
Abstract
Entity linking is an important task for information retrieval and knowledge graph construction. Most existing methods use a bi-encoder structure to encode mentions and entities in the same space, and learn contextual features for entity linking. However, this type of system still faces some problems: (1) the entity embedding part of the model only learns from the local context of the target entity, which is too unique for entity linking model to learn the context commonality of information; (2) the entity disambiguation part only uses similarity calculation once to determine the target entity, resulting in insufficient interaction between the mentions and candidate entities, and ineffective recall of real entities. We propose a new entity linking model based on graph neural network. Different from other bi-encoder retrieval systems, this paper introduces a fine-grained semantic enhancement information into the entity embedding part of the bi-encoder to reduce the specificity of the model. Then, the cross-attention encoder is used to re-rank the target mention and each candidate entity after the entity retrieval model. Experimental results show that although the model is not optimal in inference speed, it outperforms all baseline methods on the AIDA-CoNLL dataset, and has good generalization effects on four datasets in different fields such as MSNBC and ACE2004.
Introduction
The task of Entity Linking (EL) is to identify entities mentioned from unstructured text documents and link them to corresponding entities in a Knowledge Base (KB). For example, when examining the sentence, "Rolls-Royce’s vision is to provide the driving force for changing the world through aviation and two major business units," the entity is correctly identified as the Wikipedia entity "Rolls-Royce" (aeroengine business) rather than "Rolls Royce" (the car company). Entity linking is a fundamental component of various natural language processing tasks, which can facilitate the development of knowledge base population, question answering ([4, 26]), information extraction ([27, 31]) and social media analysis ([14, 18]).
An entity linking task usually consists of two subtasks: Candidate Entity Generation (CG), which extracts entity mentions from raw text input and generates possible corresponding knowledge base entities, and Entity Disambiguation (ED), which links text mentions to their corresponding entities from the candidate entity set. The task of entity disambiguation is commonly approached as a ranking problem. Candidate entities are ranked by their semantic similarity to a given mention. Some methods rely on manually designed feature parameters to model contextual information. These parameters are both sparse and difficult to calibrate. To address these issues, researchers have attempted to use neural networks to automatically learn the semantic features of mentions and entities for linking purposes. Previous studies have discovered that the contextual information of an entity in a knowledge graph is often represented by its associated relationship and its adjacent entities within the graph structure. Thus, prior research has treated different node information in the graph structure as equal. However, mentions in different contexts commonly emphasize various relation-entity pairs for the target entity. Thus, the related pairs are not equally important to the model, and they provide more discriminative information than broad, average access to the semantic information of other words. Additionally, entity embeddings used in prior studies encode too many specifics about the entity, which are too detailed for link models to learn the commonalities of contextual information effectively. To address these issues, this paper proposes the use of a dual encoder system combined with the co-attention mechanism and GCN network as the candidate entity generator module. Further, the paper proposes the addition of the FGS2EE entity fine-grained semantic type to the entity embedding part of the dual encoder. This addition aims to increase the model’s ability to learn the commonalities of semantic associations about contextual information, reduce the differences in model learning, and promote generalization performance.
In addition to entity disambiguation, a subtask of entity linking is to rerank the set of candidate entities. A reordering module can assist in correcting mispredictions of the system ([2]). When performing entity disambiguation, the model needs additional information, including the original sentence and possibly related information from various parts of the document, depending on the entity in question. Specifically, the model may need to examine the title of the entity introduction in the knowledge base and potentially the relevant section of its description. For instance, if there is a mention of "world cup" and two possible entities, "world cup 2018" and "world cup 2022", the entity description can provide crucial information, such as the 2018 World Cup being held in Russia and the 2022 World Cup being held in Qatar. Utilizing contextual information regarding time and location can significantly improve the likelihood of correctly linking the "World Cup" mention to its appropriate entity. To better capture relevant feature information of candidate entities, this paper’s reordering module implements BERT as a cross-attention encoder, selectively utilizing important contextual information.
Related work
The process of entity linking involves two stages: candidate entity generation and entity disambiguation. In these stages, the goal is to identify entity mentions from natural language questions and correctly link them to the corresponding entities in a knowledge base. Early models for entity linking ([11, 35]) utilized the probabilistic method, which involves entity coherence. However, this method’s shortcomings are also obvious. For example, there are numerous hyperparameters in the algorithm, and adjusting them for different data sets can be time-consuming. The development of deep learning has led to the proposal of utilizing neural networks to train end-to-end entity linking models. Several studies, including ([7, 33]), have demonstrated the superior performance of such models. ([6]) introduced the first neural network-based approach to training entity linking models, utilizing CNNs to generate fixed-length vectors that represent each mention, its local and document context, and the topical information associated with the candidate entity and its page text. ([13]) proposed a neural model for joint mention detection and entity disambiguation that utilizes bidirectional LSTM ([8]) to encode entities. The main idea of the approach is to consider all possible entities as potential mentions and to learn the contextual similarity scores of their candidate entities. This approach does not require complex feature engineering.
In recent years, several innovative models for joint linkage have been proposed, based on the assumption that all target entities mentioned in a document are interconnected. ([7]) published a model, which assumes topical consistency among mentions and utilizes a factor graph design. Mention and possible entities are represented as variable nodes, and feature nodes indicate a series of attributes. Local and global features are merged in the models resulting in improved performance of soft and hard attention. Additionally, context words are filtered out from local models. To solve the problem of identical mentions in different sentences linking to diverse entities in the knowledge base, ([15]) utilized a fully-connected conditional random field (CRF) model with recurrent belief propagation to calculate the maximum marginal probability. Furthermore, PageRank or Random Walk are used to choose every target entity mentioned ([21]). Generally, probabilistic models require the predefinition of numerous features, which makes the calculation of the maximum marginal probability challenging as the number of nodes increases. To automatically extract features from data, ([5]) employed graph convolutional networks to encode entity graphs in a flexible manner. Nevertheless, graph-based methods are computationally expensive due to an abundance of candidate entity nodes. To utilize graph information optimally, ([32]) presented a coarse-to-fine unsupervised knowledge extraction technique to improve the quality of the knowledge base.It saves nearly 70% of storage space and approximately 60% of running time. However, this method cannot treat all knowledge bases identically, requiring the extraction of different knowledge bases one-by-one rather than undertaking a unified extraction strategy, resulting in a huge initial workload and an impact on the final outcome due to the adopted extraction strategy.
([37]) mainly solved the problem of how to use a new aggregation operator for multi-attribute decision-making under the condition of linear Diophantine fuzzy sets. A linear Diophantine fuzzy set is a mathematical tool capable of dealing with uncertain and fuzzy information. Although ([37]) can provide support for decision analysis and similarity algorithm improvement in entity linking tasks, it has not been really applied in entity linking tasks, and it has not been able to prove the feasibility and effectiveness of this method in entity linking tasks.
This paper explores entity linking using knowledge graphs as a structured knowledge base. In contrast to previous approaches, this study utilizes semantic entity embedding and incorporates a candidate re-ranking module based on cross-attention encoder. These methods enable the system to grasp fine-grained contextual information and enhance the semantic interaction of candidates, which minimizes the effects of non-target entities on the results.
Methods
The paper proposes a method that accomplishes two major objectives, namely Candidate Generation and Candidate Reranking. The first goal is attained using the bi-encoder architecture ([12]) with semantic reinforcement to generate a set of candidate entities. These entities are retrieved as the top-k entities and considered for linking. For the second objective, this paper uses BERT as a cross-encoder to rerank the candidate entities through binary classification. The probability score of each candidate entity being a real link is calculated following this rule. Finally, the entity with the highest probability is selected as the final ground truth entity. In this section, we provide a brief overview of the bi-encoder candidate generation module, followed by information on the cross-encoder used for reranking. Figure 1 illustrates the architecture of the entire system.
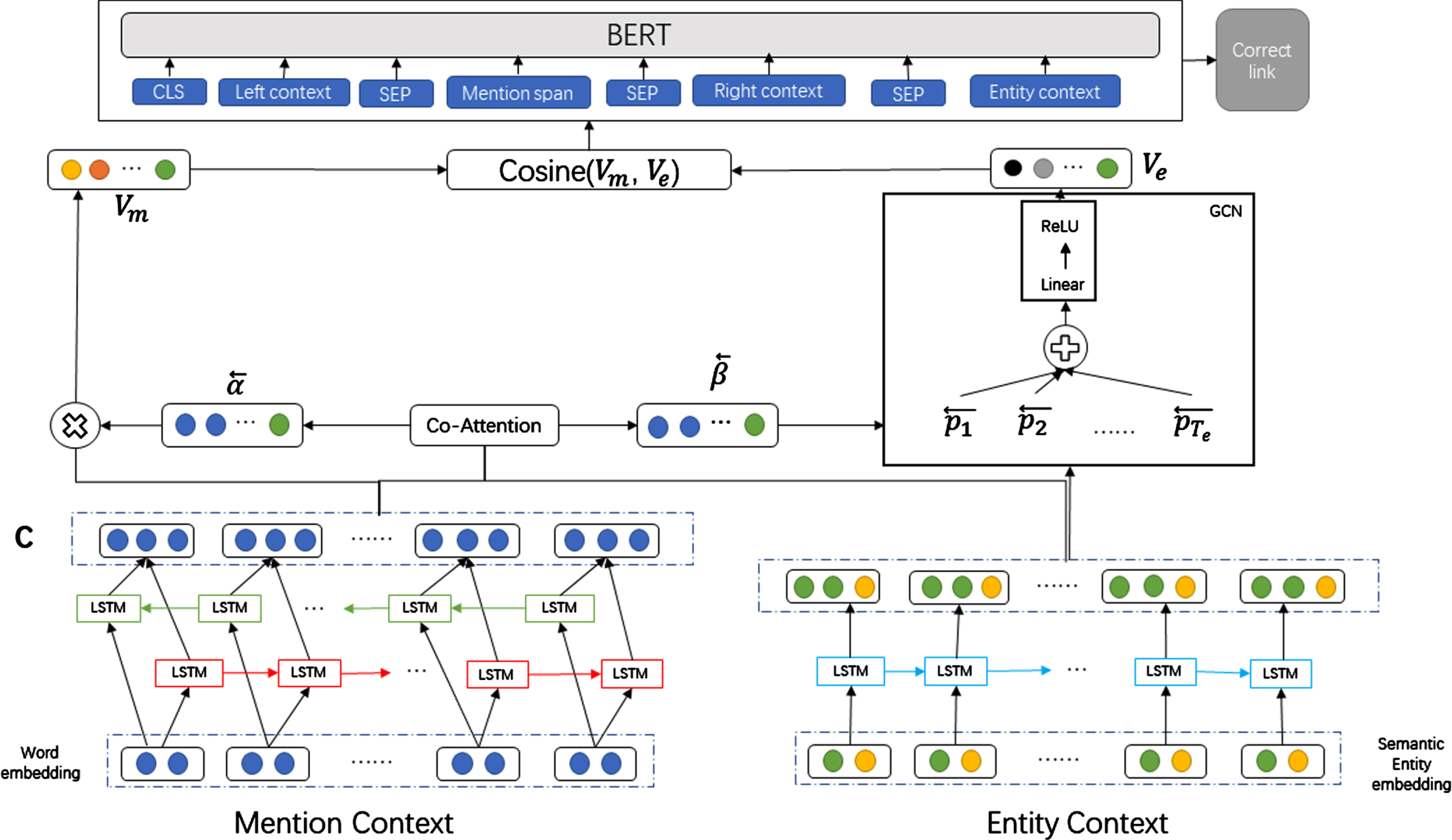
Entity link model diagram.
The proposed method in this paper employs a bidirectional long short-term memory network (BLSTM) to encode both the mention and entity parts in the candidate entity generation module. Furthermore, this paper meets the requirements of the FGS2EE method to create entity embeddings that comprise semantic enhancement information. This is accomplished by: (1) building a fine-grained semantic word dictionary; (2) extracting semantic type words from Wikipedia articles for each entity; (3) generating semantic embeddings for each entity; and (4) combining semantic embeddings with existing combined entity embeddings to develop a new semantically enhanced entity representation. Subsequently, the reordering module operates solely on a small part of the candidate entity set, reducing the overall data volume. Therefore, the reordering module adopts a more complex representation of BERT, including additional features such as semantic context.
The task of knowledge graph-based entity linking involves selecting an entity e* from a set of candidate entities
This paper does not address the identification of candidate entities itself, instead relying on results obtained from previous research methods ([30]).
Candidate generator
We utilized the bi-encoder model for creating candidate entities corresponding to each mention. The model learns representations of entities and mentions in a shared space during training by maximizing the cosine similarity between mentions and corresponding candidate entities. A context C m refers to a sentence that includes mention m which can be depicted as a sequence of words {w1, w2, ⋯ , w T m }, whereby T m designates the sentence’slength.
Encoding C
m
: The first step in encoding C
m
involves embedding each word into a low-dimensional continuous real-value vector using the word embedding matrix
where
Finally, The matrix of C
m
is derived by concatenating context vectors, that is,
Encoding C
e
: The entity context C
m
is defined as a set of relational entity pairs C
e
= {p1, p2, ⋯ , p
T
e
}, where T
e
is the total number of relational pairs. Each pair p
j
can be viewed as a sequence of words
Where α is the semantic embedding weight, and
Then, referring to the context encoding C m , extract the vectors of each pair.
Finally, the matrix of the entity context is obtained by stacking its corresponding context vectors, that is,
Construct mention representation: After encoding the mention context, C
m
, and the entity context, C
e
, the model introduces a co-attention mechanism ([17, 20]) to learn and highlight important information in both contexts. To perform this, the similarity between each context vector within the mention context vector matrix,
where T represents matrix transpose,
Next, the similar matrix is normalized by row to generate a mention context relational matrix A r . This normalization eliminates the discrepancies in scale among various eigenvalues while mitigating the unfavorable effects that may arise from singular sample data. Correspondingly, the similar matrix A is normalized by column to create an entity context relationship matrix A c :
The next step involves filtering the maximum value of every row in the similar matrix A
r
and every column in similar matrix A
c
. Utilize the softmax function to calculate the weighted vectors
Finally, a weighted summation is computed across the mention context vectors to construct the mention representation in a technically:
Construct entity representation: In the spatial domain, the graph convolutional network employs an attention mechanism that assigns varying weights to individual neighbor vertices. This enables the network to distinguish the significance of individual vertices in contributing to the feature update of the current vertex. Each element β
i
in
where σ represents the activation function ReLU, and
Once the mention representation V m and entity representation V e are obtained, their association is calculated using cosine similarity:
This paper models the reordering candidate entity problems as binary classification tasks, and fine-tunes BERT for tasks with specific domain data. For each pair of mentions and candidate entities, this article uses BERT as a cross-attention encoder to learn the joint representation of the mention and entity. Then classify the joint representation as the correct link or the wrong link. In the model test, the final entity is selected from the candidate entity as the post-processing step of the "correct link" entity probability output by the reordering model. That is to say, for each mention, the model will select the candidate entity with the highest probability from 100 candidate entities as the final link entity of the mention.
BERT receives two inputs: mention representation and entity representation, as illustrated in Fig. 2. The [SEP] symbol demarcates the division in the complete input sentence. For entity representation, the model employs the entity context sentence, which comprises various relational entity pairs and associated semantic words to facilitate the entity disambiguation task. In the current study, entity names are not entered explicitly into this input because the entity context sentence is pre-selected to always contain the entity name.
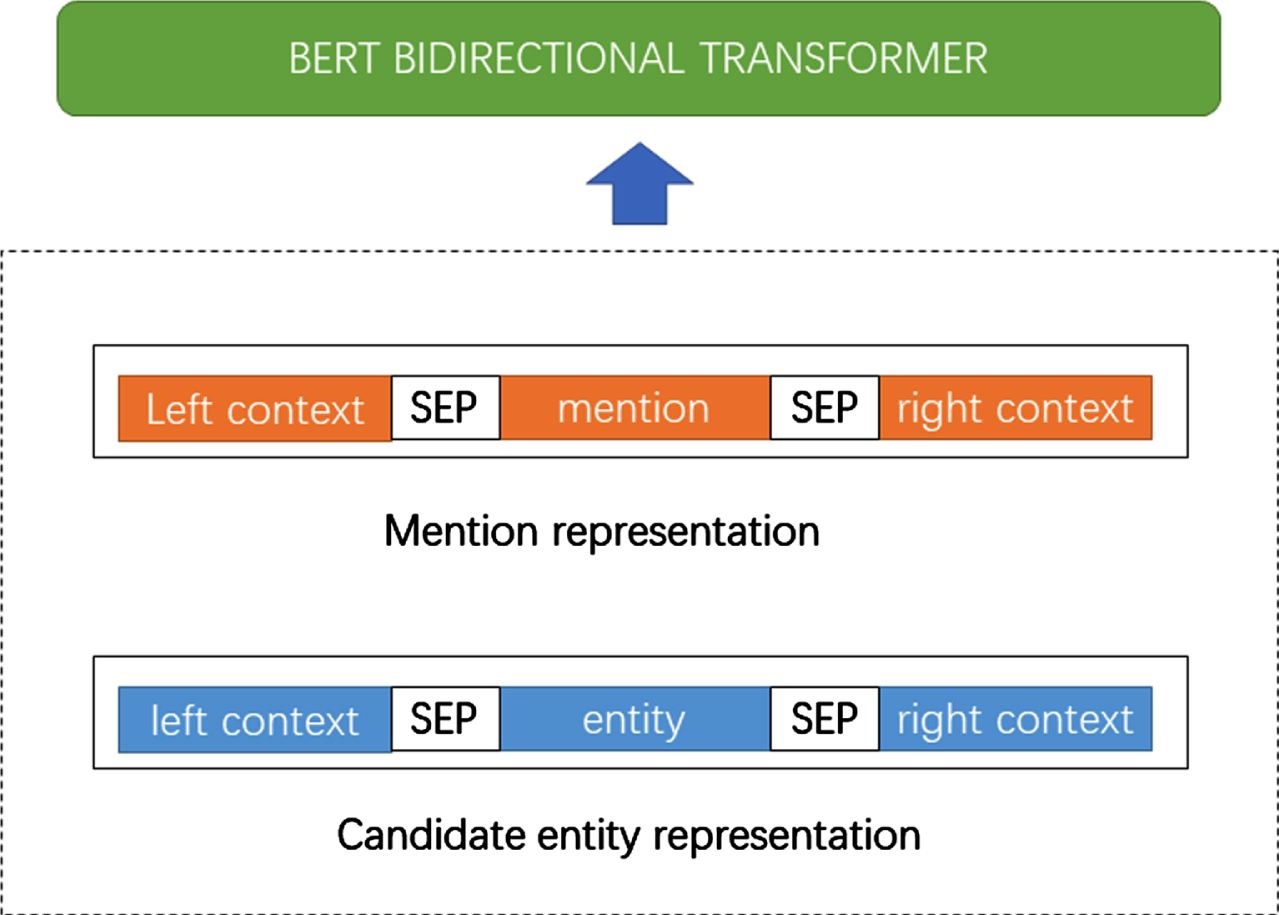
Schematic diagram of the reranker module.
The Transformer encoder enables deep cross-attention interactions between mention contexts and entity information in the knowledge base by concatenating their respective representations. As BERT utilizes self-attention to encode text pairs that are concatenated, bi-directional cross-attention interactions exist between the two. By feeding the concatenated text sequence into the BERT model, hidden representations for each word are generated, and the corresponding word embeddings for mention and relationship-entity pairs are extracted as their respective representations. The subsequent step is to compute the relevance of these representations and context, as follows:
where S (m, e) is the similarity score of mention m and entity e, and C m and C e denote the context containing mentions and the context containing entities, respectively. The candidate entities are re-ranked based on their relevance, and the entity with the highest score is selected as the definitive "correctly linked" entity.
In practice, some mentions may not correspond to any entity in the target knowledge base. To identify these unlinkable mentions, a simple thresholding method is employed. If the score of the top candidate entity is below a certain threshold, the mention is labeled as "non-linkable."
Datasets and setup
This study employs DBpedia as the knowledge base for the model, and the proposed approach is evaluated on three extensively adopted datasets.
AIDA-CoNLL ([11]) is one of the largest annotated entity linking datasets. The dataset is divided into training set (AIDA-train), validation set (AIDA-a) and test set (AIDA-b), with 946, 216 and 231 documents, respectively.
ACE2004 dataset ([25]), a subset of the ACE2004 common reference corpus, was used in this study. It comprises of 57 news articles that include 253 mentions which were annotated manually.
MSNBC ([3]), which includes 20 news documents and 658 annotated mentions, was utilized in this research.
OKE-2015 and OKE-2016 are two datasets for evaluating open knowledge extraction, which are part of the ESWC 2015 and ESWC 2016 challenges respectively. They all contain some sentences or paragraphs, and corresponding annotation information, such as entities, types, links, etc.
In this study, AIDA-CoNLL, MSNBC, and ACE2004 are selected as three datasets because they are standard datasets in the field of entity linking and have certain authority and fairness. These datasets come from different domains and text types, and can cover different scenarios and challenges. Specifically:
The AIDA-CoNLL dataset is constructed based on the news corpus CoNLL-2003 and contains 1393 news articles with 34924 entity mentions. This dataset has high difficulty and diversity because it contains multiple languages, domains and themes, as well as some rare or ambiguous entities. The MSNBC dataset is constructed based on 20 news articles from the MSNBC news website, containing 656 entity mentions. This dataset has high noise and incompleteness because it contains some spelling mistakes, abbreviations, omissions, etc. The ACE2004 dataset is constructed based on 50 news articles from the Automatic Content Extraction project, containing 257 entity mentions. This dataset has high complexity and specialization because it contains some entities involved in politics, military, economy and other fields.
The specifics of the five datasets are provided in Table 1. Similarly to prior research, this study utilizes the F1 score to assess the effectiveness of the model.
Statistics of the dataset, #Doc and #Men respectively are the number of documents and the number of mentions
Statistics of the dataset, #Doc and #Men respectively are the number of documents and the number of mentions
Hoffart et al. (2011): This article proposes a method of disambiguation of collective entities using the knowledge base and a new coherent graph. The node of the coherent graph is a candidate entity, the edge is a similarity score, and the weight of the edge is calculated based on a prior probability and similarity score. Ultimately, a random walk algorithm is utilized on the coherent graph to determine the most suitable result for the entity disambiguation.
[13] Kolitsas et al. (2018): In this article, a neural network model is proposed to handle both entity mention detection and entity disambiguation simultaneously. By employing joint training of word and character-level embeddings, the model can optimize the objective function for both tasks within a single framework while utilizing the interaction information between them. Additionally, the model reuses the candidate set previously proposed by (Hofmann et al. 2017) while creating a global score to rank the candidate entities.
[5] Cao et al. (2021): The presented article offers a method of retrieving entities from the knowledge base utilizing the autoregression model. Instead of directly selecting a tag, the system generates the name of the entity using an autoregression model. By adopting this approach, the model is able to handle emerging or infrequent entities with greater flexibility, in addition to leveraging the semantic information within the entity name to aid in entity retrieval.
[22] Manoj et al. (2021): The presented model features a pipeline structure that comprises two transformer-based models. The first model identifies entity mentions within text and generates a list of candidate entities for each mention, while the second model assigns a correlation to every candidate entity based on context and knowledge base information. The model then scores each candidate entity and selects the highest-scoring candidate entity as the final result of the entity disambiguation. As a result, the pipeline structure decomposes the entity link task into two subtasks, each targeting different functions and utilizing a diverse range of information sources, making it adaptable to various knowledge databases.
[1] Ayoola et al. (2022): The model uses fine-grained entity types and entity descriptions to execute links. The model performs reference detection, fine-grained entity type judgment and entity disambiguation for all references in the document in a forward transfer. In addition, the model also has zero sample capability and can be linked to entities without training data.
These methods all use a transformer-based neural network model for entity linking, but their architectures and training methods are different. ([13]) used a bidirectional LSTM encoder to generate mention embeddings, and a probabilistic mention-entity mapping to score candidate entities, but relied on a pre-defined candidate list, which may ignore some rare or emerging entities. ([5]) used a pre-trained BART codec architecture and a constrained beam search to generate valid entity names, this method requires a lot of pre-training data and computing resources, and may produce some wrong or inconsistent entity names. ([22]) used two transformer models based on BERT and RoBERTa to perform mention detection and entity classification respectively. The premise is that different data sources and knowledge bases need to be adapted, and some alignment or matching problems may be encountered. ([1]) used a BART codec architecture to perform mention detection and fine-grained entity type scoring in the encoder, and entity disambiguation in the decoder. However, it is necessary to label the fine-grained entity types, which may introduce some noise or bias.The method proposed in this paper leverages semantic entity embeddings combined with a candidate re-ranking module based on a cross-attention encoder. These methods enable the system to grasp fine-grained contextual information and enhance the semantic interaction between candidate objects, thereby minimizing the impact of non-target entities on the results, while not requiring the introduction of external knowledge, and only using the knowledge in the knowledge graph for entitylinking.
Training details
In the candidate entity generation phase, we employ the 300-dimensional word embeddings proposed by ([23]) as a pre-training mechanism to initialize the BLSTM and LSTM models. If a word does not exist in the pre-trained vocabulary, it is assigned a random initialization. These embeddings remain fixed during training, while the model learns the neural network parameters. In terms of hyperparameters, we experimented with varied parameter combinations. We selected the learning rate λ from 0.01, 0.005, 0.001, the hidden size k from 100, 200, 300, and the batch size B from 10, 50, 100. The optimal configuration consisted of λ = 0.001, k = 300, and B = 100. Furthermore, the word embedded dimension d w is equal to 300, while the semantic embedding weight α is equal to 0.2, and the number of semantic words T is 11. This study employs the dropout technique proposed by ([29]) to mitigate overfitting. The dropout rate, p, is set at 0.5. We trained our model on AIDA-train, optimized hyperparameters on AIDA-A, and tested on AIDA-B and two other datasets. To retain the target entity as much as possible, we used cosine similarity to determine the closest neighboring entity during the candidate entity generation stage. Furthermore, we used the top 100 entities retrieved by the model as a collection of candidate entities for the reranker module. Table 2 presents the experimental parameter values.
Parameter setting
Parameter setting
For the reranker module, this paper uses the BERT-large-uncased model, with a learning rate of 6e - 6, a batch size of 64, and a maximum sequence length of 256. For the baselines cited in this article, we use the model performance results marked in our works ([1, 22]), or refer to the model test results from the relevant literature and adopt the corresponding parameters from its default settings.
The study evaluated the proposed model’s performance on five widely-used datasets (AIDA-CONLL, ACE2004, MSNBC, OKE-2015, OKE-2016) and compared it to the performance of typical and state of the art baseline models. The experimental outcomes are tabulated in Table 3 and Table 5.
The Micro-F1 score of the model in the AIDA test set, ACE2004 test set and MSNBC test set. Among them, the best score is marked in bold, and the second best score is expressed in italics. ∗ Indicates that the baseline model does not have the test results of the corresponding data set in the original paper
The Micro-F1 score of the model in the AIDA test set, ACE2004 test set and MSNBC test set. Among them, the best score is marked in bold, and the second best score is expressed in italics. ∗ Indicates that the baseline model does not have the test results of the corresponding data set in the original paper
As shown in Table 3, the model presented in this paper outperformed all baseline models on both AIDA-CONLL and MSNBC datasets, demonstrating its superior performance. Furthermore, the proposed model improved the F1 score by 1.2 and 0.4 compared to the sub-optimal models. Nevertheless, the model ranked sub-optimally among the baseline models specifically on the ACE2004 dataset. After comparative analysis, we find that the optimal model ([22]) consists of a modular end-to-end architecture that has various module choices for the candidate entity generation stage, including Falcon candidates and DCA candidates. Additionally, the optimal model uses a corresponding Wikipedia knowledgeable list of candidate entities to generate a thorough candidate entity list, which prefer common entities and is less effective for rare or newly generated entities. Conversely, the proposed model incorporates more efficient semantic enhancement information to the entity embedding link, amplifying the model’s ability to learn entity information and extending its generalization prospects. Specifically, the semantic enhancement information significantly optimized the model’s generalization performance, as presented in Table 3, where the proposed model outperformed the optimal F1 score by 11.4 on the ACE2004 dataset, even without comparison with ([22]). Detailed scores for the accuracy rate (P), recall rate (R), and F1 score of the proposed model are available in Table 4.
The results of the model and baseline model of this paper on the AIDA-CONLL data set, where P represents accuracy, R represents recall rate, and F1 represents Micro-F1 score
The Micro-F1 score of the model in the OKE-2015 test set and OKE-2016 test set. Among them, the best score is marked in bold, and the second best score is expressed in italics. ∗ Indicates that the baseline model does not have the test results of the corresponding data set in the original paper
As demonstrated in Fig. 3, the training convergence speed using semantically-enhanced entity embedding is significantly faster than with GLoVe word embedding. A reasonable explanation for this is that the more detailed semantic information in the entity embedding assists the link model in recognizing the semantic commonalities between entities and contexts, which ultimately improves training.
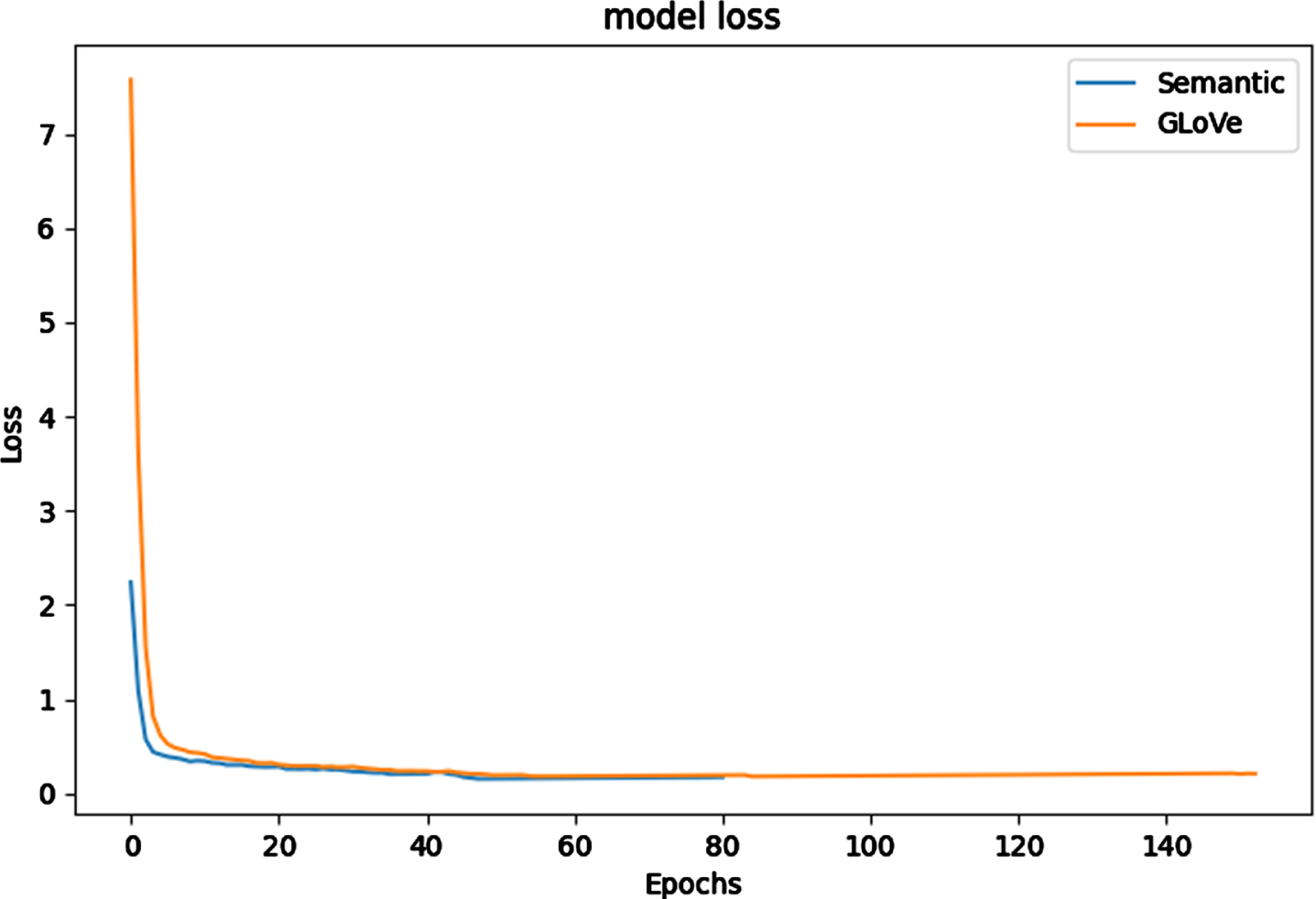
Schematic diagram of the reranker module.
It can be seen from Table 7 that the model proposed in this study still has a gap of 20 times compared with the optimal baseline model in terms of inference speed. This is because the dual encoder used needs to encode each mention individually, which means that about 4464 forward passes are required for each token in each document, which drags down the inference speed of the whole model. So in future work, we consider designing a dual-core encoder to jointly encode mentions and candidate entities in documents, which may reduce the number of forward passes to improve inference speed.
Analysis of the link results of the model on the AIDA dataset
Time taken in seconds for EL inference on AIDA-CoNLL test dataset
Here, we provide some examples of our model’s ability to perform on entity linking tasks. As shown in Table 6. In the first example, our model successfully links all mentions in the original text. But in the second example, the model fails to link the mention of "Commission". We speculate that this is due to the fact that the model emphasizes the importance of entity context information, but does not incorporate document-level context, resulting in missing information. The model was unsuccessful in linking the mention. This can be seen from Example 1. In the first example, the model successfully links both "European" and "Union" to "European Union", knowledge base page number 9317. Explain that the model captures the entity context information and accurately links to the correct entity in the knowledge base.
Mentions in the Source text are underlined. In each example, the model entity represents the mentions that our model successfully linked to. KB_ID represents the page number of the entity in the knowledge base. ∗ in the table indicates that the model was not linked successfully. NME means that the identified mention is a person’s name without a page number in the knowledge base.
Limited by the size of the table, the example we introduce here is a sentence intercepted from a document with relevant context, and does not display the entire document information.
Ablation study and discussion
We introduces semantic information embedding in the entity embedding link, and adds a cross encoder reordering module to the model that combines the original graph convolution network (GCN) and the co-attention mechanism to form the new structure proposed in this paper. Previous studies have shown ([9]) that semantic information fusion entity embedding can bring similar types of entities closer and further promote the distance between different types of entities. To investigate the effect of the semantic information embedding and reordering mechanism on system performance, the ablation experiments are conducted in this section, as presented in Table 8. We carried out four comparative experiments, namely removing both semantic information and reordering mechanism, adding semantic information but removing reordering mechanism, removing semantic information while adding reordering mechanism, and adding both semantic information and reordering mechanism simultaneously.
The ablation experiment of this model. Among them, SR means semantic enhancement (Semantic Reinforced) information, RK means reranking module (Reranking), × means the model experiment of removing the specified part, and √ means adding the model experiment of the specified part
The ablation experiment of this model. Among them, SR means semantic enhancement (Semantic Reinforced) information, RK means reranking module (Reranking), × means the model experiment of removing the specified part, and √ means adding the model experiment of the specified part
The results in the table indicate that incorporating semantic information embedding has improved the model by approximately 3.3 points, while the addition of the reordering mechanism alone has increased the model score by about 2 points. Combining both the semantic information and reordering mechanism has increased the model score by about 5 points. Fine-grained semantic information enables the entity link model to learn the commonality of semantic associations between entities and contexts, thus promoting model training. The reordering mechanism extends the top-1 result selection of the original model to top-k. This approach greatly increases the possibility that the candidate entity collection contains the correct entity, and will not have a great impact on the performance of the model.
A novel entity linking model is presented in this paper, which semantic enhancement information incorporating into the word embedding component of the dual encoder for improved accuracy and efficiency. Fine-grained semantic information can capture the semantic commonality between the entity context and the entity-entity, so as to reduce differences and promote the relevance learning of contextual information and help improve the generalization performance of the model. The effect of the reranking mechanism is to increase the probability of the correct entity re-entering the candidate set, and to improve the relative position of the correct entity in the candidate set. In comparison to the baseline model, the proposed model in this study exhibited an average increase of approximately 3.7 percentage points in recall rate, and an average increase of approximately 1 percentage point in F1 score, indicating its superior performance and efficacy.
Moving forward, our future research endeavors will focus on expanding the applicability of the proposed model and improving the inference speed of the model.Leverage it to extract semantic information from unannotated documents and explore entity linking systems for unstructured encyclopedic information outside the domain of knowledge graphs.In addition, linear Diophantine fuzzy sets have been applied to many fields, such as decision analysis, data mining, image processing and so on.However, in the field of natural language processing, linear Diophantine fuzzy sets have not received widespread attention and application.Especially on the task of entity linking, no papers have been found that use linear Diophantine fuzzy sets to deal with uncertainty and ambiguity.Therefore, we will continue to explore the use of linear Diophantine fuzzy sets to construct fuzzy aggregation operators to improve the measurement algorithm of text similarity or relevance.