Abstract
Both researchers and industry are confronted with the need to process increasingly large amounts of data, much of which has a natural graph representation. Some use MapReduce for scalable processing, but this abstraction is not designed for graphs and has shortcomings when it comes to both iterative and asynchronous processing, which are particularly important for graph algorithms.
This paper presents the Signal/Collect programming model for scalable synchronous and asynchronous graph processing. We show that this abstraction can capture the essence of many algorithms on graphs in a concise and elegant way by giving Signal/Collect adaptations of algorithms that solve tasks as varied as clustering, inferencing, ranking, classification, constraint optimisation, and even query processing. Furthermore, we built and evaluated a parallel and distributed framework that executes algorithms in our programming model. We empirically show that our framework efficiently and scalably parallelises and distributes algorithms that are expressed in the programming model. We also show that asynchronicity can speed up execution times.
Our framework can compute a PageRank on a large (>1.4 billion vertices, >6.6 billion edges) real-world graph in 112 seconds on eight machines, which is competitive with other graph processing approaches.
Introduction
The Web (including the Semantic Web) is full of graphs. Hyperlinks and RDF triples, tweets and social network relationships, citation and trust networks, ratings and reviews – almost every activity on the web is most naturally represented as a graph. Graphs are versatile data structures and can be considered a generalisation of other important data structures such as lists and trees. In addition, many structures – be it physical such as transportation networks, social such as friendship networks, or virtual such as computer networks – have natural graph representations.
Graphs were at the core of the Semantic Web since its beginning. RDF, the core standard of the Semantic Web, represents a directed labelled graph. Hence, all processing of Semantic Web data includes at least some graph processing. Initially, many systems tried to use traditional processing approaches. Triple stores, for example, tried to leverage research in relational databases to gain scalability. The most significant speed-gains, however, came from taking into account the idiosyncrasies of storing graphs [44,59]. Another example would be the advantages gained in non-standard reasoning through the use of graphs: Learning on the Semantic Web was initially based on using traditional propositional learning methods. It was the use of statistical relational learning methods that leveraged the graph-nature of the data that allowed combining statistical and logical reasoning [30]. This combination lead to significant gains.
Coupled with the ever expanding amounts of computation and captured data [23], this means that researchers and industry are presented with the opportunity to do increasingly complex processing of growing amounts of graph structured data.
In theory, one could write a scalable program from the ground up for each graph algorithm in order to achieve the maximum amount of parallelism. In practice, however, this requires a lot of effort and is in many cases unnecessary, because many graph algorithms such as PageRank can be decomposed into small iterated computations that each operate on a vertex and its local neighbourhood (or messages from the neighbours). If we can design programming models to express this decomposition and execute the partial computations in parallel on scalable infrastructure, then we can hope to achieve scalability without having to build custom-tailored solutions.
MapReduce is the most popular scalable programming model [10], but has shortcomings with regard to iterated processing [4,13,62,63] and requires clever mappings to support graph algorithms [9,35]. Such limitations of more general programming models have motivated specialised approaches to graph processing [29,41]. Most of these approaches follow the bulk-synchronous parallel (BSP) model [57], where a parallel algorithm is structured as a sequence of computation and communication steps that are separated by global synchronisations. The rigid pattern of bulk operations and synchronisations does not allow for flexible scheduling strategies.
To address the limitations of BSP, researchers have designed programming models for graph processing that are asynchronous [37], allow hierarchical partial synchronisations [32], make synchronisation optional [55], or try to emulate the properties of an asynchronous computation within a synchronous model [58].
Our proposed solution is a vertex-centric programming model and associated implementation for scalable graph processing. It is designed for scaling on the commodity cluster architecture. The core idea lies in the realisation that many graph algorithms can be decomposed into two operations on a vertex: (1) signaling along edges to inform neighbours about changes in vertex state and (2) collecting the received signals to update the vertex state. Given the two core elements we call our model
Such an approach has the advantage that it can be seen as a graph extension of the actors programming approach [22]. Developers can focus on specifying the communication (i.e., graph structure) and the signaling/collecting behavior without worrying about the specifics of resource allocation. Since
We extend our previous work [55] on
We designed an expressive programming model for parallel and distributed computations on graphs.
We demonstrate its expressiveness by giving implementations of algorithms from categories as varied as clustering, ranking, classification, constraint optimisation, and query processing. The programming model is also modular and composable: Different vertices and edges can be combined in the same graph and reused in different algorithms. Additionally the model supports asynchronous scheduling, dataflow computations, dynamic graph modifications, incremental recomputations, aggregation operations, and automated termination detection. Note that especially the dynamic graph modifications are central for Web of Data applications as they require the seamless integration of ex-ante unknown data.
We evaluated a framework that implements the model.
The framework efficiently and scalably parallelises and distributes algorithms expressed in the programming model. We empirically show that our framework scales to multiple cores, with increasing dataset size, and in a distributed setting. We evaluated real-world scalability by computing PageRank on the Yahoo! AltaVista webgraph.3
Yahoo! Academic Relations, Yahoo! AltaVista Web Page Hyperlink Connectivity Graph, http://webscope.sandbox.yahoo.com/catalog.php?datatype=g.
We illustrate the impact of asynchronous algorithm executions.
In Section 2 we motivate the programming model and describe the basic approach. We then introduce the
Consider a graph with RDFS classes as vertices and edges from superclasses to subclasses. Every vertex has a set of superclasses as state, which initially only contains itself. Now all the superclasses send their own states as signals to their subclasses, which collect those signals by setting their own new state to the union of the old state and all signals received. It is easy to imagine how these steps, when repeatedly executed, iteratively compute the transitive closure of the
Consider a graph with vertices that represent locations and edges that represent paths between locations. We would like to determine the shortest path from a special location
Every location starts out with its state set to the length of the shortest currently known path from

States of a synchronous single-source shortest path computation with four vertices.
In the next section we refine this abstraction to a programming model that allows to concisely express algorithms similar to these examples.
In the
Basic Signal/Collect graph structure
The basis for any
More specifically, every vertex
a unique id.
the current vertex state which represents computational intermediate results. The algorithm definition needs to specify an initial state.
a list of all edges
a map with the ids of vertices as keys and signals as values. Every key represents the id of a neighbouring vertex and its value represents the most recently received signal from that neighbour. We use the alias
a list of signals that arrived since the collect operation was last executed on this vertex.
An edge
a reference to the source vertex
a reference to the target vertex
In the most general model signals are messages containing algorithm specific data items. The computational model makes no assumption about the structure of signals beyond that they are computed by signal functions of the edges along which they are transmitted and processed by the collect function of the target vertex.
In a practical implementation, vertices, edges, and signals will most probably be implemented as objects. We outline such an implementation in Section 4. For this reason we also allow for additional attributes on the vertices and edges.
Consider data about people and family relationships between them: How could one map this to the
To specify an algorithm in the
We have now defined the basic structures of the programming model. In order to completely define a
The computation model and extensions
In this section we specify how both synchronous and asynchronous computations are executed in the
In order to precisely describe the scheduling we will need additional operations on a vertex. These operations broadly correspond to the scheduler triggering communication (doSignal) or a state update (doCollect):

The additional
The
Synchronous execution
A synchronous computation is specified in Algorithm 1. Its parameter
Everything inside the inner loops is executed in parallel, with a global synchronization between the signaling and collecting phases. This parallel programming model is more generally referred to as Bulk Synchronous Parallel (BSP) [57].
This specification allows the efficient execution of algorithms, where every vertex is equally involved in all steps of the computation. However, in many algorithms only a subset of the vertices is involved in each part of the computation. In the next subsection we introduce scoring in order to be able to define a computational model that enables us to guide the computation and give priority to more “important” operations.

Synchronous execution
In order to enable the scoring (or prioritising) of is a method that calculates a number that reflects how important it is for this vertex to signal. Schedulers assume that the result of this method only changes when the is a method that calculates a number that reflects how important it is for this vertex to collect. A scheduler can assume that the result of this method only changes when
Note: We have the scoring functions return doubles instead of just booleans, in order to enable the scheduler to make more informed decisions. Two examples where this can be beneficial: One can implement priority scheduling, where operations with the highest scores are executed first, or the scheduling could depend on some threshold (for example for PageRank), which allows the scheduler to decide at what level of precision a computation is considered converged.
Now that we have extended the basic model with scoring, we specify a score-guided synchronous execution of a

Score-guided synchronous execution
There are three parameters that influence when the algorithm stops:
We referred to the first scheduling algorithm as synchronous because it guarantees that all vertices are in the same “loop” at the same time. With a synchronous scheduler it can never happen that one vertex executes a signal operation while another vertex is executing a collect operation, because the switch from one phase to the other is globally synchronised.
Asynchronous scheduling removes this constraint: Every vertex can be scheduled out of order and no global ordering is enforced. This means that a scheduler can, for example, propagate information faster by signaling right after collecting. It also simplifies the implementation of the scheduler in a distributed setting, as there is no need for global synchronisation.

Score-guided asynchronous execution
Algorithm 3 shows a score-guided asynchronous execution. Again, three parameters influence when the asynchronous algorithm stops:
We refer to the scheduler that we most often use as the “eager” asynchronous scheduler: In order to speed up information propagation this scheduler calls
When using the synchronous scheduler without scoring (Algorithm 1), then the collect function processes the signals that were sent along all edges during the last signaling step. When we introduce scoring, not all edges might signal during every step. There is a similar issue with asynchronous scheduling: While no signal might be forwarded along some edges, other edges might have forwarded multiple signals. For this reason we distinguish two categories of vertices that differ in the way they collect signals: A data-graph vertex is most similar to the behaviour of a vertex in the basic execution mode: It processes A data-flow vertex is more simi- lar to an actor. It collects all signals in
Extension: Graph modifications and incremental recomputation
When an edge is added or removed, a scheduler has to update
Modifications are always applied in per-source FIFO order, which means that all the modifications that are triggered by the same source are applied in the same order in which they were triggered. There are no guarantees regarding the global ordering of modifications.
The Signal/Collect framework – An implementation
The
The framework is implemented in Scala, a language that supports both object-oriented and functional programming features and runs on the Java Virtual Machine. We released the framework under the permissive Apache License 2.04
The framework can both parallelise computations on multiple processor cores, as well as distribute computations over a cluster. Internally, the system uses the Akka5
The different system components such as the coordinator and workers are implemented as actors. The coordinator bootstraps the workers and takes care of global concerns such as convergence detection and preventing messaging overload. Each worker is responsible for storing a partition of the vertices.

Coordinator and worker actors, edges represent communication paths. Workers store the vertices.
The scheduling of operations and message passing is done within workers. Figure 2 shows that each node hosts a number of workers and each worker is responsible for a partition of the vertices. Workers communicate directly with each other and with the coordinator. Workers have a pluggable scheduler that handles the delivery of signals to vertices and the ordering of signal/collect operations.
Vertices are retrieved from and stored in a pluggable storage module, by default implemented by an in-memory hash map, especially optimised for storing vertices and for efficiently supporting the operations required by the workers.
A vertex stores its outgoing edges, but neither the vertex nor its outgoing edges have access to the target vertices of the edges. In order to efficiently support parallel and distributed execution, modifications to target vertices from the model are translated to messages that are passed via a message bus.
Every worker and the coordinator have a pluggable message bus that takes care of sending signals and translating graph modifications to messages.
The framework also supports MapReduce-style aggregations over all vertices: The map function is applied to all vertices in the graph. The reduce function aggregates the mapped values in arbitrary order. Aggregation operations are used to compute global results or to define termination conditions over the entire graph.
Graph partitioning and loading
Workers have ids from 0 ascending and by default the graph is partitioned by using a hash function on the vertex ids. This is similar to how graphs are partitioned in most other graph processing frameworks. For large graphs it usually leads to similar numbers of vertices per partition, but also to a large number of edges between partitions. To improve on this one could adopt some of the optimisations used in the Graph Processing System (GPS) [50]. Because computing a balanced graph partitioning with minimal capacity between partitions is a hard problem itself [1], this would mainly improve performance in cases where algorithms are run on the same graph repeatedly, for long-running algorithms, or when messaging bandwidth is the main bottleneck (also see discussion of limitations in Section 7).
The default storage implementation keeps the vertices in memory for fast read and write access. Extensions for secondary storage can be implemented [54]. Graph loading can be done sequentially from a coordinator actor or preferably in parallel, where multiple workers load parts of the graph at the same time. Specific partitions can be assigned to be loaded by particular workers. This can be used to have each worker load its own partition, which increases the locality of the loading.

PageRank (data-graph).
Our framework has defaults that work for a broad range of algorithms, but are not the most efficient solution for most of them. These default implementations can be replaced allowing a graph algorithm developer to choose the trade-off between implementation effort and resulting performance.
An example of a tradeoff is the propagation latency vs. messaging overhead: While sending each signal as soon as possible leads to a low latency and can perform well in local computations, sending each signal by itself will cause a lot of overhead in a distributed setting. Our implementation allows to plug in a custom bulk scheduler and bulk message bus implementation to choose a trade-off that suits the use case (throughput vs. latency).
In spite of this flexibility, our
Convergence and termination
The framework has to decide when an algorithm execution ends. It is not in general possible to say which algorithms can converge: The
For this reason the question of convergence and termination are algorithm-specific. The framework terminates as soon as an algorithm has converged, according to the score-guided execution definitions in Section 3. The framework also allows for other termination conditions in case convergence was not reached before another condition: One can give a step limit for synchronous computations and a time limit for both synchronous and asynchronous computations. The framework also supports convergence criteria based on global aggregations that are executed in step intervals for synchronous computations or in terms of time intervals for asynchronous computations.
There is also a continuous asynchronous mode where the framework keeps running and executes operations incrementally as they are triggered by modifications and signals. This mode is used by TripleRush [56] and raises the question of how to detect when a query has finished executing, given that the execution can branch many times and the number of signals/results is usually not known a priori. We solved this by implementing per-query convergence detection on top of

Delta PageRank (data-flow).

Single-source shortest path (data-graph/data-flow).
In this section we evaluate the programming model, the scalability of our implementation, and the impact of asynchronous scheduling. The different contributions require different research methods: We evaluate the programming model by adapting important algorithms in a few lines of code. In addition to the expressiveness, we also show that our implementation is able to transparently scale algorithms by empirically measuring the speedup when running algorithms while varying the number of worker threads and cluster nodes. Finally, we compare the impact of asynchronous scheduling versus synchronous scheduling on different graphs and algorithms.
Programming model
One of our main contributions is the simple, compact, yet expressive programming model. Whilst simplicity of a program is difficult to judge objectively, compactness and expressiveness are easier to show.
We demonstrate the expressiveness by giving adaptations of ten algorithms from categories as varied as clustering, ranking, classification, constraint optimisation and query processing. We show an actual implementation of the PageRank algorithm in Fig. 21 in the Appendix. As the example illustrates in comparison to the pseudocode in Fig. 3, the translation to executable code is straightforward.
Most algorithms are presented in a simplified version, more advanced versions of many of the examples are available online.6
To enhance readability and facilitate the comparison of different algorithms, each algorithm is structured in a table representing the three core elements of a computation: The initial state represents the state of the vertices when they get added to the graph. The collect method uses the vertex state, the appropriate signals for the vertex type, and other vertex attributes/methods to compute a new vertex state. The signal method uses attributes/methods defined on the source vertex and edge attributes/methods to compute the signal that is sent along the edge. All described algorithms work on homogeneous graphs that use only one type of vertex/edge, which is specified in the table. Additional information and explanations for complex functions are provided in the algorithm descriptions.Unless stated otherwise, the described algorithms use the default
PageRank This graph algorithm computes the importance of a vertex based on the link structure of a graph [46]. The vertex state represents the current rank of a vertex (Fig. 3). The signals represent the rank transferred from the source vertex to the target vertex. The vertex state is initialised with the
Convergence: If one looks how the initial rank from a single vertex spreads, then one notices that it decays with the damping factor on every hop and that it eventually tapers off to zero. The computation on all vertices can be seen as many such single-source PageRank computations (sometimes referred to as personalised PageRank) that are overlaid and will, hence, also converge. In practice the convergence to zero can take many iterations, especially when there are cycles present. For this reason we usually set the scoreSignal function to return the delta between the current state of the vertex and the last signaled state (often referred to as the residual). This allows to conveniently set the desired level of precision by for example setting a signal threshold of 0.001. This means that a vertex will only signal if the residual is still larger or equal to 0.001.

Vertex colouring (data-graph).

Label propagation (data-graph).

Relational classifier (data-graph).
It is also possible to implement PageRank as a data-flow algorithm by signaling only the rank deltas (Fig. 4). This version can be further optimised by not sending the source vertex id with the signals, which saves bandwidth.
Single-source shortest path (SSSP) This algorithm computes the shortest distance from one special source vertex
Convergence: Vertices only signal if their distance was lowered by an incoming signal. Given that the distances can never be smaller than zero and that the first change of a vertex’s state will set it to a finite number, the distance of a vertex can only be lowered a finite number of times, which means that the algorithm is guaranteed to eventually converge.
Vertex colouring A vertex colouring problem is a special constraint optimisation problem that is solved when each vertex has an assigned colour from a set of colours and no adjacent vertices have the same colour. The following simple and inefficient algorithm solves the vertex colouring problem by initially assigning to each vertex a random colour from some arbitrary set of colours (Fig. 6). Then, the vertices check if their own colour (state) is already occupied (contained in the collection of received signals). If such a conflict is encountered, they switch to a random colour except their current colour. The default
Algorithms such as this one can solve many optimisation problems such as scheduling or finding solutions for Sudoku puzzles. The described algorithm works with undirected edges. In
A Distributed Stochastic Algorithm implementation in
Convergence: The computation keeps on going until there are no more conflicts between colours. If the number of colours available is smaller than the chromatic number of the graph, then there is no solution without conflicts, which means that this algorithm is not guaranteed to converge.
Label propagation This iterative graph clustering algorithm assigns to each vertex the label that is most common in its neighbourhood [64]. Our variant is called Chinese Whispers Clustering [3] and has applications in natural language processing. The algorithm works on graphs with undirected edges which are modelled with two directed edges.
The vertex state represents the current vertex label (=cluster) and it is initialised with the vertex id (Fig. 7). This means that each vertex starts in its own cluster. Then, labels are propagated to neighbours. When a vertex receives neighbours’ labels, it appends its own label to the collection of labels signalled by the neighbours. It then updates its own label to the most frequent label in that extended collection. Ties are broken arbitrarily.
The convergence depends on the mostFrequentValue function: According to [3] the algorithm does not converge if that function does not break ties in a consistent way, but that only a few iterations are needed until almost-convergence.

Conway’s Game of Life (data-graph).

Threshold models of collective behaviour (data-graph).
Relational classifier Relational classification can be considered a generalisation of label propagation. The presented classifier (Fig. 8) is a variation of the probabilistic relational-neighbour classifier described by Macskassy and Provost [39,40]. The algorithm works on graphs with undirected edges which are modelled with two directed edges.
Convergence: According to [39] there is no guarantee of convergence, but according to [40] one can extend the algorithm with simulated annealing to ensure and control convergence.
Conway’s game of life (Life) Life is played on a large checkerboard of cells, where each cell can be in one of two states (dead/alive) [14]. The game progresses in turns and each turn the state of a cell is updated based on the states of its neighbouring cells. The game is mapped to
Convergence depends on the initial configuration and there are many (famous) initial configurations that will never converge.
Threshold models of collective behaviour Granovetter [17] describes threshold models of collective behaviour to model situations in which agents have two options and the risk/payoff of each option depends on the behaviour of neighbouring agents. The risk/payoff is determined by a threshold which can be different for every actor. Threshold models allow to model the collective behaviour of a group of actors. Granovetter uses the example of rioting, but argues that such models can also be used to model innovation, rumour diffusion, disease spreading, strikes, voting, migration, educational attainment, and attendance of social events.

Matching path queries (data-flow).

Artificial neural networks (data-graph).
Such models can be mapped to
Convergence: In the described model no person will ever stop rioting, once they decide to riot. For this reason only a finite number of ‘I am now rioting’ messages can ever be sent. This means that at some point either everyone is rioting, or the non-rioters will never receive an additional message that could shift them towards becoming rioters. For this reason, the computation is guaranteed to converge.
Matching path queries This algorithm matches path queries, which is a typical use case for a graph processing system. The signals sent in the algorithm initially come from outside the graph along a virtual edge. The signals are path queries that specify a pattern of vertices and edges that they can match. An example for such a pattern might be: Match any path that starts with a vertex that has a “professor” property, continues along an edge that has an “advises” property and ends with an arbitrary vertex.
Once a query arrives at a vertex, its first part is matched with the vertex at which it has arrived (Fig. 11). This is done with the
If the query is fully matched – meaning all parts of its path are bound to a vertex or edge – then this path is reported as a result (this could be done by adding it to some result attribute that is later picked up by an aggregation operation). If there is still a part of the query left that needs to be matched, then it is added to the state set of the vertex. During the signal operation all edges try to match the next part of the queries – the one potentially constraining the type of edge to follow – using their
Matching path queries has many use cases: From simpler ones such as triangle/cycle detection, the approach could be extended to more complex tasks such as computing random walks with restarts or even matching expressive graph query languages.
Convergence: If each query only has a finite number of expected vertex/edge matches, then the execution is guaranteed to converge, because all queries will eventually either be eliminated or become fully matched.
Artificial neural networks Artificial neural networks are the result of an attempt to imitate the structure of biological neural networks and there are “literally tens of thousands of published applications” [49, p. 748]. Neural networks consist of nodes connected by links [49, p. 737]. The nodes are mapped to vertices in
Convergence: Neural networks usually do not contain cycles, so if there are no more new inputs, then the remaining activations are guaranteed to finish propagating through the network at some point.
Sketching of some additional algorithms The “Bipartite Matching” and “Semi-Clustering” algorithms described in the Pregel paper [41] can be adapted to the
We have also implemented a triple store with competitive performance inside
The main benefit of adapting an algorithm or system to the
In this subsection we evaluate the scalability of the
Multi-core (vertically/scale up)
We determined the multi-core scalability by measuring the parallel speedup when running an algorithm on the same graph, but with a varying number of worker threads.
In a first benchmark we ran the SSSP and PageRank algorithms on a machine with two twelve-core AMD Opteron™ 6174 processors and 66 GB RAM. We executed these algorithms with both synchronous and “eager” asynchronous scheduling. They were run on the web graph dataset8
PageRank was run with a signal function that returns the delta between the previous signal state and the current state (see Fig. 4). The signal threshold was set to 0.01, which determines the precision of the result. More detailed evaluation parameters can be found in the evaluation program.9
The evaluation program used was MulticoreScalabilityEvaluation in

Multi-Core Scalability of PageRank.

Multi-Core Scalability of Single-Source Shortest Path.
The fastest running time was 7 seconds for PageRank and 1.2 seconds for SSSP. The speedup when going from 1 core to 24 cores was 9 for SSSP and around 13 for PageRank. This shows that
In order to evaluate how
We generate the graphs by using the fitted parameters for the Notre Dame web graph ([0.999 0.414; 0.453 0.229]) which we also got from [34]. With these parameters we generated graphs with between 20 to 26 iterations of the Kronecker product, which resulted in graphs with between 659 518 vertices and 2 652 653 edges up to 39 865 268 vertices and 224 276 985 edges, in between increasing approximately with powers of two. For 27 iterations the graph generator repeatedly threw errors (the machine on which it was run had 128 GB of RAM).
The partitions in of the generated graphs are in many ways unbalanced: The number of outgoing edges from a worker partition varies by a factor of around 9 between the worker with the most outgoing edges and the one with the fewest. With regards to message sending, the distribution is even more uneven: We checked the number of sent messages between the busiest worker for one run at 20 and 26 iterations, and in both cases the busiest worker sent more than 100 times as many messages as the least busy worker.
We ran the experiment on machines with 128 GB RAM and two E5-2680 v2 processors at 2.80 GHz, with 10 cores per processor. The JVM on the machines used between 300 MB (minimum on the smallest graph) and 12.5 GB of RAM (maximum on the largest graph).
Figure 15 shows the performance when running delta PageRank with a threshold of 0.01 on these synthetic graphs.11
The evaluation program used was PageRankEvaluation in
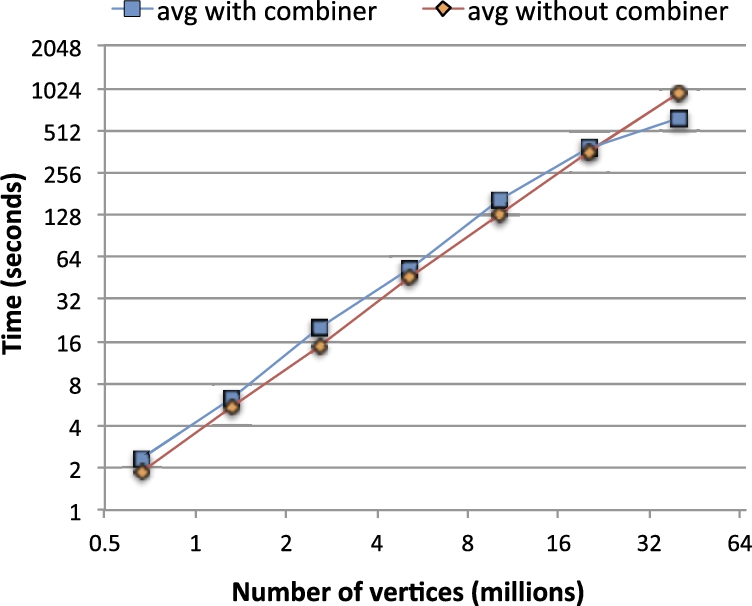
Data scalability for PageRank on synthetic Kronecker graphs. Both axes have logarithmic scales.
We determined the distributed scalability by measuring the speedup when running an algorithm on the same graph, but with a varying number of cluster nodes.
We ran this benchmark with an optimised version of the delta PageRank algorithm on the Yahoo! AltaVista webgraph12
Yahoo! Academic Relations, Yahoo! AltaVista Web Page Hyperlink Connectivity Graph, http://webscope.sandbox.yahoo.com/catalog.php?datatype=g.
The vertices were partitioned using hashing as described earlier, so most edges spanned different workers and nodes. The graph was loaded from the local file system of the machines and loading took between 45 seconds (fastest run with 12 nodes) and 235 seconds (slowest run with 4 nodes).
The huge number of signals required more efficient usage of bandwidth, which is why we used a bulk scheduler and bulk message bus. When scaling across more nodes and workers, this means that either each bulk signal has to contain fewer signals or that there is increased latency that would impair algorithm convergence. We chose to keep the latency constant, which has the effect of reducing the benefits of bulk signaling for runs with more nodes, but removes convergence characteristics as a confounding factor.
Another optimisation that we used was to have the vertex change the edge representation and for each edge only store the ID of the target vertex. The target IDs are integers, so to further reduce the memory footprint we sorted the array of target IDs and at each position only stored the delta from the previous array entry. We then took advantage of the smaller IDs by using variable length encoding on the ID deltas. Furthermore, we collected signals right when they were delivered, which makes it unnecessary to store them inside the vertex until they are collected. These optimisations reduced the memory footprint and allowed us to successfully run the algorithm on only four machines.
Every execution ran until convergence with a signal threshold of 0.01 and both the vertex state (PageRank) as well as the signals were represented as floating point numbers.
Figure 16(a) graphs the execution times. It shows that increasing the number of nodes decreases run-time. Indeed, the speedup plot in Fig. 16(b) shows that for using three times more resources we get a speedup of almost two. This is decent, considering that more nodes means a larger fraction of signals are sent across nodes (over the slow network, as opposed to fast in-memory transfers) and that there is more overhead for signaling due to smaller bulk signal sizes. More detailed evaluation parameters can be found in the evaluation program.13
The evaluation program used was DistributedWebGraphScalabilityEval in

Horizontal scalability of PageRank on the Yahoo! AltaVista Web Page Hyperlink Connectivity Graph with 1 413 511 390 vertices and 6 636 600 779 edges. The data points in Fig. 16(a) show the average execution time over 10 runs and the error bars indicate the fastest and slowest runs. Figure 16(b) plots the speedup relative to the average execution time with 4 nodes. The signal threshold used was 0.01, state and signals were represented as floats.
Comparison with other reported results We are well aware that comparing run-times between systems run on different machines is a problematic proposition at best. The main goal of the comparisons below is, therefore, to provide an intuition of the order of scalability and performance of
Pegasus [28] is a MapReduce-based system that ran 10 iterations of an iterative belief propagation algorithm on the same Yahoo! AltaVista webgraph using 100 machines of a Hadoop cluster. This computation took 4 hours.
GPS [50] computed 50 iterations of PageRank on a webgraph with 51 million vertices and 1.9 billion edges in 846 seconds using a cluster of 60 Amazon EC2 nodes (4 virtual cores and 7.5 GB of RAM each). Using a pre-partitioned graph reduced the computation time to 372 seconds. In their evaluations they describe that GPS runs more than an order of magnitude faster than Giraph.
GraphLab did not report any evaluations for the PageRank algorithm, which complicates comparison. The largest (pre-partitioned) graph it was evaluated on had 27 million vertices and 375 million edges. The non-partitioned ones were smaller.14
GraphLab did not scale up to the Yahoo! AltaVista webgraph according to the thesis defence slides of Joseph E. Gonzalez, slide 70, http://www.cs.cmu.edu/~jegonzal/talks/jegonzal_thesis_defense.pptx.
PowerGraph [16] required about 14 seconds to compute PageRank on a Twitter follower graph with 40 million vertices and 1.5 billion edges employing a cluster of 64 Amazon EC2 nodes (8 cores and 23 GB of RAM each, connected by 10 gigabit Ethernet). They report faster times with coordinated partitioning requiring an up-front loading time of more than 200 seconds. In their evaluations PowerGraph is at least an order of magnitude faster than the other frameworks they compare against.
In order to fairly compare the performance of two systems they have to be run on the same hardware. To that end we ran PageRank on both PowerGraph and
The evaluation program used was PageRankEvaluation in

Comparison between
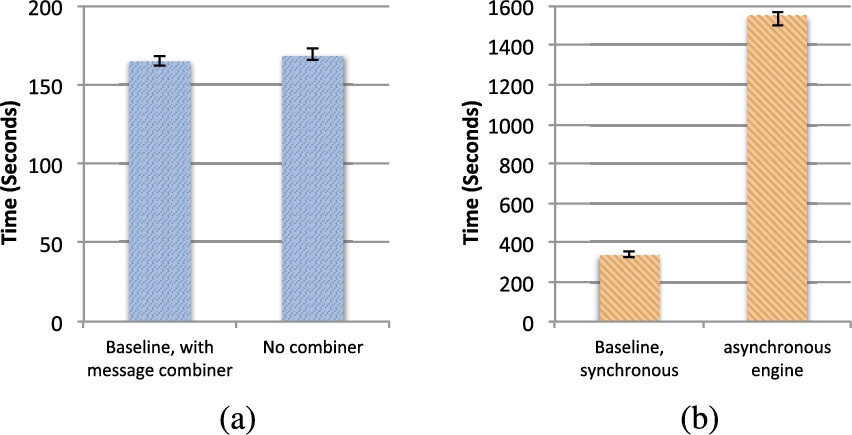
Figure 18(a) compares the baseline execution time of
In Figs 17 and 18 the bar displays the average running time over ten runs and the error bars indicate the performance of the fastest and slowest runs.
Figure 17(a) shows how the execution times change when the convergence threshold is varied around the baseline. We see that
Figure 17(b) shows the comparison of the baseline configurations of PowerGraph and
We also tested enabling delta caching for the PowerGraph synchronous and asynchronous engine. In both cases enabling delta caching resulted in the computation still running after several hours and we canceled the evaluation at that point.
We loaded the graphs from different formats and from a network drive, which is why the loading times are not comparable and are subject to variance due to local caching of the files. For
Note: PowerGraph only ran the computation on 720 242 173 vertices, because vertices without incoming or outgoing edges were discarded during the loading phase. One
Memory usage: The PowerGraph allocator reported that it used around 80 GB of the heap on each machine. The memory usage per node of
We also tried out alternative configurations: Fig. 18(a) compares the impact of using bulk messaging instead of the baseline signal combiner with
As always, given the complexity of such distributed frameworks, it is difficult to draw hard conclusions. Nonetheless, we feel that we can clearly state that the
In this section discuss and evaluate some aspects of asynchronous scheduling in
Lower latency between operations
An asynchronous scheduler is not tied to a global ordering that prescribes when information can be propagated. This flexibility can be used to reduce the latency between collecting and signaling and is especially important for use cases such as query processing, where latency is critical (see path query processing in Section 5.1). It can also lead to fewer signal operations due to faster information propagation (see the PageRank analysis in Section 5.4).
Reduction of oscillations
Some synchronous algorithms can be prone to getting trapped in oscillation patterns, where vertices cycle through states in lockstep. Asynchronous processing can reduce such oscillations and allows some of these algorithms to converge quickly.
In order to measure how much impact the lower latency signal propagation has we ran PageRank and SSSP with both kinds of schedulers in the previously described scalability experiments. As reported for the PageRank algorithm in Figs 13 and 14 asynchronous scheduling is on average between 36% (with 24 workers) and 41% (with 1 worker) faster than synchronous scheduling. This is largely because of earlier signal propagation: In all cases the asynchronous version required on average 30% fewer signal operations until convergence.
Scheduling does not have the same impact on all algorithms: The single-source shortest path algorithm took approximately the same amount of time, regardless of the scheduling.
To evaluate the impact of scheduling on oscillations we ran a greedy algorithm to solve vertex colouring problems on the Latin Square dataset.19
We used the dataset provided by CMU at http://mat.gsia.cmu.edu/COLOR04/INSTANCES/qg.order100.col.
The evaluation program used was VertexColoringSyncVsAsyncEvaluation in
Figure 19 shows the executions with “eager” asynchronous scheduling found solutions much quicker than synchronous executions. For the harder problems with fewer colours there are also several cases where a synchronous scheduling fails to find a solution within the time limit, while the asynchronous scheduling found a solution within a few seconds. One explanation is that with a synchronous scheduling the vertices tend to switch states in lockstep, which has them cycle through or oscillate between conflicts (“thrashing”). The results show that for some algorithms asynchronous scheduling can be crucial for fast convergence. Other algorithms share this property: Koller and Friedman note that some asynchronous loopy belief propagation computations converge where the synchronous computations keep oscillating. They summarize in that context that [31, p. 408]: “In practice an asynchronous message passing scheduling works significantly better than the synchronous approach.”

Vertex colouring with a varying number of colours on a Latin Square problem with 100 * 100 vertices and almost two million directed edges.
In this section we give an overview over the foundations of
Foundations
The
Bulk-synchronous parallel (BSP)
In BSP [57], a parallel computation consists of a sequence of supersteps. During each superstep, components process some assigned task and communicate with each other. There is a periodic global synchronization that ensures that all tasks of the superstep have been completed before the next superstep is started. The synchronous scheduling of
Actor model
In the actor programming model [22], many processing components take part in a computation and operate in parallel. These components can only influence each other via asynchronous message passing. The asynchronous scheduler of
Data-flow model
Depending on the context, the expression “data-flow” can have different meanings. We understand it broadly as a programming model where a computation is defined as a dependency graph in which data flows along edges and vertices use their input data to compute new data that gets sent along their outgoing edges. This model can be seen as a specialisation of the actor model, where each vertex is represented by an actor and communicates along the graph structure.
When designing a programming model for graph processing, it is important to consider the different kinds of computations on graphs. There are two fundamentally different ways of thinking about computations on graphs. One way to interpret a graph is as a data structure, where data can be associated with vertices and edges. Computations may explore this structure and modify its data, potentially iteratively, until some termination or convergence criterion is reached. We refer to computations with this characteristic as data-graph computations. Another way to interpret a graph is as a plan that determines the flow of data along processing stages. Vertices represent processing stages for data, while edges represent the (potentially cyclic) paths along which data flows. This view encompasses the data-flow programming model.

With
Researchers with roots in disparate communities such as machine learning, biology, or the semantic web have answered the call for general programming models and frameworks specialised for scalable graph processing.
Figure 20 provides a high-level overview of distributed data processing systems that support iterated processing. It differentiates systems along their ability for synchronous versus asynchronous processing of the data on the y-axis and the kind of data abstraction they operate on (key-value pairs, sets, or tables versus graphs) on the x-axis. The category “Synchronisation Required” encompasses systems that schedule iterated computations with mandatory global barriers between iterations. The “Asynchronous Possible” category encompasses systems that are able to schedule iterated computation without such global barriers. “MR Based” is used as a category label for systems that extend the MapReduce model with support for iterated processing or graph abstractions.
We focus our discussion on programming models and systems that are geared towards processing graphs, especially ones that are capable of asynchronous processing. Specifically, we first present GraphStep and Pregel, which have inspired many other graph specialised BSP-based systems. After that, we discuss GraphLab, its extension PowerGraph, and HipG in detail, because they are vertex centric approaches that are closely related to
GraphStep [12] is the programming model that is most closely related to
Pregel is a framework with a similar programming model developed by Google for large-scale graph processing [41]. The framework scales to graphs with billions of vertices and edges via distribution to thousands of commodity PCs. Pregel is based on a programming model that was inspired by BSP: A computation consists of a sequence of supersteps. During a superstep, each vertex executes an algorithm-specific compute function that can modify the vertex state, modify the graph, and send messages to other vertices. Global synchronisations ensure that all compute functions of the superstep have been completed before the next superstep is started. Within a compute function, a vertex can vote to halt the computation. A computation ends when all the vertices have voted to halt. In order to reduce the number of messages that are sent between workers/machines, Pregel supports combiners that aggregate multiple messages for the same vertex into one. For the computation of global values Pregel also supports aggregation operations.
The Pregel model merges computation, communication, and termination detection into one compute function on a vertex. This function is a black box from the perspective of the framework, which requires a manual implementation of termination detection and prevents the scheduler from separately scheduling state updates and communication.
Pregel can only handle synchronous computations. In a synchronous computation one problematic operation or node can be enough to slow all computations, while in an asynchronous computation only operations on that node or the specific operation are slowed. As we discussed in our evaluation (see Section 5.4), synchronous scheduling can also lead to convergence problems due to oscillations for some algorithms.
Pregel supports graphs with one kind of vertex type sharing a single compute function. This complicates the reusability of vertex/edge-specifications and it adds complexity when implementing algorithms with multiple kinds of vertices or edges. These constraints also make it harder to compose several algorithms within the same computation.
There are extensions to the model for incremental recomputations [5] and for custom scheduling that can imitate some of the properties of an asynchronous scheduling [58].
Google has not released its implementation of Pregel, but there exist several related open source implementations such as Giraph,27
GraphLab is a programming model and framework for parallel graph algorithms [37]. The programming model is especially suitable for computations with sparse data dependencies and for asynchronous iterative computation.
GraphLab is based on a data-graph model which simultaneously represents data and computational dependencies. A computation progresses by executing update functions on vertices. These functions can modify the vertex and edge data as well as data associated with neighbouring vertices in the data-graph. The model offers flexible scheduling of these update operations as well as functions to aggregate over the state of the entire data-graph. The scheduler supports different consistency guarantees, which permit the adaptation of some algorithmic correctness proofs from a sequential to a parallel setting.
In full-consistency mode, concurrent modifications to the neighbourhood of a vertex have to be prevented while an update function is executed. Assuming a random distribution of vertices over cluster nodes of a large cluster – an assumption currently true for many frameworks such as HipG (see below) and Pregel – the expected (and worst-case) scenario is that the vertex data and the data of neighbouring vertices are spread over almost as many nodes as there are vertices in the neighbourhood. The authors describe in a more recent publication [16] (see below) that executing an update function in full-consistency mode on a vertex with a sizable neighbourhood is a costly operation, because it requires a distributed lock of a large fraction of the cluster. They also mention that “distributed locking and synchronization introduces substantial latency” [36]. Furthermore, they describe that “the locking scheme used by GraphLab is unfair to high degree vertices” (see [16, Section 4.3.2]).
Another scheduler (“chromatic engine”) works around some of these issues in distributed computations [36]. This scheduler uses a vertex colouring to avoid the expensive locking during execution. It is equivalent to a BSP execution where at each step only vertices with the same colour are active. This scheduler requires finding a graph colouring (more constrained ones for strong consistency guarantees) and the number of processing steps and global synchronisations is multiplied by the number of colours used for the graph colouring.
GraphLab does currently not allow graph modifications during a computation and does not support graphs with multiple vertex types, which complicates composition of algorithms and reusability of components. Lastly, GraphLab has undirected edges. Hence, algorithms that exploit directionality would have to encode it in an edge’s data, complicating the framework’s ability to optimise computations based on directionality.
PowerGraph
PowerGraph [16] is a substantial redesign and reimplementation of GraphLab. The main difference in PowerGraph’s abstraction lies in the computation’s division into three phases:
To enable a more efficient implementation of the distribution PowerGraph introduces the idea of vertex cuts – essentially the replication of vertices to many machines. Whilst this reduces cross-machine communication for some algorithms and more evenly distributes the load of high-degree vertices, it introduces replication of the vertices and their associated state/data up to a factor of 5–18 for 64 machines. The variation of the overhead factor is dependent on the partitioning strategy chosen. Smarter strategies reduce the replication factor but increase graph loading time by a factor of about 5 (when using 64 machines).
In a direct comparison of the programming models, PowerGraph has consistency guarantees and the built-in optimisations for high-degree vertices going for it.
PowerGraph’s lack of support for modifications during a computation or the efficiency of the asynchronous implementation are most likely engineering related and not fundamental properties of the approach.
HipG
HipG is a distributed framework that facilitates high-level programming of parallel graph algorithms by expressing them as a hierarchy of distributed computations [32,33].
As in the Pregel model, code is executed on a vertex. But while in Pregel messages are sent to other vertices, a HipG vertex can conceptually directly execute functions on neighbouring vertices (the framework translates those function calls to asynchronous messages). HipG supports synchronisers, which are coordinators for function executions that have the option to block until all executed functions have completed. This feature can also be used to aggregate global values. A synchroniser can spawn additional synchronisers to create hierarchical computations. This is especially useful for divide and conquer algorithms on graphs.
While it is possible to write a compute function for a vertex that handles thousands of received messages at once, there is no obvious way of combining functions, which means that they all have to be executed. This could be problematic if one wants to implement an iterated computation, because it would require for a function to spawn as many new functions as there are neighbours, potentially leading to an exponential growth of functions in the system. One solution is to use a global synchroniser that repeatedly executes functions on all vertices (using a “visit” flag and only propagating onwards if the flag is not set yet) and has barriers (synchronisations) between those executions (indeed, this is how the PageRank example is implemented in the example code provided with the system33
The Parallel BGL34
Parallel Boost Graph Library:
Najork et al. [43] evaluated three different platforms and programming models on large graphs. The focus of the evaluation is to find the trade-offs between the platforms for various algorithms. The evaluation did not include vertex-centric models. Members of the same lab are also working on the Trinity graph engine, a distributed key-value store with optimisations for vertex-centric graph processing, such as bundling of messages, graph partitioning and low latency processing [61]. Trinity also supports asynchronous processing and while the technology and features of the framework are impressive, it is not publicly available and the report gives little information about the properties of the programming model and about how algorithms are expressed.
There are several systems for large-scale graph computations implemented on top of MapReduce or by generalising the MapReduce model. Most of these systems have limited support for iterated computations and do not support asynchronicity [8,20,29,52]. PrIter is a modified version of Hadoop MapReduce that supports executing processing steps only on a subset of items with priorities above a threshold [63]. Kajdanowicz et al. [27] compared the efficiency of a MapReduce-based system with a BSP-based system for processing large graphs and conclude that BSP can outperform MapReduce by up to an order of magnitude.
Piccolo and Spark are distributed processing platforms that use table-/set-based abstractions, support iteration and can serve as the foundation of more specialised graph processing frameworks [48,60]. One such extension is the aforementioned Bagel which is built on Spark.
Also noteworthy are distributed data-flow engines such as Sawzall [47], Dryad/DryadLINQ [25,26], Pig [45], and Ciel/Skywriting [42]. Computations on graphs require a custom mapping to the respective data-flow language model. Some of the languages allow to express iterated processing, but the underlying systems are not optimised for doing this efficiently on graph structured data.
There are more graph processing libraries that focus on specific algorithms, but did not offer a detailed enough explanation of a more general programming model. Also we did not cover frameworks that focus on specific aspects of scaling algorithms on architectures such as supercomputers or GPUs, because the scalability challenges are different.
As we have seen in previous sections,
In addition, our evaluation does raise some very interesting questions: Could we improve performance with a better graph partitioning scheme? How does
Due to the default partitioning scheme the vast majority of signals in the distributed version are sent over the network. This is inefficient, but it could be improved without modifying the programming model: A domain optimised hash function could be used, for example one that maps websites from the same domain to the same worker or cluster node. This should improve locality of signaling. It would be interesting to see to what degree such a scheme would suffer from imbalanced loads for different domains.
We did not encounter any problems due to high in/out-degree vertices so far. Whilst Pregel-style combiners address the problem of high in-degree vertices, the problem of high out-degree vertices could be addressed by modifying a graph: High out-degree vertices could create child vertices that each inherit a share of the outgoing edges. All state changes and further edge additions/removals are forwarded to the child vertices. High out-degree child vertices could recursively use the same scheme. A more efficient and more limited alternative is to parallelise the signaling on a vertex to “smear” the signaling workload across a cluster node instead of having the entire load on one worker.
All our experiments were run on either web-style real-world graphs or the synthetic Kronecker graphs. These graphs have an uneven degree distribution [34]. Consequently, one might argue that our findings may have a limited generalizability. As discussed above, however, we believe that
Finally, it would be interesting to experiment with a prioritising scheduler. Such a scheduler might have benefits for use cases in which computing and sending signals is very expensive relative to other tasks. Otherwise, the overhead of prioritising operations may not pay off.
Conclusions
Both researchers and industry are confronted with the need to process increasingly large amounts of data, much of which has a natural graph representation. In order to address the need to run algorithms on increasingly large graphs we have designed a programming model that is both simple and expressive. We showed its expressiveness by designing adaptations of many interesting algorithms to the programming model and the simplicity by being able to express these algorithms with just a few lines of code.
We built an open source framework that can parallelise and distribute the execution of algorithms formulated in the model. We empirically evaluated the scalability of the framework across different graph structures and algorithms and have shown that the framework scales with additional resources. The framework offers great efficiency and performance on a cluster architecture, which was shown by loading the huge Yahoo! AltaVista webgraph and computing high-quality PageRanks for its vertices in just 3 minutes on a dozen machines.
With
Footnotes
Acknowledgements
We thank the Hasler foundation for funding our research and Yahoo! for giving us access to the AltaVista Web Page Hyperlink Connectivity Graph. We thank Mihaela Verman, Lorenz Fischer, and Patrick Minder for the many interesting discussions, for feedback, and proofreading, as well as William Cohen for input on earlier versions of the project. We thank Francisco de Freitas for designing the first prototype of an Akka-based distributed version of the
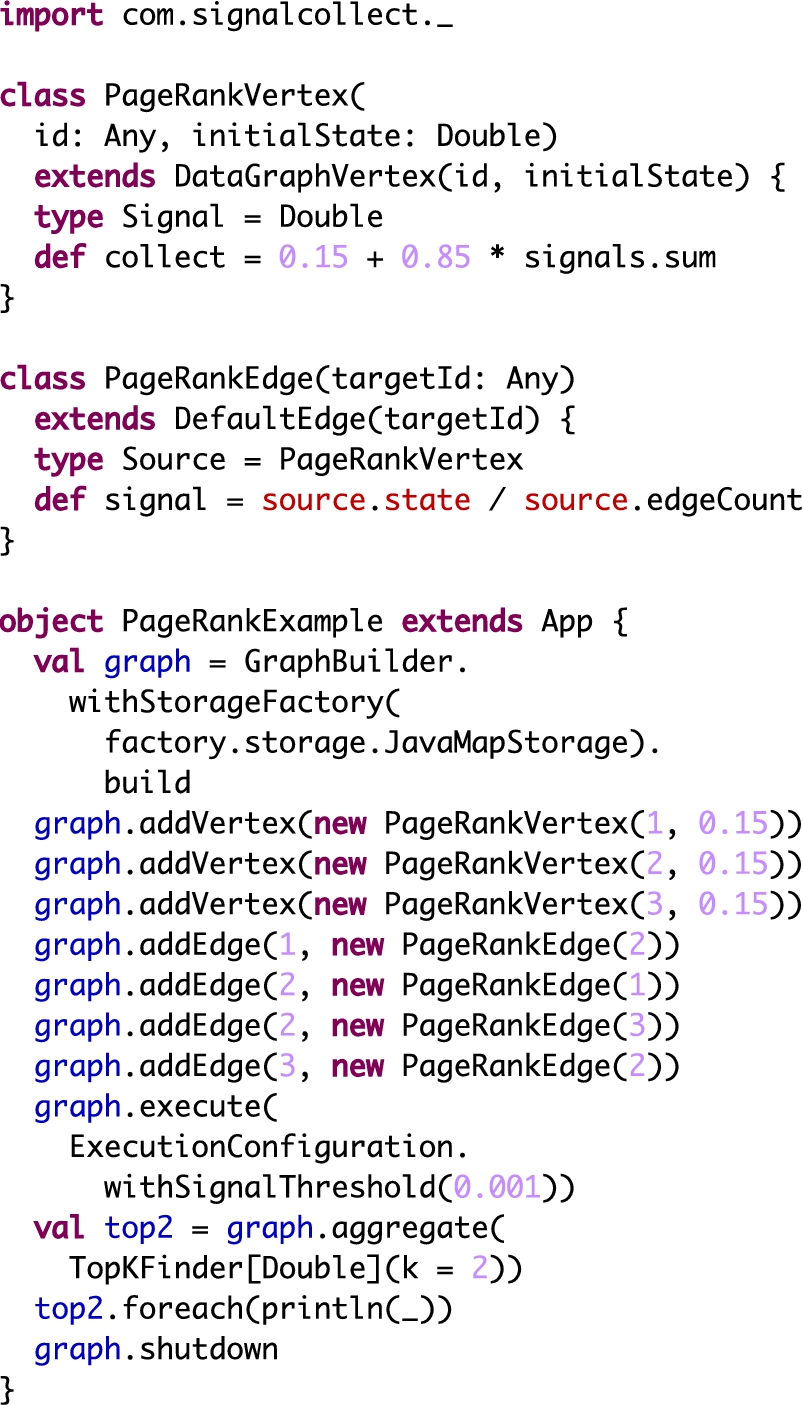
In order to show how the framework is used in practice, we show the source code of an executable algorithm in the
Source code available at https://github.com/uzh/signal-collect-evaluation/blob/master/src/main/scala/com/signalcollect/evaluation/algorithms/paper/PageRank.scala.
Executable Scala code of a PageRank algorithm definition, sequential graph building, a local execution, and an aggregation operation. Note that the actual PageRank code only encompasses the upper two class definitions. The