
Abstract
Dengue mosquitoes are the only reason for dengue fever. To effectively combat this disease, it is important to eliminate dengue mosquitoes and their larvae. However, there are currently very few computer-aided models available in scientific literature to prevent the spread of dengue fever. Detecting the larvae stage of the dengue mosquito is particularly important in controlling its population. To address this issue, we propose an automated method that utilizes deep learning for semantic segmentation to detect and track dengue larvae. Our approach incorporates a contrast enhancement approach into the semantic neural network to make the detection more accurate. As there was no dengue larvae dataset available, we develop our own dataset having 50 short videos with different backgrounds and textures. The results show that the proposed model achieves up to 79% F-measure score. In comparison, the DeepLabV3, Resnet achieves up to 77%, and Segnet achieves up to 76% F-measure score on the tested frames. The results show that the proposed model performs well for small object detection and segmentation. The average F-measure score of all the frames also indicates that the proposed model achieves a 76.72% F-measure score while DeepLabV3 achieves a 75.37%, Resnet 75.41%, and Segnet 74.87% F-measure score.
Introduction
Dengue fever poses a severe threat to human health and is transmitted through the bite of dengue mosquitoes. In recent times, the prevalence of dengue fever has escalated, becoming a significant concern for numerous countries. According to research conducted by the World Mosquito Program [2], approximately 390 million individuals contract dengue each year, resulting in roughly 36,000 fatalities. The WHO has shown its statistics that a staggering 3.9 billion people may be infected with the dengue virus [3]. Dengue lay eggs in areas with water or moisture. These mosquitoes tend to thrive in various water-holding containers such as rooftops, lawns, tires, bins, pots, nurseries, and similar locations. It takes approximately 12 days for converting eggs into young mosquitoes [5].
Abbreviations and Notations
Abbreviations and Notations
As depicted in Fig. 1, dengue eggs are mini in size, making them challenging to detect visually. Dengue larvae exhibit continuous movement within the water, displaying random patterns. Pupae, on the other hand, move slowly or remain stationary. Adult mosquitoes fly, making it hard to identify till they perch in a steady place. It is during the larvae stage in the mosquito’s life cycle that dengue can be detected. These larvae typically inhabit clean water sources or areas near water bodies. In the available literature, there are only a limited number of studies available specifically addressing the detection of dengue larvae. Existing literature on dengue primarily focuses on aspects such as its life cycle or its implications in the field of medical science. In our previous work, we detect and track dengue larvae using CNN and Kalman filtering [1]. In [6], deep learning techniques are explored for the detection of mosquito larvae, covering various mosquito species. In [7, 9] discuss the classification of larvae from different mosquito species. In another study [8], the shape of dengue larvae is compared with that of other mosquito larvae to facilitate identification. The ability of dengue larvae to move inside water containers serves as a distinguishing characteristic from other mosquito larvae. By employing tracking algorithms, it becomes possible to identify dengue larvae once the presence of water has been established. Water detection is another task and various water detection algorithm has been proposed [10].

Dengue mosquito Life Cycle.
Deep learning plays a vital role in the modern era of scientific advancements, particularly in the field of pixel segmentation [11]. Segmentation plays an important role in processing both 2D and 3D images, enabling scene understanding and image analysis. The process of image segmentation involves partitioning an image into distinct, non-overlapping regions that collectively cover the entire image [15]. One specific type of segmentation, known as semantic segmentation, is widely employed for pixel-to-pixel classification in computer vision research. This task is fundamental yet challenging, as it involves labeling each pixel in an image with a corresponding semantic category. The applications of semantic segmentation span various real-world domains, including pedestrian detection [16], defect detection [17], self-driving vehicles [18], and computer-aided diagnosis. By leveraging pixel-level attributes, the system can effectively identify areas of interest and make important classifications.
In [45, 46] image segmentation using encoder-decoder is discussed. The encoder-decoder semantic segmentation is applied to medical images and different state-of-the-art datasets. In [47] Deep Convolutional Encoder-Decoder Network was used to develop the footprint semantic segmentation. In [48], an overSegNet architecture is proposed for image over-segmentation. The establishment of pixel training datasets has been instrumental in various applications such as medical image segmentation, autonomous driving, industrial processes, and satellite image classification for terrain identification. However, recent developments have posed challenges to achieving optimal efficiency in deep learning due to the concept of large datasets [12, 13]. Another significant obstacle is the presence of multidimensional and noisy data, which further complicates obtaining accurate results through deep learning algorithms. Consequently, the current landscape calls for the development of new algorithms and architectural advancements to overcome these challenges [14]. This paper specifically addresses the utilization of a challenging dataset for experimentation, characterized by a turbid background and small object size.
Semantic segmentation is not tested on small objects, especially in turbid environments. This research paper presents the application of semantic segmentation for detecting and tracking dengue larvae which are very small in size. Our proposed model’s performance in larvae detection and tracking is validated by comparing the results with state-of-the-art semantic segmentation variants like DeepLabV3 [50], Resnet [53], and Segnet [54]. The task of detecting and tracking all the larvae within the video is highly challenging due to their rapid and unpredictable movement. Additionally, the dataset poses another challenge as certain larvae remain stationary throughout the video frames, while others exhibit movement. Consequently, our research focuses on tracking the moving objects within the video.
The paper is structured as follows. Section II provides a discussion of the Semantic segmentation model. Section III outlines the methodology employed for dengue larvae detection. In Section IV, the dengue larvae dataset is presented. Subsequently, Section V presents the experimental results. Finally, the conclusion is presented in Section VI.
Semantic segmentation is a challenging task in computer vision, where each pixel of an image is labeled with a specific class. In the past, various methods such as random forest [20] and visual grammar [21] were employed before the advent of deep learning. However, the introduction of deep learning techniques revolutionized and modernized segmentation approaches. Deep learning methods have demonstrated superior accuracy and efficiency compared to traditional methods. The high accuracy came with the introduction of a Fully Convolutional Network (FCN) [22], which significantly improved the performance of semantic segmentation. Deep learning-based methods have shown remarkable effectiveness and outperformed conventional approaches. These methods have been extensively tested on numerous available datasets and consistently exhibited superior performance compared to state-of-the-art methods.
Segmentation methods can be categorized into object segmentation and pixel segmentation. Figure 2 illustrates the fundamental distinction between these two types of segmentation. A valid dataset of images is employed for segmentation, as depicted in Fig. 2. The segmentation process begins by labeling the ground truth and background using a suitable tool to train the deep learning model. Object training data is collected from the dataset specifically for object detection, while a pixel training dataset is established for pixel segmentation. For object detection, an image data store and a box label data store are extracted. On the other hand, for pixel segmentation, a pixel-label data store is extracted alongside the image data store. In the subsequent step, these data stores are combined and utilized to train the object detector and segmentation network. Popular object-based segmentation methods include Fast RCNN, Faster RCNN [23], Yolov2 [24], and SSD detector [25]. The popular pixel-based semantic segmentation includes U-net [49], DeepLabV3 [50], PSPNet [51] and SegNet [52] The segmentation network employed in these methods ultimately leads to semantic segmentation.
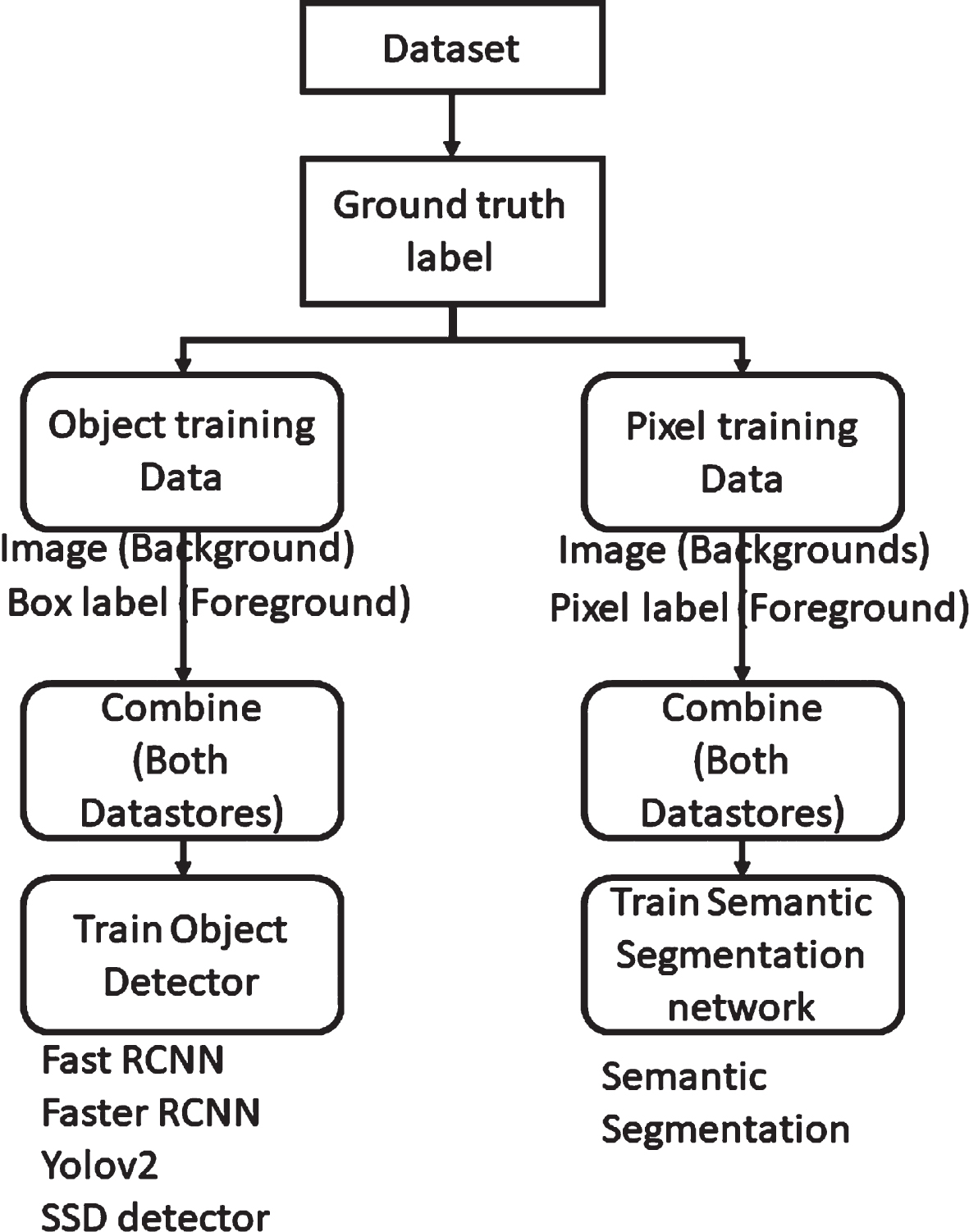
Workflow of Object and Pixel Classification.
Object-based methods typically employ a segmentation pipeline that involves extracting irregular regions from an image and defining them, followed by region-based classification. During testing, region-based predictions are converted into pixel predictions by assigning the pixel with the highest score among the region it belongs [26]. In contrast, fully convolutional networks (FCN) [27] based methods operate on pixel-to-pixel mapping without the need for region proposals. FCN is an extension of the traditional convolutional neural network (CNN) that distinguishes itself by accepting arbitrary-sized images as input and producing predictions for each pixel. Unlike CNNs that require fixed-size inputs and outputs, FCNs can handle inputs of various sizes due to the presence of convolutional and pooling layers. They are not constrained by input size and produce output corresponding to the size of the input image. Such networks are commonly employed for tasks like semantic segmentation or object detection [28].
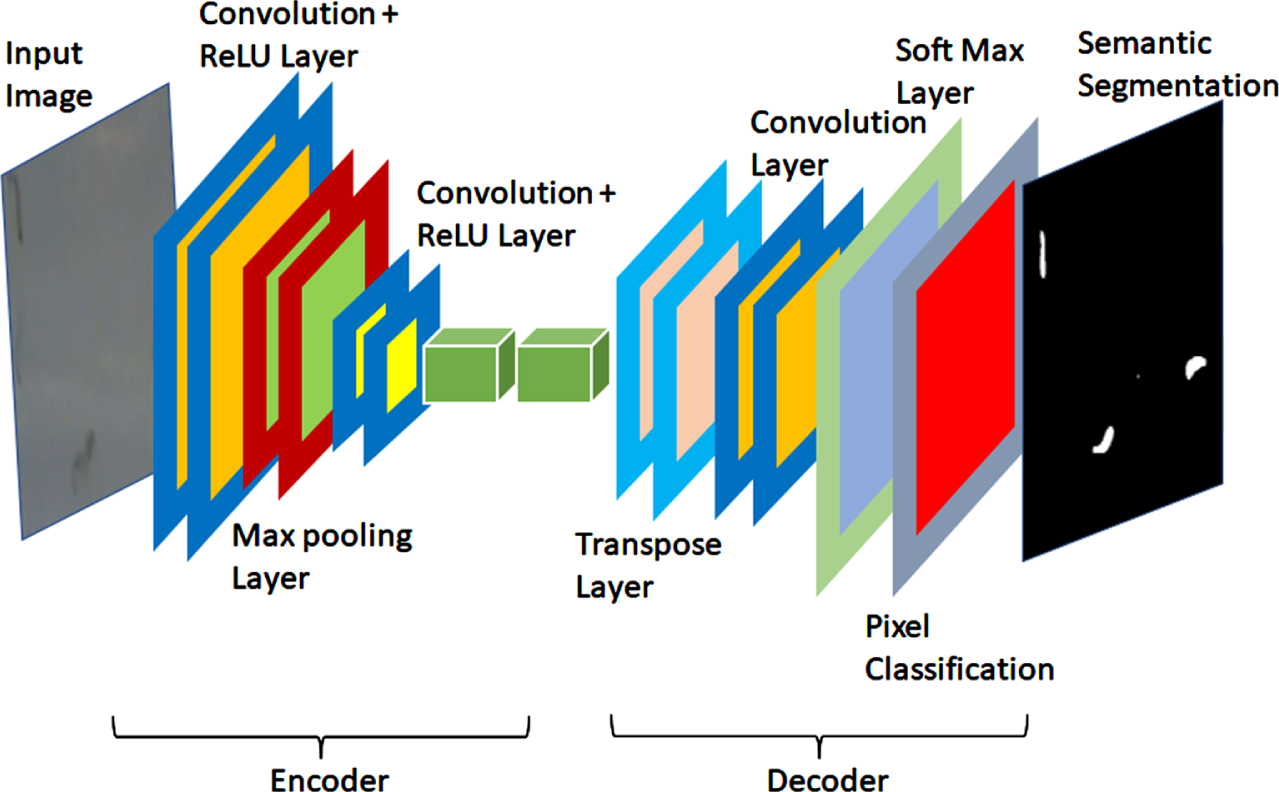
Semantic segmentation layers.
The basic deep learning network for semantic segmentation is depicted in Fig. 3. In this illustration, a frame from the dataset serves as the input to the segmentation network. The initial layers of the network consist of convolutional layers and ReLU layers. The ReLU layer feeds the input to the max pooling layer, while the convolutional layers are applied once more, followed by additional ReLU layers. In the subsequent stage, transpose and convolutional layers are employed on the previous stage’s output. Finally, softmax and pixel classification layers are applied to segment the larvae and distinguish them from non-larvae regions. The specific details regarding the detection and tracking of dengue larvae will be discussed in the following section.
Dengue larvae are typically found in deep, damp, and shaded areas. However, capturing clear videos of these larvae in their natural environment is challenging. The recorded videos containing dengue larvae are often turbid and lack clarity. In order to detect larvae in such turbid videos, it is necessary to apply filters that can convert the turbid video into a clearer version, facilitating the detection of these small organisms. Figure 4 illustrates the methodology employed to detect and track dengue larvae in turbid videos. The system takes a video containing dengue larvae as input. Frames are extracted from the video and subsequently processed for detection and tracking purposes. The size of the extracted frame from the video is 720 × 1280. Considering the challenge of unclear videos, an image enhancement block has been incorporated in the process to enhance the quality of the frames.
Various methods can be applied for image enhancement, such as filtering with morphological operators [29], histogram equalization [30], adaptive histogram equalization [32], unsharp mask filtering [31], among others. In this study, we have utilized adaptive histogram equalization to enhance the contrast of videos containing dengue larvae. The chosen method offers several advantages over other techniques, including local contrast enhancement and prevention of edge artifacts in regions. Additionally, it computes histogram equalization for distinct sections of the image. The general equation for histogram equalization is as follows:
Following the contrast enhancement step, the ground truth and foreground regions are labeled, and these labels are exported and saved in a mat file for training the semantic network. In our implementation of the semantic deep network, we utilized a filter size of 3 × 3 with 64 filters. The initial layer of the network is a 2-D convolution layer. The general equation for 2-D convolution is as 3.
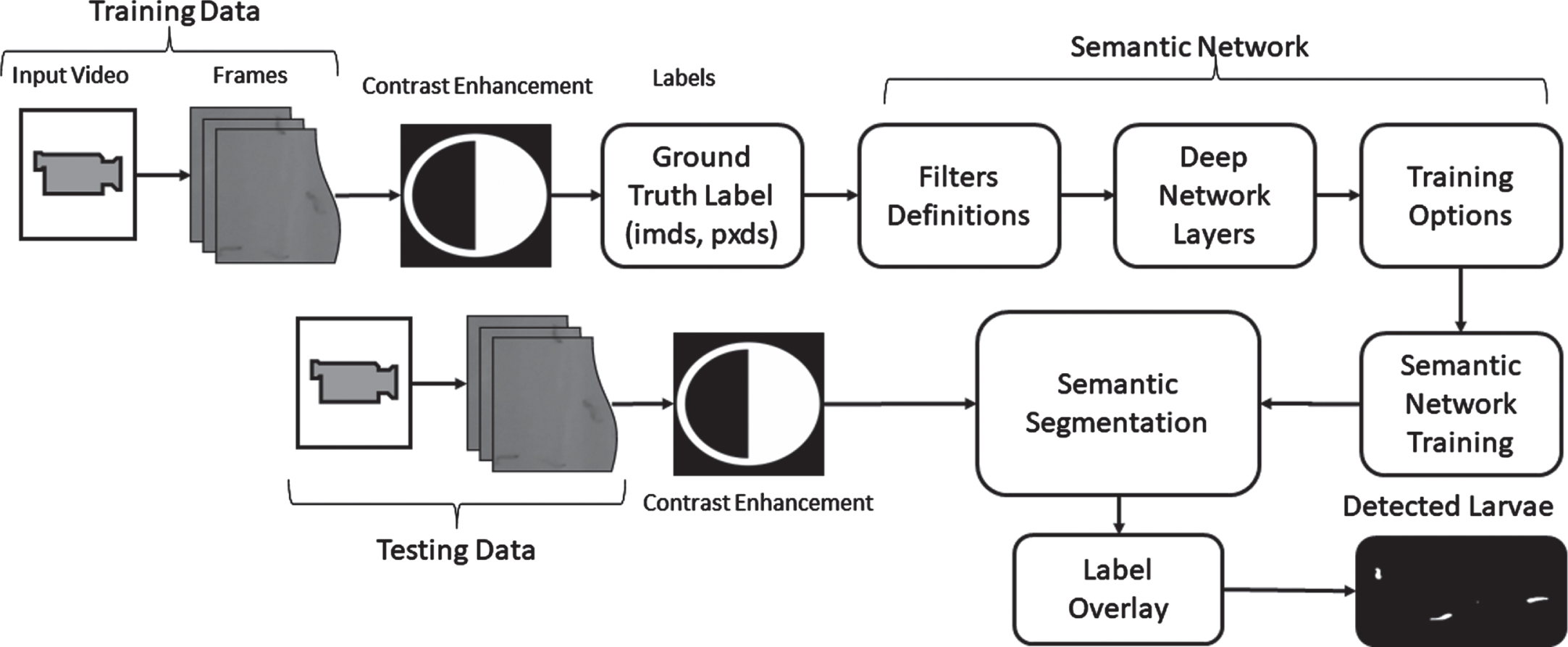
Methodology for Larvae Detection.
The coordinates of the filter f are denoted as a, b, c, while σ represents the non-linear squashing function. The 2-D convolution operation is performed using a specified kernel size, the number of filters, and a padding of 1. Following the convolutional layer, a rectified linear unit (ReLU) function, which is a non-linear activation function, is applied to the output. The ReLU function converts the weighted sum of inputs into the activation or output of a node. This non-linear function ensures that only positive values are passed through, effectively introducing non-linearity to the network. The ReLU can be explained in equation 5. The ReLU applied to the
In our approach, we implemented a max pooling layer with a pool size of 2 × 2 and a stride of 2 × 2 for downsampling the feature map. Subsequently, the convolutional and ReLU layers were repeated with identical parameters to further extract meaningful and important features. To restore the spatial dimensions of the feature map, a 2-dimensional transposed layer was introduced for upsampling. The 2-dimensional transposed layer performs the inverse operation of a convolutional layer. It synthesizes the upsampled feature map by combining different intermediate feature maps obtained through multiple convolutional operations on the original input feature map [39]. Depending on the upsampling factor, a transposed operation can be decomposed into several convolutional operations. In our implementation, we utilized a filter size of 4 with 64 filters for the transposed layer. A stride of 2 and a cropping of 1 were employed. Given an input feature map M in , the transposed layer generated the upsampled output feature map M out . This process is shown in 7.
M1 = M
in
⊛ i1, M2 = M
in
⊛ i2, M3 = M
in
⊛ i3, M4 = M
in
⊛ i4
Following the transposed layer, a 2-dimensional convolution is applied with a kernel size of 1 × 1 and 2 classes. Before the final layer, the soft-max layer is implemented in the semantic network. The softmax layer functions as a normalized exponential function, assigning decimal probabilities to a vector of N real numbers. It can be seen as an extension of the logistic function in multiple dimensions. The softmax layer is mathematically represented by equation 8.
Parameters summary used for Semantic Segmentation
The network is trained using stochastic gradient descent with momentum (SGDM) [44], employing an initial learning rate of 0.0001 and a variable number of epochs. Once the training process is completed, the testing phase begins. In the testing phase, a video is inputted into the system, as depicted in Fig. 4. The frames extracted from this testing video are fed to contrast enhancement. The enhanced frames are then processed for pixel-wise segmentation of dengue larvae and non-larvae regions. Finally, the detected larvae are labeled using a chosen method. In our case, we employed the label overlay method for larvae labeling, which labels the segmented larvae regions, aiding in their identification and visualization.
To validate the proposed model, a dataset of dengue larvae was created since there is no publicly available dataset specifically focused on dengue larvae. Collaborating with the District Health authorities in Bahawalpur and Lahore, Pakistan, we conducted field visits to sites where dengue larvae were present. The research team worked closely with the district health authority team to collect data in various locations. Multiple videos were recorded using a mobile phone camera, resulting in a dataset comprising over 50 short videos with diverse backgrounds and textures, specifically tailored for this study. For our experiments, we selected a video from the developed dataset. The details of this particular video can be found in Table 3. Each frame of the video in Table 3. has been labeled, providing ground truth data for conducting quantitative analysis of the proposed dengue larvae tracking model. We use an image size of 720 × 1280 × 3 for our experiments. We used 70% for training, 20% for validation, and 10% for testing from all the frames.
Data set description
Data set description
Figure 5 displays a video frame containing dengue larvae from Table 3. In Frame 43, the dengue larvae are marked with red boxes, highlighting their presence. While most larvae exhibit continuous movement in the water, some larvae remain stationary. Additionally, dengue pupae, which have recently transformed from larvae, can be observed. In Fig. 5, larvae 1, 3, 8, and 9 are examples of recently converted larvae from pupae. Although there are more pupae present, not all of them are in motion across all 774 frames of the video. To provide a visual representation and track the movements of the larvae, a selection of 12 frames from the video is presented in Fig. 6. These frames specifically frames 500 to 511 from the video described in Table 3. are shown for the lave movement visualization. While it is not feasible to include all 774 frames in this paper, this subset of frames showcases the dynamics of the larvae over time.

Dengue Larvae labeling.

[Left to Right] Selected frames from the video, Row 1: Frame No. 500–503, Row 2: Frame No. 504–507 and Row 3: Frame No. 508-511.

[Left to Right] Detected frames from the video, Row 1: Frame No. 500–503, Row 2: Frame No. 504–507, and Row 3: Frame No. 508–511.
We assessed the effectiveness of our dengue larvae tracking model by analyzing videos that were recorded in collaboration with district health officials. In Fig. 7, we present an example of a dengue larva tracked from frame number 500 to frame number 511 discussed in the above video. It’s important to note that not all larvae observed in the video frames were successfully tracked. Our model is specifically designed to track moving objects, so only the larvae in motion were effectively tracked. Larvae that appeared stationary in the selected frame may still exhibit movement in other frames of the video. The tracking performance varies from frame to frame, influenced by factors such as the texture and background of the container. Nevertheless, our proposed method for dengue larvae tracking employs initial frames as reference frames for detecting object motion, which aids in the tracking process. While the texture and background can impact detection, their influence on tracking is comparatively less pronounced. For quantitative and qualitative analysis, as well as comparisons with other state-of-the-art methods, we selected a set of 6 random frames from the video dataset listed in Table 3. These frames, namely numbers 55, 61, 73, 142, 162, and 173, are illustrated in Fig. 8, where we provide visual comparisons between the ground truth (highlighted in red), and the outcomes from semantic segmentation (highlighted in black). Starting with row 1, we display the ground truth, and semantic segmentation results for frame number 55. Subsequent rows exhibit frame numbers 61, 73, 142, 162, and 173, allowing for further comparisons. The experimental findings indicate that the proposed model yields favorable results for tracking dengue larvae.
Evaluation and comparison
To assess the performance of the proposed dengue larvae detection and tracking method on the dataset, Precision, Recall, and F-measure metrics are calculated. These metrics provide insights into the accuracy and effectiveness of the model. The obtained results are then compared with a state-of-the-art method, and the comparative analysis is presented in detail. Precision is a measure of the number of correct positive class predictions relative to the total number of positive class predictions. It quantifies the accuracy of positive predictions. The precision can be calculated using the following equation:

[Left to Right] Ground truth, Semantic Segmentation, Row 1: Frame No.55, Row 2: Frame No.61, Row 3: Frame No.73, Row 4: Frame No.142, Row 5: Frame No.162, Row 6: Frame No.173
In Fig. 10, the precision values of the proposed method, DeepLabV3, Resnet, and Segnet are presented. The results indicate that the precision of the proposed method and other methods are quite similar in the initial three displayed frames however, the recall is high for the proposed model with respect to other methods. For instance, in frame 55, the precision of the proposed model is approximately 74%, while the precision of DeepLabV3 is 73%, Resnet is 75%, and Segnet is around 74%. In subsequent frames, such as 61 and 73, all models exhibit nearly identical precision results, hovering around 71% to 72%. However, there is a notable disparity in precision between the proposed and other models in frames 142, 162, and 173. This divergence may be attributed to changes in texture or movement of the larvae at the bottom of the pot containing dengue larvae. Overall, the comparisons indicate that the proposed model yields favorable outcomes in comparison to other state-of-the-art models. The proposed method achieves a true positive rate of approximately 75% in relation to the total positive predictions, while other methods achieve a true positive rate of 72% and 73%. In Fig. 11, the recall results for the proposed model and other state-of-art models are depicted. The outcomes reveal that the proposed model outperforms in terms of recall for frames 55, 61, and 73. The recall values for the proposed model in these frames range between 81% and 87%, whereas for other methods, they range from 79% to 81%. In the second cluster, consisting of frames 142, 162, and 173, both proposed and other methods exhibit comparable recall results. This indicates that in this particular section of the video, all models accurately identify relevant results across all observations to a similar extent. These results shed light on the challenges associated with detecting dengue larvae, primarily due to their small size and unpredictable movements. All the models tend to over-segment the larvae region, which has an impact on the precision and recall values.
The precision and recall results show variations across different frames of the video. To comprehensively evaluate a model, it is beneficial to consider both precision and recall together, which can be achieved using a single score. The F-Measure is a commonly used metric in literature to assess the performance of detection and tracking models. It is calculated as the harmonic mean of precision and recall:
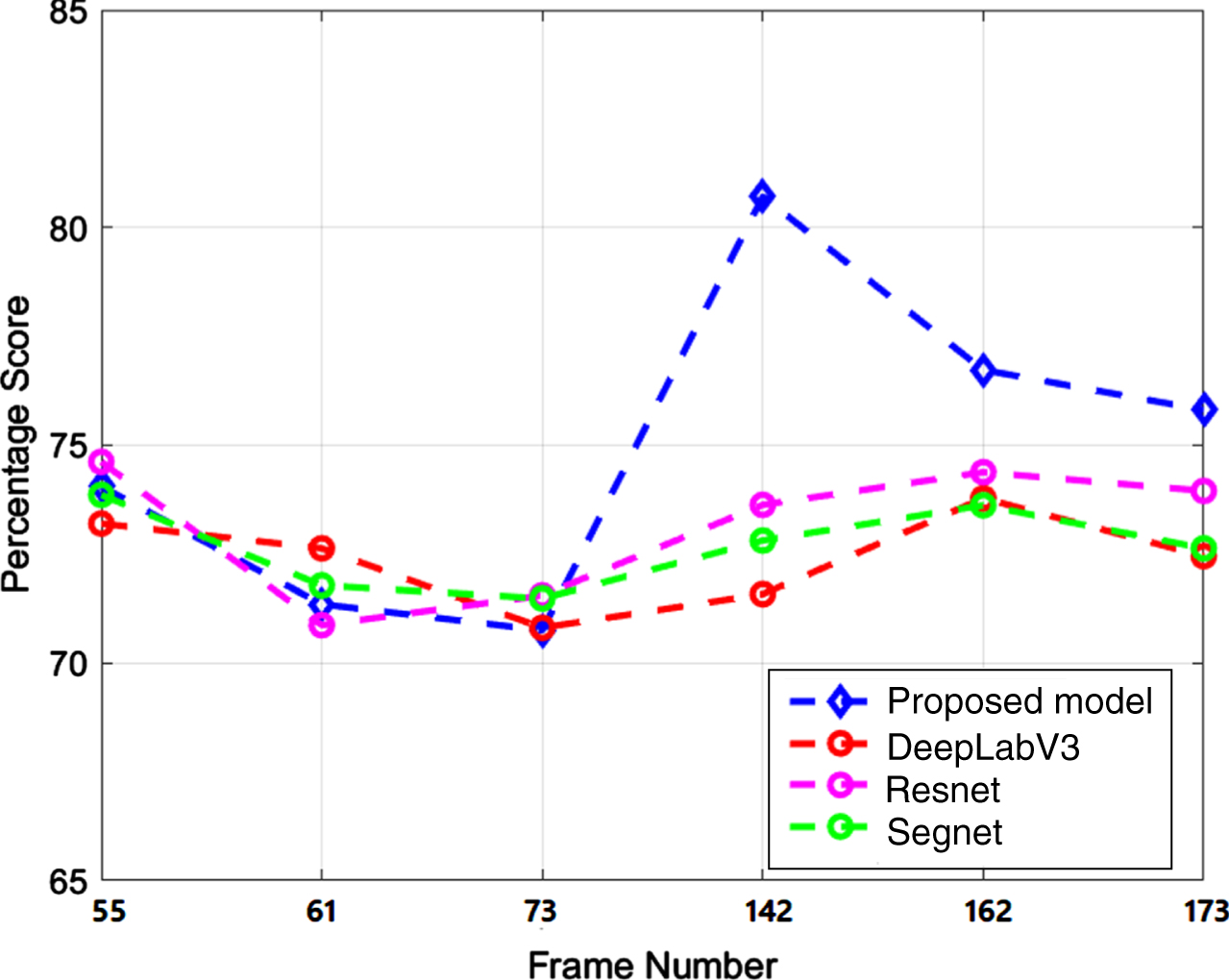
Precision of frame no. 55, 61, 73, 142, 162, and 173
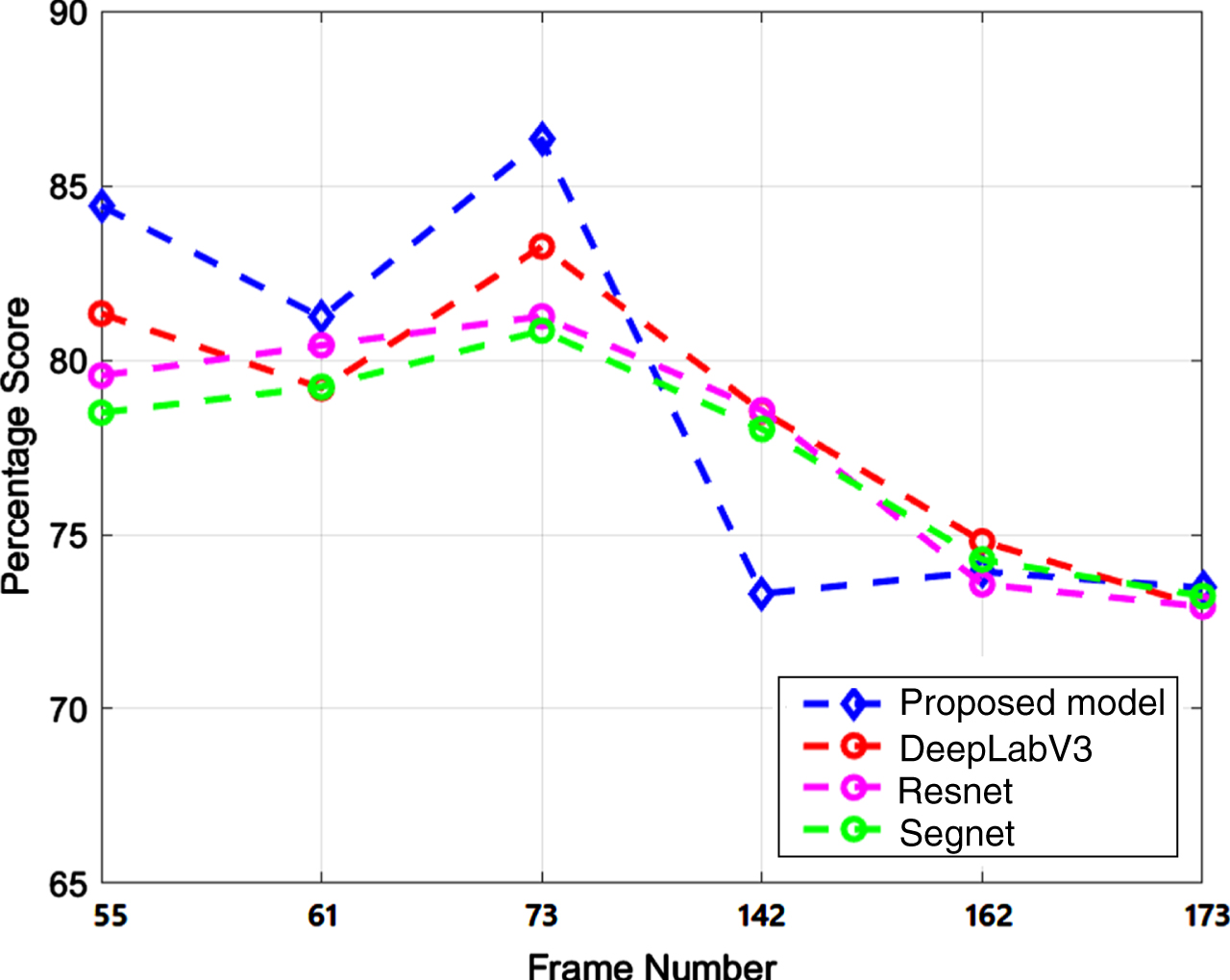
Recall of frame no. 55, 61, 73, 142, 162, and 173
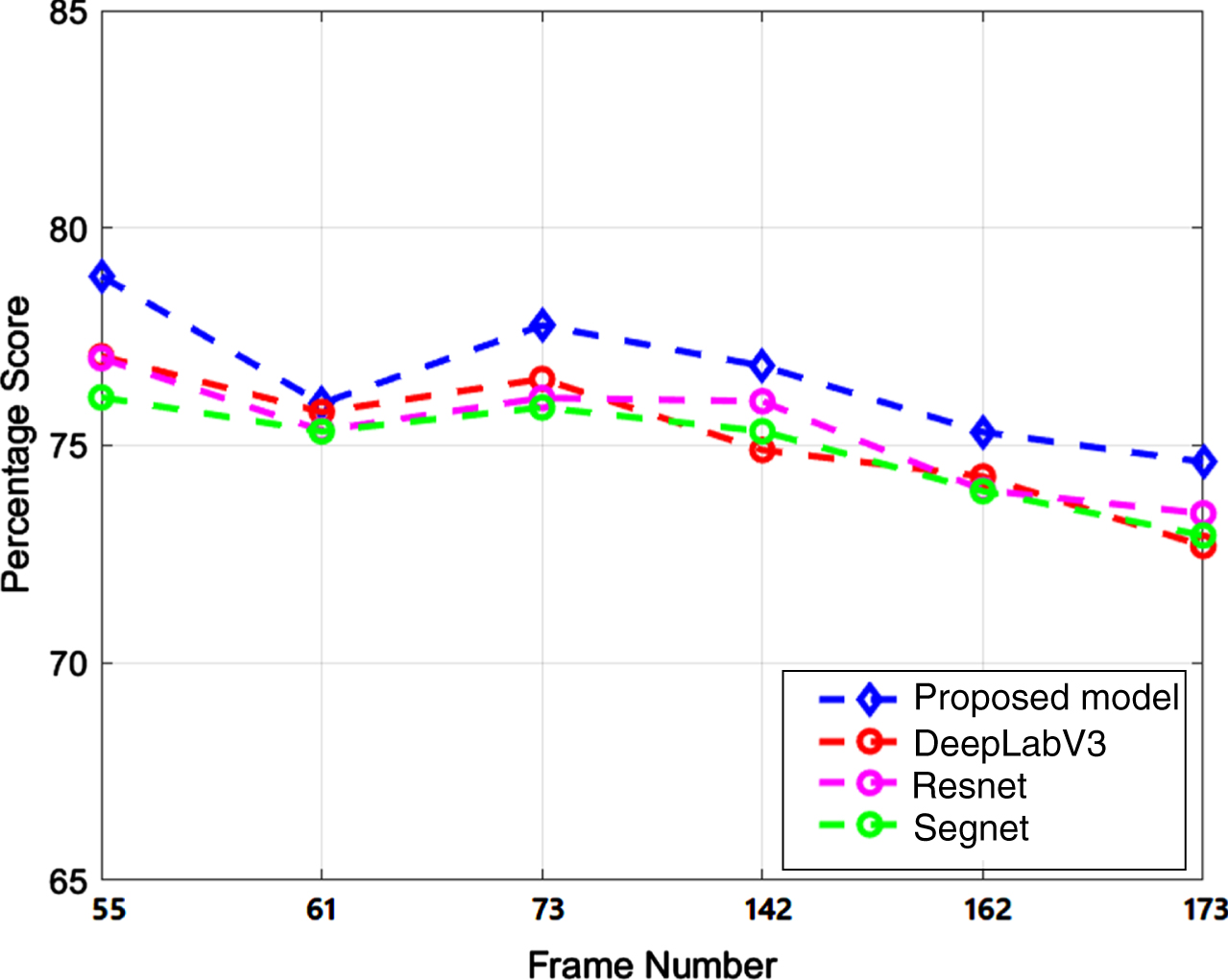
F-measure of frame no. 55, 61, 73, 142, 162, and 173
Figure 12 presents the experimental results of the F-measure score for both the state-of-the-art and the proposed model. The graph clearly illustrates that the F-measure score for the other models ranges from 73% to 77% across all cases. In contrast, the proposed model consistently achieves a higher F-measure than the other models. The F-measure for the proposed model varies between 75% and 79% in the six cases considered for comparison. This indicates that the proposed method exhibits superior accuracy in tracking moving larvae compared to the state-of-the-art. While the state-of-the-art also demonstrates remarkable performance in the detection and tracking of dengue larvae. The proposed model is particularly affected by small and fast-moving objects. Tracking the movement of larvae presents a significant challenge due to the dataset containing very small objects that move at varying speeds. These objects also exhibit diverse sizes and shapes.
The proposed model was applied to all frames in the dataset, and Precision, Recall, and F-measure values were calculated. The average Precision, Recall, and F-measure scores are presented in Table 4. The results demonstrate that the proposed method achieves a Precision score of 75%, a Recall score of 79%, and an F-measure score of 77% for dengue larvae tracking, DeepLabV3 and Resnet achieves a precision score of 73%, a Recall score of 78%, and an F-measure score of 75%, and Segnet achieves a precision score of 73%, a Recall score of 77%, and an F-measure score of 75%. These findings indicate the outstanding performance of the model in detecting and tracking dengue larvae, particularly in turbid videos. In our previous work, The dengue larvae were detected and tracked using CNN and Kalman filtering. The results achieved by semantic segmentation are much better as compared to Kalman filtering. The Kalman filtering achieved around 70% F-measure score while semantic segmentation is at 77%.
Average Precision, Recall, and F-Measure for all frames of the video
In this study, we have developed a deep learning-based semantic segmentation workflow to address the challenging task of detecting and tracking dengue larvae. The small size and high mobility of dengue larvae make their detection and tracking particularly difficult. To facilitate our research, we created a specialized dataset for dengue larvae, as no publicly available dataset existed. In collaboration with health authorities, we recorded over 50 short videos encompassing diverse locations, backgrounds, and textures. The recorded videos presented challenges such as turbidity caused by varying light conditions, backgrounds, and textures. To address the issue of turbidity, we incorporated a contrast enhancement block into the semantic network. Our proposed model was compared against state-of-the-art approaches. The qualitative and quantitative evaluations demonstrated the superior performance of our proposed model over DeepLabV3, Resnet, and Segnet. While other approaches achieved an F-measure score of 75.37%, 75.41%, and 74.87%, our proposed model achieved an F-measure score of 76.72%. In our previous work, we used CNN and Kalman filtering to detect and track dengue larvae and the models achieved a 71% F-measure score while the proposed model shows excellent results as compared to all other state-of-the-art models. These results were further validated through expert assessments by health authority officials actively involved in dengue eradication projects. We believe that our work will significantly contribute to further advancements in this field. Given the global impact of dengue fever, the automation provided by our model can play a crucial role in the eradication efforts of this life-threatening disease.