
Abstract
This paper introduces the LOD Laundromat meta-dataset, a continuously updated RDF meta-dataset that describes the documents crawled, cleaned and (re)published by the LOD Laundromat. This meta-dataset of over 110 million triples contains structural information for more than 650,000 documents (and growing). Dataset meta-data is often not provided alongside published data, it is incomplete or it is incomparable given the way they were generated. The LOD Laundromat meta-dataset provides a wide range of structural dataset properties, such as the number of triples in LOD Laundromat documents, the average degree in documents, and the distinct number of Blank Nodes, Literals and IRIs. This makes it a particularly useful dataset for data comparison and analytics, as well as for the global study of the Web of Data. This paper presents the dataset, its requirements, and its impact.
Introduction
In this paper we present the LOD Laundromat meta-dataset, a uniform collection of dataset meta-data that describes the structural properties of very many (over 650,000) Linked Data documents that together contain over 38 billion triples. These Linked Data documents range from large compressed data dumps and RDFa embedded in web pages, to dereferenceable URIs and SPARQL
Analyzing, comparing, and using multiple Linked Open Datasets currently is a hassle: finding download locations, hoping the downloaded data dumps are valid, and parsing the data in order to analyze or compare it based on some criteria. It is even more difficult to search for datasets based on characteristics that are relevant for machine-processing, such as syntactic conformance and structural properties such as the average outdegree of nodes. What is needed is a uniform representation of the dataset and a uniform representation of dataset descriptions.
The LOD Laundromat [5] realizes the first: it (re)publishes the largest (collection of) dataset(s) on the Web of Data (over 38 billion triples and counting). Every dataset is published in the same format that is fully conformant with Linked Open Data (LOD ) publication standards for machine-processability. The purpose of the LOD Laundromat is to drastically simplify the task of data preprocessing for the data consumer.
However, the creation of meta-data that uniformly describes the datasets is still left to the original data publisher. We see that many data publishers do not publish a dataset description that can be found by automated means, and that dataset descriptions that can be found do not always contain all (formally or de-facto) standardized meta-data. More importantly, the meta-data values are generally not comparable between datasets since different data publishers may interpret and calculate the same meta-data property differently. For instance, it is not generally the case that a dataset with a higher value for the
Therefore, in addition to the uniform dataset representations published by the LOD Laundromat, we need the same uniform representation for publishing dataset meta-data. Secondly, even straightforward meta-data should come with provenance annotations that describe how meta-data was generated. The LOD Laundromat meta-dataset presented here, brings exactly this: a collection of dataset descriptions, linked to the same canonical dataset representation, all modeled, created, and published in the same manner, and with provenance annotations that reflect how the meta-data was generated.
Section 2 gives an overview of comparable datasets. In Section 3 we identify shortcomings of existing meta-data standards and collections, and formulate a set of requirements for a dataset that allows large collections of datasets to be analyzed, compared, and used. Section 4 presents the meta-data we publish, the model that underlies it, dependencies on external (standard) vocabularies, a discussion in the context of the five stars of Linked Data Vocabulary use [12], and clarification of how the LOD Laundromat meta-dataset is generated and maintained. Section 5 shows the applications and use cases that the LOD Laundromat meta-dataset supports. We conclude with Section 6.
Similar datasets
SPARQL Endpoint Status1
LODStats [2] provides statistical information for all Linked Open Datasets that are published in the CKAN-powered2
Although Sindice and LODStats provide a step in the right direction by uniformly creating meta-data descriptions for many Linked Datasets, they 1) only support a subset of existing meta-data properties, they 2) do not publish exhaustive meta-data descriptions as Linked Data, and 3) they do not publish structural information on the meta-data generation procedure. Finally, they are limited to Linked Datasets that are published in only certain locations, web pages and Datahub, respectively.
In this section we present a requirements analysis for a dataset that satisfies our goal of supporting the meaningful analysis, comparison, and use, of very many datasets.
We explain problems with respect to meta-data specifications (Section 3.1), dataset descriptions (Section 3.2) and collections of dataset descriptions (Section 3.3). Based on these considerations, the requirements are presented in Section 3.4.
Meta-data specifications
Existing dataset vocabularies include VoID [1], VoID-ext [14], DCAT,4
See
VoID-ext extends the set of meta-data properties that are found in VoID as well. It includes the in- and outdegree of entities, the number of blank nodes, the average string length of literals, and a partitioning of the literals and URIs based on string length. The Data Catalog Vocabulary (DCAT) is a vocabulary for describing datasets on a higher level; i.e., it includes properties such as the dataset title, description and publishing/modification date. Such information is difficult to reliably extract from the dataset in an automated fashion.
We observe the following problems with these existing meta-data specifications:
Firstly, some existing meta-data properties are subjective. For example,
Secondly, some existing meta-data properties are defined in terms of undefined concepts. For example, LODStats specifies the set of vocabularies that are reused by a given dataset. The notion of a ‘reused vocabulary’ is itself not formally defined but depends on heuristics about whether or not an IRI belongs to another dataset. LODStats calculates this set by using relatively simple string operations according to which IRIs of the form
We observe the following problems with existing dataset descriptions: Firstly, uptake of dataset descriptions that can be found by automated means is still quite low (Section 2). Secondly, for reasons discussed above, the values of meta-data properties that do not have a well-founded definition cannot be meaningfully compared across datasets. For instance, if two dataset descriptions contain different values for the
See
Similar discrepancies exist between meta-data values that occur in different dataset description collections, e.g. between LODStats and the LOD Laundromat meta-dataset.7
E.g., according to LODStats the dataset located at http://www.open-biomed.org.uk/open-biomed-data/bdgp-images-all-20110211.tar.gz contains 1,080,060 triples while the LOD Laundromat meta-dataset states 1,070,072.
Since it is difficult to assess whether a computational procedure that generates meta-data is correct, we believe it is necessary that all generated meta-data is annotated with provenance information that describes the used computational procedure. Although relatively verbose, this approach circumvents the arduous discussion of which version of what tool is correct/incorrect for calculating a given meta-data value. We assume that there will always be multiple values for the same meta-data property. The fact that there are different values, and that these have been derived by different means, is something that has to be made transparent to the consumer of this meta-data. The onus is on the data consumer to trust one computational procedure for calculating a specific meta-data value more than another. This requires provenance that details the mechanism behind the calculated meta-data.
We observe two problems with existing collections of dataset descriptions: Firstly, even though the meta-data may be calculated consistently within a collection, the computational procedure that is used is not described in a machine-processable format (if at all). This means that values can only be compared within the collection, but not with dataset descriptions external to the collection (e.g. occurring in other collections). Secondly, meta-data that is calculated within existing collections is not always published in a machine-interpretable format (e.g. LODStats).
Requirements
Based on the above considerations, we formulate the following requirements which allow multiple datasets to be meaningfully compared based on their meta-data:
The LOD Laundromat meta-dataset must cover very many datasets in order to improve data comparability. The meta-dataset should reuse official and de-facto meta-data standards as much as possible, in order to be compatible with other dataset descriptions and to promote reuse. The meta-dataset must be generated algorithmically in order to assure that values are calculated in the same way for every described dataset. Only those meta-data properties must be used that can be calculated efficiently, because datasets can have peculiar properties that may not have been anticipated when the meta-data properties were first defined. The LOD Laundromat meta-dataset must contain provenance annotations that explain how and when the meta-data was calculated. The meta-data must be disseminated as LOD and must be accessible via a SPARQL endpoint. The LOD Laundromat meta-dataset must be able to support a wide range of real-world use cases that involve analyzing and/or comparing datasets such as Big Data algorithms that process LOD.
The LOD Laundromat meta-dataset
In this section we present the meta-data we publish, the model we use, and how we generate this dataset.
Published meta-data
The LOD Laundromat meta-dataset is generated in adherence to the requirements formulated in Section 3. Since there are multiple ways in which these requirements can be prioritized and made concrete, we will now discuss the considerations that have guided the generation of the meta-data.
Firstly, there is a trade-off between requirements 2 and 3: since the meta-dataset has to be constructed algorithmically, only well-defined meta-data properties can be included.
Secondly, there is a conflict between requirements 1 and 4 on the one hand, and requirement 2 on the other: since the LOD Laundromat meta-dataset must describe many datasets, some of which are relatively large, and we want calculations to be efficient, we chose to narrow down the set of meta-data properties to those that can be calculated by streaming the described datasets. This excludes properties that require loading (large parts of) a dataset into memory, e.g. in order to perform joins on triples.
An overview of dataset meta-data properties, grouped by the vocabularies that define them and dataset description collections that include them. For brevity’s sake, properties whose values are dataset partitions and properties that require manual intervention are excluded
An overview of dataset meta-data properties, grouped by the vocabularies that define them and dataset description collections that include them. For brevity’s sake, properties whose values are dataset partitions and properties that require manual intervention are excluded
Thirdly, because of the scale at which the LOD Laundromat meta-dataset describes datasets, it is inevitable that some datasets will have a-typical properties. This includes datasets with extremely long literals, datasets where the number of unique predicate terms is close to the total number of predicate terms, or datasets where the number of unique literal datatype equals the total number of literals. It is only when meta-data is systematically generated on a large scale, that one finds such corner cases. These corner cases can make dataset descriptions impractically large. This is especially true for meta-data properties that consist of enumerations. For instance, for some datasets the partition of all properties – as defined by VoID-ext and Bio2RDF – is only (roughly) a factor 3 smaller than the described dataset itself (and this is only one meta-data property). Or, take as example the
Under these restrictions, the meta-dataset is able to include a large number of datasets while still being relatively efficient to construct. Implementation-wise, the generation of the meta-dataset takes into account the many advantages that come from the way in which LOD Laundromat (re)publishes datasets. LOD Laundromat allows datasets to be opened as gzip-compressed streams of lexicographically sorted N-Triples and N-Quads. Since these streams are guaranteed to contain no syntax error nor any duplicate occurrences of triples, they can be processed on a line-by-line/triple-by-triple basis, making it convenient to generate meta-data for inclusion in the LOD Laundromat meta-dataset.
Table 1 gives an overview of the meta-data properties included in the LOD Laundromat meta-dataset, together with those that are included in existing dataset description standards. As can be seen from the table, the only meta-data properties that are excluded from our dataset (because of computational issues) are the distinct number of classes that occur in either the subject, predicate, or object position, as specified in VoID-ext. These three meta-data properties cannot be calculated by streaming the data a single time. In addition, all meta-data properties whose values must be represented as partitions are excluded in order to preserve brevity for all dataset descriptions, and to maintain scalability. Considering these limitations, the meta-data properties presented in Bio2RDF are similar to those in VoID and VoID-ext. Therefore, Bio2RDF is not referenced in our vocabulary. The generation of several statistics (e.g. the distinct number of URIs) requires in-memory lists. To reduce this memory consumption, we use an efficient in-memory dictionary (RDF Vault [3]).
Since we want the LOD Laundromat meta-dataset to be maximally useful for a wide range of use cases (requirement 7), we have added several meta-data properties that do not occur in existing specifications:
Next to the number of distinct IRIs, blank nodes and literals (i.e., types), we also include the number of (possibly non-distinct) occurrences (i.e., tokens).
Existing vocabularies specify the number of properties and classes (although they do so incorrectly, see Section 3). The meta-dataset also includes the number of classes and properties that are defined in a dataset, such as
Existing dataset description vocabularies such as VoID-ext use arithmetic means to describe number series such as the literal lengths in given document. The LOD Laundromat meta-dataset uses more detailed descriptive statistics, that include the median, minimum, maximum and standard deviation values as well.
Similar statistics are provided for network characteristics such as Degree, In Degree and Out Degree.
Considering that only 0.5% of the datasets publish a corresponding dataset license via RDF, we exclude this information for now. We expect these dataset licenses to increase in use and popularity though, and will include this meta-data in a future crawl.

Average out degree distribution of LOD Laundromat documents.
Online LOD Laundromat Resources
Figure 1 illustrates one of the published meta-data properties: the average out degree of datasets. The figure illustrates our previous remark that analyzing many datasets will inevitably include datasets with a-typical properties or ‘corner cases’. For instance, the dataset with the highest average out degree, contains 10,004 triples, and only one subject, thereby strongly skewing the dataset distribution. Such a-typical properties of datasets are potentially important as e.g. a means of explaining deviating evaluation results between datasets. Note that generating the data behind this figure requires the following SPARQL query, illustrating the ease of use:
Besides publishing the meta-data, and in line with requirement 5, the meta-dataset contains a provenance trail of how the meta-data was generated. The provenance trail includes a reference to the code that was used to generate the meta-data. For this we use a Git commit identifier in order to uniquely identify the exact version that was used. The provenance trail also includes all the steps that preceded the calculation of the meta-data:
Where the file was downloaded (either the original URL or the archive that contained the file).
When the file was downloaded (date and time).
Meta-data on the download process, such as the status code and headers from the original HTTP reply. For archived data the applied compression techniques (possibly multiple ones) are enumerated as well.
Detailed meta-data on the data preparation tasks performed by the LOD Laundromat in order to clean the data. This includes the number of bytes that were read (not necessarily the same as the value for
The number of duplicate triples in the original dataset.
A reference to the online location where the cleaned file is stored, and from which the meta-data is derived.
The meta-data is specified in the LOD Laundromat meta-dataset (see Table 2). Of the 26 meta-data properties that are included, 22 are linked to one or more other dataset description vocabularies. Figure 2 shows the dependencies between our meta-dataset vocabulary and other vocabularies. The referenced dataset description vocabularies are VoID and VoID-ext. Figure 38
For brevity, figures in tables in this paper do not contain the following LOD Laundromat namespaces:
For brevity, only a subset of the available meta-data properties are included in this figure.
See

Dependencies of LOD Laundromat meta-dataset vocabulary.

Example (partial) dataset meta-data description, color-coded using vocabularies from Fig. 2.
The provenance information of datasets is described using the PROV-O vocabulary [15], a W3C recommendation. Figure 4 presents an overview on how PROV-O is used by the LOD Laundromat meta-dataset. Similar vocabularies exist, such as the VoiDp [16] vocabulary which matches the provenance of Linked Datasets with the VoID vocabulary. However, because VoiDp uses a predecessor of the PROV-O standard, we model our provenance in PROV-O directly. The Provenance Vocabulary [9] aims to describe the provenance of Linked Datasets as well, but is too specific for our use considering the wide range of provenance (see below) we describe.
As the LOD Laundromat cleaning process is part of the provenance trail, we model this part of the dataset using separate vocabularies: Firstly, the LOD Laundromat vocabulary (see Table 2) describes the crawling and cleaning process of LOD Laundromat. This description includes the download time and date of the original document, and therefore specifies which version of the original document is described by the meta-dataset. Secondly, the HTTP vocabulary (see Table 2) describes HTTP status codes. Thirdly, the error ontology (see Table 2) models all exceptions and warnings, and is used by the LOD Laundromat vocabulary to represent errors that occur during the crawling and cleaning process. Each of these vocabularies are linked to other vocabularies. For instance, the HTTP vocabulary is an extension of the W3C HTTP in RDF vocabulary.12
See
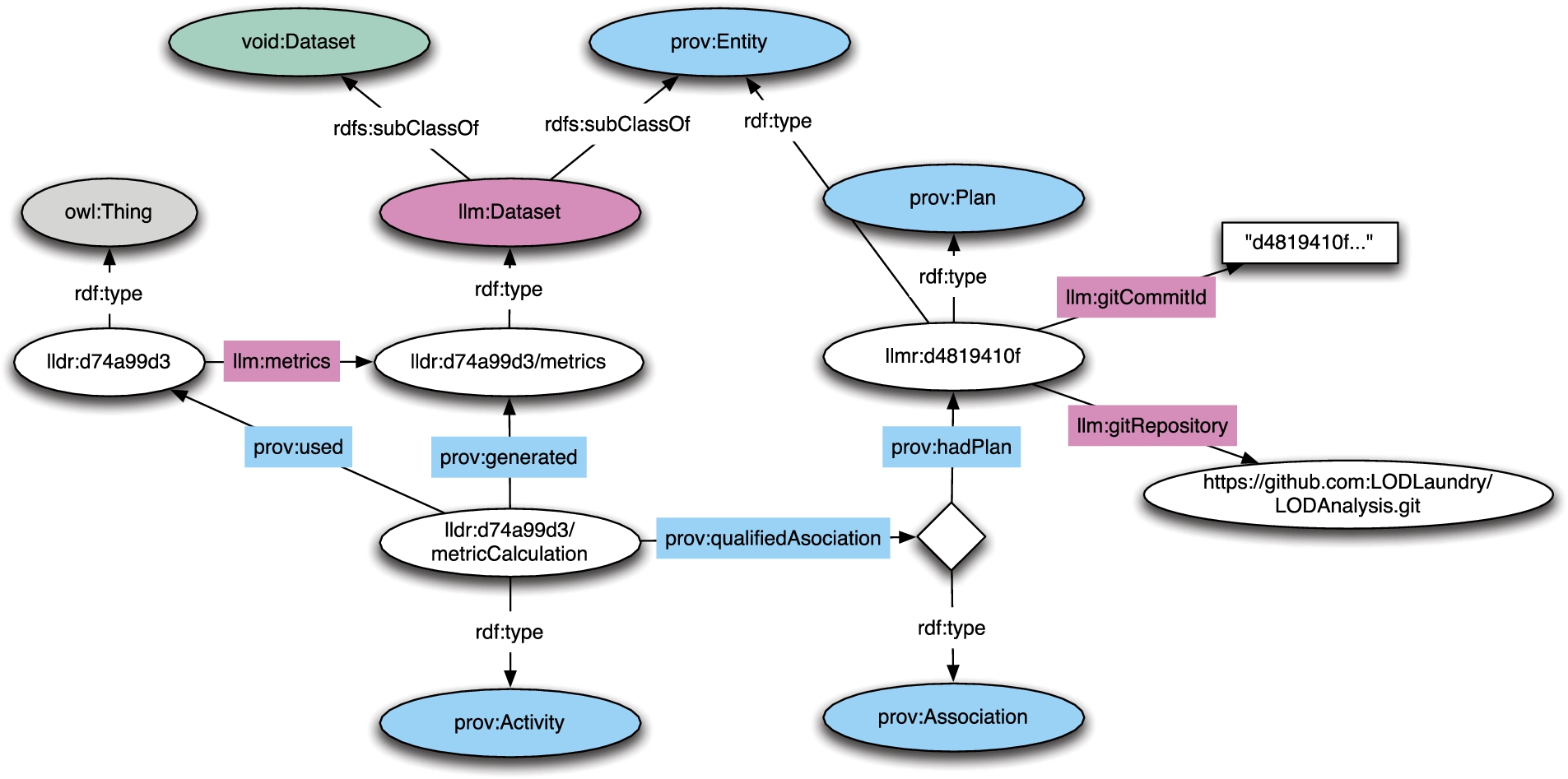
Provenance model illustration.
The LOD Laundromat meta-dataset uses the following naming scheme. As a running example, we take a Semantic Web Dog Food file that is crawled by LOD Laundromat.13
The LOD Laundromat document identifier for this dataset is generated by appending an MD5 hash of the data source IRI to http://lodlaundromat.org/resource/.14
The calculated structural properties of this dataset are accessible by appending
Provenance that describes the procedure behind the metrics calculation is accessible by appending
<
<
<
All the online resources related to the LOD Laundromat are shown in Table 2. The LOD Laundromat [5] continuously crawls and analyses Linked Data dumps. In order to get a maximum coverage of the LOD Cloud, it searches both linked data catalogs and the LOD Laundromat datasets themselves for references to datadumps. Because it does not claim to have a complete seed list that links to all LOD in the world, users have the option to manually or algorithmically add seed-points to the LOD Laundry Basket (see Table 2).
The code used to generate the LOD Laundromat meta-dataset runs immediately after a document is crawled and cleaned by the LOD Laundromat, and is published via a public SPARQL endpoint (see Table 2). The time it takes between a LOD Laundromat crawl and a published document with corresponding meta-data depends on the original serialization format, the size of the dataset, the number of errors encountered during the cleaning phase, and other idiosyncrasies a dataset might have such as only one subject for thousands of triples. The crawling and cleaning phase processes on average 460,000 triples per second, and the meta-data application is able to stream and analyze 400,000 triples per second (both on a server with 5TB SSD disk space, 32-core CPU, and 256GB of memory). Considering the costs for downloading the original document files, and a latency (with a maximum of 10 minutes) between the cleaning and meta-data generation, most datasets and the corresponding meta-data are public 15 minutes after the crawl began.
SPARQL is preferred over HDT as publishing method for the meta-data, because HDT files are static and do not support updates. In line with requirement 6, a nightly version of the meta-dataset is copied from the meta-data SPARQL endpoint and published as data dump in the same standardized N-Quad serialization format of the LOD Laundromat.
Considering some meta-data is too verbose and expensive to host as RDF, we publish non-RDF data as well. Specifically, we publish the mapping between all the IRIs and namespaces to the corresponding LOD Laundromat documents these occur in. We provide access to this meta-data via a custom RESTful API (see Table 2).
Statistics and use
This section briefly describes some of the characteristics of the dataset, and gives an indication as to how it is being used.
Dataset characteristics
As mentioned before, the LOD Laundromat crawled and re-publishes over 650,000 documents containing over 38,000,000 triples. The meta-data of these crawled documents are published in the LOD Laundromat meta-dataset, that now contains over 110 million triples, accessible via a data dump and SPARQL endpoint.
Figure 5 shows the top 10 most frequently instantiated classes. It shows that the descriptive statistics class is used frequently, which is not surprising considering that each dataset has several descriptive statistics blank-nodes to describe e.g. in degree, out degree, and IRI/literal lengths. Other frequent classes are related to provenance. This is not a surprise either, considering the extensive provenance model that the LOD Laundromat uses (see Fig. 4).
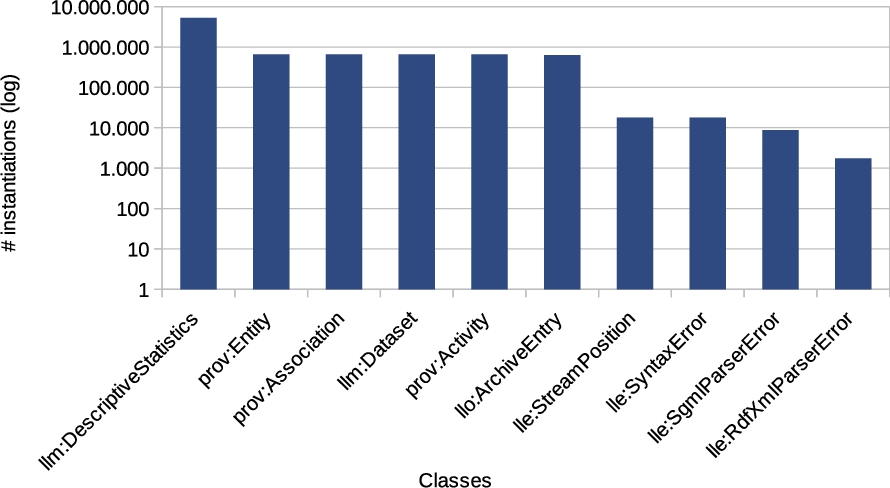
Top 10 class instances.
Figure 6 shows the top 10 most frequently occurring predicates in the dataset. These statistics show a similar pattern as the class instance frequency: properties related to descriptive statistics and provenance appear frequently.

Top 10 most frequently occurring properties.
Since the release of LOD Laundromat in September 2014 and the release of the meta-dataset in January 2015, we registered a total of 8,158 unique visitors to the LOD Laundromat website, of which 23.6% of the requests originated in the United States, and 19.2% of the requests originated from The Netherlands (see Fig. 7).

Geo-Location visitors
The SPARQL endpoint receives the following four types of SPARQL requests.
Queries executed while browsing the LOD Laundromat website. These queries can vary in length, depending on the user interaction with the website. Queries executed by the Queries executed by others via custom scripts (e.g. python, bash, java)
Frequency of predicates in SPARQL query logs. Queries that are manually written and executed via the public LOD Laundromat SPARQL graphical user interface, or via interfaces such as
Distinguishing these types of interactions with the SPARQL endpoint is not trivial: request headers are insufficient to separate these categories, and query features (e.g. number of triple patterns or projection variables) are difficult to translate to different types of SPARQL requests [18,20,21]. We do expect a large part of the logged SPARQL queries to come from the 
The number of unique IPs may not correspond to the actual number of unique users, as a single IP can be shared by employees of the same institute or company, or the same user may access the endpoint from different machines.
The index API that exposes the mappings between IRIs/Namespaces and documents, received 56,727 requests, coming from 124 unique IPs. Of these requests, 445 used the namespace-to-document index, where the remaining 56,282 used the resource-to-document index.
The server registered 5,640,331 downloads, coming from 881 IPs. The unique number of downloads is 649,908, which equals the number of available LOD Laundromat documents.
These server logs show that a relatively small number of IPs (less than 3,000) are responsible for millions of requests. In the next section we present three use cases and applications that can (at least partly) account for this large amount of use.
The LOD Laundromat meta-dataset is intended to support a wide array of non-trivial use cases. The first use case we present is the evaluation of Semantic Web (SW) algorithms. In contemporary SW research novel algorithms are usually evaluated against only a handful of – often the same – datasets (i.e., mainly DBpedia, Freebase, and Billion Triple Challenge). The risk of this practice is that – over time – SW algorithms will be optimized for datasets with specific distributions, but not for others. In [19], we re-evaluate parts of three SW research papers using
Similarly to evaluating SW algorithms, the LOD Laundromat meta-dataset can also be used to tune Linked Data applications or prune datasets with the desired property at an early stage, i.e., without having to load and interpret them. An example of this is PrefLabel,18
Another use case involves using the LOD Laundromat meta-dataset to analyze and compare datasets, e.g., in order to create an overview of the state of the LOD Cloud at a given moment in time. A common approach (see e.g. [10,13,22]) is to crawl Linked Data via dereferenceable URIs using tools such as LDspider [11], and/or to use catalogs such as datahub to discover the Linked Datasets. Both dereferenceable URIs and dataset catalogs come with limitations: most Linked Data URIs are not dereferenceable, and the dataset catalogs only cover a subset of the LOD Cloud. The LOD Laundromat on the other hand provides access to more than dereferenceable URIs only, and aims to provide a complete as possible dataset collection. The corresponding meta-dataset provides a starting point for e.g. finding datasets by Top Level Domain, serialization format, or structural properties such as number of triples. In [19] we re-evaluate (part of) exactly such a Linked Data Observatory paper [22], where we use the meta-dataset and LOD Laundromat to find the documents and extract namespace statistics.
Next to the structural meta-data properties, the provenance meta-data provides an interesting data source as well. Such provenance enables e.g. an analysis of common RDF serialization formats, as shown in Fig. 9. The following SPARQL query fetches the serialization information used by this figure:
The provenance information can be used to measure publishing best practices as well, such as whether the content length specified by the HTTP response matches the actual content length of the file. This is visualized in Fig. 10, which uses the following SPARQL query to fetch the data:

Serialization formats.

Invalid HTTP Content Lengths.
The dataset presented in this paper offers access to a large set of uniformly represented datasets descriptions, acting as an enabler for large scale Linked Data research: finding or comparing linked datasets with certain structural properties is now as easy as executing a SPARQL query. And even better: because the dataset descriptions are linked to their uniform dataset representations, the access to the underlying data is extremely easy as well.
We are exploring the possibilities of storing snapshots of both the meta-dataset and the corresponding cleaned datasets, effectively creating snapshots of the state of the LOD Cloud. At this point, we consider this future work though.
Another future improvement we consider is to publish partitions of the datasets via more scalable and efficient ways than SPARQL. As explained in Section 4, corner-cases in the LOD cloud can drastically increase the corresponding meta-data. Therefore, an efficient and scalable method is required for hosting such partitions. We consider publishing a selection of such partitions using non-SPARQL APIs with a stronger focus on scalability and efficiency.
Footnotes
Acknowledgements
This work was supported by the Dutch national program COMMIT.