
Abstract
Sentiment analysis over social streams offers governments and organisations a fast and effective way to monitor the publics’ feelings towards policies, brands, business, etc. General purpose sentiment lexicons have been used to compute sentiment from social streams, since they are simple and effective. They calculate the overall sentiment of texts by using a general collection of words, with predetermined sentiment orientation and strength. However, words’ sentiment often vary with the contexts in which they appear, and new words might be encountered that are not covered by the lexicon, particularly in social media environments where content emerges and changes rapidly and constantly. In this paper, we propose a lexicon adaptation approach that uses contextual as well as semantic information extracted from DBPedia to update the words’ weighted sentiment orientations and to add new words to the lexicon. We evaluate our approach on three different Twitter datasets, and show that enriching the lexicon with contextual and semantic information improves sentiment computation by 3.4% in average accuracy, and by 2.8% in average F1 measure.
Introduction
Sentiment analysis on social media, and particularly on Twitter, has gained much attention in recent years. Twitter offers a platform where users often express their opinions and attitudes towards a great variety of topics, offering governments and organisations a fast and effective way to monitor the publics’ feelings towards their brand, business, policies, etc.
However, sentiment analysis over social media data poses new challenges due to the typical ill-formed syntactical and grammatical structures of such content [30]. Although different type of approaches have been proposed in the last few years to extract sentiment over this type of data, Lexicon-based approaches have gained popularity because, as opposed to Machine Learning approaches, they do not require the use of training data, which is often expensive and/or impractical to obtain. These approaches use general-purpose sentiment lexicons (sets of words with associated sentiment scores) to compute the sentiment of a text regardless of its domain or context [4,14,21,34]. However, a word’s sentiment may vary according to the context in which the word is used [36]. For example, the word great conveys different sentiment when associated with the word problem than with the word smile. Therefore, the performance of these lexicons may drop when used to analyse sentiment over specific domains or contexts.
Some works have attempted to address this problem by generating domain-specific lexicons from scratch [2,9,17,19], which tends to be costly, especially when applied to dynamic and generic microblog data (e.g., [7,10]). Others opted for extending popular lexicons to fit new domains [8,15,16,31]. Automatic adaptation of existing lexicons not only reduces the burden of creating a new lexicon, but also ensures that the words’ sentiment and weights, generated and tested during the construction of existing lexicons, are taken into consideration as basis for adaptation [8,24].
In addition, while some approaches have made use of semantic information to generate general purpose sentiment lexicons [6], little attention has been given to the use of semantic information as a resource to perform sentiment lexicon adaptation. Our hypothesis is that semantics can help to better capture the domain or context for which the lexicon is being adapted, thus aiming to contribute towards a more informed calculation of words’ sentiment weights. For example, the context of the word “
In this paper, we propose a general method to adapt sentiment lexicons to any given domain or context, where context is defined by a collection of microblog posts (Tweets). A key novelty of our method is that it does not only captures the domain context (contextual or distributional semantics), it also introduces the use of conceptual semantics, i.e., semantics extracted from background ontologies such as DBpedia. In performing our study we make the following contributions:
We introduce a generic, unsupervised, method for adapting existing sentiment lexicons to given domains and contexts, defined by a collection of microblog posts (Tweets).
We propose two methods for semantically-enriching the lexicon adaptation method: (i) enrichment with the semantic concepts of words, and (ii) enrichment based on the semantic relations between words in tweets.
We study three lexicon adaptation techniques: updating the words’ sentiment weights, expanding the lexicon with new words, and the combination of both.
We evaluate our context-based lexicon adaptation method over three Twitter datasets, and show an average, statistically significant, improvement of 3.4% in accuracy, and 2.8% in F1, against the baseline methods.
We investigate the impact of the proposed semantic-enrichment approaches on the lexicon adaptation performance. We show that enrichment with semantic concepts, when used for updating the words’ sentiment weights in the lexicon, increases performance slightly over the context-based method by 0.27% and 0.25%, in accuracy and F1 respectively. Enrichment based on the semantic relations between entities in tweets brings 4.12% and 3.12% gain in accuracy and F1 when used for expanding the lexicon with new opinionated words, in comparison with lexicon expanding without semantic enrichment.
We investigate the impact of dataset imbalance when using lexicons for calculating tweet-level sentiment and show that our adapted lexicons have higher tolerance to imbalanced datasets.
The remainder of this paper is structured as follows. Related work is discussed in Section 2. Our method for sentiment lexicon adaptation and its semantic enrichment is presented in Sections 3 and 4 respectively. Experimental setup and results are presented in Sections 5 and 6 respectively. Section 7 covers discussion and future work. Conclusions are reported in Section 8.
Related work
General purpose sentiment lexicons (MPQA [21], SentiWordNet [1], Thelwall-Lexicon [35], Nielsen-Lexicon [21]) have been traditionally used in the literature to determine the overall sentiment of texts. These lexicons capture a selection of popular words and their associated weighted sentiment orientations, without considering the domain, topic, or context where the lexicons are being used. However, a word’s associated sentiment may vary according to the context in which the word is used [36]. To address this problem multiple works have emerged in recent years to: (i) create domain-specific lexicons or, (ii) adapt existing lexicons to specific domains.
Most of existing works belong to the first category, where approaches have been proposed to develop sentiment lexicons tailored for specific domains [2,9,16,17,19,31]. Works like [2,17,31] propose the use of bootstrapping methods for building sentiment lexicons. These methods use seed sets of subjective words [2,31], dictionaries [2,19], domain-specific corpora [2,9,16,19], training data from related domains [17], ratings [19] and graph-based formalisms [31] to identify words and to induce sentiment weights.
Recently, several works were focused on the development of domain-specific sentiment lexicons for social media [7,10]. To infer words and sentiment weights these approaches make use of linguistic and statistical features from tweets [10], including emoticons [15]. It is important to highlight that the informality of the language used in this type of data makes building domain-specific sentiment lexicons a more difficult task.
Rather than creating domain-specific sentiment lexicons, several approaches have proposed methods for adapting existing, well-known lexicons, to specific domains [8,24,28]. As previously mentioned, lexicon adaptation not only reduces the burden of creating lexicons from scratch, but also supplements the process with a collection of pre-existing words and their sentiment orientations and weights. Note that the lexicon adaptation problem is different in nature to the problem of domain adaptation for sentiment classifiers [11,22]. Creating sentiment classifiers requires the use of training data (labelled, in the case of supervised classification [22], or unlabelled, in the case of unsupervised learning [11]). Classifiers generated with training data from one domain tend to lower their performance when tested on data from a different domain. In this scenario, domain adaptation is usually needed and classifiers are adapted by adding, discarding or modifying features based on new training data. As opposed to these works, we focus on the problem of sentiment lexicon adaptation.
While the majority of work on lexicon adaptation focuses on conventional text, lexicon adaptation for social media data is still in its infancy. One very recent work in this line [15] has focused on updating the sentiment of neutral words in SentiWordNet. In addition to this work, we not only adapt sentiment weights, but also study the extraction and addition of new terms not provided in the original lexicon [28]. This is potentially useful in the case of social media data, where new terms and abbreviations constantly emerge. Note that, in-line with the work of Lu and colleagues [19], our proposed lexicon adaptation method is not restricted to domain-adaptation, but rather considers a more fine-grained context adaptation, where the context is defined by a collection of posts. Moreover, our approach does not make use of training data to adapt the lexicon.

Pipelines for (a) Context-based Adaptation Model, (b) Context-based Adaptation Model with Semantic Concepts Enrichment, and (c) Context-based Adaptation Model with Semantic Relations Adjustment.
Another novelty of our approach with respect to previous works, is the use of conceptual semantics, i.e. semantics extracted from ontologies such as DBPedia, to adapt sentiment lexicons. Our hypothesis is that conceptual semantics can help to better capture the domain for which the lexicon is being adapted, by enabling the discovery of relevant concepts and semantic relations between terms. The extraction of these concepts and relations (e.g., knowing that “
The main principle behind lexicon adaptation is that the sentiment of a term is not as static as given in general-purpose sentiment lexicons, but it rather depends on the context in which the term is used [29]. In this section we present our method for adapting sentiment lexicons based on words’ context in tweets.
The pipeline of our proposed context-based lexicon adaptation method consists of two main steps, as depicted in Fig. 1(a). First, given a tweet collection and a general-purpose sentiment lexicon, our approach detects the context of each word in the tweet collection and uses it to extract the word’s contextual sentiment. Secondly, a set of rules are applied to amend the prior sentiment of terms in the lexicon based on their corresponding contextual sentiment. Both steps are further detailed in Sections 3.1 and 3.2. The semantic enrichment of this pipeline is described in Section 4. Conceptual semantics are used to enrich the context or domain in which the words are used with the aim of enabling a better interpretation of this context.
Word’s contextual sentiment
The first step in our pipeline is to extract the contextual sentiment of terms (i.e., sentiment extracted based on a word’s context) in a given tweet collection. This step consists of: (i) capturing the context in which the word occurs, and (ii) computing the word’s contextual sentiment. A common method for capturing the word’s context is by looking at its co-occurrence patterns with other terms in the text. The underlying principle behind this method comes from the distributional semantic hypothesis:1
Also known as Statistical Semantics [39].
Several approaches have been built and used for extracting the words’ contextual sentiment following the above principle [18,37]. In this paper, we use the SentiCircle approach [26], which similarly to other frequency-based approaches, it detects the context of a term from its co-occurrence patterns with other terms in tweets. In particular, the context for each term t in a tweet collection

Illustrative example of extracting the contextual sentiment of the word
Figure 2 depicts the representation and extraction of the contextual sentiment of the term “
Based on the SentiCircle representation, terms with positive prior sentiment are positioned on the upper half of the circle (e.g.,
We refer the reader to the body of [26] for more details about the SentiCircle approach.
In the following subsection we describe how to adapt the sentiment lexicon using the contextual sentiment extracted in this step.
The reasons for using SentiCircle for extracting terms’ contextual sentiment are threefold. First, unlike other approaches, SentiCircle is built for social media data, and specifically for Twitter data [26]. Secondly, it enables detecting not only the contextual sentiment orientation of words (i.e., positive, negative, neutral), but also the words’ contextual sentiment strength (e.g., negative (
The second step in our pipeline is to adapt the prior sentiment of terms in a given sentiment lexicon based on the terms’ contextual sentiment information extracted in the previous step. To this end, we propose a general rule-based method to decide on the new sentiment of terms in the lexicon. In the following we give a formal definition of the general purpose sentiment lexicon and its properties, and explain how our proposed method functions on it accordingly.
Adaptation rules for sentiment lexicons, where
: add term t to lexicon
Adaptation rules for sentiment lexicons, where
The notion behind the proposed rules is rather simple: For a given term
In Thelwall-Lexicon [34], as will be explained in Section 5.1,
Since Thelwall-Lexicon uses discrete and not continuous values for priors, θ is rounded up to the nearest integer value to match the annotation format of Thelwall-Lexicon.
We use the same example depicted in Fig. 2 to show how these rules are applied for lexicon adaptation. The word “
In this section we propose enriching our original context-based adaptation model, described in the previous section, with the conceptual semantics of words in tweets. To this end, we follow two different methodologies: (1) Enriching the adaptation model with the semantic concepts of named-entities extracted from a given tweet collection, Conceptually-enriched Model. (2) Adjusting the contextual correlation between two co-occurring named-entities in tweets based on the semantic relations between them, Semantically-adjusted Relations Model. In the following subsections we describe both enrichment models and the motivation behind them.
Conceptually-enriched adaptation model
In Section 3 we showed our proposed method to adapt sentiment lexicons based on the contextual sentiment of terms in a given collection of tweets. However, relying on the context only for detecting terms’ sentiment might be insufficient. This is because the sentiment of a term may be conveyed via its conceptual semantics rather than by its context [5]. In the example in Fig. 2, the context of the word “
In order to address to above issue, we propose enriching the context-based lexicon adaptation model with the conceptual semantics of words in tweets. To this end, we add two additional steps to our original pipeline (Fig. 1(b)): conceptual semantic extraction, and conceptual semantic enrichment. These two steps are executed prior to the extraction of words’ contextual sentiment, as follows:
Note that we currently rely only on the entities’ semantic subtypes for the semantic enrichment phase, excluding the semantic types. Unlike semantic types, semantic subtypes capture more fine-grained knowledge about the entity (e.g., “

Example for sentiment relations between the entities Barack Obama and Texas with a path length of
Using the distributional semantic hypothesis, our context-based approach assigns a stronger relation to words that tend to co-occur more frequently in same context. However the document collection may represent only a partial view of the contexts in which two words my co-occur together. For example, in the GASP Twitter dataset around the dialogue for earth gas prices [33], the entities Barack Obama and Texas tend to appear together and therefore have a strong contextual relation. However, these two entities are related within a high number of different contexts. Figure 3 shows a small sample of the different semantic contexts that link the two previous entities. These contexts include Barack Obama’s birth place, his candidatures and his duties as president.
To capture the variety of contexts in which two terms can potentially appear together we compute the number of relations between these two terms in DBPedia by using the approach proposed by Pirro [23]. Our assumption is that the strength of the contextual relation between two terms, captured by their co-occurrence within the document collection, should be modified according to the number of contexts in which these terms can potentially appear together. The smaller the number of contexts, the stronger the contextual relation should be.
Based on the above assumption we propose adjusting the strength of the contextual relations between terms, captured by the context-based model, by using the semantic relations between them. To this end, we add two additional steps to the original pipeline (see Fig. 1(c)): semantic relation extraction and semantic relation adjustment. These two steps are further described below.
SELECT * WHERE {:Obama ?p1 :Texas} SELECT * WHERE {:Texas ?p1 :Obama} SELECT * WHERE {:Obama ?p1 ?n1. ?n1 ?p2 :Texas} SELECT * WHERE {:Obama ?p1 ?n1. :Texas ?p2 ?n1} SELECT * WHERE {?n1 ?p1 :Obama. :Texas ?p2 ?n1} SELECT * WHERE {?n1 ?p1 :Obama. ?n1 ?p2 :Texas} As it can be observed, the first two queries consider paths of length one. Since a path may exist in two directions, two queries are required. The retrieval of paths of length 2 requires 4 queries. In general, given a value K, to retrieve paths of length K, As mentioned earlier, our goal behind enriching the context-based model with semantic relations is to adjust the strength of the contextual relation between SentiCircle of entity Where N is the number of the semantic paths between Twitter datasets used for evaluation. Details on how these datasets were constructed and annotated are provided in [25]

As can be noted, the above equation modifies the value of
Note that the enrichment by semantic relations in this model is done in two iterations of the adaptation process. Specifically, in the first iteration the sentiment lexicon is adapted using the original context-based model (Fig. 1(a)). In the second iteration the semantically-adjusted relation model is applied on the adapted lexicon, where the semantic-relation adjustment takes place. Adaptation in the first iteration allows us to capture the contextual relations of entities within tweets and assign them a sentiment value. Note that sentiment lexicons are generic and most of the tweet entities (e.g.,
In this section we present the experimental set up used to assess our proposed lexicon adaptation models, the context-based adaptation model (Section 3) and the semantic adaptation models (Section 4). This setup requires the selection of: (i) the sentiment lexicon to be adapted, (ii) the context (Twitter datasets) for which the lexicon will be adapted, (iii) the baseline models for cross-comparison, (iv) the different configurations for adapting the lexicon and, (iv) the semantic information used for the semantic adaptation models. All these elements will be explained in the following subsections. We evaluate the effectiveness of our method by using the adapted lexicons to perform tweet-level sentiment detection, i.e., detect the overall sentiment polarity (positive, negative) of tweets messages.
Sentiment lexicon
For the evaluation we choose to adapt the state-of-the-art sentiment lexicon for social media; Thelwall-Lexicon [34,35]. Thelwall-Lexicon is a general purpose sentiment lexicon specifically designed to function on social media data. It consists of 2546 terms coupled with values between
Evaluation datasets
To assess the performance of our lexicon adaptation method we require the use of datasets annotated with sentiment labels. for this work we selected three evaluation datasets often used in the literature of sentiment analysis (SemEval, WAB and GASP) [25]. These datasets differ in their sizes and topical focus. Numbers of positive and negative tweets within these datasets are summarised in Table 2.
Evaluation baseline
As discussed in Section 2, several methods have been proposed for context-based sentiment lexicon bootstrapping and/or adaptation. In this paper we compare our adaptation models against the semantic orientation by association approach (SO) [37], due to its effectiveness and simple implementation. To generate a sentiment lexicon, this approach starts with a balanced set of 14 positive and negative paradigm words (e.g., good, nice, nasty, poor). After that, it bootstraps this set by adding words in a given corpus that are statistically correlated with any of the seed words. The new words added to the lexicon have positive orientation if they have a stronger degree of association to positive words in the initial set than to negative ones, and vice-versa. Statistical correlation between words is measured using the pointwise mutual information (PMI). From now on we refer to this approach shortly as the SO-PMI method.
We apply the SO-PMI method to adapt Thelwall-Lexicon to each of the three datasets in our study in the same manner as described above. Specifically, given a twitter dataset we compute the pointwise mutual information between each opinionated term t in Thelwall-Lexicon and each word w that co-occur with t in the twitter dataset as follows:
After that, we assign w the sentiment orientation (
Note that in addition to the lexicons adapted by the SO-PMI method, we also compare our proposed approaches against the original Thelwall-Lexicon without any adaptation.
Configurations of the lexicon adaptation models
We test our context-based adaptation model and the two semantic adaptations model under three different configurations. We use terms from the running example in Fig. 2 to illustrate the impact of each adaptation model:
Lexicon Update (LU): The lexicon is adapted only by updating the prior sentiment of existing terms. In our running example, the prior sentiment of the pre-existing word “
Lexicon Expand (LE): The lexicon is adapted only by adding new opinionated terms. Here new words, such as “
Lexicon Update and Expand (LUE): The lexicon is adapted by adding new opinionated terms (“
Unique Entity/Types/Subtypes for SemEval, WAB, and GASP datasets
Unique Entity/Types/Subtypes for SemEval, WAB, and GASP datasets
We use AlchemyAPI to extract the conceptual semantics of named entities from the three evaluation datasets (Section 4.1). Table 3 lists the total number of entities extracted and the number of semantic types and subtypes mapped against them for each dataset. Table 4 shows the top 10 frequent semantic subtypes under each dataset. As mentioned in Section 4.1, we only use the entities’ semantic subtypes for our semantic enrichment, mainly due to their stronger representation and distinguishing power than general higher level types (e.g., “Person”). Table 5 shows the number of semantic relations extracted between the entities of each dataset. This table also includes the minimum, maximum and average path length among all the extracted relations. A maximum path length of 3 was consider for our experiments.
Top 10 frequent semantic subtypes of entities extracted from the three datasets
Top 10 frequent semantic subtypes of entities extracted from the three datasets
In this section, we report the results obtained from using the different adaptations of Thelwall-Lexicon to compute tweet-level sentiment detection. To compute sentiment, we use the approach proposed by Thelwall [34], where a tweet is considered positive if its aggregated positive sentiment strength (i.e., the sentiment strength obtained by considering the sentiment weights of all words in the tweet) is 1.5 times higher than the aggregated negative one, and vice versa. Our baselines for comparison are the original version of Thelwall-Lexicon and the version adapted by the SO-PMI method.
Amount of relations and path lengths extracted for each dataset
Amount of relations and path lengths extracted for each dataset
Results in all experiments are computed using 10-fold cross validation over 30 runs of different random splits of the data to test their significance. The null hypothesis to be tested is that for a given dataset, the baseline lexicons and the lexicons adapted by our models will have the same performance. We test this hypothesis using the Paired T-Test since it determines the mean of the changes in performance, and reports whether this mean of the differences is statistically significant. Specifically, we perform a pair-wise comparison of the distributions of Precision, Recall, and F1-Measure resulted from each baseline lexicon against the distributions obtained from the lexicons adapted by each of our three adaptation models. Additionally, since we use the three proposed adaptation models under three adaptation settings (Update, Expand, Update and Expand), we also test the aforementioned hypothesis for every model-setting pair. P-values are corrected for multiple hypothesis testing by using the Bonferroni correction [32]. This correction sets the significance cut-off at
The evaluation presented in the subsequent sections consists of 5 main phases:
Measure the performance of our context-based adaptation model using the three evaluation datasets and the three adaptation settings (Section 6.1).
Evaluate the performance of the conceptually-enriched adaptation model and report the evaluation results averaged across the three datasets (Section 6.2).
Test the performance of the semantically-adjusted relations model on the three evaluation datasets (Section 6.3).
Conduct a statistical analysis on the impact of our adaptation models on Thelwall-Lexicon (Section 6.5).
Study the effect of the sentiment class distribution on the performance of our adaptation models (Section 6.6).
Results obtained from adapting Thelwall-Lexicon on three datasets using the context-based adaptation model. Bold = highest performance. LU = Lexicon Update, LE = Lexicon Expand, and LUE = Lexicon Update and Expand
The first task in our evaluation is to assess the effectiveness of our context-based adaptation model. Table 6 shows the results of binary sentiment detection of tweets performed on the three evaluation datasets using (i) the original Thelwall-Lexicon (Original), (ii) Thelwall-Lexicon adapted by the PMI method (SO-PMI), (iii) Thelwall-Lexicon adapted under the update setting (LU), (iv) Thelwall-Lexicon adapted under the expand setting (LE), and (v) Thelwall-Lexicon adapted under the update and expand setting (LUE).The table reports accuracy and three sets of precision (P), recall (R), and F1-measure (F1), one for positive sentiment identification, one for negative sentiment identification, and the third showing the average of the two.
Statistical significance over the results reported in Table 6 is computed by comparing the P, R, and F1 distributions obtained by: (i) the Original Lexicon and, (ii) the SO-PMI lexicon against the distributions that resulted from using the LU, LE, and LUE adapted lexicons. Statistical significance is reported as well per dataset. As shown in Tables 7 and 8. It can be noted that all results are statistically significant (
ρ-values of the contextually-adapted lexicons vs the Original lexicon
ρ-values of the contextually-adapted lexicons vs the Original lexicon
ρ-values of contextually-adapted lexicons vs the SO-PMI lexicon. Bold = insignificant ρ-values
From Table 6 we notice that in the case of the SemEval and GASP datasets the LU and LUE lexicons outperform the original lexicon in all the average measures by up to 6.5%. For example, LU and LUE on SemEval improve the performance upon the original lexicon by at least 6.3% in accuracy and 5.1% in average F1 (
Compared to the state-of-the-art SO-PMI method, we notice a similar performance trend for all the lexicons. In particular, the SO-PMI lexicon outperforms the original lexicon on both, the SemEval and GASP datasets by up to 2.8% in accuracy and 2.5% in average F1. However, both the LU and LUE lexicons outrun the SO-PMI lexicon by 3.9% in accuracy and 3.3% in average F1. The LE lexicon, on the other hand, gives on average 1.7% and 1.5% lower performance in accuracy and F1 than the SO-PMI, respectively.
In the case of the WAB dataset, the highest sentiment detection performance (79.24% in accuracy and 79.16% in average F1) is obtained using the original lexicon. In this case, the context-based adaptation model has a modest impact. Only the LU lexicon on WAB gives a 0.2% better precision than the original lexicon. Compared to SO-PMI, our adaptation model gives a comparable performance, except for the case of the LE lexicon, where the performance improves by 0.3% in average F1.
Overall, the average performance across the three datasets shows that the improvement of the adapted LU and LUE lexicons over the original lexicon and the SO-PMI lexicon reaches 3.9% and 2.9% in accuracy, and 3.2% and 2.4% in F1 respectively. On the other hand, the LE lexicon gives negligible performance improvements over the original lexicon, and a slightly lower performance than SO-PMI by 0.9% in accuracy and 0.6% in F1.
The variation in the performance of our adapted lexicons through the three datasets might be due to their different sentiment class distribution. According to Table 2 the class distribution in SemEval and GASP is highly skewed towards the positive and negative classes respectively. On the other hand, the WAB dataset is the most balanced dataset amongst the three. The impact of such skewness on sentiment detection is investigated further in Section 6.6.
The second evaluation task in this paper is to assess the effectiveness of our conceptually-enriched model in adapting sentiment lexicons (Section 4.1). Table 9 shows the average results across the three datasets considering the three different settings of lexicon adaptation: update, expand, and update and expand. We refer to adapted lexicons by the conceptually-enriched model under these settings as
Average results across the three datasets of Thelwall-Lexicon adapted by the semantic model. Bold = highest performance
Average results across the three datasets of Thelwall-Lexicon adapted by the semantic model. Bold = highest performance
Combined ρ-values across the three datasets of semantically-enriched lexicons vs (i) the Original lexicon and (ii) the lexicon adapted by the SO-PMI method
Combined ρ-values across the three datasets of lexicons adapted by the Semantically-adjusted Relations Model vs (i) the Original lexicon and (ii) the lexicon adapted by the SO-PMI method
As we can see in the Table 9, the original lexicon gives the lowest performance in all measures in comparison with the SO-PMI lexicon and the conceptually adapted lexicons, SLU, SLE and SLUE. In particular, the SLU lexicon achieves the highest performance among all other lexicons, outperforming the original lexicon by 4.1% in accuracy and 3.3% in average F1. The SLUE lexicon comes next with quite close performance to the SLU lexicon; SLUE produces 4.0% and 3.2% higher accuracy and F1 than the original lexicon respectively. The SLE lexicon comes third with marginal impact on sentiment detection performance.
Compared to the SO-PMI lexicon, a similar performance trend of our conceptually-adapted lexicons can be observed. Specifically, both, SLU and SLE outperform SO-PMI by up to 2.96% in accuracy and 2.6% in average F1. On the other hand, the SLE lexicon produces lower performance than the SO-PMI lexicon by 0.56% and 0.43% in accuracy and average F1 respectively.

Win/Loss in Accuracy, P, R and F1 measures of adapting sentiment lexicons by the conceptually-enriched model and semantically-adjusted relations model in comparison with the context-based model.
Combined ρ-values across the three datasets of lexicons adapted by the Context-based model vs lexicons adapted by: (i) the Semantically-enriched model and (ii) the Semantically-adjusted Relations model
The third step in our evaluation is to test the performance of the adapted lexicons by the semantically-adjusted relations model (Section 4.2). The lower part of Table 9 lists the average results across the three datasets for the adapted lexicon under the update setting (SRU), the expand setting (SRE), and the update and expand setting (SRUE). For the complete list of results we refer the reader to Table 17 in Appendix. Results reported in this section are statistically significance with
According to these results in Table 9, we notice that the three semantically adapted lexicons SRU, SRE and SRUE outperforms both, the original lexicon and the SO-PMI lexicon by a large margin. In particular, the lexicon adapted under the expand setting, SRE outperform both baseline lexicons by up to 4.3% in accuracy and 3.2% in average F1. The SRU and the SRUE lexicons come next by a performance that is 3.6% and 2.2% higher in accuracy and F1 than the baselines.
Context-based adaptation vs. semantic-based adaptation
In the previous sections we showed that lexicons adapted by our context-based model, as well as both semantically-enriched models, outperform both, the original lexicon and the SO-PMI lexicon in most evaluation scenarios.
Average percentage of words across the three datasets that had their sentiment orientation or strength updated by the context-based and semantic adaptation models
Average percentage of words across the three datasets that had their sentiment orientation or strength updated by the context-based and semantic adaptation models
In this section we investigate how the conceptually-enriched model and the semantically-adjusted relations model perform in comparison with the original context-based adaptation model. Such comparison allows us to understand and highlight the added value of using word semantics for sentiment lexicon adaptation. To this end, we compute the win/loss in accuracy, P, R and average F1 when using both semantic models for lexicon adaptation compared to the context-based model across the three datasets, as depicted in Fig. 5.
The results show that the impact of the two semantic models varies across the three lexicon adaptation settings. ρ-values of the statistical significance of these results are reported in Table 12. All results in average P, R and F1 measures are statistically significance.
From Fig. 5, we notice that under both, the lexicon update setting and the lexicon update & expand setting (Figs 5(a) and 5(c)) the conceptually-enriched model improves performance upon the context-based model in accuracy, P, and F1 by up to 0.27%, but only gives similar recall. On the other hand, the semantically-adjusted relations model always gives, under these settings, a lower performance on all measures compared to the context-based model.
A different performance trend can be noted for the expand setting (Fig. 5(b)). While the conceptually-enriched model does not show significant improvement over the context-based model, the semantically-adjusted relation model boosts the performance substantially, with 4.12% and 3.12% gain in accuracy and F1 respectively.
Hence, we can notice that while both semantic enrichment models have a noticeable impact on the lexicon adaptation performance, the conceptually-enriched model has a higher impact on tuning the sentiment of existing words in the lexicon (i.e., the update setting). On the other hand, the semantically-adjusted relations model is more useful in expanding the lexicon with new opinionated words (i.e., the expand setting). This is probably due to the mechanism in which each model functions. As described in Section 4, the enrichment with semantic concepts is done at the dataset level (Fig. 1(b)) in the first iteration of the lexicon adaptation process. On the other hand, the enrichment with semantic relations is performed during the contextual-relation extraction phase in the second iteration of the lexicon adaptation process. This will be further discussed in Section 7.
Applying our adaptation models to Thelwall-Lexicon results in substantial changes to the lexicon. Table 13 shows the average percentage of words across the three datasets that, either changed their sentiment polarity and strength, or were added to the lexicon, by both, context-based adaptation model and the conceptually-enriched model.5
Note that we do not report statistics for the semantically-adjusted relations model in Table 13, since they are similar to the once of the conceptually-enriched model.
On average only 5% of the words in the datasets were found in the original lexicon. However, adapting the lexicon by either model resulted in 38% of these words flipping their sentiment orientation and 60% changing their sentiment strength while keeping their prior sentiment orientation. Only 1% of the words that were found in Thelwall-Lexicon remained untouched. Also, 10% and 4% of previously unseen (hidden) words in the original lexicon were assigned positive and negative sentiment, and were added to the adapted lexicons accordingly. Adding semantic information helped detecting more words in the original lexicon as well as adding more positive and negative terms to the adapted lexicon. Table 14 shows an example of 10 semantic subtypes added to the Thelwall-Lexicon by our adaptation model.
Example of 10 subtypes of entities added to the lexicon after adaptation
Number of positive and negative tweets in the balanced SemEval, WAB and GASP datasets
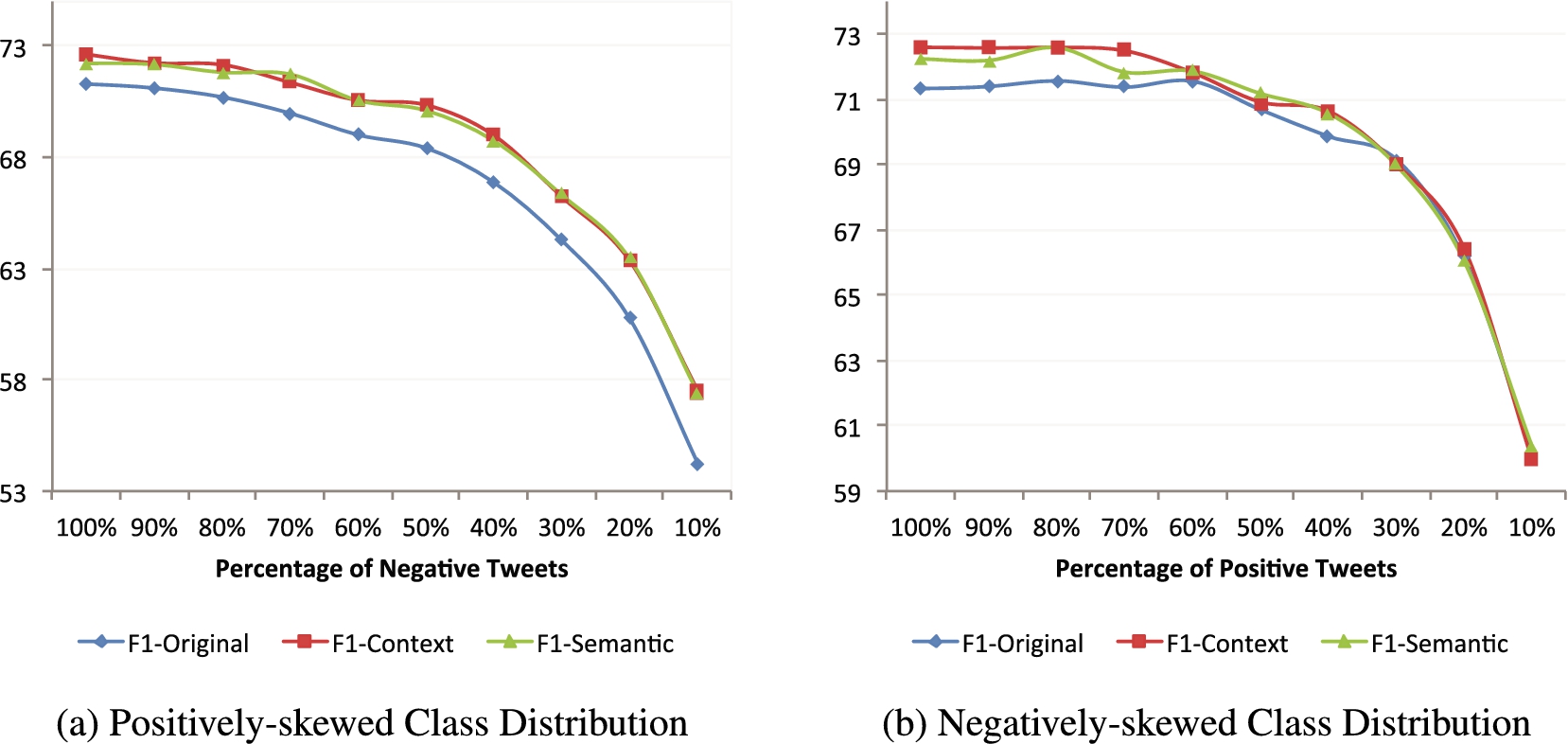
Average F1 of applying the original and the adapted lexicons on 10 folds of tweets of (a) positively-skewed class distribution and (b) negatively-skewed class distribution.
In this section we analyse the impact of sentiment class distribution in the datasets on the performance of our adaptation models. To this end, we first balance the number of positive and negative tweets in the three datasets by mapping the size of the dominant sentiment class to the size of the minor sentiment class, as shown in Table 15. Once we have a balanced dataset with the same number of elements in the positive and negative classes we imbalance this dataset by fixing one class and reducing the number of elements in the other class by 10% in each step (e.g., maintaining all elements of the positive class and reducing the elements of the negative class by 10%, 20%, 30%, … etc.). By performing this process we obtain 20 versions (folds) of the same dataset, from completely balanced, to completely skewed towards the positive class, to completely skewed towards the negative class. Figure 6 shows the average F1 of binary sentiment detection of applying the original Thelwall-Lexicon (F1-Original), the context-based adapted lexicon (F1-Context) and the semantically adapted lexicon by the conceptually-enriched model (F1-Semantic) on the 20 imbalanced folds of tweets. Note that the results here are averaged over the three datasets and the three adaptation settings.
Figure 6(a) depicts the performance over the 10 positive-skewed tweet folds. Here we can see that the performance of all lexicons decreases by gradually lowering the number of negative tweets in the data (i.e., increasing the degree positive-skewness). However, we notice that lexicons adapted by both our proposed context-based and semantic adaptation models consistently outperform the original lexicon by 3% in average F1 in all degrees of positive class skewness.
Figure 6(b) shows the performance over the 10 negatively-skewed folds. We notice that both adapted lexicons keep a 1% higher F1 on average than the original lexicon up to level where number of positive tweets is less than 40% (equals to 60% negative-skewness degree). After that level, all the three lexicons just give similar performance.
It is worth noting that all lexicons, including the original one, are more affected by the positive-skewness in the data than the negative-skewness. Lexicons applied on positively-skewed data give a 2.6% lower F1 on average than lexicons applied on negatively-skewed data. This might be due to imbalanced number of the opinionated words in Thelwall-Lexicon. As mentioned in Section 5.1, Thelwall-Lexicon has 79% more negative words than positive ones.
Overall, one can conclude that the sentiment class distribution clearly impacts the performance of the original lexicon as well as the adapted ones. The more skewed the distribution is (in either direction), the lower the performance is. Nevertheless, results show that lexicons adapted by our models are more tolerant to imbalanced sentiment distributions in the data than the original lexicon. In real life scenarios, imbalanced distributions of tweets’ sentiment are perhaps more likely to occur, and lexicon adaptation methods can therefore help enriching sentiment identification in such scenarios.
Discussion and future work
One of the most fascinating dimensions of social media is the way in which new topics and themes constantly emerge and dissipate. The ability of accurately identifying opinions and sentiment in this dynamic environment is crucial to governments, organisations and business who want to profit from the users’ opinions expressed within this medium.

Percentage of positive, negative and neutral semantic subtypes extracted from the three datasets and added to the lexicon after adaptation.
To this end, this paper proposed an approach for adapting general-purpose sentiment lexicons to particular domains or contexts. While our proposed approach is generic, this study focuses on Twitter. However, the use of contextual and semantic information may affect differently the adaptation of sentiment lexicons in different social media platforms (e.g., Facebook, Tumblr), as well as conventional data sources (e.g., online forums, product reviews websites). Further work is therefore needed to study variances across these different types of social and conventional data.
Our selection of the approach to extract the words’ contextual sentiment, SentiCircles [26], is inspired by the scope of the provided information, since it does not only capture the words’ contextual sentiment orientation but also the words’ contextual sentiment strength, which enables a more fine-grained adaptation of the lexicons.
For our experiments we selected to use Thelwall-Lexicon [35] since it is one of the most popular lexicons for sentiment analysis for the social web. However, a more extensive experimentation is needed to assess whether sentiment lexicons of different characteristics may require different types of adaptation.
In our work we have used a third-party commercial tool (AlchemyAPI) to extract the semantic concepts and subtypes of words from tweets. As future work, we plan to experiment with other entity extraction tools, such as DBpedia Spotlight6
Similarly, the approach of Pirro [23] was used to extract semantic relations between every pair of entities within our datasets. Our assumption is that different relations reflect different contexts in which the two words can appear together. However, a better filtering and/or clustering of semantic relations may be needed to provide a more fine-grained identification of these contexts.
In our experiments, we have observed that the use of semantic information helps to improve lexicon adaptation performance (Section 6.4). However, results showed that enriching the adaptation process with semantic subtypes (i.e., the conceptually-enriched adaptation model) did not have much impact on the performance when expanding the lexicon with new opinionated terms. This is probably due to the type of sentiment assigned to the semantic subtypes during the enrichment process. Figure 7 shows the sentiment distribution of the semantic subtypes for the three evaluation datasets. According to this figure, we notice that, on average, 90% of the subtypes added to the lexicon were assigned neutral sentiment after adaptation, while only 9% and 1% of the added subtypes were assigned positive and negative sentiment respectively.
Unlike enrichment with semantic subtypes, the enrichment with semantically-adjusted relations was performed in two iterations of the lexicon adaptation process. The semantic relations between two entities were used to tune the strength of the entities’ contextual relations computed in the second iteration (Section 4.2). Such enrichment strategy has proven to enhance the lexicon adaptation performance, especially when expanding lexicons with new opinionated terms (Fig. 5(b)). As future work, we plan to investigate the case of running the lexicon adaptation process for higher number of iterations, and study the impact of doing so on the lexicon’s performance as well as on the run-time complexity of our models.
Extracting semantic relations between a high number of entities via a SPARQL endpoint is a high-cost process. Specific details of the cost of extracting these relations are discussed in [23]. Our implementation uses multithreading, so that queries are sent in parallel to enhance the performance of the retrieval of relations. However, with an increase in maximum path length, the likelyhood of a path existing between two entities increases, as well as the amount of existing paths. In our implementation, we consider a maximum path lenght of 3. Note that higher values of maximum path length come close to the diameter of the DBPedia graph itself and may lead to an explosion in the number of extracted relationships.8
The effective estimated diameter of DBPedia is 6.5082 edges. See
For our evaluation we chose to compare lexicons adapted by our proposed models against the original Thelwall-Lexicon as well as the lexicon adapted by the state-of-the-art SO-PMI method. In our future work we also aim to investigate how our adapted lexicons perform when compared against lexicons generated from scratch by other existing methods. This will provide us with better insights on whether adapting lexicons is preferable, not only in terms of efficiency but also in terms of performance, on on the situations for which one method may be better than the other one.
For a more qualitative and fine-grained evaluation we also plan a manual assessment of the updates and expansions generated by our methods, so that potential adaptation mistakes for individual terms can be detected and considered for a further enhancement of our approach. In addition, an detailed error analysis of the sentiment classification is also planned, so that potential error types can be identified, categorised and used to provide further improvements.
In summary, while there is still extensive room for future work, our experiments and results show how contextual and semantic information can be combined to successfully adapt generic-purpose sentiment lexicons to specific contexts, helping therefore to correctly identify the sentiment expressed by social media users. We hope that the presented study will serve as bases for future work within the community and enable further research into the semantic adaptation of sentiment lexicons for microblogs.
Although much research has been done on creating domain-specific sentiment lexicons, very little attention has been giving to the problem of lexicon adaptation in social media, and to the use of semantic information as a resource to perform such adaptations.
This paper proposed a general method to adapt sentiment lexicons based on contextual information, where the domain or context of adaptation is defined by a collection of posts. A semantic enrichment of this method is also proposed where conceptual semantics are used to better capture the context for which the lexicon is being adapted.
An evaluation of our proposed method was performed by adapting the state-of-the-art sentiment lexicon for the social web [35] to three different contexts (Twitter datasets) using various configurations of our proposed approach. Results showed that the adapted sentiment lexicons outperformed the baseline methods in average by 3.4% in accuracy and 2.8% in F1 measure, when used to compute tweet-level polarity detection with context-based adaptation. While enriching the adaptation process with words’ semantic subtypes has modest impact on the lexicons’ performance, Enrichment based on the semantic relations between entities in tweets, yields in 4.12% and 3.12% gain in accuracy and F1 measure in comparison with context-based adaptation. Our results also showed that the lexicons adapted using our proposed method are more robust to imbalanced datasets.