
Abstract
Concrete surface crack detection plays a crucial role in ensuring concrete safety. However, manual crack detection is time-consuming, necessitating the development of an automatic method to streamline the process. Nonetheless, detecting concrete cracks automatically remains challenging due to the heterogeneous strength of cracks and the complex background. To address this issue, we propose a multi-scale residual encoding network for concrete crack segmentation. This network leverages the U-NET basic network structure to merge feature maps from different levels into low-level features, thus enhancing the utilization of predicted feature maps. The primary contribution of this research is the enhancement of the U-NET coding network through the incorporation of a residual structure. This modification improves the coding network’s ability to extract features related to small cracks. Furthermore, an attention mechanism is utilized within the network to enhance the perceptual field information of the crack feature map. The integration of this mechanism enhances the accuracy of crack detection across various scales. Furthermore, we introduce a specially designed loss function tailored to crack datasets to tackle the problem of imbalanced positive and negative samples in concrete crack images caused by data imbalance. This loss function helps improve the prediction accuracy of crack pixels. To demonstrate the superiority and universality of our proposed method, we conducted a comparative evaluation against state-of-the-art edge detection and semantic segmentation methods using a standardized evaluation approach. Experimental results on the SDNET2018 dataset demonstrate the effectiveness of our method, achieving mIOU, F1-score, Precision, and Recall scores of 0.862, 0.941, 0.945, and 0.9394, respectively.
Introduction
After a concrete bridge is built and put into service, cracks of varying degrees will appear on the bridge surface over time under the influence of the climatic environment and vehicle traffic. These cracks can induce a weakening of the bridge’s load-bearing capacity, which over time can lead to the partial collapse of the bridge concrete bridge [1]. To assess the safety condition of bridges, bridge management conducts periodic inspections to detect the various damages that exist on bridges, one of which is to detect the distribution of apparent cracks on bridges.
Traditional bridge inspection methods are based on manual inspections, using scaffolding or bridge inspection vehicles to bring inspectors into the inspection area, and bridge inspectors use professional cameras to manually photograph concrete bridge damage and use crack meters to measure crack lengths and widths. The detection of cracks in concrete bridges is a key research topic in the field of bridge system safety and maintenance, and obtaining accurate information on the location and size of the cracks can help engineers assess the overall health of the bridge and provide a basis for subsequent bridge maintenance. Manual inspection has the disadvantages of strong subjectivity, a dangerous working environment, a large workload, and low efficiency, and gradually fails to meet the needs of people.
To solve this problem, researchers have conducted a lot of research work on automatic bridge crack detection to reduce the workload of bridge maintenance personnel. For example, the use of drones equipped with high-definition cameras for the apparent inspection of bridge surfaces [2, 3]. Yu et al. [4] designed a robot that can detect cracks under bridges. They provide a safe and effective machine vision technique to inspect bridges. The advantage of the bridge inspection robot is that it can reach places that are not accessible to drones to inspect the surface of bridges. Although the new bridge inspection can solve the disadvantages of a dangerous working environment, high workload, and low inspection efficiency, these new bridge inspection drones, and wall climbing robots produce a large number of inspection images during daily inspections. A large number of inspection images still rely on manual damage identification, which still does not completely solve the problem of large workload and low inspection efficiency.
With the development of sensor acquisition, information storage, and analysis technology, bridge damage detection technology based on digital image processing has attracted wide attention from the academic community. With the excellent performance of high accuracy, detection rate, and fast reliability in image processing-based concrete bridge damage methods, it has gradually become a hot spot for research, and a large number of research results have been achieved. However, the complexity of the bridge surface environment, such as water damage, pollution, and other structures on the bridge surface, brings certain difficulties to the image acquisition process, coupled with the existence of uneven illumination in the image capture process and the lack of specification of the camera’s shooting angle and distance to the object, which leads to a complex background and multi-scale characteristics in the concrete bridge damage images, which all bring some difficulties to the traditional image processing This has led to complex backgrounds and multi-scale characteristics in concrete bridge damage images, which have posed certain difficulties to traditional image processing methods. With the development of machine learning and neural networks, more and more researchers have used deep learning techniques to segment cracks, but due to the slender structure of cracks themselves, the traditional deep learning semantic segmentation network fails to effectively extract fine crack features in the segmentation of relatively fine cracks. The accuracy of the deep learning-based semantic segmentation network on crack segmentation still needs to be improved.
To solve the above problem, we propose a multi-scale residual encoding network for concrete crack segmentation. The contributions of this paper can be summarized as follows. the method in this paper can directly segment the cracks from the image, avoiding post-processing, thus improving the crack detection accuracy. The method in this paper introduces a multi-scale convolutional feature map fusion network, which merges the feature maps layer by layer from top to bottom, preserving the fine crack features and the edge information of the cracks in the feature maps, and improving the crack detection accuracy. designed a loss function for training on the cracked data set to address the negative impact of positive and negative sample imbalance. we provide extensive experimental results to demonstrate the effectiveness of the method on the SDNET2018 dataset, which achieves 0.862, 0.941, 0.945, and 0.9394 for mIOU, F1-score, Precision, and Recall, respectively.
The rest of the paper is organized as follows. Section II investigates the current state of research in the field of concrete cracking. Section III explains the basic principles of the adopted method and briefly discusses its construction of sub-blocks. Section IV provides detailed information about the experimental setup, presents the experimental results, and gives a short discussion of the results. Finally, Section V provides an overview of the work accomplished in this paper and points out the scope for future exploration in this research area.
Related work
Cracks are one of the common concrete bridge damages, and in concrete bridge damage detection, the specific location information and dimensional parameters of the bridge cracks can help engineers to assess the overall health of the bridge and provide a basis for subsequent bridge maintenance. Therefore, in the field of concrete bridge damage detection, there are many research results in the direction of concrete crack detection.
In the early stages of research on concrete bridge crack detection, a large number of researchers used traditional digital image-based techniques for the detection of cracks in concrete bridges. The saliency feature is similar to the region of interest in the part of human vision and the focus of human eye attention, which originates from the separate, unpredictable, rare, and unique [5] composition of the role of human eye vision. In another literature [6], the researchers used an adaptive grayscale correction algorithm for crack images of roads, based on sparse features of grayscale and global contrast features, and then calculated saliency features in cracks at coarse scales based on these features, and performed local neighborhood saliency enhancement with local texture expansion for low-scale operations based on the local texture characteristics of cracks, and finally extracted the saliency features by enhancing them in space After reaching the stronger features of the crack compared to the background, the information of the crack is segmented using the segmentation algorithm of Otsu [7]. However, this method does not pay enough attention to the crack integrity and continuity properties to detect them well. Amhaz [8] used the feature of continuity between crack pixels to search for cracks in the image along the pixel points with strong continuous correlation, and the algorithm used to search for cracks was the minimum path method. yamaguchi [9] proposed a crack detection based on the seepage model algorithm. However, the authors did not link much information between cracks in the local area of the cracks, which led to poor robustness of the algorithm for the case of uneven pixel values of cracks in the image and could not identify the cracks effectively under complex cracks. The crack detection method based on the frequency domain is transformed from the spatial domain in the crack image to the frequency domain for analysis. The study [10] used the non-downsampling contourlet transform to extract the frequency features of the crack in NSCT, filtered part of the background frequency information by NSCT and finally transformed to the spatial domain, and finally used morphology to extract the crack further. The literature uses the ridge transform, which has a stronger singularity compared to the wavelet transform, to extract the features of the cracks. In the minimum path selection method Fischler [11] grayed out a crack image as a graph structure in the data structure, the pixels in the crack graph are the nodes in the graph structure, the correlation between pixels is the cost between nodes, and the authors designed a special cost function for the correlation between nodes. Finally, the shortest path algorithm in the graph structure is used to search for the crack nodes so that the pixel information of the crack can be extracted. Carlotto designed a weak contrast line feature enhancement for the crack information and then used the least-cost path search algorithm for the extraction of the crack pixels.
Due to its excellent feature extraction capabilities, machine learning plays an important role in research in the field. Choi et al. [12] proposed a method for concrete crack segmentation. The goal is to achieve real-time performance while effectively eliminating various complex background and crack-like features. König et al. [13] introduce a fully convolutional U-Net-based architecture to automate annotation tasks for semantic segmentation of surface cracks, allowing the use of small datasets through a patch-based training process. Cha et al. [14] adopted a deep convolutional neural network to automate crack detection. The network scans the whole image with a sliding window and detects cracks by classifying every window image. However, this method can detect the area of the cracks but cannot precisely localize the cracks. Zhang [15] segmented crack images into image blocks and applied a convolutional neural network to them to obtain a crack possibility plot, but the width of the cracks detected by this method was exaggerated, so its precision needed to be improved. Fan [16] also segmented the crack image into image blocks and used the blocks to train a convolutional neural network, but this method used highly similar samples. The method needed to consider the proportion of the cracks and non-cracks in the samples, which was rather difficult. Ren [17] designed an improved deep fully convolutional neural network named CrackSegNet to segment cracks into pixel-level blocks, which improved detection precision compared with other image block methods. Wang et al. [18] proposed an end-to-end bridge crack detection model based on a convolutional neural network. This model combines the advantages of Inception convolution and residual network, broadens the network width, and alleviates the training problem of the deep network. Li et al. [19] proposed a convolutional encoder-decoder network to detect cracks in images, and used image post-processing techniques to measure the maximum width and direction of cracks. Wang et al. [20] proposed an effective pavement crack segmentation model based on deep learning. The model uses pre-trained DenseNet121 as an encoder to extract road features. Li et al. [21] proposed a fully convolutional neural network based on pixel-level detection of dense connections and deep supervision networks. Chen et al. [22] proposed a simple and effective method to improve the efficiency of crack detection algorithms based on the encoder-decoder architecture. The author developed a switch module called SWM to predict whether the image is positive or negative, and then skip the decoder module to save calculation time. Wang et al. [23] studied the application of transformer technology in crack segmentation and described the advantages of transformer in crack segmentation. Ding et al. [24] studied a transformer-based crack detection method and carried it on an unmanned aircraft for application. Zhang et al. [25] used UNet with transformer to crack detection was carried out, and the UNet feature extraction module of Jiang was changed to Transformer architecture to improve the detection accuracy. Although the above crack detection network with transformer-based architecture has high accuracy, the disadvantage of transformer is that it is too computationally intensive for general computing devices to bear.
Proposed method
The main frame
In this paper, crack segmentation is mainly characterized as a binary classification task for each pixel point in the image. In a given crack image, a predicted probability map can be generated by the algorithm in this paper, characterizing the parts with higher probability as cracks and conversely the parts with lower probability as concrete background. In this paper, an encoder-decoder-based semantic segmentation network is used to predict the crack pixels. The workflow of this study is divided into two main parts: Construction of data sets and Training Network. we collected publicly available crack images, annotated the crack images at pixel level using manual annotation methods, and then composed the crack data sets. The crack segmentation dataset is constructed by widening the crack images using common image data enhancement methods. Then the end-to-end encoder-decoder network proposed in this paper is constructed and trained using the pixel-level labeled crack dataset, and the crack segmentation mask is obtained after optimizing the parameter model.The research process of this paper is shown in Fig. 1.
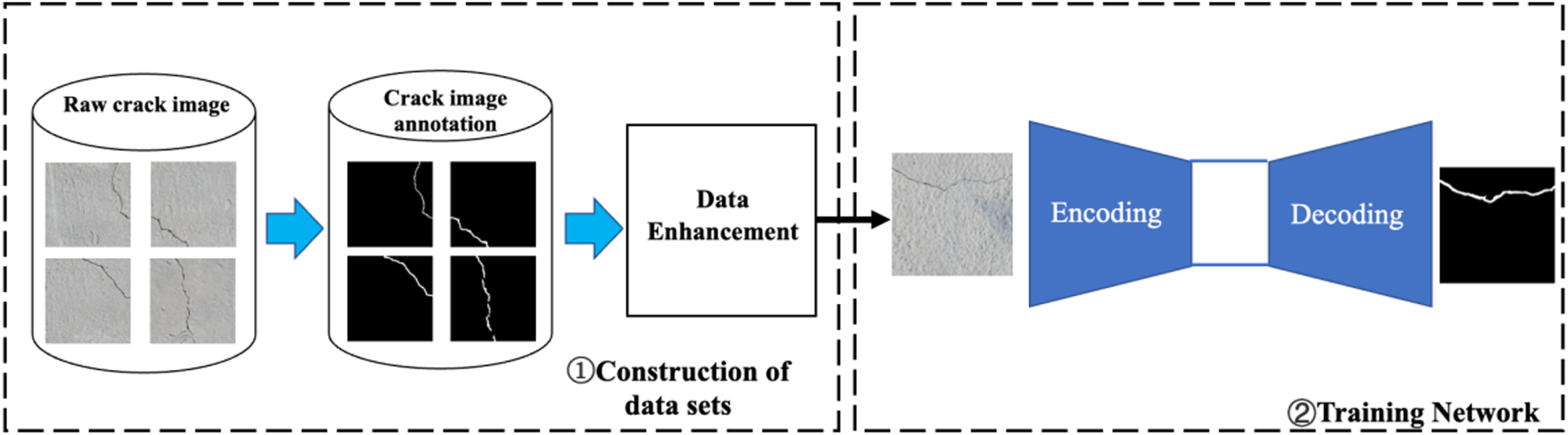
The research process of this paper.
The architecture diagram of the concrete crack segmentation network proposed in this paper is shown in Fig. 2. The network consists of three main parts: 1. an encoder-decoder segmentation network with U-NET as the main architecture; 2. an encoder based on the residual structure used; and 3. an attention mechanism module used after feature splicing. In the decoder part, to solve the problem of low accuracy in the tiny part of cracks, this paper adds the attention mechanism module to the decoder of U-NET to focus on the tiny crack pixel features in different feature maps, thus improving the segmentation accuracy of tiny cracks. In the decoder, this paper uses the attention mechanism module after stitching the feature maps to extract the crack information in different feature maps again to improve the feature extraction ability of tiny crack edges. Our proposed algorithm is an image tensor of shape 512×512×3. The network output of the algorithm ends up with a crack segmentation mask matrix of shape 512×512×1. The elements in this matrix are the probability that the pixel point is a crack pixel point, and in this paper 0.5 is the global threshold to segment the prediction map, and finally a binary image of the crack is obtained.
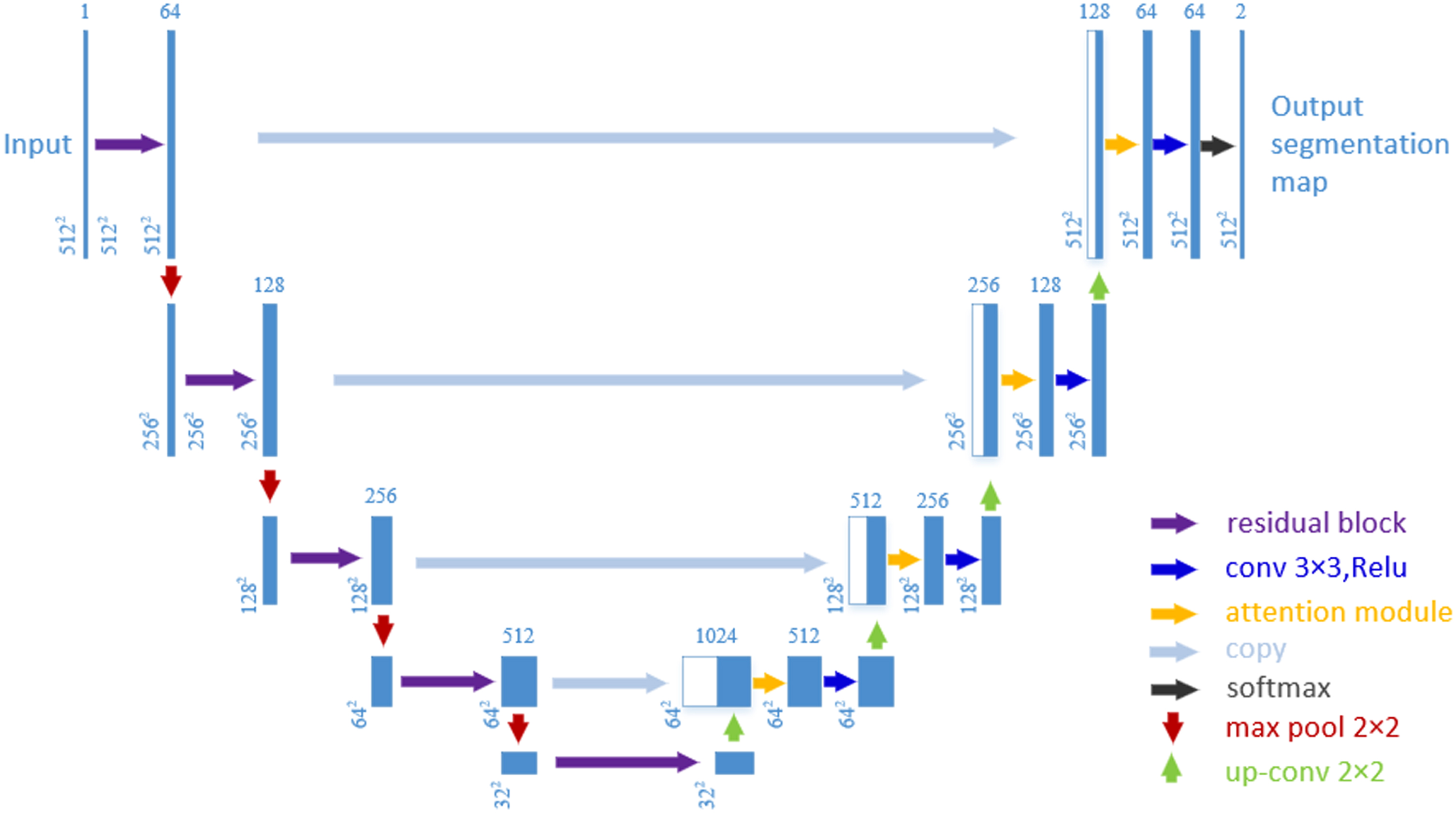
The proposed network architecture. The blue blocks represent the feature map and the arrows represent the layer-by-layer operations.
The role of the encoder is mainly to extract image features with a high level of semantic information. In this paper, we use an encoder based on the residual structure improved on the original U-NET, a classical image segmentation network, which is composed of two parts, the encoder (left side) and the decoder (right side), where the encoder is used to obtain contextual information and the decoder is used for accurate localization, and the network is symmetric to each other. The network uses a jump connection to fuse the feature maps of the encoder and decoder and passes the feature maps of the encoder directly to the decoder, which helps the encoder to recover the information loss and makes U-Net more accurate in pixel localization. The jump-connected logogram structure of U-NET is shown in Fig. 3.
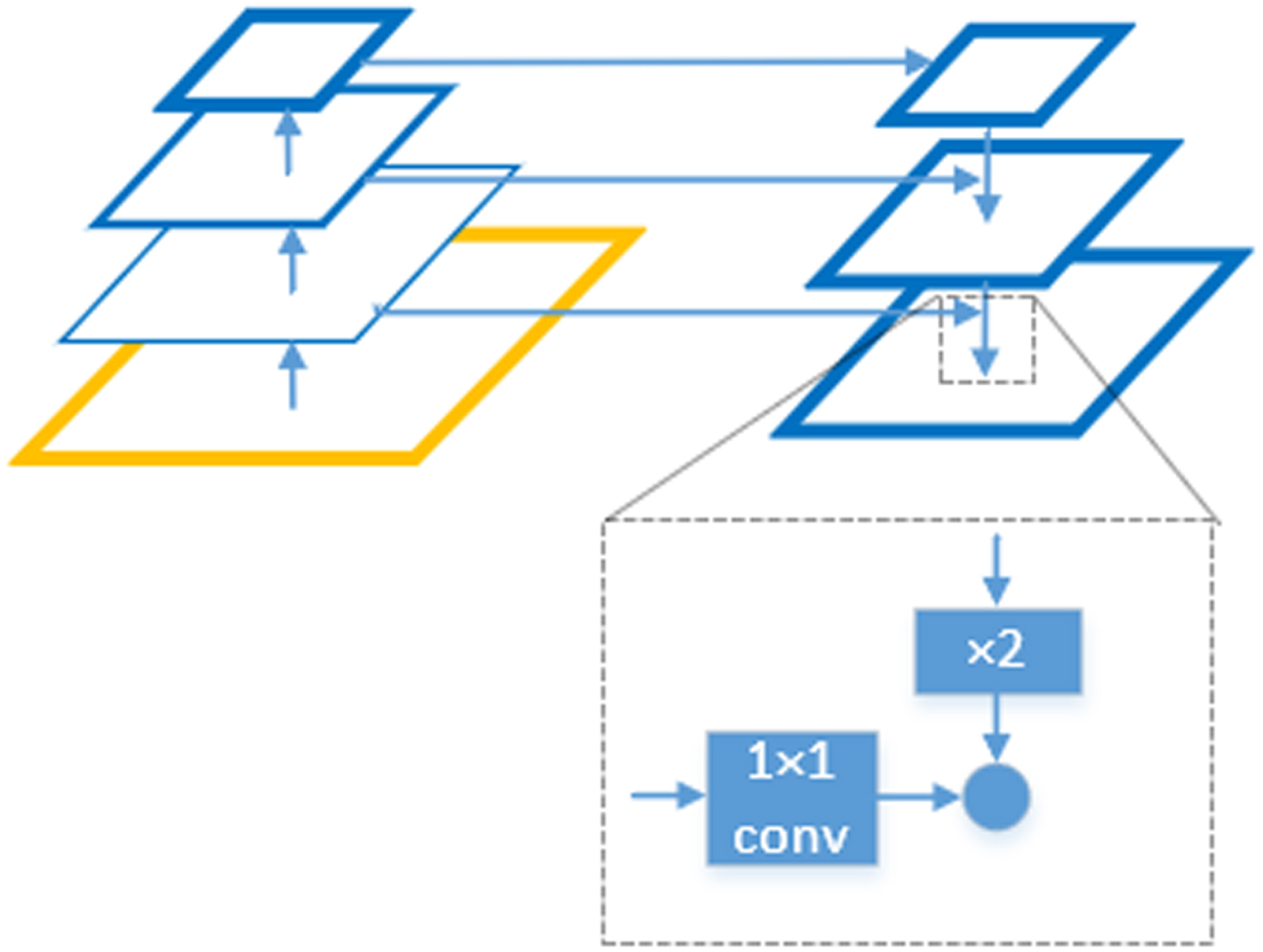
Structure of the jump connection sign graph.
However, the jump connection only directly connects the feature information from the encoder to the decoder, which is not only too single in jump connection, but also cannot extract enough information about the cracks from multiple scales. Furthermore, each convolutional layer of this network is composed of two 3×3 convolutions, and the features between convolutions are generally utilized only once, and there is a lack of connection between different convolutions, so the utilization of features is relatively low, and it cannot accurately segment the location and boundary of cracks in images, which will affect the effect of crack segmentation in the end. To address the above problems, inspired by the U-Net structure and residual module, this paper proposes an improved residual module introduced with U-Net as the framework. The residual module used in the encoder in this paper is shown in Fig. 4. Generally, the deeper the network is, the better the ability to extract features is. However, when the network increases to a certain depth, the gradient disappearance problem occurs, which leads to the degradation of the network performance. ResNet [26] solves this problem through the residual connection, which can make the network deeper and more powerful in extracting features.
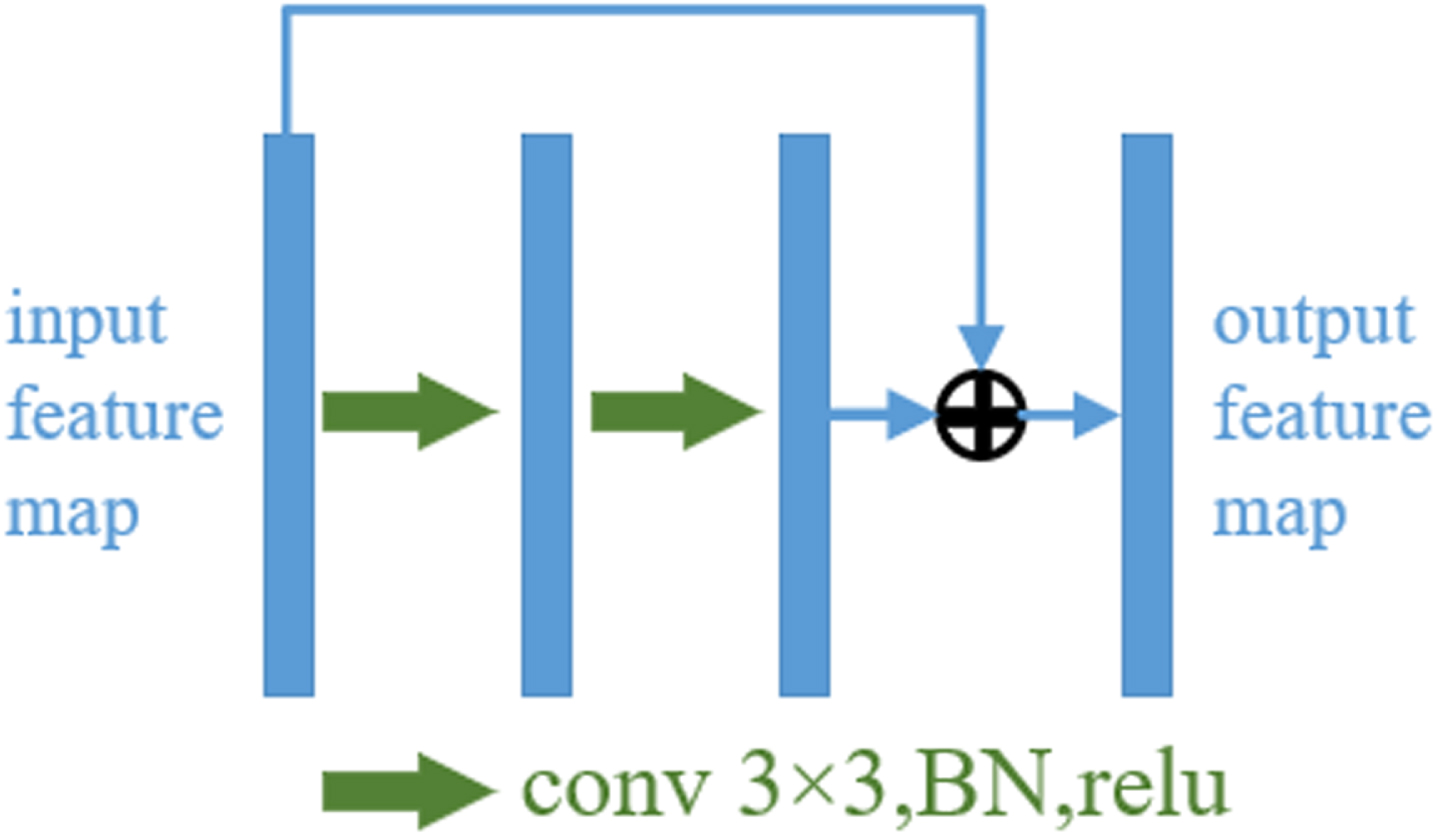
Residuals module.
The detailed architecture of the concrete crack segmentation model encoder in this paper is shown in Fig. 5. In the convolution with the same parameters as U-Net, two 3×3 convolutions are used in each stage for feature extraction, and then maximum pooling is used for the downsampling operation. Unlike U-Net, the residual module of the convolution with the same parameters as U-Net is used in each stage for feature extraction, and finally, the maximum pooling is used for the downsampling operation.
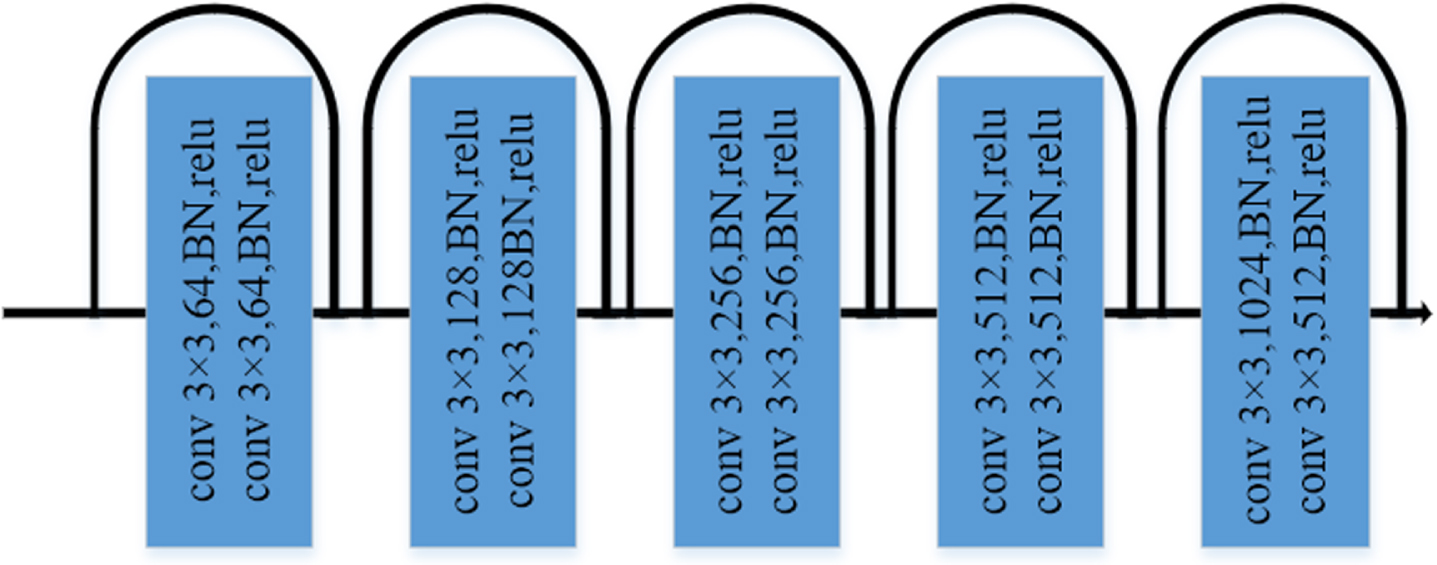
Encoder architecture.
In the field of machine vision, the attention mechanism is to weigh the regions of interest in the feature map so that the network goes more to the features of the regions of interest. The attention mechanism filters the feature map again by learning the association features between each pixel in the feature map again, and finally in the form of a mask, so that the output feature map of the network tends to extract the features of the region of interest.
The attention mechanism can enhance the attention of the network to important features, and the segmentation accuracy of the network can be improved with the same complexity and computational effort, which is widely used in feature extraction, classification, detection, and segmentation processing [27]. The literature [28] adaptively recalibrates the feature responses of channels by explicitly modeling the interdependencies between channels, which is simple in idea, easy to implement, and can be easily loaded into existing network model frameworks. The literature [29] sequentially applies the channel and spatial attention modules to improve the representation of attention by emphasizing meaningful features in both dimensions, spatial and channel. By dynamically generating convolutional kernels for images of different scales, the literature [21] shows a significant improvement in super-resolution tasks and also performs well in classification tasks.
The structure of the SE attention mechanism is shown in Fig. 6, where the features enter the SE before undergoing various convolution operations to generate a feature map of shape H×W×C. The new feature map is obtained after a compression operation and an excitation operation, respectively. The compression operation is a global maximum pooling of the input feature map to generate a feature vector of length C. This feature vector represents the global maximum features of each channel of the input feature map. Then a fully connected layer is used to further extract features from this vector and a feature vector with channel correlation is generated. The excitation process is to multiply the value of the feature vector with each channel feature of the original input feature map, and finally a feature map with channel correlation is obtained, whose output shape remains the same as the input shape. The importance of different channels varies, thus highlighting the important information and suppressing the background information.
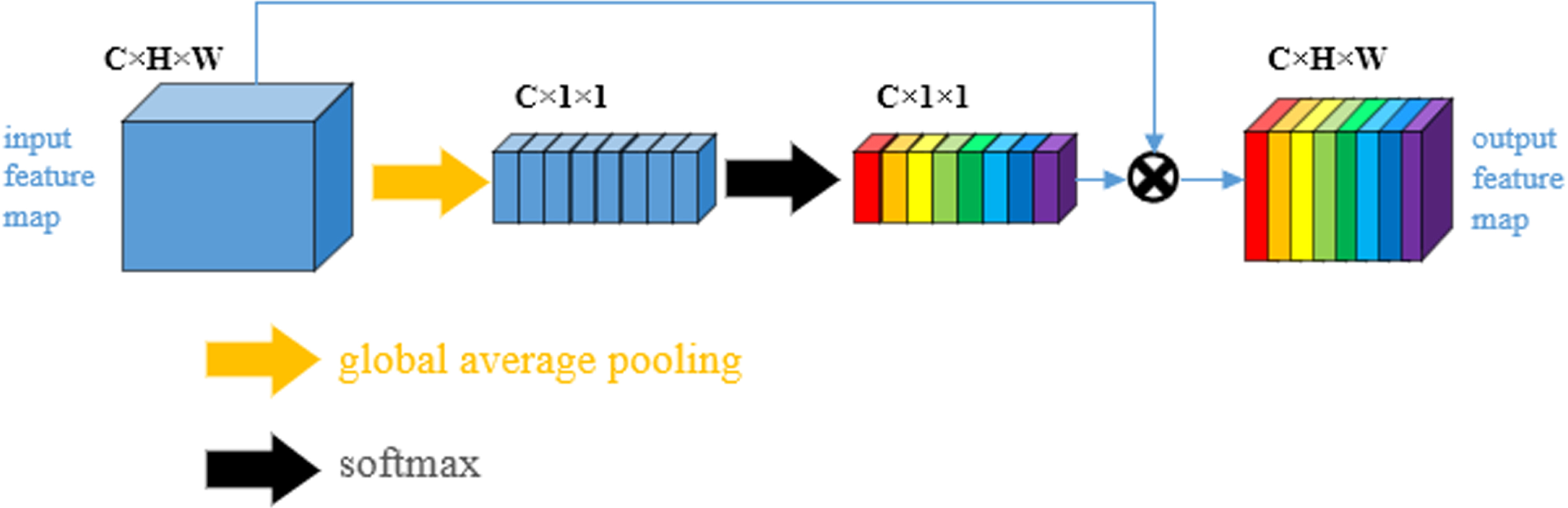
SE attention mechanism architecture diagram.
As shown in Fig. 2, to make the feature map more efficient to utilize, this paper embeds the SE attention module into the decoding network after feature splicing. Since the feature map after feature splicing contains rich global contextual semantic information, it is necessary to use the SE attention module to focus on the crack features of the semantic information as a whole, and finally use the focused feature map to predict the crack pixels.
The main goal of crack detection is to segment cracks from the image at pixel level to distinguish concrete background from cracks. Analyzed from the classification point of view, crack detection is to classify all pixels of an image and distinguish the class of this pixel as crack or concrete background. Considering that crack detection is a binary classification task, the cross entropy (cross-entropy), which is commonly used for binary classification tasks, can be chosen as the loss function for model training, which is defined as follows.
In the case of binary classification, the model prediction results in only two cases, for each category the model prediction yields a probability of p and (1-p). y i denotes the label of sample i, with 1 for positive category and 0 for negative category. p i denotes the probability that sample i is predicted to be positive.
In the crack image, the number of pixels of the crack is a very small proportion of the number of all pixels. In the binary classification task where the crack is a positive sample and the concrete background is a negative sample, the samples are extremely unbalanced. Under the condition of unbalanced samples, when the model is trained using the cross-entropy loss function, the function value will be biased towards the side with more samples, resulting in a small loss function during training, which has a bad effect on crack detection. This will seriously affect the extraction of semantic features of cracks during model training and reduce crack detection accuracy. To reduce the impact caused by sample imbalance, this paper uses a weighted cross-entropy approach, defined as follows.
The cross-entropy calculates the loss of each pixel of the image and does not consider the overall situation of crack prediction. Therefore, needs to include the crack prediction loss in the loss function to make the model more capable of generalizing cracks during training. The Dice loss function from the literature [30] is cited, and the Dice loss function is a measurement function of the closeness of two sets, defined as follows.
Where p
i
is the probability that each pixel point in the predicted map is a crack, and g
i
is the value of each pixel in the real crack map. In summary, the loss function for training the crack prediction model in this paper is:
Dataset
The experimental data is cited from the SDNET2018 dataset provided in the literature [31]. SDNET2018 is an annotated image dataset for training, validating, and benchmarking artificial intelligence-based concrete crack detection algorithms. The dataset contains over 56,000 images of cracked and uncracked concrete bridge decks, walls, and sidewalks. Two hundred and thirty images of cracked and uncracked concrete surfaces were captured using a 16 MP Nikon digital camera, and each image was then segmented into sub-images with a resolution of 256×256.
To verify the performance of RCC-Net, crack images with a resolution of 256×256 were selected in the SDNET2018 dataset, and the cracks were labeled at the pixel level using the LabelMe labeling tool, which is commonly used in machine vision.
We labeled 500 images of cracks and divided them into training and testing sets. The detailed number of divisions is shown in Table 1. A schematic diagram of the crack images and labeling is shown in Fig. 7.
Data division
Data division

Illustration of data labeling.
Semantic segmentation is to classify the pixel points in the image, and in this paper, RCC-Net is to classify the pixel points in the whole crack image into concrete background class and crack pixel class. In this paper, F1-score, Precision, and Recall are used as evaluation metrics with the following equations.
Where TP indicates the number of pixels whose real label is concrete cracks and is segmented as concrete cracks, FP indicates the number of pixels whose real label is concrete background but is segmented as concrete cracks, and FN indicates the number of pixels whose real label is concrete cracks but is segmented as concrete background.
In addition to F1-score, Precision, and Recall, mIoU is the most important metric in the field of semantic segmentation in experiments. It is taken as the ratio of the intersection of the two sets of true and predicted values on each category to the concatenation, and then the average of the intersection and concatenation ratio of all categories, i.e., the mean intersection and concatenation ratio. mIoU is given by the following formula.
The P-R curve can be used to evaluate the comprehensive performance of the segmentation network. The P-R curve is plotted by using different positive and negative thresholds in the output of the network to obtain different precision and recall rates, with the horizontal axis of the coordinate axis as the precision rate and the vertical axis of the coordinate axis as the recall rate, and bringing the values of the precision and recall rates under different thresholds into the coordinate system. If the performance of a target detection network is high, the precision rate decreases slowly with increasing recall in the P-R curve. When using P-R curves to compare different target detection algorithms, the properties of P-R curves are used such that if the P-R curve of one algorithm encloses the P-R curve of another algorithm, the comprehensive performance of this algorithm is higher than that of the enclosed algorithm.
AUC (Area Under roc Curve) is another metric used to measure the performance of a classification model, which represents the area enclosed by the ROC curve (receiver operating characteristic curve) and the horizontal coordinate. However, a perfect prediction model does not exist, and the AUC value of a prediction model usually ranges from 0.5 to 1.0.
The results derived in this paper are the quantitative values in each evaluation index, in the physical sense, the quantitative values out of these evaluation indexes can indicate the degree of similarity between the model segmentation results and the real label, in the actual scenario derived from the original information of the real crack, the higher the index to the more complete information, the closer to the real physical two-dimensional form of the crack.
To verify its effectiveness and performance. The code part of the algorithm is written in Python and built using the PyTorch framework, a software framework specifically for deep learning, PyTorch can call the GPU to make the network training more efficient. On the hardware platform, the experiments in this paper are implemented on the experimental platform used for deep learning. The specific experimental environment is shown in Table 2.
Experimental configuration
Experimental configuration
The training image resolution is 512×512. the number of training epochs is 100, the batch size is 16. the initial learning rate is 0.001. the model uses the Adam optimizer. the momentum is 10e-8. In the parameters of the Adam optimizer, the exponential decay rate is set to 0.9 by default, and the learning rate is updated using the step decay method. The decay factor is 0.01. The weight decay factor is 0.0005.
Ablation experiment of each module
To verify the effectiveness of the encoder with residual structure, SE attention module, and improved training loss function proposed in this paper, experiments were conducted on the concrete crack dataset. model(1) is the original U-NET network, model(2) represents the network trained with the new loss function, model(3) represents the use of residual structure in the encoder. model(4) is the complete network proposed in this paper, representing the use of the residual structure encoder and the attention mechanism module, and the network is trained using the improved loss function proposed in this paper.
From the experimental results in Table 3, it can be seen that firstly, all the metrics of the basic U-NET network are improved after using the improved loss function, which indicates the effectiveness of the loss function. Then, the models with the addition of the residual module and the attention mechanism have higher mIoU and F1 values than the base U-Net, respectively. The introduction of the residual structure and the SE attention mechanism module allows the network to learn features better. It can also be seen that as improvements are made to the model, the AUC evaluation index increases, indicating that the improvements proposed in this paper are effective. These methods can combine to improve the segmentation ability of the network for cracks.
Results of ablation experiments
Results of ablation experiments
We compared the P-R curves of different ablation experimental models on the concrete crack dataset. As can be seen in Fig. 8, the performance of the base model is improved by first adding the improved loss function to the baseline model, as can be seen in the P-R curves. The new loss function solves the problem that the function value is biased toward the side with more samples when the model is trained using the cross-entropy loss function under the condition of sample imbalance. Thus, the comprehensive performance of the model is improved. Later, with the addition of the residual structure of the feature extraction network and the SE attention mechanism, the performance of the model is substantially improved. In particular, the model’s performance is substantially improved by adding the feature extraction network with residual structure, which is because the residual structure enhances the feature extraction ability of the encoder and enhances the feature extraction ability of tiny cracks, thus improving the model’s performance. The small improvement in the performance of the model with the addition of the attention mechanism is because the attention mechanism can further enhance the features of tiny cracks.
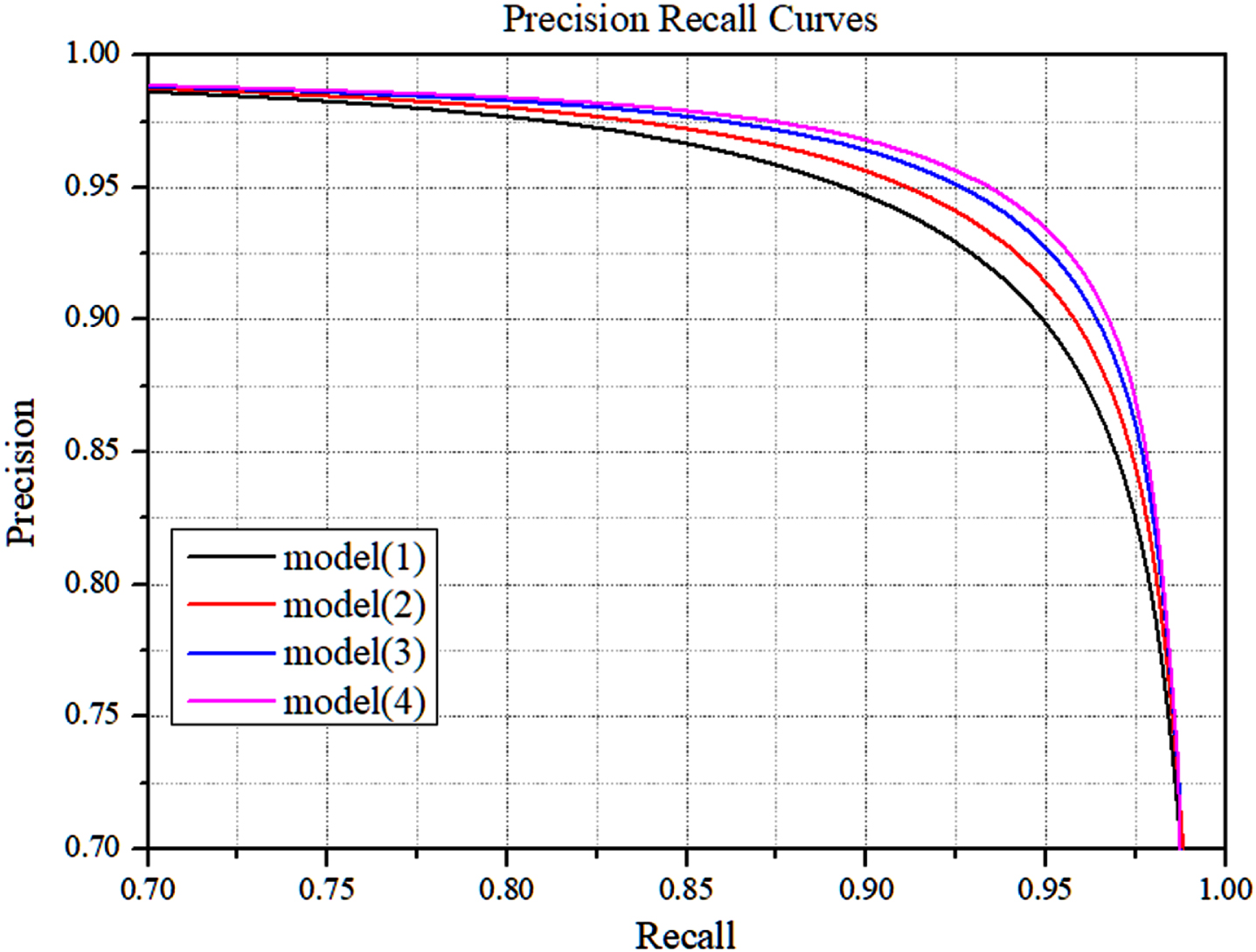
P-R curve of the ablation experiment.
To further validate the performance of the model proposed in this paper, we compare the model with other advanced semantic segmentation networks using the evaluation metrics mentioned in.HED [32] and RCF [33] are deep learning-based edge detection algorithms that are representative of crack segmentation.FCN [34] and SegNet [35] are commonly used semantic segmentation algorithms that can represent most classical deep learning semantic segmentation algorithms. otsu is an adaptive thresholding segmentation algorithm, which represents the traditional digital image processing algorithms in concrete crack segmentation.
From Table 4, it can be seen that the algorithm proposed in this paper has the best performance in all metrics. RCF is the closest to the method in this paper. there is not much difference between the performance of HED and U-NET in concrete crack segmentation. The classical semantic segmentation networks SegNet and FCN have the worst performance among the deep learning network methods due to the low utilization of feature maps by these two classical networks, which are less effective compared to U-NET segmentation. This is because there is a large amount of noise in concrete crack images, and it is difficult to weigh the segmentation threshold between noise and cracks in traditional digital image processing. Even though adaptive algorithms are considered in the traditional methods to optimize the segmentation threshold, adaptive threshold segmentation is not effective in dealing with a wide variety of environments.
Comparison with other advanced methods in evaluation indexes
Comparison with other advanced methods in evaluation indexes
The Precision-Recall curves of various representative segmentation networks are compared with our method as shown in Fig. 8. From the figure, we can see that FCN has poor performance in crack detection compared with other methods. the Precision-Recall curves of HED and U-net almost overlap, which indicates that there is not much difference in the performance of the two networks. The best performance is our method, and we can see that our method has a high level of crack segmentation in different segmentation probability thresholds.
As shown in Fig. 10, the segmentation results of this paper’s method and the original U-NET are compared. Among them, (a) is the real image of cracks; (b) is the labeled image of cracks; (c) is the segmentation result of this paper’s method; (d) is the segmentation result of U-NET. It can be seen that the original U-NET performs poorly in the segmentation effect of tiny cracks, and cannot accurately identify the tiny crack features. In this paper, by improving the residual structure of the feature extraction network of U-NET and adding an attention mechanism to the decoding network, the network’s ability to extract tiny crack features is enhanced, and the overall accuracy of crack segmentation is improved.
To further illustrate the advancement of this paper in fine crack segmentation, the RCF edge detection network with similar performance to the method in this paper is compared. Figure 9. shows the visualization results of crack detection, where (a) is the real image of the crack; (b) is the labeled image of the crack; (c) is the segmentation result of the method in this paper, and (d) is the RCF segmentation result. In the Fig. 11, it can be seen that the two methods have the same results in the segmentation of cracks with a larger width. However, in some of the fine cracks segmentation, the RCF will be disconnected, and the method proposed in this paper can effectively segment the fine cracks.
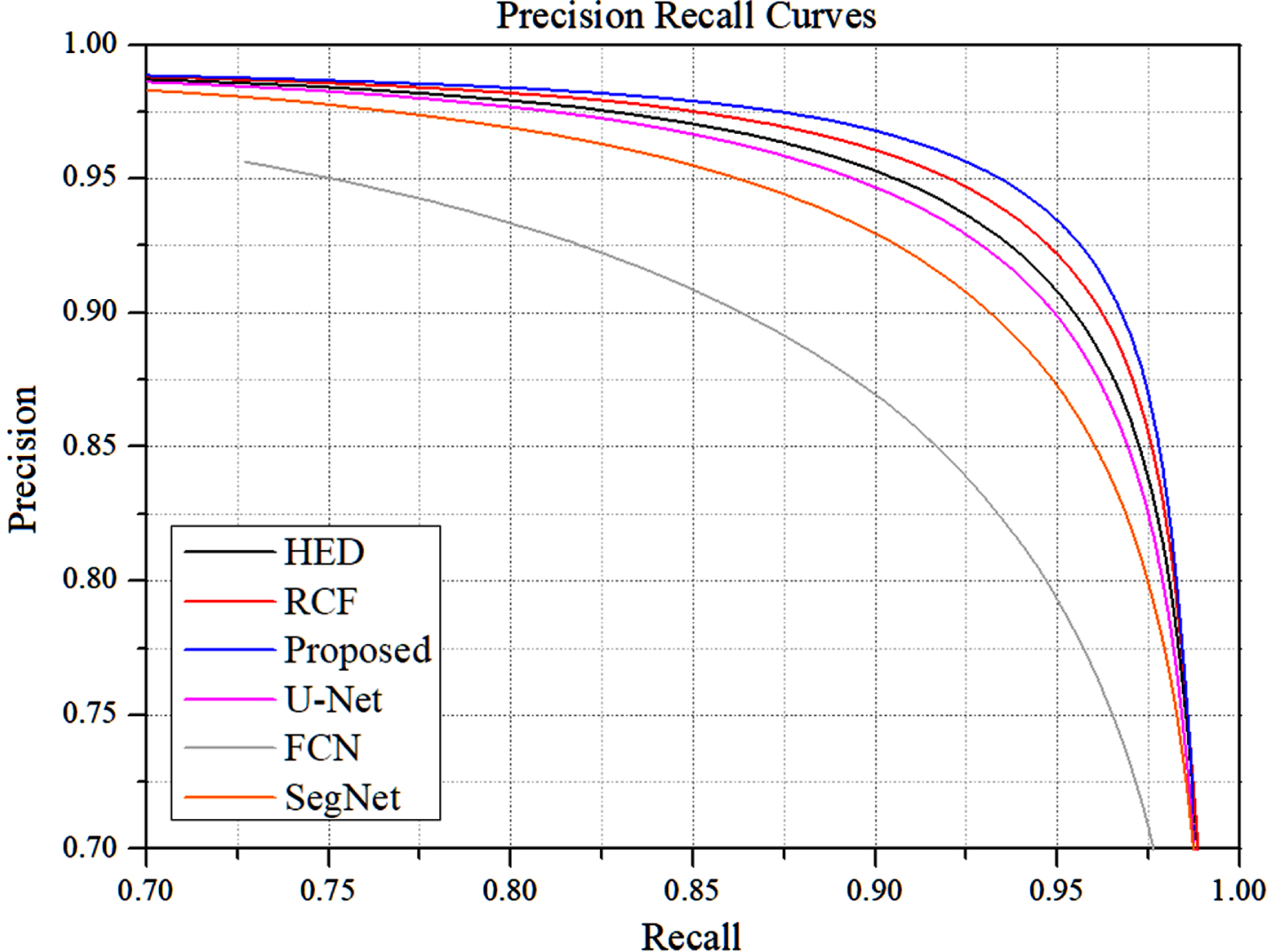
P-R curves of the proposed method and other advanced methods.
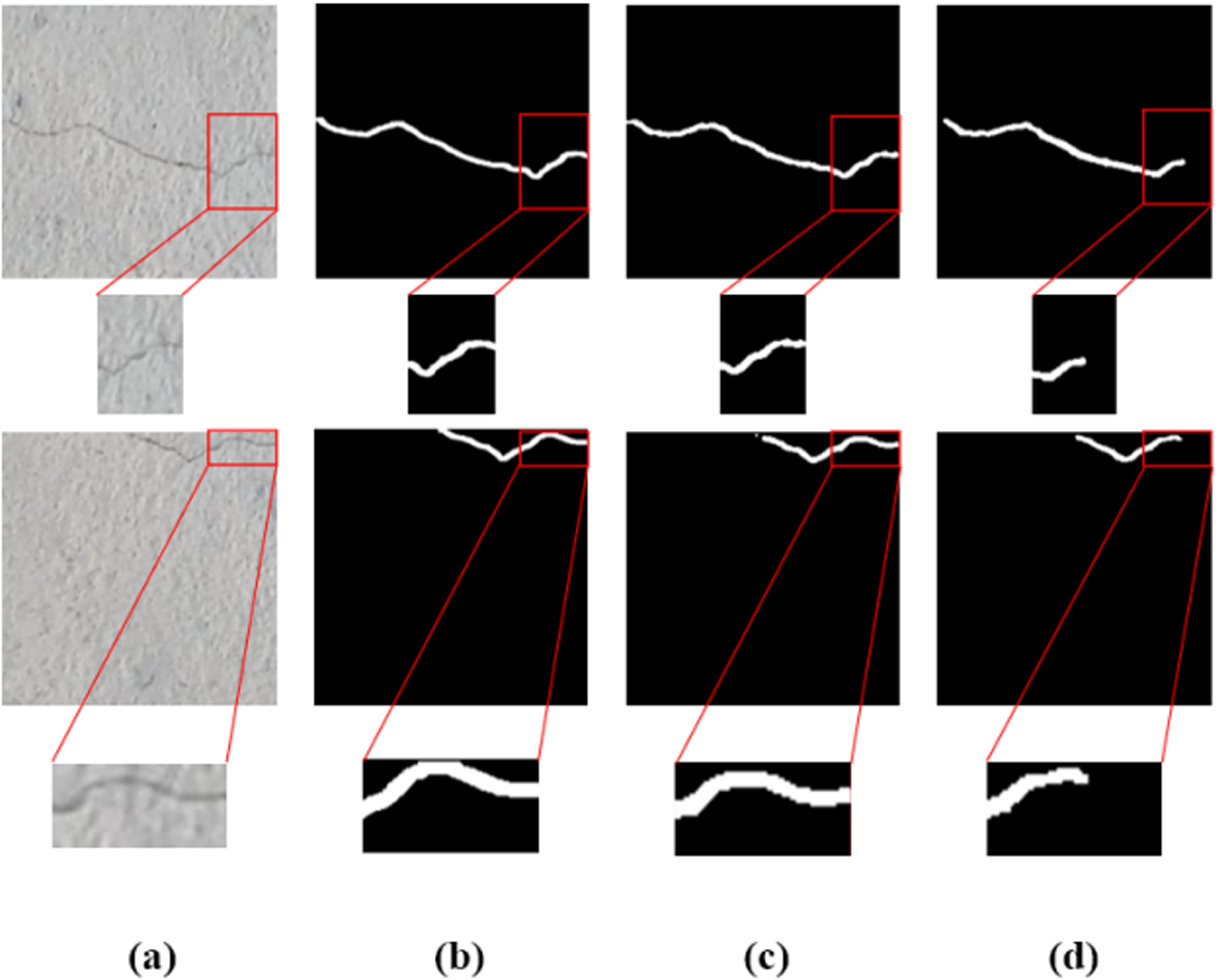
Crack segmentation results (a) concrete crack image; (b) ground truth;(c) the method of this paper; (d) the result of U-NET.

Crack segmentation results (a) concrete crack image; (b) ground truth; (c) Methods in this paper; (d)result of RCF.
Our approach used a residual structure added to the encoder to address the information loss caused by convolution, allowing the network to extract more feature information and segment cracked edges more accurately. Improvements to U-Net using the attention mechanism allow the network to better distinguish between foreground and background and effectively filter out noise. the multi-scale feature map of U-NET allows the network to learn feature information at different scales. The results of the analysis demonstrated the good performance and robustness of our method for crack segmentation.
In this paper, a multiscale residual coding network for concrete crack detection was proposed. In this network, feature maps from different convolutional layers were stitched together to enrich the semantic representation of concrete cracks in the predicted feature maps. Using an attention mechanism, features were further extracted after feature mapping was connected and the crack features in the mapping were enhanced. In addition, a specific loss function for crack detection was designed to solve the disambiguation problem of positive and negative training samples. The proposed crack segmentation network was based on deep learning, which is superior to the adaptive threshold segmentation of traditional digital image processing. Traditional digital image processing algorithms cannot effectively filter out the complex background noise in concrete crack images, resulting in poor crack segmentation performance. In contrast, this method effectively filtered out the noise and obtained high crack segmentation accuracy. The method improved the recognition performance of the U-NET segmentation network for concrete crack features. The experimental comparison shows that the improved network greatly improves the concrete crack segmentation accuracy compared with the original U-NET segmentation network. The method is especially advantageous in the extraction of tiny crack features. Compared with other advanced semantic segmentation networks and deep learning-based edge detection networks, the proposed method achievesd better results in all evaluation metrics.
Funding
This work was supported by the Research platform of Study on the spatial characteristics of traditional mountainous rural settlements in the Hechuan area of Chongqing from the perspective of rural revitalization (22CRKPT0201), This paper is supported by the school-level project “Research on Concrete Crack Segmentation Based on Multiscale Residual Coding Network” (CRKZK2022002) and Institute level project “Research on bridge detection text information construction technology based on knowledge atlas” (CRKGS202110K).