a domain [24]. The ultimate goal of using ontologies was to make the knowledge in a domain computationally useful [77]. The initial research period was followed by a time of great excitement about using ontologies to solve a wide range of problems. However, the enthusiasm dwindled in the early 2000s, as the methods and infrastructures for building and using ontologies were not mature enough at that time. Nonetheless, significant changes have taken place in the last decade: The research and development on ontologies had a big boost, more standardization efforts were on the way, and industry started to buy into semantic technologies. As a result, ontologies are now much more widely adopted in academia, industry and government environments, and are finally making an impact in many domains.
One notable example of the impact ontologies are making in healthcare is the development of the 11th revision of the International Classification of Diseases (ICD-11). ICD – developed by the World Health Organization (WHO) – is the international standard for reporting diseases and health conditions, and is used to identify health trends and statistics on a global scale [93]. ICD-11 is now using OWL to encode the formal representation of diseases, their properties, and relations, as well as mappings to other terminologies [84].
The
A lot of work has gone into developing methods and tools for publishing linked datasets of the vast
Other fields have also adopted ontologies more widely. Researchers have used ontologies in the
The examples we mentioned above are not meant to be comprehensive. They show how ontologies have been embraced by a wide range of fields in the last decade and how they are making an impact.
This paper is meant to give a retrospective overview of how the ontology landscape and ontology engineering have evolved in the last decade, current challenges, and prospects for future research. This paper can hopefully also serve as an introduction for newcomers in the field. We briefly discuss standards relevant to ontology engineering that have been adopted in the last decade (Section 2), highly visible and influential ontologies and knowledge bases that are constructed by large communities (Section 3), trends in ontology engineering from the last ten years (Section 4), and current challenges (Section 5) and opportunities for future research (Section 6).
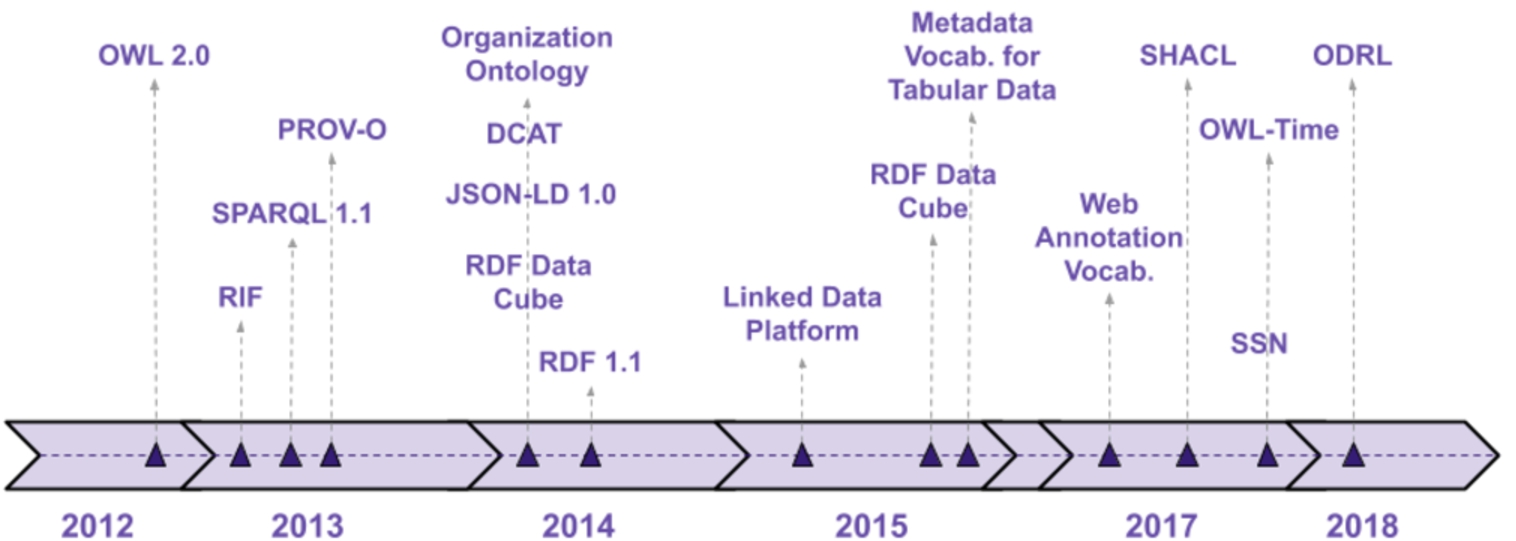
The timeline of W3C recommendations related to ontologies and vocabularies in the last decade (2010–2019). The years that do not have any recommendations are skipped.
The significant standardization efforts on ontologies and Semantic Web languages in the last decade also prove the maturation of the field. Figure 1 shows some of ontology-related standards that the World Wide Web Consortium (W3C) has adopted in the past decade. Several ontologies and vocabularies have become W3C recommendations: The Time Ontology (OWL-Time) [94] – describing the temporal properties of resources; the Semantic Sensors Network Ontology (SSN) [95] – representing sensors and their observations; the Provenance Ontology (PROV-O) [96] – describing provenance information from different systems; or the RDF Data Cube [97] – enabling publishing of multi-dimensional data on the Web.
Ontology and knowledge representation languages have also evolved as proved by the adoption of new versions of the standards: RDF 1.1 was adopted in February 2014, and introduced identifiers as IRIs, RDF datasets, and new serialization formats, such as RDFa3
Another notable W3C recommendation adopted in July 2017 is the Shapes Constraints Language (SHACL)6
Another area of substantial growth in the last decade is the development of community-authored ontologies and knowledge bases. One of the most visible community-driven projects in the Semantic Web is DBpedia [49]. DBpedia is a crowd-sourced community effort to extract structured, multilingual content from the Wikipedia infoboxes. The English version of the DBpedia knowledge base describes more than 4.5 million things to date.8
A project with a similar goal, but significantly different approach is YAGO [79]. YAGO builds a large-scale ontology also from Wikipedia infoboxes. It uses the Wikipedia categories to find a type for each entity, which is then mapped into the WordNet taxonomy [56]. In this way, YAGO creates a high-quality taxonomy which is used not only in the YAGO-driven applications, but also to perform consistency checks on the automatically extracted information. The YAGO2 ontology [29] extends the YAGO model with spatial and temporal dimensions. The spatial information is obtained by integration with GeoNames,11
Another notable large-scale, community-driven knowledge base is Wikidata12
Another high-impact project for creating vocabularies for structured data to be used on Web content is Schema.org.14
Certainly, knowledge graphs (KG) are one of the leading topics of the last decade. Even though researchers have built knowledge networks before, the phrase “knowledge graph” started catching on once Google announced their Google KG in May 2012. Since then, we have seen a flourishing of KGs. Indeed, most large companies, including Amazon, Netflix, Pintrest, LinkedIn, Microsoft, Uber, NASA, IBM, and Alibaba are developing their own KGs. Gartner also identified knowledge graphs as an emerging technology trend in their 2018 technology report [21]. Even with this high adoption, there is no single widely adopted definition of a KG. A common denominator is that KGs contain entities that are inter-related, and are usually at the data level. The level of formality varies a lot: While some use RDF and OWL and a schema, others are schema-less and use property graphs.17
A property graph is a graph for which the edges are labeled, and both vertices and edges can have any number of key/value properties associated with them.
Community curation is not only used in building large-scale knowledge bases like the ones presented above, but also for building ontologies in different domains. For example, the Gene Ontology (GO) is created by a community-driven workflow, in which community members suggest new entities, or changes to current entities using the Gene Ontology GitHub issue tracker.18
Ontology engineering did not change significantly in the last decade. Even though there has been progress in specific areas, which we will briefly discuss in this section, the work on new ontology engineering methodologies did not seem to progress much. Even to date, the most cited ontology engineering method, according to Google Scholar, is the Ontology 101 guide by Noy and McGuiness [61] from 2001.
The NeOn project (2006–2010) produced the most comprehensive methodology for building networked ontologies [78]. The NeOn methodology describes a set of nine scenarios for building ontologies focusing on reuse of ontological and non-ontological resources, merging, re-engineering, and also accounting for collaboration. In addition, the methodology also publishes a Glossary of Processes and Activities to support collaboration, and methodological guidelines for different processes and activities involved in ontology engineering. Even though the NeOn methodology had modest adoption, the work in the NeOn project produced important research that advanced the field.
In the last decade, researchers have developed other ontology engineering methodologies that have been deployed in specific projects, but are still yet to be widely adopted. For example, the UPON Lite methodology [60] supports the rapid prototyping of trial ontologies, while trying to enhance the role of domain experts and minimize the need for ontology experts. The methodology uses a socially-oriented approach and familiar tools, such as spreadsheets, to make the engineering process more accessible to domain experts. The eXtreme Design (XD) methodology [8] uses an agile approach to ontology engineering that is focused on the reuse of ontology design patterns. The methodology is inspired by the principles of extreme programming and uses a divide-and-conquer approach. XD is iterative and incremental, and tries to address one modeling issue at a time. The modeling issue, defined by a set of competency questions, is mapped to one or more ODPs, which are then integrated into the ontology, and tested using unit tests.
The Gene Ontology (GO) – arguably, the most visible and successful ontology project – has generated several ontology engineering methods and tools that are generic, reusable, and that have already been validated in several large-scale ontology development projects [22,57]. The OBO Foundry defines many of the principles20
The adoption of ontologies into mainstream is also proven by the recent publication of several books focusing on ontology engineering, such as, “Demystifying OWL for the Enterprise” in 2018 by Uschold [85], the “Ontology Engineering” in 2019 by Kendall and McGuiness [45], and the “An Introduction to Ontology Engineering” in 2018 by Keet [44].
As ontology engineering became more broadly used, knowledge engineers needed ways to optimize and accelerate parts of the ontology development process. One of the approaches was employing ontology design patterns – small, modular, and reusable solutions to recurrent modeling problems – and templates based on these patterns or other representation regularities in the ontology. Another approach was to use automation, such as bulk imports, or scripts to accelerate ontology population.
The initial work on ontology design patterns (ODP) dates back to 2005 [19]. The research on ODPs has only intensified in the last decade. One of the staples of this area is the ODP repository (
Several biomedical projects adopted the Dead Simple OWL Design Patterns (DOS-DPs)23
Other mechanisms for specifying patterns and generating axioms are the Ontology PreProcessing Language (OPPL) [16] and the Tawny OWL [54]. OPPL is a macro language based on the Manchester OWL Syntax [33] that contains instructions for adding or removing entities and axioms to an OWL ontology. Tawny OWL, which is built in Clojure25
Another approach that adopts widely-used technologies from software engineering to ontology development is OntoMaven [64]. OntoMaven adapts the Maven development process to ontology engineering in distributed ontology repositories. It supports the modular reuse of ontologies, versioning, the life cycle and dependency management.
The tooling for building ontologies has also evolved considerably in the last decade. The open-source Protégé ontology editor [59] has grown its active large community to more than 360,000 registered users. WebProtégé [32] is a Web-based editor for OWL 2.0 with a simplified user interface [34] that supports collaboration. WebProtégé also supports tagging, multi-linguality, querying and visualization. The Stanford-hosted WebProtégé server (https://webprotege.stanford.edu) hosts more than 60,000 ontology projects that users have created or uploaded to the server.
The OnToology [1] – an open-source project that automates part of the collaborative ontology development process – will generate different types of resources for a GitHub ontology, such as documentation using Widoco [20]; class and taxonomy diagrams using the AR2DTool;26
Commercial ontology engineering tools have also proliferated and gained wide adoption in the last decade. Some of the commercial offerings include the TopQuadrant’s tool suite27
Semantic Web languages, and especially OWL, have a steep learning curve [87,91] and require a change of perspective, especially for people coming from software engineering, object-oriented programming, or relational database backgrounds. Newcomers are faced not only with the daunting task of creating a new type of model for their problem or domain, but also trying to find the right tool – ontology editor, visualization, reasoner – and workflow/development process, while the resources for making an informed decision are scarce.
Many newcomers to semantic technologies start with simpler modeling languages, such as SKOS, for defining their vocabularies, but then struggle to upgrade their model into a more expressive language, such as OWL, as there is no straightforward path between the two languages [42]. Similarly, many application developers start with other types of representations – UML diagrams, mind maps, XML Schemas, spreadsheets – which then need to be converted into OWL. Existing conversion algorithms provide mostly structural transformations based on apriori-defined mapping rules. The conversion results often need to be further processed manually to try to capture the intended semantics of the data source. Although the bootstrapping of ontologies represents a crucial aspect of the ontology development process, and is also the first encounter of newcomers to ontologies – often a make or break issue – it is not as well researched as other related areas, and has less methodological and tool support. Simplifying and better supporting the initial phases of ontology development would encourage a wider adoption of ontologies.
The inherent complexity of OWL also makes it challenging to build developer-friendly APIs for accessing and handling OWL ontologies. The most comprehensive Java API for OWL 2.0 ontologies, the OWL-API [31], requires good knowledge of the OWL specification and it can be intimidating for developers. At the same time, developer-friendly approaches, such as JSON-LD31
The adoption of ontologies is also hindered by competing approaches that are simpler to use than OWL. Microdata and microformats were much more wider found in the 2013 Common Crawl dataset than RDFa [55]. Schema.org chose to use an extension of RDFS Schema as its data model,33
One key aspect of ontology engineering is reuse, both of ontologies and of parts of ontologies. Even though, several ontology repositories exist [13] – BioPortal [92] for biomedicine, AgroPortal [41] for agriculture, or general-purpose repositories, such as the Linked Open Vocabularies (LOV) [86] and Ontohub [11] – finding the right ontology for a particular task is still difficult. The testament to this challenge are the countless postings on the Semantic Web mailing lists from interested users trying to find an ontology for a particular domain or task. A common scenario is finding an ontology that can be used to annotate a corpus of text. The BioPortal Ontology Recommender34

The word clouds generated from the titles of the papers accepted at the international semantic web conference (ISWC) in the last decade, which are representative for the research topics in the semantic web in the respective years.
Reusing parts of an ontology – single entities, subtrees, or sets of axioms – is often necessary during ontology development, however enacting reuse in practice is difficult. Several published studies have shown that the level of ontological reuse is low [23,43,68]. For example, in a recent study, Kamdar et al. [43] show that the term reuse is less than 9% in biomedical ontologies, even though the term overlap is between 25–31%, with most ontologies reusing fewer than 5% of their terms from a small set of popular ontologies. The challenges related to reuse come for a wide range: from finding the ontology to reuse, to extracting the subset to reuse (although several module-extraction algorithms exist [12]), to maintaining the extracted subset as the source ontology evolves.
Due to space limitations, the challenges described in this section do not represent a comprehensive listing of challenges in ontology engineering, but rather represent issues that have been encountered all too often by the author and her collaborators. The interested reader can learn more about the current state and challenges in using ontology design pattern from Blomqvist et al. [7], about the state of ontology evolution from Zablith et al. [2], and about ontology matching from Otero-Cerdeira et al. [63]. Shaviko et al. [73] cover the state and challenges of ontology learning, while a more introductory and comprehensive view can be found in the book “Perspectives on Ontology Learning” edited by Lehmann and Völker [50].
Even though the research topics in Semantic Web have evolved in the last decade, ontologies and their engineering were always present among them. In Fig. 2, we generated the word clouds from the titles of the accepted papers at the International Semantic Web Conference (ISWC) in three different years of the last decade, which arguably represent a fairly accurate image of the research topics at the time. An investigation of the topics in the call for papers for larger Semantic Web conferences also confirms that ontologies and their engineering have always been present in the last decade. On one hand, this constancy points to how important ontologies are for the Semantic Web, and on the other hand, it is a sign that ontology engineering is still an active research topic that needs to evolve significantly in the next decade.
One of main show stoppers for a wider adoption of ontologies is their steep learning curve and the complexity of the languages and tooling, as we discussed in the previous section. There is a stringent need to simplify, if not the actual Semantic Web languages and standards, but at least the presentation and interaction of the users with the Semantic Web languages and tooling. The Semantic Web community can benefit significantly from a tighter collaboration with the Human Computer Interaction (HCI) communities and from applying HCI techniques in the design of their tooling. Two encouraging, albeit rare examples of such collaborations, are the paper by Fu et al. [18] that investigates ontology visualization techniques in the context of class mappings and the paper by Vigo et al. [87] that provides design guidelines for ontology editors. Displaying class hierarchies, which are so central to ontology development but are still cumbersome to use, is another area where HCI already provides several solutions [72].
At the same time, the user interfaces for eliciting the content of an ontology have not evolved much. Current ontology editors, including Protégé, offer an intimidating view of all features that OWL offers. It is no wonder that newcomers are scared away. We need role-based user interfaces that would enable users with different expertise to contribute effectively. These user interfaces could be automatically generated based on a user profile, and at the same time the interfaces need to enforce certain editing rules (e.g., all classes need to have a
Another opportunity for simplifying the presentation and consumption of ontologies is to continue the research on ontology summarization. Although a few summarization approaches already exist [51,67], there are still several open issues. Most notably it is not clear what is the best way to evaluate such approaches. Future directions in ontology summarization include the customization of the summarization by allowing the user to tune the model to generate different summaries based on different requirements, as well as, using non-extractive techniques, in which the summary is not using necessarily terms extracted from the ontology [67]. Effective summarization techniques could have a great impact in helping disseminate ontologies to other communities, and to help our community better find and reuse ontologies.
Knowledge graphs are gaining in popularity, and they will likely become even more widespread in the near future. Knowledge graphs can be seen both as a challenge and as an opportunity with respect to ontologies. Knowledge graphs are now widely adopted in industry, however many of these KGs do not use RDF, triplestores or semantics, but rather ML techniques for automatic building and property graphs or other graph stores for storing. Now it is a turning point, in which ontologies and semantics may become important, if in the short-term, new research and methods will be able to bridge the gap between property graphs representation and RDF, and between the different graph-database query languages and SPARQL, making semantics more accessible to developers. One active area of research is the knowledge graph embeddings [90] in which KG entities and relationships are embedded into continuous vector spaces, which can then be further used to perform efficiently many types of tasks, such as knowledge graph completion – finding missing triples in the graph; relation extraction – extracting relations from text using a KG; entity resolution – verifying that two entities refer to the same object; or question answering – trying to answer a natural language question using the information in a KG. However most of these approaches work on the data/instance level. The ontology engineering field could benefit greatly by adapting some of these techniques to ontology-specific tasks, such as, ontology learning and ontology matching. There are already promising approaches, with OWL2Vec* that computes embeddings for OWL ontologies [30], or the DeepAlignment that performs unsupervised ontology matching uses pre-trained word vectors to derive ontological entity descriptions tailored to the ontology matching task, and obtain significantly better results than the state-of-the-art matching approaches [47].
Another area that has a lot of growth now is Explainable AI, and more recently, the intersection of Explainable AI with semantics and ontologies, as demonstrated also by the Workshop on Semantic Explainability35
The goal of the paper is to give an overview of how the field of ontology engineering has evolved in the last decade. Due to space limitations, we could only cover some of the main topics in ontology engineering. We hope that the paper can serve as an entry point for a newcomer in the ontology field, and as a quick reference for the more knowledgeable researchers. As a result of the research and development efforts in the last ten years, ontologies are now adopted in wide range of domains, from biomedicine to engineering and finance. The infrastructures for storing, finding and building ontologies have also evolved significantly. Several standards pertaining to ontology engineering have been adopted in the last decade, and highly-visible efforts to build large-scale ontologies and knowledge bases are well underway. Even though the ontology engineering field still faces several challenges – many of them long-standing – we have also identified many opportunities for future research and development, and exciting new opportunities from synergies with other domains that can drive the ontology engineering field even further.
Footnotes
Acknowledgements
The author would like to thank the reviewers for providing helpful feedback, and to Jennifer Vendetti and Csongor Nyulas for proof-reading the paper.