
Abstract
Abbreviations
Mobile Ad-Hoc Network.
Route Request.
Route Reply.
Route Error.
Destination Sequence Distance Vector.
Wireless Routing Protocols.
Optimized Link State Routing Protocols.
Ad hoc On-Demand Distance Vector Routing.
Dynamic Source Routing.
Temporally Ordered Routing Algorithms.
Zonal Routing Protocols.
Introduction
The nodes in a mobile ad-hoc network are connected through a dynamic topology. They are self-configuring, infrastructure-free, and self-healing. The node’s connection changes due to the dynamic topology of MANET. Because the nodes are movable, every node can act as a router and a host. It is less expensive and takes up less space for configuration. MANET is a time-saving and efficient system to implement. MANET nodes are self-healing and self-configuring, requiring no human intervention. Applications of MANET range from being deployed in military applications, crisis management systems, wildlife monitoring systems, smart agriculture, ad-hoc gaming, and others. Features of MANET include dynamic topology, bandwidth limitation, independence in nature, resource-controlled operation, and reduced human involvement. These features make it increasingly valuable for everyday life.
In MANET, routing protocols provide secure data transmission and determine the optimum way through network traffic. Routing protocols are divided into proactive, reactive routing methods [1], and hybrid. Proactive routing protocols such as Destination Sequence Distance Vector (DSRV) [2], Wireless Routing Protocols (WRP), and Optimized Link State Routing Protocols (OLSR) monitor the network for available paths and maintain the routing table. Maintenance of the routing table necessitates a considerable quantity of database space. Reactive routing protocols such as Ad hoc On-Demand Distance Vector Routing (AODV) [3], Dynamic Source Routing (DSR), and Temporally Ordered Routing Algorithms (TORA) [4] do not keep a routing table and only update it when it is needed. According to the routing demand in the network, hybrid routing systems like Zonal Routing Protocols (ZRP) use proactive and reactive protocols.
Security Issues in MANET
There are several security difficulties in mobile ad-hoc networks. However, they employ TCP/IP protocols for transmitting packets or data from a sender to a receiver, which have five layers of protection. However, attackers can still attack them as they use different forms of attacks for different layers of TCP/IP on both broadcast and unicast protocols. Below, we discuss the different TCP/ IP protocol layers used in MANET. Figure 1 below shows the basic flow of the TCP/IP protocol.
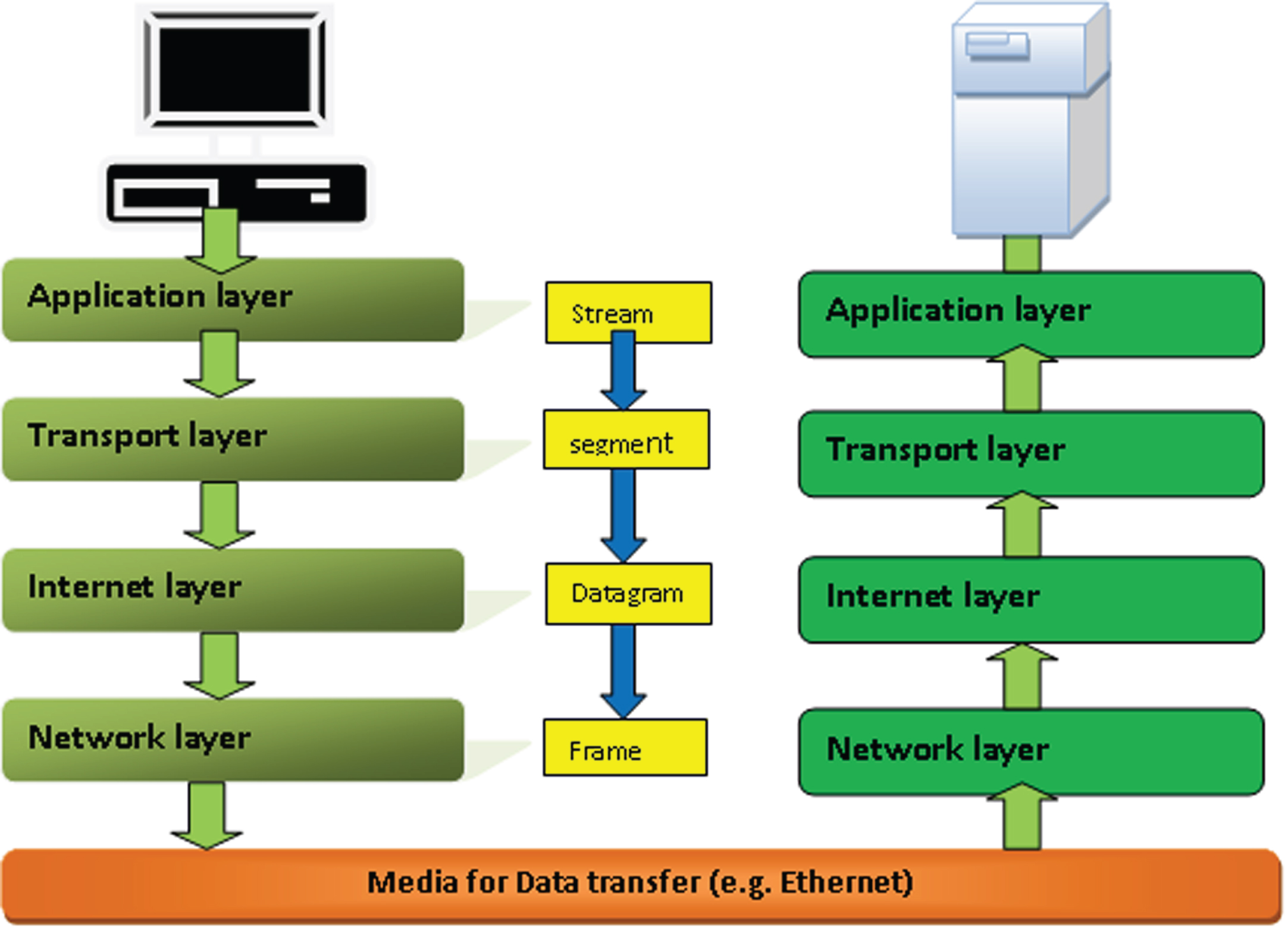
TCP/IP model.
The physical layer is the fundamental TCP/ IP layer, responsible for data transmission to subsequent TCP/IP levels. It first turns the data into a signal, then transmitted to the following levels, with various threats attempting to access it during transmission. Attacking the physical layer is more accessible than attacking any other TCP/IP layer. On this layer, the attacker uses signal jamming to monitor the frequency data travels from one layer to another and then performs a signal-jamming attack at the required frequency range.
Link-layer
TCP/IP’s second layer is the link layer, and IEEE802.11 claims it to be a crucial enabler for MANET. The attacker or malicious node repeatedly sends data into the media, disrupting the channel. The attacker node or malicious node sends RTS/CTS packets in a significant amount of data for an unlimited duration, known as an indefinite postponement attack. A signal adversary attack, in which a malicious node tries to drain the node’s battery and deplete the communication channel’s capacity, is one example of a link-layer assault.
Network layer
The network layer is the third layer of TCP/IP and is vulnerable to various attacks. One form of attack is a passive attack, while the other is an active attack. Location leaks, eavesdropping, traffic analysis, and monitoring are all part of a passive attack. During data transmission, numerous attacks such as sinkhole attacks, wormhole attacks, black hole attacks, byzantine, resource consumption, routing table overflow, cache poisoning, rushing attacks, and so on are conceivable, and the answer for all of these attacks is safe routing protocols.
Transport layer
TCP/ IP’s transport layer is the fourth layer, and strengthening security in this layer is difficult and time-consuming. The main issue arises when limited resources are available for enhancing security. As a result, attackers commonly hijack a session, attempting to attack the session in which data is being transmitted to gain access to the medium and learn what information is being passed through the network. Secure transport protocols based on public-key cryptography are one answer to this attack (TLS, SSL).
Application layer
The TCP/ IP application layer is the last layer, where many attacks may occur. Some attacks occur within the system, while others occur in the network; firewalls may avoid outside attacks, while inside attacks need an IDS (Intrusion Detection System) to detect viruses, worms, and threats. Table 1 below shows various security disputes in a MANET.
Security disputes in a mobile ad-hoc network
Security disputes in a mobile ad-hoc network
A sinkhole attack is an insider attack in which compromised nodes turn malicious and attempt to harm the network. It tries to attract the network’s attention by sending them a bogus route. When a compromised node broadcasts a fake route, the sender node begins delivering data through the broadcasted route. The malicious node then collects data packets before selectively forwarding and dropping packets from the network, increasing network overhead, and decreasing network longevity.
The sinkhole attack is depicted in Fig. 2 above, where A, B, C, D, E, and F are connected nodes in MANET. Node ‘S’ is the compromised node that sends bogus routing information to the network. The packet is sent along a fake route by the other nodes. As a result, the nodes’ energy is depleted, and the network becomes weak. The malicious node deliberately eliminates packets from the network, resulting in network depletion.
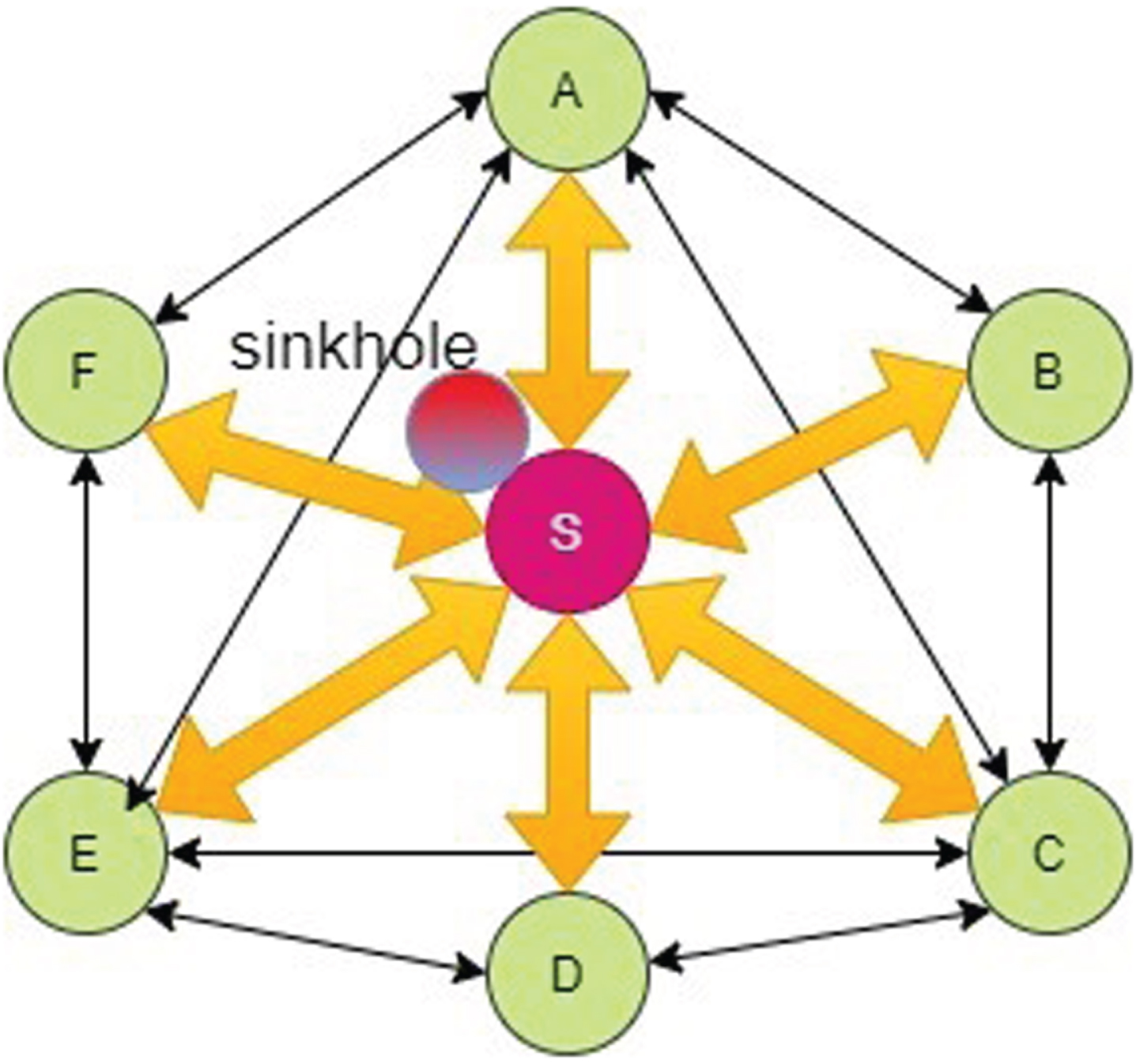
Sinkhole attack.
Sinkhole attack, being a very prominent attack as far as MANET security is concerned, many defense mechanisms have been proposed to date to counter the attack. This section discusses existing techniques and their drawbacks, as tackling the sinkhole attack in MANET is a concern.
In [4], the detection of sinkhole attacks is proposed by finding the contaminant borders of the sinkhole attack using a heuristic approach that overcomes the computational overhead by selecting a sequence number, a significant target feature. The approach is based upon a simple heuristic approach in which nodes send the fake RREP message to RREQ messages to attract traffic. The limitation of this paper is that routing protocols are used only, but they are not analyzed properly. The authors only used two protocols, AODV and DSR, and many other protocols are not discussed.
The routing attack in MANET [5] monitors the routing congestion, focusing on the route’s congestion ratio for detecting a sinkhole attack. The drawback of the proposed work is that the malicious node in the sinkhole attack creates a containment broader. Still, there are chances that the neighbour node may be the malicious node, and if the hop count is increased, then there is a chance of getting attacked by the malicious node.
In [6], sinkhole detection algorithms are used to determine the multipath selection in the network so that the best path is selected for data packet transmissions. The approach improves the network feasibility and provides secure data transmissions. The algorithm proposed is very effective in detecting sinkhole attacks in the network. It compares the two routing protocols, AODV and DSR. They used multipath selection algorithms to detect the sinkhole attack in MANET, but multipath can get the wrong path, which may cause network depletion.
In [7], a model is proposed in which direct and indirect trust are used to detect the sinkhole attack. The authors used the Cooja simulator to enhance performance and test their proposed model. That improves the additional overhead and energy consumption. The proposed model has high PDR, high throughput, low average delay, and low energy consumption and gives high accuracy (85%), low false-positive rate (1.4%), and low false-negative rate (1.8%), which is compared with SoS-RPL, INTI, and DReS models. The authors have not compared the proposed technique with other machine-learning approaches.
Authors in [8] proposed an Ant Colony Optimization-based approach for detecting sinkhole attacks in MANET. The proposed approach groups together the nodes detecting a sinkhole attack. After that, a standard voting methodology is adopted to vote a node as an intruder and discard the voted node from the network. The result shows that the proposed approach deals well in detecting and preventing a sinkhole attack without much wastage of storage and time. The main drawback of the proposed method is that the adopted voting system may result in detecting some non-malicious nodes as malicious. However, the authors claim that the proposed approach has no false positives.
Authors in [9] proposed a method to detect sinkhole attacks in WSNs. They adopted two approaches to tackle this issue. Firstly, any malicious region in the network is detected in the Geo-statistical hazard model. Then, through a distributed monitoring approach, every neighbour of some specific node is checked for posing any malicious behavior. Once detected through the author’s approach, the mitigation approach to counter the sinkhole attack must be optimized and modelled further.
In [10], the authors state that the Malicious Hardware Trojan (HT) tries to detect the DoS attack, which mainly deals with sinkhole and black hole attacks. They have used different techniques to detect sinkholes and black holes. Using the HT technology will increase the packet loss in the network, which increases the risk of network depletion. The paper only analysed the prevailing techniques and did not propose any solution.
The authors in [11] try to find the network’s best path for packet travel. They faced very many challenges in implementing an Intrusion detection system. The design of the IDS model is very motivational and helpful, but at the same time, the risk is also very high in WSN as it is used in the military, so the risk of getting attacked by an attacker is high. The risk factor in the patrolled route is high. The limitation of this paper is that packet transmission for the military area is used, but it is suitable for the small-time interval. Still, it is challenging to use for a more extended period because it can get attacked by the attacker.
Proposed work
We have employed a Fuzzy Q-learning-based approach, a reinforcement learning technique based on scalar rewards earned from the environment. Using this approach, the learning capability of the system can be reinforced. The reinforcement learning approach is suitable for learning in dynamic and complex environments such as MANET.
The SARSA learning approach is another reinforcement learning technique that combines self-supervised and supervised learning methods to enhance the training process and improve model performance. The phrase “State Action Reward State Action” is commonly associated with the Reinforcement Learning framework. In Reinforcement Learning, the interaction between an agent and its environment is often described using the notation “State-Action-Reward-State-Action” or SARSA.
A brief explanation of each component:
State (S): This represents the current situation or configuration of the environment in which the agent is situated. In many RL problems, states are used to describe all the relevant information about the environment at a particular time.
Action (A): This is the decision or choice made by the agent in a given state. The agent selects an action based on its current understanding of the environment and its goal.
Reward (R): A numerical value that the agent receives as feedback from the environment after taking a particular action in a given state. It indicates how favourable or unfavourable the action was in achieving the agent’s goal. The agent’s objective is usually to maximize its cumulative reward over time.
Next State (S’): After taking an action in a certain state, the environment may transition to a new state. This is the state that the agent ends up in after performing an action in the current state.
The notation “SARSA” specifically refers to a Reinforcement Learning algorithm that uses this sequence of interactions to update its policy and estimate the value of state-action pairs. In SARSA, the agent learns to make decisions by updating its Q-values (action values) based on the observed rewards and transitions between states and actions. The name “SARSA” is derived from the order in which these components are encountered in the learning process: State-Action-Reward-State-Action.
Q –Learning is a learning environment in which the future action (in our case, selecting the best path for message transmission) depends on the reward of going from one node to another. A fuzzy Q-learning takes values from fuzzy rules and then optimizes those values using Q-learning. Rules are constructed from expert knowledge using a human intervention fed into a fuzzy controller and eventually tuned by knowledge gained from Q-learning during run time.
The fuzzy controller is designed to arrange the output by utilizing human expertise, logic, and experience in designing a controller. The rules in a fuzzy system are based on the IF-THEN structure, best used in designing the control logic of a fuzzy controller. We have used three linguistic variables, low, medium, and high, processed through a triangular membership function.
Figure 3 above depicts a sinkhole attack in MANET. When a source node, i.e., node I, wants to send the data packets to the destination node, it broadcasts the RREQ message in the network. When every node receives an RREQ (route request) message, it checks its routing table and sends the RREP (route reply) message to the sender node. When a node I get the RREP message from every node in the network. A sinkhole node,i.e node B, says from my side. There is the shortest path to the destination node,i.e node E. In the AODV routing protocol, the destination sequence number is the most recent path used to reach the destination node, and the next hop count is used to find the distance between the two neighbouring nodes in the network. We have made fuzzy rules based on hop count and sequence number to help the fuzzy Q agent find the best route to reach the destination node. When the sinkhole node, i.e., node B, gives RREP to node I about the shortest path without checking the routing table. Node B says the sequence number is low from this side of the hop count. The fuzzy Q agent will scan the entire RREP message and compare it with the fuzzy rules base table, i.e., table number 3, and compare and conclude that the route is bad for data sending.
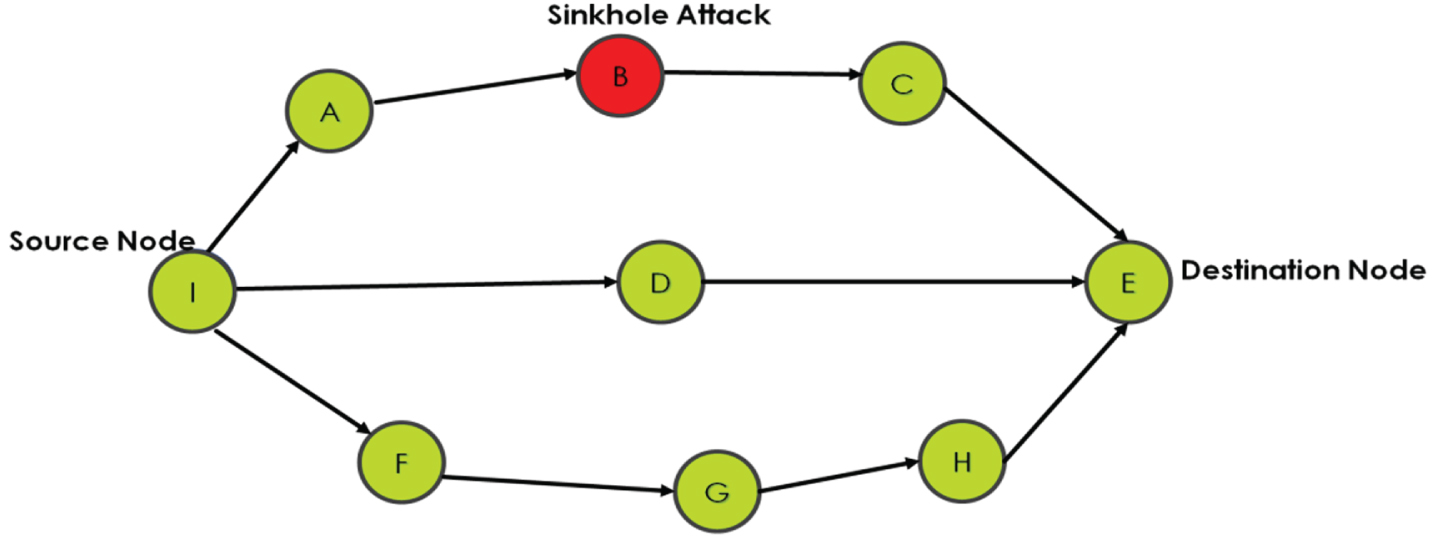
Sinkhole attack in MANET.
A low sequence number is treated as carrying the best transmission route, as stated in the AODV routing protocol [13]. We have treated medium or high sequence numbers as not a recent or unused route. So, if a sinkhole node falsely broadcasts to the source node that it has the shortest path, which other nodes in the network contradict, the source node can easily distinguish the fake broadcast message from a malicious node. Table 2 below shows our simulation parameters.
Simulation parameters
Figure 4 below shows the design of a fuzzy controller. The MANET environment informs the controller about the nodes’ sequence number and hop count. These two parameters are given to the fuzzifier, which coordinates with the rule base (designed with human intervention) and the inference engine to decide if the broadcasted path from a malicious node is excellent, good, or bad. The Q-learning agent learns about the environment by getting appropriate rewards or penalties. Based on the rules inferred, the inference engine gives its output to the DE fuzzifier, which tells the MANET about the feasibility of the broadcasted path.
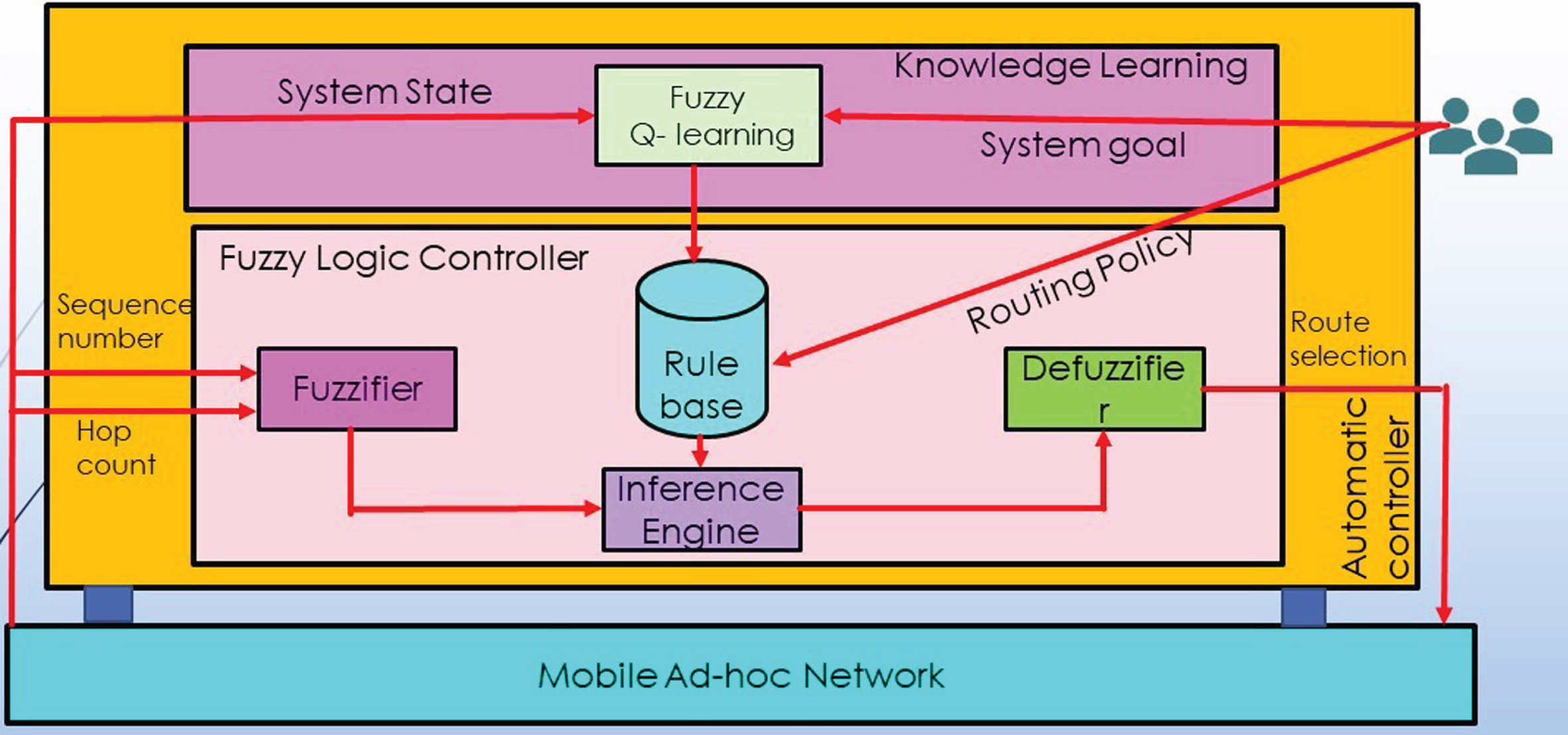
ad-hoc network with fuzzy rules.
The fuzzification process splits the input into three steps: low, medium, and high. The inference engine acts as an intelligent system. They determine the degree of match between fuzzy input and rules according to the input field. It will decide the rules that need to be fixed, combining the fuzzifier rules from the rules base. We have the fuzzy input set going into the inference engine. Now, this will incorporate the fixed rules and the control actions. Then, we will get our fuzzy input set. Once we get our fuzzy output set, then de-fuzzification starts. When de-fuzzification occurs, it converts the process and the fuzzy sets into crisp values. Different techniques are available, and you need to select the best-suited one. The expert system, so here we have a crisp input going to the fuzzy fire where fuzzification occurs. The crisp information is converted into a fuzzy input set, then this fuzzy input set passes through the inference engine, and we have a fuzzy output set. Fuzzy output goes to the de-fuzzification, where again we get a crisp output, so this was about the architecture of fuzzy logic controller.
The membership function is a graph that defines how each point in the input space is mapped to membership values between 0 and 1. It allows us to quantify linguistic terms and represent a fuzzy set graphically. A membership function for a fuzzy set A on the universe of discourse X is defined as μ A:X ⟶ [0,1]. This quantifies the degree of membership of the element in X to the fuzzy set A, and the X-axis represents the universe of discourse. In contrast, the Y-axis represents the degree of membership in the 0,1 interval. There can be multiple membership functions applicable to fuzzified a numerical value. A simple membership function is a complex function that does not add precision to the output.
A fuzzy inference system (FIS) maps an input to an output according to the fuzzy rules. For FIS, many numbers of regulations can be designed. The fuzzy rules are created based on two parameters: one is sequence number, and the other is hop count. The route is based on fuzzy linguistic variables to be excellent, good, and bad on the basics of these parameters— the fuzzy inference system association’s rules with memberships function to give the fuzzy output. The De-fuzzification converts the fuzzy output into crisp value again. Diffuzified result is obtained by
Where a i (x) is the rule strength.
Below, we show the rule constituted to detect a broadcasted route as fake or legitimate.
The objective of proposing this algorithm is to find the best route to prevent sinkhole attacks and minimize the attack risk. The fuzzy Q learning is applied to find the best route for packet transmission. Nine fuzzy rules are set on the sequence number and hop count basics. First, we see the sequence number and hop count from the source to the destination in the MANET network, then take the sequence number and hop count. The agent is rewarded if it chooses the path with the minimum average of these two parameters. Otherwise, the agent receives a penalty. The proposed algorithm is detailed below in Table 3.
FQ –SPM: Proposed algorithm
FQ –SPM: Proposed algorithm
We simulated the formulated fuzzy rules using a Q-leaning MATLAB version R2021b learning approach. The results were highly encouraging, which shows that for almost every formulated rule, the Q-values get optimized after a few iterations, and the agent learns the best path to follow based on the state–action pair of the Q –Matrix. We have shown in the graphs below the number of iterations required and the Q-values for each of the fuzzy rules formulated.
Figure 5 below shows that after almost 50 iterations, the Q - values for rule 1 get optimized and start giving the repeated values. Rule 1 states that the route can be selected as excellent given both parameters’ low values, viz. sequence number and hop count. The agent learns from the rule and will act accordingly in similar future scenarios. After getting optimized in the first state of the Q-Matrix, the agent moves to state 2, and hence, in the second step, rule 2 gets optimized.
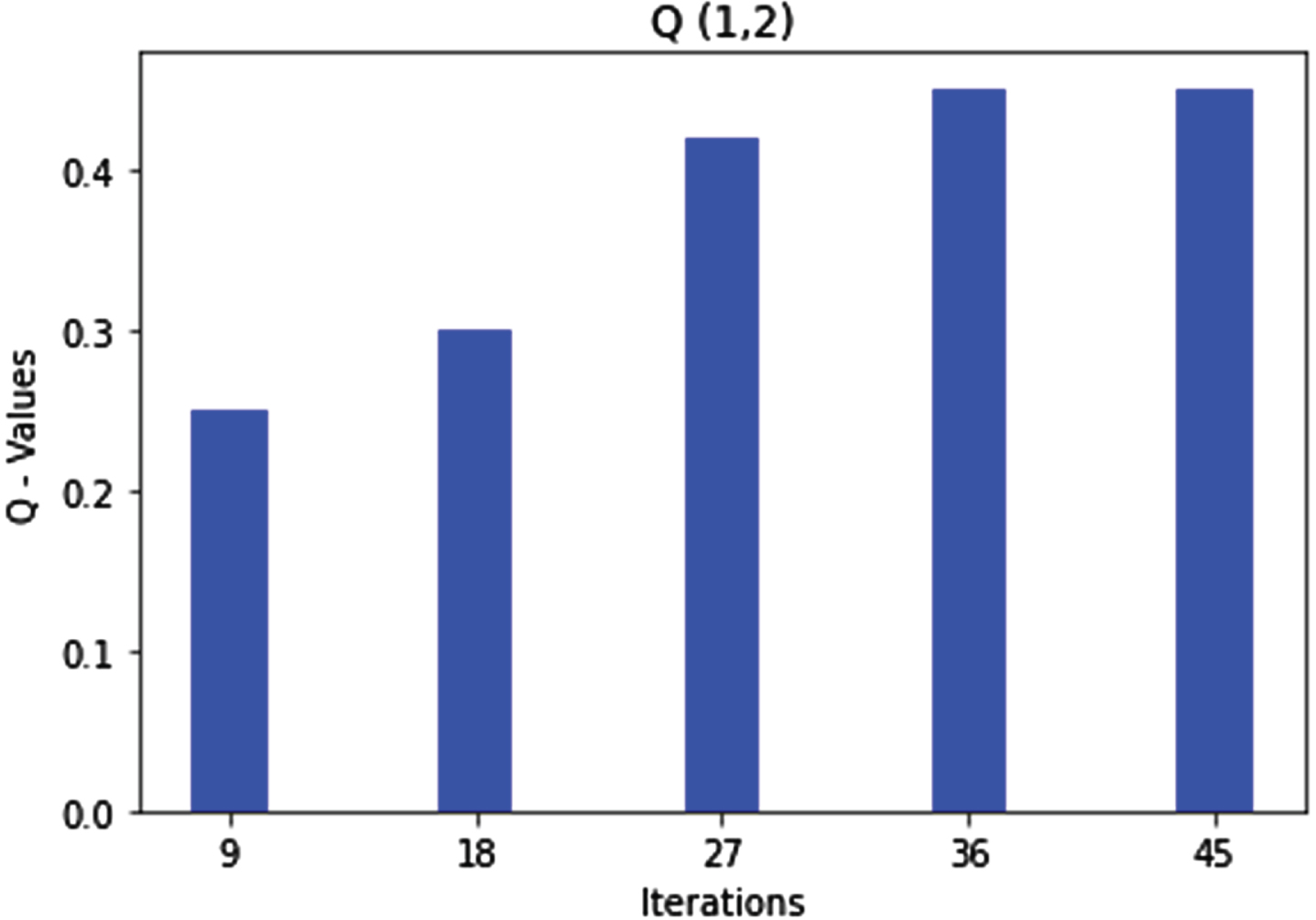
Q (1, 2) state action pair and rule1optimization.
Rule 2 states that the route can be marked as excellent if the sequence number is medium and the hop count is low. This is what we achieved in the simulation of the formulated fuzzy rules. After some iterations, state 2 of the Q-matrix gets optimized, as shown in Fig. 6 below. Hence, whenever the agent sees a route with a medium value of the sequence number and a low value of hop count, it will automatically mark the route as an excellent one; after getting optimized in the second state of the Q-matrix, the agent moves to state 3 where rule 3 gets optimized.
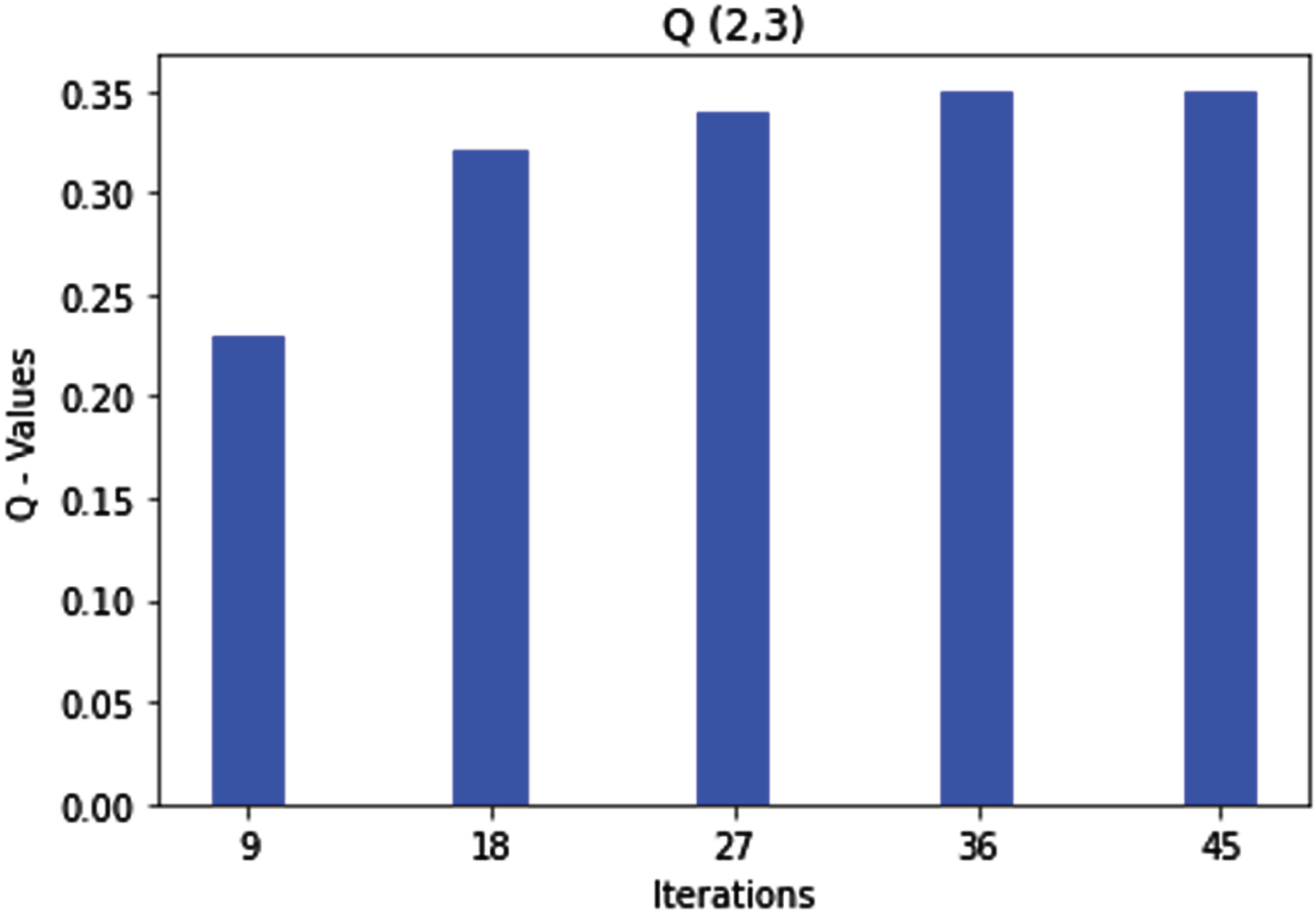
Q (2, 3) state action pair and rule2 optimization.
According to rule 5, the packet transmission route is marked as good if the sequence number is high and the hop count is low. The agent learns the same after optimization, as depicted in Fig. 7 below. The agent then moves to state 5.
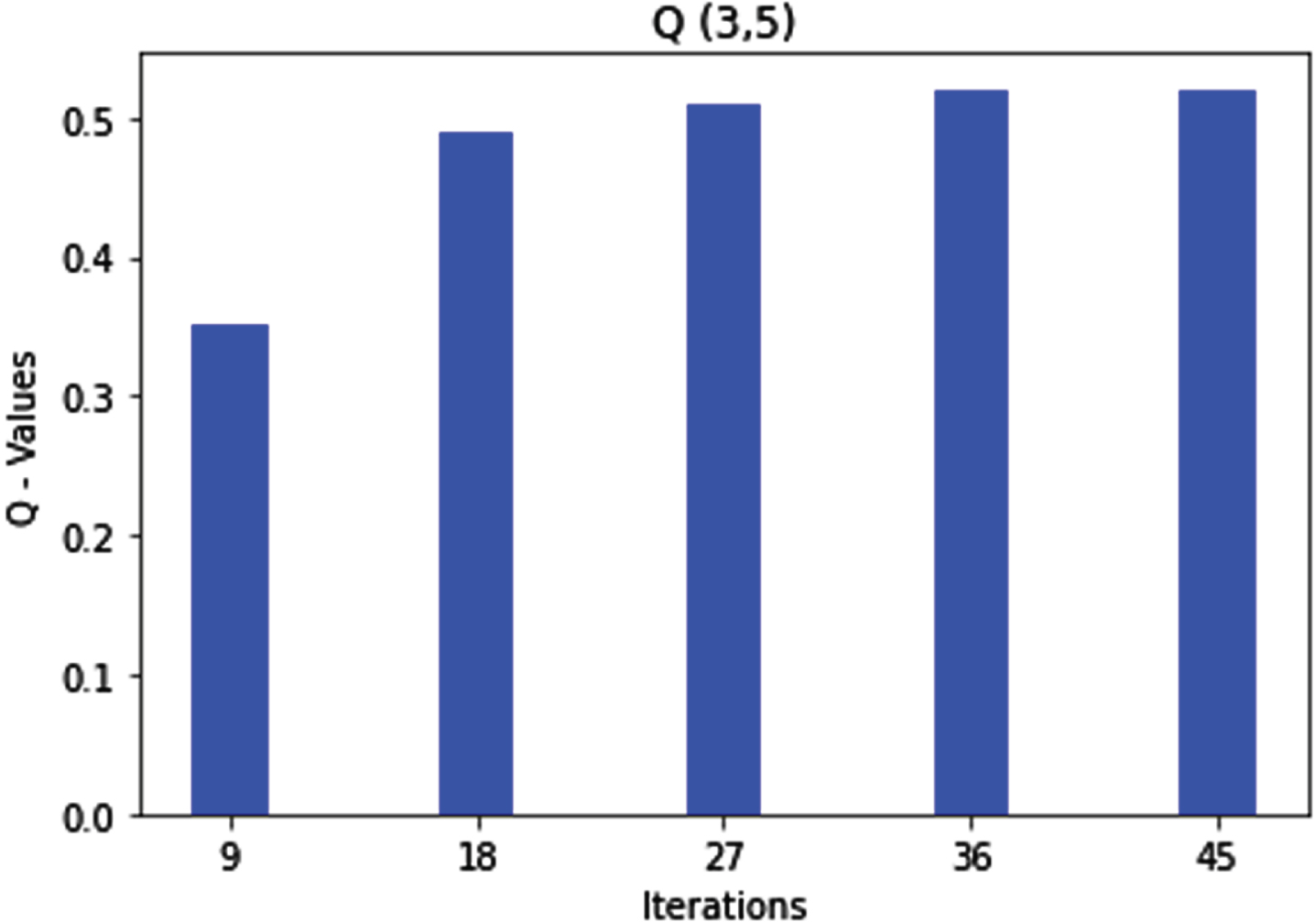
Q (3, 5) state action pair and rule 3 optimization.
Rule 4 says that if the sequence number is low and the hop count is medium, the agent marks this route as an excellent packet transmission route where the Q-values are optimized after almost 50 iterations. The agent learns the route and moves to state 1, as shown in Fig. 8.
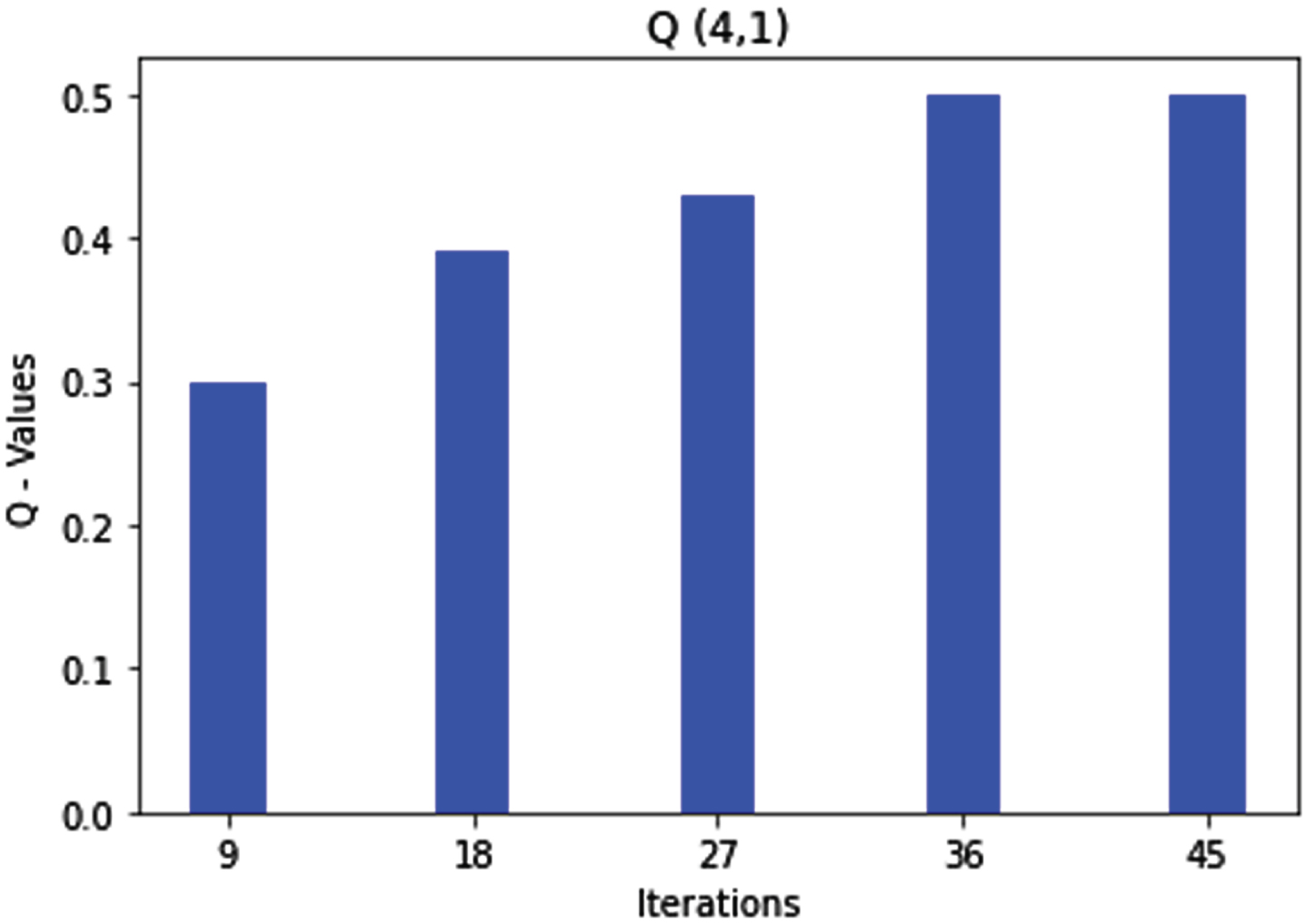
Q (4, 1) state action pair and rule4 optimization.
As per rule 5, the sequence number is medium, and the hop count is medium; therefore, the agent marks the route as good for packet transmission. After a few iterations, the Q-value gets optimized, and the agent learns the route and moves to the next state 6, depicted in Fig. 9.
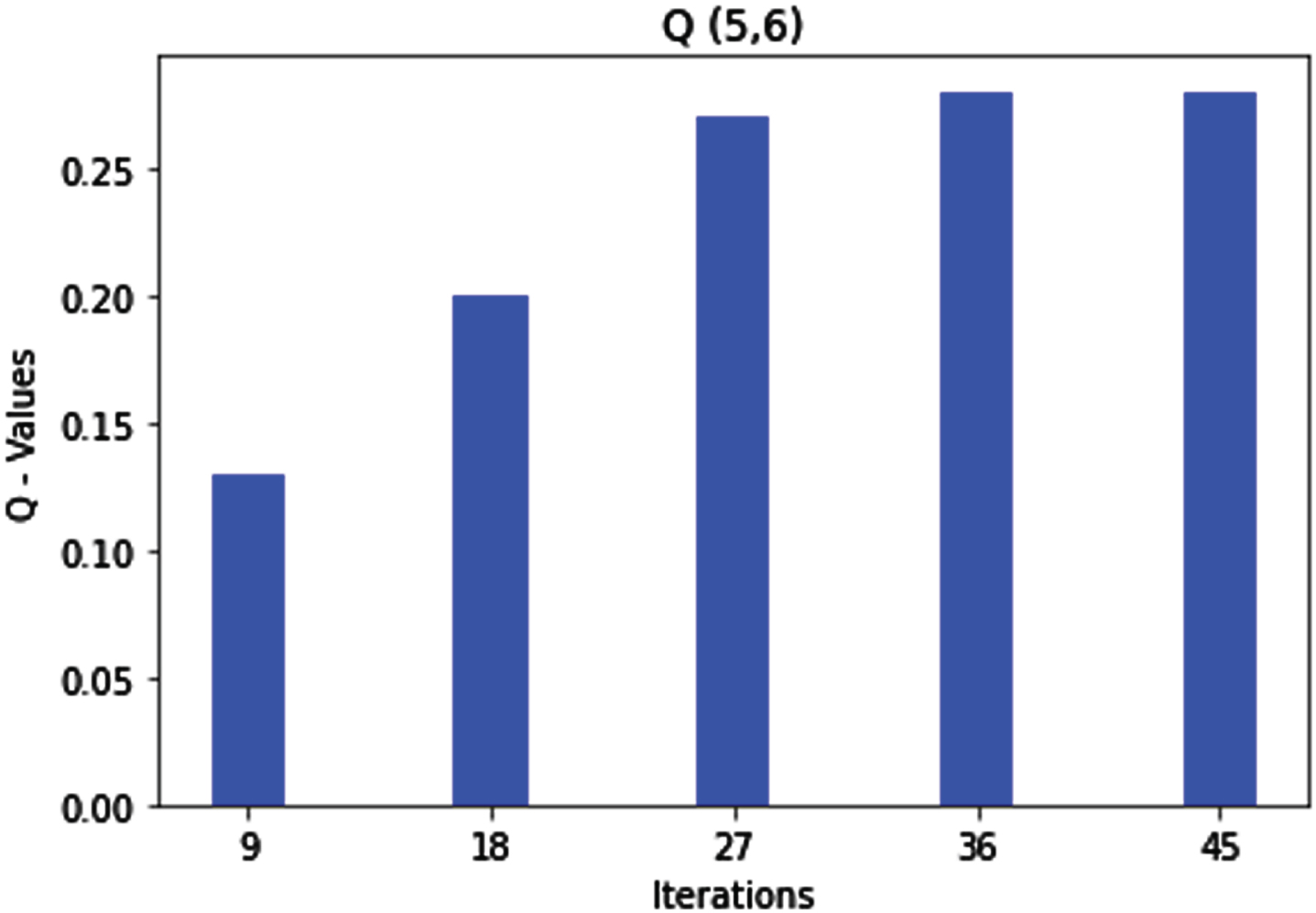
Q (5, 6) state action pair and rule 5 optimization.
Rule 6 says that if the sequence number is high and the hop count is medium, the packet transmission route should be marked as bad in this scenario. The agent learns the same after almost 45 iterations and moves to state 9 to optimize rule 9.
As per the above rule 7, if the sequence number is low and the hop count is high, the agent marks the route as a good route for data transmission. When formulated by the fuzzy Q-learning, after some iterations, the Q-values get optimized and give the repeated values, making the agent move to the next state 4, as shown in Fig. 11.
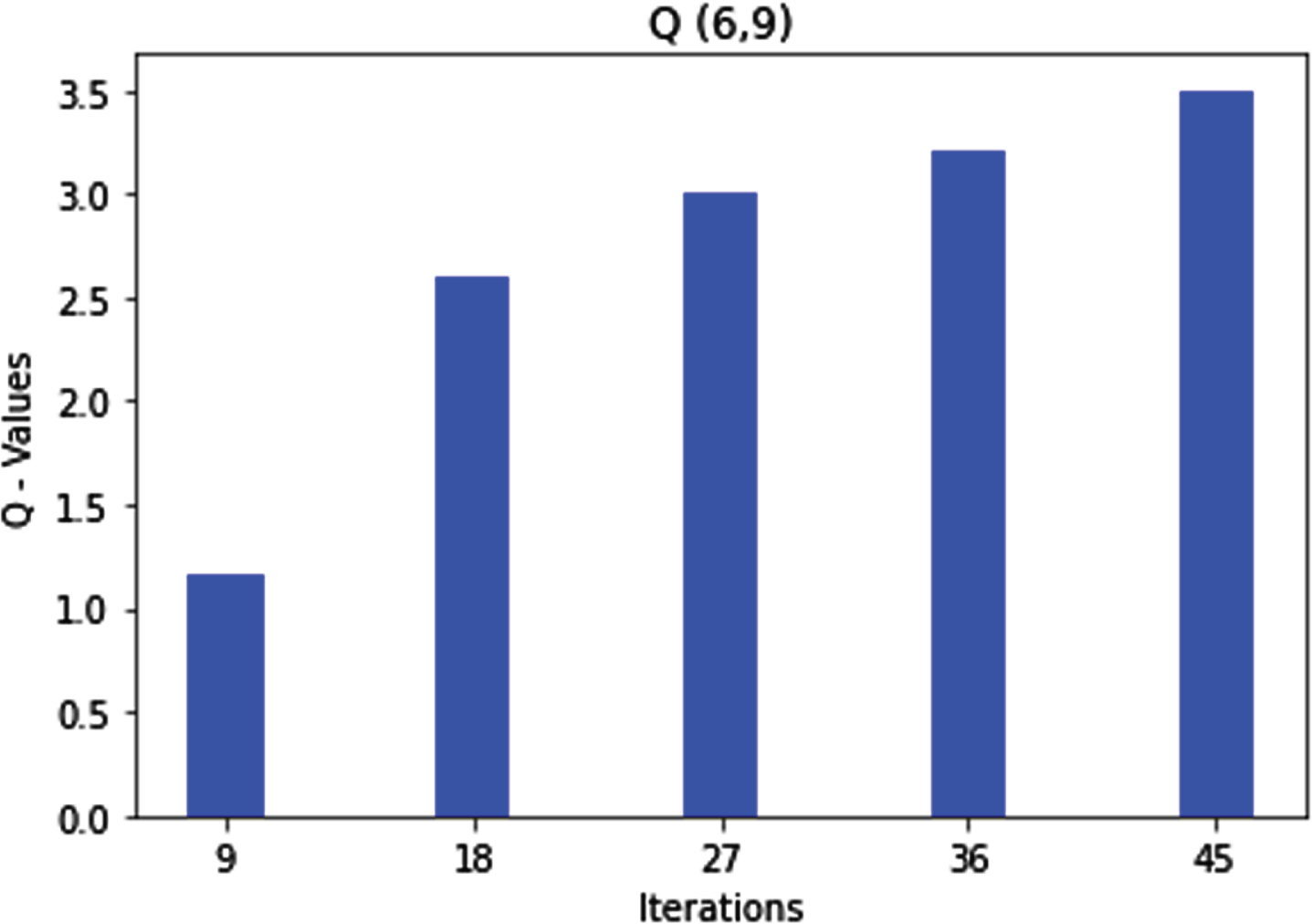
Q (6, 9) state action pair and rule6 optimization.
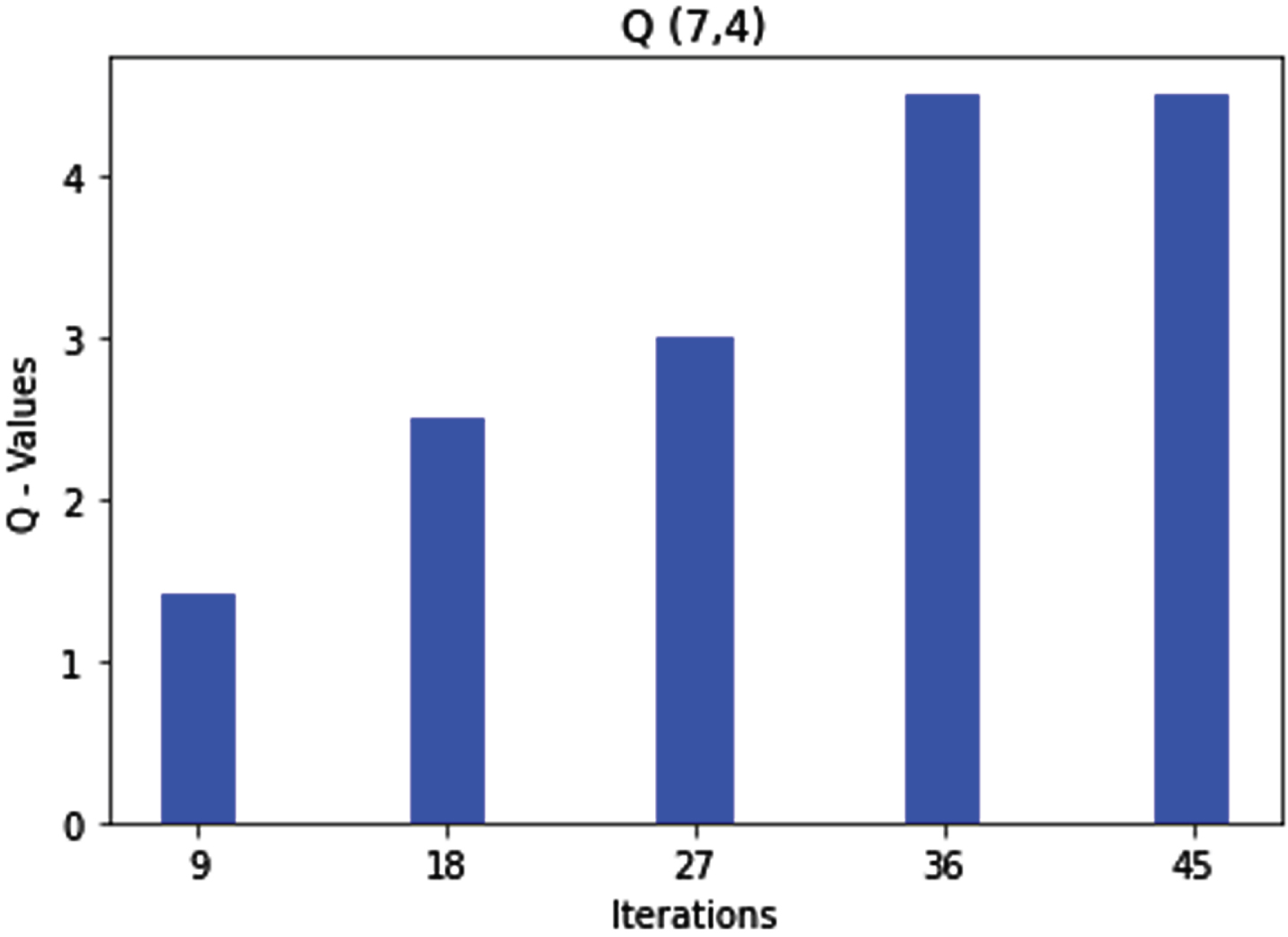
Q (7, 4) state action pair and rule7 optimization.
Similarly, Rule 8 and Rule 9 get optimized. Subsequently, if the sequence number is high and the hop count is medium, then as per rule 8, the route is marked as a bad route, and if both parameters are high, as per rule 9, the route is marked as a bad route, which is shown in the Figs. 12 and 13 respectively.
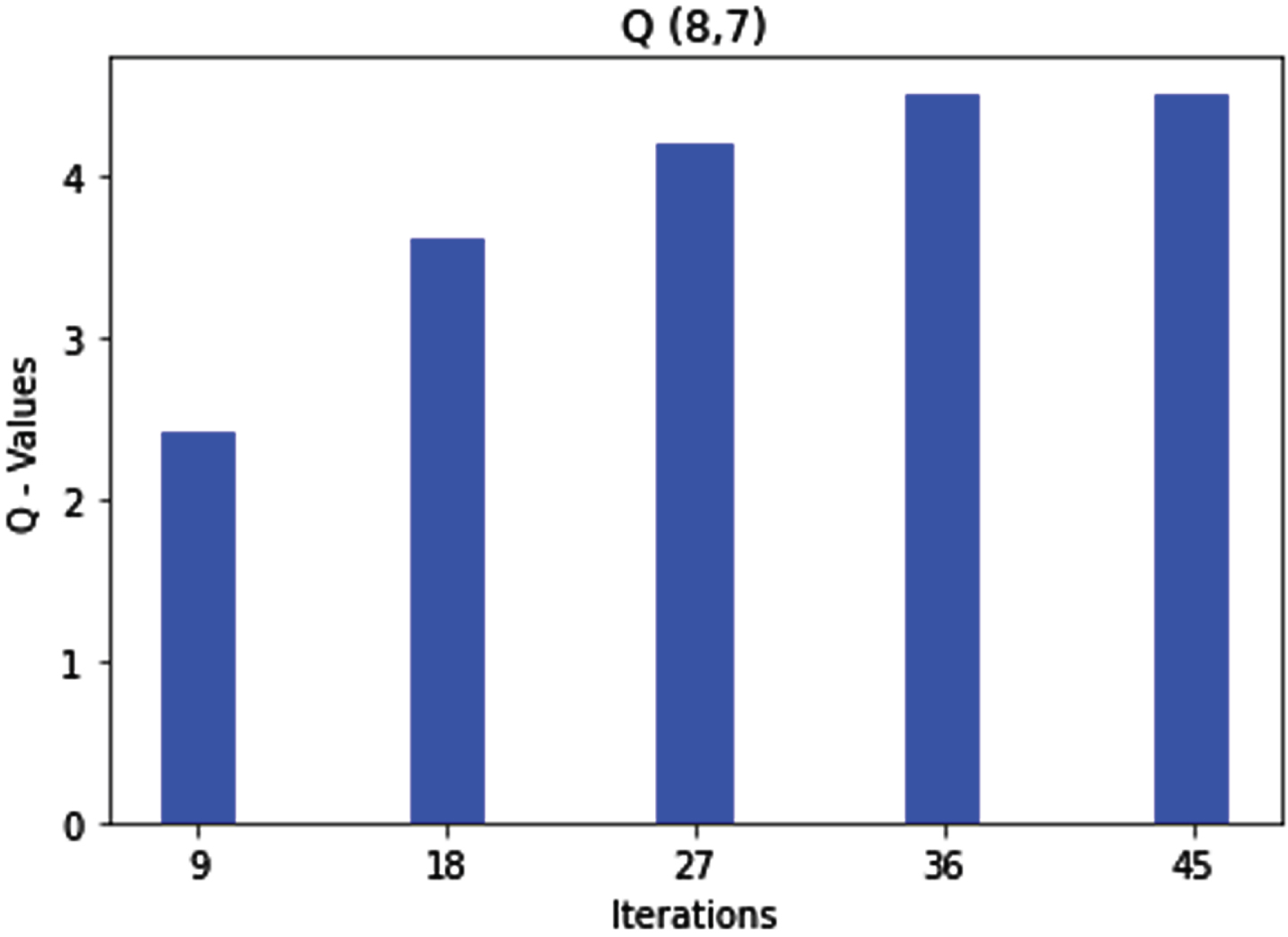
Q (8, 7) state action pair and rule 8 optimization.
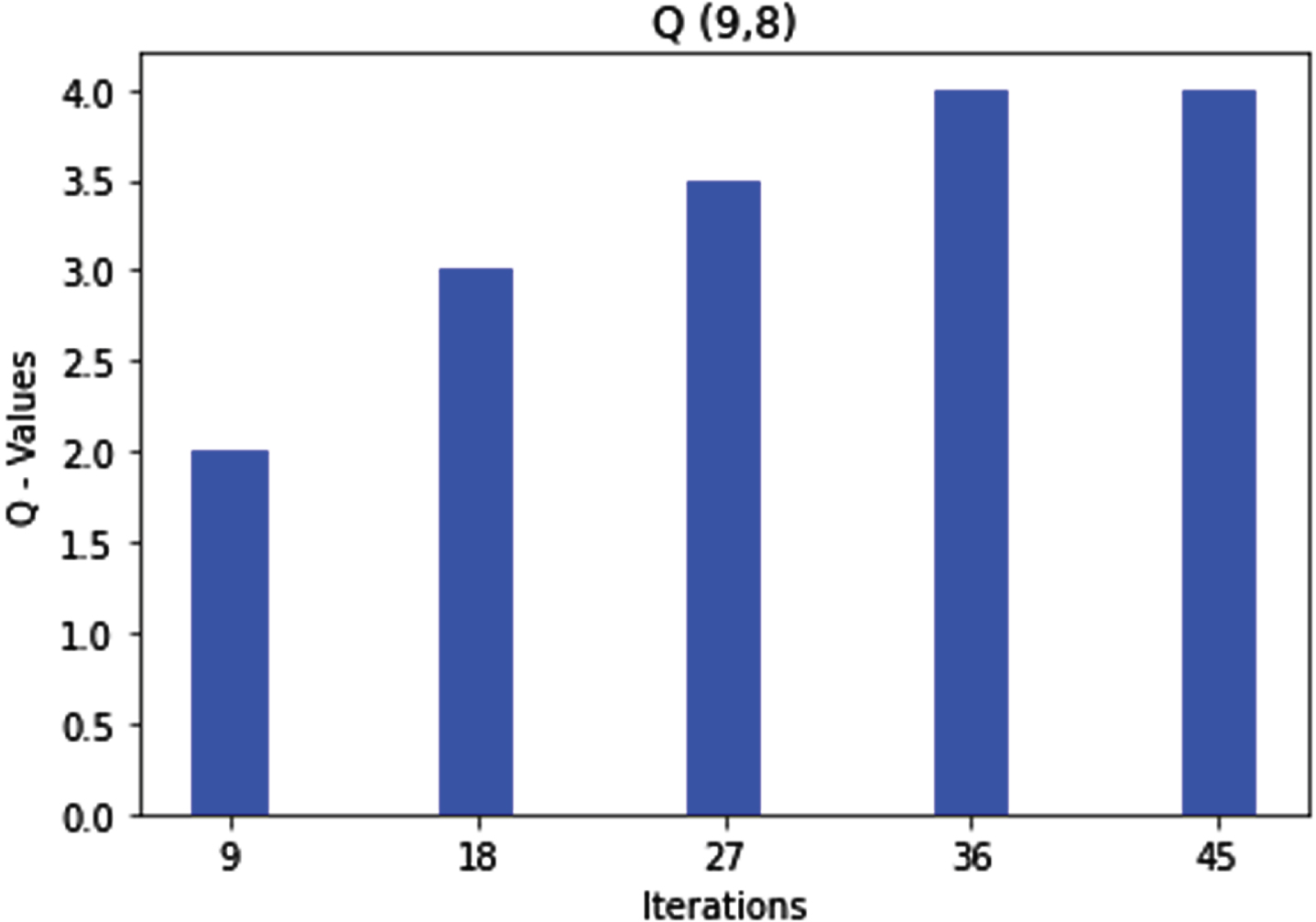
Q (9, 8) state action pair and rule9 optimization.
We have compared our proposed model with the Reference Point Group Mobility (RPGM) model [6], the Sinkhole Detection Algorithm [14], (CL-MLPS) [15], and MLSP [16] Multi-layer Security Protocol as shown in Table 4. We have chosen 13 different parameters, as shown in Table 4 below. The proposed model helps detect fake routes propagated because of a sinkhole node with the help of hop count and sequence number of nodes in MANET. As shown in Table 5, our model helps find the best route to reach the destination. We have used NetSim to simulate the creation of MANET comprising 100 nodes, out of which a few are selected as malicious or sinkhole nodes. The simulation area is 750 m×750 m, and the simulation was done for 240 seconds. All the parameters are used in AODV routing protocols. AODV routing protocols do not maintain the routing table. Instead, they are used when there is a transmission request. The data packet size is 512 bytes, and the movement model used is a random waypoint. The movement model is used to depict the movement of data packets in the network. Our proposed model will help the sender find an excellent route to reach the destination without facing any sinkhole attack in the network. The other four models help the user identify the containment border of the sinkhole attack, multi-layer security [6, 14-16] so that the sender knows where the sinkhole attack is in the network and about the malicious or sinkhole node and legitimate node in the network. Finally, we have used the true positive rate and false positive rate to compare our model with other models. The true positive rate of our model is 100, and for other models, it is 100. The false positive rate of our model is 0% because of proper human intervention in constituting the rules. The false positive rate of the RPGM model is 5, and that of the sinkhole detection algorithm is 0-5, in (CL-MLPS) the false positive rate is 8.3, MLSP false positive is 20.5 which shows that they may fall in detecting sinkhole attacks in the network. Still, our model will not fail in detecting sinkhole attacks in MANET. Table 4 below compares the proposed model and the other four models.
Comparisons of different proposed methods with our proposed model
A sinkhole attack is one of the most prominent attacks as far as a MANET environment is concerned. It not only reduces the throughput of the overall network but also affects the timely delivery of packets. A sinkhole attack may give rise to several other attacks, such as selective forwarding and selective dropping, to name a few. Hence, it is most important to tackle the sinkhole attack preeminent in MANETs efficiently, eventually saving the MANET from other serious attacks.
This paper proposes a fuzzy rule-based Q-learning approach to defying the intruder of initiating a sinkhole attack in MANETs. The proposed approach uses two parameters in an AODV protocol, namely the sequence number and the hop counts, to formulate fuzzy rules that eventually will decide on the traversal path of the packets from a source to a destination. The result shows that the formulated fuzz rules get optimized after a few iterations, allowing the fuzzy controller to decide on the traversal path of the packets. If the selected traversal path of the packets is excellent based on the input from the fuzzy rules, then the packets can be sent through that path. On the other hand, if the selected path is a bad path for the traversal of packets, then the controller decides not to send packets from the path and discards that path for packet traversal. The selected path labelled a good route can be used for packet transmission.
In the future, we would like to incorporate other reinforcement learning algorithms, such as SARSA learning, to detect different attacks in MANET.
Statement and declarations
Funding
Authors declare that they have not received any funding for carrying out the research.
Competing interests
Authors do not have any financial or no – financial interests to disclose.
Authors’ contributions
All authors contributed to the study and conception design of the manuscript. All authors read and approved the final manuscript.
Data availability
Data will be made available upon request.