
Abstract
Software-Defined Networking (SDN) is a strategy that leads the network via software by separating its control plane from the underlying forwarding plane. In support of a global digital network, multi-domain SDN architecture emerges as a viable solution. However, the complex and ever-evolving nature of network threats in a multi-domain environment presents a significant security challenge for controllers in detecting abnormalities. Moreover, multi-domain anomaly detection poses a daunting problem due to the need to process vast amounts of data from diverse domains. Deep learning models have gained popularity for extracting high-level feature representations from massive datasets. In this work, a novel deep neural network architecture, supervised learning based LD-BiHGA (Low Dimensional Bi-channel Hybrid GAN Attention) system is designed to learn class-specific features for accurate anomaly detection. Two asymmetric GANs are employed for learning the normal and abnormal network flows separately. Then, to extract more relevant features, a bi-channel attention mechanism is added. This is the first study to introduce an innovative hybrid architecture that merges bi-channel hybrid GANs with attention models for the purpose of anomaly detection in a multi-domain SDN environment that effectively handles real-time unbalanced data. The suggested architecture demonstrates its effectiveness on three benchmark datasets, achieving an average accuracy improvement of 7.225% on balanced datasets and 3.335% on imbalanced datasets compared to previous intrusion detection system (IDS) architectures in the literature.
Keywords
Introduction
Communication networks have seen tremendous achievements in recent years due to the advent of numerous mobile technologies. Packet-switching network-based applications such as Google, WhatsApp, Facebook, and Netflix have been instrumental in this. The cost-effective management of these geographically dispersed networks with retailer-defined tools and a scarcity of network administrators has long been a challenge. SDN assists in the reconfiguration of the entire network architecture as a software-based packet-switching network to resolve this concern. SDN deploys controllers, which control the entire network by issuing commands to network switches [1].
The multi-domain controller is used for dealing with large-scale networks. A hierarchy of control planes is maintained in multi-domain SDN controller architecture [2]. According to this paradigm, each domain has one controller for handling local events, while global events are handled by a higher level in the hierarchy, as indicated in Fig. 1. The multi-domain controller aids in the optimization of each SDN domain controller’s services for network supervision and high-performance application administration.
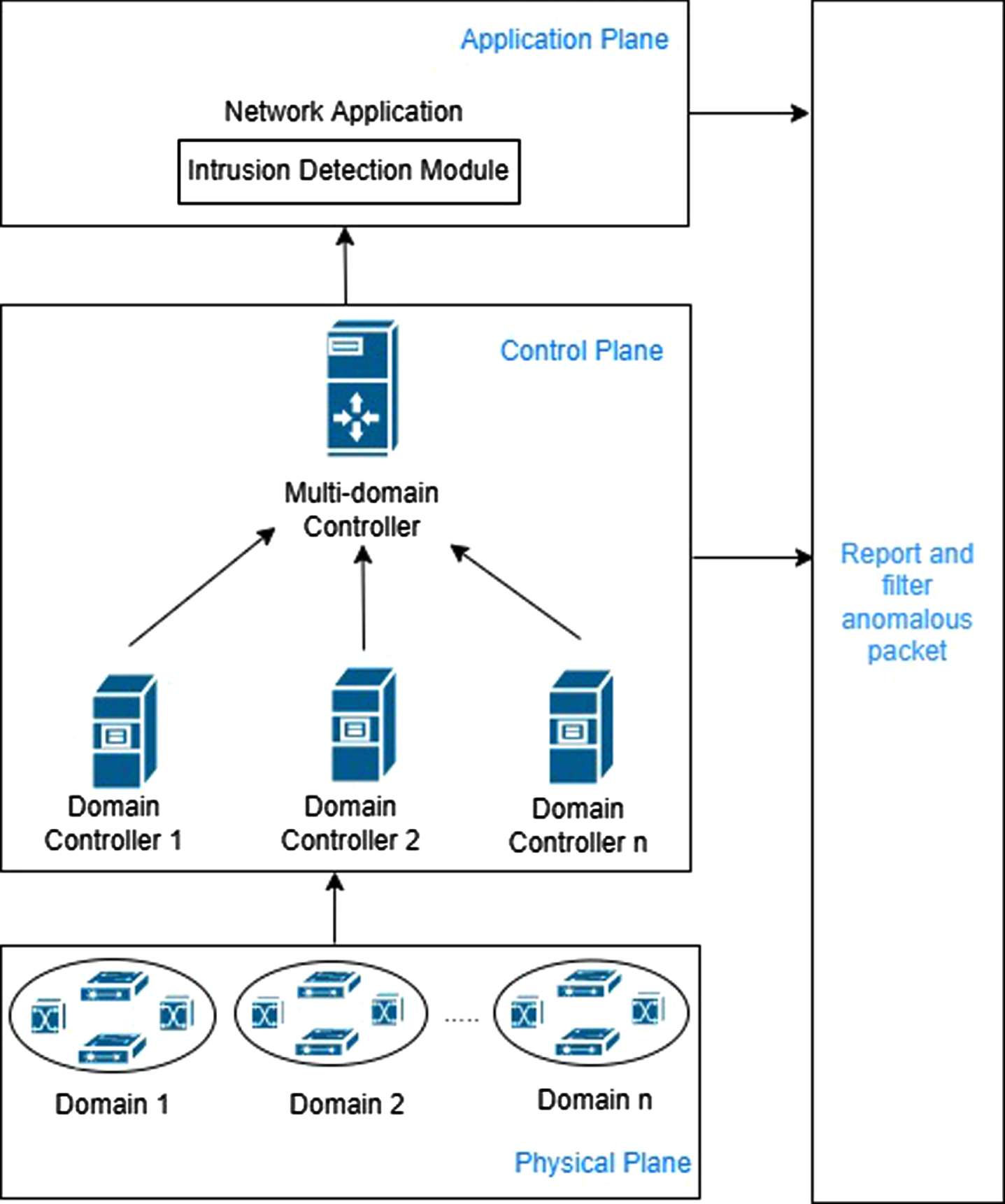
Hierarchical multi-domain SDN topology.
Despite SDN tackling traditional network attacks, it is still vulnerable to new assaults focused on the centralized controller. Hijacking the controller provides the ability for attackers to exploit many network devices. Thus, future SDN research should concentrate on detecting abnormalities to enhance network security and simplify network management.
A multi-domain controller must provide cross-domain anomaly detection as well as secure communication between controllers and switches to ensure domain controller security. Considering the absence of the need for identical features between domains, there is a need to learn invariant feature space. The proposed work challenges this issue through machine learning methodologies.
Deep learning [3] is an ideal machine learning model for handling the complex data flows within each domain, as it has the capability to learn robust feature representations through multiple layers between raw input and the target [4]. Despite the employment of many algorithms like Restricted Boltzmann Machine (RBM) [5], Autoencoder (AE) [6], Generative Adversarial Network (GAN) [7], Long Short-Term Memory (LSTM) [8], Recurrent Neural Network (RNN) [9], and Convolutional Neural Network (CNN) [10] in deep learning strategies, each one of them has its own pros and cons. As a result, in the proposed study, a supervised learning-based hybrid deep learning technique is used for the construction of an effective model.
The ability of deep learning networks to extract key features from input has improved due to the discovery of an attention mechanism ([11, 12]). The proposed approach employs attention mechanisms in a novel hybrid form for making considerable progress in the anomaly detection method.
The following are the significant contributions of this work: A novel deep learning multi-domain anomaly detection system is designed with a simple dimensionality reduction technique, hybrid GAN, and an attention mechanism to extract optimal features. Ensemble dimensionality reduction at the domain level improves network management by reducing SDN traffic and computational complexity at the SDN controller. A dual attention channel is used for the selection of the most relevant discriminating attack and benign features. The efficiency of the model is demonstrated on both balanced and unbalanced supervised datasets. The IDS within the multi-domain SDN controller exhibits superior anomaly detection capabilities, especially for anomalies that impact multiple domains simultaneously within the hierarchical multi-domain SDN architecture. The utilization of deep learning methodologies is to be more effective in processing extensive data from different controllers within the multi-domain SDN controller. The hierarchical SDN architecture facilitates prompt response from at least one controller when a service flow sends a request to enhance the performance of multi-controller networking in large-scale networks.
The aim of this research is to achieve precise anomaly detection across multiple domains. The following hypotheses are explored in this study:
The rest of this article is organized as follows: Related works related to the proposed mechanism are addressed in section 2. The system model, its security requirements, and its working methodology are presented in section 3. Section 4 provides a description of the proposed anomaly detection system. Section 5 presents an empirical study of the methodology. The findings and comparative analysis of the proposed system are provided in section 6. Finally, the conclusion is drawn along with suggested future enhancement.
Many studies rely on traditional machine learning techniques for tasks such as dimensionality reduction and classification. Traditional machine learning techniques have proven inefficient in handling large-scale network flow data. As a result, there is a need for the utilization of deep learning approaches for feature learning and classification. Deep learning, a branch of artificial neural network architectures, is favored for its ability to quickly learn and reveal hidden patterns in input distributions. In the past six years, related research has been explored from two distinct perspectives: one involving the use of deep learning methods for dimensionality reduction, and the other focusing on their application in the field of intrusion detection.
Deep learning methods for feature learning
Despite the utilization of various deep learning networks for feature dimensionality reduction, recent research has shown a preference for Autoencoders and their variants, including Denoising Autoencoders (DAE), Sparse Autoencoders, and GANs. These choices are based on their compatibility with other deep neural network architectures, their alignment with unsupervised learning paradigms, and their ability to ensure non-linear transformations.
An autoencoder-based wrapper feature selection framework was designed by Sharan Ramjee and Aly El Gamal [13]. The model’s hypothesis proposed that the significance of features was influenced by two characteristics: relevance and redundancy. Irrelevant features were considered insignificant as their removal does not lead to a reduction in classification accuracy. Conversely, redundant features were also considered insignificant since they can be inferred or approximated from other features, regardless of whether their relationship with these features is linear or non-linear, as long as the other features remain present. The framework was used in conjunction with the exclusive ranker model for the removal of features that were not found necessary for the classification mechanism and autoencoders for the elimination of correlated features. Consequently, backward feature selection was employed to improve efficiency. The classifier belongs to a category of supervised deep learning techniques tailored for specific applications. In another work [14], the authors combined unsupervised autoencoders for learning features separately among benign and anomaly flows with a supervised 1D convolution layer to reveal feature dependency among channels. Then, with the help of fully connected layers as the classifier, convolved features were refined for the promotion of other patterns’ interactions.
The following research works primarily focused on stacked autoencoders. This work [15] involved extraction of the corresponding features and maintaining the essential information using stacked autoencoder. The authors have identified the outliers based on their significant reconstruction error and restored them. Additionally, it supported two criteria like Grubbs and PauTa to facilitate the detection of outliers among the benign data. It enhanced the detection of both isolated and continuous outliers. A stacked sparse autoencoder exploited by Binghao Yan and Guodong Han [16], was used for the extraction of high-dimensional features. The optimal deep sparse features obtained were highly discriminative and significantly accelerated the classification process when used with three classifiers: support vector machine (SVM), random forests (RF), and K-nearest neighbor (KNN).
A denoising autoencoder was used in some works ([17–19]) for the introduction of noise into the neural network and avoidance of learning the identity function. In the study [17], an ensemble approach was employed to perform dimensionality reduction on network traffic data, aiming to improve the detection of attack data. The process involved using statistical machine-learning techniques to select a substantial number of features. These features were then validated using a denoising autoencoder to ensure their effectiveness and relevance in the task. Intelligent defect diagnostic method [19] was introduced by the authors for the extraction of typical features from a huge amount of unlabeled data using an unsupervised denoising autoencoder. Only a little amount of labeled data was required for fine-tuning the deep neural network. This deep neural network architecture accomplished improved performance in the classification of faults. A Robust Software Modeling Tool (RSMT) [18] was used in this work for the examination of the runtime performance of the web apps. By utilizing a stacked denoising autoencoder, RSMT successfully detected the low-dimensional representation of the observed raw web application features. Additionally, this approach enabled the automatic detection of attacks on web applications. End-to-end deep learning techniques were paired with autonomic runtime behavior monitoring and web application description for the production of reliable, high-level output from raw feature input.
Based on the literature review of dimensionality reduction, it is evident that high-computation models are frequently employed for reducing feature dimensions. Consequently, there is a need for a simple model with low computational overhead, yet capable of maintaining high performance. In this proposed research, we leverage a basic unsupervised denoising autoencoder. This approach intentionally introduces corruption into the input data and then trains the model to enhance its robustness through this process.
Deep learning methods for intrusion detection
Machine learning algorithms have been used to build most IDS. Meanwhile, deep learning approaches are also being investigated to achieve high accuracy and efficiency, particularly when handling vast amounts of data. Despite the publication of numerous papers on deep learning algorithms for intrusion detection, they can be summarized into major categories, including CNN, LSTM, RBM, Autoencoder, and Attention.
The authors in [20] preferred CNN for IDS. It was a multilayered discriminative neural network comprising convolution and pooling layers stacked one over the other. In [21], a HYBRID-CNN model was devised to facilitate dual-channel feature extraction in the SDN-based Smart Grid for identifying anomalous flow. It memorized the global features filtered by a deep neural network (DNN) while training the one-dimensional data. Then, it generalized these features with the help of the CNN network. This model appreciated the importance of both DNN’s global learning and CNN’s local generalization. In another work, the authors suggested a near real-time SDN security solution [22] for safeguarding its controller from Distributed Denial of Service (DDoS) attacks. The authors used CNN to detect DDoS attacks and mitigate the eradication of traffic impairment. The game theory (GT)-based mitigation was helpful in restoring SDN’s normal activities, providing a reasonable methodology for dealing with internal and external DDoS attacks.
LSTM is a type of RNN that learns and classifies time series data to forecast long-term dependencies more accurately than vanilla RNNs, as indicated by various studies [23]. In another study [24], the LSTM-FUZZY network was presented for the detection and mitigation of DDoS and Portscan attacks in SDN environments. The authors developed a semi-supervised LSTM for predicting normal network activities by utilizing IP flows. Then the attacks were recognized by the coupling of Bienaymé-Chebyshev’s inequality with fuzzy logic. The authors preserved the network operations by using automated mitigation policies. Anomalous flows were dropped using MacNemar’s test with a significance level of 5%. The test was conducted to assess the null hypothesis that the marginal frequencies are equal. In this work, a BiDirectional LSTM (BiLSTM) [25] was effectively employed to improve the overall anomaly detection rate. It also significantly reduced the number of false alarms for each attack class.
RBM is a two-layered energy-based model that has its scalar energies adjusted throughout the learning process for the achievement of the desired qualities [26]. In [27], the authors presented a hybrid deep learning framework for the enhancement of the reliability of the SDN. This framework was employed with a multi-objective flow routing mechanism and an upgraded RBM with SVM in SDN. In another work [28], the authors created an Anomaly Network Intrusion Detection System with the help of DRBM (Deep Restricted Boltzmann Machine), for the detection of a new attack pattern. This system was tested with the Information Security Center of Excellence (ISCX) dataset, which was a well-balanced dataset that could help eliminate biases in the RBM network’s training.
Unlike conventional deep learning networks, GAN generates adversarial data by applying non-linear transformations to actual data. The authors have presented a powerful GAN-based framework [29] for detecting anomalies in unknown data. Using a specially designed loss function and the Wasserstein distance, it focused on multiple intermediary layers for closing the gap between latent and actual space. In [30], researchers combined RF with GAN and introduced GAN-RF to identify optimal solutions for anomaly detection in imbalanced datasets. They used GAN to generate minority class samples, leading to an improvement in overall accuracy. The authors have suggested a unique deep learning model based on GAN in [31], that uses BiLSTM as a generator and CNN as a discriminator to produce synthetic electrocardiograms(ECGs) identical to actual ECG data.
Deep learning-based anomaly detection has been combined with attention mechanisms in recent years for improved performance rather than traditional solo methodologies as in [11] and [32]. In [33], the authors designed an architecture, which combined BiLSTM with an attention mechanism as well as multiple convolutional layers. The local and data packet features were retrieved using these convolutional and BiLSTM layers. After that, the attention mechanism performed feature learning on the network flow vector on its own, eliminating the need for feature engineering. This architecture addressed the issue of lower accuracy commonly associated with traditional machine learning techniques. The Attention for Network Intrusion Detection model presented by authors in another work [34], was a modified version of the transformer model that leveraged timeslot-derived features to help identify real-time network intrusions. It was employed in language translation and has proven to be effective in detecting attacks.
The multi-domain controller not only assesses the classifier’s performance but also indirectly evaluates the quality of the reduced data generated by the domain controllers. The effectiveness of dimensionality reduction becomes evident through its impact on the subsequent predictive tasks’ performance. Attackers in the real world use numerous network domains to carry out their attacks. Multi-domain attack detection with huge traffic, without any deterioration in network performance, is a critical task. Furthermore, it is worth noting that many studies have primarily focused on enhancing classifier performance using balanced datasets, which may not accurately reflect real-world traffic scenarios. Hence, the purpose of this study is to improve results for unbalanced datasets. Additionally as shown in Table 1, some research relies on unsupervised models for feature reduction, using the same model for attack classification based on reconstruction error. On the other hand, others prefer using a separate supervised classifier model for classification. To address these challenges, a hybrid deep learning approach is proposed, which improves feature reduction and classification accuracy. Unlike most studies that avoid making hypotheses about system relationships or constraints, this research incorporates hypotheses to provide explanations. Consequently, recent popular high-performance deep learning models have been used in the proposed multi-domain controller attack detection framework.
A summary of existing dimensionality reduction and intrusion detection approaches in the last six years
A summary of existing dimensionality reduction and intrusion detection approaches in the last six years
In this section, the system overview model and working techniques are presented, along with security system bottlenecks for the proposed LD-BiHGA approach.
System model
The network is logically viewed as a collection of domains based on geographical area with each domain controlled by a domain controller while the underlying domain controllers are controlled by a multi-domain controller.
Each element in the forwarding plane of every domain is directly programmed by its corresponding logical domain controller. These domain controllers communicate with the forwarding plane elements through open southbound interfaces, such as the IETF’s ForCES (Forwarding Control Element Separation) and the ONF’s OpenFlow [35]. Figure 2 shows domain controllers transmit their arbitrated results of reduced preprocessed data to a multi-domain controller. The multi-domain controller then validates the data and reports it back to the domain controllers, which in turn, route legitimate data between domains. Thus the proposed system encapsulated its functionality in the three components via a multi-domain controller, a domain controller, and domain forwarding plane elements such as switches, routers, and access points as shown in Fig. 2.
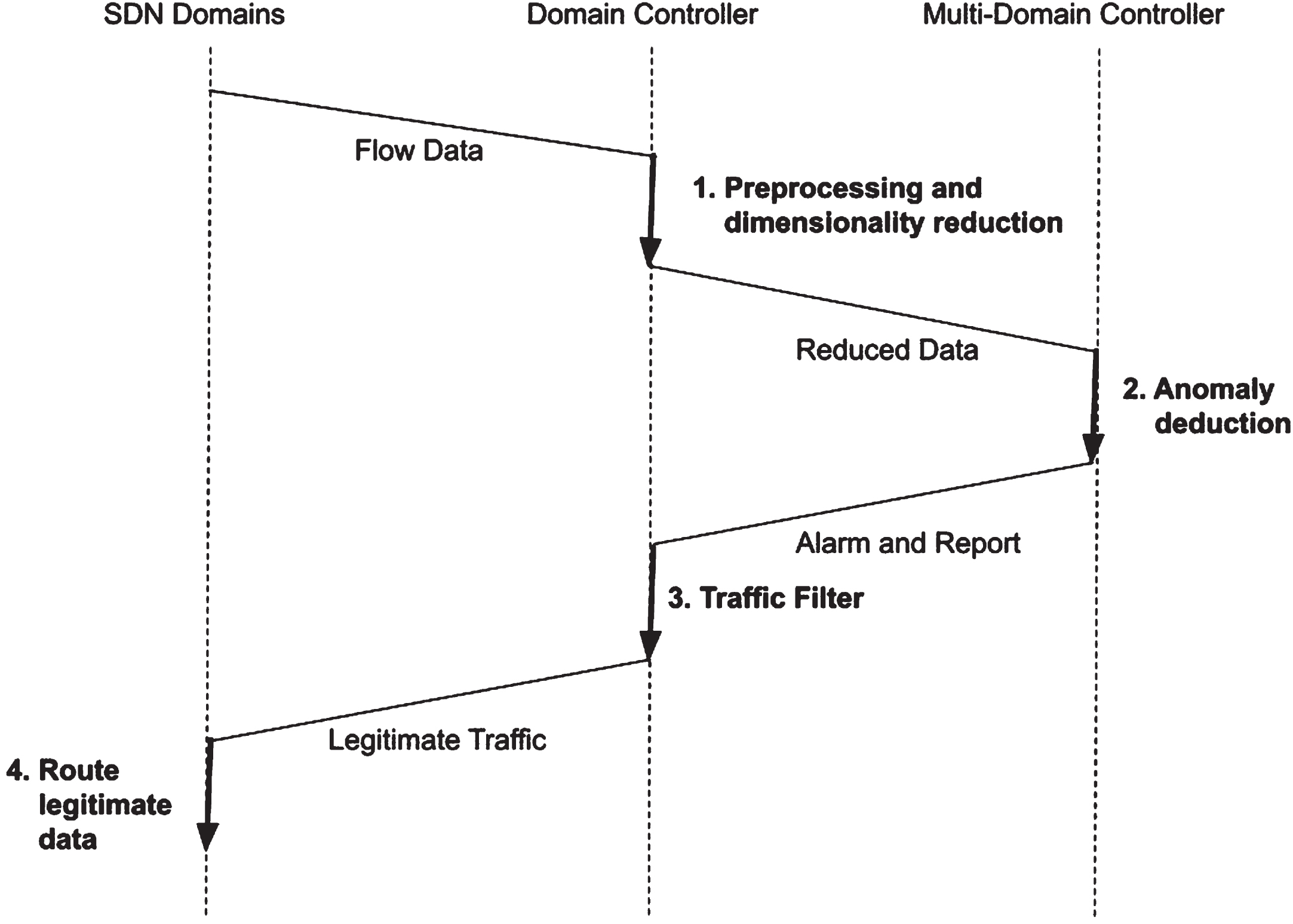
System process sequence diagram of LD-BiHGA.
Unpredictability of SDN domain data size
In a hierarchical multi-domain SDN environment, the presence of multiple domains introduces the possibility of varying data sizes, depending on the real-time demands of the network. Additionally, these SDN domains are susceptible to various attacks, underscoring the crucial role of the multi-domain controller as the central defender for the entire network. As the multi-domain controller manages SDN domains, detecting abnormalities in both small and large datasets becomes a critical concern for its effective operation.
Imbalanced SDN domain data
Some domains may contain predominantly legitimate data, while others may possess minimal legitimate data. In other words, variations in the proportion of legitimate data are inevitable, necessitating the domain controller’s ability to adapt to such diversity. Moreover, achieving reliable anomaly detection becomes challenging when dealing with a substantially lower degree of attack data.
Working methodology
The workflow of the proposed system is briefly described in this section. At each geographical domain, the devices at the physical layer send their access requests via the network. Their corresponding domain controller extracts the features by grasping the statistical flow table of the request, as shown in Figure 3. Each domain controller performs an ensemble dimensionality reduction process via three steps: data preprocessing, feature selection, and feature extraction to format data for further processing, and the dimensionality of data is thus reduced.
The reduced features of each domain are then provided to the multi-domain controller for anomaly detection. Leveraging the Bi-channel Hybrid GAN Attention (BiHGA) mechanism, the multi-domain controller identifies abnormalities in three distinct phases: dissociation, detection, and reporting. Normal and abnormal data are separated from domain-specific reduced features using the dissociation process. In the detection phase, the BiHGA algorithm comprises three stages for identifying abnormal flows: feature extraction on relevant classes, feature merging, and classification. The reporting phase is used for conveying anomaly reports to the control plane, and when an anomaly is detected, the multi-domain controller sends an alarm to its associated domain controller, instructing it to discard the packet.
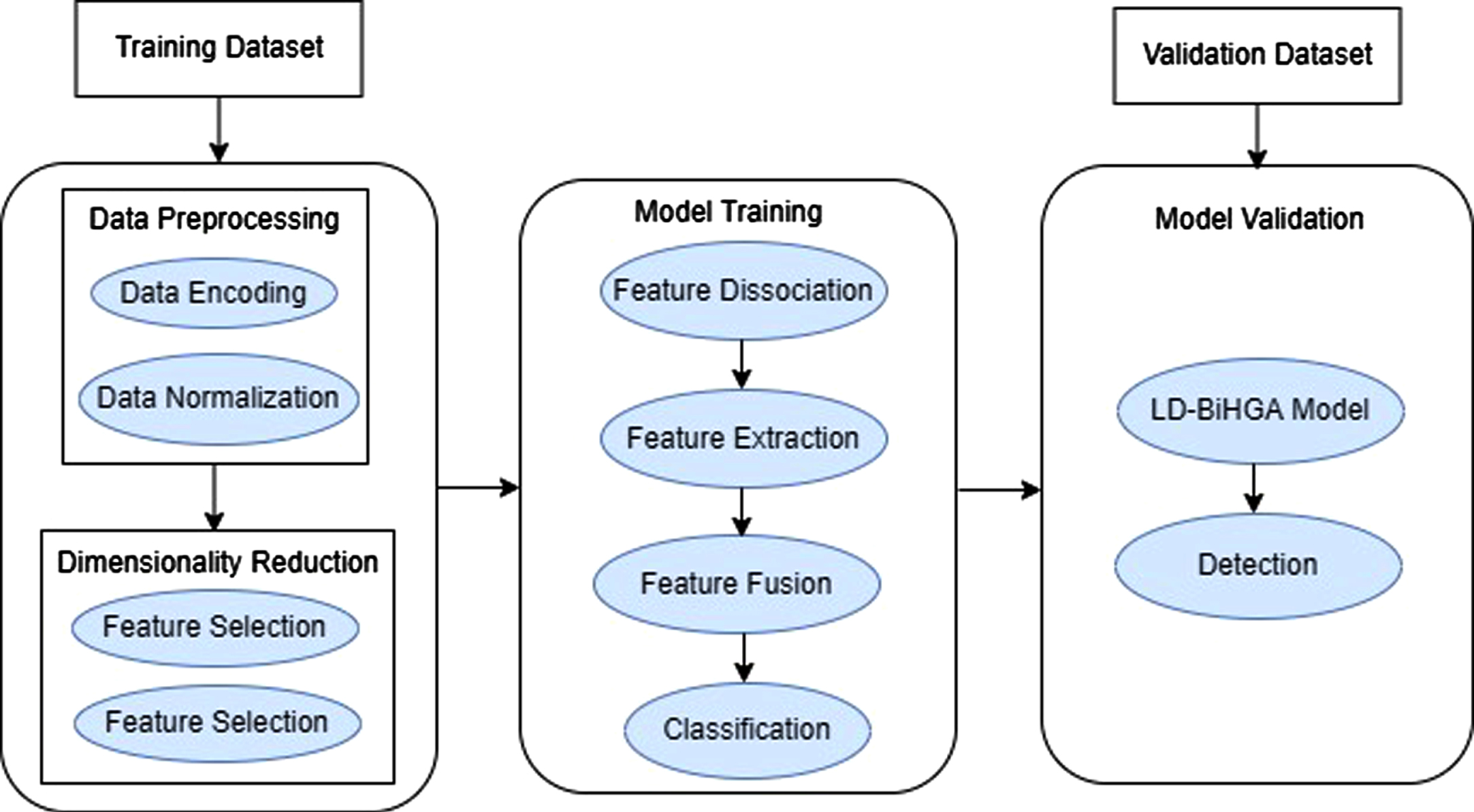
Working methodology of the proposed LD-BiHGA approach.
As shown in Fig. 4, the proposed system performs the functionalities of two primary components: domain controller dimensionality reduction and multi-domain controller traffic classification.
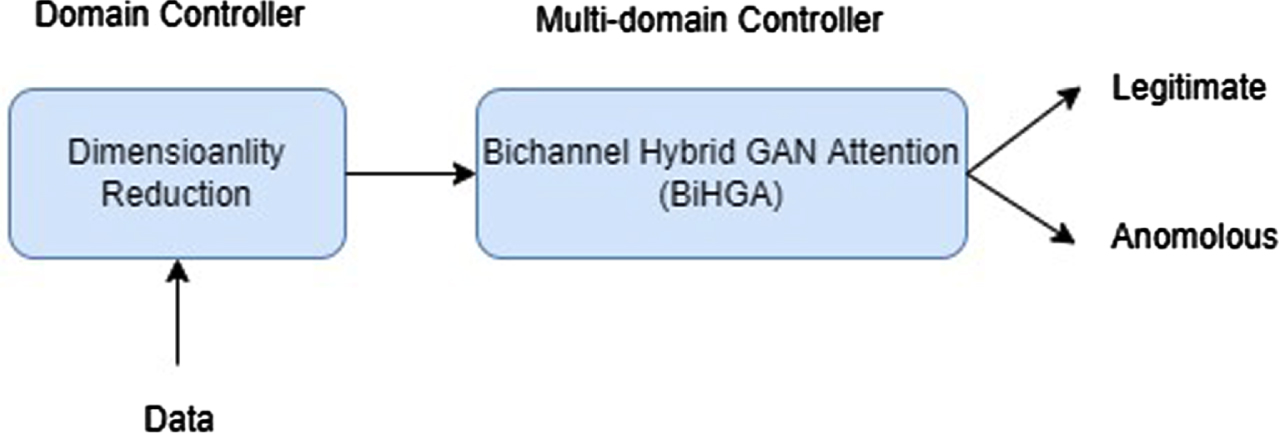
LD-BiHGA system functionality.
In one of our previous works [17], we highlighted that ensemble-based dimensionality reduction techniques have demonstrated their ability to generate improved features for subsequent classification stages. Consequently, the preprocessing stage in our proposed work employs a similar dimensionality reduction technique through the following steps:
Feature preprocessing
One-hot encoding is accomplished using feature encoding [36], and feature normalization [37] is performed via min-max normalization.
Feature selection
Highly correlated features are identified and eliminated using Spearman’s cross-correlation technique. This method is particularly recommended for feature selection due to its resistance to outliers [38] and its ability to capture non-linear relationships, which allows it to prioritize low-correlated features. Initially, the current SDN feature values (f1, f2, …, f
n
) within each domain are ranked. These values are translated to an appropriate range, ensuring that they are normalized and can be compared across different variables. Then, Pearson’s correlation [39] has been found among the ranked feature variables (r
f
1
, r
f
2
, …, r
f
n
) to obtain the Spearman’s rank correlation value. Pearson’s correlation measures the linear association between two variables and provides a value between -1 and 1, where 1 indicates a perfect positive correlation, -1 indicates a perfect negative correlation, and 0 indicates no correlation. During this step, the actual feature values are substituted with their corresponding ranks. The Spearman’s cross-correlation coefficient (ρr
f
1
,r
f
2
,…,r
f
n
) is then determined, which represents the covariance of the ranked feature variables (cov (r
f
1
, r
f
2
, …, r
f
n
)) normalized by their respective standard deviations (σr
f
1
, σr
f
2
, …, σr
f
n
). This normalization accounts for the variability in the ranked variables and ensures that the correlation coefficient is not influenced solely by the magnitude of the feature values. Equation 1 defines the formula to calculate Spearman’s cross-correlation coefficient r
s
:
Following the removal of extraneous features, the denoising autoencoder has been used to select useful features, as it performs better on noisy data and avoids overfitting concerns. Bottleneck features were extracted using pre-trained networks [40] and hence relevant features were extracted from a bottleneck layer of an appropriate size, which enhances prediction accuracy.
The detection model is designed to handle m-sample data, which is represented as a vector X = {x1, x2, …, x
m
}. Each x
i
is an n-dimensional feature vector containing n distinct features, and
In equation (2), the transformation involves using a weight matrix W and a bias value b to map each noise vector
where W′ and b′ represent the weight matrix and bias value, respectively, used to map the hidden vector h
i
to an output vector y
i
. Again, the ReLU activation function r is applied to introduce non-linearity to the decoding process. The goal of training DAE is to reduce the deviation between the noisy input
The loss function (5) calculates the mean squared difference between the original noisy input vectors
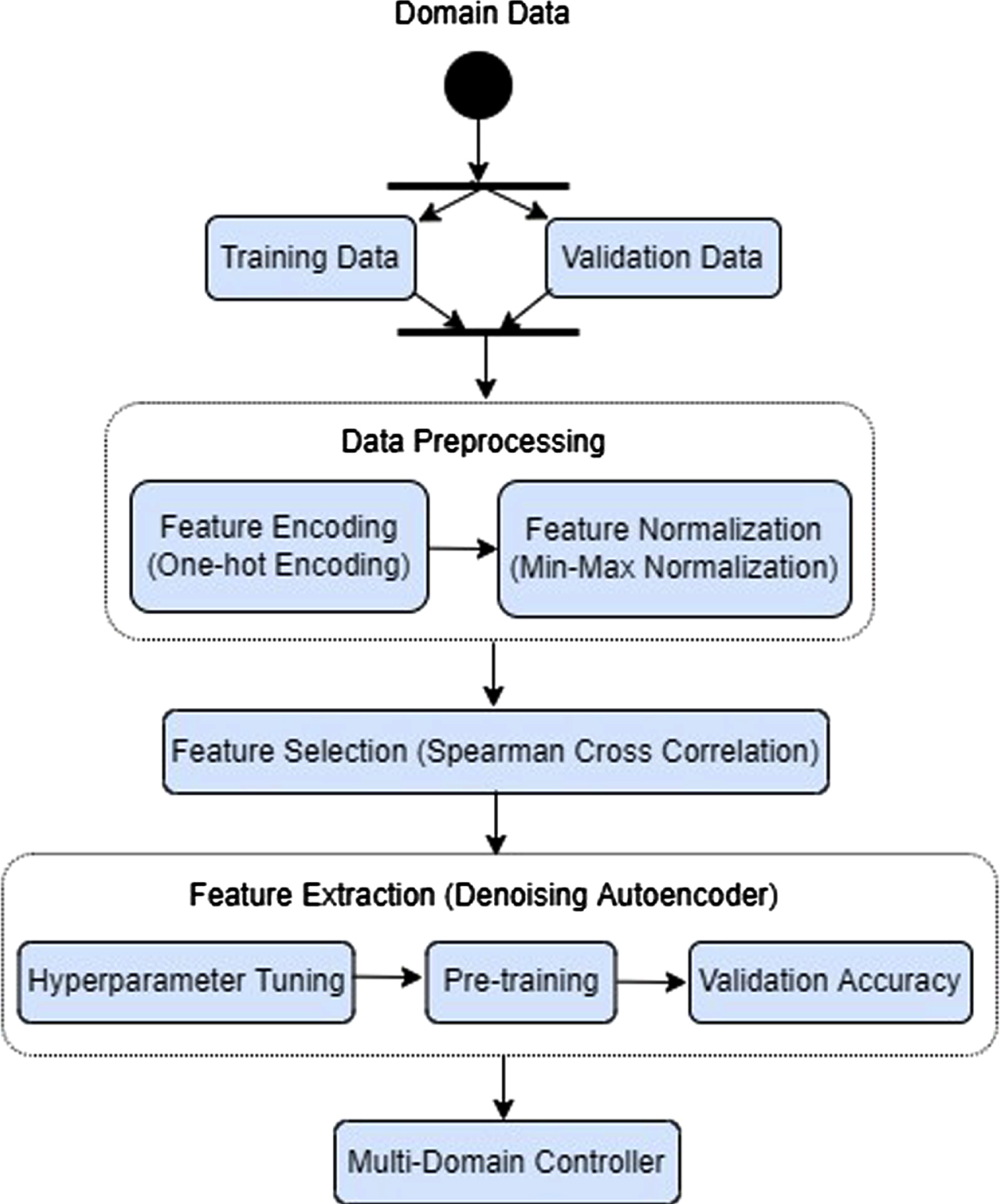
Workflow model of dimensionality reduction in SDN domain controllers.
Thus, to obtain the reduced feature subset, we employed a predictive denoising autoencoder model with a single bottleneck layer [17]. As a result, our ensemble dimensionality reduction strategy produces a simple and cost-effective model for the subsequent classification stages.
The reduced feature data was received by the multi-domain controller from its underlying domain controllers. Since, in real-time, hackers can attack the network from various domains, anomalies in the complete and collected feature set were found necessary. As the classification accuracy depends on the quality of features, one of the essential tasks of this work was to extract the optimal features, and two extraction strategies, namely, hybrid GAN and attention network have been used in Bi-HGA system for the extraction of optimal features as shown in Fig. 6.
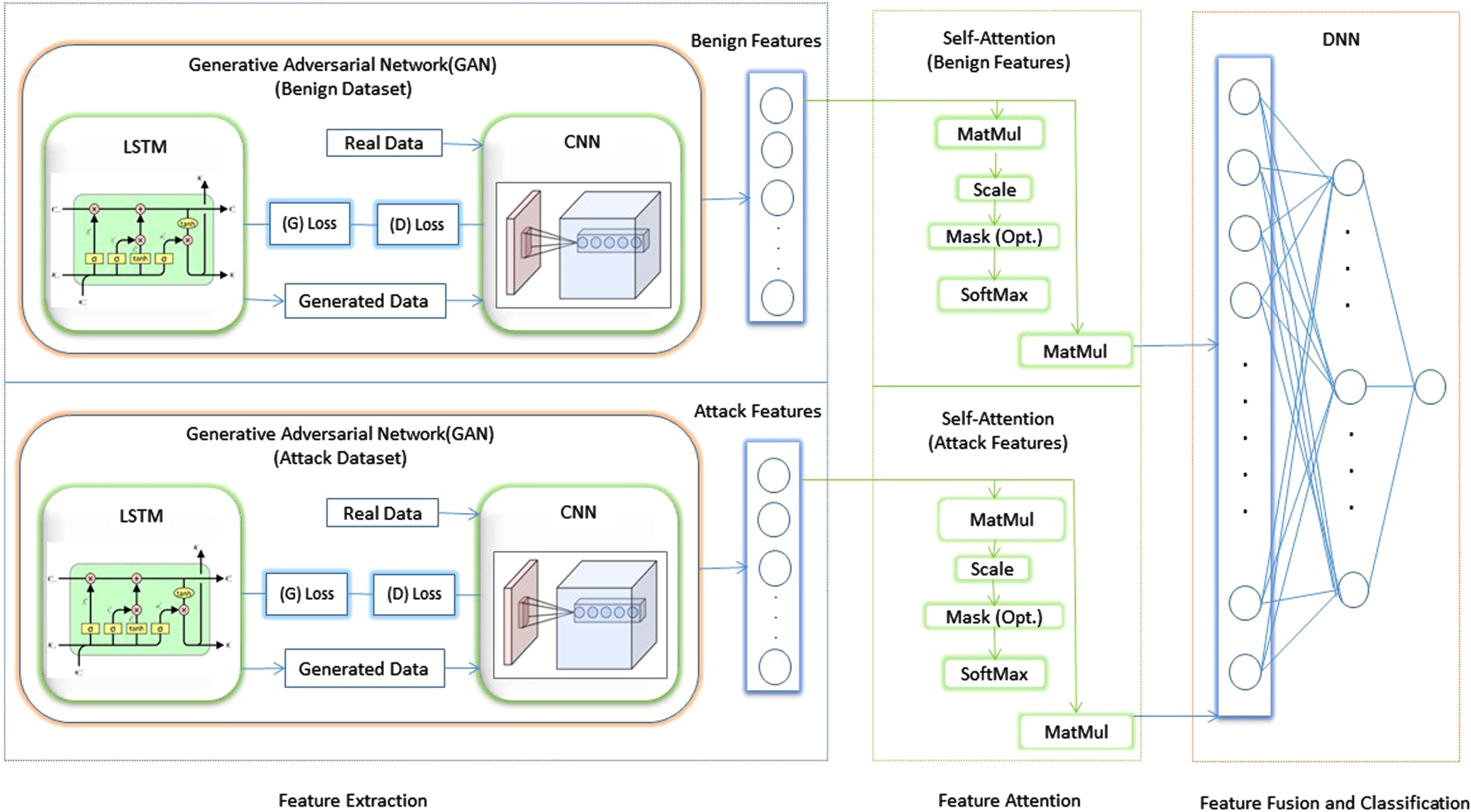
Bi-channel Hybrid GAN Attention (BiHGA) based IDS.
Data Partition To start with, the identification of reduced features of each domain required collection and partitioned based on their dual data flows. Benign and attack data were collected separately and provided to the BiHGA model, enabling it to learn features individually for each network flow category.
BiHGA algorithm
Figure 6 illustrates the structure of the BiHGA model, which incorporates an intelligent strategy for feature learning and classification. SDN, in general, encompasses flows for both benign and malicious traffic. Thus, this model contains individual feature extraction for benign and attack flows, feature attention, feature fusion, and attack classification.
Feature Extraction Utilizing a hybrid GAN approach, as demonstrated in [31], with the LSTM generator and the CNN discriminator, the features for normal and abnormal flow have been extracted separately. With the ability of GAN to do automatic creation of realistic data in a semi-supervised manner [43], it is capable of generating synthetic data features for both attacks and typical SDN flows. So, it solves the problems caused by the use of suspicious features that are not always benign or malicious. The following are the steps involved in training the GAN model: Using the random latent space, the LSTM generator generated data that resembled real data. The purpose of this generator was to figure out how real data is distributed while learning patterns that evolve over time. Generated or actual data, arbitrarily supplied into the CNN discriminator, functioned as a classifier along with the extraction of in-depth features. It helped identification of the given data that originated from the generator or real data set. That is, it made a valid guess about the distribution of real data. The loss in the generator was determined using both networks, namely the LSTM generator and the CNN discriminator. This required the combination of the losses from both networks, which were then backpropagated to the generator in the process of learning real data patterns. The duty of the discriminator was simple and losses were minimal when the performance of the generator was poor. The procedure was repeated until the CNN discriminator could no longer identify the difference between created and actual data.
These two networks adopt a two-player minimax game as stated in [44] with diminished data X={x
i
, i = 1, 2, …, n} and random latent space Z={z
i
, i = 1, 2, …, n} and are trained using equation 6:
The first term in equation (6), ɛx∼p diminisheddata (X) [log (CNN (x))] involves real data samples x drawn from the real data distribution p diminisheddata (also known as the data domain X). The conditional discriminator CNN evaluates the real data samples x and provides a measure of confidence that the input x is real. The logarithm function log is applied to this value to transform it into a log-likelihood measurement.
The second term in equation (6), ɛz∼p z (Z) [log (1 - CNN (LSTM (z))] involves latent variables z drawn from the latent space p z (also known as the noise domain Z). The standard GAN generator LSTM takes these latent variables z as input and generates synthetic data samples y=LSTM(z). The conditional discriminator CNN then evaluates the synthetic samples y and provides a measure of confidence that the input is real. Since these samples are synthetic, 1-(CNN(LSTM(z))) is used to represent the discriminator’s confidence that the input is fake. The logarithm function log is applied to this value to transform it into a log-likelihood measurement.
LSTM generator LSTM is a form of RNN that acts as a generator [45]. RNNs are mostly employed for dealing with time-series data since they can follow and recognize patterns that develop over time. However, it may suffer from a vanishing gradient problem and make the model unfit to converge to a minor loss. To address this issue, LSTM is employed as a generator. LSTM is an effective technology for improving network traffic forecasting [46]. It is employed with each flow attribute to forecast the behavior of the network [24]. Bi-LSTM simultaneously learns the time-correlated features from forward and backward directions for enhancement of accuracy prediction and so employed in this investigation [47]. Both forward and backward LSTM layers have been used in this model. Vertical flow is a one-way stream from input to hidden layer, followed by output layer, whereas horizontal flow estimates forward LSTM hidden vector
where Bi-LSTM is used for denoting LSTM functions, while the weights of forwarding LSTM and backward LSTM are represented by
In general, the GAN discriminator can extract features without any interruption from noise [49]. Thus the features extracted from the CNN discriminator were used for assistance to further processing. Hence it is dispatched to the subsequent attention layer.
Feature attention The extracted convolved features from both the benign and attack hybrid GAN models were emphasized using the LSTM-based self-attention strategy, which eliminated the vanishing gradient problem. The input F
i
(k) contained queries, keys of dimension (d
k
) and values of dimension (d
V
) [50]. The queries were organized into a matrix (Q), with the corresponding keys and values organized into matrices K and V. The weights on the values were then calculated using the softmax function and normalized to a probability distribution. This type of attention is also known as "Scaled Dot-Product Attention" as stated in Equation 11.
Following feature fusion, the network flows were classified using the fully connected layer. This layer extracted high-level features related to the output layer’s mapping. It utilized the sigmoid activation function for binary classification, making the final prediction. The BiHGA model’s pseudocode is shown in Algorithm 1.
In this study, three datasets have been considered, as portrayed in Section 5.1, for the computation of the potency of the LD-BiHGA model. Cross-validation of each dataset was made using the k-fold cross-validation technique with four folds for learning the ability of the LD-BiHGA model. The LD-BiHGA model’s implementation specifics are shown in Section 5.2, and an assessment of the performance was made using commonly used IDS metrics, which are detailed in Section 5.3.
Dataset description
Due to a lack of sharable datasets, deep learning research was suppressed. Although testbeds can generate synthetic datasets, they may not accurately reflect real-time internet traffic. As a result, these synthetic datasets may not be credible [51]. Instead, the proposed scheme was tested using different free public network flow datasets, including KDDCUP 99, CICIDS, and InSDN. The major issue with this type of diverging network traffic was attack prediction. These datasets were in the.pcap format, which had all packet features. These files were evaluated for helping the SDN controller in the simulation of the flow table using flow statistics [52]. Table 2 depicts a high-level overview of the features in the datasets.
Dataset description
Dataset description
Over the years, the KDDCup’99 dataset (Hettich and Bay) created at MIT Lincoln Labs for the purpose of the third International Knowledge Discovery and Data Mining Tools Competition has become a standard dataset for anomaly detection research. This dataset is used as a benchmark in most of anomaly detection studies. It provides labeled features for both benign and malicious network flows and does not have any raw packet-level data. There are 1,048,576 samples in all, with 41 different characteristics and one label column. There are 595,798 benign samples and 452,778 malicious samples. The 41 features are categorized as basic, content, time-based, and host-based traffic features [53]. The remaining two datasets are emphasized for addressing issues like lack of network traffic diversity and features that do not reflect the current scenario.
CICIDS2017 comprises the latest scenario with recent attacks and corresponding features [54]. The Canadian Institute for Cybersecurity (CIC) created the dataset in 2017. This CIC Intrusion Detection System (CICIDS) includes real-world threats in two files, MachineLearningCSV and GenerateLabelledFlows, which contain 86 and 79 features, respectively. A MachineLearningCSV data file that spans five days and eight traffic monitoring sessions has been used in this investigation. This data file generated eight separate data files, each containing 14 attacks. For further analysis, these eight datasets were concatenated into a single CSV file. The resulting CSV file contained 2,827,876 samples, 2,271,320 of which were benign and 556,556 of which were attack samples. There were 78 features and one label column in those samples. There was one unnecessary feature entitled "FwdHeaderLength" among the 78 features, and after deleting it, there are only 77 features left. It presented some affordable challenges to this model due to its massive and highly unbalanced data.
The earlier datasets were not compatible with SDN since they were not applied on the SDN platform. In 2020, the InSDN [55] dataset comprised of the recent attacks specific to the SDN environment, was used for clarification of the accuracy of anomaly detection systems. It also addressed the issues encountered with the CICIDS dataset, such as multiple missing values, redundant, and irrelevant records. It was categorized into three groups based on the targeted machines and the types of traffic it generated. The first group contained benign traffic, whereas the second and third groups contained anomalous traffic directed toward the OVS machine and the Mealsplotable-2 server. With 343,939 traffic cases in total, the resulting CSV file comprised 80 statistical aspects. There were 68,424 benign cases and 275,515 traffic cases among them. The tested performance of the fully featured dataset was found superior to the SDN-specific featured version of the dataset [55]. Hence, the proposed method was compared to the fully featured version of the dataset. Despite belonging to the imbalanced scenario, like the CICIDS dataset, it contained a smaller number of normal instances (20%) than attack samples (80%). But CICIDS contained 80% benign samples and 20% anomaly samples.
While these datasets proved valuable for intrusion detection research, they did not incorporate payload features to capture the actual content of network packets. Instead, their primary focus was on network flow information, facilitating the identification of potential attacks or anomalies.
Like many current deep learning methodologies, this proposed anomaly detection scheme was executed using TensorFlow and Keras. The simulation was done by running on a 64-bit machine with an Intel Core I7 processor, 16 GB of RAM, and an Nvidia GeForce GT 710 2GB GPU using Python and the Keras 2.3 library with TensorFlow as its backend for the evaluation of the suggested classification model.
The proposed system was tested using three datasets described in Table 2. Symbolic features were translated into numeric features for each dataset using a one-hot encoding technique, then rescaled to a given range using min-max normalization. The upright features of the network flow were then extracted using an ensemble dimensionality reduction approach [17]. The Spearman cross-correlation technique identified five correlated features in the KDDCUP99 dataset, 30 correlated features in the CICIDS dataset, and 36 correlated features in the InSDN datasets. Consequently, the denoising autoencoder network included 37 * 20 * 37 neurons in the KDDCUP dataset, 47 * 30 * 47 neurons in the CICIDS dataset, and 47 * 30 * 47 neurons in the InSDN dataset to remove the irrelevant features.
The dataset was split into two normal and abnormal channels, using the BiHGA algorithm for further processing. Feature extraction was done using a hybrid GAN with the LSTM generator and the CNN discriminator using the LeakyReLU activation function. Its generator is comprised of six LSTM hidden layers with 128 neurons each, two dense layers of 128 neurons each, and a dense layer of 20 neurons. Its discriminator included a single dense layer of 64 neurons, a 1D convolutional layer with 32 filters, which succeeded with one more single filter, two dense layers of 20 neurons, and a single neuron dense layer. Furthermore, the features were devoted by utilizing an attention mechanism with 20 neurons in the embedding layer and LSTM layer, a single neuron dense layer with a tanh activation function, a softmax attention layer, and a dense sigmoid layer for the generation of output. Finally, the resultant features were fused for classification with the help of FCN (Fully Connected Neural Network) with three dense layers. The first two dense layers had 12 and 8 neurons with ReLU activation functions and a single sigmoid output neuron. Table 3 summarises the general characteristics of the LD-BiHGA architecture.
Specification details of LD-BiHGA system
Specification details of LD-BiHGA system
Numerous hyper-parameters were utilized in LD-BiHGA for the regulation of the architecture learning process. Some of them are shown in Table 4. While training a neural network, the number of epochs determined the number of times the entire training set was displayed to the neural network. In order to aid neural networks in learning, loss functions quantified how well the model performed over training datasets, while regularisation terms were employed to avoid overfitting. Learning rate was used to control the speed at which the neural network learn from the estimated loss of the training dataset. Dropout was used for random removal of a predetermined number of neurons from a layer in order to avoid the overfitting issue, while batch size refers to the number of training samples used in one iteration.
Hyper-parameter search space for each methodology in the LD-BiHGA system
Validation of each dataset was done using the k-fold cross-validation technique with 30 % of the training set as its validation set for four splits.
Since this approach attempts to save processing time, the incoming network flow was just classified as benign or malicious rather than examining the nature of the attack. The corresponding domain controller was alerted when the multi-domain controller predicted the flow as harmful. The domain controller was then able to stop the malicious flow. Otherwise, the packets can be routed to the appropriate destination. The primary goal of this evaluation is to show how the LD-BiHGA model may improve its overall performance by increasing its detection rate and accuracy [56]. For this binary classifier, accuracy has been represented by the proportion of correctly classified records, with the overall harmonic mean of precision and recall as the F1 score. Mathematically, precision is defined as the ratio of correctly identified intruders by the model to all predicted intruders. The ratio of correctly identified intruders to all actual intruders was calculated by recall or detection rate. A confusion matrix is a metric table used for the assessment of the classification model outcomes. The Area Under the Curve (AUC) is a reliable indicator of the overall performance of the binary classifier. It predicts the capability of the model to distinguish between benign and malicious classes.
Result analysis
In this section, an evaluation of the detection performance of the LD-BiHGA system was done on three benchmark datasets: KDDCUP 99, CICIDS, and InSDN. It began with an ablation study in a balanced scenario, as detailed in Section 6.1. Subsequently, in Section 6.2, the system’s performance on imbalanced datasets was assessed. Finally, in Section 6.3, the performance of the proposed LD-BiHGA system with state-of-the-art approaches from the literature was compared.
Ablation study on balanced dataset scenario
An ablation study on the LD-BiHGA system was conducted to assess the efficiency of each module and gain comprehensive insights. The results of this study, conducted using the KDDCUP dataset, have been documented in Sections 6.1.1 through 6.1.3.
Model performance
A number of model comparisons were conducted in order to prove the superiority of the hybrid scheme to other hybrid deep learning strategies. The evaluation of the proposed methodology was done by looking at i) how the dimensionality reduction technique contributed to the proposed procedure for anomaly detection accuracy, ii) the supplementary details are extracted through a hybrid GAN approach, and iii) the significant features are identified by using a self-attention procedure. Three baseline architecture configurations of the proposed system were examined as milestones as follows: BiHGA component: the ensemble dimensionality reduction module was removed from the LD-BiHGA system and retained with the hybrid GAN and attention module. LD-BiA (Low Dimensional Bi-channel Attention) component: the hybrid GAN module was removed and retained with the remaining two modules. LD-BiHG (Low Dimensional Bi-channel Hybrid GAN) component: the attention module of LD-BiHGA was removed.
The findings of a detailed investigation of LD-BiHGA’s performance on the KDDCUP dataset are shown in Table 5. A comparison of LD-BiHGA with their components led to the conclusion that (i) even though the dimensionality reduction module was removed, and all features were retained, it became evident that predominant features were picked with the help of hybrid GAN and attention mechanism (ii) the effectiveness of the hybrid GAN became apparent as it extensively captured essential features (iii) the exclusion of the self-attention module resulted in a decrease in the recall score. This was due to the module’s ability to extract a significant number of intruders by selecting optimal features. Consequently, removing the hybrid GAN module had a more pronounced negative impact on performance, underscoring the significant role of hybrid GAN in this work.
Comprehensive performance of LD-BiHGA in ablation study on KDDCUP dataset
Comprehensive performance of LD-BiHGA in ablation study on KDDCUP dataset
Using a consistent baseline parameter configuration, which included the number of neurons in each layer, activation functions, and loss functions, LD-BiHGA was evaluated based on various performance metrics, including F1 score, accuracy, precision, recall, and AUC-ROC (Receiver Operating Characteristic). As demonstrated in Table 5, LD-BiHGA outperformed the other baseline models. This highlights its capacity to effectively aggregate multi-channel input, utilize convolutions, leverage long-short term memory, and harness a denoising autoencoder to achieve accuracy in anomaly detection. LD-BiHGA exhibited its best performance when utilizing convolutions and long-short term memory on the enriched data obtained from the denoising autoencoder. Additionally, a dual-channel approach was employed to pass inputs and extract their specific features.
The investigation of the ablation study, as detailed in Table 6, provides comprehensive information on various aspects, including the total number of training parameters (measured in millions) and the running time (measured in seconds) for both the proposed LD-BiHGA and other modules within the system. This table sheds light on the computational efficiency and time requirements associated with each module’s performance.
Computational complexity of LD-BiHGA in ablation study on KDDCUP dataset
Computational complexity of LD-BiHGA in ablation study on KDDCUP dataset
The following inferences have been drawn from the ablation study (i) The removal of dimensionality reduction did not have a significant impact on performance; however, it resulted in a substantial increase in computational parameters and validation time due to the use of the entire feature set. (ii) Even though the hybrid GAN module exploited huge computational parameters and time in LD-BiHGA, it made a significant improvement in the performance of the model (iii) The attention module had an influence on the performance of the model by reducing the average number of parameters and execution time.
The confusion matrix was used to assess the performance of the portrayed model. It enumerated true and false predictions. Figure 7 shows the binary class confusion matrices for all of the proposed system’s baseline models.
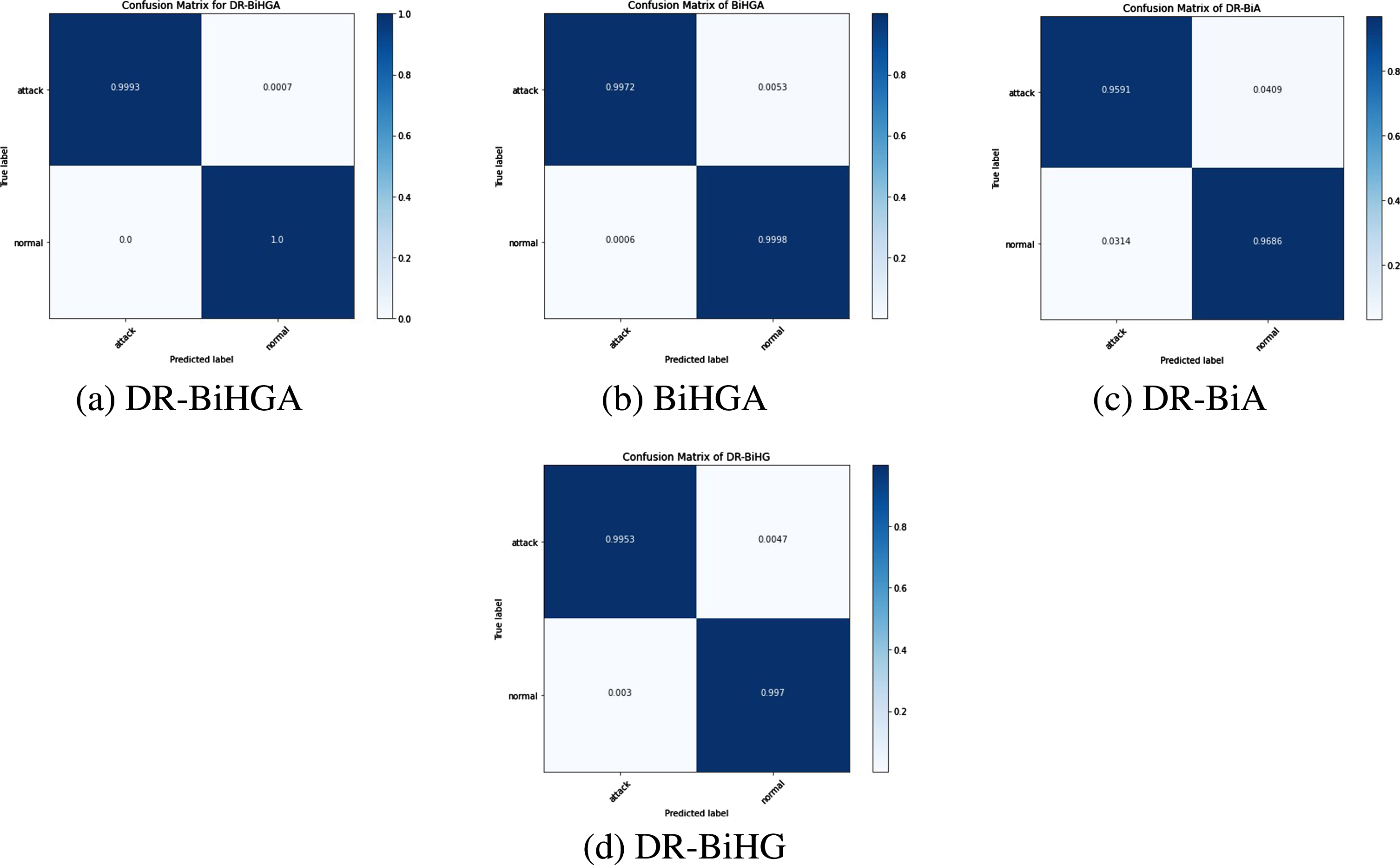
Confusion matrix of binary classification of KDDCUP in ablation study.
An analysis of the robustness of the LD-BiHGA architecture was made from the imbalanced data aspect, which was the expected scenario in real-time networks. For this analysis, the CICIDS 2017 dataset and the InSDN dataset were chosen, as they contain approximately 80% of one specific network flow and 20% of another. Despite the proportionality of data, LD-BiHGA maintained its robustness with the help of the GAN network, due to the ability of adversarial networks to generate a new set of training samples and train the model with them.
CICIDS 2017 dataset
The CICIDS dataset contained 80% of benign network flows and 20% of abnormal network flows. In this study, special attention was given to new set trials, where the entire set of normal network flows was combined with samples of attack flows at varying percentages: 5%, 25%, 50%, 75%, and 100% were considered during the cross-validation stage. Despite a decrease in recall and its corresponding F1-score with 5% and 25% of attack flows, the GAN helped the model to sustain its performance with more than 50% of attack flows, as depicted in Fig. 8.
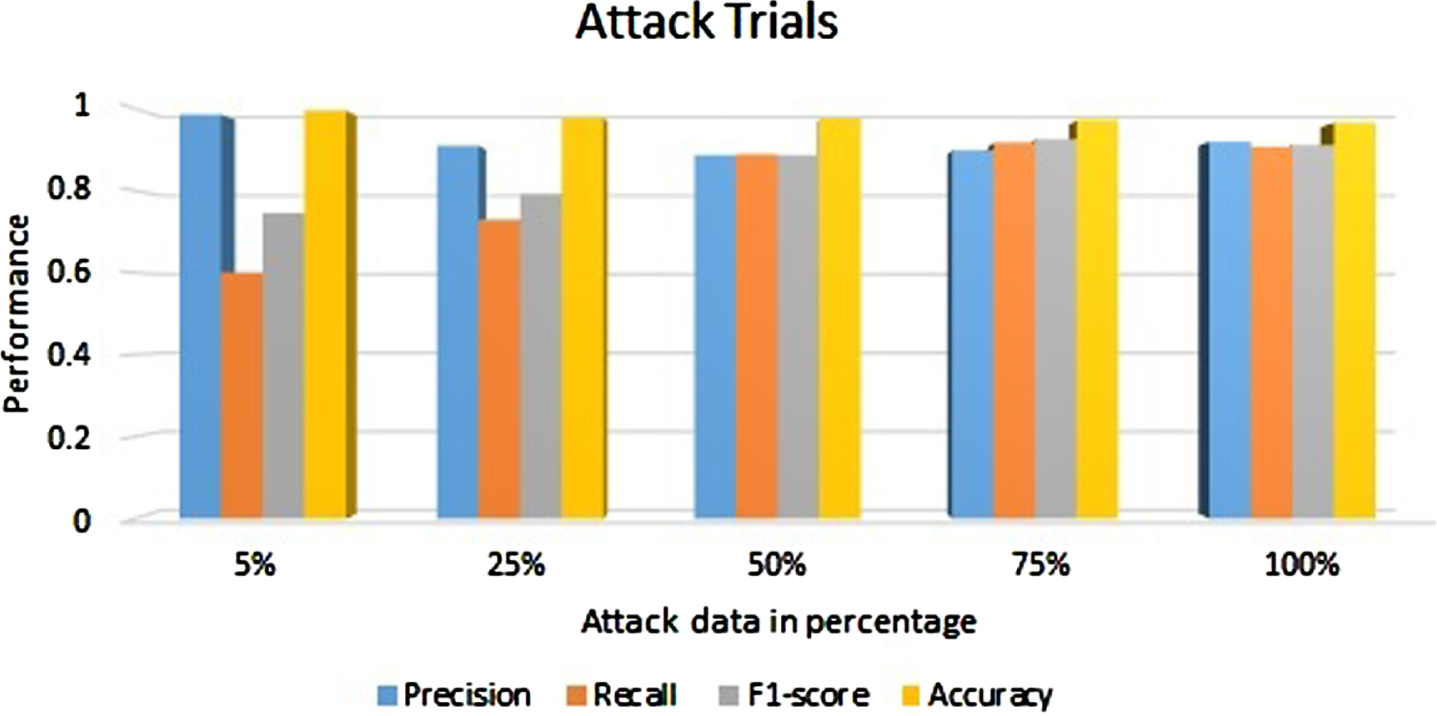
Performance of LD-BiHGA on CICIDS 2017 dataset on subsiding of attacks.
Since CICIDS is an imbalanced dataset, there is a need to examine some other impacts to provide a detailed view of the performance of the model. The confusion matrix on the CICIDS dataset illustrates the variations in the number of attacks and is displayed in Fig. 9.
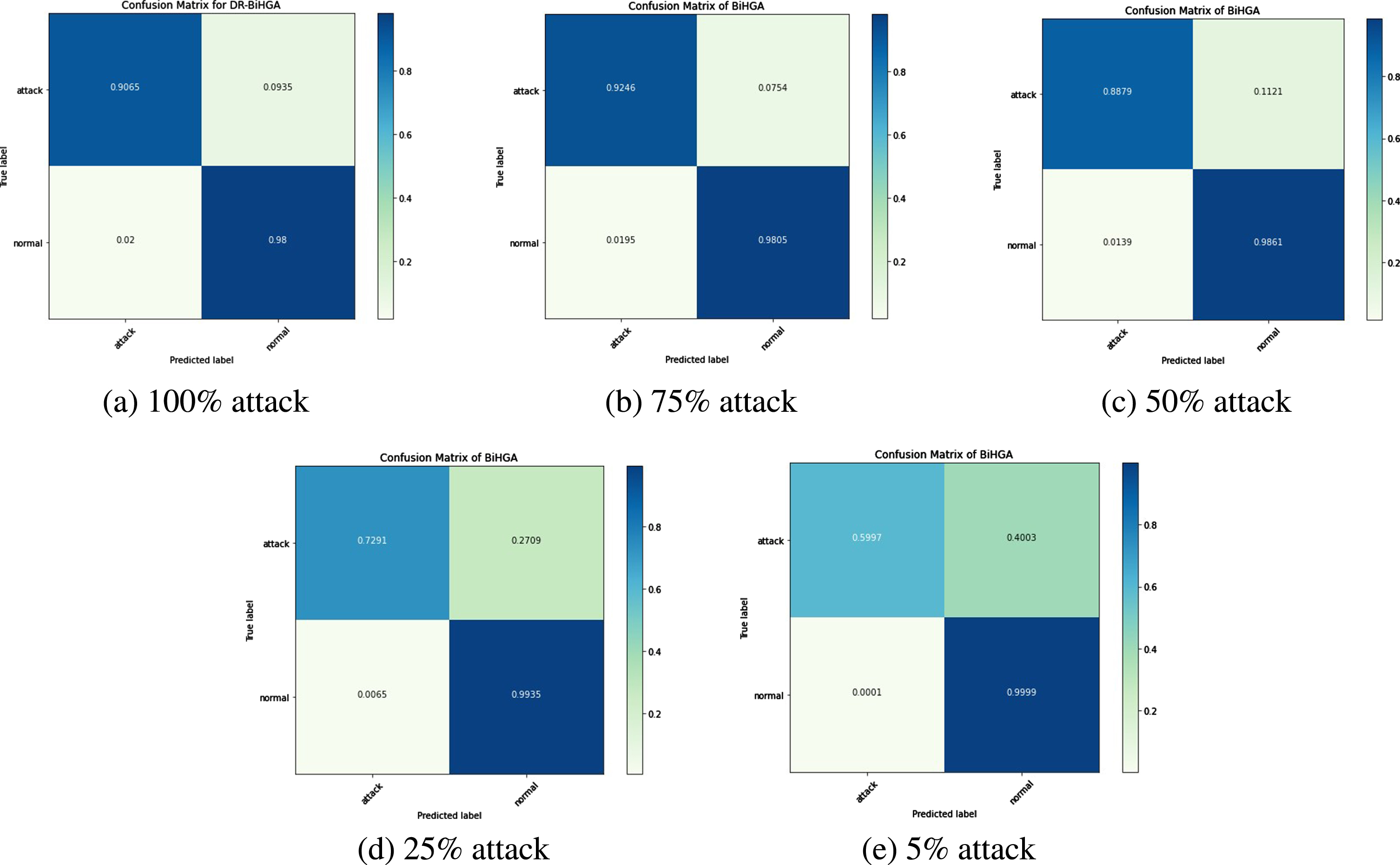
Confusion matrix of LD-BiHGA system on CICIDS dataset.
The performance of LD-BiHGA models was further investigated using ROC and precision-recall curves, as depicted in Fig. 10. Both summarise the performance of the binary classification model graphically. In this case, ROC portrayed the existence of a trade-off between a true positive rate and a false positive rate and precision-recall portrayed the trade-off between precision and recall at different thresholds. Although ROC curves are most appropriate for balanced datasets, a precision-recall curve was included in the performance study, as it was found to be more suitable for the imbalanced dataset in CICIDS, as shown in Fig. 10.
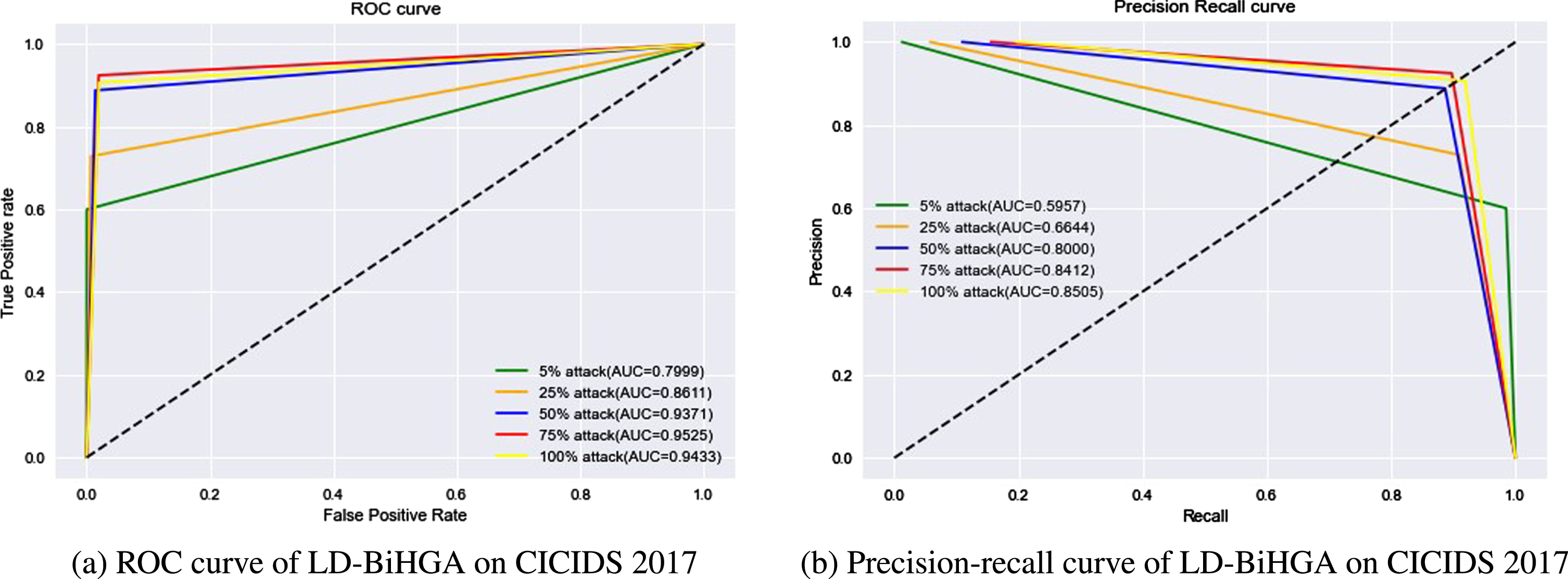
Attack declination performance of LD-BiHGA on CICIDS2017 dataset.
This dataset [55] consists of 80% anomaly flows and 20% benign network flows, in contrast to the CICIDS dataset. The deployed SDN dataset exhibited improved performance in the fully-featured version rather than in the SDN-specific version. Hence, the proposed work was evaluated using the fully-featured version. Precision, recall, accuracy, and F1-score of LD-BiHGA were compared with standard and state-of-the-art deep learning models such as RNN, LSTM, GRU (Gated Recurrent Unit) [57], OC-SVM (One-Class SVM), and LSTM-AE-OC-SVM [58]) as depicted in Figure 11. However, while some of the metrics of other techniques were found to be slightly higher, the proposed system consistently outperformed them in all performance metrics. The binary classification performance of LD-HGA, as shown in Table 7 [59], demonstrates its efficiency.
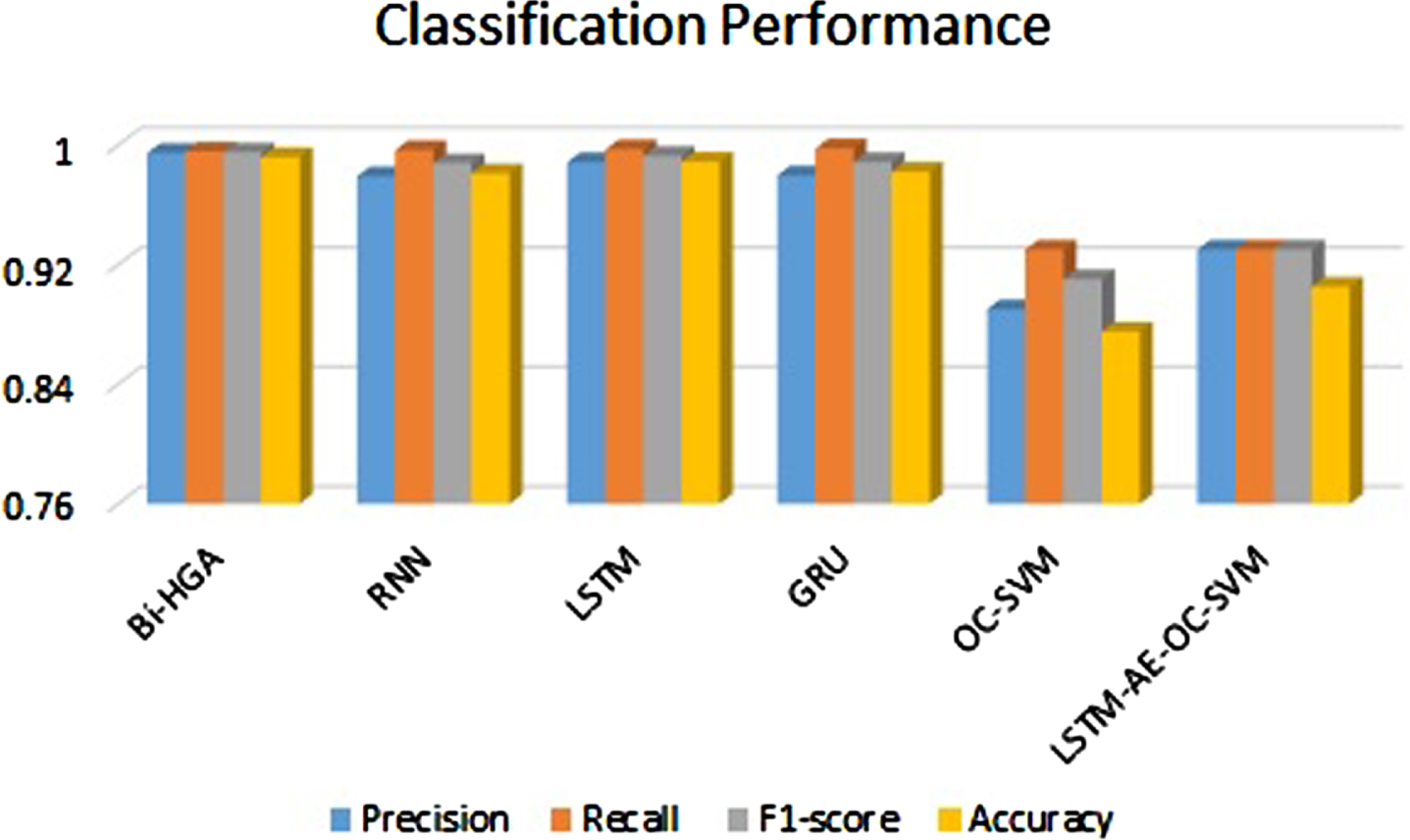
Comparative performance of LD-BiHGA on InSDN dataset.
Comparative analysis of binary classification performance of LD-BiHGA on InSDN dataset
A comparison of the LD-BiHGA architecture was made against a number of competitors in the current state-of-the-art literature to conclude this assessment. Table 8 provides details of the evaluation of the proposed LD-BiHGA compared to existing architectures in terms of various performance metrics. The detection model used by the competitors has been listed in column 3. The performance of LD-BiHGA has surpassed the competitors for both the KDDCUP and InSDN datasets. On the CICIDS dataset, the proposed system has better accuracy, and other parameters are on par with competitors. Details in Table 8 helped ascertain the performance of LD-BiHGA with 7.225% better accuracy on a balanced dataset and 3.335% better accuracy on imbalanced datasets than its competitors.
Performance comparison of LD-BiHGA with several competitors stated in current literature overbalanced and imbalanced datasets
Performance comparison of LD-BiHGA with several competitors stated in current literature overbalanced and imbalanced datasets
This work introduces LD-BiHGA, a network intrusion detection system designed to extract distinct features from benign and abnormal network flows separately and then fuse them using a fully connected network. LD-BiHGA aids the SDN controller in detecting network intrusions. While this research primarily relies on supervised learning, it also leverages unsupervised and semi-supervised learning to execute three key modules: ensemble dimensionality reduction, bi-channel feature extraction, and feature attention, resulting in impressive performance. Ultimately, these modules are combined with the fully connected neural network module to enhance its accuracy.
The evaluation of the proposed learning methodology’s performance was conducted using three benchmark datasets, each containing diverse network flows collected under various scenarios and over time. The experimental results demonstrated the proposed architecture was effective at detecting anomalies. LD-BiHGA surpassed its performance under an imbalanced flow strategy with the help of an adversarial network, GAN.
Future work should focus on addressing significant limitations, including network structure optimization, automatic hyper-parameter tuning, and multi-class attack classification. Utilizing bio-inspired optimization algorithms can automate the process of hyper-parameter tuning. Additionally, implementing multi-channel classification is essential for detecting various categories of network intrusions. Another avenue for future research involves fine-tuning the deep learning model based on the SDN-specific featured version of the dataset rather than the fully-featured dataset.
Declarations
Ethical Approval
This article does not contain any information from studies or experimentation with the involvement of human or animal subjects.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Authors’ contributions
Saranya Prabu: Conceptualization, Investigation, Writing – original draft, review, and editing. Jayashree Padmanabhan: Conceptualization, Investigation, Writing – review and editing.
Funding
This work is financially supported by Anna Centenary Research Fellowships (ACRF), Anna University, Chennai under grant number CFR/ACRF/19234391164/AR1.
Availability of Data and Code
The InSDN dataset is publicly available on https://aseados.ucd.ie/datasets/SDN/. The code associated with this research can be found within the GitHub repository located at https://github.com/Saranya-prabu/BiHGA.