
Abstract
Stream reasoning is an emerging research area focused on providing continuous reasoning solutions for data streams. The exponential growth in the availability of streaming data on the Web has seriously hindered the applicability of state-of-the-art expressive reasoners, limiting their applicability to process streaming information in a scalable way. In this scenario, in order to reduce the amount of data to reason upon at each iteration, we can leverage advances in continuous query processing over Semantic Web streams. Following this principle, in previous work we have combined semantic query processing and non-monotonic reasoning over data streams in the StreamRule system. In the approach, we specifically focused on the scalability of a rule layer based on a fragment of Answer Set Programming (ASP). We recently expanded on this approach by designing an algorithm to analyze input dependency so as to enable parallel execution and combine the results. In this paper, we expand on this solution by providing i) a proof of correctness for the approach, ii) an extensive experimental evaluation for different levels of complexity of the input program, and iii) a clear characterization of all the algorithms involved in generating and splitting the graph and identifying heuristics for node duplication, as well as partitioning the reasoning process via input splitting and combining the results.
Keywords
Introduction
The variety of real-world applications in several domains, such as the Internet of Things, Social Networks and Smart Cities, requires reasoning capabilities that can handle incomplete and potentially inconsistent input streams, and extract knowledge from them to support decision making. While semantic technologies for handling data streams focus on query pattern matching and have limited support for complex reasoning capabilities, logic-based non-monotonic reasoning approaches are very expressive but can be quite costly in terms of efficiency. Expressive stream reasoning for the Semantic Web explores advances in semantic stream processing technologies for representing and processing data streams on the one hand, and non-monotonic reasoning approaches for performing complex rule-based inference on the other hand. This combination is based on the principle of having a 2-tier approach where: i) a semantic stream query processor is used to filter semantic data elements (typically RDF triples), and ii) a non-monotonic reasoner is used for computationally intensive tasks over the filtered data. Since the grounding phase in rule-based inference is responsible for the size of the program to be evaluated, such a combined approach improves the scalability of complex reasoning over Semantic Web streams by reducing the input to the non-monotonic reasoner.
Current expressive reasoning systems over RDF data streams, like ASR [12], EP-SPARQL [2], and StreamRule [24], support non-monotonic reasoning over data streams in different ways. In particular, ASR uses the DLVhex solver [14], EP-SPARQL uses ETALIS [3] which is implemented based on SWI-Prolog1
In order to support ASP solvers for reasoning about RDF data streams, a middle layer is required for transformation between data formats. For example, the StreamRule system intercepts the query results (output RDF stream) filtered by the RDF Stream Processing (RSP) engine and translates them into ASP syntax before streaming them into the ASP reasoner Clingo. Given the data transformation overhead, the performance of the reasoning subprocess should be measured by not only the processing time of the solver but also the time required for data transformation. Moreover, the reasoning component needs to return results faster than when the new input window arrives, in order to ensure the stability of the whole system. This requires optimization techniques that can further speed up the processing [19].
We address this scalability issue by an approach to parallelization based on splitting the input stream (not the logic program) that we have first introduced in [27]. We extend our preliminary work from [27] in this paper with the following key contributions:
we propose a better characterization of our formal algorithm for analyzing dependencies among input data based on the structure of a given logic program (a set of logic rules). This program is constructed under the stratified negation fragment of normal ASP [13], which ensures uniqueness of the solution; the algorithm characterizes different relationships between two predicates appearing in the input data in form of so-called input dependency graph;
we provide a process that uses this input dependency graph to construct a plan for partitioning input data; when the graph is connected, it is decomposed into subgraphs such that the number of common nodes is as small as possible; this partitioning plan will guide the reasoning process to split input data on-the-fly;
we fully implement our approach as an extension of StreamRule for validation and testing of our algorithms. With StreamRule, our reasoner does not need to deal with input data elements that are unrelated to the reasoning task since they are filtered out by the stream processor. We believe this idea of filtering massive input to related input for specific complex reasoning tasks is promising for handling scalability of stream reasoning over Semantic Web streams.
we provide a formal proof that the correctness for the approach under the stable model semantics of ASP is guaranteed;
we conduct a detailed experimental evaluation on the effectiveness of our approach via experiments with different levels of expressivity of the logic program, namely: positive rules, recursive positive rules, and stratified negation. Results show that our approach can achieve higher expressivity and higher scalability compared to state-of-the-art stream processing engines.
The remainder of this paper is organized as follows. Section 2 provides the necessary preliminaries on ASP, the StreamRule idea and conceptual framework, and introduces our motivating example. Section 3 defines in details our input dependency analysis process, including the generation of the graph, the heuristics for node duplication and the process of building a partitioning plan. In Section 4, we report on the extension of the StreamRule system with components in charge of partitioning and combining the results of the inference process, and we provide a proof of correctness of the results for the proposed method. Section 5 provides an extensive evaluation of our approach through three different experiments. A comprehensive discussion of related work is given in Section 6, followed by concluding remarks and directions for future work in Section 7.
Answer set programming
Answer Set Programming (ASP) is a declarative problem solving paradigm with a rich yet simple modeling language and high performance solving capabilities for computationally hard problems. ASP is rooted in deductive databases, logic programming and constraint solving [13]. For this paper, we focus on normal ASP with stratified negation.
Syntax
In ASP, a variable or a constant is a term2
We do not consider functional symbols, although they are currently allowed in some extensions of ASP.
Given a rule r as above, we define
Semantics
Let P be a program. The Herbrand Universe,
StreamRule is a framework that combines the latest advances in stream query processing for Semantic Web data, with non-monotonic stream reasoning. The approach is based on the assumption that not all raw data from the input stream might be relevant for the complex reasoning, and the stream query processing can help to reduce the information load over the logic-based stream reasoner. The conceptual architecture of StreamRule is shown in Fig. 1. Abstraction and filtering on raw streaming data are performed by a stream query processor using query patterns as filters. The filtered stream is processed by a data format processor and returned as input facts to a non-monotonic rule engine together with the declarative encoding of the problem at hand. The output of the rule engine, which we call solutions or answer sets, is fed into the data format processor for transformation to any other format (such as back to RDF triples) for further processing.

Conceptual architecture of StreamRule.

Sample rules for detecting events.
The main limitation of StreamRule is that the stability of the system depends on the ability of the reasoner to produce results faster than the next input window arrives. For this reason, as a first step in targeting the scalability challenge, we focused on a mechanism to enhance the processing time of the logic-based reasoner by designing a formal strategy for input dependency analysis, and using it to enable parallelism at the reasoning layer of StreamRule (the reasoner R in Fig. 1). A follow-up of the proposed approach is that we can gather information on the process at the reasoning layer that can potentially be used to dynamically adapt the parameters of the RSP engine for adaptive scalability management. We do not tackle this aspect in this paper but it is part of our ongoing work as discussed in Section 7.
For the rest of the paper, we use RSP engine to refer to the semantic stream query processing engine (e.g., C-SPARQL [5]), solver to refer to the non-monotonic rule engine (e.g., Clingo), reasoner R to refer to the subprocess in StreamRule which includes the solver and the data format processor (the dashed box in Fig. 1), and reasoner
Consider the following example: A city manager wants to know real-time events happening in the city in order to make informed decisions on traffic management, reaction to vandalism/crime, management of traffic congestions, reduction of risks for drivers/cyclists/pedestrians, and so on. To do that, he deploys an instance of the StreamRule system that integrates and filters relevant semantic streams from different sources (via RSP engine queries) and uses them to detect events of interest, such as traffic_jam and car_fire as defined in the logic program P in Listing 1. P is given as input to the solver in StreamRule, together with
As an illustrative example, assume at time t, a filtered input window (in ASP format) arrives as follows:
In order to process W faster, partitioning W randomly as in [19] could generate wrong results. For example
Input dependency analysis
In this section, we discuss the problem of analyzing the dependency of input elements in a window W for the reasoner R with respect to a set of ASP rules in a program P with stratified negation. We first introduce the concept of input dependency graph that shows how input data items in W relate to each other with respect to the logic program P (Section 3.1). Thereafter, we present a heuristic-based algorithm for creating a partitioning plan which is used to split streaming input data on the fly (Section 3.2).
Input dependency graph
In order to build an input dependency graph among data items in an input window W, we follow a 2-step approach: first, the dependency graph as defined in [10] is extended to capture additional relationships that go beyond dependencies among IDB predicates and also consider EDB predicates; second, only predicates appearing in W and their dependencies will be extracted from the graph built in the first step, in order to capture only the relationships among input data.
The concept of dependency graph has been widely used in ASP as a tool to analyze the structure of non-ground answer set programs [10,26]. It has been efficiently used in parallel instantiation algorithms that generate a much smaller ground program equivalent to a given logic program. Note that the computation of most ASP systems follows a two-phase approach: an instantiation (or grounding) phase generates a variable-free program which is then evaluated by propositional algorithms in the solving phase. The instantiation process in ASP can be expensive from a computational viewpoint and the size of the ground program has a huge effect on the performance of the solver. To address this issue, the idea of parallel grounding has been investigated, which relies on the concept of dependency graph. As defined in [10], a dependency graph G is a directed graph where nodes are IDB predicates and arcs show the relationship between a positive IDB predicate in the body with a predicate in the head of a rule. This graph divides the input program P into subprograms, according to the dependencies among the IDB predicates of P, and identifies which of them can be grounded in parallel.
However, in this paper, we are not partitioning the logic program for the grounding process. We are focusing instead on partitioning the input on-the-fly and evaluating each partition in parallel with a copy of the whole program P. Our approach intuitively generates a smaller ground program (because of the reduced input) and a smaller search space, speeding up both grounding and solving. It is to be noted that this is not the reason why we restrict the approach to consider programs with stratified negation: we restrict the expressivity of ASP programs to ensure the correctness of results of the parallel reasoning. This is not guaranteed if we have unstratified negation.

Extended dependency graph
The reasons for us to follow the input partitioning approach are: (i) input data (or input facts) have a significant impact on the reasoning performance in a streaming scenario and can affect results more than the complexity of the rules, and (ii) in the context of dynamic environments, the amount of input data at each execution varies in terms of rate and size, thus having different effects on performance. We assume that the input predicates can be either IDB or EDB predicates. Therefore, besides the dependencies among IDB predicates defined in the dependency graph, other relationships should be taken into account, such as between two EDB predicates, or between an IDB predicate and an EDB predicate.
In order to capture this aspect, we first define an extended dependency graph from the definition in [10]. This graph shows different types of dependency among predicates in P by considering: i) the (transitive) relation between two predicates (both IDB and EDB) in the body of a rule, ii) both positive and negative literals.
Let P be a logic program. The extended dependency graph of P, denoted as
Note that
Consider the program P in Listing 1. The extended dependency graph
Based on the extended dependency graph, we introduce the concept of input dependency graph of P with respect to
Given the extended dependency graph
Let P be a logic program,
Consider the extended dependency graph
Let P be a logic program and

Input dependency graph
In Definition 3, the first condition represents dependencies among all ground atoms of two different predicates in
We will conclude this section by reporting the two algorithms that generate an input dependency graph with a given extended dependency graph and a set of input predicates. The algorithm for building an extended dependency graph is not reported because it is trivial from Definition 1.
Algorithm 1 creates an input dependency graph as defined in Definition 3.
The goal of the function

Creating input dependency graph

Check dependency between 2 vertexes
In this section, we show how to use the input dependency graph for building a plan to partition streaming data on the fly. The input dependency graph is defined as an undirected graph. Therefore, we consider separately two cases based on the connectivity of the graph: not connected and connected3
An undirected graph is connected if, for every pair of vertexes, there is a path in the graph between those vertexes.
The input dependency graph
However, there are some cases where the input dependency graph

Assume that

Input dependency graph

Decomposing process
Consider the input dependency graph

Output of the decomposing process for
Implementation
The StreamRule framework extended with the partitioning process described in this paper is shown in Fig. 6. The extension consists of the partitioning handler and the combining handler in the reasoning layer. The partitioning handler splits an input window W coming from the RSP engine into several sub-windows taking into account the input dependency. The combining handler combines outputs from parallel instances of the reasoner. For the realization of the partitioning process, the analysis of input dependency is made available within the framework initially at design time. To achieve this, a logic program and a set of input predicates are given in advance in order to build an input dependency graph as defined in Definition 3. Then the graph decomposing process described in Section 3.2 builds a partitioning plan by decomposing this graph into several components, with duplicated predicates when needed.

The Extended StreamRule.
The partitioning handler. At run-time, the partitioning handler starts to split an input window on-the-fly by using the partitioning plan provided at design-time. Algorithm 4 shows the partitioning process. First, the group() method classifies items in the window by their predicates (Line 3). For each group of items, the algorithm identifies a set of communities’ IDs that groups belong to based on the partitioning plan (Line 5). Finally, it adds that group into the proper partitions corresponding to those IDs.
The combining handler. Given a program P under stratified negation and an input window W, the answers provided by R over P and W (notated as

Partitioning method
In order to ensure our approach provides all and only the expected results when the input is split and processed in parallel, in this section we provide a sketch of the correctness proof.
Given
We introduce some notations that are used in the proof:
a is created by firing one rule r in P
a is created by firing two rules
If
Else
Similarly, when a is created by firing k rules
Suppose If a is created by firing a set of positive rules If a is created by firing a set of rules (e.g.,
Given
When
Suppose
□
We evaluate the performance of our optimized reasoner
Experiment 1: Positive rules
In this experiment, we select C_SPARQL as a comparable system to handle positive rules. We do not consider CQELS [22] because its processing mode does not allow certain positive rules to be expressed: both

Rules translated from query Q1 in CityBench.
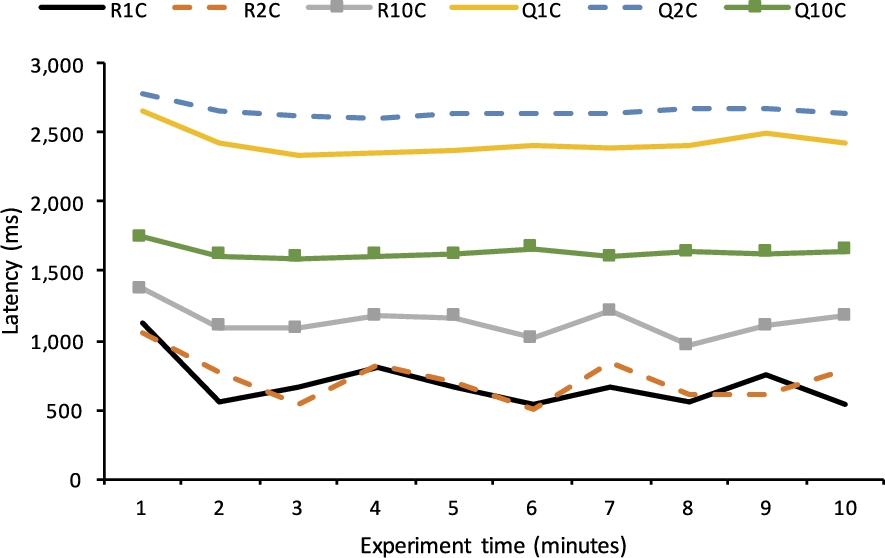
Latency (
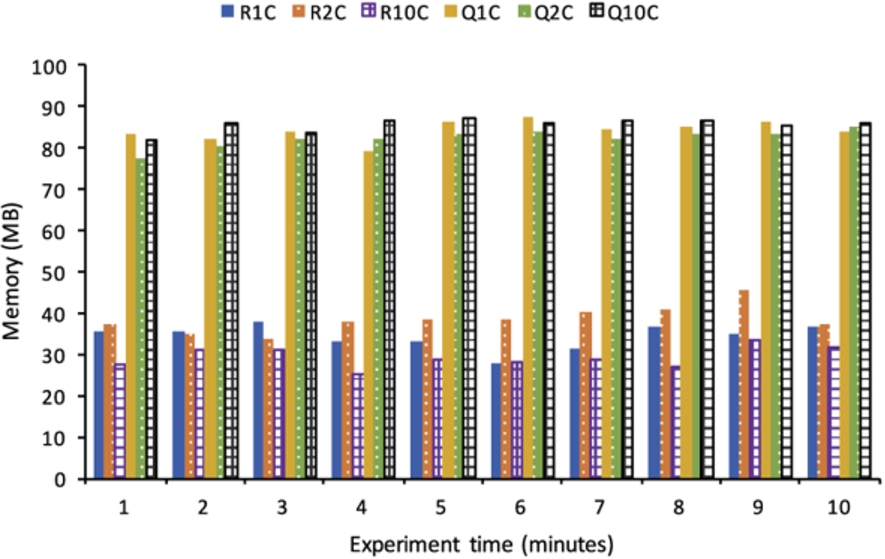
Memory consumption (

Latency (

Memory consumption (
For the experiment with recursive positive rules that are not supported by C_SPARQL, we compare

A set of ASP rules inspired from LUBM.
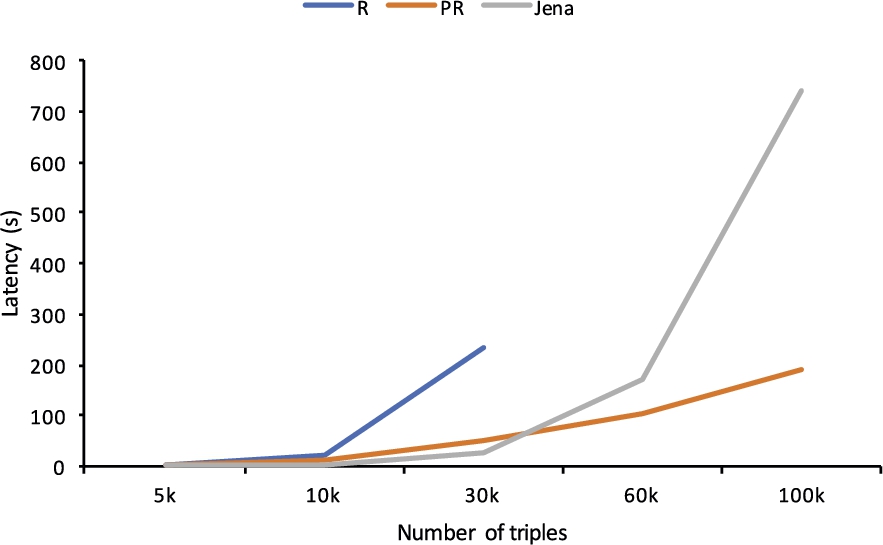
Latency (recursive rules with static setting).

Memory consumption (recursive rules with static setting).
Static setting. In this setting, we evaluate
Streaming setting. In the streaming setting, we trigger

Latency (recursive rules with streaming setting).
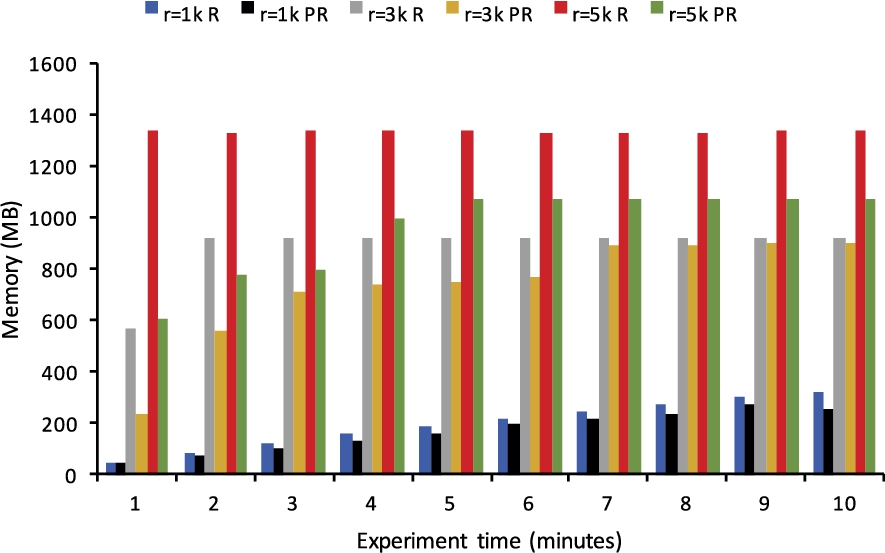
Memory consumption (recursive rules with streaming setting).
We now focus on a rule set which has stratified negations. We modify rules

Negation-as-failure rules.
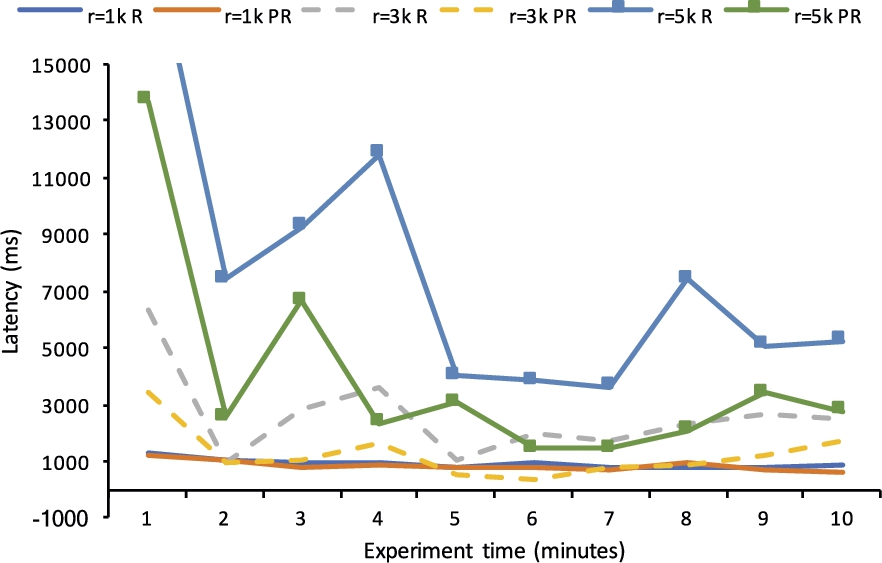
Latency (recursive and stratified negation rules).

Memory consumption (recursive and stratified negation rules).
Parallel strategies were important features of database technology in the nineties in order to speed up the execution of complex queries [9]. In Semantic Web, the parallelism in reasoning has been studied in [15,25,28–30] where a set of machines is assigned a partition of the parallel computation. [15] presents a distributed ontology reasoning and querying system which employs Distributed Hash Table method to organize the instance data. [25] has a distributed process over large amounts of RDF data using a proposed divide-conquer-swap strategy, which extends the traditional approach of divide-and-conquer with an iterative procedure whose result converges towards completeness over time. Similarly, [30] proposes a technique for materializing the closure of an RDF graph based on MapReduce [11]. The authors in [29] also use MapReduce to explore the reasoning in the form of defeasible logic. They restrict this logic to the argument defeasible logic. Afterwards, they apply a similar approach to systems based on the well-founded semantics [28]. While the works in [15,25,30] focus on monotonic reasoning, [28,29] examine non-monotonic reasoning over massive data. However, these attempts do not consider the streaming setting and do not rely on the stable model semantics.
In ASP, several works about parallel techniques for the evaluation of a logic program have been proposed [4,10,17,20,26], focusing on both phases of the ASP computation, namely grounding and solving. Concerning the parallelization of the grounding phase, the work in [4] is applicable only to a subset of the program rules. Therefore, in general, this work is unable to exploit parallelism fruitfully in the case of programs with a small number of rules. [10] explores some structural properties of the input program via the defined dependency graph in order to detect subprograms that can be evaluated in parallel. [26] extends this work with parallelism in three different steps of the grounding process: components, rules, and single rule level. The first level divides the input program into subprograms, according to the dependency graph among IDB predicates of that program. The second level allows for concurrently evaluating the rules within each subprogram. The third level partitions the extension of a single rule literal into a number of subsets. This step is especially efficient when the input program consists of few rules and two first levels have no effects on the evaluation of the program. For the solving step which is carried out after the grounding step, [20] proposes a generic approach to distribute the searching space in order to find the answer sets, which permits exploitation of the increasing availability of clustered and/or multiprocessor machines. [17] introduces a conflict-driven algorithm to compute the answer sets based on constraint processing and satisfiability checking. In short, [4,10,26] focus on parallel instantiation by splitting a logic program in order to obtain a smaller ground program, [17,20] compute the answer sets from that ground program in parallel. These approaches have been implemented in state-of-the-art ASP solvers such as Clingo and DLV. In this paper, we are not partitioning the logic program. We are focusing instead on partitioning the input and evaluating each partition on a different copy of the whole program with the intuition that this approach is data-driven and can result in a faster run-time analysis since it does not consider the whole program in any case, but only the rules that are triggered based on the (partitioned) streaming input.
A different approach to enhance the scalability of expressive stream reasoning is based on incremental methods. There are two reasoners proposed recently based on the LARS framework [7], namely Ticker [8] and Laser [6]. Ticker translates the plain LARS (more specifically, a fragment of LARS) to ASP and supports two reasoning strategies: one utilizes Clingo with a static ASP encoding and the other applies truth maintenance techniques to adjust models incrementally. Similarly, Laser also relies on incremental model update to avoid unnecessary re-computations by annotating formula with two time markers. However, this engine restricts its logic programs to a stratified tractable fragment of LARS to ensure the uniqueness of models.
Conclusion and future work
Scalability is a key challenge for the applicability of reasoning techniques to rapidly changing information. In this paper, we consider the challenge of creating new semantic knowledge from diverse and dynamic data for complex problem solving, and doing that in a scalable way. To address this challenge, we focus on an approach that leverages semantic technologies to integrate and pre-process RDF streams on one side, and expressive inference enhanced with parallel execution on the other side.
Building upon previous work, and following up on our initial investigation of the trade-off between scalability and expressivity of rule-based reasoning over streaming RDF data, in this paper we provided a clear characterization and formal definition of our approach to parallelization of stream reasoning by input dependency analysis (both at the predicate and at the atom level) that was first introduced in [27]. We implemented the proposed approach as an extension of the StreamRule reasoner and provided a proof of correctness under the assumption that no recursion through negation is present in the rules, thus guaranteeing the uniqueness of the solution. Furthermore, we considered the different levels of expressivity that are supported by the reasoning layer of our prototype implementation and conducted a detailed experimental evaluation by comparison with different systems based on their expressivity. This evaluation indicates that our reasoner not only has a competitive performance in comparison with existing systems but it also supports higher expressivity of reasoning tasks. This work is also a demonstration that expressive reasoning is possible also in streaming environments, and it paves the way for investigating feasible solutions in this space.
Our performance evaluation demonstrates that the combination of RDF Stream Processing and ASP-based reasoning for heterogeneous and highly dynamic data is possible and promising, even when recursion and default negation are used, and that the performance does not degrade for simpler tasks, thus being comparable with alternative systems.
Stream reasoning is a new and active area of research within Semantic Web, Knowledge Representation and Reasoning community and there are many open questions and interesting directions for investigation that we are currently working on as next steps, we discuss a few in the remainder of this section.
In order to avail the full power of ASP-based reasoning, the ability to generate multiple solutions is key, but this requires a deeper investigation of how correctness can be maintained when partitioning and merging results in the presence of multiple answer sets. This is a key step we are currently exploring to exploit the full expressivity of ASP-based reasoning for semantic streams.
Another direction for investigation is related to the definition of multiple heuristics for splitting the graph and duplicating nodes. Our current solution is based on finding and merging cliques using a threshold score on the ratio between common and different vertexes, to decide where to split and duplicate. Different heuristics that also consider the size of the cliques and that aim at load balancing would contribute to the overall performance of the system. Leveraging information about the distribution of ground atoms across the different predicates could also be a good information to design better heuristics and for load balancing. This could also inform the current partitioning function so that the splitting process does not rely on predicate-level analysis only. We believe this can have an important effect on computation time that needs to be further investigated.
Despite incremental evaluation and parallel execution are different ways of tackling the scalability issue, we believe a comparison with these systems in terms of expressivity vs. scalability trade-off will enable us to share important insights for future work and advances in the Stream Reasoning field. Therefore, another part of our ongoing work is to perform an extensive evaluation aimed at comparing our reasoner with Ticker and Laser. To do so, we are currently building a benchmark for ASP-based stream reasoning which builds upon state-of-the-art static ASP benchmarking [18] and RDF stream processing benchmarks (e.g., [1,23]). Our resulting benchmark is designed to cover various expressivity levels of complex reasoning and will support configurable parameters (e.g., input streaming rate, window size) for evaluating the behavior of the stream reasoners.
Footnotes
Acknowledgements
This publication has emanated from research conducted with the financial support of Science Foundation Ireland (SFI) under Grant Number SFI/12/RC/2289, co-funded by the European Regional Development Fund and partially funded by SFI under grant no. SFI/16/RC/3918.