
Abstract
When the traditional evolution model studies the regional distribution of agricultural parks, the relationship between regions is not clear enough, which leads to the lack of generality of regional distribution. In order to solve this problem, this study adopts the methods of topological division and cluster analysis, establishes the model of regional diversity and evolution of farms, and clusters the spatial information of agricultural parks. According to the feature factors, the images are classified, and the image dimension values are reduced. The data space is divided into cellular space by the method of network topology structure division, and the effective coefficient of each cell is calculated, and the spatial structure and characteristics of agricultural parks are extracted to reveal the similarities and differences between different parks. The experimental results show that the evolution model of agricultural parks constructed by topological division and clustering method shows obvious clustering characteristics in space, and the relationships among the factors are good. It is proved that the model can describe the spatial differences and evolution trends of agricultural parks more accurately, so as to provide more targeted suggestions for the planning, management and sustainable development of agricultural parks.
Keywords
Introduction
Agricultural park is an important organizational form of modern agricultural production, which concentrates agricultural production activities in a geographical scope, and improves the utilization efficiency of resources and the quality of agricultural products by using intensive management mode and advanced technical means. Therefore, it is of great significance to analyze the spatial differences and evolution modeling of agricultural parks for optimizing resource allocation and improving the level of agricultural development [1–3]. In the appraisal of rural area development degree, one can generally choose a corresponding set of appraisal standards as criteria for its development. From a point of view, it is difficult to comprehensively evaluate the development of agricultural industry in a region from a perspective [4]. Based on the agricultural garden as a research unit, this paper makes a multi-angle analysis of the development of agricultural parks from various angles [5, 6]. Reference [7] analyzed the spatiotemporal evolution of food security guarantee efficiency in different functional areas using various methods such as DEA model, Thiel index, and Gini coefficient from three dimensions: grain production and sales, factor allocation, and production efficiency. However, the accuracy of the data in this method is affected by the quality of regional statistical data, which may lead to incorrect results. Reference [8] cites the land use data and nighttime lighting data to construct an evolutionary model. However, in practice, the universality of this method is very poor, which indicates that it is inconsistent with the index, and the role of data clustering is not significant, especially the clustering degree and collaboration degree in space are poor. Reference [9] combines static spatial metrology model with dynamic panel model by exploring spatial data. However, this method cannot overcome its universality. Reference [10] used the super efficiency DEA method to calculate 21 cities and states, and constructed a theoretical model of environmental friendly agricultural production efficiency factors using the STIRPAT theoretical model. The spatial Durbin model was used for empirical analysis. However, this method has issues with incomplete and inaccurate data. Reference [11] uses InVEST model to spatially quantify the heat mitigation, runoff conservation, sediment conservation, landscape quality, urban entertainment and urban agriculture in the rapidly developing suburban catchment area of Greater Kuala Lumpur, Malaysia. Determine the synergy and trade-off between services, and evaluate the coexistence and overlap of hot spots among multiple services to complete sustainable land use management. However, when this method is used for spatial quantification and evaluation, it needs to rely on a large amount of data for quantitative indicators and trade-off methods of different services. Reference [12] puts forward an es analysis framework, which links the service flow generated by the interaction among nature, human resources and social capital with the consumption related to potential beneficiaries. The feed production, local climate control (PM10) and carbon sequestration in three national parks (Aspromonte National Park, Circeo National Park and Appennino Tosco Emiliano National Park) were analyzed. On the basis of space, the supply and demand of a specific watershed can be quantified by using synthetic indicators, and the balance of land supply and demand can be achieved by calculating the ratio of supply and demand of ecosystems. However, this method needs to consider the influence of spatial scale, and different spatial scales may lead to the change and inconsistency of supply and demand results. Reference [13] uses the concept of risk to establish a disaster model of climate, society, economy and environment factors, and completes the controllable setting of geospatial indicators through risk assessment, effectively reducing risks and implementing appropriate space-time actions. However, this method needs to fully consider the reliability and uncertainty of data to ensure the accuracy and availability of data.
Traditional research on the regional distribution of agricultural parks often uses evolutionary models, but due to unclear relationships between regions, there is a lack of generalized regional distribution; At the same time, traditional methods also have the problem of not being fast and accurate enough in processing unstructured large datasets. To address these issues, this study employed methods such as topology partitioning and cluster analysis to establish an agricultural park evolution model that can consider regional diversity. The data space was divided using network topology structure partitioning and the unit effective coefficient was calculated. This method has advantages in processing unstructured large datasets and studying the regional distribution of agricultural parks. The selection and layout of agricultural parks are not only related to the benefits of agricultural production, but also related to regional planning and land use. Through topological segmentation and cluster analysis, we can reveal the spatial differences and similarities between different parks, and provide scientific basis for rational planning and optimization of land resources. Deepen the understanding of the development law of agricultural parks and optimize the utilization of agricultural resources, and provide scientific support for improving the efficiency and sustainable development of agricultural production.
The main contributions of this paper:
(1) The clustering results are represented by a matrix, and the distances between the spatial data and the center are compared. The spatial distribution of agricultural parks is divided by similarity matrix, and the spatial information of agricultural parks is extracted by selecting the eigenvectors of normalized Laplacian matrix, and the spatial data collection is completed. Solve the problem that data clustering is not obvious in the process of feature vector mapping.
(2) The labeled low-dimensional image data of agricultural parks are classified by topological method, and the spatial image subgraphs of agricultural park data are classified. Realizing the classification and comparison of different agricultural parks will help to deeply understand the spatial differences and characteristics of agricultural parks and provide more accurate information and decision-making basis for agricultural development. By mapping high-dimensional data to low-dimensional space, the complexity of data processing and analysis is effectively reduced, and the problem of visual analysis of image subgraphs in agricultural park data space is solved.
(3) Construct the evolution model of spatial diversity based on unit space, comprehensively consider the contribution of each unit space, and optimize the unit space model of orthogonal efficiency evaluation by evaluating the cross effect of spatial sustainable development. At the same time, according to the overall comparative efficiency of low-dimensional space, the regression equation is used to solve the coordination variables, and the evolution model of agricultural regional diversity is further constructed. It provides a powerful tool and framework for studying the spatial characteristics, sustainable development and diversity evolution of agricultural parks.
Spatial difference and construction of evolution model of agricultural and forestry park
Spatial data acquisition of agricultural garden based on clustering technology
The k-means algorithm is the most widely used clustering algorithm. It takes the mean value of all data samples in each cluster subset as the representative point of the cluster, divides the data set into different categories through the iterative process, makes the measure function of evaluating the clustering performance reach the optimal, and thus makes each generated cluster compact and independent between clusters. A matrix is established to represent the clustering results:
Where,
Given the spatial data set X ={ x i |i = 1, 2, . . . , M } of agricultural gardens, xi1, xi2, . . . , x in in the spatial data sample x i = (xi1, xi2, . . . , x in ) of agricultural gardens represents n attributes of x i . If the distance d (x i , x j ) between x i and x j is smaller, the x i and x j of samples are more similar and the difference is smaller. If the distance is larger, the sample x i and x j are less similar, and the difference degree is larger.
It is assumed that the spatial data set X of agricultural landscape contains k clustering subsets X1, X2, . . . , X
k
, the sample numbers in each clustering subset are n1, n2, . . . , n
k
, and the representative points of the mean values of each clustering subset are m1, m2, . . . , m
k
. The similarity matrix was established to divide the spatial distribution of farmland parks:
Where,
Where,
Error sum of squares function refers to the sum of squares of distance from each sample point p to each cluster center m. Draw the spatial information of agricultural gardens according to the sum of error squares function, and complete the spatial data collection of agricultural gardens:
On this basis, several nodes are connected together to make the data points of each cluster space consistent with a node in the figure, and complete the spatial data collection of agricultural gardens [11–14].
Spatial data is presented as classes. Using the different farm park, the data in the park are classified and processed, and the unit space is zoned. The number of connected edges between graphs is positively correlated, that is to say, the more connected edges, the larger the cell space. When dividing a graph, the division of any isolated node will be smaller than the division of a larger subgraph of the class in which the node belongs, so it is easy to generate the division result of isolated points under this objective function. On this basis, a method of farmland region division based on topological division technology is proposed. A topology is an abstract place where different objects are represented. In the network, topological structure vividly depicts the layout and structure of the network, as well as the relationship between the various nodes. Since the end user communicates through a central workstation, this topology is advantageous to central control. Meanwhile, the utility model has the advantages of convenient use, convenient use, convenient use, etc. In this paper, a directed graph is divided into m blocks based on topological partition. Each block contains a directed tree, thus the best clustering result is obtained. It is assumed that the 3-D stereogram generated by clustering operation is F and F′ ⊂ F is a subset of all F data. The partition set {F0, F1, … , Fk-1 } of F divides the 3D region into k region, which is expressed by ∑ ={ R0, R1, …, Rk-1 }, the exponential set is expressed by η ={ 1, 2, …, k }, and the marker set is expressed by F ={ 1, 2, …, N }. Specify a unique tag for each item on the F set:
Where, e (i)represents an image on a lower dimension. If you know the set of tags, the position below the tag is χ = η × η × … × η = η N , and e i can generate an object partition in the state space [15]. Many regions can be obtained by dividing the low dimensional domain in farmland. The area varies from unit to unit. Based on this, the spatial variation models of different types of agricultural and forestry parks were established.
After spatial zoning, a spatial diversity evolution model based on cell space is established. In the space of each unit, there is a lot of spatial information, including an input exponent and an output exponent represented by x
a
= (x1j, x2j, …, x
ij
) and y
a
= (y1a, y2a, …, y
ij
). The efficiency numerical δc0 for each unit was solved using the following formula:
Where, ɛi0, δc0 and δ are the combination of differential c difference minimization and optimization. Based on the calculation results of each unit, the cross-effectiveness evaluation of spatial sustainable development is obtained. The specific expression is:
According to the above calculation method, the evaluation result of j unit sustainable development is obtained. Then, the cross effectiveness of other areas is analyzed. Its formula goes as follows:
By optimizing formula 11, the unit space model of orthogonal efficiency evaluation is obtained:
Through orthogonal efficiency evaluation unit space model, the overall comparative efficiency of space utilization in the lower dimension range is deduced, and the specific expression is:
In the formula, λ j represents a coordinated variable. Finally, optimization results are solved by regression equation, and the optimization evolution model is obtained.
On this basis, a regional diversity and evolution model of agricultural garden is established by using topological partitioning and clustering method.
Example test environment
All experiments in this paper were carried out on the MatlabR2010a platform, the interval number of each attribute in the fixed positive specification structure was 5, and the sample frequency was 10 min once. The experiment collects spatial data through ArcGIS, inputs it into MATLAB programs, and uses built-in and open-source function libraries to perform preprocessing operations such as data cleaning, conversion, and encoding. And conduct exploratory analysis, variable selection, principal component analysis, and other feature analysis operations on the data. Use k-means clustering algorithm, and use the scikit-learn class library of Python language for cluster analysis. Apply Gephi software to construct and analyze complex networks, and visualize them through UCINET. Use MATLAB to analyze the operational status, human resources, material resources, technical status, and other aspects of the clustering unit, and calculate the unit effectiveness coefficient. Write a calculation program for evaluation indicators using data analysis software and Python programming language, and conduct cross validation and comparison of the model. This article analyzes the impact of different spatiotemporal evolution patterns on practice through a comparative experiment on the central farm park of a county in Chongqing. The test case is shown in Fig. 1.
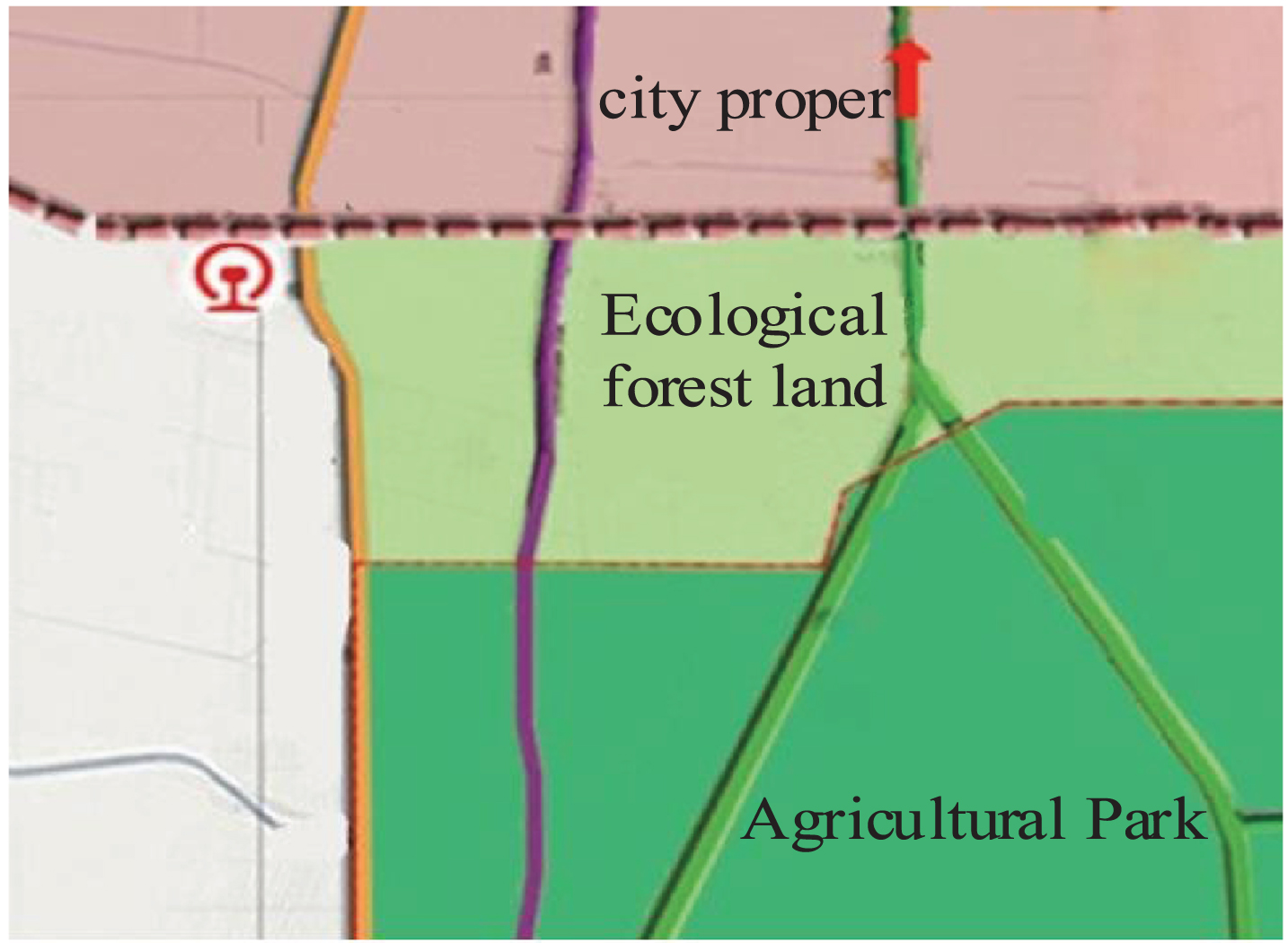
Experimental case agricultural park.
The terrain of this area is flat, wide, suitable for the construction of agricultural parks, and low land prices, near rivers and lakes or precipitation more, rich in water resources, beautiful environment, pleasant climate.
In order to verify the spatial difference and evolution modeling effect of agricultural parks, spatial data clustering, synergistic effect, operation time and topological structure are set as evaluation and verification indicators. Spatial data clustering refers to the process of classifying or grouping the spatial units of agricultural parks. By clustering the spatial units of agricultural parks, the spatial differences and similarities between different parks can be revealed. Synergistic effect refers to the interaction and cooperation effect between different agricultural parks. Synergistic effect can reflect the complementarity, resource sharing and cooperative development level between different agricultural parks, which has an important impact on the spatial difference and evolution modeling of agricultural parks. Computing time refers to the computing time required to model the spatial differences and evolution of agricultural parks. The length of computing time can reflect the complexity and computational efficiency of the model, and evaluate the practicality and operability of the model. Topological structure refers to the spatial relationship and connection mode between the spatial units of agricultural parks. Topological structure can reflect the geometric characteristics and interrelationships of the spatial pattern of agricultural parks, which is of great significance for analyzing the spatial differences of agricultural parks and the stability and reliability of the evolution model. Selecting these four indicators for evaluation and verification can reflect the spatial differences of agricultural parks and the key elements of evolution modeling from different aspects. Spatial data clustering and topological structure can help to identify and describe the spatial differences and patterns between parks, synergy can evaluate the level of cooperation and development between parks, and computing time pays attention to the computational efficiency and practicability of the model. By comprehensively considering the evaluation results of these indicators, we can fully understand the characteristics and effects of spatial differences and evolution modeling of agricultural parks, and provide a basis for further optimization and improvement. On this basis, the method in reference [11] and the method in reference [12] are compared to verify the overall effectiveness of this method, and the three methods are compared and analyzed from the perspective of spatial data clustering effect.
Spatial data clustering analysis
In order to verify the effectiveness and superiority of the method proposed in this paper in spatial data processing of agricultural parks, spatial data was imported into each evolutionary model and used as experimental variables to cluster the data. The experimental results are shown in Fig. 2.
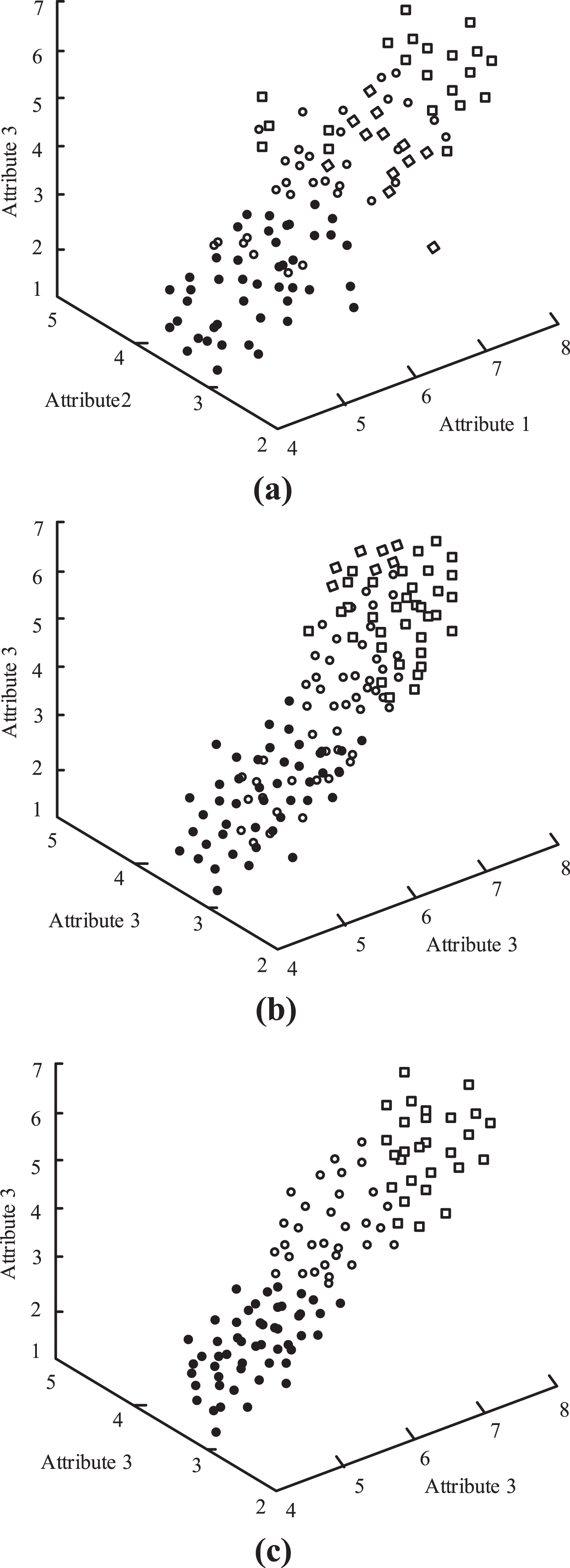
Data clustering results of different methods.
As can be seen from Fig. 2, the spatial data clustering effect of the proposed method is good. In the process of clustering, the data clustering separation of fields 1, 2 and 3 is high, and the data edge is [4, 8]. However, the data edges of fields 1, 2 and 3 in the clustering process of reference [11] are [6, 7], while the data edges of fields 1, 2 and 3 in the clustering process of reference [12] are [2, 8]. This is because the method in this paper establishes real-time feature matrix according to the minimum distance between different clusters, reduces the data dimension through feature vector mapping, and improves the degree of data clustering separation. It is proved that the proposed method can cluster all spatial data of agricultural parks. This is because this method uses image processing software to perform edge segmentation on the image, which effectively separates the edges of the data during the clustering process, thereby avoiding the problems existing in the reference [11] method. Through edge segmentation processing, we can effectively divide the data similarity, so as to better carry out spatial cluster analysis. At the same time, this method divides the data space into grid based topological structures, which can avoid the data confusion problem that occurs when the data density is high in the reference [12] method. By dividing the data space into grid based topological structures, data can be better grouped and spatial information clustering maps of agricultural parks can be constructed.
In agriculture and forestry, there are many different ecological environments. There are many different plants in different ecosystems. Every creature is in a separate space and time. In different regional evolution, different species of plants will have different responses in different regional evolution, and then affect their spatial morphology. The spatial variation and evolution pattern of each population were evaluated, and the change law of each index was evaluated, and the change law of each index coincided with the evolution law. The differences of each evolutionary model are analyzed, and the evolution details are analyzed. The calculation of this difference is as follows:
Among them, s represents the index score,
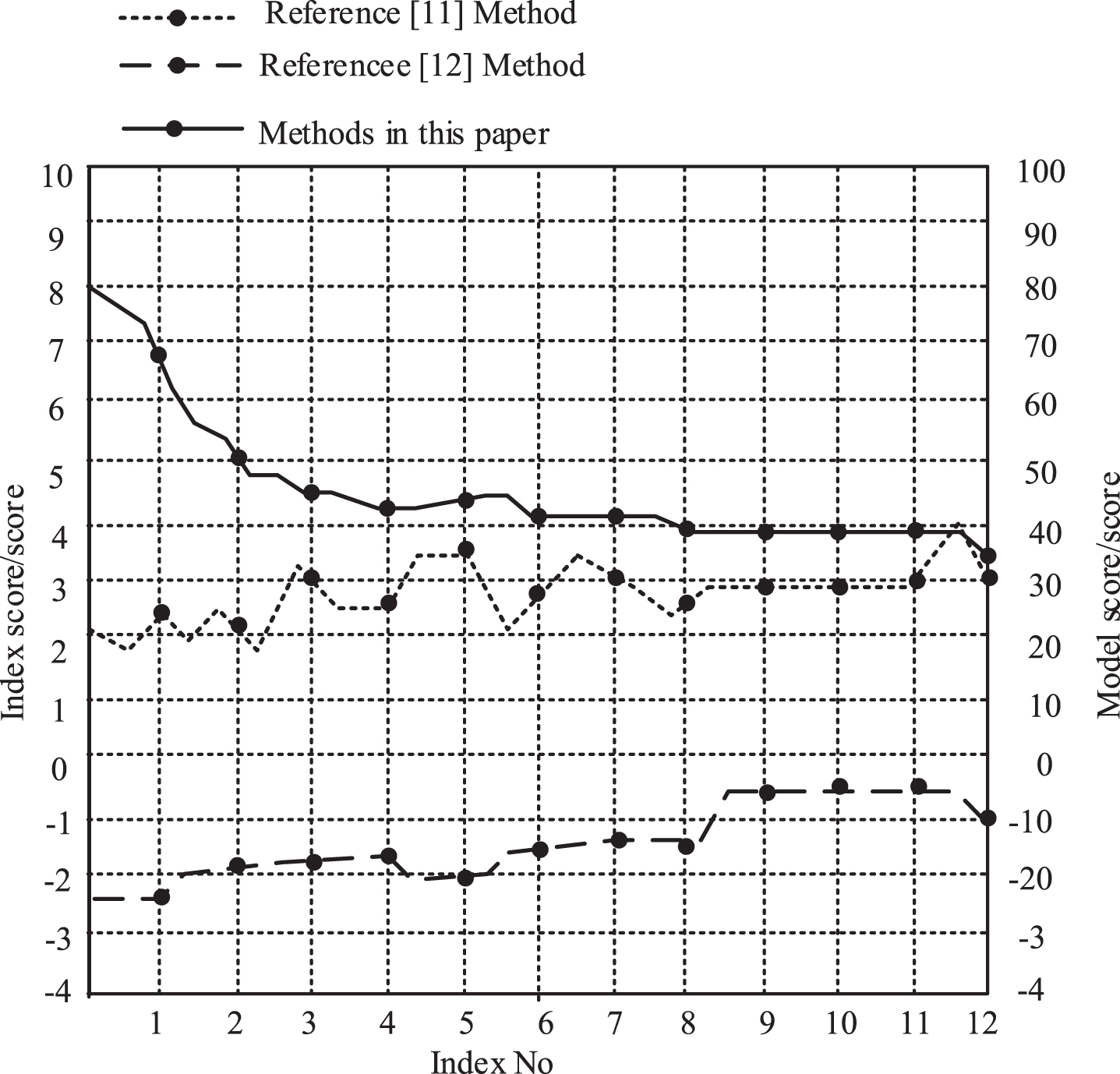
Synergistic results of different methods.
As can be seen from Fig. 3, as the number of indicators increases, the index scores and model scores of different methods both show a downward trend. However, the decline range and fluctuation trend of the method in this paper are lower than those in reference [11] and reference [12]. When the index value is 12, the index score of the method in this paper is 3.5, and the model score is 35. The index score of the method in reference [11] was 3.5, and the model score was 40. The index score of the method in reference [12] was –2.2, and the model score was –10. This is because in the process of spatial data processing, the method in this paper marks low-dimensional image data of agricultural parks based on topological division, maps high-dimensional data to low-dimensional space, and improves the spatial image processing and analysis ability of agricultural parks data. It is proved that the method in this paper has good consistency.
Classify and label the data in the space of agricultural park, and take the running time as the verification standard. The more data are classified and marked, the better the effect of the method will be. On the premise of efficiently dividing the space, the less running time, the better the comprehensive effect of the method will be. The data processing time of this method, the method of reference [11] and the method of reference [12] are tested. On the basis of evolution, the overall effectiveness of this method is verified. Table 1 shows the experimental results.
Operation time results of different methods
Operation time results of different methods
According to Table 1, the bin counts for the three different schemas do not differ significantly. When the number of boxes increases, the operation time will be extended. Experimental results show that the proposed algorithm is fast and has an obvious number of feature boxes, which can effectively ensure the accuracy and effectiveness of the model. This is because the method of this paper establishes the evolution model of agricultural regional diversity, divides the agricultural region into multiple unit spaces, improves the overall comparative efficiency of low-dimensional space utilization, and then reduces the running time.
Set the topo-mesh (KP = 0.026) random topology as the underlying physical network of agricultural garden space. In the topology network, the average node resource ratio is 0.5 and the lifetime is 480. Calculate the mapping of different algorithms in the face of virtual requests, that is, request acceptance. The highest value of request acceptance is 1, and the higher the value is, the more stable the algorithm topology is. The experimental results are shown in Fig. 4.
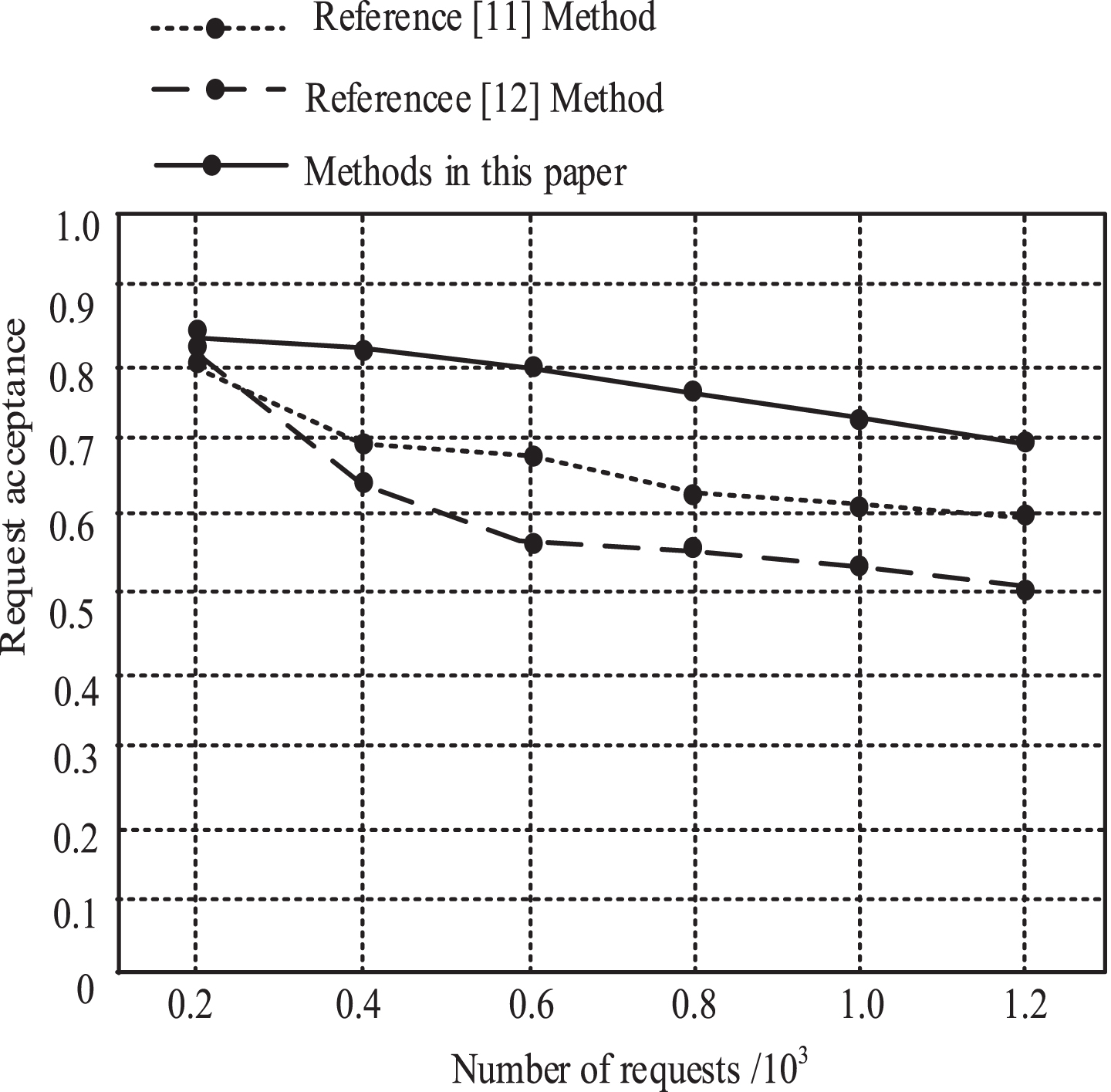
Synergistic results of different methods.
As can be seen from Fig. 4, as the number of requests increases, the request acceptance rate of different methods decreases. When the resource utilization rate reaches the utilization limit, the request acceptance rate drops slightly, which can be maintained at about 0.7, and the overall effect is better. However, the request acceptance rate of reference [11] method and reference [12] method decreased significantly, and the request acceptance rate was 0.6 and 0.5. This is because the proposed method established the similarity matrix to divide the spatial distribution of farmland parks and improved the mapping performance. It is proved that the method proposed in this paper is superior to the evolution process of spatial topological structure of agricultural gardens.
The research on spatial differences and evolution modeling methods of agricultural parks based on topological segmentation and cluster analysis provides important theoretical and practical guidance for agricultural development. By analyzing the spatial differences of agricultural parks, we can better understand the characteristics and differences between different parks, so as to formulate targeted agricultural development strategies. The spatial structure and characteristics of agricultural parks are comprehensively analyzed by the method of topological segmentation and cluster analysis, and the similarities and differences between different parks are revealed. At the same time, the evolution model is established to simulate and predict the development process of agricultural parks, which provides reference for the planning, management and sustainable development of agricultural parks.
However, there are still some limitations in this study. The data used may be incomplete and inaccurate. Therefore, in the future research, it is necessary to further improve the data acquisition and processing methods and explore more accurate and reliable model building methods. Through continuous in-depth research and exploration, the model is better applied to the planning of agricultural parks and contributes to the sustainable development of agriculture.
Fund
The study was supported by “ The key project of construction science and technology of Chongqing Municipal Commission of Housing and Urban Rural Development “Research on Chongqing Mountainous Urban Farm Planning Based on the Rural Revitalization Strategy” (Grant No. CZK 2021 No. 6-6)”.
Conflicts of interest
The authors have no relevant financial or non-financial interests to disclose.
Data availability statement
The data used to support the findings of this study are available from the corresponding author upon request.