
Abstract
Data-oriented systems and applications are at the centre of current developments of the World Wide Web. In these scenarios, assessing what policies propagate from the licenses of data sources to the output of a given data-intensive system is an important problem. Both policies and data flows can be described with Semantic Web languages. Although it is possible to define Policy Propagation Rules (PPR) by associating policies to data flow steps, this activity results in a huge number of rules to be stored and managed. In a recent paper, we introduced strategies for reducing the size of a PPR knowledge base by using an ontology of the possible relations between data objects, the Datanode ontology, and applying the (A)AAAA methodology, a knowledge engineering approach that exploits Formal Concept Analysis (FCA). In this article, we investigate whether this reasoning is feasible and how it can be performed. For this purpose, we study the impact of compressing a rule base associated with an inference mechanism on the performance of the reasoning process. Moreover, we report on an extension of the (A)AAAA methodology that includes a coherency check algorithm, that makes this reasoning possible. We show how this compression, in addition to being beneficial to the management of the knowledge base, also has a positive impact on the performance and resource requirements of the reasoning process for policy propagation.
Introduction
Data-oriented systems and applications are at the centre of current developments of the World Wide Web (WWW). Emerging enterprises focus their business model on providing value from data collection, integration, processing, and redistribution. These kind of systems are not new, as the Web has enabled for a long time tools such as news aggregators, which collect articles from various providers, and republish them as collections of short readings, often focusing on specific topics (politics, sport, etc.).1
Wikipedia:
The key aspect on which we are focusing here is the publication of Licenses and Terms and Condition documents associated with those APIs and data artifacts, that declare the associated rights and policies that should guide their use. Data Hubs collect a large variety of data sources and process them in order to implement the workflow that connects data in their original sources to applications that might want to exploit these data [12]. These systems create new challenges in terms of the volume of data to be stored and require novel processing techniques (for example stream-based analysis [26]), but more importantly they demand for more sophisticated approaches to data governance [6]. In the Web of (open) data, developers can access a large variety of information, and often publish the results of their processing. Hence, they need to be aware of any usage constraints attached to data sources they want to exploit, and they need support in publishing the appropriate policies alongside the data they distribute.
In this complex scenario, assessing what policies propagate from the licenses associated with the data sources to the output of a given data-intensive process is an important problem. Both policies and data flows can be described within the Semantic Web, relying on standards like the W3C PROV model2
W3C PROV,
ODRL Community Group, http://www.w3.org/community/odrl/.
Datanode,
In this article we illustrate how reasoning on policy propagation can be practically performed. Building upon [8], we report on an extension of the (A)AAAA methodology that includes a coherency check between the hierarchy of the FCA lattice and the Datanode ontology. This extension was necessary in order to exploit the compressed rule base during reasoning and avoid incorrect results. While the compression of the rule base reduces the number of rules to be managed, it requires the reasoner to compute more inferences. Therefore, we study the impact of rule base compression on the performance of the reasoning process. In other words, this article focuses on two contributions that relate to the aspect of reasoning with (compressed) PPRs, which was missing in [8]: 1 – the extension of the (A)AAAA methodology by adding an additional coherency check step to the Assessment phase, and 2 – the evaluation of the effect of compression on reasoning performance.
The article is structured as follows. Section 2 reviews the relevant literature. Section 3 presents an exemplary use case, and introduces the elements for reasoning on policy propagation, going through the description of the data flow, the representation of policies, and the concept of Policy Propagation Rule (PPR). Section 4 provides a summary of the (A)AAAA methodology, integrated with a novel Assessment phase that includes a coherency check algorithm that allows effective reasoning with a compressed rule base. We also evaluate the impact of this evolved methodology on the compression factor of the knowledge base of PPRs. In Section 5, we report on experimental results about the impact of a compressed rule base on reasoning. For this purpose, we compare the performance of reasoning with an uncompressed rule base against reasoning with a compressed one. We perform this comparison using two different reasoners, the first computing the inferences at query time, the second materializing them at load time. Finally, we discuss our observations before closing the article with some conclusions and perspectives on future work.
In recent years, data repositories and registries have been growing, spanning from data cataloguing services (Datahub5
Datahub.
Wikidata.
Europeana.
Socrata.
Policies can be represented on the Web in a machine-readable format. The W3C ODRL Community Group works on the development of a set of specifications to enable interoperability and transparent communication of policies associated with software, services, and data. The Open Digital Rights Language (ODRL)9
ODRL Vocabulary & Expression,
W3c Permissions & Obligations Working Group,
The RDF Licenses Dataset [28] is an attempt to establish a knowledge base of license descriptions based on RDF and the ontology provided by ODRL. It also uses other vocabularies aimed to extend the list of possible actions, for instance the Linked Data Rights11
Linked Data Rights (LDR):
Process executions can be described in the Semantic Web using the Provenance Ontology (PROV-O) [24]. PROV-O describes workflow executions in terms of agents, actions and assets involved. The Datanode ontology has been designed to describe Semantic Web applications by means of the relations between the data involved in their processes [7]. The ontology is a taxonomy of possible relations that may occur between data objects, which might be part of a process execution, such as the ones described with PROV-O. It can therefore be used to further qualify the implications of the actions performed in such a process. Datanode can describe process implications in a data-oriented way, namely as network of data objects. While policies and process executions can be represented, in the present paper we aim at studying the process of reasoning upon the propagation of policies across a data flow.
Rule-based representation and reasoning over policies is required in order to enable secure data access and usage in distributed environments, particularly in the Semantic Web [4,13,25]. Defeasible logic is used to reason with deontic statements, for example to check compatibility of licenses or to validate constraints attached to components on multi-agent systems [29]. The problem of licenses’ compatibility has been extensively studied in the literature [15,16] and tools that can perform such assessment do exist [23]. Our previous work introduces a form of policy reasoning, namely policy propagation [8]. A Policy Propagation Rule (PPR) is a Horn clause defined by associating a Datanode relation with an ODRL policy. Reasoning with Horn rules is an effective way of dealing with policies, particularly because Horn rules allow tractable defeasible reasoning [1]. While in this article we only focus on policy propagation, PPRs can in principle be integrated with rule-based reasoners for policy validation.
Formal Concept Analysis (FCA) [33] has the capability of classifying collections of objects depending on their features. We apply FCA in conjunction with the Datanode ontology to detect a common behaviour of relations in terms of policy propagation, with the purpose of compressing a PPR knowledge base. We refer the reader to [11] for a description of the Contento tool, that implements FCA as well as other functionalities for evolving concept lattices in Semantic Web ontologies, also part of the approach we present here.
The approach described in this paper clearly relates to principles and methods of knowledge engineering [32]. In [27], knowledge acquisition is considered as an iterative process of model refinement. More recently, problem solving methods have been studied in relation to the task of understanding process executions [14]. These contributions form the background of the approach we are following in the present work. The problem of compressing propositional knowledge bases has been extensively studied in the past, focusing on the optimization of a Horn minimization process to improve the performance of rule execution [5,17]. Differently, we deal with compression as a mean to reduce the number of minimal rules to be managed (each PPR being already an atomic rule), by means of an additional knowledge base (the Datanode ontology).
It is worth noting that our problem is not one of policy enforcement, but of providing the right information about policies that might affect the terms of use of a given asset produced by a complex data flow. This problem is also different from the one of minimizing access control policies (example, the abstraction by subsumption proposed in [19]), as the abstraction required is on the propagation of the policy, not the policy itself. Reasoning on policy propagation does not require the policies to be validated per se. On the contrary, we claim that validating the policies of a data artifact, which is the result of some manipulation, should consider the policies inherited from the input data, according to the particular actions performed.
To our knowledge, the problem of propagation of usage policies in data flows has not been tackled before the contribution in [8]. In [6] we proposed an approach for integrating policy propagation in the data governance activity of Data Hubs, where policies and data flows are managed by Data Hub managers. However, in [8] as well as in the present work, we do not focus on the quality of the data flow representations, and assume a machine-readable description of the policies of the input asset, as well as the existence of an accurate data flow.
In this section, we describe our approach for reasoning on policy propagation, and we present a use case as an example.
Approach
We define the problem of policy propagation as identifying the set of policies associated with the output of a process, implied by the policies associated with the input data source. In order to perform reasoning on policy propagation, we need:
descriptions of policies attached to data sources;
a description of the data flow (the actions performed on the data), and
policy propagation rules (which actions do propagate a given policy).
Description of policies We assume the policies of data sources are described as licenses or “terms and conditions” documents, and that they are expressed in RDF according to the ODRL ontology.12
ODRL 2.1:
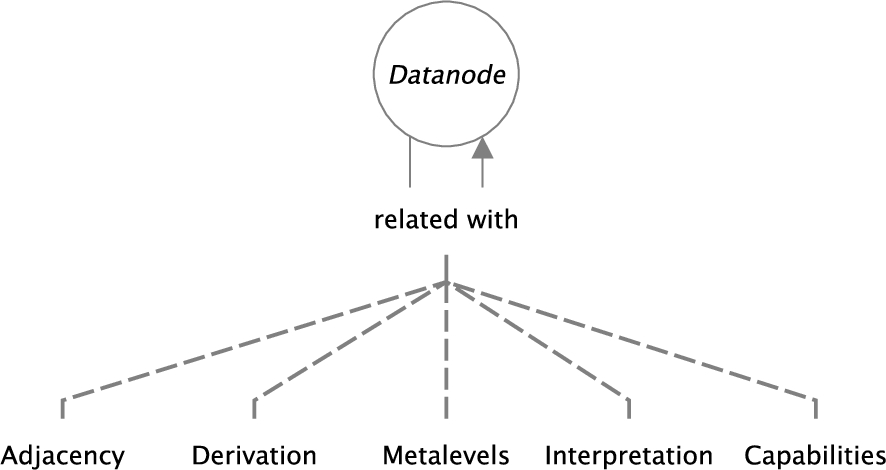
Top hierarchy of the Datanode ontology.
Description of the data flow Data flows are represented with the Datanode ontology [7]. The terms are defined under the
In this section we only summarize the basic features of the ontology, and we omit to specify inverse relations (for example
This branch of the hierarchy specializes
This dimension covers the relations between a data object and its metadata. The property
This is designed to capture the possibility that a datanode might contribute to inferences that can be made in another one. Two datanodes might be “understood” together, i.e. their content can be compared, or the interpretation (inferences) of one may affect the interpretation (inferences) of another. The more intuitive examples are
Capability is intended as the power or ability to generate an outcome.14
Definition from
In this work, we use the representations of data flows extracted from the descriptions of several Semantic Web applications prepared in [7].
Policy propagation rules A Policy Propagation Rule (PPR) establishes a binding between a Datanode relation r and a policy p. A PPR is a Horn clause of the following form:

where X and Y are data objects, p is a policy and r a Datanode relation between X and Y. When the policy p holds for a data object X, related to another data object Y by the relation r, then the policy p will also hold for the data object Y. For example a PPR could be used to represent the fact that downloading a file F distributed with an attribution requirement will result in a local copy D, which also needs to be used according to the attribution requirement. Therefore, the above abstract rule could be instantiated as follows:

In fact, we can reduce a PPR to a more compact form, i.e. a binary association between a policy p and a relation r:
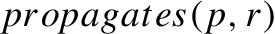
as the other components of the rule can be automatically derived for any possible X and Y.
With these elements established, we can trace the policies propagated within the data flow connecting input and output.
Sources of Terms and conditions associated with the data sources of EventMedia
Flickr APIs Terms of Use.
Eventful API Terms of Use.
LastFM Terms of Service.
Foursquare Developers Policies.
In the previous section we described the components required to reason upon policy propagation in data flows. We now introduce a motivating scenario. The following are those name spaces that will be referred to in this example, with associated prefixes:

We selected EventMedia [21] as an exemplary data-oriented system. EventMedia exploits real-time connections to enrich content describing events and associates it with media objects.15
See
The Upcoming service is not available at the time of writing, however a snapshot of the documentation can be consulted from the Web Archive, reporting a non-commercial use clause:
Flickr API Terms of Use:

Policies representation extracted from the Flickr APIs Terms of Use

The data flow of EventMedia. Input sources are the top nodes. The node at the bottom depicts the output data, which is a remodelling of the data collected from various sources according to a specific schema.
Figure 2 illustrates the EventMedia data flow and Listing 2 the equivalent RDF description. Data are processed from event directories and enriched with additional information and media from sources like DBpedia,18
DBpedia:
Flickr:
This description has been initially elaborated in [7].
Flickr API:
Eventful:

The EventMedia data flow in RDF
The data flow described so far can be leveraged by a reasoner in conjunction with the ODRL policies of the inputs, and the PPRs, to infer the policies associated with

Example of policy associated with the output of EventMedia
In [8] we considered the set of relations defined by Datanode and the policies defined in the RDF Licenses Dataset to generate a knowledge base of 3865 propagation rules. With the goal of improving the management of the rules, we studied to what extent it is possible to reduce the number of rules to be stored. This reduction requires to be complemented by inferences produced by a reasoner, relying on the axioms of the Datanode ontology. In the present work, we study whether this reasoning is practically feasible, and make the hypothesis that compressing the size of the rule base will not negatively impact the efficiency of the reasoner in computing the propagated policies.
Firstly introduced in [8], the (A)AAAA methodology covers all the phases necessary to set up a compact knowledge base of PPRs.23
In our work, it has been applied with the support of the command line tool PPR-A-FIVE:
In our work we rely on Datanode as reference ontology, even if this is not required by the methodology itself.
The methodology, illustrated in Figure 3, is composed of the following phases:
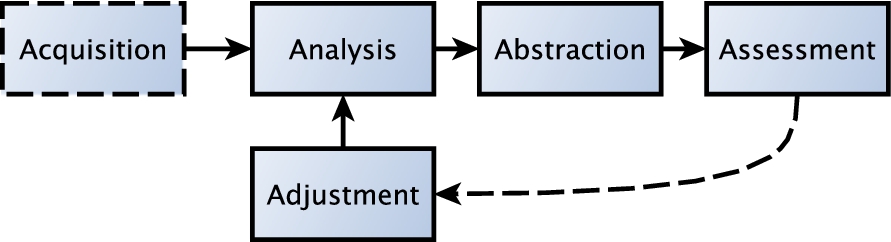
(A)AAAA Methodology.
The initial task is to set up a knowledge base of PPRs. We used the Datanode ontology to extract a list of 115 possible relations between data objects, and combined them with 113 policies derived from the ones defined in the RDF License Dataset. The combination of relations and policies lead to a matrix of 12995 cells. This phase required a manual supervision of all associations between policies and relations in order to establish the initial set of propagation rules. This was performed with the support of the Contento tool [11].
A2 – analysis
The objective of the second phase is to detect common behaviors of relations with respect to policy propagation. We achieve this by applying FCA, providing as input the binary matrix representation of the knowledge base R consisting of PPRs. The output of the FCA algorithm is an ordered set of concepts C. In FCA terms, each concept groups a set of objects (the concept’s extent) and maps it to a set of attributes (the concept’s intent). In our case, each concept represents a set of relations propagating the same set of policies. These concepts are organized hierarchically in a lattice, ordered from the top concept T, which includes all the objects and potentially no attribute, to the bottom concept B, including all the attributes with potentially an empty extent (set of objects). All other concepts are ordered from the top to the bottom. For example, usually a first layer of concepts right below T would include large groups of objects all having few attributes in common. Layers below would have more attributes and less objects, until the bottom B is reached. In our case, the top concept T would include all relations and no policy, while the bottom concept B includes all the policies but no relation. The concepts identified by FCA group relations that have a common behavior, as they propagate the same policies. The output of the process is an ordered lattice of concepts: clusters of policies that are propagated by the same set of relations.
A3 – abstraction
In this phase, we apply a method for subtracting rules in order to reduce the size of the knowledge base. The abstraction process is based on applying an ontology that organizes the relations in a hierarchy (the Datanode ontology). For instance, the relation
A general estimation of the effectiveness of the approach is given by the compression factor (
A4 – assessment
The objective of this phase is to assess to what extent the ontology and the FCA lattice are coherent. In particular, we want to:
detect mismatches (coherency check) to be resolved before using the compressed rule base with a reasoner, and
identify quasi matches that could become a full match by performing changes in the rule base or the ontology
Coherency check The abstraction process is based on the assumption that it is possible to replace asserted rules with inferences implied by subsumed relations in the ontology. This requires that all policies propagated by a given relation must be propagated by all the sub-relations in the original (uncompressed) rule base. A coherency check process is necessary to identify whether this assumption does hold for all the relations in each one of the concepts of the lattice.
In case it does not, we want to collect and report all the mismatches in order to be able to fix them at a later stage in the methodology. Listing 4 shows the algorithm used to detect such problems on a given concept in the lattice.

Coherency check algorithm
We know from the definition of a FCA lattice that super-concepts will include a larger set of relations propagating a smaller number of policies. Given a concept c, the algorithm extracts the relations (extent) of each of any super-concept (S denotes the set of all super-concepts s of c). In case these relations are not present in (the extent of) c, it is mandatory for them not to be sub-relations of any relation in the extent of c. In case they are, this means that a sub-relation is not inheriting all the policies of the parent one, thus invalidating our assumption. Mismatches M are identified and reported. Listing 5 shows the results obtained by applying the algorithm to Concept 71. In this example, a number of sub-relations of

Coherency check result for Concept 71: mismatches
Excerpt from the table of measures computed during the abstraction phase
c = Concept ID, ES = Extent Size, IS = Intersection Size, BS = Branch size, Pre = Precision, Rec = Recall, F1 = F-Measure.
Quasi matches The result of the Abstraction phase includes a set of measures between concepts and portions of the ontology. Table 2 shows an example of the measures obtained. The measures defined in the Abstraction phase are now considered to quantify and qualify the way the ontology aligns with the propagation rules: precision (
At this stage we can make the following considerations:
The presence of mismatches between the lattice and the ontology will cause the reasoner to return wrong results. They must, therefore, be eliminated.
The size of the matrix that was manually prepared in the Acquisition phase is large (13k cells), and even with the support of the Contento tool it is still possible that errors or misjudgments are made at that stage of the process.
The Datanode ontology was not designed for the purpose of representing a common behavior of relations in terms of propagation of policies. It should be possible to refine the ontology in order to make it cover the current use case in a better way (and to further reduce the number of rules).
In this phase we perform operations that change the ontology (or the PPR knowledge base) in order to repair mismatches, correct inaccuracies, refine the hierarchy of relations, and improve the compression factor as a consequence. Six operations can be performed: Fill, Wedge, Merge, Group, Remove, Add. The Fill operation modifies the PPR knowledge base by adding all the rules necessary to make an ontology branch being fully covered by a concept, therefore evolving a quasi match into a full match. All the other actions are targeted to add, remove or reposition relations in the ontology hierarchy (further details about each operation can be found in [8]). The Assessment phase of the methodology reported possible mismatches between the FCA output and the ontology hierarchy. These errors must be repaired if we want the compressed rule base to be used by a reasoner. For example, Listing 5 shows the set of mismatches detected for concept 71. In this list, the
After each operation, we run our process again from the Analysis phase to the Assessment, in order to evaluate whether the change fixed the mismatch and/or how much the change affected the compression factor. The process is repeated until all mismatches have been fixed, and there are no other quasi matches that can be adjusted to become full matches. Moreover, when new policies are defined in the dataset of licenses, the process has to be repeated in order to insert the new propagation rules. However, this is only required after changes in the licenses, as changes in the associations between policies and data objects do not affect the PPRs, e.g., changing the license of a data source or adding new data flows.
As reported in Table 3 we performed the process 27 times with the objective to improve the compression and remove errors from the PPR knowledge base, identified by the coherency check algorithm. Figure 4 shows how the compression factor
List of changes performed
List of changes performed
The first column identifies the change performed (starting from the initial state). C = Number of concepts in the FCA lattice; ≠ = Number of mismatches between the FCA lattice and the ontology; R = Number of rules before the process; A = Number of rules abstracted (subtracted);

Progress of the

Progress in the number of conflicts.
Thanks to this methodology we have been able to fix many errors in the initial data, to refine Datanode by clarifying the semantics of many properties and adding new useful ones. The inclusion of a coherency check phase is required for a safe use of the compressed rule base with a reasoner. However, the introduction of this approach allowed us to reduce the size even more. As final result we obtained: 4225 rules in total, 34 concepts, 3451 rules abstracted and 774 rules remaining, boosting the
The version of the ontology prior to performing such changes can be found at
The methodology described in the previous section allows to reduce the number of rules that need to be stored and managed. The results of applying this methodology on the PPR knowledge base derived from the RDF Licenses Dataset, show how the compression factor can be dramatically increased after several iterations. Our assumption in this work is that it might positively affect the performance of reasoning on policy propagation. Here, we therefore assess through realistic cases the performance of reasoners when dealing with a compressed knowledge base of PPRs, as compared to when dealing with the uncompressed set.
We took 15 data flow descriptions from previous work [7], referring to 5 applications that rely on data obtained from the Web. Each data flow represents a data manipulation process, consuming a data source (sometimes multiple sources), and returning an output data object. Given a set of policies
The experiments have the objective to compare the performance of a reasoner when using an uncompressed or a compressed rule base respectively. Therefore, each reasoning task is performed twice: at first time, to provide the full knowledge base of PPRs; the second time, to provide the compressed knowledge base in conjunction with the hierarchy of relations of the Datanode ontology (required to produce the inferences).
Reasoners infer logical consequences from a set of asserted facts and inference rules (knowledge base). A reasoner can compute the possible inferences from the rules and the facts any time it is queried, thus exploring the inferences required to provide the complete answer. Alternatively, a reasoner can compute all possible inferences at the time the knowledge base is loaded, and only explore the materialized facts at query time. In order to appropriately address both of those reasoning strategies, we run the experiments with two different reasoners. The first reasoner performs the inference at query time using a backward chaining approach; is implemented as Prolog program and we will refer to it as the Prolog reasoner. The second reasoner computes all the inferences at loading time (materialization); is implemented as an RDFS reasoner in conjunction with SPIN rules, and we will refer to it as the SPIN reasoner. Both reasoners are implemented in Java within the PPR Reasoner project.25
PPR Reasoner:
The Prolog implementation is a program relying on JLog, a Prolog interpreter written in Java.26

Excerpt of the Prolog reasoner program
The SPIN reasoner is built upon the RDFS reasoner of Apache Jena27

Construct meta-query of the SPIN reasoner
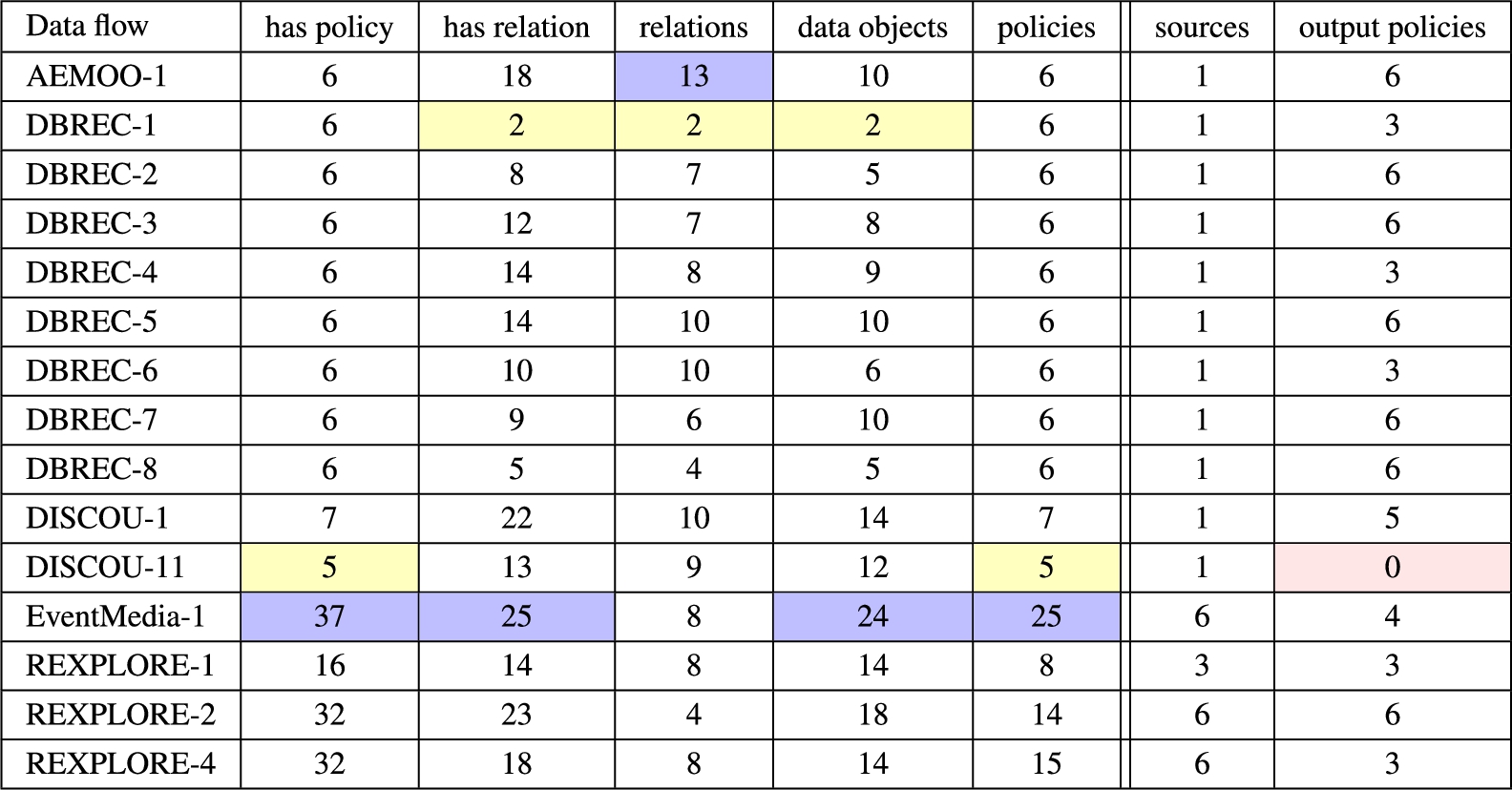
We performed the experiments with the data flows listed in Table 4. Each data flow describes a process executed within one of the 5 systems selected as exemplary data-oriented applications. These data flows were formalized before the present work (in [7]), and were reused for the experiments without changes. However, information about the policies of the input was added. Table 4 illustrates the properties of these data flows, and compares them along several dimensions. The has policy column reports the number of statements about policies, from a minimum of 5 to 37 policies. The size of the data flow is reported in the has relation column of the table, as it is measured in number of Datanode relations used, spanning from 2 to the maximum of 25. The relations column reports the number of distinct relations, the same applying to data objects, policies, sources and the propagated output policies. Highlighted are the maximum and minimum values for each of the dimensions. In one case (DISCOU-11), none of the policies attached to the source are propagated to the output.
Data flows used in the experiments
Each experiment takes the following arguments:
Input: a data flow description Compression: True/False Output: the output resource to be queried for policies
In case compression is False, we provide the complete knowledge base of PPRs as input of the reasoning process without including information on subsumption between the relations described in the dataflow. Conversely, when compression is set to True, the compressed PPR knowledge base is used in conjunction with the Datanode ontology. It is worth noting that the (A)AAAA methodology is also an ontology evolution method, as most of the operations targeted to improve the compression of the rule base are performed on the ontology by adding, removing and replacing relations in the hierarchy. In these experiments, we are considering the evolved rule base (and ontology), that has been harmonized by fixing mismatches between the rule set and the ontology.
The experiments were executed on a MacBook Pro with an Intel Core i7/3 GHz Dual Core processor and 16 GB of RAM. In case a process was not completed within five minutes, it was interrupted. Each process was monitored and information about CPU usage and RAM (RSS memory) was registered at intervals of half a second. When terminating, the experiment output would include: total time (t), resources load time (l), setup time (s), and query time (q). The size of the input for each experiment is reported in the diagrams in Fig. 6.
We consider performance on two main dimensions: time and space.

Input size for the Prolog (6a) and SPIN (6b) reasoners. It can be deduced that the size of the data flow has a small impact on the general size of the input.

Coefficient of Variation (
Time performance is measured under the following dimensions:
Resources load time.
Setup time. It includes L, in addition to any other operation performed before being ready to receive queries (e.g., materialization).
Query time.
Total duration:
Space is measured as follows:
Average CPU usage.
Maximum memory required by the process
Each experiment was executed 20 times. We compared the results of the experiments with and without compression, and verified they included the same policies. In the present report, we show the average of the measures obtained in the different executions. In order to evaluate the accuracy of the computed average measure from the twenty executions of the same experiment, we calculated the related Coefficient of Variation (
Coefficient of Variation, also known as Relative Standard Deviation (RSD).
Before discussing the results, it is worth reminding the reader that this evaluation is not targeted to compare the two implementations of a PPR reasoner, but to observe the impact of our compression strategy on the approaches of the Prolog and SPIN implementations, assuming that any other implementation is likely to make use of a combination of the two reasoning strategies they respectively implement.

Prolog reasoner: performance measures. Each diagram reports on the performance of this reasoner with an uncompressed or compressed rule base with respect to a given measure. The bars on the left (in dark orange) refer to the uncompressed rule base, while the bars on the right (in light yellow) the compressed one.

SPIN reasoner: performance measures. Each diagram reports on the performance of this reasoner with an uncompressed or compressed rule base with respect to a given measure. The bars on the left (in dark purple) refer to the uncompressed rule base, while the bars on the right (in light green) the compressed one.
Figures 8 and 9 illustrate the results of the experiments performed with the Prolog and the SPIN reasoner, respectively. For each data flow, the bar on the left displays the time with an uncompressed input, and the one on the right the time with a compressed input. We will follow this convention in the other diagrams as well. Figure 8c displays a comparison of the total time between an uncompressed and compressed input with the Prolog reasoner. In all cases, there has been a significant increase in performance with the compressed rule base: in three cases (DBREC-5, DISCOU-1, REXPLORE-4) the uncompressed version of the experiment could not complete within the five minutes, while the compressed version returned results in less then a minute. The total time of the experiments with the SPIN reasoner (Fig. 9c) is much smaller (fractions of a second), having the maximum total time of approximately 2 seconds (EventMedia-1). However, in this case too, we report an increase in every case in performance for all the data flows, with some cases performing much better than others (DBREC-3, DBREC-4). The total time T of the experiment can be broken up into setup time S (including load time L) and query time Q. This observation is depicted in Figs 8a and 9a, and in both cases the impact of the rule reduction process is evident. An interesting difference between the two implementations can be seen by comparing Figs 8b and 9b. The cost of the query time in the Prolog reasoner is very large compared to the related setup time S. The SPIN reasoner, conversely, showed a larger setup time S with a very low cost on query time Q. The reason is that the second materializes all the inferences at setup time, before query execution. This accounts for the lack of difference in query time between the uncompressed and compressed version of the experiments with the SPIN reasoner.
We did not observe changes in
A summary of the impact of the compression on the different measures is depicted in Figs 10 and 11. The first bar on the left of both diagrams illustrates the reduction of the size of the Input, while the others how much each measure is reduced. A serious improvement has been achieved in the case of the Prolog reasoner, implementing a backward chaining algorithm executed at query time. A PPR reasoner could also be implemented to perform inferencing at loading time (materialization). The experiments with the SPIN implementation is therefore used to show that the effect on reasoning performance exists in both cases, even if in different ways depending on the approach to inferencing. The main conclusion from our experiments is therefore that the methodology presented in [8] and extended with coherency check leads to a compressed PPR knowledge base that is not only more manageable for the knowledge engineers maintaining them, but also improves our ability to apply reasoning for the purpose of policy propagation. In addition, it appears clearly that, when dealing with a compressed PPR knowledge base, an approach based on materialization of inferences at load time is preferable to one based on computing the inferences at query time.
In this article, we presented an approach for reasoning on the propagation of policies in a data flow. This method is grounded on a rule base of Policy Propagation Rules (PPRs). Rules can easily grow in number, depending on the size of the possible policies and the one of the possible operations performed in a data flow. The (A)AAAA methodology can be used to reduce this size significantly, as demonstrated in [8], by relying on the inference properties of the Datanode ontology, applied to describe the possible relations between data objects. We presented an evolved version of the methodology, which was required to be sure the inferred policies were correct when using the compressed rule base. However, while this activity reduces the size of the input of the reasoner, it requires more inferences to be computed. Therefore, we performed experiments to assess the impact of the compression on reasoning performance. The present article provides two major contributions:
the (A)AAAA methodology has been extended by including a coherency check algorithm, and experimental results demonstrating that a compressed knowledge base makes the reasoning on policy propagation more efficient.
This is a preliminary step on studying compression in knowledge management and its impact on reasoning in a more general point of view. Reasoning on policy propagation requires a formalisation of the data flow, and producing such representation can be time consuming. Recent work by the authors investigate how it is possible to support users in the formalisation of data flows derived from scientific workflows [10]. It would be of interest to explore methods for supporting and automating the generation of such data flows from other pre-existing artefacts (e.g., code bases and their documentation). Future work includes defining new measures to describe the complexity of a data flow and how it affects reasoning on policy propagation, as well as studying the validation of data flows with respect to policies, particularly when multiple sources are used. Finally, we are currently setting up an experimental evaluation (including a user study) to assess the quality of the knowledge base of PPRs produced with this approach, the correctness of the reasoning results with respect to users’ expectations, and the effectiveness of the associated methodology in the environment of the MK:Smart Data Hub [12].

Prolog reasoner: impact of compression on reasoner performance. The bars show the factor by which each measure has been reduced by applying a compressed input.

SPIN reasoner: impact of compression on reasoner performance. The bars show the factor by which each measure has been reduced by applying a compressed input.