
Abstract
In this paper, a novel semi-supervised fuzzy clustering algorithm, MFM-SFCM, based on a membership fusion mechanism is proposed for Diffusion-weighted imaging (DWI) brain infarction lesion segmentation. The proposed MFM-SFCM algorithm addresses the issue of weakened constraints and insufficient influence of labeled samples on the clustering process that arises in the semi-supervised fuzzy C-means clustering (SFCM) when emphasizing supervised information. By using a new membership fusion mechanism, MFM-SFCM eliminates this issue, greatly improving the accuracy of clustering results and accelerating convergence speed. This allows fuzzy clustering to achieve good results in the segmentation of DWI brain infarction lesions using a small amount of labeled information. The effectiveness of the MFM-SFCM algorithm is demonstrated through experiments conducted on a real-world dataset of DWI brain images.
Keywords
Introduction
Traditional clustering is an unsupervised machine learning method that divides samples in a dataset into several subsets based on the principle of similarity. Clustering can effectively discover hidden structures and patterns in data, providing valuable information for data analysis, mining, and understanding. Clustering is a common image segmentation technique that can group pixels with similar features or attributes into the same category, enabling recognition and extraction of image content or targets. However, image segmentation is a very complex and challenging problem because image data typically has high dimensionality, noise, redundancy, and low contrast, resulting in unclear or discontinuous boundaries between different categories in the image [1].
To address these issues, traditional fuzzy clustering algorithms have been proposed [2]. They are unsupervised clustering algorithms based on the concept of soft partitioning, where each sample belongs to multiple subsets with different memberships, better reflecting the potential fuzziness and uncertainty in the data. Fuzzy clustering algorithms can enhance the flexibility and robustness of clustering results, making them suitable for handling complex situations such as noise, outliers, and overlapping regions. Commonly used fuzzy clustering algorithms include Fuzzy C-means (FCM) algorithm [2], Possibilistic C-means (FPCM) algorithm [3], Fuzzy Adaptive Resonance Theory (FART) algorithm, Feature Weighted Entropy-based Feature Reduction Fuzzy Clustering Algorithm (FRFCM) [4, 5], etc., which have been commonly utilized in tasks such as image segmentation [6–17].
Despite the advantages of fuzzy clustering algorithms, they still have limitations, primarily due to the disregard of prior knowledge or label information that may exist in the data. In practical applications, useful auxiliary information can often be obtained through expert knowledge or a small amount of annotation. This information can help guide and constrain the clustering process, thereby improving the clustering performance. Therefore, Pedrycz proposed a semi-supervised fuzzy clustering algorithm [6, 18–21], initially referred to as “partially supervised". This clustering algorithm uses an objective function that incorporates a supervised component of labeled samples into the FCM’s objective function, forming the semi-supervised FCM algorithm (SFCM). Therefore, it is a clustering algorithm that combines the advantages of unsupervised learning and supervised learning, utilizing a handful of labeled samples to improve fuzzy clustering algorithms. This kind of fuzzy clustering algorithms can effectively utilize label information to adjust membership functions, optimize objective functions, or add constraint conditions, thereby enhancing clustering accuracy and stability [22]. Commonly used semi-supervised fuzzy clustering algorithms include SFCM [18], Semi-supervised Fuzzy Possibilistic C-means (SFPCM) [23], etc. [24].
We proposes a novel semi-supervised fuzzy clustering algorithm based on a membership fusion mechanism for the segmentation of brain infarction lesions in DWI images. Acute cerebral infarction is a common and prevalent disease in clinical practice, characterized by the necrosis of brain tissue due to the sudden interruption of cerebral blood supply. Diffusion-weighted imaging (DWI) can reflect the diffusion changes of water molecules in the local ischemic area by applying diffusion-sensitive gradient fields. In acute cerebral infarction patients, the brain tissue experiences ischemic reactions, resulting in insufficient cerebral blood flow and restricted diffusion of free water molecules. This characteristic is manifested as high signal intensity and decreased Apparent diffusion coefficient (ADC) values in DWI images. Therefore, DWI has high sensitivity for the early clinical diagnosis of brain infarction and is one of the main techniques for diagnosing brain infarction patients [25]. When clinically evaluating patients with acute-stage (within one week of onset) brain infarction, the location, size and shape of lesion areas are closely related to the extent of functional impairment in the patients, serving as crucial reference factors for planning clinical treatments. Precise segmentation of brain infarction lesions is an essential preprocessing step for assessing patient conditions. However, the complicated and variable edema surrounding the infarction makes the entire brain infarction lesion exhibit fuzzy boundaries, irregular shapes, and uneven internal brightness in DWI images, posing challenges to exact segmentation of the lesion. Therefore, it is of great clinical significance to accurately segment the brain infarction lesions in the acute stage of patients on DWI images for image-assisted evaluation. Thus, in this study, our goal is to develop a novel algorithm that is more effective, faster, and more accurate than traditional clustering algorithms [26] for segmenting brain infarction lesions, especially with limited supervised information available.
The innovations of this research are listed below: 1) We identified a problem in the SFCM algorithm, where the influence of labeled data on the clustering centers is weakened when the membership of labeled samples is close to the known membership. 2) To address this issue, this paper proposes a semi-supervised FCM algorithm based on a membership fusion mechanism (MFM-SFCM). This algorithm eliminates the aforementioned problem and significantly improves the accuracy and stability of the clustering results. 3) Through experiments conducted on a real-world dataset of brain DWI images, we prove the superiority of MFM-SFCM. This allows fuzzy clustering to achieve good results in the segmentation of DWI brain infarction lesions using a small amount of labeled information.
Related work
FCM algorithm
In the field of objective function-based clustering algorithms, FCM is the most well-developed and widely used. This algorithm applies fuzzy techniques to K-Means. Let X be the set of objects to be classified, represented as X = {x1, x2 … x
n
}. Each sample (pattern) x
i
has f feature indicators, denoted as (xi1, xi2 … x
ij
), X ∈ Rn×f. X is divided into c clusters (2 ⩽ c ⩽ n), and a matrix V composed of c cluster center vectors is represented as V = (v1, v2, …, v
c
)
T
, V ∈ Rc×f. To get the optimal fuzzy classification, a fuzzy classification matrix U is selected from the fuzzy classification space M
fc
to make the objective function minimal:
Where k = 1, 2, …, n ; i = 1, 2, …, c
The obtained fuzzy classification matrix U(l+1) and cluster center matrix V(l) are local optimal solutions relative to the number of clusters c, the initial fuzzy classification matrix U(l), the convergence threshold ɛ, and the fuzziness index m.
The quality of semi-supervised clustering results is strongly associated with the availability of supervised information. Supervised information plays a crucial role in the success of the clustering process and the accuracy of evaluating the clustering results. There are two types of supervised information: (1) labeled samples and (2) constraints. In practice, obtaining class labels may be difficult, but it is easier to obtain pairwise constraints, such as must-link and cannot-link constraints, which indicate whether two samples should be assigned to the same cluster or different clusters, respectively. Typically, these constraints are preferred to be satisfied but not mandatory. In the SFCM algorithm, the given input information is assumed to be labeled samples. From the algorithm’s perspective, it is not difficult to transform must-link and cannot-link constraints into labeled samples for processing.
The key to SFCM is to guide the iterative optimization process using labeled samples. Pedrycz proposed the following objective function J
s
(s stands for semi-supervised) in paper [18]:
To distinguish between unlabeled and labeled samples, Pedrycz, the proposer of the SFCM algorithm, introduced a binary vector
The membership values of labeled samples, denoted as a known matrix F = [f
ik
], are given, where i = 1, 2, …, c, k = 1, 2, …, n.
The introduction of a scaling factor α (α ⩾ 0) aims to maintain a balance between the unsupervised and supervised optimization mechanisms. The value of α is directly proportional to
Observing the objective function of SFCM, we notice that when the membership of labeled samples is close to their known membership |u
ij
- f
ij
b
j
|
m
is small, it weakens the constraint on
First, we modify the objective function as follows:
This modification ensures that when |u
ij
- f
ij
b
j
|
m
is small, the term
When the number of labeled samples is 0, the objective function becomes:
To make the objective function (10) more concise, elegant, and intuitive, we can consider modifying it as follows:
In this way, when the number of labeled samples is 0, this objective function degenerates into the objective function of standard FCM:
Furthermore, regarding the balancing factor α in the objective function of SFCM, it is mentioned that the choice of α depends largely on the relative sizes of the labeled and unlabeled pattern sets, and it is directly proportional to
Where
We use Lagrange multipliers to optimize the equation (14). To reach the optimal output for the objective function, equations are given as follows:
When the membership matrix U is given, V must satisfy the following conditions for the objective function (14) to achieve an extremum:
By utilizing the obtained fuzzy membership matrix U, according to the Lagrange multipliers method, we calculate the partial derivatives of the objective function J(V) with respect to V, and then set
When the center matrix V is given, there are two cases: For any “m” value other than 2, additional computational work is required for the optimization conditions. This is because now u
ij
and the Lagrange multipliers are connected together in the shape of a polynomial equation, and the solutions of this equation need to be calculated numerically. By setting the fuzzifier or fuzziness coefficient to 2, we are able to obtain explicit formulas for updating the partition matrix. U must satisfy the following necessary conditions for the objective function (14) to achieve an extremum:
By utilizing the obtained center matrix V and the constraint
According to the Lagrange multipliers method, we calculate the partial derivatives of u
ij
and λ and set them to zero. Based on
Like the FCM algorithm, the sum of membership degrees is 1 to satisfy the property of fuzzy sets, that is, the sum of degrees of belonging to different categories for each element is 1. This ensures that the row vectors of the membership matrix are a probability distribution, reflecting the affiliation of each sample to each category. The sum of membership degrees is also a constraint condition of MFM-SFCM algorithm, which is used to construct the objective function and solve the optimization problem. By applying the constraint
By combining equation (18) and equation (19), we can obtain the following equation:
Based on the equation (15) and equation (20), witch are the Iterative formulas, the specific steps of the MFM-SFCM algorithm are listed below:
Step 1: Initialization. Given the number of clusters C, fuzziness factor m, and supervision rate η. Obtain the binary vector b = [b j ] and the initial membership matrix F = [f ij ] from the labeled information. Set the maximum number of iterations l max and the threshold ɛ for algorithm termination.
Step 2: Calculate the distances between all samples from labeled and unlabeled sets to the cluster centers.
Step 3: Update the new membership matrix U using equation (15).
Step 4: Update the new cluster centers V using equation (16).
Step 5: If ∥V(l+1) - V(l) ∥ < ɛ or the iteration count l > l max , terminate the algorithm. Otherwise, go back to Step 2.
The Principle of work of MFM-SFCM is illustrated in Fig. 1.
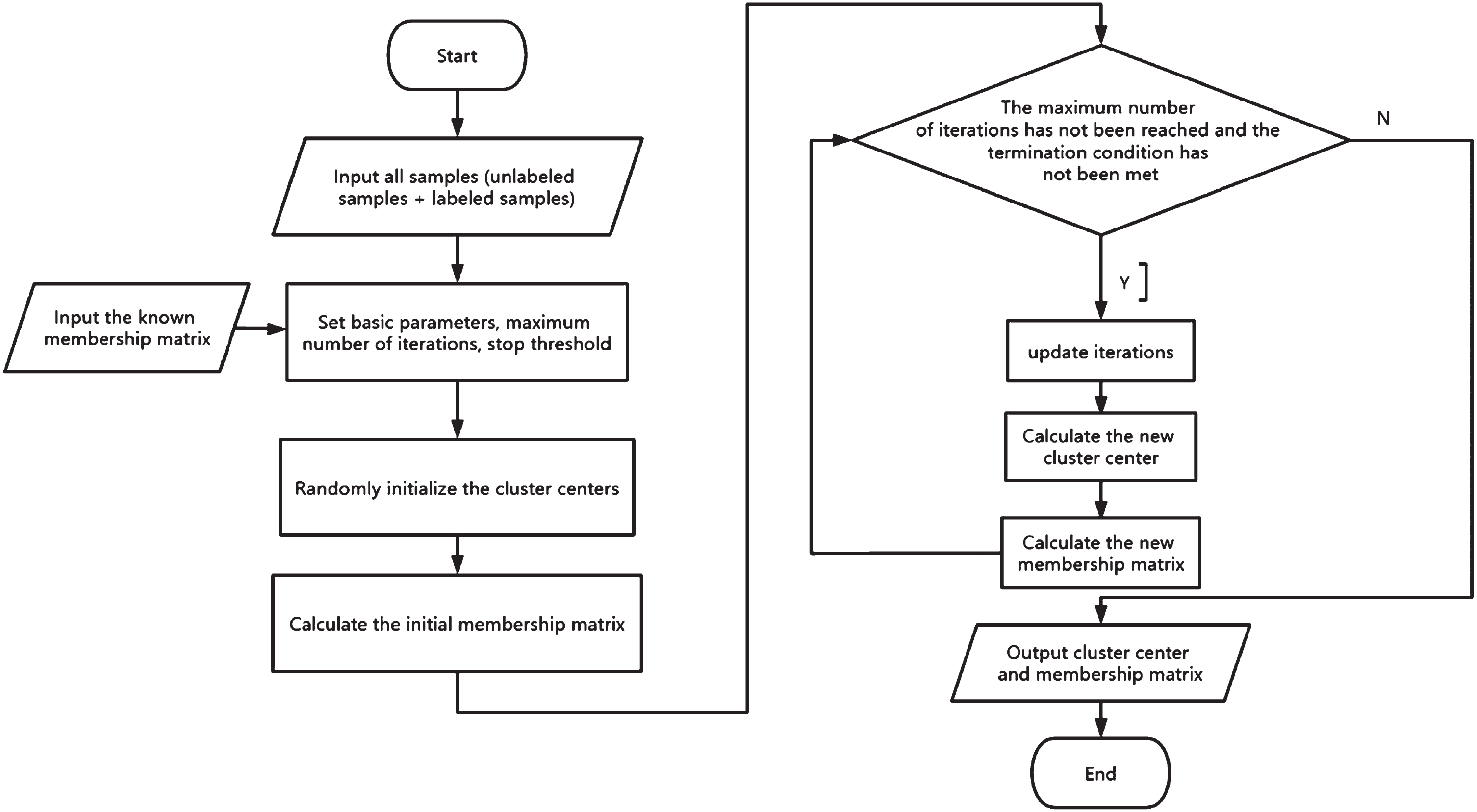
The Principle of work of MFM-SFCM algorithm.
MFM-SFCM algorithm and FCM algorithm have the following differences in their equations:
FCM’s objective function only considers the distance between the sample points and the cluster centers, while MFM-SFCM’s objective function also adds a penalty term, which measures the difference between the membership degree of the sample points and the true membership degree of the known labels.
FCM’s membership matrix and cluster center update formulas are both based on the distance matrix and the membership exponent, while MFM-SFCM also introduces a parameter η, which is used to adjust the weight balance between the supervised and unsupervised terms. These differences bring the following advantages and disadvantages:
MFM-SFCM utilizes the information of the known labels, which can improve the accuracy and robustness of clustering, especially when the data noise is large or the number of clusters is uncertain.
MFM-SFCM requires additional label information, which may not be easy to obtain or completely reliable.
MFM-SFCM requires setting a suitable parameter
MFM-SFCM and SFCM have the following differences in their equations: The objective function of SFCM has a coefficient of |u
ij
- f
ij
b
j
|
m
before the square of the distance between the sample points and the cluster centers in the penalty term, while MFM-SFCM has The objective function of the SFCM algorithm uses α to adjust the penalty term. In the objective function of the MFM-SFCM algorithm, α is set as an adaptive parameter, and an additional parameter η is added to manually adjust the balance between the unsupervised term and the supervised term (penalty term). The value of α is equal to the ratio of the total number of samples to the number of labeled samples, and we only need to find a suitable value for η between 0 and 1.
These two differences bring the following advantages: When |u
ij
- f
ij
b
j
|
m
is very small, MFM-SFCM’s objective function’s supervised term In the MFM-SFCM algorithm, the theoretical optimization interval for η is very clear compared to α in the SFCM algorithm. This interval ranges from 0 to 1. It is finite and known, and can be easily covered when adjusting, making it easier to find a suitable value for η. On the other hand, the theoretical optimization interval for α in the SFCM algorithm is infinite and unknown, which could potentially be missed during parameter optimization.
To validate the effectiveness of MFM-SFCM in handling clustering tasks, MFM-SFCM algorithm was evaluated using real DWI images provided by the hospital. We first describe the construction of the DWI dataset and the experimental setup. Then, we compare and discuss the clustering performance of MFM-SFCM with 4 other algorithms.
Data sets and settings
Data sets
The experimental data set was obtained from the clinical data of the First People’s Hospital of Changshu. 20 DWI images of brain infarction patients and uneven brightness were randomly selected by radiologists from the clinical data for the purpose of comparing the segmentation results.
Comparison algorithms
In our experiment, we compared 4 algorithms: Fuzzy C-means clustering algorithm (FCM), Kernel-GFCM (KGFCM) [27], POCS-based clustering (POCS-based) [28], and SFCM. The labeled samples for all semi-supervised algorithms were selected to be the same, and their initial membership values were also the same. FCM, SFCM, and MFM-SFCM algorithms used the Euclidean distance in the experiment. The number of clusters was set to 3 based on the composition of the dataset, representing brain infarction lesions, other brain regions, and background, respectively. Each algorithm was tested 20 times using the best parameters selected through the grid search strategy as Table 1.
Parameters used when testing algorithms
Parameters used when testing algorithms
Two evaluation metrics [29] are used to assess the performance of all algorithms: Dice coefficient(Dice) and Intersection over Union (IoU). Their function in this experiment is to measure the degree of overlap between the segmentation results and the ground truth labels.
Dice is defined as follows:
IoU is defined as follows:
Where A and B represent the pixel sets of the segmentation results and the ground truth labels, respectively, |A| and |B| represent the size of the sets, |A ∩ B| represents the intersection of the sets, and |A ∪ B| represents the union of the sets. The Dice and IoU are effective measures to assess the consistency between the segmentation results and the ground truth region. Both Dice and IoU values range between [0, 1].The quality of the segmentation improves as the values increase. Therefore, they can be used to evaluate the performance of segmentation networks on different categories, and also to compare the advantages and disadvantages of different segmentation algorithms.
The experimental hardware platform used an Intel(R) Core(TM) i5-11300H CPU with a clock frequency of 3.10GHz and 16GB of memory. The programming environment was Python 3.8.
Performance comparison
Table 2 display the clustering results of the five algorithms with the best parameters, represented by the average Dice and IoU scores. The best scores are highlighted in bold.
The analysis of the outcomes in Table 2, as well as Figs. 2, 3, 4, 5 and 6, is as follows: Compared to the two unsupervised clustering algorithms (FCM and KGFCM), the two semi-supervised clustering algorithms achieved better Dice and IoU scores. This is because FCM and KGFCM algorithms partition the data based on the image features alone, without considering the label information. As a result, they cannot effectively utilize the prior knowledge from labeled samples to guide the clustering process, leading to unsatisfactory clustering performance. In contrast, the two semi-supervised clustering algorithms (SFCM and MFM-SFCM) leverage the prior knowledge from labeled samples, which should improve the clustering accuracy. Improvements in the MFM-SFCM algorithm equation compared to the FCM algorithm equation: The objective function of unsupervised clustering algorithms like the FCM algorithm only considers the distance between sample points and cluster centers. The objective function of the MFM-SFCM algorithm adds a penalty term to measure the difference between the membership degree of sample points and the true membership degree of known labels. Additionally, the MFM-SFCM algorithm introduces a parameter η to adjust the weight balance between supervised and unsupervised terms. These improvements allow the MFM-SFCM algorithm to use known label information to improve clustering accuracy and robustness. As shown in Fig. 2, the MFM-SFCM algorithm achieves good results in all picture segmentation tasks in the dataset.However, the SFCM algorithm falls significantly behind the POCS-based algorithm on several images, as it fails to effectively emphasize the supervised information, resulting in weakened constraints and insufficient influence of labeled samples on the clustering process. Consequently, it fails to achieve effective segmentation. On the other hand, the results of the POCS-based algorithm are highly unstable, with completely different segmentation results each time, making it unsuitable for image segmentation tasks. In comparison, the proposed MFM-SFCM algorithm, which incorporates the membership fusion mechanism, achieves effective segmentation and optimal performance. Improvements in the MFM-SFCM algorithm equation compared to the SFCM algorithm equation: 1) In the penalty term of the SFCM algorithm’s objective function, the coefficient before the square of the distance between sample points and cluster centers is |u
ij
- f
ij
b
j
|
m
. In the MFM-SFCM algorithm, this is improved to As shown in Table 2, although the MFM-SFCM algorithm performs better than the POCS-based algorithm on the Dice and IoU metrics, it has a longer average runtime. This is because the MFM-SFCM algorithm needs to find the optimal value for the parameter η, a process not required by the POCS-based algorithm. This is a shortcoming of the proposed algorithm and will be the focus of analysis in the next section. It also presents a potential research direction for our future studies.
Performance of all comparison methods on DWI Image datasets
Performance of all comparison methods on DWI Image datasets
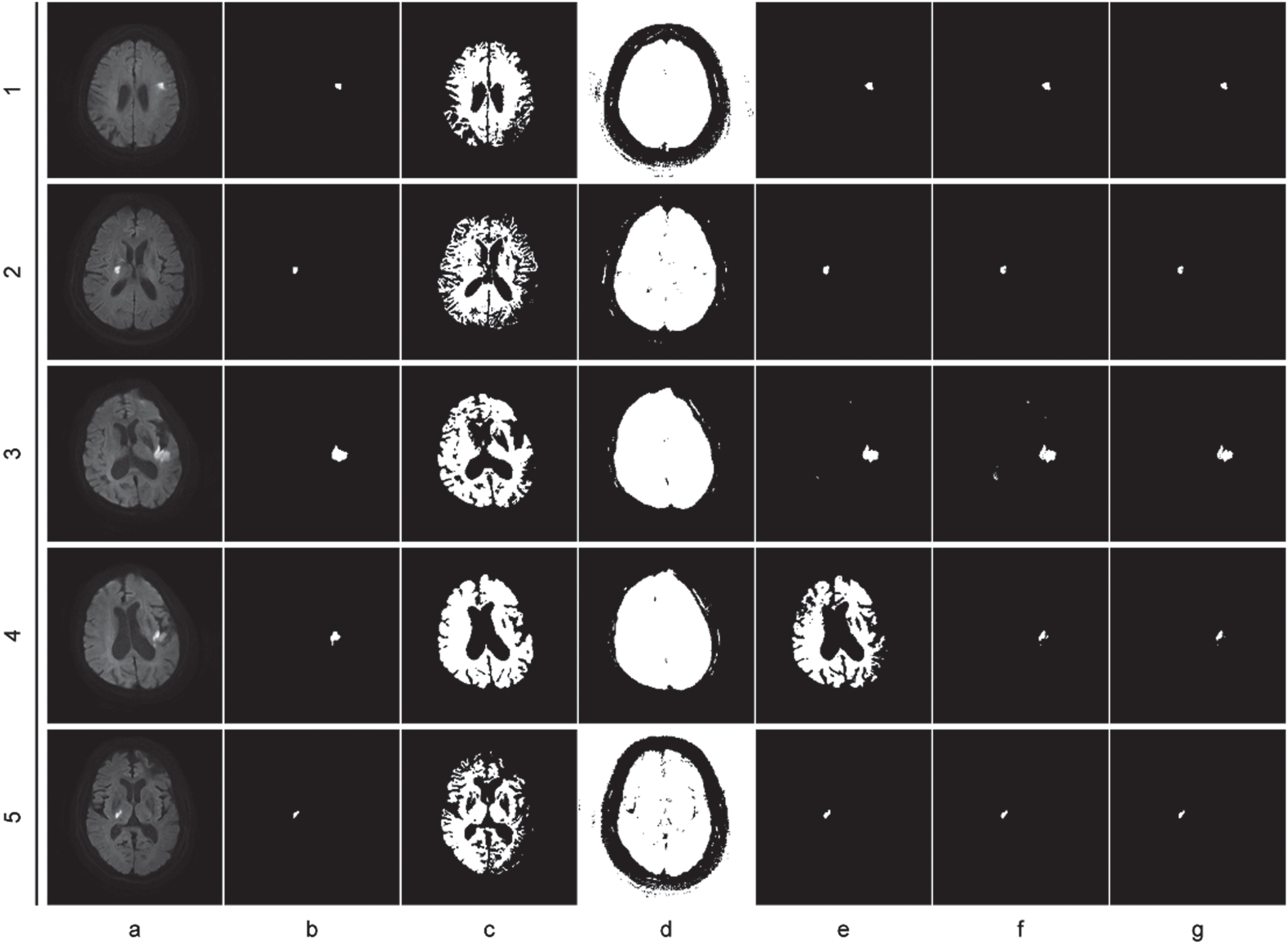
Clustering segmentations on images 1–5, (a) original image, (b) ground truth image, (c) FCM, (d) KGFCM, (e) POCS-based, (f) SFCM, (g) MFM-SFCM.
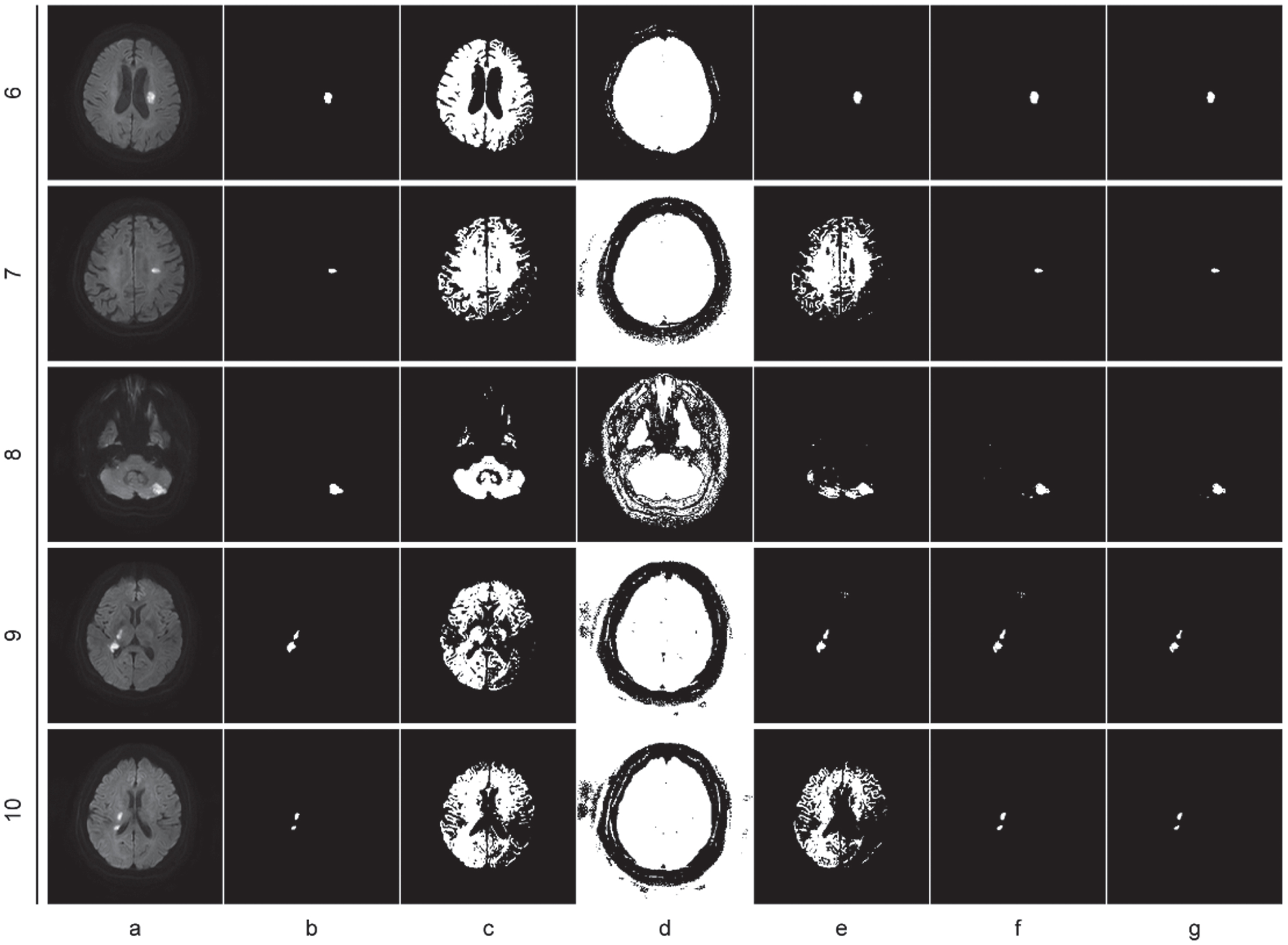
Clustering segmentations on images 6–10, (a) original image, (b) ground truth image, (c) FCM, (d) KGFCM, (e) POCS-based, (f) SFCM, (g) MFM-SFCM.
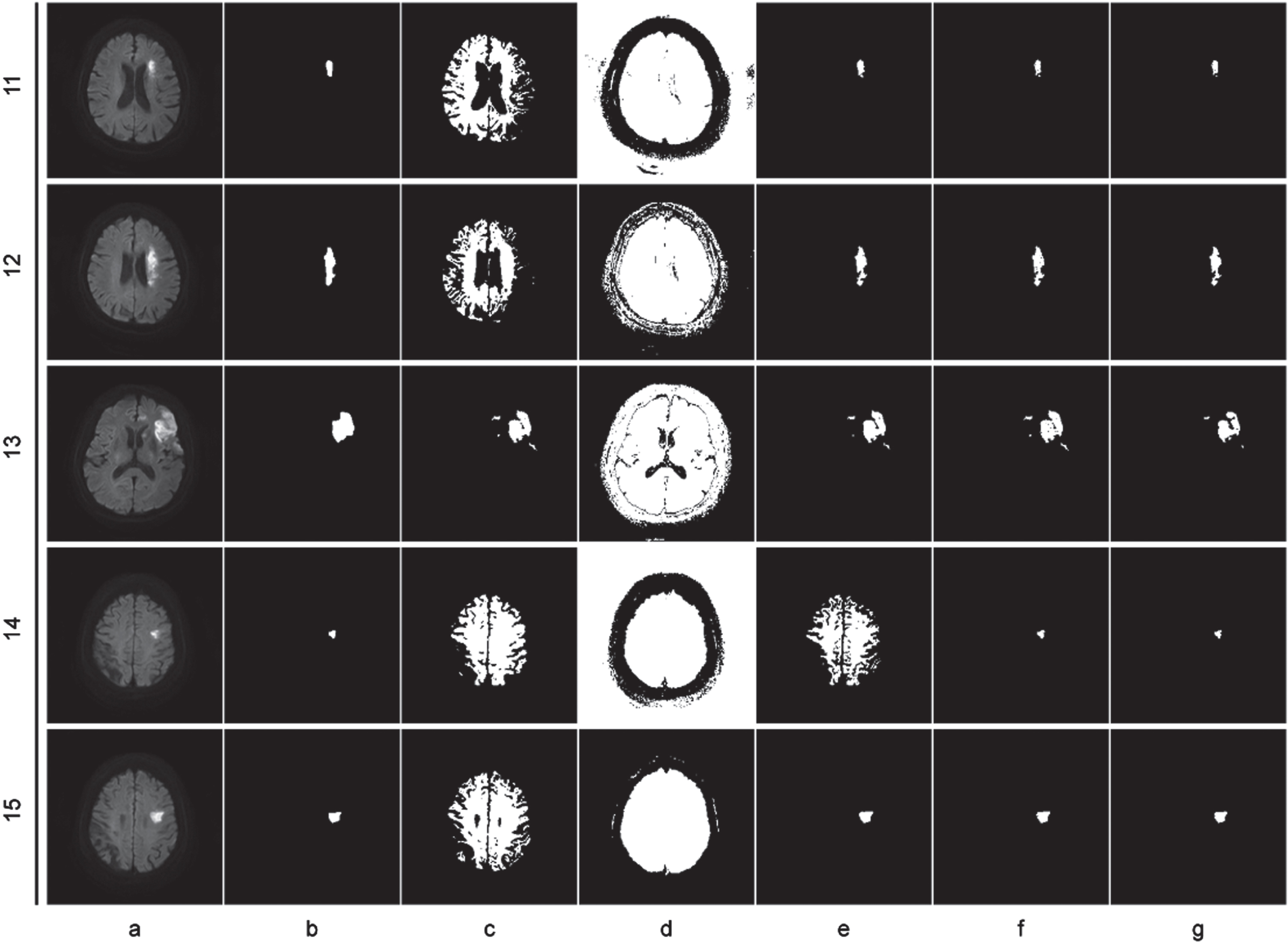
Clustering segmentations on images 11–15, (a) original image, (b) ground truth image, (c) FCM, (d) KGFCM, (e) POCS-based, (f) SFCM, (g) MFM-SFCM.
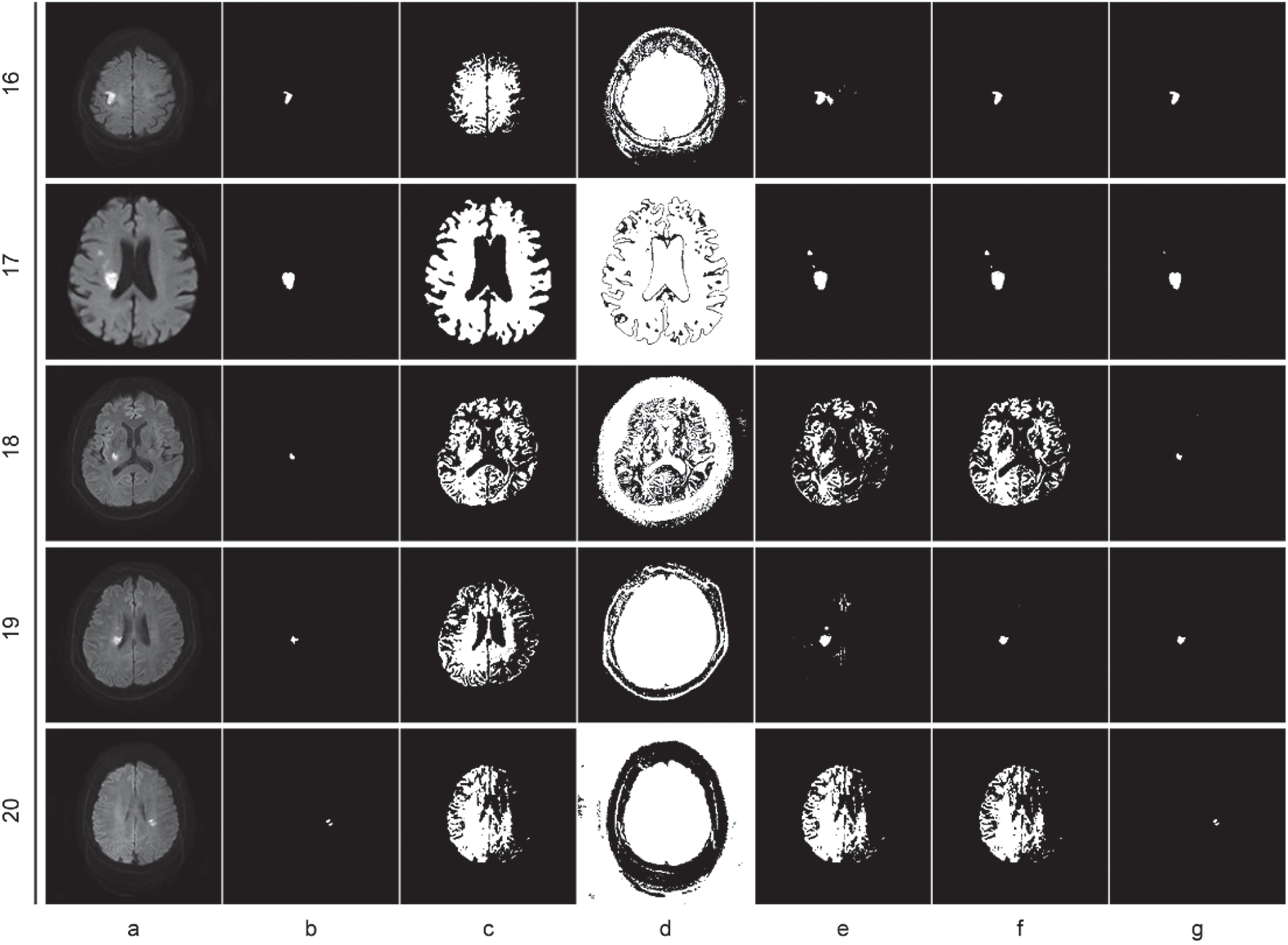
Clustering segmentations on images 16–20, (a) original image, (b) ground truth image, (c) FCM, (d) KGFCM, (e) POCS-based, (f) SFCM, (g) MFM-SFCM.
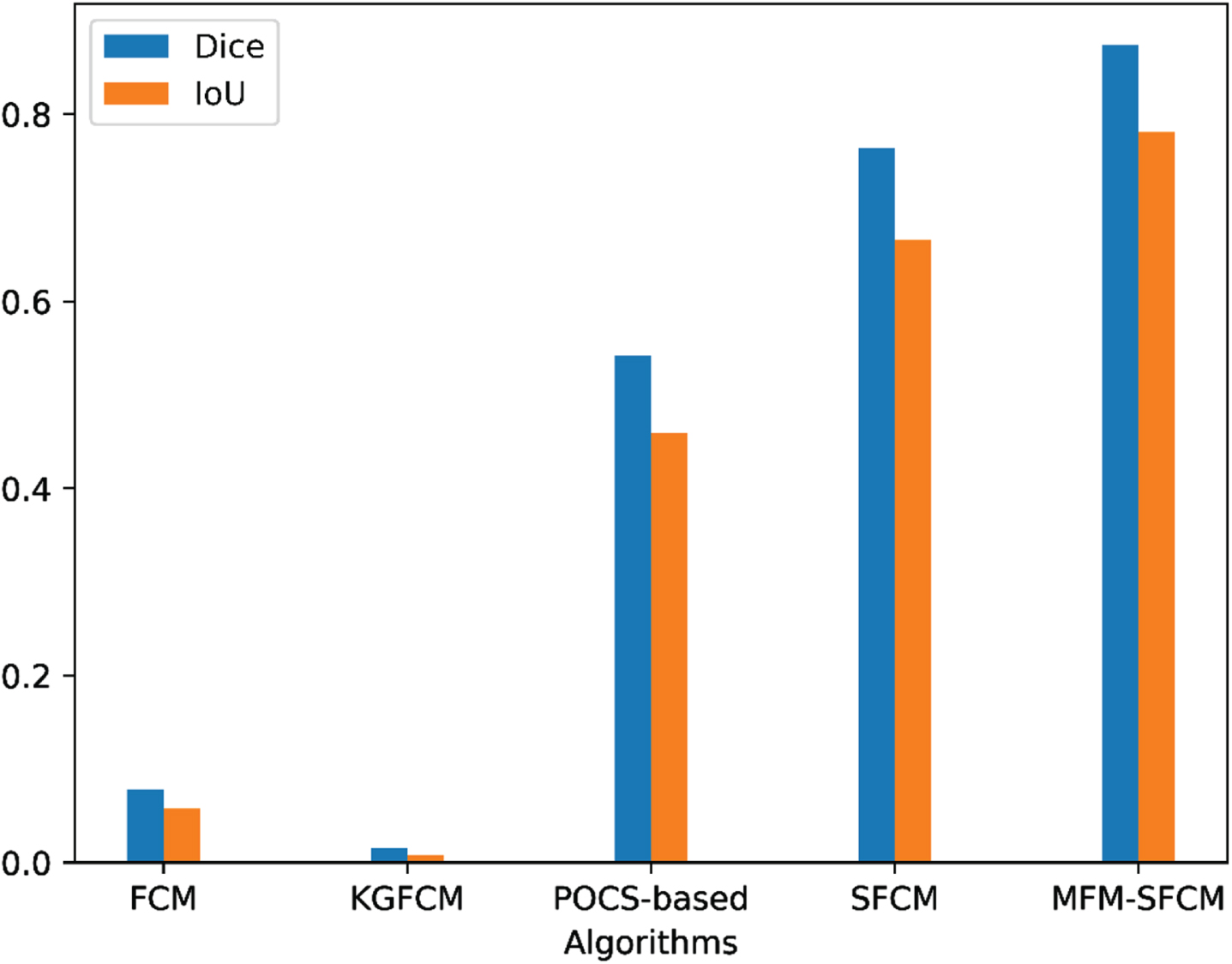
Comparison of performance of 5 algorithms in cluster segmentation.
In the experiment, the parameter η was determined within the given search grid 0, 0.01,..., 0.99. In the subsequent discussion, we explore the performance of MFM-SFCM with different parameter η. Table 3, Table 4, Fig. 7, and Fig. 8 display the average Dice and IoU scores obtained on the partial dataset when using different values of η, while keeping the parameter m fixed at 2.
Means of dice by MFM-SFCM on the images using different η, while fixing m = 2
Means of dice by MFM-SFCM on the images using different η, while fixing m = 2
Means of IoU by MFM-SFCM on the images using different η, while fixing m = 2
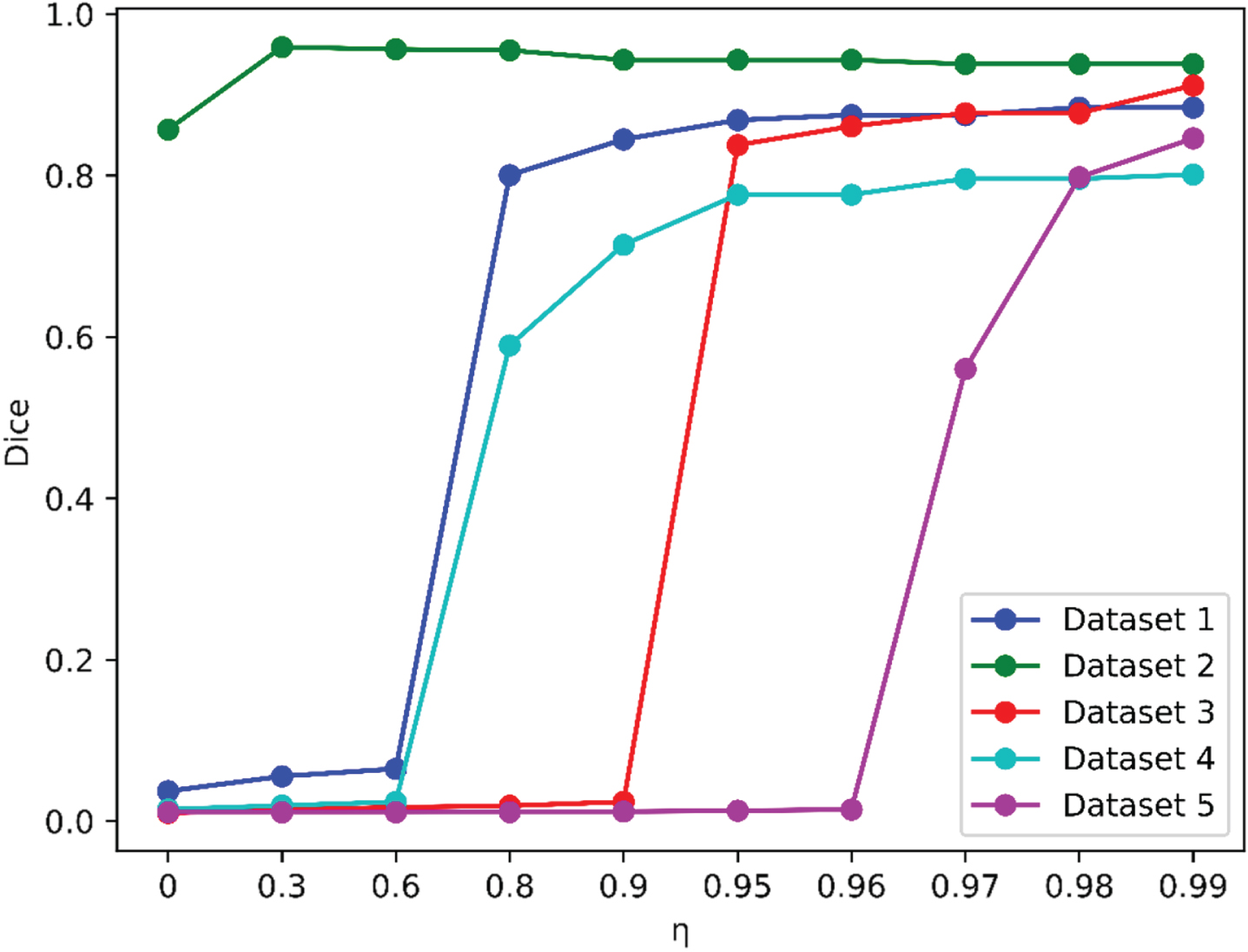
Dice Performance Comparison of Partial Datasets on Different η.
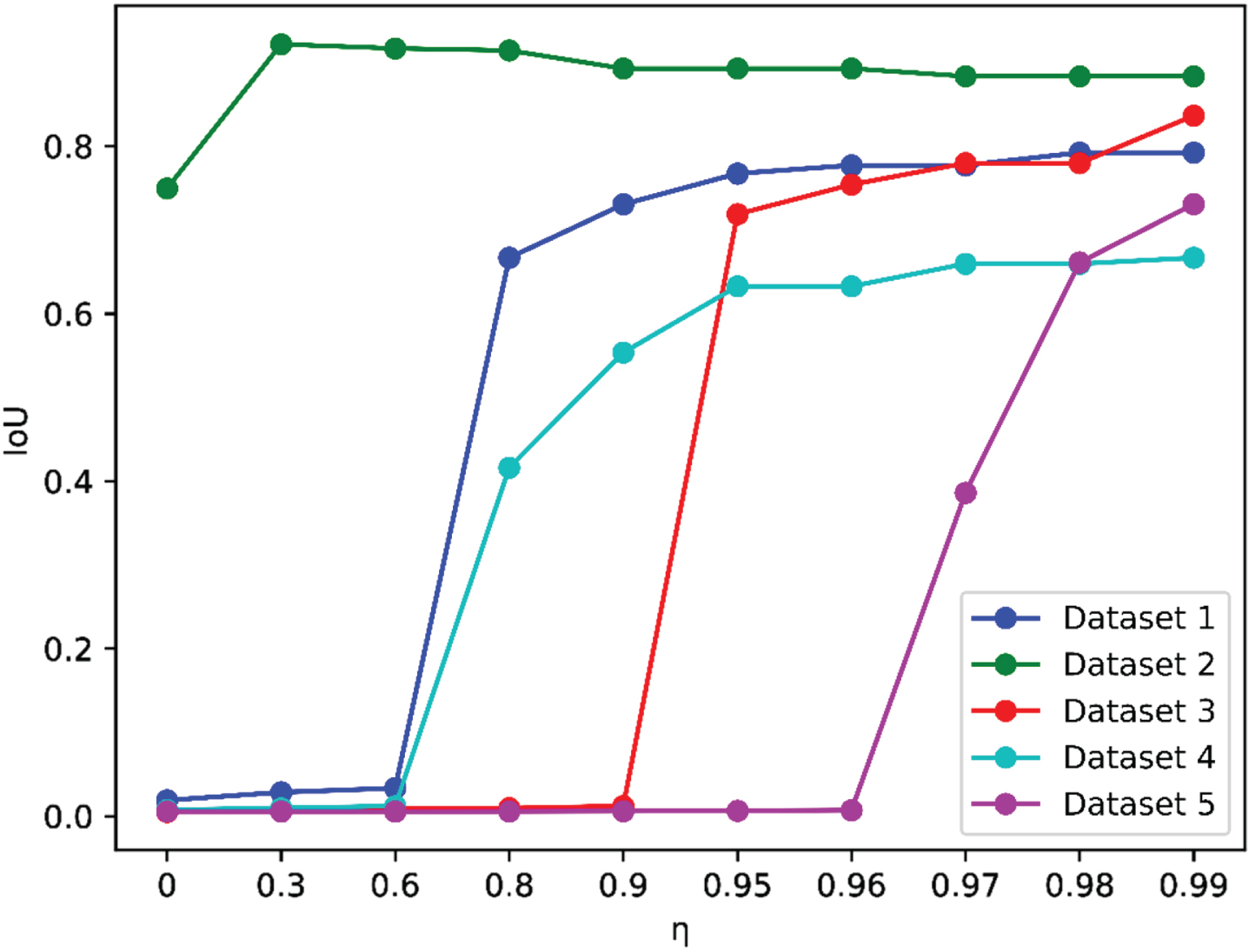
IoU Performance Comparison of Partial Datasets on Different η.
common table of abbreviations and notations
MFM-SFCM is sensitive to the parameter η. Different values of η result in different clustering performance in terms of Dice and IoU. It can be observed that in most cases, when the Dice score is high, the IoU score is also high. Therefore, using both Dice and IoU as performance metrics is feasible for determining appropriate parameters.
With a fixed value of m, MFM-SFCM obtains the worst Dice and IoU scores when η= 0. When η≠ 0, the clustering performance of MFM-SFCM improves. This is because when η= 0, MFM-SFCM degenerates into classical FCM.
It can be observed that when η takes a relatively large value, MFM-SFCM experiences a sudden and significant improvement in both Dice and IoU scores. This additionally illustrates the efficacy of the proposed membership fusion mechanism. As a result, in subsequent experiments, the range of η in the 0, 0.01,..., 0.99 search grid can be narrowed down. However, the critical value of η that leads to the significant improvement varies and does not follow a specific pattern.
In this paper, a novel semi-supervised fuzzy clustering algorithm, MFM-SFCM, based on a membership fusion mechanism is proposed for DWI brain infarction lesion segmentation. It addresses the issue of weakened constraints and insufficient influence of labeled samples on the clustering process in SFCM, where supervised information is not effectively emphasized. MFM-SFCM overcomes this limitation by introducing a new membership fusion mechanism. This significantly improves the accuracy of clustering results and accelerates convergence speed, enabling fuzzy clustering to effectively utilize a small amount of labeled information for DWI brain infarction lesion segmentation. The effectiveness of the MFM-SFCM algorithm is demonstrated through experiments conducted on a real-world dataset of brain DWI images.
Further research can explore the MFM-SFCM algorithm for years to come. One important aspect to consider is the number of clusters, and how to automate the determination of an optimal number of clusters. FCM, as the baseline algorithm for MFM-SFCM, is sensitive to noise. Therefore, applying MFM-SFCM algorithm to noisy images is also a very meaningful research. Additionally, designing a fast learning strategy for MFM-SFCM that is suitable for large-scale DWI brain images is an important area of future research.
Footnotes
Acknowledgments
This work was supported in part by the Suzhou Key Supporting Subjects [Health Informatics(No.SZFCXK202147)], in part by the Changshu Science and Technology Program [No.CS202015, CS202246], in part by the Changshu City Health and Health Committee Science and Technology Program [No. csws201913], and in part by the “333 High level personnel training project of Jiangsu Province”