
Abstract
One of the current challenges in ontology alignment is the user involvement in the alignment process. To obtain high-quality alignments user involvement is needed for validation of matching results as well as in the mapping generation process. Further, there is a need for supporting the user in tasks such as matcher selection, combination and tuning.
In this paper we introduce a conceptual ontology alignment framework that enables user involvement in a natural way. This is achieved by introducing different kinds of interruptible sessions. The framework allows partial computations for generating mapping suggestions, partial validations of mapping suggestions, recommendations for alignment strategies as well as the use of validation decisions in the (re-)computation of mapping suggestions and the recommendations. Further, we show the feasibility of the approach by implementing a session-based version of an existing system. We also show through experiments the advantages of our approach for ontology alignment as well as for evaluation of ontology alignment strategies.
Introduction
In recent years many ontologies have been developed and many of those contain overlapping information. Often we want to use multiple ontologies. For instance, companies may want to use community standard ontologies and use them together with company-specific ontologies. Applications may need to use ontologies from different areas or from different views on one area. In each of these cases it is important to know the relationships between the concepts (and relations) in the different ontologies. Further, the data in different data sources in the same domain may have been annotated with different but similar ontologies. Knowledge of the inter-ontology relationships would in this case lead to improvements in search, integration and analysis of data. It has been realized that this is a major issue and much research has recently been done on ontology alignment, i.e., finding mappings between concepts and relations in different ontologies (e.g., [11]). The research field of ontology alignment is very active with its own yearly workshop as well as a yearly event, the Ontology Alignment Evaluation Initiative (OAEI, e.g., [10]), that focuses on evaluating systems that automatically generate mapping suggestions. Many systems have been built and overviews can be found in e.g., [11,23,31,40,47,48] and at the ontology matching web site
One of the current challenges in ontology alignment is the user involvement in the alignment process [20,48]. Based on OAEI experience it is clear that there is a need for support for matcher selection, combination and tuning. There is also a need for user involvement in the matching process. First, the user could be involved during the mapping generation. Introducing domain expert knowledge already in the generation phase could significantly improve the matching results and is essential for use cases requiring very accurate mappings [22]. Further, as stated by the OAEI organizers [10], automatic generation of mappings is only a first step towards a final alignment and a validation by a domain expert is needed to obtain high-quality alignments.
In this paper we introduce a conceptual ontology alignment framework that enables user involvement in a natural way (Section 3). Existing frameworks for ontology alignment systems (e.g., [9,32]) describe different components and steps in the ontology alignment process such as preprocessing, matching, filtering and combining match results. The user involvement in these frameworks usually relates to the validation of the mapping suggestions generated by the ontology alignment system. In this paper we introduce a, for the ontology alignment community, novel framework based on interruptible sessions: computation, validation and recommendation sessions. It is the first framework that allows partial computations for generating mapping suggestions, thereby reducing the waiting time for domain experts. Currently, to our knowledge, no system allows to start validating mapping suggestions before every suggestion is computed. It also is the first framework that allows a domain expert to validate a sub-set of the mapping suggestions, and continue later on, thereby allowing the interleaving of computation and validation. Further, it supports the use of validation results in the (re)computation of mapping suggestions and the recommendation of alignment strategies to use, thereby introducing the domain expert’s knowledge in the mapping generation and recommendation processes. The framework also introduces recommendation sessions that generate recommendations for matcher selection, combination and tuning.
Further, we show the feasibility of the session-based framework by implementing a session-based version of an existing ontology alignment system (Section 4). We note that we are not aiming to build the ‘best’ possible ontology alignment system, but we want to reuse as many components as possible from an existing system (in this case SAMBO [32]), thereby showing the feasibility of extending existing systems to fit the session-based approach.2
For instance, we use the matchers from SAMBO as of 2006. The best SAMBO strategy regarding f-measure was still better than the best system at OAEI Anatomy 2009 and earlier, but in 2010 AgreementMaker implemented a strategy with f-measure 0.877. In 2014 and 2015, AML reached an f-measure of 0.944.
We also provide several experiments (Section 5). The experiments relate to some of the main features of the session-based approach (interruptible sessions, use of validation decisions from previous validation sessions, and recommendation sessions). All experiments show the advantages of using a session-based system as compared to a ‘traditional’ approach for ontology alignment. We point to alignment quality improvements based on the new functionality that the session-based approach enables in terms of performance of computation of similarity values, filtering and recommendation. Some of the experiments additionally show how a session-based system can be used for evaluating strategies (partial alignment-based algorithms and recommendation algorithms) that could not or not easily be evaluated before.
In Section 6 we discuss related work and Section 7 concludes the paper. First, however, we introduce some background in Section 2.
In general, from a knowledge representation point of view, ontologies may contain concepts, relations, axioms and instances. Concepts and relations are often organized in hierarchies using the is-a (or subsumption) relation, denoted by ⊑. The task of ontology alignment is to create an alignment between ontologies. An alignment is a set of mappings (also called correspondences) between entities from the different ontologies. The most common kinds of mappings are equivalence mappings (≡) as well as mappings using is-a and its inverse (⊑, ⊒). For instance, for concepts A from the first ontology and
Ontology alignment framework
A large number of ontology alignment systems have been developed. Many of these are based on the computation of similarity values between entities in different ontologies and can be described as instantiations of the general framework in Fig. 1. The framework consists of two parts. The first part (I in Fig. 1) computes mapping suggestions. The second part (II) interacts with the user to decide on the final alignment.
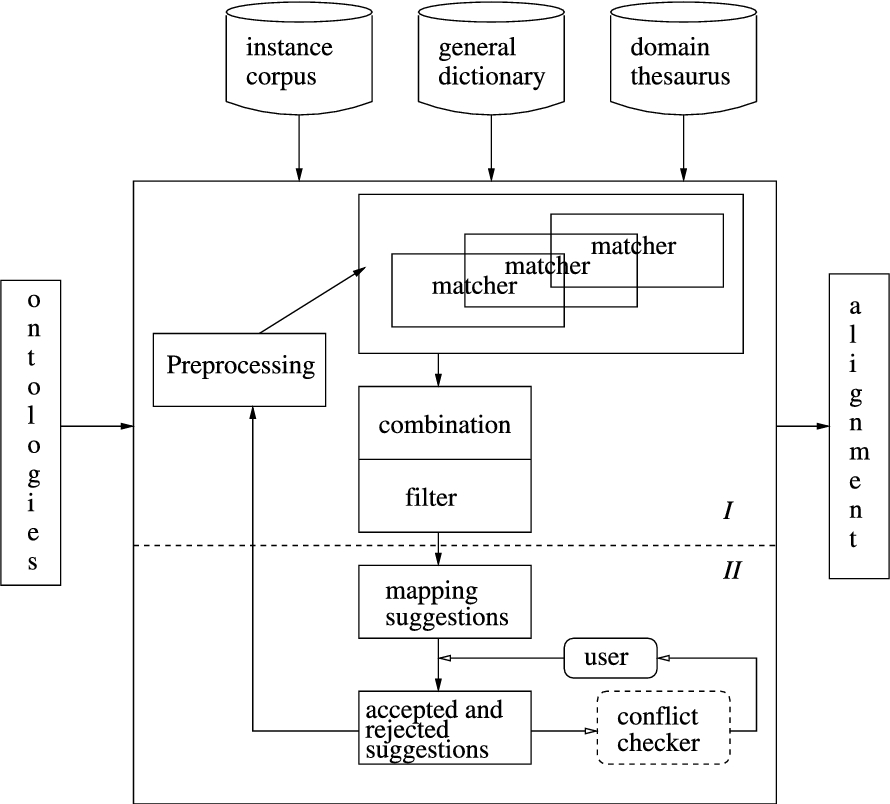
An existing framework (extension of the framework in [32]).
An alignment algorithm receives as input two source ontologies. Part I typically contains different components. A preprocessing component can be used to modify the original ontologies, e.g., to extract specific features of the concepts in the ontologies, or to partition the ontologies into mappable parts thereby reducing the search space for finding mapping suggestions. The algorithm can include several matchers that calculate similarities between the entities from the different source ontologies or mappable parts of the ontologies. They often implement strategies based on linguistic matching, structure-based strategies, constraint-based approaches, instance-based strategies, strategies that use auxiliary information or a combination of these. Each matcher utilizes knowledge from one or multiple sources. Mapping suggestions are then determined by combining and filtering the results generated by one or more matchers. Common combination strategies are the weighted-sum and the maximum-based strategies. The most common filtering strategy is the (single) threshold filtering. By using different preprocessing, matching, combining and filtering techniques, we obtain different alignment strategies. The result of part I is a set of mapping suggestions.3
Traditionally, in the OAEI it is this result (and thus part I) that is evaluated. In 2013, for the first time there was a track for evaluating interaction and thus also some issues related to part II.
In part II the mapping suggestions are then presented to the user, a domain expert, who accepts or rejects them. The accepted mapping suggestions are part of the final alignment. Any sub-set of the final alignment is a partial alignment (PA). The acceptance and rejection of suggestions may also influence further suggestions. Further, a conflict checker could be used to avoid conflicts introduced by the mapping suggestions.4
During the recent years some systems allow not only for conflict checking but also for repairing of mappings or mapping suggestions, e.g., [19,22,36,38,42].
There can be several iterations of parts I and II. The output of the alignment algorithm is a set of mappings between entities from the source ontologies. All systems implement part I while some also implement part II and allow iterations.
In Section 3 we propose a framework that includes the existing framework in some of its components.
In the implemented system (Section 4) we use algorithms that require some new notions. We define these in this section.
Partitioning using a consistent group
Given a set of equivalence mappings M between two ontologies, a consistent group is a sub-set of M such that each concept occurs at most once as first argument in a mapping in M, at most once as second argument in a mapping in M and for each pair of mappings
As an example, consider the two ontologies in Fig. 2 where the nodes represent concepts and the edges inverses of is-a relations (e.g., the concept represented by node 2 is a sub-concept of the concept represented by node 1). Assume we have a PA that contains
Given a set of equivalence mappings M between two ontologies, finding a consistent group is easy. Finding a maximal consistent group, i.e., a consistent group for which no proper superset is a consistent group, is an expensive operation. Therefore, in our implementations we use a genetic algorithm that guarantees to find a consistent group, but although we usually find large consistent groups, they may not always be maximal [3].

Ontologies.
A consistent group respects the is-a hierarchy in the two ontologies and can be used to partition the two ontologies such that each element (which is a set of concepts) in the partition of the first ontology has a corresponding element (which is a set of concepts) in the partition of the second ontology and only mappings between concepts in corresponding elements respect the structure of the ontologies. This can be done as follows. A mapping
As an example, consider the ontologies in Fig. 2 and the consistent group {
The intuition behind a segment of an ontology is that it represents a piece of the ontology. Formally, we define a segment of an ontology as a set of concepts in the ontology (usually a proper sub-set of the set of concepts in the ontology). In several of the implemented recommendation algorithms (Section 4.4) we require full knowledge about the mappings between segments from different ontologies (segment pairs). In [51] different strategies for generating segment pairs are described (e.g., based on sub-graphs of the ontologies or using clustering algorithms).
Alignment framework

Partitions.
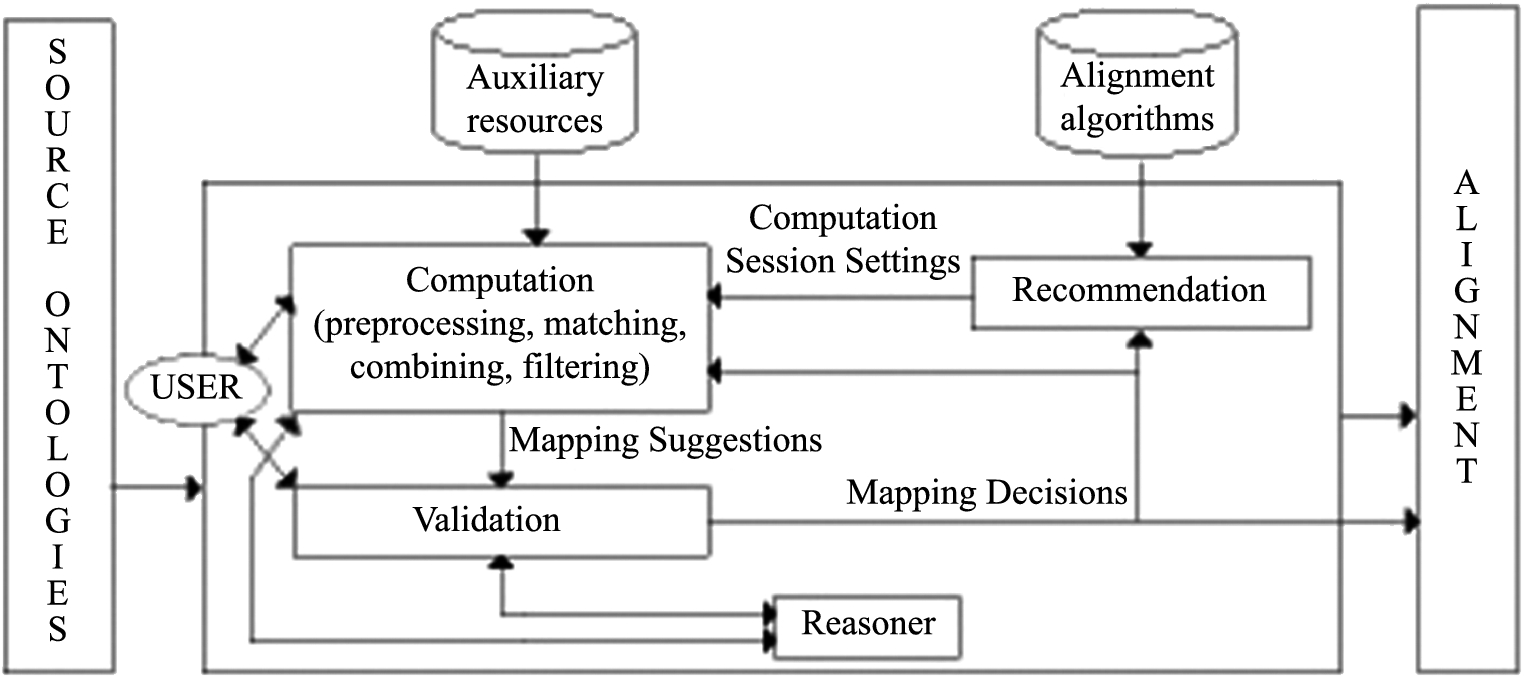
Framework.
Our new framework is presented in Fig. 4. The input are the ontologies that need to be aligned. The output is an alignment between the ontologies which consists of a set of mappings that are accepted after validation. The framework defines three kinds of sessions: computation, validation and recommendation sessions. When starting an alignment process the user starts a computation session. When a user returns to an alignment process, she can choose to start or continue a computation session or a validation session.
During the computation sessions mapping suggestions are computed. The computation may involve preprocessing of the ontologies, matching, and combination and filtering of matching results (as in part I of the old framework). Auxiliary resources such as domain knowledge and dictionaries may be used. A reasoner may be used to check consistency of the proposed mapping suggestions in connection with the ontologies as well as among each other (as in part II in the old framework). Users may be involved in the choice of algorithms. This is similar to what most ontology alignment systems do. However, in this case the algorithms may also take into account the results of previous validation and recommendation sessions. Further, we allow that computation sessions can be interrupted and partial results can be delivered. It is therefore possible for a domain expert to start validation of results before all mapping suggestions are computed. The output of a computation session is a set of mapping suggestions.
During the validation sessions the domain expert validates the mapping suggestions generated by the computation sessions. A reasoner may be used to check consistency of the validations. The output of a validation session is a set of mapping decisions (accepted and rejected mapping suggestions). The accepted mapping suggestions form a PA and are part of the final alignment. The mapping decisions (regarding acceptance as well as rejection of mapping suggestions) can be used in future computation sessions as well as in recommendation sessions. Validation sessions can be interrupted and resumed at any time. It is therefore not necessary for a domain expert to validate all mapping suggestions in one session. The user may also decide not to resume the validation but start a new computation session, possibly based on the results of a recommendation session.
The input for the recommendation sessions consists of a database of algorithms for the preprocessing, matching, combination and filtering in the computation sessions. During the recommendation sessions the system computes recommendations for which (combination) of those algorithms may perform best for aligning the given ontologies. When validation results are available these may be used to evaluate the different algorithms, otherwise an oracle5
Often the oracle would be a domain expert. In the framework we do not assume any properties of the oracle, but it is clear that the quality of the oracle/domain expert has an influence on the quality of the recommendation in a similar way as it has on the validation. In [33] different kinds of oracles representing different levels of user knowledge were discussed. Experiments in [22] for the LogMap system suggest that as long as the error rate of an oracle is less than 30%, validating the mapping suggestions is beneficial. Further, the OAEI Interactive track in 2015 introduced validations with error rates.
The framework covers different kinds of existing systems. For most tracks in the OAEI, participating systems usually compute an alignment using preprocessing, matching, combining and filtering algorithms. This is essentially a process in our framework where only one non-interrupted computation session is used and no validation nor recommendation sessions.
A slightly more complex variant is where the results of the computation session are validated by a domain expert. This conforms to one non-interrupted computation session and one non-interrupted validation session. This case is covered by systems with a user interface (e.g., SAMBO [32], AlViz [34], COGZ [13], COMA++ [6], AgreementMaker [5], LogMap [22], AML [43]).
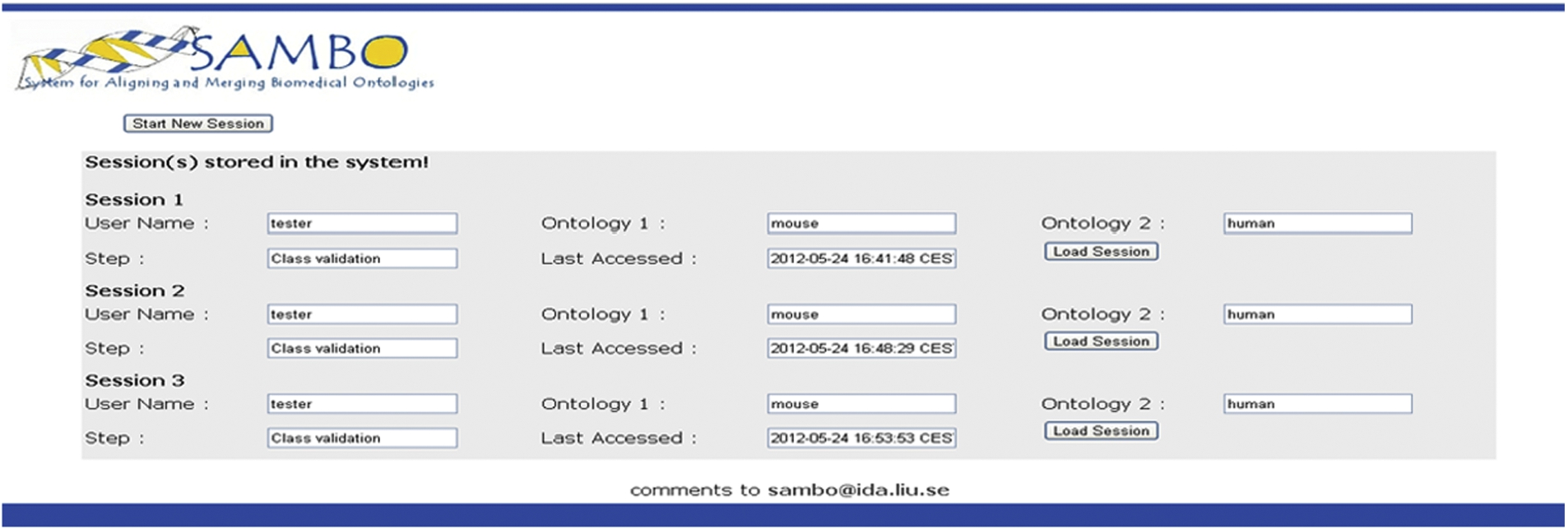
Screenshot: start session.
Some systems use an iterative approach where validation decisions can be used in a new iteration of the computation. The validation decisions could be used to prune the search space, in matching algorithms (e.g., structure-based), or in filtering approaches. This case requires iterations of a computation session followed by a validation session.
Some systems allow saving and loading alignments (e.g., [5,6,13,19,34]). Although not session-based, it can be seen as if they mimic sessions by storing the results of a run of the system (which can be seen as computation and validation sessions) and in a new run of the system these results can be used (mimicing a new computation session).
LogMap [22] allows to interrupt validation sessions and the system then automatically deals with the remaining mapping suggestions.
In addition to covering the process of many current systems, the proposed framework also supports new and additional workflows for ontology alignment systems. A typical6
The framework actually allows for a more flexible interleaving of the different kinds of sessions than shown in this typical workflow.
In Section 4.6 we give an example run of a system implemented based on the framework.
We have implemented a prototype based on the framework described above. We have used and extended some components from the SAMBO system [32], previously developed in our group, and developed and implemented several new components.7
In the text we explicitly mention which components are taken from or further developed from previous work. When nothing is mentioned, it means we have developed new algorithms.
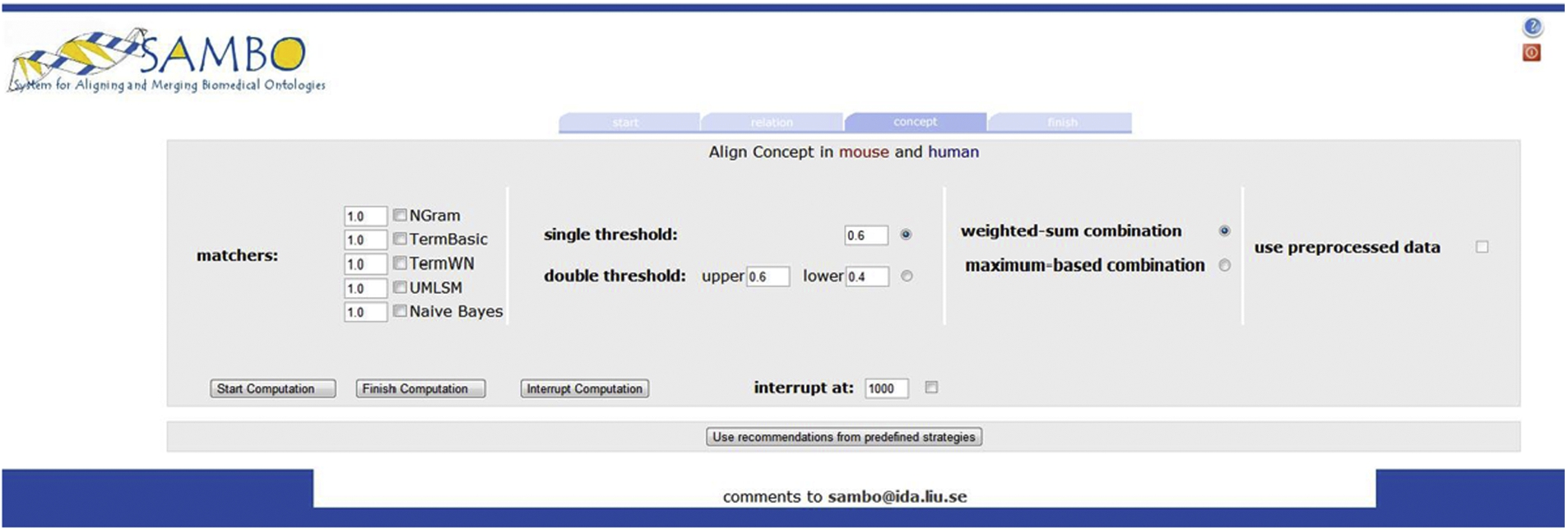
Screenshot: start computation session.
When starting an alignment process for the first time, the user starts a computation session. However, if the user has previously stored sessions, then a screen as in Fig. 5 is shown and the user can start a new session or resume a previous session. The information about sessions is stored in the session management database. This includes information about the user, the ontologies, the list of already validated mapping suggestions, the list of not yet validated mapping suggestions, and last access date. In the current implementation only validation sessions can be saved. When a computation session is interrupted, a new validation session is created and this can be stored. When a user ends or interrupts a session, the user can ask the system to, using the obtained validation decisions, filter the non-validated mapping suggestions, preprocess the data for a future session or compute a recommendation for the settings of a new computation session.
Computation sessions
Settings selection
Figure 6 shows a screenshot of the system at the start of a computation session. It allows for the setting of the session parameters. During the settings selection the user selects algorithms for the matching, combining and filtering steps as well as whether preprocessed data should be used. An experienced user may choose her own settings. Otherwise, the suggestion of a recommendation session (by clicking the ‘Use recommendations from predefined strategies’ button) or a default setting may be used. It is also possible to inspect a list of predefined strategies as well as a list of the top recommended strategies with their recommendation scores and select a strategy from these lists. The settings selection is stored in the session information database. The computation session is started using the ‘Start Computation’ button.
Preprocessing
When a PA is available (e.g., after an (interrupted) validation session – in this case this step can be initiated after the end or interruption of a previous validation session), the preprocessing step partitions the ontologies into corresponding mappable parts according to the method we developed in [28]. This method computes corresponding mappable parts that make sense with respect to the is-a structure of the ontologies as described in Section 2.2.1. As only mappings between concepts in mappable parts respect the structure of the ontologies, the matchers will not compute similarity values between all pairs of concepts, but only between concepts in mappable parts, thereby considerably reducing the search space. The method has good performance when the is-a structure of the ontologies is correct. The user may choose to use this preprocessing step by checking the ‘use preprocessed data’ check box (Fig. 6).
Matchers
Matchers compute similarity values between entities in different ontologies. Whenever a similarity value for an entity pair using a matcher is computed, it is stored in the similarity values database. This can be done during the computation sessions, but also during the recommendation sessions. In the current implementation we have used string matching for matching relations. Regarding concepts, the matchers compute similarity values between pairs of concepts as received from the preprocessing step (all pairs or pairs of concepts in mappable parts). We use the linguistic, WordNet-based, UMLS-based and instance-based algorithms from the SAMBO system [32]. The matcher n-gram computes a similarity based on 3-grams. An n-gram is a set of n consecutive characters extracted from a string. Similar strings have a high proportion of n-grams in common. The matcher TermBasic uses a combination of n-gram, edit distance and an algorithm that compares the lists of words of which the names of the concepts and relations are composed.8
This is similar to a combination of n-gram, edit distance and Jaccard. According to [2] this should give good results for the f-measure for standard ontologies. Also according to [2], for biomedical ontologies edit distance gives good precision while Jaccard gives good recall and f-measure.
The user can define which matchers to use in the computation session by checking the check boxes in front of the matchers’ names (Fig. 6). To guarantee partial results as soon as possible the similarity values for all currently used matchers are computed for one pair of entities at a time and stored in the similarity values database. When the similarity values for each currently used matcher for a pair of entities are computed, they can be combined and filtered (see below) immediately. As ontology alignment is an iterative process, it may be the case that the similarity values for some pairs and some matchers were computed in a previous round. In this case these values are already in the similarity values database and do not need to be re-computed.
Results from different matchers can be combined. In our system we allow the choice of the two most common approaches: a weighted-sum approach and a maximum-based approach. In the first approach each matcher is given a weight and the final similarity value between a pair of entities is the weighted sum of the similarity values divided by the sum of the weights of the used matchers. The maximum-based approach returns as final similarity value between a pair of entities, the maximum of the similarity values from different matchers. The user can choose which combination strategy to use by checking radio buttons, and weights can be added in front of the matchers’ names (Fig. 6).
Filtering
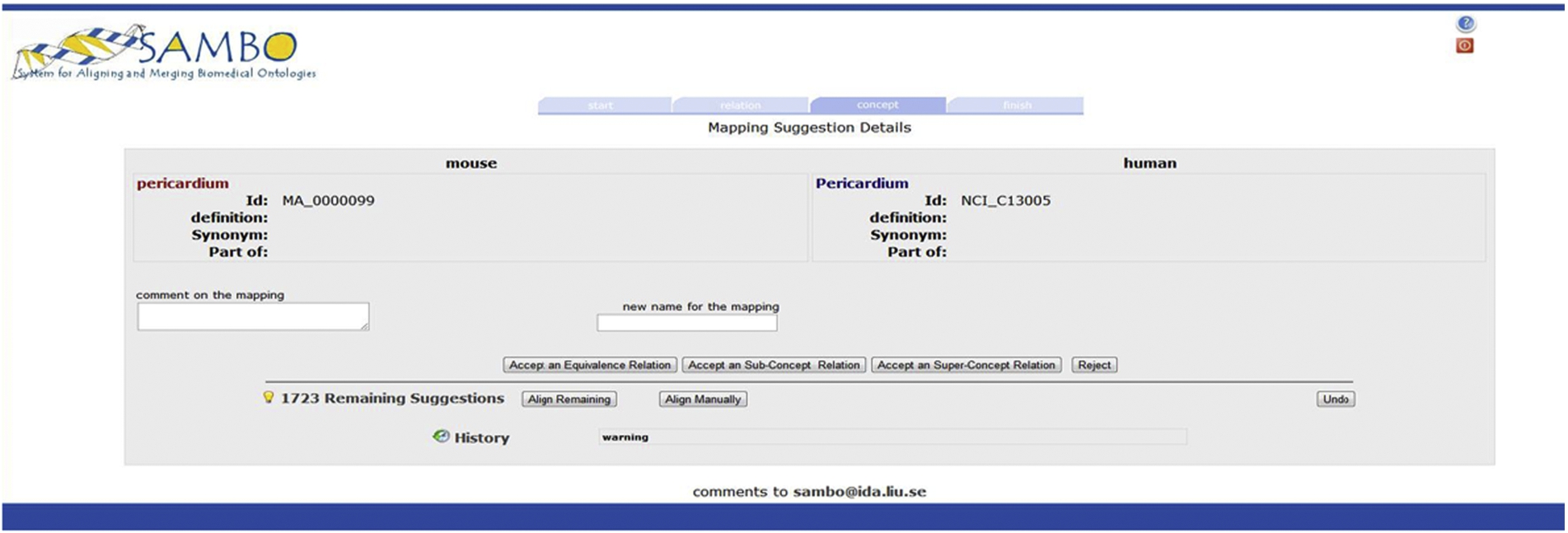
Screenshot: mapping suggestion.
Most systems use a threshold filter on the similarity values to decide which pairs of entities become mapping suggestions. In this case a pair of entities is a mapping suggestion if the similarity value is equal to or higher than a given threshold value. Another approach that we implemented is the double threshold filtering approach that we developed in [3]. In this approach two thresholds are introduced. Pairs with similarity values equal to or higher than the upper threshold are retained as mapping suggestions. These pairs are also used to partition the ontologies as described in Section 2.2.1, similar to the partitioning in the preprocessing step. The pairs with similarity values between the lower and upper thresholds are filtered using the partitions. Only pairs of which the elements belong to corresponding elements in the partitions are retained as suggestions. Pairs with similarity values lower than the lower threshold are rejected as mapping suggestions. When a PA is available, a variant of double threshold filtering can be used, where the PA is used for partitioning the ontologies [28]. The user can choose single or double threshold filtering and define the thresholds (Fig. 6). Further, to obtain higher quality mappings, we always remove mapping suggestions that conflict with already validated correct mappings [28].
The session can be interrupted using the ‘Interrupt Computation’ button. The user may also specify beforehand a number of concept pairs to be processed and when this number is reached, the computation session is interrupted and validation can start. This setting is done using the ‘interrupt at’ field (Fig. 6). The output of the computation session is a set of mapping suggestions where the computation is based on the settings of the session. Additionally, similarity values are stored in the similarity values database that can be used in future computation sessions as well as in recommendation sessions. In case the user decides to interrupt a computation session, partial results are available, and the session may be resumed later on. The ‘Finish Computation’ button allows a user to finalize the alignment process. (A similar button is available in validation sessions.)
Validation sessions
The validation sessions allow a domain expert to validate mapping suggestions. The mapping suggestions can come from a computation session (complete or partial results) or be the remaining part of the mapping suggestions of a previous validation session. For the validation we extended the user interface of SAMBO [32], which took into account lessons learned from experiments [24,25] with ontology engineering systems’ user interfaces. As stated in [12] our user interface evaluations are one of the few existing evaluations and our system is one of the few systems based on such evaluation. Through the interface, the system presents mapping suggestions (Fig. 7) with available information about the entities in the mapping suggestions. When an entity appears in multiple mapping suggestions, these will be shown at the same time. The user can accept a mapping suggestion as an ≡, ⊑ or ⊒ mapping, or reject the mapping suggestion by clicking the appropriate buttons. Further, the user can give a preferred name to equivalent entities as well as annotate the decisions. The user can also review the previous decisions (‘History’) as well as receive a summary of the mapping suggestions still to validate (‘Remaining Suggestions’). After validation a reasoner is used to detect conflicts in the decisions and the user is notified if any such occur.
The mapping decisions are stored in the mapping decisions database. The accepted mapping suggestions constitute a PA and are partial results for the final output of the ontology alignment system. The mapping decisions (both accepted and rejected) can also be used in future computation and recommendation sessions. Validation sessions can be stopped at any time and resumed later on (or if so desired – the user may also start a new computation session).
Recommendation sessions
We implemented several recommendation strategies. The first approach (an extension of our work in [51]) requires the user or an oracle to validate all pairs in small segment pairs of the different ontologies (Section 2.2.2). To generate these segments and segment pairs we first use a string-based approach to detect concepts in the different ontologies with similar names. In the implementation we used exact matching. The concepts in the sub-graphs of the is-a hierarchies of the two ontologies with the matched concepts as roots are then candidate segments and form a candidate segment pair. Among the candidate segment pairs a number of elements (15) of small enough size (maximally 60 concepts in a segment) are retained as segment pairs. As a domain expert or oracle has validated all pairs constructed from the segments, full knowledge is available for the small parts of the ontologies represented by the segments. The recommendation algorithm then proposes a particular setting for which matchers to use, which combination strategy and which thresholds, based on the performance of the strategies on the validated segments. The advantage of the approach is that it is based on full knowledge of the mappings of parts of the ontologies. An objection may be that good performance on parts of the ontologies may not lead to good performance on the whole ontologies. The disadvantage of the approach is that a domain expert or an oracle needs to provide full knowledge about the mappings of the segments. The second and third approach can be used when the results of a validation are available. In the second approach the recommendation algorithm proposes a particular setting based on the performance of the alignment strategies on all the already validated mapping suggestions. In the third approach we use the segment pairs (as in the first approach) and the results of earlier validation to compute a recommendation. The advantages of these approaches are that decisions from different parts of the ontologies can be used, and that no domain expert or oracle is needed during the computation of the recommendation. However, no full knowledge may be available for any parts of the ontologies (e.g., for some pairs in the segment pairs, we may not know whether the mapping is correct or not), and validation decisions need to be available. We note that in all approaches, when similarity values for concepts for certain matchers that are needed for computing the performance, are not yet available, these will be computed and added to the similarity values database.
Number of correct/wrong mappings that are suggested/not suggested
Number of correct/wrong mappings that are suggested/not suggested
To define the performance of the alignment algorithms several measures can be used. We define the measures that are used in our implementation. We assume there is a set of pairs of concepts for which full knowledge is available about the correctness of the mappings between the concepts in the pair. For the first approach this set is the set of pairs in the segments. In the other approaches this set is the set of pairs in the mappings decisions (accepted and rejected). For a given alignment algorithm, let then A be the number of pairs that are correct mappings and that are identified as mapping suggestions, B the number of pairs that are wrong mappings but were suggested, C the number of pairs that are correct mappings but that were not suggested, and D the number of pairs that are wrong mappings and that were not suggested (see Table 1). In A + D cases the algorithm made a correct decision and in B + C cases the algorithm made a wrong decision. In our system we use then the following measures (see Table 2).
The results of the recommendation algorithms are stored in the recommendation database. For each of the alignment algorithms (e.g., matchers, combinations, and filters) the recommendation approach and the performance measure are stored. A user can use the recommendations when starting or continuing a computation session.
In [13] a cognitive support framework for ontology alignment systems is proposed. The framework was developed using cognitive support theories, a literature review of ontology alignment tools as well as a small observational case study. Different requirements for ontology alignment systems were identified and divided into four conceptual dimensions: analysis and decision making (requirements 1.1–1.4), interaction (requirements 2.1–2.5), analysis and generation (requirements 3.1–3.4), and representation (requirements 4.1–4.7). In this section we discuss the cognitive support of our system using these requirements.
Performance measures
Performance measures
In the analysis and decision making dimension we support the following. In addition to the functionality described earlier, our system has a component for manual ontology alignment where the ontologies are represented as indented trees. In this component the user can select a concept from the first ontology and a concept from the second ontology and manually create a mapping (1.1). It also supports ontology exploration (1.1). The tool provides means for the user to accept/reject mapping suggestions (1.2). Further, the user receives information about the definitions of concepts or relations (1.3). Some information about the context of the concepts and relations is available in the mapping suggestions as well as in the manual alignment component (1.4). In the interaction dimension we support exploration (2.1) and search (2.4) of the ontologies via the manual alignment component. Exploration of potential mappings is supported through the remaining suggestions list (2.2). Further, we support exploration of already verified mappings (2.3) through the history list. The system also supports adding details on verified mappings through the annotation functionality (2.5). In the analysis and generation dimension we support the automatic discovery of mapping suggestions (3.1). The mapping state can be saved and users are allowed to return to a given state (3.3). Potential conflicts arising from adding mappings are detected and the user is notified of potential problems (3.4). Regarding the representation dimension we provide a visual representation of the ontologies using indented trees (4.1). We also provide some information regarding the mappings (4.3) via the annotation functionality. Through our PA-based algorithms we have ways to compute mappable regions (4.4). We provide progress feedback through the different tabs, sessions and the history list (4.6).
There are a number of requirements that are not supported or should be supported in a better way. We do not have a filter strategy for showing, for instance, only mappings with exact names or only mapped concepts in the ontologies (2.4). The current system does not deal with instances and thus does not support the transforming of instances from the source ontology to the target ontology (3.2). The current system detects potential conflicts but does not suggest ways of resolving them (3.4). We have worked on an integrated system for ontology alignment and debugging [19] where (3.4) is the main focus of the work. Although the system provides some information regarding the mapping suggestions (4.2) and mappings (4.3), more information available in the different databases could be presented as well as in a better way. For instance, we do not show explanations on why mapping suggestions were suggested (4.7). Although we have algorithms for computing mappable regions, we do not have a visual presentation of these (4.4). In general, the visualization of the ontologies, mappings and mapping suggestions is subject for future work and different techniques need to be investigated. For instance, indented trees are more organized and familiar to novice users, but a graph visualization may be more controllable and intuitive [14]. Further, we do not identify specific starting points (4.5).
A typical alignment process would start a computation session. We do this in a screen such as in Fig. 5. As there were no previous sessions, we can only click on the ‘Start New Session’ button. This would lead us to a settings screen such as in Fig. 6. Here we need to choose which matchers, combination strategy and filtering strategy (with threshold(s)) to use. As an example, let us choose matchers TermWN with weight 2, n-gram with weight 1 and NaiveBayes with weight 1. This also means that we use the weighted sum combination strategy. Further, we use single threshold filtering with threshold 0.5. We also decide that we want to interrupt the computation after 500 suggestions are computed.
We then start a computation session by clicking the ‘Start Computation’ button and when 500 mapping suggestions are computed using the previously selected matchers, combination and filtering methods, the session is interrupted and a validation session is started. For the computed mapping suggestions the user is shown a screen as in Fig. 7. If a concept in the first ontology appears in several mapping suggestions, these are shown in the same screen. The user can accept mapping suggestions as equivalence or subsumption mappings as well as reject suggestions. In the example in Fig. 7 the mapping suggestion would be accepted as an equivalence mapping. After each validation the system removes conflicting mapping suggestions. Using this approach 107 mapping suggestions are removed during the validation session (and thus the user did not need to unnecessarily validate these suggestions). At each time point in a validation session we can also acquire a list of the remaining mapping suggestions as well as our previous validation decisions.
After having validated all mapping suggestions we quit the session. The system then uses the validation decisions to compute recommendations for the settings of the parameters of the alignment algorithms. When we start using the system again, we decide to start a new session. In the settings screen we click on ‘Use recommendations from predefined strategies’ to view the recommended strategies. We decide to follow the top recommendation of the session-based recommendation strategy that uses the previous validation decisions (but no segments). This recommended strategy uses matchers n-gram with weight 2, TermBasic with weight 1 and UMLSM with weight 1, as well as a double threshold filtering strategy with thresholds 0.6 and 0.7. We decide again to interrupt the computation after 500 suggestions are computed. Only ‘new’ mapping suggestions will be contained in the 500, i.e., if a mapping suggestion was validated in a previous session it will be considered as handled and therefore not counted.
In the new validation session we decide to interrupt after we have validated 200 suggestions. When we restart the system, in the sessions screen (as in Fig. 5) we can select previous sessions or start a new session. We select the validation session that was interrupted and validate the remaining suggestions.
We then continue to use the recommendations by the system using the session-based recommendation strategy that uses the previous validation decisions (but no segments) after every 500 computations and the associated validations. This would lead to three more computation and associated validation sessions. For the first new computation session the recommended strategy uses n-gram with weight 1, TermBasic with weight 1, TermWN with weight 2, UMLSM with weight 2, and NaiveBayes with weight 2 as well as a double threshold filtering strategy with thresholds 0.3 and 0.5. In the next computation session the recommended strategy is the same as in the previous computation session. In the last computation session the recommended strategy uses TermBasic with weight 1, TermWN with weight 1, and UMLSM with weight 1 as well as a double threshold filtering strategy with thresholds 0.6 and 0.8.
After these sessions there are no more mapping suggestions to validate and we decide to stop the process.
This example run illustrated a rather typical way of using the system. There is, however, additional flexibility. For instance, we can interrupt computation sessions in other ways. We do not need to follow the recommendations by the system or we can use different recommendation strategies at different times. In the example we have used the validation decisions in the recommendations, but we could also use them in the preprocessing or double threshold filtering in the computation sessions by checking the ‘use preprocessed data’ button in the settings screen.
Experiments
We performed several experiments. All experiments show the advantages of using a session-based system regarding performance of computation of similarity values, filtering or recommendation. Some of the experiments additionally show how a session-based system can be used for evaluating strategies (PA-based algorithms and recommendation algorithms).
As the session-based approach allows for interrupting computation sessions and reusing the computation results from previous sessions, we investigate the influence of using sessions on the efficiency of the ontology alignment system (Section 5.2).
A second main feature of the session-based approach is that it is possible to use validation decisions obtained from previous validation sessions. Therefore, in Section 5.3 we discuss experiments related to one of the issues that can lead to reducing unnecessary user interaction. We investigate the influence using validation decisions from previous sessions for different filtering strategies. The experiments also allow us to evaluate the strategies.
A third main feature of the proposed approach are the recommendation sessions. Little research has been done on this issue, and previous approaches only consider recommendations at the beginning of an alignment session, i.e., without the possibility of using validation decisions from previous sessions. Therefore, in our third set of experiments we investigate different recommendation strategies with and without the session-based approach. Similar to the experiments on filtering, the experiments on recommendation strategies show how the session-based approach, in addition to the actual ontology alignment, also enables evaluation of different strategies. Section 5.4 describes the experiments and provides insights into the algorithms that could not have been obtained (easily) without the session-based approach.
In the remainder of this section we present the experiments set-up as well as describe the findings of the different experiments. For the details of the experiments we refer to the appendix.
Experiments set-up
We use the OAEI 2014 Anatomy track for our experiments which contains the ontologies Adult Mouse Anatomy (AMA) and the anatomy part of the NCI Thesaurus (NCI-A). (Removing empty nodes in the files) AMA contains 2737 concepts and NCI-A contains 3298 concepts. This gives 9,026,626 pairs of concepts. Further, a reference alignment containing 1516 equivalence mappings is available and thus we focus on equivalence mappings in our experiments.
We used the following alignment strategies. We used matchers n-gram, TermBasic, TermWN, UMLSM and NaiveBayes9
For NaiveBayes we generated a corpus of PubMed [46] abstracts. For each concept we used the concept name as a query term for PubMed and retrieved abstracts of documents that contain the query term in their title or abstract using the programming utilities provided by the retrieval system Entrez. We used a maximum of 100 abstracts per concept. For AMA the total number of documents was 30,854. There were 2413 concepts for which no abstract was found. For NCI-A the total number of documents was 40,081. There were 2886 concepts for which no abstract was found.
As stated in footnote 2, the best strategy regarding
For the experiments regarding filtering and recommendation we chose three alignment strategies AS1, AS2, AS3 (see Table 5 in the appendix for details) as a basis for discussion. AS1 is the strategy with best
In the first experiment we investigate the influence of using sessions and the similarity values database on the efficiency of the ontology alignment system. For each of the matchers we computed the similarity values for all pairs of concepts. When a similarity value is computed it is stored in the similarity values database. Previous approaches could not take advantage of previously stored values.11
We note, however, that some systems do cache values. Thanks to Michelle Cheatham for pointing out that the code of several systems shows that caching is used.
Our results show that using the database is advantageous for string matchers, and even more advantageous for more complex matchers for which the speed-up may be up to 25%. The session-based approach leads therefore to reduced computation times and reduced waiting times for the domain expert.
There are few approaches that can take into account already given mappings. Further, it is not common that such a set of pre-existing mappings exists. In a session-based approach, however, every validation session generates such sets, which can be used to improve the quality of the mapping suggestions and reduce unnecessary user interaction. Further, the knowledge of the domain expert is taken into account at an early stage. In the following experiments we investigate the influence of sessions and validation decisions for different filtering strategies.
For the strategies AS1, AS2 and AS3 we computed the reduction of the number of mapping suggestions by using the filter strategy that removes mapping suggestions that are in conflict with already validated correct mappings. The main lesson learned is that this strategy is effective and removing such conflicting suggestions should be done as soon as possible. Therefore, in our system we perform the removal after every validation of a correct equivalence mapping and thereby reduce unnecessary user interaction.
Further, as the session-based approach produces validated correct mappings, we can use these in the double threshold filtering approach. We computed the influence of this filtering approach in terms of the total number of mapping suggestions and the number of correct suggestions that are removed by this operation. As double threshold filtering heavily relies on the structure of the ontologies and many is-a relations are actually missing in AMA and NCI-A [30], we experimented with the original ontologies as well as repaired12
See the appendix for how we repaired the ontologies.
Lessons learned
The experiments in this section show how recommendation strategies can be used within the session-based framework as well as how well they perform. For these experiments we used Sim2 as recommendation measure.
We set up the experiments such that we could investigate different settings for the recommendation strategies. We investigated in (i) using the session-based approach or using one recommendation session at the beginning of the ontology alignment process. For the session-based approaches we also investigated (ii) the performance of the different recommendation strategies discussed in Section 4.4, (iii) the change of the quality of the recommendation strategies with respect to the validation decisions at hand, (iv) the change of the quality of the overall alignment strategy when recommendation strategies are computed after every interruption and the newly computed recommendation strategy is followed until the next interruption.
For the recommendation algorithm that computes a performance measure for the alignment strategies based on how the strategies perform on the already validated mapping suggestions, we found that the recommended strategy is always a decent strategy. The best strategy (AS1), however, only appears as a top recommended strategy when we start with a poor strategy (AS3). When we change the recommendation after each session, the recommended strategies are usually good or top strategies. When starting with the best strategy (AS1) the performance is still not so good because of the lack of negative examples (i.e., wrong mapping suggestions), but better in this approach than when the recommendation does not change after every session. We show, however, in the appendix that performance can be improved by generating negative examples when these are not available.
For the recommendation algorithm that uses segment pairs and computes a performance measure for the alignment strategies based on how the strategies perform on the already validated parts of the segment pairs, we found that the lack of negative examples leads to poor results when starting with AS1 or AS2. The recommended strategies have very high recall, but low precision. The results for AS3 show that as the number of processed suggestions increases, the recommended strategy becomes better. This is because the quality of the oracle increases. When we change the recommendation after each session, the recommended strategies in the final recommendations are good or top strategies.
When we do not use sessions we use a recommendation algorithm that uses segment pairs and computes a performance measure for the alignment strategies based on how the strategies perform on the segment pairs. This requires an oracle that has full knowledge about the mappings in the segment pairs and for this we use the reference alignment as provided by the OAEI. As this recommendation strategy is independent from the actual validation decisions, the recommendation does not change during the alignment process. It can therefore be performed in the beginning. The performance of the recommendation algorithm depends on the selected segment pairs.
Summary of lessons learned
We summarize the lessons learned in Table 3 and discuss them further in the following sections. A first kind of lessons learned relates to the usefulness of the session-based approach. A second kind of lessons learned relates to the algorithms of the actual implemented system. We learned these lessons through experiments with many alignment strategies on the OAEI 2014 Anatomy track ontologies. Although we have used only one pair of ontologies in the experiments, the lessons of the first kind, which is the focus of this paper, are general and are also true for other ontology pairs. By experimenting with other ontology pairs we may, however, learn new lessons about the actual implemented algorithms.
Use of the session-based approach and system
We showed that using the session-based approach leads to alignment quality improvements. As the approach allows for the partial computation and the partial validation of mappings suggestions, validation decisions can be taken into account during the following sessions. The validation decisions represent domain expert knowledge and can be used earlier in the alignment process than in former frameworks. During computation sessions a PA can be used for reducing the search space, which according to the experiments in [28] often leads to an improvement of
The session-based approach also supports the recommendation of alignment strategies. As, in general, we do not know which alignment strategies perform well for a particular pair of ontologies, according to our experiments using the recommendations after each session usually leads to better alignments.
Further, during computation and recommendation sessions, computed similarity values are stored in the similarity values database. Using this database in further computation sessions reduces computation times and waiting times for the domain expert.
Lessons about alignment strategies
We also learned some lessons about the actual alignment algorithms. For instance, filtering out suggestions that are in conflict with validation decisions after the locking of sessions is useful and the worse the initial strategy, the more useful this is. Also filtering after the locking of a session using the double threshold filtering method is useful, and the more complete the is-a structure in the ontologies is, the better the results.
The recommendation is important, especially when the initial strategy is not good. It is also clear that the approaches using validation decisions (with and without segment pairs) become better the more suggestions are validated. Further, when using the recommended strategy after each session improves the final result. We also found, that, when too few wrong mapping suggestions are available, we can improve the performance by automatically generating wrong mapping suggestions. For the approaches using segment pairs, the experiments show that the choice of the segment pairs influences the recommendation results (which is different from the conclusions of experiments in [51]). Therefore, strategies for choosing segment pairs need to be investigated. In our experiments among the strategies with validation decisions, the strategy with ‘validation decisions only’ performed best, but the strategy with ‘validation decisions and segment pairs’ may be improved with better segment selection strategies.
Related work
To our knowledge there is no other framework that introduces sessions. Earlier frameworks (e.g., [9,32]) and the systems built according to these frameworks have focused on the generation of mappings suggestions, similar to non-interruptible computation sessions in which validated data usually is not taken into account. Some systems also allow to validate data, similar to non-interruptible validation sessions. As there is no similar framework or system, we briefly address related work regarding the different components and used techniques.
Although there are no other systems that fully implement the session-based approach [20], some systems (e.g., [5,6,13,19,34]) do allow to mimic part of the framework through saving and loading alignments or by having a repository with ontologies and alignments.
The computation of mapping suggestions includes preprocessing, matching, combining and filtering. There are some approaches that reduce the search space by segmenting or partitioning the ontologies and using anchors (concept pairs with high similarity) to connect mappable segments [16,18] or segment similarity [6]. Some approaches use the locality of anchors to reduce the search space [17,53]. In [53] anchors can also be pairs with low similarity values. Another approach uses topic identification and clustering to reduce the search space [4]. The main difference with our approach is that we use validation decisions to partition the ontologies.
For the matching many algorithms have been proposed.13
As mentioned before, they often implement strategies based on linguistic matching, structure-based strategies, constraint-based approaches, instance-based strategies, strategies that use auxiliary information or a combination of these. The results from OAEI, e.g., [1,8] and evaluation studies such as in [2,32,39] provide some knowledge on the performance of the matchers. In our system we used linguistic matching, instance-based strategies, and strategies that use auxiliary information.The most commonly used combination strategies are the weighted-sum and the maximum-based approaches. Our system supports these. There are some more advanced combination strategies such as in the schema metamatching framework of [7] and the agent-based method in [49].
Regarding filtering, most systems use single threshold filtering, while we additionally support double threshold filtering. In contrast to most systems, our system can also take into account PAs or validation decisions. Some systems do additional checking of constraints (e.g., [16,21]) thereby adding or removing suggestions.
There are some systems that allow validation of mappings such as SAMBO [32], AlViz [34], COGZ [13] for PROMPT, COMA++ [6], AgreementMaker [5] and AML [43]. None of these systems allow, however, interruptible sessions. LogMap [22] allows interrupting user interaction. Interrupting user interaction in this case means using heuristics to deal with remaining mapping suggestions. It also allows to pause the user interaction (and save the status) and continue later. There are approaches that try to minimize user interaction. For instance, in [15] minimal mappings are computed for light-weight ontologies and these are presented for validation. AgreementMaker [5] clusters validated mappings and mapping suggestions based on a signature vector and these are shown in a visual analytics panel, thereby dealing with multiple suggestions simultaneously and aiding the user with contextual information. Validation decisions also influence the generation of mapping suggestions. Further, recently, in [41] evaluation measures for user interaction were proposed for which the evaluation can be fully automated.
There are very few recommendation approaches. In [37] it is argued that finding appropriate alignment strategies should be based on knowledge about the strategies and their previous use. As a first step a number of factors (related to input, output, approach, usage, cost and documentation) were identified that are relevant when selecting an alignment strategy. The relevant data is collected by questionnaires. The Analytic Hierarchy Process is used to detect suitable alignment approaches. The results from OAEI and evaluation studies such as in [32,39] could provide useful input data for this approach. In [9], APFEL, a machine learning approach to optimize alignment strategies is proposed. In APFEL a set of feature parameters are declared for the source ontologies, the similarity assessment, and the different matchers, combination and filter algorithms. To generate training data, an existing parametrization is used and mapping suggestions are generated. These suggestions need to be validated by the user. A machine learning approach is then used to learn an optimal parametrization. There are some approaches for tuning the parameters in the ontology alignment systems. The RiMOM [35] and UFOme [45] systems use textual and structural characteristics of the ontologies for the selection of matchers, combinations and filters. The system in [44] uses such characteristics to configure itself in an adaptive way. Falcon-OA [18] includes an approach to tune the thresholds for the matchers.
In this paper we presented to our knowledge the first session-based framework that allows a user to interrupt and resume the different stages of the ontology alignment process. The framework enables user involvement, one of the current challenges in ontology alignment, in a natural way. We showed the feasibility of the approach by implementing a session-based version of an existing system. We showed the usefulness of the approach through several experiments with many alignment strategies on the OAEI 2014 Anatomy track ontologies. We also showed that the session-based framework enabled experimentation and evaluation of new alignment approaches (both in computation and recommendation) that are based on validation decisions. These evaluations were not possible or cumbersome before.
In future work we will continue to develop and evaluate computation strategies and recommendation strategies. Especially interesting are strategies that reuse validation results to e.g., reduce the search space or guide the computation. Further, we will investigate new strategies for recommendations using validation decisions, including segment selection strategies. A further interesting track is to integrate debugging strategies into the alignment process as in [19]. In a session-based approach debugging can be performed early and thereby increase the quality of the alignment. It would also be useful to develop a software framework that implements the session-based approach and to which existing systems can be plugged in.
Top 10 strategies for
Acknowledgments
We acknowledge the financial support of the Swedish e-Science Research Centre (SeRC) as well as the EU FP7 project VALCRI (FP7-IP-608142). We thank Qiang Liu, Muzammil Zareen Khan and Shahab Qadeer for their implementation work on earlier versions of the system. We thank Michelle Cheatham, Daniel Faria, Ernesto Jimenez Ruiz, and an anonymous reviewer for useful comments to improve the paper.