
Abstract
The California Bearing Ratio (CBR) holds significant importance in the design of flexible pavements and airport runways, serving as a critical soil parameter. Moreover, it offers a means to gauge the soil response of subgrades through correlation, an aspect pivotal in soil engineering, particularly in shaping subgrade design for rural road networks. The CBR value of soil is influenced by numerous factors, encompassing variables like maximum dry density (MDD), optimum moisture content (OMC), liquid limit (LL), plastic limit (PL), plasticity index (PI), soil type, and soil permeability. The condition of the soil, whether soaked or unsoaked, also contributes to this value. It is worth noting that determining CBR is time-consuming and extensive. Acknowledging the gravity of this determination, the study introduces a pioneering approach employing machine learning. This innovative technique uses a foundational multi-layer perceptron model, harnessing the algorithm’s robust capabilities in addressing regression challenges. A hybridization approach enhances the multi-layer perceptron’s performance and achieves optimal results. This approach integrates the Bonobo Optimizer (BO), Smell Agent Optimization (SAO), Prairie Dog Optimization (PDO), and Gold Rush Optimizer (GRO). The hybrid models proposed in this study exhibit promising results in predicting CBR values. The MLAO3 hybrid model is particularly noteworthy, emerging as the most accurate predictor among the range of models, with an impressive R2 value of 0.994 and an RMSE value of 2.80.
Keywords
Introduction
In geotechnical engineering, a soil specimen’s capacity to resist a piston’s penetration is defined as the California Bearing Ratio (CBR). Specifically, the CBR represents the force necessary to drive the piston into the soil [1]. Initially conceived in California to assess soil suitability for highway construction, the CBR test was adapted by civil engineers to enhance its applicability in airport construction. Developing nations have widely adopted the CBR test for evaluating pavement soil resistance [2–5]. The CBR is the ratio of the bearing capacity of the available base material to that of a standard material (crushed rock). In structural engineering, a CBR value of 100 is allowable for crushed rock, whereas values for other materials are below 100 [6, 7].
The CBR test is conducted through two distinct methods: in the field or the laboratory. Laboratory testing is performed on compacted soils, while field testing is utilized for soils within trenches. Notably, variations in soil type, dry unit weight, and water content can lead to discrepancies between field and laboratory test results [8]. CBR testing can be carried out on unsoaked and soaked soil types, offering valuable insights into the resistance of various soil-related structures, such as road fillings, dams, airport pavements, and highway barriers. Despite its significance, the CBR determination process is time-intensive and labor-demanding, often yielding inaccurate values due to suboptimal laboratory conditions and soil samples [9, 10].
Prior research has focused on exploring various aspects of CBR, highlighting its sensitivity to soil types and properties. Much of the study has centered on the relationships between compaction characteristics, specific indices, and CBR values of soil samples [11–14]. Soils are compacted to predetermined maximum dry density (MDD) and optimum moisture content (OMC) levels using specific energy, which aids in assessing CBR. In the case of soaked CBR, samples are left to soak for four days, resulting in a total testing time of 5–6 days, potentially causing significant delays in large construction projects [15–17].
Given the substantial variability in soil characteristics, conducting the CBR test on subbase soil samples from a limited range of locations may not accurately represent all road conditions. To address this limitation, it is crucial to test a substantial number of specimens. Thus, estimating CBR values for pavement subgrade materials using easily identifiable parameters becomes paramount. Artificial intelligence (AI) methods have gained traction in addressing geotechnical engineering challenges empirically. Some studies have explored the estimation of CBR values using various artificial neural network (ANN) applications [18–20].
For instance, Baghbani et al. [21] employed support vector machines, artificial neural networks, and genetic programming to predict CBR based on a dataset with nine input variables. Their results demonstrated the efficacy of AI methods, with R2 values ranging from 0.94 to 0.99 and MAE values ranging from 0.30 to 0.51. Khatti and Grover [22] compared LSTM, LSSVM, and ANN models to predict CBR. They achieved R2 and RMSE values of 0.99 and 0.91, respectively. Nagaraju et al. [23] introduced an integrated extreme learning machine-cooperative search optimizer (ELM-CSO) method for CBR prediction, showing that ELM-CSO outperformed CSO with R2 and RMSE values of 0.97 and 0.84. Kim et al. [24] predicted CBR for fine and coarse aggregates, achieving satisfactory accuracy with R2 values of 0.938 and 0.829, respectively. Othman and Abdelwahab [25] focused on using ANN models for efficiently estimating subgrade soil CBR in Egypt based on Atterberg limits, grain size distribution, and compaction components.
Given the diverse variables and rich datasets available in previous research, developing robust predictive tools to model CBR mechanical properties and capture complex relationships between soil constituents is crucial. This paper presents a machine-learning-based model for estimating CBR using an experimental dataset from reputable sources cited above. To achieve this, a multi-layer perceptron (MLP) model is employed, incorporating Bonobo Optimizer (BO), Prairie Dog Optimization (PDO), Gold Rush Optimizer (GRO), and Smell Agent Optimization (SAO) for accurate CBR value predictions. Determining CBR values is a crucial aspect of civil engineering, but its traditional approach is labor-intensive and financially burdensome. Predicting CBR values offers a promising avenue to reduce costs and streamline project timelines. This study introduces a precise model as a viable alternative to conventional CBR determination techniques. The model effectively estimates CBR values using input variables encompassing soil indices and compaction characteristics. Rigorous comparisons of model outcomes are conducted using error indicators to ensure thorough assessment and minimize potential biases. The subsequent section will delve into data collection, the basics of the employed machine learning model, optimizer descriptions, and performance evaluation.
Materials and methodology
Data gathering
Within this present investigation, the dataset encompasses 73 samples, which have been categorized into five distinct input variables: curing period (CP), lime percentage (LI), optimum moisture content (OMC), lime sludge percentage (LS), and maximum dry density (MDD) (Suthar and Aggarwal, 2018). Table 1 offers a comprehensive statistical overview of the parameters utilized in formulating the models. This table encompasses specific attributes such as Average (Avg), maximum (Max), Standard deviation (St. Dev.), and minimum (Min). The maximum and minimum values for MDD are 45 and 5, OMC is delineated as (32.65, 13.7), CP as (1.39, 1.14), LS as (15, 0), and LI as (20, 0). As for the output parameter, the range for CBR spans from a maximum of 156 to a minimum of 2.2. Fig. 1.
The statistical features of the dataset components
The statistical features of the dataset components
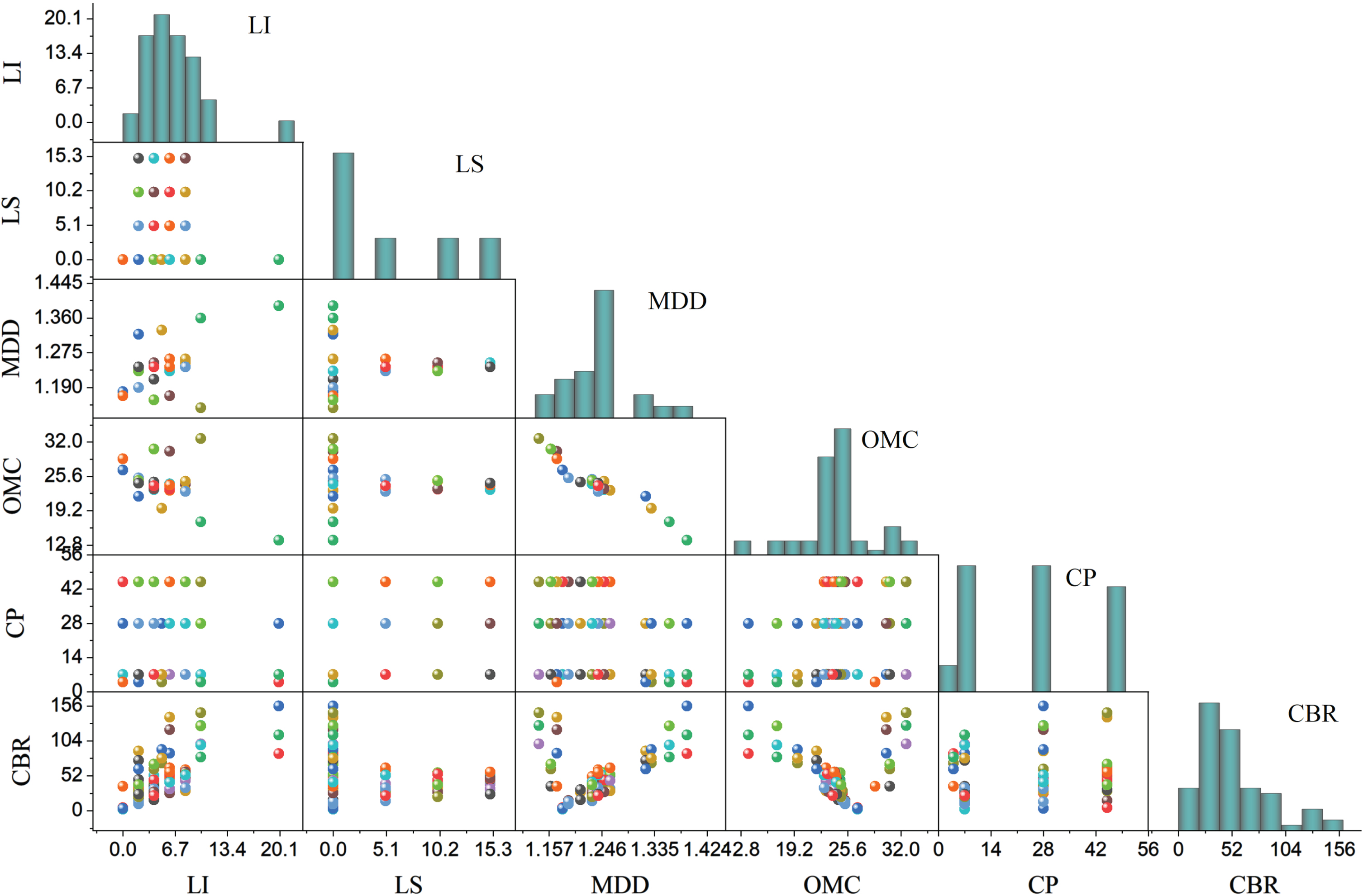
The scatter matric input and output variables.
The Multi-layer Perceptron (MLP) represents an extensively employed neural network architecture often trained through the backpropagation algorithm. MLPs are designed to handle learning and estimation processes, constituting a form of training and estimation art. These neural networks offer a versatile approach to approximating complex and nonlinear functions in real-world scenarios, showcasing their adaptability [26].
A single hidden layer within the MLP can proficiently model intricate functions thanks to its hidden neurons. A scarcity of neurons in this layer can result in suboptimal neural network performance. On the contrary, MLP neural networks can be intricate to train and susceptible to overfitting. The nodes in the output layer correspond to the number of variables being modeled.
To achieve the broad representation of the nonlinear function (l), the endeavor of function modeling involving a single predictor involves employing an MLP neural network, where X ∈ R D → Y ∈ R1. Here, Y and X denote the output and input parameters, respectively. The function (l) is mathematically expressed as shown in Equation (1):
w1 and w2 are the weights of hidden and outputlayers matrixes, respectively.
b1 and b2 show the hidden and output layers’ bias vectors, alternatively.
a shows the function of activation.
Equations (2) and (3) show the tan-sigmoid and log-sigmoid activation functions, alternatively:
Here, f shows the function of input activation. Figure 2 shows the flowchart of MLP.
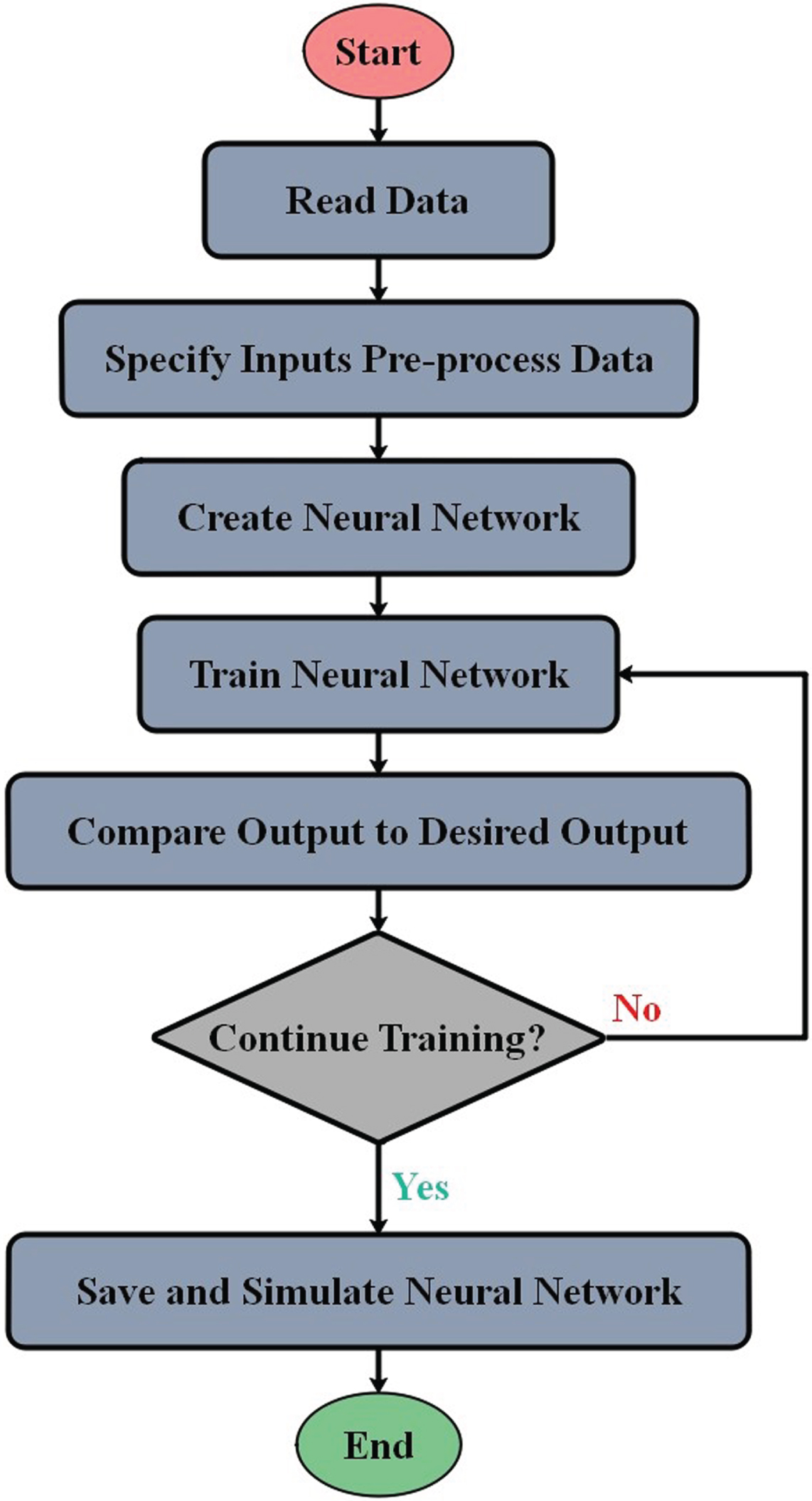
The flowchart of MLP.
The Bonobo optimizer (BO) stands as a contemporary meta-heuristic algorithm, drawing inspiration from Bonobo primates’ reproducible behavior and social interactions. Das et al. [27] have formulated the BO algorithm in a population-based configuration.
The algorithm leverages natural behaviors by emulating bonobos’ optimal behavior and strategies. The BO incorporates four distinct mating strategies for generating new bonobo solutions: extra-group mating, promiscuous, restrictive, and consort ship [27]. These mating strategies may alter based on the circumstances’ phase, whether negative (NP) or positive (PP). The positive (PP) state reflects a bonobo community characterized by ample food resources, genetic diversity among bonobos, successful mating outcomes, and protection from external communities. Conversely, the NP phase denotes unfavorable conditions within the bonobo society.
Restrictive and promiscuous mating techniques
The phase probability parameter (m m ) represents the Bonobo mating approach. Firstly, the amount of m m is valued at 0.5, which is upgraded at each iteration. If a random number, q, is an amount from zero to one, a novel bonobo is produced. It is considered to be equal to or less than m m as described in Equation (4):
Here bo stands for bonobo, n_boj and
As the best response of i - th bonobo obtains a better consequence than m - th bonobos, promiscuous mating happens. In this situation, the flag is indicated 1. On the other hand, for limited mating a bo are assigned as –1.
If part m m is lesser than q, these types of mating will happen. On the other hand, if q2 is equal to or less than the extra group (m xgm ) probability, this will result in upgrading the solution via extra-group mating.
The m e is started with 0.5 with an incremental upgrading related to the evolution’s nature, and itoptimizes the searching process for the foremost hopeful output. Var-min j and Var-max j denote the lowest and highest boundaries of the j - th variable, respectively.
In other cases, using the consortship mating strategy, a novel offspring is generated, where the amount of q2 is found to be higher than that of m xgm , as Equation (6):
In these equations, q1, q2, q3, q4, q5 are random numbers between 0 and 1.
The flowchart of the proposed algorithm is shown in Fig. 3.
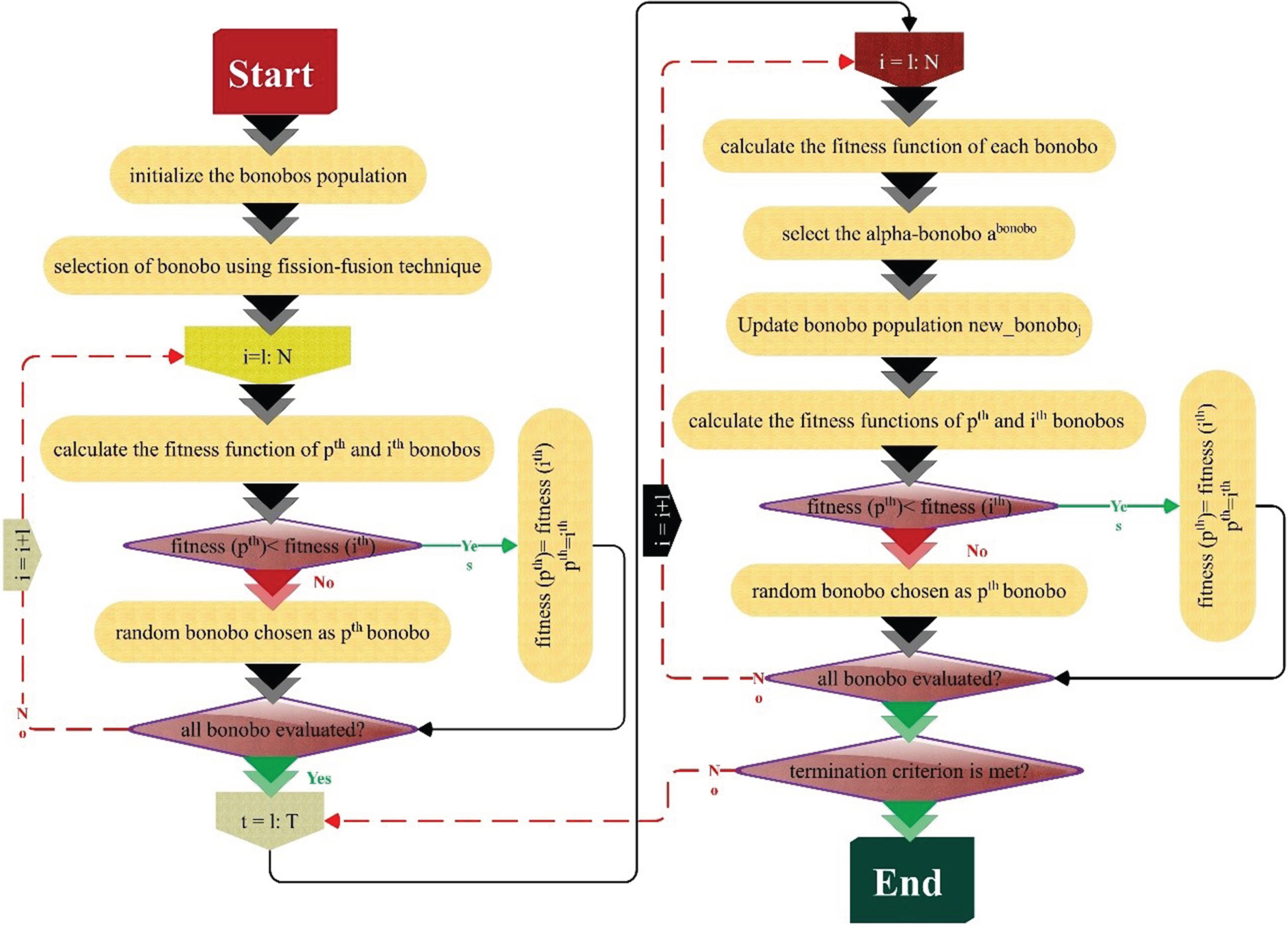
Bonobo structure.
The smelling sense is one of the initial senses through which the world is maintained. Most organisms sense the presence of harmful chemicals in their environment utilizing the smelling sense [28–30].
Sniffing mode
Because smell molecules spread in the agent’s direction, first start the process by arbitrarily developing smell molecules’ beginning location.
The smell molecules can be initialized using Equation (7):
N is the total number of small molecules
D is the total number of decision variables.
The location vector in Equation (7) gives the agent the capability to identify its own best location in the space of search, and it can be obtained utilizing Equation (8):
ub and lb indicate the upper and lower bound identified due to the decision variables, respectively
r0 refers to a random value from 0 to 1.
Each smell molecule is assigned a primary velocity among that they spread from the smell source by utilizing Equation (9).
Each smell molecule indicates a candidate solution. The location of these candidate solutions is obtained from the position vector
Δt = 1 means that the agent progresses the path simultaneously through the optimization process. The new location of the smell molecules is calculated by Equation (11):
Each smell molecule possesses diffusion velocities that can update and evaporate its location in search criteria. The updated smell velocity molecules are calculated employing Equation (12).
υ is the update variable of the velocity derived by using Equation (13).
k refers to the smell fixed that normalizes the influence of mass and temperature on the smell molecules’ kinetic energy.
m and T are the mass and temperature of the smell molecules, respectively.
The updated locations’ fitness of the smell molecule in Equation (11) is assessed. Thus, the sniffing mode is completed, and it is possible to determine the position of the agent
In the second mode, the seeking behaviors of an agent are simulated to determine the origin of a smell. The agent may sniff a new location with a higher focus on smell molecules while searching for a smell source. By using Equation (14), the agent takes the opportunity towards this novel location:
r2 and r3 are numbers from 0 to 1
r2 penalizes the influence of olf on
The agent records
If large distances segment the molecules of smell, the intensity of the smell molecule might be different over the period. This difference may “bemuse” the agent, results in the smell’s loss, and makes trailing a significant challenge. Due to its disability to preserve trailing, the agent might be caught in local minima. If this happens, the agent transfers to the random mode, which is represented using Equation (15):
SL is the step length.
r4 is a random value that penalizes the amount of SL.
The pseudo-code of the SAO algorithm is given in Algorithm 1, and the flowchart of SAO is indicated in Fig. 4.
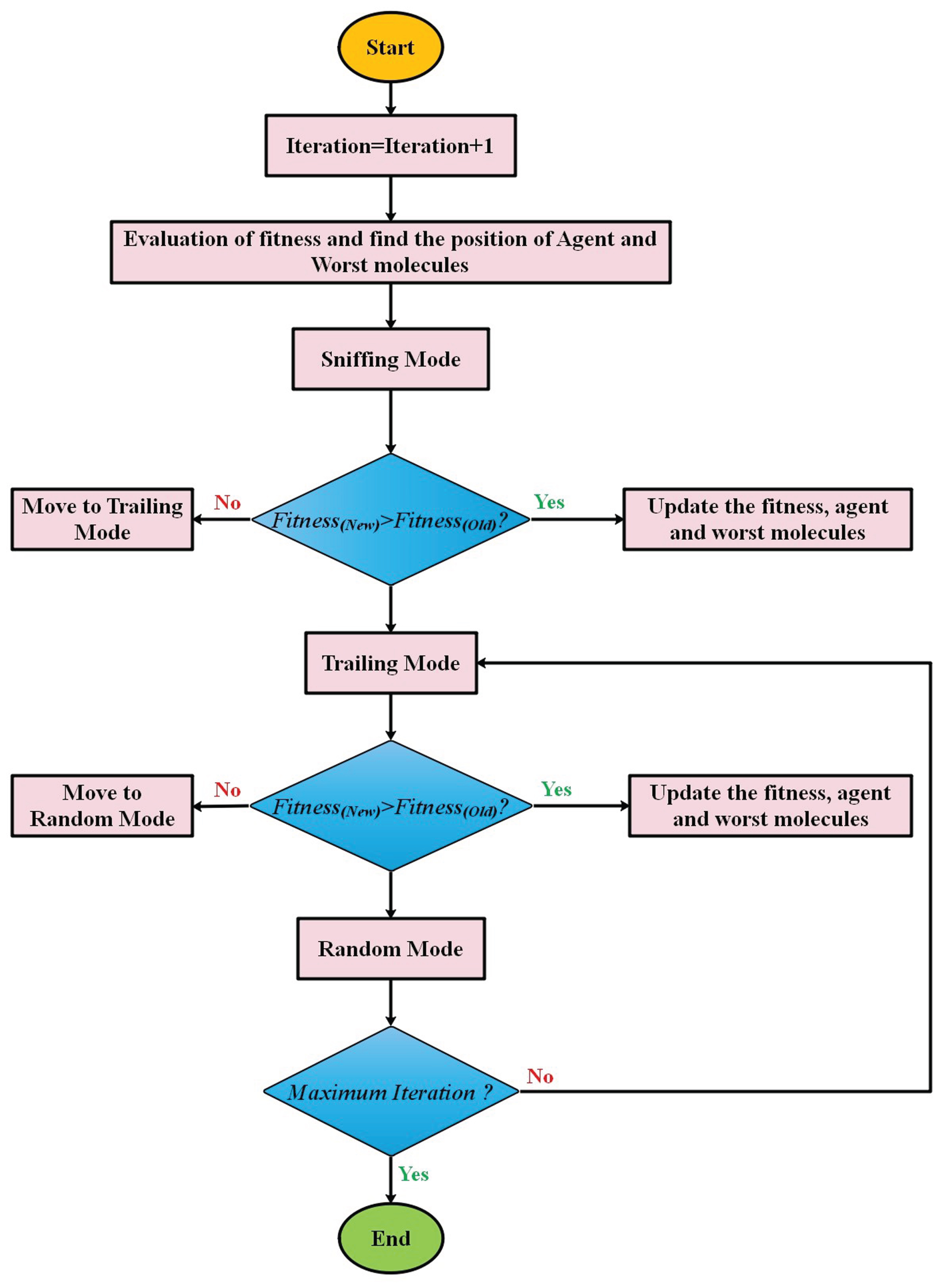
The flowchart of SAO.
Algorithm 1: Smell Agent Optimization
Initialize
Each Prairie Dog (P) in a clique (nP) is a member of k other cliques. PD operates and behaves in groups or cliques. Thus, a vector can be used to determine the location of the ith prairie dog within a specific clique. The location of each Coterie (S) within the territory is described by Equation (16):
Here Si,j is the dimension of jth of the Coterie of ith in a territory. Each prairie dog in a coterie has a position in Equation (17).
Here Pi,j is the dimension of jth of the Coterie of ith in a territory and n ⩽ k. Using a distribution of uniforms as in Equations (18) and (19), respectively, the positions of each clique and prairie dog are determined.
Here lb j and ub j show the lower and upper bounds of the dimension jth of the optimization issue and u(0,1) shows a random number with a distribution of uniform between 0 and 1.
The fitness function values for each position of the prairie dog were determined by providing the solution vector to the fitness function definition. The values that result are saved in a collection that looks like this:
PD0 is capable of switching between exploitation and search based on four positions. Divide the maximum number of iterations by 4. While the last two parts are used for development, the first is used for search. The two processes employed for search depend on 4
During the search phase, the first procedure is to have faction members scour the neighborhood for fresh food sources, as shown in Fig. 5. Equation (21) gives the foraging position update during our algorithm’s search phase. The statue aids in controlling the growth of the caves. Equation (22) provides this location update for the construction of caves.
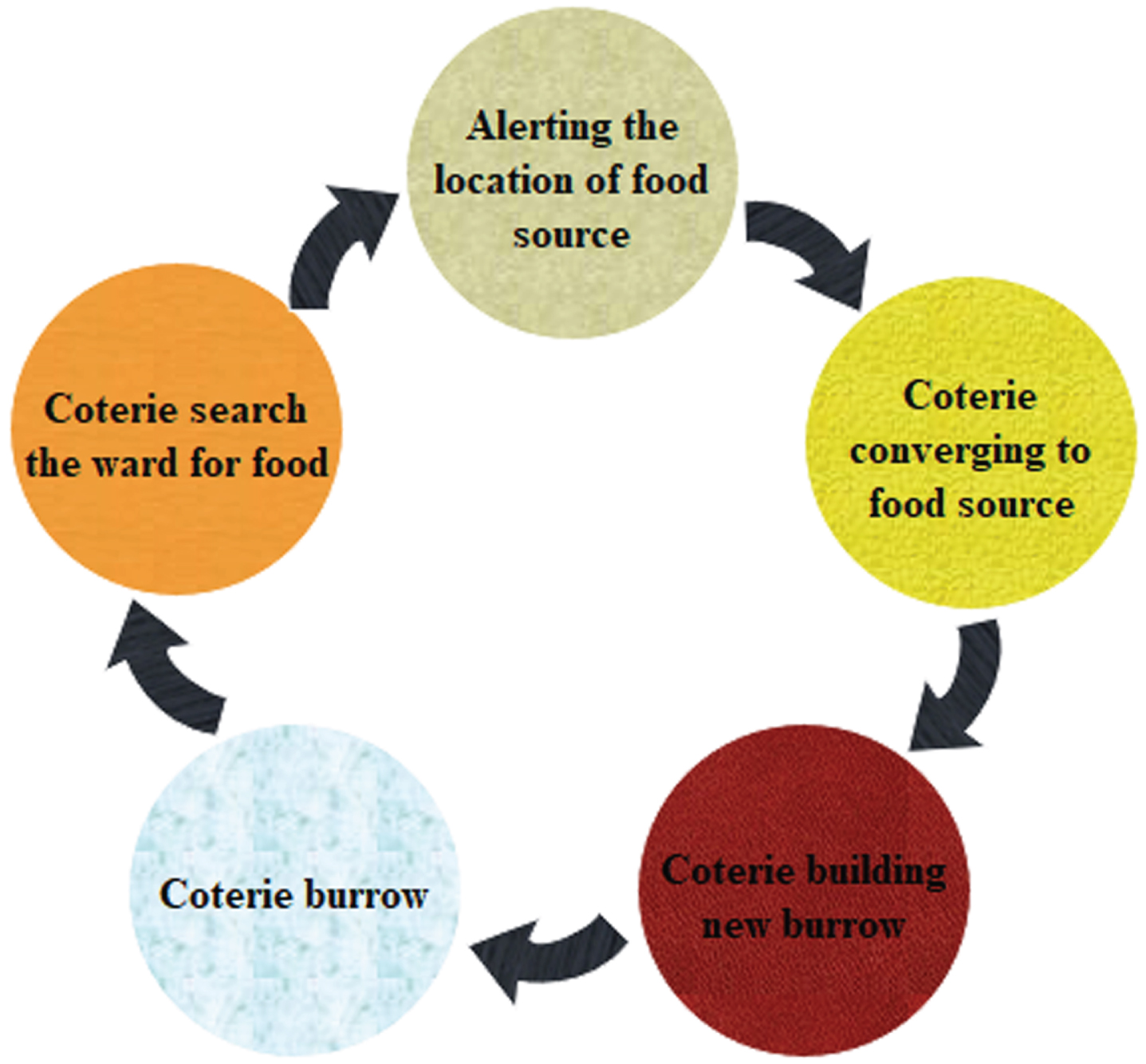
Search section’s model.
Here OBesti,j shows the overall best solution obtained so far, and eEBesti,j assess the current’s effect to achieve the best solution as in Equation (23), shows a particular food source alarm. r indicates the random solution location and EPi,j determines the randomized cumulative all prairie dogs’ effect within the colony and is given by Equation (24). C is the creek digging intensity, which relies on the food source’s quality and takes a random value given by Equation (23). Levy (n) is the distribution of Levy (n), known to promote suitable and more efficient search of the problem exploration space [31]:
Here s is a probabilistic property that ensures the search, taking values of ndash 1 or 1 relying on the iteration of current, respecting between ndash 1 and 1 if the current iteration is even or odd. However, the PDO application considered they were all the same. iter shows the current iteration, and Max It indicates the iterations’ maximum number.
Specific responses to two unique communications or alarm sounds in prairie dogs are employed to achieve exploitation in the suggested PDO, as indicated in Fig. 6. Equations (26) and (27) give the two processes envisioned in this section. As already mentioned, PDOmoves between these two processes depending on
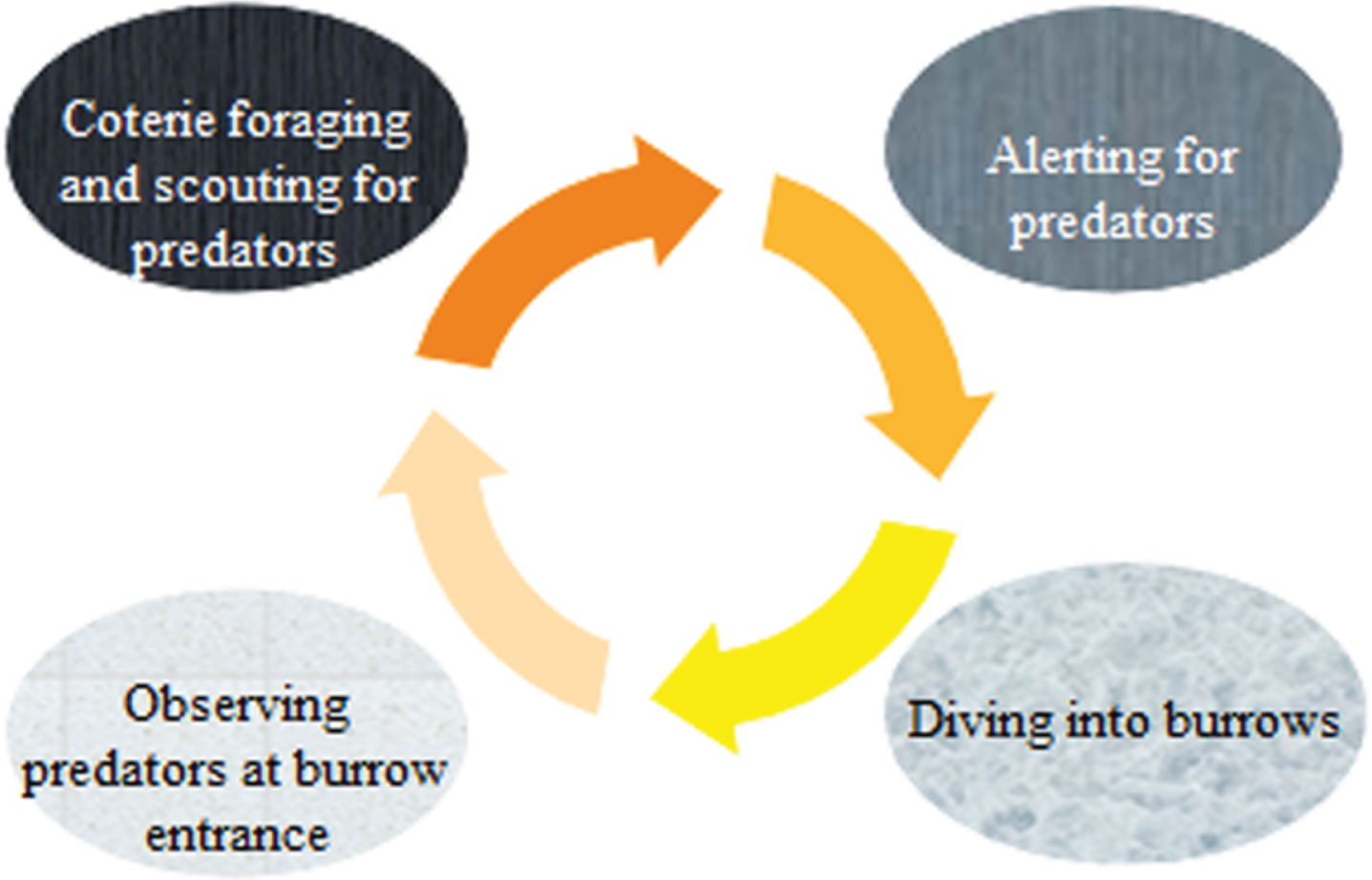
Exploitation’s model.
A small variety defining the high satisfaction of the food supply is shown in q, and the impact of the predator is shown in s. Additionally, Algorithm 2 presents the PDO pseudo-code.
Algorithm 2. Prairie Dog Optimizer pseudo-code
The flowchart of PDO is shown in Fig. 7.
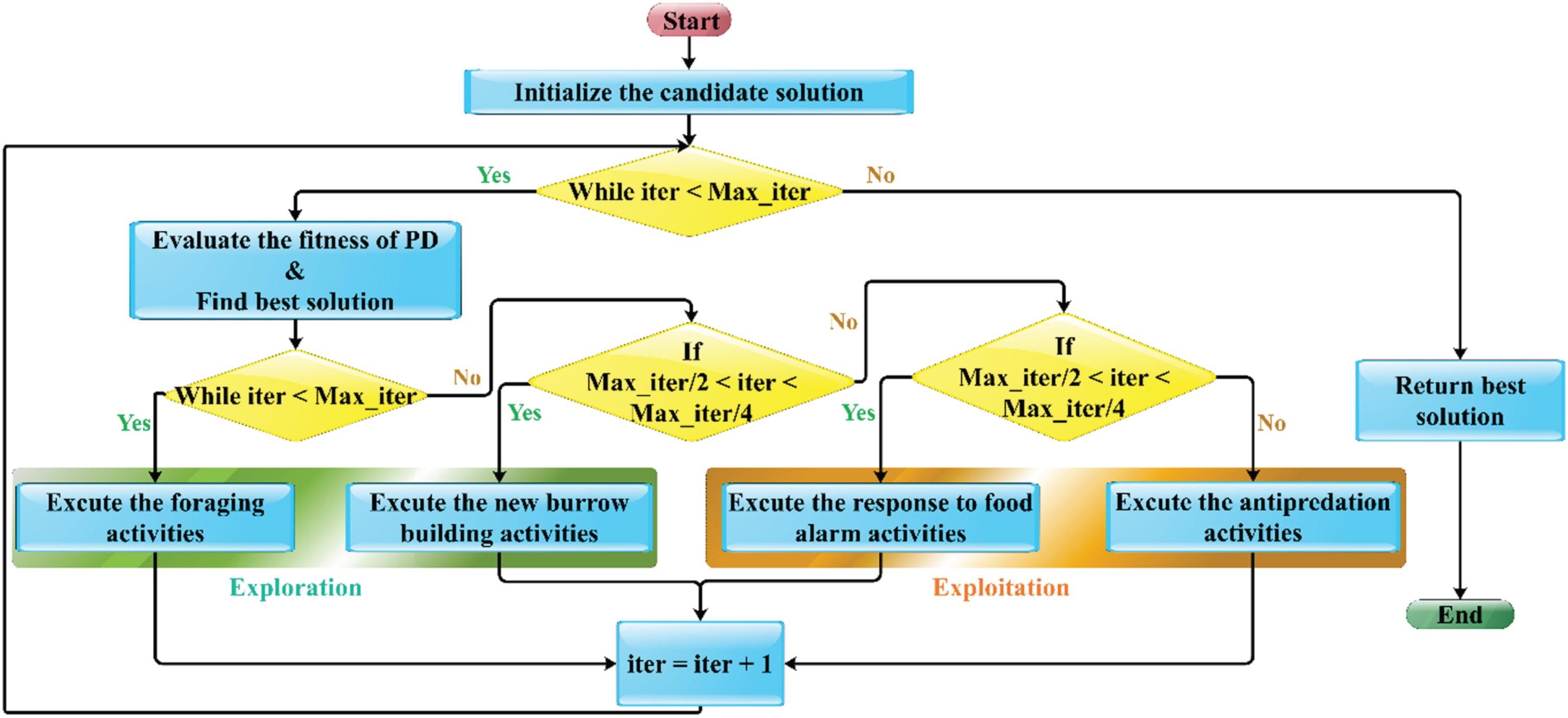
The flowchart of the PDO algorithm.
The GRO algorithm was developed by utilizing the potential of human reasoning and decision-making to locate the gold. A team of operators is dispersed randomly throughout the search area to start the search. Each operator watches for devices that produce a louder sound and listens for sounds produced by other equipment while paying attention to their own [32]. The GRO algorithm’s flowchart can be found in Fig. 8.
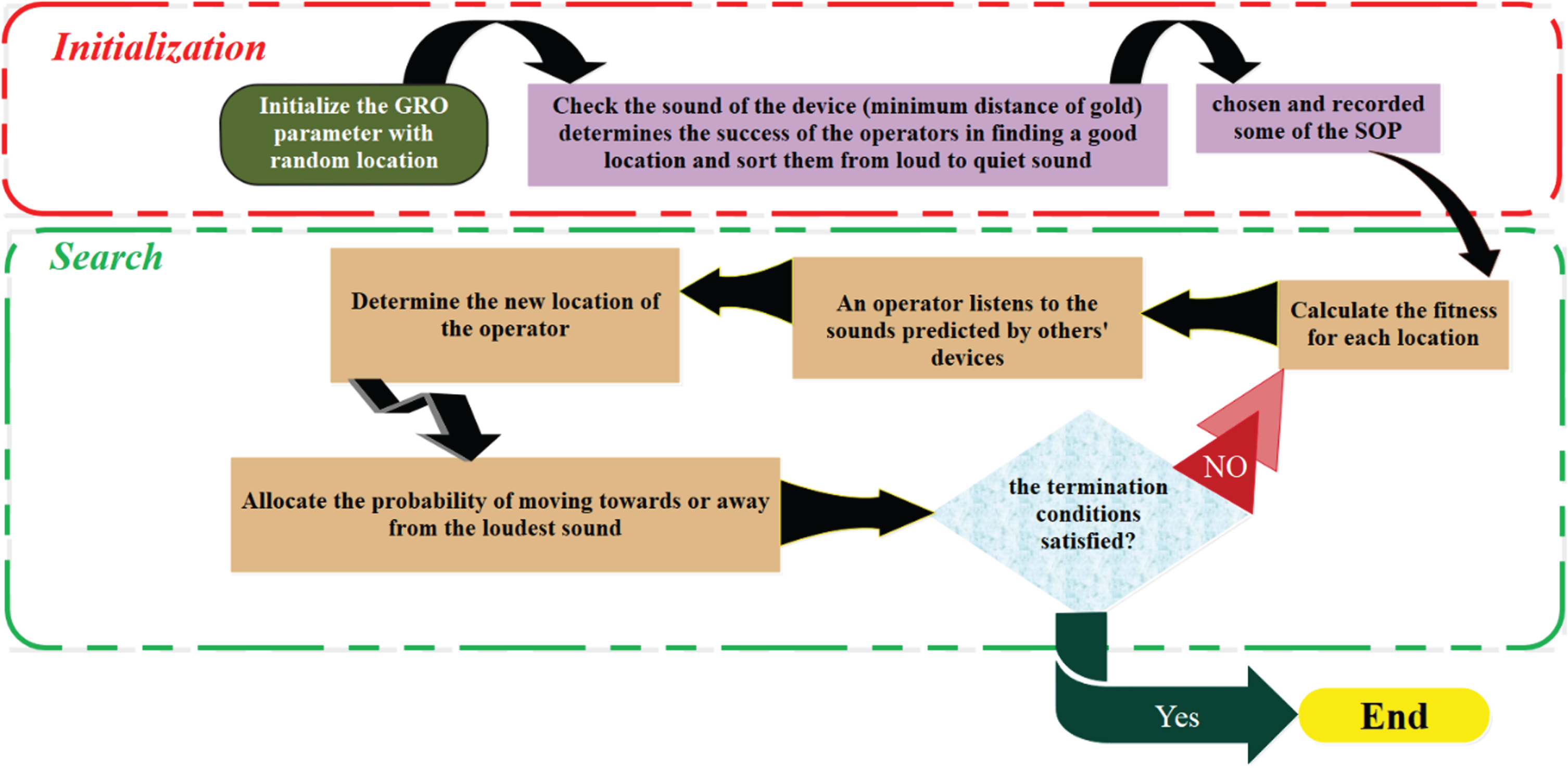
The flowchart of the GRO algorithm.
Equation (29) represents the random assignment of a location to each operator within the search area. Rand denotes a random number within the range of [0, 1], and the search spaces for the operators are defined by ub i and lb i .
An operator who successfully locates the ideal location is known as the SOP. After each iteration, it is advised to keep the top 10% of operators in the SOP.
Third step: Fitness-distance, refers to the relationship between fitness and distance
Using Equation (30), the loudness of each sound (rate) is calculated to identify the operator with the best chance of finding gold.
To mitigate environmental errors, the coefficients in Equations (31-32) are utilized, represented by D i and P i , respectively.
At this point, based on a variety of sounds, each operator makes a unique decision. Equation (32) is a representation of this procedure.
The MD coefficients, which are specified in Equation (34), represent the direction of movement:
The coefficients β and γ are selected from the range of 0 < β < γ < 1if Equation (35) fails to provide a satisfactory location, and Equation (35) is used to generate new locations.
Iterative Termination: The four termination steps, labeled as steps 1through 4, constitute a cyclic process that continues until the fulfillment of any of the subsequent conditions:
Different evaluators were exploited to assess the application of hybrid models to predict the value of the CBR. Coefficient of determination (R2), root mean squared error (RMSE), Mean squared error (MSE), Median Absolute Percentage Error (MDAPE), and Weighted Absolute Percentage Error (WAPE). The coefficient R2 determines the linear correlation degree between the actual and predicted amounts. RMSE indicates the square root of the ratio of the estimated value deviation from the actual value to the square of the number of specimens. The WAPE is equal to the sum of the absolute error divided by the sum of the actual demand.
The values of these metrics mentioned above are provided by Equations (36–40).
n shows the numbers related to the samples, d
i
shows the predicted value, b
i
indicates the experimental value,
Table 2 presents the hyperparameters for the developed models, explicitly detailing the structure in terms of layers and the number of neurons within each layer. The models listed are MLSA, MLBO, MLPD, and MLGR.
The hyperparameters of developed models
The hyperparameters of developed models
–In the first layer, the MLSA, MLBO, MLPD, and MLGR models have 13, 7, 12, and 9 neurons, respectively.
–In the second layer, the models have varying numbers of neurons for each of the four models: MLSA has 12, 4, and an empty cell denoting no neuron count; MLBO has 26, 19, and an empty cell; MLPD has 3, 6, and an empty cell; and MLGR has 5, 9, and an empty cell.
–In the third layer, the models have further varying numbers of neurons: MLSA has 6, 11, and 16 neurons; MLBO has 6, 18, and 18 neurons; MLPD has 21, 21, and 9 neurons; and MLGR has 12, 16, and 17 neurons.
The table essentially provides an overview of the model architecture, illustrating the arrangement of layers and the number of neurons within each layer for the mentioned models.
Comparison of developed models
In this study, we have developed three distinct hybrid models for predicting the California bearing ratio by combining the Multi-Layer Perceptron (MLP) with the BO and SAO, PDO, and GRO algorithms. These hybrid models utilize a data division into a training set (70%) and a test set (30%) to assess their performance. This section involves a comparative analysis of statistical indicators associated with these developed models to ascertain any superiority of one version over the others.
Tables 3 to 5 present the results of applied ML models for CBR in different layers (1, 2, and 3). The models evaluated are MLSA, MLBO, MLPD, and MLGR. The evaluation is conducted during training and testing phases, with critical indices including RMSE, R2, MSE, MAPE, and SI recorded for each phase.
The result of developed models for CBR in layer (1)
The result of developed models for CBR in layer (1)
The result of developed models for CBR in layer (2)
The result of developed models for CBR in layer (3)
In Table 3, which focuses on Layer 1, the models demonstrate varying performance across the phases. MLSA exhibits a low RMSE during training, indicating good predictive accuracy. MLBO, though presenting higher RMSE and MAPE, maintains competitive R2 values. MLPD stands out for its notably low RMSE and MAPE in the testing phase. MLGR shows solid performance in both the training and testing phases.
Table 4, for Layer 2, continues to reveal variations in model performance. MLSA showcases consistent and robust performance across phases. MLBO, while experiencing higher RMSE and MAPE, maintains competitive R2 values. MLPD displays a good balance of RMSE and MAPE in the testing phase. MLGR performs exceptionally well in the testing phase with low RMSE and MAPE.
Finally, Table 5 delves into Layer 3, unveiling further nuances in model performance. MLSA maintains its strong performance, with low RMSE and high R2 values. MLBO shows slightly increased RMSE and MAPE in the testing phase but maintains competitive performance. MLPD, despite a higher RMSE in testing, remains competitive across all phases. MLGR demonstrates excellent performance in training and holds a relatively higher RMSE in the testing phase.
In summary, these tables provide a comprehensive view of how different ML models predict CBR across various layers, showcasing their strengths and areas for improvement. The results offer valuable insights for optimizing model selection and performance across different evaluation phases. In addition, Fig. 9 indicates R2, RMSE, and MSE comparisons between the developed models.
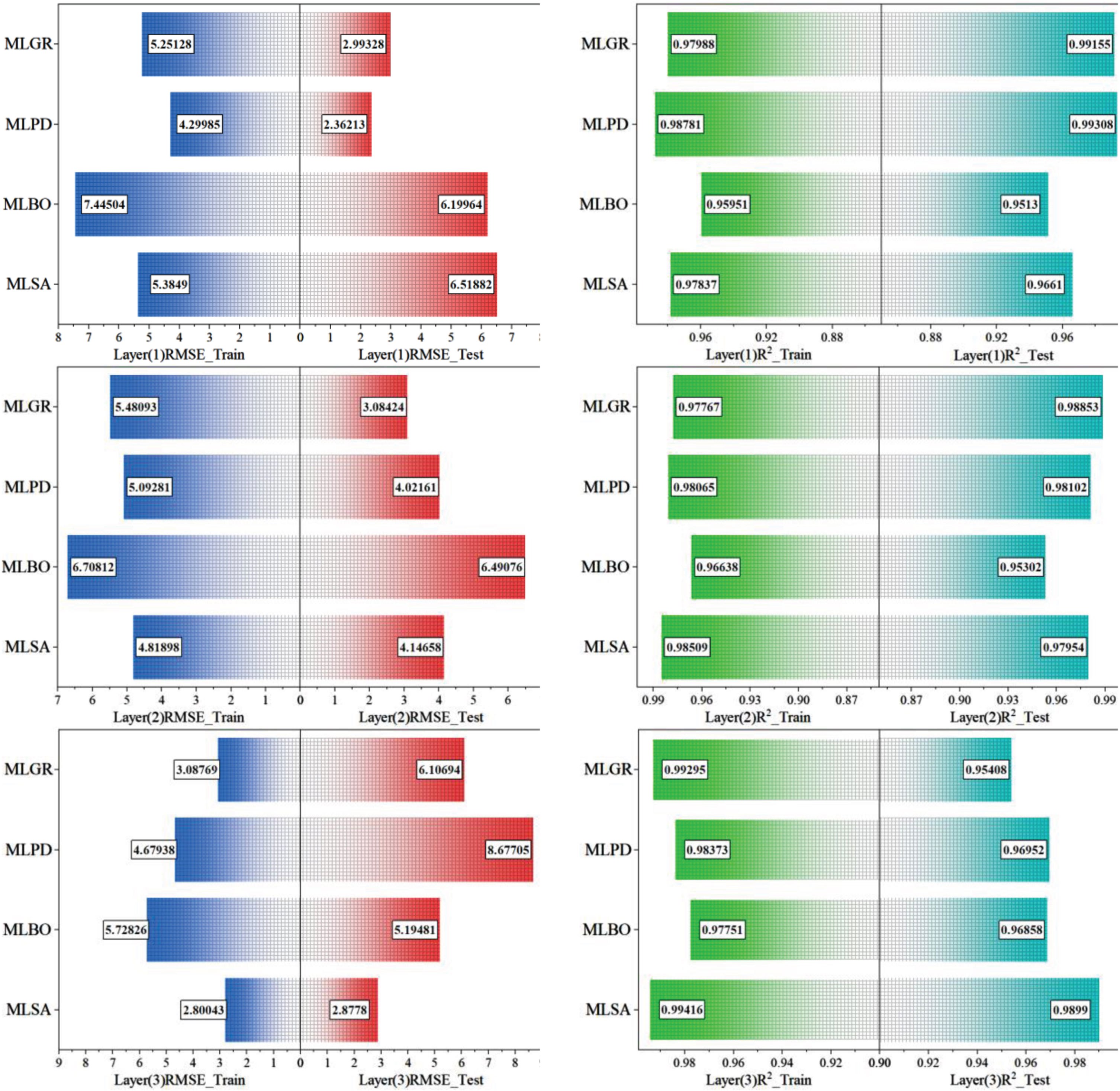
The comparison of metrics between layers.
The study illustrates the correlation between predicted and measured CBR models through stacked columns and scatter plots presented in Fig. 10, categorized into training and testing. These categories provide a comprehensive contrast for the predictions of the top-performing hybrid models, namely MLPD (layer 1), MLSA (layer 2), and MLSA (layer 3). The research findings underscore the impressive predictive accuracy of these models, revealing a robust positive correlation between expected and observed values. Notably, MLSA in layer 3 stands out as exceptionally superior due to its precise clustering of data points along linear regression lines. This model consistently exhibits minimal variation across all stages compared to the frequently higher measured values. Comparatively, the linear regression lines for MLPD in layer 1 and MLSA in layer 2 models display similar slope and intercept values, indicating equivalent prediction capabilities. However, MLPD (layer 1) and MLSA (layer 2) exhibit slightly greater dispersion among their data points. While their predicted points deviate slightly from the measured values, they still demonstrate respectable accuracy, albeit not as exceptional as MLSA in layer 3.
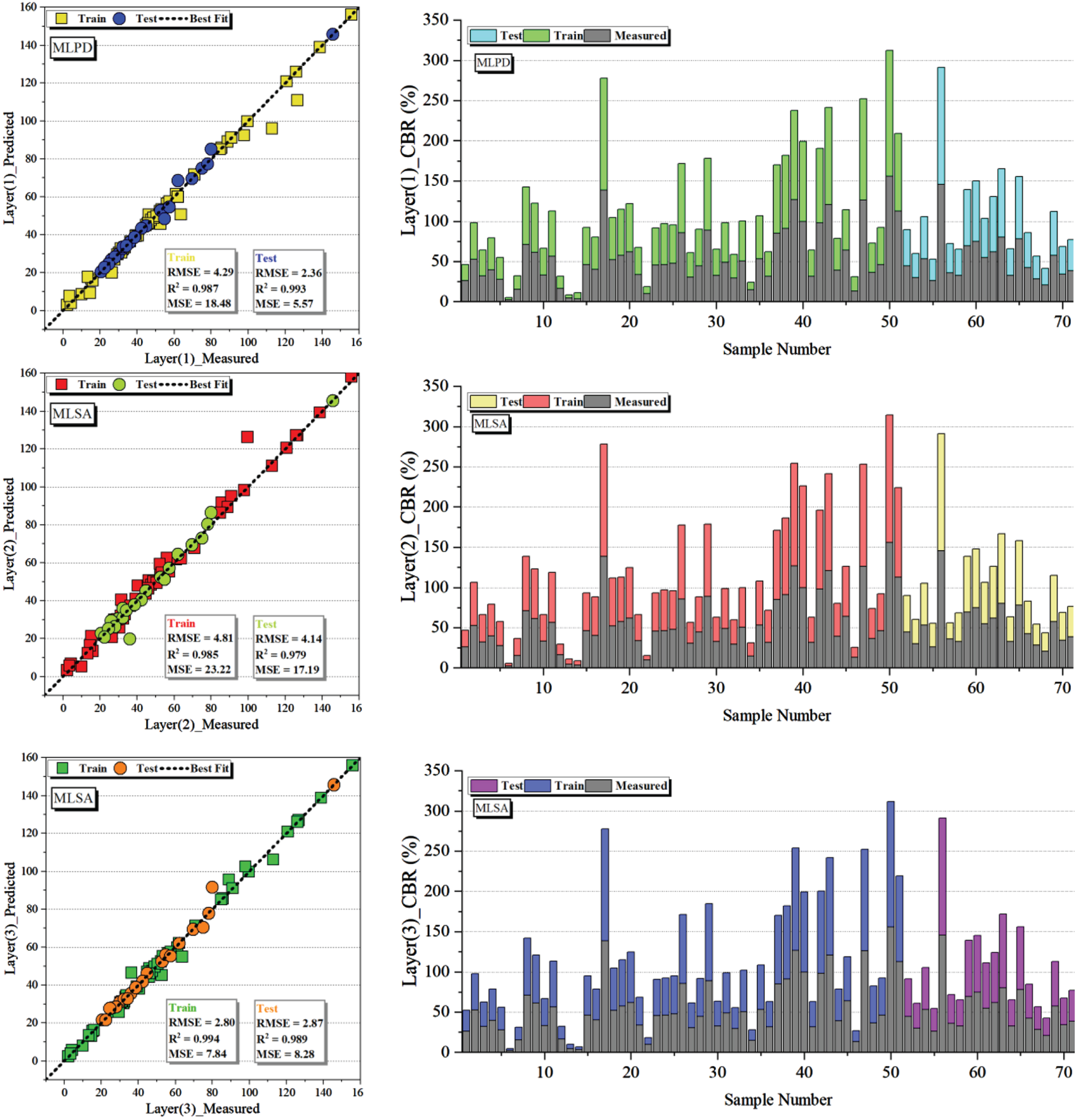
The stacked column and scatter plot of the correlation between the predicted and measured CBR models.
The study employs visual representations, specifically histograms and line plots in Fig. 11, to illustrate the error rate percentages for the hybrid models. Notably, most samples exhibit a high degree of consistency, tightly clustered within a relatively narrow error range of –15% to 15%. However, there is an outlier in the MLSA model in layer (3), which reaches as high as 30%. Among the three models under examination, the MLPD model in layer (1) stands out due to its more comprehensive range of error percentages, spanning from –20% to 20%, with a notable outlier at 120%. In contrast to the other two models, this broader range indicates increased variability and a lower level of predictive precision. On the other hand, the MLSA model in layer (2) distinguishes itself by displaying a wider range of error percentages, ranging from –19% to 19%, with an outlier at 65%.
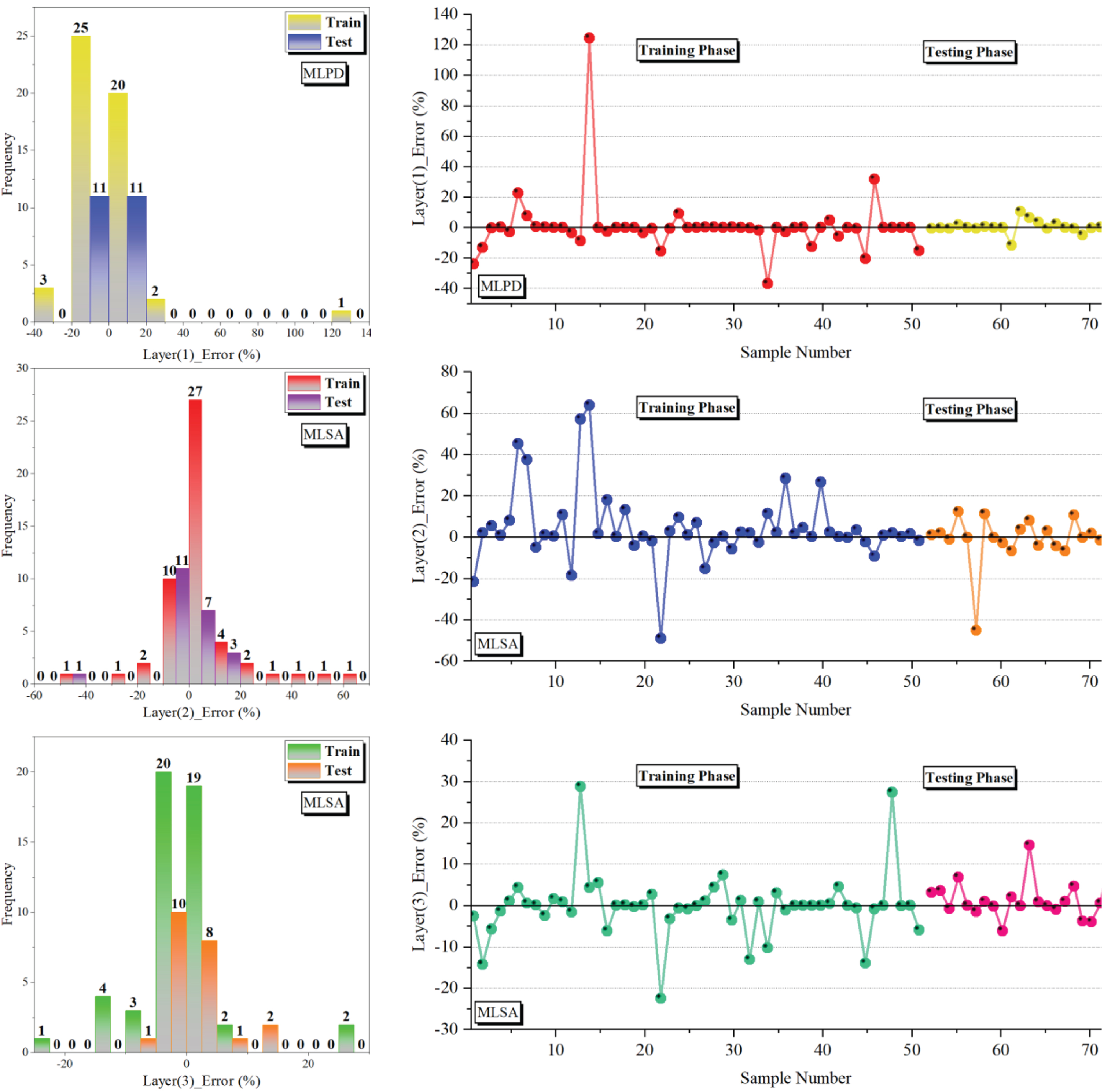
The error percentage of presented models is based on a line-symbol plot and histogram for CBR.
Figure 12 presents a box plot illustrating error percentages associated with three distinct models. Notably, the MLSA model in layer (3) emerges as a standout performer, consistently showcasing errors within the narrow range of –5% to 5% during the training and testing phases, displaying minimal variability. Conversely, the MLPD model in layer (1) exhibits error dispersion across both phases, manifesting a uniform normal distribution of errors that do not exceed the range of –20% to 20%. It is worth emphasizing that the Gaussian distribution observed in the MLPD model in layer (1) and the MLSA model in layer (2) signifies increased dispersion, accompanied by a diminished frequency of occurrences near 0%.
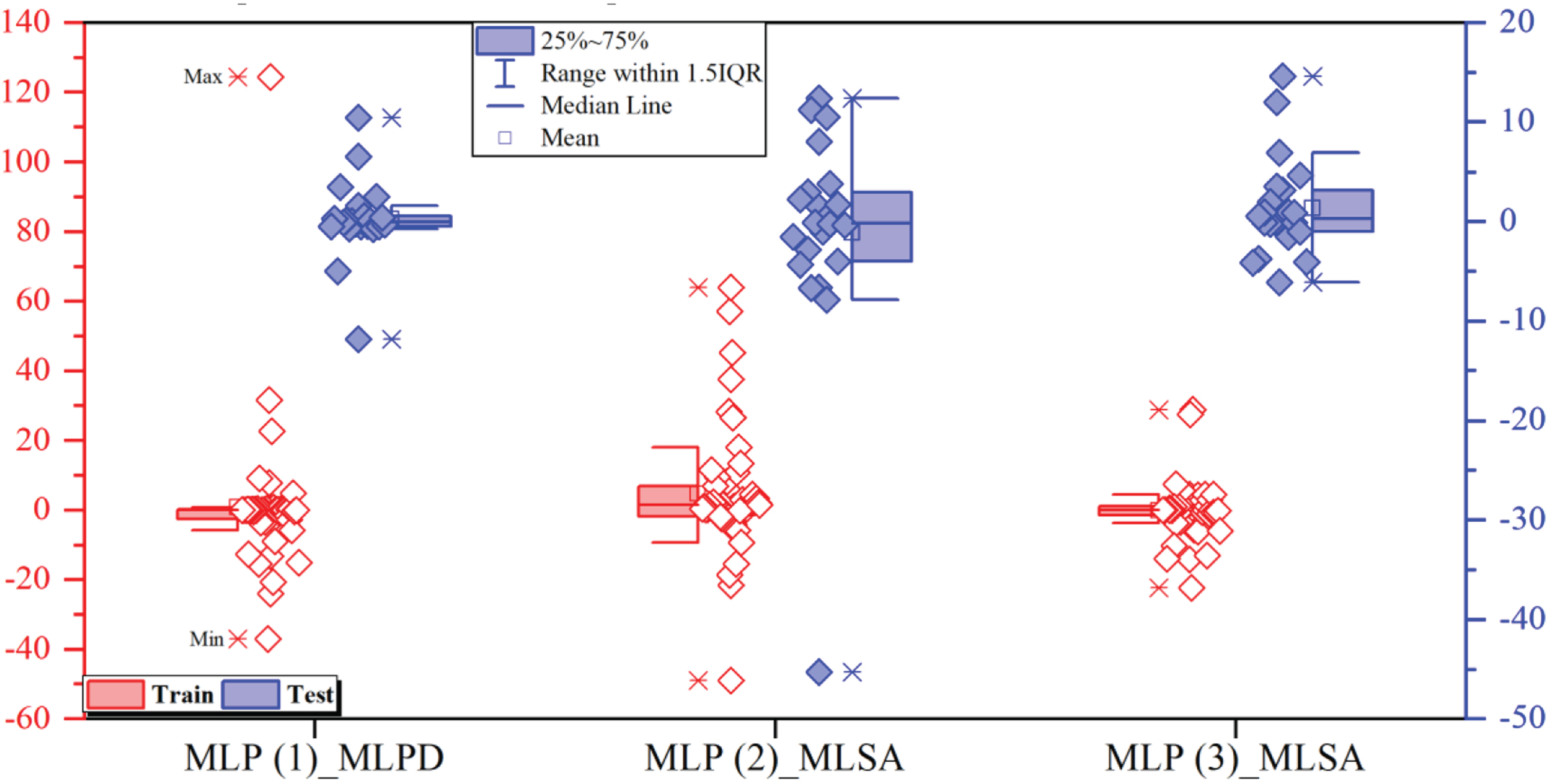
The box for the error percentage of the developed models for CBR.
Cosine amplitude method (CAM)
Academic Rephrase: Sensitivity analysis employing cosine amplitude refers to a method, either analytical or computational, that entails assessing the sensitivity of a system or model by utilizing cosine amplitudes or cosine functions. Figure 13 provides the outcomes of sensitivity analysis for input parameters LI, LS, MDD, OMC, and CP. The sensitivity indices elucidate the impact of each parameter on the model’s output, wherein higher values signify a more notable influence. Notably, LS does not exert any influence, whereas the remaining parameters exhibit varying degrees of influence. The accompanying confidence intervals quantify the uncertainty surrounding these sensitivity indices, contributing to a comprehensive grasp of the model’s responsiveness to alterations in input. These insights are pivotal for making informed decisions and refining the model effectively.
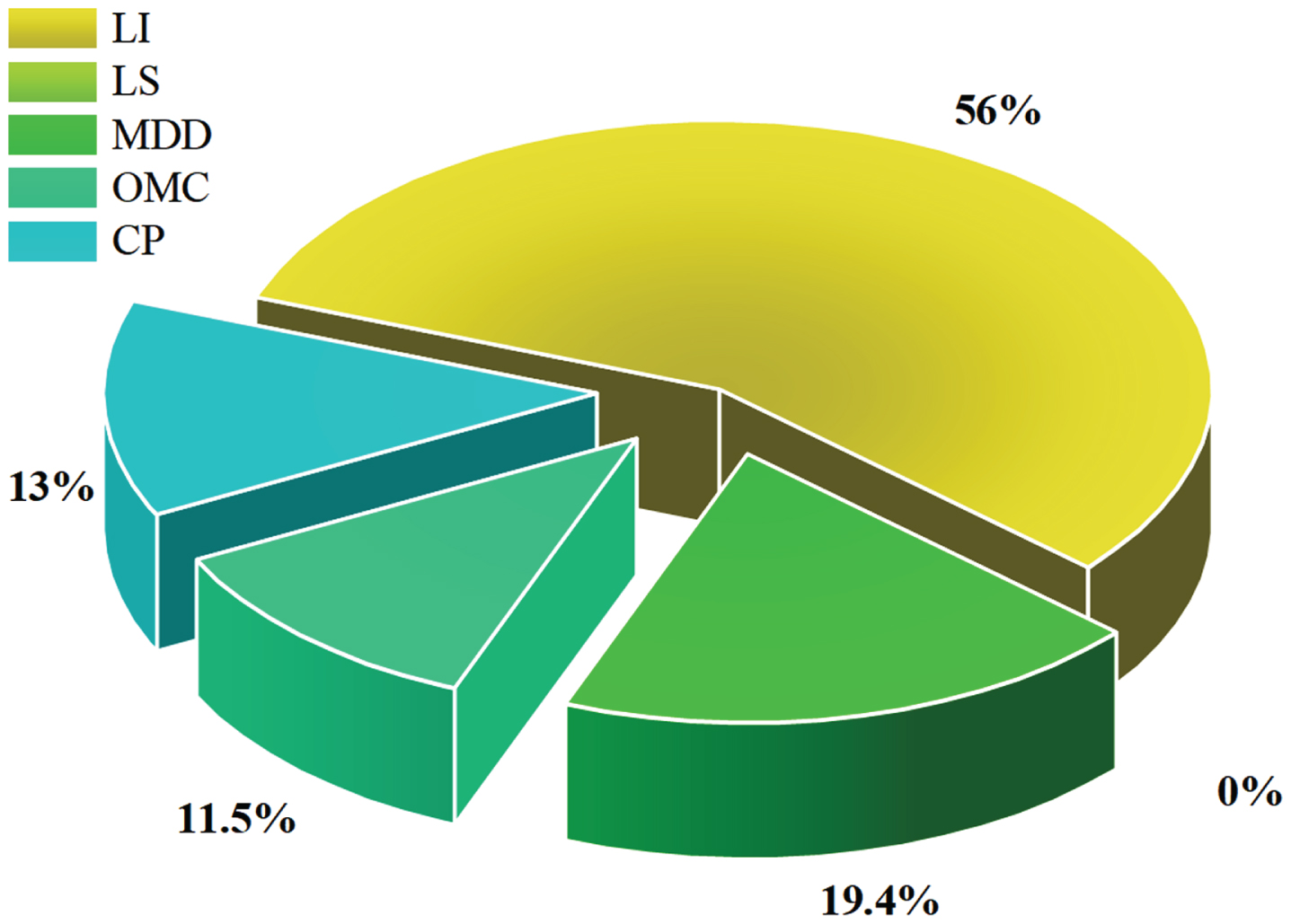
The sensitivity of each input on output.
The current study conducted an AI procedure to predict the mechanical properties of the pond ash’s California Bearing Ratio (CBR) value justified with lime sludge and lime. Nevertheless, the values obtained from the traditional method were accurate but had some disadvantages. The laboratory method is not only cost-effective in terms of time, but also it requires high costs. Artificial intelligence (AI) replaces the software method to solve these weaknesses. The system can predict the CBR precisely. For this purpose, multi-layer perceptron (MLP) produces powerful compound models consisting of Bonobo Optimizer (BO), Prairie dog optimization (PDO), Gold Rush Optimizer (GRO), and Smell Agent Optimization (SAO) for soil’s CBR value prediction. According to the results, it can be concluded as follows: In Layer 1, MLSA demonstrates notable performance in terms of RMSE during the training phase, while MLPD particularly excels in RMSE and MAPE during the testing phase. Despite having higher RMSE and MAPE, MLBO exhibits competitive R2 values. MLGR also performs commendably, showcasing a well-rounded performance across various metrics. Transitioning to Layer 2, MLSA’s performance remains stable, consistently presenting low RMSE and MAPE throughout the phases. MLBO, although displaying slightly elevated RMSE and MAPE, maintains competitive R2 values. MLPD achieves a harmonious balance with relatively low RMSE and MAPE, especially in the testing phase. In contrast, MLGR shines during testing, revealing low RMSE and MAPE values. In Layer 3, MLSA demonstrates remarkable consistency again by maintaining low RMSE and high R2 values. Despite a minor increase in RMSE and MAPE during the testing phase, MLBO sustains its competitive performance. MLPD showcases competitive performance across all evaluation phases. While MLGR excels in the training phase, it displays a comparatively higher RMSE during testing.
When comparing the models across the layers, MLPD consistently maintains competitive performance across various index values. However, it’s important to note that each model exhibits specific strengths. Hence, optimal model selection should be contingent on the specific layer and evaluation phase, ensuring an accurate prediction of CBR.
Footnotes
Acknowledgments
This work was supported by Service Science and Technology Innovation Projects of Wenzhou Association for Science and Technology in 2022, grant number jczc41, Basic Scientific Research Program of Wenzhou in 2021, grant number S20210027, Basic Scientific Research Program of Wenzhou in 2020, grant number R2020033 and Zhejiang College of Security Technology Key Scientific Research Program in 2020, grant number AF2020Z01.