
Abstract
Accurate identification and monitoring of aircraft on the airport surface can assist managers in rational scheduling and reduce the probability of aircraft conflicts, an important application value for constructing a "smart airport." For the airport surface video monitoring, there are small aircraft targets, aircraft obscuring each other, and affected by different weather, the aircraft target clarity is low, and other complex monitoring problems. In this paper, a lightweight model network for video aircraft recognition in airport field video in complex environments is proposed based on SSD network incorporating coordinate attention mechanism. First, the model designs a lightweight feature extraction network with five feature extraction layers. Each feature extraction layer consists of two modules, Block_A and Block_I. The Block_A module incorporates the coordinate attention mechanism and the channel attention mechanism to improve the detection of obscured aircraft and to enhance the detection of small targets. The Block_I module uses multi-scale feature fusion to extract feature information with rich semantic meaning to enhance the feature extraction capability of the network in complex environments. Then, the designed feature extraction network is applied to the improved SSD detection algorithm, which enhances the recognition accuracy of airport field aircraft in complex environments. It was tested and subjected to ablation experiments under different complex weather conditions. The results show that compared with the Faster R-CNN, SSD, and YOLOv3 models, the detection accuracy of the improved model has been increased by 3.2%, 14.3%, and 10.9%, respectively, and the model parameters have been reduced by 83.9%, 73.1%, and 78.2% respectively. Compared with the YOLOv5 model, the model parameters are reduced by 38.9% when the detection accuracy is close, and the detection speed is increased by 24.4%, reaching 38.2fps, which can well meet the demand for real-time detection of aircraft on airport surfaces.
Introduction
With the rapid development of the aviation industry, the airport area is expanding, the flight flow is increasing rapidly, the runway, taxiway, apron, and other airport traffic conditions are becoming more and more complex, and the probability of aircraft conflicts on the airport surface is also increasing, which has put forward higher requirements on the operational safety and efficiency of the airport [1]. In recent years, various countries are paying more and more attention to the construction of "intelligent airports," especially some airports currently under construction or renovation are beginning to introduce some technological means to enhance security measures, and airport surface aircraft detection as an important part of the construction of intelligent airports, but also gradually began to be attached to people [2]. Accurate identification and detection of aircraft on the airport surface can assist managers in rational scheduling and reduce the probability of aircraft conflicts on the airport surface. Currently, most aircraft detection is focused on aircraft detection in remote sensing images [3, 4]. The difference between airport surface aircraft detection and remote sensing image aircraft detection is that the surveillance image of the airport surface does not capture the complete outline of the aircraft as the remote sensing aerial image does. The aircraft in the airport surface video surveillance will vary in size and attitude [5]. Moreover, of the different weather conditions (snow, rain, fog, night), the impact of monitoring equipment to monitor the clarity of the target will also be relatively low, which significantly increases the difficulty of the airport surface aircraft target detection.
To address the above problems, this paper proposes a lightweight aircraft recognition model for airport field in complex environments. First, we design a new lightweight feature extraction network with five feature extraction layers, each consisting of two modules, Block_A and Block_I. The Block_A module incorporates a coordinate attention mechanism and a channel attention mechanism. The coordinate attention mechanism enables the network to focus on a larger range of location information, which helps the model to better localize and identify the target. The channel attention mechanism is used to enhance feature extraction for small targets in images. The Block_I module is mainly used for feature map scaling, and uses a multi-scale feature map fusion method to generate feature maps with rich semantic information to enhance the feature extraction capability of the network. Secondly, the designed feature extraction network, is applied to the SSD target detection network, and the SSD network is improved to increase the target recognition accuracy. The lightweight recognition model proposed in this paper has been proved experimentally to accurately recognize the aircraft in the airport field under the complex environment, and the detection speed is superior, which can well meet the demand of real-time detection of aircraft in the airport field.
The main contributions of this paper are as follows:
(1) We design a new lightweight feature extraction network, which incorporates an attention mechanism into the feature extraction network to help us obtain richer semantic information of the original image and fully extract the aircraft features of the airport scene in complex environments.
(2) We improved the SSD network and applied the design feature extraction network to it, which improved the accuracy of target detection and was able to effectively identify the airplanes in the airport field.
(3) Our improved recognition model is lightweight, which allows our model to be deployed on resource-constrained devices, which will further promote the application of computer vision in the field of smart airport construction.
Related work
In recent years, target detection methods based on convolutional neural networks have worked very well in different application areas. For example, face recognition [6, 8– 10], pest recognition [10–13], defect detection [14–16], medical image pathology detection [17–19], and target detection in remote sensing images [20–22]. The commonly used target detection methods are mainly divided into two categories: one is one-stage detection algorithms, mainly YOLO [23], SSD [24], YOLO9000 [25], YOLOv3 [26], and so on; the other is two-stage detection algorithms, mainly R-CNN [27], Fast R-CNN [28], Faster R-CNN [29], SPPNet [30], and so on. The SSD algorithm borrows ideas from Faster R-CNN and YOLO: from the regression-based model in YOLO, which directly regresses the class and location of objects, and from the design of regions in Faster R-CNN, which outputs feature maps of varying scale sizes for detection. The original SSD algorithm uses low-level feature maps to recognize small targets, resulting in low recognition accuracy. Improvements to the SSD algorithm for the problem of insufficient detection of small targets focus on using different feature extraction networks and adding attention mechanisms in the network. Different feature extraction networks can achieve different results according to their characteristics. The feature extraction networks commonly used in SSD algorithms include VGG [31], ResNet [32] and MobileNet [33]. ResNet increases the network depth compared to VGG and can improve the feature extraction ability. Fu et al. [34] designed the DSSD network, and Yi et al. [35] designed the ASSD network to use Residua-101 instead of VGG as a feature extraction network to improve the detection accuracy of small targets. However, the use of Residua-101 as a feature extraction network leads to a large number of training parameters and reduced detection speed. MobileNet is a lightweight feature extraction network that is superior in terms of model parameters and inference speed. Chiu et al. [36] used MobileNet-v2 [37] as a feature extraction network for the SSD algorithm in order to meet the requirements of running on an embedded platform, which improved the detection speed. However, the feature extraction capability of MobileNet-v2 is not as good as that of ResNet, resulting in insufficient detection capability for small targets.
Attention mechanisms [38–42] have been proposed and widely used based on human retinal properties. The attention mechanism can enhance the performance of the model by assigning dynamic weighting parameters to reinforce key information according to its importance. The main attention mechanisms commonly used in the field of computer vision are the channel attention mechanism [38, 43– 45], the spatial attention mechanism [39, 46– 48], and the attention mechanism with channel and spatial fusion [41, 50]. A typical channel attention mechanism is the Sequeeze and Excitation Net (SENet) [38], which captures the importance of each channel of the feature map and then uses this importance to assign a weight value to each feature, thus allowing the neural network to focus on specific feature channels. A representative work of spatial attention mechanism is Spatial Transformer Network (STN) [39], where not all regions in the image contribute equally crucial to the task in target detection, and STN can focus on the focused regions relevant to the task. Channel attention focuses the network on the "what" of the image, while spatial attention focuses on the "where" of the object in the image. Sanghyun et al. [41] proposed a new Convolutional Block Attention Module (CBAM) in 2018, which merges channel attention with spatial attention. To solve the problem that ordinary attention mechanisms cannot be applied to mobile networks, Hou et al. [51] proposed Coordinate Attention (CA) in 2021, which allows mobile networks to acquire information about more significant regions without introducing large overheads by embedding location information into channel attention.
In the field of aircraft detection on airport surfaces, fewer papers are available due to the specificity of industry data. The complexity of the airport surface environment poses a significant challenge to the accuracy of aircraft detection. For the problem of incomplete target contour and varying attitude in aircraft detection, Dai et al. [52] proposed a static aircraft detection method based on Faster R-CNN and multi-part combination for airport surface. Li et al. [5] proposed an airport aircraft detection method based on the part model and distance tradeoff to improve detection accuracy. To address the problem that some aircraft targets in aircraft detection are more difficult to detect when they are small, Guo et al. [53] based on the YOLOv3 detection network, replaced the convolutional layer in the backbone network with the dilated convolution to maintain higher resolution and larger receptive field and improve the accuracy of the model for small target detection. Han et al. [54] proposed an airport surfaces small target detection algorithm based on Faster R-CNN and combined with multi-scale feature fusion. Li et al. [55] constructed a new feature extraction network RPDNet4, designed a four-scale prediction module, and used an adjacent scale feature fusion technique to fuse features at different abstraction levels to improve the detection accuracy of small targets of airport aircraft.
Materials and methods
SSD detection algorithm
The SSD detection algorithm uses a multi-layer feature map generation structure to learn semantic information hierarchically so that the low-level feature map can detect small targets and the high-level feature map detects large targets, and finally uses non-maximum suppression (NMS) to remove duplicate prediction box and keep the prediction box with the best results. The detection method using feature maps of different scales can significantly improve the target detection accuracy. The original SSD network uses VGG16 as the base model and then adds new convolutional layers to VGG16 to obtain more feature maps for detection. The structure of the SSD network is shown in Fig 1, which consists of two parts: the base network and the extended network. The algorithm uses the outputs of conv4_3, conv7, conv8_2, conv9_2, conv10_2, and conv11_2 layers as feature maps at different scales for detection. The sizes of their corresponding feature maps are 38×38×512, 19×19×1024, 10×10×512, 5×5×512, 3×3×512, and 1×1×256, respectively. Six feature maps of different sizes perform classification and location regression for objects of different sizes.
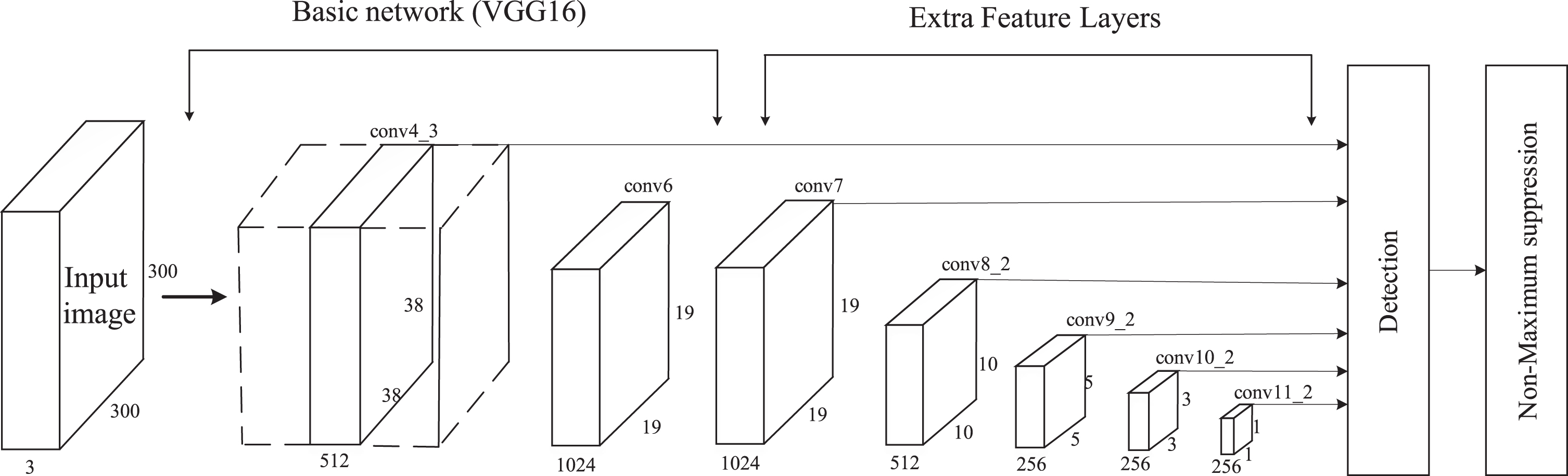
Original SSD network structure.
The original SSD detection algorithm loss function is divided into two parts: the weighted sum of the localization loss and the confidence loss, as shown in the formula (1).
In formula (1), Lconf (x, c) represents the confidence loss function, Lloc (x, l, g) represents the localization loss function, N represents the number of samples, α represents the weighting factor, x represents the matching information of the current search prediction box category, c represents the labeled category, l represents the search prediction box boundary coordinates, and g represents the labeled boundary box coordinates.
The localization loss function Lloc (x, l, g), as shown in the formula (2).
In formula (2),
The confidence loss function Lconf (x, c), as shown in the formulas (3) and (4).
In formulas (3) and (4),
As a new efficient attention mechanism, coordinated attention enables lightweight networks to obtain information about larger areas by embedding location information into channel attention, reducing the number of attention module parameters while avoiding excessive computational overhead. Its structure is shown in Fig 2.
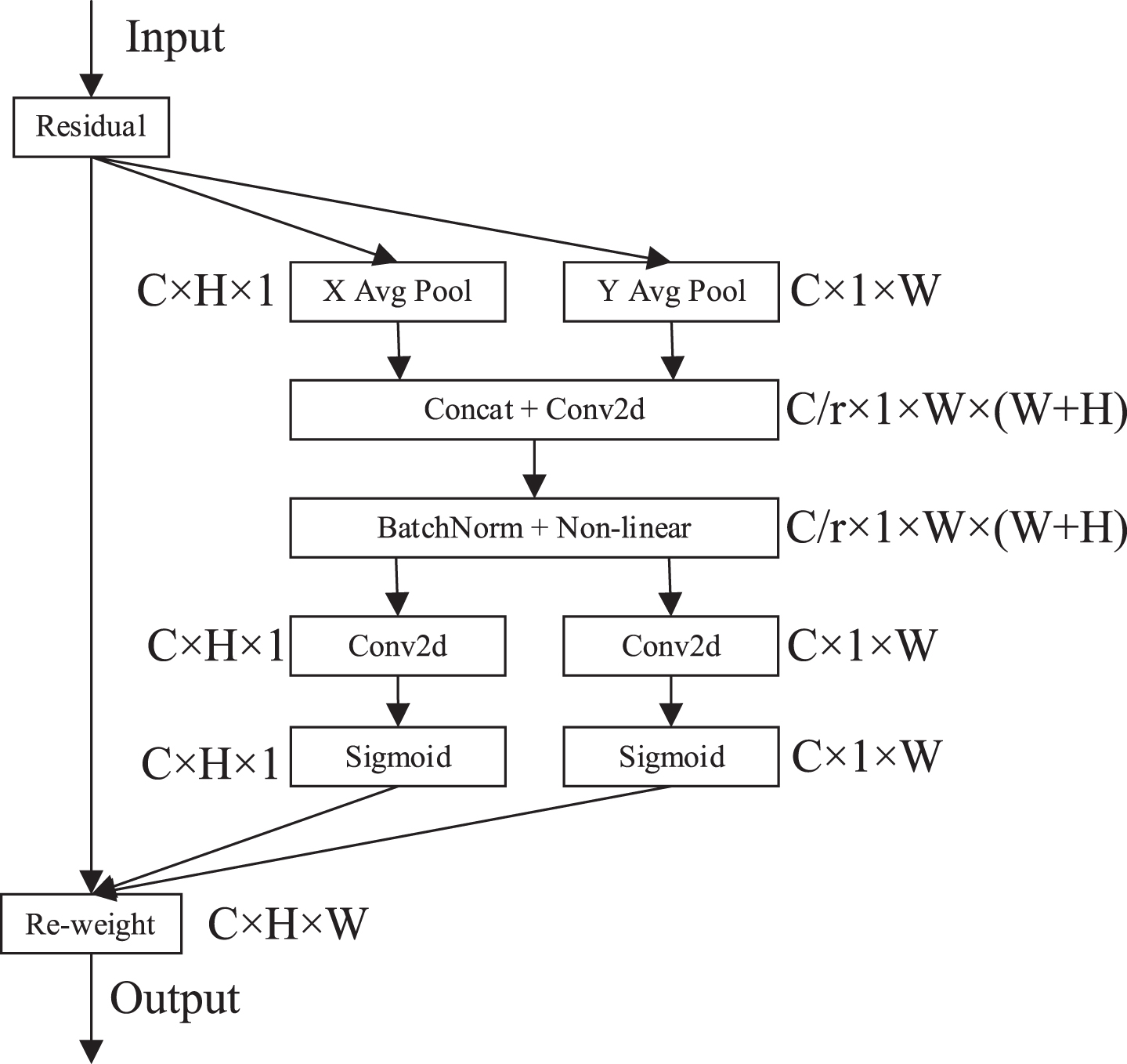
Coordinated attention structure.
The specific operation process of the CA module is as follows: Assume that the size of the input feature map is C×H×W (C represents the number of feature map channels, H represents the height of the feature map, and W represents the width of the feature map). The CA module first performs a global average pooling operation on the input feature map in the X and Y directions to obtain the feature maps in the X and Y directions, as shown in the formulas (5) and (6).
In formulas (5) and (6),
The feature maps output from the average pooling in the x-direction and the y-direction are concatenated and passed through a shared 1×1 convolutional transformation, followed by batch normalization processing and nonlinear activation operation to obtain the intermediate feature maps, as shown in the formula (7).
In formula (7), f represents the intermediate feature mapping obtained by encoding spatial information in horizontal and vertical directions, δ represents the nonlinear activation function, and F1 represents the 1 × 1 convolutional transform.
After normalization and nonlinear processing, f is cut into two independent tensors
Using this approach can reduce the model’s complexity and computational overhead. The obtained results are extended, and the matrix multiplication method is used to find the final attentional weight matrix. The final output of the coordinate attention module is shown in the formula (10).
The structure of our proposed feature extraction network MatbNet is shown in Fig 3, which consists of two main modules Block_A and Block_I (Fig 4 and Fig 5). The Block_A module consists of pointwise convolution, 3×3 depthwise convolution, Relu6 activation function, SE module, linear activation function, CA module, and summation operation. The Block_I module consists of 5×5 depthwise convolution, 3×3 depthwise convolution, Pointwise Convolution, Relu6 activation function, linear activation function, CA module, and summation operation.
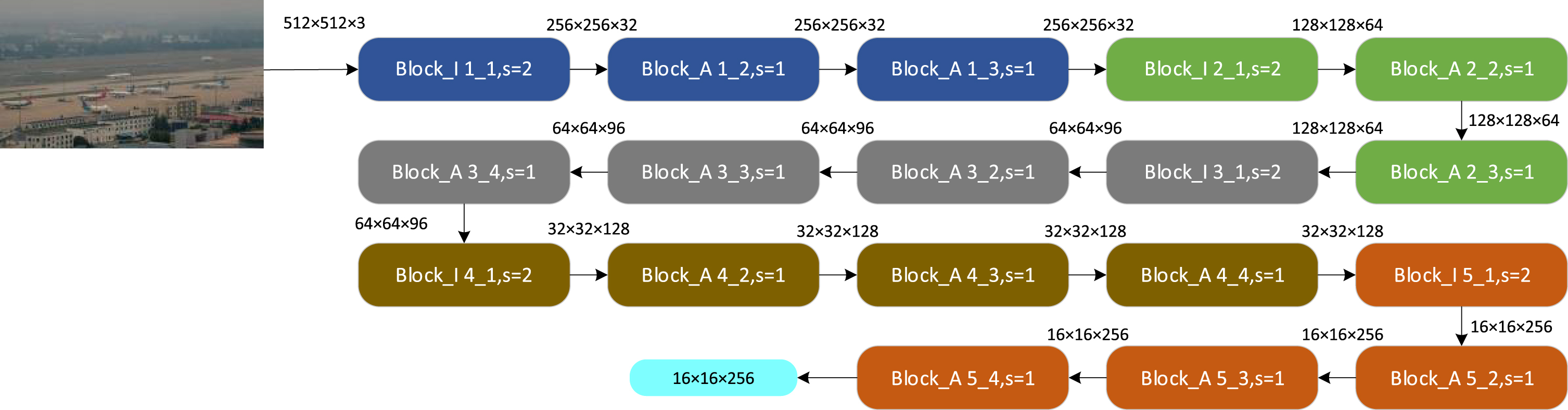
MatbNet feature extraction network.
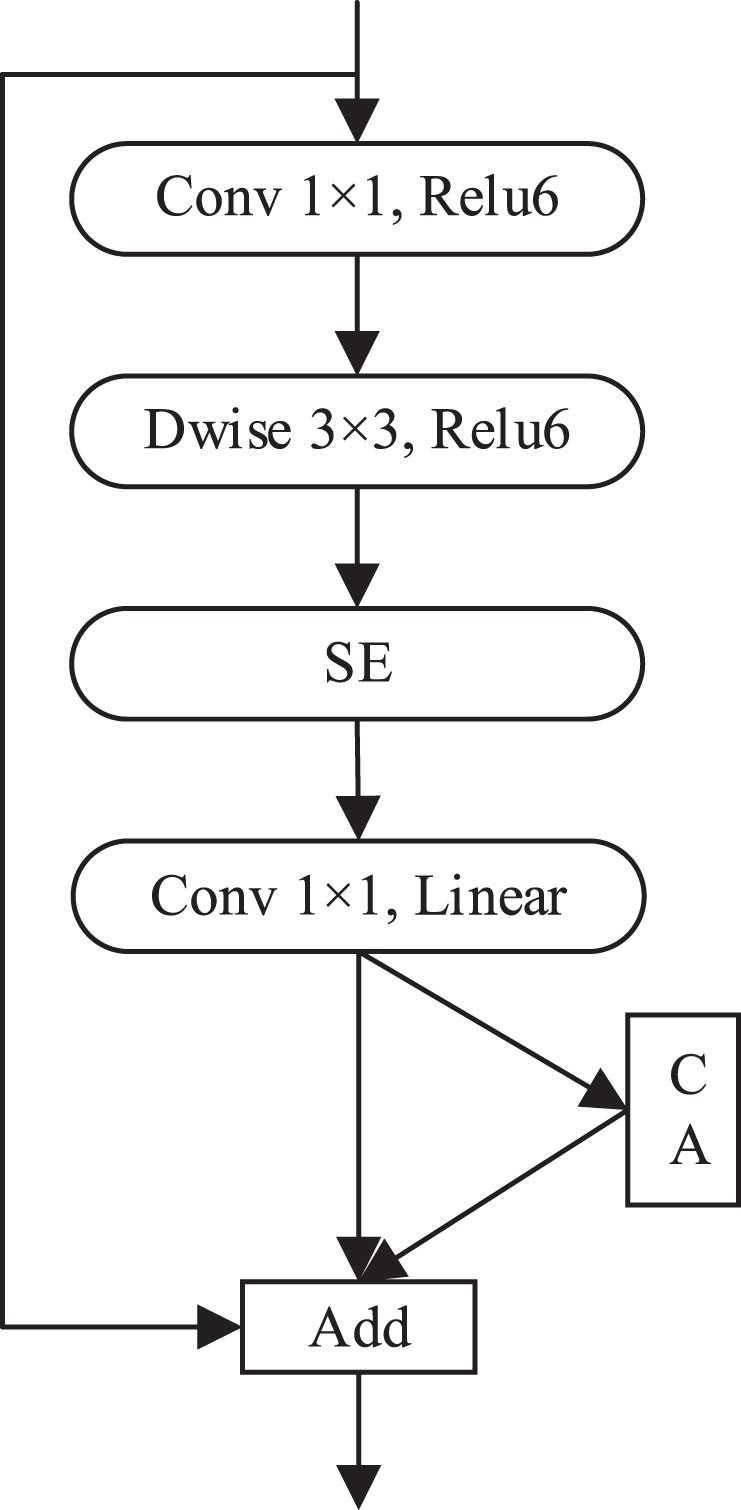
Block_A module.
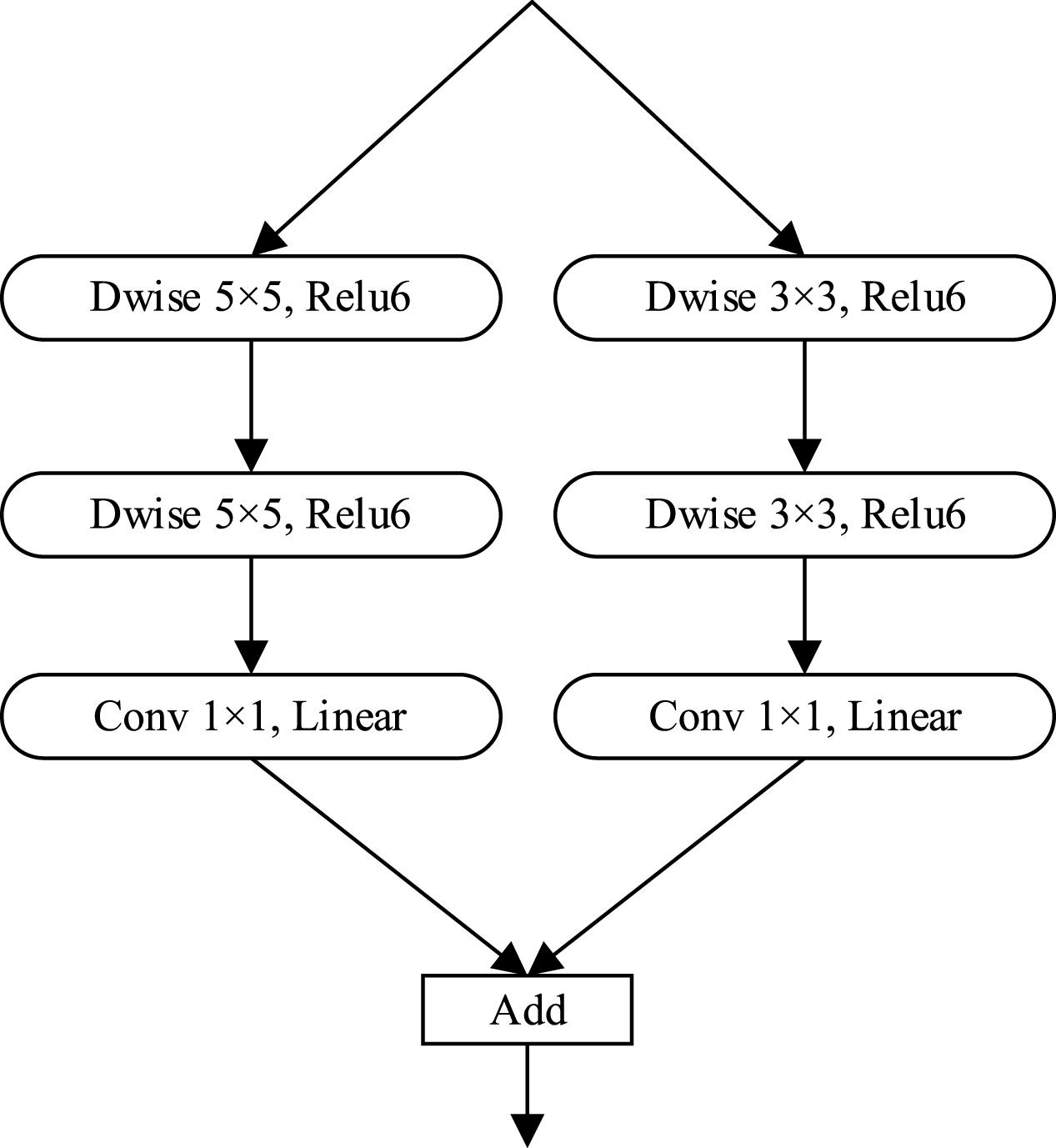
Block_I module.
The Block_A module is proposed based on the inverted residual block in MobileNet-v2. MobileNet-v2 uses depthwise convolution and pointwise convolution in depthwise separable convolution to replace ordinary convolution. The depthwise convolution performs convolution on each layer of the input feature map, and the number of convolution kernels corresponds to the number of channels of the input feature map. The pointwise convolution uses a 1×1 size convolution kernel, and the number of channels of the convolution kernel corresponds to the number of channels of the input feature map. For a 3×3 convolution kernel, the depthwise separable convolution structure can reduce the number of parameters by about nine times compared to regular convolution and is a lightweight network structure that can be better suited for embedded devices. After the inverted residual block’s pointwise convolution and linear activation, we add the CA module to encode channel relations and remote dependencies enables the network to focus on a larger range of location information.. The CA module can be used to improve the algorithm’s ability to learn and process details, enhance the extraction of aircraft features in the complex environment of the airport surface, and further improve the accuracy of aircraft detection on the airport surface. Many small targets exist when performing aircraft detection on airport surfaces. It has been demonstrated that the SE attention mechanism is more helpful for small target detection. We add the SE module to the proposed Block_A module to further enhance the detection of small targets on the airport surface. The Block_I module is proposed based on the inception module in GoogLeNet [56]. The original inception module contains more branching structures. Although it improves the model’s performance to some extent, the module introduces more parameters and increases the complexity of the computation. Considering the need for lightweight models, we propose a feature fusion module with two branching structures based on the inception idea. Using convolutional kernels of different sizes implies different receptive fields, and the summation operation allows different scale features to be fused, enabling more effective extraction of feature information.
The feature extraction network MatbNet is set up with five feature extraction layers in the direction from input to output. The different colored modules in Fig. 3 show the first to fifth feature extraction layers. The first and second feature extraction layers include a Block_I module and two Block_A modules, respectively, arranged in order from input to output. The third, fourth, and fifth feature extraction layers consist of one Block_I module and three Block_A modules, respectively, arranged in order from input to output. The specific parameter settings of the feature extraction network are shown in Fig 6.
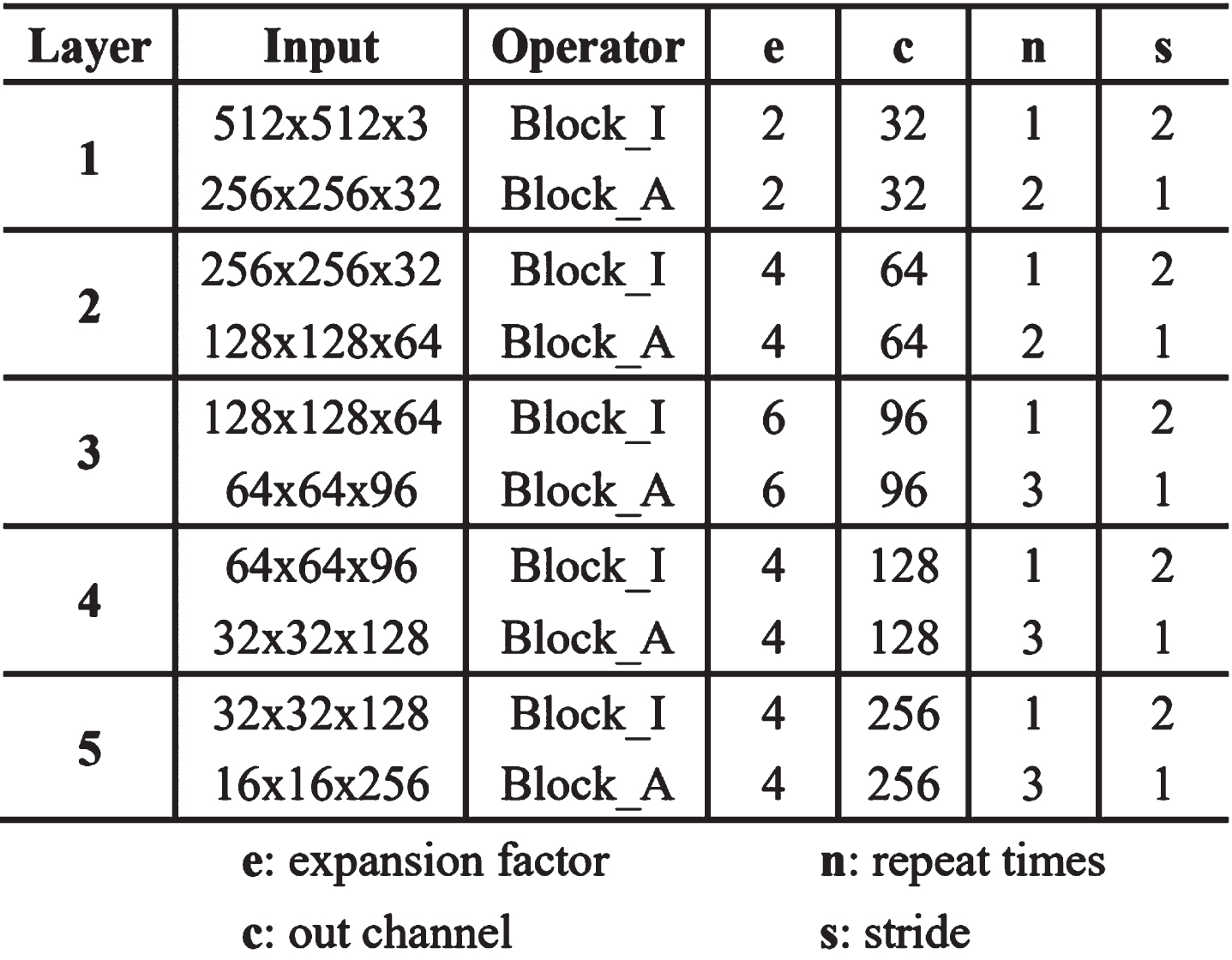
Parameter settings of feature extraction network.
For the first feature extraction layer, the parameter setting steps are as follows:
(1) An image with an input size of 512×512×3 passes through the Block_I module once, the step size s is 2, the number of output channels c is 32, the channel expansion factor e is 2, and the output size is a tensor of 256×256×32.
(2) Using the output result of (1), through a Block_A module, the step size s is 1, the output channel number c is 32, the channel expansion factor e is 2, and the output size is a tensor of 256×256×32.
(3) Using the output result of (2), through a Block_A module, the step size s is 1, the output channel number c is 32, the channel expansion factor e is 2, and the output size is a tensor of 256×256×32.
For the second, third, fourth, and fifth feature extraction layers, the parameter setting steps of the first feature extraction layer are the same.
The original SSD network resizes the input image to 300×300×3 and then performs the detection. In airport surface aircraft detection, if the image is resized to 300 × 300, most of the small target objects have only a few pixels or cause small targets to disappear, and the small target features are not apparent. This causes the accuracy of small target detection in the small target detection task not able to meet the task requirements. The improved SSD network (shown in Fig 7) resizes the input image to 512 × 512 × 3, making the feature map of the lower layer rich in small target features to facilitate enhanced detection of small targets. The lower-layer feature maps detect smaller targets, and the higher-layer feature maps are used to detect larger targets. Studies have demonstrated that the higher layer feature maps play a smaller role in performing detection tasks. Based on the characteristics of the airport surface aircraft detection dataset, the improved SSD network uses the output of five different scales of feature maps for the classification and location regression of objects of different sizes. The improved SSD network uses the proposed MatbNet feature extraction network as the base network. Then two new convolutional layers are added to the MatbNet network to obtain more feature maps for the detection task. The MatbNet feature extraction network outputs 64×64×96, 32×32×128, and 16×16×256 feature maps at three different scales, and the two newly added convolutional layers output 8×8×512 and 4×4×256 feature maps at two different scales.
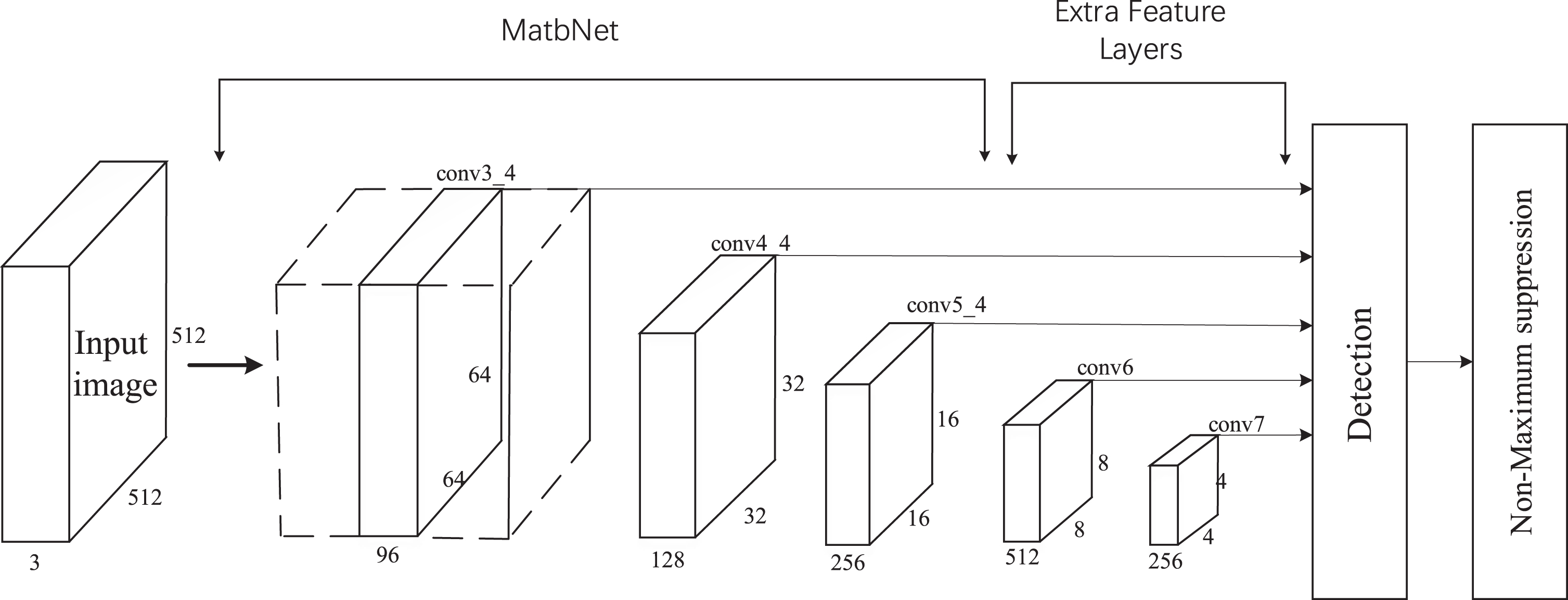
The improved SSD network.
Experimental dataset
The dataset used in the experiment is from the surveillance video of Zhengzhou Xinzheng International Airport. The acquired videos were pre-processed, and one image was extracted according to every 70 frames of video images, and 4146 images with four-pixel resolutions of 1920×1080, 1920×1200, 1858×974 and 640×640 were obtained. The images include images of different types of single-passenger aircraft, multiple-passenger aircraft, and other small target images, covering various complex weather conditions, including sunny, foggy, rainy days, snow, and night. The obtained images are labeled with the labelImg tool to make a VOC format dataset and generate the corresponding configuration files. The labeled dataset is divided according to a specific ratio: the training set contains 2984 images, the validation set contains 747 images, and the test set contains 415 images.
Experimental environment
The experimental environment is Ubuntu 18.04 operating system, Intel® Core TM i9-9900K processor, 32 GB RAM, RTX 2080Ti*2 GPU, deep learning framework using Pytorch 1.8, and general purpose parallel computing architecture CUDA 11.4. To speed up the convergence of the model during training, we used a migration learning approach, using a modified SSD network with 300 iterations on the PASCAL VOC2012 dataset to train a model to initialize the weights. The model is trained with the stochastic gradient descent (SGD) optimizer, the parameter selection momentum is set to 0.937, the weight decay is set to 0.0005, the initial learning rate is set to 0.01, the learning rate is dynamically adjusted during training, and the Num Workers in the training parameters is set to 4, the Batch Size is set to 16. The training is stopped when 500 epochs are reached. Fig 8 shows the loss values of the training set and the loss values of the test set during the model’s training.
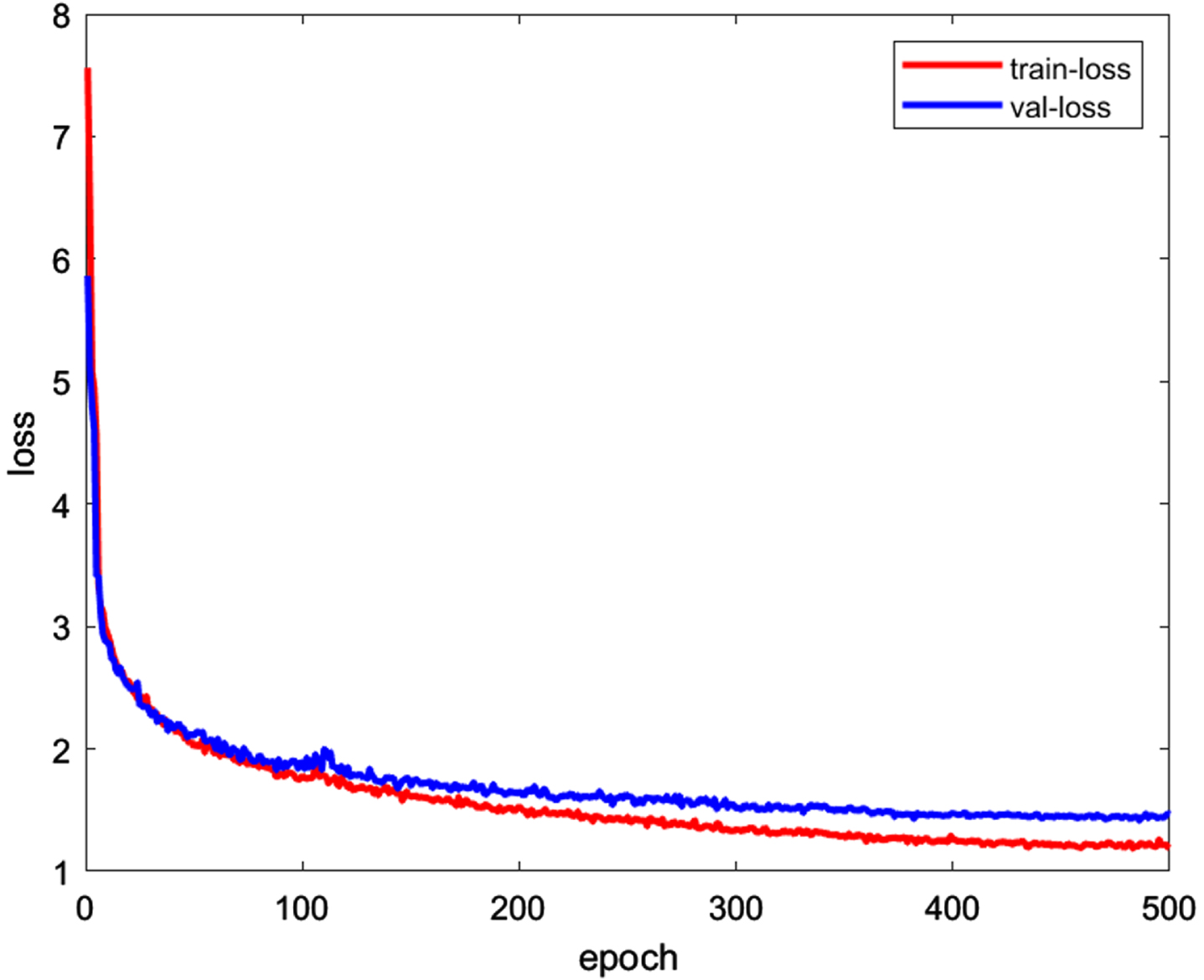
Model training loss.
In order to better evaluate the improved detection model in this paper, Average Precision(AP), mean Average Precision(mAP), and Frames Per Second(FPS) of processed images are used as evaluation criteria in the field of target detection. The AP values are derived from accuracy P and recall R to measure the accuracy of model detection. The accuracy rate represents the proportion of samples that are actually positive classes and are predicted to be positive classes to all predicted positive samples, as shown in formula (11). The recall rate represents the proportion of samples that are actually positive and are predicted to be positive to all samples that are actually positive, as shown in formula (12).
In formulas (11) and (12), TP represents the positive samples detected correctly, FP represents the positive samples detected incorrectly, and FN represents the negative samples detected incorrectly.
AP is calculated by integrating the curves of precision and recall. The higher the value of AP, the better the model’s performance, and its formula is shown in formula (13). The mAP is the average of each category of AP, which is used to measure the average detection accuracy of multiple targets. FPS is an essential measure of the real-time performance of the network, which indicates the number of frames processed per second, and the larger the FPS, the better the real-time performance.
Comparison experiments
In order to better show the advantages of the improved models, we conducted comparison experiments. The improved model is compared with Faster R-CNN, SSD, YOLOv3, and YOLOv5 models for the experiments. The models are trained and validated using the same dataset, and the results of the comparison experiments for each model in four aspects, AP, Recall, FPS, and model parameters, are shown in Table 1.
Comparison of the performance of different models
Comparison of the performance of different models
As shown in Table 1, compared with the Faster R-CNN model, the improved model has similar average precision and recall, but the number of frames per second to process images is five times higher than that of the Faster R-CNN, and the parameters of the model are about 1/6 of those of the Faster R-CNN. The improved model outperforms the YOLOv3 and SSD models in four aspects: average precision, recall, frames per second processed, and model parameters. YOLOv5 is slightly superior to the improved model regarding average precision and recall. However, the parameters of its model are about 1.6 times the parameters of our improved model, and the inference speed is slightly lower than that of the improved model. The average precision of the improved model detection is 95.6%, the number of frames per second of image processing is 38.2, and the model parameters are 25.6M, a lightweight detection network model that can meet the task requirements of real-time aircraft detection on airport fields.
To further validate the effectiveness of the improved model, the detection results of Faster R-CNN (Fig 9), SSD (Fig 10), YOLOv3 (Fig 11), YOLOv5 (Fig 12), and the improved model (Fig 13) are visualized under different environments.

Detection results of Faster R-CNN in different environments.

Detection results of SSD in different environments.

Detection results of YOLOv3 in different environments.

Detection results of YOLOv5 in different environments.

Detection results of the improved model in different environments.
Comparing with the sunny environment in part (a) of the figures, we can find that SSD, YOLOv3, and YOLOv5 have missed detection of small targets far away from the airport surface, and Faster R-CNN and the improved model have good detection effect. Comparing with the evening environment in part (b) of the figures, Faster R-CNN, SSD, and YOLOv3 do not extract enough semantic information to distinguish the background, and there is a missed detection due to the influence of the airport field lighting. In contrast, YOLOv5 and the improved model have better detection results. Comparing with the night environment in part (c) of the figures, Faster R-CNN, SSD, and YOLOv3 cannot identify the aircraft on the airport runway at night. In contrast, YOLOv5 and the improved model can identify them accurately. Comparing with the rainy environment in part (d) of the figures, SSD and YOLOv3 cannot perform accurate recognition for partially obscured aircraft. The Faster R-CNN, YOLOv5, and the improved model have good detection results. Comparing with the foggy environment in part (e) of the figures, Faster R-CNN, SSD, and YOLOv3 cannot recognize aircraft in fog, and YOLOv5 and the improved model can fully extract aircraft features in fog for accurate recognition. Comparing with the smoggy environment in part (f) of the figures, SSD and YOLOv3 cannot accurately identify aircraft with blurred images due to foggy weather. In contrast, Faster R-CNN, YOLOv5, and improved models detect them well.
In order to evaluate the performance of our proposed method, especially to verify the optimal role of the two attention modules, we designed ablation experiments on the CA module and the SE module, whose experimental results are shown in Table 2. The results show some improvement in accuracy for each case, which indicates that each attention module is valuable. When there is no SE module, small targets in the image are missed during detection (Fig 14), which indicates that the SE attention module can further enhance the detection of small targets on the airport surface. When there is no CA module, the extraction of aircraft features in the complex environment of the airport surface is not sufficient, and there are missed aircraft targets in the complex environment (Fig 15). We found that the best results were achieved when the two modules were used in combination, indicating that our method is feasible and effective.
Comparison of results of ablation experiments
Comparison of results of ablation experiments

Without SE test results.

Without CA test results.
This paper solves the problem of difficult detection of aircraft targets on airport surfaces in complex environments due to the influence of monitoring equipment and weather conditions and meets the demand for real-time aircraft detection on airport surfaces. We propose a lightweight aircraft recognition model for airport surfaces in complex environments based on SSD networks and attention mechanisms. First, a new feature extraction network MatbNet is designed based on MobileNet-v2 and the inception module in GoogLeNet, which contains two modules, Block_A and Block_I. Block_A for improved detection of obscured aircraft and enhanced detection of small targets. Block_I is used for feature fusion at different scales to extract feature information with rich semantic meaning and to enhance the feature extraction capability of the network in complex environments. Second, we use the designed feature extraction network in the improved SSD network. The experimental results show that the method proposed in this paper outperforms Faster R-CNN, SSD and YOLOv3 detection algorithms in terms of detection accuracy and model parameters, respectively 95.6% and 25.6 M. With detection accuracy close to that of YOLOv5, the model detection speed is superior to 38.2 fps, which is in line with the demand of real-time detection. Experiments show that the method proposed in this paper has a good effect on the identification of aircraft in airport field under complex environment.
However, the method in this paper is not effective for small target detection in night scenes. This is due to the fact that the clarity of the small airplane target on the distant runway under the influence of light in the night scene is very low, and the effective feature information cannot be extracted, which is difficult to recognize. As a result, the method proposed in this paper does not achieve higher accuracy. In our future research, we will focus on solving the problem of recognizing small targets in nighttime environments through the enhancement of image features and the regression of small target positions, and deploy the proposed model in practical applications.
Footnotes
Acknowledgments
The authors express gratitude to, the Open Fund from Research Platform of Grain Information Processing Center in Henan University of Technology(NO.KFJJ2022012), and the Key Scientific Research Projects of Colleges and Universities in Henan Province (NO.23A170013).
Conflict of interest
The authors declare that they do not have any conflict of interest.