
Abstract
Domain adaptation solves the challenge of inadequate labeled samples in the target domain by leveraging the knowledge learned from the labeled source domain. Most existing approaches aim to reduce the domain shift by performing some coarse alignments such as domain-wise alignment and class-wise alignment. To circumvent the limitation, we propose a coarse-to-fine unsupervised domain adaptation method based on metric learning, which can fully utilize more geometric structure and sample-wise information to obtain a finer alignment. The main advantages of our approach lie in four aspects: (1) it employs a structure-preserving algorithm to automatically select the optimal subspace dimension on the Grassmannian manifold; (2) based on coarse distribution alignment using maximum mean discrepancy, it utilizes the smooth triplet loss to leverage the supervision information of samples to improve the discrimination of data; (3) it introduces structure regularization to preserve the geometry of samples; (4) it designs a graph-based sample reweighting method to adjust the weight of each source domain sample in the cross-domain task. Extensive experiments on several public datasets demonstrate that our method achieves remarkable superiority over several competitive methods (more than 1.5% improvement of the average classification accuracy over the best baseline).
Introduction
Many real-world tasks suffer from insufficient labeled samples and discrepant distributions of the training and testing data [1]. To address these challenges, domain adaptation utilizes a related and adequately annotated domain (source domain) to assist the task of the current domain (target domain) by reducing the distribution discrepancy between the two domains. This approach has shown remarkable performance in practical applications such as object detection [2–4], natural language processing [5–8], medical image analysis [9–13] and image classification [14–18]. The domain adaptation methods for reducing the discrepancy between two domains can be roughly categorized into two types [19]: instance-based and feature-based methods. Instance-based domain adaptation methods reweight the source domain samples through weight generation rules, thereby the weighted source domain distribution becomes closer to that of the target domain. Some methods [20–22] estimate the distribution ratio between the two domains as the weight of the source domain sample. However, relying on the estimation of probability distribution limits the performance of these methods.
On the other hand, feature-based domain adaptation methods map the source and target domain data into a shared space where the domain shift is small. They align the marginal distribution [14], conditional distribution or both [16, 23] by using a proper distribution distance measure such as maximum mean discrepancy (MMD) [24]. Unfortunately, most feature-based algorithms focus on coarse domain-wise alignment and class-wise alignment, which is far from enough.
To achieve finer alignment, metric learning-based domain adaptation approaches [25–28] learn a suitable metric matrix to address the scarcity of labeled data and distribution disparity by leveraging sample information. Such a metric matrix brings similar samples closer while pushing apart dissimilar ones, thereby enhancing the classification accuracy. Nevertheless, the subspace dimension in these methods is a hyper-parameter and is not guaranteed to be optimal. Moreover, most of these methods only reduce the distribution difference from a statistical perspective, failing to preserve the geometry of the data very well. Without structure constraints, the original data structure will be destroyed.
In this paper, to tackle the aforesaid deficiencies, we propose a metric learning-based coarse-to-fine unsupervised domain adaptation method. Specifically, subspace learning can be treated as an inverse problem on the Grassmannian manifold, searching for the optimal subspace dimension by a structure-preserving algorithm. In this way, the dimension of the subspace no longer needs to be artificially set before the experiment. Meanwhile, we reduce the distribution discrepancy and improve the separability between different classes to get coarse alignment. For a finer alignment, we improve the discrimination of data by using the smooth triplet loss and preserve the geometry of data by introducing structure regularization. Finally, a graph-based sample reweighting method is utilized to adjust the weights of source domain samples in the cross-domain task.
Our contributions can be summarized as follows: We adopt a structure-preserving algorithm to automatically select the optimal subspace dimension on the Grassmannian manifold. We introduce the smooth triplet loss and structure regularization into domain adaptation and propose a coarse-to-fine unsupervised domain adaptation model. We design a graph-based sample reweighting method to pick out the most task-relevant source domain samples. Extensive quantitative evaluations on benchmark datasets validate that our method performs an outstanding improvement against previous methods.
The remainder of this article is organized as follows. In the following section, we outline the related work. Section 3 describes our novel domain adaptation model in detail. Section 4 presents the optimization process of our algorithm. An extensive experimental study is provided in Section 5. Finally, we conclude this article in Section 6.
Related work
Domain adaptation
Domain adaptation aims to reduce the distribution divergence by using different strategies. According to [19], we broadly divide existing domain adaptation approaches into two classes: instance-based and feature-based domain adaptation.
Instance-based domain adaptation methods reduce the domain shift via reweighting source instances according to their correlations with target instances. Transfer joint matching (TJM) [15] reweights the instances by minimizing the ℓ2,1-norm structured sparsity penalty. Later, metric transfer learning framework (MTLF) [22] learns the weights of source instances by minimizing the Kullback-Leibler divergence (KL-divergence) between the weighted source data distribution and the target data distribution. Recently, unsupervised domain adaptation based on adaptive local manifold learning (UDA-ALML) [29] uses the reconstruction coefficient matrix as the weight matrix when reconstructing the target samples. Moreover, transfer independently together (TIT) [30] uses the graph-based method to compute the intra-domain weights of source domain samples. Differently, intra-class weights are calculated in our method.
In recent years, feature-based domain adaptation methods have been extensively developed. Transfer component analysis (TCA) [14] minimizes the marginal distribution discrepancy between domains by using MMD distance. Based on TCA, joint distribution adaptation (JDA) [23] further considers the conditional distribution difference. Later, balanced distribution adaptation (BDA) [16] and manifold embedded distribution alignment (MEDA) [31] introduce a weight parameter to measure the influences of conditional and marginal distributions. Then, Li et al. [32] introduced a manifold regularization method to keep the neighbor relations of the data based on BDA. Joint probability domain adaptation (JPDA) [17] replaces the frequently used joint MMD with joint probability MMD to simultaneously increase the transfer performance and discriminative ability. Subsequently, Lie group manifold analysis (LGMA) [33] combines Lie group theory, weighted distribution alignment and manifold alignment to minimize the domain mismatch. Discriminative invariant alignment (DIA) [34] introduces the maximum margin criterion to improve the discriminant ability and encodes the Laplacian embedding technique to preserve the geometrical consistency of the target domain. Moreover, Yang et al. [35] introduced a class-wise sparsity regularization to maintain the row-sparsity consistency of samples from the same class. Recently, discriminative manifold distribution alignment (DMDA) [36] uses the Hilbert-Schmidt independence criterion to keep the source label information. Unlike these methods, we introduce metric learning into domain adaptation to employ sample-wise information.
Metric learning-based domain adaptation
Metric learning-based domain adaptation methods take advantage of both domain adaptation and metric learning, and thus have received tremendous attention recently. Decomposition-based transfer distance metric learning (DTDML) [25] argues that the target metric consists of the decomposition of source metrics. Then, robust transfer metric learning (RTML) [26] seeks a more robust transfer low-rank metric by designing a marginalized denoising scheme. Metric transfer learning framework (MTLF) [22] reweights source instances with the Mahalanobis distance. Later, unsupervised transfer metric learning (UTML) [27] further employs the target discriminative information. Subsequently, to achieve better performance, Kerdoncuff et al. [37] encoded optimal transport and metric learning into domain adaptation. Recently, geometric mean transfer learning (GMTL) [28] combines transfer learning and geometric mean metric learning to improve the discriminability of learned features. In contrast to these methods, we introduce a structure preservation term to retain the geometric consistency of samples and adopt a manifold dimension reduction method to select the optimal subspace dimension automatically.
Proposed method
Firstly, we state the problem of domain adaptation. Let
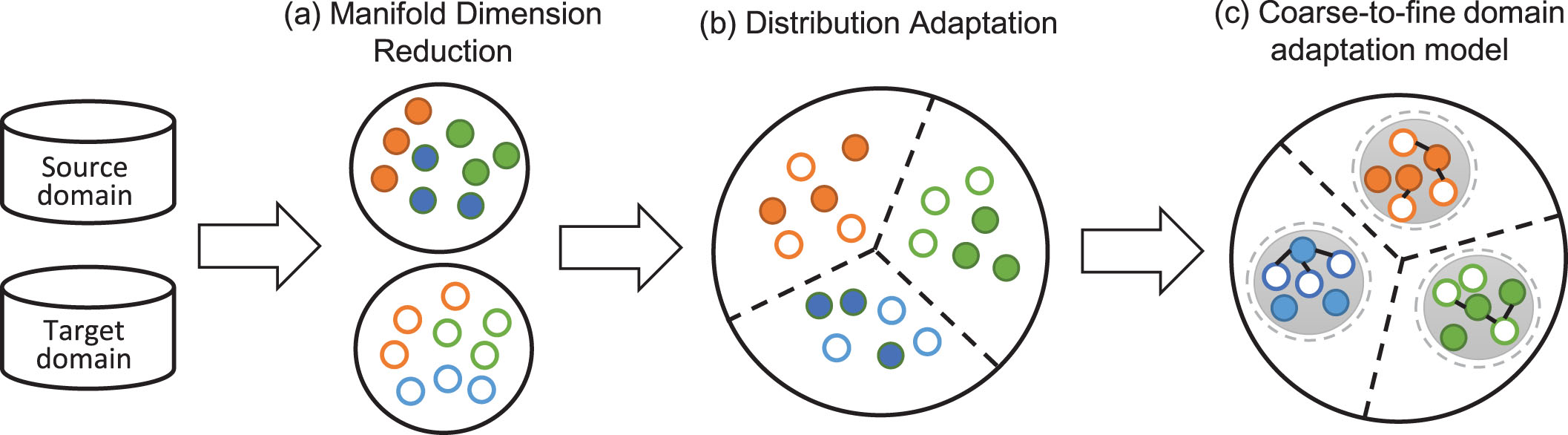
Illustration of the proposed method. (a) Manifold dimension reduction is used to map the source and target domains into the optimal subspace. (b) We reduce the domain discrepancy and improve the divisibility of data between different classes by distribution adaptation. (c) By the coarse-to-fine domain adaptation model, similar samples become closer while dissimilar samples become farther. Different colors represent different classes.
In many existing methods, samples of source and target domains are mapped into a low-dimensional domain-invariant subspace. However, the dimension of the subspace is a hyper-parameter which is artificially set before the experiment. In this paper, a manifold dimension reduction method is adopted to automatically select the optimal subspace dimension.
Motivated by [38], we regard all subspaces as points on a Grassmannian manifold and solve the subspace learning problem as an inverse problem on the Grassmannian manifold. Specifically, all subspaces can be represented uniformly by using the method of the rotation group SO (d) action. We denote the i
th
orthogonal basis as
A step further, let P
r
= [
Thus, in the learned subspace, the corresponding sample of the original sample
Distribution adaptation
Although the features are more favorable for task performance after subspace learning, the problem of the distribution gap still exists. We learn a robust cross-domain metric M to narrow the difference in marginal and conditional distributions between domains using MMD distance. Under the action of rotation matrix R and projection matrix P
r
, the forms of marginal distribution alignment and conditional distribution alignment are
Eqs. (1) and (2) align the source and target domains by minimizing the distribution divergence. To improve the inter-class divisibility of data, the distance between the means of different classes is maximized, i.e.,
Utilizing the distribution adaptation, the domain shift has been reduced. Furthermore, we hope that the learned metric M can improve the discrimination of data. Because labels in the source domain are available, we follow the idea of conventional metric learning to leverage category information, making similar source samples closer and different source samples farther away.
To achieve a fine alignment, we introduce the smooth triplet loss [39] which balances the inner-class and inter-class discrepancy into domain adaptation. The discrimination improvement term can be formulated as
and
Under the action of rotation matrix R, projection matrix P
r
and metric matrix M, the squared distance
Therefore, the final form of the discrimination improvement term is
The above term for discrimination improvement in Eq. (4) fully utilizes the distinguishable information of the source domain, but it may cause overfitting in the high-dimensional scenario since it is supervised. Therefore, we add the term for structure preservation [40] to better maintain the structure of original samples, that is
Similar to Eq. (4), the final form of the structure preservation term is reformulated as
For learning the optimal cross-domain metric, we pick out the most task-relevant source domain samples. To avoid being limited by the accuracy of the estimation algorithm, a graph-based method is employed to adjust the importance of source domain samples.
Using labels of source data and pseudo-labels of target data, each category forms a subgraph, with the samples as the nodes. For each target domain sample, k nearest source domain samples are found in its subgraph. Then we connect each target domain sample with its k nearest neighbors to construct edges in the subgraph.
We think that the source domain samples with higher degrees are more important. Therefore, we use the degree to calculate the intra-class weight of each source sample, i.e.,
With the weight of each source domain sample, Eqs. (4) and (6) are reformulated as
Incorporating Eqs. (1), (2), (3), (8) and (9), the final objective function of our model can be written as:
Given source data X s and target data X t , we can optimize each variable by fixing other variables alternately. Our optimization problem can be divided into three steps in each iteration: update the rotation matrix R, update the projection matrix P r and update the metric matrix M. The detailed optimization procedures are as follows.
1) Update the rotation matrix R. When updating R, we fix P r and M. The objective function of R is
Firstly, we consider the exponential mapping from Lie algebra
To further simplify the solution process, we solve the optimization problem by the linearization method of exponential mapping and the quadratic approximation method:
Let f (
where
According to the Karush-Kuhn-Tucker conditions, the optimal coefficient
After solving the coefficient vector
2) Update the projection matrix P r . The update to P r can be regarded as an update to the subspace dimension r. During this update, we fix R and M. The optimization problem of r* is
Eq. (14) is a finite and discrete minimization problem, thus we can solve it by traditional methods. When we get the optimal subspace dimension r*, the projection matrix is P
r
*
= [
3) Update the metric matrix M. Also, fix R and P while updating M. The optimization problem of M is
The structure of solution space can be preserved by employing the intrinsic steepest descent method [39] to solve the optimization problem in Eq. (15) on the positive definite matrix group. After obtaining M (t), M (t + 1) can be computed by the following formula:
Eqs. (16) and (17) guarantee M (t + 1) is still a positive definite symmetric matrix, which preserves the structure of the solution space.
The gradient of the objective function f (M) can be calculated by
Using the obtained rotation R, projection P r and metric M, X s and X t are transformed into the corresponding subspaces. Then we predict the target labels by the 1-Nearest Neighbor (1NN) algorithm. The complete process of our algorithm is summarised in Algorithm 1.
Parameters: T, α, β, v, h, η.
Generate pseudo labels for X
t
using a classifier trained on
Initialize the weight ω (
Compute A, B, G in Eq. (10) and construct the basis for Lie algebra {E j } 1<≤j≤m;
Solve the coefficient vector
Construct the projection matrix P r according to the dimension r;
Compute the gradient ∇M(t)f (M) and the descent direction -Q (t) according to Eq. (18) and Eq. (17), respectively;
Update the metric matrix M by Eq. (16);
Transform the original X s , X t by using R, P r , M;
Use 1NN to update the target pseudo-labels
Update the weight of the source domain sample ω (
t = t + 1.
Here we analyze the time complexity of our algorithm from the perspective of variables that need to be updated. For the rotation matrix R, it would cost O (m), where m = d (d - 1)/2 and d is the dimension of data. For the projection matrix P
r
, traversing dimensions takes O (d). For the metric M, calculating the weight of source domain sample costs O (n
c
n
t
n
s
), and computing
In this section, to evaluate the performance of our method, several cross-domain experiments are conducted on two real-world image datasets: Office+Caltech-256 1 and ImageCLEF-DA 2 . We compare our algorithm with competitive metric learning approaches and domain adaptation approaches:
Datasets
Table 1 summarizes the details of these cross-domain datasets.
Summary of datasets
Summary of datasets
We empirically set the ranges of parameters. The tuning of these parameters is independent of the automatic selection of the optimal subspace dimension. The number of iterations T is set to 10. In our objective function, α and β are both balance parameters ranging in [0.1, …, 0.8] with the step size 0.1.
To calculate ρ
i
= f [p (
The similarity in Eq. (5) is defined as
In the process of sample reweighting, we choose the number of neighbors k as
Following existing studies [14, 34], we adopt the classification accuracy to measure the performance:
Results and discussion
The 1NN results of our proposed method and other comparison algorithms on Office+Caltech-256 (800-dim SURF), Office+Caltech-256 (4096-dim DeCAF6) and ImageCLEF-DA are shown in Tables 2, 3 and 4, respectively. The bold in tables indicates the highest accuracy. In addition, the feature visualization results are displayed in Fig. 2, where different categories are represented by distinct colors. Next, we conduct a detailed analysis of the experimental results presented in each chart separately and provide a summary.
The classification accuracy (%) on the Office+Caltech-256 dataset (800-dim SURF)
The classification accuracy (%) on the Office+Caltech-256 dataset (800-dim SURF)
The classification accuracy (%) on the Office+Caltech-256 dataset (4096-dim DeCAF6)
The classification accuracy (%) on the ImageCLEF-DA dataset
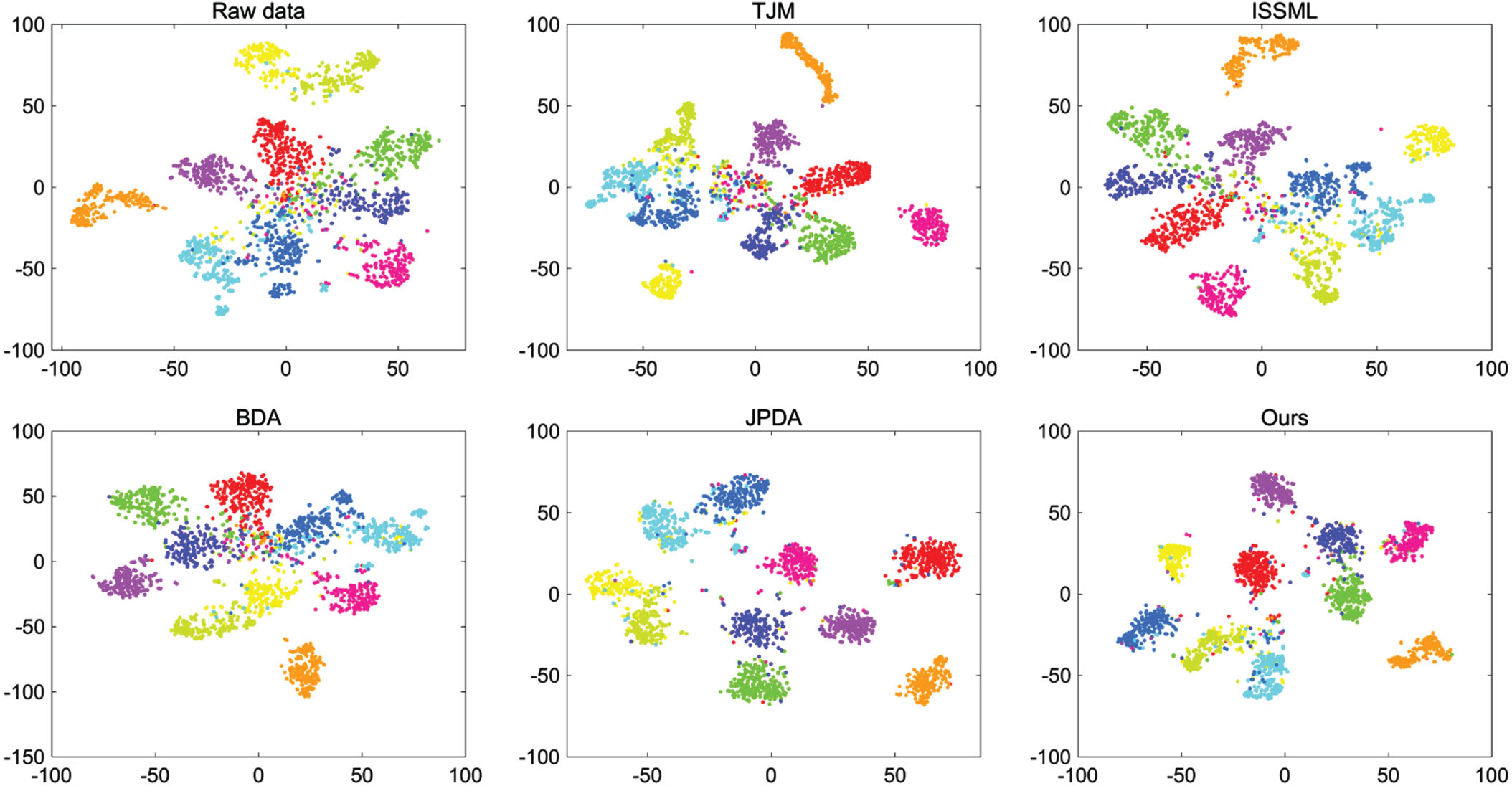
The t-SNE results on the Office+Caltech-256 dataset for the case C→A (DeCAF6).
As presented in Table 2, overall, our method achieves the highest average classification accuracy of 53.49% on Office+Caltech-256 (800-dim SURF), which is 1.58% higher than the best baseline DIA. Individually, DIA does achieve great performance by leveraging the class discriminative information for some tasks. However, it is worth noting that for tasks C→D and C→W, our method outperforms DIA with 9.62% and 5.46% improvement, respectively. Furthermore, our method achieves the best performance in 6 out of 12 tasks (W→D, D→W, D→C, C→D, C→W and A→W). For tasks D→A and W→C, the gaps between our performance and optimal performance are negligible (0.09% and 0.21%, respectively). Therefore, it can be considered that our method performs excellently in 8 out of 12 tasks, demonstrating its effectiveness.
Table 3 displays the classification accuracy on the Office+Caltech-256 dataset (4096-dim DeCAF6). Our method outperforms all baseline methods, achieving an average classification accuracy of 90.27%, which exceeds the second-best methods UTML and JPDA by 1.51%. Also, our method performs best in 7 out of 12 tasks (W→D, D→W, C→D, C→A, A→W, A→D and A→C). Notably, for task D→A, our method achieves an accuracy of 91.23%, closely approaching the optimal performance of 91.44%. Compared with baseline methods, our method shows superior performance in mosttasks.
The classification results on the ImageCLEF-DA dataset are reported in Table 4. It can be seen that the performance of our method is superior to all comparison methods and achieves the best performance in 4 out of 6 tasks. Additionally, our method attains the highest average accuracy of 87.20%, surpassing the best baseline UTML by 1.56%.
Furthermore, to present the performance of our approach more intuitively, we visualize the results for cross-domain task C→A (DeCAF6) of Office+Caltech-256 using the t-SNE [43] tool. As shown in Fig. 2, compared with other approaches, our model exhibits superior intra-class compactness and inter-class separability.
From the above comparative results, we observe that: (1) Compared with all baselines, our method achieves remarkable performance on all datasets and performs best on most tasks. (2) All domain adaptation and metric learning approaches improve the 1NN classification accuracy on all cross-domain tasks, which demonstrates the effectiveness of adopting domain adaptation and metric learning. (3) Comparing Tables 2 and 3, it is clear that classification results are affected by feature types, and all the methods perform better on deep features than on traditional features.
Finally, we discuss the main differences between our method and the other comparison methods: (1) PCA and ISSML are two metric learning approaches which assume the training and testing data follow the same or similar distributions, limiting their performance when facing samples with distribution discrepancies. (2) JDA, BDA, JPDA and DIA are four distribution alignment-based algorithms that reduce the domain shift, but they only perform domain-wise alignment and class-wise alignment. Our method introduces metric learning to address cross-domain tasks from a more meticulous perspective, thus achieving the best performance. (3) Our method outperforms metric learning-based methods CDML, RTML, UTML, MLOT and GMTL, as it selects the optimal subspace dimension automatically and preserves the structure of the data better from the geometric view. (4) Compared with TJM, MTLF and UDA-ALML, our graph-based sample reweighting method is relatively stable.
In this section, we further study the properties of our proposed method from three aspects: ablation experiments, convergence analysis and parameter sensitivity analysis.
Firstly, to show the impact of each module of our model, ablation experiments are performed on 6 cross-domain tasks. For convenience, we number each term of our objective function as follows: 1) marginal distribution discrepancy; 2) conditional distribution discrepancy; 3) manifold dimension reduction; 4) discrimination improvement; 5) structure regularization; 6) class divisibility; 7) sample reweighting. As reported in Table 5, each term improves the overall classification accuracy to some extent, which explains the rationality of our model. Specifically, when manifold dimension reduction and discrimination improvement terms are added, the classification accuracy increases the most, which further demonstrates the effectiveness of introducing the manifold dimension reduction term and the smooth triplet loss.
Ablation experiments for each module on different cross-domain tasks of the Office+Caltech-256 and ImageCLEF-DA datasets. (S) means the feature type is 800-dim SURF, (D) is 4096-dim DeCAF6. 1) marginal distribution discrepancy; 2) conditional distribution discrepancy; 3) manifold dimension reduction; 4) discrimination improvement; 5) structure regularization; 6) class divisibility; 7) sample reweighting
Ablation experiments for each module on different cross-domain tasks of the Office+Caltech-256 and ImageCLEF-DA datasets. (S) means the feature type is 800-dim SURF, (D) is 4096-dim DeCAF6. 1) marginal distribution discrepancy; 2) conditional distribution discrepancy; 3) manifold dimension reduction; 4) discrimination improvement; 5) structure regularization; 6) class divisibility; 7) sample reweighting
Secondly, we validate the convergence of the proposed algorithm by testing the classification error rates of cross-domain tasks: A→W (DeCAF6), D→A (SURF) and C→I. As shown in Fig. 3, our algorithm converges after 10 iterations and the classification error rates reach a stable level.
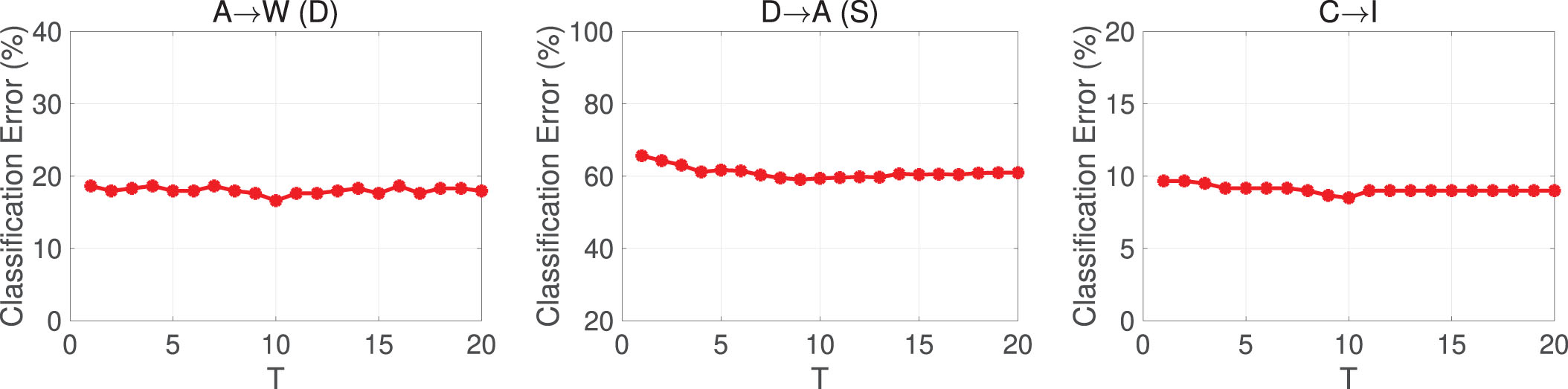
The variation of classification error along with the iteration of the algorithm for the case A→W of Office+Caltech-256 (DeCAF6), D→A (SURF) and C→I of ImageCLEF-DA.
There are several parameters in our algorithm, i.e., balance parameters α and β in the final objective function, v in calculating the similarity between samples, the bandwidth h, and η in calculating the weight of the source domain sample. To explore the influences of these parameters, we analyze the parameter sensitivity of our method on different types of datasets. Without loss of generality, we choose one task from each of the three datasets as examples, which are A→D of Office+Caltech-256 (DeCAF6), D→W of Office+Caltech-256 (SURF) and C→I of ImageCLEF-DA, respectively.
Fig. 4 shows the impact of balance parameters α and β ranging in [0.1, …, 0.8] with the step size 0.1. Note that we have α + β < 1 for α and β. In our model, α is the balance parameter of the distribution adaptation and discrimination improvement terms, and β is the balance parameter of the structure preservation term. If the value of α is too small, our model will not take into account the distribution adaptation and discrimination improvement terms. If the value of β is too large, it will cause the model to pay too much attention to the structure preservation term. Therefore, we recommend to select α ∈ [0.3, 0.8] and β ∈ [0.1, 0.6].
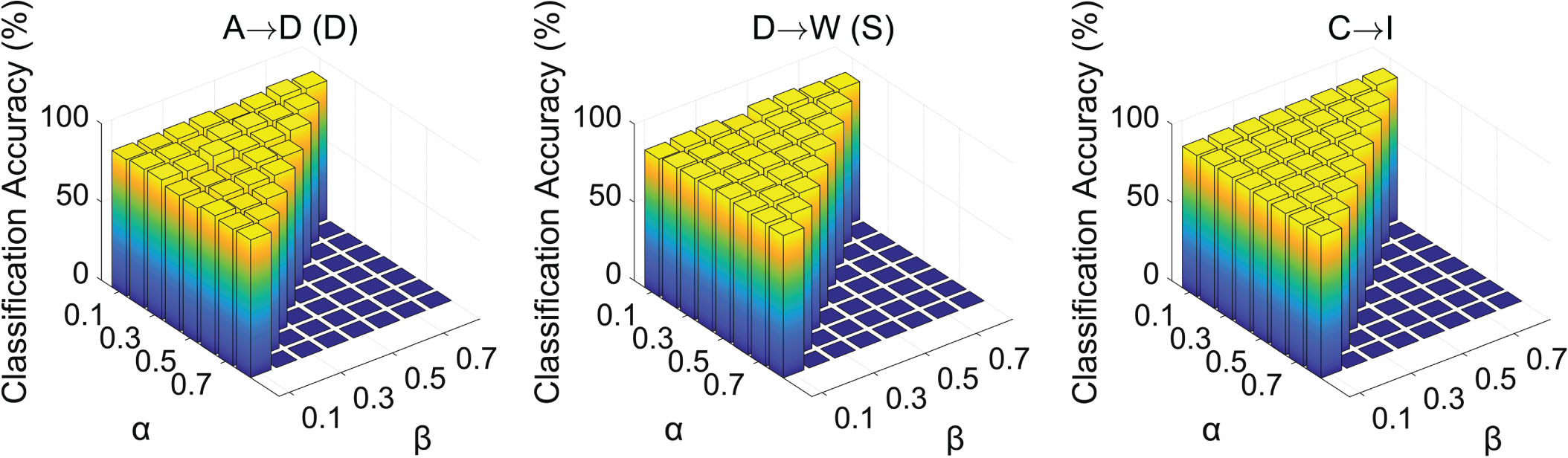
The classification accuracy with varying α and β.
Fig. 5(a) presents the performance of our method under varying values of v. Obviously, v with too-high values will destroy the model performance, and hence v ∈ [1, 5] is the best choice. Fig. 5(b) reveals how the bandwidth h influences the model performance. As shown in Fig. 5(b), the model performance is relatively stable except for task A→D (D). Considering all tasks, we suggest to choose h ∈ [1, 1000] to achieve high performance. In the process of sample reweighting, η controls the number of neighbors when constructing the subgraph. Fig. 5(c) illustrates the effect of the value of η on the model performance. It is clear that the model performs well when η ∈ [0.1, 0.4].
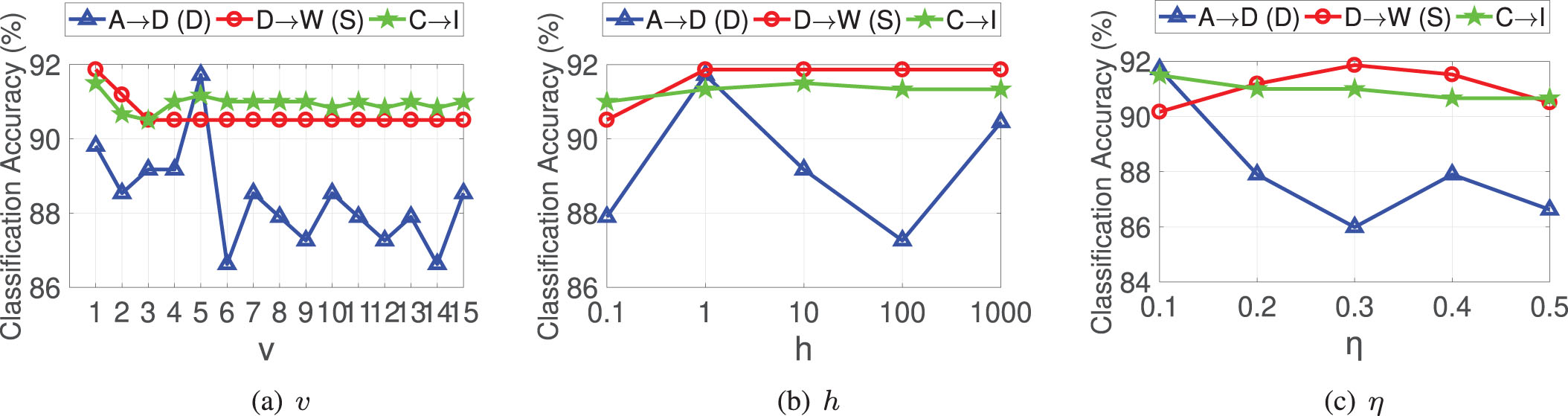
The classification accuracy with varying v, h and η, respectively.
In this paper, we propose a coarse-to-fine domain adaptation method based on metric learning. First, to solve the problem that the subspace dimension needs to be set in advance, we automatically select the optimal subspace dimension by using a structure-preserving algorithm on the Grassmannian manifold. Moreover, the separability of data is enhanced by maximizing the MMD distance between different classes. Furthermore, for a finer alignment, we improve the discrimination and preserve the geometry of data by introducing the smooth triplet loss and structure regularization. Finally, a graph-based sample reweighting method is employed to identify the importance of each source domain sample. Extensive experimental results validate the superiority of our approach.
The advanced utilization of geometric structure and sample-wise information in our method brings about excellent performance in alignment. Further, our novel ideas have the potential to transfer into the realm of deep learning. Possessed by the powerful learning ability of deep learning, massive input data issues can be effectively coped with. Therefore, as a future topic, integrating our model with deep learning holds promise and merits further investigation.
Footnotes
Acknowledgements
This work was supported in part by the National Key Research and Development Program of China under Grant 2021ZD0140300, the National Natural Science Foundation of China under Grants 12301351, 62225308 and 11771276, the Shanghai Sailing Program, Shanghai Association for Science and Technology under Grant 21YF1413500.