
Abstract
Outlier detection is critically important in the field of data mining. Real-world data have the impreciseness and ambiguity which can be handled by means of rough set theory. Information entropy is an effective way to measure the uncertainty in an information system. Most outlier detection methods may be called unsupervised outlier detection because they are only dealt with unlabeled data. When sufficient labeled data are available, these methods are used in a decision information system, which means that the decision attribute is discarded. Thus, these methods maybe not right for outlier detection in a a decision information system. This paper proposes supervised outlier detection using conditional information entropy and rough set theory. Firstly, conditional information entropy in a decision information system based on rough set theory is calculated, which provides a more comprehensive measure of uncertainty. Then, the relative entropy and relative cardinality are put forward. Next, the degree of outlierness and weight function are presented to find outlier factors. Finally, a conditional information entropy-based outlier detection algorithm is given. The performance of the given algorithm is evaluated and compared with the existing outlier detection algorithms such as LOF, KNN, Forest, SVM, IE, and ECOD. Twelve data sets have been taken from UCI to prove its efficiency and performance. For example, the AUC value of CIE algorithm in the Hayes data set is 0.949, and the AUC values of LOF, KNN, SVM, Forest, IE and ECOD algorithms in the Hayes data set are 0.647, 0.572, 0.680, 0.676, 0.928 and 0.667, respectively. The advantage of the proposed outlier detection method is that it fully utilizes the decision information.
Introduction
Outlier detection, also known as anomaly detection, refers to the identification of rare items, events or observations which difer from the general distribution of a population [43]. Outlier detection has many applications, such as insurance claim fraud detection [2, 17], fraud detection in finance [3, 12], network intrusion detection [8, 34], intelligent transportation development [11], health diagnosis [16, 29].
Based on the availability of labels in the training data sets, the existing outlier detection methods can be classified into 3 categories: unsupervised methods, semi-supervised methods,and supervised methods [20]. Supervised methods use labeled data to train an outlier detection model. Semi-supervised methods for anomaly detection aim to utilize a small pool of labeled samples. Since a labeled instance is difficult to obtain, most existing techniques are unsupervised, which can work with unlabeled data [1, 5]. Supervised anomaly detection techniques are superior in performance compared to unsupervised anomaly detection techniques since these techniques use labeled samples [15].
Degirmenci et al. [8] put forward efficient density and cluster based incremental outlier detection in data streams. Din et al. [11] exploited evolving microclusters for data stream classification with emerging class detection. Domingues et al. [10] gave a comparative evaluation of outlier detection algorithms. Du et al. [13] raised graph autoencoderbased unsupervised outlier detection. Kandanaarachchi et al. [21] brought up unsupervised anomaly detection ensembles using item response theory. Liu et al. [23] invoked data adaptive functional outlier detection. Wang et al. [36] provided outlier detection using weighted neighbourhood information network for mixed-valued datasets. Yuan et al. [38] researched outlier detection using fuzzy rough granules in mixed attribute data. Yuan et al. [39] studied hybrid data-driven outlier detection using neighborhood information entropy and its developmental measures. Jin et al. [18] introduced intrusion detection on internet of vehicles via combining log-ratio oversampling, outlier detection and metric learning. Meira et al. [26] came up with fast anomaly detection with locality-sensitive hashing and hyperparameter autotuning. Wang et al. [37] advanced autonomous hyperspectral anomaly detection network using fully convolutional autoencoder. Zhuang et al. [42] investigated hyperspectral image denoising and anomaly detection based on low-rank and sparse representations. Zhang et al. [45] considered outlier detection using three-way neighborhood characteristic regions and corresponding fusion measurement. Gao et al. [14] introduced a relative granular ratio-based outlier detection method in heterogeneous data.
Rough set theory (RST), proposed by Pawlak [27], is a mathematical tool to handle imprecision, vagueness and uncertainty. RST is widely used in feature selection [7, 23], and pattern recognition [25].
Methods for anomaly detection based on RST have been studies, and these methods have be showed better effectiveness and adaptability in detecting outliers. Jiang et al. [19, 20] proposed an outlier detection method using approximation accuracy entropy using rough set. Yuan et al. [39] introduced outlier detection using neighborhood information entropy according to the hybrid data-driving, Yuan et al. [38] extended fuzzy information entropy-based adaptive method for mixed feature outlier detection, which can applicable data sets widely concern categorical, numeric, and mixed data.
Many researchers have applied Shannon’s information entropy to rough sets [30]. By now, the mechanism for measuring uncertainty in rough sets based on Shannon’s information entropy has been formed [6, 44]. Furthermore, Singh [31, 32] gave a general model of ambiguous sets to a single-valued ambiguous numbers with aggregation operators and investigated ambiguous sets with application to decision-making from partial order to lattice ambiguous sets.
Most of the aforementioned outlier detection methods are unsupervised because they are only dealt with unlabeled data. If sufficient labeled data are available and these methods are used in a decision information system (DIS), then this means that the decision attribute is discarded and leads to information loss. Thus, these methods are not suitable for detecting the outliers in a DIS. In this paper, a supervised method for outlier detection using conditional entropy and rough set theory is proposed, and the conditional information entropy-based outlier detection algorithm is designed. The advantage of the proposed supervised method is that it fully utilizes the decision information. The main contributions are summarized as follows.
(1) Based on the rich theoretical knowledge of RST, the conditional information entropy, relative entropy and relative cardinality in a DIS are proposed, which to some extent enriches the application scenarios and scope of information entropy.
(2) In order to find outlier factors, the degree of outlierness and weight function are put forward. An outlier detection algorithm using conditional information entropy is presented. The experimental results show that the presented algorithm has better validity and adaptability for a DIS.
The rest of this paper is organized as follows. Binary relations and information entropy in a DIS are reviewed in Section 2. A conditional information entropy-based method using rough set theory is proposed in Section 3. Experiments and comparisons on UCI data sets are conducted in Section 4. The conclusion is given in Section 5. The work process of this paper is shown in Fig. 1.
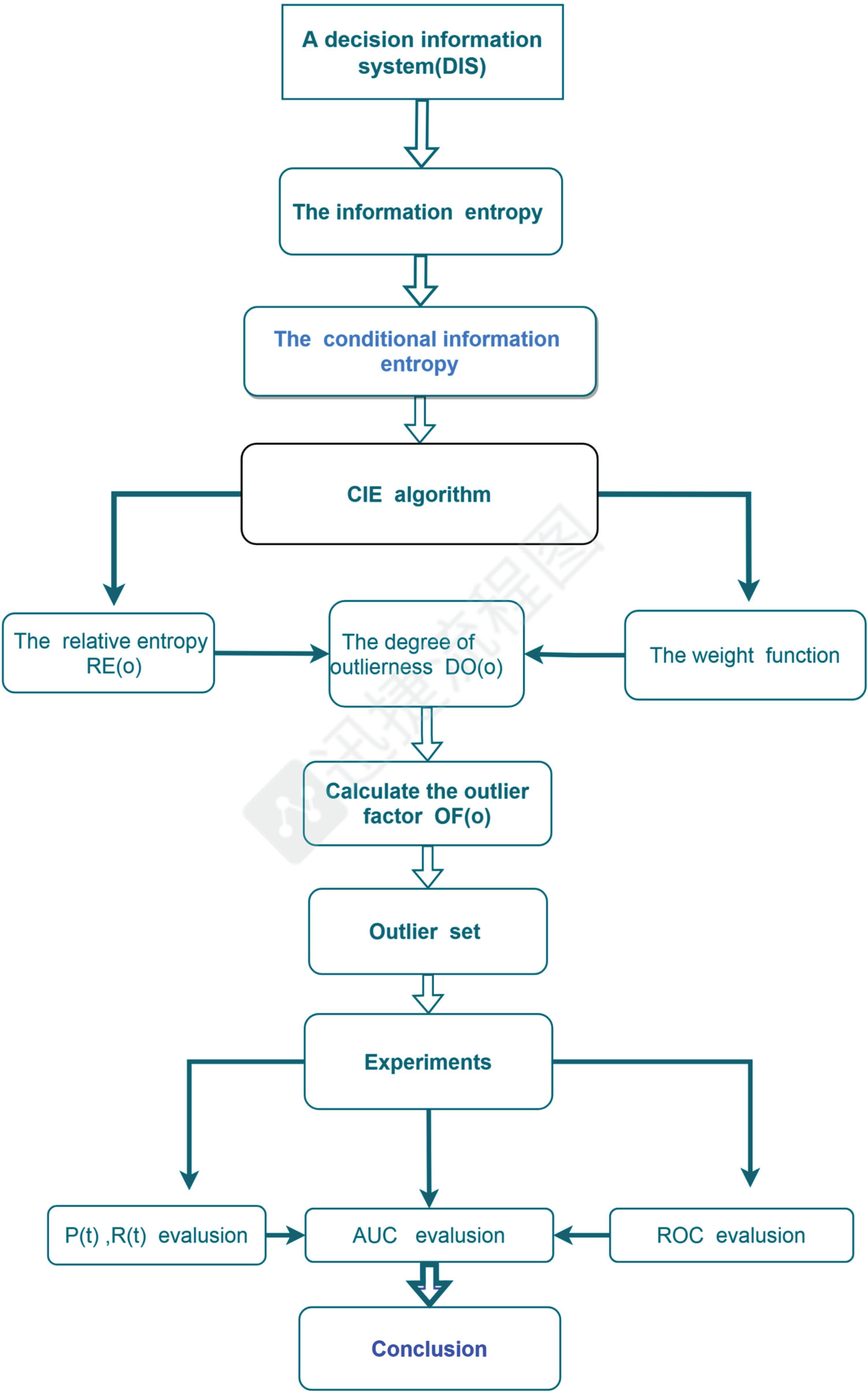
The work flow of this paper.
We first look back at binary relations and information entropy in a DIS.
Throughout this paper, O denotes a finite sets, 2 O represents the power set of O and |X| is the cardinality of X ∈ 2 O . Put
Recall that R is a binary relation on O whenever R ⊆ O × O.
(1) R is called reflexive, if (o, o) ∈ R for any o ∈ O;
(2) R is called symmetric, if (o, o′) ∈ R implies (o′, o) ∈ R;
(3) R is called transitive, if (o, o′) ∈ R and (o′, o″) ∈ R imply (o, o″) ∈ R.
R is said to be an equivalence relation on O, if R is reflexive, symmetric and transitive; R is called a tolerance relation on O, if R is reflexive and symmetric.
Information entropy in a DIS
(O, C, d) is known as a decision information system (DIS), if (O, C ∪ {d}) is an IS, where C denotes a set of conditional attributes and d a decision attribute. If P ⊆ C, then (O, P, d) is referred to as the subsystem of (O, C, d).
Let (O, C, d) be a DIS. For any P ⊆ C, define ind (P) = {(o, o′) ∈ O × O : ∀ a ∈ P, a (o) = a (o′)} ,
Clearly, ind (P) and R d are two equivalence relations on O.
Denote
Suppose that
This implies that
Thus ∀ i,
Hence
Similarly, conditional information entropy of a DIS is defined as follows.
Propositions 2.7 indicates that Definition 2.5 is reasonable.
This section studies outlier detection in a DIS using conditional information entropy. In order to detect outliers in rough sets, based on the concept of conditional information entropy defined above, we propose a new concept: relative conditional entropy, which gives a measure of uncertainty for each object in the domain O.
For a DIS (O, C, d), let P ⊆ C and x ∈ O, put
Especially, in the above definition, if O/ind (P) = {[x]
P
, O - [x]
P
}, then H
x
(P|d) =0, Correspondingly,
In this paper, we may consider those objects in O whose relative conditional entropies are always high as behaving in an unexpected way or featuring abnormal properties when comparing with other objects in O, and utilize the relative conditional entropy for outlier detection.
Since the aim of outlier detection is to find the small groups of objects in O who behave in an unexpected way or have abnormal properties. in order to find outliers in O, we first divide all the objects of O into two categories: objects belonging to the minority groups in O and objects belonging to the majority groupsin O, by virtue of a given standard. Next, we shall give a definition to characterize this standard [19].
Then RC P (x) is called the relative cardinality of the tolerance class [x] P to x.
In particular, if [x] P = O, then we assume that RC P (x) = |O|. From the above definition, it is easy to verify that for any x ∈ O and P ⊆ C, 2 - |O| ≤ RC P (x) ≤ |O|. If RC P (x) >0, then we deem object x belonging to the majority groups in O. On the other hand,if RC P (x) ≤0, then we deem object x belonging to the minority groups in O [19].
In order to find outliers in a given decision information table DIS, we need to define two kinds of sequences in DIS: the relative conditional entropy-based sequence of attributes and the relative conditional entropy-based sequence of attribute subsets [20].
We can generate another sequence if we gradually delete attributes from the original attribute set C.
In the following, we will use the above two kinds of sequences to calculate the degree of outlierness for every object in O [19].
Denote
Since objects belonging to the minority groups are more likely to be outliers than objects belonging to the majority groups. Therefore, if RC
P
(x) <0 and
Denote ω a (x) = ω{a} (x) .
From the above definition, ω p (x) is relative small if x belongs to the minority groups in O.
Let (O, C, d) be a DIS. Given μ ∈ [0, 1].
Then x ∈ O is called μ-outlier in a DIS, if OF (x) > μ .
A DIS (O, C, d) is shown in Table 1, where O = {o1, o2, o3, o4, o5, o6} , and C = {c1, c2, c3} . Pick μ=0.6. to detect CIE-based outliers in DIS, the following procedures are utilized.
Results table of DOS attack
Results table of DOS attack
The partitions induced by all singleton subsets of C and d are as follows:
From Definition 2.5.
Analogously, we can obtain that
As a matter of fact, A3 = {c2} in this example, this means that we need to discard A3. Hence, the conditional information entropy outlier factor of o1 is given as follows.
Therefore, o1 is not a outlier in DIS. Analogously, we can obtain that OF (o2) ≈0.6101 > μ, OF (o3) ≈0.5125 < μ, OF (o4) ≈0.5171 < μ,OF (o5) ≈0.5125 < μ, and OF (o6) ≈0.5932 < μ. Therefore o2 is a outlier in DIS. The other objects in O are all not outliers.
In this section, an outlier detection algorithm using conditional information entropy (denoted as CIE algorithm) is proposed.
Experiments
Experimental on twelve UCI Machine Learning data sets
To evaluate the effectiveness of the CIE algorithm, twelve data sets are selected from UCI for experiments [9]. On 12 data sets, we compare the performance of the CIE algorithm with Local Outlier Factor (LOF), k-Nearest Neighbor (KNN), Isolation Forest (Forest), One-Class Support Vector Machines (SVM) [33], Information Entropy-based (IE) [19], and Empirical-Cumulative-distribution-based Outlier Detection (ECOD) [43]. An overview of these seven algorithms used in this paper is shown in Table 1.

Most of public data sets are used for the evaluation of classification and clustering methods. For the evaluation of outlier detection, there are very few existing data sets. Accordingly, this article uses the downsampling method proposed in the document [5] to obtain some data sets for evaluating outlier detection methods. The method randomly downsamples a particular class to produce outliers while preserving all objects of the remaining classes to form a data set for evaluating outlier detection methods. In addition, for the missing values of data set, this article uses the maximum probability value method to complete the missing values, that is, the value of attribute with the highest frequency on other objects is used to fill the missing attribute values [38]. An overview of the data sets used in the paper is shown in Table 2.
Seven concerned algorithms for outlier detection
Seven concerned algorithms for outlier detection
In Table 2, the number of objects is between 132 and 4409, and the number of condictional features is between 8 and 36. The decision attribute is only one in every data set.
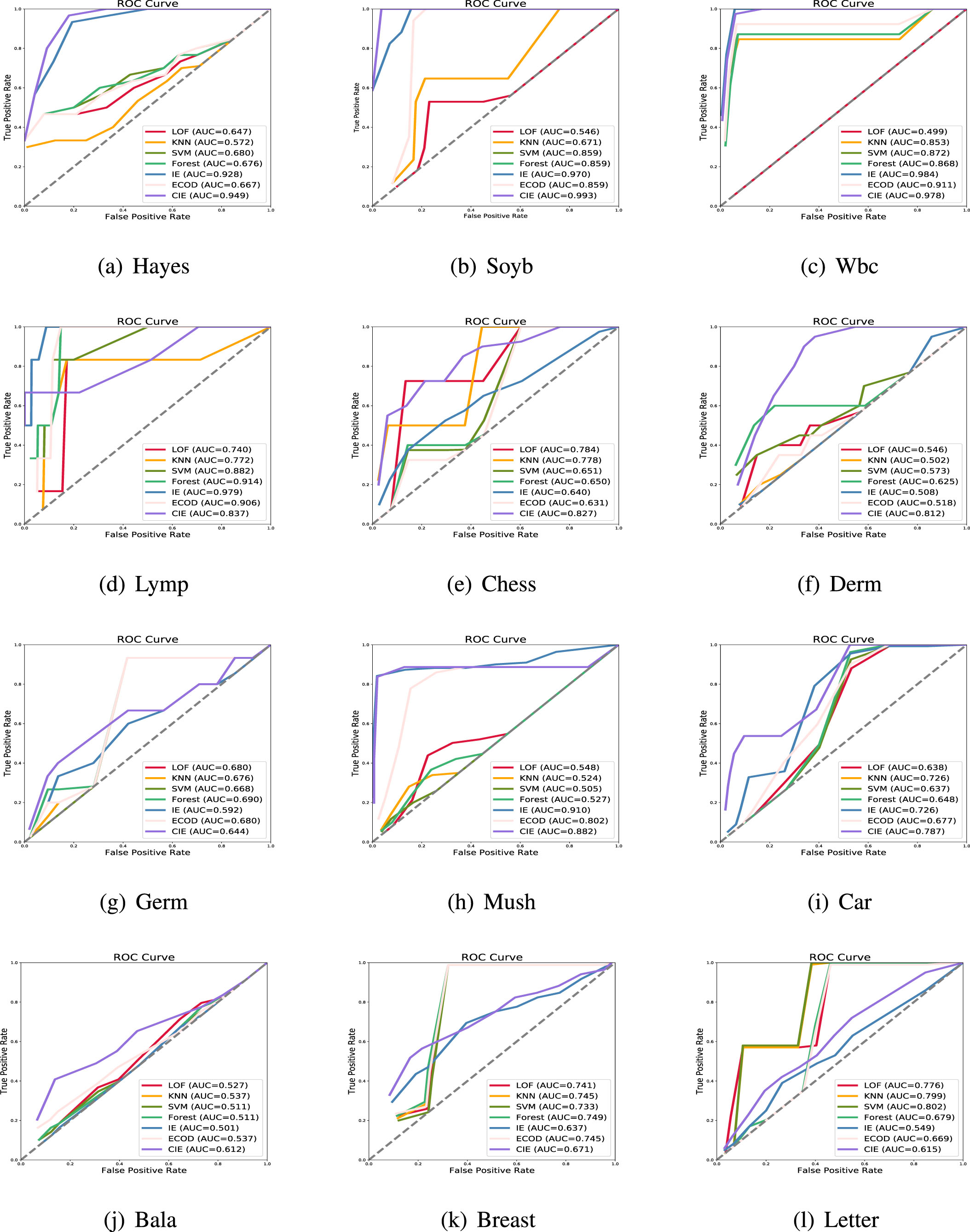
Comparison by ROC curves and AUC values based on six methods.
The comparative experiments are conducted on a computer with the Intel (R) core (TM) i7-10700 processor plat-form, 2.90 GHz frequency, 8 G memory. The operating system is Windows 10. The experimental results are performed in Python3.8.
In this paper, Precision (P), Recall (R), and Receiver Operating Characteristic (ROC) curves are used to evaluate the effectiveness of the proposed method [1]. The specific steps are as follows. In the outlier detection, most of the detection methods ultimately output the outlier factor of each object in O, and the larger the outlier factor of an object, the more likely it is the outlier. These objects can be arranged in descending order according to their outlier factor values. Given an order number t, objects with a sequence number greater than or equal to t are treated as outliers. If the given t is too small, it will cause the method to miss the true outliers. Conversely, too many objects are judged to be outliers, which leads to too excessive false positives. This trade-off can usually be measured by P and R. For a given t, OS (t)is a function of t [1]. It denotes the outlier set detected by the given t. OS
O
represents the true outlier set in the data set, and the P (t), R (t) are, respectively, calculated by
It is known that the ROC curves present a visual impression for the accuracy of diagnostic systems and display the tradeoffs between sensitivity and accuracy for various setting of the dicision criterion. And the Area Under the ROC curve(named AUC) gives expression to discrimination capacity for two classes of events. AUC analysis is widely recognized as the best method for measuring the quality of diagnostic information and diagnostic dicisions [1, 38].
The ROC curve is a curve with the false positive rate (FPR) as the abscissa and the true positive rate (TPR) as the ordinate.(FPR) and (TPR) are computed, respectively, as
The ROC curves and the corresponding AUC values are described in Fig. 1, for investigated algorithms.
Comparison by P (t) and R (t)
Tables 3–5 show the experimental results for P (t) and R (t) on 12 data sets, respectively. They illustrate the results of the P (t) and R (t) change with t. From Table 3, it can be seen that the CIE algorithm achieves superior performance on Hayes, Soyb, Wbc data sets. The analyses are mainly carried out from the following aspects.
Description of data and the details of data preprocessing
Description of data and the details of data preprocessing
The comparison of experimental results about P (t) and R (t)\label t1
The comparison of experimental results about P (t) and R (t)
The comparison of experimental results about P (t) and R (t)
(1) Given t = |OS o |, the CIE algorithm has a larger P (t). For example, for the Hayes data set, the CIE algorithm’s P (t) is 80.00%. However, for LOF, KNN, SVM, Forest, IE, and ECOD algorithms, their P (t) are 46.67%, 33.33%, 50.00%, 50.00%, 73.33%, and 46.67%, respectively. The P (t) of the CIE algorithm is larger than that of other algorithms. On Soyb, Chess, Car, Bala, Derm and Wbc data sets, the CIE algorithm’s P (t) is greater than or equal to that of other algorithms. For the Lymp, Breast, Germ, Mush and Letter data sets, the P (t) of the CIE algorithm is slightly smaller than that of the IE algorithm, but greater than other algorithms. For the Chess, Derm and Cmc data sets, the P (t) of the CIE algorithm is smaller than or equal to other algorithms.
(2) In terms of R (t), the CIE algorithm achieves maximum values in most data sets for given t = |OS o |. For example, in the Wbc data set, the CIE algorithm’s R (t) is 100.00% at first time, but, for LOF, KNN, LOF, SVM, Forest, IE, and ECOD algorithms, their R (t) are 25.64%, 84.62%, 87.18%, 87.18%, 100% and 92.31%, respectively. For Hayes, Soyb, Mush Bala, Car and Wbc data sets, the CIE algorithm’s R (t) is greater than other algorithms. On the Chess, Lymp, Breat, Derm, Germ and Letter data sets, the R (t) of the CIE algorithm is slightly smaller than that of the other’s algorithm.
(3) For the average of P (t) and R (t), the CIE algorithm achieves maximum values on the Hayes, Soyb, Wbc, Derm, Germ, Chess, Car, and Bala data sets. For example, the average P (t) and R (t) of the CIE algorithm on the Hayes data set are 60.40% and 92.33%, respectively, which is obviously larger than other algorithms. For the Lymp, Wbc and Mush data sets, the average P (t) and R (t) of the CIE algorithm are slightly smaller than that of the IE algorithm, but greater than other algorithms. However, for the Breast and Letter data sets, the average P (t) and R (t) of the CIE algorithm are slightly smaller than or equal to that of other algorithms.
From Fig. 1, the experimental result reveals that CIE algorithm attains the highist AUC value for Hayes, Soyb, Chess, Derm, Car, Bala and Wbc data sets. For example, in the Hayes data set, the AUC value of CIE algorithm is 0.949, however, for LOF, KNN, SVM, Forest, IE and ECOD algorithms, their AUC values are 0.647, 0.572, 0.680, 0.676, 0.928 and 0.667, respectively. For the Mush data set, the AUC score of the CIE algorithm is smaller than that of the IE algorithm, but higher than the others algorithms. Only for the Lymp, Germ, Breast and Letter data sets, the result of AUC from CIE algorithm are slightly smaller than or equal to that of other algorithms.
Conclusion
Based on RST and information entropy, this paper has proposed a supervised method for outlier detection in a DIS. In terms of this method, we have designed the corresponding algorithm, and carried out experiments to compare with some existing outlier detection algorithms. Experimental results have demonstrated that the designed algorithm is effective. A supervised method for outlier detection using conditional information entropy has not been studied before. This is the innovation of this paper. The existing state-of-the-art outlier detection algorithms mainly are unsupervised because they are only dealt with unlabeled data. When sufficient labeled data are available and these algorithms are used in a DIS, this means that the decision attribute is discarded and then leads to information loss. The proposed outlier detection algorithm fully utilizes the decision information. This reflects the main differences or importance between the proposed algorithm and other state-of-the-art algorithms. The proposed work has the limitation, i.e., it can it can only detect the outliers of categorical data. We wish that the proposed work could improve the accuracy of deep learning detection methods. In future work, we will extend the proposed work to mixed data and fuzzy information entropy based outlier detection.
Footnotes
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers for their valuable comments and suggestions, which have helped immensely in improving the quality of the paper. This work is supported by National Natural Science Foundation of China (11971420, 12261096), Natural Science Foundation of Guangxi Province (2020GXNSFAA159155) and Natural Science Foundation of Yulin (202125001).