
Abstract
A new Dual-Dagum-G (DDa-G) family is defined as a good competitor to the Beta-G and Kumaraswamy-G generators, which are widely applied in several areas. Some of its mathematical properties are addressed. We obtain the maximum likelihood estimates, and some simulations prove the consistency of the estimates. The flexibility of this family is shown through a COVID-19 data set. We propose a new regression based on a special distribution of the DDa-G family, and provide a sensitivity analysis by using data from 1,951 COVID-19 patients collected in Curitiba, Brazil.
Keywords
Introduction
Over the last few decades, many generators have been studied in the distribution theory literature. Two generators that stand out are the Beta-G (B-G) (Eugene et al., 2002) and Kumaraswamy-G (Kw-G) (Cordeiro & de Castro, 2011) classes.
Regarding the B-G family, we can say that, although it contains the incomplete and complete beta functions, its flexibility in terms of adjustment to real data is widespread. Several authors introduced new distributions in this family in different contexts: cancer recurrence (Paranaíba et al., 2011), waiting times before service of 100 bank customers (Abd El-Bar & Ragab, 2015), test on the endurance of deep groove ball bearings (Abu-Zinadah & Bakoban, 2017), survival times of 33 patients suffering from acute Myelogeneous Leukaemia (Mead et al., 2017), among others. More than one-hundred different published distributions in this class can be found to date.
The second family stands out because of the simplicity of its density function, which does not include complicated functions. Further, its suitability for the most diverse types of data sets is widely discussed in the literature. We can cite, for example, the work that originated this family and used data from adult numbers of T. confusum cultured at 29
We know through an analysis of these works that the fits of both classes to real data have a better performance compared to other known classes. We can note that the data sets studied in the aforementioned works are of different types. However, many authors end up repeating the same data sets used in previous works by other authors.
In this sense, we define a new class from the Dagum distribution (Dagum, 1975) and use data bases never published before. The data bases in question concern a very current topic: COVID-19. We understand the importance of studies on this pandemic that impacted the world, and then use COVID-19 data from two cities in Brazil.
The remainder of the paper is organized as follows. Section 2 defines the new family. In Section 3, we present some of its generated distributions. The main properties of the new family are reported in Section 4. Estimation including the case of censoring is addressed in Section 5. A simulation study is done in Section 6. In Section 7, we construct the Log-Dual-Dagum-Weibull regression, and estimate the parameters. Two applications to real data are reported in Section 8, including a regression application and a sensitivity analysis. Conclusions end the paper in Section 9.
The new family
The new generator is defined based on the survival function of the Dagum distribution (Dagum, 1977). Kleiber and Kotz (2003) and Kleiber (2008) analyzed characteristics and properties of this distribution. The Dagum distribution presents forms of the increasing, decreasing, bathtub and inverted bathtub risk function (Domma, 2002). This behavior has aroused the interest of several authors to study it in survival analysis (Domma et al., 2011a, b). In this sense, we propose the Dual-Dagum-G (DDa-G) family.
Let
where
Henceforth, Eq. (1) refers to the random variable
The probability density function (pdf) of
where
Equations (1) and (2) do not involve complicated mathematical functions, which is an advantage of this family when compared, for example, with the Beta generator.
The hazard rate function (hrf) of
Dual-Dagum-Weibull (DDa-W)
The DDa-W density (for
where all parameters are positive. For
The cdf of the log-logistic (LL) distribution is (for
Inserting this expression and its derivative in Eq. (2) leads to the DDa-LL density (for
Shapes of the (a) 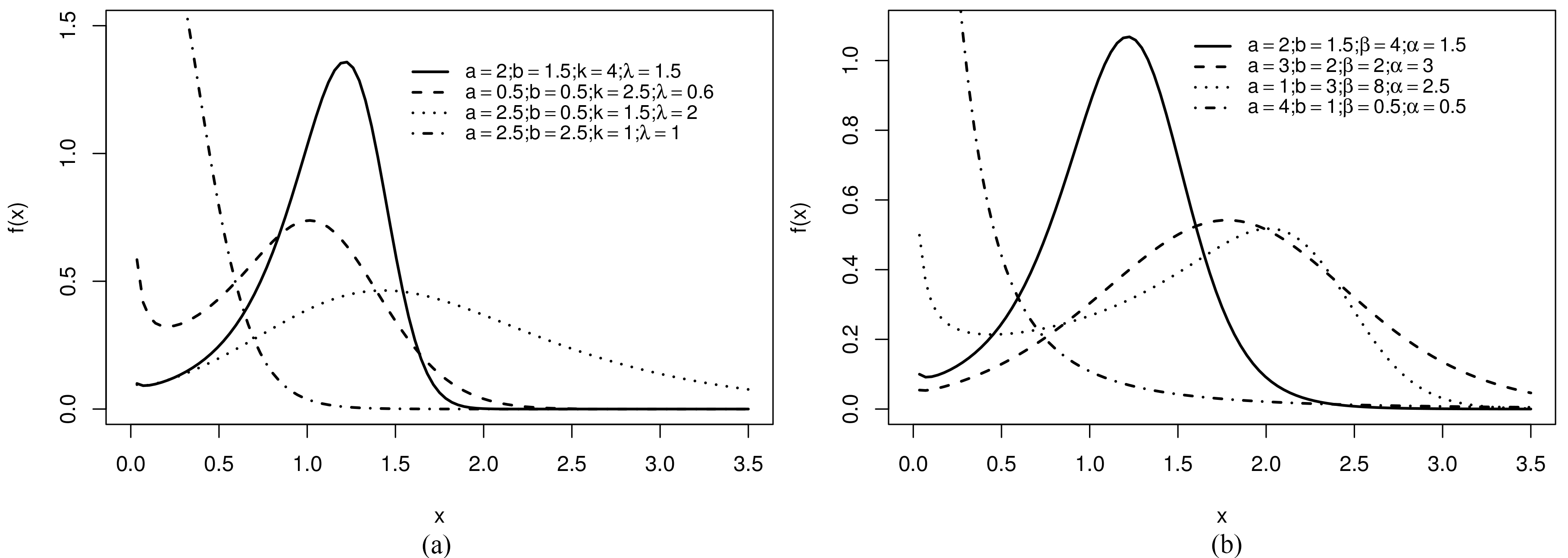
Shapes of the (a) 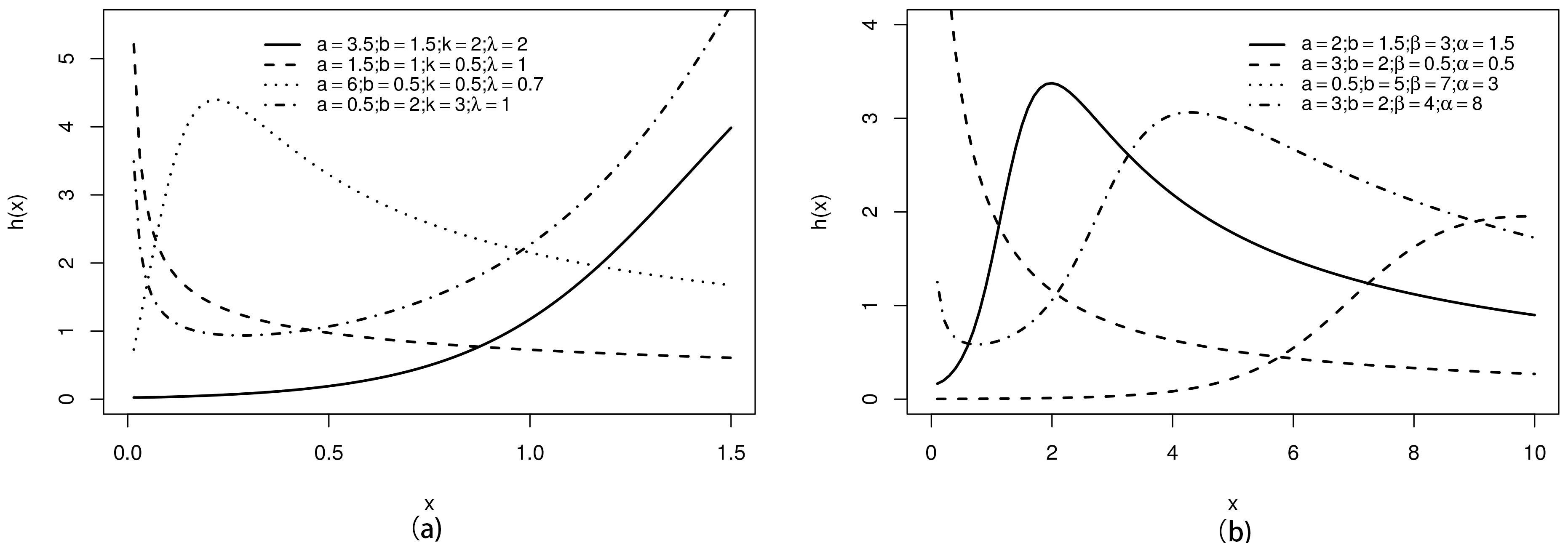
Figures 1 and 2 display shapes of the pdf and hrf of the previous generated models, which show their flexibility in fitting data with different shapes. For example, the Weibull pdf presents only decreasing and unimodal shapes, whereas the DDaW pdf has an extra shape: decreasing-increasing-decreasing.
Linear representation
For any real
where
and
By using Eq. (4) in Eq. (1) gives
By expanding the binomial term,
where
where
Next, we use a theorem of Henrici (1993) for a power series raised to any real power different from zero
where the coefficients are determined recursively from
Formulas for other functions may be found in Hairer et al. (1993).
A random variable
Simulation results for the MLEs
By differentiating Eq. (5) and using the concept of exp-G distribution, we can write
where
Equation (6) is the linear representation for the DDa-G family density in terms of exp-G densities. So, it can provide some mathematical properties for sub-models of the new family from exp-G properties.
Let
Equation (7) reveals that the qf of the proposed family is a function of the baseline qf.
The skewness and kurtosis of
and
reported by Kenney and Keeping (1961) and Moors (1988), respectively.
Figures 3 and 4 display the skewness and kurtosis of the DDa-W distribution as functions of both
Bowley’s skewness of the DDa-W distribution. (a) as function of 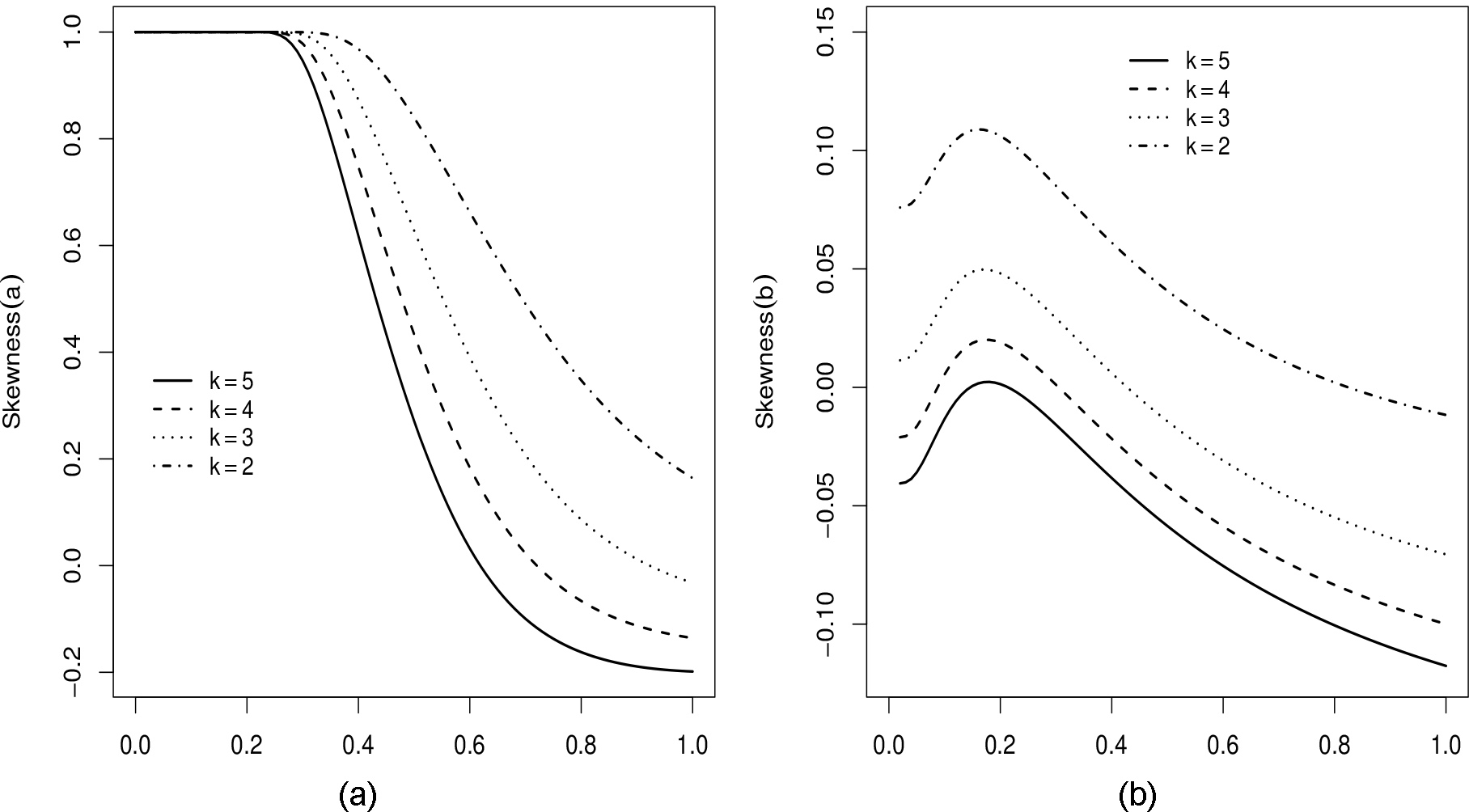
Moors’ kurtosis of the DDa-W distribution. (a) as function of 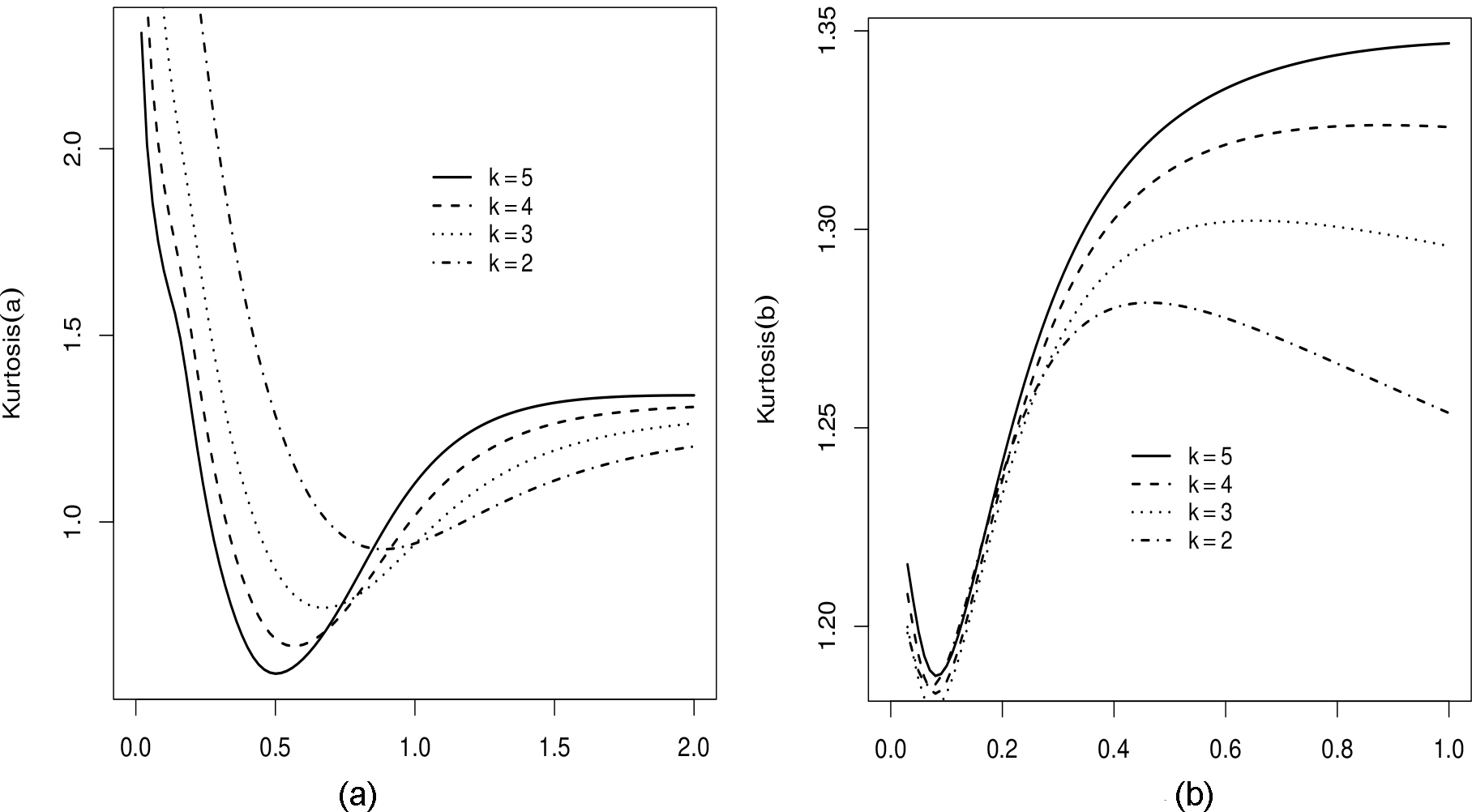
From now on, let
Moments for several exp-G distributions reported by Nadarajah and Kotz (2006) give
Generating functions
The generating function (gf)
where
Estimation
The estimation of the unknown parameters of the DDa-G distribution is performed by the maximum likelihood method. Let
The R software has the AdequacyModel computational library (Marinho et al., 2019) as a good alternative for maximizing
Simulation study
We adopt the exponential (E) baseline (with the expected value
Generate Return
We consider 2,000 Monte Carlo replications and the BFGS algorithm in the R software for maximizing the log-likelihood, obtain the MLEs and their averages, biases and mean square errors (MSEs). The simulation process is carried out as below:
Simulate DDa-E observations for fixed Three scenarios considered are: We calculate the MLEs from each generated data set, and obtain the averages, biases and MSEs.
Table 1 reports these findings. The average estimates converge to the true parameter values and the biases decrease when
If
where
The survival function corresponding to Eq. (8) is
The pdf of the standardized random variable
The lifetimes
The LDDa-W regression for the response variable
where
Let
where
The Weibull and Birnbaum-Saunders distributions are taken as baselines to prove the flexibility of the new family. The data sets were obtained from the open data portal of the Federal Government linked to the Ministry of Health and comprise events from 2020–2021 (accessed on August 23, 2021). The data portal is available at
All computations are done in R using
The new distributions are compared with well-known models belonging to the Kw-G and B-G classes using the statistics: Cramér-von Mises (
The Kumaraswamy-Weibull (Kw-W) density (Cordeiro et al., 2010) (for
The Beta Weibull (B-W) density (Lee et al., 2007), and explored by Cordeiro et al. (2013) (for
where The Beta-Birnbaum-Saunders (B-BS) density (Cordeiro & Lemonte, 2011) (for
The Kumaraswamy-Birnbaum-Saunders (Kw-BS) density (Saulo et al., 2012) (for
In the following, we calculate descriptive statistics, MLEs, their standard errors (SEs) and adequacy statistics to compare the fitted distributions to the data sets.
The first application represents the times (in days) of 564 COVID-19 patients from the date of entry in the Intensive Care Unit (ICU) until cure in Recife (State of Pernambuco). In this context, the cure characterizes the evolution of the case as hospital discharge. Discharge from hospital can only mean that the patient no longer needs hospitalization.
The descriptive statistics for the time until cure for COVID-19 data in Recife include: mean
The values of the statistics
Parameter estimation results for COVID-19 times in Recife, and adequacy measures
Parameter estimation results for COVID-19 times in Recife, and adequacy measures
The Vuong test (Vuong, 1989) also reveals that the DDa-W distribution is better than the DDa-BS (
Figure 5 displays the histogram of the data, where
The study comprises the time (in days) elapsed from the date of hospitalization until death by the coronavirus, of 1,951 patients in Curitiba-PR, with all observations failing, that is, censored times were not considered in the study, with occurrences of death in 2020 and 2021.
The explanatory variables are (for
The computational part is developed in R using
We adopt the Akaike information criterion (AIC), corrected Akaike information criterion (CAIC), and Bayesian information criterion (BIC) to choose the appropriate model. We compare the fits of the LDDa-W Eq. (8) with the log-Kumaraswamy-Weibull or Kumaraswamy Gumbel (Kw-Gu) (Cordeiro et al., 2012), log-beta Weibull (LBW) and log-Weibull (LW) models. The densities for the alternative regressions are reported below:
Estimation results from some fitted regressions to the COVID-19 data in Curitiba, and the adequacy measures
Estimated DDa-W, DDa-BS, Kw-W and Beta-W densities.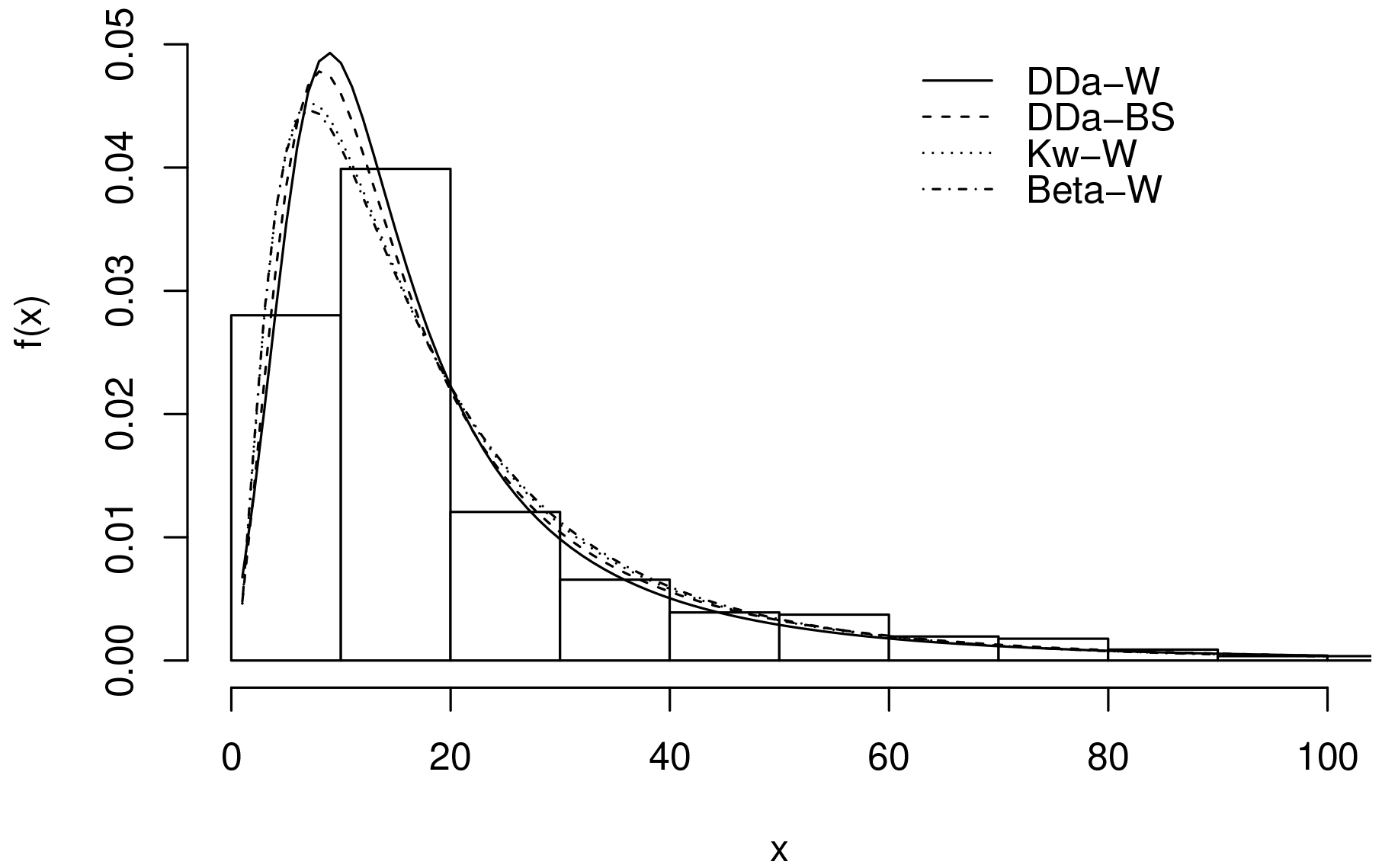
The LW (or Gumbel) density function
where The LBW density function
where The Kw-Gu density function
where
The failure rate function is useful to aid in model identification more suitable for the variable time. In this context, the TTT plot (not shown here) for the data under study shows an increasing appearance for the most part, but due to its final behavior, it indicates an inverting bathtub risk function. The descriptive statistics for the time until death for COVID-19 data in Curitiba include: mean
Next, we provide results from the fit of the regression
where
Table 3 provides some findings from the regressions fitted to the current data. They indicate that LDDa-W model provides the best fit to the data. Further, all covariates (
Thus, the time to death decreases when the age increases. Regarding the patient’s gender, male patients present smaller time until death than female patients, since the estimate of its coefficient is negative.
After the LDDa-W regression estimation, the plots of the empirical and estimated survival functions support the model adequacy to these data.
Also, as part of the analysis, it is important to verify if there are observations influencing the model’s adjustment. A sensitivity analysis was carried out to investigate this fact using the Cook’s distance and will be presented below.
Under the Generalized Cook Distance (Cook, 1977), the observations #349, #826 and #897 are the ones that stand out the most, thus indicating that they can be possible influential observations.
The observation #349 refers to a female individual, aged 84 years and with a time of hospitalization until death of 172 days. The observation #826 is identified as a 78-year-old male and has a time to death of 6 days. And the observation #897 refers to the male individual aged 61 years old, whose hospitalization time until death was only 3 days. The observations #349, #826 and #897 represent individuals with peculiar behaviors, but do not show signs of error in data collection or transcription, and therefore must be kept in the database. The final model is given in Eq. (12).
The impact of possible influential observations detected should be analyzed in order to assess the estimates and sensitivity of the model. This analysis considers new estimates for the model parameters from sub-samples referring to the withdrawal of these observations individually and in groups.
It is considered that the changes in the estimated values for the parameters are not very expressive and there is significance of the explanatory variables when considering the level of 10%. In addition, there was no change in the sign of the coefficient of the explanatory variables, so the inclusion or exclusion of the identified observations does not presuppose changes in the interpretation of the results.
Conclusions
One of the main objectives of distribution theory is to define a family of models to better explain lifetime phenomenon in several areas of knowledge. We proposed the Dual-Dagum-G (“DDa-G”) family, which can generalize all classical continuous distributions. Its parameters are estimated by maximum likelihood, and a simulation study showed the consistency of the estimators. We showed the flexibility of the new family by means of two real COVID-19 data sets. We proved that the new Log-Dual-Dagum-Weibull (LDDaW) regression outperformed regressions based on well-known Kumaraswamy-G and Beta-G generators. After verifying the good fit of the new regression, a sensitivity analysis was performed, where it was possible to verify the occurrence of influential observations. As future work, it could be interesting to investigate other methods of sensitivity analysis, such as the local influence, if the results obtained through the Cook Distance prevail and still carry out a residual analysis for the new regression model.