
Abstract
Domain-independent information systems like ontology editors provide only limited usability for non-experts when domain-specific linked data need to be created. On the contrary, domain-specific applications require adequate architecture for data authoring and validation, typically using the object-oriented paradigm. So far, several software libraries mapping the RDF model (representing linked data) to the object model have been introduced in the literature. In this paper, we develop a novel framework for comparison of object-triple mapping solutions in terms of features and performance. For feature comparison, we designed a set of qualitative criteria reflecting object-oriented application developer’s needs. For the performance comparison, we introduce a benchmark based on a real-world information system that we implemented using one of the compared object-triple mapping (OTM) solutions – JOPA. We present a detailed evaluation of a selected set of OTM libraries, showing how they differ in terms of features. We further narrow down the set of selected OTM libraries to contain only RDF4J-compatible ones and use the benchmark to measure their time and memory efficiency.
Introduction
The idea of the Semantic Web [4] might not have seen such an explosive success as the original Web, but with technology leaders like Facebook,1
E.g. the Czech linked open data cloud
Let’s consider a fictive national civil aviation authority (CAA), which is a public governmental body and is obliged to publish its data as open data. The CAA decides to develop a safety management system for the oversight of aviation organizations under its jurisdiction, involving safety occurrence reporting, safety issues definition, and aviation organization performance dashboard. The CAA can then concentrate on suspicious patterns identified by the system (e.g., from frequently occurring events) during its inspections at the aviation organizations or during safety guidelines preparation. To establish data and knowledge sharing between the CAA and the aviation organizations, CAA decides to share the safety data as 5-star Linked Data [81]. To achieve this, the system is designed on top of a proper ontological conceptualization of the domain. This allows capturing safety occurrence reports with deep insight into the actual safety situation, allowing to model causal dependencies between safety occurrences, describe event participants, use rich typologies of occurrences, aircraft types, etc. Furthermore, integration of other available Linked Data sources, e.g., a register of aviation companies (airlines, airports etc.) and aircraft helps to reveal problematic aviation organizations. A subset of the described functionality has been implemented in the SISel system [51]. Another system with related functionality aimed at the spacecraft accident investigation domain was built at NASA by Carvalho et al. [12,13].
To be usable by non-experts, the system is domain-specific, not a generic ontology editor/browser. No matter how the user interface is implemented, it is supposed to communicate with the backend through a well-designed domain-specific API. Business logic implementing such API requires efficient access to the underlying data. Using common Semantic Web libraries like Jena [11] or RDF4J [9] for such access ends up with a large amount of boilerplate code, as these libraries work on the level of triples/statements/axioms and do not provide frame-based knowledge structures. The solution is to allow developers to use the well-known object-oriented paradigm, which is well supported in IDEs and which provides compile-time checking of the object model structure and usage. However, to match objects to triples, one needs an object-triple mapping (OTM) that defines the contract between the application and the underlying knowledge structure. Many libraries trying to offer such a contract exist. However, these libraries differ a lot in their capabilities as well as efficiency, neither of which is systematically documented. In this survey paper, we provide a framework for comparing various OTM solutions in terms of features and performance. In addition, we use this framework and try to systematize the existing OTM approaches with the aim of helping developers to choose the most suitable one for their use case.
Contribution
The fundamental question of this paper is: “Which object-triple mapping solution is suitable for creating and managing object-oriented applications backed by an RDF triple store?”. The actual contribution of this paper can be split into three particular goals:
Select a set of qualitative criteria which can be used to compare object-triple mapping library features relevant for object-oriented applications.
Design and develop a benchmark for performance comparison of object-triple mapping libraries. This benchmark should be easy to use and require as little effort as possible to accommodate a new library into the comparison.
Compare object-triple mapping solutions compatible with a selected storage in terms of their features and performance.
The remainder of this paper is structured as follows. Section 2 presents the necessary background on the RDF language, OTM systems, and Java performance benchmarks. Section 3 reviews existing approaches to comparing OTM libraries and benchmarking in the Semantic Web world in general. Section 4 presents the framework designed in this work. Section 5 introduces the OTM libraries chosen for the comparison and discusses the reasons for their selection. Sections 6 and 7 actually compare the selected libraries using the framework designed in Section 4. The paper is concluded in Section 8. Appendices A.1 and A.2 contain full reports of time performance, resp. scalability comparison.
Background
The fundamental standard for the Semantic Web is the Resource Description Framework (RDF) [19]. It is a data modeling language built upon the notion of statements about resources. These statements consist of three parts, the subject of the description, the predicate describing the subject, and the object, i.e., the predicate value. Such statements – triples – represent elements of a labeled directed graph, an RDF graph, where the nodes are resources (IRIs or blank nodes) or literal values (in the roles of subjects or objects) and the edges are properties (in the role of predicates) connecting them. RDF can be serialized in many formats, including RDF/XML, Turtle or N-triples. Taking an RDF graph and a set of named graphs (RDF graphs identified by IRIs), we get an RDF dataset.
The expressive power of RDF is relatively small. To be able to create an ontology (a formal, shared conceptualization) of a domain, more expressive languages like RDF Schema (RDFS) [8], OWL [20] and OWL 2 [56] were introduced. They extend RDF with constructs like classes, domains and ranges of properties, and class or property restrictions. A simplistic example of an RDFS ontological schema can be seen in Fig. 1, its serialization in Turtle [60] is then displayed in Listing 1.5
Prefixes introduced in listings are reused in subsequent listings and figures as well.
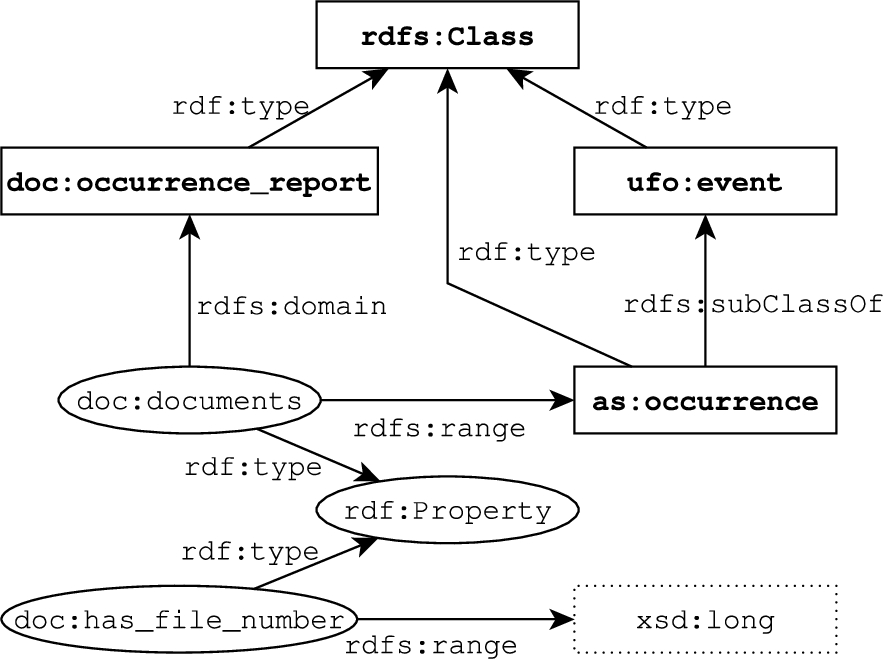
RDF graph representing a simple RDFS ontology. Prefixes used in this figure are defined in Listing 1.

Turtle serialization of an RDFS schema
The SPARQL Query Language (SPARQL) [34] and SPARQL Update [27] are standardized languages used to query and manipulate RDF data. A SPARQL query example is shown in Listing 2; it selects all classes and, if present, also their immediate super types.
The primary focus of this paper (as well as most of the discussed OTM solutions) is on RDFS. However, OWL (2) is referenced in several places to provide further context.

A SPARQL query example
Ontological data are typically stored in dedicated semantic databases or triple stores, such as RDF4J [9], GraphDB [5] or Virtuoso [22]. To be able to make use of these data, an application needs means of accessing the underlying triple store. Unfortunately, there is no common standard for accessing a semantic database (like ODBC [54] for relational database access). This lack of standardization gave rise to multiple approaches and libraries that can be basically split into two categories (as discussed in [46]):
libraries like Jena [11], OWL API [38], or RDF4J (former Sesame API) [9]. Such libraries are suitable for generic tools like ontology editors or vocabulary explorers that do not make any assumptions about the ontology behind the data the application works with.
libraries like AliBaba [52], Empire [30], or JOPA [49] are examples of libraries which employ some form of object-triple (OTM) (or object-ontological (OOM)) mapping to map semantic data to domain-specific objects, binding the application with some assumption about the form of data.
Domain-specific libraries are more suitable for creating object-oriented applications. Such applications express the domain model in the form of object classes, and their properties (attributes or relationships). OTM, in this case, allows to automatically map the notions from the object-oriented realm to the semantic data model and vice versa. Domain-independent libraries perform no such thing. They treat the underlying data at the same level as the RDF language, i.e., at the level of statements, without any assumption about their meaning. Therefore, a domain-specific application attempting to use such libraries would either need to treat its data in the same manner, which makes it extremely difficult to understand, develop, and maintain; or the developer would end up writing their own version of an object-triple mapping library. Either way, it is more favorable to leverage dedicated object-triple mapping solutions. In addition, some OTM libraries allow accessing various data sources in a unified way, support transactional processing and compile-time checking of correct model usage. Table 1 shows a simplified mapping between RDF(S) terms and object model artifacts considered by the majority of the OTM solutions. We shall use these notions throughout this paper.
Simplified mapping between RDF(S) terms and object model artifacts
Simplified mapping between RDF(S) terms and object model artifacts
An analogous division where indirect and direct models correspond to the domain-independent and domain-specific approaches respectively is used in [61]. The authors argue that direct models are more suitable for domain-specific applications and propose a hybrid approach where parts of the application model are domain independent and parts are domain specific.
The difference between domain-independent and domain-specific libraries is similar to the difference between JDBC [40] and JPA [39] in the relational database world. JDBC is a row-based access technology, which requires a lot of boilerplate code. In addition, not all databases fully adhere to the SQL6
Structured Query Language, a data query, definition, manipulation and control language for relational databases.
There exists a number of OTM libraries. However, their user base is still relatively small, which is reflected in the small amount of information available about them. Some libraries are tied to a specific underlying storage, others’ APIs do not reflect the specifics of semantic data access. Ultimately, one would like to be able to determine which of the libraries is the most suitable for his/her object-oriented application.
As was already stated, the developed comparison framework consists of a set of qualitative criteria and a performance benchmark. The benchmark is written in Java, which is hardly a surprise since Java is the most prominent language in the Semantic Web community. Therefore, approaches to performance testing in Java were also reviewed.
Java-based performance testing has certain specifics which are given by the nature of the Java platform where each program is compiled into an intermediate language – the bytecode – and interpreted at runtime by the Java virtual machine (JVM). The JVM is able to optimize frequently executed parts of a program. These optimizations occur during execution of the application. The JVM also automatically manages application memory via a mechanism called garbage collection which automatically frees memory occupied by objects that are no longer referenced. Of course, if the application forgets to discard objects it does not use anymore – it has a so-called memory leak – it may eventually run out of free memory. Although garbage collection is nowadays extremely efficient, it still requires CPU time and may influence the application performance. Java benchmarks thus usually take into account application throughput and its dependence on the amount of available memory (heap size). The best known benchmarks in this area are SPEC [71] and DaCapo [7]. DaCapo measures application throughput w.r.t. heap size. In addition, it samples heap occupation and composition and new object allocation rate. The authors of [29] count garbage collection events and the time JVM spends executing them.
Generally, when benchmarking Java applications, it is necessary to execute a warm-up period which allows the JVM to perform code optimizations. Otherwise, the results could register a significant speedup after the initial unoptimized phase. Georges et al. [28] discuss further practices for executing Java application benchmarks and interpreting their results, introducing a statistically rigorous methodology for Java benchmarking. Their methodology was used in the experiments in this work.
Related work
This section overviews existing related approaches. First, we present existing object-triple mapping library comparisons (both feature and performance-wise) and then take a look at established storage benchmarks and discuss how our benchmark framework complements them.
There are very few comparisons of OTM libraries. Most benchmarks and comparisons concentrate on the underlying storage and its performance. While this is certainly a very important aspect, one needs to be able to make a qualified decision when choosing from a set of object-triple mapping libraries. Holanda et al. [37] provide a performance comparison between their solution – JOINT-DE – and AliBaba. However, their benchmark uses a minimalistic model (create operation works with a single entity with one string attribute) and no other library is taken into account. Cristofaro [18] provides a short feature comparison of various OTM libraries supporting the Virtuoso storage server [22]. A more recent and elaborate feature-based comparison can be found in [66]. It compares a set of selected libraries from the point of development activity, documentation, ease of use and querying capabilities. In [33], authors of the well-known LUBM benchmark [32] do not present any actual comparison but they introduce a set of requirements a Semantic Web knowledge base system benchmark should fulfill. Although they again target mainly semantic database benchmarks, the criteria defined in their article apply to a large extent to this work as well and their satisfaction will be shown in Section 4.
The number of benchmarks comparing storage systems is, on the other hand, relatively large.7
See for example the list at
This section introduces the comparison framework which consists of two parts:
A set of criteria used to evaluate the features supported by the compared libraries. A performance benchmark.
Feature criteria
We have designed a set of criteria, which can be used to evaluate an OTM library’s suitability in a particular use case. The criteria can be split into three main categories:
General criteria are based on the principles known from application development and relevant object-relational mapping features. These criteria take into account specific features of the Semantic Web language stack based on RDF and its design. They are not specific to OTM libraries and could be applied to libraries used to access semantic data in general. Mapping criteria concern important techniques used for the object-triple mapping. They are motivated by the differences of ontologies on the one side and the object-model on the other [68].
GC1 – transactions Transactional processing, i.e., splitting work into individual, indivisible operations, is one of the fundamental paradigms of computer science [79]. It originated in databases but, due to its universally applicable principles, it is used throughout information systems with various levels of granularity. Nevertheless, support for transactions is one of the main features an OTM library has to provide, be it using an internal transaction engine or relying on the underlying storage.
Transactions are characterized by the ACID acronym, which stands for Atomicity of the transaction, eventual Consistency of data, Isolation of concurrent transactions and Durability of the transaction results. Given the complex nature of transaction isolation where several isolation levels exist,8
E.g.
GC2 – storage access variability Storage access variability refers to the library’s ability to connect to semantic storages of various vendors. While application access to relational databases is standardized in two ways – the Open Database Connectivity (ODBC) [54] is a platform-independent database access API; the Java Database Connectivity (JDBC) [40] is a Java-based database access API (a JDBC driver can use an ODBC driver internally) – the semantic world lacks a corresponding standard. For instance, although RDF4J-based access is supported by most of the industry’s biggest repository developers, it is not possible to use it to connect to a Jena SDB store, which is backed by a relational database. To allow access to different storages, the OTM library has to account for this either by having modules for access to various storages or by defining an API whose implementations would provide access to the repositories. Another possibility, although probably not very efficient, could be accessing the storage using a SPARQL [23] or Linked Data Platform [69] endpoint.
GC3 – query result mapping Besides reading individual instances with known identifiers, it is often necessary to read a set of instances corresponding to some search criteria (for example, read all reports with the given severity assessment which document events that occurred during the last month). Naturally, mapping of SPARQL query results to objects is expected, as SPARQL is the standard query language for the Semantic Web, but other languages like SeRQL (a Sesame query language) can be supported. A similar feature is supported by JPA [39] where SQL results can be mapped to entities or dedicated Java objects.
GC4 – object-level query language Related to GC3 is the question of query languages supported by the OTM library. While SPARQL is adequate in most situations, it can be cumbersome to work with, especially given the fact that one has to deal with IRIs and prefixes. When querying the data from an object-oriented application, it is convenient to be able to leverage the object model in the queries. This is again supported by JPA [39], where one can use the Java Persistence Query Language (JPQL) – a query language with SQL-like syntax but exploiting classes, attributes, and relationships instead of tables and columns. Furthermore, it also defines the Criteria API which allows one to construct queries dynamically at runtime using builder objects. Criteria API is especially suitable when a large number of optional filtering criteria can be used in the query and juggling with string concatenation would be difficult and error-prone. In addition, Criteria API provides the benefit of compile-time syntax checking, because it uses regular Java classes and methods.
Prototypical solutions already exist in the Semantic Web community. For instance, Hillairet et al. [36] use the Hibernate Query Language, an implementation of the standard Object Query Language [14] (OQL)9
JPQL is another implementation of a subset of OQL.
GC5 – detached objects As pointed out in [37], applications need to be able to detach persistent objects from their connection to the storage in order to work with them, for instance, when the entity is passed up through web application layers and transferred over the network in response to a client request or stored in an application-level cache. The opposite (an object which is always managed) can lead to an excessive amount of retained connections to the storage, blocking the resources of the machine. The difference between detached and managed entities is indeed in that managed entities are tracked by the persistence library which watches for changes in these objects.
GC6 – code/ontology generator Setting up a database schema or an object model may seem like a one-time work but as the application evolves, so does often the schema. Keeping both the ontology schema and the object model in sync automatically can spare the developer a decent amount of time and bugs (e.g., a typo in an IRI). For this reason, JPA allows one to generate database schema from an object model [39]. In addition, many JPA implementations support also the converse – generating an object model from database tables. There also exist libraries like Owl2Java [83] which allow generating an object model from an ontology. To this end, three approaches to object model vs ontology schema transformation are discussed in [63] – manual mapping of an object model, its automatic generation from an ontological schema and a hybrid approach, which the authors deem most useful based on its correctness/efficiency ratio. In the hybrid scenario, a basic model is generated automatically and the developer then fine tunes it manually. Conversely, one could start with an object model, generate an ontology schema from it and continue extending the schema further.
OC1 – explicit inference treatment An RDFS repository may respond to a query with asserted and inferred statements. While they are indistinguishable from the formal point of view [2], this holds only for the retrieval scenario. Statement removal (possibly as part of an update) works differently: asserted triples can be directly deleted but the existence of inferred statements is only implied by the presence of other statements. Consider triples  and an application which maps values of
and an application which maps values of

This is hardly the expected behavior. An OTM library has to deal with such situations, e.g., by marking inferred attributes as read-only or by keeping track of inferred values and indicating an error whenever the application attempts to remove or modify such a value. This issue would be even more important if the repository supported SPIN [43] rules or OWL, which allow richer inference.
OC2 – named graphs Named graphs [10] are an important feature of RDF, as they allow to split RDF data into meaningful and identifiable parts inside an RDF dataset. Although there exist different semantics for treatment of named graphs, triple stores mostly adopt the one where the dataset’s default graph represents a union or merge of its named graphs [82]. This strategy makes named graphs suitable for logical structuring of data. Consider a company repository containing information about projects, business contracts and employees. It is sensible to let the employees occupy a different named graph than projects, possibly together with a different degree of access control.
OC3 – automatic provenance management RDF allows to record provenance information about the data using the RDF reification vocabulary [8] (in addition, an OWL 2-compliant PROV-O ontology [48] has been introduced by W3C). This approach, although not without flaws [65], provides an interesting alternative to auditing in JPA, which is not standardized and is done in an ad hoc manner. Quasthoff and Meinel [62] introduce a prototype able to generate provenance data in RDF processing. More specifically, it connects newly created statements to triples upon which they are based. An example of benefits of automatic provenance tracking can be formulated in terms of the benchmark model introduced later in Section 4.2.1 – instead of manually assigning the last editor or author of a report, the OTM could set it based on user session information available in the application. It should be possible to configure for which entities or which attributes the provenance data should be generated and how to retrieve relevant information (e.g., user).
MC1 – inheritance mapping Class hierarchies represent a major component of every domain conceptualization. Although RDFS does not support advanced class declaration expressions like disjointness, intersection, or union, which are part of OWL [20], it allows building class hierarchies using the RDFS
Mapping ontological inheritance to an object model may bring subtle conceptual issues. For example, take an ontology containing the following statements:

and a corresponding object model, i.e., entity classes
We shall use the
Simply put, being able to treat instances of different classes using the same interface.
If inference is not enabled,
If inference is enabled and the application attempts to remove the loaded entity
The OTM library might attempt to look for an explicit class assertion in the same RDFS class inheritance hierarchy. However, that would lead to an ambiguous result because both
MC2 – unmapped data access An application’s object model may represent only a part of the domain ontology. Similarly, one may start building an application using a simplified object model and gradually extend its coverage of the underlying ontology. Yet, there exist situations in which access to the portion of the ontology not mapped by the object model may be required. Consider an aviation safety occurrence reporting application (will be discussed in the next section) based on an aviation safety occurrence reporting ontology which extends a generic safety reporting ontology [45]. The generic safety ontology can be used for other high-risk industries such as power engineering, railroad transportation, etc. There may exist an application used, for example, by a national safety board, which allows browsing safety occurrence reports from different industries using an object model based on the generic ontology. Yet, the application could provide access to the industry-specific property values without them being mapped by the object model.
Another example of the benefits of accessing unmapped ontological data is ontology-based classification. In the aviation safety reporting tool, events can be classified using RDFS classes from a predefined vocabulary [64]. However, the application does not need to map these classes in order to use them if the OTM library allows access to these unmapped types.
MC3 – RDF collections and containers By default, all RDF properties are plural. In addition, RDF does not impose any kind of ordering restriction on their values, giving them effectively the semantics of a mathematical set. RDF defines the notions of containers and collections, which allow to represent groups of values with different kinds of semantics. For instance, an RDF container
To provide a full picture of the object-triple mapping landscape, we complement the (qualitative) feature comparison with a (quantitative) performance comparison. To make the comparison more usable and repeatable, it was decided to design a benchmark framework which could be used to compare as large variety of OTM libraries as possible.
As [33] and [57] point out, a benchmark should aim at simulating real-world conditions as much as possible, especially avoiding microbenchmarks, which are easy to get wrong. Luckily, we had an experience of developing ontology-based safety information solutions for the aviation domain in the INBAS12
Source code is available at
We took an excerpt of the RT model and modified it by removing some of the attributes which use features already present in other parts of the model. It is built upon a conceptualization of the aviation domain called the Aviation Safety Ontology [44] which is based on the Unified Foundational Ontology (UFO) [31]. RDFS serialization of the model ontology is visualized in Fig. 2. The model primarily concerns occurrence reports which document safety occurrences. Each occurrence may consist of several events structured in a part-of hierarchy. Events may be factors of other events, for example, one event may cause or mitigate another event. Reports can reference resources, which are typically file and document attachments. A question-answer tree represents a dynamically generated form structure. Basic provenance data (author, last editor, date of creation and last edit) are stored for each report as well.

Benchmark ontology visualization. Rectangles with solid line represent RDFS classes, rectangles with dotted line denote literal datatypes and ellipses are RDF properties used as RDF triple subjects/object. Each edge represents an RDF triple with a source/target node label representing the triple subject/object and the edge label representing the triple predicate. Unlabeled edges ended with a hollow arrow denote triples with the
The goal of the benchmark is to exercise both common mapping features known from JPA and features specific to OTM revealed in our experience with building ontology-based applications. Therefore, the model contains both singular and plural relationships, properties with literal values, inheritance, and references to resources not mapped by the object model (the

UML class diagram of the benchmark model.
We conclude this part with a remark regarding instance identifiers. The identifier attribute was not included in declarations of the entity classes in the model because various libraries use various types for the identifier, e.g.,
The set of operations executed by the benchmark is supposed to represent a common domain-specific application functions. Therefore, the scenarios include a basic set of create, retrieve, update and delete (CRUD) operations, plus a batch persist and a find all query. The CRUD operations represent a typical form of operation of a business application, where data are persisted, updated, queried and occasionally deleted. The find all query is another example where the user requests a list of all instances of some type, e.g., for a table of all reports in the system. The batch persist, on the other hand, may represent a larger amount of data being imported by an application at once.
Each operation consists of three phases; it has optional set up and tear down phases, which are not measured but are used to prepare test data and verify results respectively. Between these optional phases is the actual execution phase, duration of which is measured. Test data are generated before each operation.
OP1 – create OP1 represents a typical operation performed by a domain-specific business application. It creates an object graph centered around an entity (an
Set up Persist
Execution Assign each generated report a random author and last editor and persist it in a separate transaction.
Tear down Verify the persisted data.
OP2 – batch create As was already stated, the batch create operation represents, for example, data being imported or processed by an application in one transaction. Thus, the mode of operation is almost the same as OP1, only now all the entities are persisted in one large transaction.
Set up Persist
Execution Assign each generated report a random author and last editor and persist all of them in one large transaction.
Tear down Verify the persisted data.
OP3 – retrieve OP3 stands for the application requesting a specific entity together with its object graph (an instance and its property values in RDF terms). Again, to increase the clarity of the measurement, multiple objects are read one by one. This operation also verifies that all the required data were loaded by the persistence library.
Set up Persist test data using the same process described in set up and execution of OP2.
Execution Iterate through all existing reports, read each report using the existing report’s identifier. Verify that the loaded report corresponds to the existing one.
OP4 – retrieve all A “find all instances of a type” query is a typical operation for many applications. Its implementations can vary. Some libraries support mapping SPARQL query results to objects, so a SPARQL
Set up Persist test data using the same process described in set up of OP3.
Execution Read all reports and verify them. If the library API provides a dedicated method for this task, use it. Otherwise, use a SPARQL
OP5 – update Update merges a modified entity into the repository. Several of its attributes and attributes of objects it references are updated, with both literal values and references to other objects being changed. Also, a reference to a new object that needs to be persisted is added. This operation is done in a single transaction. Several objects are updated in this way. Note that this scenario simulates an entity being updated externally and then being merged into the repository. For libraries which do not support detached objects, an instance is first loaded from the repository and the changes are made on this managed instance.
Set up Persist test data using the same process described in set up of OP3.
Execution For one half of the existing reports, perform the following updates (each object in a separate transaction):
set a different last editor (singular reference attribute) and last modified date (singular datetime attribute), change occurrence name (singular string attribute), change severity assessment (singular integer attribute), increment revision number by one (singular integer attribute), add a newly generated attachment (plural reference attribute),
and merge the updated entity into the repository.
Tear down Verify the updates.
Evaluation of benchmark criteria defined in [33] on our benchmark. SUT stands for system under test
Evaluation of benchmark criteria defined in [33] on our benchmark. SUT stands for system under test
OP6 – delete While modern triple stores do not particularly concentrate on removal operations since storage capacity is relatively cheap and many systems tend to create new versions instead of modifying existing data, business applications sometimes need to delete data, e.g., for privacy or security reasons. OP6 represents deletion of an object and most of its references. Once again, multiple objects are deleted in separate transactions to improve result robustness.
Set up Persist test data using the same process described in set up of OP3.
Execution Delete one half of the existing reports, including their dependencies, i.e., everything from their object graph except the author and last editor.
Tear down Verify that all relevant data were removed.
A benchmark runner is used to execute the operations according to a configuration. The runner collects a number of statistics:
The fastest and slowest round execution time, Mean round execution time, Q1, Q2 (median) and Q3 of round execution times, Total execution time, Standard deviation of round execution times.
In addition, it allows a file to be configured into which raw execution times for rounds are output so that they can be further analyzed.
The whole benchmark framework is available online.15
In this section, we introduce the libraries selected for the comparison. Several OTM libraries were selected based on their popularity, level of maturity, and development activity – libraries with latest changes older than five years were omitted. The feature comparison is platform agnostic, so a diverse set of libraries was chosen:
ActiveRDF
AliBaba
AutoRDF
Empire
JAOB
JOPA
KOMMA
RDFBeans
RDFReactor
The Semantic Framework
Spira
SuRF
However, since the benchmark part of the comparison framework is based on Java, only Java OTM libraries were evaluated so that platform specifics (e.g., code being compiled to native code like in C
Since RDF4J is an evolution of the Sesame API, we will use the terms interchangeably throughout the paper. We will stress the difference when necessary.
AliBaba
Empire
JOPA
KOMMA
RDFBeans
The mapping in the selected Java libraries is realized via annotations which specify the mapping of Java entity classes to RDFS classes and attributes to RDF properties. Listing 3 shows an example entity class declaration in Empire.
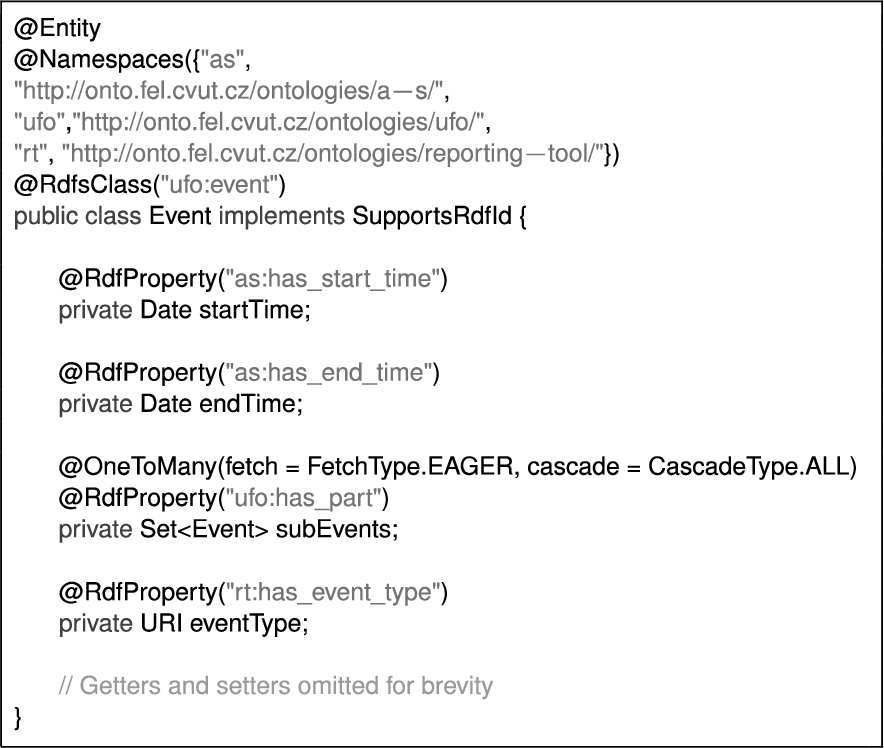
Example of an Empire Java entity class with annotations specifying mapping to the RDF(S) data model. Getters and setters are methods used to get and set the values of attributes respectively
The following paragraphs introduce all the evaluated OTM solutions.
ActiveRDF [59] is an object-oriented API for Semantic Web data written in Ruby. It is built around the premise that dynamically-typed languages like Ruby are more suitable for semantic data representation because, like RDF, they do not require objects to conform to a specific class prescription. ActiveRDF represents resources by object proxies, attaching to them methods representing properties. Invocations of these methods translate to read/write queries to the storage. In addition, it supports an object-oriented query syntax based on PathLog [26] and is able to actually generate convenience filter methods automatically.
In fact, ActiveRDF is not a typical OTM library like AliBaba or Empire where RDFS classes are mapped to entity classes. Instead, it treats RDF resources as objects to which it dynamically attaches methods corresponding to their properties. One caveat of the highly dynamic nature of ActiveRDF is pointed out in [72] – it does not offer type correctness and typographical error verification present in libraries based on statically-typed languages such as Java.
AliBaba
AliBaba [52] is a Java library for developing complex RDF-based applications. It is an evolution of the Elmo [55] library. AliBaba is an extension to the original Sesame API, so it supports only storages accessible via a Sesame/RDF4J connector. Its API is centered around the
In addition to OTM, AliBaba contains an HTTP server which can automatically make resources accessible as REST services, providing querying, inserting and deleting capabilities.
AutoRDF
AutoRDF [15] is a library facilitating handling of RDF data written in C
Empire [30] is an RDF-based implementation of the JPA standard [39]. Therefore, its API should be familiar to developers used to working with relational databases in Java. However, since parts of JPA deal with the physical model of the relational database under consideration (e.g., the
It adds a set of RDF-specific annotations which are used to express the mapping of Java classes and attributes to RDFS classes and properties (see Listing 3). It does not support anonymous resources, so all instances it works with must have an IRI.
JAOB
The Java Architecture for OWL Binding (JAOB) [78], as its name suggests, is primarily intended for OWL ontologies. However, with minor adjustments, RDF(S) ontologies can be manipulated by it. First, the annotation used for declaring class mapping is called
JAOB is built on top of OWL API, so it supports only ontologies stored in files. It basically works as (un)marshaller, so it is able to load or save collections of mapped objects. However, there is, for example, no direct way to update an entity in JAOB.
JAOB also contains a generator which allows generating Java classes based on an ontology schema and vice versa.
JOPA
The Java OWL Persistence API (JOPA) [46,49] is a persistence library primarily designed for accessing OWL ontologies. However, it can be used to work with RDF data as well. Its API is designed so that it resembles the JPA as much as possible, but it does take semantic data specifics like named graphs or inference into account. JOPA tries to bridge the gap between the object-oriented application world, which uses the closed-world assumption (missing knowledge is assumed false), and the ontological world, which is based on the open-world assumption (missing knowledge can be true in some worlds and false in others), by splitting the model into a static and dynamic part. The static part is mapped to the object model and its validity is guarded by integrity constraints with closed-world semantics [75]. The dynamic part is not directly mapped (although it is accessible to a limited extent) and may evolve freely without affecting the object model.
Using JOPA with RDF(S) ontologies requires minor adjustments because JOPA is OWL-based. These adjustments are similar to those described for JAOB.
KOMMA
The Knowledge Management and Modeling Architecture (KOMMA) [80] is a Java library for building applications based on semantic data. A part of this system is an object-triple mapping module, but the library itself has much richer functionality, including support for building graphical ontology editors based on the Eclipse Modeling Framework.18
RDFBeans [1] is another OTM library built on top of RDF4J. It allows two forms of an object model: 1) the object model may consist of Java classes representing the RDFS classes; 2) the object model may consist of interface declarations forming the mapping, RDFBeans will generate appropriate implementations at runtime using the dynamic proxy mechanism. RDFBeans supports, besides the basic features like transactions and inheritance, also mapping of Java collections to RDF containers, or operation cascading, e.g., when an updated entity is merged into the storage, objects referenced by this entity are merged as well. Instances of entity classes without an explicitly declared identifier attribute are mapped to RDF blank nodes.
RDFReactor
RDFReactor [77] is yet another Java OTM library. It supports code generation and uses proxy objects to access RDF data directly, instead of storing attribute values in entities. In addition to the mapped properties, RDFReactor entity classes also contain an API for type information manipulation – methods
All entity classes mapped by RDFReactor extend the
The Semantic Framework
The Semantic Framework (SF) [41] is a Java library for object-oriented access to ontologies. Similar to JAOB or JOPA, the SF is primarily built for OWL, but it can, again, be used with RDFS as well. It internally uses OWL API to process RDF files and its core is an extension of the Jenabean library [17]. The combination of Jena (internally used by Jenabean) and OWL API is, in our opinion, rather odd given the fact that Jena is also able to process RDF files. The mapping is realized using annotations in entity classes.
Spira
Spira [47] is a library for viewing RDF data as model objects written in Ruby. It allows to access RDF data both as domain objects (entities) and as RDF statements. In particular, one may view and edit statements representing an entity directly from its object representation. On the other hand, it is also possible to create RDF statements directly, without any object representation of the resource. Spira allows to ‘view’ resources as instances of various classes without requiring them to explicitly have the corresponding RDF type. It also allows to map one Ruby class to multiple ontological types, to work both with named and anonymous resources, or to use localized property values, i.e., a single-valued property can have a value in multiple languages.
Spira uses RDF.rb19
Selected OTM libraries compared using criteria defined in Section 4. × means no support, ∘ represents partial support (consult the main text for further details), ✓ is full support of the feature and N/A signifies that the feature cannot be evaluated in the particular case
SuRF [3] is a Python object RDF mapper. SuRF is built on top of the RDFLib20
SuRF contains a search API which can be used to retrieve instances of the mapped classes and filter them by their attribute values. One subtle feature of SuRF is that it allows to retrieve resources regardless of whether they are actually present in the triple store. To check for their existence, a dedicated
There are several OTM libraries which were omitted from the selection. Elmo [55], Jastor [74], Jenabean [17], Owl2Java [83] or Sommer [73] are obsolete, with their last versions published more than five years ago.
We also wanted to include a purely SPARQL endpoint-based solution which would allow us to compare the performance of a storage agnostic library to libraries exploiting vendor-specific optimizations. However, RAN-Map [76] is not published online (neither sources nor binaries) and TRIOO [24] is buggy and we were not able to adapt it to the benchmark application without significant changes to its code base (for example, it does not insert resource type statements on persist).
Libraries like JOINT-DE [37] (and the original JOINT), Sapphire [72] and the Semantic Object Framework [16] were excluded because their source code is not publicly available and the articles describing them do not provide enough details to evaluate the comparison criteria.
Feature comparison
Comparison of features of the selected libraries according to the criteria defined in Section 4 is summarized in Table 3. In the table, ✓ signifies that the criterion is fully satisfied according to the condition defined in Section 4. ∘ signifies partial satisfaction and the text should be consulted for further details, and × means the criterion is not satisfied. We now expand on the results.
GC1 – transactions
AutoRDF, JAOB and the Semantic Framework do not support transactions likely due to their lack of support for triple stores in general (more details in Section 6.2). While ActiveRDF, RDFReactor and Spira do support access to regular triple stores and, for example, RDFReactor internally makes use of the store’s transactional mechanism, they do not allow the programmer to control the transactions externally. Empire’s API hints towards support for transactional processing but its implementation is rather strange. As will be discussed in Section 7, operations which insert/update/remove data are automatically committed without any way of preventing this behavior. So, for example, it is not possible to bind updates to multiple entities into one transaction.
AliBaba, KOMMA, and RDFBeans support transactions by relying on the underlying storage’s transaction management, i.e., starting an OTM-level transaction begins a database-level transaction and its end causes the database-level transaction to end as well. SuRF, on the other hand, tracks the changes to objects by marking their updated attributes dirty and allows the programmer to commit the changes manually. JOPA handles transactions by creating clones of the manipulated objects and tracking their changes locally, pushing them into the storage on commit. In addition, the changes are stored in transaction-local models and are used to enhance results of subsequent operations in the same transaction, e.g., when an entity is removed, it will not be in the results of a find all query executed later in the same transaction.
GC2 – storage access variability
AutoRDF, JAOB and the Semantic Framework support only access to RDF data stored in text files, albeit with various serializations. AliBaba and RDFBeans are tightly bound to the Sesame API, so they can access exclusively Sesame/RDF4J storages.
While KOMMA does not have any other implementation than RDF4J storage access, its internal APIs are designed so that new storage connector implementations can be added.
ActiveRDF supports access to various storages, including Jena, Sesame or a generic SPARQL endpoint. Empire contains storage access modules which can implement the required access API. For instance, it provides a connector to the Stardog database.21
In contrast to JAOB, which does not provide any query API at all, AutoRDF, RDFBeans, the Semantic Framework and Spira do not provide a query API either but contain at least a find all method, which allows to retrieve all instances of the specified type. In case of RDFBeans the situation is peculiar because its
While ActiveRDF does not support mapping SPARQL query results to entities, its advanced query API obviates this issue by supporting almost complete SPARQL grammar [59].
Finally, AliBaba, Empire, JOPA and KOMMA support mapping SPARQL query results to entities by allowing to specify target entity class when retrieving query results.
GC4 – object-level query language
ActiveRDF contains a variation of a criteria query API containing methods representing query operations like selection, filtering and projection. Additionally, it automatically generates methods for filtering objects by their properties, e.g., it will provide a method
None of the other libraries support any object-level query language, so their users have to resort to SPARQL queries, if available.
GC5 – detached objects
ActiveRDF, AliBaba, AutoRDF, RDFReactor, Spira, and SuRF do not support detached objects because their entities act as proxies which load attribute values from the repository when they are accessed for the first time, or on each access, depending on the internal implementation. Conversely, setting attribute values causes the changes to be written into the storage immediately (except for SuRF which tracks changes locally). Therefore, they have to hold onto a connection to the storage in order to provide basic data access functions. Similarly, although it would appear that KOMMA does support detached objects because it is possible to close a KOMMA
Empire, JAOB, JOPA, RDFBeans and the Semantic Framework, on the other hand, allow working with the entities completely independently of the persistence context from which they were retrieved because they store the data in the actual objects.
GC6 – code/ontology generator
Empire, RDFBeans, the Semantic Framework and Spira do not contain any generator capable of creating entity classes from ontology schema or vice versa. ActiveRDF and SuRF do not contain code generators either, but they do not actually use any static object model and all entity classes are generated on demand at runtime.
AliBaba, AutoRDF, JAOB, JOPA and KOMMA contain generators able to build an object model from the ontology. The AliBaba generator supports both RDFS and OWL, but it is less configurable. AutoRDF supports several OWL constructs, but its core is RDFS-based. On the other hand, the generators in JAOB and JOPA are OWL-based and expect the ontology to contain declarations of OWL classes and object, data and annotation properties. KOMMA reuses the AliBaba code generator but the feature is undocumented.
JAOB is the only library with a generator capable of creating an ontology schema based on an object model. This generator is able to create classes and their hierarchies, plus OWL data and object property declarations with domains and ranges and information about whether the property is functional or not [20].
OC1 – explicit inference treatment
JOPA allows marking entity attributes as possibly containing inferred data. Currently, this makes them effectively read-only. However, in the future, the implementation may permit additive changes. AliBaba, KOMMA and RDFReactor allow marking attributes as read-only, a mechanism which could be used to prevent attempts at modification of inferred statements.
OC2 – named graphs
Alibaba, AutoRDF, JAOB, RDFBeans, the Semantic Framework, Spira, and SuRF are not aware of RDF named graphs and work only with the default graph.
Empire supports named graphs to a limited extent. Named graph access is specified via the
OC3 – automatic provenance management
None of the evaluated libraries fully supports automatic provenance management. However, AliBaba and KOMMA support the notion of behaviors which could be used to generate provenance data. A behavior adds custom functionality to entities and may be shared by multiple entity classes. One such implementation could be invoked by entity setters, extract user information and insert corresponding provenance statements into the repository. In Spira, Active Model24
See
Inheritance mapping is probably the most complex feature in the comparison framework, with many subtle issues. Despite this, several evaluated libraries take a straightforward approach which can often lead to unexpected results.
Consider Empire which does support multiple inheritance in that it is able to work with classes which inherit mapped getters/setters from multiple interfaces. However, it is unable to persist more than one type for an entity. So if each interface declares a mapped type, only one of them gets persisted. KOMMA and RDFBeans suffer from the same issue, i.e., they correctly interpret inherited attributes, but always persist only a single type. To illustrate the issue, let us have interfaces
The Semantic Framework appears to also support multiple inheritance thanks to its use of Java classes and interfaces. However, the implementation extracts only attributes declared in a particular class, without regard for any fields inherited from its superclass. This in effect means that any values of fields declared in a superclass are ignored when persisting an instance.
JAOB does not support inheritance mapping. SuRF allows to specify multiple superclasses when loading a resource but they do not represent mapped ontological classes, they are regular Python classes adding custom behavior to the instance. On the other hand, similarly to ActiveRDF, since loaded instances contain attributes corresponding to all properties found on the resource, the concept of inheritance mapping does not really apply in this case. Appropriate type assertion presence on a resource can be of importance w.r.t. the type hierarchy, but such an issue is more closely related to the way libraries handle explicit and inferred statements.
JOPA currently supports only class-based inheritance, so mapping classes with multiple supertypes is not possible. However, the semantics of its treatment of inheritance is precisely defined – it requires an explicit type assertion and supports polymorphic instance access, i.e., an inferred supertype may be specified for loading as long as an unambiguous asserted subtype can be found for a resource. Similarly, RDFReactor and Spira support only single type inheritance. On the other hand, Spira allows an entity to specify multiple types, so multiple ontological classes can be combined into a single mapped Ruby class, which can be used as another class’s parent.
AliBaba and AutoRDF are thus the only libraries fully supporting class hierarchy mapping. Since AliBaba is a Java library, it relies on interfaces to support multiple inheritance. AutoRDF is able to exploit the built-in support for multiple inheritance in C
MC2 – unmapped data access
Providing access to unmapped properties is more challenging in statically typed languages like Java or C

UML object diagram of the object model used by the benchmark.
AliBaba, JOPA, KOMMA and RDFReactor, although being Java libraries, do attempt to supply this access. In JOPA, there are two relevant attribute annotations – a
ActiveRDF and SuRF, due to their lack of a static model, naturally allow to access all the properties of a resource. In Spira, all model objects can be manipulated also at the RDF statement level thanks to the integration with RDF.rb.
Support for RDF collections and containers is scarce among the evaluated libraries. The only libraries which fully implement this feature are AliBaba, KOMMA and RDFBeans. AliBaba supports RDF lists and RDF containers. Both are mapped to instances of
The approaches of the Semantic Framework and JOPA may be regarded as partial support. The Semantic Framework automatically stores array and
Performance comparison
All the benchmark operations revolve around an object graph whose template is shown in Fig. 4. As can be seen, there is one central
Experiment setup
The experiments were conducted on a machine with the following setup:
OS: Linux Mint 17.3 64-bit CPU: Intel Core i5-750 2.67 GHz (4 cores) RAM: 16 GB Disk: Samsung SSD 850 EVO 250 GB Java: Java HotSpot JDK25 Java Development Kit.
AliBaba 2.1, built locally, sources downloaded from
Empire 1.0, built locally, sources downloaded from
JOPA 0.10.7, retrieved from Maven Central,
KOMMA 1.3.3-SNAPSHOT, built locally, sources retrieved from https://github.com/komma/komma,
RDFBeans 2.2, retrieved from Maven Central.
After publishing the initial performance results, we received optimization suggestions from the authors of KOMMA. They provided a significant performance boost for KOMMA and were incorporated into the benchmark setup. However, these optimizations are undocumented.
The scalability of the performance benchmark allows custom specification of the size of the data. For our experiments, we used the following values:
300 The same setup as OP1. 300 The same setup as OP3. The same setup as OP3. One half of the reports (every odd one, to be precise) are updated. The same setup as OP3. One half of the reports (again, every odd one) are deleted, together with their dependencies.
The benchmark was run for several values of heap size. The results should then reveal how sensitive the libraries are to restricted heap size and how they scale as the heap size changes. The heap size was fixed (using the
32 MB
64 MB
128 MB
256 MB
512 MB
1 GB
The maximum number of statements generated by the benchmark for OP3 (the other operations are either the same or very similar) was
Memory
Measuring memory utilization turned out to be a bit tricky. Most of the literature concentrates on obtaining and analyzing heap dumps in the search for memory leaks (e.g., [57]) which was not the goal of this comparison.
Sampling heap occupation or object allocation rate (as DaCapo [7] does) is difficult to set up and its information value is arguable. Peak or average heap size or occupation also provide unclear benefits. In the end, a different strategy was used – a separate runner was developed which executed a series of CRUD operations similar to the ones used in the performance benchmark for a specific period of time. More precisely, the runner executed OP1, OP4, OP5 and OP6 in a sequence over and over until a specified timeout. This way, all the libraries were used for the same amount of time. To collect the results, the Java virtual machine was configured to output detailed information about garbage collection events (using the
The particular setup for the memory benchmark was as follows:
Runtime: 4 h, Heap size: 40 MB, Default garbage collector settings for the JVM used in the benchmark.
After the execution, GCViewer27
The number of young generation garbage collection events (YGC),
The number of full garbage collection events (FGC),
Accumulated garbage collection pause time (GCT),
Application throughput.
Let us now delve into the results of the experiments and attempt to interpret them. First, performance results are detailed, followed by a discussion of scalability of the evaluated libraries. Finally, memory utilization experiments are examined. Complete results can be found in the appendix and also – together with the underlying data – online.28
At
In this part, relative performance differences between the evaluated libraries are discussed. As a representative example, results for benchmark with heap size set to 1 GB are visualized in a plot in Fig. 5. Table 4 complements the plot visualization with information on execution time mean, standard deviation, the 95% confidence interval and the application average throughput. Throughput illustrates how many reports was the OTM library able to process per second. A report in this context denotes the object graph shown in Fig. 4. More specifically, this means:
Each persisted report consists of 11 entities mapped to 68 triples ( Each loaded report consists of 13 entities mapped to 90 triples ( Each updated report consists of 90 triples loaded for the merge and 9 triples updated. Each removed report represents 90 triples loaded and 68 of them removed (
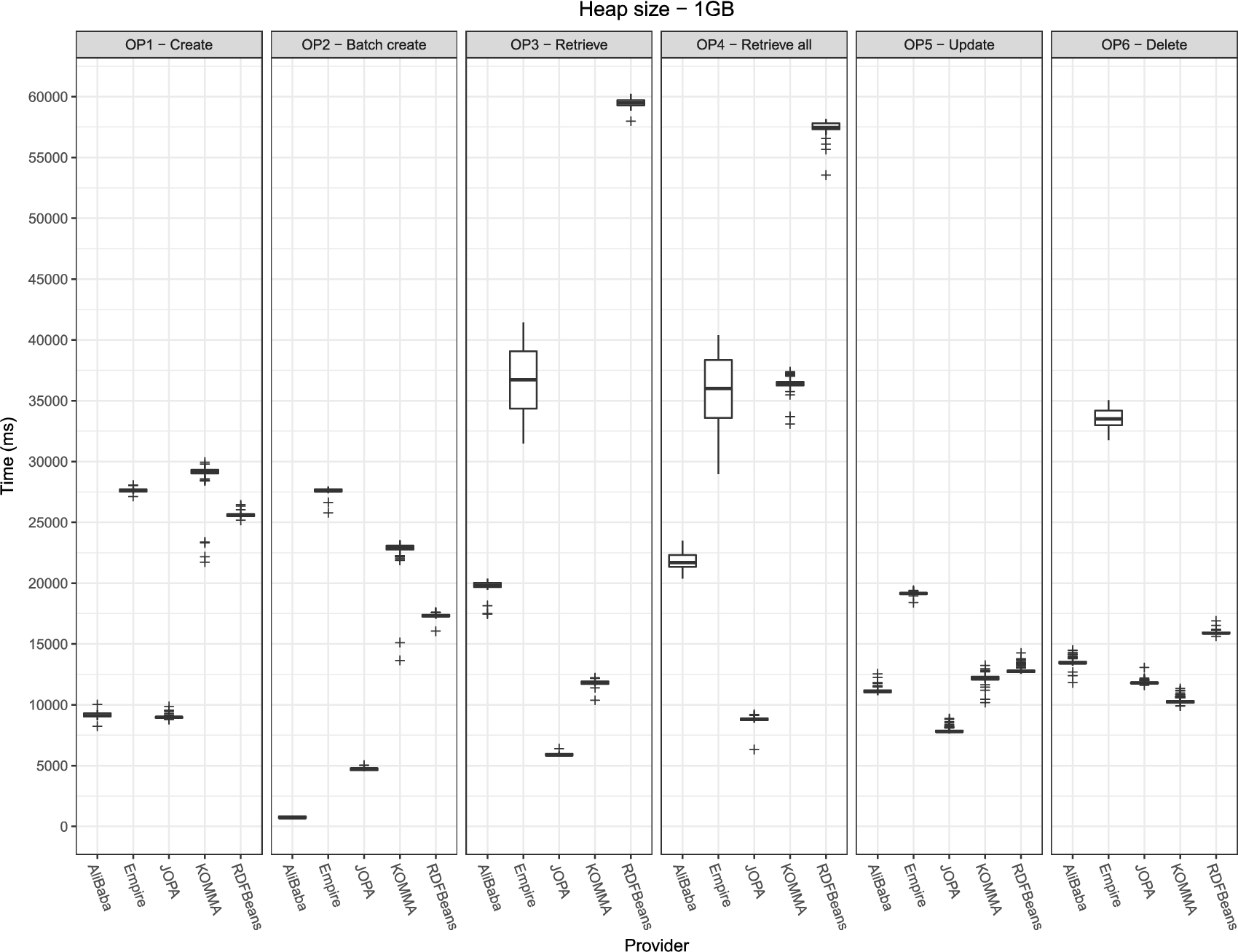
Performance of the individual libraries on a 1 GB heap. The plots are grouped by the respective operations. Lower is better.
All the libraries performed relatively consistently, with low deviation and the confidence interval size within 2% of the execution time mean, as suggested by [28]. Only Empire exhibited larger standard deviation for the retrieval operations (OP3 and OP4). KOMMA displayed large standard deviation and many outliers when running with 32 MB heap but this is most likely due to the high stress put on the garbage collector which has to pause the application relatively often. The following paragraphs elaborate on individual operation results.
Create (OP1) and batch create (OP2) The character of OP1 and OP2 suggests that the libraries should perform better in OP2 because they have to execute only a single transaction compared to a linear number of transactions in OP1. The only library that defied this expectation and performed virtually the same in both OP1 and OP2 was Empire. This is due to the fact that Empire actually commits the transaction after each data modifying operation of its
Results of the performance benchmark with all libraries running on a 1 GB heap. (

The performance of KOMMA depends on whether a data change tracker is enabled. If it is enabled, it attempts to remove old attribute values on change. This leads to significantly worse performance. When it is disabled, KOMMA’s performance is comparable to that of Empire and RDFBeans. The data change tracker relevance for persist is given by the fact that KOMMA does not implement a dedicated persist operation, instead, it allows to register an identifier to a particular type. Persisting attribute values then requires calling setters on the managed instance returned by the registration method. Whenever an attribute is set, the value is inserted into the repository and the object state and KOMMA’s internal attribute cache are refreshed.
RDFBeans performed slightly better than Empire and KOMMA. Two factors of the implementation of its
See
It can be seen that AliBaba and JOPA have very similar performance in OP1. In the batch scenario (OP2), on the other hand, AliBaba was able to perform a round in under one second, an order of magnitude faster than in OP1. The large difference is given by the transaction commit mechanism, which synchronizes a binary object store with its persistent version, potentially stored on the system disk.
Retrieve (OP3) and retrieve all (OP4) JOPA performed the best in both retrieval scenarios. Looking through the source code, all the libraries use different strategies for loading entity attributes.
AliBaba uses a single SPARQL
Empire adopts a different strategy. A SPARQL
JOPA does not use SPARQL to retrieve entities for two reasons. One is our experience showing that filtering using the RDF4J API is more efficient. The other, and more important, is that a SPARQL query does not allow to specify whether inferred statements should be included or not and the result does not indicate the origin of the resulting statements (see OC1 in Section 4). Instead, JOPA uses a single call to get all statements concerning the specified subject and then processes these statements, populating the resulting object with appropriate values. While this strategy may turn out inefficient in cases where the object model represents only a tiny portion of the graph around the loaded subject, it does sufficiently well in most cases. Indeed, the results show that it outperforms all the other strategies by a considerable margin.
KOMMA supports two strategies for loading an entity. One relies on a dedicated
RDFBeans returns a fully initialized object, but it loads its attributes one by one using the RDF4J filtering API. Moreover, similarly to persist, it first checks for the subject’s existence in the repository, which involves a rather costly statement filter with a bound subject. Thus, it was the slowest for both OP3 and OP4.
Update (OP5) OP5 showed comparable performance by AliBaba, JOPA, KOMMA and RDFBeans, with JOPA outperforming the others. Empire performed the worst. The update is also interesting in terms of the internal implementation in the particular libraries.
AliBaba, because it does not support detached objects, requires the user to first load the required entity and then update it manually, essentially corresponding to the behavior Empire and JOPA implement internally. However, this can become extremely cumbersome – for instance, consider an object coming to the REST API of an application in a PUT request, signifying a data update. Then the application would either have to determine the changes by scanning the incoming object and comparing it to an existing object in the database, or use the incoming object as the new state and replace the existing data completely by iterating over all its attributes and merging their values into the repository. The approach of JOPA (see below) is much more flexible because it allows, for example, to specify whether the merge operation should be cascaded to objects referenced by the entity being merged.
Empire internally loads all the data concerning the subject which is being merged, removes them and then inserts the new, updated, data. While efficient, it is hardly the correct behavior. Consider a situation when the application is using a legacy RDF triple store and the object model covers only a part of the data schema. Invoking
JOPA internally loads the instance into which updates will be merged (the same behavior is expected in JPA [39]). It then compares the merged instance with the loaded one and propagates the changes into the repository. The semantics of update in JOPA is supposed to correspond to JPA as much as possible. For instance, JPA specifies that when merging an entity with references to other objects, these references should not be merged and, actually, if they contain changes, these changes should be overwritten with the data loaded from the repository [39]. Of the benchmarked libraries, only JOPA behaves in this way.
Since KOMMA does not support detached objects, updating an object requires loading a corresponding instance from the repository and updating the required attributes in the same manner as with AliBaba. The optimized instance loading query from OP3 implementation was used to retrieve the instance to update.
RDFBeans works similarly to Empire in that it simply removes all statements concerning the updated subject and inserts new statements corresponding to the updated object. This, on the one hand, gives RDFBeans a significant performance boost, on the other hand, it can lead to incorrect behavior. As mentioned when discussing Empire, it can lead to the loss of data not mapped by the object model. RDFBeans performed better because it does not load the data to be removed before the actual removal, it directly issues the delete command.
Delete (OP6) Except for Empire, all the libraries exhibited comparable performance for OP6, with KOMMA winning by a narrow margin.
AliBaba does not have a dedicated remove method, so entity removal in its case is a little complicated. It consists of loading the object to be removed, setting all its attributes to
The performance of Empire suffers from the fact that it uses the same strategy for loading statements as in the case of OP3, i.e., a SPARQL
To avoid this issue, JOPA employs the epistemic remove strategy. Epistemic remove deletes only statements asserting properties mapped by the object model. Although less efficient than removing all statements concerning an individual, it is safer in terms of data consistency.
Unfortunately, AliBaba, Empire and JOPA do not deal with the situation where the removed resource is an object of other statements, i.e., it could be referenced by other instances (whether mapped by the object model or not). Relational databases resolve this problem with referential integrity which does not allow removal of a certain record as long as there are references to it in the form of foreign keys. In the open world of ontologies, a reference to an individual completely suffices to prove its existence. However, for an object model, this may not be (and often is not) the case. Therefore, OTM libraries should face this issue. In this regard, KOMMA and RDFBeans come with a solution.
Both KOMMA and RDFBeans perform entity removal by removing all statements whose subject or object is the resource being removed. This sufficiently deals with the issue of referential integrity. On the other hand, this solution can lead to unintended data removal. For example, one may remove an instance without knowing by how many other resources (mapped or not) it is referenced. Another user can then load an object which formerly referenced the removed one and find out that the connection has been severed for reasons unknown. We believe that this issue deserves a more thorough and systematic approach.
There are multiple ways of testing the scalability of an application or a library. In the case of this research, it was tested how well the libraries scale with regards to the memory available to the application.
Most of the libraries had issues running on the smallest, 32 MB heap. The only library able to perform the whole benchmark on a 32 MB heap was RDFBeans. AliBaba and JOPA were able to execute OP1, but failed on the other operations. KOMMA managed to execute OP1 and OP2, but with large standard deviation and many outliers. Empire finished the OP6 benchmark, but its standard deviation was so large that the results are all but inconclusive. In addition, Empire ran out of memory also for OP4 on a 64 MB heap. The fact that it did not happen for OP3, which is similar to OP4, is likely due to the individual instances loaded by OP3 being discarded right after the verification phase, whereas for OP4 all the instances are loaded at once and then verified.
Contrary to the expectations, with increasing heap size, the benchmark runtime did not decrease. In fact, in some cases, it tended to increase slightly. This increase could be explained by the garbage collector having to manage a larger amount of memory. Overall, once the heap size passed the threshold after which the benchmark did not run out of memory, there was no definitive trend in terms of application performance with respect to the heap size. This can be seen in an example plot for OP1 in Fig. 6 (all plots regarding scalability w.r.t. heap size can be found in Appendix A.2).

Benchmark performance of OP1 w.r.t. heap size. Lower is better.
To summarize, the benchmark developed as part of the OTM comparison framework appears not suitable for measuring scalability of the OTM libraries. In hindsight, this seems logical. Concerning scalability w.r.t. heap size, once the benchmark data fit into the available memory, increasing the heap size brings no performance benefit. Especially since garbage collection is triggered after the setup of each round. A more useful scalability comparison could involve a variable number of concurrent clients. However, this is not supported by the presented benchmark. On the other hand, a concurrent access-based benchmark would have to be carefully designed in terms of data correctness and objectivity.
Memory utilization is summarized in Table 5. It shows that both KOMMA and RDFBeans are relatively memory efficient, creating large numbers of short-lived objects which can be disposed of by the less-impactful young generation garbage collection. AliBaba required significantly more full garbage collections but the application throughput remained over 96%. JOPA’s memory utilization fits between AliBaba and KOMMA with throughput nearing 99%. This has to be considered in the context of performance, where both AliBaba and JOPA clearly outperform RDFBeans and, in most operations, also KOMMA, indicating that especially JOPA uses longer-living objects as a means to cache relevant data or to fetch the data more efficiently in terms of execution time.
Memory utilization summary. YGC (FGC) is young generation (full) garbage collection event count, GCT is the total time spent in garbage collection and Throughput is the application throughput
Memory utilization summary. YGC (FGC) is young generation (full) garbage collection event count, GCT is the total time spent in garbage collection and Throughput is the application throughput
Finally, the throughput of the benchmark application running Empire was approximately 85%, significantly less than the other libraries. However, when we tried the same experiment, but only with a 1 h runtime, its throughput was comparable to the other libraries. We suspect that there may be a memory leak in Empire. For the shorter runtime, the leak had not enough time to fully manifest. It would also explain Empire failing to execute OP4 on a 64 MB heap.
We have introduced a novel framework for comparison of object-triple mapping libraries. It consists of a set of qualitative criteria describing features important for developers of domain-specific object-oriented applications and a performance benchmark written in Java. The framework was used to compare a diverse set of OTM libraries. The results indicate that significant differences exist between the evaluated OTM providers in terms of features, performance and their treatment of semantic data – for instance, some expect the object model to completely cover the schema of the data, others also support access to a subset of the schema.
Feature comparison conclusions
The evaluated libraries may be split into several groups based on different points of view. One contains solutions which appear to be proof-of-concept prototypes with limited functionality. This group contains AutoRDF, JAOB, and the Semantic Framework – their usability is restricted to a rather small set of specific cases. Another group consists of libraries in which entities are merely proxies of the underlying RDF data. Such libraries could be problematic especially in larger (web) applications because they generally do not support detached objects. On the other hand, thanks to the fact that they use dynamically generated proxies, they are able to support a wide variety of shared behavior in entities. In case of ActiveRDF and SuRF, this is enhanced by the fact that they do not require a predefined object model. The last group may be denoted as general purpose persistence libraries and it contains Empire, JOPA and RDFBeans. These libraries attempt to provide functionality similar to JPA but in the world of ontologies.
In general, most of the libraries suffer from the fact that there is no formalization of the object-triple mapping. Such a gap leads to potentially inconsistent behavior and straightforward solutions which fail to handle less frequent cases. To give a final recommendation, for multiuser applications with non-trivial business logic, we believe that support for transactions (GC1), detached objects (GC2), query result mapping (GC3) and inheritance mapping (MC1) are a must have for an OTM library. Explicit treatment of inferred knowledge (OC1) would be important in scenarios where the mapped data are involved in inference.
Performance comparison conclusions
Several conclusions may be derived from the performance comparison results. AliBaba demonstrated very good performance and supports a rich set of features. However, while restriction to Sesame-based storage is not a big problem thanks to its wide support among triple store implementors, the unintuitive cascading strategy and lack of support for detached objects can be of concern. Empire exhibited worse than average time performance and a potential memory leak in query mapping. On the other hand, its API directly implements portions of the JPA standard [39] which can make it suitable for existing projects migrating from relational to semantic databases. JOPA provides rich features as well as excellent performance, memory utilization, and sound data access patterns for the general case. The performance of KOMMA critically depends on the use of optimization hints provided by its authors. Without them, KOMMA performed in most cases significantly worse than the other libraries. With them, its performance rivals the performance of AliBaba and JOPA. However, its API made it more difficult to use in the benchmark than the other libraries. RDFBeans is the most suitable library for environments with extremely limited memory. In comparison to the other four libraries evaluated in the performance benchmark, its time performance is, apart from retrieval operations, average.
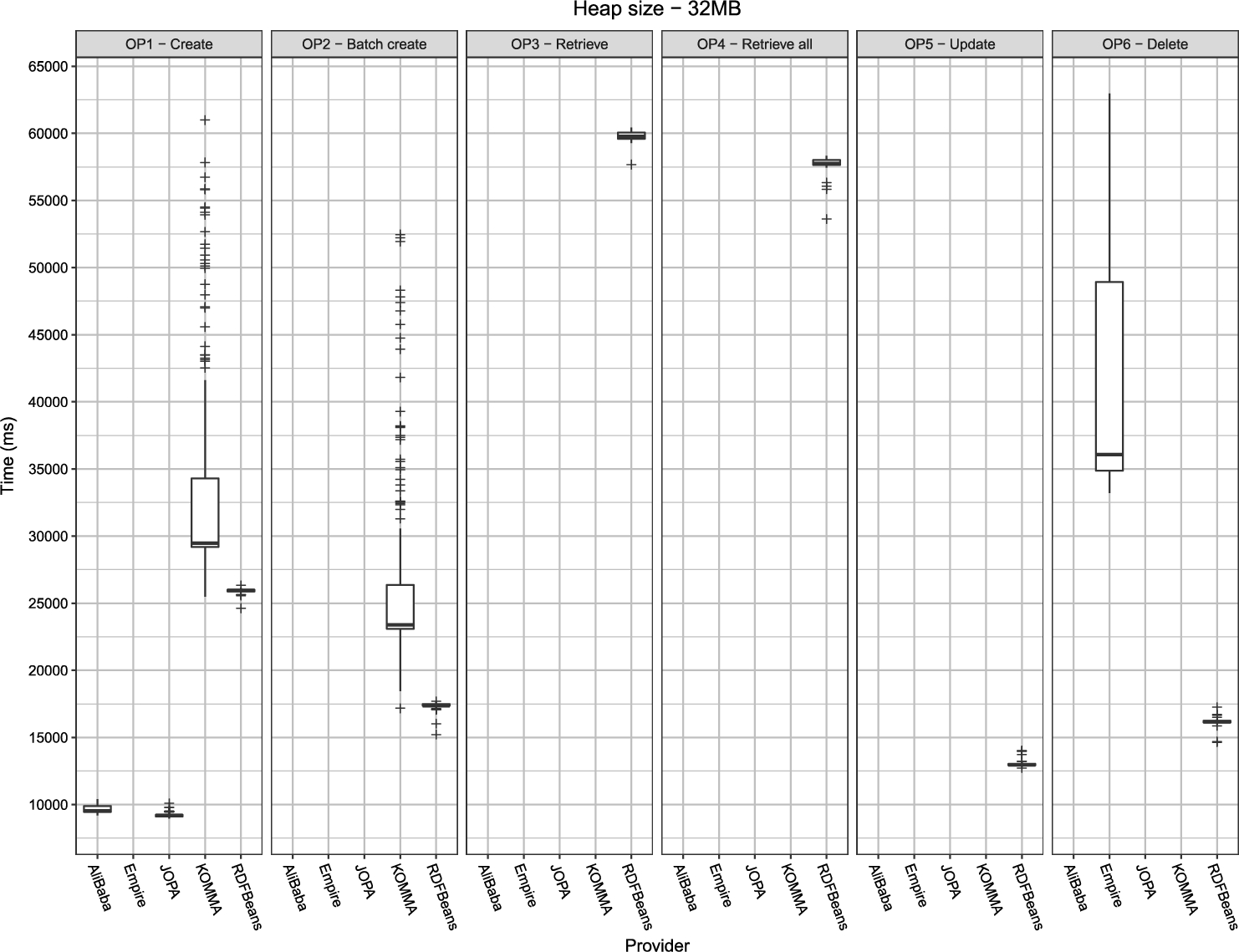
Performance of the individual libraries on a 32 MB heap. The plots are grouped by the respective operations. Lower is better.
Overall, while the slowest player in an ontology-based application stack will always be the triple store (given the size and complexity of data in processes), the benchmark showed that OTM libraries significantly differ in terms of performance. These differences are given by the effectiveness with which OTM solutions access the underlying storage. Application developers thus may choose a library suitable for their case, e.g., RDFBeans for applications with limited resources, AliBaba for batch processing scenarios, JOPA for general cases. However, we argue that more important than performance differences are the differences in the semantics of the implementation, where, for example, Empire and RDFBeans can have unexpected side-effects in scenarios where the mapping does not cover the whole RDF data schema.
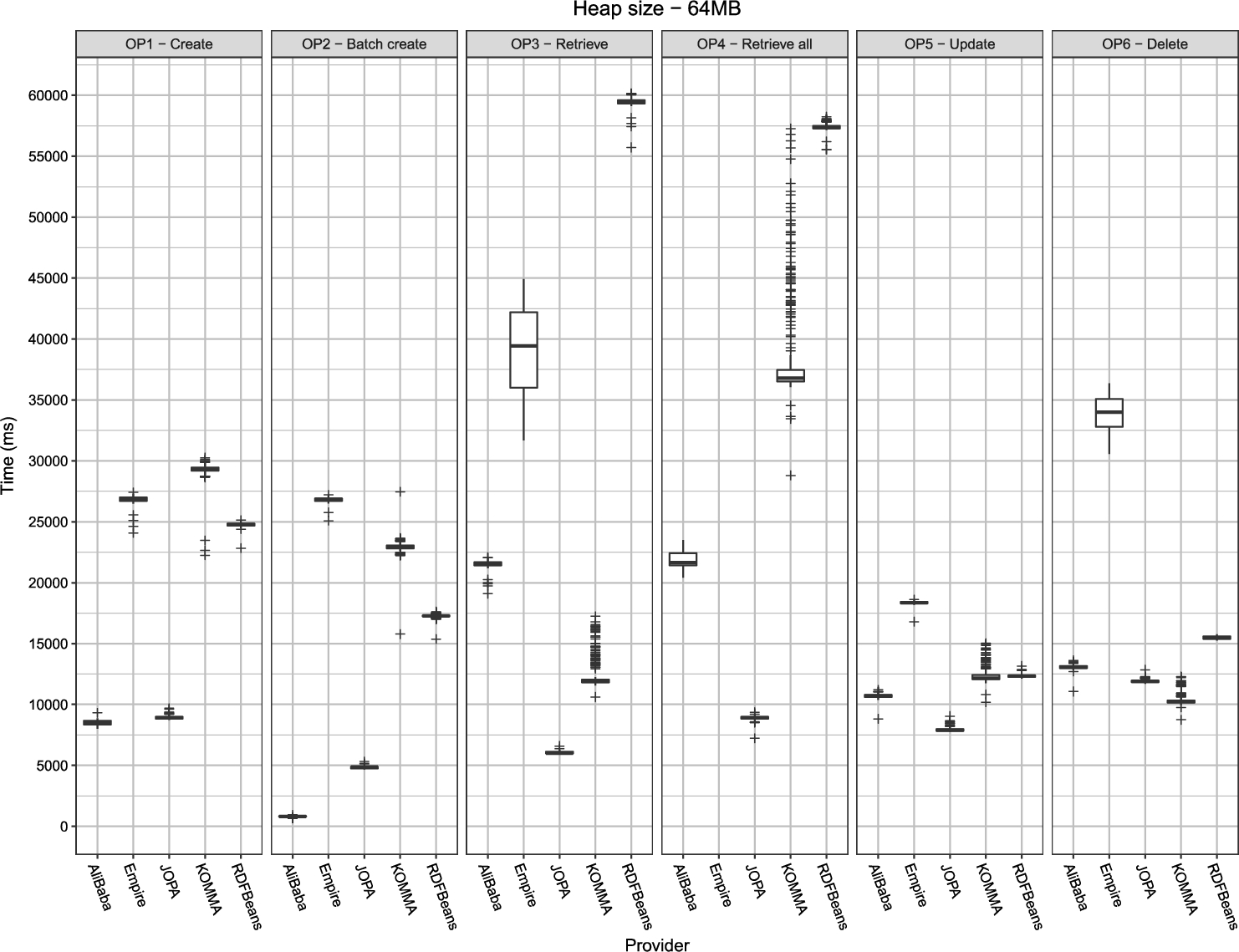
Performance of the individual libraries on a 64 MB heap. The plots are grouped by the respective operations. Lower is better.
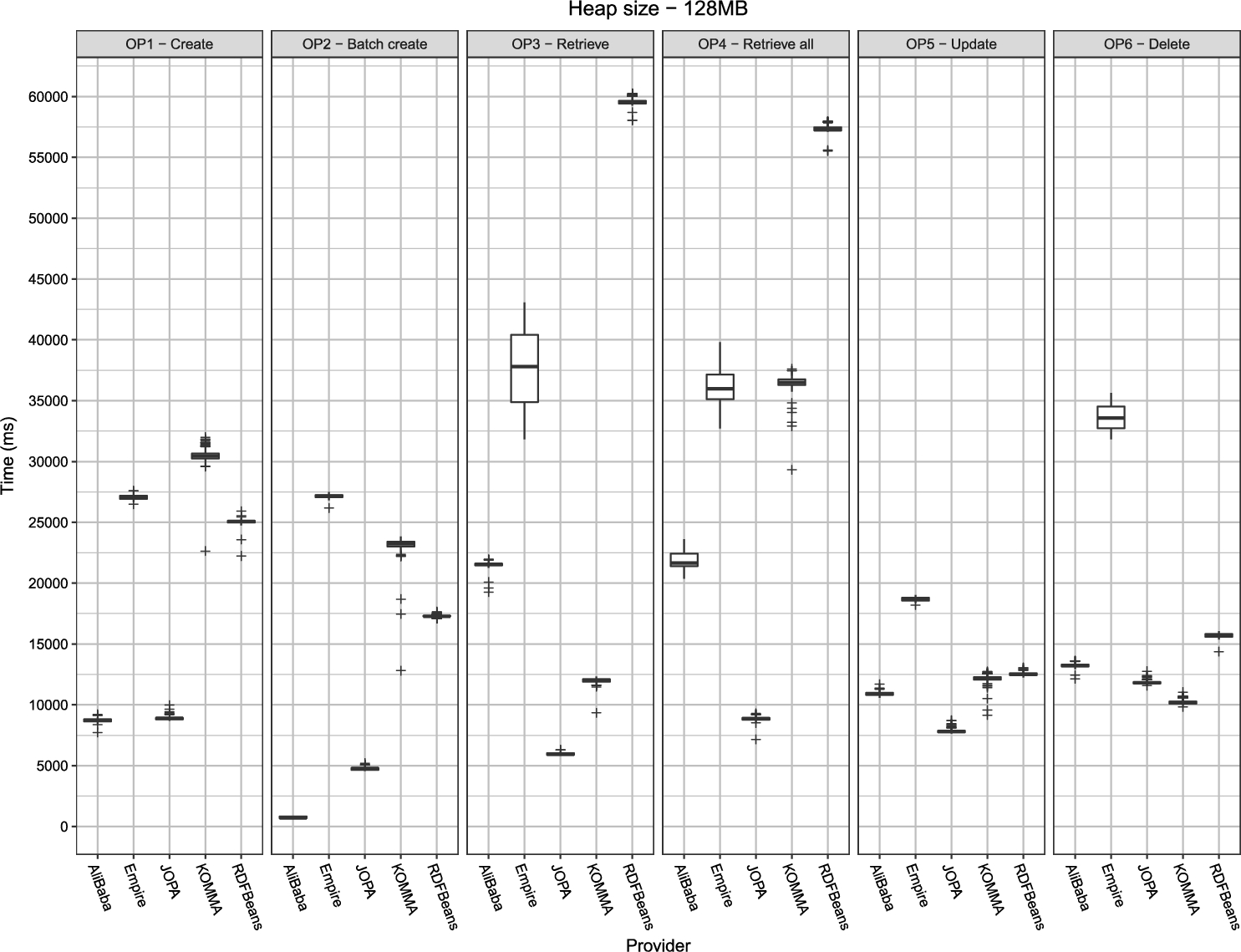
Performance of the individual libraries on a 128 MB heap. The plots are grouped by the respective operations. Lower is better.

Performance of the individual libraries on a 256 MB heap. The plots are grouped by the respective operations. Lower is better.
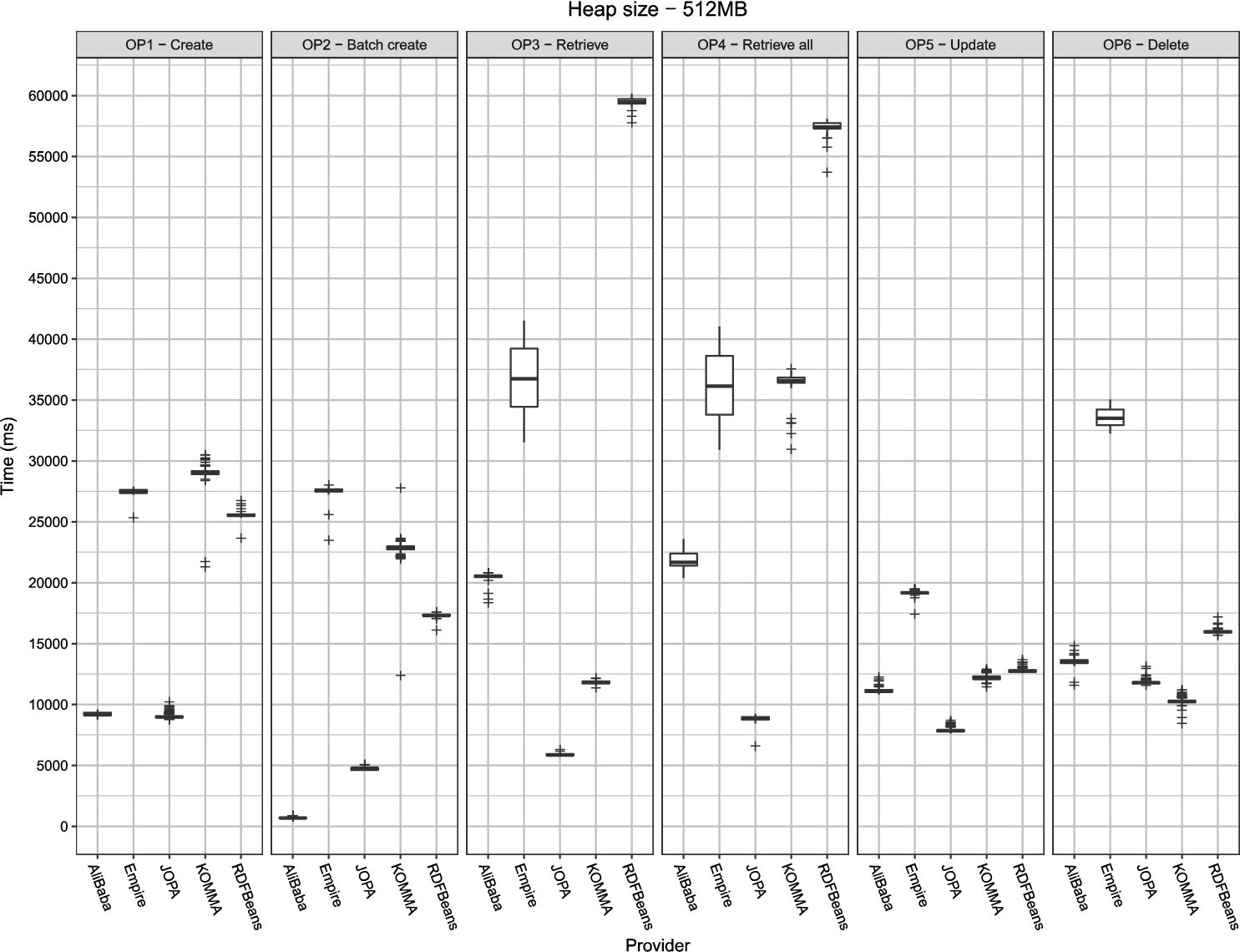
Performance of the individual libraries on a 512 MB heap. The plots are grouped by the respective operations. Lower is better.

Performance of the individual libraries on a 1 GB heap. The plots are grouped by the respective operations. Lower is better.

Scalability w.r.t. heap size. Lower is better.
Regarding the libraries’ memory scalability and efficiency, the benchmark indicates that heap size is of little concern. Most real-world applications nowadays use vastly more than 32 MB of heap. None of the evaluated solutions showed any memory-related performance issues after crossing this threshold (with the exception of a possible memory leak in Empire). However, as was stated earlier, a more realistic concurrent access-based scenario running for a longer period of time could be more revealing.
The performance benchmark was designed so that adding new libraries into the comparison would be relatively straightforward. However, attention must be paid to providing equal conditions to all compared libraries. For this reason, the evaluation provided in the paper concentrated on a single triple store implementation. The performance benchmark is published online and so are the results of the comparison presented in this work. We believe that these results might help potential users of OTM libraries in deciding which one to choose. In addition, the benchmark can be considered an example application for each of the libraries, complete with an object model declaration and the persistence layer setup and usage. Given the scarce documentation of most of the evaluated libraries, this can be a welcome benefit.
In the future, the benchmark should be extended to allow evaluating scalability w.r.t. multiple concurrent users, providing an even more realistic test case for the OTM libraries.
Results of the performance benchmark with all libraries running on a 32 MB heap. (
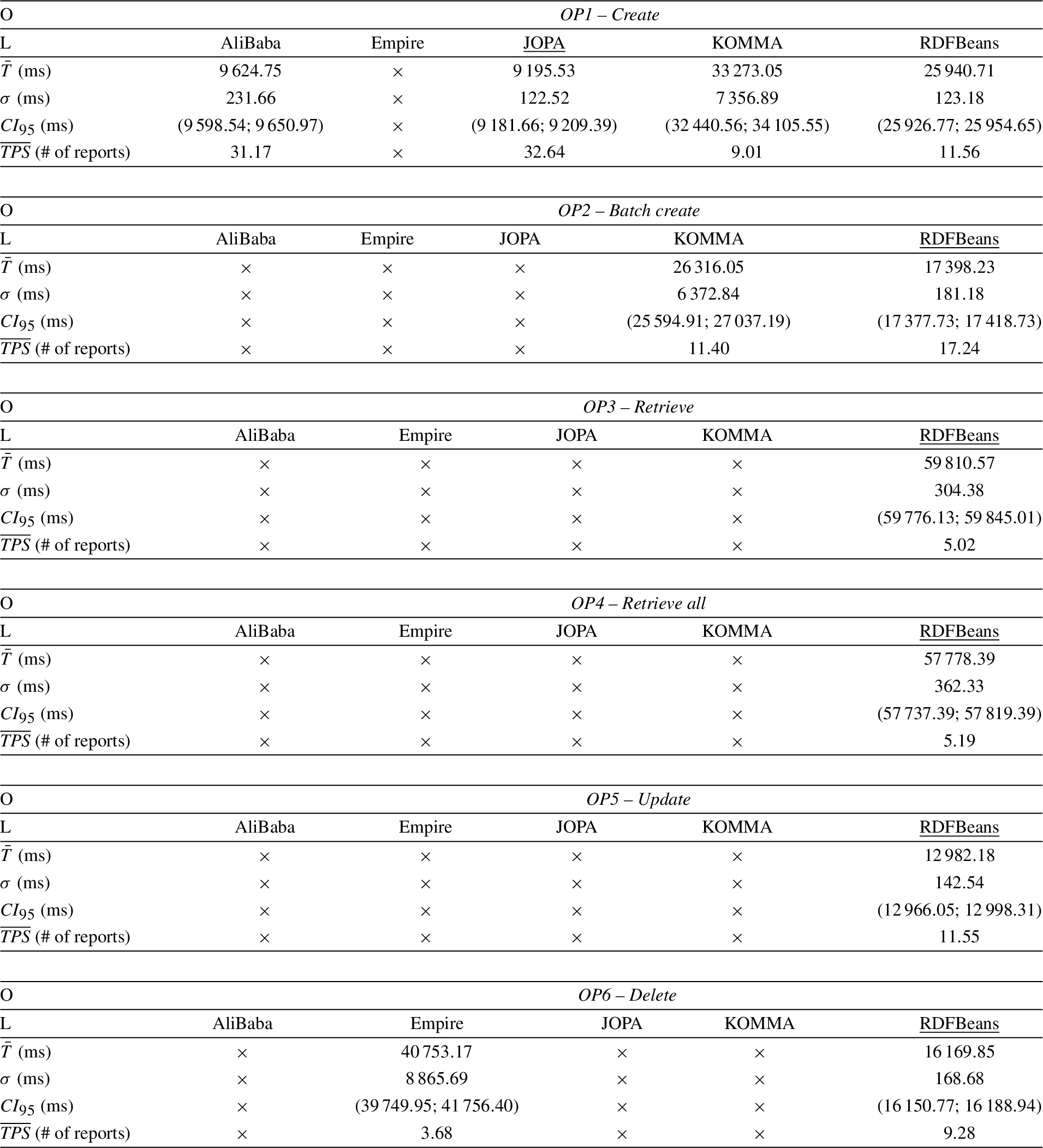
Results of the performance benchmark with all libraries running on a 64 MB heap. (

Results of the performance benchmark with all libraries running on a 128 MB heap. (

Results of the performance benchmark with all libraries running on a 256 MB heap. (

Results of the performance benchmark with all libraries running on a 512 MB heap. (

Results of the performance benchmark with all libraries running on a 1 GB heap. (

Footnotes
Acknowledgements
We would like to thank the reviewers for their detailed and insightful comments. This work was supported by grants No. GA 16-09713S Efficient Exploration of Linked Data Cloud of the Grant Agency of the Czech Republic and No.SGS16/229/OHK3/3T/13 Supporting ontological data quality in information systems of the Czech Technical University in Prague.