
Abstract
This study proposes a method to help people with different degrees of hearing impairment to better integrate into society and perform more convenient human-to-human and human-to-robot sign language interaction through computer vision. Traditional sign language recognition methods make it challenging to get good results on scenes with backgrounds close to skin color, background clutter, and partial occlusion. In order to realize faster real-time display, by comparing standard single-target recognition algorithms, we choose the best effect YOLOv8 model, and based on this, we propose a lighter and more accurate SLR-YOLO network model that improves YOLOv8. Firstly, the SPPF module is replaced with RFB module in the backbone network to enhance the feature extraction capability of the network; secondly, in the neck, BiFPN is used to enhance the feature fusion of the network, and the Ghost module is added to make the network lighter; lastly, in order to introduce partial masking during the training process and to improve the data generalization capability, Mixup, Random Erasing and Cutout three data enhancement methods are compared, and finally the Cutout method is selected. The accuracy of the improved SLR-YOLO model on the validation sets of the American Sign Language Letters Dataset and Bengali Sign Language Alphabet Dataset is 90.6% and 98.5%, respectively. Compared with the performance of the original YOLOv8, the accuracy of both is improved by 1.3 percentage points, the amount of parameters is reduced by 11.31%, and FLOPs are reduced by 11.58%.
Introduction
According to the latest report of the World Health Organization [1] statistics, hearing impairment currently affects 1.59 billion people worldwide, i.e., 20.3% of the total global population, of which 430 million people (5.5% of the global population) have moderate or severe hearing impairment. Hearing-impaired people are expected to reach nearly 2.5 billion by 2050 [2]. In the face of such a severe problem, if it is not addressed and solved promptly, it will substantially impact individuals, families, and society [3].
Sign language, as an essential tool for communication among deaf people [4], is also simultaneously promoted to hearing-impaired people and their family and friends, thus promoting better integration of hearing-impaired people into their social life [5], which can be applied in the fields of assistive devices for people with disabilities, medical and health care, and home service robots. Sign language recognition is a multi-type visual language composed of manual components (hand shape, hand/arm movements, and posture) and non-manual components (facial expressions, head movements, mouth, shoulder, and torso movements) [6–8]. Recognition of non-manual components varies greatly depending on individuals, cultures, and contexts, so this study focuses on manual components. Moreover, because the current form of sign language expression fails to be completely unified and has a particular grammatical system, in special education, the same way as standard teaching is generally chosen to recognize words by learning letters, which ultimately achieves the effect of sign language learning [9, 10].
To improve the accuracy and operation speed of sign language recognition, C. T. Nhu et al. propose a sign language recognition system based on ionic liquid strain sensors, which detect the relative positions of the fingers by wearing gloves with strain sensors and then transmit the signals from the sensors to the data acquisition and processing circuitry system and finally decodes them into letters [11]. K. E. Aziz et al. choose the traditional machine learning method for sign language recognition, which employs a dynamic color-based Skin threshold segmentation based on dynamic color and mean shift segmentation of the original image are combined to obtain the skin region and attempts to recognize the hand by placing points at regular intervals along the perimeter of the hand blob [12]. However, traditional machine learning-based sign language recognition methods do not have high recognition accuracy when it comes to complex sign language actions and complex environments, as well as larger datasets, and could be slower. Along with developing deep learning, M. A. Hossen et al. propose a new method for recognizing Bengali sign language based on a Deep Convolutional Neural Network (DCNN), which mainly uses the features learned from the pre-trained network and fine-tunes the top layer of the network [13]. A. M. Rafi et al. proposed d a VGG19-based convolutional neural network to recognize the BdSL alphabet with 38 categories and 12,581 gestures [14]. N. Pereira developed a sign language recognition system based on the YOLOX variant and proposed PereiraASLNet, which uses customized classes for the letters a-z and the Pascal VOC XML American Sign Language dataset developed by Roboflow for training [15].
In this paper, the SLR-YOLO algorithm for improving YOLOv8 is proposed by replacing the SPPF module of the backbone network with the RFB module, adopting the BiFPN bidirectional feature pyramid at the neck of the network, along with the Ghost module, and choosing the Cutout method for data enhancement. The final accuracy of the improved SLR-YOLO model on the validation sets of the American Sign Language Letters Dataset and Bengali Sign Language Alphabet Dataset is 90.6% and 98.5%, respectively. Compared with the performance of the original YOLOv8, both datasets have a 1.3 percentage point improvement in accuracy, an 11.31% reduction in the number of parameters, and an 11.58% reduction in FLOPs. The main contributions of this study are as follows: In the backbone part, an RFB module is added to enhance the feature extraction capability of the network. In the neck part, the BiFPN module is used to enhance the feature fusion, fusing the feature high-level semantic information and the underlying location information; at the same time, the Ghost module is added to lighten the network and reduce the model computation to improve the operation speed. To introduce partial occlusion in the training process and improve the data generalization ability, Mixup, Random Erasing, and Cutout are added to compare the three data enhancement methods and select the optimal solution. Real-time recognition of the content of the changing sign language, which is conducive to later application development and deployment.
The organization of the paper is as follows: section 2 introduces the related work, and section 3 describes our proposed model SLR-YOLO in detail. Section 4 performs comparative experiments and ablation studies to verify the model’s validity. Finally, the conclusion is presented in Section 5.
Related works
Currently, the methods of sign language recognition can be divided into contact recognition methods, which mainly use sensors, and non-contact recognition methods, which mainly use gyroscopes, Kinect, and Leap somatosensory interaction devices, cameras, and depth cameras. Contact recognition methods, mainly through the device, obtain the signal amplitude, frequency, or peak number of features and then complete the corresponding action recognition. The idea of using data glove sensors to interact with objects has existed since 1999 [16]. There have been various breakthrough advances in the decade or so since then. Literature [17] used the DGMM dynamic Gaussian mixture model to recognize 274 Chinese sign language dictionary entries based on data gloves. In addition, data gloves are also used in the development of intelligent medical and interactive body sensing domains. Literature [18] has made a tremendous breakthrough in medicine by combining data gloves with medical simulation in terms of matching accuracy between real and virtual hands. By constructing a multi-channel data transmission based on hand posture and emotion recognition, the data glove reads the subject’s physiological signals [19]. It directly controls the gestures of the virtual hand. Using contact methods, such as data gloves, reduces the computational cost by collecting less data redundancy. However, it is costly and needs to be worn all the time during use, which makes the user experience poor.
Non-contact recognition methods can also be subdivided into gesture estimation methods using somatosensory interaction devices and visual methods using cameras or depth cameras. ANSARI, Z.A et al. and Raghuveera, T et al., which capture sign language through Microsoft Kinect and are used for the recognition of different alphabets, can achieve nearly 100% accuracy for easily distinguishable sign languages [20, 21]. However, the Kinect depth map still suffers from low resolution and needs further optimization. Leap, which is also a somatosensory interaction device, also works well [22]. J. Jenkins and S. Rashad developed a sign language recognition prototype using a Leap Motion Controller (LMC) and used Support Vector Machines (SVMs) and Deep Neural Networks (DNNs) to recognize the 26 letters of the alphabet [23]. Additionally, the data generated by the Leap Motion device allows for sign language recognition to be accomplished in virtual reality (VR) environments, where Vaitkevičius, A et al. used a generated virtual 3D (3D) hand model and a Hidden Markov Classification (HMC) algorithm to construct a system that learns hand gestures [24]. However, Leap Motion devices have been discontinued in 2020, and there is a relatively limited supply of new devices.
In order to reduce the price of data acquisition equipment, machine learning, and deep learning methods are pushed, which can be used to capture images using only a camera. Zhu et al. [25] used a gesture recognition algorithm based on a statistical model derived from the HMM (HHMM) with good recognition results. However, the Hidden Markov Model (HMM) module only applies to strongly displaced activities. Cai Linqin et al. proposed an improved dynamic temporal regularization (IDTW) algorithm for recognizing dynamic gestures, which utilizes weighted distances and restricted search paths to avoid the huge computational effort of the traditional DTW algorithm and improve the recognition performance [26]. In order to reduce the cost and complexity of communication between deaf people and others and improve the recognition’s fault tolerance range and accuracy, the deep learning method is chosen to complete the whole sign language recognition process. In the field of deep learning gesture recognition, there have been more studies. Wu X et al. [27] proposed a gesture recognition algorithm based on Faster R-CNN as a two-stage detection model based on Fast R-CNN speed can be improved. However, the use of selective search is still relatively time-consuming. Deep learning-based Convolutional Neural Network (CNN) handles robust modeling of static symbols in a sign language recognition context [28]. After this, Wu et al. [27] proposed a novel recognition algorithm based on a dual-channel convolutional neural network (DC-CNN), choosing gesture image and hand edge image as the two input channels of the CNN, which improves the recognition rate of gestures and enhances the generalization ability of the CNN, but the model’s ability to adapt to complex environments is yet to be improved. D. R. Kothadiya et al. proposed the Transformer encoder as a tool for sign language recognition. A multi-head attentional coding framework can achieve accuracy with a few training layers, but it is not as good as CNNs for local information acquisition [29]. One-stage detection models are faster compared to two-stage models. A. Sayeed et al. used the improved InceptionV3 architecture to recognize the Bengali symbol alphabet corresponding to sign language. The trained model achieved an overall accuracy of 94.41% [30]. Liao S et al. [31] proposed a Mobilenets-SSD network and added self-obscuring and object-obscuring gestures to the dataset to create a more complex environment in gesture recognition. With the promotion of YOLO, many researchers started to use it and achieved good results. Buttar, A.M et al. [32] used YOLOv6 to create a sign language detector for static gestures, which is very helpful for sign language users. Zhang L et al. [33] developed and optimized an improved YOLOV3 model for thyroid nodule detection in b-mode and Doppler ultrasound images, which can effectively detect thyroid nodules with an average precision of 94.53%, and the average recall is 95.00%. Juan, Wan converted CSI data of gesture action region into gray-value images and, at the same time, used the YOLOv3 algorithm to train and recognize the gray-value images, and then verified the customized dynamic gestures by recognizing the confusion matrix and obtained a better recognition effect [34]; Thai Li et al. [35], proposed an improved YOLOv5 s train driver gesture recognition algorithm. By adding the CBAM module and BiFPN module and improving the K-means clustering algorithm, the prediction frame accuracy is better, which shows that the original performance of the model can be improved by altering the model module. Wei Xiaoyu et al. [36] proposed to use the YOLOv3 model for improved gesture recognition and the ReXNet model for hand key point detection, fused with the Ghost Module module to lighten the network and achieve real-time detection effect. Inspired by the above research, we propose a network called SLR-YOLO to accomplish real-time recognition of sign languages.
Methodology
YOLOv8 network architecture
In order to ensure that the recognition selected algorithm has a better match with the gesture database and can realize the effect of real-time detection, the single target detection algorithm is selected. It is also known from the research results of [5] that the recognition effect of the YOLO series is better than SSD and Faster RCNN, so we consider comparing the more classic models of YOLO series algorithms: YOLOv5, YOLOv6, YOLOv7, and YOLOv8 and choose the model with the highest accuracy and the fastest speed as the basis, and then solve the occlusion of the gesture recognition based on this, large number of model parameters and other problems. In this part of the training and validation process, the American Sign Language Letters Dataset and the maximum model are used for pre-training, training 100 epochs, and the batch is 8. The final result parameters are shown in Table 1.
Comparison of YOLO series algorithms
Comparison of YOLO series algorithms
As can be seen from Table 1, the accuracy of the YOLOv5, YOLOv6, and YOLOv7 models is only 0.61–0.96 of that of YOLOv8, while the number of parameters of YOLOv8 is only slightly larger than that of YOLOv7 and smaller than that of YOLOv6. Therefore, the YOLOv8 model is chosen to be improved in this study. The main direction of improvement is to further improve the gesture recognition accuracy and, at the same time, to lighten the network to ensure that the running speed is not too low.
YOLOv8 is a single target detection algorithm proposed by Ultralytics. Since the YOLOv8 paper is not publicly available, its specific structure will be presented, as shown in Fig. 1.
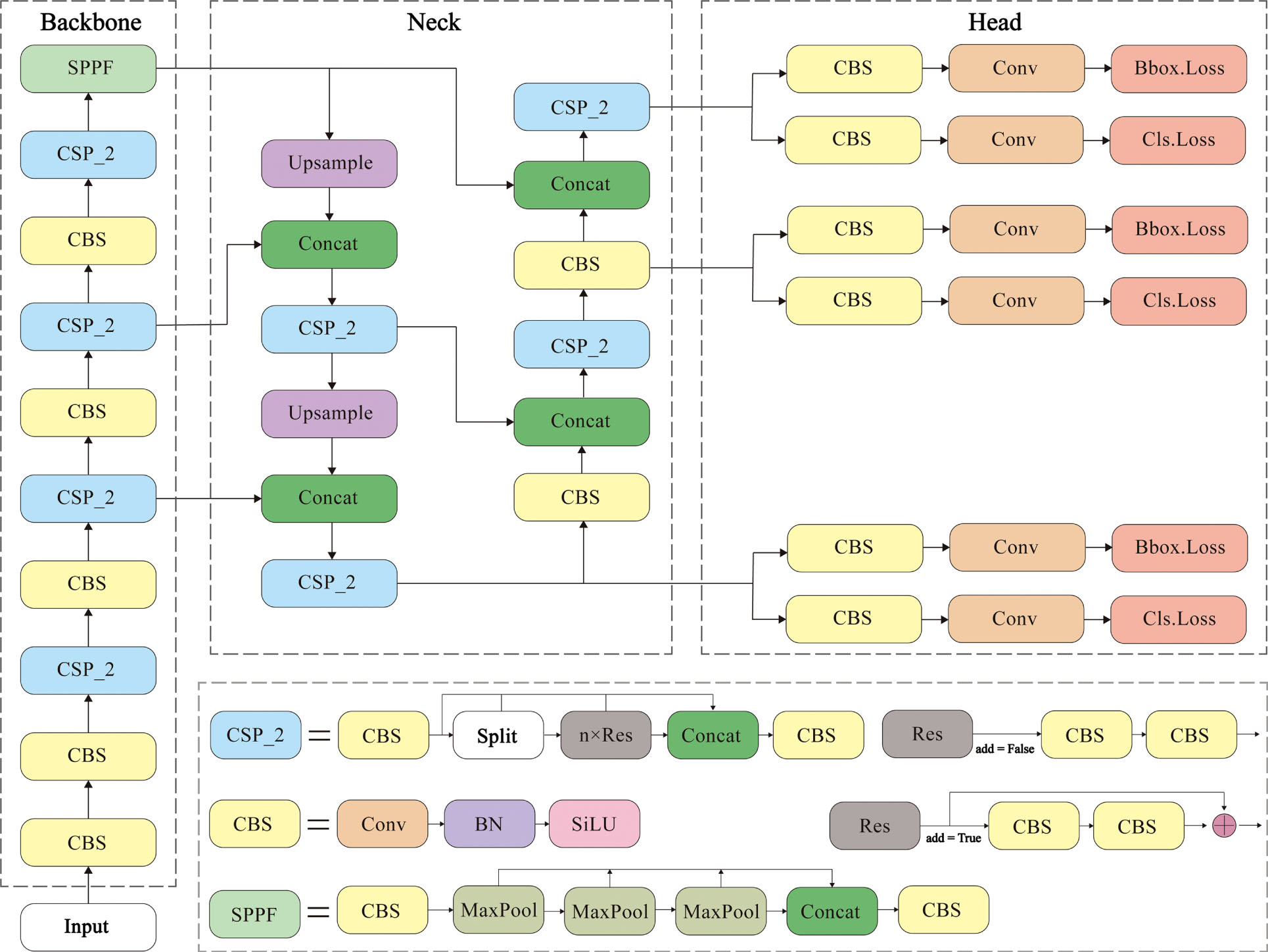
Structure of the original YOLOv8.
The algorithm is mainly improved based on YOLOv5. In the backbone part, the newly proposed C2f module for lightweight feature extraction replaces the C3 module in YOLOv5, and the SPPF module in YOLOv5 is retained. In the neck part, the PAN-FPN idea is invoked to remove the convolution module in the upsampling stage. In contrast, the C2f module replaces the C3 module with a richer gradient flow, and the performance of the model is improved by pairing different ratios of the model with different numbers of channels. In the head part, the Decoupled-Head structure separates the classification head from the detection head; the previous Anchor-Base structure is discarded, and the Anchor-Free structure is used to reduce the time consumption and computation. In the loss computation, the VFL Loss is used for the classification loss, and the DFL Loss and CIOU Loss are discarded from the previous IOU matching allocation and adopt the TaskAlignedAssigner positive sample allocation strategy. In the data enhancement part of training, the Mosiac operation proposed by YOLOX is followed, which is turned off in the last ten epochs to improve the model accuracy.
To ensure that the letters corresponding to each sign language can still be accurately recognized in a cluttered environment and with partial occlusion, this paper proposes an SLR-YOLO model.
Data Augmentation
In order to prevent the occurrence of the overfitting phenomenon, data augmentation is used to improve the model-fitting ability. Mixup [40], Cutout [41], and Random Erasing [42] improve the model generalization ability while simulating partial occlusion and completing the recognition by focusing on the other parts. Mixup is to generate a new image by selecting two images in a batch and mixing them in a particular proportion; Cutout is to randomly overwrite the input sign language image with a fixed size; Random Erasing, based on Cutout, can generate rectangles with random proportions, and the filling is chosen to be a random number or pixel mean, which can simulate some more complex occlusion problems and effectively expand the number of datasets.
Figure 2 shows a sample of the data enhancement processing. (a) is an original image in American Sign Language LettersDataset. (b) results from Mixup processing. (c) is the result of processing using Cutout. (d) is the result of processing using Random Erasing.

Sample of the data enhancement process.
Feature extraction is the most crucial step in the training process and is the key to improving detection performance. In the training process, if it is superimposed, although it can improve the accuracy, it will increase the parameters and computational cost. The original YOLOv8 model uses the SPPF module, a proposed structure with less computation based on the SPP module. To improve the discriminability and robustness of the features and create a more efficient detection model, we chose the RFB module, which simulates the sensory field mechanism of human vision and is more powerful and faster.
RFB [43] is proposed by combining the idea of using different sizes of convolutional kernels to obtain the receptive field in Inception [44] with the idea of choosing different numbers of dilations in ASPP, which is a combination of multi-branching and expanding convolutional layers with different kernels. In the shallow feature map with a smaller receptive field, the detection of sign language targets is improved. In the deep feature map, the number of computational parameters is reduced. In contrast, the feature mapping relationship between different layers is increased to retain the relatively complete semantic information, improving the accuracy of the target inspection.
The specific module explanation diagram is shown in Fig. 3, in which the circles of different sizes represent different sizes of convolution kernels, the boxes of different distributions represent different dilated convolution layers, and the rate represents the parameters of the dilated convolution layers through which the two parts constitute a multi-branch structure. Different feature maps are obtained in each branch. Then, the output of the different feature maps obtained is concatenated to complete the fusion of different features.
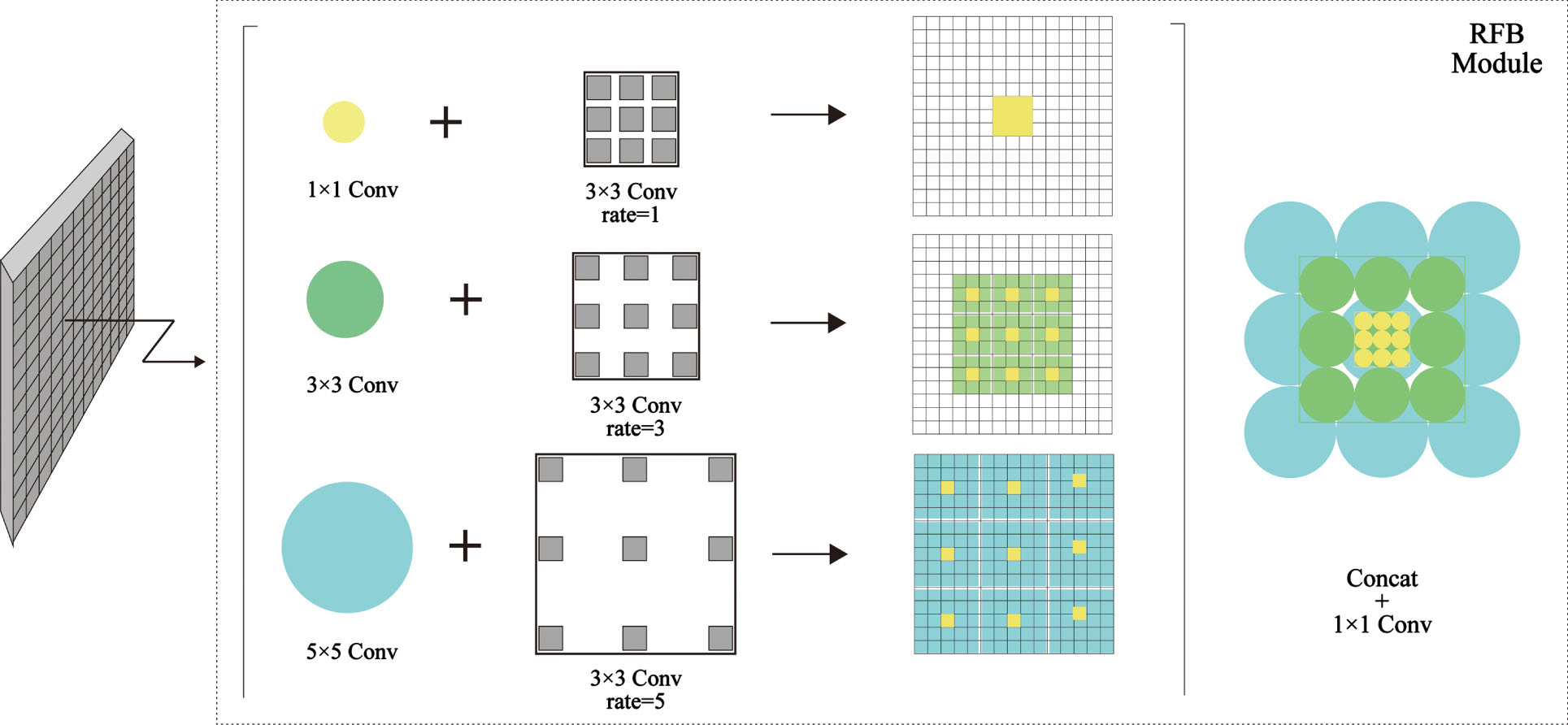
Explanatory diagram of the RFB module [43].
After the image has gone through backbone feature extraction, it enters the neck of the model for detection and then output. In the original YOLOv8 model, PANet is used as the neck network, which adds a bottom-up pathway based on FPN, which can realize the fusion of feature high-level semantic information and bottom-layer positional information and shorten the information path between the bottom-layer and the top-layer features. However, it also increases the amount of model computation. In order to further improve it and to fuse more features without increasing the cost, a simple and efficient weighted feature fusion mechanism, BiFPN [45] module, is introduced. The network structure is shown in Fig. 4, where C3, C4, and C5 are the inputs, and P3, P4, and P5 are the outputs.
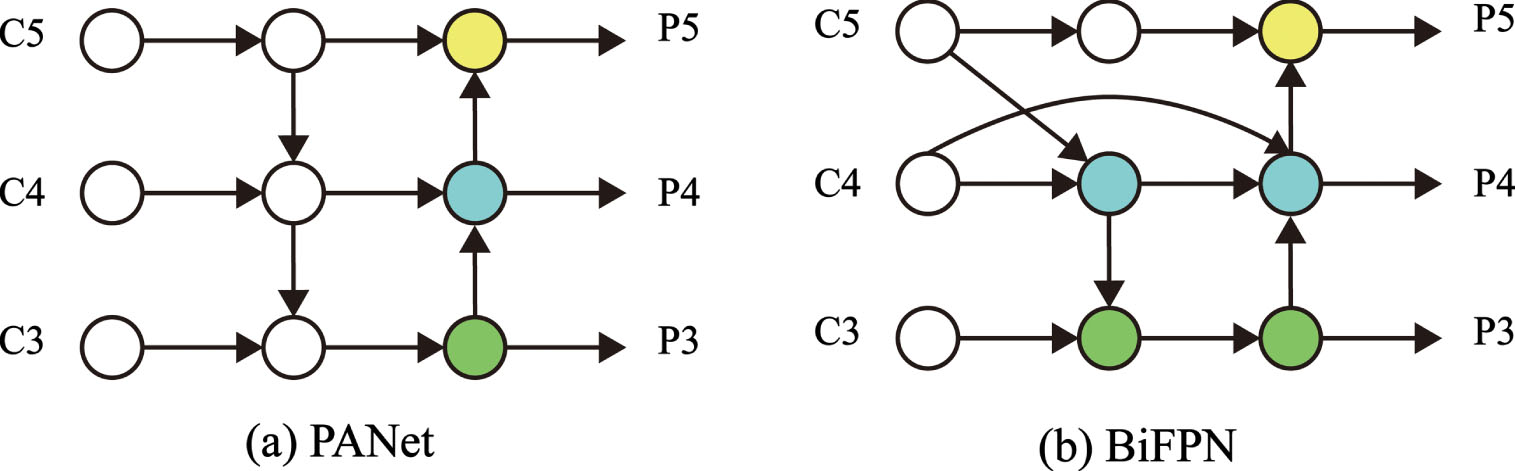
BiFPN module [45].
BiFPN module treats a pair of top-down, bottom-up paths as a feature layer and can be stacked many times to get more high-level feature fusion. Before this, when fusing different resolution features, most treated the input features equally or adjusted them to the exact resolution and then added them together. In the BiFPN structure, considering the different resolutions of different features, the contribution of feature fusion needs to be adjusted accordingly, adding extra weight to each input, and the network then learns to judge the importance of each input feature by itself. Based on this idea, three weighted feature fusion methods are tried:
Unbounded fusion: computed as in Equation (1), as a more straightforward method, a learnable weight can be added directly, but the scalar weights are unbounded and may cause training instability.
Softmax-based fusion: calculated as in Equation (2), Softmax is applied to each weight so that the weights are normalized, and the range is controlled to between [0,1] and training is stable, but the extra Softmax slows down the hardware GPU.
Fast normalized fusion: the formula is Equation (3), scales the range to between [0,1] for fast training stability and is used here.
While focusing on the accuracy of the model, the computation speed and the number of parameters are also important considerations. The Ghost module [46] can generate many Ghost feature mappings that can fully reveal the information of the intrinsic features from a series of low-cost linear change operations based on a set of intrinsic feature mappings. Thus, some convolution modules in the original YOLOv8 model Backbone are replaced with Ghost modules.
Convolutional neural networks have a large amount of redundancy in the computation of intermediate feature maps, and the arbitrary convolutional layer operations used to generate n-feature maps when no processing is done are represented by Equation (4):
Where
The optimized reduced FLOPs and parameter generation redundant feature maps are calculated using Equation (5), with m original feature maps generated using one convolution (m ⩽ n):
Where
To further obtain the required n feature maps, a series of low-cost linear operations are applied to each of the original features in Y′ to generate s phantom feature maps, which are calculated as in Equation (6):
Where y
ij
is the jth phantom feature map generated, is the jth linear operation, and is the ith original feature map in Y′ and can have one or more phantom feature maps
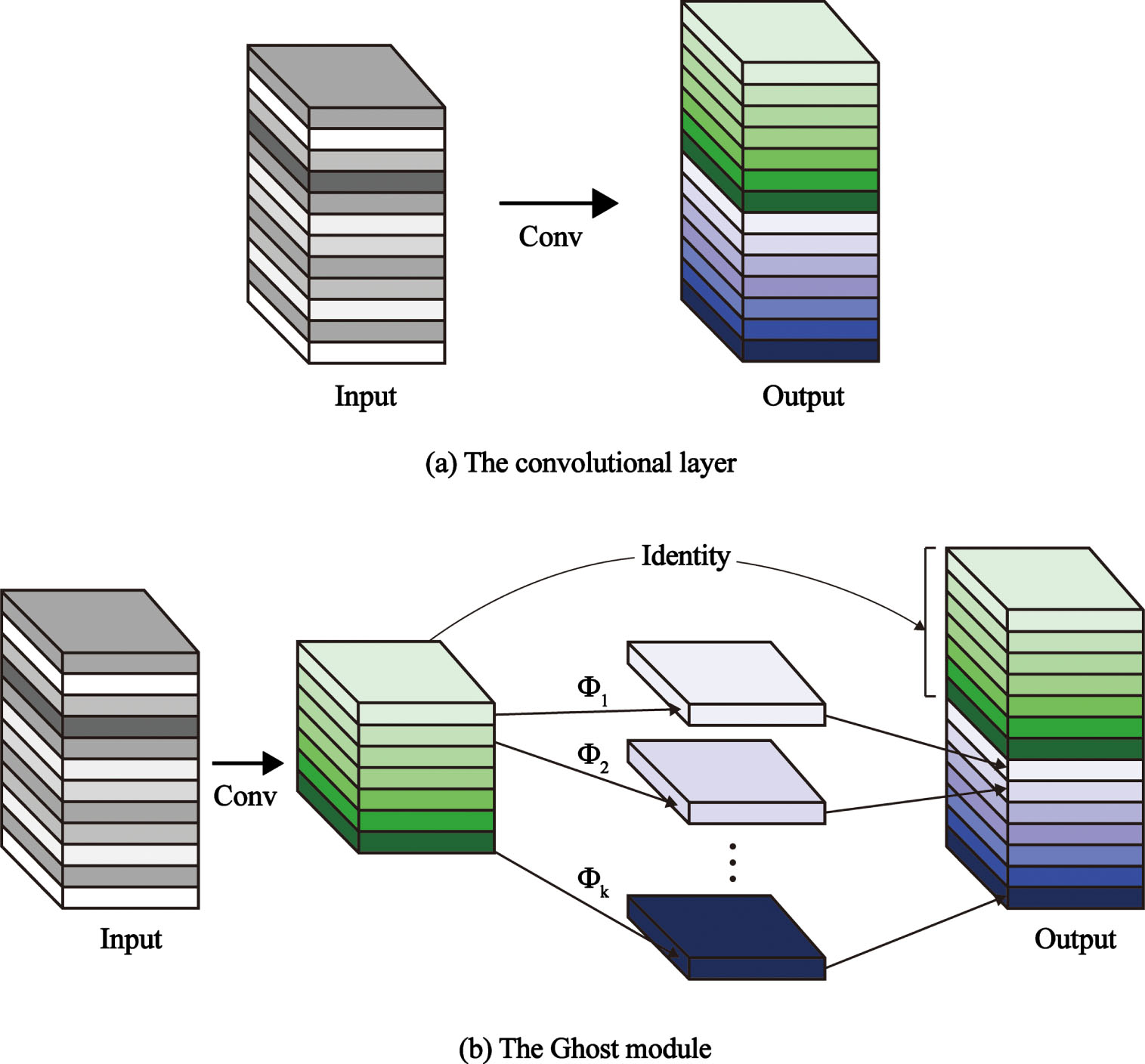
The Ghost module [46].
The improved SLR-YOLO network replaces the SPPF module at layer 9 of YOLOv8 with the RFB module and the CSP_2 module at layers 12, 15, 18, and 21 with the C3Ghost. It adds BiFPNs at the four concats of the neck, where BiFPN_Concat3 at layer 17 indicates that three features are fused, and similarly, BiFPN_Concat2 indicates fusion of two places, and the specific overall structure of SLR-YOLO is shown in Fig. 6.
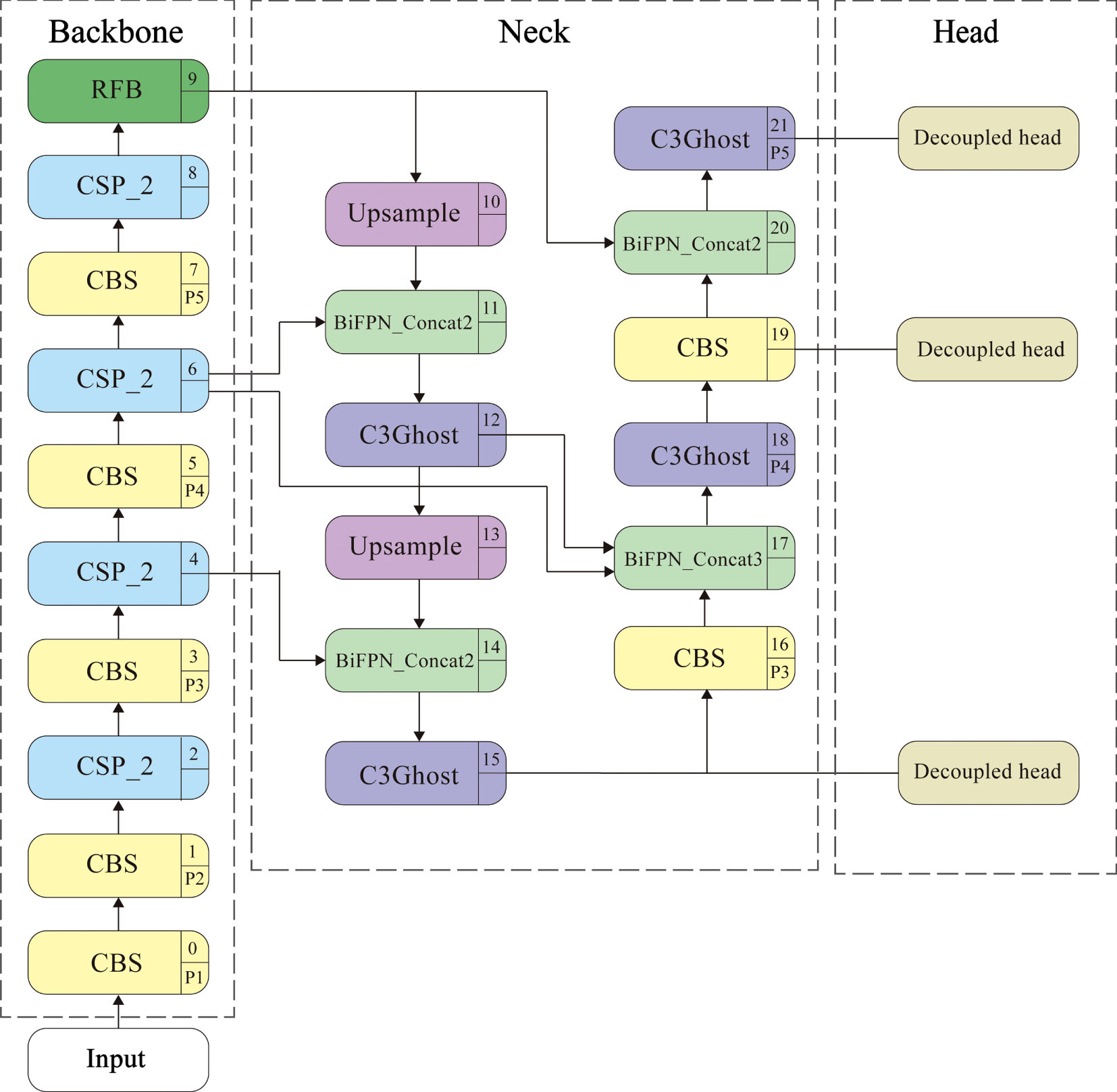
The GR-YOLO model.
Datasets
This paper uses the open source datasets American Sign Language Letters Dataset (ASLL) [47] and Bengali Sign Language Alphabet Dataset (BdSL) [48] are used for training. Among them, the American Sign Language Dataset contains 26 English alphabets with a total of 1728 images, each of which has a size of 608×608, with images expanded by oversampling and data warping. The ratio of the training set to the test set is set to 9:1 during training. Thus, 1555 images are used for training and 173 for testing.
There are 38 different alphabetic symbols in Bengali Sign Language Alphabet Dataset for vowels and 27 for consonants, with 320 samples for each category, totaling 12,160. The samples were collected from 42 hearing impaired and 298 general population, aged 12–30, with male to female ratio of 1.35, using the “Bangladesh Sign Language Dictionary” published by the National Center for Special Education (NCSE) under the Ministry of Social Welfare (MoSW). The collection process was done in collaboration with the Bangladesh National Federation of the Deaf (BNFD) by selecting a set of certified symbols for all the alphabets and supervised by a certified instructor, Ms. Ferroza Begum Rani.
Experimental setup
The whole process is run in the deep learning PyTorch framework. The experimental hardware environment is AMD Ryzen 9 5900HX with Radeon Graphics (processor), NVIDIA GeForce RTX 3080 Laptop GPU, 32 GB of RAM, and the software environment is Windows 11 operating system. The software environment is Windows 11 operating system, pytorch version 1.12.0, CUDA 11.6, compiled language python3.8. Parameter training is performed using SGD optimizer, bathsize is set to 8, the training period is 100, the category confidence threshold of the target is 0.5, the weight decay coefficient is 0.0005, and the initial learning rate is 0.01. Linear learning rate with One Cycle learning rate adjustment is used.
Performance evaluation
Precision and Recall are the primary indexes to objectively evaluate the model’s recognition effect before and after the experiment. Precision (P) is the proportion of correctly predicted targets among all the targets predicted by the model, and Recall (R) is the proportion of correctly predicted targets among all the actual values. Then, these two indexes are integrated to compute the mean average precision (mAP) as the final evaluation indexes, and the specific computational equations are presented in Equation (7), Equations (8) and (9).
True Positives (TP) is the number of correct gesture image recognition; False Positive (FP) is the number of incorrect gesture image recognition; and False Negatives (FN) denotes the number of missed images in gesture image recognition. P and R denote the accuracy and recall throughout the evaluation process. In addition, the number of detected frames per second (FPS) is used as a speed evaluation index, making it possible to analyze and understand the model from more dimensional perspectives during the evaluation process.
Data Processing
To enhance the generalization ability of the algorithm and, at the same time, to be able to generate close to partial occlusion, the methods of Mixup, Cutout, and Random Erasing are chosen so that the model can achieve correct recognition by learning other partial information. These three methods are added and combined to add in the model respectively to carry out an experimental effect comparison, and its specific experimental results are shown in Table 2.
The table only shows the effect of the American Sign Language Letters Dataset on the three data enhancement methods used alone and in conjunction with each other, where the value after the method indicates the set probability of occurrence. Overall, the data can be kept in a small range for fluctuation, and the mAP value is more stable, so adding the data enhancement elements is considered after the other improvement methods have been determined. Finally, the final enhancement method is selected based on the experimental results after adding the enhancement elements.
Comparison of combinations of data enhancement methods
Comparison of combinations of data enhancement methods
Module comparison of fused feature models
In order to ensure the global nature of information utilization, the feeling field needs to be improved to extract the high-level semantics, and the effect is compared by incorporating the modules of SPPF, SimSPPF, ASPP, and RFB into the backbone of the model. The experimental results are shown in Table 3. YOLOv8_SPPF represents the original model structure of YOLOv8, YOLOv8_SimSPP, YOLOv8_ASPP, and YOLOv8_RFB represents the situation after improving the SPPF into different modules, respectively, and the P, R, and mAP values are used to judge whether the improvement is necessary.
By analyzing the data in Table 3, it can be seen that the two datasets perform similarly in this section. The P and R assessment indexes of YOLOv8_ASPP are decreasing to different degrees relative to YOLOv8_SPPF, and the mAP value is the best. However, it has a large amount of data, the value of GFLOPs reaches 31.0, and the number of model parameters reaches 14,417,858, which makes the computation speed too slow to consider. YOLOv8_SimSPPF, as one of the innovations of YOLOv6, changed the SPPF activation function to ReLU, which improved the R value in both datasets, but the mAP value decreased in both datasets. Only YOLOv8_RFB improved the mAP and strengthened the feature extraction ability of the network by simulating the sensory field of human vision, and the P value was also increased.
Comparison of PANet and BiFPN test results
Comparison of PANet and BiFPN test results
To address the issue of low sign language recognition rate caused by factors such as skin color similar to the background color and background clutter, the neck of the network of the YOLOv8 model was improved, comparing the evaluation indexes of the feature fusion network PANet and BiFPN, and concluding that the advantages of replacing the PANet with the BIFPN module outweigh the disadvantages. As can be seen from Table 4, the BiFPN network adds bidirectional cross-scale connections to PANet. Compared with PANet without any changes, the number of model parameters and computational FLOPs only grows slightly. However, the P-value grows by 1.5 percentage points and 0.7 percentage points in the two datasets, and there is also a slight increase in the mAP. Thus, BiFPN can fuse multiple features and improve the network at a lower cost.
For the improved network’s speed of operation, lightweight is accomplished using the Ghost module, which generates more feature maps with fewer parameters. It is also convenient if subsequent deployment is required. In order to determine that the addition of Ghost in different locations will have different effects, this study puts the Ghost module in different locations of the network model for feature fusion. The final experimental results are shown in Table 5, where YOLOv8_RBC represents the replacement of RFB, BiFPN, and the addition of the Cutout occurring with a probability of 0.2 on top of YOLOv8. Gbackbone is the addition of the Ghost module to the trunk part, and Gneck is the addition of the Ghost module to the neck part.
From Table 5, it can be found that when switching into the Ghost module only in the backbone network and when switching to the Ghost module in both backbone and neck networks, the model data volume and FLOPs value decrease, but the mAP value also decreases, which cannot achieve the effect of model detection. In contrast, when only the Ghost module is added in the neck part, the mAP of the ASLL dataset is 90.6%, which is still improved compared with no Ghost module, increasing by 0.4 percentage points. The mAP of the BdSL dataset is 98.5%, the same as when no Ghost module is added. In both datasets, the model parameters are reduced by 16.70% compared to YOLOv8_RBC, and the FLOPs values are also reduced by 13.70%. Ultimately, fusing only the Ghost module into the neck network of YOLOv8_RBC can minimize the model parameters at the lowest cost while ensuring that the recognition results are maintained or even better.
Test results for different regions of the Ghost module embedding model
Test results for different regions of the Ghost module embedding model
To evaluate the effectiveness of our proposed model, we compare our method with several prevailing methods. The results of Flexible Ionic Liquid Strain Sensors and C. T. Nhu’s method are from paper [11]. The results for both YOLOX-nano and YOLOX-tiny are from [15], and the results for improved YOLOv5 are from [5], and in this article the SSD and Faster RCNN methods are also compared, and neither of them are as good as improved YOLOv5.
According to Table 6, the model we provided achieves high accuracy in contactless recognition by comparing the other methods. Although it is 0.1% lower than YOLOX-tiny, this is the best on Inference Time, which is 3.4, so our method is still competitive. The results show the model has a solid, comprehensive ability in real-time sign language recognition.
Results of state-of-the-art methods on ASLL
Results of state-of-the-art methods on ASLL
To further determine the validity of the SLR-YOLO model, experiments were conducted on BdSL, and the results of the tests are shown in Table 7. The results of Skin Calibration and Geometric Hashing are from [12], the results of DCNN are from [13], the results of VGG19 are from [14], and the results of Modified InceptionV3 data results are from [30].
Results of state-of-the-art methods on BdSL
Results of state-of-the-art methods on BdSL
It is clearly illustrated that SLR-YOLO pushes mAP to 98.5. None of the other methods have as high an accuracy as Modified InceptionV3, while our method, although lower than Modified InceptionV3 in Precision metrics, performs well in both Recall and mAP metrics. So, from the data sources given in the table, the accuracy of SLR-YOLO is still good.
As a further proof of whether the improvement is effective or not, the following ablation experiments are carried out based on YOLOv8, and the most suitable method for this study is selected by comparing the performance of different models, and the results are shown in Table 6, YOLOv8 + RFB + BiFPN + cutout + Gneck, which is the SLR-YOLO model.
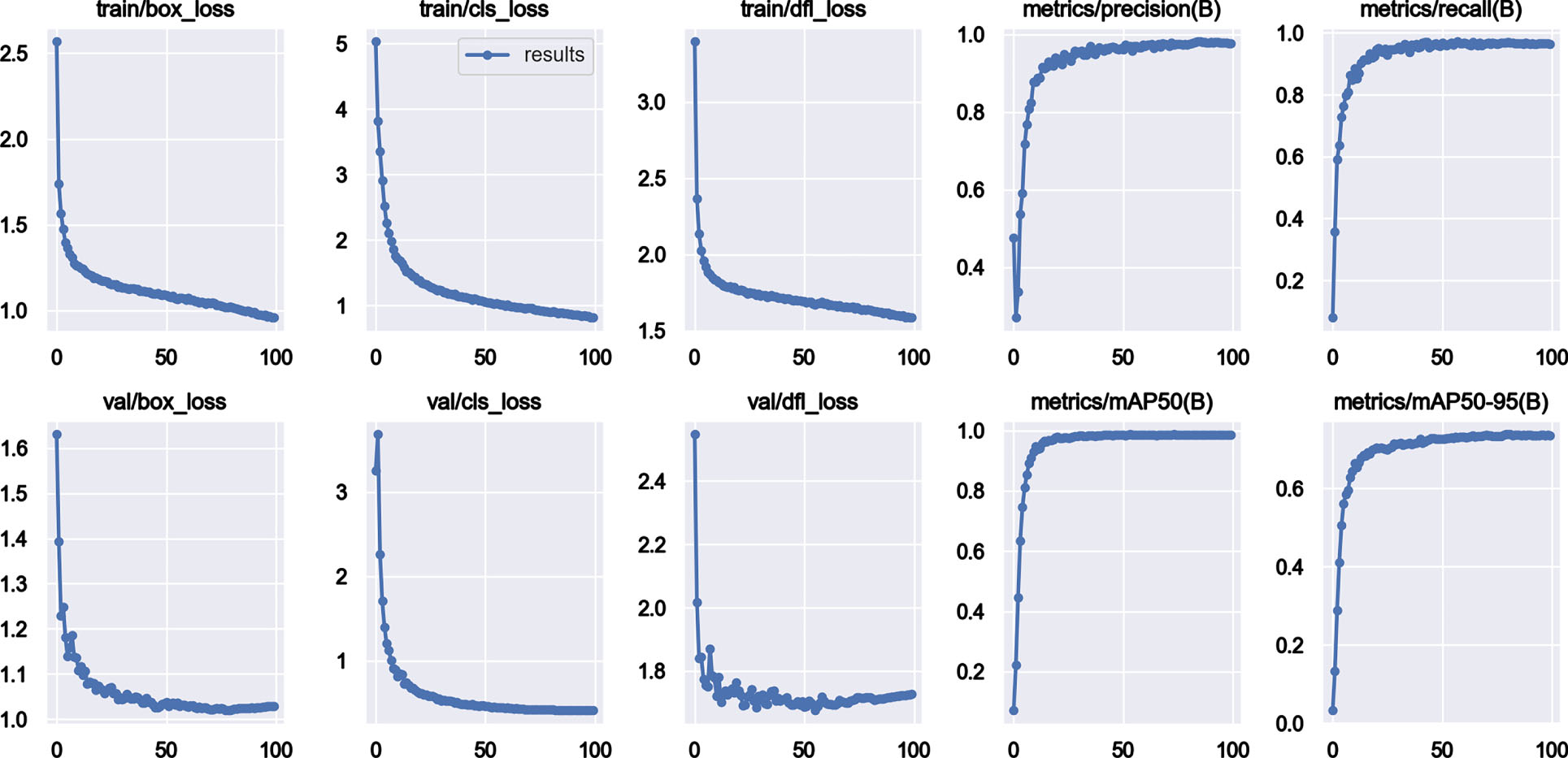
As seen in Table 8, the FPS values of the network models before and after the improvement in both datasets do not change much, and both can be used for real-time detection. It is verified in the ASLL dataset and the BdSL dataset that the improved model SLR-YOLO achieves an mAP value of 90.6% in the dataset ASLL and 98.5% in the BdSL dataset, which is an improvement of 1.3 percentage points in both datasets compared to the original YOLOv8, and the amount of the model parameters decreases by 11.31%, and the FLOPs decrease by 11.58%.
Test results of ablation experiments
Test results of ablation experiments
Based on the YOLOv8 model, the comparison of the addition of single modules is shown in Table 3, and it was determined by the comparison that the SPPF module was changed to the RFB module. After the combination of RFB and BiFPN, the mAP value is increased. After that, by comparing the different data enhancement methods, the values are guaranteed to be flat or slightly increase in P, R, and mAP values only when Cutout is used alone and occurs with a probability of 0.2. A comparison of the effect of the Ghost module added at different locations is shown in Table 5, which ultimately improves the mAP values while decreasing the parameter counts and the floating-point values.
Analysis of experimental results of ASLL
In the ASLL dataset, this study’s improved SLR-YOLO confusion matrix is shown in Fig. 7. As can be seen from the figure, the improved network has a high accuracy rate, with the vast majority of the data on the diagonal. However, there are also some cases of letter confusion, such as detecting T as the letter A, because of the effect of partial occlusion or background clutter and the similarity of some inter-sign language movements, which can easily cause inaccurate detection results. In order to more intuitively show the comparison of the network detection effect before and after the improvement, the sign language images in the test set are randomly selected for testing, and the results are shown in Fig. 8.
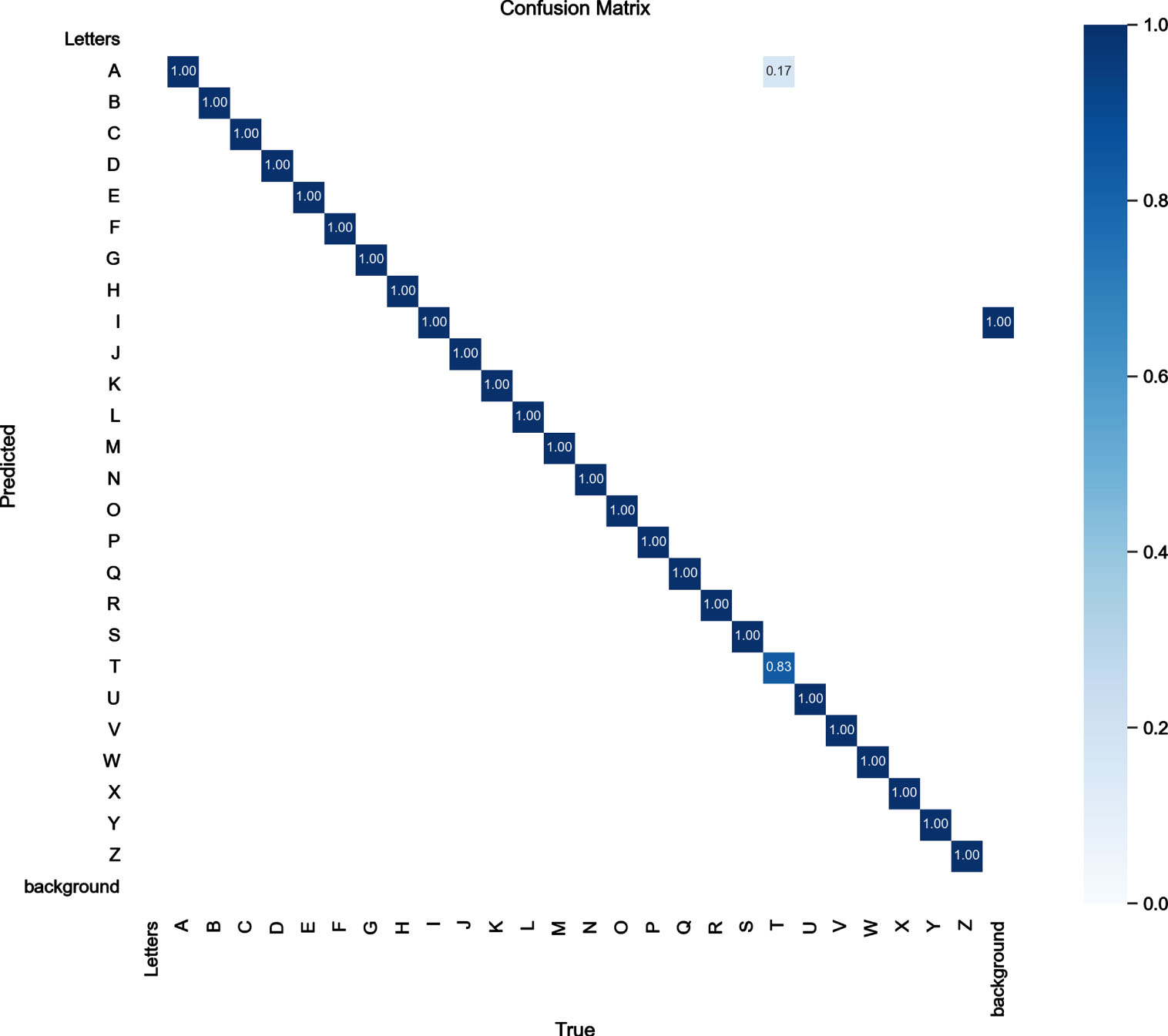
SLR-YOLO confusion matrix on ASLL.
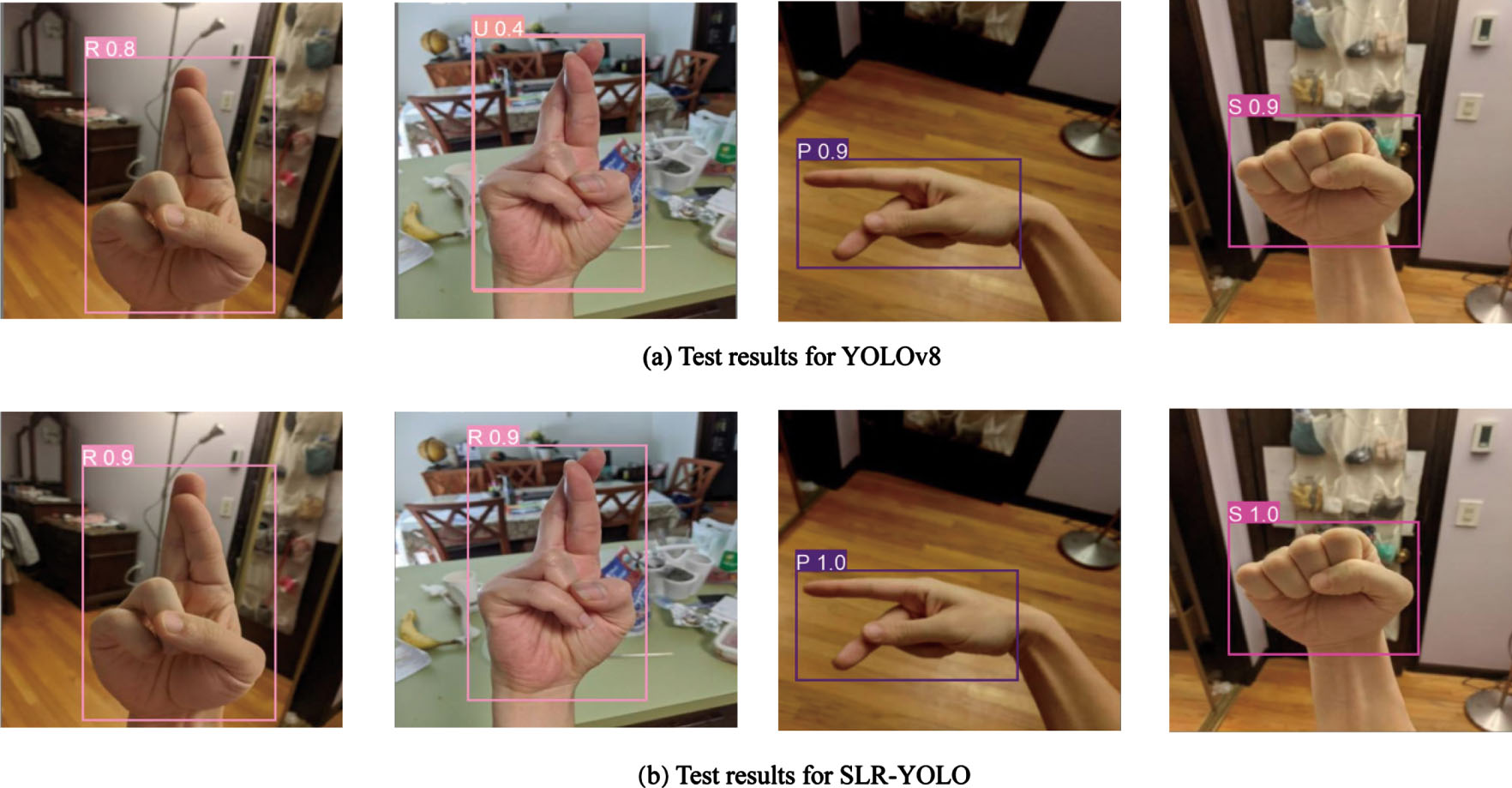
Comparison of YOLOv8 and SLR-YOLO test results on ASLL.
A comparison of the detection results of YOLOv8 and SLR-YOLO is shown in Fig. 8. As seen in Fig. 8(a), YOLOv8 has a detection error when the background is complex and mistakenly detects the letter R as the letter U. In Fig. 8(b), the improved network correctly detects the gesture corresponding to the letter, and much of the recognition has a higher confidence. Figure 9 shows the results of the ASLL dataset run in the improved SLR-YOLO model.
SLR-YOLO model test result on ASLL.
In the BdSL dataset, and the situation is similar to that of ASLL. The detection results of YOLOv8 and SLR-YOLO were compared, and the specific recognition results are shown in Fig. 10. Figure 11 shows the operation results of the improved model.
In summary, the improved model performs better and can adapt well in environments where the background color is close to skin color, cluttered background, partial occlusion, etc., with improved robustness and generalization ability.
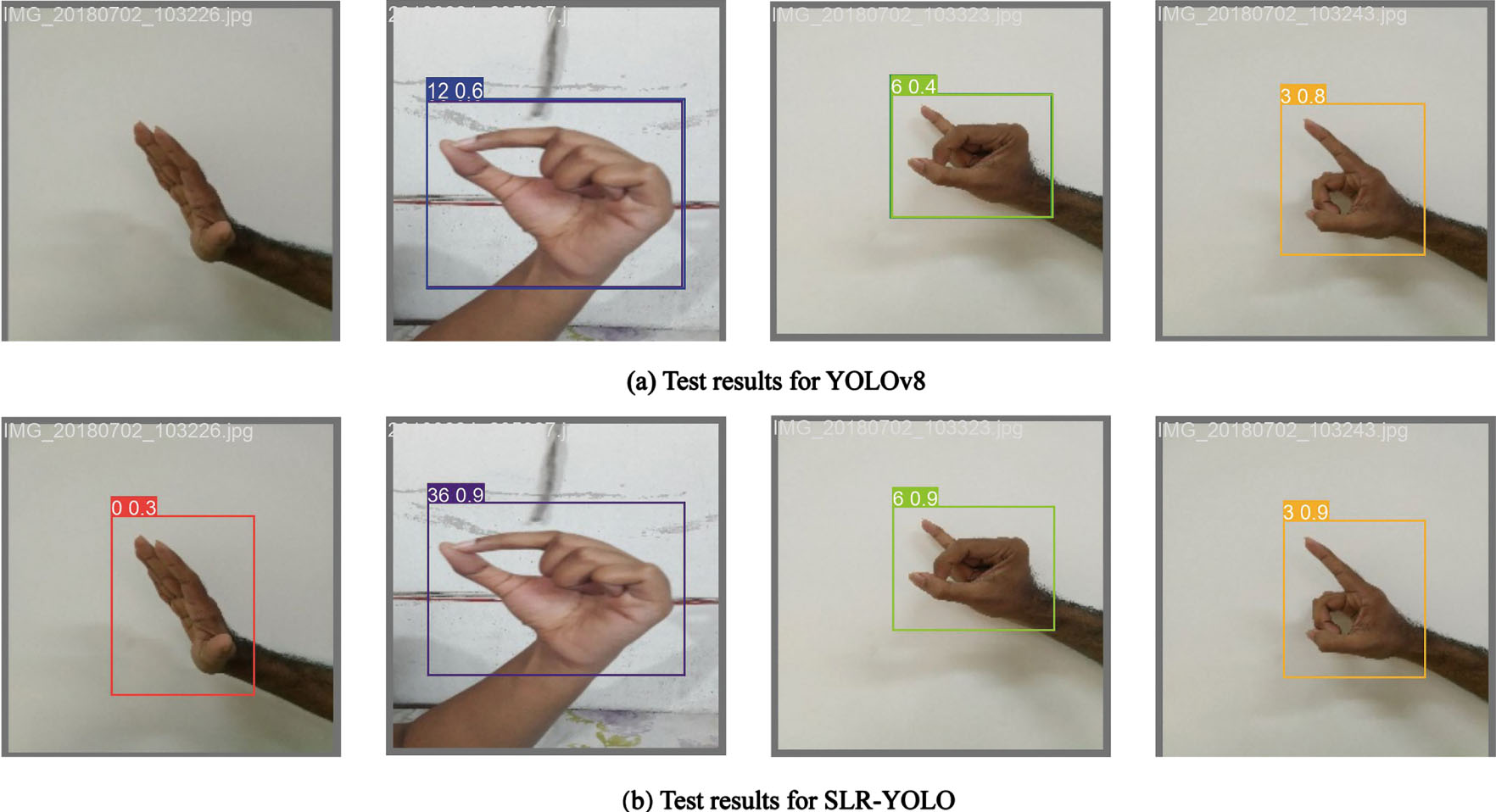
Comparison of YOLOv8 and SLR-YOLO test results on BdSL.
SLR-YOLO model test result on BdSL.
The real-time experiments were conducted to confirm the real-time capability of the model, and a portion of the results is shown in Fig. 12.

Real-time validation results.
In this paper, we propose a novel detector named SLR-YOLO for real-time sign language recognition, which is based on YOLOv8 with improvements of the backbone, neck, and data augmentation. The SPPF module is replaced with an RFB module in the backbone network part to enhance the feature extraction capability of the network. In the neck part, BiFPN is used to enhance the feature fusion so that the high-level semantic information of the features and the underlying location information are fused to achieve better results, and the Ghost module is added to lighten the network, reduce the number of model parameters, and improve the computational speed. The data enhancement method of Cutout is chosen by comparison, which introduces partial occlusion while improving the data generalization ability. Compared with the state-of-the-art methods, SLR-YOLO has a mAP of 90.6 and an Inference Time of 3.4 milliseconds on ASLL and achieves 98.5 mAP, 96.9% Precision, and 97.8% Recall on BdSL, which can prove that our proposed model is in real-time sign language recognition competitive. The experimental results show that SLR-YOLO can meet the accuracy and detection speed requirements.
It is necessary to recognize the limitations of this work in that the entire sign language recognition is carried out only for the manual component and with static sign language pictures as input.The performance of SLR-YOLO needs to be improved in terms of faster processing of more information and practical applications. In the next step of our research, we will add the recognition of non-manual components, in addition to adding gesture tracking and application deployment research, so that gesture recognition can practically promote the communication and interaction between people with disabilities and ordinary people, as well as with robots, and can be better used in the fields of disability assistive devices, medical and healthcare, and service robots.
Data availability
Data will be made available on request.
Footnotes
Acknowledgments
This work was supported by the Natural Science Foundation of Xinjiang Uygur Autonomous Region (Grant No.2021D01C052).