
Abstract
The contextual information in the built environment is highly heterogeneous, it goes from static information (e.g., information about the building structure) to dynamic information (e.g., user’s space–time information, sensors detections and events that occurred). This paper proposes to semantically fuse the building’s contextual information with extracted data from a smart camera network by using ontologies and semantic web technologies. The developed ontology allows interoperability between the different contextual data and enables, without human interaction, real-time event detections and system reconfiguration to be performed. The use of semantic knowledge in multi-camera monitoring systems guarantees the protection of the user’s privacy by not sending nor saving any image, just extracting the knowledge from them. This paper presents a new approach to develop an “all-seeing” smart building, where the global system is the first step to attempt to provide Artificial Intelligence (AI) to a building.
Keywords
Introduction
In Greek mythology, Argus Panoptes was a giant with a hundred eyes. It was impossible to deceive his vigilance, for only some of his eyes slept while the rest were awake [37]. Argus was the servant of Hera. At his death, Hera rewarded the giant’s fidelity by placing his eyes on the feathers of the peacock, her sacred animal. “To have the eyes of Argus” is a popular expression which means to be lucid and vigilant.
The term Panoptes means “all-seeing”, which within the built environment is a quest in terms of access control, flow control and activity control. In that context, a Panoptes building would characterize a smart building equipped with a network of cameras which could, in real-time, combine the different information seen and deduce the triggering of actions.
In classical multi-camera based systems (MCBS) there is a monitor room with a central processing server where all the information is collected and analyzed in real-time by one or more human operators.
However, as the size of the network increases, it becomes more difficult (or even impossible) for the human operators to monitor all the video streams at the same time and to identify events. Furthermore, having a large amount of information makes it infeasible to create a relation between past and current actions.
Based on our experience, some issues and limitations of MCBS deployed in built environments have been identified, such as:
Selecting and filtering relevant information from the large amount of generated data.
Dealing with missing information and non-detectable information. For example, a person may become not-visible to a camera due to their position or an obstruction.
Reconfiguration of the cameras according to their context. The camera should adjust its configuration to ease the task of identifying a specific object or action. For example, the cameras should be able to adjust their parameters (e.g., aperture and shutter speed) according to the light in the environment.
Integration of data from different nodes and different domains. A MCBS should be able to link the contextual information with the information coming from the different camera nodes to identify events and take decisions.
Privacy protection. There are many privacy laws that restrict the monitoring of people, therefore, a MCBS should be able to extract the useful information from an image/video while protecting the privacy of the individuals.
Many efforts have been devoted to deal with the aforesaid limitations of the MCBS. The most prominent one is to rely on smart cameras (SCs) to perform visual tasks semi-autonomously (with minimal human interaction).
Smart cameras are specialized cameras that contain not only the image sensor but also a processing unit and some communication interfaces. In a few words, SCs are self-contained vision systems [33,58]. The use of SCs in the built environment has become a growing trend due to the rich contextual data provided.
In the built environment, context is an essential factor since it provides information about the current status of users, places, objects, sensors and events. We assume that a smart building is a context-aware system because it extracts, interprets and uses the contextual information to automatically adapt its functionality according to the contextual changes.
A Panoptes building is a type of smart building that uses only SC sensors and its main task is to monitor the different activities that occur in the built environment; in contrast to the smart building which uses different types of sensors and which mainly focuses on managing/monitoring the energy consumption.
The creation of a Panoptes building is a complicated task due to the integration of data coming from different domains around the knowledge of the building.
Many works have been done using semantic web standards such as Resource Description Framework (RDF) and Web Ontology Language (OWL) to represent contextual data [20]. On those systems, the ontology plays a crucial role in enabling the processing and sharing of information and knowledge, i.e., the use of an ontology allows interoperability between different domains.
This paper presents an ontology for a Panoptes building that re-purposes and integrates information from different domains composing the built context. The proposed ontology is the kernel of the WiseNET (Wise NETwork) system, which is a context-aware system whose main function is to perform reasoning about heterogeneous sources of information [30]. Explicitly, the WiseNET system enhances the information of a smart camera network (SCN) with contextual information to allow autonomously real-time event/anomalies detection and system reconfiguration.
The main contribution of this paper is the semantics-based system, which allow us to overcome the MCBS limitations and some computer vision problems, especially the privacy protection which nowadays is an important factor to consider. This is achieved by the semantic fusion of Industry Foundations Classes (IFC) data with sensor information and other domain information in the Panoptes context.
The rest of the paper is organized as follows. Section 2 introduces the terminology used in the paper as well as summarizes related works. Section 3 gives an overview of the WiseNET system. Section 4 describes the development process of the WiseNET ontology and its links to existing ontologies. Section 5 presents the ontology population from the IFC data. Section 6 presents the ontology population from the SCs which consists of a static population, performed during the system configuration, and a dynamic population which is performed each time the SCs detect a person. Section 7 presents some evaluations and use cases and finally, Section 8 presents the conclusions and prospectives.
Background and related work
Nowadays, MCBS have become a part of our daily life. They can be found in cities, commercial centers, supermarkets, offices, and even in houses.
The advances in image sensor technology allow us to have SCs, which are low-cost and low-power systems that capture high-level description of a scene and analyze it in real-time [58]. These SCs can extract necessary/pertinent information from different images/video by employing different image processing algorithms such as face detection [55], person detection [11], people tracking [18], fall detection [44], object detection [15], etc.
Smart camera networks have been used in the built environment for a long time. The main applications focus on the following problematics:
Most of the previous applications use a SCN deployed in a built environment to obtain and analyze different types of information. Therefore, they might be considered as Panoptes building applications.
The main function of a Panoptes building is to combine the different information obtained by the SCN and to deduce the triggering of actions/events in real-time. In this context, a Panoptes building application should understand the static building information as well as perceive (accurately) the dynamic and evolving data, i.e., it should be aware of its context.
The creation of a context-aware system in the built environment is a complex task; it requires information from different domains such as environment data, sensing devices, spatio-temporal facts and details about the different events that may occur.
For example, the required event information could be a set of concepts and relations concerning the different events that may occur in a built environment, their location, the time they occurred, the agents involved, the relation to other events and their consequences. In the case of the sensor information, the required data could be the description of the different sensing devices, the processes implemented on them and their results. Regarding the environment, the required data could be the building topology and the different elements contained in the spaces.
The built environment data can be obtained using the Building Information Modeling (BIM) of a building. BIM becomes a general term designing the set of numerical data, objects and processes appended during the life-cycle of a building [14]. From the design, construction and facility management steps, the BIM allows practitioners and managers to exchange data in a uniform way using the IFC standard [54].
The IFC gives the base of description of all elements making the building, both semantic and graphic [24]. This allows to aggregate all heterogeneous software dedicated to the built environment in an interoperable manner.
In the domain of interoperability three levels are described: technical, organizational and semantics [23]. The IFC aims the technical interoperability level [31]. The organizational level is in charge of the practitioners according to the law of each country and the rules of each enterprise. The semantics level aims to clearly specify the meaning of each element making the BIM.
An important work was made to bring the IFC EXPRESS schema into the semantic web world using OWL as the schema modeling language [41]. The result is the
According to Studer, an ontology is a formal, explicit specification of a shared conceptualization [47]. In other words, an ontology is a set of concepts and relations used to describe and represent an area of concern. Currently, the most common language for representing ontologies is OWL-2, which is the recommendation of the World Wide Web Consortium (W3C) [56].
Other recommended technologies/languages in the semantic web domain are: RDF, used for representing information in the form of a graph composed of triples [10]; RDF Schema (RDFS), which provides a vocabulary for creating a hierarchy of classes and properties [3]; SPARQL,1
SPARQL is a recursive acronym for SPARQL Protocol and RDF Query Language.
Currently (February, 2017) SWRL is not a W3C recommendation yet.
One important application of ontology is semantic fusion, which consists in integrating and organizing data and knowledge coming from multiple heterogeneous sources and to unify them into a consistent representation. Some important works in this domain are:
Hong et al. presented some context-aware systems where the ontology plays a central role for enabling interoperability between devices and agents which are not designed to work together [20].
Dibley et al. developed an ontology framework that combines a sensor ontology with a building ontology and other supporting ontologies [12].
San Miguel et al. used an ontology for combining image processing algorithms with knowledge about objects and events [43].
Chaochaisit et al. presented a semantic connection between sensor specification, localization methods and contextual information [6].
Town presented an ontology that fuses multiple computer vision stages with context information for image retrieval and event detections [53].
Suchan and Bhatt developed a framework to reasoning about human activities using commonsense knowledge founded in qualitative spatio-temporal relations and human-object interactions [48].
Based on the state of the art, the information extracted by a SCN could be converted to semantic data. Moreover, a specially designed ontology would enable to deal and merge multi-sources of heterogeneous data (i.e., from different cameras, other types of sensors, a priori data from the environment). Hence, we propose the creation of a semantic based system which is a context-aware system that uses an ontology to combine the information extracted by a SCN with logic rules and knowledge of what the camera observes, building information and events that may occur.
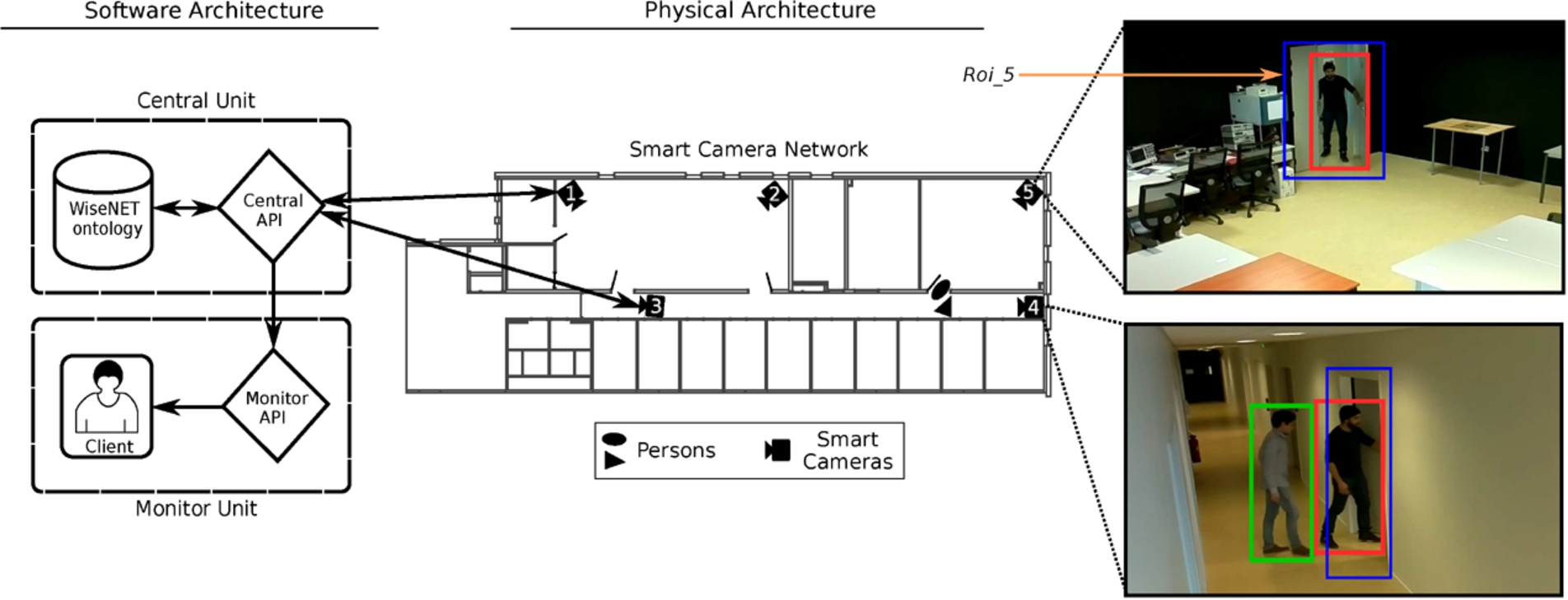
WiseNET system overview: the smart camera network is in charge of extracting pertinent information from a scene, to convert the data into knowledge and to send it to the central API, which afterwards populates the WiseNET ontology with that knowledge. The central API is also responsible for reconfiguring the image processing algorithms in the smart cameras and for transferring data to the monitor unit from which a client/user may visualize the history of activities. Notice that all the smart cameras are connected to the central API, however to keep the image cleaner, only the connection of two smart cameras are shown. The color code of the bounding boxes in the camera images (right side) are: blue represent regions of interest (i.e.,
We developed a new framework called WiseNET, which is a semantics-based system that fuses heterogeneous sources of data such as data coming from sensors and the different contextual information. Due to the application of the paper (Panoptes building), we focus on a specific type of sensor: SCs; however, the system is defined to include other type of sensors such as temperature, humidity, depth sensor, etc.
The main goal of WiseNET is to improve classical computer vision and deep learning systems by considering the contextual information of the environment and by performing real-time reasoning. As a result, WiseNET may overcome some limitations of computer vision (e.g., false detections and missed detections), some drawbacks of deep learning (e.g., the need of a large amount of training and testing data) and limitations of MCBS (presented in Section 1) while allowing real-time event/anomalies detection and system reconfiguration.
Figure 1 illustrates an overview of the WiseNET architecture. The system is articulated in three sections: the smart camera network, the monitor unit and the central unit.
The SCN is a set of smart cameras distributed in an environment. The main functions of the SCN, in the WiseNET system, is to extract low-level features from a scene (such as person detection as shown in Fig. 1), to convert the extracted data into knowledge and to send it to the central unit. More information regarding the type of smart cameras used can be found in [30].
Monitor unit
The monitor unit’s main function is the visualization of the static and dynamic information; this unit automatically retrieves information and presents it in a graphical manner, for example an occupancy map (as shown in Fig. 1) or a heat map (as shown in Fig. 10). Also, the monitor unit implements some queries to answer questions such as: how many people are present in a room? what is the location of a person? and many others (see Section 4.1).
Central unit
The central unit is composed of two elements the central API and the WiseNET ontology:
Our system differs from other computer vision systems mainly by four factors. Firstly, rather than improving algorithms [59] or processing signals [44] it aims to give a meaning to the information extracted by using computer vision techniques [53]. Secondly, no images are sent, the SCs only send the extracted knowledge. Thirdly, the WiseNET system combines context information with the camera information to overcome missed detections or non-detectable information (e.g., people outside a camera’s field of view). Finally, the system uses an ontology to fuse the different kinds of information presented in a Panoptes building, such as: information of the environment, time, SCs, events, detectable objects, etc.
The focus of this paper is the description of the central unit. In Sections 4 and 5, the WiseNET ontology development process will be shown as well as its population with static data. In Section 6, the central API will be presented, specifically the process of dynamically inserting data into the ontology.
Formal modeling
The WiseNET ontology is the kernel of the WiseNET system. It is defined in OWL-2 and it incorporates a vast corpus of concepts in the domain of a Panoptes building. The ontology provides a vocabulary for combining, analysing and re-purposing the information coming from the SCN deployed in a built environment. The main function of the WiseNET ontology is to perform real-time event/anomalies detection and initiate system reconfiguration.
Selected competency questions used for developing the WiseNET ontology
Selected competency questions used for developing the WiseNET ontology
X, X1 are id’s and T is a variable.
Full list of prefixes and namespaces used in WiseNET ontology and in this document
The ontology development process followed was the Noy and McGuinness methodology [36]. This methodology consists of seven steps which are: determine the scope of the ontology, consider reuse, enumerate classes, define classes and properties, define constrains and create instances (ontology population shown on Sections 5 and 6).
Scope of the ontology
The ontology scope was determined by thinking about the kind of knowledge that should be covered by the ontology and its use, i.e., its domain.
Table 1 presents some competency questions that helped to determine the focus of the ontology. These questions should be answered by the ontology eventually providing the different kinds of knowledge that should be contained in the WiseNET ontology. Roughly, it is knowledge about the environment, events, people, sensors and time.
Links to existing ontologies
When developing a new ontology it is recommended to reuse existing ontologies as much as possible. Thus, one can focus on defining the specific knowledge of the application. The reuse of external ontologies not only saves time but also gives the advantage of using mature and proved ontological resources that have been validated by their applications and (some) by the W3C.
The WiseNET ontology reuses resources from many different ontologies (see Table 2). However, there are six key ontologies that cover most of the required concepts of the different domains, these are:
The
The
The
The
The
The
Figure 2 shows the primary classes and properties reused by the WiseNET ontology. The external ontologies were not imported, from most of them only a small portion was reused. Not importing the external ontologies results in ease of ontology maintenance and performance improvement, which is a critical factor since our goal is to obtain real-time reasoning.

Primary classes and properties reused by the WiseNET ontology. Classes are marked with (+) and properties with (−). The namespaces and brief description of the ontologies can be found in Table 2.
Many of the competency questions involve more than one type of knowledge. Hence, the WiseNET ontology should be able to collect and combine the information from the different domains. In that context, it is necessary to define new concepts (classes and properties) that allow us to complete the information from the different domains, to describe attributes of instances according to our needs and, more importantly, to relate (i.e., link) the different domains.3
The complete set of classes and properties of the WiseNET ontology can be found at
After having the complete terminology of the ontology, some constraints and characteristics of the class expressions and the property axioms need to be defined. Axioms are a set of formulas taken to be true and which every assignment of values must satisfy. Those constraints and characteristics determine the expressiveness and decidability of the ontology, and their definition depends on the description logic used.
Description logics (DLs) are a family of formalism used for representing knowledge [1]. The most notable applications for the DLs is to provide the logical formalism for ontologies languages such as OWL. OWL-2, the current W3C ontology language recommendation, is based on the expressive description logic
Definition of
constructors
Definition of

SWRL rule for

SWRL rule for
Horrocks and Sattler presented a tableau decision procedure for

A fragment of the graph showing the main classes and properties required to be extracted from the IFC file. On the right side a 2D view of the third storey of the I3M building is shown. The graph represents a small selection of spaces and elements present on the third floor. The colors of the graph nodes have two functions, first to make a correlation between the graph and the 2D view, second, to denote different IFC classes: the
However, knowledge representation formalisms of the semantic web (such as DLs) have expressive limitations, for example composition of complex classes from classes and properties. Those limitations can be overcome by rule-based knowledge, specifically by using SWRL (Semantic Web Rule Language) rules [21]. SWRL rules are represented as implication of an antecedent (Body) and a consequent (Head):
Reasoning becomes undecidable for the combination of OWL + SWRL, therefore the expressivity of SWRL needs to be reduced in order to assure decidability. Although, many procedures exists to guarantee decidability of SWRL, the DL-safe rules were adapted [34]. This procedure consists in restricting the number of possible variables assignments, i.e., restricting the application of rules only to known OWL individuals (named individuals).
Examples of DL-safe rules implemented in the WiseNET ontology are presented in Listing 1 and Listing 2. The first one states that if there are two spaces ‘x’ and ‘y’, and both contain the door ‘d’, then those spaces are connected to each other. The second one states that if there are two spaces ‘x’ and ‘y’, and two SCs ‘s1’ and ‘s2’, and ‘x’ is connected to ‘y’, and ‘s1’ is located in ‘x’ and ‘s2’ is located in ‘y’, then those SCs are nearby each other.
Notice that the property
Once the ontology is formally defined and implemented in a triplestore (a database for the storage of triples), the last step of the ontology development is the insertion of instances (population). The next two sections will present the population from an IFC file and the SC information respectively.
After inserting the WiseNET ontology in the system, the a priori information about the built environment needs to be populated. The required information can be extracted from the IFC file of the environment. This population is performed only once, at the initialization of the system, and is thus considered as a static population. Notice that if there is a reconfiguration of the building, the static population should be re-performed using the new IFC file.
The I3M (Institut Marey et Maison de la Métallurgie) building located in Dijon (France), is used as an example for this section. The I3M building has three storeys, from which we will focus on the third storey where a SCN has been deployed.
An IFC2x3 file, describing all the elements composing the I3M building, was obtained from the company in charge of the construction of this building and it was generated using the Revit CAD software.4
Only a small portion of the IFC file is needed in the WiseNET system. Therefore, to improve the ontology performance (and reduce its complexity), only the required information is extracted from the IFC file and populated in the ontology.
Figure 3 shows, in the form of a graph, the main classes and properties required to be extracted from an IFC file and populated on the ontology. The extracted/populated data consists of information about the building, building storeys, spaces, elements contained in those spaces and the relation between the different concepts (e.g., the building topology).

SPARQL query for extracting instances from the
A framework was developed for extracting and populating the required IFC data into the WiseNET ontology (see Fig. 4). The framework employs semantic web technologies and it consists mainly of four processes: a requirements checker of the IFC file, a conversion of the IFC into RDF, the extraction of the pertinent instances and finally, the population of the extracted instances and their relating properties into the WiseNET ontology.

Extraction and population framework.
The framework starts with an IFC file of a built environment, in this case the I3M building. To make use of the proposed framework the IFC file must contain instances of the following entities:

SPARQL query for inserting relations on the WiseNET ontology. Lines that start with
Afterwards, the IFC file is converted to RDF by using the IFC-to-RDF converter by Pauwels and Oraskari [39]. The result of the conversion is the
The ABox of the
Line 4 obtains the building instance by using its class.
Line 7 acquires the array of building storeys that decompose the building; and line 8 obtains the storeys inside that array.
The same is done for the spaces that decompose the storeys on lines 11–12.
Lines 15–16 obtain the elements that are contained in a space.
Lines 19–22 filter out the undesired elements just leaving the doors, windows and walls.
Line 25 gets the classes of all the elements and line 26 filters out the binding to
The result of the query is the extracted table, where its columns corresponds to the variables used with the SELECT operator (line 1).
In
Population query
The population query consists in creating the relations between the extracted instances. To accomplish this, the extracted table is processed row by row.
For exemplification, let us assume that the first row of the extracted table has the following values:
where
Now, those instances are the input of the population query shown in the Listing 4, where:
Line 1 inserts the defined triples into the WiseNET ontology.
Lines 3–5 relate the extracted instances of the
Lines 8–11 states the class of each instance.
This process needs to be repeated for all the rows of the extracted table, which is achieved by using an external loop.
To summarize, in order to populate the WiseNET ontology with the a priori environment knowledge, the relevant information from the IFC file needs to be extracted, then shared and inserted into the WiseNET ontology using queries, rules and linked data techniques such as Uniform Resource Identifiers (URIs) and RDF.
Linked data technology connects data from one data-source to other data-sources, in our case, linked data allows the WiseNET ontology to obtain extra information from the
IFC extension
The IFC data could be enhanced to allow the deduction of security restrictions and the design of rules regarding the space usage. Particularly, we propose to extend the IFC by adding extra information concerning:
The IFC extension is performed during the System Configuration (see Section 6.1).

Graphic User Interface (GUI) of the System Configuration software. In this example the
The built information has already been added to the WiseNET ontology, the next step is to populate the information about the sensors.
A complete SCN has been installed in the third storey of the I3M building.5
A demonstration of the deployed network can be found at
There are two types of information that need to be populated concerning the SCs. Firstly, the SC setup information, which consists in describing the SCs and their relation to the built environment. Secondly, the information about detections which occurs each time the SCs perform a detection.
The first one is inserted once, during the system configuration, therefore it is considered as a static population. The second one will be inserted each time there is a detection, therefore it is considered as a dynamic population.
Figure 5 presents the System Configuration interface used for adding and setting up SCs in the system and to extend the IFC information. The System Configuration helps specifically to perform the following tasks:
The system automatically proposes a set of elements for representation (e.g., doors and windows) according to the selected space. This information is obtained by querying the
The details of the image processing algorithms are outside the scope of this paper and they will be presented in a future work.
The System Configuration software is connected to a SPARQL endpoint that inserts the information set by the user.
This step can be seen as a soft camera calibration that requires only the knowledge of the location of the cameras in the building. This differs from many MCBS, that require overlapping between the fields of views of the cameras and their orientation, leading to a time-consuming and skill-dependent calibration process [46].
An important contribution of using an ontology during the SC setup is the automatic suggestion of pertinent elements according to the space. This is achieved by using the static population of the building information.
The dynamic population consists of two phases, first the knowledge extraction performed by the SCs and then the knowledge processing performed by the central API.
Knowledge extraction
The main functions of the SCs are: to detect pertinent information using different image processing algorithms, to extract the knowledge from it and to send it to the central API.

Example of a message sent by the smart camera to the central API. Notice that the message is composed of two detections
For our Panoptes building application the main detectable objects are people. After detecting some pertinent information, the SC describes what it observes by using the vocabulary defined in the WiseNET ontology, i.e., extract the knowledge of the scene. This addition of semantic meaning to what the camera observes is a problem known as
Finally, an SC-message containing the scene description is created using the JSON syntax (a lightweight format to serialize structure data7
JSON (JavaScript Object Notation)
For instance, consider the scene observed by the
The details of the process to obtain the array of visual descriptors is beyond the scope of this paper and will be presented in a future work.
It is important to remark that the choice of visual descriptors may vary according to the application and resources, therefore it is possible to use different color spaces, physical characteristics (e.g., height, head size and shoulder width) [4], or robust feature descriptors such as Histogram of Oriented Gradients (HOG) [11], Scale-Invariant Feature Transform (SIFT) [29] or Speeded-Up Robust Features (SURF) [2].
Once the central API receives the SC-message, it creates and inserts the
A

Semantic network of Detection and PersonInSpace events, using as example the instances in Listing 5.

Dynamic population process performed by the central API. The process starts with the reception of a message from a smart camera, and finishes with the insertion of pertinent knowledge. The GET, UPDATE and CREATE processes involve SPARQL queries using SELECT, DELETE and INSERT commands. PIS-E stands for
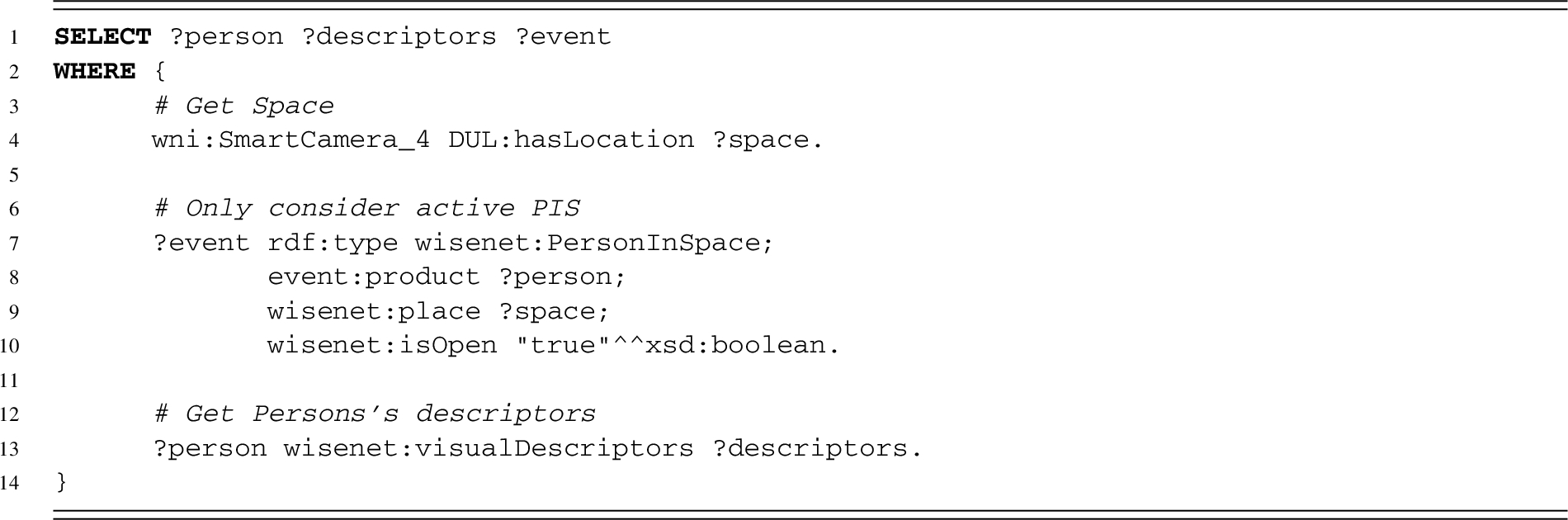
Query to get
To achieve the semantic network creation-insertion, the central API performs the process presented in Fig. 7. The process starts by receiving a SC-message, then the
Getting all
Line 4 gets the space where the SC is located.
Lines 7–10 get all the active
Line 13 gets the visual descriptor array of the person.
Comparing the visual descriptors of the selected
The Chebyshev distance is defined as
If the Chebyshev distance between the detection’s visual descriptor and the visual descriptor of an existing
If no matching
Lines 4–8 get the active events in the neighbor spaces.
Lines 11–13 check that the last detection of the
Lines 16–18 check that the last detection of the
After executing the query in Listing 7, the visual descriptors of the selected
If a corresponding
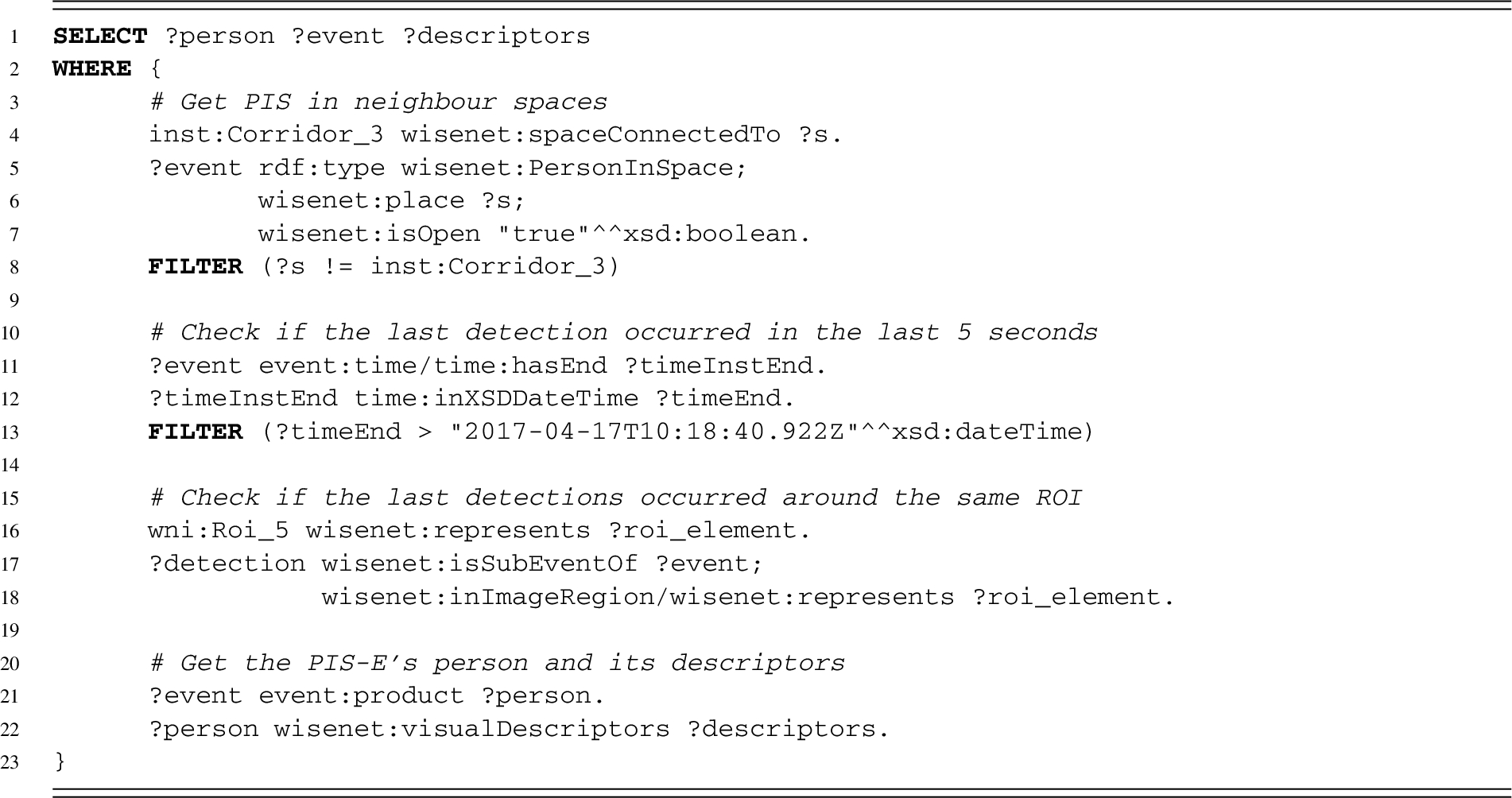
Query to get related
The workflow continues by creating and inserting the new
The process is then repeated for each detection in the SC-message.
Finally, the central API performs a cleaning process which consists of:
Notice that the central API executes by demand, it does not run in the background, i.e., that it only runs each time a SC-message is received or when a service request is received (e.g., by the monitor API).
This paper focused on creating an ontology model to fuse and re-purpose the different types of information required by a Panoptes building. Once the model is assembled it needs to be evaluated to verify if it satisfies its intent.
Currently, the smart camera network (SCN) has been deployed and the algorithms of motion detection, face detection, fall detection and person detection were implemented on it. This section presents an evaluation of the WiseNET ontology, some use cases of the complete system and a discussion on how WiseNET may overcome some issues of classical computer vision.
WiseNET ontology evaluation
According to Hitzler et al. the accuracy criteria is a central requirement for ontology evaluation [19]. This criteria consists in verifying if the ontology accurately captures the aspects of the modeled domain for which it has been designed for.

Queries to answer selected competency questions. Lines that start with # are comments

Queries to answer selected competency questions (continued from Listing 8). Lines that start with # are comments
The development of the WiseNET ontology was based on some competency questions (see Table 1), therefore the evaluation consists in showing that those questions can be answered by the ontology. Listings 8 and 9 present the queries to answer some competency questions. These questions were selected because they involve aspects which are important in a Panoptes building.
Lines 5–8 get the
Line 9 gets the starting times of the
Lines 16 get the ROIs that the SC observes.
Line 17 gets the type of elements that those ROIs represent.
Line 18 removes the binding.
Lines 25–27 get the
Lines 28–29 get the starting and end time of the
Lines 30–31 considers only the
Lines 38–41 get the
Line 42–43 get the duration and its units of the
Lines 50–51 get all the Line 53 groups the results by spaces. Line 48 counts the number of
Notice that the space more visited could be easily obtained by adding the line
Line 5 gets all the
Lines 6–7 get the detections attached to each
Line 8 gets the detections that have the same starting time than the
Lines 9–11 filters the detections to keep only those that were made around a door.
Line 13 groups the results by doors.
Line 14 orders the doors in a descending order according to their number of detections, and provides only the first one, the most used one.
Consider the test scenario depicted in Fig. 8, where two people are walking in the I3M building. The SCN extracts the pertinent information from the scene, and then sends the SC-messages to the central API. The central API processes those messages and generates the new knowledge that will be inserted into the ontology by following the workflow shown in Fig. 7.

WiseNET system people tracking. Two people are walking in a built environment while being detected by the SCN. For conciseness we only considered 3 SCs and 9 timestamps (numbers in red). Notice that at timestamp 5,
Table 4 shows the dynamic population performed by the central API at each timestamps of Fig. 8. It is important to remark the following:
For each detection performed by the SCs, a
The
The first time a person is detected in a new space a
If a detection is made around an ROI, then the new
The timestamps shown are continuous, meaning that between all the timestamps there exists many others. For example between timestamps 3 and 4 there is a detection (at timestamp 3.5 for example) that explains the creation of
At timestamp 5 the
During the test scenario, the central unit was deployed on a Intel(R) Xeon E5-2430@2.20 GHz CPU with 4 GB RAM and 40 GB HDD. The time performance of the dynamic population was evaluated by verifying the time required to process different number of detections, as shown in Fig. 9. The graph was obtained by sending to the central API a single SC-message composed of multiple different detections. From the graph, it can be observed that the time to deal with 15 detections (<1 s) is still compatible with real-time analysis.
Dynamic population performed during the people tracking scenario shown in Fig. 8. The processing time denotes the time required by the central API to perform the dynamic population
Regarding the privacy protection, it is important to remark that the SCN used in the WiseNET system does not send or save any images, thereby protecting the privacy of the individuals. However, one exception could be made if the ontology infers that an illegal act is occurring, in which case, the central API can use that inferred knowledge to send a message to the SC telling it to start recording and to save the images locally (to have them as proof).
From the dynamic population many use cases could be imagined. For example, Fig. 10 shows a heat map representing the number of people in each space at timestamps 2 and 3 from Fig. 8. The heat map was obtained by using the query to answer the Question 5 in Listing 8. At timestamp 3 the system deduces that a person passed from one space to another by using a specific door (shown by the arrow in Fig. 10). This deduction was obtained by knowing that the spaces involved in the
More use cases could be developed such as:
A semantics-based system such as WiseNET appears promising to overcome some of the computer vision limitations, in particular:
Another way to avoid false detections could be the addition of logical rules, such as, if a person is detected for the first time inside a room without passing through a door this could be considered as a false detection. Moreover, some semantics of the image could also be exploited as the position of the floor and the dimensions of the people.
Graph showing the average time required by the central API to process different number of detections. Heat map representing the number of people. The timestamps 2 and 3 were taken from Fig. 8. The right side shows what the SCs observe and the left side shows what the WiseNET system deduces from it. In the camera images, the blue bounding box represents an ROI, the green bounding box represents a detection and the red one represents a detection around an ROI. The complete heat map can be found at 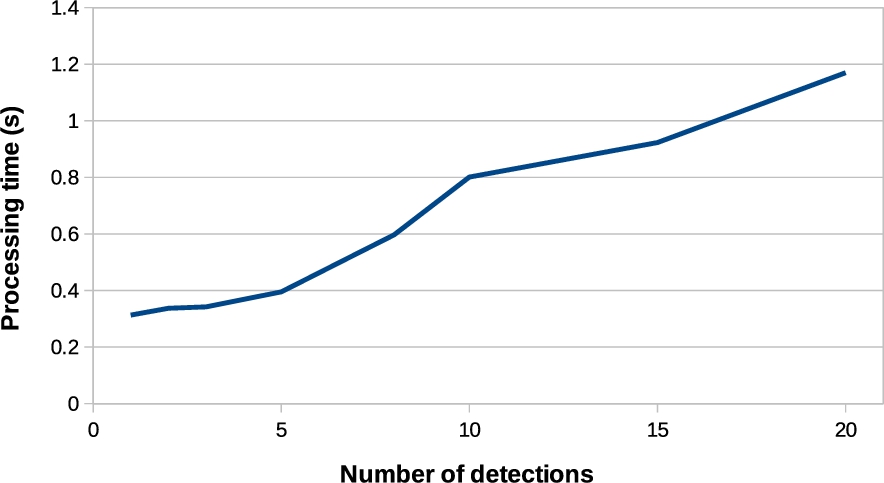

Those and other advantages of WiseNET will be deeply studied in future works, specifically a quantitative evaluation will be done comparing the system’s performance using other computer vision techniques such as deep learning.

Example of occlusion. The timestamps used were taken from Fig. 8. Even if one of the people disappeared at timestamp 5, the WiseNET system deduces (deduction box) that he is still inside the space because his last detection was not made around the ROI. In the camera images, the blue bounding box represents an ROI, the green bounding box represents a detection and the red one represents a detection around an ROI.
In this work we tried to develop an “all-seeing” smart building, which we have called Panoptes building. With that motivation, the WiseNET ontology was developed. Its main goal is to fuse the different built environment contextual information with that coming from the SCN and other domains, to allow real-time event detections and system reconfiguration. The purpose of the developed ontology is to create a kernel of a Panoptes building system, rather than working towards publishing another generic ontology. The ontology development procedure was performed using different semantic technologies, and it consisted of: defining a set of questions that the ontology should answer (competency questions); reusing different domain ontologies (
The WiseNET system is a semantics-based real-time reasoning system, that fuses different sources of data and is expected to overcome limitations of MCBS. The WiseNET system selects relevant information from the video streams and adds contextual information to overcome problems of missing information due to false/missed detections. Additionally, it relates events that occurred at different times, without human interaction. It also protects the user’s privacy by not sending nor saving any image, just extracting the knowledge from them. It may as well, reconfigure the SCN according to the inferred knowledge. To summarize, the WiseNET system enables interoperability of information from different domains such as the built environment, event information and information coming from the SCN.
A future goal of the WiseNET system is to offer services to building users according to information coming from a network of heterogeneous sensors deployed on the built environment and contextual information. This is a highly complex task due to the large scope of the building system, that goes from the static physical structure of the built environment to the internal environment in terms of the dynamic building users and the way how they interact with the building facilities.
The future works will focus on completing the externalization of the ontology knowledge using the bi-directionality between the SCN and the central unit, which is a novelty in the semantic web domain. Specifically, the mechanism of using the ontology to interact with external devices by checking the inferred knowledge and using it to reconfigure the SCN by: triggering a specific action (e.g., recording and triggering an alarm), changing the image processing algorithm or by saying to the SC to focus on a specific ROI. Moreover, the dependency on the central API leaves open the question of automatically output the ontology knowledge, especially the inferred knowledge.
Immediate next steps involve adjusting the WiseNET with the updated version of the
Footnotes
Acknowledgements
The authors would like to thank the Conseil Régional de Bourgogne Franche Comté and the french government for their funding.
We would also like to thank Ali Douiyek and Arnaud Rolet for the technical assistance and management of the technical team. As well as D. Barquilla, T. Coulon, Q. Enjalbert, A. Goncalves, L. Lamarque, E. Grillet, G. Kasperek, M. Le Goff, E. Menassol and K. Naudin for their help in the development of the website and the 3D visualization tools of the building.