Representing uncertain information is crucial for modeling real world domains. In this paper we present a technique for the integration of probabilistic information in Description Logics (DLs) that is based on the distribution semantics for probabilistic logic programs. In the resulting approach, that we called DISPONTE, the axioms of a probabilistic knowledge base (KB) can be annotated with a real number between 0 and 1. A probabilistic knowledge base then defines a probability distribution over regular KBs called worlds and the probability of a given query can be obtained from the joint distribution of the worlds and the query by marginalization. We present the algorithm BUNDLE for computing the probability of queries from DISPONTE KBs. The algorithm exploits an underlying DL reasoner, such as Pellet, that is able to return explanations for queries. The explanations are encoded in a Binary Decision Diagram from which the probability of the query is computed. The experimentation of BUNDLE shows that it can handle probabilistic KBs of realistic size.
Representing uncertain information is of foremost importance in order to effectively model real world domains. This has been fully recognized in the field of Artificial Intelligence where uncertainty has been the focus of much research since its beginnings. In particular, the integration of logic and probability allows to model complex domains with many entities interconnected by uncertain relationships. This problem has been investigated by various authors both in the general case of first order logic [6,22,42] and in the case of restricted logics, such as Description Logics (DLs) and Logic Programming (LP).
DLs are fragments of first order logic particularly useful for knowledge representation. They are at the basis of the Semantic Web. The Web Ontology Language (OWL) is a family of languages that are syntactic variants of various DLs. Many proposals have appeared on the combination of probability theory and DLs [23,24,35,39,40]. Probabilistic DLs play an important role in the Semantic Web where knowledge may come from different sources and may have different reliability.
In LP, the distribution semantics [65] has emerged as one of the most effective approaches for representing probabilistic information. It underlies many probabilistic logic programming languages such as Probabilistic Horn Abduction [47], PRISM [65,66], Independent Choice Logic [48], Logic Programs with Annotated Disjunctions [74], ProbLog [50] and CP-logic [75]. A program in one of these languages defines a probability distribution over normal logic programs called worlds. This distribution is extended to queries and the probability of a query is obtained by marginalizing the joint distribution of the query and the programs. The languages following the distribution semantics differ in the way they define the distribution over logic programs but have the same expressive power: there are transformations with linear complexity that can convert each one into the others [16,73].
The distribution semantics was applied successfully in many domains [7,50,66] and various inference and learning algorithms are available for it [8,31,54].
In [9,60,61] we applied this approach to DLs obtaining DISPONTE for “DIstribution Semantics for Probabilistic ONTologiEs” (Spanish for “get ready”). The idea is to annotate axioms of a theory with a probability and assume that each axiom is independent of the others. A DISPONTE knowledge base (KB) defines a probability distribution over regular KBs (worlds) and the probability of a query is obtained from the joint probability of the worlds and the query. The DISPONTE semantics differs from previous proposals because it provides a unified framework for representing different types of probabilistic knowledge, from assertional to terminological knowledge. DISPONTE can be applied to any DL, here we present it for a prototypical expressive DL, , that is the basis of OWL DL.
We also present the algorithm BUNDLE for “Binary decision diagrams for Uncertain reasoNing on Description Logic thEories” [62], that performs inference over DISPONTE DLs. BUNDLE exploits an underlying reasoner such as Pellet [69] that returns explanations for queries. BUNDLE uses the inference techniques developed for probabilistic logic programs under the distribution semantics, in particular Binary Decision Diagrams (BDDs), for computing the probability of queries from a covering set of explanations. BUNDLE first finds explanations for the query and then encodes them in a BDD from which the probability can be computed in time linear in the size of the diagram.
BUNDLE’s worst case complexity is high since the number of explanations may grow exponentially while the computation of the probability through BDDs has #P-complexity in the number of explanations. Nevertheless, we applied BUNDLE to various real world datasets and we found that it is able to handle domains of significant size.
The present paper extends previous work [9,60–62] in various ways. With respect to the most recent work [62], the DISPONTE semantics is described in more detail with several examples; inference under this semantics is illustrated according to different techniques; we discuss how a lower bound on the probability of a query can be computed, with the quality of the bound monotonically increasing as more time for inference is allowed; BUNDLE is presented in more detail together with an extended description of Pellet’s functions and a discussion about its computational complexity. Moreover, we elaborated a detailed comparison with related work and performed an extensive experimental analysis of BUNDLE in order to investigate its performance in practice. In particular we present a more in-depth comparison with PRONTO, a system for inference in the probabilistic DL , and an analysis on the inference time trend with increasing sizes of the Tbox, the Abox and the set of probabilistic axioms.
The paper is organized as follows. Section 2 introduces Description Logics with particular reference to while Section 3 discusses DISPONTE. Section 4 illustrates how to compute the probability of queries to DISPONTE DLs and Section 5 describes the BUNDLE algorithm. Section 6 discusses the complexity of reasoning and Section 7 related work. Section 8 shows the results of experiments with BUNDLE and, finally, Section 9 concludes the paper.
Description Logics
Description Logics are knowledge representation formalisms that possess nice computational properties such as decidability and/or low complexity, see [3,5] for excellent introductions. DLs are particularly useful for representing ontologies and have been adopted as the basis of the Semantic Web.
While DLs are a fragment of predicate logic, they are usually represented using a syntax based on concepts and roles. A concept corresponds to a set of individuals of the domain while a role corresponds to a set of couples of individuals of the domain. In order to illustrate DLs, we describe as a prototype of expressive description logics. In the rest of the paper we use A, R and I to indicate atomic concepts, atomic roles and individuals, respectively. A role is either an atomic role or the inverse of an atomic role . We use to denote the set of all inverses of roles in R. Concepts are defined as follows. Each , ⊥ and ⊤ are concepts and if , then is a concept called a nominal. If C, and are concepts and , then , and are concepts, as well as and and and for an integer .
An RBox consists of a finite set of transitivity axioms, where , and role inclusion axioms, where . A TBox is a finite set of concept inclusion axioms, where C and D are concepts. We use to abbreviate and . An ABox is a finite set of concept membership axioms, role membership axioms, equality axioms and inequality axioms, where C is a concept, and . A knowledge base consists of a TBox , an RBox and an ABox .
A KB is assigned a semantics in terms of interpretations where is a non-empty domain and is the interpretation function that assigns an element in to each , a subset of to each and a subset of to each . The mapping is extended to all concepts (where and denotes the cardinality of the set X) as:
adds to datatype roles, i.e., roles that map an individual to an element of a datatype such as integers, floats, etc. Then new concept definitions involving datatype roles are added that mirror those involving roles introduced above. We also assume that we have predicates over the datatypes.
The satisfaction of an axiom E in an interpretation , denoted by , is defined as follows: (1) iff is transitive, (2) iff , (3) iff , (4) iff , (5) iff , (6) iff , (7) iff . satisfies a set of axioms , denoted by , iff for all . An interpretation satisfies a knowledge base , denoted , iff satisfies , and . In this case we say that is a model of .
A knowledge base is satisfiable iff it has a model. An axiom E is entailed by , denoted , iff every model of satisfies also E. A concept C is satisfiable relative to iff has a model such that .
A DL is decidable if the problem of checking the satisfiability of a KB is decidable. In particular, is decidable iff there are no number restrictions on non-simple roles. A role is non-simple iff it is transitive or it has transitive subroles.
A query over a KB is usually an axiom for which we want to test the entailment from the KB. The entailment test may be reduced to checking the unsatisfiability of a concept in the KB, i.e., the emptiness of the concept. For example, the entailment of the axiom may be tested by checking the unsatisfiability of the concept .
The DISPONTE semantics for DLs
DISPONTE applies the distribution semantics [65] of probabilistic logic programming to DLs. A program following this semantics defines a probability distribution over normal logic programs called worlds. Then the distribution is extended to queries and the probability of a query is obtained by marginalizing the joint distribution of the query and the programs.
Syntax and intuition
In DISPONTE, a probabilistic knowledge base is a set of certain axioms or probabilistic axioms. Certain axioms take the form of regular DL axioms. Probabilistic axioms take the form
where p is a real number in and E is a DL axiom.
The idea of DISPONTE is to associate independent Boolean random variables to the probabilistic axioms. By assigning values to every random variable we obtain a world, the set of axioms whose random variables are assigned the value 1.
Every formula obtained from a certain axiom is included in a world w. For each probabilistic axiom, we decide whether to include it or not in w. A world therefore is a non probabilistic KB that can be assigned a semantics in the usual way. A query is entailed by a world if it is true in every model of the world.
The probability p can be interpreted as an epistemic probability, i.e., as the degree of our belief in axiom E. For example, a probabilistic concept membership axiom
means that we have degree of belief p in . The statement that Tweety flies with probability 0.9 can be expressed as
A probabilistic concept inclusion axiom of the form
represents the fact that we believe in the truth of with probability p. For example, the axiom
means that birds fly with a 90% probability.
Semantics
We follow the approach of [49] and first give some definitions. An atomic choice is a couple where is the ith probabilistic axiom and . k indicates whether is chosen to be included in a world () or not (). A set of atomic choices κ is consistent if only one decision is taken for each probabilistic axiom; we assume independence between the different choices. A composite choice κ is a consistent set of atomic choices. The probability of a composite choice κ is , where is the probability associated with axiom . A selection σ is a total composite choice, i.e., it contains an atomic choice for every probabilistic axiom of the theory. A selection σ identifies a theory called a world in this way: where is the set of certain axioms. Let us indicate with the set of all selections and with the set of all worlds. The probability of a world is . is a probability distribution over worlds, i.e., .
We can now assign probabilities to queries. Given a world w, the probability of a query Qis defined as if and 0 otherwise. The probability of a query can be obtained by marginalizing the joint probability of the query and the worlds:
where (4) and (5) follow for the sum and product rule of the theory of probability respectively and (6) holds because if and 0 otherwise.
Consider the following KB, inspired by the people+pets ontology proposed in [43]:
The KB indicates that the individuals that own an animal which is a pet are nature lovers with a 50% probability and that has the animals and . Fluffy and are cats and cats are pets with probability 60%. The KB has four possible worlds, corresponding to the selections:
and the query axiom is true in the first of them, while in the remaining ones it is false. Each pair in the selections contains the axiom identifier and the value of its selector (k).
The probability of the query is .
Let us consider a slightly different knowledge base:
Here individuals that own an animal which is a pet are surely nature lovers and has the animals and . Moreover, we believe in the fact that and are cats and that cats are pets with a certain probability.
This KB has eight worlds and the query axiom is true in three of them, those corresponding to the following selections:
so the probability is
Note that if the regular DL KB obtained by stripping the probabilistic annotations is inconsistent, there will be worlds that are inconsistent too. These worlds will entail the query trivially, as does the regular KB. A DISPONTE KB with inconsistent worlds should not be used to derive consequences, just as a regular DL KB that is inconsistent should not.
However, apparently contradictory probabilistic information is allowed. For example, the KB
states that the probability of flying for a bird is 0.9 and the probability of flying for , a particular bird, is 0.1. The two probabilistic statements are considered as independent evidence for flying and are combined giving the probability 0.91 for the query . In fact, this KB has four worlds and is true in three of them, giving . Thus knowledge about instances of the domain may reinforce general knowledge and vice-versa.
The knowledge base
means that all individuals in the friend relationship with are persons, that is a friend of , that is a friend of and that given three individuals a, b and c, there is a 40% probability that if a is a friend of b and b is a friend of c then a is a friend of c. In particular, we have a 40% probability that, if is a friend of and is a friend of , then is a friend of . Since the first two are certain facts, then is a friend of with a 40% probability and is a person also with a 40% probability.
The final report of the W3C Uncertainty Reasoning for the World Wide Web Incubator Group [71] discusses the challenge of reasoning with uncertain information on the World Wide Web. Moreover, it also highglights several use cases for the representation of uncertainty: combining knowledge from multiple, untrusted sources; discovering and using services in the presence of uncertain information on the user requirements and the service descriptions; recommending items to users; extracting and annotating information from the web; automatically performing tasks for users such as making an appointment, and handling healthcare and life sciences information and knowledge.
By introducing probability in an expressive description logic, such as that is one of the bases of OWL, we are able to tackle these problems as shown in the following example.
Consider a KB similar to the one of Example 2 but where we have a single cat, . Suppose the user has the knowledge
and there are two sources of information with different reliability that provide the information that is a cat. On one source the user has a degree of belief of 0.4, i.e., he thinks it is correct with a 40% probability, while on the other source he has a degree of belief 0.3, i.e., he thinks it is correct with a 30% probability. The user can reason on this knowledge by adding the following statements to his KB:
The two statements represent independent evidence on being a cat.
The query axiom is true in 3 out of the 4 worlds, those corresponding to the selections:
So . This is reasonable if the two sources can be considered as independent. In fact, the probability comes from the disjunction of two independent Boolean random variables with probabilities respectively 0.4 and 0.3:
Inference
We propose an approach for performing inference over DISPONTE DLs in which we first find explanations for the given query and then compute the probability of the query from them. In order to discuss the approach, we first need to introduce some definitions.
A composite choice κ identifies a set of worlds , the set of worlds whose selection is a superset of κ, i.e., the set of worlds “compatible” with κ. We define the set of worlds identified by a set of composite choices K as .
A composite choice κ is an explanation for a query Q if Q is entailed by every world of . A covering set of explanations for Q is a set of composite choices K such that every world in which the query is true is included in .
Two composite choices and are incompatible if their union is inconsistent. For example, the composite choices and are incompatible where is a probabilistic axiom. A set K of composite choices is pairwise incompatible if for all implies and are incompatible. For example
with
and
is pairwise incompatible.
We define the probability of a pairwise incompatible set of composite choices K as
Two sets of composite choices and are equivalent if , i.e., if they identify the same set of worlds. For example, K in (18) is equivalent to
with
and
Inference with the splitting algorithm
If E is an axiom and κ is a composite choice such that , the split of κ on E is the set of composite choices . It is easy to see that κ and identify the same set of possible worlds, i.e., that . For example, the split of in (22) on contains in (19) and .
Given a finite set K of finite composite choices, there exists a finite setof pairwise incompatible finite composite choices such that K andare equivalent.
Given a finite set of finite composite choices K, there are two possibilities to form a new set of composite choices so that K and are equivalent:
removing dominated elements: if and , let .
splitting elements: if are compatible (and neither is a superset of the other), there is a . We replace by the split of on E. Let .
In both cases . If we repeat these two operations until neither is applicable we obtain a splitting algorithm (see Fig. 1) that terminates because K is a finite set of finite composite choices. The resulting set is pairwise incompatible and is equivalent to the original set. For example, the splitting algorithm applied to (21) can return K (18). □
Ifandare both pairwise incompatible finite sets of finite composite choices such that they are equivalent then.
For example, K in (18) and with and are equivalent and are both pairwise incompatible. Their probabilities are
and
Note that if we compute the probability of in (21) with formula (20) we would obtain which is different from the probabilities of K and above, even if is equivalent to K and , because is not pairwise incompatible.
We can thus define the probability of a generic set of composite choices K as , where is a mutually incompatible set of composite choices that is equivalent to K, i.e., such that . Given a query Q, the set is a set of pairwise incompatible composite choices. Since , then .
If is a set of explanations for Q that is covering, then and are equivalent so . Thus we do not have to generate all worlds where a query is true in order to compute its probability, finding a mutually incompatible covering set of explanations is enough. Moreover, an additional result is given by the following theorem.
Given two finite sets of finite composite choicesand, if, then.
Let be the result of the application of the splitting algorithm to . We can apply the same operations of the algorithm to obtaining for a certain . At this point, we can continue applying the splitting algorithm. If there exists a and a such that , at least one of κ and must not belong to , otherwise κ would have been removed when splitting . κ is removed from K while remains. If there is a compatible couple and in K, we can assume that one of the two, say , does not belong to , since otherwise it would have been split before. We add to K the split of on an atomic choice in but not in .
Let be the results of the splitting algorithm so applied. is such that, for each element of , contains an element such that . Therefore, in the summation in (20), for each term in there will be a term in with a larger or equal value so . □
Thus, if K is a finite set of finite explanations for a query Q but we don’t know if K contains all possible explanations for Q, i.e., we don’t know whether K is covering, then will be a lower bound of . So we can compute progressively more accurate estimates from below of by considering an increasing set of explanations. Only when K contains all possible explanations, then .
The problem of computing the probability of a query can thus be reduced to that of finding a covering set of explanations K and then making it pairwise incompatible, so that the probability can be computed with the summation of (20). To obtain a pairwise incompatible set of explanations, the splitting algorithm can be applied.
Inference through Binary Decision Diagrams
As an alternative to the splitting algorithm, given a covering set of explanations K for a query Q, we can define the Disjunctive Normal Form (DNF) Boolean formula as
The variables are independent Boolean random variables whose probability of being true is for the variable . The probability that assumes value 1 is equal to the probability of Q. We can now apply knowledge compilation to the propositional formula [15], i.e. translate it to a target language that allows answering queries in polynomial time. A target language that was found to give good performances is the one of Binary Decision Diagrams (BDD). From a BDD we can compute the probability of the query with a dynamic programming algorithm that is linear in the size of the BDD [50]. Riguzzi [54] showed that this approach is faster than the splitting algorithm.
A BDD for a function of Boolean variables is a rooted graph that has one level for each Boolean variable. A node n in a BDD has two children: one corresponding to the 1 value of the variable associated with the level of n, indicated with , and one corresponding to the 0 value of the variable, indicated with . When drawing BDDs, the 0-branch – the one going to – is distinguished from the 1-branch by drawing it with a dashed line. The leaves store either 0 or 1.
BDDs can be built by combining simpler BDDs using Boolean operators. While building BDDs, simplification operations can be applied that delete or merge nodes. Merging is performed when the diagram contains two identical sub-diagrams, while deletion is performed when both arcs from a node point to the same node. In this way a reduced BDD is obtained, often with a much smaller number of nodes with respect to the original BDD. The size of the reduced BDD depends on the order of the variables: finding an optimal order is an NP-complete problem [10] and several heuristic techniques are used in practice by highly efficient software packages such as CUDD.1
Available at http://vlsi.colorado.edu/~fabio/CUDD/.
Alternative methods involve learning variable order from examples [20].
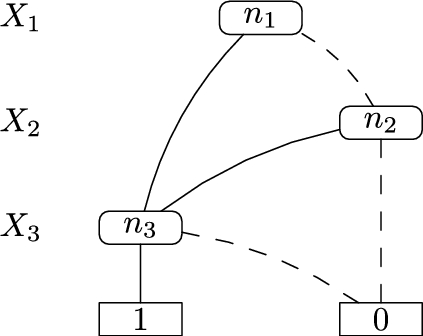
For instance, a BDD for the function
is shown in Fig. 2.
A BDD performs a Shannon expansion of the Boolean formula , so that, if X is the variable associated with the root level of a BDD, the formula can be represented as where () is the formula obtained by by setting X to 1 (0). Now the two disjuncts are pairwise exclusive and the probability of can be computed as . In other words, BDDs make the explanations pairwise incompatible. Figure 3 shows function Prob that implements the dynamic programming algorithm for computing the probability of a formula encoded as a BDD.
The function should also store the value of already visited nodes in a table so that, if a node is visited again, its probability can be retrieved from the table. For the sake of simplicity Fig. 3 does not show this optimization but it is fundamental to achieve linear cost in the number of nodes, as without it the cost of the function Prob would be proportional to where n is the number of Boolean variables.
Function that computes the probability of a formula encoded as a BDD, where is 0 or 1 and is the variable associated with .
Let us discuss inference on some examples.
Let us consider the KB of Example 2. A covering set of explanations for the query axiom is where and . If we associate the random variables to (13), to (14) and to (15), is shown in (24) and the BDD associated with the set K of explanations is shown in Fig. 2. By applying the algorithm in Fig. 3 we get
so which corresponds to the probability given by the semantics.
Let us consider a slightly different knowledge base:
A covering set of explanations for the query axiom is where and . If we associate the random variables to (25), to (26), to (27) and to (28), the BDD associated with the set K of explanations is shown in Fig. 4. By applying the algorithm in Fig. 3 we get
so .
The BUNDLE algorithm computes the probability of queries from a probabilistic knowledge base that follows the DISPONTE semantics. It first finds a covering set of explanations for the query and then makes them pairwise incompatible by using BDDs. Finally, it computes the probability from the BDD by using function Prob in Fig. 3.
The problem of finding explanations for a query has been investigated by various authors [21,27,29,30]. Schlobach and Cornet [67] called it axiom pinpointing and considered it a non-standard reasoning service useful for tracing derivations and debugging ontologies. In particular, they define minimal axiom sets or MinAs for short.
(MinAs).
Let be a KB and Q an axiom that follows from it, i.e., . We call a set a minimal axiom set or MinA for Q in if and M is minimal w.r.t. set inclusion. The set of all possible MinAs is called All-MinAs(). The problem of enumerating all MinAs is called min-a-enum.
All-MinAs() can be used to derive a covering set of explanations. min-a-enum can be solved either with reasoner dependent (glass-box) approaches or reasoner independent (black-box) approaches [30]. Glass-box approaches are built on existing tableau-based decision procedures and modify the internals of the reasoner. Black-box approaches use the DL reasoner solely as a subroutine and the internals of the reasoner do not need to be modified.
The techniques of [21,28–30] for axiom pinpointing have been integrated into the Pellet reasoner [69]. By default, Pellet solves min-a-enum with a hybrid glass/black-box approach: it finds a single MinA using a modified tableau algorithm and then finds all the other MinAs using a black box method (the hitting set tree algorithm). The method involves removing an axiom of the MinA from the KB and looking for alternative explanations. By repeating this process until the query is not entailed, the set of all explanations is found.
BUNDLE is based on Pellet and uses it for solving the min-a-enum problem. In the following, we first illustrate Pellet’s algorithm for solving min-a-enum and then we show the whole BUNDLE algorithm.
Axiom pinpointing in Pellet
Pellet exploits a tableau algorithm [68] that decides whether an axiom is entailed or not by a KB by refutation: axiom E is entailed if has no model in the KB. The algorithm works on completion graphs also called tableaux: they are ABoxes that can also be seen as graphs, where each node represents an individual a and is labeled with the set of concepts it belongs to. Each edge in the graph is labeled with the set of roles to which the couple belongs to. The algorithm starts from a tableau that contains the ABox of the KB and the negation of the axiom to be proved. For example, if the query is a membership one, , it adds to the label of a. If we query for the emptyness (unsatisfiability) of a concept C, the algorithm adds a new anonymous node a to the tableau and adds C to the label of a. The axiom can be proved by showing that is unsatisfiable. The algorithm repeatedly applies a set of consistency preserving tableau expansion rules until a clash (i.e., a contradiction) is detected or a clash-free graph is found to which no more rules are applicable.
In the following we describe the tableau algorithm used by Pellet for concept unsatisfiability, which checks if it is possible or not for a class to have any instances. Instance and subclass checking can be performed similarly. The algorithm is shown in Fig. 5.
Tableau algorithm executed by Pellet.
The rules used by Pellet to answer queries to knowledge bases are shown in Fig. 8. Some of the rules are non-deterministic, i.e., they generate a finite set of tableaux. Thus the algorithm keeps a set of tableaux T. If a non-deterministic rule is applied to a graph G in T, then G is replaced by the resulting set of graphs. For example, if the disjunction is present in the label of a node, the rule generates two graphs, one in which C is added to the node label and the other in which D is added to the node label.
An during the execution of the algorithm can be [27]: 1) , the addition of a concept C to ; 2) , the addition of a role R to ; 3) , the merging of the nodes a, b;4) , the addition of the inequality to the relation ≠; 5) , the detection of a clash g. We use to denote the set of events recorded during the execution of the algorithm. A clash is either:
a couple where C and are present in the label of node a, i.e. ;
a couple , where the events and belong to .
Each time a clash is detected in a completion graph G, the algorithm stops applying rules to G. Once every completion graph in T contains a clash or no more expansion rules can be applied to it, the algorithm terminates. If all the completion graphs in the final set T contain a clash, the algorithm returns unsatisfiable as no model can be found. Otherwise, any one clash-free completion graph in T represents a possible model for and the algorithm returns satisfiable.
Each expansion rule updates as well a tracing function τ, which associates sets of axioms with events in the derivation. For example, , () is the set of axioms needed to explain the event (). For the sake of brevity, we define τ for couples (concept, individual) and (role, couple of individuals) as and respectively. The function τ is initialized as the empty set for all the elements of its domain except for and to which the values and are assigned if and are in the ABox respectively. The expansion rules (Fig. 8) add axioms to values of τ.
If are the clashes, one for each tableau G of the final set, the output of the algorithm Tableau is where a is the anonymous individual initially assigned to C. However, this set may be redundant because additional axioms may also be included in τ, e.g., during the rule, where axioms responsible for each of the successor edges are considered [27]. Thus S is pruned using a black-box approach shown in Fig. 6 [27]. This algorithm executes a loop on S in which it removes one axiom from S in each iteration and checks whether the concept C turns satisfiable w.r.t. S, in which case the axiom is reinserted into S. The idea is that, if the concept turns satisfiable, we can conclude that the axiom extracted is responsible for the unsatisfiability and hence has to be inserted back into S. Vice-versa, if the concept still remains unsatisfiable, we can conclude that the axiom is irrelevant and can be removed from S. The process continues until all axioms in S have been tested and then returns S.
The algorithm for computing a single MinA, shown in Fig. 7, first executes Tableau and then BlackBoxPruning.
The output S of SingleMinA is guaranteed to be a MinA, as established by the following theorem, where stands for the set of MinAs in which C is unsatisfiable.
Let C be an unsatisfiable concept w.r.t.and let S be the output of the algorithmSingleMinAwith input C and, then.
SingleMinA returns a single MinA, i.e. a single explanation. To solve min-a-enum and find the remaining ones, Pellet exploits the hitting set algorithm [52].
Reiter considers a universal set U and a set of conflict sets, where denotes the powerset operator. The set is a hitting set for if each contains at least one element of H, i.e. if for all (in other words, H ‘hits’ or intersects each set in ). H is a minimal hitting set for if H is a hitting set for and no is a hitting set for . The hitting set problem with input , U is to compute all the minimal hitting sets for . The idea here is that the explanations for unsatisfiability correspond to minimal conflict sets and an algorithm that generates minimal hitting sets can also be used to find all minimal conflict sets [27,30]. The universal set corresponds to the total set of axioms in the KB, and an explanation (for a particular concept unsatisfiability) corresponds to a single conflict set.
The algorithm constructs a labeled tree called Hitting Set Tree (HST) starting from a single explanation, the MinA S; then it removes each of the axioms in S individually, thereby creating new branches of the HST, and finds new explanations along these branches. The first step consists of initializing an HST with S in the label of its root node, i.e. . Then it selects an arbitrary axiom E in S, generates a new node w with an empty label in the tree and a new edge with axiom E in its label. Then, the algorithm invokes SingleMinA with arguments C and the knowledge base , to test the unsatisfiability of C w.r.t. . If C is still unsatisfiable it obtains a new explanation for C and it labels w with this set. The algorithm repeats this process (removing an axiom from S and executing SingleMinA to add a new node) until the unsatisfiability test returns negative (the concept turns satisfiable): in that case the algorithm labels the new node with and makes it a leaf. The algorithm also eliminates extraneous unsatisfiability tests based on previous results: once a path leading to a node labeled is found, any superset of that path is guaranteed to be a hitting set as well, and thus no additional unsatisfiability test is needed for that path, as indicated by a X in the node label. When the HST is fully built, all leaves of the tree are labeled with or X. The distinct non leaf nodes of the tree collectively represent the set of the unsatisfiable concept. The algorithm is shown in Fig. 9. The correctness and completeness of the hitting set algorithm are given by the following theorem.
Let C be a concept unsatisfiable inand letbe the set of explanations returned by Pellet’s hitting set algorithm. Then
Pellet’s can also take as input a maximum number of explanations to be generated. If the limit is reached during the execution of the hitting set algorithm, Pellet stops and returns the set of explanations found so far.
Hitting set tree algorithm.
Overall BUNDLE
The main algorithm, shown in Fig. 10, first builds a data structure that associates each probabilistic DL axiom with its probability . Then it uses Pellet’s function to compute the MinAs for the unsatisfiability of a concept C. These MinAs correspond to all conflict sets found by the Hitting Set Algorithm. BUNDLE exploits the version of this procedure in which we can specify the maximum number of explanations to be found.
Function Bundle: computation of the probability of an axiom C given the KB .
Two data structures are initialized: is an array that maintains the association between Boolean random variables (whose index is the array index) and couples (axiom, probability), and stores a BDD. is initialized to the zero Boolean function (lines 8–9).
Then BUNDLE performs two nested loops that build a BDD representing the set of explanations. To manipulate BDDs we used JavaBDD2
Available at http://javabdd.sourceforge.net/
that is an interface to a number of underlying BDD manipulation packages. As the underlying package we used CUDD.
In the inner loop, BUNDLE generates the BDD for a single explanation, indicated as , which is initialized to the one Boolean function (lines 11–25). The axioms of each MinA are considered one by one. If the axiom is certain, then the one Boolean function is stored in (line 14). Otherwise, the value p associated with the axiom is extracted from . The axiomis searched for in to see if it has already been assigned a random variable. If not, a cell is added to to store the couple (line 19). At this point we know the couple position i in the array , that is the index of its Boolean random variable . We obtain a BDD representing with BDDGetIthVar in . is finally conjoined with the current to get the BDD representing a single explanation (line 24).
In the outermost loop, BUNDLE combines BDDs for different explanations through disjunction between and the current explanation (line 26).
After the two cycles, function Prob of Fig. 3 is called over to return the probability of the query to the user.
We now prove BUNDLE correctness.
(BUNDLE correctness).
Given a DISPONTE knowledge base, a query Q and a limitfor the number of explanations to find, the probability returned by BUNDLE,is:
a lower bound onif a maximum number of explanations to compute is set, i.e.,
equal to, i.e.,otherwise
Let K be . By Theorem 5
if a maximum number of explanations is set and
otherwise. Since BUNDLE computes for the Boolean function
the theorem holds. □
Let us consider the KB presented in Example 5 and the query . Let us also consider the corresponding , and the covering set of explanations where and . Here we restrict explanations to contain only probabilistic axioms for the sake of simplicity.
At the start, BUNDLE initializes to the zero Boolean function and starts to loop over the explanations. It enters the inner loop considering the explanation and initializing to the one Boolean function. At this time is empty, thus random variable is associated to by adding this pair to in position 1. Function BDDGetIthVar returns a BDD in that corresponds to the expression . Then is combined with using the and operator. Now, the computation continues by analyzing the second axiom of . The axiom does not have a random variable associated with it yet, so the new variable is created and the pair is added to in position 2. is then generated and combined with the corresponding to the current explanation using the and operator. Now all the axioms in have been considered, so the final is combined with with the or operator.
Then, BUNDLE starts to consider . is set to one. The axiom does not appear in so variable is associated to and , representing , is joined with . The axiom is found in in position 2, so the function BDDGetIthVar returns the BDD representing . Finally is combined with the current . corresponding to the second explanation is completed so it is combined with obtaining the one shown in Fig. 2. Now BUNDLE calls function Prob which computes the probability and returns .
Computational complexity
Jung and Lutz [26] considered the problem of computing the probability of conjunctive queries to probabilistic databases in the presence of an ontology. Probabilities can occur only in the ABox while the TBox is certain. In the case where each ABox assertion is associated with a Boolean random variable independent of all the others, they prove that only very simple conjunctive queries can be answered in PTime, while most queries are #P-hard when the ontology is a DL-Lite TBox and even when the ontology is an TBox.
The class #P [72] describes counting problems associated with decision problems in NP. More formally, #P is the class of function problems of the form “compute ”, where f is the number of accepting paths of a nondeterministic Turing machine running in polynomial time. A prototypical #P problem is the one of computing the number of satisfying assignments of a CNF Boolean formula. #P problems were shown very hard. First, a #P problem must be at least as hard as the corresponding NP problem. Second, [70] showed that a polynomial-time machine with a #P oracle () can solve all problems in PH, the entire polynomial hierarchy.
The setting considered by [26] is subsumed by DISPONTE as it is equivalent to having probabilistic axioms only in the ABox of a DISPONTE KB. So the complexity result provides a lower bound for DISPONTE.
In order to investigate the complexity of BUNDLE, we can consider the two problems that it solves for answering a query. The first one is axiom pinpointing. Its computational complexity has been studied in a number of works [44–46]. Baader et al. [4] showed that there can be exponentially many MinAs for a very simple DL that allows only concept intersection.
Given an integer , consider the TBox
The size of is linear in n and . There are MinAs for since, for each , it is enough to have or in the set.
Thus the number of explanations for may be even larger. Given this fact, we do not consider complexity with respect to the input only. We say an algorithm runs in output polynomial time [25] if it computes all the output in time polynomial in the overall size of the input and the output. Corollary 15 in [46] shows that min-a-enum cannot be solved in output polynomial time for TBoxes unless . Since is a sublogic of , this result also holds for .
The second problem to be solved is computing the probability of a query, that can be seen as computing the probability of a sum-of-products, as explained below.
(Sum-of-products).
Given a Boolean expression S in disjunctive normal form (DNF), or a sum-of-products, in the variables and , the probability that is true with ,compute the probability of S, assuming all variables are independent.
sum-of-products was shown to be #P-hard [see e.g. 51]. Given that the input of the sum-of-products problem is of at least exponential size in the worst case, this means that computing the probability of an axiom from a knowledge base is intractable.
However, the algorithms that have been proposed for solving the two problems were shown to be able to work on inputs of real world size. For example, all MinAs have been found for various entailments over many real world ontologies within a few seconds [27,30]. As regards the sum-of-products problem, algorithms based on BDDs were able to solve problems with hundreds of thousands of variables (see e.g. the works on inference on probabilistic logic programs [31,50,53–59]). Also methods for weighted model counting [12,64] can be used to solve the sum-of-products problem.
Moreover, Section 8 shows that in practice we can compute the probability of entailments on KBs of real-world size with BUNDLE, too.
Related work
Bacchus [6] and Halpern [22] discuss first-order logics of probability and distinguish statistical statements from statements about degrees of belief. Halpern [22] presents two examples: the probability that a randomly chosen bird flies is 0.9 and the probability that Tweety (a particular bird) flies is 0.9. The first statement captures statistical information about the world while the second captures a degree of belief. In order to express the second type of statement, called a “Type 2” statement, Halpern proposes the notation , where the function w is used to indicate the probability, while in order to express the first, called a “Type 1” statement, he proposes the notation . The latter formula can be read as: given a randomly chosen x in the domain, if x is a bird, the probability that x flies is 0.9, or the conditional probability that x flies given that it is a bird is 0.9. DISPONTE allows to define only “Type 2” statements since the probability associated with an axiom represents the degree of belief in that axiom as a whole.
Lutz and Schröder [41] proposed Prob- that is derived directly from Halpern’s probabilistic first order logic and, as DISPONTE, considers only “Type 2” statements. They do so by adopting a possible world semantics and allowing concept expressions of the form and in the language, the first expressing the set of individuals that belong to C with probability greater than n and the second the set of individuals a connected to at least another individual b of C by role R such that the probability of is greater than n. Moreover, the ABox may contain expressions of the form and directly expressing degrees of belief, together with where is an ABox. Prob- is 2-EXPTIME-hard even when probability values are restricted to 0 and 1. Prob- is complementary to DISPONTE as it allows new concept and assertion expressions while DISPONTE allows probabilistic axioms.
Jung and Lutz [26] presented an approach for querying probabilistic databases in the presence of an OWL2 QL ontology. Each assertion is assumed to be stored in a database and associated with probabilistic events. All atomic events are assumed to be probabilistically independent, resulting in a semantics very similar to the distribution semantics. The authors are interested in computing the answer probabilities to conjunctive queries. Probabilities can occur only in the data, but neither in the ontology nor in the query. Two types of ABoxes are considered: a general one where events are Boolean combinations of atomic events, and a restricted one, where each assertion is associated with a distinct atomic event. For Boolean conjunctive queries, the latter setting is subsumed by DISPONTE. Only very simple conjunctive queries in the latter setting can be answered in PTime, while most queries are #P-hard. The authors underline the general interest and usefulness of the approach for a wide range of applications including the management of data extracted from the web, machine translation, and dealing with data that arise from sensor networks.
Heinsohn [23] proposed an extension of the description logic that is able to express statistical information on the terminological knowledge such as partial concept overlapping. Similarly, Koller et al. [35] presented a probabilistic description logic based on Bayesian networks that deals with statistical terminological knowledge. Both Heinsohn and Koller et al. do not allow probabilistic assertional knowledge about concept and role instances. Jaeger [24] allows assertional knowledge about concept and role instances together with statistical terminological knowledge and combines the resulting probability distributions using cross-entropy minimization but does not allow “Type 2” statements as DISPONTE.
Ding and Peng [17] proposed a probabilistic extension of OWL that admits a translation into Bayesian networks. The semantics defines a probability distribution over individuals, i.e. , and assigns a probability to a class C as , while we assign a probability distribution to worlds. PR-OWL [11,13] is a probabilistic extension to OWL that consists of a set of classes, subclasses and properties that collectively form a framework for building probabilistic ontologies. It allows to use the first-order probabilistic logic MEBN [36] for representing uncertainty in ontologies.
DISPONTE differs from [23,24,35] because it provides a unified framework for representing different types of probabilistic knowledge: from assertional to terminological degree of belief knowledge.
DISPONTE differs from [17] because it specifies a distribution over worlds rather than individuals and from [11,13] because it does not resort to a full fledged first-order probabilistic language, allowing the reuse of inference technology from DLs.
Luna et al. [40] proposed an extension of , called , that adopts an interpretation-based semantics. allows statistical axioms of the form , which means that for any element x in the domain , the probability that x is in C given that it is in D is α, and of the form , which means that for each couple of elements x and y in , the probability that x is linked to y by the role R is β. The semantics of is based on probability measures over the space of interpretations with a fixed domain. allows to express “Type 1” knowledge but not “Type 2”. A KB can be represented as a directed acyclic graph in which a node represents a concept or a role and the edges represent the relations between them: if a concept C directly uses concept D, then D is a parent of C in . Moreover, each restriction and is added as a node to . contains an edge from R to each restriction directly using it and from each restriction to the concept C appearing in it. is a template for generating, given the domain , a ground graph in which each node represents an instantiated logical atom or . Inference can then be performed by a first order loopy belief propagation algorithm on the ground graph.
A different approach to the combination of DLs with probability is taken in [18,38,39]. The logic proposed in these papers is called and allows both terminological probabilistic knowledge as well as assertional probabilistic knowledge about instances of concepts and roles. Terminological probabilistic knowledge is expressed using conditional constraints of the form that informally mean “generally, if an object belongs to C, then it belongs to D with a probability in ”. PRONTO [32,34] is a system that performs inference under this semantics. Similarly to [24], the terminological knowledge is interpreted statistically while the assertional knowledge is interpreted in an epistemic way by assigning degrees of beliefs to assertions. Moreover it also allows to express default knowledge about concepts that can be overridden in subconcepts and whose semantics is given by Lehmann’s lexicographic default entailment [37]. These works are based on Nilsson’s probabilistic logic [42], where a probabilistic interpretation defines a probability distribution over the set of interpretations . The probability of a logical formula F according to , denoted , is the sum of all such that and . A probabilistic knowledge base is a set of probabilistic formulas of the form . A probabilistic interpretation satisfies iff . satisfies , or is a model of , iff satisfies all . is a tight logical consequence of iff p is the infimum of in the set of all models of . Computing tight logical consequences from probabilistic knowledge bases can be done by solving a linear optimization problem.
Nilsson’s probabilistic logic differs from the distribution semantics: while the first considers sets of distributions, the latter computes a single distribution over possible worlds. Nilsson’s logic allows different conclusions: consider a DISPONTE KB composed of the axioms and and a probabilistic theory composed of and ; DISPONTE allows to say that , while with Nilsson’s logic the lowest p such that holds is 0.5. This is due to the fact that, while in Nilsson’s logic no assumption about the independence of the statements is made, in the distribution semantics the probabilistic axioms are considered as independent. While independencies can be encoded in Nilsson’s logic by carefully choosing the values of the parameters, reading off the independencies from the theories becomes more difficult.
The assumption of independence of probabilistic axioms does not restrict expressiveness as one can specify any joint probability distribution over the logical ground atoms, possibly introducing new atoms if needed. This is testified by the fact that Bayesian networks can be encoded in probabilistic logic programs under the distribution semantics [74] and by the applications of the distribution semantics to a wide variety of domains [7,50,66].
Bayesian network.
For example, the Bayesian network in Fig. 11 can be encoded with the following ProbLog program burglary:0.1.earthquake:0.2.alarm :- burglary,earthquake.alarm :- burglary,\+ earthquake,al_tf.alarm :- \+ burglary,earthquake,al_ft.alarm :- \+ burglary,\+ earthquake,al_ff.al_tf:0.8.al_ft:0.8.al_ff:0.1.where an additional probabilistic fact has been added for each row of the conditional probability table for alarm (excluding the first that models a deterministic dependency).
Other approaches, such as [14,19], combine a lightweight ontology language, DL-Lite and Datalog respectively, with graphical models, Bayesian networks and Markov networks respectively. In both cases, a KB is composed of a set of annotated axioms and a graphical model. The annotations are sets of assignments of random variables from the graphical model. The semantics is assigned by considering the possible worlds of the graphical model and by stating that an axiom holds in a possible world if the assignments in its annotation hold. The probability of a conclusion is then the sum of the probabilities of the possible worlds where the conclusion holds. Our approach represents a special case of these in which each probabilistic axiom is annotated with a single random variable and the graphical model encodes independence among the random variables. This special case is of interest as inference technology from DLs can be directly employed.
Experiments
In order to test the performance of BUNDLE we performed several experiments.
Comparison with PRONTO
We compared BUNDLE with PRONTO by running queries w.r.t. increasingly complex ontologies. The experiments have been performed on Linux machines with a 3.10 GHz Intel Xeon E5-2687W with 2GB memory allotted to Java.
In the first experiment we generated the test ontologies by randomly sampling axioms from a large probabilistic ontology that models breast cancer risk assessment (BRCA) as shown in [33]. The main idea behind the design of the ontology was to reduce risk assessment to probabilistic entailment in . The BRCA ontology contains a certain part and a probabilistic part. The tests were defined by randomly sampling axioms from the probabilistic part of this ontology which were then added to the certain part. So each sample is a probabilistic KB with the full certain part of the BRCA ontology and a subset of the probabilistic constraints. We varied the number of these constraints from 9 to 15, and, for each number, we generated 100 different consistent ontologies.
In order to generate a query, an individual a is added to the ontology: a is randomly assigned to each class that appears in the sampled conditional constraints with probability 0.6. If the class is composite, as for example PostmenopausalWomanTakingTestosterone, a is assigned to the component classes rather than to the composite one. In the example above, a will be added to PostmenopausalWoman and WomanTakingTestosterone. The ontologies were translated into DISPONTE by replacing each constraint with the axiom . For each ontology, we performed the query where the class C is randomly selected among those that represent women under increased and lifetime risk such as WomanUnderLifetimeBRCRisk and WomanUnderStronglyIncreasedBRCRisk. We then applied both BUNDLE and PRONTO to each generated test and we measured the execution time for inference and the memory used. Figure 12(a) shows the execution time averaged over the 100 KBs as a function of the number of probabilistic axioms and, similarly, Fig. 12(b) shows the average amount of memory used. As one can see, inference times are similar for small knowledge bases, while the difference between the two reasoners rapidly increases for larger knowledge bases. The memory usage for BUNDLE is always less than 53% than PRONTO.
Comparison between BUNDLE and PRONTO on the BRCA KB.
Average execution time for the queries to the Cell, Teleost and NCI KBs and number of queries terminated with a time-out (TO). The first column reports the expressiveness of each KB and the size of the non-probabilistic TBox
Dataset & Infos
Size of the Probabilistic TBox
0
250
500
750
1,000
Cell, 1,263 TBox axioms
runtime (s)
0.76
2.84
3.88
3.94
4.53
TO
0
28
39
50
55
Teleost, 3,406 TBox axioms
runtime (s)
2.11
8.87
31.80
33.82
36.33
TO
0
7
32
32
44
NCI, 5,423 TBox axioms
runtime (s)
3.02
11.37
11.37
16.37
24.90
TO
0
1
24
23
36
A second test was performed over larger KBs, following the method of [34]. We considered three different datasets: an extract from the Cell3
ontology. The Cell ontology represents cell types of the prokaryotic, fungal, and eukaryotic organisms. The NCI ontology is an extract from the NCI Thesaurus that describes human anatomy. The Teleost_anatomy (Teleost for short) ontology is a multi-species anatomy ontology for teleost fishes.
For each of these KBs, we considered the versions of increasing size used by [34]: they add 250, 500, 750 and 1,000 new probabilistic conditional constraints to the publicly available non-probabilistic version of each ontology. We converted these KBs into DISPONTE in the same way as for the BRCA ontology and we created a set of 100 different random subclass queries for each KB. For generating the queries we built the hierarchy of each KB and we randomly selected two classes connected in the hierarchy, so that each query had at least one explanation. We imposed a time limit of 5 minutes for BUNDLE to answer each query. If this limit is reached, BUNDLE’s answer is “time-out”.
In Table 1 we report, for each version of the datasets, the average execution time and the number of queries that terminated with a time-out (TO) for BUNDLE. The averages are computed on the queries that did not end with a time-out. In addition, for each KB we report its expressiveness and its number of non-probabilistic TBox axioms. In all these cases, PRONTO terminates with an out-of-memory error.
As can be seen, BUNDLE can manage larger KBs than PRONTO due to the lower amount of memory needed, as confirmed by the previous tests on BRCA. Moreover, BUNDLE answers most queries in a few seconds. However, some queries have a very high complexity that causes BUNDLE to reach the time-out, confirming the complexity results. In these cases, since the time-out is reached during the computation of the explanations, limiting the number of explanations is necessary, obtaining a lower bound on the probability that becomes tighter as more explanations are allowed.
Tests with not entailed queries
In a further test we investigated cases for which subsumption does not hold. Thus, for the same versions of increasing size of the Cell, NCI and Teleost KBs we randomly created 100 different subclass queries that do not have explanations. In Table 2 we report for each KB the runtime in seconds. As for the previous test, we setted a time-out of 5 minutes but this limit was never reached.
Average execution time for the queries without explanations to the Cell, Teleost and NCI KBs
Dataset
Size of the Probabilistic TBox
0
250
500
750
1,000
Cell
runtime (s)
0.47
1.52
2.43
2.52
3.14
Teleost
runtime (s)
1.15
4.51
12.76
14.69
15.27
NCI
runtime (s)
1.42
4.15
5.99
7.41
7.63
Inference with a limit on the number of explanations
We studied how the execution time and the probability of queries vary when imposing a limit on the number of explanations. The experiments have been performed on Linux machines with a 3.10 GHz Intel Xeon E5-2687W with 2GB memory allotted to Java.
KB that is part of the myGrid project. The Grid KB has already been used for testing the performances of Pellet in [30]. It belongs to the bioinformatics domain and contains concepts at a high level of abstraction. For the test, we used a version of the Grid KB with expressiveness that contains 2,838 axioms, 550 atomic concepts, 69 properties and 13 individuals, downloaded from the Tonesrepository.7
We associated a probability of 0.5 to each axiom of the KB and then we ran 100 different subclass queries.
We first computed the correct probability of each query by using BUNDLE without a limit on the number of explanations. Then we ran each query several times, each time with an increasing limit. The maximum number of explanations is 16: there were 20 queries with 16 explanations but most of the queries have a number of explanations between 1 and 5. We computed the relative error e between the correct probability p of a query and the probability returned by BUNDLE with a limit on the number of explanations with the formula . Then we averaged the relative error over all the queries.
In Fig. 13 we show how the mean relative error varies with respect to the limit on the number of explanations. As can be seen, the quality of the answer increases as the limit on the number of explanations increases. Table 3 reports the execution times, averaged over all the 100 queries. The row of Table 3 with “–” in the first column contains the average execution time for BUNDLE without a limit on the number of explanations. Figure 14 shows the execution time as a function of the limit on the number of explanations, based on the values of Table 3.
Average execution time depending on the limit on the number of explanations for the Grid KB. The last row reports the time spent for finding the set of all explanations
Limit on the explanations
Runtime (s)
0
0.81
2
1.40
4
1.44
6
1.46
8
1.49
10
1.52
12
1.55
14
2.10
16
9.36
–
18.44
Mean relative error of the probability of queries as a function of the limit on the number of explanations for the Grid KB.
Average execution time (s) as the limit on the number of explanations to the queries varies for the Grid KB.
Scalability of BUNDLE
Finally, we did a scalability test with two different KBs: the full version of the NCI Thesaurus (NCI_full for short) with expressiveness that contains 3,382,017 axioms and the Foundational Model of Anatomy Ontology (FMA for short)8
with expressiveness. FMA is a KB for biomedical informatics that models the phenotypic structure of the human body anatomy. It contains 88,252 axioms in the TBox and RBox and 237,382 individuals. The experiments have been performed on a Linux machine with a 2.33 GHz Intel Dual Core E6550 with 2GB memory allotted to Java.
For NCI_full we generated 10 ontologies of increasing size that contain of the axioms. Then we randomly selected an increasing number of certain axioms from these subontologies and made them probabilistic. We sampled 5,000, 10,000, 15,000, 20,000, 25,000 different probabilistic axioms, obtaining 50 different probabilistic KBs with total size from 338,201 to 3,382,017 axioms. Then we randomly created 100 subclass queries for each of the 50 subontologies and ran them. Figure 15 shows the trend of the runtime averaged over the queries with respect to the total size of the ontologies and the subset of probabilistic axioms. The maximum time spent for computing the probability of a query is 266.24 seconds with the KB that contains of the axioms.
Average execution time (s) for the queries to the NCI_full KB on versions of increasing size of the ontology and of the probabilistic part. On the x axis is reported the total number of axioms of the KB (including the probabilistic ones) and on the y axis the number of probabilistic axioms considered.
Finally, we exploited the FMA ontology for running a scalability test where only the size of the ABox varies. We generated versions of the ontology that contain the entire TBox and RBox, 500 probabilistic axioms and an increasing number of individuals. The size of the ABox varies between 50,000 and all the individuals contained in the full ABox with a step of 50,000. We generated 100 instance-of queries by randomly selecting an individual and a class among those to which it belongs. Figure 16 shows how the runtime averaged over the queries varies with respect to the size of the ABox. With 237382 individuals, that correspond to the entire ABox, BUNDLE raises an out-of-memory error. The maximum inference time reached is 298.98 seconds with 200,000 individuals.
Average execution time (s) for the queries to the FMA KB with respect to the increasing size of the ABox. BUNDLE cannot manage the entire ABox (237382 individuals).
As can be seen, BUNDLE can manage very large ontologies and answer queries in a relatively short time.
Conclusions
We have presented the DISPONTE semantics for probabilistic DLs that is inspired by the distribution semantics of probabilistic logic programming. We have discussed the application of DISPONTE to , a prototype of an expressive DL. DISPONTE minimally extends the language to which it is applied and allows both assertional and terminological probabilistic knowledge. We have also presented the algorithm BUNDLE that is able to compute the probability of queries from DISPONTE KBs. BUNDLE has been both compared with the probabilistical reasoner PRONTO and tested for scalability on several real world KBs. The experiments show that BUNDLE is able to deal with ontologies of significant complexity, even if in some situations only an approximated answer takes a reasonable amount of time. BUNDLE is available for download from http://sites.unife.it/ml/bundle together with the datasets used in the experiments.
In the future, we plan to consider extensions of the semantics including statistical or “Type 1” knowledge in the terminology of [22]. Moreover, alternative approaches for inference will be considered, in particular reasoning algorithms returning a pinpointing formula [1,2]: such a formula compactly encodes explanations for the query and can be converted directly into a BDD. We will also consider non-Boolean conjunctive queries and develop inference algorithms for answering them. One possibility would be to first retrieve the instances satisfying the query and then compute explanations for each of them. We have also started to study the problem of learning the parameters [63] and we are planning to tackle the problem of learning the structure of probabilistic KBs.
References
1.
F.Baader and R.Peñaloza,
Automata-based axiom pinpointing, Journal of Automated Reasoning45(2) (2010), 91–129.
2.
F.Baader and R.Peñaloza,
Axiom pinpointing in general tableaux, Journal of Logic and Computation20(1) (2010), 5–34.
3.
F.Baader, D.Calvanese, D.L.McGuinness, D.Nardi and P.F.Patel-Schneider, eds, The Description Logic Handbook: Theory, Implementation, and Applications, Cambridge University Press, Cambridge, UK, 2003.
4.
F.Baader, R.Peñaloza and B.Suntisrivaraporn, Pinpointing in the Description Logic EL+, in: Proc. of 30th Annual German Conference on Advances in Artificial Intelligence, KI 2007, Osnabrück, Germany, September 10–13, 2007, J.Hertzberg, M.Beetz and R.Englert, eds, Lecture Notes in Computer Science, Vol. 4667, Springer, Berlin, 2007, pp. 52–67.
5.
F.Baader, I.Horrocks and U.Sattler, Description logics, in: Handbook of Knowledge Representation, Chap. 3, Elsevier, Amsterdam, The Netherlands, 2008, pp. 135–179.
6.
F.Bacchus, Representing and Reasoning with Probabilistic Knowledge – A Logical Approach to Probabilities, MIT Press, Cambridge, MA, USA, 1990.
7.
E.Bellodi and F.Riguzzi,
Experimentation of an Expectation Maximization algorithm for probabilistic logic programs, Intelligenza Artificiale8(1) (2012), 3–18.
8.
E.Bellodi and F.Riguzzi,
Expectation maximization over binary decision diagrams for probabilistic logic programs, Intelligent Data Analysis17(2) (2013), 343–363.
9.
E.Bellodi, E.Lamma, F.Riguzzi and S.Albani, A distribution semantics for probabilistic ontologies, in: Proc. of the 7th International Workshop on Uncertainty Reasoning for the Semantic Web (URSW 2011), Bonn, Germany, October 23, 2011, F.Bobillo, R.N.Carvalho, P.C.G.da Costa, C.d’Amato, N.Fanizzi, K.B.Laskey, T.Lukasiewicz, T.Martin and M.Nickles, eds, CEUR Workshop Proceedings, Vol. 778, 2011, pp. 75–86, CEUR-WS.org.
10.
B.Bollig and I.Wegener,
Improving the variable ordering of OBDDs is NP-complete, IEEE Transactions on Computers45(9) (1996), 993–1002.
11.
R.N.Carvalho, K.B.Laskey and P.C.G.da Costa, PR-OWL 2.0 – Bridging the gap to OWL semantics, in: Proc. of the 6th International Workshop on Uncertainty Reasoning for the Semantic Web (URSW 2010), Shanghai, China, November 7, 2010, F.Bobillo, R.N.Carvalho, P.C.G.da Costa, C.d’Amato, N.Fanizzi, K.B.Laskey, K.J.Laskey, T.Lukasiewicz, T.Martin, M.Nickles and M.Pool, eds, CEUR Workshop Proceedings, Vol. 654, 2010, pp. 73–84, CEUR-WS.org.
12.
M.Chavira and A.Darwiche,
On probabilistic inference by weighted model counting, Artificial Intelligence172(6–7) (2008), 772–799.
13.
P.C.G.da Costa, K.B.Laskey and K.J.Laskey, PR-OWL: A Bayesian ontology language for the Semantic Web, in: Uncertainty Reasoning for the Semantic Web I, ISWC International Workshops, URSW 2005–2007, Revised Selected and Invited Papers, P.C.G.da Costa, C.d’Amato, N.Fanizzi, K.B.Laskey, K.J.Laskey, T.Lukasiewicz, M.Nickles and M.Pool, eds, Lecture Notes in Computer Science (LNCS), Vol. 5327, Springer, Berlin, 2008, pp. 88–107.
14.
C.d’Amato, N.Fanizzi and T.Lukasiewicz, Tractable reasoning with Bayesian Description Logics, in: Proc. of the Second International Conference on Scalable Uncertainty Management, SUM 2008, Naples, Italy, October 1–3, 2008, S.Greco and T.Lukasiewicz, eds, Lecture Notes in Computer Science (LNCS), Vol. 5291, Springer, Berlin, 2008, pp. 146–159.
15.
A.Darwiche and P.Marquis,
A knowledge compilation map, Journal of Artificial Intelligence Research17 (2002), 229–264.
16.
L.De Raedt, B.Demoen, D.Fierens, B.Gutmann, G.Janssens, A.Kimmig, N.Landwehr, T.Mantadelis, W.Meert, R.Rocha, V.Santos Costa, I.Thon and J.Vennekens, Towards digesting the alphabet-soup of statistical relational learning, in: 1st Workshop on Probabilistic Programming: Universal Languages, Systems and Applications, NIPS*2008 Conference, Whistler, Canada, 2008, pp. 1–14.
17.
Z.Ding and Y.Peng, A probabilistic extension to ontology language OWL, in: HICSS 2004 – Proc. of the 37th Annual Hawaii International Conference on System Sciences, Island of Hawaii, USA, January 5–8, 2004, IEEE Computer Society Press, Washington DC, USA, 2004, pp. 1–10.
18.
R.Giugno and T.Lukasiewicz, P-SHOQ(D): A probabilistic extension of SHOQ(D) for probabilistic ontologies in the Semantic Web, in: Proc. of the European Conference on Logics in Artificial Intelligence, JELIA 2002, Cosenza, Italy, September, 23–26, S.Flesca, S.Greco, N.Leone and G.Ianni, eds, Lecture Notes in Computer Science (LNCS), Vol. 2424, Springer, Berlin, 2002, pp. 86–97.
19.
G.Gottlob, T.Lukasiewicz and G.I.Simari, Conjunctive query answering in probabilistic Datalog+/− ontologies, in: Proc. of the 5th International Conference on Web Reasoning and Rule Systems – RR 2011, Galway, Ireland, August 29–30, 2011, S.Rudolph and C.Gutierrez, eds, Lecture Notes in Computer Science (LNCS), Vol. 6902, Springer, Berlin, 2011, pp. 77–92.
20.
O.Grumberg, S.Livne and S.Markovitch,
Learning to order BDD variables in verification, Journal of Artificial Intelligence Research18 (2003), 83–116.
21.
C.Halaschek-Wiener, A.Kalyanpur and B.Parsia, Extending tableau tracing for ABox updates, Technical report, University of Maryland, 2006.
22.
J.Y.Halpern,
An analysis of first-order logics of probability, Artificial Intelligence46(3) (1990), 311–350.
23.
J.Heinsohn, Probabilistic description logics, in: UAI’94: Proc. of the Tenth Annual Conference on Uncertainty in Artificial Intelligence, R. Lópezde Mántaras and D.Poole, eds, Seattle, Washington, USA, July 29–31, 1994, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1994, pp. 311–318.
24.
M.Jaeger, Probabilistic reasoning in terminological logics, in: Proc. of the 4th International Conference on Principles of Knowledge Representation and Reasoning (KR’94), Bonn, Germany, May 24–27, 1994, J.Doyle, E.Sandewall and P.Torasso, eds, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1994, pp. 305–316.
25.
D.S.Johnson, C.H.Papadimitriou and M.Yannakakis,
On generating all maximal independent sets, Information Processing Letters27(3) (1988), 119–123.
26.
J.C.Jung and C.Lutz, Ontology-based access to probabilistic data with OWL QL, in: Proc. of the 11th International Semantic Web Conference on The Semantic Web – ISWC 2012, Part I, P.Cudré-Mauroux, J.Heflin, E.Sirin, T.Tudorache, J.Euzenat, M.Hauswirth, J.Xavier Parreira, J.Hendler, G.Schreiber, A.Bernstein and E.Blomqvist, eds, Boston, MA, USA, November 11–15, 2012, Lecture Notes in Computer Science (LNCS), Vol. 7649, Springer, Berlin, 2012, pp. 182–197.
27.
A.Kalyanpur, Debugging and repair of OWL ontologies, PhD thesis, The Graduate School of the University of Maryland, 2006.
28.
A.Kalyanpur, B.Parsia, B.Cuenca-Grau and E.Sirin, Tableaux tracing in SHOIN, Technical Report 2005-66, University of Maryland, 2005.
29.
A.Kalyanpur, B.Parsia, E.Sirin and J.A.Hendler,
Debugging unsatisfiable classes in OWL ontologies, Journal of Web Semantics3(4) (2005), 268–293.
30.
A.Kalyanpur, B.Parsia, M.Horridge and E.Sirin, Finding all justifications of OWL DL entailments, in: The Semantic Web, 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, November 11–15, 2007, K.Aberer, K.Choi, N.Fridman Noy, D.Allemang, K.Lee, L.J.B.Nixon, J.Golbeck, P.Mika, D.Maynard, R.Mizoguchi, G.Schreiber and P.Cudré-Mauroux, eds, Lecture Notes in Computer Science (LNCS), Vol. 4825, Springer, Berlin, 2007, pp. 267–280.
31.
A.Kimmig, B.Demoen, L.De Raedt, V.Santos Costa and R.Rocha,
On the implementation of the probabilistic logic programming language ProbLog, Theory and Practice of Logic Programming11(2–3) (2011), 235–262.
32.
P.Klinov, Pronto: A non-monotonic probabilistic Description Logic reasoner, in: Proc. of the 5th European Semantic Web Conference on The Semantic Web: Research and Applications, ESWC 2008, Tenerife, Canary Islands, Spain, June 1–5, 2008, S.Bechhofer, M.Hauswirth, J.Hoffmann and M.Koubarakis, eds, Lecture Notes in Computer Science (LNCS), Vol. 5021, Springer, Berlin, 2008, pp. 822–826.
33.
P.Klinov and B.Parsia, Optimization and evaluation of reasoning in probabilistic Description Logic: Towards a systematic approach, in: Proc. of the 7th International Semantic Web Conference on The Semantic Web – ISWC 2008, Karlsruhe, Germany, October 26–30, 2008, A.P.Sheth, S.Staab, M.Dean, M.Paolucci, D.Maynard, T.W.Finin and K.Thirunarayan, eds, Lecture Notes in Computer Science (LNCS), Vol. 5318, Springer, Berlin, 2008, pp. 213–228.
34.
P.Klinov and B.Parsia, A hybrid method for probabilistic satisfiability, in: Proc. of the 23rd International Conference on Automated Deduction – CADE-23, Wroclaw, Poland, July 31–August 5, 2011, N.Bjørner and V.Sofronie-Stokkermans, eds, Lecture Notes in Computer Science (LNCS), Vol. 6803, Springer, Berlin, 2011, pp. 354–368.
35.
D.Koller, A.Y.Levy and A.Pfeffer, P-CLASSIC: A tractable probabilistic Description Logic, in: Proc. of the Fourteenth National Conference on Artificial Intelligence and Ninth Innovative Applications of Artificial Intelligence Conference, AAAI’97, Providence, Rhode Island, July 27–31, 1997, B.Kuipers and B.L.Webber, eds, AAAI Press/The MIT Press, Menlo Park, CA, USA, 1997, pp. 390–397.
36.
K.B.Laskey and P.C.G.da Costa, Of starships and Klingons: Bayesian logic for the 23rd century, in: Proc. of the 21st Conference in Uncertainty in Artificial Intelligence, UAI’05, F.Bacchus and T.Jaakkola, eds, Edinburgh, Scotland, July 26–29, 2005, AUAI Press, Arlington, Virginia, 2005, pp. 346–353.
37.
D.J.Lehmann,
Another perspective on default reasoning, Annals of Mathematics and Artificial Intelligence15(1) (1995), 61–82.
38.
T.Lukasiewicz,
Probabilistic default reasoning with conditional constraints, Annals of Mathematics and Artificial Intelligence34(1–3) (2002), 35–88.
J.E.Ochoa Luna, K.Revoredo and F.Gagliardi Cozman, Learning probabilistic Description Logics: A framework and algorithms, in: Proc. of the 10th Mexican International Conference on Advances in Artificial Intelligence, MICAI 2011, Part I, Puebla, Mexico, November 26–December 4, 2011, I.Z.Batyrshin and G.Sidorov, eds, Lecture Notes in Computer Science, Vol. 7094, Springer, Berlin, 2011, pp. 28–39.
41.
C.Lutz and L.Schröder, Probabilistic Description Logics for subjective uncertainty, in: Proc. of the Twelfth International Conference on Principles of Knowledge Representation and Reasoning, KR 2010, Toronto, Ontario, Canada, May 9–13, 2010, F.Lin, U.Sattler and M.Truszczynski, eds, AAAI Press, Menlo Park, CA, USA, 2010, pp. 393–403.
R.Peñaloza and B.Sertkaya, Axiom pinpointing is hard, in: Proc. of the 22nd International Workshop on Description Logics (DL 2009), Oxford, UK, July 27–30, 2009, B.Cuenca Grau, I.Horrocks, B.Motik and U.Sattler, eds, CEUR Workshop Proceedings, Vol. 477, 2009, pp. 1–12, CEUR-WS.org.
45.
R.Peñaloza and B.Sertkaya, Complexity of axiom pinpointing in the DL-Lite family, in: Proc. of the 23rd International Workshop on Description Logics (DL 2010), Waterloo, Ontario, Canada, May 4–7, 2010, V.Haarslev, D.Toman and G.E.Weddell, eds, CEUR Workshop Proceedings, Vol. 573, 2010, pp. 1–12, CEUR-WS.org.
46.
R.Peñaloza and B.Sertkaya, Complexity of axiom pinpointing in the DL-Lite family of Description Logics, in: Proc. of the 19th European Conference on Artificial Intelligence, ECAI 2010, Lisbon, Portugal, August 16–20, 2010, H.Coelho, R.Studer and M.Wooldridge, eds, Frontiers in Artificial Intelligence and Applications, Vol. 215, IOS Press, Amsterdam, The Netherlands, 2010, pp. 29–34.
D.Poole,
The Independent Choice Logic for modelling multiple agents under uncertainty, Artificial Intelligence94(1–2) (1997), 7–56.
49.
D.Poole,
Abducing through negation as failure: stable models within the Independent Choice Logic, Journal of Logic Programming44(1–3) (2000), 5–35.
50.
L.De Raedt, A.Kimmig and H.Toivonen, Problog: A probabilistic Prolog and its application in link discovery, in: Proc. of the 20th International Joint Conference on Artificial Intelligence, IJCAI 2007, Hyderabad, India, January 6–12, 2007, M.M.Veloso, ed., Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2007, pp. 2462–2467.
51.
A.Rauzy, E.Châtelet, Y.Dutuit and C.Bérenguer,
A practical comparison of methods to assess sum-of-products, Reliability Engineering and System Safety79(1) (2003), 33–42.
52.
R.Reiter,
A theory of diagnosis from first principles, Artificial Intelligence32(1) (1987), 57–95.
53.
F.Riguzzi, A top down interpreter for LPAD and CP-logic, in: Proc. of the 10th Congress of the Italian Association for Artificial Intelligence on Artificial Intelligence and Human-Oriented Computing, AI*IA 2007, Rome, Italy, September 10–13, 2007, R.Basili and M.T.Pazienza, eds, Lecture Notes in Computer Science (LNCS), Vol. 4733, Springer, Berlin, 2007, pp. 109–120.
54.
F.Riguzzi,
Extended semantics and inference for the Independent Choice Logic, Logic Journal of The IGPL17(6) (2009), 589–629.
55.
F.Riguzzi,
MCINTYRE: A Monte Carlo system for probabilistic logic programming, Fundamenta Informaticae124(4) (2013), 521–541. doi:10.3233/FI-2013-847.
56.
F.Riguzzi,
Speeding up inference for probabilistic logic programs, The Computer Journal57(3) (2014), 347–363.
57.
F.Riguzzi and T.Swift, Tabling and answer subsumption for reasoning on logic programs with annotated disjunctions, in: Technical Communications of the 26th International Conference on Logic Programming, ICLP 2010, July 16–19, 2010, Edinburgh, Scotland, UK, M.V.Hermenegildo and T.Schaub, eds, LIPIcs, Vol. 7, Schloss Dagstuhl – Leibniz-Zentrum fuer Informatik, Dagstuhl, Germany, 2010, pp. 162–171.
58.
F.Riguzzi and T.Swift, The PITA system: Tabling and answer subsumption for reasoning under uncertainty, Theory and Practice of Logic Programming11(Special Issue 4–5 of the 27th International Conference on Logic Programming (ICLP 2011)) (2011), 433–449.
59.
F.Riguzzi and T.Swift, Well-definedness and efficient inference for probabilistic logic programming under the distribution semantics, Theory and Practice of Logic Programming13 (Special Issue 2 of the 25th Annual GULP Conference) (2013), 279–302.
60.
F.Riguzzi, E.Bellodi and E.Lamma, Probabilistic Datalog +/− under the distribution semantics, in: Proc. of the 2012 International Workshop on Description Logics, DL-2012, Rome, Italy, June 7–10, 2012, Y.Kazakov, D.Lembo and F.Wolter, eds, CEUR Workshop Proceedings, Vol. 846, 2012, pp. 519–529, CEUR-WS.org.
61.
F.Riguzzi, E.Bellodi, E.Lamma and R.Zese, Epistemic and statistical probabilistic ontologies, in: Proc. of the 8th International Workshop on Uncertainty Reasoning for the Semantic Web (URSW), Boston, USA, November 11, 2012, F.Bobillo, R.N.Carvalho, P.C.G.da Costa, C.d’Amato, N.Fanizzi, K.B.Laskey, K.J.Laskey, T.Lukasiewicz, T.Martin, M.Nickles and M.Pool, eds, CEUR Workshop Proceedings, Vol. 900, 2012, pp. 3–14, CEUR-WS.org.
62.
F.Riguzzi, E.Bellodi, E.Lamma and R.Zese, BUNDLE: A reasoner for probabilistic ontologies, in: Proc. of the 7th International Conference on Web Reasoning and Rule Systems, RR 2013, W.Faber and D.Lembo, eds, Mannheim, Germany, July 27–29, 2013, Lecture Notes in Computer Science (LNCS), Vol. 7994, Springer, Berlin, 2013, pp. 183–197.
63.
F.Riguzzi, E.Bellodi, E.Lamma and R.Zese, Parameter learning for probabilistic ontologies, in: Proc. of the 7th International Conference on Web Reasoning and Rule Systems, RR 2013, Mannheim, Germany, July 27–29, 2013, W.Faber and D.Lembo, eds, Lecture Notes in Computer Science (LNCS), Vol. 7994, Springer, Berlin, 2013, pp. 265–270.
64.
T.Sang, P.Beame and H.A.Kautz, Performing bayesian inference by weighted model counting, in: Proc. of The Twentieth National Conference on Artificial Intelligence and the Seventeenth Innovative Applications of Artificial Intelligence Conference, July 9–13, 2005, Pittsburgh, Pennsylvania, USA, M.M.Veloso and S.Kambhampati, eds, AAAI Press/The MIT Press, Menlo Park, CA, USA, 2005, pp. 475–482.
65.
T.Sato, A statistical learning method for logic programs with distribution semantics, in: Proc. of the Twelfth International Conference on Logic Programming, Tokyo, Japan, June 13–16, 1995, L.Sterling, ed., MIT Press, Cambridge, MA, USA, 1995, pp. 715–729.
66.
T.Sato and Y.Kameya,
Parameter learning of logic programs for symbolic-statistical modeling, Journal of Artificial Intelligence Research15 (2001), 391–454.
67.
S.Schlobach and R.Cornet, Non-standard reasoning services for the debugging of description logic terminologies, in: Proc. of the Eighteenth International Joint Conference on Artificial Intelligence, IJCAI-03, Acapulco, Mexico, August 9–15, 2003, G.Gottlob and T.Walsh, eds, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2003, pp. 355–362.
68.
M.Schmidt-Schauß and G.Smolka,
Attributive concept descriptions with complements, Artificial Intelligence48(1) (1991), 1–26.
69.
E.Sirin, B.Parsia, B.Cuenca-Grau, A.Kalyanpur and Y.Katz Pellet,
A practical OWL-DL reasoner, Journal of Web Semantics5(2) (2007), 51–53.
70.
S.Toda, On the computational power of PP and +P, in: 30th Annual Symposium on Foundations of Computer Science (FOCS), Research Triangle Park, North Carolina, USA, 30 October–1 November 1989, IEEE Computer Society Press, Washington DC, USA, 1989, pp. 514–519.
71.
URW3-XG, Uncertainty reasoning for the World Wide Web, Final report, 2008, http://www.w3.org/2005/Incubator/urw3/XGR-urw3.
72.
L.G.Valiant,
The complexity of enumeration and reliability problems, SIAM Journal on Computing (SICOMP)8(3) (1979), 410–421.
73.
J.Vennekens and S.Verbaeten, Logic Programs with Annotated Disjunctions, Technical Report CW386, KU Leuven, 2003, http://www.cs.kuleuven.ac.be/~joost/techrep.ps.
74.
J.Vennekens, S.Verbaeten and M.Bruynooghe, Logic Programs with Annotated Disjunctions, in: Proc. of the 20th International Conference on Logic Programming, ICLP 2004, Saint-Malo, France, September 6–10, 2004, B.Demoen and V.Lifschitz, eds, Lecture Notes in Computer Science (LNCS), Vol. 3132, Springer, Berlin, 2004.
75.
J.Vennekens, M.Denecker and M.Bruynooghe,
CP-logic: A language of causal probabilistic events and its relation to logic programming, Theory and Practice of Logic Programming9(3) (2009), 245–308.