
Abstract
Failure mode and effect analysis (FMEA) is an effective quality management tool used to improve product quality and reliability. However, with the application of FMEA, its shortcomings are exposed regarding risk assessment, weight determination, and failure mode risk prioritization. This paper proposes a new FMEA model using VlseKriterijumska Optimizacija I Kompromisno Resenje (VIKOR) method based on the Interval-valued linguistic Z-numbers (IVLZNs). Specifically, IVLZNs and the Interval-valued linguistic Z-numbers weighted arithmetic averaging (IVLZNWAA) operator are used to evaluate and aggregate risk information of failure modes; the maximum deviation method is used to determine the weight of risk factors; the IVLZNs-VIKOR method is used to determine the risk priority of failure modes. Then, a numerical example is given to verify the effectiveness of the proposed model. Finally, a comparative analysis is made to demonstrate the feasibility and rationality of the proposed method.
Keywords
Introduction
FMEA is a quality management tool, which can help application subjects discover and identify existing or potential failure modes so that failure modes can be prevented by taking measures in advance [1]. Especially with the increasing complexity of products and systems, enterprises need to use effective tools to control and improve the quality and reliability of products to meet the competitive needs in the industry. FMEA has been widely used in various fields due to its practicality, effectiveness, and simplicity, such as the aviation industry [2], medical industry [3], energy industry [4], oil and gas industry [5], water gasification system [6], robot industry [7] and so on.
Traditional FMEA sets three risk factors O (occurrence), S (severity), D (detection) for the failure mode, and scores O, S, and D on a scale of 1 to 10 respectively. Multiply the scores of the three riskfactors to get the RPN value. Finally, rank the risk priority of the failure mode by comparing the RPN value of each failure mode. The higher the RPN value, the higher the risk level of the corresponding failure mode. However, the traditional FMEA also has some shortcomings, which can be divided into three aspects as follows [8]:
Assessing the risk of failure modes: the traditional FMEA requires team members to give risk assessment information for each failure mode using exact values. But in the real world, using accurate values for decision-making is not conform to the decision-making habits of decision-makers;
Determining the relative importance of risk factors: the traditional FMEA does not consider the relative importance of risk factors, but the relative importance of O, S, and D may be different in different practical applications;
Ranking the failure modes: the multiplication of O, S, and D values for different failure modes may result in the same RPN value, according to the ordering rules, the risk priorities of the corresponding failure modes are the same. But in fact, their risk effects may not be the same.
More and more studies have been conducted to address the limitations of traditional FMEA models. Regarding the risk assessment of failure modes, because the decision-making environment in real life is more and more complex and full of uncertainty, in which the decision-making judgment made by the decision-makers is also full of fuzziness and randomness. To reduce the impact of fuzziness and uncertainty on the evaluation process, many scholars have introduced various methods to FMEA models. Fan et al. [9] improved the FMEA model using D-numbers. Yu et al. [10] combined the intuitionistic fuzzy set (IFS) and the hesitant fuzzy set (HFS) to express expert evaluations. Lin et al. [11] applied the neutrosophic set to the FMEA to handle the information uncertainty. Yu et al. [12] combined the cloud model and rough set theory to deal with randomness and uncertainty. In the decision-making process, the knowledge and experience level of decision-makers are limited, and their familiarity with the assessment object is also different. Therefore the reliability of the assessment information also needs to be considered. In 2011, Zadeh proposed the concept of Z-number, which can solve the problem of information reliability in decision-making [13]. A Z-number contains two components, which can not only represent the constraints on the evaluation but also represent the reliability of the constraint information [13]. Z-number theory can be applied in FMEA to cover reliability [14]. In the actual decision-making process, decision-makers prefer to use linguistic words, phrases, or sentences to express their judgments. Linguistic term sets play an increasingly important role in the decision-making field. Wang proposed the linguistic Z-numbers based on Z-numbers and linguistic term set, which can more flexibly and accurately describe cognitive information and measure the reliability of information [15]. Then Huang applied the linguistic Z-numbers to FMEA [16]. Peng introduced hesitant uncertain linguistic Z-numbers [17]. Then Liu et al. [18] improved the FMEA model based on the hesitant uncertain linguistic Z-numbers.
Regarding the risk priority ranking of FMEA failure modes, Liu et al. [19] summarized five categories of methods for failure mode prioritization in a review of FMEA, including multi-criteria decision-making (MCDM), mathematical programming (MP), artificial intelligence (AI), hybrid methods, and others. Among them, the implementation process of FMEA is very similar to the process of multi-criteria decision-making, so MCDM methods are popularly applied to FMEA to solve the shortcomings of risk priority ranking based on RPN values. Ghoushchi et al. [20] presented the MOORA method based on the Z-number theory (Z-MOORA) to prioritize the failure modes. Fang et al. [21] developed an integrated FMEA approach based on rough set theory and prospect theory. Sarwar et al. [22] applied the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) method to rank the failure modes. Yu et al. [23] prioritize failure modes using the Preference Ranking Organization Method for Enrichment of Evaluations (PROMETHEE) II method. Akram et al. [24] obtained the most crucial failure mode based on the ELimination and Choice Translating REality-I (ELECTRE-I) approach. Du et al. [25] applied Three-way rules to FMEA of reliability management of offshore wind turbine systems. Tian et al. [26] proposed a fuzzy VlseKriterijumska Optimizacija I Kompromisno Resenje (VIKOR) method to determine the priority ranking of failure modes. The VIKOR method was proposed by Opricovic in 1998 [27] and used for multi-criteria optimization of complex systems. The VIKOR method has been applied to deal with various MCDM problems, which include supplier selection [28], site selection [29], risk evaluation [30], and so on. This technology is a method in the compensation model, which focuses on ranking and selecting a group of schemes with contradictory attributes, and finally provides a compromise solution by considering both the maximum group utility and the minimum individual regret [31]. FMEA is concerned with risk, while the VIKOR method can consider the risk preference of decision-makers. Therefore, the VIKOR method is very effective in ranking failure modes.
Through the above literature review, we know that Z-numbers are an effective information evaluation tool in FMEA models. However, in decision-making, interval values are more suitable for describing fuzzy information than single values [32]. Peng defined uncertain Z-numbers [33]. Tian defined the likelihood, diversity degree, and comparison rules for uncertain linguistic Z-numbers [34]. To more effectively apply Z-numbers to deal with the uncertainty of information in FMEA, this paper proposed the Interval-valued linguistic Z-numbers (IVLZNs). The main purpose of this paper is to develop a new FMEA model using VIKOR based on IVLZNs. Firstly, this paper defines IVLZNs and proposed the operation rules, comparison method, distance measure, Interval-valued linguistic Z-numbers weighted arithmetic averaging (IVLZNWAA) operator, and some related theorems of IVLZNs. Then IVLZNs are applied to the risk assessment of FMEA to remedy the deficiencies of traditional FMEA in information assessment. And IVLZNWAA operator is used to aggregate evaluation information, in which the weight of experts is determined based on the distance measure. Finally, the VIKOR method was extended to rank the failure modes in the IVLZNs environment, in which the weight of risk factors is obtained using the maximum deviation method.
The remainder of this article is organized as follows. Section 2 introduces some basic knowledge including traditional FMEA, linguistic term set, linguistic scale function, and Z-numbers. In Section 3, we define the IVLZNs and their operation rules, comparison method, IVLZNWAA operator, distance measure, and some related theorems. In Section 4, we propose a new FMEA model based on the IVLZNs-VIKOR method. Section 5 provides a case study to verify the effectiveness of the proposed method. In addition, a sensitivity analysis and comparative analysis are conducted to prove the validity and practicability of the proposed model. Section 6 summarizes this paper and put forward some future research directions.
Preliminaries
Traditional FMEA
The traditional FMEA ranks failure modes based on RPN values [35]. Firstly, an FMEA team be set up to identify the known or potential failure modes and analyze their failure causes and effects. Secondly, team members are provided with the ten-point numerical scale to evaluate the three risk factors of each failure mode: occurrence (O), severity (S), and detection (D). Thirdly the RPN value of each failure mode can be calculated by multiplying O, S, and D:
Then Failure modes can be prioritized based on RPN value. The higher the RPN value, the higher the risk level of the corresponding failure mode. Therefore, the most critical failure mode can be identified. Finally, according to the ranking results, some targeted measures can be taken to prevent the occurrence of failure modes.
Linguistic Term Sets
The set is ordered: s
i
⩾ s
j
, if i ⩾ j; There is the negation operator: neg (s
i
) = s2t-i; Max operator: max(s
i
, s
j
) = s
i
, if s
i
⩾ s
j
; Min operator: min(s
i
, s
j
) = s
i
, if s
i
⩽ s
j
.
When language information is fused, the results usually cannot match the elements in the original linguistic term set. Therefore, to fully contain and preserve language information, Xu [39] extended the discrete linguistic term set S to a continuous term set
To deal with the uncertainty in decision-making, Xu proposed uncertain linguistic variables [40]:
Linguistic scale function
The linguistic scale functions can be used to convert linguistic terms into numerical values and assign different semantic values to linguistic terms, which helps to use data more effectively and express semantics more flexibly.
1) The following function is mapped based on the subscript function. And the evaluation scale of the original language is averaged. The expression is as follows:
2) The following function is mapped based on the exponential scale, and the decision preference of the decision maker is considered. The expression is as follows:
Interval-valued linguistic Z-numbers (IVLZNs)
The Interval-valued linguistic Z-number set is simplified as an Interval-valued linguistic Z-number (IVLZN) z
i
= (A
i
, B
i
), and
Interval-valued Linguistic Z-numbers Operations
According to the operation results, the results obtained based on the above operators are also IVLZNs, and the operations satisfy the following properties:
(1) According to operations (1) and (2), the properties (1) and (2) can be easily proved.
(2) For Property (3), since
where
According to operation (3), we can get
where
Thus, λ (z i ⊕ z j ) = λz i ⊕ λz j (λ > 0), which completes the proof of property (3).
Similar to property (3), properties (4)-(8) can be proved, which are omitted here.
Comparison Method for IVLZNs
The accuracy function of z i can be defined as follows:
When When S (z
i
) > S (z
j
) or S (z
i
) = S (z
j
) and H (z
i
) > H (z
j
), z
i
is greater than z
j
, denoted by z
i
≻ z
j
; When S (z
i
) = S (z
j
) and H (z
i
) = H (z
j
), z
i
equals z
j
, denoted by z
i
∼ z
j
; When S (z
i
) = S (z
j
) and H (z
i
) < H (z
j
) or S (z
i
) < S (z
j
), z
i
is less than z
j
, denoted by z
i
≺ z
j
.
In this section, the distance measurement of IVLZNs is proposed by referring to the distance measure formula of language Z-numbers [15].
Generally, a distance measure should satisfy three properties to be reasonable and effective [43]. The distance measure of Definition 10 satisfies following three axioms.
d (z
i
, z
j
)⩾ 0, ifandonly z
i
= z
j
, d (z
i
, z
j
) = 0 ; d (z
i
, z
j
) = d (z
j
, z
i
) ; d (z1, z2) + d (z2, z3) ⩾ d (z1, z3) .
Thus, Equation (6) satisfies property (3).
(IVLZNWAA) operator is defined as follows:
In particular, if ω = (1/n, 1/n ⋯ , 1/n) T , then the IVLZNWAA operator degrades to the IVLZNAA operator.
(2) When n = k, Equation (7) can hold as the following equation.
(3) When n = k+1, we can get
Obviously when n = k+1, Equation (7) also holds. Thus, Equation (7) can hold for any i.
(1) Idempotency: suppose z = ([a l , a u ] , B), if z i = z (i = 1, 2, ⋯ , n), then IVLZNWAA (z1, z2, ⋯ z n ) = z;
(2) Boundedness: suppose the minimum and maximum IVLZN in
as
(3) Monotony: if
(2) Since the minimum and maximum IVLZNs in
(3) Since
The Proposed FMEA Model
In this section, we construct a new FMEA model based on the IVLZNs-VIKOR method to solve the FMEA problem. Figure 1 shows the operation process of the proposed model. In general, the operation of the model consists of three stages: Obtain the IVLZNs risk evaluation matrix; Obtain the collective evaluation matrix; Obtain the priority ordering of failure modes.
Next, we make the basic assumptions of the FMEA problem and introduce the detailed steps of the proposed model. For a risk assessment problem, suppose there are m identified failure modes FM
i
(i = 1, 2, ⋯ , m) and n risk factor RF
j
(= 1, 2, ⋯ , n). And qexperts TM
p
(p = 1, 2, ⋯, q)form an FMEA team to assess the risk. Experts use two linguistic term setsS ={ s0, s1, ⋯ , s2t } and S′ =
Collect the original risk evaluation information of experts and convert it into IVLZNs evaluation matrix
Step 2.1 Calculate the distance from the individual evaluation matrix to the positive ideal decision matrix by the following Equation (8):
The average decision matrix can reasonably represent the risk assessment level of all experts for failure modes. Therefore, to ensure group consistency, the average decision matrix is taken as the positive ideal decision matrix. The positive ideal decision matrix is defined as follows:
Step 2.2 Determine the expert weight based on the relative distance between the individual decision matrix and the positive ideal decision matrix.
Step 2.3 Aggregate the individual evaluation matrix according to expert weight. Obtain collective evaluation matrix Z = (z ij ) m×n by IVLZNWAA operator.
Step 3.1 Determine the relative weight of risk factors
This paper uses the maximum deviation method to obtain the relative weight of risk factors. The maximum deviation method [44] is very popular in multi-attribute decision-making problems and is often used to determine the objective weight of attributes. The central idea is that if there is little difference in the attribute value of each scheme under a certain attribute, then the attribute will play a small role in the ranking results of alternatives. The attribute will be given a smaller weight. On the contrary, if the attribute values of each scheme vary greatly under a certain attribute, indicating that the attribute plays an important role in the final selection of the optimal scheme, then this attribute will be given a larger weight.
Similarly, in the FMEA risk assessment, if the difference between the risk values of each identified failure mode in a certain risk factor is very small, it means that the risk factor has little influence on the final failure mode risk priority ranking, and the risk factor is given a smaller weight. On the contrary, give more weight.
Under the risk factor RF j , the deviation between the failure mode FM i and other failure modes can be obtained by the distance formula proposed in this paper:
Based on the idea of the maximum deviation method, we can establish the following nonlinear optimization models:
By solving the model, the weight of the risk factor RF j can be calculated by Equation (14):
Step 3.2 Calculate the comprehensive risk values of failure modes using the IVLZNs-VIKOR method.
Step 3.2.1 Determine the positive ideal solution
Step 3.2.2 Calculate the group utility value S i and individual regret value R i of each failure mode:
Step 3.2.3 Calculate the closeness coefficient for each failure mode:
Step 3.3 Rank the failure modes in ascending order of S i , R i , Q i . Get the optimal solution or a set of compromise solutions. If the following two conditions are met, the failure mode with the highest risk can be obtained by sorting according to the minimum Q value [45]:
And DQ = 1/(m - 1), m is the number of failure modes.
If the above two conditions cannot be met at the same time, then a set of compromise solutions is proposed:
If condition 2 is not satisfied, FMσ(1) and FMσ(2) are compromise solutions;
If condition 1 is not satisfied, then FMσ(1), FMσ(2), ⋯ , FMσ(M)are compromise solutions;FMσ(m) is determined by the relation Q (FMσ(M) - FMσ(1)) < DQ for maximum M.
Implementation
An airline company intends to analysis the failure modes and effects of the aircraft landing systems. After analyzing the system structure and previous data, 10 high-risk failure modes were first identified for further analysis, which is denoted as FM1, FM2, ⋯ , FM10. An FMEA team composed of three experts(TM1, TM2, TM3)was established to complete the risk assessment of failure mode, to identify the most critical failure mode of the aircraft landing system. The FMEA decision-making process based on the IVLZNs-VIKOR method is as follows.
Collect the original risk evaluation information of experts and convert it into IVLZNs evaluation matrix
Step 2.1 Calculate the distance from the individual evaluation matrix to the positive ideal decision matrix. Via Equation (9), the average decision matrix can be computed as shown in Table 2. Then the distance can be calculated by Equation (8) as follows:
Step 2.2 Determine the expert weight based on the relative distance between the individual decision matrix and the positive ideal decision matrix according to Equation (10). The calculation results are as follows:
The IVLZNs evaluation matrix by the FMEA team members
The IVLZNs evaluation matrix by the FMEA team members
The average decision matrix
Step 2.3 Aggregate the individual evaluation matrix according to expert weight the of Step 2.2 and by Equation (11), the collective evaluation matrix can be calculated using IVLZNWAA operator formula, as shown in Table 3.
The collective evaluation matrix
Step 3.1 Determine the relative weight of risk factors
According to Equations (12) and (13), nonlinear optimization models are established as follow
Next, solve the model. By Equation (14), the relative weight of O, S, and D is calculated as w = (w O , w S , w D ) = (0.19, 0.42, 0.39).
Step 3.2 Calculate the comprehensive risk values of failure modes using the IVLZNs-VIKOR method.
Step 3.2.1 According to Equations (15) and (16), the positive ideal solution and the negative ideal solution are determined as
Step 3.2.2 Calculate the group utility value S i and individual regret value R i of each failure mode by using Equations (17) and (18).
Step 3.2.3 Calculate the closeness coefficient for each failure mode. Since the worst solution of individual regret value mostly occurs in risk factors S and D, the relative weight of S and D is relatively large, and the FMEA itself is concerned about risk, the value of v is set as 0.3 in this paper, giving greater weight to individual regret value. The results are presented in Table 4.
The values of S i , R i , and Q i for all failure modes
Step 3.3 Rank the risk priorities of each failure mode according to S i , R i , and Q i , and the results are illustrated in Table 5.
Ranking of all failure modes according to S i , R i , and Q i
By ranking S i , R i , and Q i , according to the rules described in Section 4, Q6 -- Q2 = 0.107 < 0.111, Q8 -- Q2 = 0.127 > 0.111. Therefore, the compromise is FM2 and FM6.
The sensitivity analysis of the parameter v is performed to explore the influence of changing values of v on the risk priority ranking of failure modes. v is the weight of the maximum group utility. In the practical example, the value of v is determined by the preference of the decision-makers. If v > 0.5, it means that decision-makers prefer to maximize group utility; ifv < 0.5, it suggests that decision-makers prefer to minimize individual regret; if v = 0.5, it means to balance group maximum utility and individual minimum regret according to consensus.
Figure 1 shows the ranking results of failure modes as v take different values in the interval from 0 to 1. As can be seen, the ranking orders of FM7, FM9, and FM10 are not sensitive to the value of v. It suggests that their risk priorities of them are the same when considering group utility maximization and individual regret minimization. In addition, the ranking orders of FM1, FM2, FM3, and FM8 decrease as the value of v increases, indicating that their risk priority is decreased when decision-makers focus more on group utility maximization. And the ranking of FM2 has a smaller variation as the value of v increases from 0 to 0.9, which means that its risk level is high regardless of the pay more attention is to group utility or individual regret. The ranking orders of FM4, FM5, and FM6 increase as the value of v increases, which means that FM4, FM5, and FM6 have a higher level of risk when decision-makers focus on maximum group utility. The results of sensitivity analysis prove that the proposed model can fully consider the group utility value and individual regret value. Especially for problems like FMEA, which focuses on risk, the model can meet the risk preference of decision-makers by adjusting the parameter.
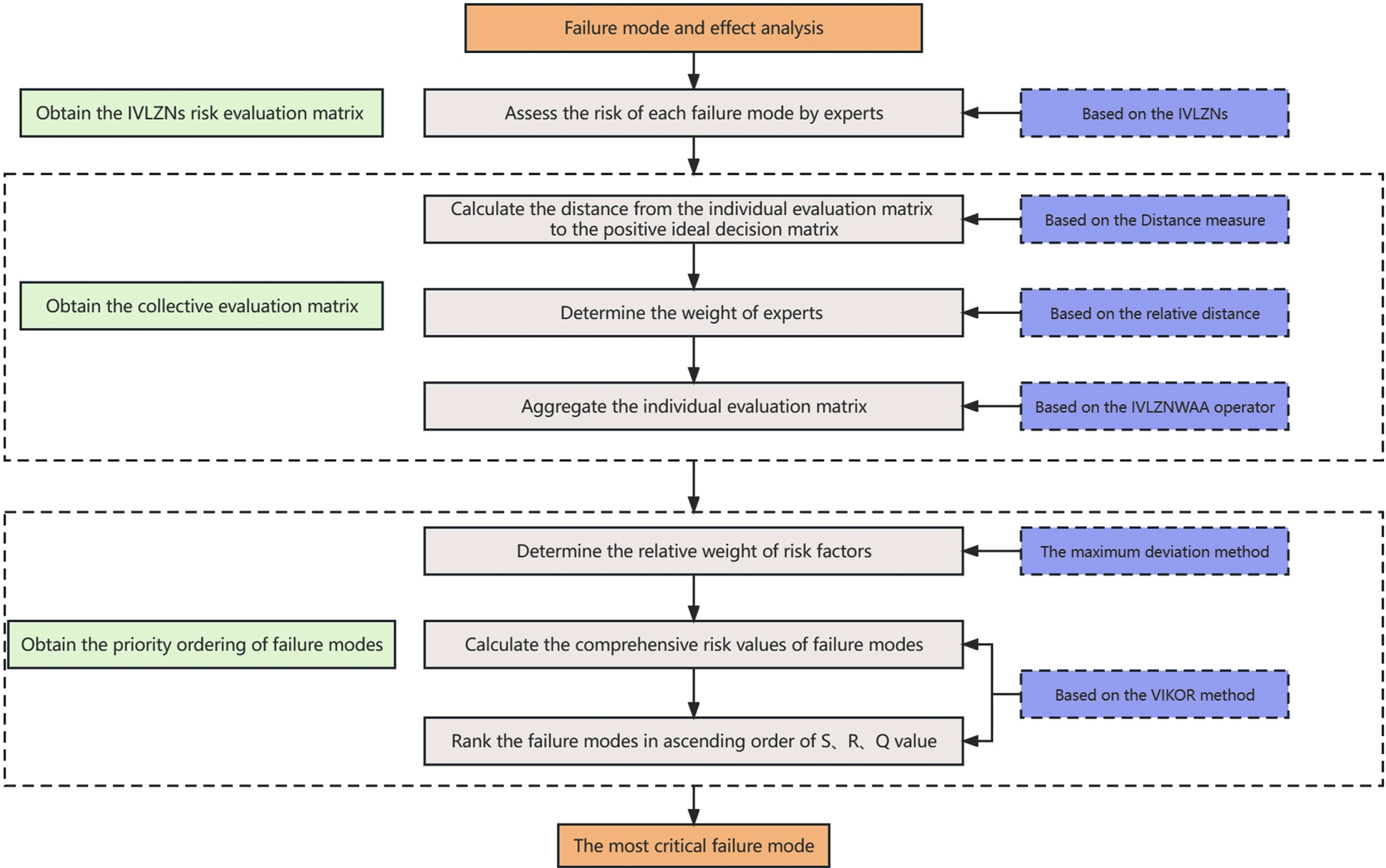
Procedure of the proposed FMEA model.
To prove the feasibility and effectiveness of the method proposed in this paper, different methods are applied to the above numerical examples for comparative study. The traditional FMEA method and the TOPSIS method based on Z-number distance measurement in this paper are selected for the comparison analysis. The traditional FMEA method sorts the failure modes according to the RPN value obtained by direct multiplication of attribute values. The TOPSIS method is based on the distance measure proposed in this paper to calculate the degree of proximity to the positive ideal solution to sort the failure modes. The sorting results of different methods are shown in Fig. 3.
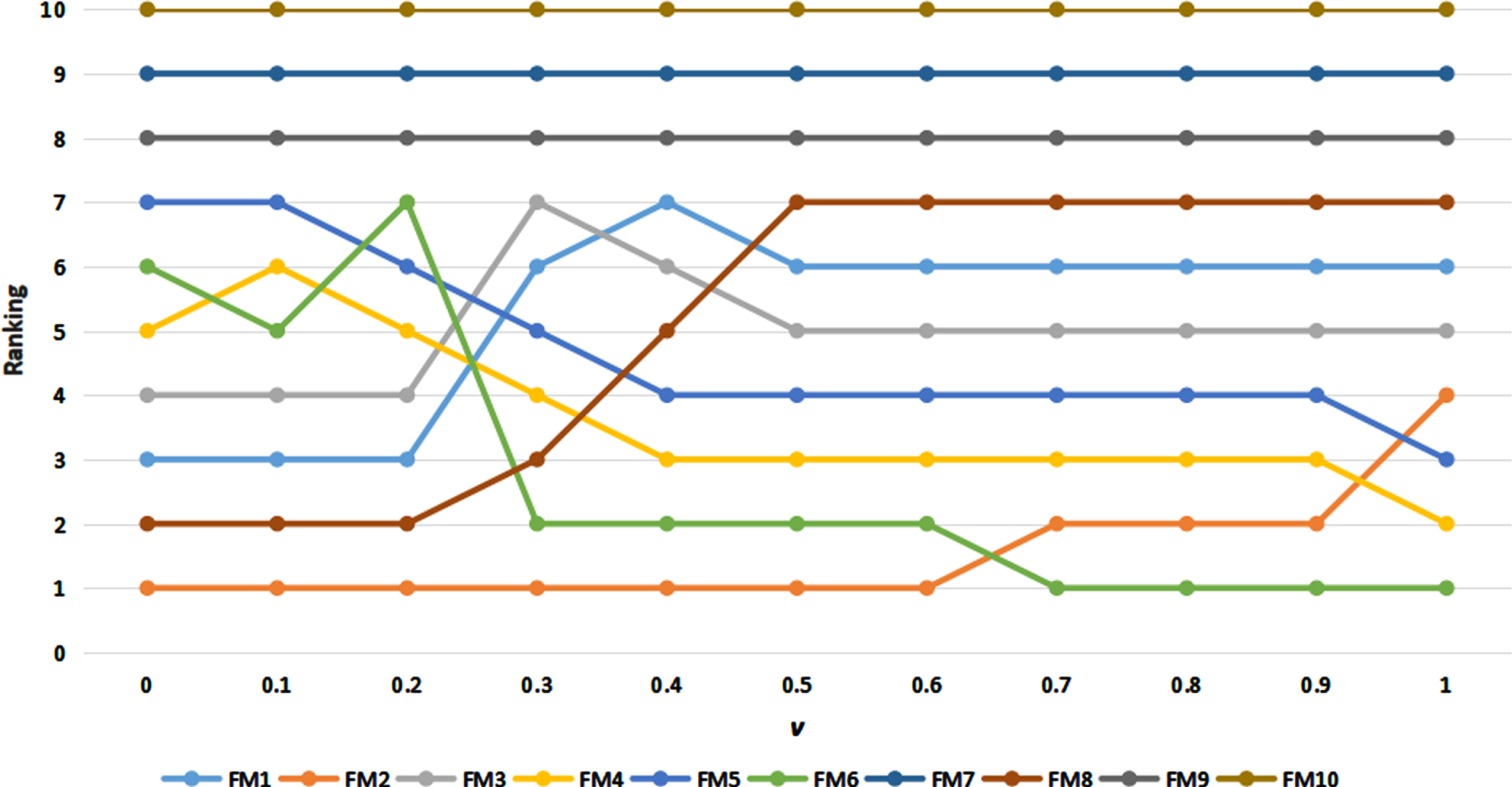
Variation of failure modes’ ranking as the weight v changes.
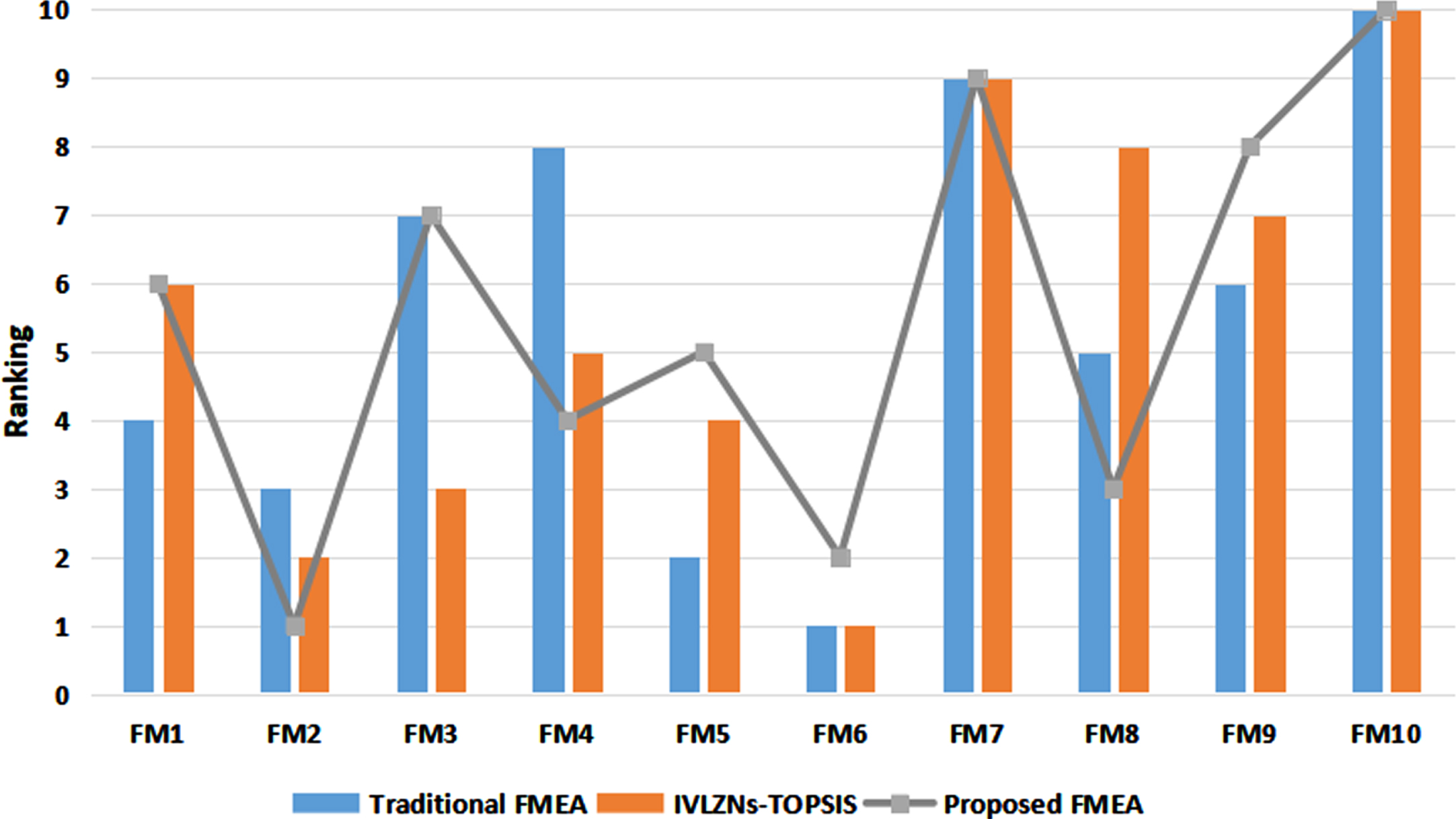
Ranking results by different FMEA methods.
As can be seen, the ranking results obtained from the above methods are inconsistent with the results obtained by the proposed method. The difference in rankings can be explained by the following reasons:
1) Although the traditional FMEA method is used in the same language environment as this paper, the traditional FMEA method does not consider expert weight and attribute weight. And the RPN value is obtained by multiplying three risk values directly, which is unreasonable. However, the proposed method is based on distance measures to calculate expert weight, which guarantees the consistency of expert cognition. At the same time, the maximum deviation method is used to construct an optimization model to solve the attribute weight, taking into account the relative importance of risk factors. In addition, the sorting mechanism of the two methods is different, the VIKOR method is utilized to rank the failure mode in the proposed model of this paper.
2) The TOPSIS model based on distance measure in this paper emphasizes that the optimal solution should be as close to the positive ideal solution as possible and as far away from the negative ideal solution as possible. However, the proposed method of this paper is based on the VIKOR method to rank, which emphasizes the maximum group utility and the minimum individual regret.
Based on the above analysis, the advantages of the proposed method are summarized as follows: The proposed method in this paper is based on the IVLZNs environment. It not only retains the good attribute of Z-numbers to measure the reliability of the information but also improves the Z-numbers. IVLZNs can meet the needs of decision-makers to express evaluation with linguistic information, which is more in line with the habits of decision-makers. At the same time, IVLZNs generalize the first component of Z-numbers to the interval value, which further expresses the uncertainty of the decision. The proposed method in this paper uses the linguistic scale function to transform qualitative language evaluation information into quantitative data, which can fully preserve the ambiguity of the original information. In addition, two different linguistic scale functions are selected to deal with the two components of Z-numbers respectively, which conforms to the different semantic environments in practical decision making. Therefore, it is more flexible when dealing with language decision problems. The IVLZNs operation rules, comparison method, distance measure, and aggregation operator defined in this paper provide effective tools for multi-attribute decision-making in the IVLZNs environment. Based on this, a new FMEA model is established. in which the expert weight is obtained by the relative distance from the ideal solution, and the individual evaluation matrix is aggregated by the aggregation operator. The VIKOR method is applied to obtain the risk priority for failure modes, taking into account the decision maker’s risk appetite.
It must be admitted that this paper uses the linguistic scale function to convert qualitative information to quantitative data, which involves a lot of calculations of the linguistic scale function and its inverse function, which makes the calculation process more complicated. However, the amount of computation can be reduced by using some programming tools, such as R and MATLAB.
In the increasingly complex decision environment, using Z-numbers to represent decision information can measure the fuzziness and reliability of decision information at the same time. Based on the good performance of Z-numbers, this paper defined the IVLZNs and put forward its operation rules, comparison method, aggregation operator, and distance measure formula. Under the IVLZNs environment, a new FMEA model was constructed. Firstly, IVLZNs were applied to express experts’ evaluation information. Next, a distance measure was used to obtain the expert weight, and the individual evaluation matrix was aggregated by the IVLZNWAA operator. After that, the VIKOR method with IVLZNs was used to acquire the risk priority ranking of failure modes, in which the relative importance of risk factors was calculated by the maximum deviation method. Finally, a case study about the failure mode and effect analysis of the aircraft landing systems was given. A sensitivity analysis and comparison analysis was conducted to demonstrate the flexibility and effectiveness of the proposed method.
The main contributions of this study can be summarized as follows. First, this paper defined the IVLZNs, which expands the theoretical system of Z-numbers and enriches the fuzzy decision theory. Second, the algorithm rules, comparison method, aggregation operator, and distance measurement are proposed, which provide effective mathematical tools for constructing more multi-attribute decision-making methods. Third, based on the distance measure of IVLZNs, the classical VIKOR method is extended, and the IVLZNs-VIKOR method is applied to the construction of a new FMEA model. It not only enriches and develops the VIKOR method but also provides a new tool for prioritizing failure modes in the IVLZNs environment. Finally, the proposed method is proved to be flexible, and the ranking results can be changed according to the risk preference of decision makers to meet the decision needs.
The proposed method is easy to calculate, but involves frequent conversion of the linguistic scale function and its inverse function, resulting in a large amount of computation. In the future, the model can be developed by R and other programming tools to achieve fast operations. In addition, this paper applies the proposed method to the risk evaluation of the aircraft landing systems, and we will apply the proposed model to more practical multi-criteria decision-making problems for future study, for example, when the financing company has several alternative loan repayment plans [46], the most suitable plan can be determined by using the proposed method through expert evaluation. Finally, exploring different distance and similarity measurements of IVLZNs is a direction for future research.