
Abstract
Knowledge bases are in widespread use for aiding tasks such as information extraction and information retrieval, for example in Web search. However, knowledge bases are known to be inherently incomplete, where in particular tail entities and properties are under-represented. As a complimentary data source, embedded entity markup based on Microdata, RDFa, and Microformats have become prevalent on the Web and constitute an unprecedented source of data with significant potential to aid the task of knowledge base augmentation (KBA). RDF statements extracted from markup are fundamentally different from traditional knowledge graphs: entity descriptions are flat, facts are highly redundant and of varied quality, and, explicit links are missing despite a vast amount of coreferences. Therefore, data fusion is required in order to facilitate the use of markup data for KBA. We present a novel data fusion approach which addresses these issues through a combination of entity matching and fusion techniques geared towards the specific challenges associated with Web markup. To ensure precise and non-redundant results, we follow a supervised learning approach based on a set of features considering aspects such as quality and relevance of entities, facts and their sources. We perform a thorough evaluation on a subset of the Web Data Commons dataset and show significant potential for augmenting existing knowledge bases. A comparison with existing data fusion baselines demonstrates superior performance of our approach when applied to Web markup data.
Introduction
Knowledge bases (KBs) such as Freebase [3] or YAGO [36] are in widespread use to aid a variety of applications and tasks such as Web search and Named Entity Disambiguation (NED). While KBs capture large amounts of factual knowledge, their coverage and completeness vary heavily across different types or domains. In particular, there is a large percentage of less popular (long-tail) entities and properties that are under-represented. For instance, Freebase is missing statements for 63.8% (Wikidata for 60.9% and DBpedia for 49.8%) of all entities considering a selected set of properties used to describe books, such as language, publisher or number of pages (see Section 3). Here, gaps are in particular observable for less popular books or attributes, such as translator or number of pages.
Recent efforts in knowledge base augmentation (KBA) aim at exploiting data extracted from the Web to fill in missing statements. These approaches extract triples from Web documents [10], or exploit semi-structured data from Web tables [30,31]. After extracting values, data fusion techniques are used to identify the most suitable value (or fact) from a given set of observed values, for example, the correct director of a movie from a set of candidate facts extracted from the Web [11]. To this end, data fusion techniques are fundamental when attempting to solve the KBA problem from observed Web data.
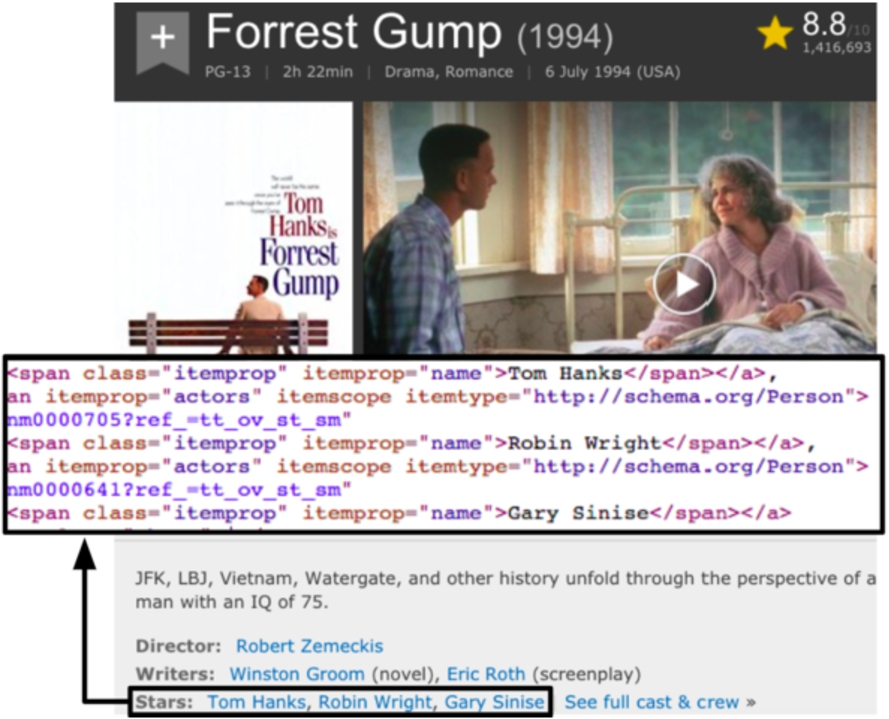
Example of embedded entity annotation unsing structured markup of Web pages.
Although the extraction of structured data from Web documents is costly and error-prone, the recent emergence of embedded and structured Web markup has provided an unprecedented source of explicit entity-centric data, describing factual knowledge about entities contained in Web documents. Figure 1 shows an example of a web page containing entity markup, where explicit entity information about the actor Tom Hanks is embedded in a machine readable format. Building on standards such as RDFa,1
RDFa W3C recommendation: http://www.w3.org/TR/xhtml-rdfa-primer/.
Through its wide availability, markup lends itself as a diverse source of input data for KBA. In particular when attempting to complement information about long-tail attributes and entities, the diversity and scale of markup provide opportunities for enriching existing knowledge bases [23].
However, the specific characteristics of facts extracted from embedded markup pose particular challenges [40]. In contrast to traditional, highly connected RDF graphs, markup statements mostly consist of isolated nodes and small subgraphs, where entity descriptions often describe the same or highly related entities, yet are not linked through common identifiers or explicit links. For instance, in the WDC2013 corpus, 18,000 disconnected entity descriptions are retrieved when querying the label of instances of type schema:Product for ‘Iphone 6’. Also, extracted markup statements are highly redundant and often limited to a small set of highly popular predicates, such as schema:name. Another challenge is data quality, as data extracted from markup contains a wide variety of errors, ranging from typos to the frequent misuse of vocabulary terms [21]. In this work, we introduce KnowMore, an approach based on data fusion techniques which exploits markup crawled from the Web as diverse source of data to aid KBA. Our approach consists of a two-fold process, where first, candidate facts for augmentation of a particular KB entity are retrieved through a combination of blocking and entity matching techniques. In a second step, correct and novel facts are selected through a supervised classification approach and an original set of features. We apply our approach to the WDC2015 dataset and demonstrate superior performance compared to state-of-the-art data fusion baselines. We also demonstrate the capability for augmenting three large-scale knowledge bases, namely Wikidata,5
Freebase and DBpedia6 through markup data based on our data fusion approach. The main contributions of our work are threefold:The paper is structured as follows: Section 2 discusses related work on knowledge base augmentation and data fusion, while Section 3 introduces the motivation, problem statement and an overview of our approach. Section 4 and 5 describe the detailed steps for entity matching, data fusion and deduplication, while Section 6 describes the experimental setup, followed by the presentation of the results in Section 7. We assess the potential to generalise our supervised approach across distinct types in Section 8 and provide a thorough discussion of the potential of markup data for KBA as well as limitations of our work in Section 9 and conclude by proposing future work (Section 10).
In this section we review related literature. We focus on two main lines of work, namely knowledge base augmentation and data fusion as the most closely related fields to our work.
Knowledge base augmentation (KBA)
The main goal of KBA is to discover facts pertaining to entities and augmenting Knowledge Bases (KBs) with these facts [15,38].
Some previous works have proposed to augment KBs through inference on existing knowledge, i.e. KB statements. Such works typically focus on predicting the type [19] of an entity or finding new relations based on existing data [5,6,34]. Other prior works are more closely relevant to our problem setup; in that they focus on predicting relations with external data. Notable works propose the use of Wikipedia as a text corpus annotated with entities, search for patterns based on existing KB relations, and further apply the patterns to find additional relations for DBpedia [1] or Freebase [25]. News corpora have also been used for augmenting DBpedia through similar approaches [14]. Paulheim et al. [26] proposed to identify common patterns of instances in Wikipedia list pages and apply the patterns to add relations to the remaining entities in the list. Dong et al. proposed ‘Knowledge Vault’ [10], a framework for extracting triples from web pages, aimed at constructing a KB from Web data. Dutta et al. [13] focus on the mapping of relational phrases such as facts extracted by ‘Nell’ and ‘Reverb’ to KB properties. Furthermore, they group the same semantic relationships represented by different surface forms together through Markov clustering. Recent works by Ritze et al. use relational HTML tables available on the Web to fill missing values in DBpedia [30,31]. The authors propose to first match the tables to the DBpedia entities, and then compare several data fusion strategies such as voting and the Knowledge-Based Trust (KBT) score to identify valid facts.
Ristoski et al. proposed an approach to enrich product ads with data extracted from the Web Data Commons [29]. The approach extracts attribute-value pairs from plain text and matches them to database entities with supervised classification models. The notable methods described in previous works are tailored to specific data sources, which have different characteristics compared to markup data. Hence, merely adopting the existing methods to cater for markup data is not sufficient. However, we have revised and adopted some of the features in our proposed approach.
Other works suggest using the whole Web as a potential data corpus through search engines [16,39]. QA-based approaches are often designed to facilitate the filling of values of a specific set of properties, and rely on manually created templates. This limits their application to a constrained sets of properties.
Existing works typically assume that, there is only one true value for a property when resolving conflicts. In contrast, we aim for higher recall by allowing multiple (non-redundant) correct values, catering for the fact that multiple-cardinality properties are wide-spread. Another limitation of existing KBA works is that the novelty of the discovered facts is ignored; there is an overlap between the result and the facts existing in a KB. On the contrary, our approach aims at providing correct and novel results that are of immediate value to the KB.
Data fusion
Data fusion is defined as “the process of fusing multiple records representing the same real-world object into a single, consistent, and clean representation” [2]. In the context of the Semantic Web, previous works on data fusion can be categorized into two classes – heuristic-based and probability-based.
Whereas previous works focus only on the correctness of the source and assign equal weights to all the facts from the same source, in contrast, we not only consider the source quality but also features of the predicates, facts and entities. Hence, distinct facts from the same source are classified differently, depending on multiple feature dimensions. Thus, through a more fine-grained classification, our data fusion approach is able to improve both precision and recall. Another difference is that our query-centric data fusion approach does not require the fusion of the entire dataset after partial changes to the corpus, but can be applied iteratively over specific subsets.
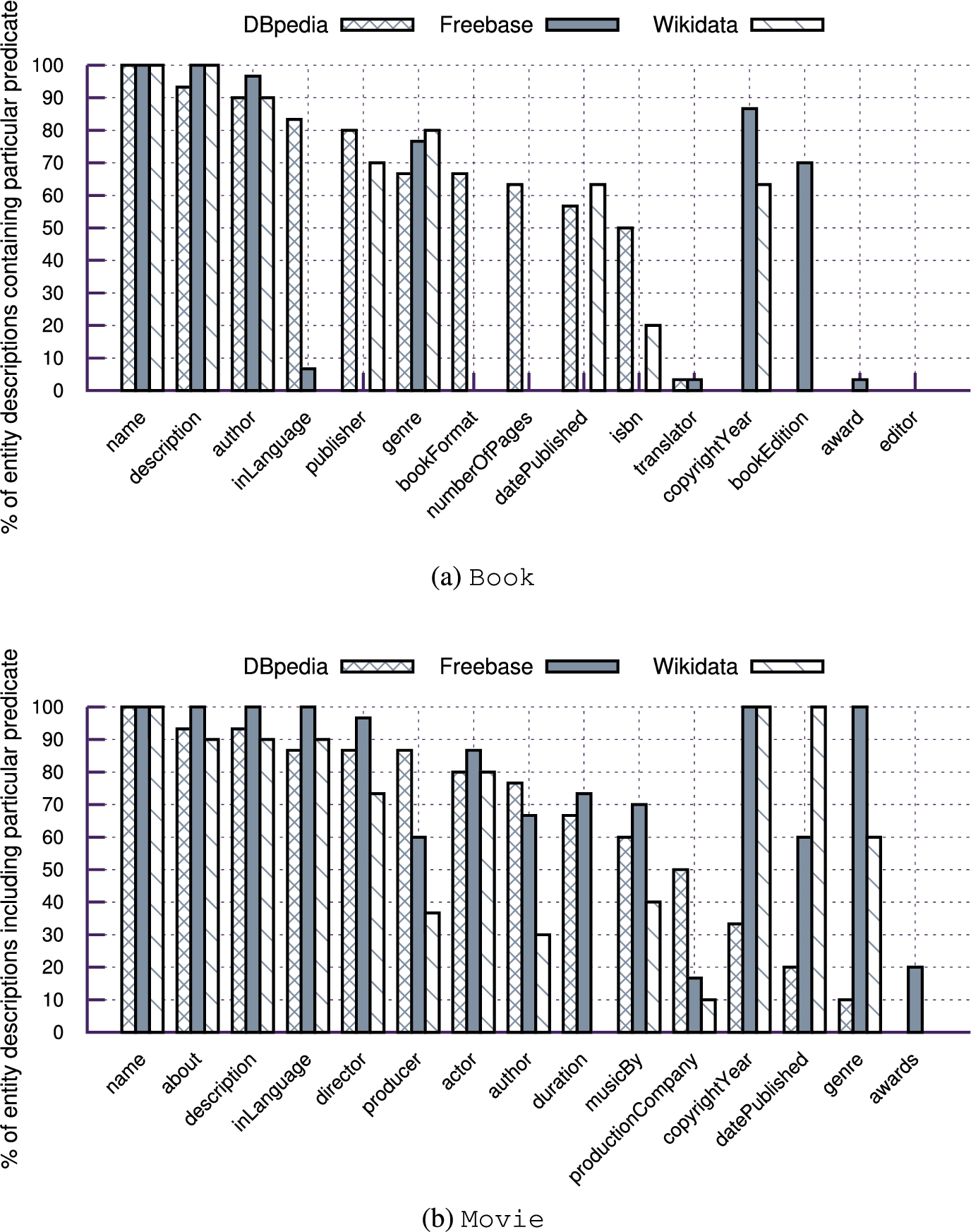
Proportion of book and movie instances per KB that include selected popular predicates.
Our recently published work presents an entity summarization approach that retrieves entities from WDC and selects distinct facts to build entity descriptions based on clustering [42]. Additional recent work [41] proposes a data fusion approach focused on ensuring correctness of facts obtained from noisy entity descriptions in Web markup. While the focus of the former work was on deduplication, the main focus of the latter was correctness. In contrast, this paper proposes a complete two-step pipeline aiming at obtaining correct and non-redundant facts which augment existing KBs.
Motivation
Previous works [9,32,40] have investigated the nature of several type-specific subsets of Web markup, namely bibliographic data, metadata about learning content, books and movies. These works assess markup data on several dimensions, such as data quality, the source distribution and the schema usage. Results show the complementary nature of markup data when compared to traditional knowledge bases, where the extent of additional information varies strongly between types.
For a preliminary analysis of DBpedia, Freebase and Wikidata, we randomly select 30 Wikipedia entities of type Movie and Book and retriev the corresponding entity descriptions from all three KBs. We select the 15 most frequently populated properties for each type and provide equivalence mappings across all KB schemas as well as the schema.org vocabulary manually.7
The mappings are online at: http://l3s.de/~yu/knowmore/.
Example of an entity description of entity “Brideshead Revisited” (of type Book) extracted from Web markup
In addition, coverage varies heavily across different properties, with properties such as editor or translator being hardly present in any of the KBs.
Tail entities/types as well as time-dependent properties which require frequent updates, such as the award of a book, are prevalent in markup data [23], yet tend to be underrepresented in structured KBs. Hence, markup data lends itself as data source for the KBA task. However, given the specific characteristics of markup data [40], namely the large amount of coreferences and near-duplicates, the lack of links and the variety of errors, data fusion techniques are required which are tailored to the specific task of KBA from Web markup.
For the purpose of this work, an entity description is considered a semi-structured representation of an actual entity, where the latter is either a physical (e.g. a person) or an abstract notion (e.g. a category or theory). Entity descriptions which represent the same entity are considered to be coreferences.
In particular, our work is concerned with entity descriptions extracted from structured Web markup of Web documents. We refer to such a dataset as M, where the WDC dataset is an example. Data in M consists of entity descriptions
For simplicity, we use http://example.url to represent the original URL:
There exist
We define the task of augmenting a particular entity description
For a query entity q that is represented through an entity description
Note that
A fact is correct with respect to query entity q, i.e. consistent with the real world regarding query entity q according to some ground truth (Section 6).
A fact represents novel, i.e. not duplicate or near-duplicate, information with regard to the entity description
The predicate
As an illustrative example, let q be the book Brideshead Revisited. In a given KB, such as DBpedia, there is an entity description9
Our approach (KnowMore) for addressing the KBA problem defined above consists of two steps as shown in Figure 3, namely (i) entity matching, and (ii) data fusion. We introduce the intuition behind each step below and describe the actual method in the following sections.
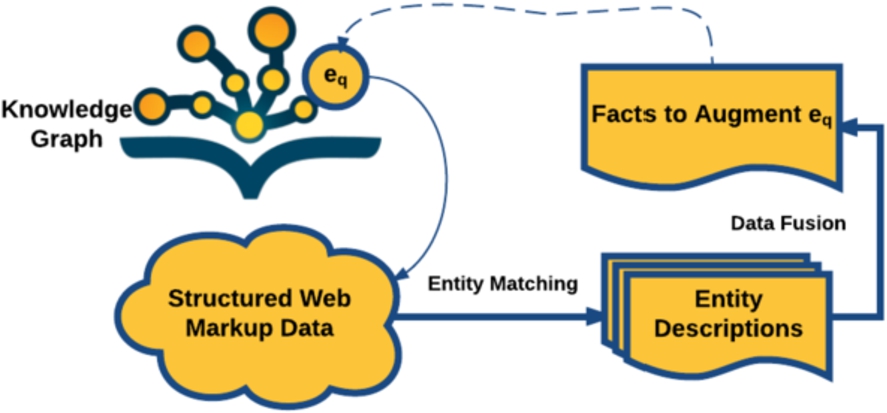
Overview of pipeline.
Data cleansing to improve general data quality. Blocking with standard BM25 entity retrieval on the value of property name of all indexed entity descriptions to reduce the search space. This step results in a set of candidate entity descriptions Validation of each entity description
Hence, we retrieve the set E containing candidate entity descriptions represented through facts
For clarity, we summarize the notations used for identifying each step of the
Summary of involved steps
We describe each step of the approach in the following two sections in detail.
The entity matching step (
Data cleansing
This initial data cleansing step aims at (i) resolving object references and (b) fixing common errors [21] to improve overall usability of the data.
While schema.org property range definitions are not bound in a strict way but constitute mere recommendations, previous studies [9] observe a strong tendency towards statements which refer to literals rather than objects, i.e. URIs. For instance, within a markup corpus of 44 million quads, 97% of transversal properties referred to literals rather than URIs/objects, despite the fact that only 64% of quads involved properties where schema.org recommends literals as property range [9]. Given this prevalence of literals in Web markup and the need to homogenise entity descriptions for further processing, we resolve object references into literals by replacing object URIs with the labels of the corresponding entity.
In addition, based on earlier work [21] which studied common errors in Web markup, we implement heuristics and apply these to E as a cleansing step thereby improving the quality of the data. In particular, we implemented the heuristics as proposed in [21] to:
Applying these heuristics improves the performance of the subsequent step by providing a wider and higher quality pool of candidates.
Blocking
Blocking is typically used as a pre-processing step for entity resolution to reduce the number of required comparisons by placing potentially relevant entity descriptions, i.e. potential coreferences, into the same block so that the entity resolution algorithm is applied to entity descriptions within the same block only [7].
Related work [37] shows that string comparison between labels of markup entities is an efficient way for obtaining potential coreferences, whereas the Lucene BM25 retrieval approach has been used successfully by previous works on entity resolution as summarized by [7].
Therefore, we implement the blocking step through entity retrieval using the BM25 retrieval model, i.e. a probabilistic ranking function used to rank matching documents according to their relevance to a given search query, to reduce the search space. We created an index for each type-specific subset using Lucene, and then use the label of
Given that the name10
property is one of the most frequently populated properties for the considered entity types, i.e. 90.2% of entity descriptions of type Book and 86.8% of entity descriptions of Movie are annotated with a name, entity retrieval on the name/label ensures comparably high recall during the blocking step.For instance, considering the query “Brideshead Revisited” (of type Book), as part of the blocking step we query the Lucene index and obtain 1,657 entity descriptions consisting of 15,940 quads. An excerpt of the result set is shown in Table 3.
Excerpt from the result set (1,657 entity descriptions in total) for the query “Brideshead Revisited” (of type Book) after blocking
When attempting to match entities, one can build on the observation that particular property-value pairs can be considered near-unique identifiers for a specific entity, so-called pseudo-key properties. For instance, taxID can be considered one of the pseudo-key property for instances of type Person, and isbn for instances of type Book. However, as studied by Meusel et al. [23], resolving coreferences simply through pseudo-key properties does not produce sufficient results when applied on sparsely described and heterogeneous entity descriptions obtained from Web markup.
Thus, we adapt the entity matching approach described in [29] to filter out noise in
In order to compute the similarity for each property, we consider all properties as attributes of the feature space
In order to compute
We then train a supervised classification model, to make the decision whether or not
The final result of the entity matching step is the set of coreferring entity descriptions
Returning to our running example “Brideshead Revisited”, after removing the unmatched entity descriptions from the blocking result through the entity matching step, there are 44 matched entity descriptions remaining in the result set. Some examples are shown in Table 4, where, for instance, _:node3 had been removed since it refers to the stage play rather than the book and does not match entity q.
Excerpt from result set (44 entity descriptions in total) for the query, “Brideshead Revisited” (of type Book) after entity matching
This step aims at fusing candidate entity descriptions in E by detecting the correct and novel facts
Correctness – supervised classification
Features for supervised data fusion from markup data
Features for supervised data fusion from markup data
†-features extracted based on clustering result.
The first step (
While we aim to detect the correctness of a fact, we consider characteristics of the source, that is the Pay-Level-Domain (PLD, i.e. the sub-domain of a public top-level domain, which Website providers usually pay for), from which a fact originates, the entity description, the predicate term as well as the fact itself. The four different categories are described below.
Given that our candidate set contains vast amounts of near-duplicate facts, we approach the problem of identifying semantically equivalent statements through clustering of facts which use varied surface terms for the same or overlapping meanings. We employ the X-Means algorithm [27], as it is able to automatically determine the number of clusters. This clustering step aims at grouping or canonicalizing different literals or surface forms for specific object values. For instance, Tom Hanks and T. Hanks are equivalent surface forms representing the same entity. To detect duplicates and near-duplicates, we first cluster facts that have the same predicate p into n clusters
From the computed features we train the classifier for classifying the facts from F into the binary labels {‘correct’, ‘incorrect’}. More details about the training and evaluation through 10-fold cross-validation are presented in Section 7.2. The ‘correct’ facts form a set
Again returning to our running example, after removing wrong facts from the candidate facts, such as datePublished: 1940 through the classification step, we obtain 37 correct facts in the result set for the query Brideshead Revisited, type:(Book). An excerpt of the resulting facts are shown in Table 6.
Excerpt from result set (37 distinct correct facts) for query “Brideshead Revisited” (of type Book) for
A fact f is considered to be novel with respect to the KBA task, if it fulfills the conditions: i) is not duplicate with other facts selected from our source markup corpus M, ii) is not duplicate with any facts existing in the KB. Each of these two conditions corresponds to a deduplication step.
In our running example, the fact author: Waugh, Evelyn is removed during the deduplication with regard to M as it is a duplicate of fact author: Evelyn Waugh, which has been selected as more representative.
With respect to the KBA task, consider the augmentation of the example entity “Brideshead Revisited” (of type Book) as illustrated in Table 7. The example facts #2 and #3 would be valid results of the KBA task for DBpedia since they are novel, while only fact #2 is a valid augmentation for Freebase and Wikidata as it is the only fact that is novel.
Novelty of correct, distinct facts with regard to KBs for the query “Brideshead Revisited” (of type Book)
Novelty of correct, distinct facts with regard to KBs for the query “Brideshead Revisited” (of type Book)
Note that our deduplication step considers and supports multi-valued properties. By relying on the clustering features, computed during the fusion step, we select facts from multiple clusters (corresponding to multiple predicates) as long as they are classified as correct. As documented by the evaluation results (Section 7), this does not negatively affect precision while improving recall for multi-valued properties.
Data
The full list of entities can be found online 13 . An analysis of the completeness of these obtained entity descriptions is shown in Fig. 2 in Section 3.1.
This section describes the ground truth used for training and testing together with the evaluation metrics used for assessing performance in different tasks.
Ground truth via crowdsourcing
Level 3 workers on CrowdFlower have the best reputation and near perfect accuracy in hundreds of previous tasks.
We consider distinct metrics for evaluating each step of our approach.
Furthermore, we demonstrate the potential of our approach for augmenting a given KB by measuring the coverage gain, which we introduce as a means to measure the capacity of our approach to populate gaps in existing KBs (Section 3.1). The coverage gain of predicate p is computed as the percentage of entity descriptions having p populated through the
Configuration & baselines
Performance of
Performance of
In this section, we present experimental results obtained through the setup described in the previous sections.
Entity matching
As the entity matching step (
As presented in Table 8, our supervised matching approach
Correctness – data fusion
The results for
The presented F1 score of the
The reason that the baseline
The
A more detailed discussion of the potential impact on the KBA task is provided in Section 9, investigating the KBA potential beyond the narrow definition of the investigated task of this setup, e.g. by augmenting additional predicates not already foreseen in a given KB schema or to populate KBs with additional entities.
We ran 20 iterations of 10-fold cross validation for different baselines and our approach in order to test the statistical significance of our results, as suggested in [8]. We conducted paired T-tests and employed Bonferroni’s correction for Type-I error inflation. We found that all comparisons were statistically significant at the 95% confidence interval (
Novelty
This section presents the evaluation results for the deduplication steps introduced in Section 5.2.
Diversity. Table 10 presents the evaluation result before (
Diversity
before and after deduplication
Diversity
The
Novelty with respect to KB. The results before (
Novelty of
Since our approach is not aware of the total number of novel facts for a particular entity description on the Web a priori, in this evaluation, we consider all the novel facts in
Consider
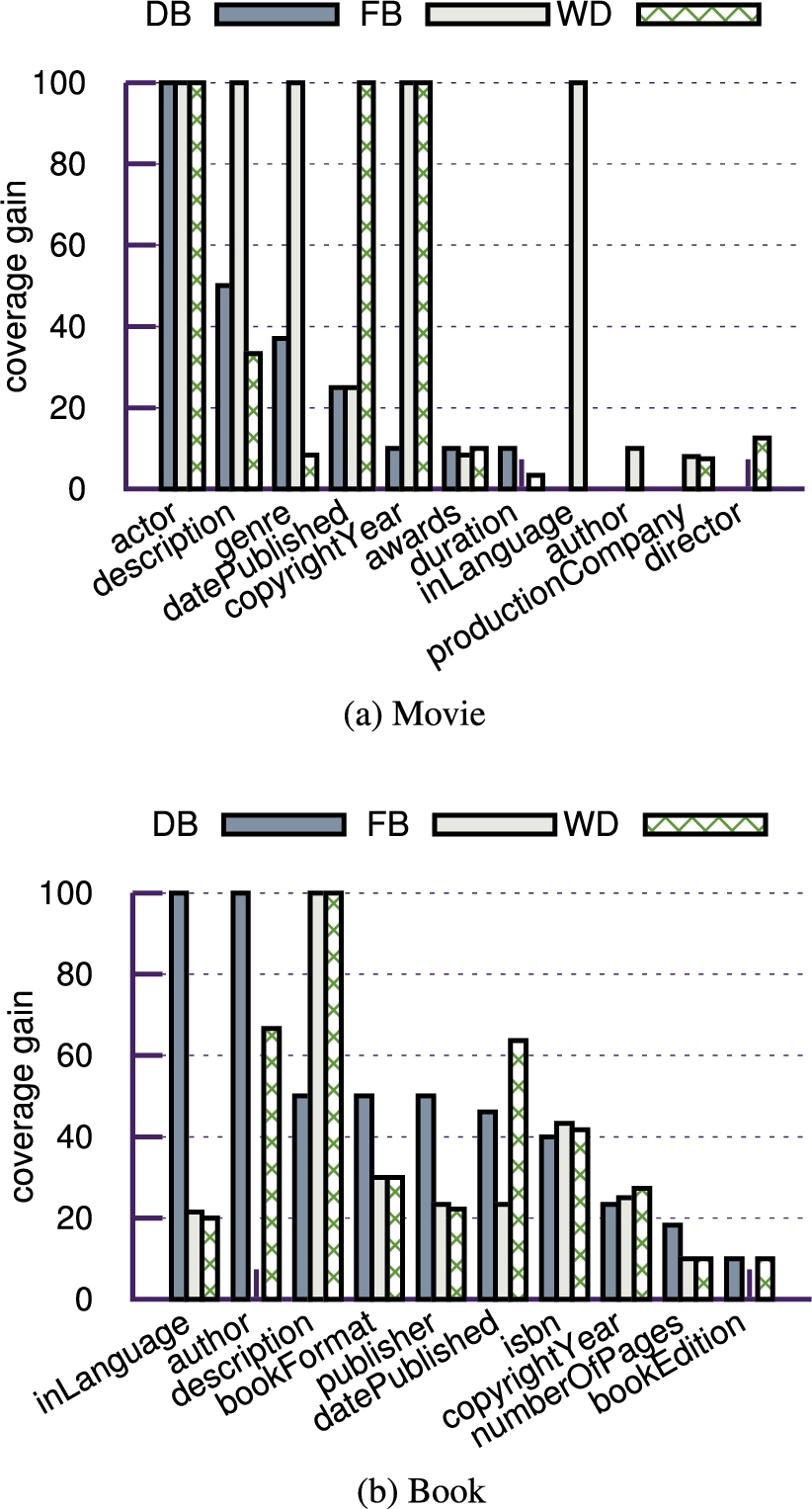
Proportion of augmented entity descriptions with
This section discusses the coverage gain, as an indicator of the
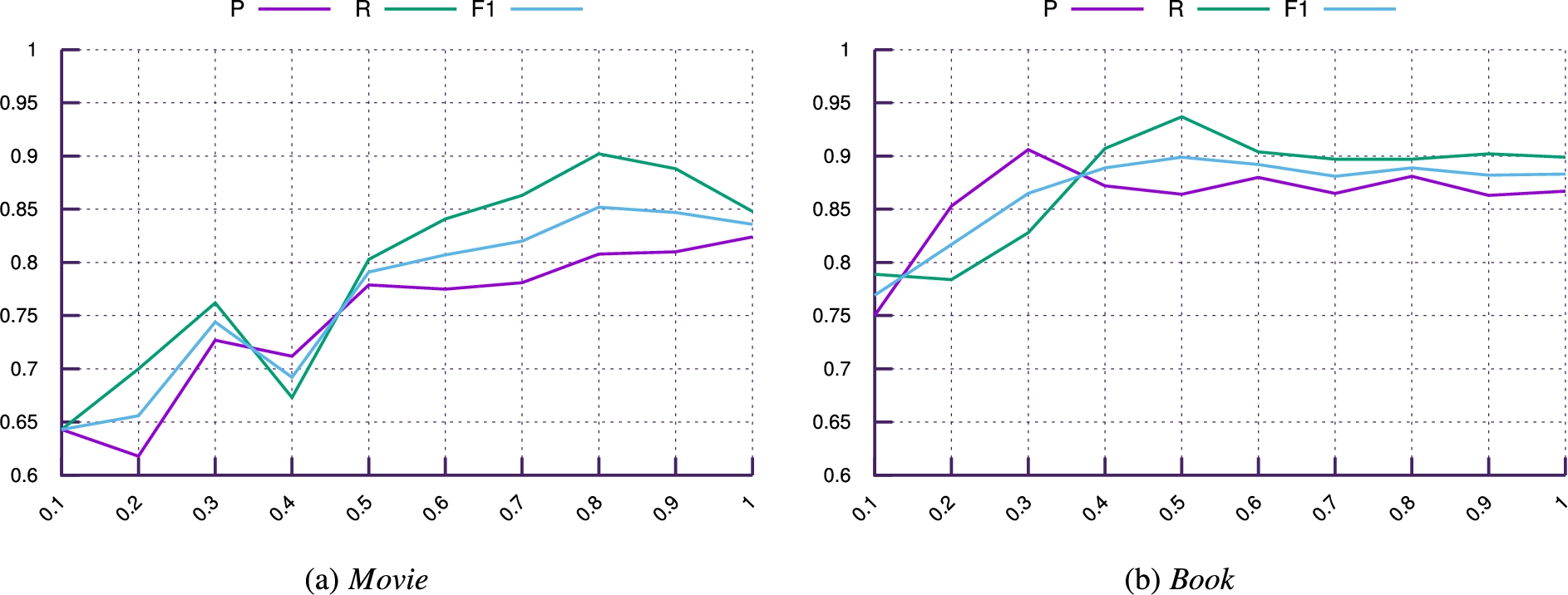
P, R and F1 score using different size of the training data for
Figure 4 shows the coverage gain on the previously empty slots as shown in Fig. 2 per predicate and KB for our selected 30 entities (per type). Based on the evaluation result, the
For a more thorough discussion of the KBA potential of the
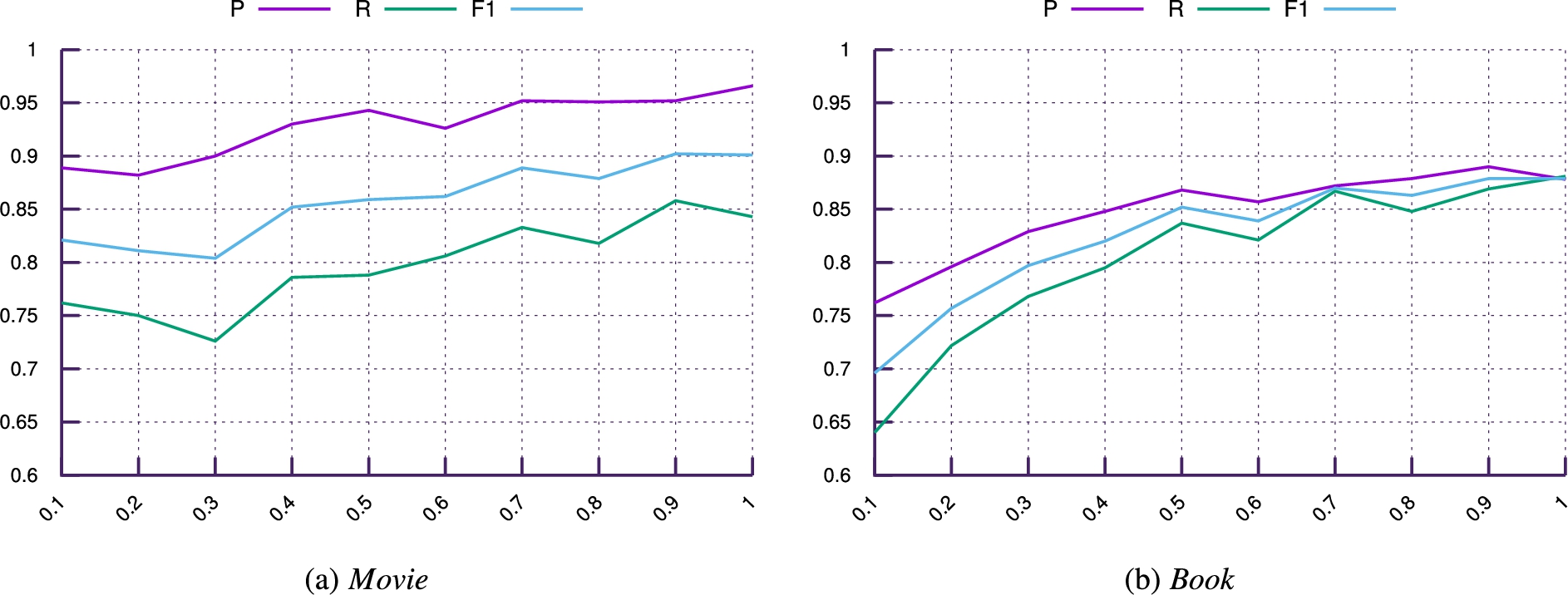
P, R and F1 score using different size of training data for
As introduced earlier, our approach has been trained on two specific types (Book and Movie). The intuition behind this choice is that (i) different properties have varied contribution on different types when computing the similarity between entity descriptions in the entity matching step and (ii) particular features such as predicate term
As described in Section 6.2, our ground truth consists of judgments for 217 (298) entity descriptions for Movie (Book) entities for the entity matching step
Figure 5 presents the results for
Similar characteristics can be observed for the
Model performance across types
In this section, we assess the performance of
Discussion & limitations
Potential of KBA from web markup
Beside the specific KBA task evaluated in this paper, where we aim at (i) augmenting existing entities in a given KB by (ii) populating a given set of properties from a given KB schema for these entities, markup data shows large potential to augment KBs with properties and entities not yet present in KBs. Investigating the data from our two datasets (Movie, Book) and another set of 30 randomly selected entities of type Product, we observe that a large proportion of statements in the WDC dataset involve properties not yet present in any of the KB schemas. For instance, for movies (books), 62.5% (66.8%) of entity descriptions in F contain facts not yet present in our set of mapped predicates. Comparing product descriptions from F, we detect 20.6% statements containing properties not yet present in the DBpedia ontology at all (verified through manual inspection).
In order to better highlight the potential of Web markup data to support knowledge base augmentation, we apply
To assess performance in such cases, we randomly select 30 names of products under the requirement that each appears in at least 20 different PLDs in WDC, to ensure that there is sufficient consensus on the name being a legitimate product title. Manual inspection confirmed that none of such randomly selected products is represented in DBpedia.
By running the
Data fusion performance for Product entities
Data fusion performance for Product entities
Results indicate that the performance gain of our approach is particularly evident on such long-tail entities as represented in our Product dataset.
Results demonstrate that
In contrast to related KBA approaches such as [16] or [39], it is worth noting that our approach is trained for particular entity types only, not towards particular properties, as is the case with the aforementioned approaches. Hence,
Performance strongly differs between query sets, and hence, type-specific markup datasets, what presumably is caused by the variance in quality and quantity of facts in the WDC corpus between distinct types. Particular challenges arise from entities with a large amount of coreferences, where data usually originates from a wide variety of sources with varying degrees of quality. Compared to the baselines, our results indicate a particular strong performance gain of our approach in such cases.
Another limitation is our exclusive focus on schema.org statements. This constraint is motivated by the costliness of providing high-quality schema mappings between markup statements and three KBs and the fact that schema.org is the vocabulary of most widespread use [23]. While schema.org adopters usually are motivated by the goal to improve their search result rankings, one assumption is that other vocabularies might show a different distribution of types and predicates, due to distinct motivations. This deserves deeper investigation as part of future work.
In this context, it is worth noting that our KBA task setup ignored a large part of the markup data, i.e. 49.3% of facts in our type-specific subsets do not involve any of our selected schema.org properties. To consider other vocabularies, we are currently aiming at including a preliminary schema matching step with the intention of improving recall further.
Another important aspect concerns the temporal nature of fact correctness, specifically for highly dynamic predicates, such as the price tag of a particular product. While we do not consider temporal features as such, we argue that the dynamic nature of markup annotations is well-suited to augment particularly dynamic statements. This suggests particular opportunities for updating or complementing KBs with dynamic knowledge sourced from Web markup.
Conlusions and future work
We have introduced
Our evaluation of the KBA task on two types demonstrates a strong potential to complement traditional knowledge bases through data sourced from Web markup. We achieve a 100% coverage for particular properties, while providing substantial contributions to others. In addition, we demonstrate the capability to augment KBs with additional entity descriptions, particularly about long-tail entities, where for randomly selected entities of type Product from WDC, we are able to generate new entity descriptions with an average size of 6.45 facts.
While our experiments have exploited the WDC corpus, we will consider more targeted Web crawls, which are better suited to augment entities (or properties) of a particular type or discipline. Here, targeted datasets which are retrieved with the dedicated aim to suit a particular KBA task are thought to further improve the KBA performance. Another identified direction for future research is the investigation of the complementary nature of other sources of entity-centric Web data, for instance, data sourced from Web tables, when attempting to augment KBs.
Additional objectives for future work have surfaced during the experiments. For instance, identity resolution problems might occur during the matching step originating from different meanings of a particular entity. Current work aims at pre-clustering result sets into distinct entity meanings, from which we will be able to augment distinct disambiguated entity descriptions. Finally, we are investigating an iterative approach which enables the generation of entity-centric knowledge bases of a certain length (hop-size), rather than flat entity descriptions. This would further facilitate research into the generation of domain or type-specific knowledge bases from distributed Web markup.
Footnotes
Acknowledgements
This work has been partially funded by the European Union’s Horizon 2020 research and innovation program (Grant No. 687916 – AFEL project). The authors would like to thank Robert Meusel for his inspiring feedback and support with the presented work.