
Abstract
Measurement units and their relations like conversions or quantity kinds play an important role in many applications. Thus, many ontologies covering this area have been developed. Consequently, for new projects aiming at reusing one of these ontologies, the process of evaluating them has become more and more time consuming and cumbersome. We evaluated eight well known ontologies for measurement units and the relevant parts of the Wikidata corpus. We automatically collected descriptive statistics about the ontologies and scanned them for potential errors, using an extensible collection of scripts. The computational results were manually reviewed, which uncovered several issues and misconceptions in the examined ontologies. The issues were reported to the ontology authors. This caused new bugfix releases in three cases.
In this paper we will present the evaluation results including statistics as well as an overview of detected issues. We thereby want to enable a well-founded decision upon the unit ontology to use. Further, we hope to prevent errors in the future by describing some pitfalls in ontology development – not limited to the domain of measurement units.
Introduction
Units of measurement are an essential part in many aspects of modern life: The correct handling of the scale a value is measured in is crucial not only in science, but also in trade, industry, and administration. A well documented use of units is especially important, when a project is carried out by different partners with different backgrounds. One of the most prominent examples of neglecting this fact is the crash of the Mars Climate Orbiter in 1999, which the NASA investigation board attributed to a mismatch of used units between two components of its software [13].
Similar integration challenges arise on an even larger scale in the context of Big Data: With the increasing need to integrate datasets of different origins, data annotation – preferably using Semantic Web techniques – gains importance. Using a machine readable annotation is essential for (semi)automatic discovery, verification, and integration.
As part of these semantic descriptions and to cover the field of measurement units and related concepts, over the last years several projects were initiated to create respective ontologies [5,12,15,16].
Most of these attempts were embedded in bigger research projects and, thus, catered to their specific needs. This led to a variety of different approaches to model the domain at hand. The created ontologies differ not only in the modeled subset of concepts and relations, but also in the type and number of units included. Engineers or researchers who wish to use an existing ontology in their work are now faced with the choice between several ontologies.
To assist in this decision making process, we analyzed eight ontologies in the field of measurement units and the respective parts of the emerging Wikidata corpus [26]. Our analysis is focuses on the individuals and values in the ontologies, in contrast to earlier efforts that mostly focused only on the schemata. We used a collection of scripts to extract several kinds of statistics and to detect contradictions between the data sources. The manual review of the results confirms not only the different emphases of the ontologies, but also reveals the existence of several issues in all of them. Our contribution is as follows:
We provide an extensible collection of scripts, which can be used by unit ontology developers to validate their work against other ontologies.
We provide a mapping between the concepts of all selected ontologies.
We identified multiple issues in existing ontologies and reported them to the respective authors. This triggered the publication of new releases of OM 1, OM 2, and SWEET to fix the issues found.
We identified issue classes and hint towards preventive actions.
We present the analysis of existing ontologies to support potential users in the decision process of selecting a unit ontology for reuse.
The paper is structured as follows: Section 2 will give an overview of the analyzed ontologies and present previous work on ontology evaluation. In Section 3 we will describe the general approach and some implementation details, before in Section 4 the various aspects of the analysis will be presented. Limitations of our approach will be discussed in Section 5. We conclude with suggestions to ontology authors to prevent some of the encountered issues in Section 6 and final remarks in Section 7. The terminology used will be specified in Appendix.
Related work
The discussion of related work is split into two parts: First, we will present the analyzed ontologies and specify the respective version we used. The second part will then describe previous work on ontology evaluation.
Ontologies for measurement units
Over the last years, several projects were initiated to create ontologies modeling the domain of measurement units. The following selection focuses on ontologies that model a reasonable number of relevant individuals and classes in an OWL compatible format. There are, of course, several other unit ontologies within and beyond the OWL world, but they do not meet this basic condition. In addition, the selection contains an OWL compatible knowledge base which provides data on measurement units.
The selection evaluated in this work includes:
Measurement Units Ontology (MUO);1
Extensible Observation Ontology (OBOE);2
Version 1.0 from
Ontology of units of Measure and related concepts (OM 1);3
Version 1.8.6 from
Ontology of units of Measure (OM 2);4
Version 2.0.6 from
Library for Quantity Kinds and Units (QU);5
Quantities, Units, Dimensions and Data Types Ontologies (QUDT);6
Version 1.1 from
Semantic Web for Earth and Environmental Terminology (SWEET);7
Version 3.1 from
Units of Measurement Ontology (UO)8
Version 2017-04-24 from
Version 2017-03-22 from
Wikidata (WD);10
Status as of 2017-06-27; using
We are aware of the current efforts towards a second version of QUDT. At the time of writing, however, the ontology has only been partly published. The available parts do not allow a meaningful comparison. Thus, the analysis of QUDT 2 is left open for future work.
DBpedia extracts structured data from Wikipedia11
On the other hand, Wikidata – a sister project to Wikipedia – aims at collecting factual knowledge for Wikipedia in a central repository [26]. This information can then be linked directly from different Wikipedia articles and thus provide a consistent view even across several language versions. Wikidata also includes a large number of measurement units and their relations. As this data can also be accessed through a SPARQL endpoint, WD is included in the selection.
In the following “OM” will refer to both OM 1 and OM 2, when a statement applies to both ontologies alike. If only one ontology is affected, we will use “OM 1” or “OM 2” respectively.
The selected ontologies use different terms to refer to the same concepts. For example, the concept “kind of quantity” is denoted as “physical quality” (MUO), “quantity kind” (QU, QUDT), and “physical quantity” (WD). OBOE, OM, SWEET, and UO do not provide an explicit entity for this concept, but model the respective entities as subclasses of “physical characteristic” (OBOE), “quantity” OM, “property” (SWEET), and “quality” (UO). Therefore, a clear specification of the terminology used in this survey is needed. This is provided in Appendix. Where possible, it is compliant with the International Vocabulary of Metrology [10].
Motivated by the lack of published evaluation processes as well as examination results for well known ontologies, an early evaluation approach was developed by Gómez Pérez [6]. This approach consists of two steps: In a first analysis step, the ontology is inspected regarding consistency, completeness, conciseness, expandability, and sensitiveness. Consistency is defined as the absence of contradictions between formal definitions and the modeled world, contradictions between informal definitions and the modeled world, contradictions between formal and informal definitions, and contradictions between formal definitions (“inferential consistency”). Completeness is informally defined as “each definition is complete” and “all that is supposed to be in the ontology” is included. Conciseness is the absence of redundancies and “unnecessary or useless definitions”. Expandability is an assessment of the effort to add new definitions. Sensitiveness describes the impact of small changes to the whole ontology. In a second synthesis step the ontology is then corrected.
This approach was applied to the Standard Unit Ontology (SU), which contains 61 individuals and one class, by two ontology engineers and two domain experts. They used a checklist of eight possible errors in taxonomies to decide on its consistency, completeness and conciseness. As a result, Gómez Pérez concluded that SU is consistent and concise, but incomplete. Further, they identified seven problems by inspecting the ontology’s source code. These errors were related to completeness, conciseness, expandability, and missing code conventions. However, the theoretical criteria were not consistently applied in the evaluation process. The choice of SU indicates a particular need for evaluation and improvement in the domain of measurement units.
Based on Gómez Pérez’s criteria, Rijgersberg et al. evaluated five ontologies concerned with units of measurement [17]. They used a checklist of 34 requirements related to “completeness of the modeled scope”, “quality of formal definitions”, “understandability and extensibility”, and “completeness in the natural language documentation”. The results indicated that none of the ontologies contained all important concepts of this domain.
Consequently, they developed OM 1. Subsequently, Rijgersberg et al. published a comparison of OM 1 with QUDT 1.0.0 [16]. They compared the schemata of both ontologies and outlined the differences in the modeling. Further, they compared the number of kinds of quantities and measurement units as well as the support of five use cases. Overall, the results indicated that OM 1 outperformed QUDT 1.0.0.
Another domain specific comparison approach was introduced by Marcus P. Foster. He suggested a ranking of measurement ontologies in five levels regarding the supported concepts and use cases [4]. Ontologies of the first level “standardize characters for unit symbols and operators”. On the second level they “additionally represent the concepts of unit and dimension” and “support the operations of unit conversion and unit conformance”. On the third level they “additionally include the concept of quantity and system of quantities”. On the fourth level they additionally provide a “full descriptions of quantities, prefixes, ordinal and nominal measurement scales, and systems of quantities and units”. On the fifth level they “also incorporate the concepts (precision, accuracy, distribution etc.), relations and operations associated with calculating and representing measurement uncertainty”. QUDT was classified as a third level and OM 1 as a fourth level ontology.
This ranking provided a fast overview regarding scope and level of development of ontologies. However, the order of requirements for each ranking-level seems biased by the authors background in parts. For example, an ontology might provide concepts of quantity and system of quantities, as required by the third level, without supporting unit conversion, as required by the second level.
Chau Do and Eric J. Pauwels applied MathML to map unit ontologies [3]. They manually created a predefined mapping of the seven SI base units. Then the definitions of unit composition and unit conversion were used to map the remaining measurement units. This approach was applied to OM 1, QUDT, and SWEET. During the evaluation of their mapping approach, they discovered several problems caused by “incorrect information in the ontologies”. Some examples were provided for each ontology. However, as the work was not focused on ontology evaluation, they did not continue to systematically search for errors. Unfortunately, not all ontologies in our selection provide definitions of unit composition and unit conversion. Therefore, this mapping approach is not applicable in our analysis.
Samadian et al. compared the Ontology for Engineering Mathematics (EngMath), MUO, OM, and QUDT [18]. Tailored to the specific requirements of a medical data integration project, the comparison was focused on the conversion of measurement units, the modeling of their mathematical relations, and the extensibility of the ontology. OM was the most suitable ontology for their purpose. But, due to the narrow focus, the benefit for other projects is limited.
In [23] a comprehensive list of 16 use cases in the field of unit ontologies was presented. For each use case, the required concepts and relations were identified and categorized into necessary and optional requirements. While necessary requirements are mandatory for a use case, optional requirements “simplify the implementation of a use case or increase its usefulness”. A metric was developed to measure the suitability of a given ontology with respect to those use cases. Finally, a selection of seven ontologies (MUO, OBOE, OM 1, QU, QUDT, SWEET, and UO) was analyzed and compared using this metric. OM 1 surpassed the other ontologies in each use case with the closest overall contenders being QUDT, QU, and SWEET. This evaluation, however, remained on a conceptual level. The individuals of the ontologies have not been considered.
Zhang et al. tried to compare the four unit ontologies OM 1, QUDT, QUDV, and UO [27]. They focused on the OWL standard vocabulary used for modeling and possible reuse of the ontologies. However, their approach lacks a general methodology, which could be extended to include other ontologies in the comparison. Furthermore, the used OWL language features in an ontology do not enable any conclusions regarding its usefulness in other projects.
A domain independent approach of ontology comparison is the usage of general quality criteria as implemented by, e.g., OntoClean [7] and the OntOlogy Pitfall Scanner! (OOPS!) [14]. OntoClean provides a “methodology for validating the ontological adequacy and logical consistency” and “is based on highly general ontological notions” like identity and unity. It can be used to check for common pitfalls related to taxonomic relationships. On the other hand, OOPS! (semi)-automatically checks for many common pitfalls in OWL ontology development. For instance, this includes unconnected ontology elements or missing human readable annotations. It is easy to use and can give an initial impression of the quality. However, a detailed analysis of domain specific issues is out of the scope for both methods.
Although the comparison in [16] includes some statistics, all mentioned evaluation efforts are manual assessments almost exclusively remaining on a conceptual level or only cover general quality issues. Thus, there is a lack of evaluation concerning the individuals of unit ontologies.
Methods
The evaluation of unit ontologies on the level of individuals consist of two major aspects: One is coverage, which revolves around what concepts are modeled as well as how many and what kind of individuals are included. This corresponds to the particular aspect of the completeness criteria of [6] to define every concept “that is supposed to be in the ontology”. The other one is correctness, which is concerned with how reliable the included values are in an application’s context. It is related to all aspect of the consistency criteria of [6]. Further, it is related to particular aspects of the completeness and conciseness criteria [6], namely completeness of definitions and the absence of redundancies.
A strictly manual assessment of the selected ontologies is not appropriate. On the one hand, subtle differences like a missing digit in a 15 digit number, that we discovered using our approach, might be overlooked. On the other hand, the sheer number of concepts and relations to review might lead to a lapse in concentration and thus missing certain issues. Further, an automated approach ensures the identical evaluation of all selected ontologies and as well of new ontologies which might be added in the future.
A reasoner12
Openllet 2.6.3 from
Despite an extensive search, we are not aware of a comprehensive reference dataset in the field of measurement units. There are some datasets [8,19,24,25], but those either cover only a subset of the units in use or omit some of the major concepts as listed in Appendix. Further, some of these datasets have been used to create some of the selected ontologies. Therefore, the results would likely be biased in favor of these ontologies.
For a suitable replacement, we turned to the information contained within the selected ontologies. We extracted relevant entities from the ontologies into an ontology-agnostic relational model (cf. Fig. 1) and subsequently mapped them semi-automatically to one another. This resulted in a reference dataset for the further analysis.
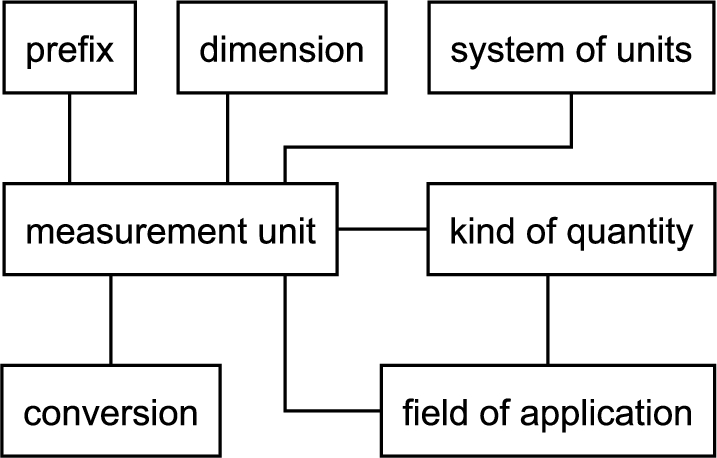
Ontology-agnostic model of the created reference dataset.
The created dataset can be used to detect deviations between the ontologies. In most cases, these deviations can be backtracked to issues within at least one ontology.13
The other major cause of deviations was a difference in precision of conversion factors.
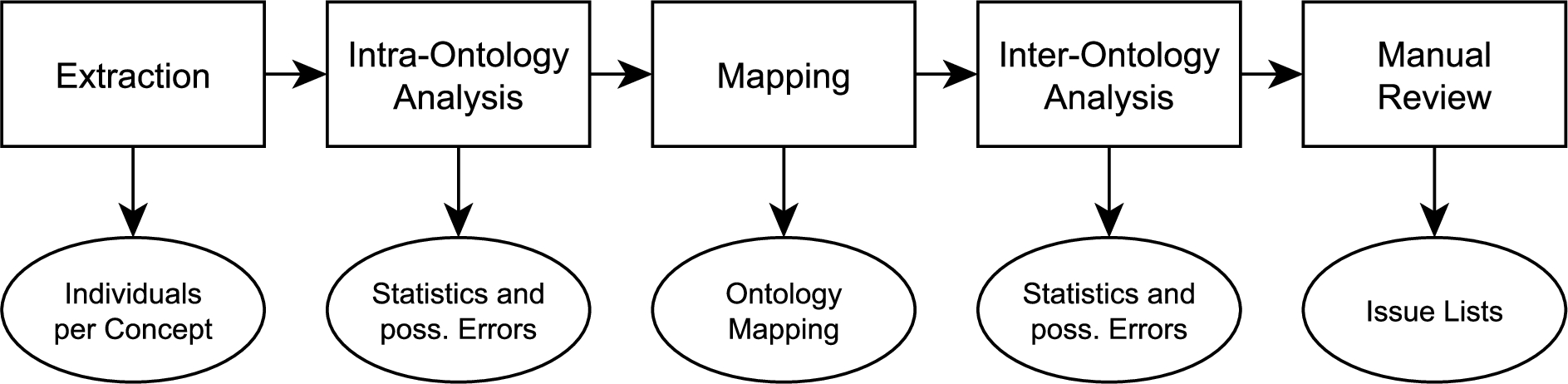
Schematic of evaluation approach and the respective results.
Following the previous discussion, we decided against a strictly manual assessment and for a semi-automatic approach as shown in Fig. 2. To apply it to the selected ontologies we created an implementation in the form of a collection of scripts. It is publicly available for free use and extension [20]. To easily be able to run just a subset of scripts, but yet preserve dependencies, each script will store its results into a set of JSON files, which will then be used by its successors.
In the following, we will describe each step in detail. The intermediate results of each step are available at [21]. Note that the received results were not only used to assess the given ontologies, but also to improve upon our analysis process. The results of the first analysis phase, e.g., allow to verify the extraction process and hint towards erroneous queries, which can then be corrected.
The first step requires the extraction of individuals. For each ontology we formulated SPARQL queries to obtain the individuals per concept as well as the respective relations (cf. Fig. 1). Those ontologies that are given in an OWL-compatible format are added to a Sesame triple store14
Most ontologies only model a subset of the examined concepts, so some SPARQL queries could be omitted. The scripts interpret a missing query as a missing concept or relation in the specific ontology. This removes the need to explicitly state the absence of those concepts and relations. Furthermore, it allows to add queries for new ontologies one by one, instead of having to provide all queries at once. Note that we provided queries for each relevant concept and relation of the analyzed ontologies.
The result of the extraction is a unified, relational representation of the data contained per ontology, as described in Section 3.1. This removes all ontology-specific modeling techniques and ensures a common format for further analysis. As a side effect, the approach may also be used to compare against other datasets not necessarily provided as an ontology. To include those datasets only an extraction process has to be provided, whereas all following steps are independent of the original source format.
In addition to the extraction of individuals and relations, the transitive closure of conversions for each ontology is computed in this step. This significantly expands the number of available conversions: If, for example, the conversions milligram to gram and gram to kilogram exist, the missing, but inferable conversion milligram to kilogram is added. As a consequence, a wider range of conversions can be validated later on as compared to only resorting to the conversions explicitly defined within the ontologies.
The extracted data allows for a first analysis. This phase is called “intra-ontology analysis”, as it is concerned with each ontology individually. Tests that involve multiple ontologies are subject of the “inter-ontology analysis” later on (cf. Section 3.2.4).
Most checks at this phase concern the completeness of definitions in the ontologies. This includes the following aspects:
Is at least one label attached to each individual?16
This check is also part of the OOPS! pitfall catalogue: “P08. Missing annotations” [14].
Are there individuals with multiple labels in the same language?
Where applicable, is each individual part of at least one relation?
Are all relevant values attached to each individual?
Is each individual only assigned to a single concept?
The check for multiple labels per individual seems superfluous at first glance. However, this particular check allowed us to identify several occurrences of labels that were annotated with the wrong language tag.
Furthermore, a first set of statistics can be extracted at this point. The most prominent statistic here is the count of individuals and relations (cf. Table 1). Other examples include the usage of certain keywords like “per” and “reciprocal” to examine the uniformity in naming conventions used or the distribution of languages within the given labels (cf. Table 5).
In the third step the individuals for each concept and relation are mapped to one another. Since, e.g., a unit must not be mapped to a dimension, the mappings work on each class of individuals separately. Besides reducing the computational effort, this allows to employ different mapping strategies. The result of the process are multiple mapping sets. Each of these sets includes all individuals that are mutually identical.
The mapping process uses three kinds of sources to determine whether two individuals are identical. The first source are
The second and most frequent sources of mappings are the individuals’ labels. Whereas often a mere comparison by name might be sufficient, others like the measurement units themselves need a more sophisticated approach. In the following we will highlight some of the challenges encountered and outline our solutions. The solutions are implemented using regular expressions unless noted otherwise.
A first obstacle was due to the differences in British and American spelling of some terms like “metre” vs. “meter”. Similarly, different spellings exist for certain prefixes and other modifiers. The prefix “deca”, e.g., also appears as “deka”. All occurrences were replaced by a uniform variant.
Some ontologies are adding suffixes to the labels of individuals of some classes, which results in labels like “length dimension” or “Antal (jednotka)”.17
“Jednotka” is the Czech translation of “unit”.
Another challenge was posed by different orderings of certain phrases. The label for the unit square meter, e.g., appears as “square meter” or “meter squared”. For this and similar pairs like “cube” and “cubed” we unify the order and spelling. A similar issue arises with the use of systems of units within unit labels. Examples are the two labels “US Survey Foot” and “Foot US Survey”. We created a list of such modifiers and harmonized their position within the labels.
As noted before, the labels for reciprocal measurement units include wordings using “per” and “reciprocal”. We replaced all uses of “reciprocal” by “per”.
The wide range of languages in Wikidata posed a particular challenge for the mapping. We found examples of measurement units where the label in some languages was plain wrong: See, e.g.,
On the other hand, some individuals have the same label although they depict different measurement units: See, e.g.,
Another challenge in WD are duplicates with no overlap in the languages of their labels. See
As the other ontologies besides OM and WD only use English labels or omit the language tag altogether (cf. Table 5), we decided just to map measurement units based on three types of labels: English labels, labels without a given language and an artificial label created from the local name of the URI. The published code, however, also includes a mapping implementation that involves all languages which can be activated in the configuration.
The manual review of the mappings uncovered several missed mappings. As adding specialized code for particular individuals would have made the codebase unnecessarily complex, we predefined certain mappings in separate files. This constitutes the final source of mapping information.
At this step the reference corpus described in Section 3.1 is available. This allows for the creation of comparative statistics. Here, we focused on the overlap in unit-individuals between the different ontologies (cf. Tables 3 and 4). Similarly, we created a list of common measurement units18
“Common” is here defined as being present in at least half of the analyzed ontologies.
The major results of this step, however, are aimed at the discovery of differences between the ontologies. Oftentimes these point towards issues present in the ontologies. A first example here is the list of conversions. To further expand the validation at this point, also the conversions as given by the prefix ⋈ unit-relation are included. This and the aforementioned computing of transitive closure allows to compare a large fraction of the conversions present.
The comparison process provided one challenge: Some ontologies provide a more precise conversion factor than others. In a first, naïve comparison this fact is disregarded. This results in an extensive list of differences. Many of those are equivalent, however, if rounding values is assumed valid. So in a second comparison we applied a filter to reveal more substantial differences. That filter determines for two values if one is the rounded variant of the other within certain limits. The result only contains the differences that also fail this test.
Another check addresses the measurement units that have varying definitions in different systems of units. To detect those we mapped the mapping sets of units again – this time ignoring the system modifiers in the labels. This results in sets of mapping sets. If one of at least two contained mapping sets has no system modifier within its labels, it is a candidate of a vague unit designation. To illustrate the approach here, assume the first mapping process created sets for acre, acre (international), and acre (U.S. survey). Removing the system modifiers results in a label of “acre” for all three of these sets, so they are mapped to one another by the second mapping. As one of the original sets’ labels did not include a system modifier, we probably identified one case of vague designations. On the other hand, if each of the original sets’ labels would have included a system modifier, no issue had been raised.
Besides uncovering differences between ontologies, the mapping also allows to discover duplicates within one ontology. As the mapping algorithm is agnostic to the ontology an individual originates from, it also maps individuals from the same ontology to one another, if they fulfill the aforementioned criteria. Some of these potential duplicates are added to represent different names for the same unit, like “grade” and “gon” [8], and are properly connected by
The mapping was also used to identify prefixed measurement units that were not flagged as such by their respective ontology. For measurement units that have not been flagged in any ontology, we also used a heuristic to identify missing prefix associations. This heuristic checks the unit label for appearances of prefixes at the start of each word. That way, e.g., the prefix “kilo” will be detected in the units “kilometer” or “meter per kilogram” and they will be marked as prefixed. Additional refinements for some special cases, e.g., prevent the detection of “milli” in “part per million” and ensure it for “hecto” in “hectare”. This heuristic leads to the further detection of missing relations as well as to a more conclusive comparison of the portion of prefixed measurement units (cf. Tables 1 and 3).
The previous steps maintain their results in the form of JSON files. To ease the manual review, the final step will convert all results to HTML files. This includes, e.g., a list of mappings found for each concept, tables showing a statistical overview similar to the ones presented in Section 4.1, or lists of potential issues for various issue class.
For the review of some issue classes, it proved helpful to adapt the presentation of the results or even provide different representations. For example, multiple lists are created to spot mappings that are missed by the algorithm. One list shows the created mapping sets in a lexicographical ordering of the labels. Another list also shows the created mapping sets in an lexicographical ordering of the labels, but the words within each label are ordered lexicographically beforehand. For example, the labels “meter kilogram per second” and “kilogram meter per second” of equivalent measurement units both turn into “kilogram meter per second”. Each of these representations can assist in finding additional mappings.
Number of individuals per concept and number of relations between two concepts per ontology after extraction. (A ⋈ B denotes a relation between concept A and B)
Number of individuals per concept and number of relations between two concepts per ontology after extraction. (A ⋈ B denotes a relation between concept A and B)
Information is included in the ontology, but not explicitly modeled using a specific concept or relation.
It is important to highlight, that the results just contain statistics and potential issues. A manual review of these potential issues is indispensable to get a reliable list of issues for the evaluation. For example, the mentioned list with lexicographically sorted words within the labels will group “mole per kilogram” and “kilogram per mole” although they are different measurement units.
While reviewing the existing results oftentimes new issues are identified, which are not yet covered. During the evaluation process this occurred on different occasions. In order to ensure a fair comparison for all involved ontologies we added new scripts to check for these issues and repeated the evaluation process.
The analysis of the examined ontologies using the collection of scripts provides a deeper insight into the ontologies with respect to broadness and completeness. Furthermore, it reveals several issues of different types and some pitfalls specific to unit ontologies. The raw results are publicly available [21]. In this section first a statistical overview of the ontologies will be discussed, followed by a description of discovered issue classes and an overview of issues per ontology.
The presented statistics are based on most recent releases of all ontologies at the time of writing. Note that Wikidata is constantly evolving and no specific version-numbers are issued. The numbers stated in the following for Wikidata will probably already have changed by the time of reading. They can, however, give a first impression about the amount of data managed by the project.
Statistics
For an initial overview the supported concepts and relations in the ontologies as well as the respective number of individuals are given in Table 1. Also included are the number of non-prefixed and prefixed units, which incorporate the results of the aforementioned heuristic to identify prefixed units.
Comparison of the total number of individuals as present in all ontologies with the number of distinct objects after the mapping
Comparison of the total number of individuals as present in all ontologies with the number of distinct objects after the mapping
Number of units occurring in a certain number of ontologies
The first notable observation is the absence of a connection between prefixed units and prefixes in MUO, QUDT and UO, even though both exist. First of all, despite containing both prefixed units and prefixes MUO, QUDT and UO do not model the connection between both. This hinders attempts to retrieve multiples or submultiples of a given unit. Furthermore, individuals for the concepts of field of application, dimension and system of units are just included in small subset of the ontologies.
OM is the only ontology with two versions present in this analysis. Most improvements between both OM versions are concerned with the simplification of the ontology structure, which is outside of the scope of this paper, but is documented in the SPARQL queries provided [20]. An important observation in the comparison of both versions is the absence of almost 40% of the individuals for kinds of quantities and systems of units in OM 2. This also has a major impact on the number of app ⋈ qk and qk ⋈ unit relations. Remarkably, the numbers for system ⋈ unit remain almost the same. This suggests, that the removed individuals for systems of units were poorly connected anyways. In contrast to the absence of many kinds of quantities and systems of units, there is a considerable increase of app ⋈ unit relations, whose number has more than doubled.
The number of measurement units in WD exceeds the number of measurement units in the other ontologies by far. Manual inspection reveals a large number of historic measurement units to be present in WD, which might explain this large number. Another reason are possible duplicates that were not recognized due to the reasons mentioned in Section 3.2.3. The second place is taken by OM, which does not suffer from these limitations. If the prefixed units are discarded, however, the situation changes in favor of QUDT. A closer look at the actual individuals in the ontologies suggests that a systematic way has been used to create the prefixed pendants for all SI units in OM, which vastly increased the total number of units.
In the next step, the individuals for each concept were mapped to one another. Table 2 compares the number of individuals present in the ontologies and the number of mapped distinct units overall. The number of found mappings especially for measurement units is surprisingly low. To eliminate shortcomings of the mapping process itself the list of mapped units was carefully examined by hand, which led to a number of mappings added manually, but to no substantial overall change. Due to the wide range of languages we were not able to perform this manual duplicate search for WD to the same extent as for other ontologies. Therefore in some of the further analysis the values reported for WD are not as reliable as the ones reported for the other ontologies.
Following up on differences in the number of units included and the lack of mappings, we analyzed the frequency in which units appear in the different ontologies. Table 3 lists the number of prefixed and non-prefixed units which are present in a certain number of ontologies. The actual number of widely used measurement units was less than anticipated as over 85%19
Excluding WD lowers this number to 70%.
Also notable is the fact that there seems to be little consensus which units are essential to an ontology. Only 17 units are present in all ontologies.20
Units present in all ontologies: ampere, candela, day, degree, degree Celsius, hour, kelvin, lumen, meter, minute, mole, newton, pascal, radian, second, siemens and volt.
To explore this even more, the overlap between the ontologies with respect to the included units is given in Table 4. It displays the fraction of both prefixed and non-prefixed units from one ontology, that are included in another.21
A similar table showing the same relation but just for non-prefixed units can be created using the provided scripts. Although the exact numbers differ of course, the general trend remains the same.
Percentage of units from one ontology (row) that are also present in another ontology (column)
As can be seen, for any two given ontologies less than three quarters of the units of one ontology are part of the other. Even the smaller ontologies with respect to the number of units include units, that are not covered by the larger ones. There are different possible reasons for this fact. The ontologies were created for different projects or domains and hence needed to meet different demands regarding the included units. This is especially noticeable in the different sets of compound units included.22
In the absence of a respective modeling in most ontologies, exact numbers for the share of compound units could not reliably be extracted.
WD provides a wealth of languages for its labels – totaling over 300 different language tags including multiple regions for some of the languages. Following this observation we were interested in the frequency of each individual language. An excerpt of this is given in Table 5. Note that just the five most frequent languages for each type are shown for WD, while all present languages are listed for the other ontologies. Most ontologies choose to only add English labels. When the language tags were missing, the label turned out to be in English in all cases examined (QU, QUDT, UO). The only exception for domain ontologies is OM which also added Dutch and Chinese labels for a subset of individuals. In WD English is not as dominant as in other ontologies: Considering just the subset of analyzed individuals English is surpassed by German and rivaled at least by Russian in numbers. On the other end of the spectrum are OBOE and SWEET which omit labels altogether for most of their individuals.
The final examined aspect is the coverage of relations. It is important not only to include individuals for each type, but also to link them together in an appropriate manner. All measurement units, e.g., could be linked to at least one kind of quantity to represent what physical property can be measured using a particular unit. That statement, however, does not hold true for all relations: Not all measurement units can be linked to a matching prefix as there is no prefix for non-prefixed measurement units. This also shows that both types within a single relation have to be considered individually in terms of coverage. Hence, in the example for each prefix there should at least be one unit be linked to it. The current state of the ontologies is shown in Table 6.
Labels per language as present in the ontologies. Only the most frequent languages are shown for WD. (Σ total number of individuals; ∅ missing labels; ♢ labels without language tag)
Note that a frequency of 1.00 does not suggest that all possible links are included, but only that each individual is part of at least one link. To illustrate this restriction, assume an ontology includes just two measurement units
Individuals present in at least one relation. Total represents the number of individuals of that type, while the respective frequencies are given as fraction of that total number
The analysis revealed several classes of issues affecting the ontologies. Some are relevant to all kinds of ontologies, others are specific to unit ontologies. In the following we describe common issue classes encountered, except the most obvious classes like missing, wrong or duplicated values, assignments or entities. Note that each of these classes only applies to a subset of ontologies. An ontology specific discussion will follow in the next section.
This would erroneously imply that liter is an SI unit, which is wrong [8]. Similarly, a fraction is not identical to its simplified form (e.g.,
The namespaces in
Depending on the usage context of an ontology or the specific task it was created for, some of the listed issues might not be considered problems at all. For example, concatenated labels might not do harm or even be an advantage, if the ontology is just used for manual labeling. However, if the same ontology is used for automatic annotation, it is hard to work around that issue.
Ontology assessment
A full list of issues found was sent to the authors of the respective ontologies. They were also asked about the status of the development, the intended handling of the issues and were asked for permission to report on their answer. Helpful responses were provided by authors of OM, QUDT, SWEET, and UO. They affirmed the ongoing development of their ontologies. The authors of OM fixed the reported issues immediately. Furthermore, the new community project maintaining SWEET has also started to handle the reported issues. Similarly, the authors of UO have fixed most issues, but so far did not provide a new release. All the other ontologies at the time of writing still contain the reported issues. As WD is a collaborative project we did not report discovered issues to specific authors. However, a more detailed verification and correction will be subject of future work.
In the following we discuss each ontology with regard to encountered issues. If not stated otherwise, the ontologies turned out to be inferential consistent.
In six labels the Unicode symbol #160 (“no break space”) was used instead of a space (e.g. in “calorie at 15␣°C”). This might cause problems when comparing labels to different inputs. We found two most likely unintended unit duplicates (
We started our analysis with version 1.8. As of the latest version, 2.0.6, the following issues remain to be addressed:
All IRIs contain the version number of the ontology. Four entities classified as units should be scales instead. For example,
That caused the temperature scale classes to be a subclass of
Further, we found the following issues that have been fixed in the current version (2.0.6). Most of these issues have also been fixed in the current version of OM 1 (1.8.6).
OM 2 was inferential inconsistent due to missing datatype declarations of property values of
This means that every individual of the class
QUDT contains two entities with this name: an individual http://qudt.org/ vocab/unit #AtomicMassUnit and a class http://qudt.org/ schema/qudt #AtomicMassUnit .
The prefix
Further, we found the following general issues, that have been fixed in the current version (3.1): Most adversely, the SWEET unit module file
RDF Validation:
The approach, which is also used in the Gene Ontology, is explained on
WD contains links to entities from OM 1 and QUDT. The links to QUDT, however, point to the URLs of an HTML representation of QUDT, but do not refer the entities themselves. The references to OM 1 contain one wrong entry: The unit
The evaluation of the selected ontologies is based on the detection of deviations between the ontologies. Issues affecting objects that are only present in one ontology can thus not be detected. Similarly, issues that affect all ontologies will remain unnoticed.

Reasonable interpretations of conversion factor and offset.
The inevitable manual review of the potential issues carries the risk of human error, which might lead to missing out on some issues or false positives. To expose false positives, we requested the ontology authors to comment on the issues. However, for some ontologies we were unable to obtain substantial responses from the respective authors. So we could not discuss some issues in detail with them.
The decision upon the correctness of values is difficult in the case of conversion factors. Though it is usually easy to identify a number that is way off, certain differences in rounded values are harder to spot and verify. Some stem from minor deviations in the definitions for units of the same name, but belonging to different systems of units. Others, however, can be traced back to varying degrees of precision used by the ontology authors. Furthermore, as for some conversions no precise value can be given using floating point arithmetics,27
E.g., the conversion factor between degree Fahrenheit and Kelvin, which equals
As previously noted, the coverage of concepts and individuals by the different ontologies is diverse. Therefore, the overlap for some concepts is limited. As a consequence, some characteristics that might be of interest in the ontology selection process could not be acquired to a meaningful degree and hence are left out for the time being. Examples include dimensions, the distribution of units over the various fields of application or the number of compound units. In conjunction with the relatively small overlap in units as shown in Table 4, this would not result in any reliable comparison of the different ontologies.
In the development of the implementation, some errors were discovered which did not lead to a separate automatic script. For example, some natural language descriptions were attached to the wrong individual or contained typos and wrong information. Natural language processing would be required to automatically detect this, which is outside the scope of this work.
The evaluation of the nine ontologies or knowledge bases uncovered several modeling pitfalls in the measurement unit domain. In this section we try to give suggestions on how to avoid them.
Given that in most cases the offset value is zero, the problem is usually reduced to two reasonable interpretations. However, two ontologies (OBOE and SWEET) used more than one interpretation within their conversion definitions. This highlights the importance of a proper definition and its documentation for error prevention and later usage. Ideally, the modeling approach allows only one reasonable interpretation. The authors of OM 1 employed definition individuals to model conversion that allow only one interpretation:
However, in favor of a leaner structure, the additional definition individuals have been removed in OM 2.
Conclusion
We presented the first in-depth evaluation of unit ontologies considering individuals and included facts. We evaluated eight major ontologies for measurement units and the relevant parts of the Wikidata corpus. The gathered information is important for projects that intend to use a unit ontology as it accelerates the decision making process in selecting a suitable ontology.
The evaluation is based on an extensible collection of scripts. Due to the modular nature of the implementation, it can easily be extended by adding further scripts for new checks and comparisons or by adding other ontologies to be evaluated. The implementation [20] and the presented results [21] are publicly available. Every interested party is welcome to use, review or improve them. This way, both developers as well as users of unit ontologies now and in the future can use these results to choose or improve their ontologies.
The analysis provided not only statistical information about the ontologies, but also highlighted several issues within. The respective ontology authors were contacted and this led to at least three new releases of the analyzed ontologies which fixed the reported issues. As a byproduct, a mapping between the evaluated ontologies was created that can be used to integrate or migrate between the involved ontologies.
During the analysis we identified several classes of issues concerning the development of ontologies – not limited to the domain of measurement units. We hope that the characterization of this issue classes will help ontology authors to prevent them in future.
Our future work will focus on a more detailed analysis of Wikidata. Major challenges are the detection of wrong labels in the wealth of more than 300 different languages and the mapping of identical entities with disjoint label language sets.
Footnotes
Acknowledgements
Part of this work was funded by DFG in the scope of the LakeBase project within the Scientific Library Services and Information Systems (LIS) program. We specially thank the ontology author Hajo Rijgersberg (OM) for the feedback on our work. Likewise, we thank the reviewers Steve Ray, Hajo Rijgersberg and one anonymous reviewer for many helpful comments on earlier drafts of this manuscript.