
Abstract
The redundancy of the data is an active research topic. While an agent works in a multi-agent system, the number of messages between them increases. This is due to the fact that the functionalities data depends on other agents in terms of functional requirements. Typically, only one agent in a multi-agent system is responsible for accessing a database instead of replicating the database on each agent. A database is stored on multiple agents rather than a single agent to avoid a single point of failure. In this approach, the system has a higher load because one agent is responsible for all agent queries and must send duplicate messages to multiple agents, resulting in redundant data. In this research, we present Multi-Agent System for Commodity Data (MASCD) framework, the multi-agent system based communication using the distributed hash system, to reduce data redundancy in multi-agent system communication. Our anticipated method demonstrated how we divided the database names and efficiently distributed data to each agent. The database splitting is based on manufacturer names or product names. We utilize a table based on prime numbers. Through the hash function, we ascertain the index of the agent granted access to the relevant data. Each agent is accountable for its data. We use a Distributed Hash Table for efficient querying that stores data as key-value pairs. Each agent maintains a Finger Table containing the next and previous nodes for agent communication purposes. Using FIPA messages, we demonstrated how an agent could interact optimally. In conclusion, we illustrate the application of the proposed approach through a case study of mobile phones and university information systems.

Introduction
Today, data redundancy is a significant research topic in multi-agent systems. This is because the quantity of messages sent between agents in a multi-agent system rises dynamically with time. In addition, the system’s workload is increased because a single agent must respond to all agent queries. A network of autonomous software agents working together to accomplish tasks and communicate with one another in a multi-agent system. Agents make decisions independently. Agents must work together and coordinate their efforts because they have unique goals and strategies. Agents take action based on various factors, including what they observe in their immediate surroundings and how they interact with other agents. The areas of robotics, autonomous driving, and commercial games have all shown significant interest in multi-agent systems. In [1], as the size of the problem increases, the complexity of the modeling and calculation tasks increases significantly. As a result, we cannot deal with these scenarios by employing a centralized method. Because of this, we made use of a multi-agent system in order to deal with the various scenarios. One of its most significant advantages is that the multi-agent system can function in a decentralized setting [2]. Inter-agent negotiations are conducted through Agent Communication Languages (ACL). In [3] there are two of the most familiar agent communication languages, i.e., KQML and FIPA. It is based on speech-act theory. KQML is a usual agent communication language where agents can freely share and discuss information and ideas. Messages in KQML follow a specific protocol. It’s a protocol for dealing with messages that uses the principles of speech acts theory [4].
Therefore, communication significantly impacts the multi-agent system, but an issue that arises in multi-agent system is the overhead associated with the communication. In a multi-agent system, data redundancy is the problem’s primary source, resulting in increased storage needs. For instance, a self-driving automobile is currently making its way up a mountain, and the front camera of this car can take pictures of the trees on both sides, which results in the interchange of noisy and comparable data throughout the observation, leading to data redundancy. In [5] the technique of temporal massage decreases data redundancy in agent communication. For this model, buffers are used. The first is the sender buffer, while the second is the receiver buffer. Both the sender and the receiver may utilize buffers to hold messages temporarily. The sender only sends a new message when significant new information is compared to the previous message. This model likewise includes a message encoder and a local action generator. However, the temporal complexity of finding the message increases by a factor of O(n) in the event of transmission loss [5].
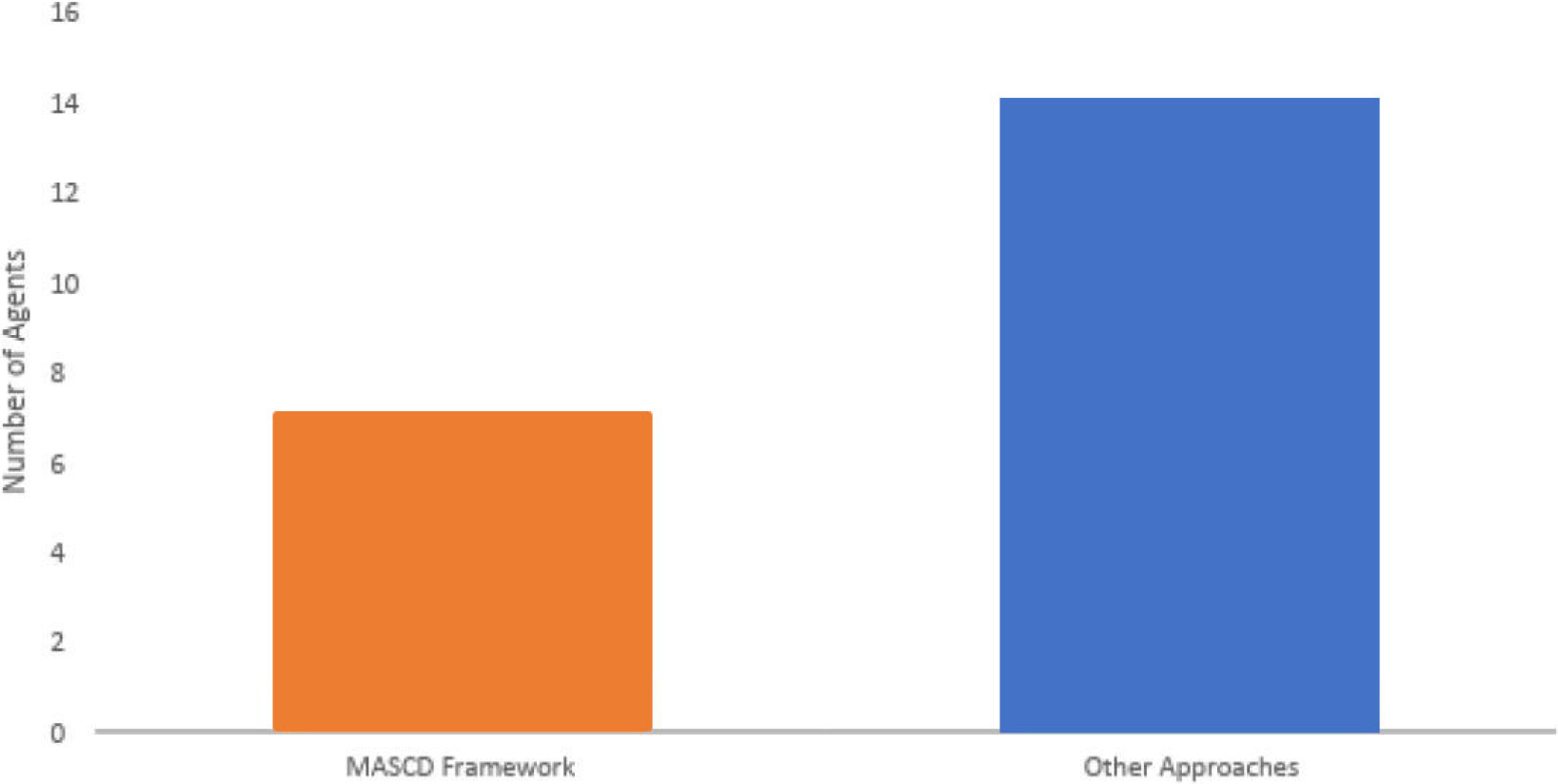
Our primary research objective is to decrease the time to resolve queries and eliminate data redundancy in real-time. Data redundancy proves to be a significant hurdle in agent communication, preventing the multi-agent system from functioning optimally. Agent database storage strategies are expanding as a result of redundancy. The overall performance of multi-agent system is dynamically affected by the growing volume of messages sent and received between agents over time. In prior methods, access to a database was typically delegated to one of the agents working in a multi-agent system. Because one agent is responsible for every other agent’s query and must transmit the same messages to multiple agents, which causes data duplication, a centralized approach leads the system to have a higher burden than a decentralized approach. This research provides Multi-Agent System for Commodity Data (MASCD), an approach to decreasing duplicate data in multi-agent system communication. To implement Distributed Hash Table (DHT), we first partitioned the database into smaller subsets and assigned each agent to handle a smaller portion of the database. This method is employed when there is a lot of data since it makes query-finding data easier. No prior research has recommended a method that utilizes a hash-table database for this specific issue. The main issue is finding a way to reduce the volume of messages without impairing the multi-agent system’s performance as a whole.
The remaining paper structure is defined in the following section. The first section provides an introduction and background information. In Section 2, a related work is presented. A distributed hash table is the main component of the MASCD framework which is explained in Section 3. In Section 4, case studies are provided to exemplify our suggested approach. These real-world case studies illustrate the viability of our suggestion and are based on actual basic cases. This chapter concludes the thesis and offers suggestions for future research.
Literature review
In references [6, 7], KQML and FIPA are depicted as prevalent languages that facilitate agent communication and collaboration. They endorse the effective dissemination of knowledge and ensure a seamless exchange of information. Messages in KQML are based on a protocol. That’s because it’s a method for transmitting and receiving messages. Agents can share information via a communication facilitator. They proposed new features for e-commerce agents to carry out. Their research’s primary objective is to lessen the network overhead burden. In [8], an impactful multi-agent communication approach is provided because of the significant problem in multi-agent reinforcement learning: limited bandwidth; therefore, agents should generate and send only informative messages. In [9], the primary consideration in a multi-agent system is how effectively information is communicated. Agent Communication Languages (ACL) significantly impact multi-agent systems, but they incur overhead. Two-tiered communication architecture was proposed for efficiency purposes. In [10], multi-agent system describes how smart sensor nodes in a wireless sensor network should act. When collecting data, it is essential that sensor nodes are close to each other and that there is a high chance of redundancy. Mobile agents are used to gather data for this reason. In order to collect data and increase energy efficiency, [11] proposed the Itinerary Energy Minimum Algorithm (IEMA). We can ascertain the number of mobile agents by presenting a genetic framework that accounts for the time complexity. Multiaccess edge computing (MEC) is a technology that enables self-driving vehicles to compete in time-sensitive and data-intensive computational activities. In this method, automobiles produce an excessive amount of redundant data. Within the framework of the proposed technique, the minimum possible number of pictures is transferred to MEC servers [12]. In [13], they presented a new strategy that they referred to as message dropout. To improve the performance of multi-agent deep reinforcement learning in two different scenarios. In [14], they investigated a few value-based multi-agent strategies. We look into value-based solutions for multi-agent reinforcement learning (MARL) problems in the recently popularized centralized training with decentralized execution (CTDE) regime.
As stated in [15], many agents can learn to work together towards MARL by using mutual knowledge between actions to regularise the cumulative return. For a given Maximum Mutual Information (MMI) regularized objective function, we propose a manageable bottom-bound strategy. To solve the problems that have been occurring with traffic light control systems, a multi-agent communication and action rectification (MaCAR) Framework has been presented in [16]. This strategy maximizes traffic efficiency while making the most of the available road space and helps to prevent road rage incidents. This framework facilitates the active communication of agents with one another. In multi-agent systems, communication between agents is an essential component. They suggested a new strategy in the context of a multi-agent system founded on Khalimsky’s idea. This method typically performs data routing in wireless sensor networks [17]. In [18], they explored how the formulation of control policies in a multi-agent system is affected by the choices made about communication. The authors proposed an Markov decision process (MDP) based distributed framework to model the expenses of sending messages. In [19], to address this problem, they designed a dynamic event-triggered communication mechanism (DECM) for coordinating conversations across agents. It is crucial to cut down on extraneous information and non-transferable between different agents for efficiency. In [20], a novel platform based on the multi-agent system is presented. They employed a Jabber protocol to enable instantaneous communication between applications (XMPP – Extensible Messaging and Presence Protocol). This system complies with FIPA and provides a straightforward technique for creating agents employing this modern communication method. In [21], with the use of a multi-agent system application, they show how to create a smart grid efficiently. The appliances in a smart house are modeled after autonomous agents. The HEMS (Home Energy Management System) was created with the help of multi-agent system. It opens the way for networked homes to share information and collaborate. In [22, 23] an alternative cognitive radio spectrum sensing framework based on a multi-agent architecture has been proposed for 5G wireless communication systems. The waste of materials and excess energy use are both mitigated by this system. Furthermore, it prevents agents from communicating the same information twice.
In [24], they employed consensus strategies to have agents work together on unmanned aerial vehicles. Their framework enables agents to handle various task assignments in a dynamic environment with less communication overhead and a new storage mechanism. In [25, 26], they combine the two methods of control in order to study the bounded consensus issue in multi-agent systems. It uses quantized control and event-triggered control, which rely on an undirected graph, to lighten the communication load and get around network limits like bandwidth limitations. Event-triggered quantized communication protocols are developed to achieve bounded consensus in multi-agent systems. In [27], they presented an event-triggered distributed subgradient method for tackling convex optimization problems. These issues are modelled as the union of the convex cost functions of all involved agents.
In [28], that study provided a load-sharing control finding method for an inverter-based microgrid. It adopts a decentralized multi-agent system strategy that emphasizes effective communication. After an event, the agent will notify any other agents in the area of its current status. Data exchange between agents is impossible if this condition is not met. In [29], for systems with multiple agents performing random switches, they suggest an adaptive optimum decision solution. Random switching is widely used in the realm of communication. It offers a precise online decision-making solution for several agents in a short amount of time. It’s a smart strategy for minimizing time complexity. In [30], for combining FIPA performatives with Timed-Arc Petri-Nets (TAPN) in RESTful, event-driven, or event-driven distributed multi-agent systems, a formal paradigm is proposed – real-time multi-agent systems (RTMAS). A multi-agent system with a time limit was the topic of their conversation. While TAPN has been used to describe FIPA in prior works, the lack of timing is the primary problem in RTMAS. According to [31], there are two different categories that multi-agent navigation can fall into. Both centralized and decentralized methods are included in this category. To counter multi-agent navigation, many types of sensor noise are utilized. They created a framework to create an efficient distributed multi-agent navigation collision avoidance policy.
In [32], The cost of communication is decreased through numerous algorithms. Our primary concern is guaranteeing the network’s long-term survival. Improved estimation accuracy and reduced communication costs are achieved by employing a distributed version of the neighbor-partial diffusion least-mean-square algorithm (NPDLMS). Multi-agent robotics needs communicative drones. Centralized and decentralized mission control were used. We employ centralized architecture for real-time monitoring. Otherwise, a decentralized application [33]. In [34], they introduced a communication protocol called Communication Collective to decrease network latency. Due to rising urban populations and reducing automobile costs, traffic congestion is a persistent issue in many countries [35]. The signal control system helps choose a “green time” for faster network-wide transit based on limited environmental data. A geometric fuzzy multi-agent system (GFMAS) should be used for improved accuracy and performance. Utilizing cutting-edge technology, they are creating sensing applications [36]. They utilized the Gaussian process regression (GPR) method, which enables agents to anticipate the behavior of ecological systems.
According to [37], today’s society has its most significant difficulty managing large amounts of data. We employ wireless sensor networks to create data propagation networks that include many sensors. One of the main functions of sensors and big data is to keep an eye on a process, gather data, and send it to a central location for processing. In [38], the author presents A focused communication architecture for multi-agent reinforcement learning. In this concept, agents interact in partially viewable settings to learn which messages to send and to whom. In [39], two distinct contributions can be found in their work. First, they show that policy gradient iterations can be used outside of Markovian frameworks. Second, break down the problem into elements of a policy for wants.
Multi-Agent System for Commodity Data (MASCD) framework.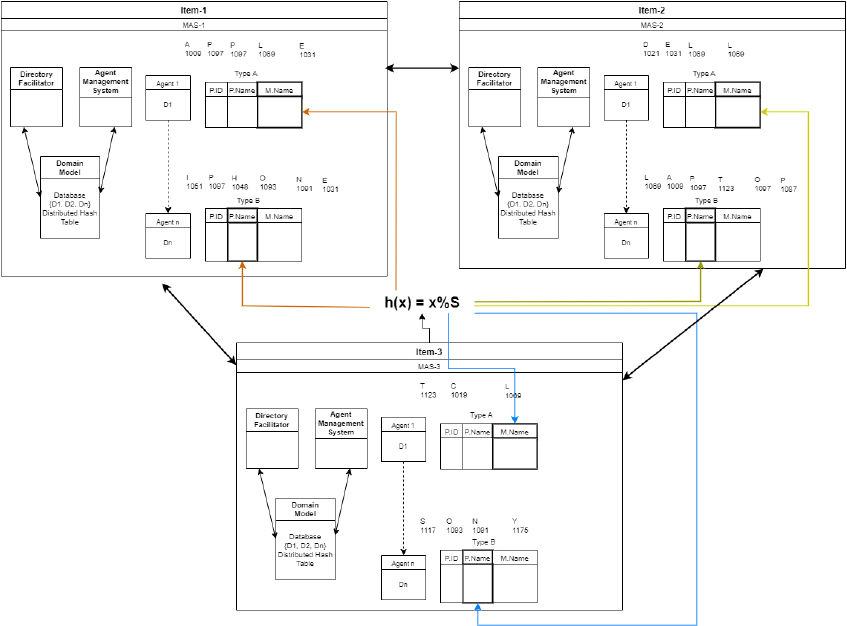
This section outlines the Multi-Agent System for Commodity Data (MASCD) system we developed to reduce data redundancy in multi-agent system communication. Our entire framework is depicted in Fig. 1. There are three multi-agent systems in our framework. Each multi-agent system has a different domain model. We handle a broad spectrum of product data in our Multi-Agent System for Commodity Data (MASCD). Based on the specific needs of a query, our agents are capable of interacting efficiently with other multi-agent systems and communicating effectively amongst themselves. This applies whether a query originates within our system or externally from another multi-agent system. Each multi-agent system consists of a range of modules, which we delve into extensively in the following section. It is explicitly stated that agents must utilize FIPA messages for communication. In the MASCD framework, we use a DHT to reduce data redundancy in agent communications. To accomplish this, we have segmented the database into smaller subgroups and deftly disseminated the data of these subsets across all agents. Our approach accommodates two scenarios in which a database is divided. In scenario 1, we divide the database according to the product names, and in scenario 2, we do the same according to the manufacturer names. The hash function is in charge of data distribution. We work with a variety of commodities or product data in MASCD. Agents can proficiently interact with other multi-agent systems depending on the query’s specifications, whether it originates from within or outside the multi-agent system.
The division of the database into chunks is depicted in Fig. 2. Data is given to the hash function, which converts it into keys, each intended for a different agent. The key-value pairs are kept in the DHT. As a result, each agent is responsible for a particular key and collection of information. Agents receive the data according to the product name. The agent database contains a large number of entities. However, we prioritize the main entity and distribute information to various agents based on the product name. For instance, we prioritize the student as the main element in the student database. In order to do this, a DHT is used. A decentralized method of key-value pair storage for data is the DHT. The DHT makes it easier to extract data from enormous volumes of data. A DHT node is analogous to an agent accountable for the keys and values with which it is associated. With this decentralized approach, agents create a system devoid of centralized power. Each agent keeps track of the addresses of the subsequent and preceding nodes in a finger table.
Distributed hash table (DHT) representation.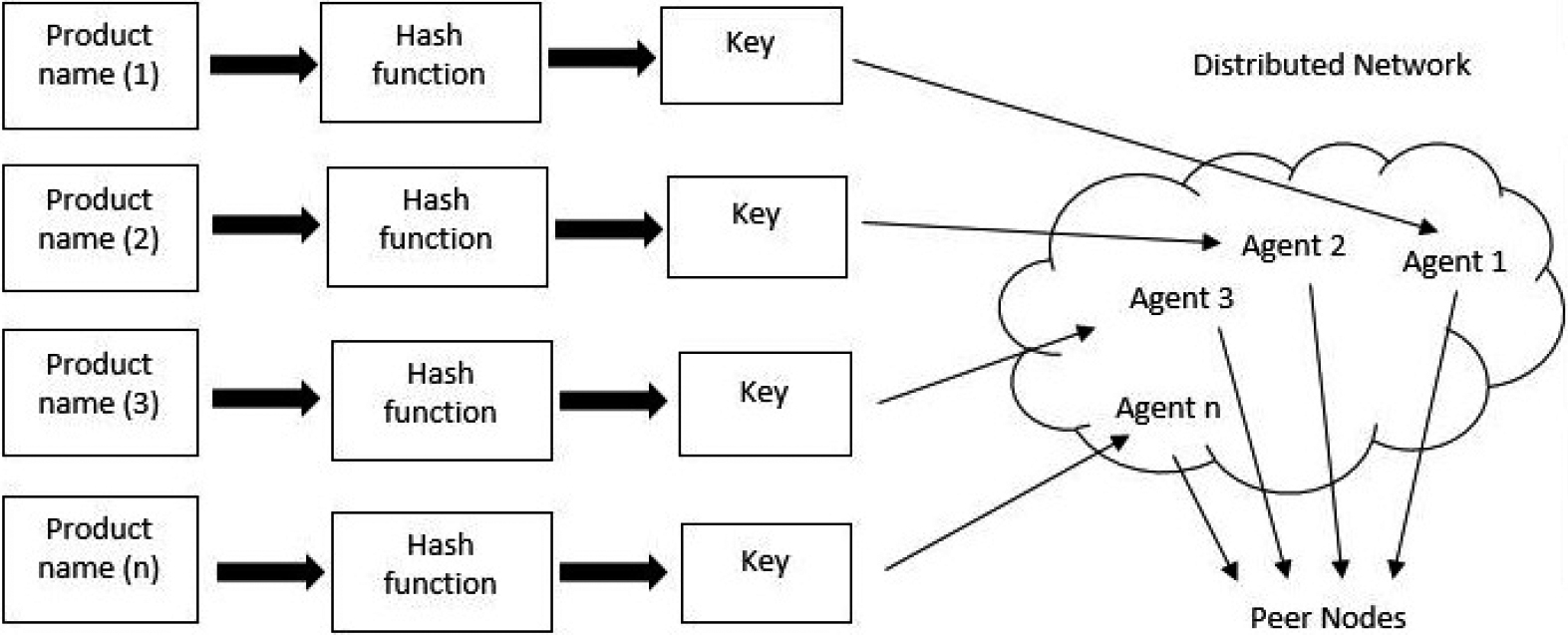
The addresses of the successor and predecessor nodes are stored in a finger table on each node of a distributed hash table. The agent determines whether data is present before responding to a request for data. In order to find out if the requested id and the subsequent or preceding id are the same when an agent is unaware of data, it checks the finger table. If the finger table does not contain a match, we count the number of instructions in both the clockwise and backward directions. The query is transmitted to the subsequent node if the clockwise steps are less than the number of anti-clockwise steps; otherwise, the question goes oppositely. Since agents are connected circularly, the finger table of an agent’s successor and predecessor nodes is updated whenever an agent enters or exits the system. Assume that each agent has access to a database subset, which reduces data redundancy and storage space.
Equation (1) illustrates how each node’s Finger Table contains the address of the subsequent ID and the ID of its preceding nodes – the external loop cycles through 1 to N, where N represents the total count of agents. Simultaneously, the internal loop manages ‘j’ as the current agent and records the addresses of the following and preceding agents in the current agent’s Finger Table. The subsequent section describes the various elements that constitute the proposed DHT framework.
In our paper we have used the word optimized in terms of an efficient approach. The proposed approach ensures that rather than overloading a single agent with queries including repeated queries we use a distributed has table based approach to distribute the database. We can formally present the message redundancy problem in multi-agent systems as.
Let D be the set of all data items in the multi-agents system.
Let A be the set of all agents in the system.
Let
Let
The goal is to minimize the overall data redundancy subject to certain constraints.
Objective function
Equation (2) represents the sum of communication indicators across all agents and data items. Minimizing this sum encourages reducing redundancy by minimizing the number of times data items are communicated.
Equation (3) ensures that an agent can only communicate a data item if it has a local copy of that item.
Equation (4) ensures that each data item is available at least once in the system.
Equation (5) imposes constraints on the total communication overhead for each agent, where B is a predefined threshold. This formulation is a simplified representation and can be adapted based on the specific characteristics and requirements of the multi-agent system. The binary variables
Our framework consists of various modules, each of which is covered below.
Directory facilitator (DF)
The focal point of our framework is the DF. It offers services related to the yellow pages, suggesting that DF gives the agents access to a service repository. Service descriptions are created by agents and stored in the DF. Users can obtain reports on the requested service by accessing the DF. The DF provides services that offer platform agents a list of skills and abilities. The directory facilitator’s Knowledge Base is a digital repository for service descriptions. DFAgentDescription objects contain the details of the DFAgent’s description. In our design, agents’ primary objective is to interact with one another as effectively as feasible. Each agent is accountable for their data since we wish to eliminate data redundancy; as a result, agents must first specify their services in the directory facilitator. Each agent’s essential duties include effective communication, keeping track of particular key and detailed information, and maintaining the finger table if a node joins, leaves, or fails. The Knowledge Base is in charge of storing the agent’s services. DF also has a search feature for getting data from a specific agent and registers and deregisters for storage.
Agent management system (AMS)
Lifecycle management is one of the services that may be obtained using the Agent Management System (AMS) [44]. The creation, deletion, and restart processes are included in the management of the life cycle of the agents. In addition, it is in charge of delivering services to agents, such as name lookup and registration, and it is responsible for authenticating agents. The “white pages” function of the platform is provided by the AMS, which is responsible for controlling the lifecycle of the management system used by the agents. It offers the “white pages” service, which monitors the current locations of mobile agents and sends that information to users. Therefore, the AMS is utilized to create an agent for some purpose or delete some agents in the event that we so desire.
Agents
A software or computer program that makes decisions on behalf of its users is known as an agent [43]. It is autonomous or partially autonomous. Each agent has specific plans and objectives, and successful interaction requires collaboration and coordination. In our proposed design, we seek to facilitate effective agent communication. Intelligent agents possess reactiveness, proactivity, and sociality; hence, the agent must be intelligent. They can make quick decisions based on nearby observations and interactions with other agents.
Distributed hash table (DHT)
The core component of our proposed architecture is a DHT. It searches enormous amounts of data in a decentralized storage system to locate information. By using this technique, data duplication between agents is minimized. Data redundancy is the main problem in agent communication, which contributes to system inefficiency and storage increase. We use a distributed hash table as a result. The database is partitioned into subgroups in our suggested manner, and the data from each subset is then given to various agents. When a request for a date is made, it is sent to a random agent; if that agent cannot fulfill the request, it is sent to the following or prior agent. Each node is in charge of this data. In the context of DHT, a chord is a specific type where each agent maintains the node addresses before and after it. We assume that data is kept in some repository. We talk about minimizing redundant information in agent communication. Our proposed approach offers a significant advantage of data partitioning, wherein each agent handles a specific data set, eliminating data redundancy within the system.
Finger Table (FT)
Every node in a DHT keeps track of the addresses of the next and previous nodes through a structure known as a Finger Table. This structure makes DHTs exceptionally effective for quick searches across vast data. Access to the nodes in the Finger Table is straightforward, facilitating efficient execution of queries. Being the core element in the Chord DHT, the Finger Table plays a pivotal role in the overall functionality of the Chord.
Agent communication channel (ACC)
The ACC facilitates two-way communication between agents operating on different systems. Agents in the same location can communicate with one another via notifications. An agent communication channel allows agents to exchange information with one another. Achieving objectives and increasing the system’s effectiveness calls for cooperation between agents.
Agent communication language (ACL)
Negotiation between agents takes place through the use of ACL. The most well-known ACLs are KQML and FIPA, based on speech-act theory. These languages are deployed on JADE and AnyLogic, respectively.
Query in a distributed hash table (DHT)
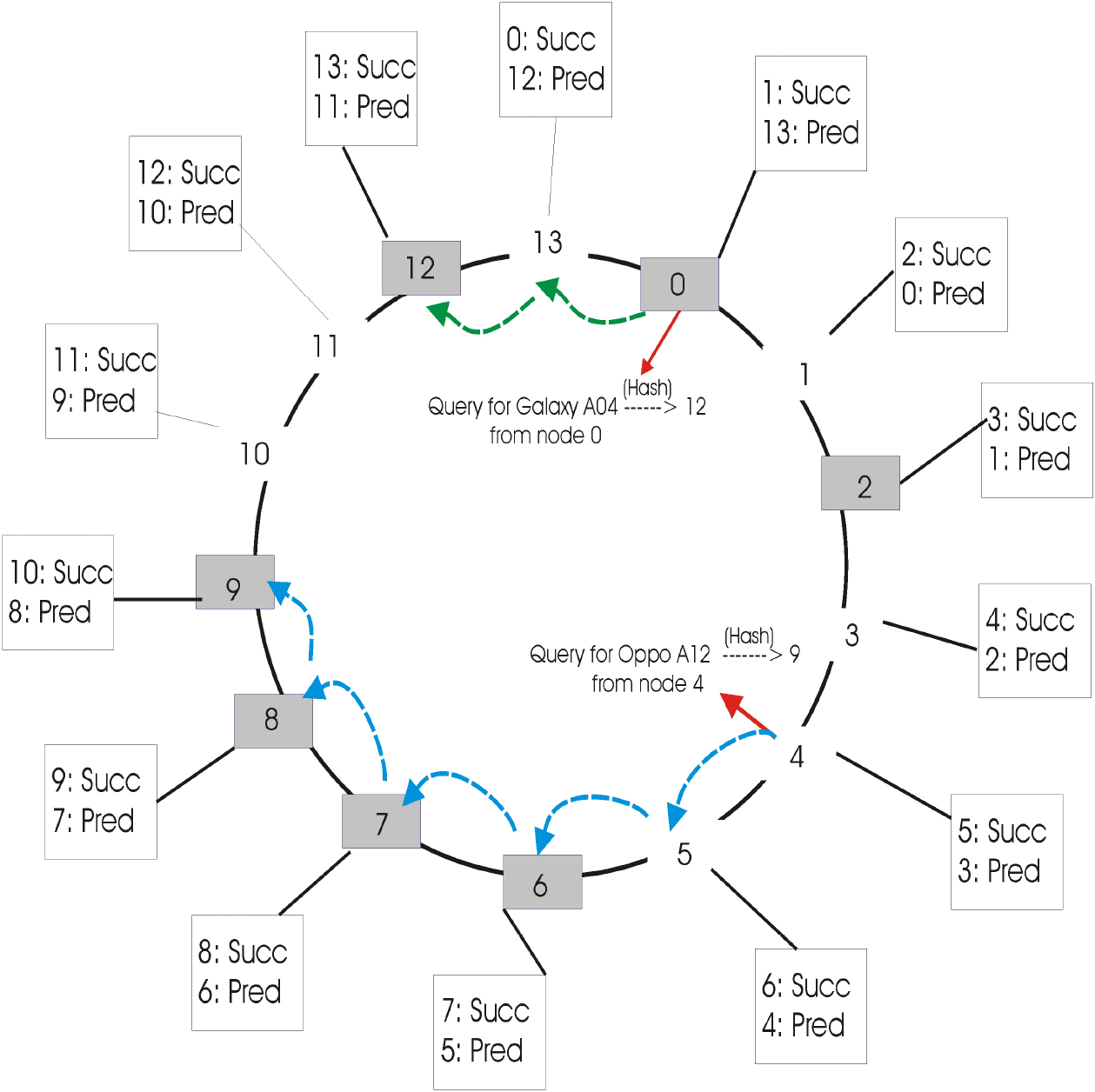
In our framework, we postulate that each agent has a section of the database at their disposal, communicating through a messaging transit system. These database subsets are labeled D1, D2, and up to Dn. Every agent in our setup holds a finger table, providing addresses of both its predecessor and successor. When a request reaches an agent without an acknowledgment symbol, steps are calculated in clockwise and anti-clockwise directions. We present below several reasons for choosing a particular course of action. There are two scenarios for counting steps in the clockwise direction: Case 1 and Case 2 described in Fig. 3. We decide between these two cases depending on the conditions for counting clockwise steps. Meanwhile, we consider Case 3 and Case 4 for counting steps in the anti-clockwise direction.
Distributed hash table (DHT) queries.
In cases no 3 and 4, choosing the route involves going the other way around. The source ID in the scenarios mentioned above refers to the identifier associated with the origin of the data request. The requested id is the hash id of the ordered product data or a destination id queried by some user. The number of steps in a multi-agent system determines the maximum no of the agents. We must decide if the requested id is larger than or less than the source id in order to count the number of clockwise steps between them. There are unique formulas for each event, and depending on the circumstances, we choose formulas and count the number of clockwise and anti-clockwise steps. If the count of clockwise steps is lower than the count of anti-clockwise steps, the inquiry progresses forward. Otherwise, the inquiry goes in a backward direction. We are currently looking at a mathematical illustration of data retrieval from the agent. Let A represent the group of agents A
Equation (6) shows that an agent retrieves data from the Finger Table when he cannot satisfy a request for data.
The results of our suggested strategy are shown in Fig. 4. Each node has a distinct id, host, and port, as well as storage for the addresses of its predecessor and successor nodes. A finger table on each node in a distributed hash table contains the addresses of successor and predecessor nodes. When an agent is asked for data, it checks to see if it has any. An agent checks the next and previous nodes if it has no data, and if neither can answer the query, it checks a random node in either a clockwise or anti-clockwise manner.
Distributed hash table (DHT) representation.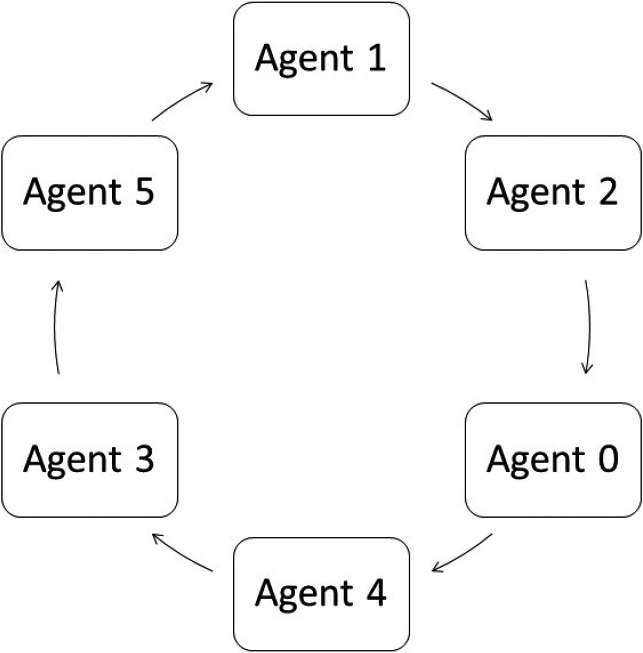
Whenever a new agent joins or leaves the system, we ensure to update the finger tables of its successor and predecessor nodes. This approach reduces data redundancy and minimizes storage requirements as each agent only possesses a portion of the database. We implement the distributed hash table using Node.Js. The code snippet in Table 1 showcases the implementation of the distributed hash table, incorporating the addresses of the subsequent and predecessor nodes.
Implementation of distributed hash table (DHT) in node js
Footnotes
Author’s Bios