
Abstract
Novel Internet of Things (IoT) applications and services rely on an intelligent understanding of the environment leveraging data gathered via heterogeneous sensors and micro-devices. Though increasingly effective, Machine Learning (ML) techniques generally do not go beyond classification of events with opaque labels, lacking machine-understandable representation and explanation of taxonomies. This paper proposes a framework for semantic-enhanced data mining on sensor streams, amenable to resource-constrained pervasive contexts. It merges an ontology-based characterization of data distributions with non-standard reasoning for a fine-grained event detection. The typical classification problem of ML is treated as a resource discovery by exploiting semantic matchmaking. Outputs of classification are endowed with computer-processable descriptions in standard Semantic Web languages, while explanation of matchmaking outcomes motivates confidence on results. A case study on road and traffic analysis has allowed to validate the proposal and achieve an assessment with respect to state-of-the-art ML algorithms.
Introduction
The Internet of Things (IoT) paradigm is emerging through the widespread adoption of sensing micro- and nano-devices dipped in everyday environments and interconnected in low-power, lossy networks. The amount and consistency of pervasive devices increases daily and then the rate of raw data available for processing and analysis grows up exponentially. More than ever, effective methods are needed to treat data streams with the final goal of giving a meaningful interpretation of retrieved information.
The Big Data label has been coined to denote the research and development of data mining techniques and management infrastructures to deal with “volume, velocity, variety and veracity” issues [33] emerging when very large quantities of information materialize and need to be manipulated. Hence, Machine Learning (ML) is adopted to classify raw data and make predictions oriented to decision support and automation. Progress in ML algorithms and optimization goes hand in hand with advances in pervasive technologies and Web-scale data management architectures, so that undeniable benefits have been produced in data analysis. Nevertheless, some non-negligible weaknesses are still evident with respect to the increasing complexity and heterogeneity of pervasive computing scenarios. Particularly, the lack of machine-understandable characterization of outputs is a prominent limit of state-of-the-art ML techniques for a possible exploitation in fully autonomic application scenarios.
This paper proposes a framework named MAFALDA1
The name should give a retcon with the well-known Quino comic strip to hint at the shrewd gaze of Mafalda character with her investigating attitude to life and her curiosity about the world.
The proposal leverages both general theory and technologies of Pervasive Knowledge-Based Systems (PKBS), intended as KBS whose individuals (assertional knowledge) are physically tied to objects disseminated in a given environment, without centralized coordination. Each annotation refers to an ontology providing the conceptualization and vocabulary for the particular knowledge domain and an advanced matchmaking can operate on the above metadata stored in sensing and capturing devices. No fixed knowledge bases are needed. In other words, inference tasks are distributed among devices which provide minimal computational capabilities. Stream reasoning techniques provide the groundwork to harness the flow of annotation updates inferred from low-level data, in order to enable proper context-aware capabilities. Along this vision, innovative analysis methods applied to data extracted by inexpensive off-the-shelf sensor devices can provide useful results in event recognition without requiring large computational resources: limits of capturing hardware could be counterbalanced by novel software-side data interpretation approaches.
MAFALDA has been tested and validated in a case study for road and traffic monitoring on a real data set collected for experiments. Results have been compared to classic ML algorithms in order to evaluate the provided performances. The experimental test campaign allows a preliminary assessment of both feasibility and sustainability of the proposed approach.
The remainder of the paper is as follows. Section 2 outlines motivation for the proposal, before discussing in Section 3 both background and state of the art on semantic data mining and ML for the IoT. The MAFALDA framework is presented in Section 4, while Section 5 and Section 6 report on the case study and the experiments, respectively. Conclusion finally closes the paper.
Motivation for the work derives from the evidence of current limitations featuring the typical IoT scenarios. There, information is gathered through micro-devices attached to common items or deployed in given environments and interconnected wirelessly. Basically, due to their small size, such objects have minimal processing capabilities, small storage and low-throughput communication capabilities. They continuously produce raw data whose volume requires to be processed by advanced remote infrastructures. Classical ML techniques have been largely used for that, but often representations of detected events are not completely manageable in practical applications: this is mostly due to the difficulty of making descriptions interoperable with respect to shared vocabularies. In addition, usually ML solutions are very much tailored (i.e., trained) to a specific classification problem. In spite of increasing device pervasiveness (miniaturization) and connectivity (interconnection capability), data streams produced at the edge of the network cannot be fully analyzed locally yet. Commonly adopted data mining techniques have two main drawbacks: i) they basically carry out no more than a classification task and ii) their precision increases if they are applied on very big data amounts, so on-line analyses hardly achieve high performance on typical IoT devices, due to computational and storage requirements. These factors still prevent the possibility of actualizing thinking things, able to make decisions and take actions locally after the sensing stage.
IoT relevance could be enhanced by annotating real-world objects, the data they gather and the environments they are dipped in, with concise, structured and semantically rich descriptions. The combination of the IoT with Semantic Web models and technologies is bringing about the so-called Semantic Web of Things (SWoT) vision, introduced in [49] and developed, e.g., in [16,41,46,59]. This paradigm aims to enable novel classes of intelligent applications and services grounded on Knowledge Representation (KR), exploiting semantic-based automatic inferences to derive implicit information from an explicit event and context detection [48]. By associating a machine-understandable, structured description in standard Semantic Web languages, each classification output could have an unambiguous meaning. Furthermore, semantic-based explanation capabilities allow increasing confidence in system outcomes. If pervasive micro-devices are capable of efficient on-board processing on locally retrieved data, they can describe themselves and the context where they are located toward external devices and applications. This enhances interoperability and flexibility and enables autonomicity of pervasive knowledge-based systems, not yet allowed by typical IoT infrastructures.
Two important consequences ensue. First of all, human-computer interaction could be improved, by reducing the user effort required to benefit from computing systems. In classical IoT paradigms, a user explicitly interacts with one device at a time to perform a task. On the contrary, user agents – running on mobile computing devices – should be able to interact simultaneously with many micro-components, providing users with context-aware personalized task and decision support. Secondly, even if ML techniques, algorithms and tools have enabled novel classes of analyses (particularly useful in the Big Data IoT perspective), the exploitation of logic-based approximate discovery strategies as proposed in the present work compensates possible faults in data capture, device volatility and unreliability of wireless communications. This supports novel, resilient and versatile IoT solutions.
Background
Hereafter main notions on Machine Learning and Description Logics are briefly recalled in order to make the paper self-contained and easily understandable. Then, most relevant related work is surveyed.
Basics of machine learning
Machine Learning (ML) [58] is a branch of Artificial Intelligence which aims to build systems capable of learning from past experience. ML algorithms and approaches are usually data-driven, inductive and general-purpose in nature; they are adopted to make predictions and/or decisions in some class of tasks, e.g., spam filtering, handwriting recognition or activity detection. Basically, ML problems can be grouped in three categories: classification,2
It should not be mistaken for the same-name problem in ontology management, consisting of finding all the implicit hierarchical relationships among concepts in a taxonomy.
The implementation of a ML system typically includes training and testing stages, respectively devoted to build a model of the particular problem inductively from training data and to system validation. Evaluation of classification performance is based on considering one of the output classes as the positive class and defining:
true positives (
false positives (
true negatives (
false negatives (
The following performance metrics for binary classification are often adopted:
Precision (a.k.a. positive predictive value), defined as Recall (a.k.a. sensitivity), defined as F-Score, defined as the harmonic mean of precision and recall: Accuracy, defined as
Multiclass generalizations of the above formulas [52] have been also adopted in this paper.
Each available dataset to be classified is split in a training set for model building and a test set for validation. There exist several approaches for properly selecting training and test components. Among others, in k-fold cross-validation, the dataset is partitioned in k subsets of equal size; one of them is used for testing and the remaining
As detailed in the further Section 6, the performance of classification in the approach proposed here has been compared to the following popular ML techniques:
C4.5 decision tree [43]: it adopts a greedy top-down approach for building a classification tree, starting from the root node. At each node, the information gain for each attribute is calculated and the attribute with the highest score is selected. Functional Tree [13,26]: a classification tree with logistic regression functions in the inner nodes and leaves. The algorithm can deal with binary and multiclass target variables, numeric and nominal attributes, and missing values. Random Tree [40]: it combines two ML algorithms, namely model trees and random forests, in order to achieve both robustness and scalability. Model trees are decision trees where every leaf holds a linear model optimized for the local subspace of that leaf. Random forests follow an ensemble learning approach which builds several decision trees and picks the mode of their outputs. K-Nearest Neighbors, KNN [2], is an instance-based learning algorithm. It locates the k instances nearest to the input one and determines its class by identifying the single most frequent class label. It is generally considered not tolerant to noise and missing values. Nevertheless, KNN is highly accurate, insensitive to outliers and it works well with both nominal and numerical features. Multilayer Perceptron [22]: a feedforward Artificial Neural Network (ANN), consisting of at least three layers of neurons with a nonlinear activation function: one for inputs, one for outputs and one or more hidden layers. Training is carried out through backpropagation. The Deep Neural Network (DNN) name characterizes ANNs having more than one hidden layer and using gradient descent methods for error reduction in backpropagation.
Description Logics – also known as Terminological languages, Concept languages – are a family of logic languages for Knowledge Representation in a decidable fragment of the First Order Logic [4]. Basic DL syntax elements are:
concepts (a.k.a. class) names, standing for sets of objects, e.g., vehicle, road, acceleration;
roles (a.k.a. object property) names, linking pairs of objects in different concepts, like hasTire, hasTraffic;
individuals (a.k.a. instances), special named elements belonging to concepts, e.g., Peugeot_207, Highway_A14.
A semantic interpretation
Syntax elements can be combined using constructors to build concept and role expressions. Each DL has a different set of constructors. Concept expressions can be used in inclusion and definition axioms, which model knowledge elicited for a given domain by restricting possible interpretations. A set of such axioms is called Terminological Box (TBox), a.k.a. ontology. Semantics of inclusions and definitions is based on set containment: an interpretation
Adding new constructors makes DL languages more expressive. Nevertheless, this usually leads to a growth in computational complexity of inference services [6]. This paper refers specifically to the Attributive Language with unqualified Number restrictions (
OWL 2 Web Ontology Language Document Overview (Second Edition), W3C Recommendation 11 December 2012,
Syntax and semantics of
The semantic-enhanced machine learning approach proposed here is basically general-purpose, but it has been particularly devised for the Internet of Things. In IoT scenarios, smart interconnected objects gather environmental data samples, useful to identify and predict many real-world phenomena which exhibit patterns: early research has shown state-of-the-art ML is effective in the domain of ubiquitous sensor networks [35], although carried experiments involved a problem of limited size and complexity and a fixed server (and then a centralized architecture) has been used to store and analyze sensor data. Extracting high-level information from the raw data captured by sensors and representing it in machine-understandable languages has several interesting applications [21,34]. The paper [14] surveyed requirements, solutions and challenges in the area of information abstraction and presented an efficient workflow based on the current state of the art.
Semantic Web research has addressed the task of describing sensor and data features through ontologies; relevant collections are on the following ontology catalogues: Linked Open Vocabularies (LOV) [54], LOV for Internet of Things (LOV4IoT),4
Semantic Sensor Network Ontology, W3C Recommendation 19 October 2017, https://www.w3.org/TR/2017/REC-vocab-ssn-20171019.
Unfortunately, the above solutions only allow elementary queries in SPARQL fragments on RDF annotations. More effective techniques such as ontology-based Complex Event Processing (CEP) [7] exploit a shared domain conceptualization to define events and actions to be run on an event processing engine. Also the ENVISION [29] and ETALIS [3] projects combine CEP with semantic technologies to perform Semantic Event Processing from different sources: context and background knowledge are represented in RDF, while SPARQL queries are exploited to identify complex event patterns from incoming facts populating a knowledge base. The ACEIS CEP middleware [15] processes urban data streams in smart city applications: a semantic information model has been designed to represent complex event services and it is leveraged for discovery and integration of sensor data streams via SPARQL queries. Nevertheless, a fundamental limitation of CEP approaches is that pattern detection relies on rigid Boolean outcomes of defined queries and rules, whereas a more flexible approximated match could better support classification. In fact, the adoption of KR techniques on large amounts of instances is useful to annotate raw data and produce high-level descriptions in a KB. This is suitable for advanced reasoning, aiming to improve standard data mining and ML algorithms [44]. In [32] a post-processing of ML operations – based on ontology consistency check – aims to improve results of association rule mining. Semantically inconsistent associations were pruned and filtered out, leveraging logic reasoning. The framework proposed in [60] combines ontology-based Linked Open Data (LOD) sources as background knowledge with dynamic sensor and social data, in order to produce dynamic feature vectors for model training. Similarly, [59] exploits ontology-based data annotation to perform classification and resource retrieval. A LOD-inspired approach and an architecture are presented in [18] to define, share and retrieve rules for processing sensor data in the IoT. While the above works define from scratch complete semantic IoT platforms, the present paper focuses on a specific ML approach, which could be integrated in larger frameworks. Furthermore, the above proposals exploit SPARQL queries for reasoning and implementing rules on annotated data, while the approach proposed here aims to provide more thorough and robust answers, by supporting also non-exact matches via non-standard DL inferences. Extensions to standard reasoning algorithms, supporting uncertainty and time relationships, have been also proved as effective in tasks such as activity recognition [36].
Some of the most successful ML methods, such as ANN and deep learning techniques, suffer from opaqueness of models, which cannot be interpreted by human experts and therefore cannot explain reasons for the outcomes they provide. This is a serious issue for ML adoption in all those sectors which require accountability of decisions and robustness of outputs against accidental or adversarial input manipulation [24,37]. Research efforts to build decipherable results of ML techniques and systems are therefore more and more expanding. The approach adopted in this paper could be an example of that, as it combines semantic similarity measures and classical (frequentist) data stream mining [25]. Another conceptually easy approach is to exploit ensemble learning, by combining multiple low-dimensional submodels, where each individual submodel is simple enough to be verifiable by domain experts [37]. In [27] Bayesian learning is used to generate lists of rules in the if …then form, which can provide readable reasons for their predictions. That method is competitive with state-of-the-art techniques in stroke prediction tasks over large datasets, although training time appears as rather long for IoT scenarios. The regression tool in [30] is able to translate automatically components of the model to natural-language descriptions of patterns in the data. It is based on a compositional grammar defined over a space of Gaussian regression models, which is searched greedily using marginal likelihood and the Bayesian Information Criterion (BIC). The approach supports variable dimensionality (number of features) in each regression model, thus allowing the selection of the desired tradeoff between accuracy and ease of interpretation.
Semantic-enhanced ML methods can achieve the same goals through formal, logic-based descriptions of models and outputs in order to develop explanatory functionalities, so increasing users’ trust. Furthermore, they can be integrated in larger cognitive systems, where models and predictions are used for automated reasoning. Semantic data mining refers to data mining tasks which systematically incorporate domain knowledge in the process. The framework proposed here belongs to this research area, which has been surveyed in [10,45] and includes ontology-based rule mining, classification and clustering. Ontologies are useful to bridge the semantic gap between raw data and applications, as well as to provide data mining algorithms with prior knowledge to guide the mining process or reduce the search space. They can be successfully used in all steps of a typical data mining workflow. In Ontology-Based Information Extraction (OBIE) [57], ontologies are also exploited to annotate the output of data mining, and this aspect is also adopted in our approach. In [53], the authors propose to use wireless sensor networks and ontologies to represent and infer knowledge about traffic conditions. Raw data are classified through an ANN and mapped to ontology classes for performing rule-based reasoning. In [8], an unsupervised model is used for classifying Web Service datatypes in a large number of ontology classes, by adopting an extended ANN. Also in that case, however, mining is exploited only to map data to a single class.
The exploitation of matchmaking through non-standard inferences enables a fine-grained event detection by treating the ML classification task as a resource discovery problem. Promising semantic-based approaches also include fuzzy DL learning [28], concept algebra [56] and tensor networks based on Real Logic [51]. While their prediction performance appears good, computational efficiency must be still evaluated completely and accurately, before considering them suitable for IoT scenarios.
Summarizing, most semantic-enhanced data mining and machine learning approaches currently support meaningful data description and interpretation, but provide limited reasoning capabilities and have complex architectures. Conversely, classical ML algorithms can achieve high prediction performance, but their models and outcomes often have poor explainability. This paper proposes an approach aiming to combine the benefits of Semantic Web technologies with state-of-the-art learning effectiveness, particularly for IoT data stream mining.
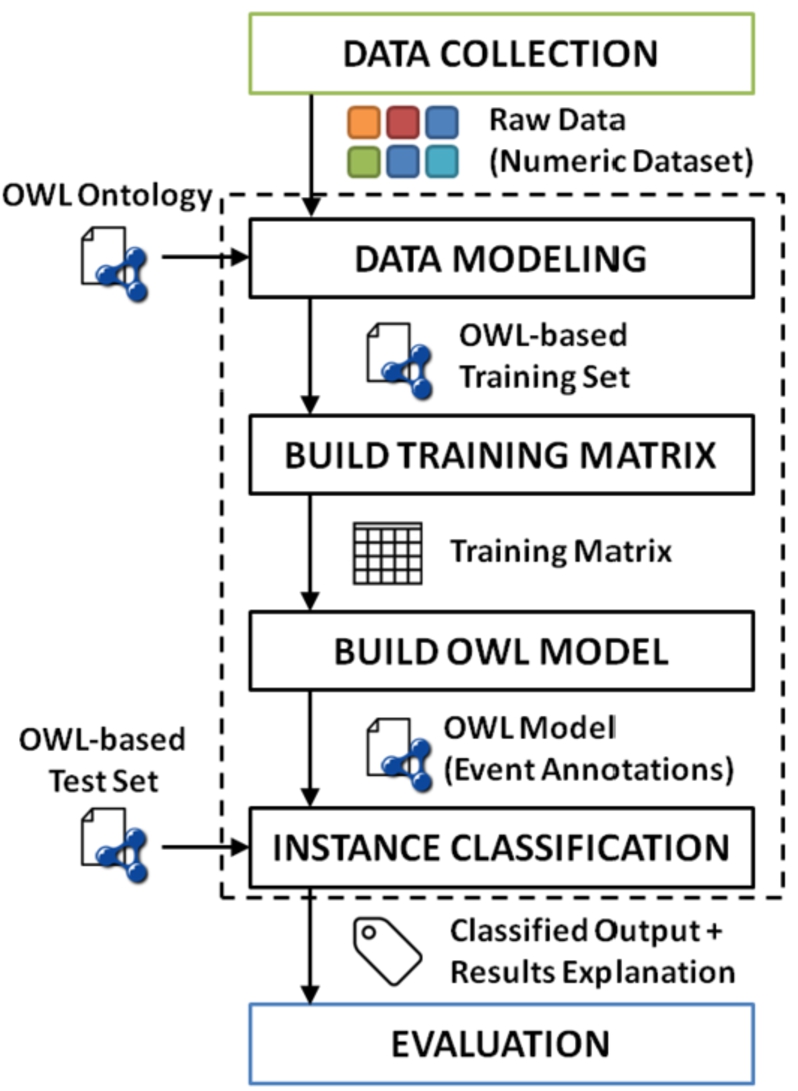
MAFALDA preserves the classical data mining and machine learning workflow: data collection and cleansing, model training, validation and system usage. Nevertheless, as reported in Fig. 1, semantic enhancements grounded on DLs change the way each step is performed. Details about the devised methodology are outlined hereafter.
Framework architecture.

Class hierarchy in the domain ontology for the case study.
Data range modeling.
The overall workflow starts with raw data gathered e.g., by sensors dipped in a given environment extracting several different parameters, a.k.a. features. In order to support semantic-based data annotation and interpretation, an ontology
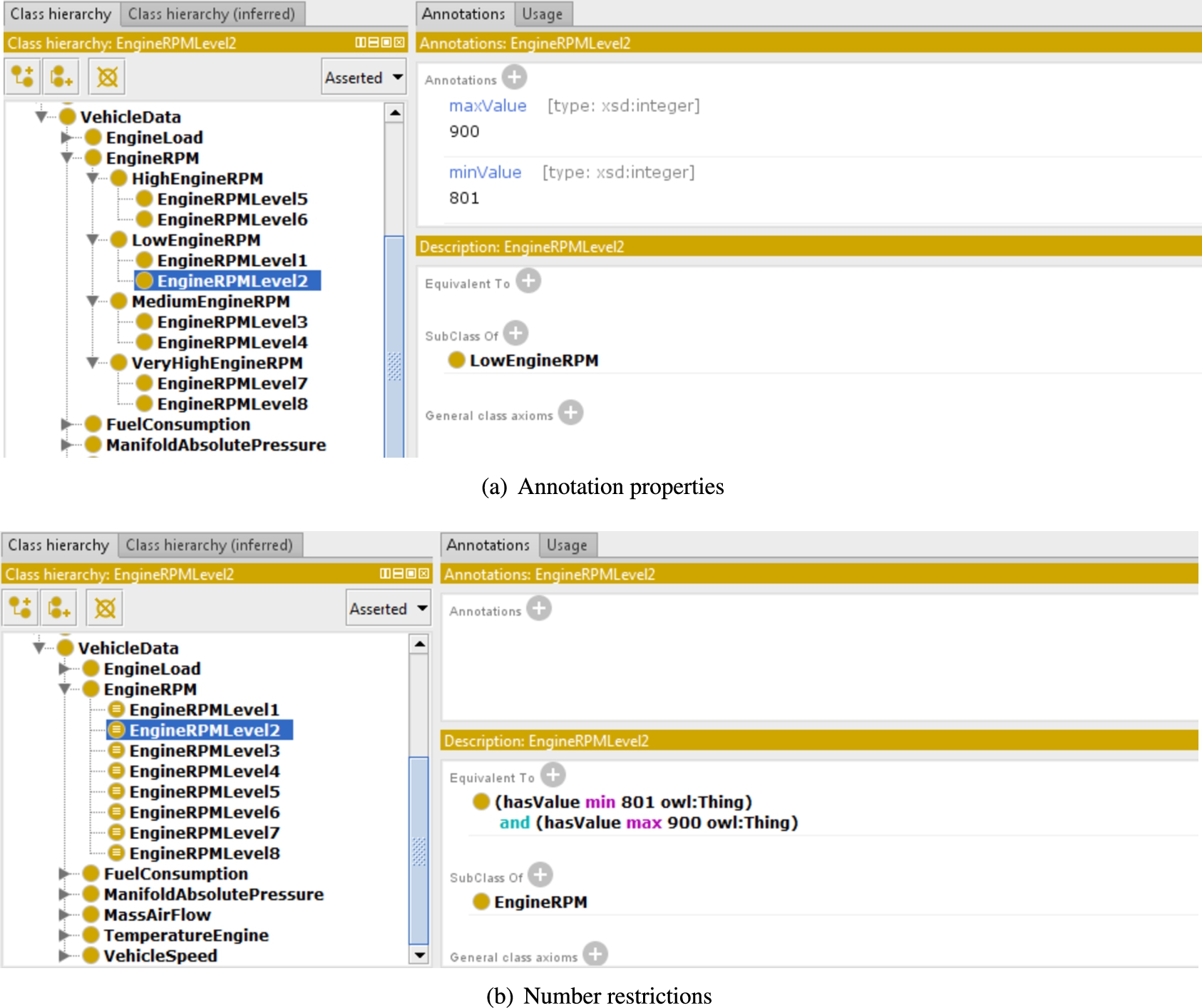
As an example, Fig. 2 shows the class hierarchy of the domain ontology modeled for the case study in Section 5. Two different modeling approaches have been investigated to represent data ranges for measured parameters in the knowledge base.8
Both the proposed OWL ontologies are available in the project repository:
According to the proposed modeling, a generic data corpus can be translated to an OWL-based dataset, where each record corresponds to an instance of a proper KB. Regardless of the particular ontology modeling, each individual also includes a set of annotation properties setting up the real output class for each observable event. As shown in Fig. 4, the annotation property name reflects the output attribute, while the annotation value refers to the output concepts associated during the dataset building. In particular, the Traffic Danger ontology [55] has been exploited in the road monitoring case study described in Section 5 to model traffic congestion and road surface conditions, while novel classes have been defined to represent the different driving styles. In this way, both a single event annotation and the overall dataset – described w.r.t. well-known vocabularies – can be also: (i) published on the Web following the Linked Data guidelines [20]; (ii) shared with other users or IoT devices on the same network; (iii) reused locally for further reasoning and processing tasks. The modeling effort is basically a study and manual design procedure. As per many engineering activities, it could be supported by software tools for computer-aided design. Protégé by Stanford University9
In this phase training data are automatically generated, able to define the model used afterward by the ML algorithm for predictions on test data. In the proposed approach, there is a semantic annotation for each possible output class, connoting the observed event/phenomenon according to input data. In these terms, the framework presents a twofold modeling effort: the Knowledge Base definition (which is basically human-driven, manually pursued) and the training set generation (automatically carried out after the first step). The annotations will be expressed in Concept Components according to the following recursive definition:
(Concept Component).
Let C be an
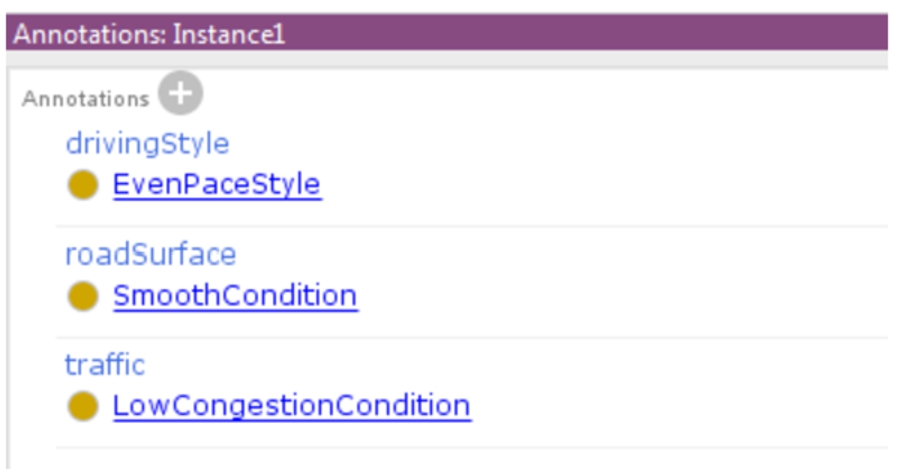
Example of output class annotation.
The training phase is carried out on a set S of n training samples, each with at most m features. Let us suppose w distinct outputs exist in the training set and the system must be trained to recognize them. Each feature value is mapped to the most specific corresponding concept in the reference ontology
Samples are processed sequentially by Algorithm 1 in order to build the so-called Training Matrix

Creation of the Training Matrix
Customized thresholds allow to focus sensitivity on the features with highest variance and/or the outputs most difficult to predict. In the road monitoring case study described in Section 5, the threshold value has been calculated in a way not disadvantaging sensors with lower sampling rate or events which occur less often in the training dataset. In detail, each element
The adopted formula is:
Therefore, this training approach produces a KB with conceptual knowledge (the TBox) modeled – as said – by human experts and factual knowledge (the ABox) created automatically from the available data stream, with instances representing the events the system is able to recognize.
This task refers to the typical ML problem of assigning each input instance to a possible output class, based on its features. The classification exploits a semantic matchmaking process based on Concept Contraction and Concept Abduction non-standard inference services [50].
Given an ontology
MAFALDA first labels instance elements to be classified with respect to the reference ontology, like in Section 4.1. Their conjunction is then taken as annotation of the instance itself. A linear combination of the penalty values obtained from matchmaking yields the semantic distance between the input instance and each event description
After the penalty scores calculation, the predicted/recognized event will be the one with the lowest distance. Since semantic matchmaking associates a logic-based explanation to ranked (dis)similarity measures, the classification outcome has a formally grounded and understandable confidence value. This is a fundamental benefit with respect to the majority of standard ML techniques, which produce a prediction not simply intelligible. Furthermore, notice that the proposed approach does not take the instance annotation directly as output, because the inherent data volatility in IoT contexts could lead to inconsistent assertions, which would be impossible to reason on.
Evaluation
The system evaluation works with a test set, consisting of several classified instances referred to the same ontology used for building the training set. The goal is to check how often (and possibly, how much) the predicted event classes correspond to the actual events associated to each instance of the test set. Beyond classical performance indicators for classifying ML algorithms (like the confusion matrix and statistical metrics as accuracy, precision and recall), the graded nature of predictions of MAFALDA, e.g., the average semantic distance of the predicted class from the actual one, allows applying typical error measures of regression analysis like the Root Mean Square Error (RMSE).
Cross-validation can be used to tune system parameters if performance is not satisfactory. Moreover, if computing resources permit it, incoming test data can also be used to update the training matrix on-the-fly, in order to allow the model to evolve when new data is observed.
Case study: Road and traffic monitoring
Mobility services are one of the main IoT application areas. The presented case study refers to a prototypical system for road and traffic monitoring created e.g., to improve the functionality of navigation systems with real-time driver assistance. Useful insight on travel conditions is provided both among nearby vehicles (in a peer-to-peer fashion through VANETs – Vehicular Ad-hot NETworks) and on a large scale (e.g., by updating a remote Geographical Information System with real-time and history information toward road policy makers). In particular, the proposed knowledge-based system exploits the semantic descriptions of vehicles and context annotations to:
interpret vehicle data extracted via the mandatory On-Board Diagnostics10 California Environmental Protection Agency, On-Board Diagnostics (OBD) Program,
integrate environmental information;
detect potential risk factors.
The implementation is based on the Java language in order to be compatible with both Java SE (Standard Edition) and Android platforms. The prototype includes the Mini-ME lightweight matchmaker [50], which provides the required inferences for the
A dedicated dataset has been collected for experimental analyses.11
A subset of the collected data is publicly available on the project GitHub repository cited in Section 4.1.
The case study aims to identify driving style as well as road characteristics and traffic conditions, by analyzing parameters gathered by the car and by the user’s smartphone. It is purposely kept simple to give an immediate proof of concept, but classification can be largely enriched at will without modifying the theoretical settings. In detail, the system should detect the following classes:
Smooth, Uneven or FullOfHoles road surface conditions;
Low, Normal or High traffic congestion conditions;
Aggressive or EvenPace driving style.
During the dataset creation, each driver who collected a trace has been asked to label manually the records with the event characteristic for each of the above categories. Gathered information represent the raw data in the ML problem. Timestamp and GPS coordinates (also taken through the smartphone) have been added to each record.
Analyzed data consist of:
altitude change, calculated over 10 seconds;
speed: current value, average and variance in the last 60 seconds and change in speed for every second of detection;
longitudinal and vertical acceleration, measured by the smartphone accelerometer and pre-processed with a low-pass filter to delete high frequency signal components due to electrical noise and external forces;
engine load, expressed as percentage;
engine coolant temperature, in °C;
Manifold Air Pressure (MAP), a parameter the internal combustion engine uses to compute the optimal air/fuel ratio;
Mass Air Flow (MAF) Rate measured in g/s, used by the engine to set fuel delivery and spark timing;
Intake Air Temperature (IAT) at the engine entrance;
Revolutions Per Minute (RPM) of the engine;
average fuel consumption calculated as needed liters per 100 km.
As shown in Fig. 2, the above parameters have been represented in the domain ontology and divided in subclasses, each characterized by a value range. At the end of the training phase, the ABox created automatically from the available data stream contains instances representing the events that the system should be able to recognize.
In addition to evaluations on the static data set, a mobile application for smartphones has been developed to validate the framework in a real usage. It is an evolution of [47], devoted to evaluate vehicle health and driver risk level, exploiting semantic-based matchmaking to suggest users how to reduce or even eliminate danger and get better vehicle performance and lower environmental impact. By exploiting this new version, implemented using Android SDK Tools, Revision 24.1.2 – corresponding to Android Platform version 5.1, API level 22 – and tested on a LG E960 Nexus 4 smartphone, the user can:
select a dataset related to the cars used in the experiments (Fig. 5(a)) and train the prediction model;
view and query all available sensed data, as shown in Fig. 5(b);
open a measurements dashboard (see the screenshot in Fig. 5(c)). For each device, a colored icon indicates a low (white), medium (yellow) or high (red) measured value.
Moreover, the user can start the classification view in Fig. 5(d). The smartphone camera viewfinder is used as background allowing the user to see the classification outputs without looking away from the road. The application queries vehicle information via OBD-II and executes the algorithm described in Section 4. The user interface shows at the bottom a compact device dashboard (a smaller version of the one in Fig. 5(c)), while three large icons are displayed at the top, related to the event outputs (road conditions, traffic and driving style). Also in this case, classified output levels correspond to different colors (green, yellow and red). In the picture, the algorithm detects a smooth road and low traffic (green icons) and an aggressive driving style by the user (red icon).

Mobile application screenshots.
Experiments report in several different test configurations
This section reports on the experiments carried out on the dataset collected as stated before. Results are summarized and compared through classic ML metrics such as weighted precision, recall, F-score and overall accuracy.
Configuration selection
A preliminary test (Table 2) compares performance indexes of the modeling techniques described in Section 4.1 with data ranges expressed through number restrictions (
Precision and recall values are plotted in Fig. 6. The best configuration is AP1, presenting the highest values for recall, F-score and accuracy; precision is only slightly lower than configurations with larger
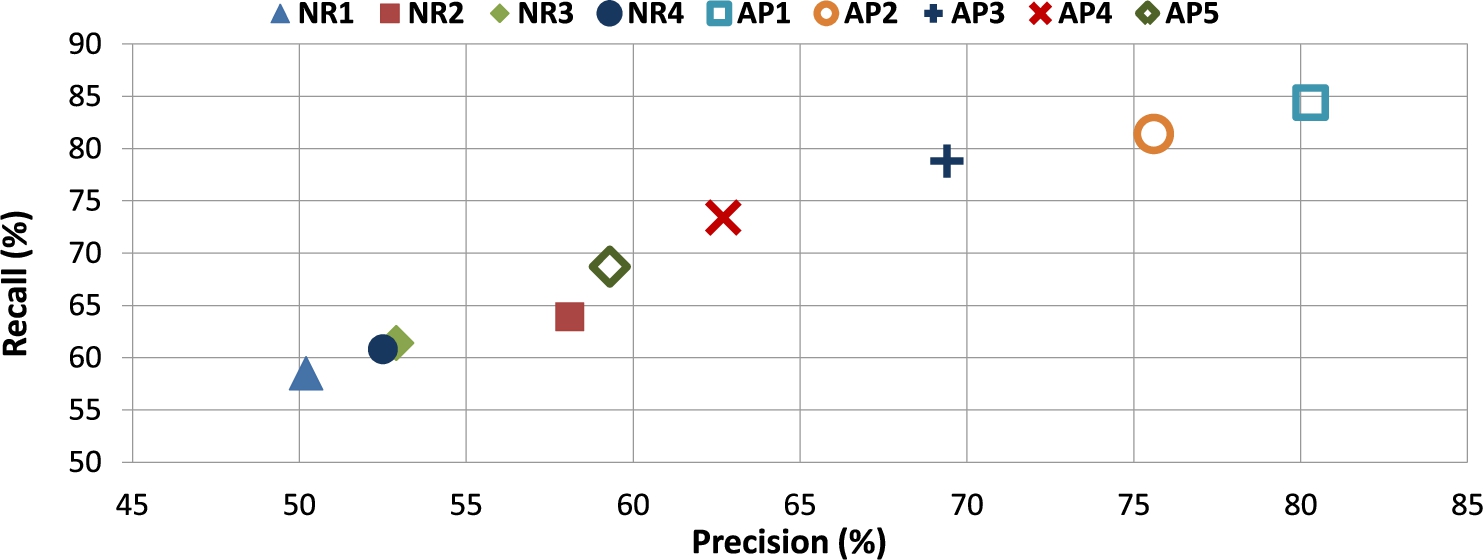
Precision/recall plot.
Parameters of the reference classification algorithms
Comparison of ML algorithms
The same training and test sets have been used with classical Machine Learning algorithms to compare and evaluate results obtained with the best configuration of MAFALDA. The following algorithms recalled in Section 3.1 have been used for comparison:
J48 implementation of C4.5;
Functional Tree (FT);
Random Tree (RT);
K-Nearest Neighbors (k-NN);
Multilayer Perceptron;
Deep Neural Network (DNN) Classifier.
Algorithms 1–5 have been tested in their implementation from Weka13
Weka version 3.6.12,
TensorFlow version 1.4.0,
Moreover, the experimental analysis has measured processing time of compared algorithms on a PC testbed, equipped with Intel Core i7-3770K CPU at 3.5 GHz, 12 GB DDR3 SDRAM memory, 2 TB SATA (7200 RPM) hard disk, 64-bit Microsoft Windows 7 Professional, 64-bit Java 8 SE Runtime Environment build 1.8.0_31-b13, and 64-bit Python 3.6.3 environment. Training and evaluation times, reported in Table 4, represent the average interval (computed on five runs) needed to build the model – starting from each training set exploited for accuracy analysis – and perform the evaluation on the related test set. The highest training time has been taken by the DNN Classifier, due to the complex model and the expensive optimization function, whereas the lowest is by k-NN, where the training task only validates input data. Conversely, the evaluation time is highest in the case of k-NN, since the algorithm calculates the distance among samples. Random Tree has the lowest overall time, due to the very simple model used to classify the test instances. MAFALDA exhibits a very low training time, making the approach suitable for on-the-fly data stream processing, while evaluation time is higher due to semantic matchmaking. The above behavior gives however a satisfactory performance tradeoff in case of mobile ad-hoc scenarios as they are typically characterized by data rates higher than query rates.
Processing time of MAFALDA has been analyzed on two more platforms:
Nexus 4 smartphone, equipped with Qualcomm Snapdragon S4 quad-core CPU at 1.5 GHz, 2 GB RAM and Android 5.1.1 operating system; Raspberry Pi Model B,15
The overall process includes several sub-steps:
Ontology Loading: the OWL file containing the TBox
Data Mapping: for each of the 6030 data records in the training set, the concept subclass(es) corresponding to the parameter values are identified;
Matrix Creation: the Training Matrix using the concepts detected in the previous step is created/updated;
Matrix Normalization: this activity normalizes the matrix values and calculates the reference thresholds;
OWL Model Creation: starting from the normalized matrix, the semantic annotations describing each event are generated;
Classification: every data record is classified in the test set.
On both platforms, processing times obtained with a KB modeled with annotation properties are slightly faster than those obtained with number restrictions. Data mapping is by far the longest phase, due to the large amount of sensed data to manage. However, the time needed for a single mapping is very low (shorter than 1.2 ms on PC, 48 ms on smartphone and 70 ms on Raspberry). In case of number restrictions, ontology loading and data mapping are slower, due to the higher time needed to parse this kind of logic descriptions. Conversely, OWL model creation is faster because event annotations usually contain fewer concepts. In fact, for each parameter at most one subclass is associated to the event annotation given the explicit incompatibility among concepts induced by the number restrictions.
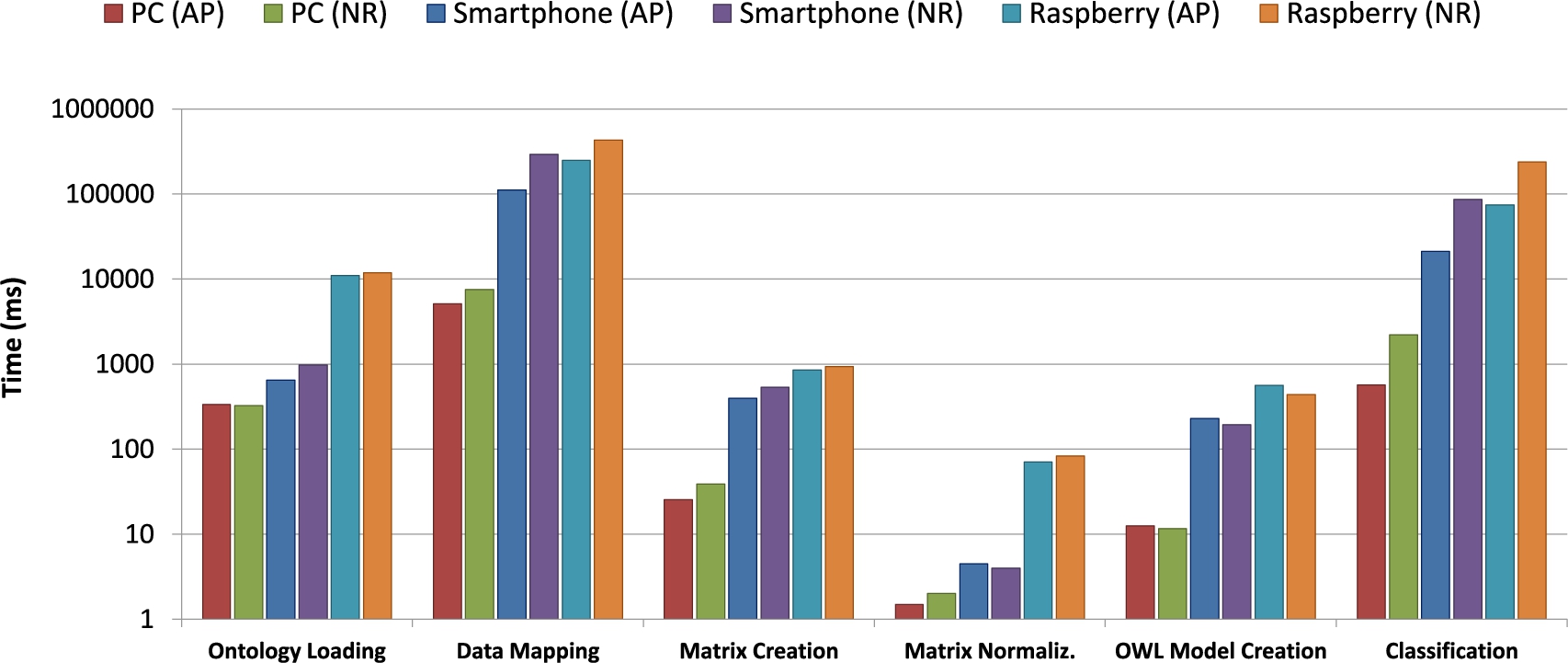
Processing Time.
Considering the faster approach with annotation properties, the average turnaround time for training the classification model (i.e., build and normalize the training matrix and then create the event annotations) is 40 ms on PC, 630 ms on smartphone and 1.48 s on Raspberry. This can be deemed as acceptable also for mobile and embedded systems. It is useful to point out that model training is performed only once after training set selection. Furthermore, processing time is clearly negligible with respect to data gathering: in the tested case, 6030 records read at 1 Hz frequency correspond to over 1.5 hours of data collection. Then, the classification task starts. For each test sample, classification is executed in about 0.22 ms on PC, 8 ms on mobile and 29 ms on Raspberry.
In addition to adequate prediction performance and computational sustainability, a major goal of the proposed approach is to improve explainability w.r.t. the state-of-the-art techniques. Models and outputs generated by all the above algorithms applied to the first Peugeot 207 training set have been compared in a qualitative assessment. Figure 8 shows the model produced by MAFALDA. Classes are not simply labeled, but they are annotated as described in Section 4.2. Annotations are machine-understandable and easily readable. As said, the further semantic matchmaking enables also logic-based explanation of results: this grants accountability for classification outcomes. Finally, non-monotonic inference services and approximated matches increase resilience against missing or spurious sensor readings in test samples during system usage.

Example of the model generated by MAFALDA for road surface.
Figure 9 shows the model produced by the C4.5 decision tree (for the sake of readability, the figure reports only on a portion of the whole model). Every node tests a feature with a threshold: branches define paths leading to leaf nodes, which represent classification decisions. Also in this case, the model is easily readable both by humans and software systems: every class is basically represented by a clause in Disjunctive Normal Form. Nevertheless, the use of sharp thresholds in propositional atoms may make the approach vulnerable to slight sample data variations, e.g., due to measurement problems. Functional Tree and Random Tree models – not reported for the sake of conciseness – are similarly readable, although nodes contain logistic or linear functions, respectively, instead of Boolean propositions. Due to the same reason, however, they are more robust against input perturbation.
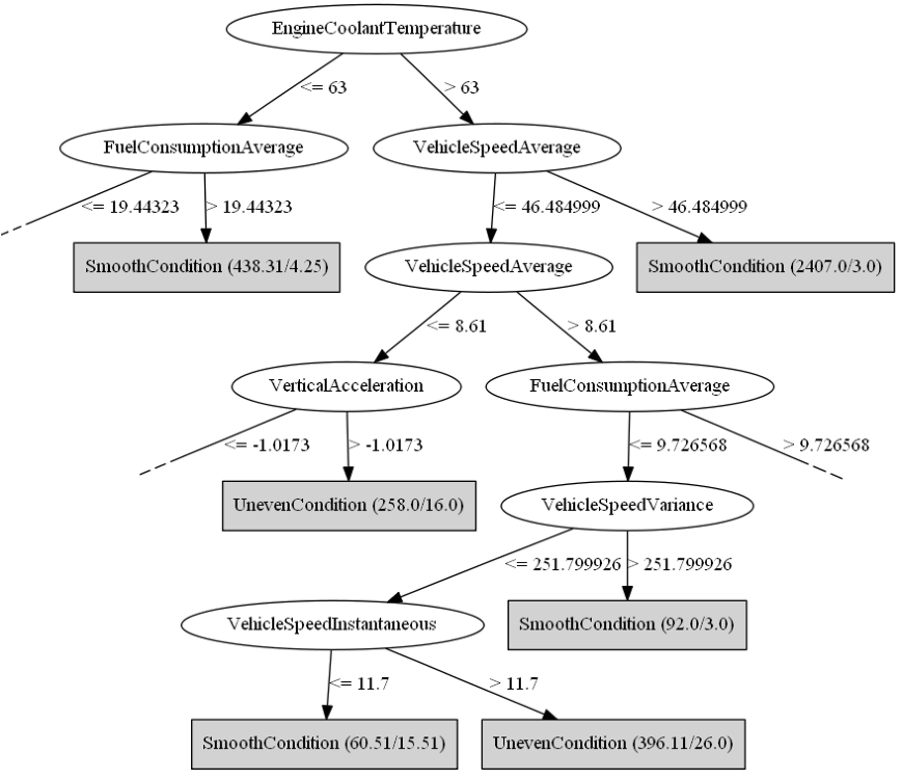
Example of model for C4.5 decision tree classifier.
Models generated by k-NN basically consist in point clouds – where each element represents a training sample – in an n-dimensional space, if n is the number of features. k-NN extensions toward hierarchical multi-label classification [42] have been proposed to predict structured outputs, but they are applicable only to multi-label classification problems, i.e., when each sample can be labeled as belonging to multiple classes simultaneously; this is unlike most IoT and data stream mining scenarios.
Finally, the model generated by Multilayer Perceptron is depicted in Fig. 10: input features are in green, output classes in yellow, neurons are organized in layers and their connections are shown. The model for the DNN Classifier is structurally similar. Such models are practically black boxes, both for humans and automatic systems, because the relationship between input sample features and output class label is encoded only in node thresholds and edge weights. For example, the first node of the second hidden layer is modeled as
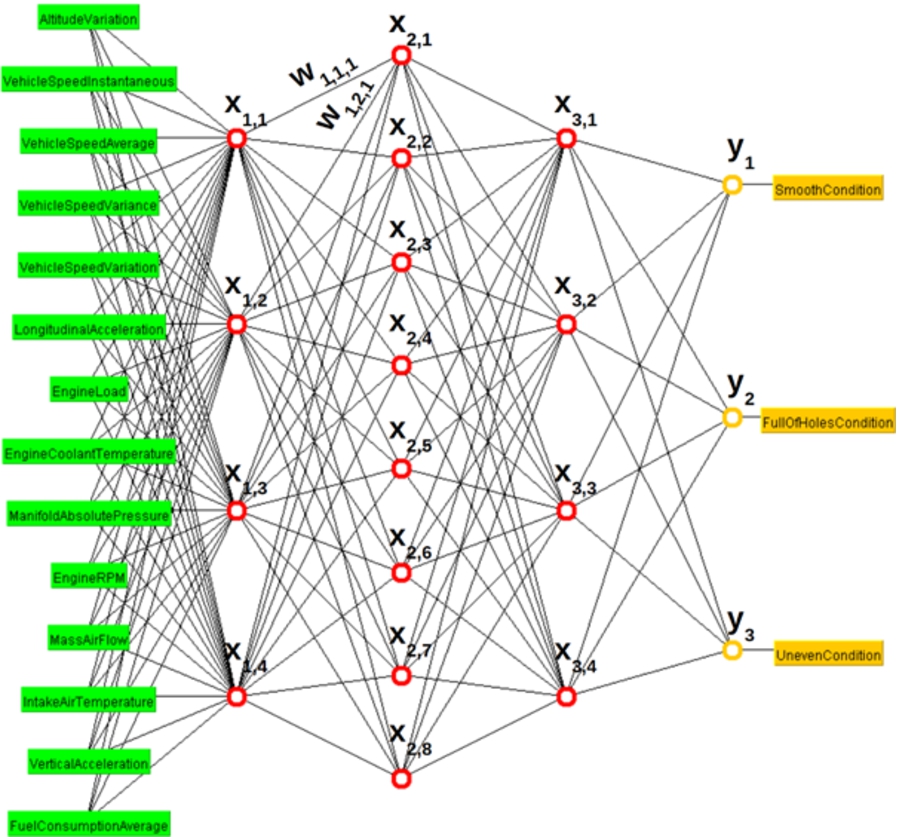
Example of model for Multilayer Perceptron classifier.
The main outcomes of experiments are summarized hereafter:
In the reference road and traffic analysis case study, the best algorithm performance has been achieved using annotation properties and a low base threshold value. As number restrictions on disjoint value ranges cause more frequent inconsistency between output classed and test samples, semantic penalties become higher, leading to lower precision and recall. Prediction performance of MAFALDA is acceptable w.r.t. classical ML algorithms for IoT scenarios. Precision is comparable and recall is slightly lower in the case study. Processing time of MAFALDA is in the same order of magnitude as other ML algorithms. It has very fast model training and relatively slow evaluation time (though absolute values appear as adequate, with 8 ms per classification sample on the 2013 mobile device exploited in the case study). Hence, the semantic matchmaking induces a slowing down of the evaluation w.r.t. training. Anyway, in typical wireless sensor network and IoT scenarios where queries are less granular than input data streams, this however achieves satisfactory performances. Computational performance trends are predictable on PC vs mobile vs single-board computer platforms. Even for the latter, absolute values of training and classification times are small w.r.t. typical IoT application requirements. This is a significant outcome because it suggests that the proposed approach is responsive even with multiple features. MAFALDA achieves high explainability w.r.t. the state-of-the-art techniques. Other ML algorithms, such as decision trees, produce models with arguably similar or better readability for humans; notwithstanding, the proposed approach allows both formal semantic-based representation of the trained models and automatic logic explanation of classification outcomes. This makes the approach dependable and accountable, facilitating adoption even in critical scenarios. Moreover, MAFALDA output is expressed in standard Semantic Web languages, therefore it can be immediately used for further reasoning tasks. This facilitates integration in larger knowledge-based system architectures and is currently not allowed by other competitor approaches.
Conclusion and future work
This paper has introduced a novel approach for semantic-enhanced machine learning on heterogeneous data streams in the Internet of Things. Mapping raw data to ontology-based concept labels provides a low-level semantic interpretation of the statistical distribution of information, while the conjunctive aggregation of concept components allows building automatically a rich and meaningful representation of events during the model training phase. Finally, the exploitation of non-standard inferences for matchmaking enables a fine-grained event detection by treating the ML classification problem as a resource discovery.
A concrete case study on driving assistance has been developed through data gathered from real vehicles via On-Board Diagnostics protocol (OBD-II) and exploiting sensing micro-devices embedded on users’ smartphones. A realistic dataset has been so built for experimentation. Subsequent extensive evaluations have allowed assessing performance of the proposed framework compared with state-of-the-art ML technologies, in order to highlight benefits and limits of the proposal. Main highlights are competitive prediction performance and speed w.r.t. existing approaches, combined with more expressive classification outputs and easily understandable models. In general, the main benefit of using Semantic Web technologies is to get meaningful information from data, but the main drawback is higher processing time: this paper demonstrates it is not necessarily true.
Several future perspectives are open for semantic-enhanced ML and particularly for the devised framework. A proper extension of the baseline training algorithm can enable a continuously evolving model through a fading mechanism allowing the system to “forget” the oldest training samples. A further extension of the training algorithm could aim at distributing the processing on more than one node, with a final merging step. This should reduce the communication overhead within a sensor network if intermediate nodes have enough storage capacity. Further variants could increase the flexibility of the proposed approach at the classification stage. For example, it could be useful to investigate the possibility of creating dynamically super-classes with a range combining those of the concepts found in the description: this would avoid affecting the result of the inference algorithms for descriptions that would otherwise be similar. Finally, adopting a more expressive logic language such as