
Abstract
Hybrid tabular-textual question answering (QA) is a crucial task in natural language processing that involves reasoning and locating answers from various information sources, primarily through numerical reasoning and span extraction. Cur-rent techniques in numerical reasoning often rely on autoregressive models to decode program sequences. However, these methods suffer from exposure bias and error propagation, which can significantly decrease the accuracy of program generation as the decoding process unfolds. To address these challenges, this paper proposes a novel multitasking hybrid tabular-textual question answering (MHTTQA) framework. Instead of generating operators and operands step by step, this framework can independently generate entire program tuples in parallel. This innovative approach solves the problem of error propagation and greatly improves the speed of program generation. The effectiveness of the method is demonstrated through experiments using the ConvFinQA and MultiHiertt datasets. Our proposed model outperforms the strong FinQANet baselines by 7% and 7.2% Exe/Prog Acc and the MT2Net baselines by 20.9% and 9.4% EM/F1. In addition, the program generation rate of our method far exceeds that of the baseline method. Additionally, our non-autoregressive program generation method exhibits greater resilience to an increasing number of numerical reasoning steps, further highlighting the advantages of our proposed framework in the field of hybrid tabular-textual QA.
Introduction
The advancement of information technology has brought about a significant transformation in knowledge acquisition, shifting from traditional document retrieval to intelligent question answering (QA) systems. These QA systems have enabled computers to better comprehend natural language queries posed by users and provide precise answers to their questions. As a result, QA systems are widely recognized as the primary means of accessing information in the future. Extensive research has been conducted in this area, and QA systems have found application in various fields. They can be categorized into two types: single data source QA systems and mixed data source QA systems, depending on the structure of the data source. Previous studies on QA systems have primarily focused on homogeneous data, such as unstructured text [1–3] or structured data [4, 5]. In contrast, the domain of hybrid tabular-textual QA poses a greater challenge, as it involves reasoning from heterogeneous information and often requires numerical reasoning in addition to span extraction to provide answers to questions [6–11].
To enhance the numerical reasoning capability of hybrid tabular-textual QA models, TAGOP [7] utilizes sequence tagging to extract supporting facts and then performs a single arithmetic operation using pre-defined operators. In order to facilitate multi-step reasoning, FinQANet [8] and MT2Net [11] employ an auto-regressive long short-term memory (LSTM) decoder that gradually generates the program sequence based on the RoBERTa [12] representation. In this decoding process, each step produces either an operator or an operand. However, this autoregressive decoding approach is hindered by significant exposure bias. During training, the model relies on gold references as the decoding history, using it to make predictions. However, during inference, if the model cannot generate accurate predictions, the decoding history, which is likely incorrect, can negatively impact subsequent predictions. This leads to a cascade of errors as subsequent steps are impacted [13]. Unfortunately, this issue is prevalent in hybrid QA, where the performance of current methods is subpar. Consequently, due to error propagation, the accuracy of program generation substantially decreases as the number of decoding steps increases.
Non-autoregressive generation offers a solution to the exposure bias issue by reducing the dependency on earlier prediction results, while also improving generation speed through better parallelization. This study introduces a multi-tasking hybrid tabular-textual question answering (MHTTQA) approach. Instead of generating the program sequence in a step-by-step manner, this approach utilizes only the encoder representation (without de-coding history). For each reasoning step, an independent numerical reasoning tuple generator is employed to predict the operator and its operands. The numerical reasoning tuple generator incorporates a soft masking mechanism [14] to derive its specific input representation from the encoder representation by highlighting the operand representations of the step. This is followed by an operator generator, an operand generator, and an or-der predictor. Additionally, a length predictor is utilized to control the number of numerical reasoning tuples generated. By not relying on previous decoder history steps, this method avoids the exposure bias problem in generation and significantly improves generation speed through parallelization.
Our main contributions are as follows A MHTTQA framework is proposed in this study. The framework constructs a multi-task program that utilizes operands to synthesize and reason with multiple forms of text metadata in order to extract the correct answer. The Evidence Reasoning stage is responsible for accurately locating the answer location, capturing the semi-structured information within the form text metadata, and extracting cell-text association information. This stage also performs interrelated subtasks to generate the appropriate answer to the given question. Experiments conducted on the ConvFinQA [10] and MultiHiertt [11] datasets demonstrate that the pro-posed model outperforms the strong FinQANet and MT2Net baselines, achieving substantial improvements in performance. The proposed model establishes a new state-of-the-art while also being faster in generating programs. Further analysis reveals that the MHTTQA model exhibits significantly smaller performance loss compared to the baselines as the number of numerical reasoning steps increases.
The subsequent sections of this paper are organized as follows. Section 2 encompasses a comprehensive re-view of relevant work on hybrid tabular-textual question answering techniques. Section 3 focuses on detailing the MHTTQA Framework. Section 4 outlines the datasets and preprocessing methods employed, presents the experimental results, and discusses the implications of these findings. Finally, Section 5 concludes the paper and outlines future research directions.
Related work
Hybrid tabular-textual question answering
In the field of QA systems, there is a significant amount of research focused on hybrid tabular-textual QA. This approach combines structured table data with unstructured textual data to pro-vide more comprehensive answers to questions. The initial concept was introduced in a study [6], which created a dataset called HybridQA by manually linking table cells to corresponding Wikipedia pages. Since then, several studies have built upon this concept. Specifically, TAT-QA [7] and FinQA [8] were introduced as da-tasets in the financial domain, with a focus on financial reports that require advanced numerical reasoning. To further enhance these datasets, extensions such as TAT-HQA [9] and ConvFinQA [10] were introduced, allowing for deeper analysis and more nuanced questioning. These developments demonstrate the ongoing evolution of hybrid tabular-textual QA and its improved capabilities.
Another significant contribution in the field of hybrid QA systems is the MultiHiertt dataset [11]. This dataset stands out for its inclusion of multiple hierarchical tables along with extensive unstructured text, which adds another level of complexity and expands the potential applications of hybrid QA systems.
Numerical reasoning
Numerical reasoning plays a critical role in various natural language processing (NLP) tasks [15, 16], including text QA [3, 18], table QA [4, 5], and hybrid tabular-textual QA [7–10, 20]. Recognizing the importance of numerical reasoning, researchers [21–23] have focused on enhancing the effectiveness of pre-trained language models by incorporating this capability. For instance, TAGOP [7] is a model capable of performing single arithmetic operations using predefined operators. Building upon this, advanced models such as FinQANet [8] and MT2Net [11] have been developed to enable multi-step reasoning. These models utilize an LSTM de-coder to generate a program in an autoregressive manner. This represents a significant advancement towards achieving more intelligent and autonomous reasoning in QA systems.
The MHTTQA framework
In conventional approaches, certain models interrogate each message from the corpus individually and select the answer with the highest confidence. Alternatively, they add a quiz linear layer after the long coding model to directly determine the start and end positions of the answers. However, these methods fail to effectively capture the semi-structured information present in tables and the correlation information between cells and short texts. In this study, we propose the use of an operant-based multitasking program to synthesize reasoning across multiple table-text metadata and extract the correct answer.
Question outline
When dealing with a hybrid of tabular and textual content, researchers commonly utilize numerical reasoning or span extraction to reason the answer from diverse information. As illustrated in Fig. 1, given a question Q, the system’s objective is to locate the answer from both tables T and texts E. In certain cases, the model only needs to extract an answer span A from the input. However, for other cases involving numerical reasoning, the model must generate a program sequence G = {g0, g1, …, g n }, where g i represents a token within the program. This token is deter-mined either by extracting it from the input or selecting it from predefined special tokens, including operators and special operands. The probability of obtaining an answer A is computed by summing the probabilities of all possible programs G i that can result in the answer A:
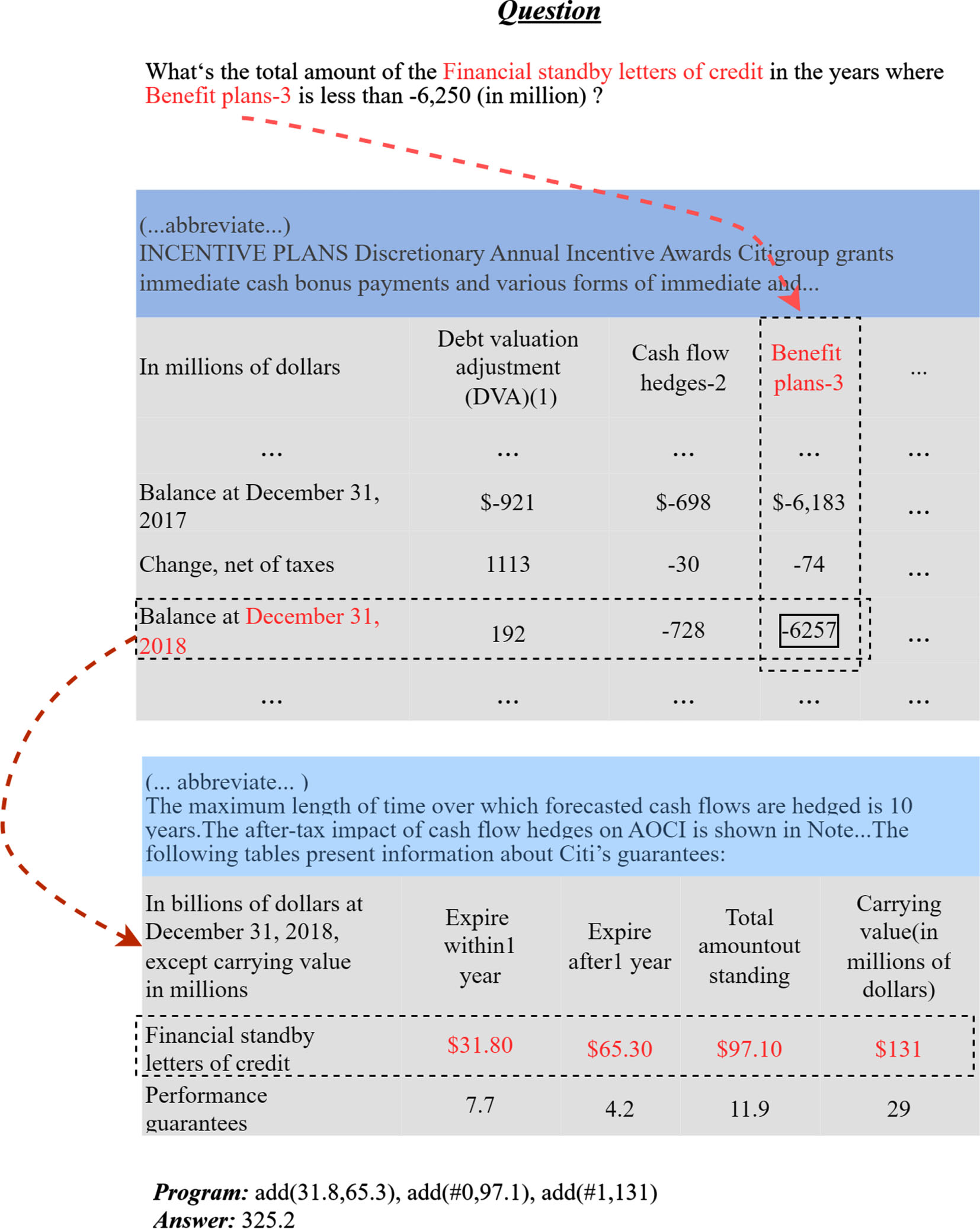
An example from the MultiHiertt dataset. In the numerical reasoning question, the system is tasked with identifying the year in the first table that has less than –6,250 Benefit plans-3. Once the relevant year is located, the system needs to extract the corresponding numbers from the second hierarchical table to use as operands in an addition calculation. To facilitate understanding, the relevant information is highlighted in light blue boxes, which can be seen more clearly in a color-coded representation.
The MultiHiertt dataset includes documents that may contain more than 3,000 tokens, surpassing the input length limitation of PLMs. To address this challenge, we follow the retrieval design method of the MT2Net model and convert the data cells of tables into records, associating each record with its respective row and column headers. To train a RoBERTa-based binary classifier (bi-classifier) for supporting fact classification, we concatenate the question with each sentence, treating the resulting concatenation as input [24]. Subsequently, we select the top n sentences based on the predictions of the supporting fact classification model to serve as input for the next stage. To determine whether the next stage involves span extraction or numerical reasoning, we employ another classifier.
Span extraction
In hybrid tabular-textual question answering (HQA), the common approach involves extracting one or multiple spans from tables or texts and utilizing the generated answers, often obtained through numerical reasoning. Building upon the work of [11] to enhance model performance, this paper adopts a similar approach by formulating the span extraction task as a question-answer problem, similar to MT2Net. This approach entails independently encoding the text and label annotations, followed by integrating the label knowledge into the text representation using a carefully designed semantic fusion module.
Numerical reasoning
Fact retrieval has successfully retrieved multiple pieces of table-text data, but the specific sections of the answers remain unknown. Thus, extracting answer fragments from the retrieved data becomes necessary. The conventional approach involves adding a linear answer layer immediately after the pre-trained model to predict the start and end positions of the answers. Unfortunately, this approach often results in the loss of semi-structured information inherent in the table. Additionally, it is susceptible to exposure bias and the error transfer effect during answer generation. Consequently, errors tend to accumulate, leading to a rapid degradation in model performance as the number of inference steps increases.
The paper presents the MHTTQA model, which introduces an independent numerical reasoning tuple generator. This component aims to tackle the exposure bias problem observed in step-by-step program generation models, while also improving generation speed through enhanced parallelization. The model framework is illustrated in Fig. 2.
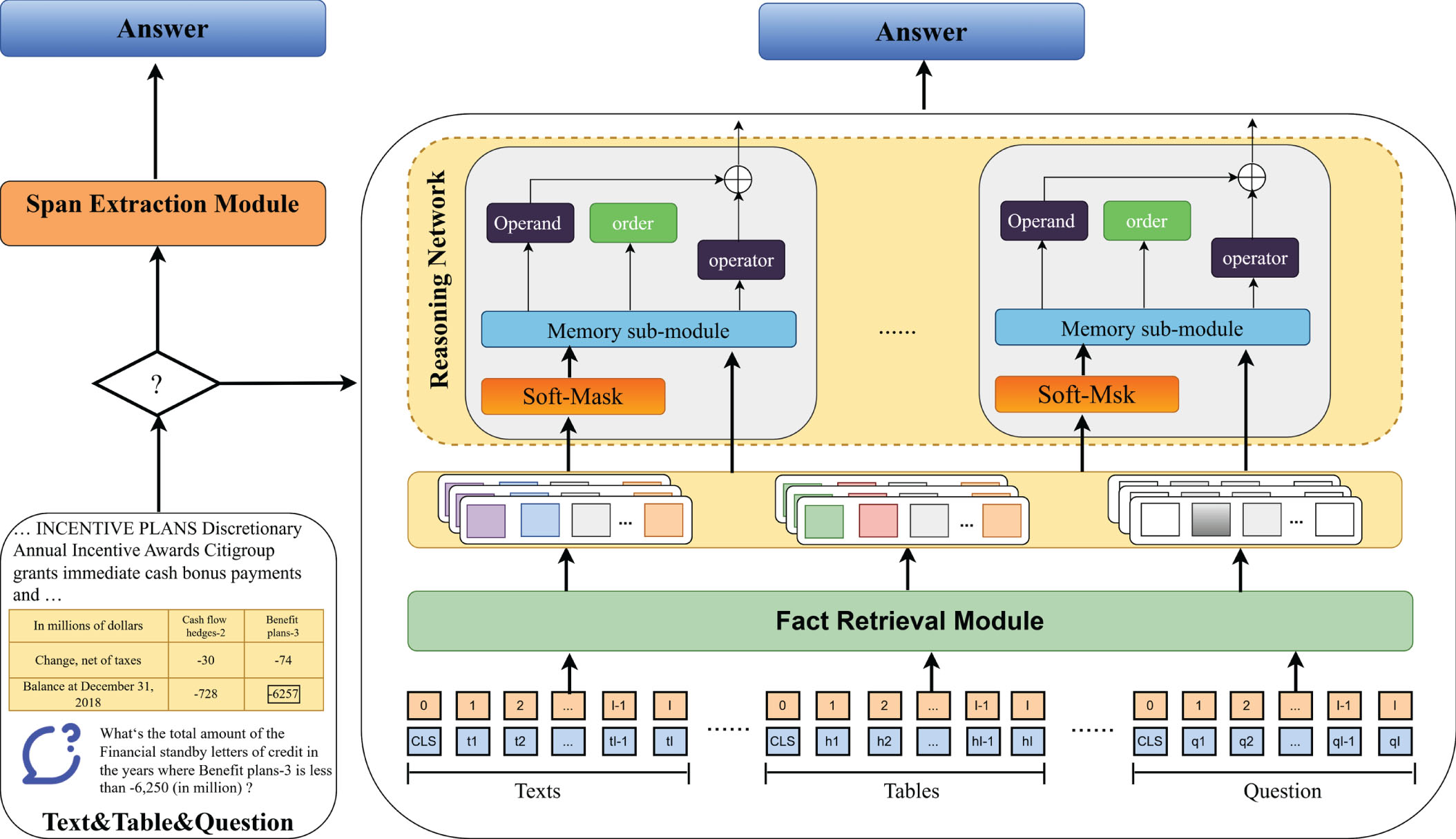
The framework of MHTTQA model.
In the first step, the model utilizes a bi-classifier to retrieve the most relevant facts, and another bi-classifier is employed to identify the question type using a similar approach as MT2Net. In the case of span extraction questions, our model also utilizes the T5-base model, similar to MT2Net, to generate the answer. This is done by providing the concatenated input of the question and the sentences containing the supporting facts. However, for numerical reasoning questions, our model takes a non-autoregressive approach to program generation, which differs significantly from the autoregressive LSTM decoder used in MT2Net [25].
The input to the RoBERTa encoder consists of a concatenation of special tokens (constants within 10 and common order values), the question, tables, and texts. The encoder then generates contextual vectors h t as its output.
The Soft-Masking Operand Extractor utilizes a 2-layer feed forward network (FFN) as the Soft-Masking Operand Extractor over the full RoBERTa representation h
t
. Its purpose is to identify all operands of the expected reasoning program within the input. The probability p
t
of a token being an operand is calculated, and then a soft mask [14] h
t
is applied using this probability.
A large
The Length Predictor utilizes a multi-class classifier to predict the number of reasoning steps. Each reasoning step consists of a complete program tuple, including an operator, operands, and order. The classifier is implemented as an FFN layer, which takes the RoBERTa representation of the [CLS] token without soft masking as input.
Tengxun Z et al. used the soft-masking mechanism to enhance the numerical representation [27]. Inevitably, the method is running into overparametization. In order to improve the performance of model, we use residual learning to alleviate the above problem. By merging soft mask and original presentation, the final output is as follow:
The Soft-Masking Operand Generator also utilizes the soft masking mechanism to extract the two operands of the specific reasoning step from the input in the Numerical Reasoning Tuple Generator.
where
When the operator is subtraction, division, exponentiation, or greater, the order of the two operands becomes significant in the Order Predictor. In this study, the mean pooling is applied to both the embedding of the [CLS] token and the soft-masked embeddings h
r
to generate the input. A bi-classifier is then employed to predict the order of the operands, determining whether their order matches the original input or if they should be reversed.
In order to collectively optimize all the objectives for numerical reasoning, the process minimizes the weighted sum of the negative log-likelihood losses from each individual module.
where NLL stands for the negative log-likelihood loss function, r indicates the ground truths, ω = {α, β, γ, δ, ɛ} represents the weight of each module, and n is the maximum number of reasoning steps.
Datasets and preprocessing
The experiments in this study were conducted using two datasets: ConvFinQA [22] and MultiHiertt [6]. The ConvFinQA dataset consists of 14,115 data points, which are divided into three parts: train, development, and test, with 11,104, 1,490, and 1,521 examples respectively. This dataset presents a significant challenge in modeling complex and long-range numerical reasoning paths within real-world conversations [10]. On the other hand, the MultiHiertt dataset contains 10,440 data points with each document consisting of multiple hierarchical tables and longer unstructured text [11]. The MultiHiertt dataset is also divided into train, development, and test parts with 7,830, 1,044, and 1,566 examples respectively. It is worth noting that the test set labels for both the ConvFinQA and MultiHiertt datasets are not publicly available.
The performance evaluation of the models was conducted using different metrics for each dataset. For Multi-Hiertt, the metrics used were exact matching (EM) and the numeracy-focused F1 [3]. On the other hand, for ConvFinQA, the evaluation included the metrics of execution accuracy (Exe Acc) and program accuracy (Prog Acc), as suggested in previous studies.
The baselines used in this study are GPT-2 [26] and T5 [27], both of which are generative models. TAGOP [7] is the first model to employ the sequence tagging method for fact extraction, followed by a single arithmetic operation using predefined operators. FinQANet [8] and MT2Net [11], on the other hand, are capable of per-forming multi-step reasoning. These models utilize an autoregressive LSTM decoder to generate the program.
In the model settings, hyperparameters were tuned using the development set. In order to ensure a fair comparison with the existing state-of-the-art results, the experiment settings for FinQANet and MT2Net, GPT-2, and T5 were adopted using the medium and large models respectively. For the rest of the baselines, the RoBERTa-large model was used. Model training was performed on a single RTX3090 GPU, with the maximum number of reasoning steps set to 5 for ConvFinQA and 10 for MultiHiertt. To focus specifically on program generation and ensure a fair comparison, only the program generation module of MT2Net and FinQANet was replaced with the MHTTQA, while leaving the other parts unchanged. Since FinQANet utilizes a single LSTM to decode either the program sequence or the span to extract, depending on the question type, the length predictor of MHTTQA for prediction is set to 0. In this case, the span with the highest prediction probability is directly extracted from the output of the operand extractor to handle span extraction questions in the ConvFinQA dataset.
Results and discussion
Main result
In this work, we compared the performance of MHTTQA with both the base and large settings, against our baselines. The main results of this comparison are shown in Table 1.
Table 1 indicates that pre-trained models such as GPT-2 and T5 do not outperform LSTM in terms of performance. This could be because these models were not specifically pre-trained for the generation of numerical reasoning programs. However, even with the RoBERTa base setting, our method achieves better performance on both datasets. Furthermore, utilizing the RoBERTa large setting further improves the performance of MHTTQA, resulting in significant improvements on both the ConvFinQA (+4.14/+5.80 Exe/Prog Acc points) and MultiHiertt (+6.14/+4.70 EM/F1 points) datasets.
Main results on ConvFinQA and MultiHiertt
Main results on ConvFinQA and MultiHiertt
Since this approach focuses solely on modifying the program generation aspect, we evaluated the performance of MHTTQA and MT2Net on all numerical reasoning questions using the MultiHiertt development set. The results of this evaluation are provided in Table 2. It is evident from Table 2 that MHTTQA displays significant improvements compared to the MT2Net baseline, with an increase of +6.25 EM and +6.75 F1 in the field of numerical reasoning.
Main results of numerical reasoning on MultiHiertt
To assess MHTTQA’s ability to mitigate the error accumulation problem associated with autoregressive program generation, the performance of MHTTQA and MT2Net was analyzed based on different numbers of reasoning steps. To ensure fairness, both MHTTQA and MT2Net employed RoBERTa-large as the encoder. It’s worth noting that the analysis was conducted on the development set since the test set is not accessible to the public. The results of MT2Net are sourced from [11], and Fig. 3 presents the findings of our analysis.
Figure 3 illustrates that while the metrics reach their highest values with 2 reasoning steps, the overall performance tends to decline as the number of reasoning steps increases. Our approach consistently outperforms MT2Net across all metrics. Notably, as the number of reasoning steps expands beyond 3, the improvements our method offers over the autoregressive MT2Net baseline become notably more substantial.
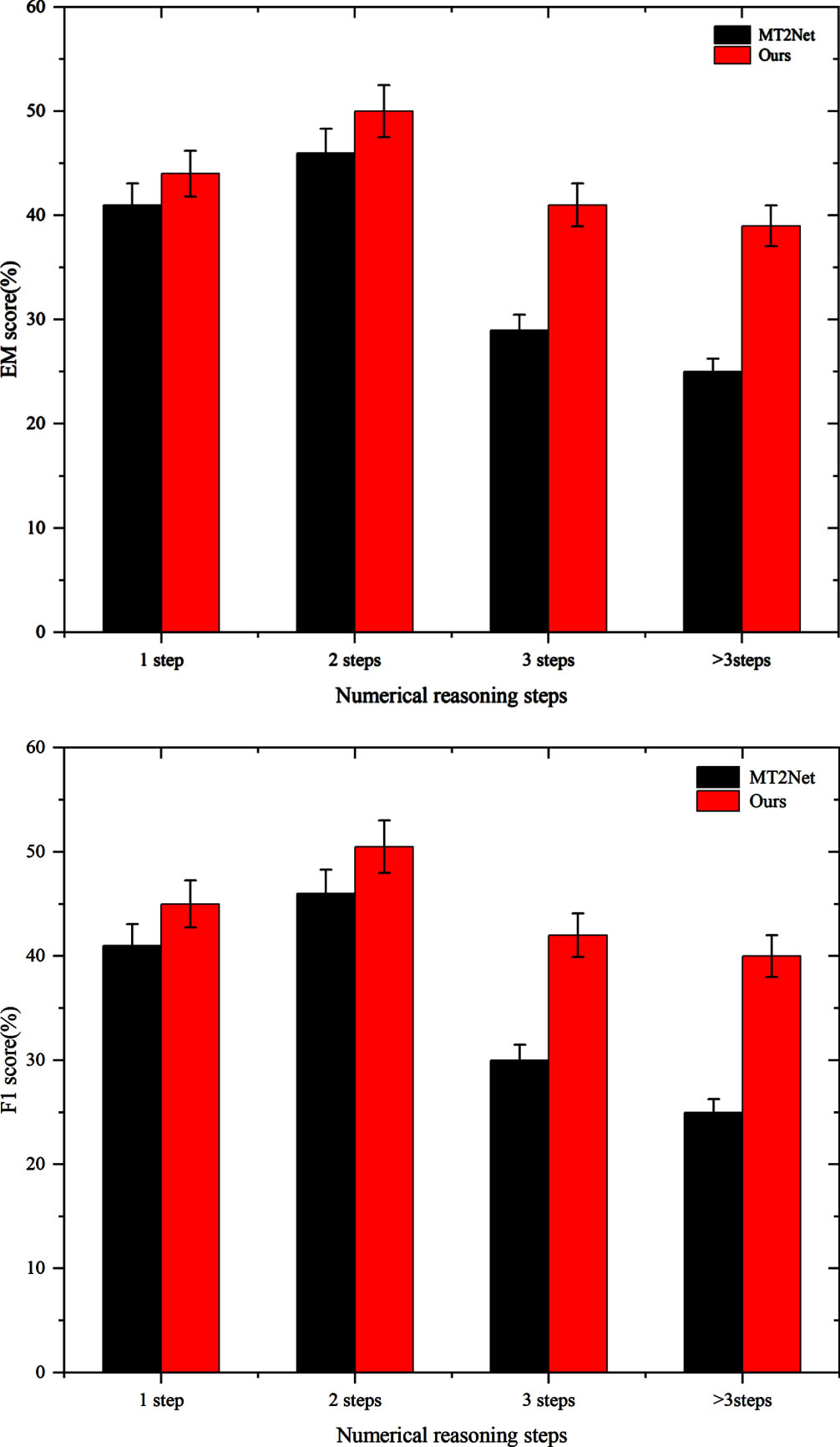
Performance of different numerical reasoning steps on the development set of MultiHiertt.
The performance deterioration observed with the increasing number of reasoning steps in our non-autoregressive method is significantly less pronounced compared to the autoregressive MT2Net. This highlights the inherent advantage of using MHTTQA in addressing questions that necessitate inference with lengthy program sequences. Intuitively, as the generation of longer program sequences is prone to exposure bias, autoregressive models are more susceptible to this issue, whereas non-autoregressive generation mitigates this concern in our method.
To gain a deeper understanding of how different components of the neural architecture performance generalization (NAPG) affect performance, an extensive analysis of various hyperparameter values associated with the convergence of training losses in the MultiHiertt model was conducted. The primary objective of this investigation was to identify how adjusting these hyperparameters could impact the overall performance of the model.
The exploration methodology was specifically designed to isolate the effects of individual hyperparameters. In each experiment, a single hyperparameter’s value was increased to 2 while keeping all others at their default value of 1. This approach was crucial in order to observe the impact of each component when augmented, thereby allowing us to infer its contribution to the overall performance of the model.
After completing the initial round of testing, we proceeded with a more advanced level of experimentation. We identified all hyperparameters that displayed positive impacts in either the base or large settings of the model. Once these hyperparameters were identified, we concurrently increased their values to observe their collective influence on the model’s performance similar with [28]. The hyperparameter that demonstrated the most significant improvements was assigned a higher value to further enhance its effect.
The results are presented in Table 3. It is important to note that there is variation in the optimal settings for achieving the best performance, depending on the model setup. Through the range of scenarios tested for the base model setting, the most effective configuration was found to be using a δ value of 2, while keeping the other hyperparameters at their default values of 1. Conversely, for the large model setting, the best configuration involved a δ value of 2 combined with an ɛ value of 1.5, while keeping the remaining hyperparameters at 1. This demonstrates the intricate balance needed to tune the hyperparameters for optimal model performance in different settings.
Effects of different hyperparameters in MHTTQA
The application of non-autoregressive methods in program generation provides our approach with a significant advantage in terms of parallelization. To evaluate the speed benefits of this approach, we conducted a comparative analysis of the program generation speed between our MHTTQA method and the LSTM de-coder used in MT2Net.
Our analysis consisted of monitoring the time taken by the program generation modules as they processed all the numerical reasoning queries in the MultiHiertt training set. The findings of this analysis are presented in Table 4, enabling a straightforward comparison of the performance of these two distinct methods.
The findings presented in Table 4 demonstrate that MHTTQA significantly outperforms MT2Net in program generation, reducing the time required by over 90%. This notable difference in speed highlights the significant advantage of utilizing non-autoregressive decoding techniques over autoregressive methods. The main reason for this performance disparity is that non-autoregressive decoding techniques benefit from parallelization, enabling the simultaneous execution of multiple operations and substantially reducing the overall program generation time. These results strongly emphasize the superiority of MHTTQA in terms of speed and efficiency.
Time costs for program generation.
The MHTTQA design is characterized by elementwise computations, a single FFN for length prediction, and three sets of FFNs with distinct parameters but identical architectures for operand generation, operation generation, and order prediction. During program tuple sequence generation, the length predictor only requires computation once, and the elementwise computations can be efficiently parallelized. Additionally, for each set of FFNs with varying parameters but identical architectures, the activation function can be parallelized, while the linear layers with different parameters can be parallelized using the batch matrix-matrix multiplication function avail-able in most contemporary linear algebra libraries.
When comparing non-autoregressive decoding with its autoregressive counterpart, it is important to note that non-autoregressive approaches do not consider the decoding history. This disregard for past context may potentially have a detrimental effect on coherence. However, in the context of program generation for numerical reasoning, coherence may be less significant. On the other hand, autoregressive decoding is highly susceptible to being misled, particularly in program generation scenarios where the prediction quality is low, as indicated by the results in Fig. 3.
Conclusion
Hybrid tabular-textual question answering (QA) involves the integration of diverse information sources, with numerical reasoning being a particularly challenging aspect compared to extractive QA. The current autoregressive methods face a substantial issue of exposure bias, especially when the program generation performance is unsatisfactory. In order to overcome this issue, we propose a multitasking hybrid tabular-textual question answering (MHTTQA) framework specifically designed for numerical reasoning. This frame-work enables parallel program generation by independently generating complete program tuples that include both the operator and its operands. By alleviating the exposure bias problem that affects previous autoregressive decoding methods, MHTTQA significantly improves program generation speed.
Our experiments conducted on the ConvFinQA and MultiHiertt datasets yielded significant results. Firstly, our proposed model demonstrated substantial improvements over the strong baseline models of FinQANet and MT2Net. Specifically, we observed an increase of 4.77 and 4.90 in Exe/Prog Acc points respectively, compared to FinQANet. Similarly, in comparison to MT2Net, our model achieved an enhancement of 7.57 in EM points and 3.64 in F1 points. These performance gains establish our model as the new state-of-the-art, while also exhib-iting a considerable increase in program generation speed, approximately 19 times faster. Secondly, our method demonstrated a significantly smaller decline in performance compared to the auto-regressive LSTM decoder of MT2Net when dealing with a higher number of numerical reasoning steps. Going forward, our plan is to simplify the complexity of numerical reasoning and improve the accuracy of reasoning. In addition, since this is the first attempt at this work, our experiments are concentrated within a specific dataset. How to improve the generalization ability of the model, the framework based on multi-task can have better performance.