
Abstract
In the current industry, quality inspection in semiconductor manufacturing is of immense significance. Significant achievements have been made in fault diagnosis in fabricated semiconductor wafer manufacturing due to the development of machine learning. Since real-time intermediate signals are non-linear and time-varying, the signals undergo various distortions due to changes in equipment, material, and process. This leads to a drastic change in information in intermediate signals. This paper presents a fault diagnosis model for semiconductor manufacturing processes using a generative adversarial network (GAN). The study aims to address the challenges associated with efficient and accurate fault identification in these complex processes. Our approach involves the extraction of relevant components, development of a paired generator model, and implementation of a deep convolutional neural network. Experimental evaluations were conducted using a comprehensive dataset and compared against six existing models. The results demonstrate the superiority of our proposed model, showcasing higher accuracy, specificity, and sensitivity across various shift tasks. This research contributes to the field by introducing a novel approach for fault diagnosis, paving the way for improved process control and product quality in semiconductor manufacturing. Future work will focus on further optimizing the model and extending its applicability to other manufacturing domains.
Introduction
Over the past two decades, there has been a surge in semiconductor technology manufacturing due to the increased demand for IoT devices. As a result, investors have recognized the importance of the semiconductor industry and given it high priority. However, manufacturing semiconductors involves a huge complexity with hundreds of processing steps, and achieving precision in quality inspection in the intermediate stages has become increasingly challenging for effective process control [1]. Furthermore, due to project delivery deadlines and budget constraints from clients, implementing conventional inspection methods for diagnosing faults in the processing steps of semiconductor manufacturing has become highly challenging. To overcome these challenges, virtual metrology techniques have been proposed, which satisfy the substantial economic and time duration requirements from clients [2]. The objective of the virtual metrology is to build a healthy model between ailment observing data and real-time inspection results in obtaining the best wafer quality. Therefore, virtual metrology predicts the quality of the new wafers during the processing steps of the semiconductor manufacturing without real-time inspection. Since there are more than three hundred processing steps, it is necessary to store the high dimensionality signal from the semiconductor manufacturing data in each processing steps. But the improvement of virtual metrology hinders substantially due to this high dimensionality signal [3]. Several traditional techniques are available to analyze the high dimensionality signal, including Linear Regression Classifier, Linear Discriminant Regression Classifier, Linear Collaborative Discriminant Regression Classifier, Unilateral Structure-Based Matrix Regression Classifier, Bilateral Structure-Based Matrix Regression Classifier, and Kernel Non-Linear Collaborative Discriminant Regression Classifier [4]. Beyond the traditional methods and their development, the latest improvements in machine learning methods will yield better results. Several machine learning-based methods have been adopted to work with hundreds of signals in intermediate steps to monitor the wafer health, increasing the reliability and efficiency of modeling the virtual metrology structure while decreasing costs [5, 6]. Although better results have been achieved, human intervention plays a significant role in intermediate steps depending on the real-time wafer structure based on its application during the semiconductor manufacturing process. Therefore, the precision of the end semiconductor product highly depends on the expertise of human knowledge [7], which again increases human costs in the respective domain. Deep learning has seen an exponential rise and garnered significant attention due to its impressive ability to represent learning. With deep learning, models build numerous processing layers to understand representations of data samples with several levels of extraction [8]. However, gathering several hundred labeled data from the tested location using only deep learning methods is challenging, which is a substantial hindrance in the application of the enhanced data-driven approach [9]. To overcome this scenario, several hundreds of intermediate signals are studied to aid the training model. Therefore, a complete self-automated process is required in real-time manufacture of the semiconductor industry. Therefore, one of the classifications of machine learning structures called Generative Adversarial Network (GAN) imparts. At high intensity to generate improved illustration, image enhancement can be implemented for real-time signals using GAN. GAN creates special results especially in real-time CCTV face recognition applications. Also, when there is necessity to convert dimensionality between 2D and 3D, the respective model must do real-time data retrieving and create standard with essential features. Then merge the data to calculate aptness record and threshold with respect to the benchmark. Pre-processing steps includes data segmentation and purifying. After pre-processing, arises the GAN training which creates outcome of the anticipated pattern generation and précised image generation which follows the generative models with deep learning methods that works on large datasets [11]. The working of GAN is executed in the following three steps. Firstly, it generates data using a probabilistic description to create the learning generative model. Secondly, it trains the model in real-time challenging situations such as changes in procedure, components, and manufacturing materials. Finally, it uses a deep convolutional neural network to train the entire system. GAN is a sensational method in machine learning concepts. In general, GAN is a creative model that creates the dataset exactly like the training data. But the reality is that the created model is a new one that is not available in real-time. It resembles the data given for training. To achieve this objective, GAN builds a paired training dataset, i.e., generator pairing. Now, it understands how to generate the output as expected using a discriminator that recognizes actual data from the generator output. Thus, the target of the generator is to deceive the discriminator, and the discriminator strives to avoid being deceived. GAN learns complex distribution by using two different networks, generator, and discriminator. The generator understands how to generate random data by integrating the response from the discriminator. It aims to make the discriminator categorize its output data as real. Between the generator and the discriminator, the training for the generator requires tougher incorporation than the training for the discriminator. The training for the generator contains a random input, a generator network that converts the random input into a data request, a discriminator network that categorizes the created data, a discriminator output, and a generator loss that fines the generator for failing to mislead the discriminator. The generator updates its weights in the network from the discriminator data through backpropagation since the discriminator input is directly connected to the generator output. After receiving signals from the intermediate stages with noise, the generative network must initiate training to understand the mapping from the target signal to a signal with a similar noise. Therefore, it is the responsibility of the generative network to create a signal with a similar kind of noise from the intermediate stages, rather than a noisy signal. In this paper, GAN is trained over the input noisy signals to determine the noisy distribution and create noisy samples. Then, the noisy bits sampled so far are used to create a paired training dataset. This paired training dataset is used to train the deep convolutional neural network to identify the noisy from the intermediate signal. The rest of the paper is organized as follows: Section 2 describes other related works that have been proven successful. The model developed in this paper is explained in Section 3. Section 4 details the experimentation conducted for this work, and finally, Section 5 concludes the overall performance and discusses future work.
Related work
Lee et al. proposed an FDC-CNN fault detection and classification convolutional neural network for fault diagnosis in semiconductor manufacturing. They applied this process to multivariate sensor signals and improved the speed of the training network and classification process. Additionally, they were able to easily plot real-time signals without requiring specialized human knowledge. However, to evaluate the interchangeable correlations, data in the CNN is insufficient due to the extracted features of non-linear data in the real-time signals. Therefore, de-CNN is used to overcome this challenge [11]. Lee et al. proposed an ensemble convolutional neural network to diagnose fault detection in semiconductor manufacturing. They constructed the ensemble CNN using a multi-channel fusion convolutional neural network (MCF-CNN) and two 1-D CNNs. The challenges caused by data loss were overcome by coupling features between the extraction of multi-sensor information by MCF-CNN and the extraction of single-sensor data by the 1-D CNN system. SVM was adopted to increase the robustness of the system [12]. Wise et al. proposed a model in which they replicated the local and global behavioral processes. They constructed the local model based on the information obtained from normal wafers in the experiment and applied it to assess subsequent wafers. The global model was constructed using all the experiments, including normal wafers, and was later evaluated on the faulty wafers [13]. Ziani et al. proposed the BPSO-RFC+SVM algorithm (Binary Particle Swarm Optimization, Regularized Fisher Criterion, and Support Vector Machines) for fault diagnosis in semiconductor manufacturing. They used RFC to select the relevant features that help in determining the class separability. The selected feature values were then used in the BPSO method. To enhance the robustness of the model, SVM algorithm was incorporated [14]. Song et al. propose an End-to-End Object Detection with Transformers using deep learning for improving defect pattern recognition (DPR) in wafer maps, which involves transferring learning weights and fine-tuning parameters. Experimental results demonstrate that the DETR-based algorithm enhances accuracy by 8.4% compared to the enhanced Mask R-CNN detector, showcasing its effectiveness in wafer defect detection [15]. Ji et al proposes an effective CNN-based classification of wafer map defects using Generative Adversarial Networks (GANs) to enhance classifier performance by compensating for the lack of training data. The proposed method is evaluated on the ‘WM-811k’ dataset containing 811K real-world wafer maps. Comparative analysis against standard augmentation techniques shows significant performance improvement, boosting accuracy from 97.0% to 98.3% [17]. Wang et al. proposed a method for balanced probability distribution and class distribution adaptation between domains in transfer learning. They aimed to fit the weight in marginal and conditional distributions [18]. Premkumar et al. proposed Deep belief networks (DBNs), a type of deep learning algorithm that can be used to detect malicious activities in IoT networks. The authors of the paper propose a DBN-based intrusion detection system (IDS) that can detect DoS, infiltration, and other attacks with high accuracy. The IDS was evaluated on the CICIDS2017 dataset, and it achieved an accuracy of 97.8% and a detection rate of 97.6%. The method was evaluated on a real-world dataset and showed promising results. The DBN-based IDS was trained on a dataset of 49,797 network traffic records, which included both normal and malicious traffic. The IDS was able to detect 10 different types of malicious activities, including DoS, infiltration, and port scanning. The IDS achieved an accuracy of 97.8% and a detection rate of 97.6% on the CICIDS2017 dataset [26]. Vakharia et al. proposes a new method for detecting compound faults in ball bearings that is more accurate than traditional methods. The method was evaluated on a real-world dataset and showed promising results. The method uses a deep learning model called Multiscale-SinGAN to generate synthetic images of ball bearings with compound faults. The synthetic images are then used to train an Extreme Learning Machine (ELM) classifier. The ELM classifier is used to classify real-world images of ball bearings as either healthy or faulty. The method was evaluated on a dataset of 1,000 real-world ball bearing images, and it achieved an accuracy of 95% [27]. Hao et al. proposes a new fault diagnosis method for electrically driven feed pumps that is more accurate than traditional methods. The method was evaluated on a real-world dataset and showed promising results. The GAN is used to generate synthetic fault data that is similar to the real-world fault data. The SAE is used to learn the features of the fault data, and it is then used to classify real-world fault data. The method was evaluated on a dataset of 1,000 real-world fault data, and it achieved an accuracy of 98.89%. The proposed method has the potential to improve the reliability and safety of electrically driven feed pumps. It could also be used to diagnose other types of rotating machinery [28]. Vakharia et al. proposes a DCGAN is a deep learning model that is used to generate realistic images for predicting tool wear that is more accurate and computationally efficient than traditional methods. The dragonfly algorithm is a metaheuristic optimization algorithm that is used to find the best set of features. The machine learning model is a support vector regression model. The method was evaluated on a dataset of 1,000 real-world tool wear images, and it achieved an accuracy of 98.5% [29].
Proposed method
The proposed model is presented in Fig. 1. The primary objective of our proposed work is to diagnose faults in semiconductor wafer map manufacturing using Generative Adversarial Network (GAN). As mentioned earlier, we build paired training data from the received noisy signal, and then train the deep CNN to identify the noise in the real-time intermediate signals. However, it is challenging to train the generator network to understand the mapping from the target signal to the signal with similar noise of the received intermediate signals, especially when there are several hundreds of intermediate signals with various concerns. Therefore, instead of generating noisy signals, it is easier to train the generator network to generate noisy signals, i.e., to create signals that can manage similar random zero-mean noise.
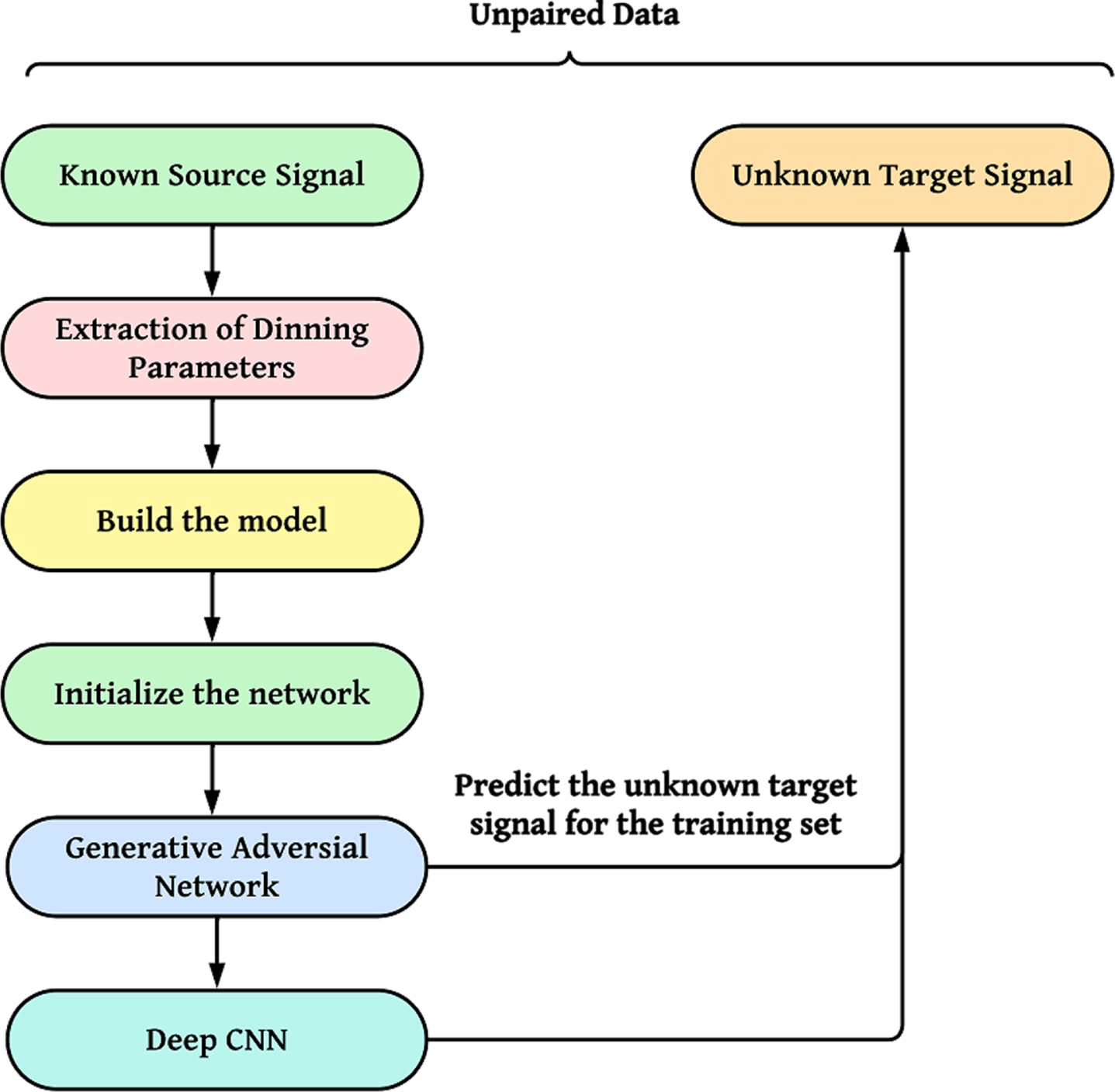
Proposed GAN model for fault diagnosis.
The first step is to extract the approximate noisy portions from the received real-time intermediate signals, which will create a paired training dataset. Extracting approximate noise portions from real-time intermediate signals can be done using various techniques. Here are some steps we followed to create a paired training dataset: The first step is to collect the real-time intermediate signals. Once we have collected the signals, we pre-process them to extract the relevant information. This involve filtering the signals to remove unwanted noise, segmenting the signals into individual noise events, and extracting features such as the duration of each noise event and the intensity of the noise. To create a paired training dataset, we define the noise portions that we want to extract from the signals. This involves specifying the type of noise and the level of noise. Once we have defined the noise portions, we label the data by associating each noise event with the corresponding noise level. This can be done manually by a human annotator, and using bat algorithms. Once we labeled the data, we train a machine learning model to predict the noise level from the input signals. The model can be trained using our learning algorithms. The resulting model can then be used to automatically detect and classify noise portions in real-time signals.
The process of extracting approximate noise portions from real-time intermediate signals can be divided into several steps, which involve mathematical expressions. Here is an end-to-end description of the process with the relevant mathematical expressions: Let x (t) be the real-time intermediate signal collected from a sensor at time t. The pre-processing step involves mathematical operations, such as feature extraction. Let F (x (t)) be a set of features extracted from the signal x (t), such as the energy, variance, or spectral centroid. The features are computed over each segment separately. The noise portions to be extracted depend on the type of noise. Let N = {n1, n2, …, n
m
} be a set of noise classes, each representing a specific type of noise. Each noise class can be associated with a range of noise levels, such as low, moderate, or high. The labeling step involves associating each segment s
i
with a noise class n
j
and a noise level l
k
. This can be done manually by a human annotator and using a bat algorithm. Let L = {(s
i
, n
j
, l
k
)} be the set of labeled segments. The training step involves using the labeled data L to train a machine learning model that can predict the noise class and level of a new segment based on its features. Let f (x (t)) be the trained model, which takes the features of a segment x (t) as input and outputs the predicted noise class and level. The final step involves using the trained model f (x (t)) to extract the approximate noise portions from real-time signals. This can be done by applying the model to each segment of the signal x (t) and selecting the segments that are classified as noise. The selected segments can be stored as a paired training dataset, where the input is the noisy segment x (t) and the output is its corresponding noise class and level.
This dataset is used to train the generator and discriminator networks in GAN to generate noisy signals and model the unit. To train a Generative Adversarial Network (GAN), to generate noisy signals and model the unit, we used a paired training dataset consisting of real-time intermediate signals and their corresponding noise portions. Here’s how the dataset can be used to train the generator and discriminator networks in GAN: The generator network G is a deep neural network that takes a random noise vector z as input and generates a synthetic noise signal The discriminator network D is a deep neural network that takes a real-time intermediate signal x and a synthetic noise signal The GAN training process involves optimizing two loss functions: the generator loss L (G) and the discriminator loss L (D). The generator loss is the negative of the discriminator loss, i.e., L (G) = - L (D). The discriminator loss is a binary cross-entropy loss that measures the difference between the predicted scores and the true labels. Let ytrue be the true label, which is 1 for real noisy signals and 0 for synthetic noisy signals. Then, the discriminator loss is defined as:
The first step of GAN training is to train the discriminator network by minimizing the discriminator loss L (D). This involves feeding the discriminator network with real-time intermediate signals x and their corresponding noise portions ytrue, as well as synthetic noisy signals
Once the discriminator is trained, we use it to train the generator network by maximizing the generator loss L (G). This involves feeding the generator network with random noise vectors z and computing the synthetic noisy signals
The parameters of the generator network are updated using backpropagation and gradient ascent:
The training process is iterated until the generator and discriminator networks converge to a stable equilibrium, where the generator produces realistic noisy signals and the discriminator cannot distinguish between real and fake noisy signals.
Thus, the GAN training process involves a min-max game between the generator and discriminator networks, where the generator tries to generate realistic noisy signals that fool the discriminator, while the discriminator tries to distinguish between real and fake noisy signals. This process leads to the generation of noisy signals that closely resemble the real noisy signals in the training dataset.
To improve the accuracy of the model, the distribution of noisy signals can be better understood from noise-predominant signals. One approach is to extract a set of approximate noise portions from the fragile environment to minimize the impact of initial environment.
In semiconductor fault diagnosis, the input signals are often contaminated by noise, which can obscure the fault signatures and reduce the accuracy of the diagnosis. By extracting a set of approximate noise portions from the input signals, we remove the noise and reveal the underlying fault signatures. This improve the accuracy of the diagnosis and reduce the false positive and false negative rates.
In some cases, the fault signatures in the input signals may be weak or difficult to distinguish from noise. By extracting a set of approximate noise portions, we enhance the fault signatures and make them more prominent, making it easier for the diagnostic model to detect and classify the faults.
We have a dataset of vibration signals representing different types of faults in a semiconductor manufacturing process, recorded under varying environmental conditions. The goal is to train a diagnostic model that accurately classify the faults, regardless of the other conditions. However, the dataset contains a significant amount of noise due to variations in the manufacturing process and measurement system.
We extract a set of approximate noise portions from the input signals using a noise extraction algorithm, empirical mode decomposition (EMD). Let N denote the set of extracted noise portions, which can be represented as a matrix N of size (n×t), where n is the number of noise components and t is the length of the input signal.
We then use a fault detection algorithm, a deep neural network (DNN), to diagnose the faults based on the remaining signal after removing the noise portions. Let X denote the input signal after removing the noise, which can be represented as a matrix X of size (m×t), where m is the number of input signals. The diagnostic model can be trained using a paired dataset (X, Y), where Y is the corresponding fault label for each input signal in X. The dataset can be split into training, validation, and test sets, and the model can be optimized using a suitable loss function, such as binary cross-entropy or categorical cross-entropy.
The overall process can be represented mathematically as:
The bat algorithm is a nature-inspired optimization algorithm that is commonly used for solving optimization problems in fault diagnosis in semiconductors. Here’s how the bat algorithm can be applied to create approximate noise portions in semiconductor fault diagnosis:
The first step is to define the optimization problem. In this case, the goal is to find the set of approximate noise portions that can best approximate the noise in the input signals. The objective function should be designed to measure the quality of the noise portions. One possible objective function is the mean squared error (MSE) between the input signals and the signals reconstructed using the noise portions: The bat algorithm starts with a population of candidate solutions, or “bats,” that are randomly generated. Each bat represents a set of noise portions. For each bat, the objective function is evaluated to determine its fitness. The bats are updated iteratively using the following formula: The algorithm stops when certain convergence criteria are met, such as a maximum number of iterations or a minimum improvement in the objective function.
Once the bat algorithm has converged, the resulting set of approximate noise portions is applied to the input signals to remove the noise and improve the accuracy of the diagnostic model. It’s important to note that the application of the bat algorithm requires careful consideration of the signal characteristics, including the frequency content, amplitude range, and noise characteristics. Additionally, the optimization process may need to be adapted to the specific requirements of semiconductor fault diagnosis, such as the need for real-time processing and low computational complexity. In our work, we adopt CNN to identify the noisy signal in real-time intermediate signals, which indicates a fault in the semiconductor. To train the CNN, we build a paired training dataset, as discussed in the first section of this paper. During the training process, new datasets are obtained in each iteration, which contributes to the augmentation of the signal. The final output from the CNN is used to distinguish between the real-time intermediate signal and the target signal.
To adopt Convolutional Neural Networks (CNN) for identifying noise signals in real-time intermediate signals, which indicate faults in semiconductors, we follow these steps: Collect the dataset of intermediate signals from semiconductor devices, including both faulty and non-faulty signals. Preprocess the data by normalizing the signal values and converting them into a suitable format for input into a CNN. Divide the dataset into a training set and a testing set. The training set will be used to train the CNN, while the testing set will be used to evaluate its performance. Design a CNN architecture suitable for signal processing tasks. You may want to consider using a combination of convolutional layers, pooling layers, and fully connected layers. Train the CNN on the training set using an appropriate optimization algorithm, Adam. Monitor the training progress using metrics such as loss and accuracy. Test the trained CNN on the testing set to evaluate its performance. Calculate metrics such as accuracy, precision, recall, and F1-score to measure the model’s performance. Fine-tune the CNN by adjusting the hyperparameters and architecture to improve its performance. Once the CNN has been trained and tested, deploy it in a real-time system for monitoring intermediate signals from semiconductor devices.
It’s worth noting that the success of a CNN model in identifying noisy signals and indicating faults in semiconductors heavily depends on the quality and quantity of the data used for training.
In the proposed deep CNN, support vector machines are used in the convolutional layer to classify the input images, followed by rectified linear units to train the inputs. Additionally, global average pooling is applied to reduce the overfitting tendency, and the rescaled hinge loss function is used to reduce the noise. Finally, Nestrov-accelerated adaptive moment estimation is employed to reduce time and memory consumption. The architecture of the proposed deep CNN is illustrated in Fig. 2 [20].
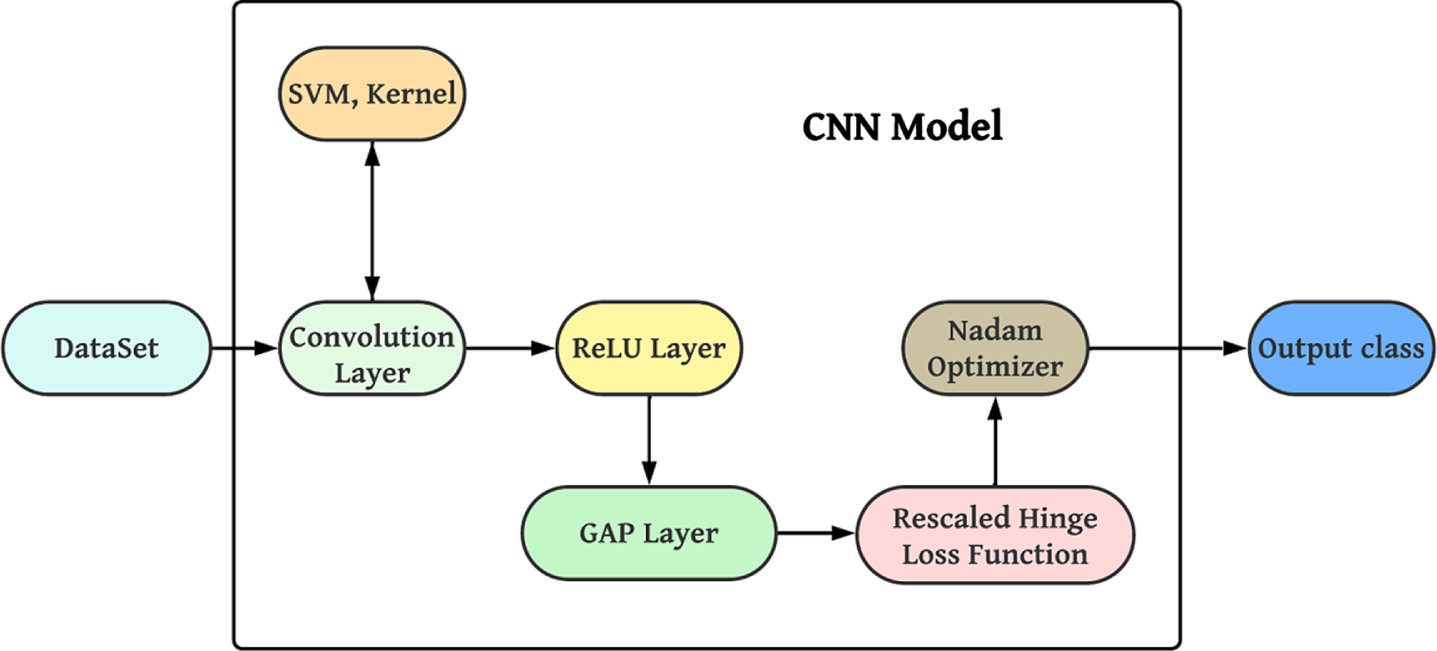
Proposed Deep CNN Model.
The dataset required to perform the proposed method was collected from a WM-811 K dataset where each wafer map was collected from real world dataset. For the experimentation, healthy and faulty wafers were randomly selected. The dataset consists of 153 healthy and 18 faulty wafers. Sample images are shown in Figs. 3 and 4. All the deliberately induced wafers were marked as faulty wafers. The dataset were created by several induced fault types in real time and machine state signals which are represented in Figs. 5 and 6.

Sample faulty wafer images.

Sample healthy wafer images.
Fault Diagnosis Types.
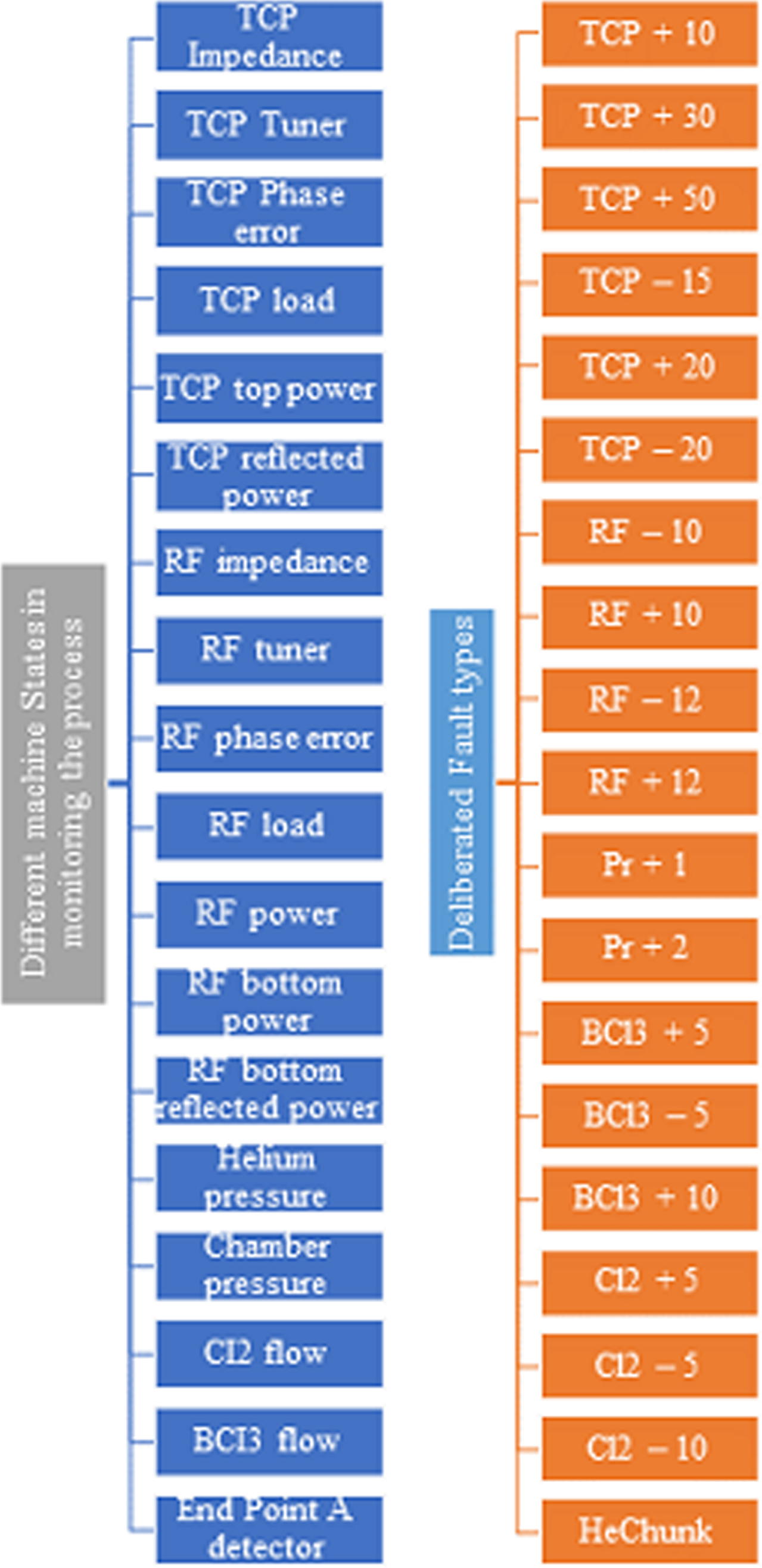
Different Machine States in process monitoring and Delibrated fault types.
The experiments were conducted using a personal computer with a Core i7 CPU, 32-GB RAM, and NVIDIA GeForce RTX 16 graphics card. Initially, for the experimentation process, the developed model was trained with a probability of 0.55 for unknown target signals and a probability of 1 for known source signals. In the end, the developed model was trained with all unknown target signals. The performance of the developed model was evaluated using 12 shift tasks, namely E12, E13, E14, E21, E23, E24, E31, E32, E34, E41, E42, and E43. In E12, the subscript 12 represents the analyzed signal from Experiment 1 as the source data used to train the model, while the unknown data from Experiment 2 was used for testing.
In this paper, we compared our developed model with several existing methods and experimented all 12 tasks. The fault diagnosis is accessed using the three following factors:
The confusion matrix in predicting the healthy wafers and the faulty wafers is shown in Fig. 7.
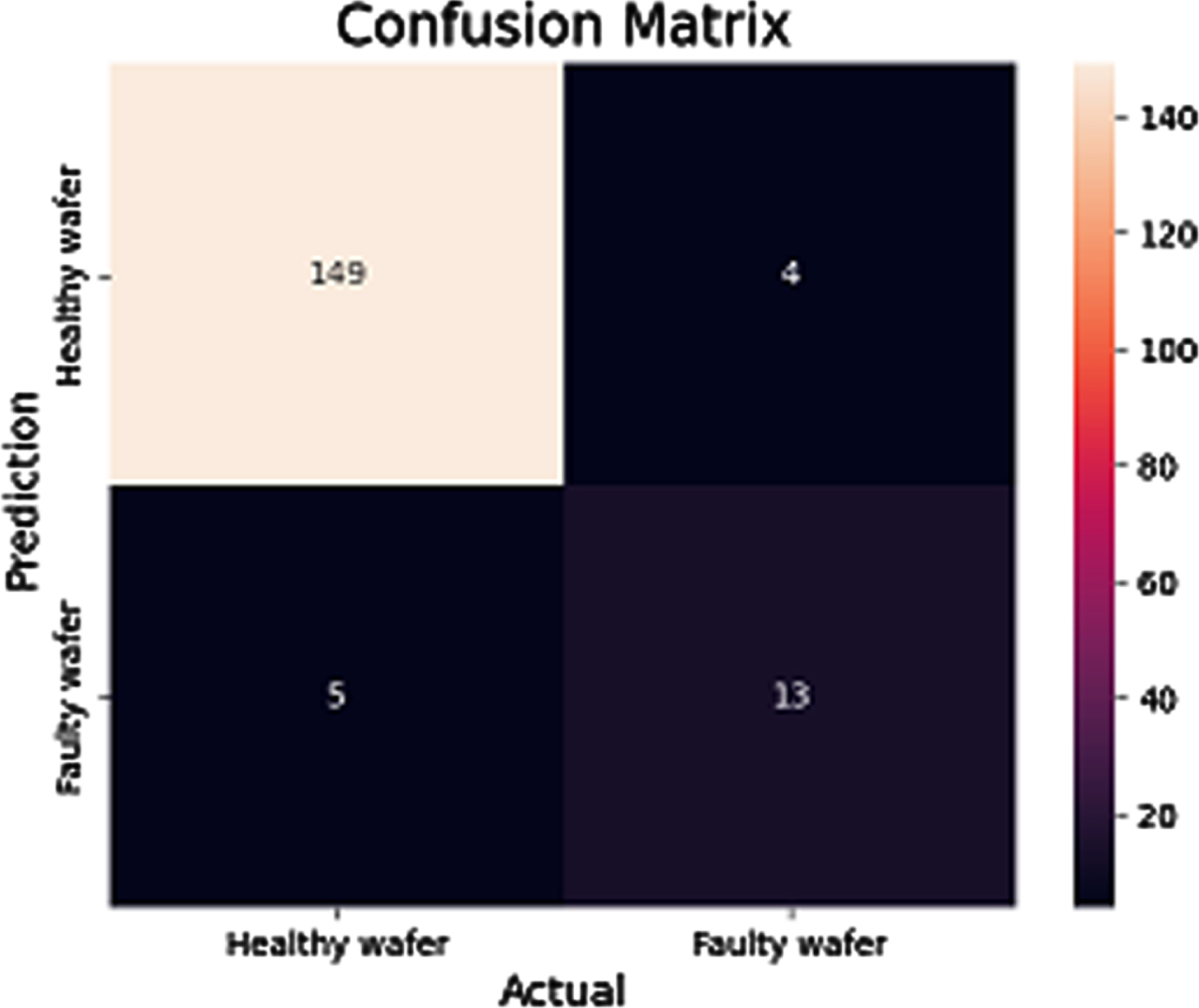
Confusion matrix in predicting between healthy and faulty wafers.
Fault Diagnosis parameters compared among existing models
The Fig. 8 shows the accuracy performance of the developed model on 12 shift tasks. The results are compared to the performance of several other models. The overall accuracy of the developed model is high, with an average accuracy of 93.2%. The best performance is on Task E43, with an accuracy of 98.78%. The worst performance is on Task E12, with an accuracy of 86.32%. The developed model outperforms all of the other models on most of the tasks. The only exception is Task E32, where the model by Gong et al. has a slightly higher accuracy. The results suggest that the developed model is a promising approach for shift tasks. It is able to achieve high accuracy on a variety of tasks, and it outperforms other existing models. Task E12: This task is the most challenging, as it involves shifting between two very different datasets. The developed model achieves an accuracy of 86.32%, which is still a significant improvement over the other models. Task E43: This task is the easiest, as it involves shifting between two very similar datasets. The developed model achieves an accuracy of 98.78%, which is the highest accuracy of any model on any task. Other tasks: The developed model achieves high accuracy on all of the other tasks, with an average accuracy of 93.2%.
The developed model is able to achieve high accuracy on a variety of shift tasks, and it outperforms other existing models. This suggests that the developed model is a promising approach for shift tasks. Similarly, Figs. 9 and 10 represents the comparison of proposed method with existing method in terms of sensitivity and specificity.
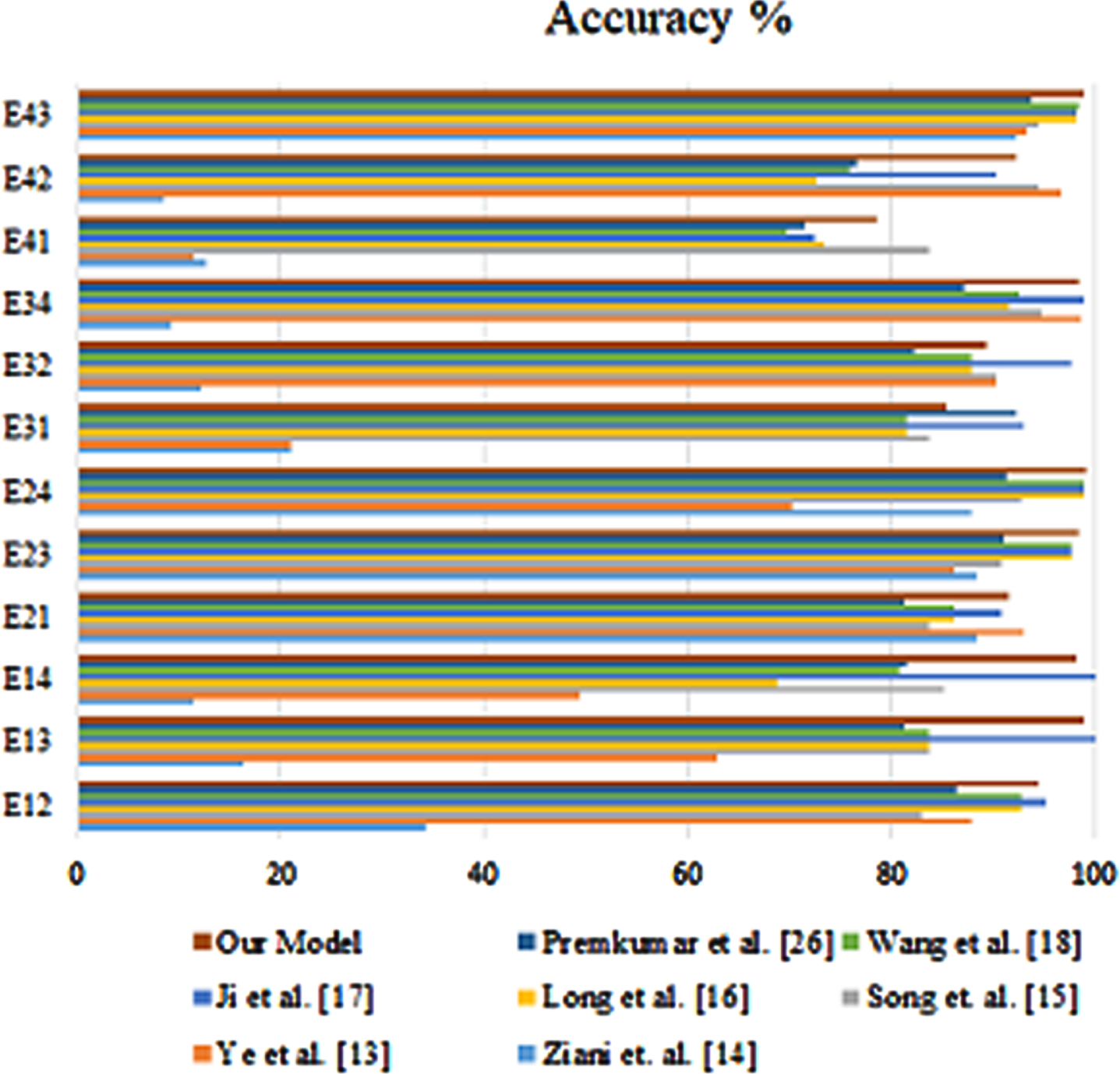
Accuracy of the proposed method with existing methods.
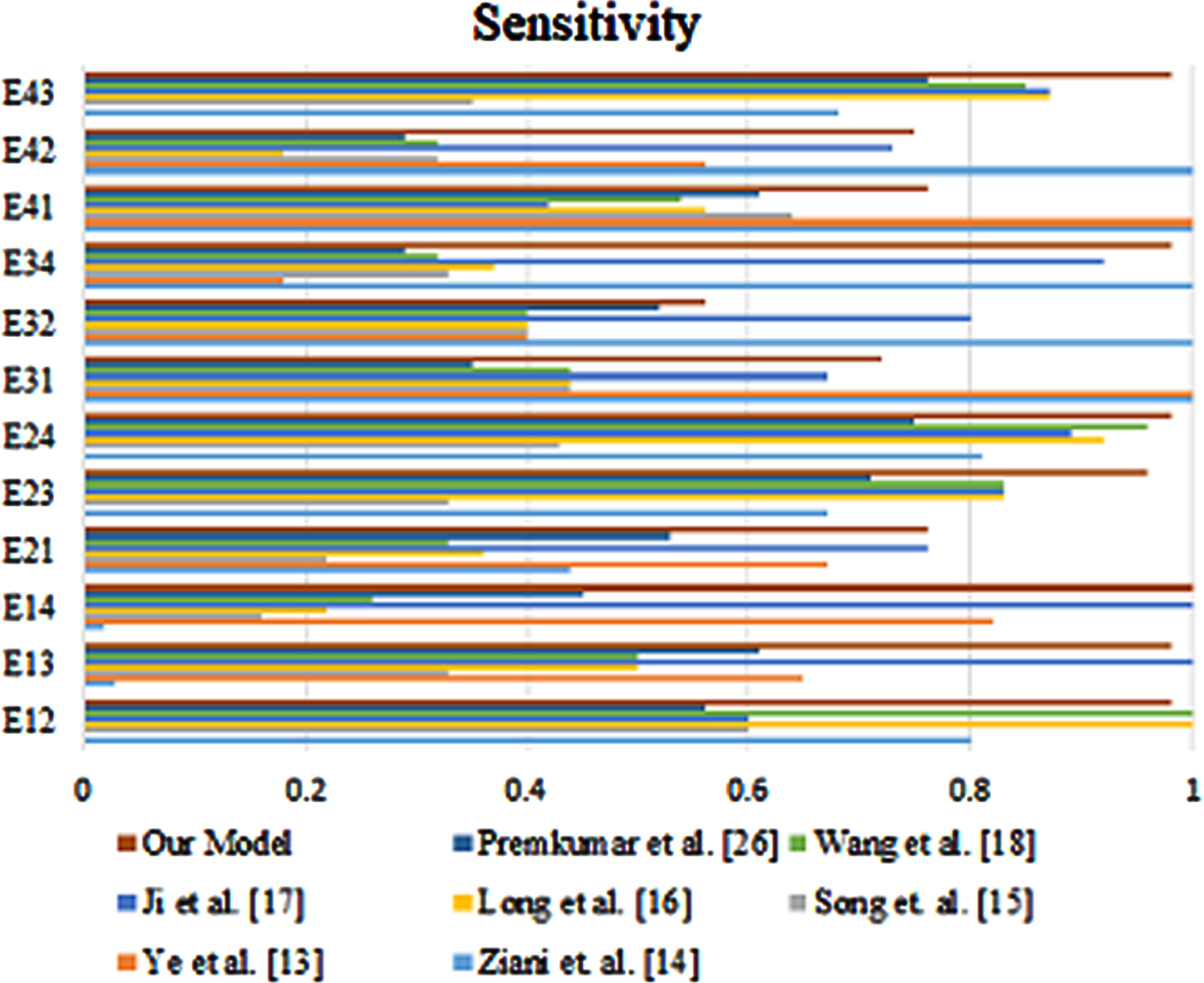
Sensitivity of the proposed method with existing methods.
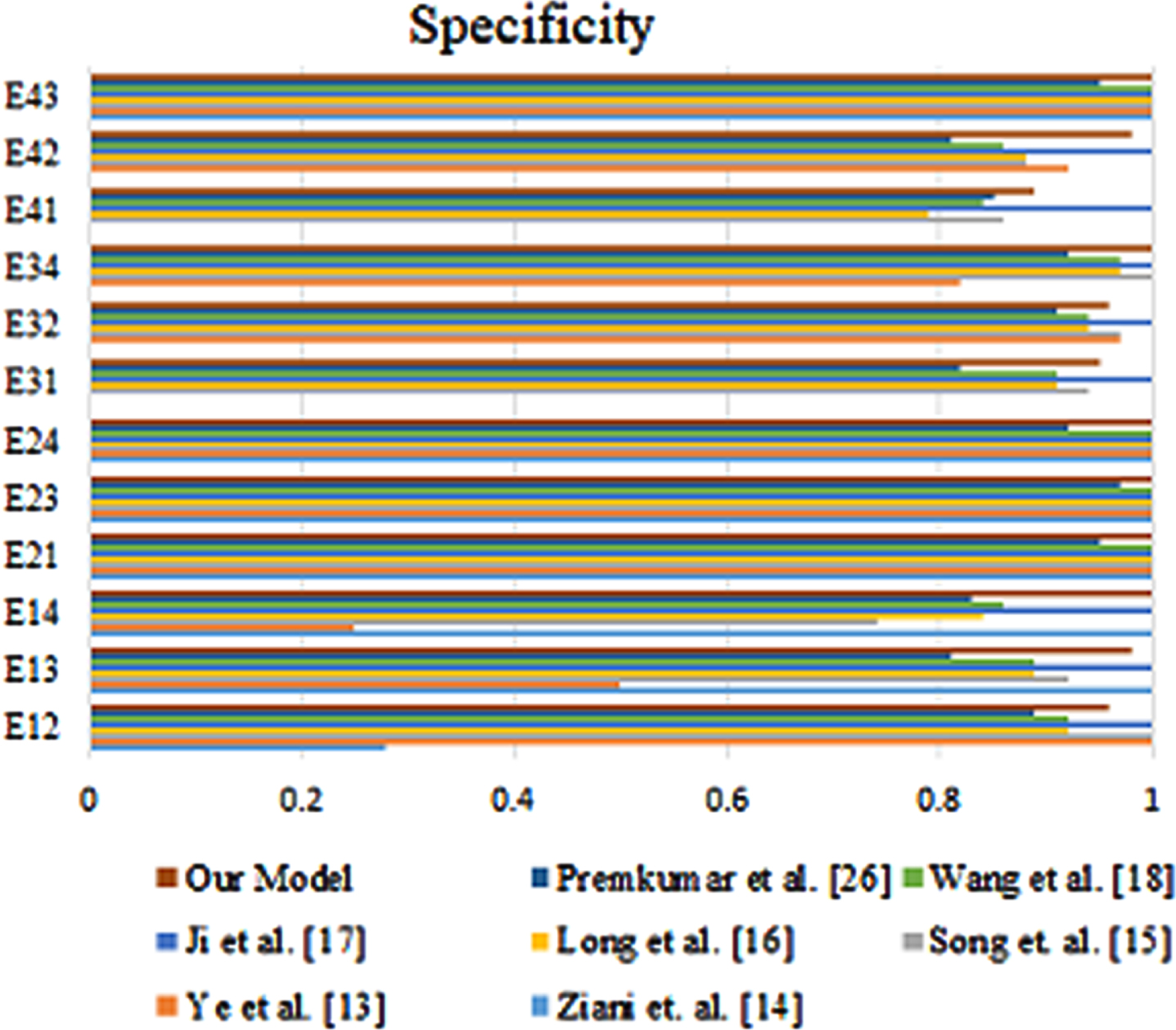
Specificity of the proposed method with existing methods.
This study introduces a novel fault diagnosis model for semiconductor manufacturing, leveraging generative adversarial networks (GANs). Addressing the challenge of accurate fault identification in complex processes, the manuscript details our approach, experimental setup, and comparison with existing models. Our methodology includes data extraction, a paired GAN-based generator model for predicting unknown target data, and a deep convolutional neural network implementation. Experiments span 12 shift tasks, assessing the model’s performance across various scenarios. Results reveal the proposed model’s superiority in accuracy, specificity, and sensitivity compared to six existing models. This model’s robustness in predicting normal and faulty portions underscores its reliability. Our contribution lies in presenting an efficient GAN-based approach for fault diagnosis, with promising implications for improving semiconductor manufacturing efficiency, quality, and process control. Future research will fine-tune the model for real-time applicability and potential expansion to other manufacturing sectors.