
Abstract
Rivers serve as vital water sources, maintain ecological equilibrium, and enhance landscapes. However, the looming issue of floating debris stemming from improper waste disposal and illegal discharge, poses an imminent threat to river ecosystems and their aesthetic appeal. Conventional human-led inspections prove labor-intensive, inefficient, and prone to errors. This study introduces an innovative approach for river debris detection, employing Unmanned Aerial Vehicles (UAVs) imagery in conjunction with a refined YOLOv5n model. This approach offers three key contributions. Primarily, the YOLOv5n model is bolstered by integrating the Efficient Channel Attention (ECA) module and reshaping the MobileNetV3 backbone to align with MobileNetV3S, thereby significantly streamlining computational demands and model intricacy. Additionally, precision and speed are augmented by eliminating the detection head for larger targets, while decreasing computational requirements. Subsequently, to counter dataset scarcity, we curate a UAV-derived river debris dataset, encompassing five prevalent debris types, serving as an indispensable resource for method refinement and assessment. Lastly, the upgraded model’s evaluation on Jetson Nano yields an mAP of 87.2%, merely 0.7% lower than the original YOLOv5n model. Remarkably, the refined model achieves substantial reductions of 57.1% in parameters, 52.6% in volume, and 54.8% in GFLOPs. Additionally, inference time is abbreviated to 57.3ms per Jetson Nano image, 13.4ms faster than the original. These findings underscore edge computing’s potential in river restoration. In conclusion, the fusion of deep learning object detection and UAV imagery empowers adept river debris detection.
Introduction
Rivers are the carriers of water resources and one of the most basic natural resources for human survival and life. The development, utilization, management, and protection of water resources are inseparable from rivers [1]. However, the acceleration of economic development and industrialization has led to frequent river pollution incidents, among which river floating debris is a great concern, mainly human-discarded garbage and dead plants and animals. If not cleaned in time, it will affect not only impact reducing the aesthetics of rivers but also the water ecology. Therefore, an extensive and rapid inspection of rivers and prompt treatment of the presence of floating materials are needed to enhance the protection of the aquatic environment.
Currently, the detection of floating materials in rivers mainly relies on managers to go to the scene to conduct regular inspections of rivers [2]. However, rivers usually have wide areas. There are many shortcomings in relying only on manual inspection, such as difficulty inspecting blind areas of sight, high labor intensity and cost, and difficulty giving timely feedback on actual river information. To solve these problems, more and more intelligent methods are being applied to river floating debris detection. Zhang et al. [3] installed cameras on both sides of the river and then used a modified RefineDet method to detect floating objects in the images. Although the camera installation method has some advantages, the monitoring range of individual cameras is limited, and the cost of mass deployment is high. Cheng et al. [4] proposed a radar-vision fusion-based surface small target detection method. They deployed it on unmanned surface vehicles(USVs), which were then used to detect and collect river floaters. Although the high degree of automation of USVs can reduce staffing, it does not quickly respond to the overall situation of river floaters in the region, and the cost of purchasing USVs is extremely high.
Unmanned Aerial Vehicles (UAVs) are autonomous flying machines equipped with sensors, cameras, and navigation systems that collect visual and data insights from aerial perspectives. They play crucial roles in photography, surveillance, mapping, research, and deliveries, spanning various industries. As UAV technology advances, their accessibility grows, finding applications in power inspection [5], agricultural production [6], urban measurement [7], and forest protection [8]. Unlike conventional river debris detection methods, UAVs offer agility, efficiency, and wide coverage, reducing labor risks and costs. River managers can use UAVs with high-res cameras to swiftly assess rivers, optimizing monitoring routes to align with river landscapes and enhance supervision effectiveness. UAVs have emerged as indispensable tools, revolutionizing operations and insights across domains.
In recent years, deep learning-based object detection methods have rapidly developed and achieved satisfactory results in UAV image detection. For example, Hu et al. [8] proposed a pine forest disease detection method based on UAV remote sensing. The method used the improved Mask R-CNN to detect pine forest diseases in UAV images and identify the severity of pine forest diseases, which has important implications for forest disease control and forest protection. Aiming at the problem of the time-consuming, labor-intensive, and limited number of samples to identify maize tassels manually in the past. Liu et al. [9] used UAVs to obtain maize images in the planting area and then used the improved Faster R-CNN to detect the maize tassel in the image. This way improved the detection efficiency, and the accuracy rate reached 95.95%, which provides technical support for ensuring the quality and yield of corn. Therefore, it is highly feasible and technically advantageous to combine the increasingly mature deep learning-based object detection method with UAV photography technology to detect river debris images intelligently.
While deep learning-based object detection methods exhibit high accuracy, they heavily rely on robust computing resources and extended detection cycles. This raises a crucial concern: as detection precision improves, computational demands escalate, potentially making these algorithms unsuitable for real-time applications. In the context of river floating debris detection, delayed detection can lead to substantial repercussions, such as delayed responses to pollution incidents or obstructed navigation along waterways. Thus, achieving a harmonious balance between detection accuracy and efficiency becomes imperative. The key challenge lies in preserving detection precision while simultaneously reducing the model’s computational load and detection time. This necessity offers significant advantages for promoting advanced object detection technologies across various applications, encompassing not only river floating debris detection but also extending to the wider landscape. In a world increasingly shaped by the dominance of Internet of Things (IoT) devices, embedded sensors, and edge computing, the relevance of this research transcends the immediate domain of river float detection.
Therefore, we made a lightweight improvement to YOLOv5n. Firstly, the backbone of YOLOv5 is reconstructed by referring to the MobileNetV3S [10] network structure, and the network model is compressed without significantly reducing the feature extraction capability. To address the high computational overhead of the fully connected layer in the MobileNetV3 block, we used adaptive one-dimensional convolution to improve the performance without reducing the model complexity. Then, the size of river floaters in the aerial images is analyzed to be in the range of small targets, so the detection head for detecting large targets is removed in the detection phase to save unnecessary computational overhead and speed up the detection speed. Finally, we deployed the improved model to the Jetson Nano platform and tested the model’s performance. The experimental results show that the approach provides a technical reference for river regulation on edge computing devices. In summary, our contributions are as follows: We have successfully curated a comprehensive river floating debris dataset by employing UAV photography, available for download on the Cloud disk https://figshare.com/articles/dataset/__zip/24123666. This dataset encompasses five prevalent categories of river floating debris: plastic bottles, plastic bags, plastic cups, cans, and cartons. For the need for river floating debris detection in UAV images, we propose a lightweight object detection method based on YOLOv5n. The method first fuses the ECA(Efficient Channel Attention) module [11] with the MobileNetV3 block and then reconstructs the backbone of YOLOv5n by referring the fused block to the MobileNetV3S network structure. Finally, for the case of the small target size in the image, the method removes the detection head for detecting large targets to save unnecessary computational overhead. The improved model is deployed on the Jetson nano edge computing platform for testing. The experimental results show that our method can quickly and accurately detect river floating debris in UAV images and provide technical support for river remediation.
The rest of the paper is organized as follows: Section 2 describes the deep learning-based target detection algorithm with lightweight networks. Section 3 details the network structure of the model with details of the improvements. Section 4 presents the dataset and discusses the experimental results of the dataset. Finally, the paper is summarized in Section 5.
Related work
Deep learning-based object detection algorithm
In recent years, deep learning methods represented by Convolutional Neural Network (CNN) have seen rapid development in computer vision. Furthermore, deep learning-based object detection methods far surpass traditional object detection methods in terms of detection performance with their powerful adaptive learning ability and feature extraction capability. So, more and more scholars have started to use deep learning methods for UAV image target detection. Current UAV image detection methods based on deep learning can be divided into one-stage and two-stage object detection algorithms.
Two-Stage object detection algorithms generally focus on finding the object’s approximate location and roughly determining whether the object is in the foreground or background in the first stage, ensuring good recall of the detector by obtaining many region proposals. The image features of each potential anchor are recalculated in the second stage, and then these features are classified at a finer granularity. Finally, the final prediction is obtained by calculating the Intersection of the Union (IoU) of the enclosing frames and removing the duplicate detection for the same instance, i.e., post-processing the results using Non-Maximum Suppression (NMS). Two-stage object detection algorithms are usually more advantageous in accuracy than one-stage object detection algorithms but lack speed. Typical algorithms are R-CNN [12], Faster R-CNN [13], Mask R-CNN [14], etc. For example, Liu et al. [15] designed a multi-branch parallel feature pyramid network (Multi-branch ParallelFeature Pyramid Networks, MPFPN) based on Faster R-CNN network to capture richer feature information of small targets in UAV images for the problem of little feature information available in UAV images, in addition. By introducing the Supervised Spatial Attention Module (SSAM) to attenuate the interference of background noise, the detection performance of small targets on UAV images is effectively improved. However, false detections for objects never labeled in the training images exist. Lin et al. [16] proposed a multi-scale feature extraction backbone network Trident-FPN based on the Cascade R-CNN network. Also, they introduced an attention mechanism to design an attention double-headed detector, which effectively improved the negative impact on the target detector due to the large-scale difference between the UAV image targets. However, the large computational overhead of the region proposed network still needs to be improved.
The One-Stage object detection algorithm combines two stages of the two-stage object detection algorithm into one stage, i.e., the precise location of the object and the prediction of the category are done directly in one stage. It is more streamlined in method but more dependent on feature extraction, feature fusion, and positive and negative sample split. Typical algorithms include YOLOv4 [17], YOLOv5, RetinaNet [18] etc. For real-time UAV image object detection, researchers have applied single-stage target detection algorithms to the UAV image domain. For example, Zhang et al. [19] proposed a depth-separable attention-guided network based on YOLOv3, which effectively improved the detection of small target vehicles in UAV images by introducing an attention module and replacing part of the standard convolution with depth-separable convolution. The detector’s performance in UAV image-intensive detection tasks is improved firstly by using the designed Strip Bottleneck (SPB) module to improve the detection of targets at different scales, and secondly by using a feature map upsampling strategy based on the Path Aggregation Network (PANet) proposed.
Lightweight network structure
Currently, the lightweight of convolutional neural networks has become a hot research topic in academia and industry. The lightweight neural networks are divided into Pruning, Quantization, Distillation and Adopting a lightweight network structure.
In 2016, Han Song et al. [20] proposed the concept of Deep Compression, which achieved compression of network models through pruning, shared weights and Hoffman coding, setting the basic idea for following model compression methods. In 2015, Hinton [21] proposed the KnowledgeDistillation (KD) method, introduced the concept of teacher networks and student networks and guided the training of streamlined, low-complexity student networks through soft labels output from complex but superior-performing teacher networks. The small network distilled from the large network is computationally inexpensive and comparable in accuracy to the large network.
In addition to the model mentioned above compression methods, we can also design lightweight networks by adjusting the network’s internal structure. In April 2017, the Google team proposed MobileNetV1 [22], a lightweight convolutional neural network designed for mobile devices. Compared to traditional CNNs, MobileNet uses depthwise separable convolutions instead of traditional convolutions, significantly reducing the number of model parameters and computational cost while maintaining comparable accuracy. In 2018, the Google team proposed MobileNetV2 [23], which improved upon MobileNetV1 in both accuracy and model size. The highlights of MobileNetV2 include inverted residuals and linear bottlenecks. Inverted residuals utilize a 1x1 convolution layer for feature reduction before depthwise separable convolutions, followed by another 1x1 convolution layer for feature expansion, effectively reducing computational cost and increasing non-linear expression. Linear bottlenecks replace ReLU activation functions with linear activation functions in the last 1x1 convolution layer of inverted residuals to reduce feature loss and enhance model expression. In 2019, the Google team continued to improve upon the MobileNet series, proposing MobileNetV3 [10], which has two versions: MobileNetV3-Large and MobileNetV3-Small. MobileNetV3-Large is a more powerful network suitable for high-precision tasks, while MobileNetV3-Small is more lightweight and suitable for resource-constrained mobile and embedded devices. MobileNetV3 introduces several new technologies and designs, including SE attention modules in blocks that adaptively adjust the weights of different channels, the use of Hardswish activation functions instead of ReLU to reduce computational cost without sacrificing performance, and the use of neural architecture search (NAS) for model search and optimization to further improve model performance and efficiency.
In 2018, Megvii Technology proposed ShuffleNetV1 [24], a lightweight convolutional neural network designed for mobile devices, similar to MobileNet. ShuffleNetV1 addressed the problem of reduced accuracy caused by dense 1x1 convolutions in small networks by introducing pointwise group convolution to reduce the complexity of 1x1 convolution. However, group convolution lacks channel interaction between groups, so the authors proposed using channel shuffle to solve this problem. Pointwise group convolution divides the input feature matrix into multiple groups at the channel level, with the same number of channels in each group. Then, independent pointwise convolution operations are performed on the channels in each group, and the results are merged in the channel direction. The basic idea of channel shuffle is to group the input feature maps according to a certain rule and then mix the different parts of the grouped features. In the same year, Megvii Technology proposed a new version, ShuffleNetV2 [25], based on ShuffleNetV1, with a new block design. It uses a new channel split operation to separate the input features into two parts for depth-wise separable computation, and completes information exchange through channel concatenation, without using 1x1 group convolution or pointwise addition operations. In addition, when downsampling or doubling the number of channels, ShuffleNetV2 cancels the channel split operation, doubling the number of channels after concatenation. These improvements significantly improve the performance and efficiency of the network.
The improved edge YOLOv5n
Overview of YOLOv5n
YOLOv5n, the lightest model in YOLOv5, has a short training time, fast detection and convenience. As shown in Fig. 1, it consists of 3 parts: Backbone for feature extraction, Neck for feature fusion, and Head for object detection.
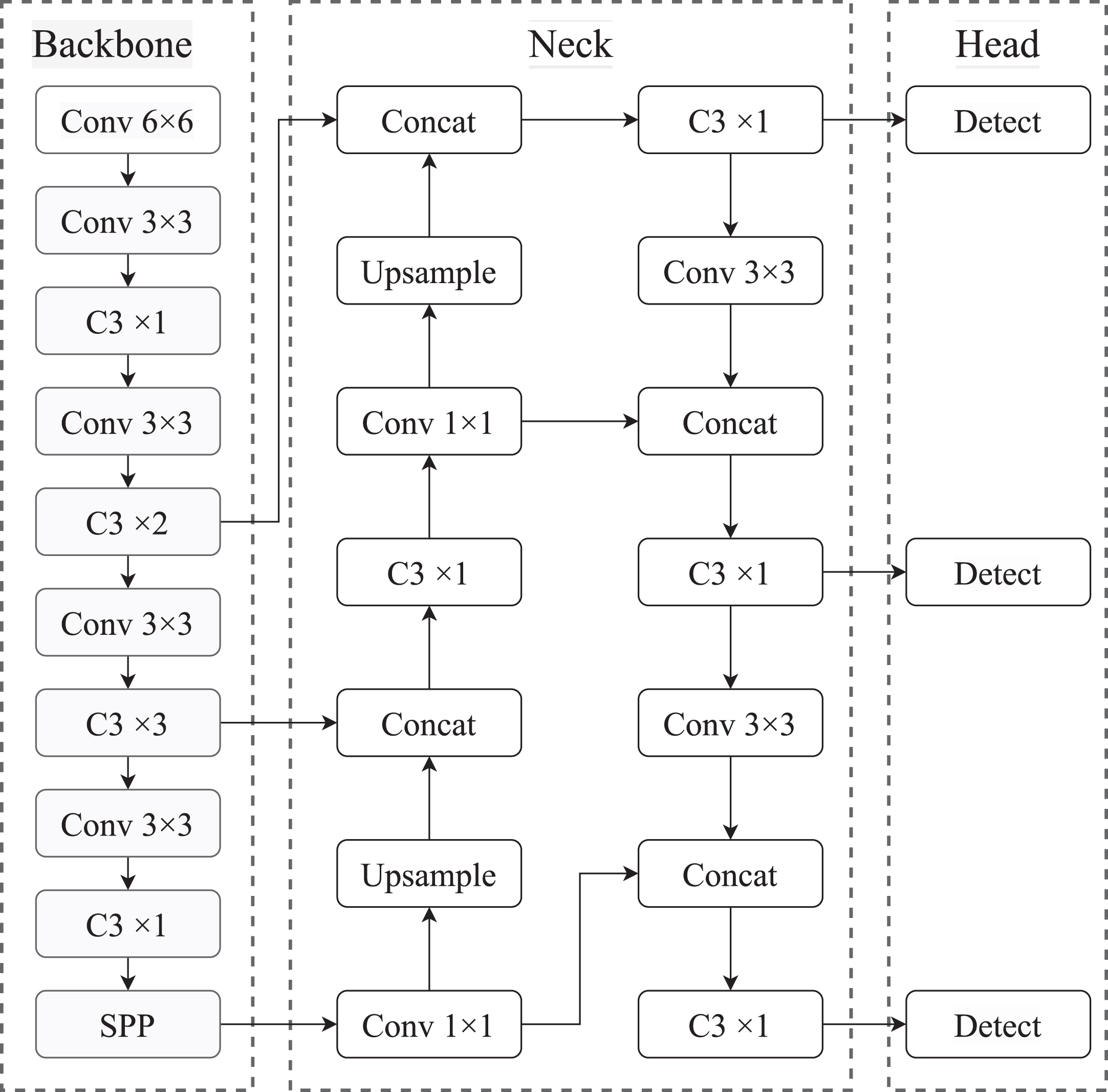
Network Structure of the origin YOLOv5n.
In Backbone, YOLOv5n uses CSPDarknet to extract rich feature information from the input images. The C3 module, which borrows the Cross Stage Partial structure from CSPNet [26], enhances the feature learning capability, reduces the computational effort of the network model, and optimizes the repetitive gradient information in network propagation. In addition, SPP [27] achieves feature fusion at different scales, which mines the contextual information more effectively. Assuming the input window of the network is 640×640, Backbone generates three feature maps at different scales, 80×80, 40×40, and 20×20, and then inputs them into Neck for feature fusion. In Neck, a feature pyramid is generated using PANet for the feature maps outputted by Backbone. PANet [27] uses a lateral join and upsampling operation to fuse shallow spatial and in-depth semantic features effectively. Secondly, a bottom-up path expansion is added to transfer the shallow features’ precise localization information to enhance objects’ detection capability at different scales. Finally, in Head, the output feature maps of the three scales are detected to generate the final output vectors with category probability, object score and bounding box. Then, according to NMS [28], the detection results of the three detection layers are filtered to get the final detection results.
In this study, we deployed the trained YOLOv5n model to Jetson nano for testing and found that its model size is 3.8MB, GFLOPs is 4.2, and the average inference time for a single image is 70.7ms. Although YOLOv5n balances detection accuracy and speed well compared to other versions, it wants to be deployed on resource-limited edge devices but still has some drawbacks, such as slow inference speed, large model, and extensive computation.
We have performed a lightweight optimization on YOLOv5n, yielding an enhanced version showcased in Fig. 2. The network architecture comprises three core components: Backbone, Neck, and Head. Within the Backbone segment, we substituted the fully connected layer in the MobileNetV3 block with a one-dimensional convolution utilizing adaptive dimensionality. This was followed by the reintegration of the refined MobileNetV3 block into the backbone of YOLOv5n. These adjustments notably curtailed both network computation and parameter count. The Neck segment predominantly incorporates two modules: Feature Pyramid Networks (FPN) and Path Aggregation Networks (PAN). FPN facilitates the transfer of semantic insights from deep to shallow feature mappings, while PAN conveys localization information from shallow to deep feature layers. The fusion of these modules significantly enhances the detection prowess of dense objects. Lastly, in the Head component, we streamlined efficiency by eliminating the maximum detection head, thereby reducing unnecessary computational overhead.
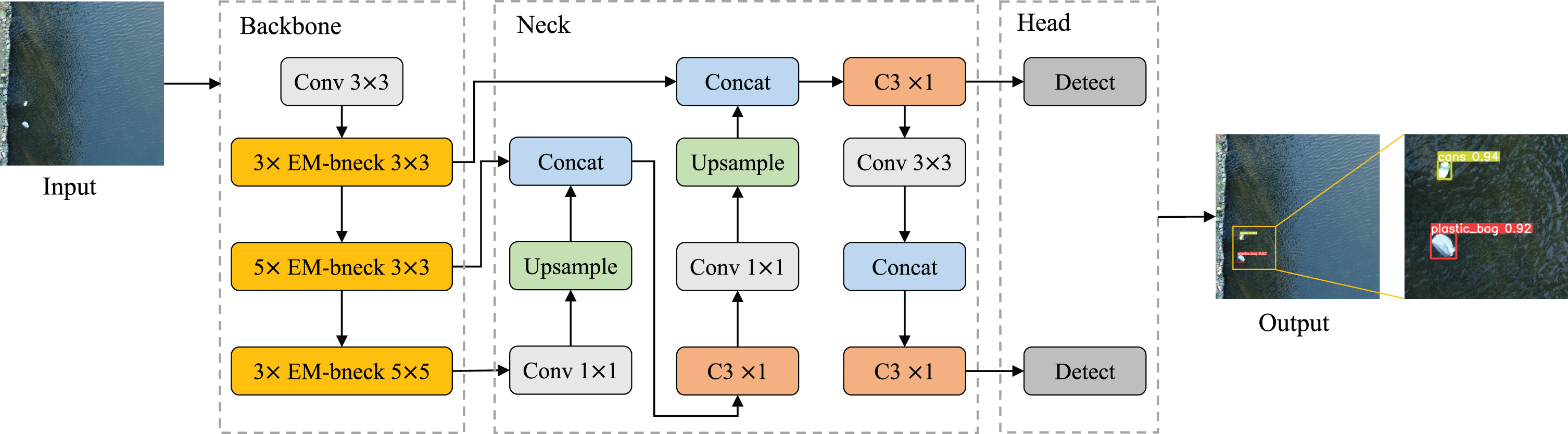
Network Structure of the Improved YOLOv5n.
The MobileNetV3 block is shown in Fig. 3. For the input feature matrix F, the feature information is first mapped into higher dimensions using 1×1 convolution for dimensional expansion. Then DW convolution is used for feature extraction to obtain the feature matrix F Dwise . Then, the feature matrix F Dwise is recalibrated by explicitly modeling the interdependencies between channels through the SE block. This attention mechanism allows emphasizing the information-rich features at the channel level and suppressing the less useful features. Finally, the output matrix is obtained by dimensionality reduction using a 1×1 convolution.
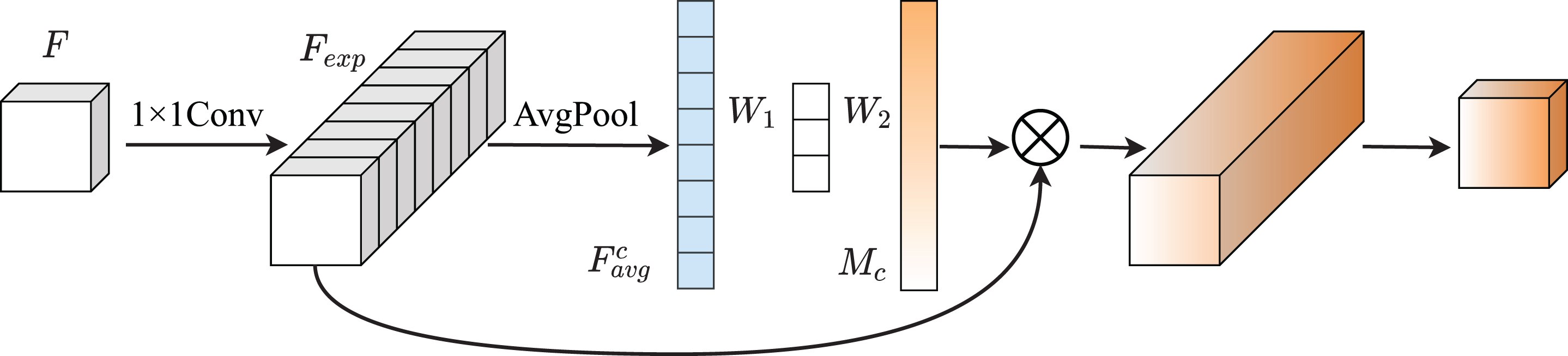
MobileNetV3 Block.
In the MobileNetV3 block, the SE block computes the channel attention map in the following steps. First, the feature matrix F
Dwise
is pooled globally at the channel level, and the global information is compressed into the channel to obtain the feature vector
ECANet [11] experimentally demonstrates that dimensionality reduction brings side effects to channel attention prediction for the fully connected layer in the SE block. Moreover, capturing the dependencies among all channels is both inefficient and unnecessary. Therefore, inspired by ECANet, we improve the channel attention in the MobileNetV3 block by replacing the fully connected layer in the SE block with an adaptive dimensional one-dimensional convolution, which can better capture global and local information while reducing the number of parameters. The improved MobileNetV3 block is shown in Fig. 4.

Efficient MobileNetV3 block.
After global averaging pooling in each channel in the feature matrix F
Dwise
, a one-dimensional convolution with adaptive dimensionality is used to aggregate the feature information within the k adjacent channels. Finally, the Hardswish function is used for activation to generate the channel attention map
Where σ represents the Hardswish function activation, C1D k represents the one-dimensional convolution, and k represents the size of the convolution kernel, where the value of k is calculated as follows.
MobileNetV3 has been accumulated from the first two generations of V1 and V2 and has excellent performance and speed. It is sought after by academia and industry and is more suitable for edge computing devices such as mobile embedded devices.
We restructure the backbone of YOLOv5n based on the Efficient MobileNetV3 block in subsection 3.3, borrowing the network structure of MobileNetV3-Small. The details of the reconfigured backbone are shown in Table 1. The reconstructed backbone has 12 layers in total, and we use the feature maps of the output of backbone layer 4, layer 9, and layer 12 as the basis for feature fusion.
Details of the restructured backbone
Details of the restructured backbone
As shown in Fig. 5, we analyzed our own constructed river floating debris dataset and found that most of the targets in it are more petite than 1/10 of the original image in size, which are small targets. In YOLOv5n, when the input size of the network input window is 640×640, the model will use detection heads of size 80×80, 40×40, and 20×20 for detecting small, medium, and large targets, respectively. Therefore, combined with the target size information in the dataset, we remove the detection head of size 20×20 used for detecting large targets to reduce the computational overhead and speed up the detection. The specific operation is shown in Fig. 2. After the 20×20 feature map is subjected to 1×1 convolution, upsampling, and fusion operations to transfer the deep semantic information to the shallow feature map, it will not be fused with the down-sampled feature map and output the feature map. After removing the detection head for detecting large targets, although the overall detection accuracy will be reduced, the computation of the model is reduced, and the detection speed is accelerated, which is in line with our aim of lightweighting the model.
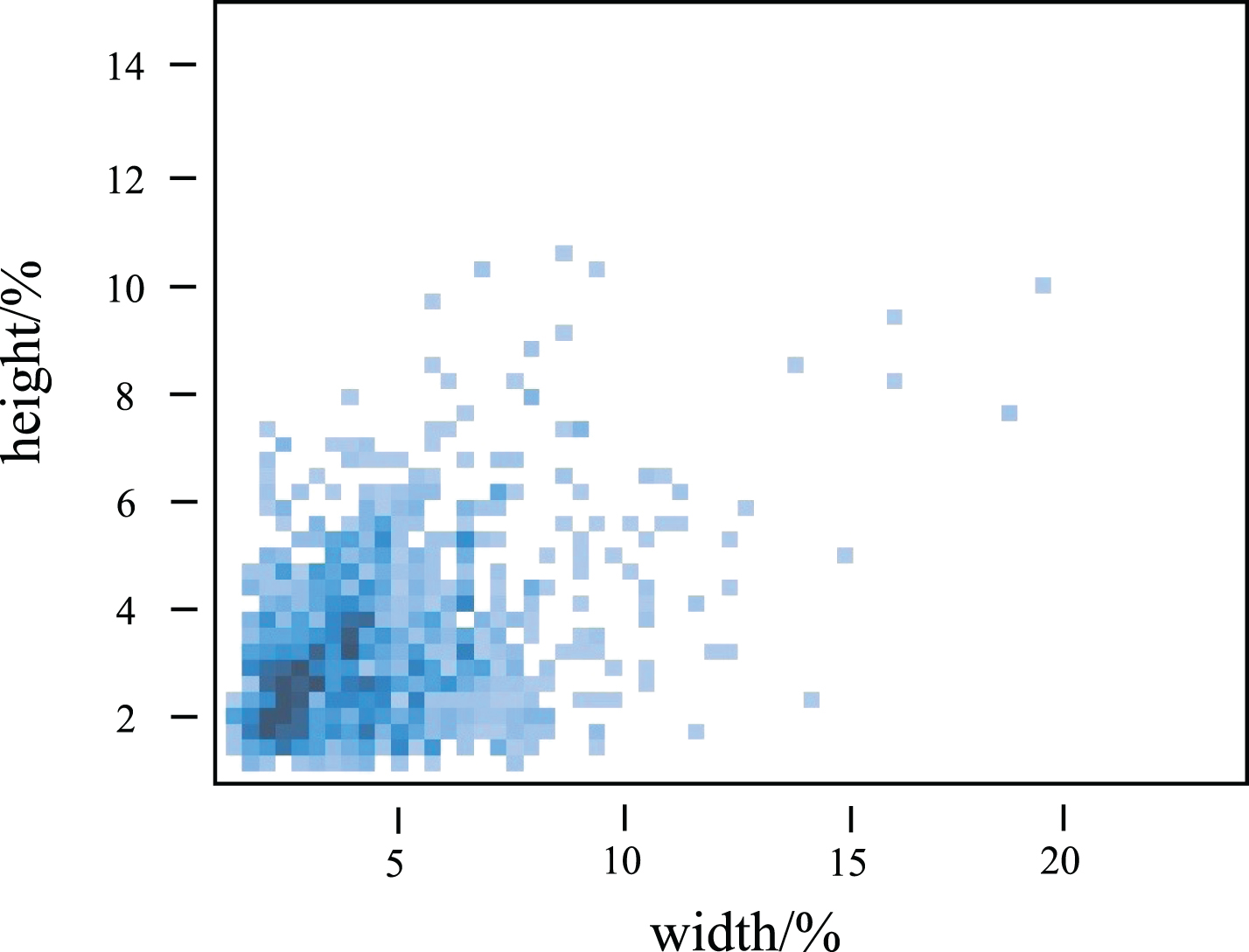
The ratio of the width and height of the floating debris in the dataset to the original image.
System overview
The overview of our system is as follows. First, we use a UAV to collect river images and then transmit the images to the server via 4G/5G module. On the server, we annotate the images to form a dataset, then train our model and select the best model. For the selected models, we deploy them on the Jetson Nano and then detect the images transmitted over WiFi/Bluetooth. For the detection results, we transfer them to the server for presentation. The system overview diagram is shown in Fig. 6. The dataset acquisition will be described in detail in 4.2, and the details of the experimental environment will be described in 4.3.
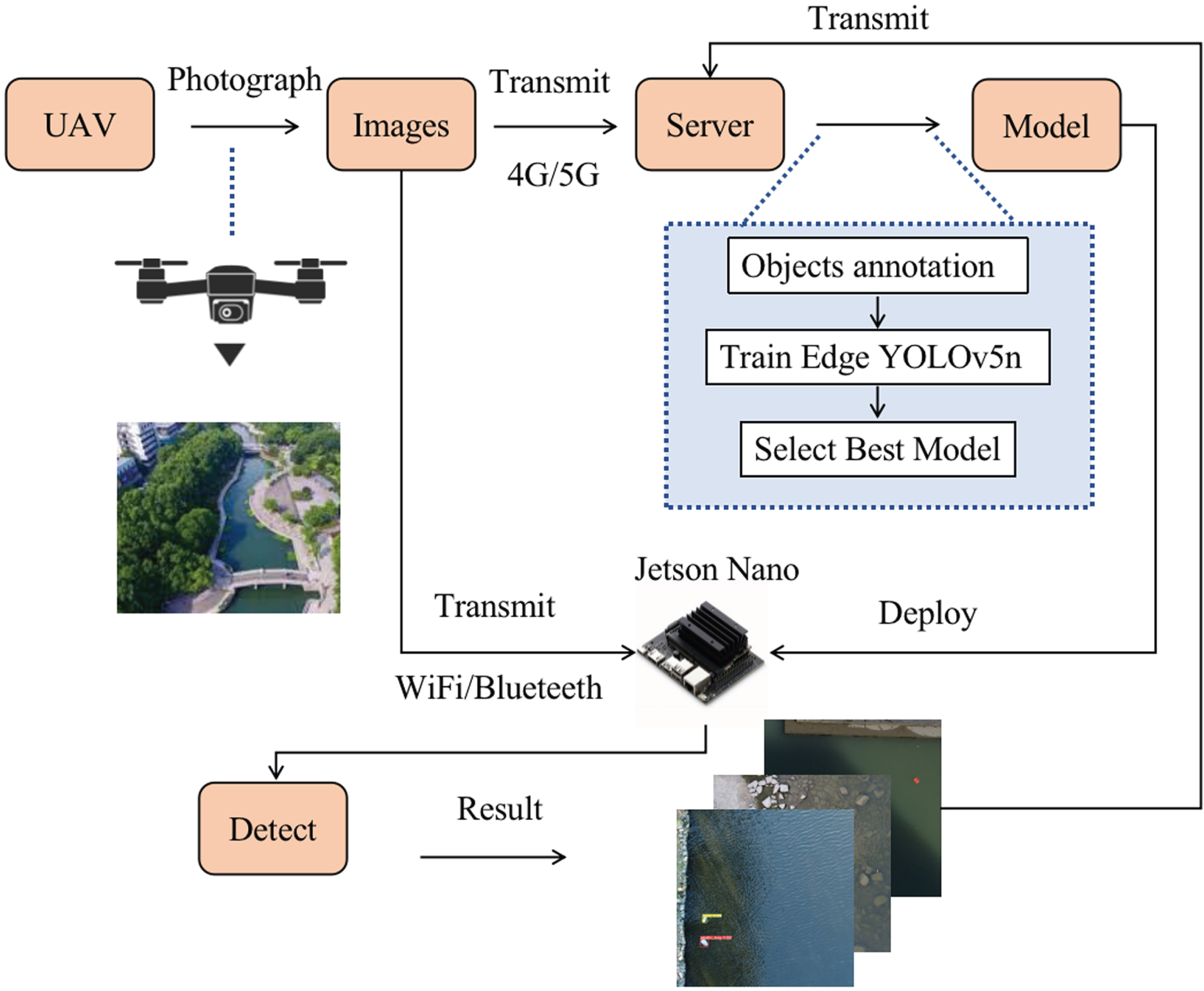
System overview.
The data used in this paper are all from the photography of the river in Ningbo, Zhejiang, China, by the DJI mini2 UAV. During the shooting process, the camera shooting angle is perpendicular to the river surface, the flying height is 7- 15 meters, and the camera resolution is 4000×3000. A total of 840 images of river floating debris were collected in this study, including five common types of floaters: plastic bottles, plastic bags, plastic cups, cans, and cartons.
Given the network’s challenge in training on high-resolution images, we adopted a strategy to enhance efficiency. Original images were divided using a sliding window of 1600×1600 and a step size of 800. This process yielded 1785 images after eliminating those lacking targets. Annotations were then added using LabelImg, adhering to the Pascal VOC format, with annotations stored as XML files. Specific annotation statistics are detailed in Table 2. To ensure robust training, the dataset was split into training, validation, and test sets in a 6:2:2 ratio. Notably, a snapshot of images from the dataset is showcased in Fig. 7, offering a visual insight into the data.

Samples of the dataset.
Details Of dataset
We trained and tested the model on a server with NVIDIA GeForce GTX 3080Ti (12GB RAM) GPU with Ubuntu 20.04.3 LTS, Pytorch1.8.1, cuda11.4.0, cudnn11.4 deep learning framework. We set the network input size to 640×640, batch size to 16, used stochastic gradient descent (SGD) [29] as the optimizer, initial learning rate to 0.01, weight decay to 0.0005, and momentum to 0.937. The maximum number of training iterations is 1000, and training is stopped when the mAP of the validation set does not improve for 60 consecutive rounds. During testing, an IOU threshold of 0.6 is applied to discard duplicate detection. After the model training was completed, we tested the trained model on the Server with Intel Core i7-11700 Processor and Jetson Nano, intending to obtain the inference time of the model on the embedded device. For inference, the input size of the network was 640×640.
Evaluation metrics
We use precision, recall, mean average precision (mAP), parameters, model size, FLOPs(Floating Point Operations), and speed as model evaluation metrics. Precision is used to measure the accuracy of model detection. Recall measures the comprehensiveness of model detection. Map reflects the global detection performance of the model, which is the average of each type of AP. AP can be obtained by calculating the area under the corresponding precision-recall curve. FLOPs is used to measure the computational complexity of the model, 1GFLOPs=19FLOPs. Speed is used to evaluate the detection speed of the model. These metrics are defined as follows.
YOLOv5 divides positive and negative samples by clustering or manually setting anchors and calculating the maximum aspect ratio of their width and height with respect to the target, comparing it to a threshold. Samples with a ratio less than or equal to the threshold are considered positive, while those with a ratio greater than the threshold are negative. True positive (TP) represents the number of positive samples that are correctly predicted, while false positive (FP) represents the number of positive samples that are incorrectly predicted as negative. False negative (FN) represents the number of negative samples that are incorrectly predicted as positive. AP computes the area under the Precision-Recall curve, and mAP@0.5 is the average of all categories APs at threshold IOU=0.5. N represents the number of debris categories.
Comparisons to YOLOv5n
To validate the efficacy of the refined backbone, we reconstructed the backbone of YOLOv5n using diverse lightweight networks while maintaining the Neck and Head unchanged. Subsequently, we evaluated the modified model’s performance under this setup. The results are summarized in Table 3, showcasing the outcomes of the reconstructed backbone model. With 1,092,389 parameters, a size of 2.5MB, and 2.2 GFLOPs, all smaller than the baseline, our model notably curtails the inference time from 34.4ms to 22.5ms on CPU and from 70.7ms to 61.4ms on Jetson Nano, all while incurring only a marginal 0.5% reduction in mAP. This empirically attests to the efficacy of our approach. Furthermore, the backbone reconstructed using MobileNetV3 proves particularly effective. For instance, the MobileNetV3L-reconstructed backbone boasts a 89.6% mAP, the highest in the table, reflecting a 1.7% improvement over the baseline—an affirmation of its superior feature extraction capacity. In this work, we evaluate the performance of MobileNetV3S for backbone reconstruction, observing a modest 1.3% mAP decrease after reconstruction but noteworthy inference time reduction. This substantiates our preference for enhancing YOLOv5n based on MobileNetV3S. The above analysis substantiates our model’s resource-efficient nature with a mere 0.5% mAP reduction while significantly cutting down CPU and Nano detection times by 11.9ms and 9.3ms, respectively, ultimately corroborating the potency of our approach.
Results of different backbone
Results of different backbone
Shifting focus to the rationale behind the designed Efficient MobileNetV3 block, we delve into a comparative exploration between YOLOv5n and Edge-YOLOv5n through the lens of feature maps generated by the backbone network. Taking a snapshot from the test set, as depicted in Fig. 8, where F k signifies the k feature map output from the backbone network, several insights emerge: (1) Network depth influences feature maps, shifting from texture to semantic representation. (2) Parallel levels in both algorithms yield analogous feature maps. F1 captures contours, F2 emphasizes textures, and F3 prioritizes abstract semantics. (3) Edge-YOLOv5n’s feature maps marginally weaken the depiction of floating debris compared to YOLOv5n. For instance, in F2, Edge-YOLOv5n’s texture expression is less distinct, and in F3, pixel value contrast between debris and surroundings is less pronounced than YOLOv5n.

The visualization of the impact of changes in the detection window on inspection performance.
Figure 9 unveils the detection outcomes, where both methods identify plastic bottles with a slight divergence of 0.01 in detection box scores. These findings underscore that while Edge-YOLOv5n’s backbone network’s feature extraction may slightly lag YOLOv5n’s, it retains remarkable efficiency. Moreover, Edge-YOLOv5n adeptly balances detection speed and accuracy, seamlessly aligning with the study’s requisites.

Visualization of YOLOv5n and Edge-YOLOv5n detect results.
To further measure the detection performance of this paper’s algorithm for river floaters from the UAV viewpoint, we compared it with YOLOX-Nano [30], FastestDet [31], YOLOv4-Tiny [17], NanoDet [32], MutualGuide [33] and PicoDet-M [34], which are lightweight objects detection models, under the same experimental environment, and the results are shown in Table 4. The experimental results show that the model’s performance in this paper is excellent, where the detection speed is the fastest, reaching 21.1 ms. Compared with YOLOX-Nano, YOLOv4-Tiny, NanoDet, MutualGuide and PicoDet-M, although the detection accuracy of the proposed model is slightly reduced, the model size and GFLOPs are both smaller than those of the compared models. It is worth noting that FastestDet’s number of parameters, GFLOPs, and Model Size is smaller than our model, but its mAP and Speed are not as good as ours. This may be due to the high parallelism of the network in FastestDet and the fact that it has more ReLU and ADD operations. Overall, the excellent performance of the models in this paper is again verified after the comparison.
Performance comparison with different detection models
Performance comparison with different detection models
The choice of detection window size is a trade-off between speed and accuracy. The larger the detection window, the higher the detection accuracy, but the slower the detection speed.
As shown in Table 5 and Fig. 10, the accuracy of detection decreases as the size of the detection window decreases, but the speed of detection increases. When the detection window size is less than 512, the detection accuracy decreases rapidly, and the detection speed is not significantly improved. Therefore, in practical applications, the detection window size can be set to 512 if the ultimate detection speed is pursued.
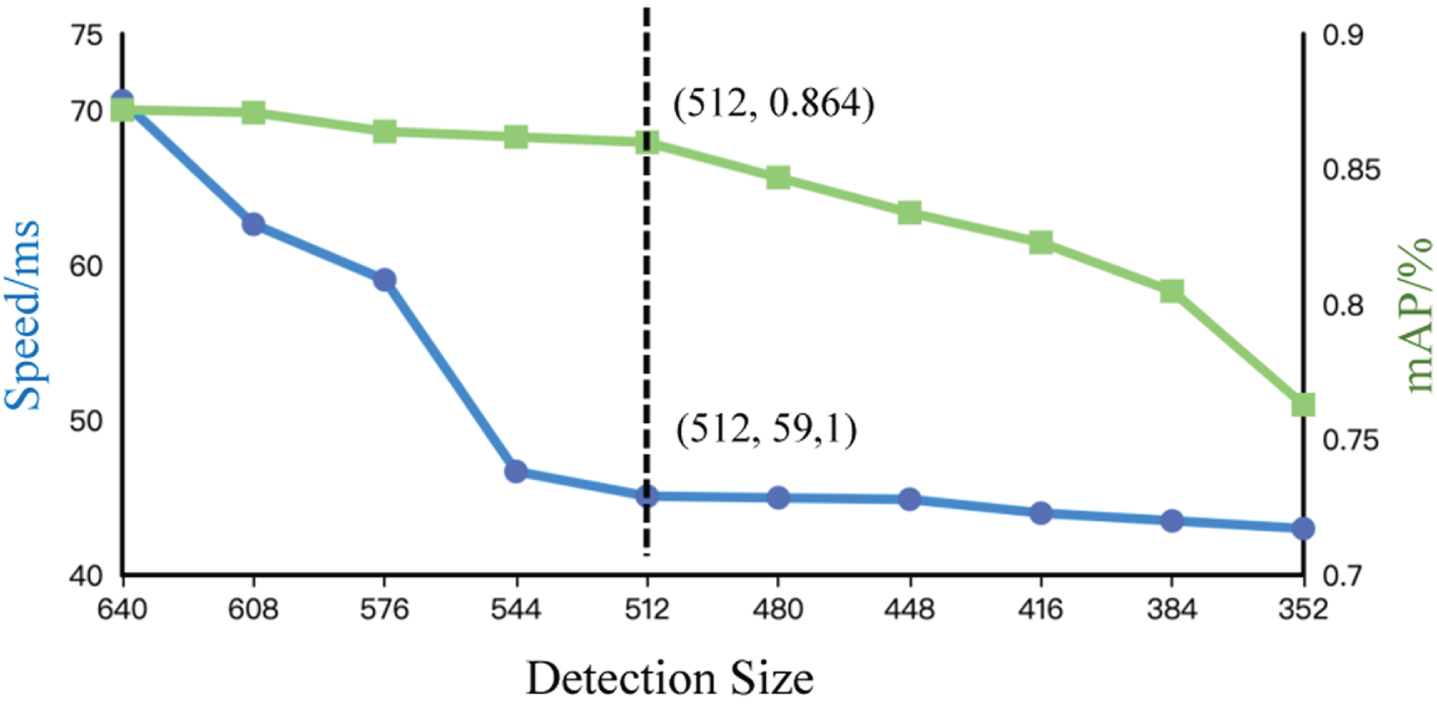
Illustration of the trends of mAP and Speed with detection size.
Performance comparison with different detection size
To understand more intuitively the effect of different improvement methods on the model performance, we conducted ablation experiments, and the experimental results are shown in the following Table 6.
Ablation study
Ablation study
Effect of E-MobileNetV3S: After refactoring
YOLOv5n’s backbone using the E-MobileNetV3S, the number of parameters is reduced from 1765930 to 1092389, the model size is reduced from 3.8MB to 2.5MB, and the GFLOPs are reduced from 4.2 to 2.2. Most importantly, the time to infer a picture is reduced from 70.7ms to 61.4ms, while the mAP only decreased by 0.5%. Our approach improves in all aspects compared to the backbone reconstruction using MobileNetV3S alone. It is essential to note that the mAP of the model improves by 0.8% while the inference speed is accelerated. The above analysis verifies that the reconstructed backbone can reduce the model size and speed up the inference speed while ensuring the accuracy of model detection.
Effect of 2detect head: Based on the reconstructed backbone, reducing one detection head for checking large targets decreases the number of parameters from 1092389 to 756995, the model size from 2.5MB to 1.8MB, the GFLOPs from 2.2 to 1.9, the time to infer a picture by 4.1ms, and the mAP of the model by only 0.2%. This validates that there are few large targets in this dataset and that reducing a detection head with the smallest scale is effective for lightweight river floater detection.
To achieve precise and timely river floater detection, we leverage UAVs to capture river images and propose a streamlined YOLOv5n-based method. Our approach addresses several key aspects. Firstly, we overcome dataset limitations by crafting a UAV-sourced river floaters dataset. Secondly, we enhance the YOLOv5n model by integrating the EMobileNetV3 block into its backbone, resulting in substantial reductions in computation and parameters. Moreover, we enhance detection efficiency by eliminating the detection head for large targets. Experimentation underscores the superiority of our model over YOLOv5n and other detection algorithms, bolstering its practical significance for river monitoring.
While our study advances river debris detection in aerial imagery and its efficacy, certain areas warrant further refinement. Firstly, the limited dataset’s potential to engender model dependency and constrain generalization to new data necessitates dataset expansion. Secondly, the challenge posed by obstructions like riverside trees demands investigation to enhance detection accuracy. Lastly, there is potential to reduce computational demands through AI and data optimization [35], and to enhance computing power through technological and paradigmatic shifts, which should be explored.