Implementing semantics-aware services, which includes semantic Web services, requires novel techniques for modeling and analysis. The problems include automated support for service discovery, selection, negotiation, and composition. In addition, support for automated service contracting and contract execution is crucial for any large scale service environment where multiple clients and service providers interact. Many problems in this area involve reasoning, and a number of logic-based methods to handle these problems have emerged in the field of Semantic Web Services. In this paper, we lay down theoretical foundations for service modeling, contracting, and reasoning, which we call ServLog, by developing novel techniques for modeling and reasoning about service contracts with the help of Concurrent Transaction Logic. With this framework, we significantly extend the modeling power of the previous work by allowing expressive data constraints and iterative processes in the specification of services. This approach not only captures typical procedural constructs found in established business process languages, but also greatly extends their functionality, enables declarative specification and reasoning about services, and opens a way for automatic generation of executable business processes from service contracts.
The move towards service-aware systems, starting with emergence of service-oriented architectures and service computing [36], and newer approaches such as artifact-centric [29] and data-aware systems [13], microservices [35], and not least the emerging field of service science [43], calls for the development of novel techniques to support various service-related tasks such as service modeling and discovery, service process specification, automated contracting for services, service enactment and monitoring. These issues have been partially addressed by a number of pioneering projects in the area of Semantic Web Services, such as WSMF [20], OWL-S [32],1
and more recently [41]. Nevertheless, many core issues remained largely unsolved. The present paper builds on the previous efforts while primarily addressing the behavioral aspects of services, including service contracting and service contract execution. It complements approaches such as OWL-S and WSMO, which primary focused on semantic annotations for Web services, brings new insights, and points to new directions for research in Semantic Web Services.
In a service-oriented environment, interaction is expected among large numbers of clients and service providers, so making contracts through human interaction is not feasible. To enable automatic establishment of contracts, a formal contract description language is needed, and a reasoning mechanism must verify that the contract terms are fulfilled, as well as support the execution of the contract. A contract specification has to describe the aspects of a service, such as values to be exchanged, procedures, and guarantees. A service contracting and contract execution reasoning mechanism has to decide whether such a specification can actually satisfy the constraints of the parties involved in the contract, and if so, support the execution of the contract in a way that the constraints are satisfied. The present paper develops just such a unifying logical framework, called ServLog.
ServLog is based on Concurrent Transaction Logic (CTR) [11] and continues the line of research that employs CTR as a unifying formalism for modeling, discovering, choreographing, contracting, and enactment of Web services [17,18,39,40,42]. Transaction Logic has also been successfully used in a number of other domains ranging from security verification policies to reasoning about actions and other service-related issues [7,8,22,24,37]. The present work builds on the results reported in [39,40], but greatly extends that previous work through generalization and addition of new modeling and reasoning techniques. All this is achieved while at the same time significantly simplifying the technical machinery. The contributions with respect to our previous work are detailed in Section 6. With ServLog we lay down the theoretical foundations for service contracting. Specifically, we extend the expressive power of the constraint language used for specifying contracts, allow iterative processes, and allow to pass arguments to processes. We also extend our reasoning techniques to deal with the new expressive variety of modeling primitives, making it possible to address an array of issues in service contracts, ranging from complex process descriptions to temporal and data constraints. The inference procedure for CTR developed here also contributes to the body of results about CTR itself – it covers CTR conjunctive formulas that enable execution of constrained transactions, which previous CTR proof theory was not able to handle. We also develop a logical language for specifying and enacting processes of great complexity.
While this paper aims to be self-contained and we went to great length to provide sufficient details on CTR, it is clear that we must assume certain background from the reader. Specifically, the paper requires proficiency in basic predicate calculus and logic programming.
The remainder of this paper is organized as follows. Section 2 informally describes the basic techniques from service contract specification used in ServLog and introduces the problem of service contracting and service contract execution. Section 3 gives a short introduction to CTR to keep the paper self-contained. Section 4 formally defines modeling constructs. Section 5 describes the reasoning procedure of ServLog – the key component of service contracting and contract execution in our framework. Section 6 discusses related works and contrasts them with ServLog. Section 7 concludes the paper.
Service modeling, contracting, and contract execution
There is a number of modeling languages for capturing interactions between services and clients (or among internal tasks within the same service), some focusing on specific features and targeting different audiences (e.g. business analysts, Web service developers, etc.). For example, the Business Process Model and Notation (BPMN)6
http://www.omg.org/spec/BPMN/2.0/.
is a standard for business process modeling and provides a graphical notation for specifying business processes (BPMN distinguishes between public and private processes, choreographies, and collaborations; it can provide different views of internal and external interactions). Another approach to modeling service processes is the WSMO model of choreography,7
http://www.wsmo.org/TR/d14/.
which is limited to server-side interactions. In contrast, the model of the W3C Choreography Group includes both service-side interactions and client-side interactions.8
At a higher level of abstraction, however, all interactions can be represented through control and data dependencies between tasks. ServLog captures this level of abstraction in a logic and enables powerful forms of automated reasoning about it. Figure 1 depicts the main aspects of service behavior addressed by ServLog.
Elements of the reasoning architecture for services in ServLog.
The service process is described through its control and data flows – a specification that tells how to interact with the service and how data flows among tasks. A service process may also expose inner workings of the service (interactions that are not between the service and the client but between internal tasks of the service or third parties) for common situations in which the service allows the client to impose constraints on how the service process is to be executed.
The service policy component in Fig. 1 is a set of constraints on a service process and on its input. The contract requirements included on the client side of the figure represent the contractual requirements of the user that go beyond the basic functions of a service. (Examples of basic services are selling books and helping with travel arrangements, while an example of a service requirement is the request that the amount should be charged only after shipping.) In ServLog, service processes are described via control and data flow graphs, while service policy and client contract requirements are described via constraints.
We will now discuss these modeling aspects in more detail using a typical order placement scenario. This scenario describes the flow of interaction between a client and a service, where the interaction starts with the user placing an order, after which the service initiates a concurrent execution of processing the order items, handling shippers for the items, and receipt of a payment. The order processing workflow ends once the above tasks all finish. Processing the order items, handling shippers, and payment receipt are specified in further details, leaving the possibility for the client and the service to make some choices during the interaction (for example, providing a full payment for the order or paying per item). At the same time, the scenario shows how data (e.g. ) flows through the workflow tasks as the interactions happen. In addition, the scenario includes a set of non-trivial constraints imposed by the client and the service, which affect the execution. For example, the service has the policy (expressed as a constraint) of booking a shipper only if there are at least seven items to be sent with the shipper. The description of the scenario ends with the definition of the problems addressed in this paper, namely service contracting and service contract execution.
Service process example: A hierarchical control and data flow graph.
Service process Figure 2 shows the service process described earlier as a hierarchical control and data flow graph, called a process graph. The control flow aspect of process graphs is typically used to specify local execution dependencies among the interactions of the service; it is a good way to visualize the overall flow of control. Data flow complements the control flow by specifying the data dependencies among the interactions.
With Fig. 2 we are not attempting to suggest yet another notation for service processes; the purpose is to introduce and explain our running example in a compact and focused way. Representing the same information, say, in BPMN would have been much bulkier and would require inventing additional notation to compensate for features (such as data flow) that BPMN lacks.
Control flow The nodes in a service process graph represent interaction tasks, which can be thought of as functions that take inputs and/or produce outputs. Some tasks are meant to be executed by the service and some by the client. The distinction between service and client tasks is part of the service process description. In general there can be several actors involved, some acting as clients in one context and services in another.
In Fig. 2, tasks are represented as labeled rectangles. The label of a rectangle is the name of the task and the graph inside the rectangle is the definition of that task. Such a task is called composite because it has nontrivial internal structure. Tasks that do not have associated graphs are primitive. A service process graph can thus be viewed as containing a hierarchy of tasks. The graph shown at the top is the root of the hierarchy. In our example, the tasks of the top-level graph include process_order_items, handle_shippers, and handle_payment. These tasks are composite and their rectangles are shown separately. The task place_order is an example of a primitive task. Such tasks have grey background in the figure. Three such tasks, place_order, full_payment, and pay_one_item, are client tasks. The rest are service tasks.
The top-level graph and each composite task has an initial and a final interaction task, the successor task(s) for each interaction task, and a sign that tells whether all these successors must be executed concurrently (represented by AND-split nodes), or whether only one of the alternative branches needs to be executed non-deterministically (represented by OR-nodes).9
This non-determinism has an XOR flavor.
For instance, in the top-level graph, all successors of the initial interaction place_order must be executed whereas in the definition of pay either full_payment or pay_per_item is to be executed.
Composite tasks may be marked with the suffix “*”, which means that these tasks may execute multiple times. We call these tasks iterative and differentiate them from non-iterative tasks. Iteration is indicated through recursive occurrences of the same tasks – by placing tasks inside their own definitions. Figure 2 shows two iterative tasks: process_order_items and pay_per_item. For example, process_order_items is an iterative task where a sequence of sub-tasks, select_item followed by process_item can be executed multiple times (for example for each item in the purchase order). Iteration is indicated by an occurrence of a process_order_items box to the right of the process_item box. Note that recursive occurrences of tasks may be followed by other tasks, which gives us a general mechanism for capturing different kinds of iterations, including loops and nesting.
It should now be clear how the control flow aspect of the service process graph in Fig. 2 represents the virtual manufacturer scenario described earlier: first the order is placed (place_order), then the items in the purchase order are processed (process_order_items), delivery is arranged (handle_shippers), and payment is settled (handle_payment). These three tasks are executed in parallel. Once all of them complete, handling of the order is finished (end_order). The other parts of the figure show how each of the above tasks is executed. The important thing to observe here is that some tasks are complex and some primitive; some are to be executed in parallel (the AND-nodes) and some in sequence; some tasks have non-deterministic choice (the OR-nodes) and some are iterative.
Data flow Interaction with a service typically involves passing data and the flow of that data is normally captured using data dependencies between tasks. Such dependencies complement the control flow and complete the description of the service process graph.
Since tasks can be conceptualized as functions that take input and produce output, arguments are attached to tasks to capture both input and output. In Fig. 2, each task-label has one or more arguments. For example, handle_payment has the arguments (Order#,Price), meaning that, to execute handle_payment, Order# and Price must be provided.10
In general, arguments can be in or out (and even in-out). In logic programming, this is typically specified via modes. In our description, the mode should be clear from the context. We avoid specifying the modes explicitly in order to avoid unnecessary distraction.
In our scenario, Order# and Price will be provided by the service’s task place_order, which will generate an order number and compute the price based on the items selected by the client (and the pricing data stored in the database). These data items will then be passed to other tasks, such as handle_payment.
Data-passing between tasks is captured via the shared argument names and through a shared data space (e.g., a database) of the workflow process.11
ServLog is independent of the choice of such a shared space.
Data-passing through shared arguments is possible between a task and its direct successors, or within the definition of the same composite task. The scope of arguments is relevant in this case: argument names of a task are logical variables. When they are shared with the task’s direct successors, they refer to the same data items, i.e., data is passed from tasks to their direct successors using shared arguments. This aspect should be familiar from basic logic and logic programming. For example, data identified by Order# in process_order_items(Order#) is the same as the data identified by Order# in place_order(Order#,Price), i.e., place_order passes Order# to process_order_items. In case of a composite task, the names of its arguments are global to that task’s definition, meaning that if subtasks in its definition use the same argument names as the composite task then they refer to the same data items. In this way, the composite task passes data to its subtasks. For example, the composite task process_order_items passes Order# to its process_item subtask.
Note also that sharing via shared variables is bi-directional, as pure logic has no notion of explicit input and output. However, for practical reasons, some logic programming systems accept mode specification and do mode-inference, which allows the user to identify the producers of data.
Data-passing through shared data space is used when passing data is not possible through shared arguments due to the difference in scope of the arguments. This often occurs when data needs to be shared between tasks that have no control dependencies in the control flow part of the service process graph. For example, if select_item(Order#,Item) needs to pass Order# and Item to book_shipper(Ord#,Shipper,Itm), data-passing through shared argument names is not an option, since these subtasks appear inside composite tasks that are not related via control dependencies. To capture such data-passing, a shared database can be used as follows: select_item can store Order# and Item, and book_shipper can read them later. This is depicted by the dashed arc going from select_item to book_shipper. The label on the arc represents the data items that are being passed. In our case, Order# is being passed as Ord# and Item as Itm.
Data items can be consumable or non-consumable. In case of data-passing through shared argument names, data is non-consumable: data-producing tasks share data via all of their out-ports with the receiving tasks. The latter can further share this data with their descendants, and so on. In our example, place_order produces Order#-items, and that item is then shared with process_order_items, handle_shippers, and handle_payment. Note the emphasis on sharing: all tasks involved work on the same copy of the data – the phenomenon that is familiar from basic predicate logic and logic programming. In case of data-passing through a shared database, data can be consumable or non-consumable. It is consumable when each query to the databases is followed by deletion of the queried data item. It is non-consumable data if such deletion is not implied. In our example, the data items that we employ for passing data through a shared database are consumable.
Another aspect of the service process graphs concerns transition conditions on arcs. For example, producer(Item,Producer) in the definition of process_item and itemAvailable(Order#,Producer,Item) or itemUnavailable(Order#,Producer,Item) in the definition of inform_client.12
Such conditions represent relations queried by service tasks, but which the tasks do not modify (and thus are not used for data passing). That data is not being consumed by the service tasks.
Another example of transition condition is a test of the form . A transition condition signifies that in order for the next interaction with the service to take place, the condition must be satisfied. Transition conditions are Boolean tests attached to the arcs in the service process graphs. These tests may also be queries to the underlying database. Only the arcs whose transition conditions evaluate to true can be followed at run time. For uniformity, ServLog treats transition conditions formally as a separate type of task.
The final remark concerns the nature of primitive tasks. A primitive task is a black box that performs operations in a way that is completely hidden from ServLog’s reasoning system. It does not mean that the work performed by the task is trivial. For example, place_order may perform database updates to record the order number, price and customer’s information, send an email notification to the customer, perform a credit check, and do many other things. The point is that all these operations might not be of much interest to the service’s logic designer and she might decide to abstract them away. If, however, the details of some formerly primitive task might become important for the reasoning mechanism, the tasks may be elaborated upon and become composite. We will illustrate this idea in a very concrete way in Fig. 6 of Section 4.
Service policies and client contract requirements Apart from the local dependencies represented directly in control flow graphs, global constraints often arise as part of policy specification. Another case where global constraints arise is when a client has specific requirements to the interaction with the service. These requirements usually have little to do with the functionality of a service (e.g., handling orders); instead they represent guarantees that the client wants before entering into a contract with the service. We call such constrains client contract requirements. In Fig. 3 we give an example of global constraints that represent service policies and client contract requirements for our running example.
Global behavioral constraints on iterative processes.
Constraints can be imposed on separate tasks (e.g., a task must or must not execute, may execute a certain number of times) or it can involve several tasks (a task must execute in a certain relationship to another task, e.g., before, after, between). Furthermore, constraints can be combined using Boolean connectives (e.g., a task must execute but after its execution some other task must not execute or must execute some number of times).
Other constraints may involve data only. Examples of such constraints include service pre- and post-conditions. For instance, the requirement that “a confirmation number must be available after the execution of the book_shipper service” is a post-condition for that service, where the confirmation number is a data item in the constraint. Since data in such constraints arise as a result of interactions, this kind of constraint can be seen as a special case of constraints on interactions. Other types of constraints involve Quality of Services (QoS) and Service Level Agreements (SLAs). For instance, “availability provided by the book_shipper service is always greater than the requested availability” is a QoS requirement. ServLog can also model QoS constraints but the treatment of such specialized constraints is outside the scope of this paper.
Example of well-formed formula that represents the top-level composite task of Fig. 2.
Service contracting and service contract execution With a modeling mechanism in place, we define service contracting and service contract execution in ServLog as follows:
Service contracting: Given a service process (i.e., control and data flow) and a set of service policies and client contract requirements (i.e., constraints), decide whether an execution of the service process that satisfies both the service policies and the client contract requirements exists. Note that it does not matter in the end if this is actually executed but the important aspect is that there is at least one and execution of the contract can proceed.
Service contract execution: Execute tasks in the process in a way where client and service take turns as prescribed by the control and data flows and the constraints. When a step is proposed, the logic’s proof system verifies if acceptance of that step still leaves the possibility of a successful execution of the entire service process that satisfies all the constraints. If so, the step is accepted and executed; it is rejected otherwise. A list of possible allowed steps can also be suggested by the system at each turn.
To solve the above two problems, Section 4 formally defines service processes, service policies, and client contract requirements using Concurrent Transaction Logic (CTR). Section 5 then extends the original proof theory of CTR to make it possible to address the above reasoning tasks.
Overview of CTR
Concurrent Transaction Logic (CTR) [11] is an extension of classical predicate logic, which allows programming and reasoning about state-changing processes. Here we summarize the relevant parts of CTR’s syntax and give an informal account of its semantics. For details we refer the reader to [11].
Basic syntax The atomic formulas of CTR are identical to those of classical logic, i.e., they are expressions of the form , where p is a predicate symbol and the ’s are terms constructed of constants, variables, and function symbols. Complex formulas are built with the help of connectives and quantifiers. Apart from the classical ∨, ∧, ¬, ∀, and ∃, CTR has two additional infix connectives, ⊗ (serial conjunction) and ∣ (concurrent conjunction), and a modal operator ⊙ (isolated execution). For instance,
is a well-formed formula in CTR, while Fig. 4 contains an example of a well-formed formula that represents the top-level composite task of Fig. 2.
Informal semantics Underlying the logic and its semantics is a set of database states and a collection of paths. For this paper, the reader can think of states as just relational databases, but the logic is more general and can deal with a wide variety of states. Formally, in this paper, a state is a pair consisting of a state identifier and a relational database.
A path is a finite sequence of state identifiers (constants used to refer to the actual states). For instance, if are state identifiers, then , , and are paths of length 1, 2, and n, respectively.
As in classical logic, CTR formulas take truth values. However, unlike classical logic, the truth of CTR formulas is determined over paths, not at states. If a formula, ϕ, is true over a path , it means that ϕ can execute starting at state . During the execution, the current state will change to , etc., and the execution terminates at state . In such a case we will also call the path an execution of ϕ.
Although we are interested in execution of CTR formulas over paths, if a formula involves the concurrency operator, the subformulas may be executed in an interleaved fashion, like database transactions. For instance, if , the concurrency operator means that legal executions of ϕ consist of an execution of some part of , e.g., p, then of some execution of , e.g., u then again of some part of , such as q or even , then the remaining part of , i.e., v, etc. The concurrency operator does not preclude the two parts of ϕ from executing one after another (in any order), but this type of non-interleaved execution is less interesting. In the first, interleaved execution, the two parts of ϕ execute not on paths but on multi-paths, i.e., on sequences of paths. Execution of one part of ϕ may be broken by executions of another part, so the intervening gaps in the execution of are filled by executions of (and vice versa).
A multi-path (or an m-path) is a sequence of paths. If and are two m-paths, their concatenation, , is the m-path and their interleaving, , is an m-path of the form such that it is a topological sort of the two sequences μ and . For example, one interleaving of and of is . Also, is another interleaving, meanwhile is a degenerate interleaving.
Finally, a path is a merge of an m-path if there are integers such that , , . Note that for the merge to be possible, the end-state of each path in the m-path must be the start-state of the subsequent path for each . For instance, is a merge of the m-path .
A multi-path structure is a mapping that, for each multi-path μ, tells which ground atomic formulas are true on μ. Informally, this can be understood as telling which ground atomic transactions can execute along μ. Note that CTR formulas hold truth values not over states, but over multi-paths.
First, we connect truth over path of length 1 to database states.
If s is a state identifier and p is a fact that is true in the database associated with s then p is true over the path (and the m-path ).
CTR connectives are used to construct composite formulas out of the atomic ones, and the statements below define which composite formulas are true on which multi-paths.
: execute ϕ then execute ψ. Model-theoretically: is true over an m-path μ in a multi-path structure if ϕ is true over a prefix m-path of μ, (in that same structure), and ψ is true over the suffix m-path, . That is, if .
: ϕ and ψ execute concurrently, in an interleaved fashion. That is, is true over an m-path μ in a multi-path structure if ϕ is true over an m-path (in that same structure), ψ is true over an m-path , and μ is one of the interleavings .
: ϕ and ψ execute along the same path. That is, is true on an m-path μ if both ϕ and ψ are true on μ. In practice, this is best understood in terms of constraints on execution. For instance, ϕ can be thought of as a non-deterministic transaction and ψ as a constraint on the execution of ϕ. It is this feature of the logic that lets us specify constraints as part of service contracts.
: execute ϕ or execute ψ non-deterministically. That is, is true on an m-path μ if either ϕ or ψ is true on μ.
: execute in any way provided that this will not be a valid execution of ϕ. That is, is true on any m-path on which ϕ is not true. Negation is an important ingredient in temporal constraint specifications.
: execute ϕ in isolation, i.e., without interleaving with other concurrently running tasks. That is, is true on any singleton m-path (an m-path that contains just one path) where ϕ is true. Note: is never true on an m-path that consists of more than one path, so the execution of cannot be broken by other executions. This operator enables us to specify non-interleaved parts of service contacts.
When considering the entire service, we are interested in its executions over paths, not m-paths: executions over m-paths are used only to represent concurrently running subtasks of the service. To complete the picture, we define truth of CTR formulas over paths:
ϕ is true over a path, π, if it is true over an m-path, μ, and π is a merge of μ.
CTR contains a special propositional constant, , which is true only on paths of length 1, that is, on database states. In service processes, is often used as the exit condition for iterative tasks. Another propositional constant that we will use to represent constraints is , defined as ; this constant is true on every path.
Concurrent-Horn subset of CTR The implication is defined as . The form and the purpose of the implication in CTR is similar to that of Datalog: p can be thought of as the name of a procedure and q as the definition of that procedure. However, unlike Datalog, both p and q take truth values over execution paths, not at individual states.
More precisely, means: if q can execute along a path , then so can p. If p is viewed as a task name, then the meaning can be re-phrased as: one way to execute task p is to execute its definition, q.
To specify service processes we use concurrent-Horn goals and concurrent-Horn rules.
(Concurrent-Horn goal).
A concurrent-Horn goal is either an atomic formula or has the form , , , or , where ϕ and ψ are concurrent-Horn goals.
When confusion does not arise, we will often talk about CTR goals, omitting the “concurrent-Horn” adjective.
Concurrent-Horn goals occur in our setting in two places: as bodies of the rules that are used to define composite tasks and as formulas that are formal embodiments of control flow graphs. In the latter case, we will be interested in finding out whether a control flow graph can be enacted. Such a question corresponds to proving a statement of the form , where ϕ is a CTR goal and is the set of variables that occur in ϕ.
(Concurrent-Horn rule).
A concurrent-Horn rule is a CTR formula of the form
where is an atomic formula, is a concurrent-Horn goal, and is the set of variables that occurs in head and body.
Since all variables in a rule are quantified the same way (universally outside of the rule), we will usually omit explicit quantifiers – a common practice that simplifies the notation.
The concurrent-Horn fragment of CTR has an SLD-style proof procedure that proves concurrent-Horn formulas and executes them at the same time [11]. The present paper significantly extends this proof theory to formulas that contain the ∧ connective thus enabling execution of constrained transactions, which are non-Horn. We also deal with a much larger class of constraints than [17,39], including iterative processes.
Primitive updates In CTR, primitive updates are ground (i.e., variable-free) atomic formulas that change the underlying database state. Semantically they are represented by binary relations over state identifiers. For instance, if belongs to the relation corresponding to a primitive update u, it means that u can cause a transition from state to state . We will conveniently represent this kind of situation using the following notation:
Usually the binary relations that represent primitive updates are defined outside of CTR. In that case, they are called transition oracles [9–12]. Transition oracles can be defined using formal English or a number of other formal languages. They can also be represented in CTR as partially defined actions [37]. In either case, the primitive updates can be defined to perform any kind of transformation. For instance, they can add or delete single tuples or sets of tuples, add and delete entire relations, and so on.
In the examples, we will be representing primitive updates using predicate symbols that have variables (e.g., place_order(Order#,Price)). It should be understood that such a predicate represents a family of related updates, one for each instantiation of the variables. Clearly, place_order(12365409,$123) and place_order(09865412,$321) cause similar, but different state transitions.
Constraints Because formulas are defined on paths, CTR can express a wide variety of constraints on the way formulas may execute. One can place existential constraints on execution (these are based on serial conjunction), or universal constraints, which are based on serial implication. To express the former, we use the propositional constant introduced above. For example, is a constraint that is true on a path if ψ is true somewhere on that path. To express universal constraints, the binary connectives “⇐” and “⇒” are used, which are defined via ⊗ and ¬ as follows: and . A moment’s reflection should convince the reader that means that whenever ϕ occurs then ψ must have occurred just before it and that means that whenever ψ occurs then ϕ must occur right after it. Thus, constrains executions to be such that every subpath encountered in the course of the execution satisfies ψ (including subpaths of the form , where is an arbitrary intermediate state).
Executional entailment The notion of executional entailment is the key semantic concept in CTR that brings the informal notion of execution into the logic. Let be a set of CTR formulas, ϕ is a CTR formula and is a sequence of database states. Then the statement
is true if and only if (i.e., ϕ is true on the path in ), for every multi-structure that satisfies .
Related to this is the statement
which are true iff (2) is true for some sequence of database states .
The aforementioned proof theory for CTR assumes that is a set of concurrent-Horn rules and it manipulates the statements of the form . It is sound and complete in the sense that there is a proof of if and only if is true.
Formalizing service contracts in ServLog
This section formally defines the core modeling elements of ServLog. First we define service processes directly in CTR. Section 4.2 then introduces service policies and contract requirements as constraints that can be expressed in CTR. Section 4.3 then defines an important notion, which we call the service contract assumption.
Modeling service processes
(Task).
A task is represented by a predicate. The name of the predicate is the name of that task and the arity specifies the number of arguments that the predicate takes. For notational simplicity, we assume that each predicate name has exactly one arity, so each task is uniquely defined by its name.
In service contract specifications, the actual invocations of tasks are represented by task atoms.
(Task atom).
A task atom is a statement of the form
where p is a task predicate of arity n () and are terms (defined as in first-order logic) that represent the arguments that p takes. The terms representing the arguments of the task are placeholders for data items that the task manipulates (its inputs and outputs).
For brevity, we will often write task atoms as , , etc., where , stand for the tuples of arguments that the task takes.
When confusion does not arise, the term “task” will refer both to tasks and task atoms.
We distinguish between two main types of task predicates: composite and primitive. Composite task predicates are the ones defined by rules (i.e., they are allowed in the rule heads) and primitive tasks are not allowed in the rule heads. The primitive task predicates are further subdivided into update-tasks, query-tasks, and builtin test tasks. The update task predicates are those used as the primitive updates of CTR, the query tasks are the ones whose predicates are used to represent the facts stored in database states, and the builtin tests use predicates whose truth is independent of the database state. These three categories of predicates are disjoint. The transition conditions on the arcs of service process graphs, which were introduced in Section 2, are also treated in ServLog as tasks: specifically as query tasks or builtin tests – whichever applies in each case.
In this paper, we will be using the builtins “=” (identity), “!=” (distinct values), “>”, “<”, and others, as needed. The identity predicate is true if and only if a and b are the same ground (i.e., variable-free) term and holds if a and b are distinct ground terms. Clearly, the truth of these predicates is independent of the database state (or of a path) where the predicate is evaluated.
From now on, when talking about CTR goals and rules, we assume that the atomic formulas are task atoms only. In addition, the predicates occurring in the rule heads must correspond to composite tasks only.
(Task occurrence).
A task p occurs in a CTR goal Ω if Ω contains a task atom for some .
(Immediate subtask).
Let p and q be a pair of tasks and R be a set of rules. We say that p is an immediate subtask of q with respect to R if and only if R contains a rule of the form and p occurs in Ω.
(Subtasks).
Let p and q be a pair of tasks and R be a set of rules. Then p is a subtask of q with respect to R if and only if p is either an immediate subtask of q or there is an immediate subtask r of q such that p is a subtask of r.
(Non-iterative rule).
A rule in R is non-iterative if and only if it has the form
where q does not occur in Ω and none of the tasks that occur in Ω have q as a subtask.
Here is an example of a non-iterative rule (p and r are assumed to be primitive tasks here): . As seen in this example, variables in ServLog are represented as symbols prefixed with “?”.
(Iterative rule).
A rule in R is iterative if and only if q either occurs in Ω directly or it is a subtask of a task that occurs in Ω.
Here are examples of iterative rules:
Note that here q and are both iterative tasks that are mutually dependent on each other (are subtasks of each other). In practice, however, the most common form of iterative tasks is a loop of the form
where Φ and Ψ do not depend on q.
(Service process).
A service process is a pair , where Ω is a CTR goal and R is a set of iterative and non-iterative rules whose heads are task atoms of the tasks that occur in Ω or are subtasks of these tasks.
Recall that primitive tasks come in three guises: updates, queries, and builtins. Similarly, we classify composite tasks based on the rules that define them. Namely, if a task is defined by at least one iterative rule (i.e. there exists an iterative rule with the task as its head), we call the task iterative; if it is defined only by non-iterative rules then the task is non-iterative.
Equipped with this mechanism for defining service processes in ServLog, one can capture a wide range of control and data flow constructs that often appear in business process languages and notations. For example, the service process introduced in Fig. 2 is represented in ServLog as shown in Fig. 5.
The top-level graph is specified as a CTR goal at the very beginning. The tasks appearing in that goal are defined by the rules that follow. This service process illustrates data flow through variables as well as via a shared database. For example, passing data from process_order_items to book_shipper is done via the underlying database by having process_order_items insert and then querying this data item by the task handle_shippers. In order to fully capture the dataflow, we introduce three additional database query predicates:
producer(?Item,?Producer), which returns a producer for the given item,
itemAvailable(?Order#,?Producer,?Item), which is true if the given item is produced by the given producer and the item is in stock, and
itemUnavailable(?Order#,?Producer,?Item), which is the negation of itemAvailable.
While the set of available producers is relatively static, the relation itemAvailable can be modified by the contact_producer(?Producer,?Item) task. For instance, after contacting the producer an item might become reserved.
Data flow types supported by ServLog are simple yet powerful: tasks can share data through shared variables or through the underlying shared database – the former is standard in classical logic and in logic programming languages, the latter is a feature of CTR. For instance, in the subprocess process_item in Fig. 5, the same data is passed through the shared variables and to the query producer, and also other tasks (e.g., contact_producer). These data come from the task process_order_items and then are passed along to the top-level invocation of process_item. Inside process_item, new data is obtained by the query producer and then is passed to the subtasks contact_producer and inform_client through the shared variable ?Producer.
ServLog representation of the service process from Fig. 2.
In Section 2, we explained the nature of primitive updates as “black boxes” whose inner workings are hidden from ServLog’s reasoning mechanism. In Fig. 5, for example, the tasks place_order, select_item, and some others are said to be primitive CTR updates that correspond to primitive tasks in Fig. 2 and their implementation is opaque to the system. However, as explained there, ServLog lets the service logic designer to represent tasks at different levels of abstraction and primitive tasks may be expanded into complex tasks, if desired. Figure 6 illustrates this point using some earlier primitive tasks as an example.
We now formalize service policies and contract requirements as constraints in ServLog. Note that constraints are not defined directly as CTR formulas (unlike task definitions). The main reason for this is that constraints represent patterns that executions of service processes must follow and specialized language constructs for such patterns make specification of constraints easier to understand. Nevertheless, the constraints of ServLog can be expressed as CTR formulas (see Appendix C), so CTR is indeed used here as a unifying formalism for both service task definition and constraints. Recall that whereas CTR can represent constraints, they are not Concurrent Horn formulas and are therefore not handled by the existing CTR proof theory – the extension of the CTR proof theory to handle constraints is proposed in Section 5.2 and is an important contribution of this paper.
A constraint specifies the rules governing the occurrences of various tasks during the execution of a service. Each occurrence of a task is represented by a pattern, which specifies the task name and various conditions on the arguments with which that task can be invoked during the execution. These conditions can require that certain arguments must be bound to specific values and they can also require that certain arguments must be shared within a task occurrence or across the occurrences of different tasks.
(Task pattern).
A task pattern has the form where each is either a regular ground term (of the kind that may occur in a task atom) or a placeholder. A placeholder is either a named logical variable (which will be designated with the prefix ’_’, e.g., _Ord#) or a don’t care placeholder, denoted by ’_’. Each occurrence of a don’t care placeholder represents a new logical variable that does not occur in other patterns.
We will often need to perform two operations: matching and refinement. The former is the usual matching operator of first-order logic: it is a substitution, θ such that . Since is ground, θ will normally be a ground substitution. In this case we will say that the pattern and the ground task match. Note that different occurrences of ’_’ may be mapped by θ to different constants, since such occurrences represent different logical variables. Refinement is defined next.
(Refinement).
The refinement operation takes a ground task atom and a pair of task patterns and yields another task pattern as follows:
Here the arguments in_ground_task and in_pattern must have the same task name and in_ground_task must match in_pattern. The task-pattern out_pattern may have a different task name. The result of the operation, refined_pattern, is defined as follows: Let θ be the substitution that matches in_pattern against in_ground_task. If out_pattern has variables other than those in in_pattern, θ can map them to anything (to some other variable or constant). Then
One can verify by direct inspection that the task atom p(2,1,abc,cde,13,cde,13,5) matches the pattern p(_,1,abc,_foo,_bar,_foo,_bar,_), that
and that
The last example also illustrates the situation where in_pattern has named placeholders that do not occur in out_pattern; the number of arguments in the input and output patterns can also differ.
(Constraints).
In this definition, we will use , , etc., to represent tuples that include placeholders as some of the arguments in task patterns. The uppercase symbols , , etc., will denote tuples of arguments in task atoms (i.e., they do not contain placeholders). The task names p, q, r, and the task patterns mentioned in the constraints, below, do not need to be distinct.
The set of constraints supported by ServLog is formally defined as follows. For each constraint we first give its syntax followed by a brief informal explanation and then provide a formal semantic definition. Appendix C provides alternative representation of these constraints as CTR formulas.
Existence constraints:
: task p must execute at least n times (n ⩾ 1).
Formally, an execution satisfies this constraint if and only if there are ground task atoms that executed at some states (i.e., ) such that matches , .13
The notation was introduced in (1) in Section 3. Recall that since cause state transitions, they are primitive update tasks.
: task p must not execute.
Formally, an execution satisfies this constraint if and only if there is no state in that execution such that and matches .
: task p must execute exactly n times (n ⩾ 1).
An execution satisfies this constraint if and only if it satisfies but not .
Serial constraints:
: whenever p executes, q must execute after it. Task q is not required to execute immediately after p, and several other instances of p might execute before q actually does.
Formally, an execution satisfies this constraint if and only if whenever there is a state in this execution, such that and matches , there must be a state in that same execution such that , , and matches .
For instance, if the above constraint has the form then the sequence is a valid execution, but is not.
: whenever q executes, it must be preceded by an execution of p. Task p does not have to execute immediately prior to q.
An execution is said to satisfy this constraint if and only if whenever there is a state in this execution such that and matches , there must be a state in that same execution such that , , and matches .
For instance, if the constraint is
then the sequence is a valid execution, but is not.
: if task p executes then task q cannot execute in the future.
Formally, an execution satisfies this constraint if and only if whenever there is a state in this execution such that and matches , there is no state in that execution such that , , and matches .
: task q must execute between any two executions of p and r. That is, after an execution of p, any subsequent execution of r has to wait until q is executed.
An execution satisfies this constraint if and only if whenever there are states , () such that , , matches , and matches , then there must be a state such that , , and both and match .
: task q must not execute between any pair of executions of p and r. Thus, if q executes after p, no future execution of r is possible.
An execution satisfies this constraint if and only if whenever there are states , () such that , , matches , and matches , then there is no state such that , , and both and match .
Immediate serial constraints:
: whenever p executes, q must execute immediately after it.
Formally, an execution satisfies this constraint if and only if whenever there is a state in this execution such that and matches , then must hold and must match .
: whenever q executes, p must have been executed immediately before it.
Formally, an execution satisfies this constraint if and only if whenever there is a state in this execution such that and matches , then must hold and must match .
: whenever p and q execute, q must not execute immediately after p. That is, after p there must be an execution of a task other than q before q is allowed again.
An execution is said to satisfy this constraint if and only if whenever there is a state in this execution such that , where matches , and for some , then must not match .
Composite constraints: If then so are (a conjunctive constraint) and (a disjunctive constraint).
Nothing else is in .
Note the use of different arrows between the arguments in some of the constraints. The convention here is that the task at the tail of the arrow represents the condition of the constraint (if or whenever the task executes) and the task at the head of the arrow indicates the effect of the constraint (the task must or must not execute in a given relationship to the task at the tail of the arrow). We use strong arrows to indicate immediacy (execution must take place right before or after) and dashed arrows indicate that immediacy is not required. Slashed arrows indicate negative relationships (e.g., the task in the head must not execute). Note also that the negation of can be defined as follows:
The following is an example of a legal constraint in :
The constraint requires that p executes at least twice and arguments 1 and 3 have the same value in each execution, while the second argument is the integer 1. In the constraint , the placeholder is shared between p and r. This means that whenever p is executed, r must follow immediately and r’s second argument must be the same as the first argument in p.
The constraints from Fig. 3 can now be represented in ServLog, as depicted in Fig. 7.
Many other types of constraints can be naturally expressed in , as shown below:
– task p can execute at most n times and each time the second argument must be 1. This constraint was defined in item 1 above.
– if p is executed with its second argument 4, then q must also execute (before or after p) and its first and last arguments must be 2 and 3 respectively.
– if p is executed, then q must also be executed, and vice versa.
– every occurrence of task p must be followed by an occurrence of task q with the same argument and there must be an occurrence of p before every occurrence of q and their arguments must be the same.
– if task p is executed then q must execute after it, with the same argument, and before that q there can be no other p.
– if task q is executed, it has to be preceded by an occurrence of p. The next instance of q can execute only after another occurrence p.
– tasks p and q must alternate when they execute with the same argument.
– executions of p and q must be next to each other with no intervening tasks in-between.
– it is not possible for p and q to execute in the same service process run.
– q must not execute between any two executions of p with the same arguments, and p must not execute between any two executions of q with the same arguments.
The service contract assumption
We now introduce modeling assumptions, which tighten the form of the constraints and tasks that are allowed in service processes. These assumptions do not limit the modeling power of the language in the sense that any service process can be represented by another process that satisfies these assumptions. However, these assumptions greatly simplify the reasoning system of Section 5.
(Service contract assumption).
A service process G and a set of constraints satisfy the service contract assumption if and only if the set of constraints is based on primitive update tasks and the primitive update tasks of G satisfy the independence assumption.
The last two notions in this definition are spelled out in Definitions 4.13 and 4.14 below. Also recall that a primitive task is one that is not defined by a rule and a primitive update task is just a primitive CTR update.
(Constraints based on primitive update tasks).
A set of constraints is based on primitive update tasks if and only if all tasks appearing in the constraints are primitive update tasks.
This restriction does not limit the modeling power of the language, since one can always instrument composite tasks in such a way that the resulting set of constraints will be based on primitive update tasks. More specifically, one can insert “bounding” primitive update tasks at various locations in the definition of composite tasks, and then transform constraints on composite tasks into constraints on those bounding primitive update tasks. These bounding tasks are defined as no-ops and their only purpose is to capture the various stages in the life cycle of a task. Examples include the beginning and end of a task, the beginning and end of an iteration, and so on.
The rationale behind restricting constraints to primitive update tasks is that specifying constraints directly over composite tasks can be highly ambiguous. For instance, what should the sentence “task b must start after task a” mean exactly? Should b start after a begins or after a ends? Similar ambiguity exists with other constraints, such as before and between constraints. Requiring that constraints are based on primitive update tasks avoids ambiguity and complications without limiting the modeling power.
The following example illustrates the process of inserting bounding tasks to delineate the beginning and the end of a composite task:
Every non-iterative composite task of the form can be changed to:
Every iterative composite task, for example, of the form , can be changed to:
In fact, there are many other ways to insert bounding tasks, which would enable many more kinds of constraints. For instance,
These bounding tasks are regular primitive updates that insert unique tokens every time they execute. For example, might insert , , , and so on, on each successive execution.
A constraint such as , where p and q are composite tasks, can now be interpreted as (), or (), or () ∧ (). By exposing the bounding primitive subtasks, ServLog enables many kinds of constraints that cannot be specified on composite tasks directly. For instance, the constraint () or the constraint ().
An important benefit of the use of bounding start- and end-tasks is that they enable easy specification of pre- and post-conditions for any task in a service and even for the entire service. For instance, if and are bounding primitive tasks for the entire service and precond is a query then establishes precond as a precondition for the entire service. Likewise, establishes postcond as a post-condition for the service. A service can have several pre- and post-conditions and some of these constraints can belong to client requirements while others can be specified as part of the service policy.
(Independence assumption).
Two primitive update tasks are said to be independent if and only if they are represented by disjoint binary relations over database states.
A service process satisfies the independence assumption if and only if all its primitive update tasks are independent of each other.
Independence implies that any transition between a pair of states is caused by precisely one primitive update task, and no other task can cause that transition.
Any set of primitive update tasks can be instrumented so that the tasks would become independent. For example, each primitive update task, t, can be made to insert a unique token every time it executes. Specifically, t might insert on the first execution and then , , etc., on subsequent executions. As a result, any transition between any pair of states would be possible by at most one primitive update task.
Without the independence assumption it is hard to come up with an effective algorithm for checking satisfaction of constraints by service executions, and it is hard to develop a simple enough proof theory for finding service executions that satisfy such constraints. To see this, suppose that the independence assumption is not satisfied and there are two distinct primitive update tasks such that and hold. Suppose that we are now trying to execute p at state s. In the presence of constraints such as , , and the like, it would be hard to determine whether p can be executed, since one must first determine if execution of p amounts to execution of another, prohibited task, such as q, in this example.
Reasoning about contracts in ServLog
We begin with an example that shows how service contracting and contract execution are intended to work. The example illustrates most of the aspects of service modeling introduced in Section 4: service processes (control and data flows), client contract requirements, and service policies. The last two are represented via constraints. Section 5.2 formalizes the decision procedure as an extension to the proof procedure of the original CTR.
Informal example
For simplicity, the example uses propositional tasks only, but the proof procedure in Section 5.2 is designed to work for the more general case where tasks have arguments. For concreteness and to illustrate the interactive aspect of our model, we assume the following division among the tasks involved:
Service tasks: a, f, g
Client tasks: d, e, h
Service process:
Process formula:
Rules:
Client contract requirements:
Service policy:
Service contracting As explained at the end of Section 2, service contracting is an interactive decision procedure that checks whether an execution of the service process exists and satisfies both the service policies and the client contract requirements. In our example this amounts to finding an execution path of (3) such that the constraints (4) and (5) are satisfied. For example, is an execution path for (3) path that satisfies the constraints, but is an execution that violates . The proof procedure introduced in Section 5.2 is designed to find paths on which the constraints are satisfied, if such paths exist. Note it does not matter if the path that was found will actually be the one to be executed – all that is needed is to find out if the contract is satisfiable. If service contracting does not find a path that satisfies the constraints, it means that no execution will ever be successful and the contract is unsatisfiable.
Service contract execution If a contract is satisfiable, its execution deals with the actual interactions performed by the client and the service. The idea is based on the same proof theory that is used for service contracting, but it is applied differently. When a task is chosen for execution by the client or the service, the proof theory of Section 5.2 checks if acceptance of that task still leaves the possibility of a successful execution of the remainder of the service process (that satisfies the constraints). If so, the task is accepted and executed; otherwise the task is rejected and a different task must be chosen for execution by the agent in question. Note that such a task must exist because when accepting the previous task we must have checked that some continuation is possible.
Contract execution for our example works as follows:
Suppose the service selects task a. (This is the only task that can possibly be chosen according to our process specification.) We already checked (while doing service contracting) that there is a legal execution that starts with a, so the task is accepted.
The remainder of the process is (where B and C are replaced with their definitions). The next step can be taken either by the client (e.g., by picking d or e) or by service (e.g., by picking f). It is also possible for the system itself to execute an internal action by picking state (here the client and the service “take a short break”). Let us assume that the client takes initiative and picks e for execution. The system checks if e can be executed and finds that this would violate the constraint ; so e is rejected. Suppose that the client does not give up and selects d for execution. Again, the system checks if d is allowed to execute given the constraints. In this case no constraint forbids the execution of d because is a valid execution of the remainder of the process, so d is accepted.
It would be very inefficient if the system had to go back to the beginning of the path in order to check if acceptance of an action permits a valid continuation. To avoid this, we modify the constraints after acceptance of each action so that we will never have to look back in order to decide whether to accept or reject an action. For instance, after accepting d the system revises the constraints by replacing with . This is possible because after the execution of d the constraint will be satisfied iff f is executed at some point in the future, whence . The system now checks whether an execution of the remaining process exists under the updated set of constraints (since we have two constraints and , the last one can be removed).
For the remainder of the process, , only f and can be chosen. Let us assume that the internal action is picked for execution. The system now checks whether an execution of the remaining part of the process, , exists given the updated set of constraints . It is easy to see that cannot execute to satisfy because there is no f in . Therefore, is rejected. The only other way to proceed is for the service to pick f (recall that f can be executed only by the service). Proceeding as before, the proof theory would check if f can execute. There are no constraints to prevent that, so the system updates the constraints and checks if a legal continuation is possible. The update replaces with , since executing f means that the number of required occurrences of f decreases by 1. The remaining part of the process, has a legal execution {f, h} with respect to the updated set of constraints , so f is accepted.
To proceed, we need to expand C using the rule in (3), which gives us – the same process as in the previous step. Although the set of constraints has now changed, because of the task f must still be executed for the same reasons as in the previous step. This task is accepted because a legal continuation exists, and now the set of constraints gets changed to .
Now the remainder of the process is and can be successfully picked for execution and the remainder of the process becomes . Either g can now be attempted by the client or h by the service. However, the constraint prevents the former, so the service proceeds by picking h and, since no constraint prevents it from going ahead, it is executed. At this point, the remainder of the process is empty and we are done.
Note that other executions are also possible and could have been taken. For instance, if the service continued to press initiative in step 2, it could have picked f and the execution could have become a, f, d, f, f, h or a, f, f, d, f, h.
As we saw above, both service contracting and contract execution rely on the same inference rules which do not explicitly differentiate between client and service tasks, however the difference plays out in the way the inference rules are applied.
Proof system
Let be a constraint (which can be composite), where includes both the service policy and the client contract requirements. Let G be a service process and G and satisfy the service contracts assumption. We consider the following reasoning problems in ServLog:
Contracting: The problem of determining if contracting for a service is possible amounts to finding out if there is an execution of the CTR formula . Formally, contracting aims to determine if there is a path on which is true in every multi-path structure that makes all composite task definitions true.
Contract Execution: The problem of contract execution amounts to producing an interactive proof that can execute along some path. In that proof, the client and the service take turns that are prescribed by the process specification and by the ownership of the primitive tasks, as illustrated in the previous subsection. This proof must be constructive – a sequence of applications of the inference rules of CTR, which starts with an axiom and ends with the aforesaid formula . Each such proof provides a way to execute the process without violating any of the constraints in .
The rest of this section develops a proof theory for formulas of the form , where G is a service process and .
To simplify matters, we will assume that the service process G has no disjunctions in the rule bodies and in its CTR goal part. This does not limit the generality, as such disjunctions can always be eliminated through a simple transformation similar to the one in classical logic. For instance, the disjunction in
can be eliminated by transforming this rule into
Hot components We recall the notion of hot components of a CTR goal from [11]: hot(ψ) is a set of subformulas of ψ that are “ready to be executed” and corresponds to the notion of goal selection in SLD-style resolution proof theories. Hot components are defined inductively as follows:
hot(()) = {}, where () is the empty goal
hot(ψ) = {ψ}, if ψ is an atomic formula
hot() = hot()
hot() = hot() hot()
hot() = {}
Additional constraints The set of constraints is changing as tasks in the process execute. The exact mechanism is explained in the inference rule “executing primitive update tasks,” below. It involves three new constraints: , , and , plus a generalization of the constraint , which allows exceptions. We did not introduce these before, since the new constraints are technical means by which the proof theory works and they are unlikely to be employed by users directly.
The meaning of the constraint , where is a task pattern for a primitive update, is that the very next task to be executed must match . More precisely, an execution satisfies if holds and matches .
The constraint means that no task that matches can execute at the current state. Formally, an execution , such that holds for some task atom , satisfies if does not match .
The constraint says that must be immediately preceded by unless it is the first task to be executed. That first task can be a q-task, if it matches . Formally, an execution satisfies this constraint if and only if either satisfies or holds, where matches , and satisfies .
The generalization of has the following syntax:
where , , and , ( means that the sets of exceptions are empty), are task patterns. The use of “∖” here indicates that must hold, except for the tasks that match one of the exceptions .
Formally, an execution satisfies the constraint (6) if and only if whenever there is a state in this execution such that and matches but of the ’s then there is j, , such that holds and matches .
Note that, when the set of exceptions is empty, the constraint (6) reduces to the old form of the -constraint. Therefore, to simplify the language, in the rest of this section we will be using only the generalized form of this constraint.
Substitutions As usual in logic proof theories, we will rely on the notion of substitution, which is a mapping from variables to terms. If σ is a substitution and ψ is a service process or a term then we write for the result of applying the substitution σ to ψ. We call an instance of ψ. If has no variables left, we say that is a ground instance and that σ is a ground substitution.
Sequents Let be a set of composite task definitions. The proof theory manipulates expressions of the form , called sequents, where is a set of task definitions, is an identifier for the underlying database state, ψ is a CTR goal, and is a (possibly composite) constraint, which may include the constraints in as well as the new constraints (, , etc.) introduced just above. Informally, a sequent is a statement that , which is defined by the rules in , can execute along some path that starts at state so that all the constraints in will be satisfied. Each inference rule has two sequents, one above the other. This is interpreted as: if the upper sequent is inferred, then the lower sequent should also be inferred. As in classical logic, any instance of an answer-substitution is a valid answer to a query.
The inference system presented here extends the inference system for Horn CTR [11] with two additional inference rules (Rules 2 and 3). Other rules from [11] (e.g., Rule 6) are also significantly modified. The new system reduces to the old one when the constraint is a CTR tautology (). The new system also extends and simplifies the proof theory developed in [39].
All rules and the axioms operate with constraints, which get modified as a result of the rule application. However, some of the rules require the constraint to be a conjunction of the existence, serial, and the additional constraints introduced in this section. We call such constraints conjunctive. A conjunctive constraint can be viewed as a set, so we will often write meaning that c is a conjunct in .
The notion of a proof A proof of a sequent seq is a series of sequents, , where and each is either an axiom-sequent (below) or is derived from earlier sequents by one of the inference rules below.
Axiom All axioms have the form , where is a database state identifier and is a conjunctive constraint that does not contain constraints of the form , , and , where .
Inference rules In Rules 1–7 below, σ denotes a substitution, ψ and are service processes, and are constraints, , , are database state identifiers, and p is a task.
Eliminating disjunctive constraints: Let ψ be a CTR goal and a disjunct in the disjunctive normal form of (i.e., is a conjunctive constraint). Then Note that is a conjunction of existence and serial constraints.
Solving builtin tests: Let χ be a conjunction of builtin test tasks. Suppose there is a ground substitution σ such that evaluates to true. Then
Commutativity with respect to builtin tests: Let χ be a conjunction of builtin test tasks and ψ a CTR goal. Then
Applying composite task definitions: Let r ← β be a rule in , and assume that its variables have been renamed so that none are shared with ψ. If p and r unify with the most general unifier σ then where is obtained from ψ by replacing a hot occurrence of p with β.
Executing query tasks: Suppose that and share no variables and either (i) p is a primitive query task such that (∃) is true in the state ; or (ii) and σ is the identity substitution. Then where is obtained from ψ by deleting a hot occurrence of p.
Executing primitive update tasks: Let be a primitive update task such that , , and has no constraint of either of the forms below. In the description below, we assume that is a task pattern such that matches and that denotes an arbitrary task pattern:
such that does not match
and matches neither nor any of the ’s
, where does not match .
Then the inference rule has the following form: where is a conjunctive constraint, is obtained from ψ by deleting the hot component p, and is constructed out of as follows.
Initially, is empty (a tautology, ). Then constraints are added to it (as conjuncts) according to the cases below. (Again, in all these cases, we assume that matches and , are arbitrary task patterns.)
If , where , add the following to :
;
If , where , add the following to :
;
If , add the following to :
;
If , add the following to :
, where
If , add the following to :
, where
If , add the following to :
, where .
If , add the following to :
where ;
If , add the following to :
, where
If , add the following to :
, where ;
If , add the following to :
, where are arbitrary task patterns;
If , add the following to :
, where and
If , add the following to :
where and
For all other constraints in , copy them over to , but leave out the constraints of the form:
, for any task pattern
Executing atomic tasks: If is a hot component in ψ then where is obtained from ψ by deleting a hot occurrence of .
The above inference system is sound and complete for proving constrained service processes, if the service processes and the constraints satisfy the service contracts assumptions.
Soundness of the inference system is proved in Appendix A and completeness in B. □
The following example illustrates the inference procedure.
Here p, q, and s are assumed to be primitive tasks, and in the case of p and s they can be executed with any integer argument. Furthermore, in this example we assume that the execution of p, s, and q modifies the database, as follows: adds ; adds ; adds ; and q deletes . These assumptions were needed in order to show that the constraint is satisfied in this example. If we did not make these assumptions, then the constraint might not be satisfied in which case the inference procedure would not infer the constraint. The goal G can be executed in several ways such that is satisfied. We show one possibility, which corresponds to one derivation of the sequent , , where is an identifier for , the empty state. In this derivation, we use the top-down method, i.e., we start with the goal and apply the inference rules backwards. Each sequent is derived from the previous one by an inference rule. The deduction succeeds when the last sequent is an axiom. We start with the sequent
Here, instead of a state identifier () we put the corresponding database state ({ }) explicitly. To make the sequent easier to read, we will continue doing this in the rest of this example.
Hot components: . By inference rule 1 (eliminating disjunctive constraints) we obtain:
Hot components: . By inference rule 4 (composite task definitions) we obtain:
Hot components: . By inference rule 6, choosing and executing this primitive task with the argument , we obtain (recall that the execution of adds the fact to the database):
Hot components: . By inference rule 5 (executing query tasks):
Hot components: . By inference rule 6 applied to the primitive task and the earlier assumption, this execution adds the fact to the database:
Hot components: . By inference rule 6 applied to the primitive task q (which, as mentioned above, deletes ):
Hot components: . By inference rule 4 (composite task definitions):
Hot components: . By inference rule 5 (executing query tasks) and choosing :
Hot components: . By inference rule 6 for executing the primitive task and by the earlier assumption, it adds the fact to the database:
Hot components: . By inference rule 4 (composite task definitions), where we use the second rule for r:
Hot components: . By rule 5 applied to we derive:
During the deduction, we executed the following sequence of primitive tasks:
It is easy to see that this sequence indeed satisfies the constraint , which required to be executed at least twice.
Decidability and complexity
In general, query answering in CTR is semi-decidable [11], like in classical logic, so no effective procedure exists to answer all possible queries and terminate. Appendices A and B show that the same is true for ServLog. In [8], various subsets of CTR were investigated for their decidability and complexity properties. One important restriction studied there is called full boundedness. In terms of ServLog, this roughly means that every update task must diminish some bounded from below, discrete measure (e.g., a positive integer measure). In that case, the CTR proof procedure is data-complete for NP [8] (i.e., NP-complete when the rules are fixed but data is allowed to vary). Fortunately, all existing workflow modeling systems are implicitly based on the assumption that any useful workflow must be fully bounded (where the bounds can be defined for different processes). Typically this is manifested by imposing upper bounds on the number of iterations, the number of steps, and other similar restrictions. It is also easy to instrument ServLog service processes so that they become fully bounded. For instance, primitive update tasks could be forced to diminish a global discrete and bounded resource. More importantly, the recent trend in logic programming is to avoid restricting the expressive power of programs by curtailing the usefulness of logical frameworks with restrictions, such as full boundedness. Instead, new approaches aim to develop tools for detecting non-terminating behavior and help the programmer correct the problem [23,31]. It is our contention that this is a more productive direction for Transaction Logic-based approaches than the restriction-based approaches. We should also note that some decidability results developed for other approaches carry over to ServLog – see the discussion of artifact systems [16] in Section 6.
Related work
ServLog builds on the service contracting framework that was partially developed in [39,40], greatly expanding and generalizing it, while at the same time simplifying the technical details. The major simplifications and extensions include:
Removing the unique task occurrence restriction and obviating the need for complex simplification transformations.
Tasks are no longer limited to propositional constants. This provides the ability to represent complex data flow among tasks as well as general transitional constraints.
General iterative and even mutually recursive tasks in the specification of service processes.
Generalization of the proof theory, which now deals with the many new additions to the language, and handles constrained (non-Horn) formulas, which previous CTR proof theory was not able to handle.
Proofs of soundness and completeness for the generalized proof theory.
The present paper significantly extends this proof theory to formulas that contain the ∧ connective thus enabling execution of constrained transactions, which are non-Horn. We also deal with a much larger class of constraints than [17,39], including iterative processes.
Declare [45] is a service flow language that is closely related to ServLog. It uses Linear Temporal Logic to formalize service flows and automata theory to enact service specifications. The relations between tasks are described entirely in terms of constraints. Apart from the obvious radical differences in the formalisms, some other important differences are worth noting. First, the constraint algebra of ServLog is more expressive than the one used in Declare. Second, by combining constraints with service processes (conditional control flow and data flow), ServLog incorporates current practices in workflow modeling. Third, data flow and conditional control flow are easily available in ServLog, while they have not been developed in the context of Declare. Declare was also formalized using Abductive Logic Programming in [34]. While this formalization supports different verification tasks, the focus remains on modeling service flow exclusively in terms of constraints and does not deal with control and data flow.
In [48 ,49] the authors propose a combination of colored Petri nets, Declare, and DCR graphs as a way of modeling procedural processes with data support. This combination can be seen as either “adding declarative control-flow to CP-nets” or as “adding data-flow to declarative formalisms.” From the modeling perspective, the approach requires the user to be familiar with three formalisms, as opposed to our framework where all aspects are represented within a single logical language. The authors do not provide a precise formalization of the combination of the three languages, so it is unclear how certain elements such as atomic transactions, hierarchical definitions of tasks, and constraints over complex tasks can be expressed in the combination of those three languages. From the analysis point of view, the authors address the problem of simulation: checking whether a transition is enabled in the CP-net model, and subsequently whether it is also allowed according to the declarative constraint. This is done using model checking. Our approach differs conceptually in that we rely on a logical proof theory as opposed to model checking.
In the same spirit of extending Declare with data elements, [33] extends the Declare notation by allowing activities to have associated multiple ports (denoting events associated to the activity lifecycle) and constraints to be attached to ports thereby allowing data-aware conditions. These extensions are then formalized in the Event Calculus (EC). In terms of modeling, the focus remains on modeling service flow exclusively in terms of constraints and this does not address the aforesaid limitations with respect to control and data flow (e.g., it is unclear how elements such as hierarchical definitions of tasks can be achieved with the proposed extensions). For reasoning, the paper defers to generic EC reasoners, which are significantly more complicated than those for CTR.
Another related approach to service modeling and verification is based on the business artifact model [16,19,29]. In this approach, tasks (which they call “services”) are represented as transformations on objects, called artifacts and they have pre- and post-conditions. In addition, various constraints can be specified using Linear Temporal Logic (like Declare) where first-order statements are allowed in place of propositions. In ServLog, artifact-based systems correspond to a very special form of service processes of the following form:
The artifacts are represented here via variables, but they can also be represented as data items passed around via the underlying database. While the control structure of artifact systems is a small subset of what ServLog services can have, the constraints used in those systems form a superset of the constraints in ServLog: they can be arbitrary LTL formulas. (It is not clear, however, whether this generality makes a difference in practice.) It is interesting to note that the decidability results from [19] carry over from artifact systems to the special case of the ServLog service processes described above and thus give us a decidable subset of Transaction Logic that is different from the one mentioned in Section 5.3.
An emerging area related to our work is that of compliance checking between business processes and business contracts. For example, in [25,26] both processes and contracts are represented in a formal language called FCL. FCL is based on a formalism for the representation of contrary-to-duty obligations, i.e., obligations that arise when other obligations are violated as typically happens with penalties embedded in contracts. Based on this, the authors give a semantic definition for compliance, but no practical algorithms. In contrast, ServLog provides a proof theory for verifying feasibility of service contracting as well as for contract execution.
Several other approaches to service contracting and contract execution are relevant to our work [2,3,5,14], but not directly related. Most of these present logical modeling languages for contracts in various settings. Being based on normative deontic notions of obligation, prohibition, and permission, we believe that these works are complementary to ours and the approaches could be combined.
Other popular tools for process modeling are based on Petri nets, process algebras, and temporal logic. A related area of research is data-centric business and service modeling and verification, for which a representative approach is [47]. Approaches in this area primarily combine databases and model checking techniques for the purpose of automated verification. The advantage of CTR over these approaches is that it is a unifying formalism that integrates a number of process modeling paradigms ranging from conditional control flows to data flows to hierarchical modeling to constraints, and even to game-theoretic aspects of multiagent processes (see, for example, [18]). Moreover, as shown in [17], CTR modeling sometimes leads to algorithms with better known complexity for special cases than general model checking.
Finally, it is worth mentioning our work in the context of general AI techniques on reasoning about actions. A key differentiation of our approach based on CTR is that, while many works in AI focus on reasoning about actions, CTR also has constructs for defining transactions and executing them. These issue and further comparison are discussed in detail in the original and follow-up papers [6,9–11,37].
Conclusions
The main contribution of this paper is ServLog, a unifying logical framework for semantics-aware services addressing two core aspects of services: modeling and contracting. In particular, this work adds a few new building blocks to the theoretical foundations for service contracting. It offers an expressive set of modeling primitives and addresses a wide variety of issues in service contracts. These primitives range from complex process description (including iteration and conditional transitions between tasks) to temporal and data constraints. Despite its expressive power, ServLog still provides a reasoning procedure for automated service contracting.
In the context of established business process languages (e.g., BPMN, WS-BPEL), ServLog not only captures typical procedural constructs found in such languages, but also greatly extends them, enables declarative specification and reasoning, and opens the way for automatic generation of business processes from service contracts. Furthermore, in the context of Semantic Web Services, ServLog complements established approaches such as OWL-S and WSMO, which primary focused on semantic annotations for Web services, and brings new directions for research in Semantic Web Services related to service contracts.
The approach presented in this paper has been implemented for the propositional case (when tasks do not have parameters) in the GEECoP (Graphical Editor and Engine for Constrained Processes)14
http://sourceforge.net/projects/gecop/.
tool with promising results (further described in [44]).
Future work may include support for reasoning about quality of service (QoS) and non-functional properties in service contracts – see, e.g., [15] for an example of a framework for QoS-based Web service contracting, which could be combined with ServLog, and a more complete implementation of the reasoning framework based on recent results on efficient implementation of Transaction Logic [21]. Another challenging issue is generation of service contracts in ServLog from informal, often ambiguous, natural language contracts. It would be also interesting to do a methodological comparison of the expressive power of ServLog with workflow specification languages based on automata, pre/post conditions, and temporal constraints. In this respect, the recent framework introduced in [1] for comparing distinct workflow models by means of views might be relevant. Explicitly treating violations and reasoning about the effects of violations in contracts is also an interesting direction for further research in ServLog. Service discovery is complementary to the problem of service contracting addressed by ServLog. Some approaches to semantic service discovery are based on Transaction Logic (e.g. [30]) and could be combined with ServLog. Such a combination would be yet another intriguing continuation for the present work. ServLog, as a logical framework for specification of and reasoning about service contracts, is orthogonal to implementation issues such as centralized or distributed provisioning of services. ServLog can be instantiated in different settings; for example, when different tasks are provisioned in a distributed or decentralized environment. Studying the implications of instantiating ServLog in different environments is interesting from a practical perspective. We are also investigating applicability of ServLog and CTR to other areas such as smart contracts15
See for example Bitcoin contracts at https://en.bitcoin.it/wiki/Contracts.
Here, ServLog could prove to be a useful approach for modeling and reasoning about distributed cryptocurrency contracts.17
For a relevant related idea, see [4], where the authors proposed timed automata for formalizing Bitcoin contracts.
Footnotes
Acknowledgements
We thank the anonymous referees for their valuable comments, which helped to improve this paper. Michael Kifer was partially supported by the NSF grant 0964196.
Soundness of the inference system
Completeness of the inference system
Representing constraints of ServLog as CTR formulas
This appendix provides direct definitions of the constraints introduced (Section 4.2) and the additional ones from Section 5.
The following CTR formulas are equivalent to the semantic definitions of the constraints in given in Sections 4.2 and 5. In the formulas below, we use to represent the set of variables appearing in ,18
Note that all underscores (unnamed placeholders) are replaced with new variables, e.g. .
The constraints in are now represented in CTR as follows:
References
1.
S.Abiteboul, P.Bourhis and V.Vianu, Comparing workflow specification languages: A matter of views, in: Database Theory – ICDT 2011, Proceedings of the 14th International Conference, Uppsala, Sweden, March 21–24, 2011, T.Milo, ed., ACM, pp. 78–89. doi:10.1145/1938551.1938564.
2.
M.Alberti, F.Chesani, M.Gavanelli, E.Lamma, P.Mello, M.Montali and P.Torroni, Expressing and verifying business contracts with abductive logic programming, in: Normative Multi-Agent Systems, 18.03–23.03.2007, G.Boella, L.W.N.van der Torre and H.Verhagen, eds, Dagstuhl Seminar Proceedings, Vol. 07122, Internationales Begegnungs- und Forschungszentrum für Informatik (IBFI), Schloss Dagstuhl, Germany, 2007, http://drops.dagstuhl.de/opus/volltexte/2007/901.
3.
J.Andersen, E.Elsborg, F.Henglein, J.G.Simonsen and C.Stefansen, Compositional specification of commercial contracts, International Journal on Software Tools for Technology Transfer8(6) (2006), 485–516. doi:10.1007/s10009-006-0010-1.
4.
M.Andrychowicz, S.Dziembowski, D.Malinowski and L.Mazurek, Modeling bitcoin contracts by timed automata, in: Formal Modeling and Analysis of Timed Systems – Proceedings of the 12th International Conference, FORMATS 2014, Florence, Italy, September 8–10, 2014, A.Legay and M.Bozga, eds, Lecture Notes in Computer Science, Vol. 8711, Springer, 2014, pp. 7–22. doi:10.1007/978-3-319-10512-3_2.
5.
S.Angelov and P.Grefen, B2B E-Contracting: A Survey of Existing Projects and Standards, Report I/RS/2003/119, Telematica Instituut, 2003.
6.
R.Basseda, M.Kifer and A.J.Bonner, Planning with transaction logic, in: Web Reasoning and Rule Systems – Proceedings of the 8th International Conference, RR 2014, Athens, Greece, September 15–17, 2014, R.Kontchakov and M.-L.Mugnier, eds, Lecture Notes in Computer Science, Vol. 8741, Springer, 2014, pp. 29–44. doi:10.1007/978-3-319-11113-1_3.
7.
M.Y.Becker and S.Nanz, A logic for state-modifying authorization policies, ACM Transactions on Information and System Security13(3) (2010), 20:1–20:28. doi:10.1145/1805974.1805976.
8.
A.J.Bonner, Workflow, transactions, and Datalog, in: Proceedings of the Eighteenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Philadelphia, PA, USA, May 31–June 2, 1999, V.Vianu and C.H.Papadimitriou, eds, ACM Press, 1999, pp. 294–305. doi:10.1145/303976.304005.
9.
A.J.Bonner and M.Kifer, An overview of transaction logic, Theoretical Computer Science133(2) (1994), 205–265. doi:10.1016/0304-3975(94)90190-2.
10.
A.J.Bonner and M.Kifer, Transaction Logic Programming (or A Logic of Declarative and Procedural Knowledge), Technical Report CSRI-323, University of Toronto, 1995. http://www.cs.sunysb.edu/kifer/TechReports/transaction-logic.pdf.
11.
A.J.Bonner and M.Kifer, Concurrency and communication in transaction logic, in: Logic Programing, Proceedings of the 1996 Joint International Conference and Syposium on Logic Programming, Bonn, Germany, September 2–6, 1996, M.J.Maher, ed., MIT Press, 1996, pp. 142–156.
12.
A.J.Bonner and M.Kifer, A logic for programming database transactions, in: Logics for Databases and Information Systems (the Book Grow Out of the Dagstuhl Seminar 9529: Role of Logics in Information Systems, 1995), J.Chomicki and G.Saake, eds, Kluwer, 1998, pp. 117–166.
13.
D.Calvanese and G.D.Giacomo, Foundations of data-aware process analysis: A database theory perspective, in: Proceedings of the 32nd ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, PODS 2013, New York, NY, USA, June 22–27, 2013, R.Hull and W.Fan, eds, ACM, 2013, pp. 1–12. doi:10.1145/2463664.2467796.
14.
S.Carpineti, G.Castagna, C.Laneve and L.Padovani, A formal account of contracts for web services, in: Web Services and Formal Methods, Third International Workshop, WS-FM 2006, Vienna, Austria, September 8–9, 2006, M.Bravetti, M.Núñez and G.Zavattaro, eds, Lecture Notes in Computer Science, Vol. 4184, Springer, 2006, pp. 148–162. doi:10.1007/11841197_10.
15.
M.Comuzzi and B.Pernici, A framework for qos-based web service contracting, ACM Transactions on the Web3(3) (2009), 10:1–10:52. doi:10.1145/1541822.1541825.
16.
E.Damaggio, A.Deutsch and V.Vianu, Artifact systems with data dependencies and arithmetic, ACM Transactions on Database Systems37(3) (2012), 22:1–22:36. doi:10.1145/2338626.2338628.
17.
H.Davulcu, M.Kifer, C.R.Ramakrishnan and I.V.Ramakrishnan, Logic based modeling and analysis of workflows, in: Proceedings of the Seventeenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Seattle, WA, USA, June 1–3, 1998, A.O.Mendelzon and J.Paredaens, eds, ACM Press, 1998, pp. 25–33. doi:10.1145/275487.275491.
18.
H.Davulcu, M.Kifer and I.V.Ramakrishnan, CTR-S: A logic for specifying contracts in semantic web services, in: Proceedings of the 13th International Conference on World Wide Web – Alternate Track Papers & Posters, WWW 2004, New York, NY, USA, May 17–20, 2004, S.I.Feldman, M.Uretsky, M.Najork and C.E.Wills, eds, ACM, 2004, pp. 144–153. doi:10.1145/1013367.1013391.
19.
A.Deutsch, R.Hull and V.Vianu, Automatic verification of database-centric systems, SIGMOD Record43(3) (2014), 5–17. doi:10.1145/2694428.2694430.
20.
D.Fensel and C.Bussler, The web service modeling framework WSMF, Electronic Commerce Research and Applications1(2) (2002), 113–137. doi:10.1016/S1567-4223(02)00015-7.
21.
P.Fodor and M.Kifer, Tabling for transaction logic, in: Proceedings of the 12th International ACM SIGPLAN Conference on Principles and Practice of Declarative Programming, Hagenberg, Austria, July 26–28, 2010, T.Kutsia, W.Schreiner and M.Fernández, eds, ACM, 2010, pp. 199–208. doi:10.1145/1836089.1836114.
22.
P.Fodor and M.Kifer, Transaction logic with defaults and argumentation theories, in: Technical Communications of the 27th International Conference on Logic Programming, ICLP, Lexington, KY, USA, July 6–10, 2011, J.P.Gallagher and M.Gelfond, eds, LIPIcs, Vol. 11, Schloss Dagstuhl – Leibniz-Zentrum fuer Informatik, 2011, pp. 162–174. doi:10.4230/LIPIcs.ICLP.2011.162.
23.
T.W.Frühwirth, A devil’s advocate against termination of direct recursion, in: Proceedings of the 17th International Symposium on Principles and Practice of Declarative Programming, Siena, Italy, July 14–16, 2015, M.Falaschi and E.Albert, eds, ACM, 2015, pp. 103–113. doi:10.1145/2790449.2790518.
24.
A.S.Gomes and J.J.Alferes, Extending transaction logic with external actions, Theory and Practice of Logic Programming13(4–5 online supplement) (2013). http://journals.cambridge.org/downloadsup.php?file=/tlp2013020.pdf.
25.
G.Governatori, Z.Milosevic, S.Sadiq and M.Orlowska, On compliance of business processes with business contracts, Technical report, University of Queensland, 2007. http://digilib.library.uq.edu.au/eserv/UQ:12216/isf.pdf.
26.
G.Governatori and S.Sadiq, The journey to business process compliance, in: Handbook of Research on BPM, IGI Global, 2008, pp. 426–454, http://espace.library.uq.edu.au/eserv/UQ:159187/main.pdf.
27.
M.Hepp, F.Leymann, J.Domingue, A.Wahler and D.Fensel, Semantic business process management: A vision towards using semantic web services for business process management, in: IEEE International Conference on e-Business Engineering (ICEBE 2005), 18–21 October 2005, F.C.M.Lau, H.LeiX.Meng and M.Wang, eds, IEEE Computer Society, Beijing, China, 2005, pp. 535–540. doi:10.1109/ICEBE.2005.110.
28.
M.Hepp and D.Roman, An ontology framework for semantic business process management, in: eOrganisation: Service-, Prozess-, Market-Engineering: 8. Internationale Tagung Wirtschaftsinformatik – Band 1, WI 2007, Karlsruhe, Germany, February 28–March 2, 2007, A.Oberweis, C.Weinhardt, H.Gimpel, A.Koschmider, V.Pankratius and B.Schnizler, eds, Universitaetsverlag, 2007, pp. 423–440, http://aisel.aisnet.org/wi2007/27.
29.
R.Hull, Artifact-centric business process models: Brief survey of research results and challenges, in: On the Move to Meaningful Internet Systems: OTM 2008, OTM 2008 Confederated International Conferences, CoopIS, DOA, GADA, IS, and ODBASE 2008, Proceedings, Part II, Monterrey, Mexico, November 9–14, 2008, R.Meersman and Z.Tari, eds, Lecture Notes in Computer Science, Vol. 5332, Springer, 2008, pp. 1152–1163. doi:10.1007/978-3-540-88873-4_17.
30.
M.Kifer, R.Lara, A.Polleres, C.Zhao, U.Keller, H.Lausen and D.Fensel, A logical framework for web service discovery, in: Proceedings of the ISWC 2004 Workshop on Semantic Web Services: Preparing to Meet the World of Business Applications, Hiroshima, Japan, November 8, 2004, D.Martin, R.Lara and T.Yamaguchi, eds, CEUR Workshop Proceedings, Vol. 119, CEUR-WS.org, 2004, http://ceur-ws.org/Vol-119/paper3.pdf.
31.
S.Liang and M.Kifer, A practical analysis of non-termination in large logic programs, Theory and Practice of Logic Programming13(4–5) (2013), 705–719. doi:10.1017/S1471068413000446.
32.
D.L.Martin, M.Paolucci, S.A.McIlraith, M.H.Burstein, D.V.McDermott, D.L.McGuinness, B.Parsia, T.R.Payne, M.Sabou, M.Solanki, N.Srinivasan and K.P.Sycara, Bringing semantics to web services: The OWL-S approach, in: Semantic Web Services and Web Process Composition, First International Workshop, SWSWPC 2004, San Diego, CA, USA, July 6, 2004, Revised Selected Papers, J.S.Cardoso and A.P.Sheth, eds, Lecture Notes in Computer Science, Vol. 3387, Springer, 2004, pp. 26–42. doi:10.1007/978-3-540-30581-1_4.
33.
M.Montali, F.Chesani, P.Mello and F.M.Maggi, Towards data-aware constraints in declare, in: Proceedings of the 28th Annual ACM Symposium on Applied Computing, SAC ’13, Coimbra, Portugal, March 18–22, 2013, S.Y.Shin and J.C.Maldonado, eds, ACM, Coimbra, Portugal, pp. 1391–1396. doi:10.1145/2480362.2480624.
34.
M.Montali, M.Pesic, W.M.P.van der Aalst, F.Chesani, P.Mello and S.Storari, Declarative specification and verification of service choreographiess, ACM Transactions on the Web4(1) (2010), 3:1–3:62. doi:10.1145/1658373.1658376.
35.
S.Newman, Building Microservices, O’Reilly Media, Inc., 2015.
36.
M.P.Papazoglou, Service-oriented computing: Concepts, characteristics and directions, in: 4th International Conference on Web Information Systems Engineering, WISE 2003, Rome, Italy, December 10–12, 2003, IEEE Computer Society, 2003, pp. 3–12. doi:10.1109/WISE.2003.1254461.
37.
M.Rezk and M.Kifer, Transaction logic with partially defined actions, J. Data Semantics1(2) (2012), 99–131. doi:10.1007/s13740-012-0007-8.
38.
D.Roman, U.Keller, H.Lausen, J.de Bruijn, R.Lara, M.Stollberg, A.Polleres, C.Feier, C.Bussler and D.Fensel, Web service modeling ontology, Applied Ontology1(1) (2005), 77–106, http://content.iospress.com/articles/applied-ontology/ao000008.
39.
D.Roman and M.Kifer, Reasoning about the behavior of semantic web services with concurrent transaction logic, in: Proceedings of the 33rd International Conference on Very Large Data Bases, University of Vienna, Austria, September 23–27, 2007, C.Koch, J.Gehrke, M.N.Garofalakis, D.Srivastava, K.Aberer, A.Deshpande, D.Florescu, C.Y.Chan, V.Ganti, C.-C.Kanne, W.Klas and E.J.Neuhold, eds, ACM, 2007, pp. 627–638, http://www.vldb.org/conf/2007/papers/research/p627-roman.pdf.
40.
D.Roman and M.Kifer, Semantic web service choreography: Contracting and enactment, in: The Semantic Web – ISWC 2008, Proceedings of the 7th International Semantic Web Conference, ISWC, Karlsruhe, Germany, October 26–30, 2008, A.P.Sheth, S.Staab, M.Dean, M.Paolucci, D.Maynard, T.W.Finin and K.Thirunarayan, eds, Lecture Notes in Computer Science, Vol. 5318, Springer, 2008, pp. 550–566. doi:10.1007/978-3-540-88564-1_35.
41.
D.Roman, J.Kopecký, T.Vitvar, J.Domingue and D.Fensel, WSMO-Lite and hRESTS: Lightweight semantic annotations for Web services and RESTful APIs, Journal of Web Semantics31 (2015), 39–58. doi:10.1016/j.websem.2014.11.006.
42.
P.Senkul, M.Kifer and I.H.Toroslu, A logical framework for scheduling workflows under resource allocation constraints, in: VLDB 2002, Proceedings of 28th International Conference on Very Large Data Bases, Hong Kong, China, August 20–23, 2002, Morgan Kaufmann, pp. 694–705, http://www.vldb.org/conf/2002/S20P01.pdf. doi:10.1016/B978-155860869-6/50067-6.
43.
J.C.Spohrer and W.M.Murphy, Service science, in: Encyclopedia of Operations Research and Management Science, S.I.Gass and M.C.Fu, eds, Springer US, 2013, pp. 1385–1392. doi:10.1007/978-1-4419-1153-7_1175.
44.
H.Staffler, A system for modeling and reasoning about constrained processes, Master’s thesis, Univeristy of Innsbruck, 2009.
45.
W.M.P.van der Aalst, M.Pesic and H.Schonenberg, Declarative workflows: Balancing between flexibility and support, Computer Science – Research and Development23(2) (2009), 99–113. doi:10.1007/s00450-009-0057-9.
46.
L.Vasiliu, S.Harand and E.Cimpian, The DIP project: Enabling systems & solutions for processing digital content with semantic web services, in: Knowledge-Based Media Analysis for Self-Adaptive and Agile Multi-Media, Proceedings of the European Workshop for the Integration of Knowledge, Semantics and Digital Media Technology, EWIMT 2004, London, UK, November 25–26, 2004, P.Hobson, E.Izquierdo, I.Kompatsiaris and N.E.O’Connor, eds, QMUL, 2004, pp. 25–26.
47.
V.Vianu, Automatic verification of database-driven systems: A new frontier, in: Database Theory – ICDT 2009, Proceedings of the 12th International Conference, St. Petersburg, Russia, March 23–25, 2009, R.Fagin, ed., ACM International Conference Proceeding Series, Vol. 361, ACM, 2009, pp. 1–13. doi:10.1145/1514894.1514896.
48.
M.Westergaard, CPN tools 4: Multi-formalism and extensibility, in: Application and Theory of Petri Nets and Concurrency – Proceedings of the 34th International Conference, PETRI NETS 2013, Milan, Italy, June 24–28, 2013, J.M.Colom and J.Desel, eds, Lecture Notes in Computer Science, Vol. 7927, Springer, 2013, pp. 400–409. doi:10.1007/978-3-642-38697-8_22.
49.
M.Westergaard and T.Slaats, Mixing paradigms for more comprehensible models, in: Business Process Management – Proceedings of the 11th International Conference, BPM 2013, Beijing, China, August 26–30, 2013, F.Daniel, J.Wang and B.Weber, eds, Lecture Notes in Computer Science, Vol. 8094, Springer, 2013, pp. 283–290. doi:10.1007/978-3-642-40176-3_24.


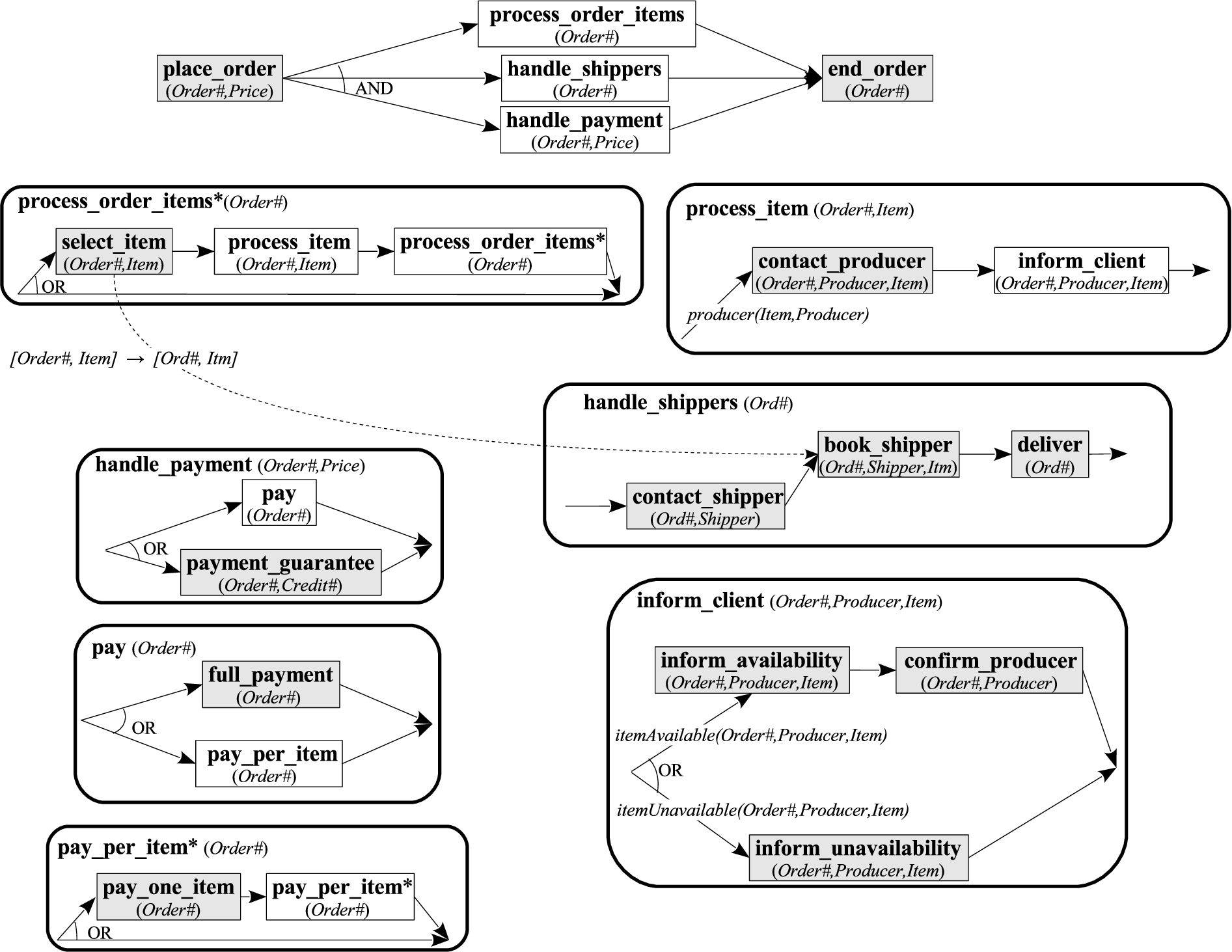




 : if task p executes then task q cannot execute in the future.
: if task p executes then task q cannot execute in the future. : task q must not execute between any pair of executions of p and r. Thus, if q executes after p, no future execution of r is possible.
: task q must not execute between any pair of executions of p and r. Thus, if q executes after p, no future execution of r is possible.
 – q must not execute between any two executions of p with the same arguments, and p must not execute between any two executions of q with the same arguments.
– q must not execute between any two executions of p with the same arguments, and p must not execute between any two executions of q with the same arguments.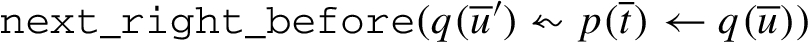 , plus a generalization of the constraint
, plus a generalization of the constraint  says that
says that  Note that
Note that 
 where
where 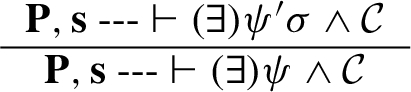 where
where  , where
, where  where
where  , add the following to
, add the following to 
 , where
, where 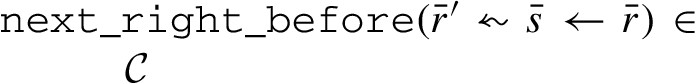 , add the following to
, add the following to  , add the following to
, add the following to 
 where
where  where
where