
Abstract
In this paper we are concerned with developing information extraction models that support the extraction of common sense knowledge from a combination of unstructured and semi-structured datasets. Our motivation is to extract manipulation-relevant knowledge that can support robots’ action planning. We frame the task as a relation extraction task and, as proof-of-concept, validate our method on the task of extracting two types of relations: locative and instrumental relations. The locative relation relates objects to the prototypical places where the given object is found or stored. The second instrumental relation relates objects to their prototypical purpose of use. While we extract these relations from text, our goal is not to extract specific textual mentions, but rather, given an object as input, extract a ranked list of locations and uses ranked by ‘prototypicality’. We use distributional methods in embedding space, relying on the well-known skip-gram model to embed words into a low-dimensional distributional space, using cosine similarity to rank the various candidates. In addition, we also present experiments that rely on the vector space model NASARI, which compute embeddings for disambiguated concepts and are thus semantically aware. While this distributional approach has been published before, we extend our framework by additional methods relying on neural networks that learn a score to judge whether a given candidate pair actually expresses a desired relation. The network thus learns a scoring function using a supervised approach. While we use a ranking-based evaluation, the supervised model is trained using a binary classification task. The resulting score from the neural network and the cosine similarity in the case of the distributional approach are both used to compute a ranking.
We compare the different approaches and parameterizations thereof on the task of extracting the above mentioned relations. We show that the distributional similarity approach performs very well on the task. The best performing parameterization achieves an NDCG of 0.913, a Precision@1 of 0.400 and a Precision@3 of 0.423. The performance of the supervised learning approach, in spite of having being trained on positive and negative examples of the relation in question, is not as good as expected and achieves an NCDG of 0.908, a Precision@1 of 0.454 and a Precision@3 of 0.387, respectively.
Introduction
Embodied intelligent systems such as robots require world knowledge to reason on top of their perception of the world in order to decide which actions to take. Consider the example of a robot having the task to tidy up an apartment by storing all objects in their appropriate place. In order to perform this task, a robot would need to understand where the “correct” or at least the “prototypical” location for each object is in order to come up with an overall plan on which actions to perform to reach the goal of having each object stored in its corresponding location.
In general, in manipulating objects, robots might have questions such as the following:
Where should a certain object typically be stored?
What is this object typically used for?
Do I need to manipulate a certain object with care?
The answers to these questions require common sense knowledge about objects, in particular prototypical knowledge about objects that, in absence of abnormal situations or specific contextual conditions or preferences, can be assumed to hold.
In this article, we are concerned with extracting such common sense knowledge from a combination of unstructured and semi-structured data. We are in particular interested in extracting default knowledge, that is prototypical knowledge comprising relations that typically hold in ‘normal’ conditions [41]. For example, given no other knowledge, in a normal situation, we could assume that milk is typically stored in the kitchen, or more specifically in the fridge. However, if a person is currently having breakfast and eating cornflakes at the table in the living room, then the milk might also be temporarily located in the living room. In this sense, inferences about the location of an object are to be regarded as non-monotonic inferences that can be retracted given some additional knowledge about the particular situation. We model such default, or prototypical, knowledge through a degree of prototypicality, that is, we do not claim that the kitchen is ‘the prototypical location’ for the milk, but instead we model that the degree of prototypicality for the kitchen being the default location for the milk is very high. This leads naturally to the attempt to computationally model this degree of prototypicality and rank locations or uses for each object according to this degree of prototypicality. We attempt to do so following two approaches. On the one hand, we follow a distributional approach and approximate the degree of prototypicality by the cosine similarity measure in a space into which entities and locations are embedded. We experiment with different distributional spaces and show that both semantic vector spaces as considered within the NASARI approach as well as embedded word representations computed on unstructured texts as produced by predictive language models such as skip-grams provide already a reasonable performance on the task. A linear combination of both approaches has the potential to improve upon both approaches in isolation. We have presented this approach before including empirical results for the
The prototypical knowledge we use to train and evaluate the different methods is on the one hand based on a crowdsourcing experiment in which users had to explicitly rate the prototypicality of a certain location for a given object. On the other hand, we also use extracted relations from ConceptNet and the SUN database [70]. Objects as well as candidate locations, or candidate uses in the case of the instrumental relation, are taken from DBpedia. While we apply our models to known objects, locations and uses, our model could also be applied to candidate objects, locations and uses extracted from raw text.
We have different motivations for developing such an approach to extract common sense knowledge from unstructured and semi-structured data.
First, from the point of view of cognitive robotics [39] and cognitive development, acquiring common sense knowledge requires many reproducible and similar experiences from which a system can learn how to manipulate a certain object. Some knowledge can arguably even not be acquired by self experience as relevant knowledge also comprises the mental properties that humans ascribe to certain objects. Such mental properties that are not intrinsic to the physical appearance of the object include for instance the intended use of an object. There are thus limits to what can be learned from self-guided experience with an object. In fact, several scholars have emphasized the importance of cultural learning, that is of a more direct transmission of knowledge via communication rather than self-experience. With our approach we are simulating such a cultural transmission of knowledge by allowing cognitive systems, or machines in our case, to acquire knowledge by ‘reading’ texts. Work along these lines has, for instance, tried to derive plans on how to prepare a certain dish by machine reading descriptions of household tasks written for humans that are available on the Web [66]. Other work has addressed the acquisition of scripts from the Web [54].
Second, while there has been a lot of work in the field of information extraction on extracting relations, the considered relations differ from the ones we investigate in this work. Standard relations considered in relation extraction are: is-a, part-of, succession, reaction, production [11,52] or relation, parent/child, founders, directedBy, area_served, containedBy, architect, etc. [56], or albumBy, bornInYear, currencyOf, headquarteredIn, locatedIn, productOf, teamOf [6]. The literature so far has focused on relations that are of a factual nature and explicitly mentioned in the text. In contrast, we are concerned with relations that are (i) typically not mentioned explicitly in text, and (ii) they are not of a factual nature, but rather represent default or prototypical knowledge. These are thus quite different tasks.
We present and compare different approaches to collect manipulation-relevant knowledge by leveraging textual corpora and semi-automatically extracted entity pairs. The extracted knowledge is of symbolic form and represented as a set of (
The paper is structured as follows: In Section 2, we discuss related work from the fields of relation extraction, knowledge base population and knowledge bases for robotics. In Section 3, we describe our approach to relation extraction in general and continue by introducing two models based on semantic relatedness as a ranking measure. These two models have been described in earlier work [5] and are described here again for the sake of completeness and due to the fact that we compare this previous work to a novel approach we introduce in Section 3.3. The model introduced in Section 3.3 is a supervised model that is trained to extract arbitrary relations. Afterwards, in Section 4, we present our datasets that are used for training and evaluating the proposed models. We evaluate and compare all models in Section 5, showing that both unsupervised approaches and their combination perform very well on the task, outperforming two naive baselines. The supervised approach, while being superior with respect to Precision@1, does not show any clear benefit compared to the unsupervised approach, a surprising result.
In Section 6, we exploit insights gained from the evaluation to populate a knowledge base of manipulation-relevant data using the presented semi-automatic methods. Finally, in Section 7, we summarize our results and discuss directions for future work.
Related work
Our work relates to the four research lines discussed below, namely: (i) machine reading, (ii) supervised relation extraction, (iii) encoding common sense knowledge in domain-independent ontologies and knowledge bases, and (iv) grounding of knowledge from the perspective of cognitive linguistics.
The machine reading paradigm In the field of knowledge acquisition from the Web, there has been substantial work on extracting taxonomic (e.g. hypernym), part-of relations [22] and complete qualia structures describing an object [14]. Quite recently, there has been a focus on the development of systems that can extract knowledge from any text on any domain (the open information extraction paradigm [20]). The DARPA Machine Reading Program [1] aimed at endowing machines with capabilities for lifelong learning by automatically reading and understanding texts (e.g. [19]). While such approaches are able to quite robustly acquire knowledge from texts, these models are not sufficient to meet our objectives since: (i) they lack visual and sensorimotor grounding, (ii) they do not contain extensive object knowledge. While the knowledge extracted by our approach presented here is also not sensorimotorically grounded, we hope that it can support planning of tasks involving object manipulation. Thus, we need to develop additional approaches that can harvest the Web to learn about usages, appearance and functionality of common objects. While there has been some work on grounding symbolic knowledge in language [50], so far there has been no serious effort to compile a large and grounded object knowledge base that can support cognitive systems in understanding objects.
Supervised relation extraction While machine reading attempts to acquire general knowledge by reading texts, other works attempt to extract specific relations using classifiers trained in a supervised approach using labeled data. A training corpus in which the relation of interest is annotated is typically assumed (e.g. [11]). Another possibility is to rely on the so called distant supervision approach and use an existing knowledge base to bootstrap the process by relying on triples or facts in the knowledge base to label examples in a corpus (e.g. [27,27,28,63]). Some researchers have modeled relation extraction as a matrix decomposition problem [56]. Other researchers have attempted to train relation extraction approaches in a bootstrapping fashion, relying on knowledge available on the Web, e.g. [7].
Recently, scholars have tried to build models that can learn to extract generic relations from the data, rather than a set of pre-defined relations (see [37] and [8]). Related to these models are techniques to predict triples in knowledge graphs by relying on the embedding of entities (as vectors) and relations (as matrices) in the same distributional space (e.g. TransE [10] and TransH [69]). Similar ideas were tested in computational linguistics in the past years, where relations and modifiers are represented as tensors in the distributional space [3,67].
Ontologies and KB of common sense knowledge DBpedia1
YAGO [62] is an ontology automatically extracted from WordNet and Wikipedia. YAGO extracts facts from the category system and the infoboxes of Wikipedia, and combines these facts with taxonomic relations derived from WordNet. Despite its high coverage, for our goals, YAGO suffers from the same drawbacks as DBpedia, i.e., a lack of knowledge about common objects, that is, about their purpose, functionality, shape, prototypical location, etc.
ConceptNet2
NELL (Never Ending Language Learning) is the product of a continuously-refined process of knowledge extraction from text [48]. Although NELL is a large-scale and quite fine-grained resource, there are some drawbacks that prevent it to be effectively used as a commonsense knowledge base. The inventory of predicates and relations is very sparse, and categories (including many objects) have no predicates.
OpenCyC3
Several projects worldwide have attempted to develop knowledge bases for robots through which knowledge, e.g. about how to manipulate certain objects, can be shared among many robots. Examples of such platforms are the RoboEarth project [68], RoboBrain [58] or KnowRob [65].
While the above resources are without doubt very useful, we are interested in developing an approach that can extract new knowledge leveraging text corpora, complementing the knowledge contained in ontologies and knowledge bases such as the ones described above.
Grounded knowledge and cognitive linguistics Many scholars have argued that, from a cognitive perspective, knowledge needs to be grounded [23] as well as modality-specific to support simulation, a mental activity that is regarded as ubiquitous in cognitive intelligent systems [4]. Other seminal work has argued that cognition is categorical [24,25] and that perceptual and cognitive reasoning rely on schematic knowledge. In particular, there has been substantial work on describing the schemas by which we perceive and understand spatial knowledge [64].
The knowledge we have gathered is neither grounded nor schematic, nor modality-specific in the above senses, but rather amodal and symbolic. This type of knowledge is arguably useful in high-level planning but clearly is not sufficient to support simulation or event action execution. Developing models by which natural language can be grounded in action has been the concern of other authors, e.g. Misra et al. [46] as well as Bollini et al. [9]. Some work has considered extracting spatial relations in natural language input [32]. Differently from the above mentioned works, we are neither interested in interpreting natural language with respect to grounded action representations nor in extracting spatial relations from a given sentence. Rather, our goal is to extract prototypical common sense background knowledge from large corpora.
This section presents our framework to extract relations between pairs of entities for the population of a knowledge base of manipulation-relevant data. We frame the task of relation extraction between entities as a ranking problem as it gives us great flexibility in generating a knowledge base that balances between coverage and confidence. Given a set of triples
Here we use the terminology
Our general approach to produce these rankings is to design a scoring function
In this work, we present different scoring functions and evaluate them in the context of building a knowledge base of common sense triples. All of our proposed approaches rely on distributional representations of entities (and words). We investigate different vector representations and scoring functions, all with different strengths and weaknesses. In the following, for the sake of making the article self-contained, we give a short introduction to distributional representations.
Word space models (or distributional space models, or word vector spaces) are abstract representations of the meaning of words, encoded as vectors in a high-dimensional space. Traditionally, a word vector space is constructed by counting cooccurrences of pairs of words in a text corpus, building a large square n-by-n matrix where n is the size of the vocabulary and the cell
This is the key point to linking the vector representation to the idea of semantic relatedness, as the distributional hypothesis states that “words that occur in the same contexts tend to have similar meaning” [26]. Several techniques can be applied to reduce the dimensionality of the cooccurrence matrix. Latent Semantic Analysis [33], for instance, uses Singular Value Decomposition to prune the less informative elements while preserving most of the topology of the vector space, and reducing the number of dimensions to 100-500.
Recently, neural network based models have received increasing attention for their ability to compute dense, low-dimensional representations of words. To compute such representation, called word embeddings, several models rely on huge amounts of natural language texts from which a vector representation for each word is learned by a neural network. Their representations of the words are therefore based on prediction as opposed to counting [2].
Vector spaces created on word distributional representations have been successfully proven to encode word similarity and relatedness relations [15,53,55], and word embeddings have proven to be a useful feature in many natural language processing tasks [16,18,34] in that they often encode semantically meaningful information of a word.
We argue that it is possible to extract interaction-relevant relations between entities, e.g. (
In the beginning of this section, we motivated the use of distributional representations for the extraction of relations in order to populate a database of common sense knowledge. As outlined, we frame the relation extraction task as a ranking problem of triples
In this section, we propose a neural network-based word embedding model to obtain distributional representations of entities. By using the relation-agnostic cosine similarity5
We also experimented with APSyn [57] as an alternative similarity measure which, unfortunately, did not work well in our scenario.
Many word embedding methods encode useful semantic and syntactic properties [31,43,47] that we leverage for the extraction of prototypical knowledge. In this work, we restrict our experiments to the skip-gram method [42]. The objective of the skip-gram method is to learn word representations that are useful for predicting context words. As a result, the learned embeddings often display a desirable linear structure [43,47]. In particular, word representations of the skip-gram model often produce meaningful results using simple vector addition [43]. For this work, we trained the skip-gram model on a corpus of roughly 83 million Amazon reviews [40].
Motivated by the compositionality of word vectors, we derive vector representations for the entities as follows: considering a DBpedia entity6
For simplicity, we only use the local parts of the entity URI, neglecting the namespace
For any entity vector that can not be derived from the word embeddings due to missing vocabulary, we assume a similarity of −1 to every other entity.
Locations for a sample object, extracted by computing cosine similarity on skip-gram-based vectors
Vector representations of words (Section 3.1) are attractive since they only require a sufficiently large text corpus with no manual annotation. However, the drawback of focusing on words is that a series of linguistic phenomena may affect the vector representation. For instance, a polysemous word as rock (stone, musical genre, metaphorically strong person, etc.) is represented by a single vector where all the senses are conflated.
NASARI [12], a resource containing vector representations of most of DBpedia entities, solves this problem by building a vector space of concepts. The NASARI vectors are actually distributional representations of the entities in BabelNet [51], a large multilingual lexical resource linked to WordNet, DBpedia, Wiktionary and other resources. The NASARI approach collects cooccurrence information of concepts from Wikipedia and then applies a cluster-based dimensionality reduction. The context of a concept is based on the set of Wikipedia pages where a mention of it is found. As shown by Camacho-Collados et al. [12], the vector representations of entities encode some form of semantic relatedness, with tests on a sense clustering task showing positive results. Table 2 shows a sample of pairs of NASARI vectors together with their pairwise cosine similarity ranging from −1 (opposite direction, i.e. unrelated) to 1 (same direction, i.e. related).
Examples of cosine similarity computed on NASARI vectors
Examples of cosine similarity computed on NASARI vectors
Following the hypothesis put forward in the beginning of this section, we focus on the extraction of interaction-relevant relations by computing the cosine similarities of entities. We exploit the alignment of BabelNet with DBpedia, thus generating a similarity score for pairs of DBpedia entities. For example, the DBpedia entity
Locations for a sample object, extracted by computing cosine similarity on NASARI vectors
In the previous sections, we presented models of semantic relatedness for the extraction of relations. The employed cosine similarity function of these models is relation-agnostic, that is, it only measures whether there is a relation between two entities but not which relation in particular. The question that naturally arises is: Instead of using a single model that is agnostic to the relation, can we train a separate model for each relation in order to improve the extraction performance? In this section we try to answer this question by introducing a new model, based on supervised learning.
To extend the proposed approach to any kind of relation we modify the model presented in Section 3.1 by introducing a parameterized scoring function. This scoring function replaces the cosine similarity which was previously employed to score pairs of entities (e.g. Object-Location). By tuning the parameters of this new scoring function in a data-driven way, we are able to predict scores with respect to arbitrary relations.
We define the new scoring function
In order to learn the parameters
5 triples
The training of the scoring function is framed as a classification where we try to assign scores of 1 to all positive triples and scores of
Due to the moderate size of our training data, we regularize our model by applying Dropout [61] to the embedding vectors of the head and tail entity. We set the dropout fraction to 0.1, thus only dropping a small portion of the 100 dimensional input vectors.
The supervised model differs from the unsupervised approaches in that the scoring function is tuned to a particular relation, e.g. the
The following section introduces the datasets that we use for this work. We consider three types of datasets: (i) a crowdsourced set of triples expressing the
Crowdsourcing of object-location rankings
In order to acquire valid pairs for the
To select the objects and locations for this experiment, every DBpedia entity that falls under the category
Simple Knowledge Organization System:

Every DBpedia entity that falls under the category

These steps result in 336 objects and 199 locations (as of September 2016). To select suitable pairs expressing the
We use the URI counts extracted from the parsing of Wikipedia with the DBpedia Spotlight tool for entity linking [17].
In order to collect the judgments, we set up a crowdsourcing experiment on the CrowdFlower platform.11
−2 (
−1 (
Contributors were shown ten examples per page, instructions, a short description of the entities (the first sentence from the Wikipedia abstract), a picture (from Wikimedia Commons, when available12
Pictures were available for 94 out of 100 objects.
After running the crowdsourcing experiment for a few hours, we collected 12,767 valid judgments, whereas 455 judgments were deemed “untrusted” by CrowdFlower’s quality filtering system. The quality control was based on 57 test questions that we provided and a required minimum accuracy of 60% on these questions for a contributor to be considered trustworthy. In total, 440 contributors participated in the experiment.
The pairs received on average 8.59 judgments. Most of the pairs received at least 5 separate judgments, with some outliers collecting more than one hundred judgments each. The average agreement, i.e. the percentage of contributors that answered the most common answer for a given question, is 64.74%. The judgments are skewed towards the negative end of the spectrum, as expected, with 37% pairs rated unexpected, 30% unusual, 24% plausible and 9% usual. The cost of the experiment was 86 USD.
To use this manually labeled data in later experiments, we normalize, filter and rearrange the scored pairs and obtain three gold standard datasets:
For the first gold standard dataset, we reduce multiple human judgments for each Object-Location pair to a single score by assigning the average of the numeric values. For instance, if the pair (
The second and third gold standard datasets are produced as follows: The contributors’ answers are aggregated using relative majority, that is, each object-location pair has exactly one judgment assigned to it, corresponding to the most popular judgment among all the contributors that answered that question. We extract two sets of relations from this dataset to be used as a gold standard for experimental tests: one list of the 156 pairs rated 2 (usual) by the majority of contributors, and a larger list of the 496 pairs rated either 1 (plausible) or 2 (usual). The aggregated judgments in the gold standard have a confidence score assigned to them by CrowdFlower, based on a measure of inter-rater agreement. Pairs that score low on this confidence measure (⩽ 0.5) were filtered out, leaving 118 and 496 pairs, respectively. We refer to these two gold standard sets as locatedAt-usual and locatedAt-usual/plausible.
The SUN database [70] is a large-scale resource for computer vision and object recognition in images. It comprises 131,067 single images, each of them annotated with a label for the type of scene, and labels for each object identified in the scene. The images are annotated with 908 categories based on the type of scene (bedroom, garden, airway, …). Moreover, 313,884 objects were recognized and annotated with one out of 4,479 category labels.
Despite its original goal of providing high-quality data for training computer vision models, the SUN project generated a wealth of semantic knowledge that is independent from the vision tasks. In particular, the labels are effectively semantic categories of entities such as objects and locations (scenes, using the lexical conventions of the SUN database).
Objects are observed at particular scenes, and this relational information is retained in the database. In total, we extracted 31,407 object-scene pairs from SUN, together with the number of occurrences of each pair. The twenty most occurring pairs are shown in Table 4.
Most frequent pairs of object-scene in the SUN database
Most frequent pairs of object-scene in the SUN database
According to its documentation, the labels of the SUN database are lemmas from WordNet. However, they are not disambiguated and thus they could refer to any meaning of the lemma. Most importantly for our goals, the labels in their current state are not directly linked to any LOD resource. Faced with the problem of mapping the SUN database completely to a resource like DBpedia, we adopted a safe strategy for the sake of the gold standard creation. We took all the object and scene labels from the SUN pairs for which a resource in DBpedia with matching label exists. In order to limit the noise and obtain a dataset of “typical” location relations, we also removed those pairs that only occur once in the SUN database. This process resulted in 2,961 pairs of entities. We manually checked them and corrected 118 object labels and 44 location labels. In some cases the correct label was already present, so we eliminated the duplicates resulting in a new dataset of 2,935 object-location pairs.13
Of all extracted triples, 24 objects and 12 locations were also among the objects and locations of the crowdsourced dataset.
While the methods we propose for relation extractions are by design independent of the particular relations they are applied to, we have focused most of our experimental effort towards one kind of relation between objects and locations, namely the typical location where given objects are found. As a first step to assess the generalizability of our approaches to other kinds of relations, we created an alternative dataset revolving around a relation with the same domain as the location relation, i.e., objects, but a very different range, that is, actions. The relation under consideration will be referred to in the rest of the article as
We built a dataset of object-action pairs in a
To use this data as training and test data for the proposed models, we randomly divide the complete set of positive
We filter out all generated triples that are falsely labeled as negative in this process.
Examples of DBpedia entities in a
This section presents the evaluation of the proposed framework for relation extraction (Sections 3.1, 3.2 and 3.3). We apply our models to the data described in Section 4, consisting of sets of (
We start our experiments by evaluating how well the produced rankings of (
The second part of our experiments evaluates how well each proposed method performs in extracting a knowledge base. The evaluation is performed for (
Ranking evaluation
With the proposed methods from previous sections, we are able to produce a ranking of e.g. locations for a given object that expresses how prototypical the location is for that object. To test the validity of our methods, we compare their output against the gold standard rankings locatedAt-Human-rankings that we obtained from the crowdsourced pairs (see Section 4.1).
As a first evaluation, we investigate how well the unsupervised baseline methods perform in creating object-location rankings. Secondly, we show how to improve these results by combining different approaches. Thirdly, we evaluate the supervised model in comparison to our baselines.
Unsupervised object-location ranking evaluation
Apart from the NASARI-based method (Section 3.2) and the skip-gram-based method (Section 3.1) we employ two simple baselines for comparison: For the location frequency baseline, the object-location pairs are ranked according to the frequency of the location. The ranking is thus the same for each object, since the score of a pair is only computed based on the location. This method makes sense in absence of any further information on the object: e.g. a robot tasked to find an unknown object should inspect “common” rooms such as a kitchen or a studio first, rather than “uncommon” rooms such as a pantry.
The second baseline, the link frequency, is based on counting how often every object appears on the Wikipedia page of every location and vice versa. A ranking is produced based on these counts. An issue with this baseline is that the collected counts could be sparse, i.e., most object-location pairs have a count of 0, thus sometimes producing no value for the ranking for an object. This is the case for rather “unusual” objects and locations.
For each object in the dataset, we compare the location ranking produced by our algorithms to the crowdsourced gold standard ranking and compute two metrics: the Normalized Discounted Cumulative Gain (NDCG) and the Precision at k (Precision@k or P@k).
The NDCG is a measure of rank correlation used in information retrieval that gives more weight to the results at the top of the list than at its bottom. It is defined as follows:
While the NDCG measure gives a complete account of the quality of the produced rankings, it is not easy to interpret apart from comparisons of different outputs. To gain a better insight into our results, we provide an alternative evaluation, the Precision@k. The Precision@k measures the number of locations among the first k positions of the produced rankings that are also among the top-k locations in the gold standard ranking. It follows that, with
Table 6 shows the average NDCG and Precision@k across all objects: methods NASARI/Cosine (Section 3.2) and SkipGram/Cosine (Section 3.1), plus the two baselines introduced above.
Average Precision@k for
and
and average NDCG of the produced rankings against the gold standard rankings
Average Precision@k for
Both our methods that are based on semantic relatedness outperform the simple baselines with respect to the gold standard rankings. The location frequency baseline performs very poorly, due to an idiosyncrasy in the frequency data, that is, the most “frequent” location in the dataset is Aisle. This behavior reflects the difficulty in evaluating this task using only automatic metrics, since automatically extracted scores and rankings may not correspond to common sense judgment.
The NASARI-based similarities outperform the skip-gram-based method when it comes to guessing the most likely location for an object (Precision@1), as opposed to the better performance of SkipGram/Cosine in terms of Precision@3 and rank correlation.
We explored the results and found that for 19 objects out of 100, NASARI/Cosine correctly guesses the top ranking location where SkipGram/Cosine fails, while the opposite happens 15 out of 100 times. We also found that the NASARI-based method has a lower coverage than the skip-gram method, due to the coverage of the original resource (NASARI), where not every entity in DBpedia is assigned a vector.15
Objects like
The results from the previous sections highlight that the performance of our two main methods may differ qualitatively. In an effort to overcome the coverage issue of NASARI/Cosine, and at the same time experiment with hybrid methods to extract location relations, we devised two simple ways of combining the SkipGram/Cosine and NASARI/Cosine methods. The first method is based on a fallback strategy: given an object, we consider the pair similarity of the object to the top ranking location according to NASARI/Cosine as a measure of confidence. If the top ranked location among the NASARI/Cosine ranking is exceeding a certain threshold, we consider the ranking returned by NASARI/Cosine as reliable. Otherwise, if the similarity is below the threshold, we deem the result unreliable and we adopt the ranking returned by SkipGram/Cosine instead. The second method produces object-location similarity scores by linear combination of the NASARI and skip-gram similarities. The similarity score for the generic pair s, o is thus given by:
Rank correlation and precision at k for the method based on fallback strategy
Rank correlation and precision at k for the method based on fallback strategy
Table 7 shows the obtained results, with varying values of the parameters threshold and α. While the NDCG is only moderately affected, both Precision@1 and Precision@3 show an increase in performance with Precision@3 showing the highest score of all investigated methods.
In the previous experiments, we investigated how well our (unsupervised) baseline methods perform when extracting the
As before, we test the model on the human-rated set of objects and locations locatedAt-Human-rankings described in Section 4.1 and produce a ranking of locations for each object. Table 8 shows the performance of the extended model (SkipGram/Supervised) in comparison to the previous approaches.
Average precision at k for
and
and average NDCG of the produced rankings against the crowdsourced gold standard rankings. SkipGram/Supervised denotes the supervised model based on skip-gram embeddings trained for the locatedAt relation
Average precision at k for
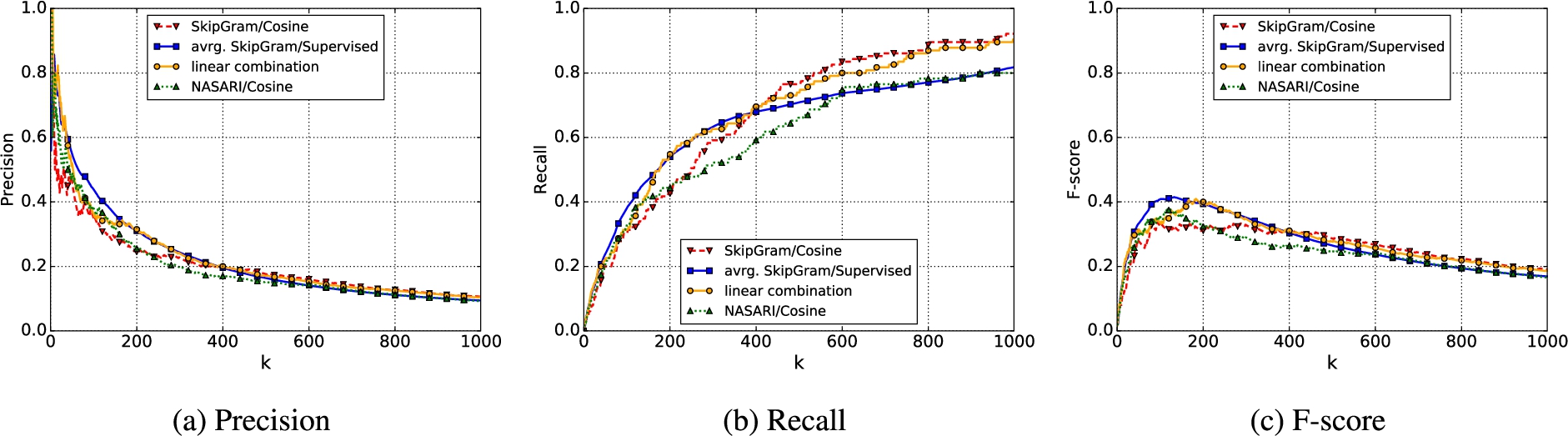
Evaluation on automatically created knowledge bases (“usual” locations).
Overall, we can observe mixed results. All of our proposed models (supervised and unsupervised) improve upon the baseline methods with respect to all evaluation metrics. Compared to the SkipGram/Cosine model, the SkipGram/Supervised model decreases slightly in performance with respect to the NDCG and more so for the Precision@3 score. Most striking, however, is the increase in Precision@1 of SkipGram/Supervised, showing a relative improvement of 30% to the SkipGram/Cosine model and constituting the highest overall Precision@1 score by a large margin. However, the linear combination (
While the presented results do not point to a clear preference for one particular model, Section 5.2 will investigate the above methods more closely in the context of the generation of a knowledge base.
In the previous section, we tested how the proposed methods perform in determining a ranking of locations given an object. For the purpose of evaluation, the tests have been conducted on a closed set of entities. In this section we return to the original motivation of this work, that is, to collect manipulation-relevant information about objects in an automated fashion in the form of a knowledge base.
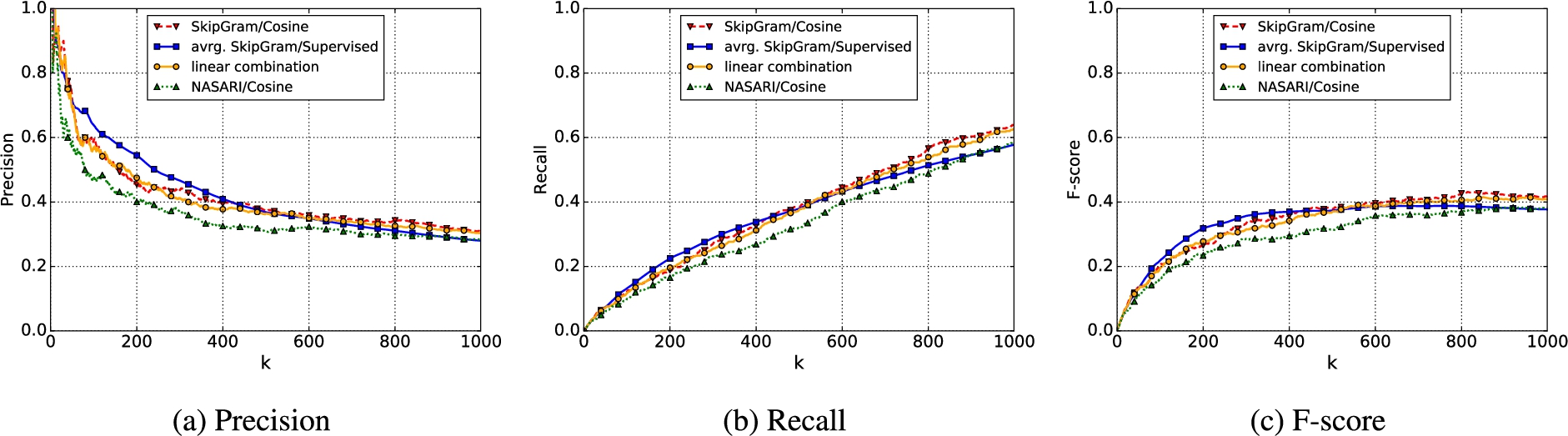
Evaluation on automatically created knowledge bases (“plausible” and “usual” locations).
All the methods introduced in this work are based on some scoring function of triples expressed as a real number in the range the locatedAt-usual and locatedAt-usual/plausible datasets (Section 4.1) for the the usedFor-Extracted-triples dataset (Section 4.3) for the
We introduce the
In general, we extract a knowledge base of triples by scoring each possible candidate triple, thus producing an overall ranking. We then select the top k triples from the ranking, with k being a parameter. This gives us the triples that are considered the most prototypical. We evaluate the retrieved set in terms of Precision, Recall and F-score against the gold standard sets with varying values of k. Here, the precision is the fraction of correctly retrieved triples in the set of all retrieved triples, while the recall is the fraction of retrieved triples that also occur in the gold standard set. The F-score is the harmonic mean of precision and recall:
For the
Figures 1 and 2 show the evaluation of the four methods evaluated against the two aggregated gold standard datasets for the
One of the reasons to introduce a novel technique for relation extraction based on a supervised statistical method, as stated previously, is to be able to scale the extraction across different types of relations. To test the validity of this statement, we apply the same evaluation procedure introduced in the previous part of this section to the
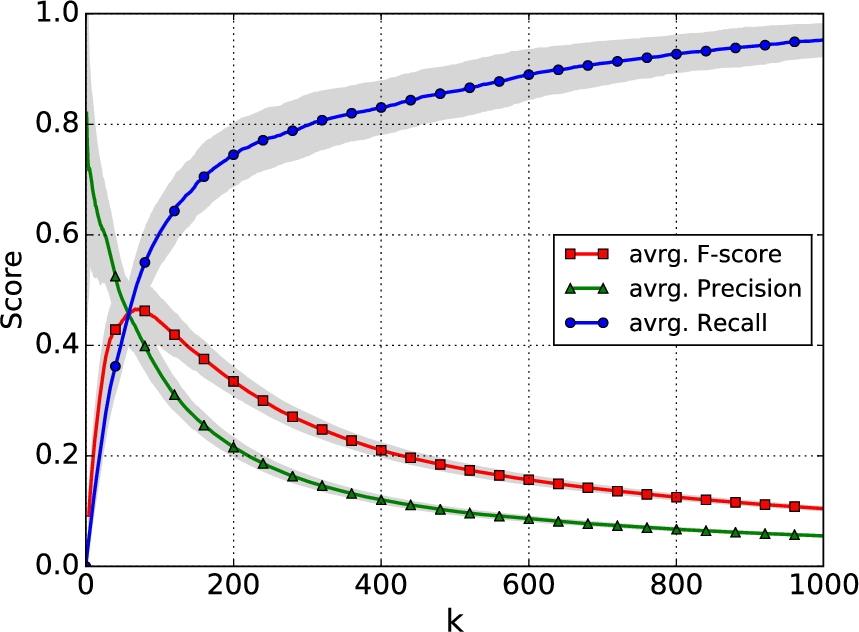
Evaluation of knowledge base generation for the
Figure 3 displays precision, recall and F-score for retrieving the top k results. The results are averaged scores over 100 experiments to account for variations in performance due to the random partitioning in training and evaluation triples and the generation of negative samples. The standard deviation for precision, recall and F-score for all k is visualized along the mean scores.
The supervised model achieves on average a maximum F-score of about 0.465 when extracting 70 triples. This is comparable to the achieved F-scores when training the scoring function for the
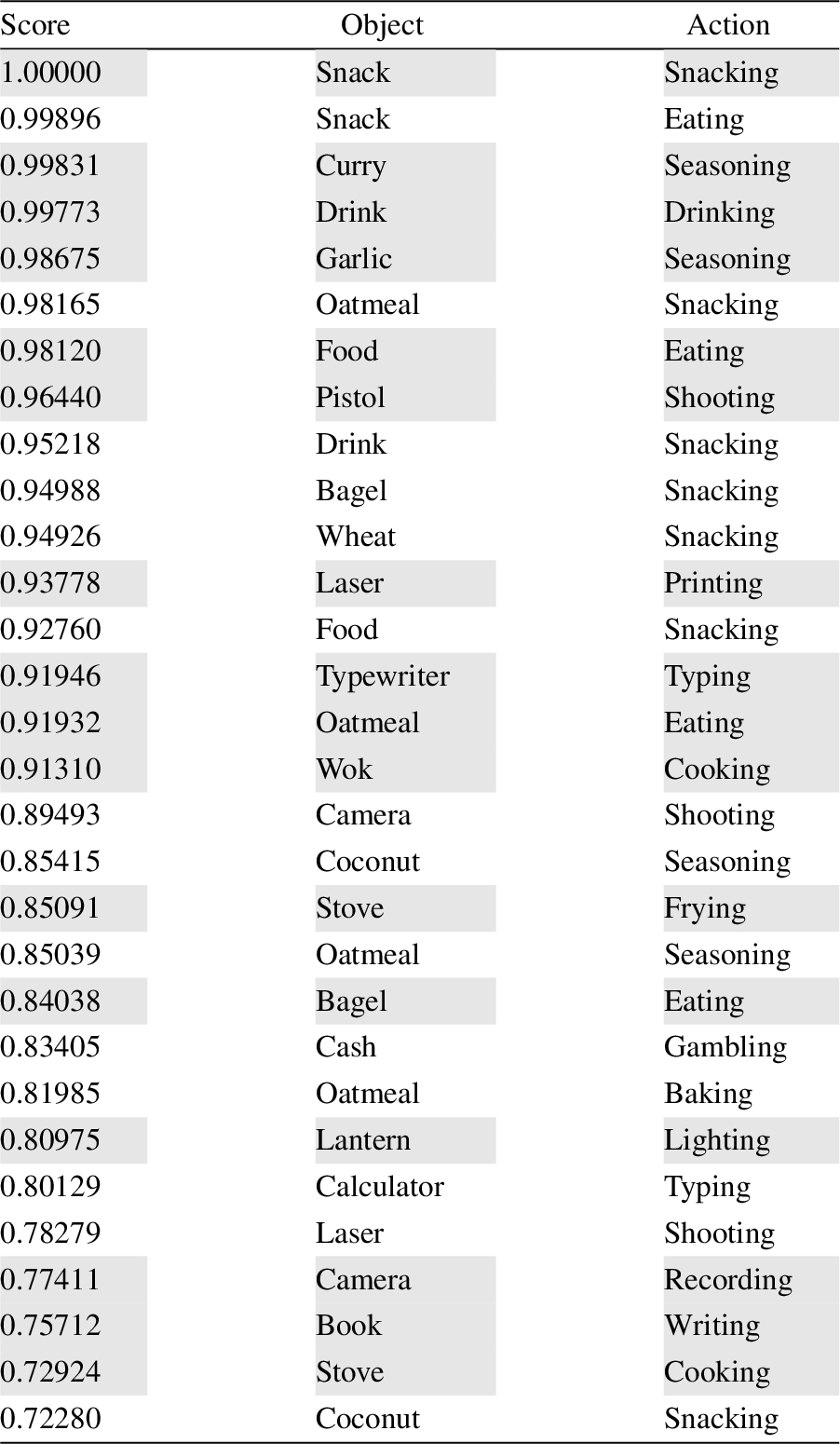
A list of the top 30 extracted triples for the
Given these results, we can aim for a high-confidence knowledge base by selecting the threshold on object-location similarity scores that produces a reasonably high precision knowledge base in the evaluation. For instance, the knowledge base made by the top 50 object-location pairs extracted with the linear combination method (
The full automatically created knowledge base and used resources are available at
The knowledge base created with this method is the result of one among many possible configurations of a number of methods and parameters. In particular, the creator of a knowledge base involving the extraction of relations is given the choice to prefer precision over recall, or vice-versa. This is done, in our method, by adjusting the threshold on the similarity scores. Employing different algorithms for the computation of the actual similarities (word embeddings vs. entity vectors, supervised vs. unsupervised models) is also expected to result in different knowledge bases. A qualitative assessment of such impact is left for future work.
We have presented a framework for extracting manipulation-relevant knowledge about objects in the form of (binary) relations. The framework relies on a ranking measure that, given an object, ranks all entities that potentially stand in the relation in question to the given object. We rely on a representational approach that exploits distributional spaces to embed entities into low-dimensional spaces in which the ranking measure can be evaluated. We have presented results on two relations: the relation between an object and its prototypical location (
We have shown that both an approach relying on standard word embeddings computed by a skip-gram model as well as an approach using embeddings computed for disambiguated concepts rather than lemmas perform very well compared to two rather naive baselines. Both approaches were presented already in previous work. As main contribution of this paper, we have presented a supervised approach based on a neural network that, instead of using the cosine similarity as measure of semantic relatedness, uses positive and negative examples to train a scoring function in a supervised fashion. In contrast to the other two unsupervised approaches, the latter learns a model that is specific for a particular relation while the other two approaches implement a general notion of semantic relatedness in distributional space.
We have shown that the improvements of the supervised model are not always clear compared to the two unsupervised approaches. This might be attributable to the fact that the types of both relations (
As an avenue for future work, the generalizability of the proposed methods to a wider set of relations can be considered. In the context of manipulation-relevant knowledge for a robotic system, other interesting properties of an object include its prototypical size, weight, texture, and fragility. Additionally, we see possibilities to address relations as can be found in ConceptNet 5 [60] such as
We also plan to employ retrofitting [21] to enrich our pretrained word embeddings with concept knowledge from a semantic network such as ConceptNet or WordNet [44] in a post-processing step. With this technique, we might be able to combine the benefits of the concept-level and word-level semantics in a more sophisticated way to bootstrap the creation of an object-location knowledge base. We believe that this method is a more appropriate tool than the simple linear combination of scores. By specializing our skip-gram embeddings for relatedness instead of similarity [30] even better results could be achieved.
In the presented work, we used the frequency of entity mentions in Wikipedia as a measure of commonality to drive the creation of a gold standard set for evaluation. This information, or equivalent measures, could be integrated directly into our relation extraction framework, for example in the form of a weighting scheme or hand-crafted features, to improve its prediction accuracy.
Footnotes
Acknowledgements
The authors wish to thank the anonymous reviewers of EKAW, who provided useful feedback to make this extended version of the paper. The work in this paper is partially funded by the ALOOF project (CHIST-ERA program) and by the Cluster of Excellence Cognitive Interaction Technology ‘CITEC’ (EXC 277), Bielefeld University.