
Abstract
Large-scale knowledge graphs such as those in the Linked Open Data cloud are typically stored as subject-predicate-object triples. However, many facts about the world involve more than two entities. While n-ary relations can be converted to triples in a number of ways, unfortunately, the structurally different choices made in different knowledge sources significantly impede our ability to connect them. They also increase semantic heterogeneity, making it impossible to query the data concisely and without prior knowledge of each individual source. This article presents FrameBase, a wide-coverage knowledge base schema that uses linguistic frames to represent and query n-ary relations from other knowledge bases, providing multiple levels of granularity connected via logical entailment. Overall, this provides a means for semantic integration from heterogeneous sources under a single schema and opens up possibilities to draw on natural language processing techniques for querying and data mining.
Introduction
Over the past few years, large-scale knowledge bases (KBs) have grown to play an important role on the Web. Increasing numbers of institutions publish their data using Semantic Web standards [2] and Linked Open Data (LOD) principles, contributing to the LOD cloud. This data can be used for a variety of purposes. For instance, commercial search engines exploit these KBs to provide direct answers to user queries, while IBM’s Watson question answering system [21,34], which defeated human champions of the Jeopardy! quiz show, used them to find or to rule out answer candidates.
KBs of this sort are mostly based on simple statements expressed as subject-predicate-object triples, as defined by the RDF model [29]. Such triples are convenient to process and can be visualized as entity networks with labeled edges.
Whereas triple representations work straightforwardly for relations involving two entities, many interesting facts relate more than just two participants – a problem that has gained renewed attention in several recent papers [25,43] as well as in the current W3C proposal to add roles to schema.org [5]. For a birth event, for instance, one may wish to capture not just the time but also the location and the parents. For an actress starring in a movie, the name of the portrayed character may be relevant. Such facts naturally correspond to n-ary relations. In order to capture them as triples, several different representation schemes have been proposed.
Figure 1 shows some possibilities of expressing that two entities John and Mary married in 1964. These different modeling patterns are used across different KBs in the LOD cloud, which will be discussed in more detail later in Section 2.
The basic-triple pattern in Fig. 1(a) is very simple and just establishes pair-wise connections between the arguments of the n-ary relation. If one regards every triple as representing an underlying n-ary relation with only two arguments given, it could be said that this pattern occurs in every KB in the LOD cloud. It lacks the expressive power to connect more than two arguments of the same n-ary relation.
The triple-reification1
This kind of reification is different from the other kind that is discussed in this paper, which is explained in Section 2.1.2. Both kinds of reification have in common that they consist of creating an entity for something that was not represented explicitly by a single entity before. To avoid confusion, we will refer to this kind of reification as triple-reification, while the other kind – more related to the field of linguistics – will be referred to as “reification” without any qualifier.
The singleton-property pattern in Fig. 1(c) [43] improves the pattern above, but still carries some of the same problems.
The pattern in Fig. 1(d) is an event-centric pattern used frequently in specific parts of many KBs (e.g. Freebase [4]), usually to represent public events by means of a reduced ad-hoc vocabulary. It uses specific properties connected to an event class. The event class is often specific but sometimes may also be general (since more specific information can often be explicitly or implicitly inferred from the specific roles).
The pattern in Fig. 1(e) is similar to the previous one but uses a reduced set of generic roles. It is found in some KBs and schemas such as the Simple Event Model (SEM) Ontology [70] and LODE (Linking Open Descriptions of Events) [61].
The pattern in Fig. 1(f) is based on “role classes” that substitute for the regular object of a triple, and to which additional properties can be appended.
Other more ad-hoc solutions exist as well.2
One is to encode the value of the third, fourth, etc. argument in the IRI of a property connecting the first two, e.g.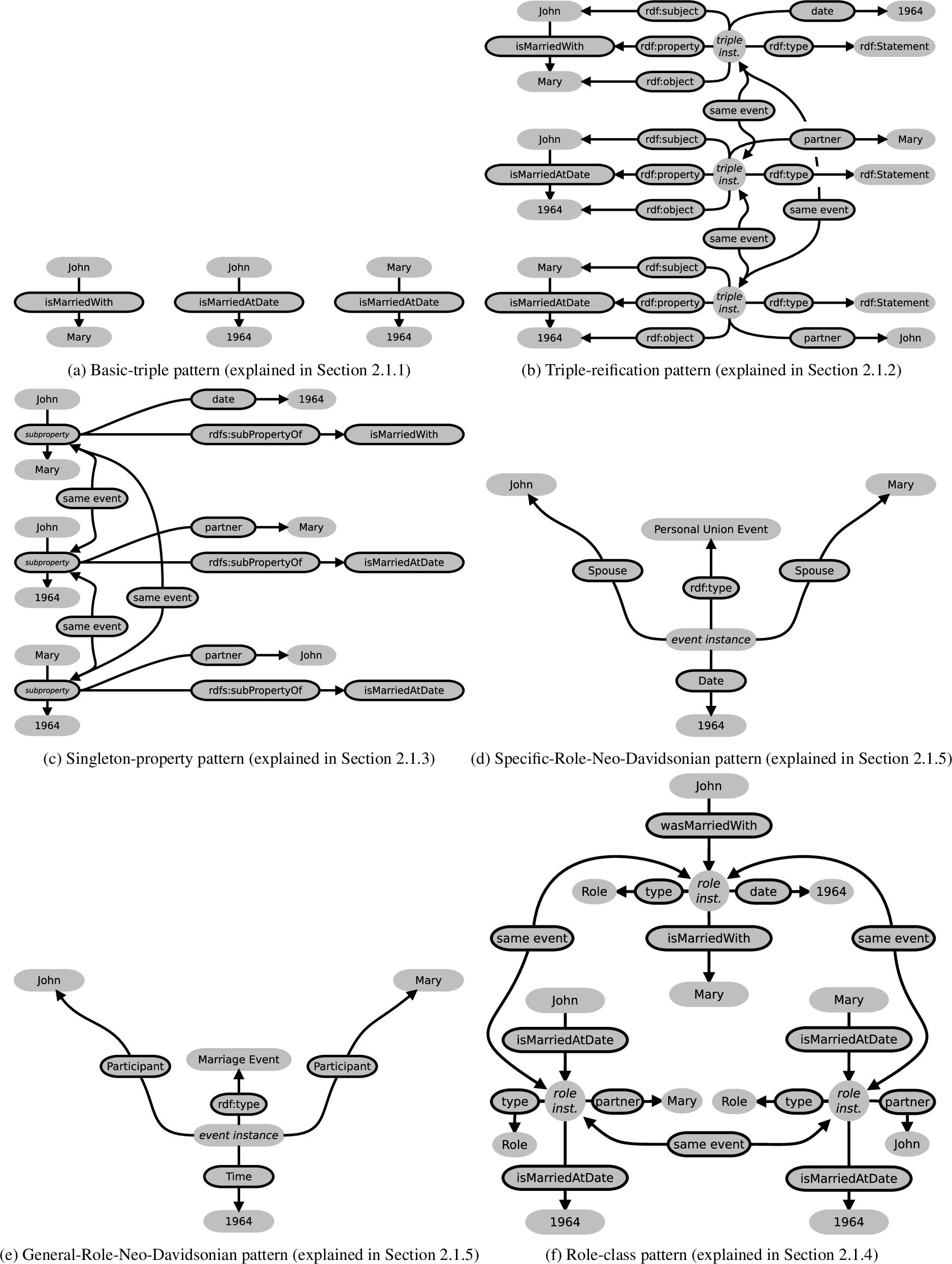
The same information represented using different modelling patterns used in different KBs in the LOD. The property “same event” is meant to link entities that are not logically equivalent but represent the same underlying event.
Table 1 provides examples of these different modeling patterns in terms of the involved triples given in an N-triples-like format. These correspond to Fig. 1, but the parts corresponding to Fig. 1(a), (b), (c), and (f) are restricted to the structures surrounding the triple
Triple representations of n-ary relations
As the examples show, this sort of semantic heterogeneity leads to significant data integration challenges. One KB might use a simple binary property between two entities, whereas another may instead choose a more complex representation that accommodates additional arguments (as will be analyzed in Section 2.1). The representations can easily be so at odds with each other that no particular mapping between entities could bridge the differences. There are entities at each side that have no counterpart at the other. This leads to several challenging problems:
When
When
Similarly to the previous point, when
In this article, we describe how these problems are addressed by

Knowledge represented the examples in Fig. 1, represented under the FrameBase model, which combines expressiveness with conciseness by combining different representation layers.
The latter is achieved by offering a two-layered structure with a mechanism to convert back and forth between the Neo-Davidsonian representation and one based on direct binary predicates, using a vocabulary of automatically generated binary properties exploiting the ties to resources in linguistics. These are more concise and can be used when only two arguments are relevant, either in the KB or in a query.
This article builds upon previously published work on FrameBase [53,54] and extends it by:
Including an expanded and updated analysis of the state of the art.
Describing the addition of miniframes to the FrameBase schema.
Linking with external Linked Open Data resources such as Lexvo.org [12,13] and the Princeton RDF WordNet [40].
Creating 10,270 new Direct Binary Predicates and Reification–Dereification rules based on nouns, for which the head verbs have been extracted with a novel method.
Adding linguistically rich annotations to all Direct Binary Predicates using the Lemon model [41].
Incorporating, in Section 6, results from additional work [54–56] on the classification and generation of integration rules.
Including new illustrations, an updated structure, and a more in-depth analysis of several aspects of FrameBase.
This paper is structured as follows. Section 2 reviews related work and conducts a more thorough analysis of existing approaches for modeling n-ary relations and their space efficiency. Then, an overview of FrameBase is given in Section 3. Section 4 explains how the FrameBase schema is constructed, including rules to convert between different levels of granularity and expressiveness. Section 5 provides an evaluation of the quality of the FrameBase schema. Section 6 presents a typology and examples of integration rules used to capture knowledge from external KBs into the FrameBase schema, and existing methods to automatically create the simplest kinds of rules. Section 7 discusses challenges regarding the creation of more complex integration rules, and possible ways to address them. Section 8 provides a conclusion and outlines other potential lines of future work.
In this section, we review prior work in this area. In particular, Section 2.1 provides a deeper analysis of the patterns introduced in Fig. 1. Section 2.2 discusses previous work on integrating knowledge. Section 2.3 introduces FrameNet, which serves as the backbone of our schema, as well as other related work based on it.
Modeling patterns for N-ary relations
Triple count associated to different approaches or patterns for modeling n-ary relations
Triple count associated to different approaches or patterns for modeling n-ary relations
Different approaches or patterns for modeling n-ary relations exist, as summarized in Fig. 1 and Table 1. In Table 2, we provide a novel analysis of their general space efficiency, which has consequences with regards to their applicability for large-scale KBs. Each row considers the space efficiency of a specific modeling pattern for representing an event with n participants, where
Figure 1 can be regarded as a specific case of Table 2 with
Similarly, Table 1 can be seen as a specific case of Table 2 with
Each pattern will be discussed in detail in the following subsections.
A common way to represent n-ary facts is to simply decompose them directly into binary relations between two participants [14]. However, in doing so, important information may be lost. For instance, given three triples sharing the subject, one of these with property
Triple-reification pattern
The RDF standard includes a method for performing reification [29] of triples, which introduces a new Internationalized Resource Identifier (IRI) for a statement and then describes the original RDF triple using three new triples with
Triple-reification is used in the different versions of YAGO [31,64,65] to attach additional information to the event represented by the original RDF triple (evoked by its property). It has also been proposed in the W3C WebSchema drafts [5]. This pattern is exemplified in Fig. 1(b) (in YAGO, the Formally, the event represented by a triple and the triple as a statement are different entities with different properties. For instance, an institution may endorse the triple as a statement without endorsing the marriage. Using triple-reification, both are represented by the same RDF resource identifier, which conceptually is meant to be unambiguous. This is a potential source of confusion and inconsistency. The number of triples increases by a factor of 4. For each triple The advantage of being able to include the original non-triple-reified triple only applies to the primary binary relation, and not to the other The choice of the primary pair of entities and their binary relation (John and Mary in Fig. 1(b)) is arbitrary, and a third party willing to query the KB cannot replicate the choice independently. If their choice is different, they will not obtain any results. A possible solution, which is actually implemented in YAGO, is to include the triples for the other pairs and reify them, too, but this adds yet another factor of overhead, besides data redundancy that would complicate updates.
If the triplestore implementation makes use of quads,3
The “singleton property” approach [43] aims to solve some of the issues with triple-reification by instead declaring a subproperty of the original property in the primary pair, and using this subproperty as the subject for the other arguments of the n-ary relation. This is shown in Fig. 1(c).
While the approach enables us to use RDFS reasoning to obtain the triple with the parent property that relates two of the participants, and also reduces the overhead of triple-reification, it still suffers from the problems mentioned above related to the existence of a primary pair. For example, the non-triple-reified binary relationships for the other pairs cannot be inferred from that subproperty using RDFS.
Role-class pattern
Schema.org is an effort sponsored by Google, Yahoo, and Microsoft to establish common standards for semantic markup in Web pages. It offers a method to qualify a binary predicate by adding additional information to it [32], which in practice is equivalent to representing the n-ary relation arising from adding arguments to the binary relation underlying the binary predicate. This works by substituting the object of the binary predicate with a fresh instance of a class Role (or a subclass thereof with its own properties), and appending to this role instance the original object by means of the same binary predicate, alongside other properties such as time, instrument, etc. In order to avoid confusion, it is relevant to note that Schema.org’s use of the term “role” differs from its standard use in linguistics, which are qualifying properties such as agent and patient [23]. This definition has also been adopted in ontologies, for instance
This transformation offers a certain level of compatibility between the simple pattern with the direct binary predicate and the complex pattern, because the binary predicate is preserved in the complex pattern, with the same subject. However, the object changes, and therefore the simple pattern as such is not truly preserved after the transformation. Besides, the definition or original contract of the direct binary predicate is broken in the complex pattern. For example,
An example of how this conflation can lead to problems can be fully appreciated with intransitive predicates. For instance, if the predicate is
Furthermore, the complex pattern produced by this method, given a direct binary predicate between two entities and a further qualifying value (like time in the example), is not equivalent to the one produced by another binary predicate between one of these entities and the qualifying value. This produces a similar effect of redundancy as in the method using triple-reification.
Neo-Davidsonian pattern
Another approach, and the one that FrameBase adopts, is to make use of Neo-Davidsonian representations [33, p. 600f.]. This means that we first define an entity that represents the event or situation (also referred to as a frame) underlying the n-ary relation. Then, this entity is connected to each of the entities filling the n arguments by means of properties describing the respective semantic roles [25,44] associated with each argument position.
The process of converting from the binary representation to the Neo-Davidsonian one is called reification, but this is different from triple-reification discussed above. In triple-reification, an entity is defined that stands for a whole triple so that additional triples can be used to describe the reified triple as a unit that represents a statement. However, in the context of event semantics, reification is used to denote the process by which an entity is defined that refers to the event, process, situation, or more generally, frame, evoked by a property or binary relation. Having done this, additional information about it can then easily be added. Both kinds have in common that a new entity is defined to refer to something that before was not explicitly represented by an entity in the KB, but in one case it is an RDF statement, while in the other it is an event.
The Simple Event Model (SEM) Ontology [70] uses the general-role Neo-Davidsonian pattern in Fig. 1(e). It defines four very general entities, Event, Actor, Place, and Time. It also establishes a framework for creating more specific ones by extending these, but it does not provide these extensions, nor ways to integrate existing KBs in a way that would solve the problem of semantic heterogeneity. Similarly, LODE (Linking Open Descriptions of Events) [61] specifies only very general concepts such as the four just mentioned.
Freebase [4] was built both by tapping on existing structured sources and via collaborative editing. Although it uses its own formalisms, there are official and third-party translations to RDF. Freebase makes use of mediators (also called compound value types, CVTs) as a way to merge multiple values into a single value, similar to a
Knowledge integration
Connecting and integrating different knowledge sources is a long-standing problem. For KBs, there has been substantial work on ontology alignment [17] to identify matching classes from different sources, and in some cases also instances and properties [39,42,63].
However, relatively little work has considered scenarios in which the same type of ontological knowledge is modeled in different ways, as in the different modeling patterns illustrated in Fig. 1 and explained in Section 2.1. In these cases, alignment by means of binary properties such as equivalence or subsumption is no longer sufficient because an entity in a KB may not have a direct counterpart in another KB. For instance, neither any of the properties in Fig. 1(a), nor the statement instance in Fig. 1(b), the subproperty in Fig. 1(c), nor the event instance in Fig. 1(d) can be connected by
The EDOAL (Expressive and Declarative Ontology Alignment Language) format [10] has been proposed to express complex relationships between properties. It defines a way to describe complex correspondences but it does not address how to create them. Similarly, complex correspondence patterns between ontologies have been described and classified in an ontology [60]. However, this approach does not provide any method to create the correspondence patterns, neither fully nor semi-automatically. The iMAP tool [15] searches a space of possible complex relationships between the values of entries in two KBs, e.g.,
Unlike previous work, the approach presented in this paper does not focus on matching pairs of entities but provides techniques to match knowledge that can also be expressed with complex patterns involving multiple entities at one side. However, these techniques can be combined with the existing work on creating the one-to-one mappings.
FrameNet
FrameNet [22,58] is a well-known resource in natural language processing (NLP) that defines over 1,000 frames, which represent abstract concepts that encompass situations, events, or processes. These are evoked by certain words, called Lexical Units (LUs), which can be any part of speech: nouns, verbs, adjectives, etc. For example, the verb to buy and the noun acquisition can evoke (depending on the intended sense) a “commercial transaction” frame. Frames have associated participants (called Frame Elements or FEs for short). For instance, the “commercial transaction” frame has FEs for the seller, the buyer, the goods, and so on.
FrameNet includes a corpus of text that has been annotated with frames and FEs. Each annotation consists of a frame and an LU that appears (possibly inflected) in a piece of text, and some FEs whose values also appear in the text. This information can be used for training semantic role labelling (SRL) systems, also known as semantic parsers, to extract semantics or meaning from arbitrary text.

Overview of the structure of the FrameBase system.
There has been previous work on producing conversions of FrameNet to RDF as a resource [45] instead of a schema. Also, previous work [24] has proposed a framework, in the form of a meta-schema, for using frames as units of meaning to address the semantic heterogeneity problem. The framework serves as a model that can be instantiated to generate schemas from FrameNet, but it does not provide a specific one.
FRED [48] builds semantic representations of text, based on Discourse Representation Theory and with links to VerbNet [46], FrameNet [22], DOLCE Ultra-Lite [49], and other knowledge sources. Our work, in contrast, does not focus on creating representations from text but rather on converting all the knowledge in such knowledge sources to a unified schema.
As pointed out in the previous section, there are a number of different patterns used to represent n-ary relations in KBs.
This paper describes the construction of FrameBase, an extensible KB schema that allows for representing a wide range of knowledge, aiming at an optimal balance between the existing modeling patterns. The paper also discusses methods to integrate knowledge from external KBs.
FrameBase consists of two layers. The more expressive but also more verbose layer of the FrameBase schema is referred to as the reified layer. It consists of classes, representing frames, which can be events, situations, processes of a very general kind. It also contains frame-element properties that specify qualities about frame instances: agents participating in different ways, time, place, cause, consequence, instrument, etc. The frames are organized in a hierarchy of macroframes, miniframes, and synset- and LU-microframes, ordered here from more general to more specific kinds of frames. Synsets and LUs (Lexical Units) are concepts imported from WordNet [18] and FrameNet [1], respectively, which are both resources from computational linguistics. FrameNet constitutes the backbone of FrameBase and is a compilation of such frames and FEs to annotate the semantics of natural language. WordNet is a computational lexicon that includes word senses grouped by synonymy and other semantic relations. Both synsets and LUs are closely related to sense-disambiguated words and therefore they are used to produce the most specific frames, whereas miniframes and macroframes represent groups of near-synonymous or related concepts.
The less verbose but also less expressive layer of the FrameBase schema is the dereified layer, which consists of direct binary predicates (DBPs). These are properties for simple binary relationships between elements of a given frame. Rather than having to query such relationships via a common frame instance, this layer enables direct querying of these binary relationships.
Data from external KBs in the LOD cloud can be imported using integration rules, which can create FrameBase instance data from the instance data of the external KBs. This paper also describes the creation of these rules in manual, semi-automatic, and automatic ways, exploiting the linguistic aspects of FrameBase inherited from FrameNet. The results for automatic and semi-automatic methods are evaluated empirically. We also provide examples of how the resulting FrameBase instance data can be queried. Figure 3 provides a general overview of the dataflow in the FrameBase system.
FrameNet-based representation
The use of FrameNet as the backbone of FrameBase is motivated by the following considerations.
FrameNet has long been used to describe the semantics of general natural language. It thus provides a relatively large and growing inventory of frames and roles, with a coverage of different domains. The average number of FEs per frame is 9.45.
FrameNet comes with a large collection of English sentences annotated with frame and frame-element labels, which enables semantic role labeling [26]. This strong connection to natural language facilitates question answering [38] and related tasks.
While FrameNet’s lexicon and annotations cover the English language, its frame inventory is abstract enough to be adopted for languages as different as Spanish and Japanese [62]. This also makes it more suitable as a basis for language-independent knowledge representation than more language-specific syntax-oriented SRL resources such as PropBank [35], although being more abstract can make the SRL task more challenging.
In terms of what is expressed as a frame and what is expressed as a role or frame element, FrameNet provides a reasonable level of granularity for the phenomena that humans care to describe. From a theoretical perspective, there is no universally appropriate single level of reification. Any frame element might itself be reified, and any two elements of a frame could be connected directly by a predicate. Using FrameNet strikes a well-motivated balance, at a point that is granular enough to constitute a model for natural language semantics. However, as Section 4.4 will explain in more detail, a second level of representation is provided in FrameBase, which is based on the direct binary predicates between frame elements, and therefore less expressive but more concise.
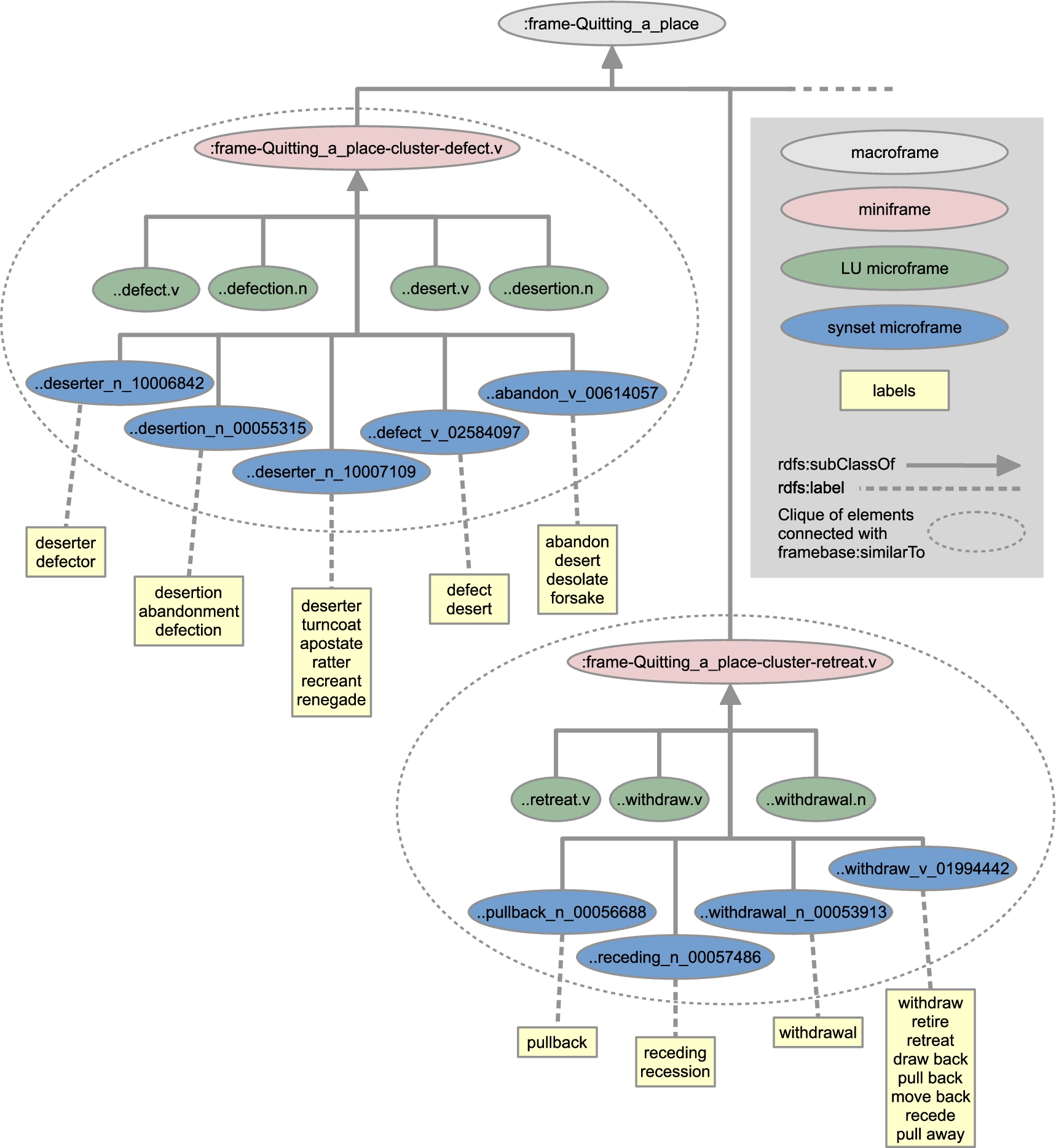
Example of some microframes and labels under the general frame class
The FrameBase schema consists of a reified layer and a dereified layer, connected by inference rules. The reified layer provides a comprehensive hierarchy of frames and FEs, with lexical labels in English. The dereified layer provides direct binary predicates that can be used between the values of the FEs. The creation of the schema is carried out in the following steps.
FrameNet–WordNet mapping
While FrameNet [22,58] is the largest high-quality inventory of semantic frame descriptions and their participants, WordNet [18] is the most well-known resource capturing meanings of words in a lexical network, covering for example nouns and named entities missing in FrameNet. WordNet, for instance, serves as the backbone of YAGO’s ontology. This section proposes a novel way of mapping the two resources, which later enables us to integrate both of them into FrameBase’s schema.
WordNet contains synsets, which are sets of sense-disambiguated synonymous words with a given part of speech (POS), such as noun or verb. FrameNet contains lexical units (LUs), which are also POS-annotated words associated with frames. Because of the semantics of the containing frame, LUs are also disambiguated to a certain extent, though not with the same granularity as in WordNet (for instance, WordNet has different senses for the verb to assert corresponding to stating something categorically and to declaring or affirming something solemnly as true; this is a nuanced difference that is conflated under a single LU in the frame Statement). The objective at hand is to produce an alignment of synsets and LUs with the same meaning, which can be later used to enrich FrameBase’s FrameNet-based schema with relations and annotations from WordNet.
More specifically, the objective is to map each LU to exactly one synset. While there are some LUs that could be mapped to more than one synset, as a general rule the restriction to a single one favors precision, which is desirable for the purpose of obtaining a clean knowledge base (even at the cost of some recall). The only cases where this model would be detrimental to precision are those for which LUs do not have any associated synset, but these are few and most can easily be avoided by omitting LUs with parts of speech not covered in WordNet, such as prepositions.
This choice allows for modeling the mapping as a function
The lexical overlap
The gloss overlap
Parameters a and b are trained with a greedy search starting at several randomized seeds, obtaining optimal values
Hierarchy construction
In FrameBase, frames are modeled as classes whose instances are specific events or situations. The frame elements of each frame are properties whose domain is that frame. The class hierarchy of frames is created as follows.
We use
http://framebase.org/ns
as default prefix.
Another example covering both inheritance and perspectivization is the following. Using RDFS inference, an instance of
Algorithm 1 describes how the clusters are created, defined in a set C of pairs of microframes representing edges of a graph. In the main loop, the algorithm independently considers each macroframe m. Such macroframes have microframes as direct descendants. First, for a given m, an empty set Algorithm for generating clusters Example of six clusters of LU- and synset-microframes under the macroframe 

In general, these lexical relations do not necessarily imply any close semantics (e.g., the verb create and the noun creature), but when restricted to synsets all tied to the same FrameNet frame, such cases are normally factored out. Therefore, from the pairs in
Finally, the transitive closure of the symmetric closure of C is calculated, which effectively creates cliques for the clusters.
Figure 5 presents examples of clusters under a single macroframe.
Once C is obtained, the property
This is yet another different but related use of the term reification. In general, reification means the process of making something real, and in the context of knowledge bases, can be used whenever a new entity is created for something that was only implicitly represented before, generally as a function of pre-existing entities.
The use of the property
Names, definitions, and glosses in FrameNet and WordNet are also used to create text annotations for our schema. Lexical forms are attached with

Example of Lemon annotation for LU-microframe.
Following the best practices in the Linked Open Data community, we link synset-microframes to IRIs in the canonical RDF translation of WordNet [40]. We also provide links to word-sense IRIs in Lexvo.org, a KB that connects information about languages, words, characters, and other human language-related entities [12,13]. This allows FrameBase to be transitively connected to other KBs in the Linked Open Data web, as well as provide multilingual support.
In general, the schema depends on OWL inference, albeit of a lighter kind, consisting merely of RDFS inference plus support for
While frames are convenient for representational purposes, users wishing to query the knowledge base benefit from direct binary predicates between pairs of frame elements. For example, for a birth event, binary predicates like
Thus, FrameBase presents a novel mechanism to convert between frame representations and direct binary predicates. This mechanism can also allow us to avoid materializing frame instances when only two frame elements are needed.
Structure of ReDer rules
The dereification rules have the form expressed in Fig. 7. Additionally, for each dereification rule there is a converse reification rule so that one can go back from binary predicates to the frame representation. Each Direct Binary Predicate (DBP) has only one set of possible frame and frame elements associated, and therefore chaining reification and dereification rules is an idempotent operation. We call the pair of a reification rule and its converse dereification rule a ReDer (reification-dereification) rule. An example of a ReDer rule is provided in Fig. 8.

The general pattern of a ReDer rule. The conjunction of the three triples below is semantically equivalent to the triple above.

A particular example of a ReDer rule. The direct binary predicate
The ReDer rules can be implemented in different ways.
As SPARQL CONSTRUCT queries, due to SPARQL’s prominence as a standard query language for KBs [28]. These can be used to materialize the DBPs into the KB.
As clauses, with triples as atoms, to be fed into general-purpose inference engines, with or without materialization. For example, ReDer rules can also be implemented as rules for the Rubrik reasoner in Jena [6].
Given an instance set (ABox), the reified and dereified layers can be stored using different strategies.
Materializing both the reified and dereified layers. This is the simplest but less space-efficient approach. Ensuring consistency between both layers after updates to a single one requires some bookkeeping.
Materializing the reified layer and virtualizing the dereified layer. This means that the triples with DBPs as predicates are not stored in the KB like the rest, but they can be inferred at query time. A general-purpose inference engine like the Rubrik reasoner [6] could handle ReDer rules, since these can be written as definite clauses. This offers moderate space efficiency. Only the dereification sense of the rules is used. Ensuring consistency after updates is trivial if only the materialized layer is updated.
Materializing frame instances with two FEs in the dereified layer and the rest in the reified layer. This offers the highest space efficiency. Ensuring consistency after updates is the most complex of the three cases, because knowledge has to be moved between the reified and dereified layers when triples with FE predicates are added or deleted.
This choice of the storage strategy is in theory orthogonal to the implementation of the ReDer rules. In practice, however, storage strategy 1 is relatively trivial to implement using SPARQL CONSTRUCT implementations of the ReDer rules, while storage strategy 2 is trivial to implement using dereification rules in Jena format. Storage strategy 3 would require internal logic (which has not been implemented so far), making the choice of the format a design choice.
Besides the plain
The ReDer rules are automatically built using the syntactic annotations of English sentences given for different LUs in FrameNet, like the grammatical function (GFs) and phrase types (PTs) [58]. These are used in FrameNet to describe the syntactic valence properties of individual lexical items. In particular, in the annotated sentences in FrameNet, each instance of an example sentence annotated by a frame is accompanied by the GF and PT associated with each of the FEs of that frame filled in that sentence.
FrameNet provides three kinds of GF labels.
External Argument (Ext). In the case of verb LUs, it represents the subject of the LU (“[The physician] performed the surgery” [58]), any constituent that controls the subject of the LU (“[The doctor] tried to cure me”), or a dependent of a governing noun (“We are glad for the [American] decision to provide relief”). In the case of adjective LUs, it is the subject of a copular verb (“[The chair] is red”), or other semantically similar constructions (“We consider [Pat] very intelligent”). In the case of noun LUs, the external argument can be interpreted as the subject of a semantically related verb in a periphrasis (“[He] made a statement to the press”). Object (Obj). The syntactic object of a verb LU (“Voters approved [the stadium measure]”). Dependent (Dep). This is the general grammatical function assigned to adverbs, Prepositional Phrases (PPs), and some other attached constituents, but in our case only PPs are used. In these cases, the PP annotation is attached (between square brackets) to the preposition forming the PP. It can be used for verb LUs (“Give the gun [to the officer]”; PP[to]), adjective LUs (“Lee is certain [of his innocence]”; PP[of]) or noun LUs (“The letter was [to the President]”; PP[to]).
Some of the PT labels that can be found are N (noun), NP (noun phrase), Obj (object) and PPinterrog (PP interrogative).
Only constituents tagged with frame elements are assigned grammatical functions. While target words (LUs) are occasionally tagged with frame elements, they are never assigned a grammatical function.
ReDer rules and new DBPs are created using ReDer rule constructors. Each constructor specifies certain conditions on the annotations associated with a pair of FEs in an example sentence. When the conditions are met, a new DBP is generated and a ReDer rule containing the pair of FEs is created.
The constructors are shown in Figs 9–14. As in the general reification-dereification rule pattern in Fig. 7, the postfixes “-S” and “-O” in the constructors indicate the data associated with the FEs that fill the first and second arguments of the DBP, respectively, or equivalently, the respective subject and object of the resulting RDF triple. The creation of the DBP implies the creation of a dereification rule following the pattern in Fig. 7, with

Agent-Verb-Patient ReDer rule constructor and some examples of ReDer rules created.

Patient-Verb-Agent ReDer rule constructor and some examples of ReDer rules created.
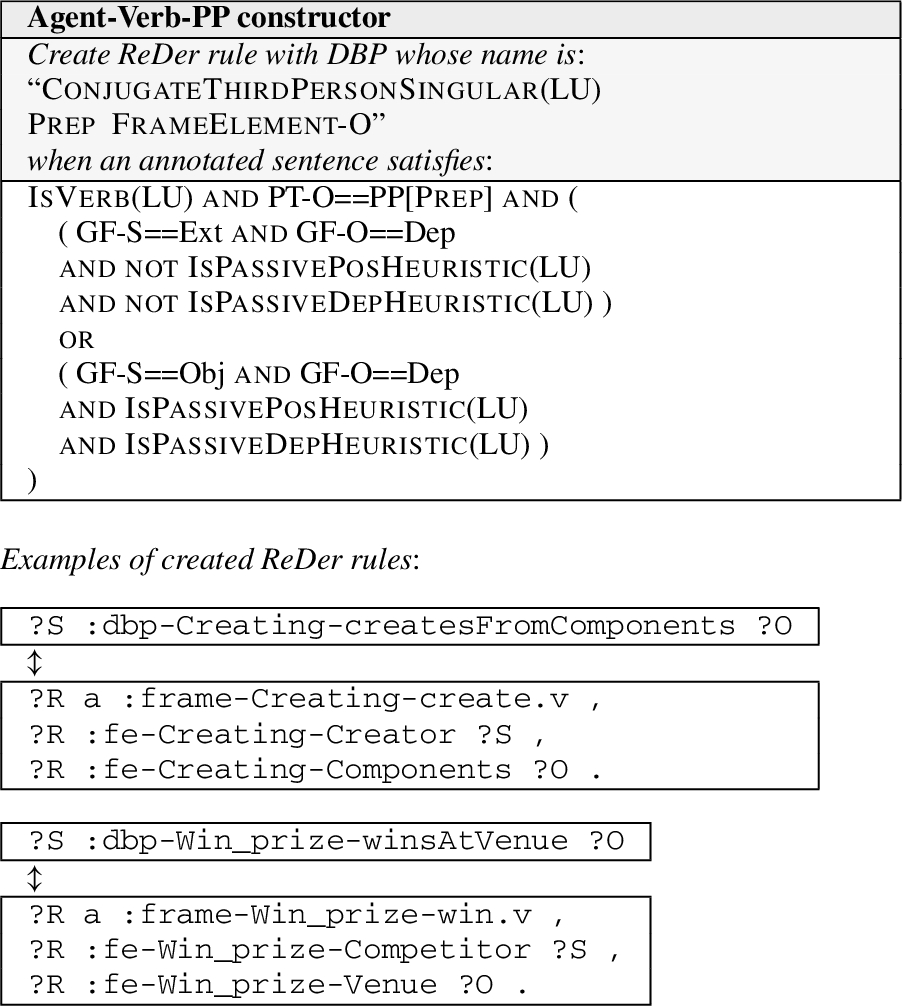
Agent-Verb-PP ReDer rule constructor and some examples of ReDer rules created.

Patient-Verb-PP ReDer rule constructor and some examples of ReDer rules created.
The Agent-Verb-Patient constructor in Fig. 9 creates DBPs whose lexical heads are verbs, whose subjects in the KB are agents, and whose objects are patients, thus having a lexical representation in the form of linguistic predicates in active voice. The constructor inverts example sentences that are deemed to be in passive form.
There is no explicit syntactic annotation in FrameNet to indicate if the verb LUs are evoked in passive form. Therefore, two different heuristics are used for detecting this. One (
The Patient-Verb-Agent constructor in Fig. 10 is the converse of the Agent-Verb-Patient constructor: it also creates DBPs whose lexical head are verbs, but whose subject in the KB is a patient, and whose object is an agent, thus having a lexical representation using the passive voice. Every time the Agent-Verb-Patient constructor is invoked on an example sentence and a pair of FEs, the Patient-Verb-Agent constructor is invoked as well, creating the converse DBP.
The Agent-Verb-PP constructor in Fig. 11 creates DBPs whose lexical heads are verbs, whose subjects in the KB are agents, and whose objects are complements that are contained in a PP in the example sentence. In the DBP label, a new PP is included using the name of the FE-O, following the convention used to name predicates in many LOD KBs (e.g., diedOnDate, isWrittenByAuthor, etc.). However, the preposition in the PP in the example sentence is not always the most appropriate to insert in the DBP label. Therefore, Algorithm 2 is used, where different options are tried in order, with more precise but narrow-scoped ones first.

Agent-Verb-Noun-PP ReDer rule constructor and some examples of created ReDer rules.

Agent-Verb-Particle-Noun-PP ReDer rule constructor and some examples of created ReDer rules.
The Patient-Verb-PP constructor (Fig. 12) changes agent with patient with respect to the constructor Agent-Verb-PP, in the same way Patient-Verb-Agent does with respect to the constructor Agent-Verb-Patient. It creates verb-based DBPs whose subjects in the KB are patients instead of agents, and the DBP has a lexical representation using passive voice.
Using only agent and patient as subject of the triple prevents the constructors from forming DBPs that would rarely be useful, like those connecting the time and place, or the place and the cause.
The Agent-Verb-Noun-PP constructor (Fig. 13) and the Agent-Verb-Particle-Noun constructor (Fig. 14) create ReDer rules with DBPs whose heads are nouns, based on noun LU-microframes. In these cases, a verb is needed that takes the noun as an argument, normally as a direct object. Across RDF vocabularies and ontologies, this verb is sometimes made implicit in human-readable IRIs and lexical labels alike. For example
The difference between these two constructors is that in the Agent-Verb-Noun-PP constructor (Fig. 13), the noun is part of the object of the verb, while in the Agent-Verb-Particle-Noun-PP constructor (Fig. 14) it is part of a PP with its own preposition.
In both cases, the verb governing the noun is obtained using the same method. For each noun LU in an annotation, the head verb is extracted by parsing the example annotated sentences with the Stanford dependency parser and searching the paths of dependencies indicated in the constructors Agent-Verb-Noun-PP and Agent-Verb-Particle-Noun-PP.6
We use collapsed CC-processed dependencies, version 3.2.0.
The Agent-Verb-Noun-PP constructor contains several possible dependency paths using dependencies of type “dobj” (direct object), “cop” (copula), “nsubj” (nominal subject), and “prep” (preposition).
(LU (LU (LU (LU (LU
The Agent-Verb-Particle-Noun-PP constructor fires in cases of phrasal verbs, where the head verb must be extracted with a particle.
(LU

The algorithm that is used to select the preposition.
The Subject-Copula-Adjective-PP constructor in Fig. 15 creates adjective-based DBPs using the copular verb “to be”.
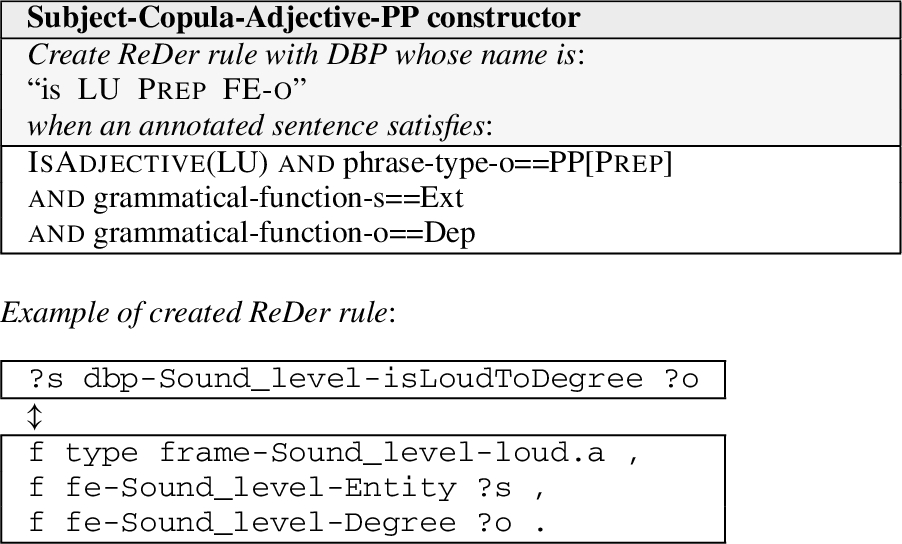
Subject-Copula-Adjective-PP ReDer rule constructor and some examples of created ReDer rules.
With the rules obtained with the process above, the same DBP can be associated with different reified patterns (i.e., pairs of frame elements in a given LU-microframe), owing to different senses or syntactic frames for a given verb – for example the transitive and intransitive syntactic frames for ergative verbs such as to break. This would conflate different senses, and if the reification and the dereification directions of the rules were chained, it would logically entail different pairs of frame elements, which would not be sound. Furthermore, a given reified pattern can also produce different DBPs, which would lead to redundancy. To achieve the idempotency mentioned earlier, a DBP should not be connected to more than one reified pattern (i.e. not present in more than one ReDer rule). To avoid redundancy, a reified pattern should not be connected to more than one DBP (ditto). Therefore, it is necessary to find an
For alternative applications where the
In this section, we evaluate the results of the methods used to create the FrameBase schema (Section 4) as well as some practical examples resulting from the integration of knowledge (Section 6).
First, Section 5.1 presents the evaluation of the FrameNet-WordNet mapping described in Section 4.1. Then, Sections 5.2 and 5.3 present our findings for the methods for constructing the schema hierarchy (Section 4.2) and the construction of the ReDer rules (Section 4.4). These two sets of results (summarized in Table 3) cover all the parts of the schema that are created automatically, and since the original resources (FrameNet and WordNet) are created manually, these results provide a complete evaluation of the quality of the FrameBase schema with respect to the standard of human-level annotations.
Quality measures for the FrameBase schema for intra-cluster pairs of microframes, verb-based ReDer rules, and noun-based ReDer rules. Nuanced correctness is a variable collected over correct elements, that reflects how perfectly accurate the element is (perfect synonymy for pairs of microframes, readability for rules)
Quality measures for the FrameBase schema for intra-cluster pairs of microframes, verb-based ReDer rules, and noun-based ReDer rules. Nuanced correctness is a variable collected over correct elements, that reflects how perfectly accurate the element is (perfect synonymy for pairs of microframes, readability for rules)
Comparison of FrameBase’s FrameNet–WordNet mapping to state-of-the-art approaches in terms of precision, recall, F1, and accuracy, from the original papers. †Mappings from WordNet 1.6 to WordNet 3.0 are used to convert from the MapNet gold standard
To evaluate the created schema, the created FrameNet–WordNet mapping has been compared to the gold standard used to evaluate MapNet [66]. This gold standard uses older versions of FrameNet and WordNet, so mappings from WordNet 1.6 to 3.0 [9] had to be applied, removing those with a confidence lower than one, and the few LUs of FrameNet 1.3 that are not contained in FrameNet 1.5 were discarded. 5-fold cross-validation was used for obtaining the results. Table 4 compares the results against state-of-the-art approaches and the scores that they report on the MapNet gold standard. As stated as goal when setting the cardinality restrictions in Section 4.1, the approach described in Section 4 achieves higher precision (albeit with a very narrow margin) while still maintaining good recall. For this reason, we consider it more appropriate than the previously existing ones to be used in the following steps because high precision is usually prioritized for tasks related to knowledge representation. It must be noted, however, that there are minor differences since our results in Table 4 are evaluated without the few frames dropped between FrameNet 1.3 and 1.5, and some results [37,66] also without using the inter-version WordNet mapping. However, this also means that our new mapping developed for FrameBase provides results for more recent and updated versions of FrameNet and WordNet.
Examples of ReDer rules created and evaluated. “C” stands for “Correct” and “R” for “Readable”
Examples of ReDer rules created and evaluated. “C” stands for “Correct” and “R” for “Readable”
It may be relevant to note that there is in practice an upper bound to precision scores in tasks like this because of the subjective component of any gold standard. The creators of the gold standard [66] report “0.90 as Cohen’s Kappa computed over 192 LU-synset pairs for the same mapping task” by [11]. More generally, Fellbaum & Baker [19] maintain that “both people and automatic systems, when asked to assign tokens in a text to the appropriate senses in dictionaries, find the task difficult and do not agree among themselves”.
The frame hierarchy in the FrameBase schema is based on FrameNet and WordNet and the mapping created between the two resources. It provides 19,376 frames, including 11,939 LU-microframes and 6,418 synset-microframes, all with lexical labels. A total of 18,357 microframes are clustered into 8,145 logical clusters, which are the sets of microframes whose elements are linked by a logical equivalence relation. The size of the schema is 250,407 triples.
The quality of the microframe clusters has been evaluated by asking two independent reviewers to evaluate a random sample of 100 intra-cluster pairs of LU-microframes. Each pair has been annotated with two variables: correctness (1 if the pair is correct, 0 otherwise) and synonymy (only applying when the pair is correct; assigned value 1 if they are WordNet-level synonyms, or 0 if there is a change of nuance higher than that but still having significant semantic overlap). A resulting average correctness of
Reification–dereification rules
Additionally, reification-dereification rules are provided, with the same number of direct binary predicates, with both human-readable IRIs and lexical labels. 83,790 are verb-based, 3,190 are noun-based, and 7,248 are adjective-based. For evaluating them, the same methodology was used, with two independent human annotators. Two different variables were used for each rule: correctness and readability. A ReDer rule is considered correct if the new name can be interpreted as a relation such that the dereified side is a necessary and sufficient condition of the reified side. A correct rule is considered to be not easily readable if the name of the direct binary predicate contains a preposition that is appropriate for some but not all possible objects, or it is not appropriate for the frame element in the name, or it contains a frame element whose meaning is not obvious for a layperson. For the latter task, the annotators were asked to provide an assessment of whether a layperson could understand certain terms: for instance, “patient” in FrameNet has a different meaning than the usual one in general language.
The obtained average correctness for verb-based rules is
The maximum of Cohen’s Kappa is defined as the highest value that it could achieve given the distribution of scores from the raters, and can be useful when interpreting the value obtained for the coefficient [68].
Table 5 provides some examples of the evaluated rules. Rules 1–2 are both correct and readable. Rules 3–4 are correct but not readable. In rule 3, the preposition “in” would be more appropriate. In rule 4, the term “Locus” is too specialized. Rules 5–7 are not correct. In rule 5,
Knowledge from other KBs such as Freebase can be integrated using integration rules. In practice, these result in a graph transformation from the source KB to FrameBase. Formally, these are rules whose antecedent and consequent are graph patterns sharing some variables. Whenever there is an instantiation of variables that, applied to the antecedent, returns a subset of the source KB, then the consequent, after having applied the same instantiation of variables, can be added to the FrameBase instance data (the ABox in the jargon of description logics).
When the sources are in RDF, the most obvious choice for implementing integration rules is using SPARQL CONSTRUCT queries with the WHERE clause containing the antecedent and the CONSTRUCT clause containing the consequent. Additionally, SPARQL CONSTRUCT queries support predicates and logical operators that allow for imposing additional logical conditions on the WHERE clause to match the original KB (i.e., for the rule to be fired). For non-RDF sources, a simple choice would be applying an off-the-shelf RDF converter8
to pre-process the source, after which SPARQL CONSTRUCT queries can still be used.The SPARQL examples in this and the next sections use the following prefixes.
In Section 6.1, some examples of manually built integration rules are presented for integrating events from two different sources: DBpedia and schema.org. Besides showing concrete examples of rules, the section provides an assessment of the expressiveness of the FrameBase schema in its current state, by reviewing to which extent external knowledge can be integrated when using manually built rules. It also introduces a basic typology of integration rules. These are important steps before reviewing the task of integrating knowledge automatically.
Subsequently, Section 6.2 discusses the creation of ReDer rules based on existing work. Finally, in Section 6.3, we provide examples of queries that make use of the schema.
We will first show two simple examples of integration rules integrating knowledge from Freebase. They belong to two basic rule types that we label Class-Frame and Property-Frame, which will later serve as the basis for constructing more complex rules.
Class-Frame integration rules integrate a class from the source KB into a frame in FrameBase, and the outgoing properties from the external class into FE properties. The following example integrates a class
Property-Frame integration rules translate a property from the source KB into a frame and two FEs in FrameBase. The structure is similar to that of ReDer rules, but the property in the antecedent is not a FrameBase DBP, although the similarity of the structure will be exploited later to automatically produce integration rules of this type from existing ReDer rules. The following example integrates a property
The next example pertains to the
The
For example, using RDFS inference, the substitutions for
Similarly, the substitutions for
In the rule for
Below, we also present the translation of the class
We omit the subclasses here, but these have very few genuine properties, and therefore the specialization is relatively simple. Besides, the taxonomy of schema.org events has some inconsistency issues that makes its use complex: the Event class is defined as capturing events such as concerts, lectures, and festivals, with properties such as “typical age range”, but there are sub-events such as
The only extension of the FrameBase schema used for these examples was the frame
Some integration rules, namely Property-Frame rules as well as some complex Class-Frame rules, declare new instances in the CONSTRUCT clause. This can be achieved either by means of anonymous nodes, as in the examples, or by coining new, essentially skolemized IRIs. In any case, the integration rules do not link or merge frame instances that are created by different rules or different instantiations of the same rule but should correspond to the same n-ary relation. This is a later step for which an out-of-the-box entity de-duplicator [39,42,63] could be applied. What the integration rules provide are instances of the same type that actually represent the same thing (event, situation, process, i.e. frame), so that the entities can actually be linked and – if the de-duplication process has high enough precision – merged, so the full efficiency indicated in Table 2 is achieved. This would not be possible with the heterogeneous models in Fig. 1.
Automatically built integration rules
We have recently been able to devise basic Class-Frame and Property-Frame integration rules using automatic methods guided with KB specific heuristics, which have been tested for Freebase and Yago [56]. To build Class-Frame integration rules, a support vector machine is used to classify pairs consisting of an external class and a FrameBase frame class, using lexico-semantic features. The support vector machine is trained with a manually built gold standard for Freebase. In order to increase precision, instead of using the SVM directly, we use the scoring function from the SVM (the distance from the hyperplane) to filter the pairs classified as true, selecting the best candidate for each external class. Then, for each mapped pair (
Number of statements and distinct frame types in the integrated data, from YAGO2s and from Freebase. The numbers in parentheses include the equivalent microframes that can be obtained with RDFS inference
Number of statements and distinct frame types in the integrated data, from YAGO2s and from Freebase. The numbers in parentheses include the equivalent microframes that can be obtained with RDFS inference
The method described for creating Property-Frame rules has also been extended by applying a previous canonicalization to the properties from the external KB and creating additional ReDer rules [55], as well as using a more advanced similarity function with a weighted combination of lexical and semantic features, and coreness features of the FEs in FrameNet. The canonicalization addresses certain common types of ambiguity in the names of properties in LOD datasets, like the omission of the verb. For instance, given a property named “author”, it is not clear from the name alone if it is meant as
The ability to create Property-Frame integration rules towards FrameBase in this way, exploiting its linguistic nature and its corpus of annotations, is especially important. First, because traditional ontology alignment systems cannot produce such complex mappings, as was discussed in Section 2, and therefore their recall will be effectively equal to zero in this task. Second, because the same ontology alignment systems can be re-used to create Class-Frame rules (mapping classes with classes and properties with properties, if the ontology alignment system allows declaring constraints related to the properties’ domains). We will discuss the creation of complex Property-Frame rules in Section 7.
Additionally, a demo system has been developed that allows us to re-use these methods as search and suggestion engines behind an intuitive GUI, enabling human-level accuracy while minimizing the effort for the user [57].
FrameBase facilitates novel forms of queries. The query in Fig. 16, for instance, uses reified patterns to find the heads of the World Bank.

Example query using reified pattern.
The results in Table 7 show example instances integrated into the FrameBase schema from both Freebase (rows 1–3, extracted from the second example integration rule above) and YAGO2s (rows 4–5, extracted with a similar integration rule made for YAGO2s) [56].
Results from the query
Alternatively, if the triple
The methods described in Section 6.2 create basic Class-Frame and Property-Frame integration rules. However, as some examples in Section 6.1 illustrate, integration rules can become very complex. In the following, we present instructive examples of complex integration rules.
Complex property-frame integration rules
A DBP from the dereification rules can also be used to obtain the same non-optional results, as illustrated in the query in Fig. 18. Either of the verb-based DBPs leads or heads can be used because the LU-microframes for these verbs are in the same cluster as the nouns leader and head, and there is a dereification rule between the Leader and Governed FEs for both.
Microframes from the cluster where An advantage of this approach is that it provides richer ReDer rules for FrameBase, but the disadvantage is that because it is driven by FrameBase, it may have poor recall for real-world datasets, both because of its reliance on FrameNet example sentences and because of FrameNet’s non-specialized vocabulary, instead of the kind of knowledge present in a particular knowledge base. This problem could be significantly reduced by also updating the similarity function between DBPs and source properties, in order to account for hypernymy and synonymy relations that would allow capturing very specific concepts in source KBs for which hypernyms can be found in FrameBase (for instance, “catalyzesChemicalReaction” from a source KB could match the more general ‘increasesSpeedOfProcess” created from FrameBase annotations).
Example query using a dereified pattern. Example of a very complex noun-based ReDer rule.



There are multiple ways in which Class-Frame rules can differ from their basic pattern. We will use the examples in Section 6.1 to illustrate this.
Sometimes, a class integration rule may need to instantiate multiple frames rather than just a single one. We distinguish two main types of this phenomenon. The instantiated frame instances may be connected by FEs. Examples of this include the frame Several frames can also be evoked separately, without the instances being directly connected by any FE. When these frames describe different perspectives of the same event, there is the possibility that FrameNet links them by means of perspectivization, and therefore FrameBase can infer one from another. In this case, inference is possible because RDFS subclass and subproperty properties are used in FrameBase to reflect the perspectivization relation between frame classes and FEs respectively. Another example are Another possible source of complexity is that FEs can be inverted. In this case, the integration rules need to invert the order of the arguments, as in the second occurrence of
Arbitrary combinations of these phenomena are possible, as, e.g., in the rule integrating the Event class from schema.org.
A possible way to address this problem may be by defining a reduced alphabet of transformations over a basic Class-Frame rule, similar to our list above, so that a complex Class-Frame rule can be represented as a basic initial one followed by a sequence of transformations, and this representation can be acquired via supervised learning.
However, the high number of variables involved would mean that any attempt to train a system would face extreme sparsity. Inter-annotator agreement, which is already low for simple integration rules [56], would probably be even lower. Investigating how to produce such genuinely complex rules entirely automatically thus remains an important research challenge.
In the short term, we believe that a combination of automated assistance and user feedback, as provided by user interfaces such as Klint [57], may be the best strategy whenever complex rules are needed and high-quality integration is desired.
Conclusion
FrameBase is a novel approach for integrating knowledge from different heterogeneous sources and connecting it to decades of work from the NLP community. It provides a flexible and homogeneous model to describe n-ary relations, which combines efficiency and expressiveness, and is based on a linguistically sound foundation. The ties with natural language can be exploited to automatically integrate knowledge from external sources. FrameBase opens up several new research directions, which we enumerate next.
Integrating additional sources Either using a unified approach [56] or focusing on Property-Frame rules and combining them with existing ontology alignment systems [55], additional sources could be integrated. Both generic KBs such as Wikidata [16] and domain-specific ones such as from the biomedical domain could be incorporated.
Interfacing from natural language Due to its use of linguistic resources for ontological purposes, FrameBase has significant potential for text mining and other natural language related tasks. Both pure Semantic Role Labelling (SRL) systems for FrameNet such as SEMAFOR [8] as well as text-to-ontology systems such as FRED [48] and Pikes [7] could be adapted to produce FrameBase data from natural language text. Similar methods could also enable question answering [38]. For example, for the example in Fig. 16 in Section 6.3, given the question “Who has been the head of the World_Bank?”, the SRL tool SEMAFOR [8] successfully extracts the frame Leadership with lexical unit head.noun and frame elements Governed and Leader. Based on this, and after a named entity disambiguator such as AIDA [30] has matched World_Bank to the entities in the KBs, a structured query can easily be built. Although accurate semantic role labeling is still very challenging, semantics has become one of the largest research areas in natural language processing and thus FrameBase can benefit from progress made in this area in the future.
Natural language generation FrameBase also offers opportunities for natural language generation from KBs. Dereification rules can be interpreted as syntactic templates [69] for simple English sentences without subordinate clauses. For instance,
Implementing virtual querying Currently, the integration rules for integrating source KBs into FrameBase have been implemented as SPARQL CONSTRUCT queries applied over the sources’ data, which can be used to materialize the integrated knowledge. An alternative implementation would involve virtual querying: using the integration rules to provide FrameBase-adapted virtual views of the source KBs. This would make it possible to re-use existing SPARQL endpoints from the different sources and enable access to the most recent version of the source data.
Further information Details and more information about FrameBase are available at http://framebase.org. The FrameBase data is freely available under a Creative Commons Attribution 4.0 International license (CC-BY 4.0).
Footnotes
Acknowledgements
This research was partially funded by the European Union Seventh Framework Programme (FP7/2007–2013) under grant agreement No. FP7-SEC-2012-312651 (ePOOLICE project) as well as by the Danish Council for Independent Research (DFF) under grant agreement no. DFF-4093-00301. Additional funding was provided by China 973 Program Grants 2011CBA00300, 2011CBA00301, and NSFC Grants 61033001, 61361136003, 20141330245.