A criterion is proposed for testing the hypothesis about the nature of the error variance in the dependent variable in a linear model, which separates correctly and incorrectly specified models. In the former one, only the measurement errors determine the variance (i.e., the dependent variable is correctly explained by the independent ones, up to measurement errors), while the latter model lacks some independent covariates (or has a nonlinear structure). The proposed MEMV (Measurement Error Model Validity) test checks the validity of the model when both dependent and independent covariates are measured with errors. The criterion has an asymptotic character, but numerical simulations outlined approximate boundaries where estimates make sense. A practical example of the test’s implementation is discussed in detail – it shows the test’s ability to detect wrong specifications even in seemingly perfect models. Estimations of the errors due to the omission of the variables in the model are provided in the simulation study. The relation between measurement errors and model specification has not been studied earlier, and the proposed criterion may stimulate future research in this important area.
Consider a typical model, so often to be found in different versions in statistical literature:
where are covariates (explanatory or independent variables); is the response (dependent) variable; are the “actual parameters” to be estimated; is the error term. There are many interpretations of such linear models and, respectively, ways to make estimates. In (Kukush & Mandel, 2019) we considered 16 different scenarios, where assumptions about measurements with or without errors and causal and non-causal interpretations of the coefficients were combined. And still, those combinations do not cover the other aspects of modeling, such as “endogenous” and “exogenous” variables; “latent and observable” variables; normal errors distributions or not; homoskedasticity, etc. So, the “simple” Eq. (1) becomes too complicated under exact specifications.
It is enough to say, that one cannot realistically assume that anything could be measured without errors – and yet this assumption prevails in all statistical literature, in standard statistical textbooks, and even in specialized volumes for linear models like in (Agresti, 2015). Similarly, statistical books and articles usually do not use causal terminology, while very developed causality modeling works (Pearl, 2009; Morgan, 2014) tend to consider the coefficients , obtained by usual regression as causal only because those regressions are embedded into a special framework (directed acyclic graphs). However, it does not make them by default causal, as shown in detail in (Mandel, 2017, 2018). There is a corpus of works for causal discovery in observational data (Peters et al., 2017; Janzing & Schölkopf, 2018; Glymor et. al., 2019), and some part of it is related to errors in variables; recently this literature was reviewed for the first time by Linda Valeri in (Yi et. al., eds., 2021), but it is far from being an established part of the statistical toolkit.
Among many problems let us focus on one – on the interpretation of the so-called random term in Eq. (1). Technically, it looks like a value needed to be added to the deterministic term of the equation to be equal to the value precisely (or, in backward interpretation, as “residual” when Y is already estimated). Neither the nature of that addition nor the reason for its appearance is usually considered. It is just assumed, that some difference always exists and one needs to minimize it (the whole idea of LS and all other methods is exactly that). Typically, it is considered as some kind of construction with convenient features, like this: “…are independent and identically distributed random variables with zero mean and constant variance” (Demidenko, 2004, p. 3).
This type of treatment of those “residuals” holds a key question about their nature unanswered. Say, if two covariates should determine , but we have in a model just one of them, then the interpretation and assumption about i.i.d. in literature will not change. Equally, if suddenly the third (unnecessary) covariate is included in a model (with spoiling effect) – the interpretation, again, will be as it is. But the crucial difference is that only when two causal variables are in a model, becomes a pure error of measurement, while in any misspecification it is not true. One somehow should distinguish between errors due to misspecification and due to mismeasurement. The lack of clarity in this question is a strong contributor to the sad situation of the “reproducibility crisis” (Baker, 2016) and “statistical significance crisis” (Wasserstein & Lazar, 2016; Amrhein et al., 2019), in our opinion.
Despite awareness of that type for a long time, the new studies confirm, that statistics remains not a reliable tool for the actual researchers. Gould et al. (2023) have convincingly shown that even if many specialists (more than 200) receive the same set of biological and environmental data, which have no political or ideological connotation (to avoid easily expected biases), the conclusions could be vastly different. Such an experiment was done for the first time and was different from the earlier ones when multiple groups tried to reproduce the conditions of the original study. In that study, with the same data sets, only statistical tools and the researcher’s imagination played a role. Unfortunately, the authors of this mega study did not provide the exact reasons for the results differentiation (like one used this criterion, another – another one, etc.), and we cannot say for sure, what exactly happened, but it is clear that “the standard statistical treatment” was not in place, with gradual drifting of the estimates of the effect from positive to negative. In the same vein, we do not know how researchers accounted for measurement errors if they did. All that raises profound questions about the level of confidence society should have about the typical statistical study.
The misspecification error alone could be very significant, as shown in Section 3. However, the main focus of the paper is to analyze the effect of the measurement errors on the conclusion about the quality of the Eq. (1). We try to deal with just one question: in what case one may say with confidence, that the built model does not reflect just measurement errors but measures something more substantial. Or, in other words, having any idea about the possible level of the measurement errors in the data – can one say, that the model captures strong (not necessarily causal) relations between variables, which are not hidden by measurement errors? Such situations are technically related to the so-called equation error model (see Section 1.5 in (Kukush, 2011)).
The proposed criterion we named MEMV (Measurement Error Model Validity) test, for it distinguishes valid (i.e., complete) models where only inevitable measurement errors play a role, and invalid (incomplete) models, where hidden covariates (not included in a model) affect the variance of the independent covariate. Moreover, even in a complete model, the test rejects the validity hypothesis when assumed errors in covariates are too high. The test allows, more specifically, answering the following question: is the quality of the model (say, coefficient of determination or another indicator) higher than the level that could be obtained just by accounting for the measurement errors? If yes, then the model makes sense; if no – it does not, regardless of its goodness-of-fit level. This type of criterion could be very useful in situations, where a researcher has a plausible idea about the level of measurement errors either for or for , or just knows for sure about it (when, for example, the precision of the measurement devices is accessible). In a certain sense, it inverses the usual formulation of the errors in variables problem: how to adjust the coefficients of regression to account for measurement errors of different types (Kukush, 2011; Schennach, 2016; Yi et al., 2021). In this latter scenario, one gets the estimates with wider confidence intervals, but still believes that she found “something”. In the former scenario, one knows that nothing good could be expected if the model covers just errors and (erroneously) the hidden factors and nothing more.
The rest of the article is organized as follows. Section 2 describes a specific case of Eq. (1), where the covariates are observed with additive measurement error; in our approach, the variance is a parameter of interest and plays a role of nuisance parameter (unlike under usual treatment); based on the assumption of the independent observations, we constructed a consistent and asymptotically normal estimator of , that yields a one-sided Wald test which serves as a desired criterion for the separation of the correctly and incorrectly specified models. Section 3 contains the results of the simulation experiment. Section 4 demonstrates how to implement the test on the real data and presents some non-trivial results; Conclusion summarizes the main results and outlines the area of future research. Appendix 1 contains proofs of the asymptotic properties of the estimators; Appendix 2 studies the behavior of the test for large sample size and the growing level of the presumed measurement errors.
All the vectors in the paper are column ones. Abbreviation r.v. means random variable; Var stands for the variance of a r.v. and Cov for the variance-covariance matrix of a centered random vector.
Hyrothesis testing concerning the error variance
Basic regression model
We deal with a linear functional errors-in variables model
Here is a nonrandom vector of covariates; is an observable response variable; is a vector of measurement errors; is another error term that may appear not only as a result of measurement, but as an effect of misspecification (e.g., lack or of covariates actually affecting ); instead of true covariates , we observe a surrogate data ; is a vector of unknown regression parameter, and is the vector transposed.
Concerning error terms, we assume the following.
The error in response is a centered r.v., and the measurement error in covariates is a centered random vector; moreover, and are independent with finite 2nd moments.
The error variance is not vanishing and unknown, while the measurement error covariance matrix is known, where is a positive semidefinite matrix (see Remarks below for more detail).
Remark 1. It is allowed that some components of have zero variance. Thus, a subgroup of covariates can be observed without measurement error.
Remark 2. In practice, sometimes can be reliably estimated by repeated measurements of covariates. Another possible case is as follows: components of are independent and with known from the passport information of measurement devices. In case we have the ordinary linear regression Eq. (2) with both observable and .
Remark 3. Other possible cases of available information concerning and will be indicated in Conclusion. Note that some information about the error covariance structure should be available, otherwise the Eqs (2) and (3) is not identifiable, and in that case even for Gaussian errors it is impossible to estimate all the model parameters consistently as the sample size tends to infinity (Chen & Van Ness, 1999).
Individual observations in a data set are modeled as independent copies of the basic model
Here are nonrandom and unknown vectors; are independent i.i.d. random values distributed as in the Eqs (2) and (3), are i.i.d. random vectors distributed as , and the two sequences are assumed mutually independent; – number of observations. Based on observations
we want to estimate and test a hypothesis that its value does not exceed a fixed level.
Consistent estimators of model parameters
As a consistent estimator of , we use the so-called adjusted least squares (ALS) estimator (Cheng & Van Ness, 1999):
Hereafter, the bar stands for averaging over the whole sample, in particular , ; denotes the pseudo-inverse matrix of a matrix . If the matrix is nonsingular, then Eq. (7) takes a form
where is the inverted matrix. Under mild assumptions this happens with probability tending to 1 as (see statement 1 of Theorem in Appendix 1).
A consistent estimator of is based on the following computation:
Thus, is expressed through the residual sum of squares ,
Let us introduce estimating functions
With probability tending to 1 as , the pair is a solution to the estimating equations
The estimator Eq. (10) is consistent, i.e. converges in probability to as (see Appendix 1). Hence the right-hand side of Eq. (10) is positive with probability tending to 1. For finite sample, it can happen that , and we modify the estimator Eq. (10) as follows
Asymptotic normality of the estimators and Wald test
Let us denote the following vector of parameters:
The corresponding unbiased estimating vector function is as follows
where the components and are given in Eqs (11) and (12). The estimating equation for is
Actually, is a Borel function of observations such that is a solution to Eq. (17) if it has a solution. Under the corresponding model assumptions, the Eq. (17) has a solution with probability tending to 1 as (see Appendix 1).
Under a bit stronger model assumption, the estimator is consistent (i.e. converges to true in probability as ) and asymptotically normal. Sufficient conditions for the consistency and asymptotic normality of are given in Appendix 1. They include finiteness of error moments of some order greater than 4, convergence of sample means of up to 4th order, and non-singularity of the matrix
The asymptotic covariance matrix can be found from the sandwich formula (Carrol et al., 2006):
Here and the functions are evaluated at the true point . We assume that is nonsingular, and therefore, is nonsingular as well. In our case, is symmetric, hence and Eq. (19) takes a form
Notice that and , therefore, the matrix has a block-diagonal structure
A consistent estimator of can be found as
where and are consistent estimators of and , respectively. In view of Eqs (22) and (20), the matrix estimators can be constructed as follows:
The pseudo-inverse matrix has a block-diagonal form
The lower right entry of in Eq. (23) is an approximation to the asymptotic variance of the estimator . Due to the block-diagonal structure of , it holds
Here is the lower right entry of given in Eq. (25). Let be the square root of the approximation Eq. (26). Estimated asymptotic standard deviation of equals
Let be a given upper bound for the variance , that is a known upper estimate of measurement error variance, obtained outside of the model. We test a one-sided compound null hypothesis
vs. one-sided compound alternative
Given a confidence level , according to Wald test we propose the following decision rule:
Here is upper quantile of normal law, a critical value of the test. The asymptotic significance level of the test equals , or more precisely, Type I error satisfies relations:
and
The test is consistent, i.e., Type II error satisfies the following:
The rejection criterion Eq. (30) can be written in a quite simple practical form. Remember that the residual sum of squares RSS was introduced in Section 2.2. For practical use, one can put in Eqs (30) and (31) . As a result, we reject with confidence 0.99 if
Otherwise, we do not reject . We call this procedure Measurement Error Model Validity test (MEMV test).
The -value for this criterion is calculated as follows:
where is cumulative distribution function of standard normal law. Small -value (usually less than 0.05) indicates strong evidence against the null hypothesis. Large -value (usually larger than 0.05) indicates strong recommendation not to reject the null hypothesis. In simulation study reported in Section 3, under validity of the corresponding -values are large, which leads to the absence of Type I errors (except extreme cases when P/A is close to 1 with very small sample size), and under validity of the corresponding p-values are either small or take moderate values larger than 0.05, which leads to certain level of Type II errors.
A disadvantage of the decision rule Eqs (30) and (31) lies in the fact that the test is asymptotic, i.e., it works well for large . But we do not know precisely which is large enough for typical model parameters. Some empirical suggestions are provided in Sections 3 and 4.
Applied to the measurement error Eqs (2) and (3), the Gleser-Hwang effect (Cheng & Van Ness, 1999, Section 2.4.1) says that every non-asymptotic confidence set for the regression parameter with positive confidence level will be unbounded with positive probability. For the same reason it is impossible to construct a non-asymptotic test for the above-mentioned null hypothesis, with a fixed non-asymptotic significance level.
Remark 4. Once is not rejected, we infer that the data fit the Eqs (2) and (3) with given upper bound for the variance . If is rejected, then we infer that the term in Eq. (2) contains misspecification error and we need more explanatory covariates in the linear Eq. (2).
Let us consider an example, related to the well-known Hooke’s law in mechanics. Suppose that we made measurements of applied force and measurements of extension of the string , , where and are the corresponding true values. Error variances and are recorded in the passport of measuring devices. We assume that is known, while is unknown. One can check the null hypothesis
If is not rejected then we confirm the Hooke’s law , and if is rejected then we deny the Hooke’s law and infer that either extension depends not only on applied force, but on some other covariates, or it depends on the force only but in a nonlinear way.
Simulations
In order to test the behavior of different statistics associated with the proposed criteria the simulation experiment was performed with different data settings. The following parameters were used to manipulate the data.
Number of covariates affecting the outcome equals two. Both were generated as the uniformly distributed random variables within the different ranges to observe the scaling effect: in the range [0, 1.5]; – in the range [0, 0.3].
Number of observations in each data set: 30, 100, 500, 5000.
Level of measurement errors in in Eq. (5) was regulated as follows: it was proportional to average level of covariates (0.75 and 0.15 respectively) times a factor 0.01, 0.05, and 0.2. The resulting values were considered as standard deviation for a normal random variable, which was added to the actual values of . It means that if relative errors compared to average were 1%, 5%, and 20%, while the individual relative errors in each observation could be much smaller or larger.
A square root of variance in Eq. (28), a measurement error for , was set, similarly to ones for , as 1%, 5%, 20% of the average value.
“Presumed/Actual” (or P/A) ratio was set at three levels: 0.5, 1, and 2. For each level P/A, the ratios were generated as random within a narrow range; as result, they were located from 0.4 to 2.4 range, i.e., assumed values could be 2.5 times smaller or 2.5 larger than the actual generated errors.
Variance in Eq. (28) is a researcher’s guess about the measurement error variance of the measurement error in the dependent variable. It was generated as a product of the error and the P/A ratio. It reflects a realistic situation that a researcher should be more or less aware about the real measurement level and does not apply too high or too low P/A ratio to make an estimate.
Models of two types were constructed: when was a linear function of the two covariates with errors, as described above, and when also contains the third covariate (representing all unobserved factors), which created another source of variance, different by its nature from the measurement error. They were named models without or with inclusion, respectively. The was generated as uniformly distributed variable in range [0, k], where k average ()*f, where f takes values 0.1; 1; 3. If f 0.1 – the added covariate should not affect too much, while with f 3 it is a very significant contributor into variation. All estimates of the parameters were made, of course, without accounting for this covariate, because in practice no one knows about its existence and character.
Combination of the listed conducting parameters – inclusion of parameter 2 (a sample size from the list above); measurement levels (parameter 3) for , , and P/A ratio (parameter 5) – yields 162 types of data. For each type, 30 random datasets were generated that gives 4860 data sets for each given data size. It allows to calculate the errors of the first and second types across all parameters’ combinations with confidence probability 0.99 Eqs (32)–(34) and -value Eq. (2.3), together with other characteristics.
Some simulations results are summarized in Table 1. In its first section, it shows the average values across all respective datasets. It reduces the volatility of the indicators, which otherwise is much higher in specific groups. Still, some regularity is to be seen.
Average values and correlations of -values for different indicators1
Indicators
Inclusion of and type of Ho
Sample size
30
100
500
5000
EIV test, share of rejection
All cases
0.13
0.27
0.41
0.52
Yes
0.25
0.43
0.52
0.6
No, Ho true
0.01
0
0
0
No, Ho false
0
0.21
0.57
0.86
Determination,
All cases
0.73
0.73
0.73
0.72
Yes
0.63
0.62
0.63
0.62
No, Ho true
0.82
0.83
0.82
0.82
No, Ho false
0.82
0.83
0.82
0.82
Error of type II
All cases
0.60
0.45
0.3
0.19
Yes
0.71
0.51
0.39
0.30
0, Ho true
n/a
n/a
n/a
n/a
0, Ho false
0.99
0.79
0.41
0.14
-value
All cases
0.47
0.41
0.38
0.37
Yes
0.34
0.29
0.27
0.26
No, Ho true
0.89
0.9
0.94
0.97
No, Ho false
0.33
0.19
0.09
0.02
Correlations with -values
EIV test
All cases
0.47
0.61
0.77
0.91
Yes
n/a
0.69
0.79
0.93
No, Ho true
0.00
0.00
0.00
0.00
No, Ho false
0.12
0.36
0.56
0.57
Determination,
All cases
0.43
0.36
0.30
0.27
Yes
0.04
0.43
0.37
0.34
No, Ho true
0.04
0.05
0.14
0.19
No, Ho false
0.23
0.10
0.03
0.02
1n/a stands for “not available”, either theoretically (as in a row for type II errors) or actually, when all tests showed one (positive) result and correlation does not exist.
Percent of Ho rejections is visibly increasing when sample size is growing – with all other conditions kept the same, from 13% for 30 to 52% for 5,000 cases. Especially sharp growth is for situations when Ho is false, from 0 to 86%. This effect is not present only when an unobservable covariate is not added and Ho is true – in this case, the test always works correctly (not rejecting hypothesis), with just 1% of errors for 30 observations, that is expected.
Ideally, a rejection rate should not depend on : it has to reflect just specific features of the data, like interplay between measurement errors, as it was intended for. But dependence happens, and it sheds light not only on this specific problem but on any procedure of the statistical estimation. Typically, since a sample size is in a denominator of the formulas for sampling errors and similar statistics, the larger sample – the higher probability that certain types of “significant differences” will be always found, at any confidence level. This fact is one of the key issues of the mentioned above “-value crisis” and, particularly, inspired the proposal of the so called -values, which is free of this distortion effect (Demidenko, 2016; in fact it just shifts the difficulties and responsibilities from statistician to the decision maker, providing her with probability, not with sharp cut threshold as -value with related confidence.) This problem is lurking in our case as well: the larger a sample, the more likely that Ho will be rejected, but we anyway incline to believe more in estimate based on 5,000 rather than 30 cases. On the other hand – mechanical raise of rejections percent with sample size growth seems unnatural and disturbing. Maybe, one could just use caution looking at the rates of growth in Table 1 and coordinating his/her results with it (for example, use bootstrap for double checking).
Coefficient of multiple determination shows level of approximation by covariates in each specific dataset. It is, generally, does not depend on sample size and other circumstances, but is strongly affected by adding the hidden covariate into the model (see Table 2).
Table 1 does not show the type 1 error for the simple reason: it is always equal to 0. Even a model with the sample size 10 (not shown there) yields no errors. This is quite amazing result, which talks a lot about selectivity and directionality of the criterion. The only situation when type I error appears is when presumed variance is practically equal to the actual variance (i.e. when P/A ratio is around 1) and sample size is small, like 30 or less. This is quite paradoxical: if one knows exactly what are the errors in variable, the probability to make a mistake in the model’s specification raises! But, at the second glance, the reason for that is clear: the closer are two values, the higher is the chance, that small random fluctuation shifts the decision into the wrong direction. Relation of the P/A ratio and the error of the type II is also non-trivial.
Errors of type II behave in predictable way: their average level for all situations drops from very high 60% for small samples size 30 to more acceptable level of 19% for 5,000. When H0 is false (i.e. the only source of variance is the measurement errors) and the unobserved covariate is not in a model, the error drops from 99% to 14%. It means, if one wants to make sure that measurement errors do not disturb model too much – only big number of observations should be available to conclude it with good confidence; even samples as big as 500 observations are not enough for that. It’s a very important conclusion for practical purposes (see Section 4). On the other hand, when the latent covariate is there – even 5,000 cases yield the high errors, 30%. However, the real influence of this hidden covariate depends also very much on its comparative size to the observed covariates (see Table 2 and Section 4).
As for -values, the most interesting fact is that if the hidden covariate does not exist and Ho is hold, they are much larger than ones for situation where H0 is false – about 0.9 vs ones from 0.33 to 0.02. This is understandable, because in the case of true huge -values indicate our confidence in accepting the null hypothesis, and in the case of false small -values indicate our confidence in rejecting the null hypothesis. To look at -values closer, the lower part of Table 1 presents their correlations with other statistics in the original data (each correlation was calculated for 4860 observations for each data size or smaller, depends on number of filtering conditions).
Correlations of -values under false are strongly negative with growth of the sample size: the larger is sample, the less is -value, that follows from considerations discussed above.
Determination is not strongly related to -value in scenario of the correct model (without adding the covariate), but positively correlated with p-value when the latent covariate is added.
Table 2 shows several indicators from another point of view. The “Scaling parameter” in the first column of Table 2 means the percentage of the respective field on the row: for example, 0.01 for Y measurement level means the error is proportional to 1% of the Y variance, while the same 0.01 for “Factor f for X3” means that the share of the unobserved variable X3 is proportional to 1% of the average value of two other X as explained in the description of the simulation (p. 7). Different levels of errors, either in or in , do not affect strongly any statistics, but the effect of size (i.e., how much variance of y is to be explained by variance in x) is very strong for all of them: with raising relative importance of added covariate the percent of test rejections grows from 20 to 84; determination drops from 0.82 to 0.27; errors of type II sharply fall from 77% to 5%, and -values – from 0.51 to 0. Therefore, for the hidden covariate to be the main factor affecting everything, the size of the effect is a key, not the very fact of it. More details on this problem can be found in (Kukush & Mandel, 2019).
In total, out of all 216 (54*4) combinations of the conducting parameters with size included, small average -values (less than 0.05) were observed in 40 cases (19%). The reliable separation (with small -value) of the correct and incorrect models is practically possible only if some influential unknown covariates are present; if not – the decision will not be strongly supported, even when the level of errors in variables is as big as 20%, as in our experiments. It, however, does not mean that if the third covariate is added the correct model always will be detected with high power: in 60% of all cases with inclusion (out of which 45% have of about the size of the correct covariates and ) -value is very high. These observations emphasize how difficult is to make a correct decision about the truthful models.
Average values of indicators as functions of scaling parameters
Scaling parameter
Test rejection, %
Determination, R2, %
Error of type II
-value
Y measurement error,
0.01
26
83
0.37
0.37
0.05
37
76
0.39
0.42
0.20
36
59
0.4
0.44
X measurement error,
0.01
29
75
0.41
0.38
0.05
39
74
0.33
0.41
0.20
31
68
0.41
0.44
Factor f for X3
0.01
20
82
0.77
0.51
1
31
79
0.61
0.35
3
84
27
0.05
0.00
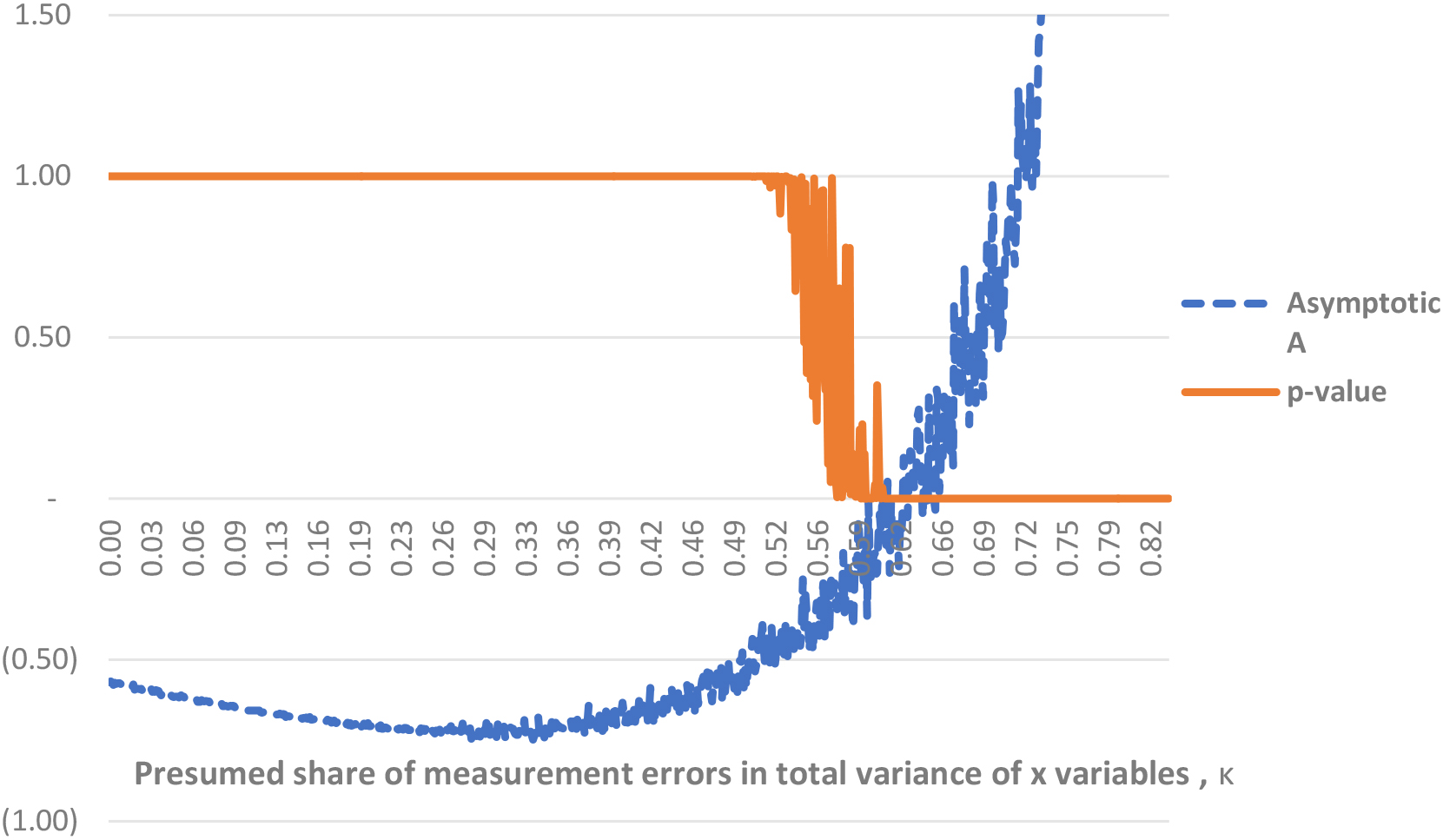
In a practical case, where the covariance matrix of measurement errors in is unknown, we can use the test with presumed value , as proposed in Appendix 2. Here k is a share of error variance in the total x variance under assumption that relative errors are the same for each x variable. In Fig. 1 we see that for , the corresponding p-value is close to 1, and for , the -value is close to 0. With certain precision, this corresponds to the intervals where the asymptotic value of the test statistic is negative () and positive (), respectively. See Appendix 2 for the relation between -values and the behavior of .
In fact, from all observed in simulations one main idea could be informally derived: the proposed criterion separates situations with and without “improper covariates”. It behaves very differently in those two scenarios. Could we use it for this purpose directly? If one may confidently conclude that a given model with all assumptions about measurement errors contains or not the unobserved covariates, it will be an important result in statistical modeling. This type of criterion could replace many heuristic ones in a large area of research for the “best variables selection” (see, for example, Lipovetsky, 2006, and references therein).
The proposed criterion does not answer this question strictly, but leads to the right direction. It turns out that the key results from (Kukush & Polekha, 2006) combined with ones from the current paper could be used to formulate the correct criterion for answering the question: are there hidden independent covariates in data or not? But this special topic will be considered in a separate paper.
Asymptotic value of the numerator in (A13) of the test statistic and -value of the test as a function of .
In order to demonstrate the effect of the incompleteness of the model, considered above, in more general terms, we performed a separate simulation study. It does not cover all possible sources of the model’s misspecification, but one very common problem: how omitting some variables effects the estimation of the model’s coefficients. It is clear that a researcher is almost never sure that the model is ideally specified, and most often the number of variables used is less than exists in nature. It is a well-known problem, but surprisingly just few simulation studies were performed on it (Erees, 2009), and none, as far as we know, with errors in the variables. Even though we do not file this gap completely, our simple simulation provides some important insight that the bias due to variables omission could be extremely high, that makes the problem of the testing model’s validity very actual. The simulation was organized as follows.
The datasets with 6 independent X and one dependent Y variables by 1000 of observations were set in three versions. First, as random variables slightly correlated among themselves (correlations varied between 0 and 0.55, what is rather typical in the real data; without multicollinearity). Second, the same data set with the error 10%: to each individual value of the random value from normal distribution with zero mean and 0.1 standard deviation was added. Third, the same as the second, but with 20% error (0.2). Thus, all X variables were assumed to be measured with the same error rate; it also was true for Y (the error was 0.1y or 0.2y).
Deviations of the coefficients from the actual values.
Confidence intervals and t-statistics for deviations from actual values.
Then the sets of one thousand true positive coefficients was created in such a way, that each of them was a random value between 1 and 100 and was used for all three data sets. For example, the first set of the true coefficients (for variables x1, x2, .., x6) was 25, 31, 12, 92, 56, and 45. The second – 85, 13, 28, 47, 91, 89, and 38, and so on thousand times. It means, that no variable was set up as being more important than others during whole simulation. This setting allows for averaging of the results for all variables without loss of generality. The fact that all coefficients were only positive numbers, allows to calculate the deviation from the real value in percents, as absolute difference between actual and estimated values divided by actual value. It makes all deviations comparable among the different levels and between different variables. Then for each of three datasets, six models were run – from 6 variables of the complete model to 1 variable of the severely incomplete model. The main results of the simulation could be presented in two charts.
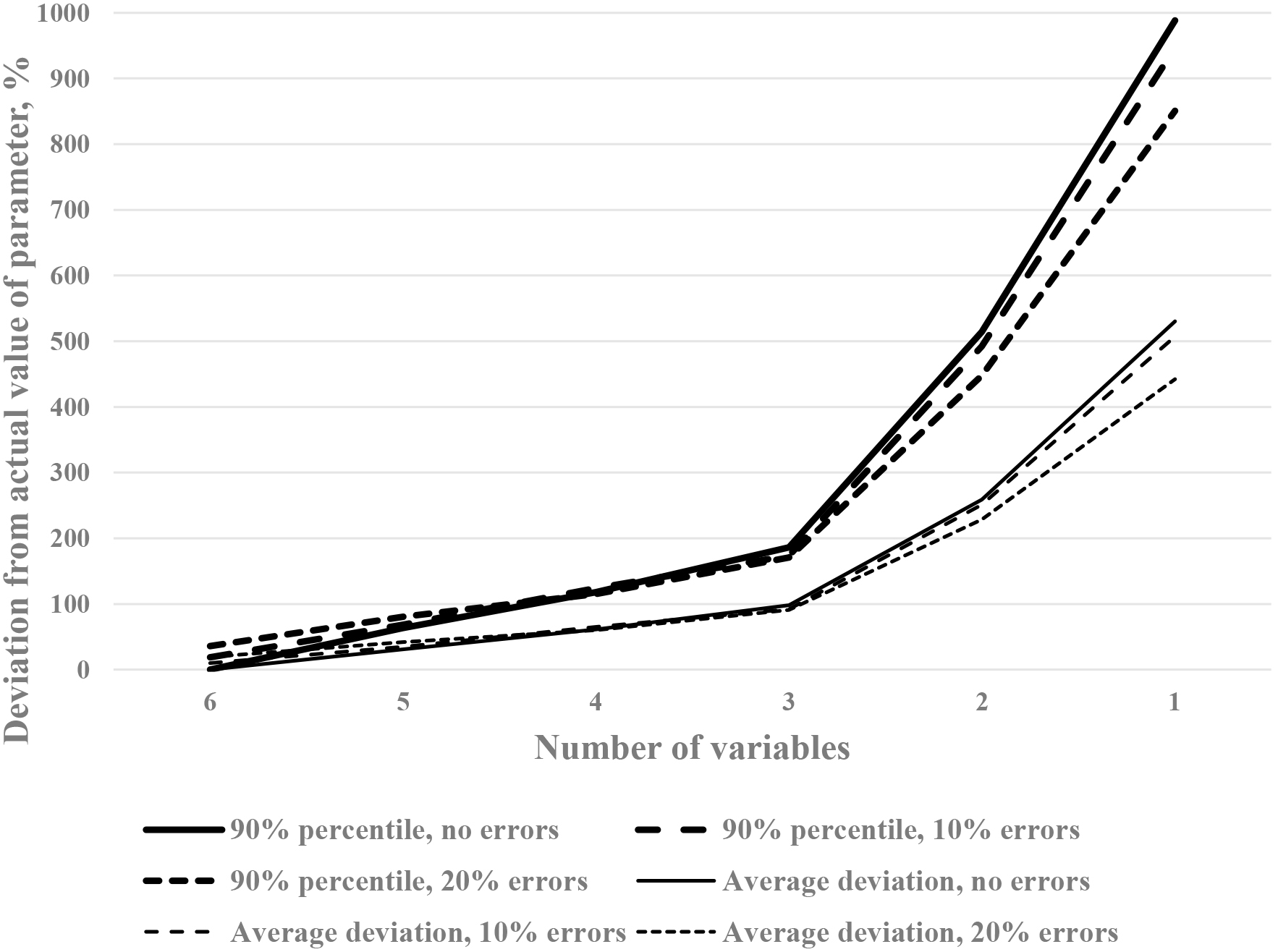
Figure 2 shows the behavior of two statistics. The Average deviation is the average value of all deviations for all variables (say, for 5 variables it is an average of 500 values). It is clear that the average deviations of actual values from the estimated are doubled (reach 100%) when the number of variables is 3 instead of 6, after which the deterioration sharply increases and reaches 5-fold difference when just one variable is used.
Another statistic is 90% percentile of the deviations: one may see that ten percent of all deviations exceed nine or ten-fold difference against the actual values when just one variable is in a model (or five-fold with 2 variables).
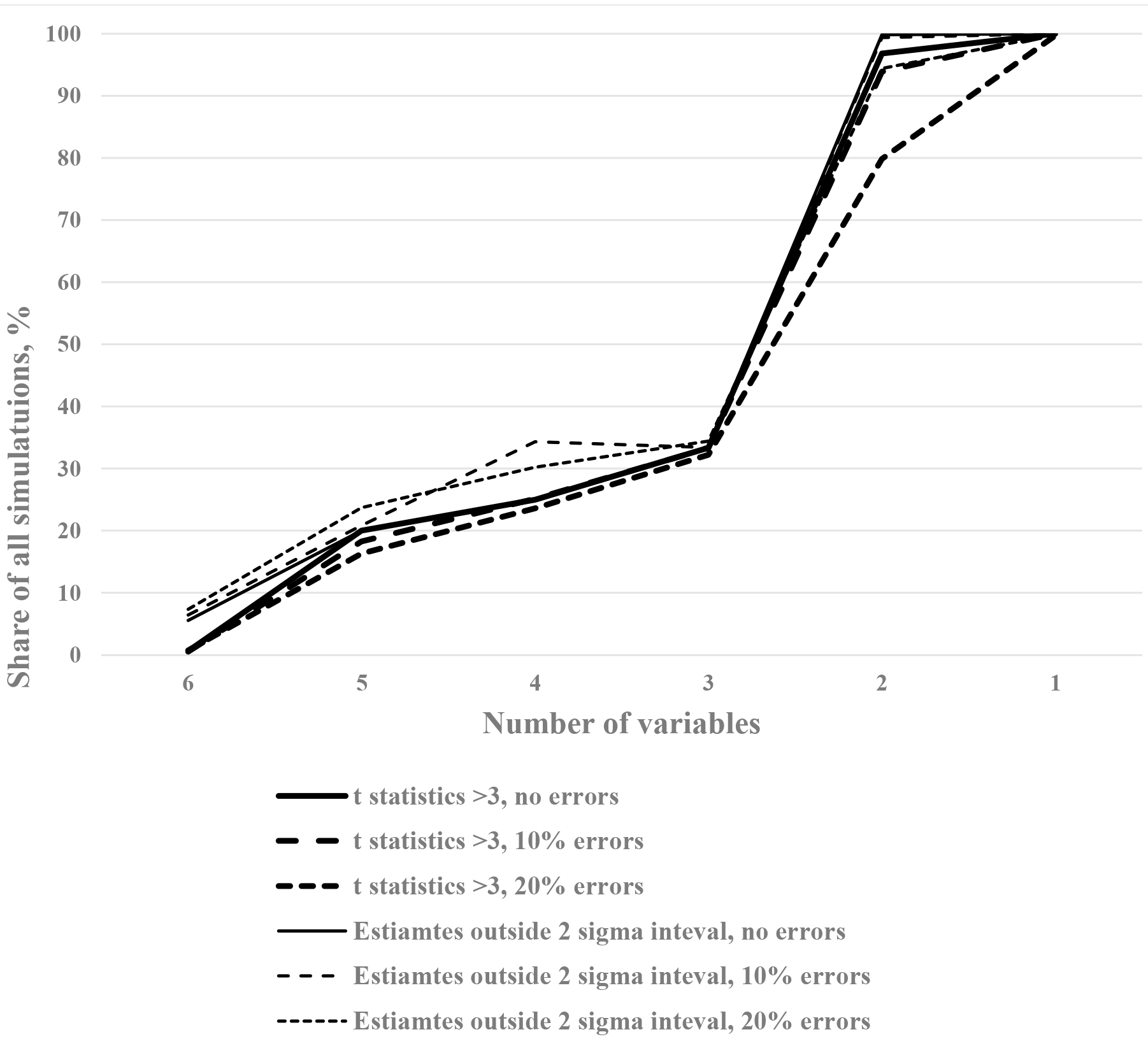
In Fig. 3 two other indicators are demonstrated. One shows the percent of t-statistics, exceeding 3, i.e., significantly different from the actual values. Again, 3 variables play a role of the threshold here: 30% of all estimates are outside the acceptable bounds for the parameters, while with two variables almost all estimates with or without errors lie in that zone. Similarly, the percentage of estimates outside the borders of the 95% confidence interval (two sigma) more or less repeats the same pattern – a sharp rise after number of variables is less than three.
This simple simulation shows, that the problem of variables’ omission, so common in practice, would often lead to serious deviations of the actual values from the estimates, which cannot be compensated by more sophisticated techniques. Since different studies omit different variables, it may contribute into reproducibility crisis, mentioned earlier.
Real data example: Calories in food
To demonstrate how the proposed test may work in practice, let us consider a simple example with real data, which were discussed in (Mandel, 2017, 2018) in connection with casual modeling problem. It is a collection of 872 types of foods, where the content of fats, proteins, carbohydrates, and total amount of calories is measured per 100 grams of food https://www.csun.edu/science/ref/spreadsheets/xls/nutrition.xls. Since calories could be obtained only from those three ingredients (not from, say, water or fiber), the model with three independent covariates is causal, linear and complete. The remaining variance in (calories), if any, could be explained only by measurement errors in and . In that respect, a model is ideal for the study and exactly fits description of the model in Eqs (2) and (3). Let consider application of the proposed test to two situations described earlier: for complete model and for the model with added hidden covariate. We start with the simplest case.
Complete model: no hidden covariates.
A certain number of foods does not have one of the ingredients. We took the subset without fat (241 foods), i.e., just with two independent covariates, Carbs and Proteins (to be called w1 and w2 in Eq. (3)). As expected, the model shows very high goodness-of-fit, with OLS estimates of the coefficients 3.91 and 3.94 and with 95.6%. Those coefficients match perfectly those widely known in the nutrition literature, reported usually just as equal to each other, 4.
Now, let us check the hypothesis about validity of this model. As formulated in Eqs (28)–(35), the test compares two errors in , measured as variances, the true one and the estimated. We have no idea how big or small the real error in is, neither how big are the errors in covariates (which is indeed the case – the publishers of the data did not say anything about errors). In order to test the validity, one has to make plausible assumptions about the errors and make test’s calculations. But what is plausible?
The best way is to use relative errors, i.e., fraction of the presumed to the standard deviation of the respected covariate or response variable . This fraction cannot be higher than 1, and we run the estimates, respectively, in a range from 0 to 1. Another assumption was that relative errors for each covariate are the same (it could be easily relaxed without loss of generality). P/A ratio was also set in a respective range in such a way that its maximum value does not allow the measurement error exceed the standard deviation of . The results could be briefly summarized as follows.
When critical value of the test in Eq. (30) is set as 3 (which yields the confidence probability 0.99), the Ho was not rejected under any conditions.
When critical value was set to 2 ( 0.95), the rejection took place only if the assumed measurement errors, both for and , are very small.
The rule of thumb recommendation may be provided, that the presumed variance for measurement error should be about , where is the number of observations and – the number of covariates. In our case, it gives a relative error close to 90%: the larger presumed values of errors are more preferable than the smaller ones for test to work more confidently. Yet very large values would definitely eliminate any probability of rejection.
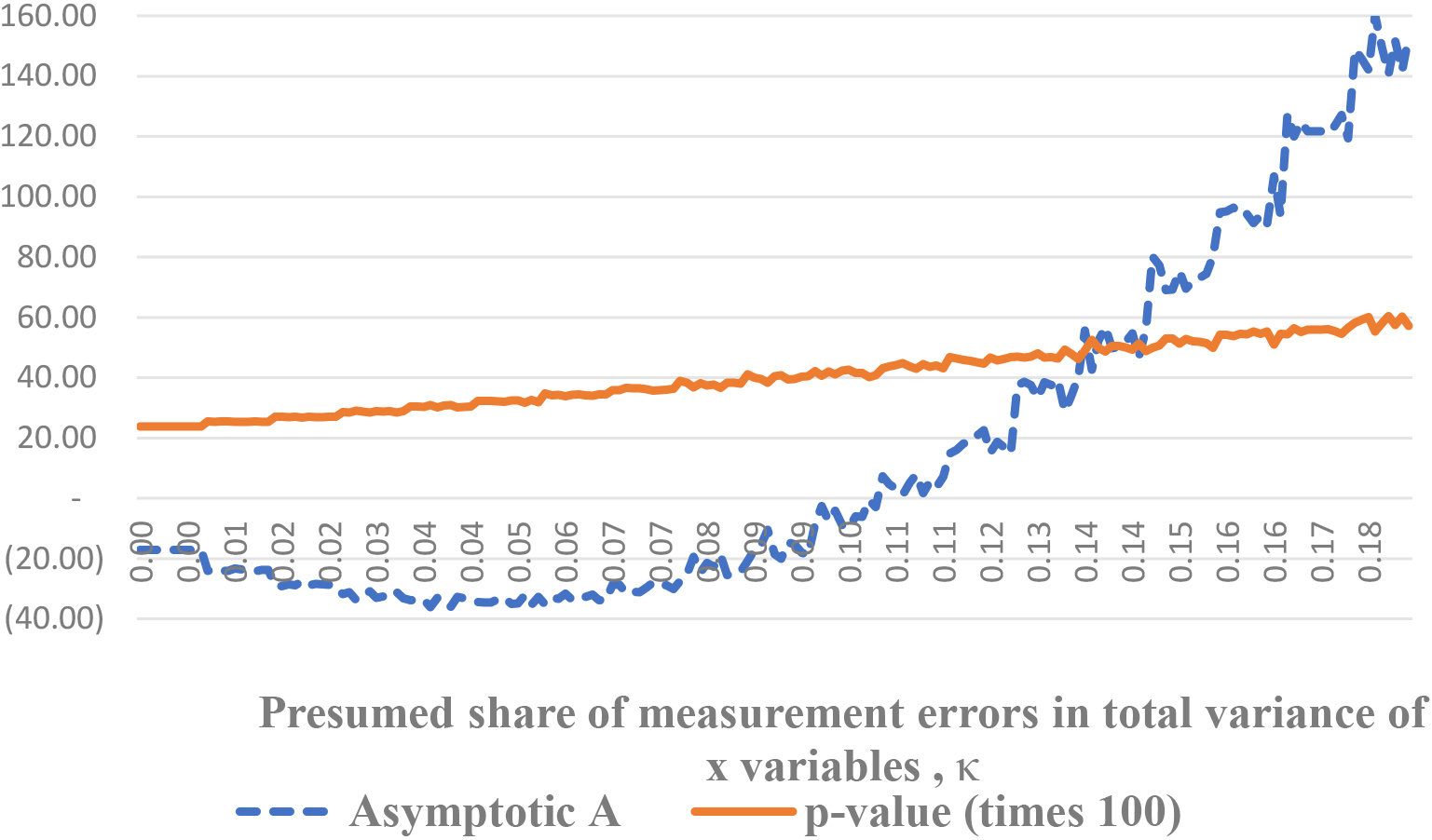
Those conclusions are independently supported by considerations related to the sign of the numerator in Eq. (51). Despite the fact that sample size here is not that big, a chart like one on Fig. 1 shows the similar non-monotone curve for (Fig. 4). It crosses zero at about 10% point, which corresponds with beginning of -value raise.
The described effects are intuitively clear, even if not immediately obvious. Imagine, we presume that a data has no measurement errors at all, the function is strictly linear. Of course, Ho should be rejected, because we do observe unexplained variance in variable! The test demonstrates just that. In this specific dataset, the plausible level of errors in is very high (see the rule of thumb in the paragraph 3 above), and even for that reason we should not reject hypothesis.
Asymptotic value of the numerator in (A13) of the test statistic and -value of the test as a function of for Carbs and Protein model.
Thus, overall, the MEMV test provides very strong evidence that the model is valid, which is indeed true in this case of the complete model. What if it the model is incomplete?
Misspecified model: hidden covariate.
Let us consider much more common scenario, with hidden covariate(s) in a model, while researcher has no idea about it. For testing we may use the entire food dataset, but use the same two covariates as before assuming that the very notion of Fat is unknown to the statistician. Expectedly, the quality of the regression model drastically dropped, with just 15.3% (vs. 95.6% for the complete case discussed earlier), and coefficients severely biased: 2.5 and 5.5 vs correct 4 for both covariates. This model, however, perfectly satisfies the standard statistical requirements: t statistics for coefficients are 10.4 and 8.3, much higher than usually required 3, and -values are practically zero, thousand times smaller than the infamous 0.05, which once again tells about fragility of all that type of “requirements”. Can the proposed test conclude that something is still wrong?
Yes, it can. The hypothesis that model is correct is rejected immediately and on entire range of assumptions about errors. Difference in presumed errors for practically is negligible for this conclusion. The test detects, that despite all “perfect” statistics, the model is invalid, and with very high confidence, when 0.99 (see more details in Kukush & Mandel, 2019).
But possibly, the test worked very well because the original model was too weak, judging by common sense about low determination (15%), not by other indicators (-stat and -value)? Let us check it on another pair of covariates, giving much more formal “confidence” that model is good. It turned out, that if we exclude Protein, but leave Carb and Fat, the model will seem just perfect: the determination is 95.4%, the coefficients are very close to the real ones – 3.6 and 8.8 (vs. 4 and 9), and, of course, t statistics (63 and 129) and -values (0) are much smaller than any typically accepted levels. But the model is incomplete, and we know that. What about the test? It does not disappoint even in this difficult for detection situation.
In the same fashion as before, the test rejects the hypotheses, but, remarkably, does it for much shorter range of the available presumed errors for covariates. This range becomes even shorter with increasing of errors for : up to about 16% for small errors in y and up to 10% when error for is around 60%. It makes a lot of sense. When determination is very high and the model is valid, big measurement errors in covariates are actually impossible, there is no room for them, and Ho almost never is to be rejected with high confidence on the very narrow range for errors. However, when the same high determination takes place on invalid model, as in this case, the restriction for errors in covariates remains, but its range becomes much larger (by three times) and confidence in rejection much higher (0.99 vs 0.95). Thus, even in this almost extreme case, the test worked and detected the invalidity of the model, which would escape our attention otherwise. The decision is justified with less confidence, in general, than it was in a model with Protein and Carbohydrates, with determination 6 times smaller, but still justified.
Those examples show how the MEMV test could be used in practice. The radical difference between superficially almost identical models shows it very well: in both cases (complete and incomplete) approximation is extremely high ( 0.95), but the test convincingly reveals the qualitative difference. It seems it can play an important role in separation of the complete and incomplete models in the very common situation of errors in variables for any linear models.
Resuming, here are short recommendations how to use the proposed measurement errors model validity test in practice.
If error variance of variable and error covariance matrix of variable are known (like when measurement devises with given calibration are used for both and ), use the test directly with and .
If error variance of variable is known but error covariance matrix of variable is unknown, then set and , where is a sample covariance matrix of (see Appendix 2), and use the test for different presumed values . Plot the dependence of -value of the test as a function of , i.e., build a chart like the one in Fig. 1. Set the confidence level (e.g., 0.99). Indicate the intervals for where the corresponding -value is less than (where is rejected and the model is invalid), and the intervals where corresponding -value is greater than or equal to (where is not rejected and the model could be valid). Then select one or another interval for and make the corresponding decision according to your ideas a about possible level of measurement errors of variable. Since k represents the error’s share in the total x variance, if k is less than presumed level of errors – the Ho is accepted. Keep in mind though, that it is not a universal situation: sometimes a plot for A8 may have several crossing points with the horizontal axis. If you are not able to make the final choice, then you need more information about measurement errors of variable.
In a the case when the error variance of variable is known and the error covariance matrix of some components of variable is known, while for the rest components it is unknown, make the analysis similar to the paragraph 2 above with a block diagonal matrix , with blocks and , , where is a sample covariance matrix of , a surrogate data for unobservable components .
If error variance of variable is unknown and error covariance matrix of variables is known, then the proposed test is not applicable. But another test developed in (Kukush & Polekha, 2006) can be used. We intend to study that test in future research.
If error variance of variable is unknown and error covariance matrix of variable is unknown or only partially known, one can try the test from (Kukush & Polekha, 2006) with matrix selected as in the paragraphs 2 or 3 above. This case will be also studied in future research.
Finally, suppose that error variance of variable and error covariance matrix of variable with known characteristics and (those nominal values are usually taken from passports of measurement devices) and unknown positive factor . It may happen, when, for example, all variables are measured with the same device, but accuracy of this device is not precisely known, i.e. we do not know the exact . Under a presumed upper bound , one can check the null hypothesis: “” (this will be studied in future research); and without a presumed upper bound, one can use a test developed in (Kukush & Tsaregorodtsev, 2017).
Conclusion
We considered the classical measurement error Eqs (2) and (3) where the variance-covariance matrix of the measurement error in the predictors is known (e.g., in situation of repeated observations of covariates or when we trust the passport information about the precision of measurements), and the variance of the error in the response is unknown. Given upper estimate of , we checked a hypothesis that the true value of does not exceed the upper estimate. In case the hypothesis is rejected, we infer that either error in the response variable contains misspecification component (i.e., model lacks explaining covariates), or actual level of measurement errors in the data exceeds the upper estimate. Further study to be performed would demonstrate that this mixture can also be untangled: situation with misspecification could be separated from the one with measurement errors only.
Theoretical exploration, intensive numerical simulations and practical example allow listing the following important features of the proposed MEMV test:
under almost all circumstances it separates valid and invalid models with error of type I equal to zero, but with very different level of errors of type II;
it is very sensitive to the presence of the hidden (unobservable) covariate and detects it even in situations, when everything tells the opposite: a model seems close to perfect (very high approximation, very good values of traditional indicators, like -values or t statistics, etc.);
sample size plays generally an expected role in the test – the level of the errors of second type is dramatically decreased when raises, yet it also demonstrates (not always) the known problem that tendency to reject hypotheses is increasing with rise of the sample size;
to make a confident conclusion that only errors determine variance, while hidden covariates are not presented in the model, one should have many cases available (more than 500 at least);
the most important factor among others (like errors in variables, assumptions about the error level, etc.) affecting the correct decision is the relative size of the hidden covariate (i.e., the share of variance of to be explained by variance in ): when it is high compared to observed ones, the quality of the decision is dramatically improved (with -value close to zero), although the test works also when it is not that high;
dependence of the correct decision on the assumption about errors in the independent variable is, counter-intuitively, very low, or even close to zero, much smaller than on the same assumptions about errors in covariates;
we did not consider the case where is unknown and with known matrix and unknown scalar factor , because in this case the Eqs (2) and (3) is not identifiable and the regression parameter cannot be estimated consistently (this is shown in (Cheng & Van Ness, 1999) for the structural normal model, where the errors and regressor are normally distributed). In future we intend to construct Wald test in the important case, where the variance-covariance matrix of the augmented error is known up to a scalar factor, while some components of the augmented error are allowed to be identical zero.
A survey of more than 1,500 scientists in different fields revealed that more than 80% of the participants consider as the most important improvement to be made to increase the reproducibility of the scientific results is “better understanding statistics” (Amrhein, 2016). Problem of measurement errors, with all its importance and universality, is still out of the mainstream statistical thinking. But without “better understanding” of this problem the lack of reproducibility will embarrass scientific community as it did before and does now. Our study shows a possible way to address some critical topics in one undeservedly neglected area.
Footnotes
Acknowledgments
Authors are grateful to Prof. Y. N. Tyrin for inspirational discussions and suggestions during several last decades.
Appendix 1: Asymptotic properties of estimators
Let us introduce additional conditions on the Eqs (2) and (3) described with two main conditions in Section 2. We start with the moment conditions on error terms.
(iii) For some fixed , and .
Next come conditions on the empirical moments of the regressor. Below denotes th coordinate of covariate . Remember that bar means averaging over .
(iv) There exists , and is a nonsingular matrix.
(v) There exists , and for each , there exist
(vi) There exists such that for all it holds that , where comes from condition (iii).
The final condition involves the estimating function introduced in Eqs (11), (12), and (16). The existence of the limit below will follow from conditions (i–v).
(vii) At the true point of parameter , the matrix
is nonsingular.
Consider also two weaker conditions.
(viii) At the true point of parameter , the matrix
is nonsingular.
(ix) At the true point of parameter , the matrix
is nonsingular.
Below denotes convergence in distribution.
Theorem. For the Eqs (2) and (3), assume conditions (i–vi). Then the next statements hold true.
1. The estimating Eq. (17) has a solution with probability tending to 1 as , and the resulting estimator , which is defined in Eqs (15), (8), (14), converges in probability to the true value , moreover
Then and converge in probability to and , respectively, and converges in probability to .
3. Under additional condition (viii), asymptotic variance of is equal to the lower right entry of , and ; under another additional condition (ix), the asymptotic covariance matrix of is positive definite.
4. Under additional condition (vii), the matrix is positive definite.
Proof of Statement 1. The symmetric matrix converges in probability to the nonsingular matrix from condition (iv), therefore, is nonsingular with probability tending to 1 as . Hence the estimator satisfies Eq. (8) with probability tending to 1 as . From this explicit formula we get directly that is consistent, i.e., it converges in probability to . Next, the estimator Eq. (10) converges in probability to , and the right-hand side of Eq. (10) is positive with probability tending to 1 as . Hence the estimator Eq. (14) coincides with Eq. (10) with probability tending to 1 as , and therefore, is consistent. Thus, the estimating Eq. (17) has a solution with probability tending to 1 as , with components of the estimating function given in Eqs (11) and (12).
The asymptotic normality of is proven in a standard way, based on the equality that holds with probability tending to 1:
where . By Taylor expansion of in a neighborhood of the true value , we obtain (remember that is consistent):
with
Hereafter and denote random sequences that are bounded in probability or converge to zero in probability, respectively. Next, by Central Limit Theorem (CLT) in Lyapunov form (see a convenient statement of CLT in Theorem 8 from (Kukush & Tsaregorodtsev, 2016)),
and by Law of Large Numbers
where denotes convergence in probability, matrices , are ven in Eq. (42), moreover is nonsingular due to condition (iv). Now, Eqs (44)–(48) imply that , hence . The convergence Eqs (40)–(42) follows from Eqs (44), (47), (48) and Slutsky’s Lemma (see Theorem 4.1 in (Billingsley, 1999)).
Notice that conditions (i–vi) are used in particular to prove the convergence Eq. (47), to show that the second limit in Eq. (42) exists and to check the corresponding Lyapunov’s condition.
Proof of Statement 2. The convergence in probability of both and follows from the conditions (i–vii) and Law of Large Numbers. This implies the convergence of because the matrix is nonsingular and .
Proof of Statement 3. The matrix is block-diagonal, and under additional condition (viii). Next, under additional condition (ix), and it is positive definite.
Proof of Statement 4. Under additional condition (vii), the matrix Eq. (44) is positive definite, because is positive definite.
This completes the proof of the theorem.
Appendix 2: p -values for large sample size
Consider the Eqs (2) and (3), but now, for simplicity, the vector is random (and not necessarily centered). Variables are assumed to be independent, with finite 4th moments. We also assume that conditions (i)–(ii) from Section 2.1 are satisfied, except the following: matrix is now unknown. Denote , ; we assume that is nonsingular. Note that , and is nonsingular as well.
Based on i.i.d. of the observed pairs given in Eq. (6), we want to compute -value Eq. (2.3). Since is unknown, we use a certain presumed matrix instead. Because is positive definite, the will be selected as where is the sample covariance matrix of ,
Here regulates the level of the assumed errors in covariates. We also suppose that is nonrandom, does not depend on the sample size, and has the same values for all x variables. Hence converges almost surely (a.s.) to .
For the corresponding residual sum of squares RSS (see Section 2.2), the relation holds holds
Hereafter denotes the almost sure convergence as .
The statistic from Eq. (2.3) is a fraction; denote its numerator and denominator as and , respectively. We have
Consequently, we obtain the following asymptotics for -value Eq. (2.3):
In cases Eqs (52) and (53), the null hypothesis is not rejected for large enough (here is quite large), and in case Eq. (51), the null hypothesis Eq. (28) is rejected for large enough (here is comparatively small). For finite sample, at each interval for with , we have quite large -values and the null hypothesis is not rejected.
Consider a particular case and (i.e., it is assumed that there is no measurement errors in covariates), then
If , then , is false and rejected for large . If
then , is true and not rejected for large .
References
1.
AgrestiA. (2015). Foundations of linear and generalized linear models. John Wiley & Sons.
2.
AmrheinV.GreenlandS., & McShaneB. (2019). Scientists rise up against statistical significance.Nature, 567(7748), 305-307.
3.
BakerM. (2016). Is there a reproducibility crisis?Nature, 533(7604), 452-454.
4.
BillingsleyP. (1999). Convergence of probability measures. 2nd ed. John Wiley & Sons, Inc.
5.
CarrollR.J.RuppertD.StefanskiL.A., & CrainiceanuC. (2006). Measurement error in nonlinear models: a modern perspective. 2nd ed. New York: Chapman and Hall/CRC.
6.
ChengC.-L., & Van NessJ.W. (1999). Statistical regression with measurement error. London: Arnold Publishers.
7.
DemidenkoE. (2004). Mixed models: theory and applications. John Wiley & Sons.
8.
DemidenkoE. (2016). The p-value you can’t buy.The American Statistician, 70(1), 33-38.
9.
EreesS. (2009). Problem of omitted variable in regression model specification, https://acikerisim.deu.edu.tr/xmlui/bitstream/handle/20.500.12397/8322/243816.pdf?sequence=1#:∼:text=The%20omission%20from%20a%20regression,biased%20estimates%20of%20model%20parameters.
10.
GlymourC.ZhangK., & SpirtesP. (2019). Review of Causal Discovery Methods Based on Graphical Models.
11.
GouldE., et al. (2023). Same data, different analysts: variation in effect sizes due to analytical decisions in ecology and evolutionary biology. Ecology and Evolutionary Biology, Life Sciences, Research Methods in Life Sciences, https://ecoevorxiv.org/repository/view/6000/.
12.
JanzingD., & SchölkopfB. (2018). Detecting non-causal artifacts in multivariate linear regression models. In: Dy, J., & Krause, A., editors. Proceedings of the 35th International Conference on Machine Learning, pp. 2250-2258.
13.
KukushA. (2011). Measurement error models. In: Lovric, M., editor. International Encyclopedia of Statistical Science. Springer, pp. 795-798.
14.
KukushA., & PolekhaM. (2006). A goodness of-fit-test for a multivariate errors-in-variables model.Theory of Stochastic Processes, 12(28), no. 3-4, 67-79.
15.
KukushA., & TsaregorodtsevY. (2016). Goodness-of-fit test in a multivariate errors-in-variables model AX=B. Modern Stochastics: Theory and Applications, 3(4), 287-302.
16.
KukushA., & TsaregorodtsevY. (2016). Convergence of estimators in the polynomial measurement error model.Theory Probability and Math Statist, 92, 81-91.
17.
KukushA., & MandelI. (2019). Does Regression Approximate the Influence of the Covariates or Just Measurement Errors? A Model Validity Test. https://arxiv.org/abs/1911.07556.
18.
LipovetskyS. (2006). Entropy criterion in logistic regression and Shapley value of predictors.Journal of Modern Applied Statistical Methods, 5(1), 95-106.
19.
LipovetskyS. (2023a). Review of the book: “Handbook of Measurement Error Models, by G.Y. Yi, A. Delaigle, and P. Gustafson, eds.”.Technometrics, 65(2), 302-304.
20.
LipovetskyS. (2023b). Statistical modeling of implicit functional relations.Stats, 6(3), 889-906.