
Abstract
National Football League (NFL) kickers have displayed improvement in both range and accuracy in recent years. NFL management in turn has displayed a rather low tolerance for missed field goals, particularly in game-deciding situations. However, these actions may be a consequence of a perceived appreciable variability in NFL kicker ability. In this paper, we consider shrinkage estimation of NFL kicker field goal success probabilities. The idea derives from the literature on estimating batting averages in baseball, though the classic James-Stein shrinkage approaches there do not apply to independent binary field goal attempt trials. We study a variety of weighting schemes for shrinking model-based kicker-specific field goal success probability estimates to a league-wide estimate, as a function of distance. As part of the development, we briefly detail collecting NFL play-by-play data with the R statistical software package, identify the complementary log-log link function as preferable to the more commonly applied logit link function in a generalized linear model for field goal success, and demonstrate the desired variance-reduction, both in and out of sample, enjoyed by our proposed shrinkage estimators. We illustrate our methods by ranking NFL kickers from 1998 to 2014, analyzing individual kicker success at mid-range and long-range field goal attempts, and studying kicker ability over the last decade. Stadium effects are added to the model and found to be highly significant and to have an impact on the kicker rankings.
Keywords
Introduction
Given the high frequency of personnel transactions involving field goal kickers in the National Football League (NFL), there appears to be a perception of considerable variability among their abilities to carry out their duties, at least among general managers. In particular, when kickers miss field goals or extra points that are perceived to cost their team a game, they are sometimes terminated shortly thereafter, presumably reasoning that a replacement would have a better chance of success from the same distance. Consider the 2010 New Orleans Saints. In Week 3, Garrett Hartley missed a 29 yard field goal attempt in an overtime loss. He was replaced by veteran John Carney, who in turn missed a 29 yard field goal attempt in another loss two weeks later. Hartley then regained his job the following week. The Saints are not the only team with a quick trigger on in-season kicker personnel decisions. Table 1 summarizes the number of kickers who have been released, for reasons not listed as injury, over the 2000-2014 timeframe. On average, there are more than 3 such kickers released per season. These counts were assembled by inspection of season summaries of kickers found on and subsequent post-hoc inspection of various websites that track transactions.
Number of mid-season performance-based kicker changes over time
Number of mid-season performance-based kicker changes over time
Quantitative analyses (Morrison and Kalwani, 1993) have found surprisingly limited evidence of differences among kickers. In an investigation of weather and distance effects on kicking, Bilder and Loughin (1998) chooses not to model individual kicker effects, describing kickers as “interchangeable parts.” In a study of whether “icing the kicker” affects kickers (it does!), Berry and Wood (2004) also assumes that dependence of log-odds of success on distance to be the same for all kickers. If there are differences among kickers in the way they are affected by field goal attempts of increasing distance, these effects may be subtle enough to go undetected without large samples. Due to these subtleties, estimation of success probabilities for particular kickers can be a difficult task.
We consider the problem of estimating probabilities of field goal success using play-by-play data available on the web. As with analogous investigations in the literature, we develop generalized linear models which assume kicks to be independent Bernoulli trials. However, we show that the complementary log-log (CLL) link provides a better fit than the logistic regression models typically applied in prior work. In models that include kicker effects, estimates of field goal success for inexperienced kickers may have high sampling variance due to small samples. We investigate a number of shrinkage techniques that borrow information from field goal attempts by other kickers in an effort to reduce the sampling variance in these kicker-specific estimates.
The textbook by Morris and Rolph (1981) uses the problem of estimating field goal success probabilities after regression on distance (grouped into intervals with 10 yard widths) as an introduction to logistic regression. Berry and Berry (1985) develops a generalized linear model for field goal and extra point success probabilities using a customized link function that is derived from consideration of three factors: distance, left-right error, and the chance of a non-goalpost related error (a fumble or blocked kick). Other work investigating additional factors beyond distance that may be associated with field goal success probabilities, such as weather and psychological pressure, includes Bilder and Loughin (1998); Pasteur and Cunningham-Rhoads (2014); Berry and Wood (2004); Clark et al. (2013). All of these contributions are in agreement that the single most important factor in predicting field goal success is the distance of the attempt. Morrison and Kalwani (1993) fails to reject the hypothesis of equal success probability among all kickers. Pasteur and Cunningham-Rhoads (2014) uses cross-validation to select variables and finds that adding distance to an intercept-only model decreases a predictive mean squared error criterion by 14%, but that adding an additional 7 variables (including temperature, wind, kicker fatigue, defense quality, and whether the kick was in Denver) brings about a further reduction that is less than 2%. Since many failed extra point attempts are a consequence of poor snaps or holds, we restrict our attention to field goal attempts and do not consider extra point success probabilities or data in our analyses.
Our aim in this paper is not to select variables for the best model, nor to account for the various subtle (in comparison to distance) effects of weather or psychological pressure, but rather to demonstrate the potential advantages of shrinking regression-based estimators towards a central value with the goal of variance-reduction. Indeed, this work is motivated by the success of James-Stein shrinkage techniques (Efron and Morris, 1975; Brown, 2008) for the problem of predicting batting averages in baseball.
In Section 2, we describe our data collection procedure and consider data-driven selection of the link function in a generalized linear model for field goal success. In Section 3, we consider a variety of shrinkage estimators for the kicker and distance-specific success probabilities as functions of model parameters. In Section 4, we illustrate several applications of our shrinkage estimators, including a ranking of kickers and a discussion of long field goal attempts and stadium effects. We present a summary and conclude in Section 5.
Data collection: web scraping with R
Like most other work in the area, we assume kicks to be independent and model the
dependence of success probability on explanatory variables using generalized linear
models. The explanatory information we consider includes only the distance of the attempt
and who the kicker is. Using the
The dataset contains 17, 104 attempts from more than K = 111 kickers. Kickers who made or missed all of their career attempts are excluded from consideration to avoid separability issues with maximum likelihood estimation. (Jaret Holmes played for three teams from 1999-2001, making all five of his field goal attempts and all four of his extra point attempts successfully. Danny Boyd was even better, making 5/5 field goals and 7/7 extra points for Jacksonville in 2002.)
Outcomes were dichotomized as “good” or “not good”, the latter event includes blocks and fumbled holds. Our reasoning is that the blame for failed attempts usually rightly falls on the kicker, but sometimes the snap, the hold or the blocking are at fault. The records online do not easily allow for determination of blame. An example of an entry that was scraped from the url (http://www.pro-football-reference.com/boxscores/199809060cin.htm). (a game from week 1 of the 1998-1999 season) appears in Fig. 1.

Play-by-play item containing relevant information on a field goal attempt.
Occasionally, comparisons between total kick frequencies computed from play-by-play data with kicker career totals will reveal slight discrepancies, where certain plays are absent from the pro-football-reference play-by-play information. For example, in a 1998 Week 1 game of the New England Patriots at the Denver Broncos, Adam Vinatieri of the New England Patriots had a 37 yard field goal attempt during the second quarter. The pro-football-reference play-by-play account of the event is blank (see Fig. 2). We resorted to the site to attempt to rectify this particular record. Though we could not find links on the site to play-by-play information for games before 2001 (a situation in which automated screen-scraping is then difficult), we were able to find some urls, with links provided by a search engine.

Play-by-play item for a blocked kick by Adam Vinatieri in a 1998 Week 1 game that appeared as a blank on pro-football-reference.com
For notation, we let k = 1, …, K index the kickers
(K = 111 in our application) and let j = 1, …,
N (N = 17104) index all of the field goal attempts.
For each attempt, we let binary outcome
O
j
= 1 if the kick is good, and
O
j
= 0 otherwise. The probability of
success of attempt j is denoted
π
j
. The general form for the log-likelihood
function of all of the probability parameters
{π
j
} for independent, dichotomous data with
outcomes o
j
is given by
Generalized linear models adopt a link function g, through which the
probabilities π
j
are transformed to an
expression that is linear in regression coefficients introduced to model the effects of
available explanatory variables (and reduce the dimension of the parameter space). We
define d
j
as the distance of the jth attempt
and define indicator variables for kicker k as
X
jk
= I (jthattemptisbykicker k),
for k = 1, …, K, with regression coefficients
β1, …, β
K
. The probability parameters are now,
after transformation by the link function g, linear in the regression
coefficients,
We refer to β
k
as a kicker-specific slope and can test the
significance of estimated regression coefficients by comparison with a generalized linear
model with only one slope, β, to accommodate all kickers,
In applications in which statistical regression models are developed for binary response
variables, logistic regression seems to be the most popular choice (Pasteur and Cunningham-Rhoads, 2014; Morris and Rolph, 1981; Bilder
and Loughin, 1998; Berry and Wood,
2004), perhaps because of its interpretability, particularly through odds ratios.
However, several other link functions are easily explored using statistical software for
generalized linear models. We introduce a superscript notation for probability functions
associated with kickers that will simplify the shrinkage estimation exposition in Section
3. Let π
k
(d) denote the
success probability function for kicker k at any distance
d. We consider three choices for the link function: logistic, probit,
and CLL. Let Φ and Φ-1 denote the cumulative
distribution function and quantile function, respectively, of a random variable with
standard normal distribution. Then the links and inverse links (probability functions) for
these three candidates are given below:
The log-likelihood function of a specified link function uses the reparameterizations
above. As an example the log-likelihood for the logistic link is given by
Table 2 summarizes the maximized log-likelihood function when using the logit, probit, and CLL link functions for estimating field goal success probability in our data set. Tests comparing the nested models within a column of the table are all highly significant on 110 degrees of freedom (comparing models with K = 111 different slopes to a model with a single slope), indicating significant differences among the estimated slopes. With such a large sample, there does appear to be enough data to detect potentially subtle differences among kickers.
Comparison of link functions: – 2 × maximized log-likelihood using full or restricted
data set
Comparison of link functions: – 2 × maximized log-likelihood using full or restricted data set
Figure 3 presents the inverse link functions applied to the empirical success frequencies against distance. The lines overlaid on the plots are from maximum likelihood estimation of the single-slope model. Residuals computed as standardized differences between transformed success frequencies and the estimated link functions are plotted against distances in Fig. 4, providing an enhanced visualization of the fits. Link-specific lowess smoothers overlaying these plots suggest that the residuals from the CLL fit exhibit the least dependence on distance.

The fits provided by three inverse link functions. Plot (a) presents the three fits to the empirical frequency data: logit link fit solid/blue, probit link dashed/red, complementary log-log link dot-dashed/green. Plots (b), (c) and (d) present the fits after link transformation. All four plots have distance in yards as the horizontal axis.
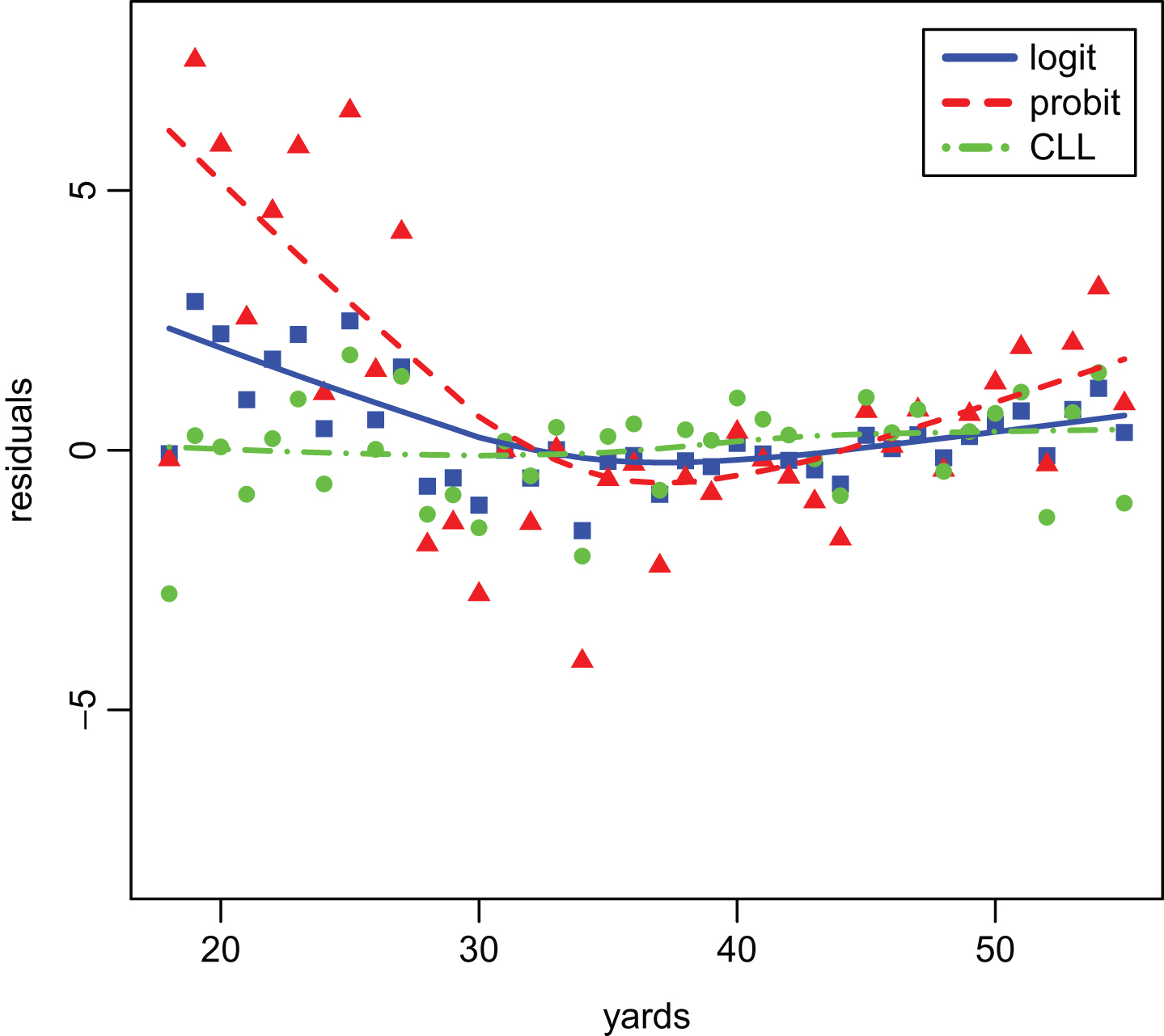
Residuals from three link functions in generalized linear models (logit as blue squares, probit as red triangles and complementary log-log as green circles). Residuals are differences from link-transformed empirical success frequencies and estimated link functions and have been normalized to have unit variance. Plotted against distances with at least 100 attempts, with Lowess smoothers overlaid using solid lines.
In an analytical comparison of link functions, McCullagh et al. (1989) observes that for trials with intermediate success probability, 0.1 ≤ π ≤ .9 (the vast majority of field goal attempts), probit and logistic functions are nearly linearly related, so that discrimination between the fits of models using these two links is difficult. Additionally, for trials with success probability approaching one (which occur as field goal attempt distances decrease towards 17 yards), the CLL approaches one more slowly than either of the other two link functions. The CLL link can also differ (Dobson and Barnett, 2011) from logit and probit links for small values of π, which are often of greatest interest when assessing kickers. Close inspection of Fig. 3 and Fig. 4 seem to reflect these observations, with better agreement with empirical frequencies on short kicks than that provided by either logit or probit. Fitting these models using kicks at the extremes may be problematic in that misses at short distances are likely due to mishandled snaps and attempts at long distances may lead to selection bias since these attempts are probably only afforded to very good kickers. In light of these issues, log-likelihood ratios are also reported after restricting attention to kicks with distances between 25 and 50 yards. With this restriction, the CLL link achieves the maximum likelihood among the link functions for models with either a single slope or with kicker-specific slopes.
The statistic proposed by Hosmer and Lemeshow
(2004) (HL) offers another way to assess goodness-of-fit in regression models for
binary data with continuous explanatory variables. The HL statistic is a Pearson-style
measure of goodness-of-fit whose sampling distribution under a correctly specified model
can be approximated by a chi-square distribution. The HL procedure partitions all kicks
into 10 groups of roughly equal size. (We accomplished this using the algorithm laid out
in the documentation for PROC LOGISTIC within the SAS statistical software package (SAS Institute, 2011). The procedure then computes,
for each group, observed (O
i
) and expected
(E
i
) counts of successful kicks by
averaging estimated probabilities within group, in order to compute the
χ2 statistic, X:
The summary statistics necessary for computation of the HL statistic are given in Table 3 for the logit and CLL links. The logistic regression model does not provide a good fit for the 10th group, where the estimated success probability is highest. The average estimated probability among these 1708 kicks is for an estimated expected cell count of e10 = 1708 × 0.9692 = 1655.34. However, the observed count is o10 = 1676 successful kicks, resulting in a large contribution, (1676 - 1655.3) 2/{1655.3 (1 -0.9692)} =8.4, to the chi-square statistic.
Summary statistics for Hosmer-Lemeshow assessment of the complementary log-log and logit link functions
Table 4 gives HL chi-square statistics andp-values on 8 degrees of freedom for each of the three link functions with either a single slope, or with kicker-specific slopes. The models with the CLL link function are the only ones that do not exhibit significant lack-of-fit. With such a large sample size (N = 17, 104 attempts), even subtle lack-of-fit is likely to be detected, as in the logistic (p = .0291,. 0657) and probit (p < .0001, p = .0001) models. Despite this significance, neither of the two provides a bad fit.
Hosmer-Lemeshow statistics and p-values for two models, each using the three different link functions
Lastly, a link function could be chosen on the basis of how well probabilities estimated using the link can predict successful and unsuccessful field goal attempts. A decision rule which predicts a successful field goal when the estimated success probability exceeds some threshold ( has as its sensitivity and specificity the corresponding relative frequencies of successes among kicks which fall, respectively, above or below this threshold. A plot of sensitivity against one minus specificity is called the receiver operating characteristics (ROC) curve and the area under this curve (AUC) is a common way of assessing the capacity of a fitted model to predict successes and failures. The AUC for models with a single slope that are not kicker-specific will necessarily be the same for all three links, as the ordering of the estimated probabilities is determined only by the distance of the attempts. However, small differences in AUC exist among the three links when kicker-specific slopes are included in the model. This ordering is consistent with that implied by visual inspection of Fig. 3. The AUC values, all close to 0.75, are presented in Table 5.
Area under the curve (AUC) for the three link functions
Since the CLL link enjoys the smallest HL and largest AUC under cross-validation (as described in Section 3.1), computations under the other two link functions are excluded from presentation in the remainder of the paper.
Model-based estimates of kicker-specific success probabilities have large variance except in cases where the number of observed attempts for a given kicker is very large. As an example, consider interval estimation of the probability of success when kicking a 45 yard field goal using the CLL link function. For Adam Vinatieri, who has 572 career attempts, the 95% interval estimate is (0.69, 0.78). However, the 95% interval estimate of 45 yard field goal success probability for Garrett Hartley, who has 115 career attempts, is (0.59, 0.80), more than twice as wide as the interval estimate for Vinatieri. Estimators with reduced variance may be constructed by taking a weighted average of the kicker-specific maximum-likelihood estimator (MLE) and one developed for the average of all kickers. That is, the variance of an estimator may be reduced by shrinking it towards another estimator which has much lower variance.
Efron and Morris (1975) and Brown (2008) employed this method, viewed from an empirical Bayes perspective, to predict end-of-season batting averages in Major League Baseball. In particular, the papers propose shrinking hitter-specific estimates based on a small number of at-bats towards the early season batting average among all hitters. The methods are based on the theory James and Stein (1961) develops for estimation of the mean of a multivariate normal distribution. That theory does not apply directly to estimation of success probabilities for independent binary trials, as in field goal attempts, but the idea of variance-reduction is worth exploring.
Without any shrinkage, the kicker-specific MLE of the success probability at a given
distance d is given by
The estimator with complete shrinkage is simply the empirical frequency of all kicks taken
by all kickers at that distance,
These empirical frequencies are plotted in the top left graphic in Fig. 3.
Proposed shrinkage estimators
For shrinkage estimators of the success probability at a given distance,
π (d), we consider estimators that are weighted
averages of the MLE and empirical frequency estimators defined above,
and ,
respectively. These shrinkage estimators may be written in a general form using a
weighting function ω:
The first shrinkage estimator we propose is simply the midpoint between the two
components. We refer to this shrinkage estimate, obtained by setting
ω = 1/2, as the midpoint estimator (denoted by superscript M):
One approach towards constructing a shrinkage estimator that weights model-based
kicker-specific estimates more heavily is simply to weight components in inverse
proportion to their standard errors. This will upweight the MLE,
for veteran kickers for whom more information is available. For the MLE, we rely upon the
GLIMMIX procedure of SAS to produce asymptotic standard errors to accompany the maximum
likelihood estimator, denoted by .
For the empirical frequency component ,
we use
where N
d
denotes the total number of kicks
attempted at distance d in the entire dataset. If the empirical frequency
is 0, such as at d = 65, we used .
The resulting inverse variance (IV) weighted shrinkage estimate can then be written in the
general weighted average form by taking
ω = SE
EF
/(SE
k
+ SE
EF
):
Note that because sample sizes differ, this weighting scheme can lead to different weights at different distances.
Another approach is to choose a weighting function for the MLE that is increasing in
n
k
towards a maximum weight of one. Any
cumulative distribution function (CDF) has this property. We choose the exponential
distribution function, which for a suitably chosen rate parameter a,
increases rapidly for small n with diminishing returns on large
n
k
:
This choice leads to the exponentially weighted shrinkage estimator,
The quantity a in the exponential weights estimator can be viewed as a tuning parameter, whose value is “fit” using the entire dataset and whose performance is evaluated by cross-validation (see Section 3.2). For the a parameter, mean values 100 < a < 700 were considered, reasoning that the kick counts fell in the interval 4 < n k < 572. A search of values of a, to the nearest multiple of 10, achieves a Hosmer-Lemeshow (HL) statistic of HL = 9.32 at an optimized value of a = 670. Using the exponential CDF with mean a = 670 for a weight function, the corresponding weights on the model-based estimates for kickers with sample sizes of n k = 10, 50, 100, 200, 400 would be 0.02, 0.07, 0.14, 0.26, 0.45, respectively.
Figure 5 presents a plot of the weight function, ω for these different shrinkage estimators. The two separate curves provided for the IV weighted estimator corresponds to kicks at d = 45 and d = 55 yards. The empirical frequencies at these two distances were and , respectively. For these two distances, plots against sample size suggest that the model-based standard errors may be roughly approximated by and , respectively. Because of the dependence of the empirical frequency on sample size, with little information to go by for kicks as long as d = 55 yards, the IV weighted estimator places more weight on the first component for a kick at d = 55 yards than one at d = 45 yards. All of these curves, with vertical axis given on the right of the plot, are superimposed over a frequency histogram showing how the N = 17, 104 attempts are distributed across the K = 111 kickers. The frequencies of kickers with different experience levels is given on the left vertical axis.

Weight functions for shrinkage estimation, “exp” plots the weights based on the exponential distribution and IV plots the weights proportional to the inverse of the variances of the components.
The estimators of success probability can be naturally shrunk towards central values by
means of a Bayesian generalized linear model with CLL link utilizing empirical Bayes
estimation (see e.g.,Carlin and Louis (1997)).
In such a model, as fit using the
The hyperparameters for the intercept are the default choices for the
Fig. 7 illustrates the reduction in variance due to shrinkage. For attempt distances, d = 30, 40, 50, 60 yards, random samples of 10 kicks were selected. The estimated success probability estimates are plotted using different colors, with estimation technique on the horizontal axis. Not only is the reduction in variation apparent, but the model-based estimates at 60 yards are shifted downward. The explanation for this shift is lack-of-fit of the model for very long attempts. Shrinkage towards the empirical frequency tends to alleviate bias caused by this poor fit.

Model-based maximum-likelihood and shrinkage (midpoint) estimates of success probability, colored according to attempt distance (30, 40, 50, and 60 yards plotted with black, red,green and blue lines, respectively).
While HL is useful for quantifying how well several fitted models align with observed data, it may not tell the entire story as to how well the fitted model would generalize to observations made in the future, or out-of-sample data. Cross-validation (CV) can be used to quantify the degree to which a model fitted to observed data generalizes to data not used to fit the model or to compare the capacity of several models to generalize. Pasteur and Cunningham-Rhoads (2014) uses five-fold CV to select weather, pressure, and fatigue variables for a multiple logistic regression model. In five-fold CV, the dataset is partitioned into five subsets of equal size. The first subset is held out of the process where the model is fit, and then the fitted model is used to estimate the probabilities of the events that were held out. HL is then computed only for the held-out subset. This step is repeated four more times, holding out each subset exactly once. As can be seen from inspection of the first two numerical columns of Table 6, neither the model-based estimate (CLL) nor the empirical frequency (EF) generalize well under 5-fold CV, in the sense that there is disagreement between the number of observed and expected successful kicks when attempts are put into the 10 groups for the HL statistic. Recall that the midpoint estimated probability for any kick is simply the midpoint between CLL and EF. While this shrinkage estimate has a greater HL than its CLL and EF components when the entire dataset is used both to fit the model and to compute the goodness-of-fit statistic, it shows better agreement between observed and expected successful kicks under CV. The CV procedure was repeated four times, using four random partitions of the dataset into five subsets. Each time, the midpoint estimate enjoys a better fit for the held-out data than either of its two components, as quantified by the HL statistic. The shrinkage estimators based on the exponential weights, with a = 660, 670 or 680 also performed better than either component by itself. In computation of these estimates, the step of tuning the a “parameter” was not repeated during cross-validation. Rather, estimates based on values of a = 660, 670, 680 (which did the best on the entire dataset) were computed for every observation, and only those results are reported here. If this weighting scheme is tolerable, then it appears to perform comparably to the simple midpoint shrinkage estimator. Among the six estimators reported in Table 6, there is no dominant choice when considering performance under cross-validation. One clear observation, however, is that the midpoint and exponential shrinkage estimators are generalizing to out-of-sample data better than either the CLL or EF components by themselves.
Hosmer-Lemeshow statistics under 5-fold cross-validation for the estimators ,
, ,
(under different tuning parameters
a), , and the Bayes estimator
Hosmer-Lemeshow statistics under 5-fold cross-validation for the estimators , , , (under different tuning parameters a), , and the Bayes estimator
Ranking kickers
In addition to estimating the success probability for a given kicker from a given distance, the estimation methodology can be used to rank NFL kickers. Historically, comparisons among kickers in sports media have been made using the overall number (as on espn.go.com) or proportion of successful attempts (as on sports.yahoo.com or si.com) without regard to distance, as it not obvious how to incorporate distance and degree of difficulty based on summary statistics. Alternatively, Berry and Berry (1985) suggests averaging model-based kicker-specific estimates over the league-wide distribution of attempt distances. A histogram for these attempts is given in Fig. 8. The average distance over all 17, 104 attempts was 36.6 yards. Tables 7, 8, and 9 present a ranking of kickers under this summary statistic, using several different methods of estimation, along with the standard “overall” metric.
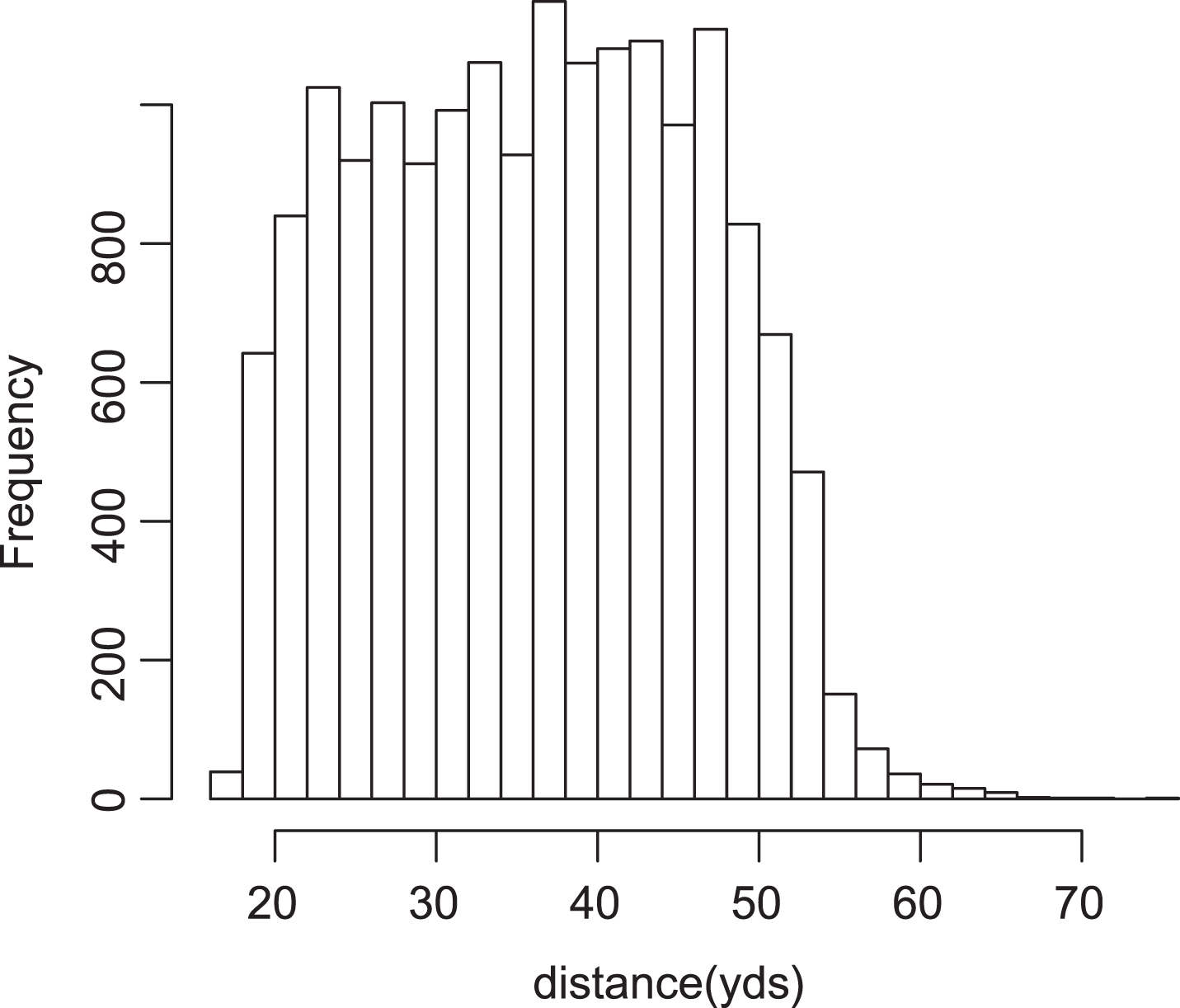
Frequency histogram of attempt distances.
Kicker ranking by shrinkage estimate over distribution of all kicks. The columns include the average attempt distance, actual success frequencies for kicks of less than 40 yards, 40-49 yards, and at least 50 yards, overall proportion of successful field goal attempts, ranking by overall success proportion, kicker-specific MLE () and midpoint shrinkage estimate of success probability ()
Ranking by shrinkage estimate over distribution of all kicks, continued
Ranking by shrinkage estimate over distribution of all kicks, continued
For veteran kickers with a large number of kicks that are similar in distribution to that of the whole league, the effect of shrinkage is minimal. Adam Vinatieri has succeeded on 84% of 572 attempted kicks at an average distance of 35.8. His model-based estimate averaged over the distribution of all NFL kicks in 1998-2014 is 0.83 and the shrinkage estimate is only slightly different at 0.82. Conversely kickers like Patrick Murray and Greg Zuerlein have achieved very successful records so far in their young careers, hitting 20/24 (83%) and 73/89 (82%), at longer-than-average average distances of 41.1 yards and 40.0 yards respectively. Their model-based estimates averaged over the league-wide distribution of distances is more favorable (87% and 86%; note the bump up in rank from that based on the empirical frequency) but the shrinkage estimate brings these closer to more average kickers (84% for both kickers).
These tables suggest a ranking that places many current kickers among the best over the last 16 year period. Justin Tucker has been successful on 105 out of 116 attempts, with average distance for an overall mark of 91%. The kicker-specific, model-based estimate averaged over the league-wide distribution of attempt distances is 92%, but the midpoint technique shrinks this back to 87%. By any of the three methods, Tucker is ranked to be the most accurate among the K = 111 kickers underconsideration.
A topic of interest for many fans, writers and announcers is the effects of certain stadiums on the chances of making a field goal. The open end of Heinz Field receives particular attention for increased difficulty due to wind (Batista, 2002). Modeling fixed factorial effects for stadiums enables investigation of this issue. Though a likelihood ratio test finds evidence of stadium effects (χ2 = 112, p < 0.0001, df = 50), their inclusion does not lead to an improved fit as assessed by Hosmer-Lemeshow, where there is a greater discrepancy between observed and expected counts than the model based on kickers and distances alone (HL = 8.3with stadium effects and HL = 1.9 without stadium effects, from Table 3). Nevertheless, including these effects does help to identify the more difficult and more favorable stadiums in which to kick, though again the estimation may suffer from selectionbias.
Success probabilities for each stadium can be estimated by back-transforming the marginal mean on the CLL scale. These marginal means average equally over all kickers and correspond to the average distance of yards. These estimates provide a ranking of stadium difficulty and are given in Table 11 along with empirical game and field goal attempt counts. We make no attempt to shrink these estimates, rather, we simply restrict our attention to stadiums for which more than 100 attempts are available in our dataset. Table 11 also gives average distances at which coaches have allowed their kickers to attempt field goals, game counts and empirical successrates.
Stadium effects and success frequencies. The columns include number of games, average
distance, attempts per game, empirical success rates as counts and as a percentage and
model-based success probability estimate () and standard error
Stadium effects and success frequencies. The columns include number of games, average distance, attempts per game, empirical success rates as counts and as a percentage and model-based success probability estimate () and standard error
The ranking in Table 11 seems to corroborate the anecdote that Heinz Field is a tough place to kick, as does the lower-than-average distance of field goal attempts. The new stadium in Denver, “Sports Authority Field at Mile High,” also has a reputation as a good place to kick and it does turn up high on this list. The estimates based on marginal means also tend to be lower than the empirical success rates. This observation may possibly be due to the fact that marginal means average equally over all kickers. Empirical success rates will tend to involve more attempts from high-frequency kickers, who tend to be better kickers.
The capacity to kick long-distance field goals is of particular interest to many football
fans as well as NFL team management. One way to enrich the model to allow rankings among
kickers to vary across distance is to expand the degree of the polynomial to quadratic.
Using L and Q superscripts for the linear and quadratic
kicker effects leads to the following representations of the generalized linearmodel:
For this investigation, attention is restricted to the K′ = 54 veteran kickers with at least 100 attempts in their careers, since small sample sizes present greater separability issues for fitting quadratic models. A comparison of the model with kicker-specific slopes nested within the quadratic model is not significant using this restricted dataset (χ2 = 63.3, df = 54, p = 0.181). This non-significance could possibly be explained by selection bias, as kickers with many attempts will all tend to be good enough to remain in the league. While not significant, there is a preponderance of kickers for whom the estimated quadratic coefficients have small p-values, suggesting that there are some kickers for whom quadratic coefficients are non-zero. In fact the average p-value for these 54 tests of the form is 0.16 providing anecdotal evidence of curvature. For one further bit of evidence, a comparison of nested models based on the logit link function is weakly significant, (χ2 = 72.8, df = 54, p = 0.0450), though the fit is not as good as that provided bythe CLL.
Table 10 enables simultaneous inspection of kickers who have estimated success probabilities that rank highly (top 20) in at least one of the three distances, 35, 45 or 55 yards. Entries in the table are sorted by the success probability estimate at 55 yards, . Estimates at d = 35, 45 are also given along with ranks which enable identification of kickers who seem to have strengths at either medium or long distances (or both). While some kickers are accurate from any distance, for example current kickersBailey, Tucker, Walsh, and Barth, others have a decent shot at making long kicks but can be less accurate than is desired at short distances, for example Edinger and Hollis. Lastly are the kickers who rarely miss from intermediate distances, but are not estimated to have a big enough leg to have much more than a coin flip chance of success on long field goals, for example Gould, Kasay, and Stover. For comparison with observed data, the last three columns give empirical success frequencies after binning kicks into 10-yard intervals surrounding d = 35, 45, 55 yards. Clustering can be used to group kickers, based on their trivariate estimated success probability at the three distances, 35,45 and 55 yards, such that within groups, kickers are similar. The default hierarchical clustering algorithm implemented by SAS PROC CLUSTER suggests the existence of three clusters, and that cluster assignment is mostly determined by . The first 8 kickers in Table 9 form a “big leg” cluster, the last four kickers form the “accurate but no leg” cluster, and the remainder fall somewhere in between. The means of the estimated success probabilities for these three groups are plotted against yards in Fig. 6. This does suggest that there may be somewhat of a trade-off between a “big leg” and accuracy at closer ranges.
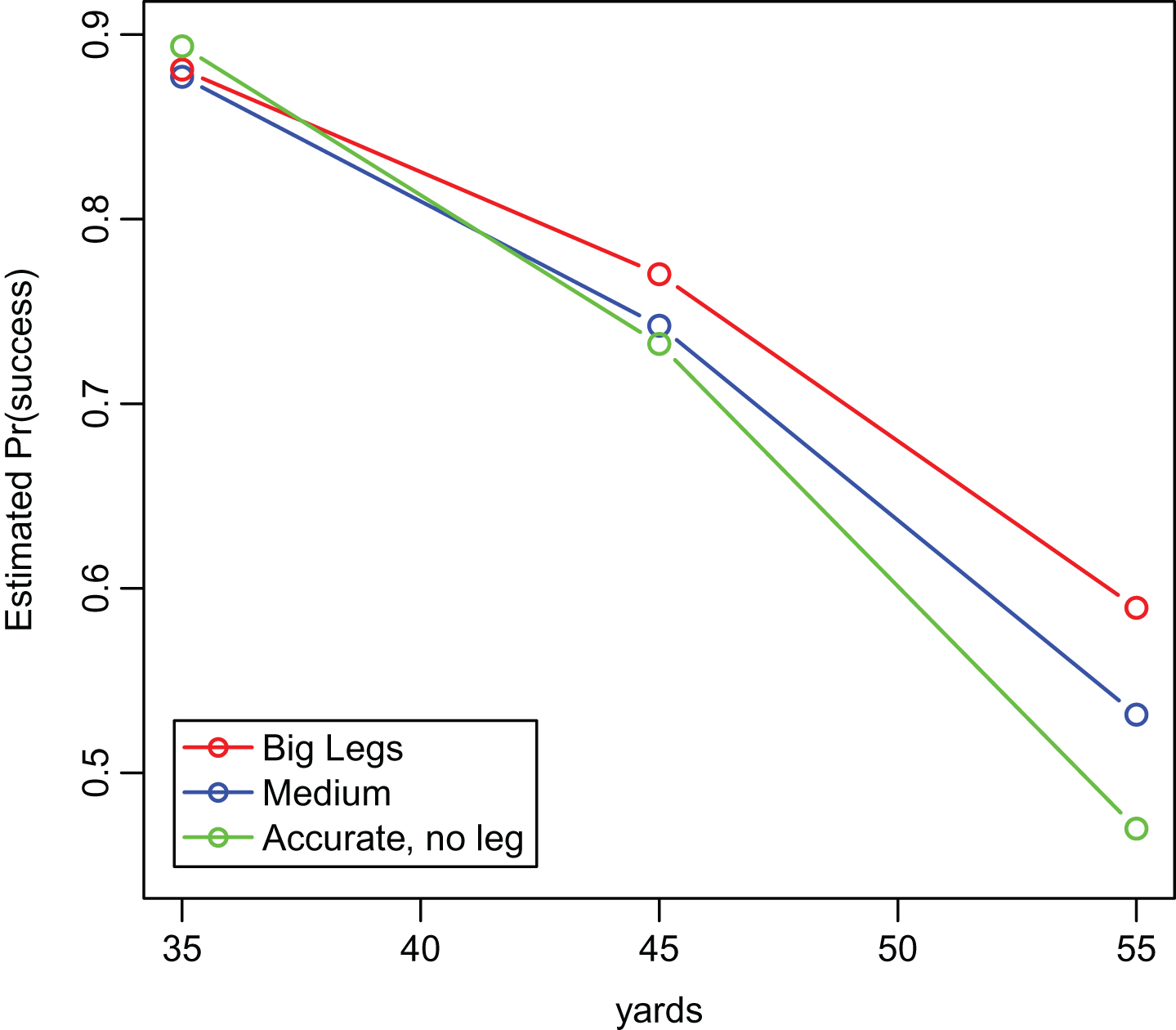
Three clusters of kickers using shrinkage estimates of success probabilities at three distances.
Rankings of kickers among the top 20 at three different distances: 35, 45, and 55 yards. The columns include career span within the data set, ranks at each of the three distances, success probability shrinkage estimate at each of the three distances, and the empirical success probability at three distance ranges 30-39, 40-49, and 50-59 yards. Dashed lines separate clusters
Table 13 helps quantify the variance-reducing property of shrinkage estimation by comparison of the coefficient of variation among kickers with maximum likelihood (no shrinkage) estimates. The table gives results for both linear and quadratic fits, with diminished coefficient of variation for shrinkage estimates, particularly for shorter attempts.
Summary statistics among estimated success probabilities for 54 veteran kickers
Another way to rank kickers is to consider big-legs and stadium effects and shrinkage
estimation all together. Stadium effects can bias a ranking and by including them in the
model, together with quadratic distance effects, one can attempt to rank kickers on an
even footing. The model is then given by
Rankings of kickers among the top 20 at three different distances: 35, 45, and 55 yards, including adjustment for stadium effects.The columns include career span within the data set, ranks at each of the three distances, success probability shrinkage estimate at each of the three distances, and the empirical success probability at three distance ranges 30-39, 40-49, and 50-59 yards. Dashed lines separate clusters
The analyses in this paper cover a wide time span. Kicker ability appears to be changing, especially in the last 10 years, with improving accuracy and experience among kickers (Clark et al., 2013). The frequencies of long field goal attempts are also increasing. Figure 9 shows the log of attempt frequencies against year, with separate plotting characters and colors for each distance, rounded to the nearest five yards. The log-scale is better for visualizing the increase in frequencies. In fact, the log of the frequency of kicks between 53 and 57 yards, denoted in the graph as “55”, and also of kicks between 48 and 52 yards, denoted as “50”, appear to be linearly increasing with season. The figure overlays lines using estimated coefficients from Poisson regressions of frequency on year, separate for each 5-yard distance interval, with the natural log-link function for the generalized linear model. The slopes are significant for distances of 50, 55, and 60 yards.

Log of attempt frequencies over season separated by distances rounded to the nearest five yards starting at 40 yards. Lines are linear regressions of log-transformed attempt frequencies on year.
With the goal of variance-reduction akin to that achieved by Efron and Morris (1975) and Brown (2008) in the prediction of end-of-season batting averages, we presented a flexible framework for the construction of shrinkage estimators of field goal success probabilities. This framework allows for model-based kicker-specific maximum likelihood estimates to be balanced with model-free empirical frequencies aggregated over all kickers. For the model-based estimator, various link functions were assessed using maximum likelihood, Hosmer-Lemeshow statistics and restrictions on data motivated by possible selection bias. The complementary log-log function was selected by all criteria. Findings from several choices for the weight functions of the model-based estimate were presented, including constant, functional, or distribution-based weights, but our investigation was by no means exhaustive. We recommend the midpoint estimator which weights the two components equally on the basis of simplicity and generally good performance as measured by the Hosmer-Lemeshow statistic under cross validation. Interested readers are invited to give other weighting schemes a try. In particular, it seems that low-frequency kickers ought to be estimated using more shrinkage toward the empirical frequency. Since these kickers constitute a comparatively small fraction of the data set, they do not carry much weight as we assess the performance of shrinkage estimators. It is reasonable that in some personnel decisions, they should carry more weight, and a different shrinkage approach and method of assessment may be more appropriate.
Another limitation of the study has to do with failed attempts that are not the fault of the kicker, or perhaps partially the fault of the kicker. If a snap or hold is bad, but an attempt is made and missed, it may appear in a verbal recap, but appears in the play-by-play simply as “no good.” Our model does not account for this type of event. Excluding blocked kicks is also problematic as it is possible that longer attempts may be more likely to be blocked by lesser kickers, so that these failed attempts contain information about kicker ability.
Using the approach of Berry and Berry (1985) to average success probability estimates over the observed distribution of attempt distances, rankings for kickers were provided. Interestingly several current kickers came out on top. In addition to this overall ranking, distance was fixed at several lengths, d = 35, 45 and 55 yards, corresponding roughly to estimated success probabilities for elite (top 20) kickers in the range of 0.9, 0.8, and 0.6 respectively. These estimates are based on a version of the model that expands the degree of polynomial dependence on distance to be quadratic. Presentation of the bestkickers side-by-side enables investigation of kickers who have “big legs,” with a decent shot at long kicks, in comparison to those who are “automatic” at medium distances. An attempt to refine these rankings was made by adding stadium effects, which were found to be highly significant. The estimated marginal (averaged over kickers) means for stadiums with adequate sample sizes were back-transformed to give a ranking of the toughest venues in which to kick.
General managers have made kicker personnel changes with surprising frequency, perhaps overreacting after the sting of a loss which involved a missed field goal. Let us consider the case of Garrett Hartley in more detail. Hartley began his career with the New Orleans Saints in 2008 by making all 13 of his field goal attempts. The following year he made all but two field goal attempts, with the misses coming from 58 and 37 yards. As mentioned in Section 1, in 2010 Hartley missed a 29 yard attempt in overtime in a week 4 loss and the Saints chose to sign John Carney. Carney proceeded to make 5 out of 6 field goals for the two games he replaced Hartley, missing from 29 yards in week 5, the exact same yardage which precipitated Hartley’s demotion. So the following game, Carney was demoted in favor of Hartley and Hartley proceeded to make 16 of the 18 remaining kicks he attempted in the season. The frequency of personnel changes among kickers, averaging more than 3 mid-season cuts per year, is surprising in light of the small number of total kickers over the 16 year period of this study. Though kickers may lose their jobs, many find employment shortly after termination, with a small number moving on through free agency. Whether the high turnover is a result of misunderstanding of the sampling variability inherent in estimating success probabilities from a small number of binary trials, or due to reaction to fan hostility is unclear.
Over the last five years, there has been an increase in the distances at which field goals are attempted, most likely due to increases in kicker abilities. Attempting to model this increase could lead to improvements in the estimation of success probabilities and would be an excellent avenue for further study. Another potentially interesting topic that could be investigated would be the effect of age on elite kickers who have exhibited longevity in the league. Here it is implicitly assumed to be constant, but we may wonder if it is reasonable to expect the same degree of accuracy at all stages of a kicker’s career.