
Abstract
It is obvious that the problem of Frequent Itemset Mining (FIM) is very popular in data mining, which generates frequent itemsets from a transaction database. An extension of the frequent itemset mining is High Utility Itemset Mining (HUIM) which identifies itemsets with high utility from the transaction database. This gains popularity in data mining, because it identifies itemsets which have more value but the same was not identified as frequent by Frequent Itemset Mining. HUIM is generally referred to as Utility Mining. The utility of the items is measured based on parameters like cost, profit, quantity or any other measures preferred by the users. Compared to high utility itemsets (HUIs) mining, high average utility itemsets (HAUIs) mining is more precise by considering the number of items in the itemsets. In state-of-the-art algorithms that mines HUIS and HAUIs use a single fixed minimum utility threshold based on which HAUIs are identified. In this paper, the proposed algorithm mines HAUIs from transaction databases using Artificial Fish Swarm Algorithm (AFSA) with computed multiple minimum average utility thresholds. Computing the minimum average utility threshold for each item with the AFSA algorithm outperforms other state-of-the-art HAUI mining algorithms with multiple minimum utility thresholds and user-defined single minimum threshold in terms of number of HAUIs. It is observed that the proposed algorithm outperforms well in terms of execution time, number of candidates generated and memory consumption when compared to the state-of-the-art algorithms.
Keywords
Introduction
Data mining applications mainly focus on generating rules [7, 23], patterns [24], or user behavior prediction from the database which are used to provide the best strategies to improve the profit, growth of a business. To be specific, finding useful itemsets from the transactional database identifies the transactions with high profit which is used for planning the best business strategies [14].
The famous procedure in data mining to find the useful itemset is Frequent Itemset Mining [7, 23], which will filter all the less frequent itemset from the transaction database. In frequent itemset mining, the algorithms discover all the frequent itemsets whose frequency is greater than or equal to a given threshold value, which is referred to as minimum support. This technique is the straight approach in identifying strategies from the transactional database.
Less frequent doesn’t mean less profit. Sometimes, the less frequent itemsets may yield higher profit than the frequent ones but that may not be identified by frequent itemset mining algorithms as a profitable itemset. Those less frequent but yet profitable itemsets are discovered by using the utilities of the items considered in the transaction [21]. Here, the utilities of the items are defined in terms of quantity and profit per unit.
The high utility itemset mining (HUIM) algorithm mines all the possible itemsets that have utility values greater than the given fixed utility value [21] which is the minimum support for the utility value. Many algorithms were proposed to mine high utility itemsets (HUIs) [5, 31] with fixed minimum utility. Research outcomes have even improved the efficiency of the HUI mining algorithms in larger transactional databases. Genetic algorithmic approaches were introduced in improving the efficiency of mining HUIs from large transactional databases [13].
The HUI algorithm requires better pruning strategies to reduce the complexity of the candidate search space and a better approach to replace the unfair measure used in the mining process. Using a single fixed utility to evaluate the candidates is unfair since the items involved in each itemset will have different profits, quantities and importance [10]. If the minimum utility is fixed as a higher value, then the algorithm will miss many important HUIs during the mining process. Similarly, if the value is fixed as a lower value then many non-deserving HUIs will be discovered which will pollute the results. To overcome this drawback, high average utility itemset mining (HAUIM) was proposed [10]. In HAUIM, the algorithm mines both longer patterns and shorter patterns with high utility. In HUIM, the shorter pattern with high utility will not be considered as HUI because it will have only the least amount of items in the pattern which may not exceed the given fixed threshold value.
In this paper, the proposed algorithm HAUIM-AFSA-MMU mines high average utility itemsets (HAUIs) using Artificial Fish Swarm Algorithm (AFSA) by using multiple minimum utility thresholds. As discussed earlier, shorter patterns with high profits will be discovered, since the algorithm considers only the average of the items’ utilities rather than the sum of their utilities. So, this algorithm will overcome the problem of identifying the shorter itemsets with high profit and also not limited with a single fixed utility threshold value because it uses multiple minimum average utilities based on the number of items in the transaction database. The results show that it outperforms in discovering more HAUIs when compared to other HAUIM algorithms.
Frequent itemset mining vs utility mining
Utility mining is the extension of frequent itemset mining [1], and also it overcomes the problem in frequent itemset mining.
Before getting into the itemset mining, let us get familiar with the definitions of the terms in use. Transaction - set of items purchased by a customer of an organization Transaction database - a database that consists of transactions made by a customer Item - an atomic unit in the transaction Itemset - random collection of items that need not belongs to a group or transaction
Frequent itemset mining
For instance, consider the following transactions made by a set of customers of an organization on a particular day.
Let I be the set of items, where I={a,b,c,d} and T be the sample transaction, where T={T1,T2,T3,T4} such that for each transaction Ti, it holds the subset of set of items I and also in Ti ‘i’ is used to represent each transaction uniquely in a transaction database. Table 1 shows the sample transaction T to be used for mining frequent itemset.
A sample transaction database T
A sample transaction database T
The objective of the frequent itemset mining is to find the itemsets that have appeared in more transactions. Many popular algorithms are proposed to find frequent itemsets. These algorithms take the min_support as a measure to work on the transaction database. The measure min_support refers to a threshold value that determines the minimum number of times the item or itemset should appear in the database to be identified as frequent itemset.
For the above sample transaction database, let the threshold min_support value to find frequent itemset be 3.
The support value for all possible itemset for the sample transaction database T under consideration is listed in Table 2.
Support value for all possible itemsets
The support value for the itemset say X is calculated by counting the number of occurrences of X in the transaction T under consideration. The min_support value has been fixed as 3 for this example. Itemsets with support value greater than or equal to min_support value are listed as Frequent itemsets (Theorem 1).
Considering the above formula, the following itemsets are identified as frequent itemset from the sample set of transactions T.
The above 5 itemsets have support value greater than or equal to min_support and hence they are grouped as frequent itemsets of the sample transaction T.
The itemset listed as frequent actually appeared more number of times or equal number of times than min_support in transaction database T. The actual objective is to mine the transaction database to find useful itemsets which improves the growth of the organization [17]. Frequent Itemset Mining does not consider itemsets’ quantity or value in terms of profit, which is the main limitation in frequent itemset mining.
High utility itemset mining
High utility itemset mining identifies all the itemsets with utility greater than or equal to the utility measure given by the user. High utility itemsets identified are aimed to provide high profit in a customer transaction database. Many methodologies have been proposed in mining high utility itemsets [25, 34] which would be helpful in deciding on marketing strategies to improve the business.
Now, let us consider the items in the same sample transaction T with an additional information ‘profit’ as shown in Table 3.
Items in sample transaction T with profit [utility] value per unit
Items in sample transaction T with profit [utility] value per unit
Items with profit value determine that item b has more profit compared to other items in the sample transaction T.
To get more understanding, let us include the units of purchase of each item in all the transactions in T as given in Table 4 and determine the profit obtained by each transaction.
Transactions with items’ unit of purchase
The profit of transaction (Transaction utility TU(T
i
)) T
i
with n number of items is calculated by using the following formula (Theorem 2),
The transaction utility P (T i ) of each transaction is calculated and given in Table 5. By observing the items in transaction (Table 5) and profit value per unit of each item (Table 3), it is obvious that,
Actual Profit obtained from each transaction in T
T2 and T3, the itemset [a,b,c] collectively yields more profit than other itemsets
The itemset with item b yields more profit
The transaction with item d yield lower profit
Also, transaction weighted utility of an itemset X TWU (X) is calculated by adding transaction utilities of all transactions containing the itemset X as given below (Theorem 3),
The transaction weighted utility for all possible itemset of sample transaction database T is calculated and listed in Table 6. By fixing the minimum utility min_utility, the list of itemsets having utility greater than or equal to user-defined min_utility forms the high-utility itemset from transaction database T.
Utility value for all possible itemsets
If min_utility for the transaction database T under consideration be 4200, then the list of itemsets declared as high utility itemsets are,
By comparing the itemsets that are declared as frequent by frequent itemset mining and the itemsets declared as high utility itemset by high utility itemset mining, it is obvious that frequent itemset does not include certain itemsets like item b or itemset [a,b,c] which yields high profit and listed as high utility itemset. And also, the itemset d is declared as frequent, but that does not yield comparatively high profit and not listed as high utility itemset, because the profit per unit for item d is less than the average profit per unit of all items appeared in the transaction.
Hence by all the observations made on transactions T, the following are the major limitations of frequent itemset mining addressed by high utility itemset mining. Itemsets declared as frequent by frequent itemset mining may not yield profit. [Example: Item d in example Transactions T] Itemsets yielding high profit may not be frequent, such significant itemsets are missed by frequent itemset mining. [Example: Itemset [a,b,c] is not frequent but yields high profit]
This limitation in frequent itemset mining, introduces high utility itemset mining, an extension from frequent itemset mining. Based on the utility, itemsets are filtered from the transactions and hence not missing out the itemsets that yield high profit [17].
Frequent Itemset Mining (FIM) mines the frequent itemset, whereas High-Utility Itemset Mining (HUIM) generates high utility itemsets from the transaction database [1]. Combining these methods to generate itemsets which are both frequent and have high utility, and applying business strategies based on such itemsets will yield periodical high profit.
Philippe Fournier-Viger et al. [21] designed a methodology called Periodic High-utility itemset Miner (PHM) to mine periodic (frequent) high utility itemset from transaction databases. This methodology mines itemsets that are both frequent and with high utility.
High Average Utility Itemsets (HAUI)
High Average Utility Itemset (HAUI) mining discovers the itemsets with high average utility when compared to High Utility Itemset mining (HUIM) [26] where it mines the itemsets based on their utility alone. HUIM decides HUIs by checking whether the utility of the itemset is greater than the given threshold but mostly the utility of the itemsets with short length (length denotes the number of items in an itemset) may not be discovered as high utility itemsets by HUIM. In HAIUM, it uses a fair method of average utility which is compared against the given threshold. HAUIM mines HAUIs based on the average utility [11, 38] which implies that the shorter patterns will not be affected as in HUIM.
Related work
The various state-of-the-art algorithms for mining HUIs and HAUIs are discussed in Table 7. Based on the discussion in Table 7, it is obvious that the proposed algorithm is the first algorithm to work on mining HAUIs using an artificial fish swarm algorithm. So far many genetic and optimization algorithms are applied to mine HUIs and many such algorithms are proven [13, 36]. For mining HAUIs, the optimization techniques are not applied in any existing works. Also, multiple minimum average utility [35] for each item is fixed instead of a single minimum utility threshold to mine HAUI is proposed in this work. There are proven works were HUIs, HAUIs and association rules [40] are mined with multiple thresholds.
HUI and HAUI mining algorithms
HUI and HAUI mining algorithms
Definition 1: Utility of an item
The utility of an item say i
j
in a transaction Tq is denoted as u(i
j
, T
q
) and it is calculated as:
Definition 2: Utility of an itemset in a transaction
The utility of an itemset say X in a transaction Tq is denoted as u(X, T
q
) and it is calculated as:
Definition 3: Average utility of an itemset in a transaction
The average utility of an itemset X in a transaction Tq is denoted as au(X, T
q
) and it is represented as:
Definition 4: Average utility of an itemset in a transaction database
The average utility of an itemset X in a transaction database Dis denoted as au(X) and it is represented as:
Definition 5: Multiple minimum average utility (MAU)
If there are n items in a transaction database, then there should be n computed minimum average utility which means one minimum average utility for each item i
j
represented as
Algorithm Description - HAUIM-AFSA-MMU
The Artificial Fish Swarm Algorithm (AFSA) is a metaheuristic optimization algorithm that is inspired by the behavior of fish in a school. The algorithm was first proposed by Bastos Filho and Lima Neto in 2003.
In the AFSA, each fish represents a solution to the optimization problem. The fish swim in the search space and adjust their positions according to their own and their neighbors’ behaviors. The algorithm includes four main steps: Initialization: A set of fish (i.e., solutions) is randomly generated in the search space. Foraging: Each fish evaluates its fitness (i.e., objective function value) and moves toward better solutions in its local search space. Prey and predator: Fish randomly switch between being a prey and a predator, where predators move to a random location and prey try to avoid them. Update: The positions of the fish are updated based on their individual behavior and their interactions with their neighbors.
The AFSA has been successfully applied to a wide range of optimization problems, including function optimization, parameter optimization, and feature selection. Its advantages include easy implementation, robustness, and fast convergence to a global optimum.
In the proposed algorithm, the fish are referred to as itemsets. The input and output parameters are given in the algorithm. The MAU table is set by fixing minimum utility values for all the items considered in the transactional database using eq. (8) and (9). The initial population of itemsets are generated based on the roulette wheel selection and an empty HAUI set is created.
Roulette wheel selection is a commonly used selection method in evolutionary algorithms. It is a stochastic method that selects individuals from a population based on their fitness values, with the probability of selection proportional to the fitness. This reduces the complexity of the candidate generation.
Once the initial population of size N is generated, the algorithm is repeated for max_iter number of times to identify the HAUIs. During each iteration, each itemset in the population will forage, prey and update its position as explained above based on its utility value and based on the best itemset identified. Each time, the utility of the itemset is evaluated and if it is greater than the average of minimum utilities of all items in the itemset then it is moved to the set HAUIs.
Significance of AFSA
The effectiveness of any optimization algorithm depends on the specific problem being solved, the characteristics of the objective function, and the available computational resources. Different optimization algorithms may perform better or worse depending on the problem at hand [2-4]. The Table 8 shows the comparison of the efficiency of the Artificial Fish Swarm Algorithm (AFSA) with other popular optimization algorithms.
Efficiency comparison of AFSA with other algorithms
Efficiency comparison of AFSA with other algorithms
The following are some insights into the potential advantages of the Artificial Fish Swarm Algorithm (AFSA) over other optimization algorithms.
Therefore, it is essential to consider the nature of the problem and conduct appropriate comparisons with other algorithms to determine the most suitable one for a particular task. In that connection, AFSA is the best suited algorithm to find HAUI in the given set of transactions.
In this section, the performance of the proposed algorithm HAUIM-AFSA-MMU is compared against the other multiple minimum utility HAUI mining algorithms - HAUI-MEMU, HAUI-MEMU+. The algorithms were executed on a machine with i7 3.40 GHz CPU, 16 GB RAM and 64 bit operating system.
Data sets
The following table shows the datasets that were considered for evaluating the performance of the proposed algorithms with other algorithms that mines HAUI. The datasets are taken from SPMF –a java open source library with in-built data sets [32]. The dataset has transactions, each represented in a single line. Each line has set of items represented using their unique_IDs followed by their utilities (product of quantity and profit). All the four datasets mentioned in Table 9 has the same format as explained above.
Datasets
Datasets
In this section, the efficiency of the proposed algorithms is compared with other multiple minimum utility mining algorithms that mines HAUIs. The performance based on runtime is compared in two categories, one with fixed β and various glmau values as shown in Fig. 1 and the other with fixed glmau and various β values as shown in Fig. 2. The proposed algorithm shows better efficiency than the other algorithms in comparison. In particular, the proposed algorithm performs better in dense datasets like chess and mushroom than sparse datasets. The proposed algorithm effectively reduces the runtime by reducing the multiple dataset scans. The decrease in runtime when beta value increases is because the minimum average utility of the item will be comparatively high with increased beta values.
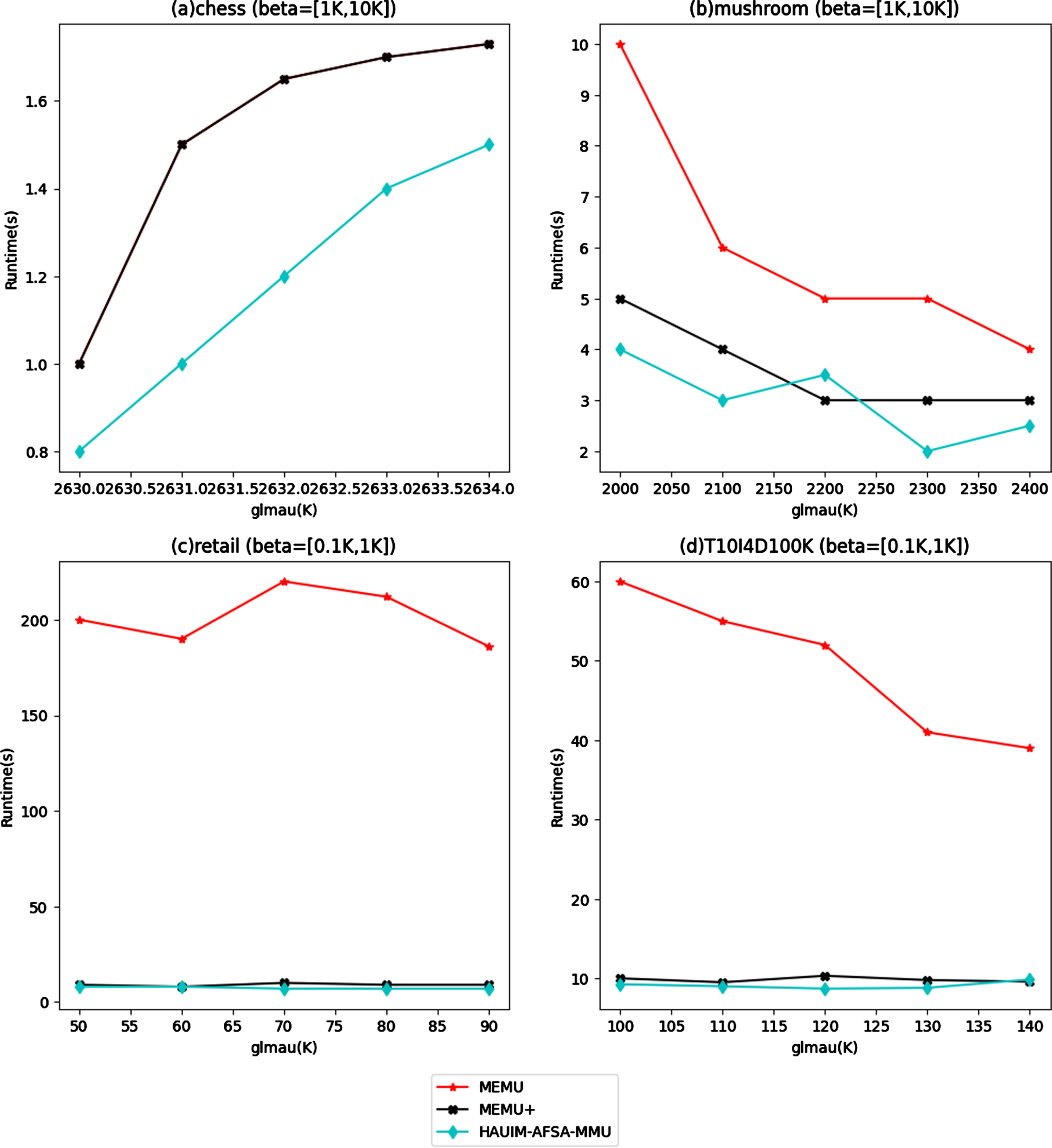
Runtime comparison for fixed β and various glmau values.
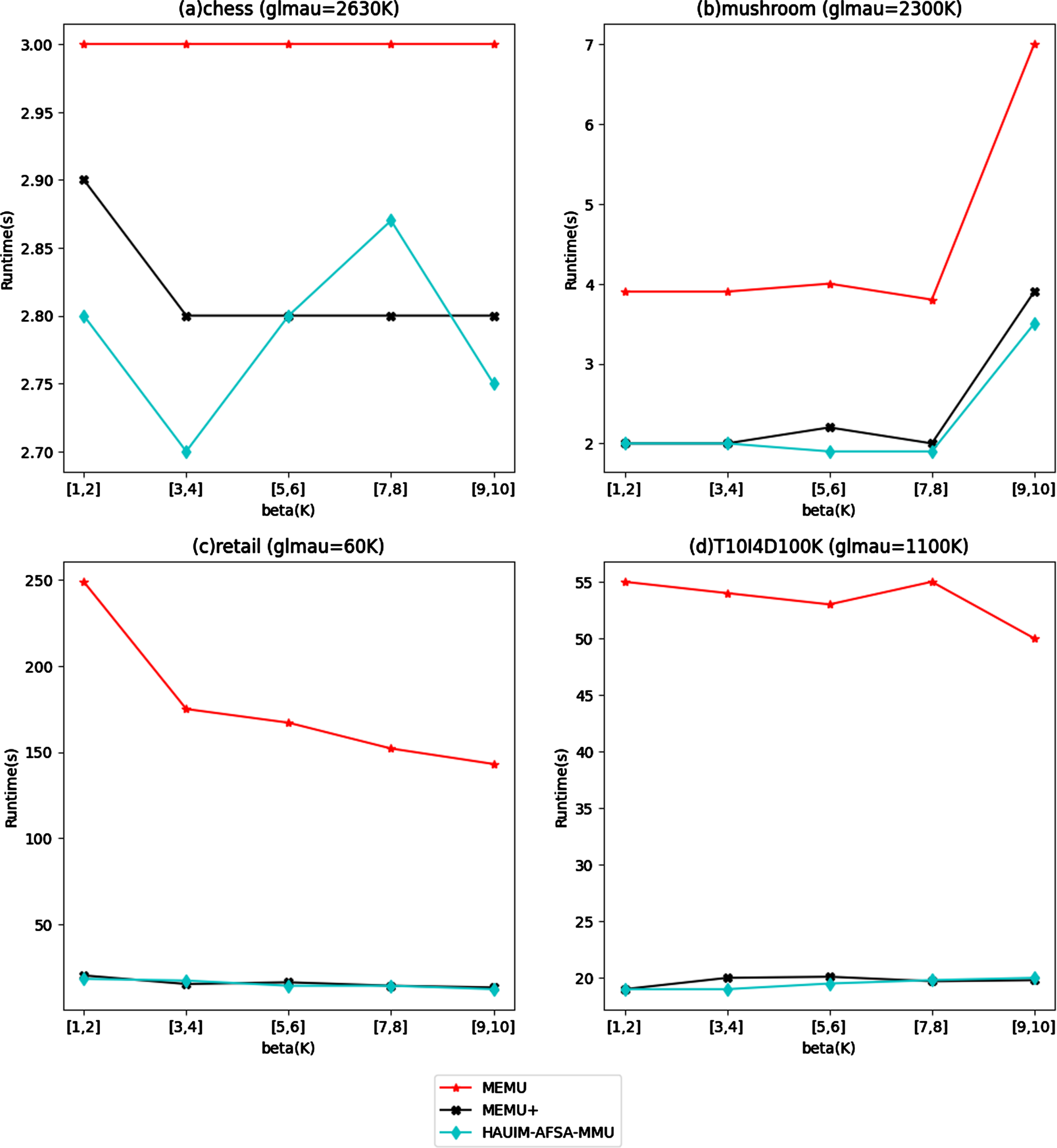
Runtime comparison for fixed glmau and various β values.
In this section, the memory usage of all three algorithms on the considered four data sets is compared. The memory comparison for fixed β and various glmau values is shown in Fig. 3 and the memory usage for fixed glmau and various β values is shown in Fig. 4. By observing Fig. 3, it is obvious that the proposed algorithm performs better in the heavily dense chess data set and it consumes less memory than the other two algorithms. The less memory usage in the proposed algorithm is due to its property of neglecting the individual with less fitness in each iteration and thus reduces the total search space.
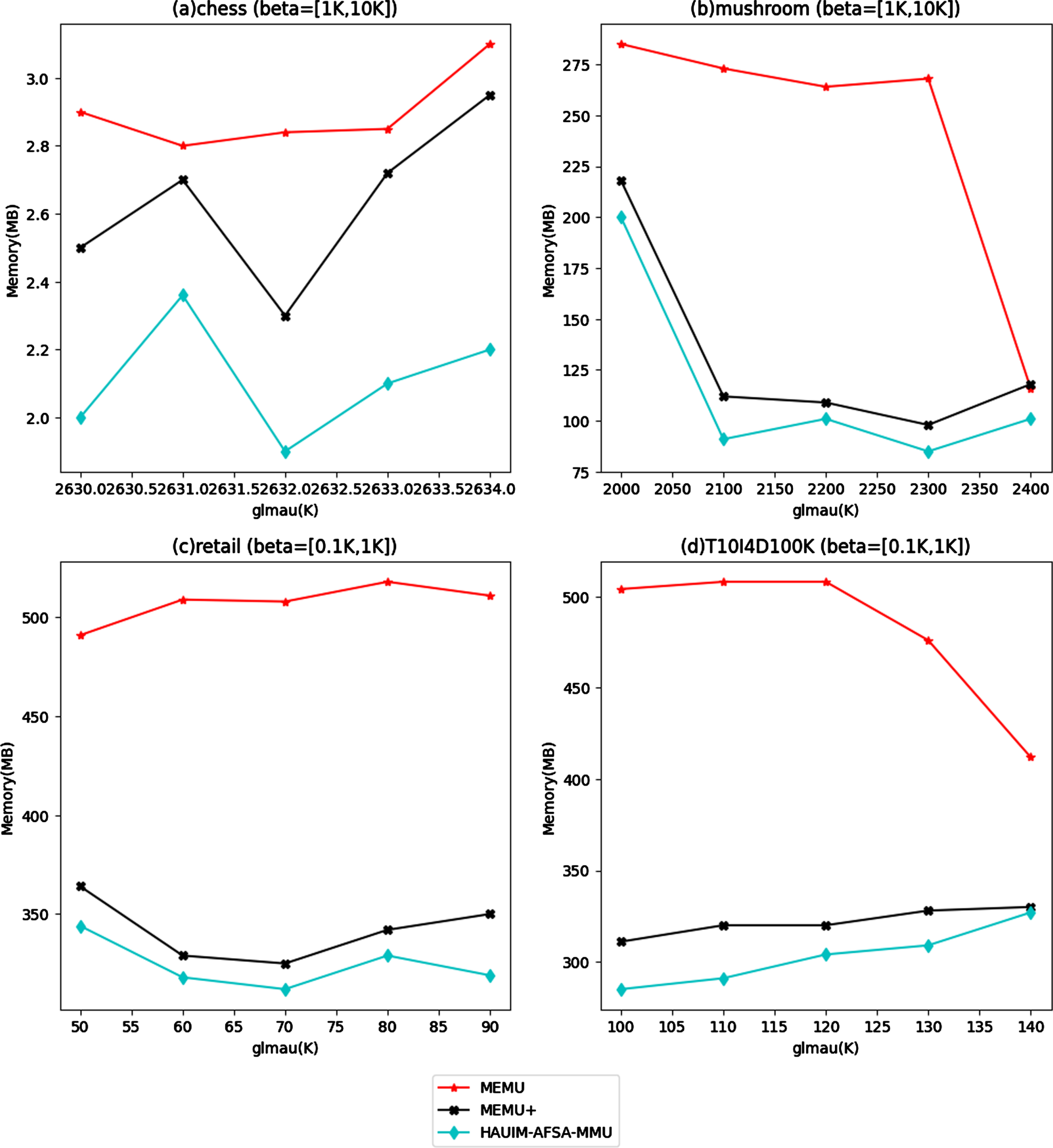
Memory comparison for fixed β and various glmau values.
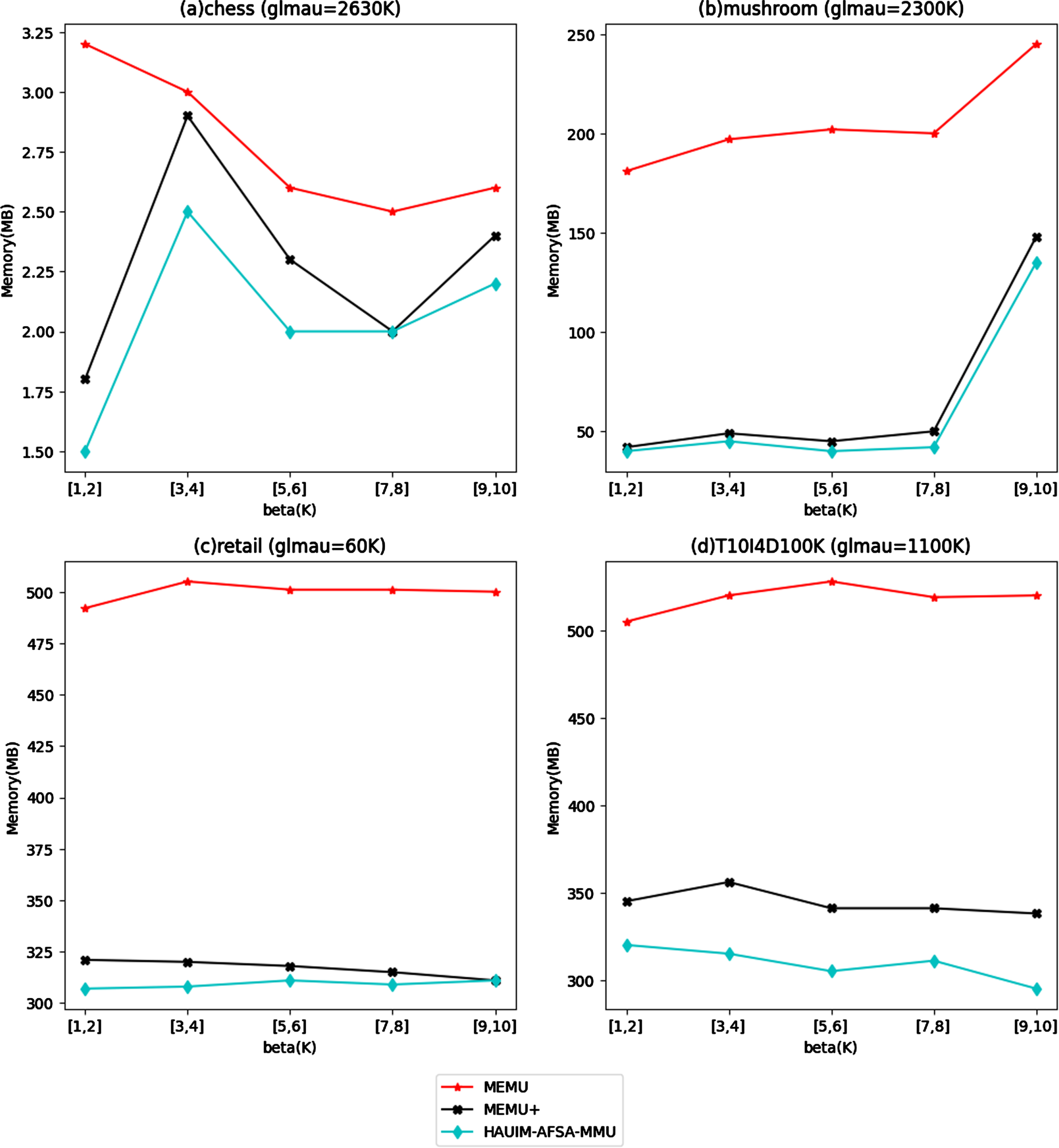
Memory comparison for fixed glmau and various β values.
In this section, the candidate generated by each algorithm for the four different data sets for fixed β, various glmau values and for fixed glmau with various β values are shown in Figs. 5 and 6. The candidate generation in the proposed optimization algorithm is lesser because it reduces the search space. Optimization algorithms are designed to find the optimal solution within a given search space. The algorithm does this by iteratively exploring the search space and narrowing down the range of possible solutions until it arrives at an optimal or near-optimal solution. Here in this case it is a vector of probabilities representing the items in the transaction database. The proposed HAUIM-AFSA-MMU algorithm reduces the search space in the following ways.
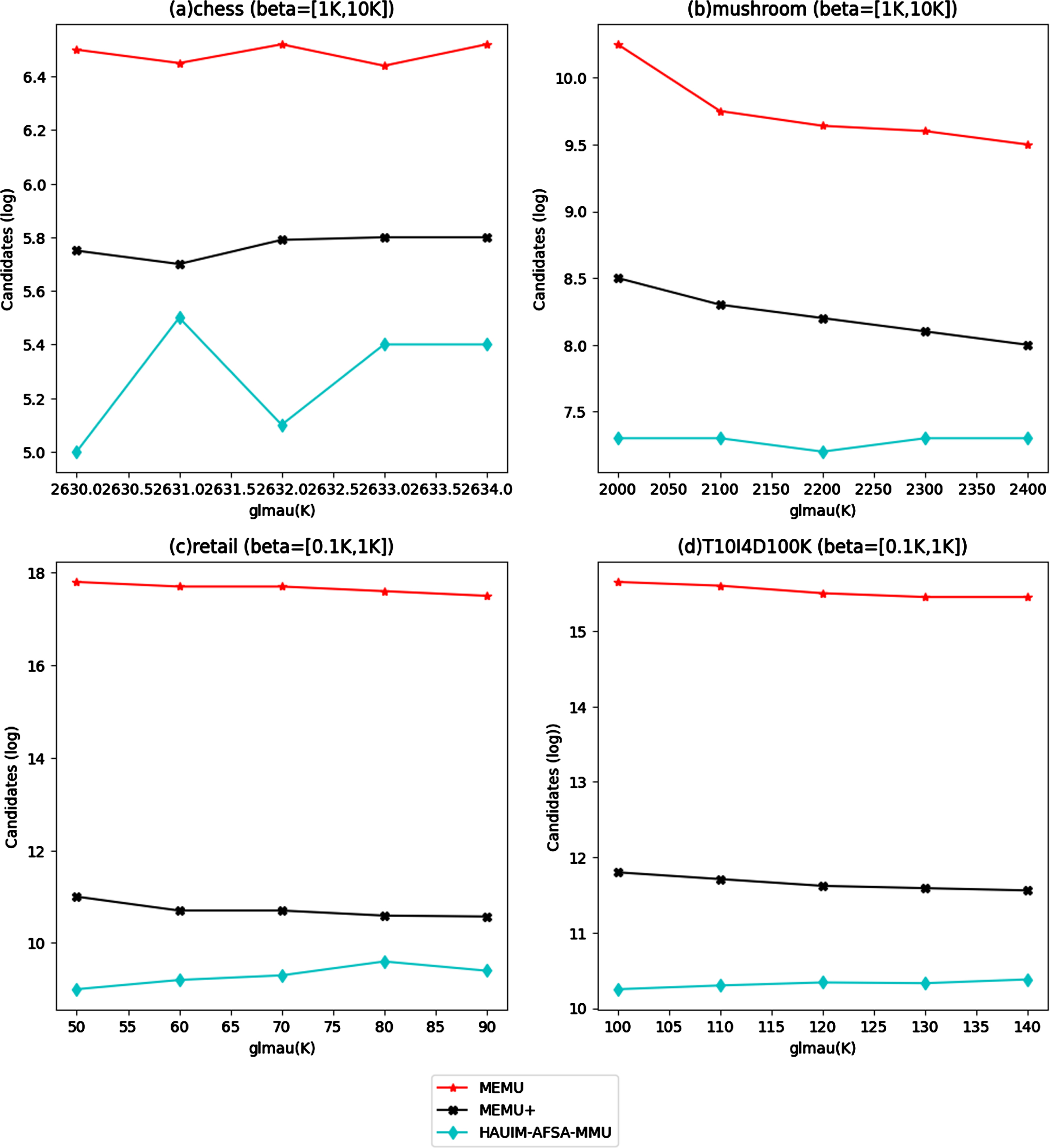
Candidate comparison for fixed β and various glmau values.
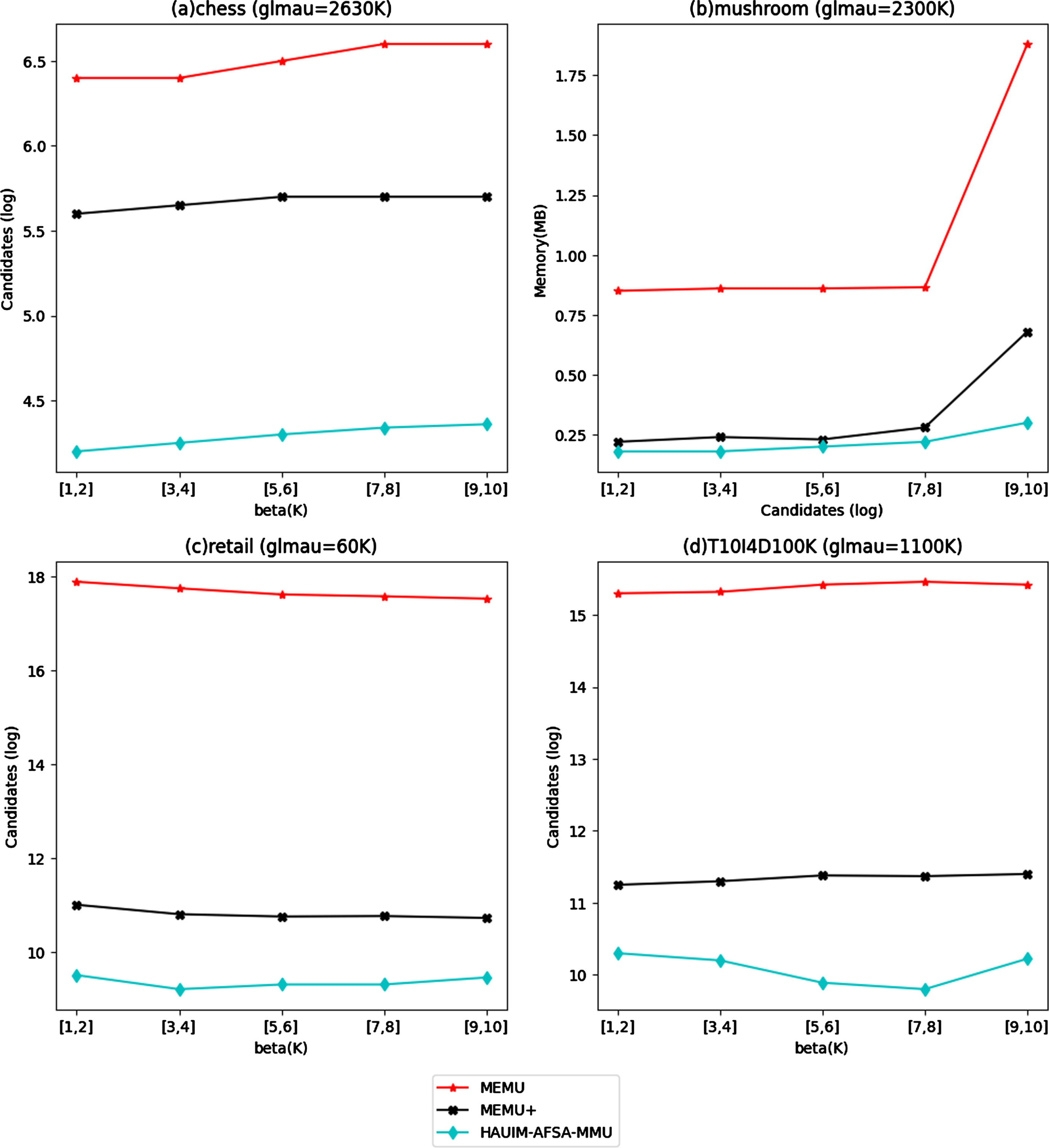
Candidate comparison for fixed glmau and various β values.
Overall, the proposed algorithms reduce the search space by focusing on promising regions and discarding unpromising ones. This enables it to efficiently reduce the candidates to generate HAUIs.
Additionally, the Friedman test is used to determine the statistical significance of the variations in the performance of the three algorithms. The rank of each algorithm on each data set is used in the Friedman test [6, 22], a nonparametric statistical test. The Equations (10) and (11) show the Friedman statistics calculation.
If the Friedman test finds that the null hypothesis, according to which all techniques perform uniformly is false. Individual Friedman tests are run to see if the performances of the three algorithms using the four datasets differ significantly in terms of getting optimal values. The tests’ null hypothesis is that all configurations with particular glmau are similar in terms of the best values for each of the three algorithms. A confidence level of 0.05 with a 95% degree of confidence is used to determine the Fisher distribution’s critical value.
The value of F F is distributed for the given setup with three algorithms and four datasets with 2 (k-1) and 6 ((N-1)(k-1))degrees of freedom. As discussed earlier, k represents the number of algorithms which is 3 and N represents the number of datasets considered which is 4. The optimal values obtained for three algorithms on four datasets for a fixed glmau is listed in Table 10. Based on the observations on the results in the Table 10, it is obvious that the proposed algorithm HAUIM-AFSA-MMU shows better performance than the other two algorithms under consideration. Friedman tests prove that the proposed algorithm is statistically significant under the given setup.
Optimal value comparison of four data sets on three algorithms
In this paper, an algorithm is proposed to mine HAUI using AFSA optimization technique with multiple minimum utilities fixed for each item in the dataset. The experimental results discussed here shows that the proposed HAUIM-AFSA-MMU algorithm has outperformed in most of the cases than the other three algorithm considered in both time and space complexity. Parameter sensitivity is the major limitation of the AFSA algorithm discussed in this paper. As discussed in section 6.2, AFSA uses minimal parameters which is a limitation in using AFSA, proper parameter tuning is still necessary for optimal performance. Our future work focuses on modelling new approaches in fixing minimum average utility for each item in the dataset. The metrics like, the external utility of each item, the total weighted utility of the transactions in which the item appears may also be considered to fix the minimum utility to each item in the database. The minimum utility of each item can also be fixed by comparing the utility strength of the similar item in the transaction database. Many such strategies can be evolved in fixing the multiple utilities. These metrics will be considered in building the new algorithm in our future work. Future works may also include reducing the AFSA limitations to mine better HAUIs.