
Abstract
A recommendation system serves as a distributed information filter, predicting customer preferences in reviews, ratings, and comments. Analysing customer behaviour aids in understanding needs and predicting intentions. E-commerce tracks product usage and sentiment to provide a personalized network based on consumer preference modelling. The challenge lies in optimizing item selection for suitable consumers to enhance performance. To address this, an imperative is the item recommendation approach for modelling future consumer behaviour. However, traditional machine learning methods often overlook dynamic product recommendations due to evolving user interests and changes in preferences reflected in customer ratings, causing cold-start issues. To overcome these challenges, a comprehensive deep learning approach is introduced. This approach incorporates a deep neural network for consumer preference prediction, utilizing a multi-task learning paradigm to accommodate variations in consumer ratings. The research contribution lies in applying this network to predict consumer preference scores based on latent multimodal information and item characteristics. Initially, the architecture manages changing consumer aspects and preferences by extracting features and latent factors from customer review rating data. These latent factors include customer demographic information and other concealed features that signify preferences based on experiences and behaviours. Extracted latent features are processed using a sentiment analysis model to generate embedding latent features. A finely-tuned deep neural network with hyper-parameter adjustments serves as a prediction network, forming a customer performance-oriented recommendation system. It processes embedded latent features along with associated sentiments to achieve high prediction accuracy, reliability, and latency. The deep learning architecture, enriched with consumer-specific discriminative information, generates an objective function for item recommendations with minimal error, significantly enhancing predictive performance. Empirical experiments on Amazon review datasets validate the proposed model’s performance, showcasing its enhanced effectiveness and scalability in handling substantial data volumes.
Keywords
Introduction
E-commerce platforms commonly employ recommendation systems to offer personalized product suggestions amidst a vast array of choices, ensuring quality and user-specific factors [1]. These systems utilize sentiment and user-generated content such as reviews, ratings, and comments, harnessing artificial intelligence and machine learning models for tailored recommendations. By discerning users’ intentions from their product reviews and past transaction ratings, these systems predict their future purchasing behaviour. Traditional methods of user-specific item prediction predominantly rely on machine learning approaches.
In e-commerce applications, user profiles are constructed as online personalized networks encompassing user interests, demographic information, personal characteristics, and diverse preferences [2]. Within the realm of recommendation tasks, a multitude of literature falls under two primary categories using machine learning techniques. The first category entails matrix factorization, while the second employs probabilistic methods. Matrix factorization models involve factorizing observed matrices based on user-product interactions, utilizing two latent factors from low-rank matrices to predict missing entries and generate item recommendations. On the other hand, probabilistic approaches work with partially observed data in the user-product matrix to estimate latent matrix attributes.
In spite of the comprehensive analysis of item recommendation methods [4, 5], conventional batch-based models are commonly adopted based on the assumption that user ratings for all items are determined by the user-item matrix. These models utilize individual user ratings to generate rating information through processing user-item data samples during the training phase. However, handling larger training data proportions in batch mode has led to increased complexities. Moreover, the batch learning approach can result in time drift, as it does not effectively capture the evolving user data over specific time intervals. These assumptions pose challenges, especially when the model needs to predict future user intentions accurately. To address these challenges adeptly, an advanced user preference projection model utilizing multitask learning needs to be developed.
Research contribution
The architectural contribution of this research lies in the utilization of a deep neural network to forecast consumer preference scores based on measured multimodal latent information and item characteristics. This latent structural information encompasses both items and user interactions, forming multimodal features. Within varying preferences, the focus of modelling enriches feature representation on the item side. In the initial stages, the architecture manages shifts in consumer aspects and preferences. This is achieved through feature extraction techniques, which uncover features by considering numerous latent factors present in customer review rating data. These latent factors stem from customer demographic information and other concealed attributes tied to consumer preferences, shaped by their experiences and behavioural patterns. The derived latent features undergo processing via a sentiment analysis model, leading to the creation of embedding latent features.
This article introduces a novel architecture, the Deep User-Item Evolution Prediction, for forecasting customer purchasing behavior by combining a multitask learning approach with deep learning models. The recommended recommendation strategy involves Time-Varying Multi-Preference Modeling of consumer behaviors, taking into account Multidimensional Attributes of products. This method effectively addresses the challenges of sparsity and cold start problems while simultaneously extracting multidimensional attributes from user ratings of product items. A key component is the incorporation of Latent Discriminant Analysis, which absorbs latent preferences from both explicit and implicit attributes in user ratings and product characteristics. However, this recommendation approach does encounter issues, including rating errors and the introduction of noise during the processing of user-item rating data. This has led to an examination of the consumer preference model’s strength, as overfitting concerns arise. To counter these, the consumer preference learning employs low-rank constraints and representations, integrating them to formulate a user’s interest within the user-item matrix. In this work, an Iterative Singular Value Decomposition approach is implemented to alleviate low-rank matrix constraints. Furthermore, the proposed model is designed with a Deep Neural Network architecture to enhance item recommendations tailored to users’ preferences, utilizing various strategies.
The article is structured into distinct sections. Section 1 introduces the architecture, namely the Deep User-Item Evolution Prediction model, and its objective of predicting customer buying behaviour. Section 2 entails a comprehensive literature review that establishes connections with the proposed architecture. In Section 3, the architecture’s core component, a hyperparameter-tuned deep neural network for personalized product recommendations, is elaborated. Section 4 is dedicated to in-depth experimental analysis. The architecture’s accuracy and effectiveness are thoroughly evaluated using Amazon dataset. Comparative results against conventional architectures are presented, showcasing performance metrics and highlighting the strengths of the proposed approach. Finally, Section 5 concludes the article by summarizing the key findings and insights derived from the research. This structure ensures a cohesive presentation of the architecture, its development, empirical evaluation, and overall contributions to the field.
Related work
Various machine learning models have been extensively studied with regards to their architectures for user preference modelling, user similarity estimation of processed items, and efficient prediction analysis design and implementation. Each machine learning model, when applied to predicting user behaviour on evolving data, is thoroughly examined and evaluated for its performance. In-depth representation and evaluation are provided for models that outperform the baseline architecture. Similarities in performance with the current architecture are also illustrated.
Fast tensor factorization model for dynamic mutual influence extraction towards context-aware recommendation
In this method, Dynamic Mutual Influence architecture encompasses the utilization of the Fast Tensor Factorization based recommendation method. This approach integrates implicit user feedback modelling derived from user reviews. These models for implicit feedback analyse how the context of a product or item contributes to user recommendations based on their preferences. The computation of the similarity between users and items involves matrix calculations, which generate the context necessary for rating prediction [11]. Additionally, positive and negative associations between consumer and item within the context of unobserved data are computed to facilitate user-item recommendations. The matrix factorization technique is employed in a closed form, enabling the generalization of associations and continuous calculation of pairwise interactions among various user-item context connections.
A meta-heuristic approach for evolving user behaviour classification
This method utilizes incremental iterative algorithms to generate and refine a recommendation list comprising diverse product items across various data points and time slots, considering distinct user characteristics. In contrast to traditional recommendation techniques, this specific approach conducts batch recommendations by integrating an iterative bagging procedure into the consumer-item matrix. Moreover, the model challenges the conventional consumer-item assumptions by consistently revising them during each calculation, thereby generating novel user-item assumptions. Through the process of updating user-item assumptions, the most recent product item samples are integrated into the user-item matrix recommendation list using an iterative smoothing method. Ultimately, the optimal solutions for this distinctive recommendation approach are implemented through incremental classifiers, enhancing the stability of the recommendations provided [6].
Neural factorization machines for sparse predictive analytics
In this approach, Neural Factorization Machine (NFM) for prediction under sparse settings has been carried out NFM seamlessly combines the linearity of FM in modelling second-order feature interactions and the non-linearity of neural network in modelling higher-order feature interactions. Conceptually, NFM is more expressive than FM since FM can be seen as a special case of NFM without hidden layers [22].
An attribute-aware attentive GCN model for attribute missing in recommendation
In this approach, attributes have been widely recognized as significant supplementary factors. However, there’s a challenge when dealing with missing attributes for items/users (for instance, some movies lacking genre data), where a default value (“other”) is used to represent these missing attributes, leading to suboptimal outcomes. To enhance performance, an attribute-aware attentive graph convolution network has been developed and integrated. This network effectively captures complex interactions among users, items, and attributes. Moreover, to achieve effective node representation, a message-passing approach is adopted to aggregate messages from directly connected node types (such as users or attributes). The model also incorporates associated attributes to bolster the learning of user and item representations. This inherent capability addresses the issue of missing attributes for various users. Additionally, since attributes can influence user preferences for an item differently, an attention mechanism filters messages transmitted from an item to a target user, taking attribute information into account [23].
Recommendation framework based on embedding spectral clustering in heterogeneous networks (RESCHet)
In this study, the architecture is divided into two main components. Initially, clusters are derived from the Heterogeneous Information Network (HIN) [24]. This is achieved through the utilization of Metapath2vec, a method to embed HIN. Each user’s vector is created by reducing non-relevant nodes of different types and then combining the sequence using a non-linear technique. A highly accurate similarity matrix is generated among users, relying on the cosine similarity of these vectors. Next, using a straightforward spectral clustering method, clusters that exhibit the highest user similarity are formed. In the second phase of the research, user recommendations are crafted based on cluster members and the Hadamard product. Additionally, atomic meta-paths are defined according to the users within the clusters [25].
Proposed system
Deep user-item evolution prediction architecture to predict the consumer buying behaviours by incorporating multitask learning paradigms and deep learning models to the evolving user characteristics and products specification have been described. Further particle swarm optimization (PSO) was employed to determine the potential user preference on evolving characteristics of the user through deep learning models and the different list of items for a projected consumer has been estimated. The proposed architecture is illustrated below
Design goals
The consumer preference learning approach is represented with respect to following utilities in order to generate productive results.
The model must be capable of learning additional details related to the user item matrix, and training the classifier without requiring any additional access to the existing data. The model must be able to manage the existing knowledge acquired from matrix factorization. Finally, the model must have the ability to integrate the advanced classes obtained from processing the user item matrix with new data.
Missing value prediction
A procedure for predicting missing values has been utilized to address the absence of certain attributes within the dataset, resulting in the completion of a comprehensive data sample. Data imputation involves the process of introducing new values to the vacant entries within the consumer-item matrix by incorporating a meta-heuristic technique. In this study, missing values within attributes or elements of the user-item matrix have been repeatedly imputed to encompass the range of feasible values for the absent entries. These imputed values, generated multiple times, have been examined to derive a singular value for each missing entry through a combined estimation approach based on well-defined fitness criteria [12].
Primarily, factor analysis has been employed for the purpose of Missing Value Imputation. Factor analysis calculates the maximum shared variance within a specific data field. It also adheres to the Kaiser criterion, leveraging Eigen values as indicators of the shared variance within the given data field, aiding in the imputation of missing values for that particular data aspect. These data aspects entail interactions between users and items. Ultimately, the missing values can be generated using the maximum likelihood method, utilizing the computation of data field similarity to fill in the gaps present in the specific data segment.
Computation
Determine the mode (most frequent value) among the existing non-missing values within the attribute. Subsequently, replace each missing value (represented as NaN) within the attribute with this specific mode value. This process is performed in an isolated manner for each missing value, treating them independently from one another. This approach is applicable to categorical features, encompassing both numeric and string data.

In this example, the missing values in the “Category” attribute (Products C and E) have been replaced with the mode value, “Electronics,” as determined from the non-missing values. This approach ensures that each missing value is handled independently and replaced with the mode value of the attribute, maintaining the categorical information in the dataset.
Exploiting evolving user characteristic through feature extraction strategies
Normally, Amazon dataset is illustrated as user item rating matrix in structure as it represents the similarity among user and item. Every data cell of the user-item matrix is illustrated as data tuples structure of the form
Where Ui indicates the existing consumer preferences and Rj indicates a current consumer preference to the specific Item Ij. Further it considers the ratings of specific product to user, which are determined by the explicit user attribute and implicit user features of item collectively.
Particularly, users are expected to provide ratings for items in a similar manner to other users under the condition that the attributes of two different consumers align closely in terms of both implicit and explicit attributes. Feature abstraction strategies play a vital role in creating user profiles that are convenient for real-world applications. These strategies are subsequently utilized for automatically clustering the evolving user characteristics. The proposed research methodology’s architecture is depicted in Fig. 1. Within this multitask learning framework, multiple rating prediction approaches are simultaneously learned for both the active consumer and related consumers.
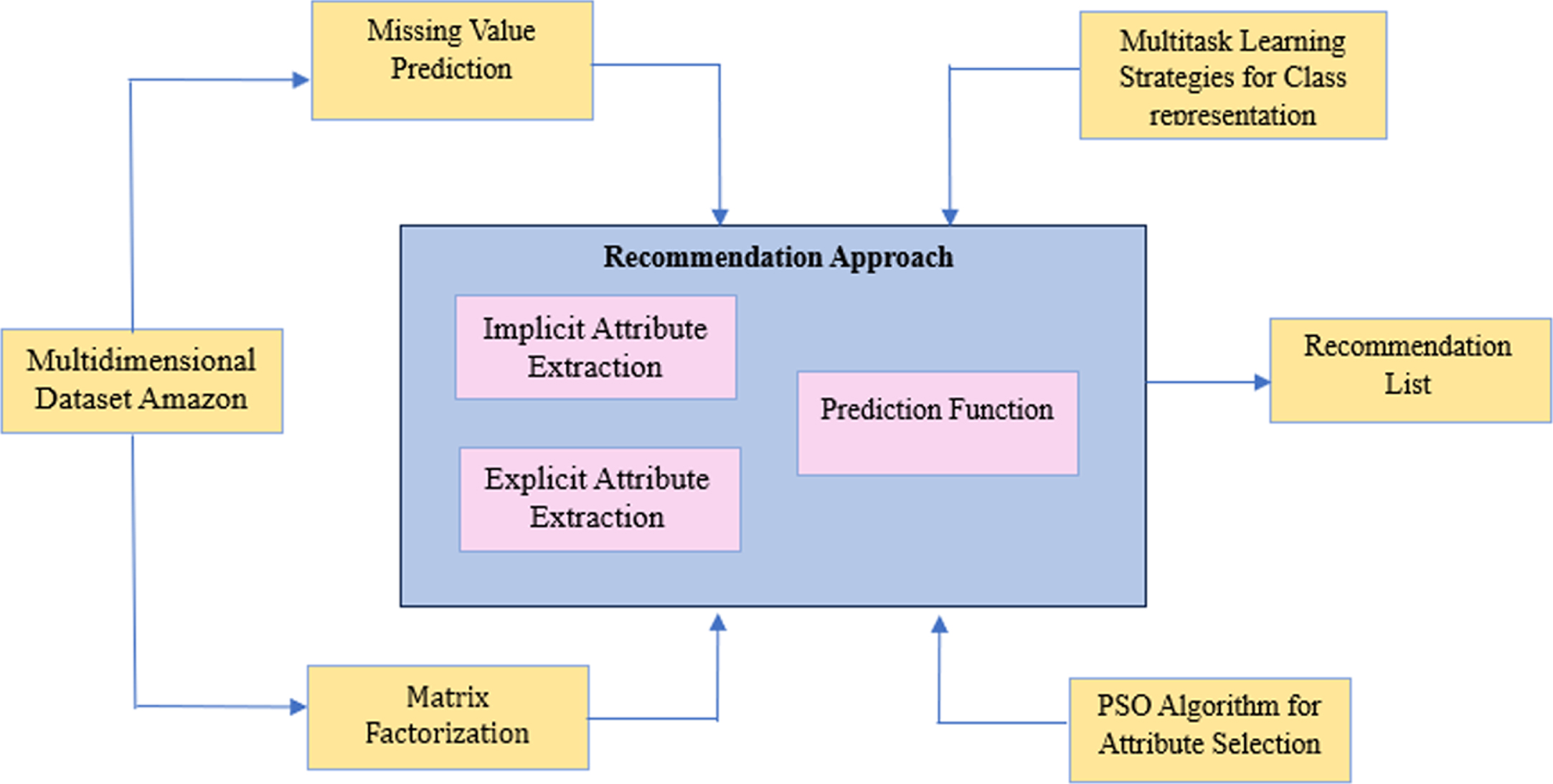
Architecture of Proposed Methodology.
The active consumer refers to a set of consumers closely linked to the consumer being considered. Different models are concurrently learned, leveraging a combined representation of user-item attributes (users and items) encompassing both implicit and explicit attributes, thus enabling multitasking capabilities. The research methodology assumes that user behavior or intention is inherently dynamic, constantly changing. Despite its adaptability to various behaviors or intentions across user characteristics in the realm of recommendation concepts [13], certain constraints need to be integrated to attain stable solutions.
The proposed solution needs to effectively handle a substantial volume of evolving user characteristics within the user-item dataset. It should possess the capability to identify and capture sudden and significant changes in data streams, enabling the organization of evolving user data for recommendation purposes. The recommendation model for items or users should adopt a non-iterative approach, as this is deemed more efficient. Lastly, the classifier’s structure within the recommendation model must be designed to be simple and easily interpretable, allowing for adjustments in response to changes in user behaviour or intentions.
The evolving user’s behaviour is identified and extracted using the WordNet tool, chosen for its capacity to dynamically discern changes in user behaviour or intentions. The dynamic shifts in user behaviour are assessed based on data concepts and semantics. The resulting extracted feature is structured as a vector space model. This vector space model is then subjected to frequency-based methods to calculate the frequency of similar features between a consumer’s context and an item [14]. Instead of considering individual ratings, the similarity among users is computed based on the overall stability of their ratings. The computation of similarity between consumers and items is influenced by the latent factors within the matrix. To achieve this, matrix factorization is employed to decompose a user-item matrix M into the product of multiple latent factors within the matrix.
Where n is indicated as ordinary number with a value 2 or 3
Matrix factorization is conceptualized as a latent factor technique, highly proficient in predicting item ratings for specific users. The latent factors within the model are harnessed to gauge user preferences toward specific items based on latent reasons. The prediction of user ratings is further determined by estimating potential interactions between user latent variables and observed variables during the training phase. This approach effectively computes the user’s likely rating through the interplay between latent and observed variables.
Clustering plays a pivotal role in recommendation systems by creating clusters based on extracted features that represent user preferences. These clusters determine the extent of changes an item exhibit for its target consumer within the rating matrix. Product item recommendations are streamlined by employing preference elicitation techniques to formulate hypotheses regarding preferential dependencies. Clusters emerge as a consequence of interactions between items and users [15]. User ratings for items are computed by collaboratively processing extensive explicit and implicit features of both the items and users. The recommendation system is structured to ensure accuracy in alignment with the aforementioned hypothesis. The primary objective of this recommendation approach is to establish a suitable association among the attributes of consumers and items.
Matrix factorization is employed in feature extraction to capture both implicit and explicit attributes of users and items. Denoted as UI& I1, these sets represent the implicit attributes for users and items, respectively. Vector Containing the Implicit Attributes of user UI ={ ui1, ui2, ui3 … u in }
Vector Containing the Implicit Attributes of items I1 ={ ai1, ai2, ai3 … a in }
Above data representation depicts the user and item implicit attributes of the weight vector of user attributes towards designing the item prediction function to the recommendation solutions on employing k-NN approach.
Implicit attributes defined user preference clustering
In this part, user preference clustering is processed on the vectors containing the implicit attributes of the user and item. Fitness criteria for the clustering the vector is modelled using the condition such that user rate the item similarly to the other user if two items contain unique implicit attributes and condition that two consumers contain similar implicit attributes, then consumer more similar to be select the similar item. On tremendous growth of the consumer and product item in the e commerce applications, recommendation approaches face continuous scalability issues due to less configuration of the computational resources exceeding above the tolerating limit [16].
To address the scalability concerns arising from limited computational resources, Particle Swarm Optimization (PSO) emerges as an optimal approach for solving NP-hard optimization problems. PSO yields nearly optimal solutions within a suitable timeframe for a range of challenges. Moreover, Particle Swarm Optimization is harnessed to recognize implicit user attributes and product items using historical ratings in a user-item matrix. These implicit user attributes and items are regarded as efficient feature representations that facilitate the learning of associations between product items and users.
By integrating observed attributes with latent (implicit attributes) using prediction methods in recommendation applications, a notable enhancement in prediction accuracy can be achieved. Moreover, assuming user preferences allows for the establishment of a preference structure for user information. This structure aids in measuring the similarity between a new user’s preferences and those of other users, utilizing a fitness function as the basis. User ratings for items are determined by considering user behaviour and intentions concerning specific item attributes, as well as other consumer attributes. Consumer rating prediction objective function is provided as
Where P is value of the Consumer rating prediction to the item
Ui = (U1, U2 … Un) is user Vector containing the user attributes
Ii = (I1, I2 … In) is item vector containing Item attributes.
URi is the User rating.
IRj is the Product rating.
The primary intension of the item recommendation approach is to compute an appropriate relationship between the multidimensional user attributes and item attributes to produce a precise recommendation on basis of Pbest computation of the consumer rating. Pbest is considered as largest consumer preference provided to the product item. User Item Matrix containing the historical rating data is identified on processing of implicit attributes and explicit attributes projected on learning of the consumer characteristics to the item [17].
Prediction model has been constructed on incorporating the implicit and explicit attributes of the user-item matrix provides good prediction accuracy. It is highly capable to extract the implicit attributes of the evolving user using matrix factorization. Let Ui and Ii represent the implicit feature values to items and users. Those attributes values of item and user are composed as vectors for processing using PSO technique. Vector containing the implicit attributes with different weights is given as Vu and Vi. Similarity computation between user and item is computed on vectors is given as
User preference computation determines the explicit interest of the user to the item through multi-dimensional item attributes and consumer rating. Particular model can provide user complete characteristics of the interest to the item. Figure 2 illustrates the user preference learning on explicit attributes. Particular approach determines the user preferences to item using the user- Item matrix. Further it is adaptable to product item recommendation on basis of user behaviour or intension changes. Preference identification on variation of the user rating has been performed using multidimensional item attributes [18].
Item Rating Recommendation using user preference clustering on explicit attributes.
User rating inferring strategies are mentioned for processing of the explicit item attributes. Furthermore, significance of the explicit attributes for user rating to item will be considered on basis of following strategies User preferences to item rely on explicit attributes weights. Model description for Item Attribute is represented in vector composed of explicit attributes. User preference-based Recommendation model combines multidimensional item attributes and the user rating. User preference modelling uses the top to bottom approach to determine the item recommendation.
Prediction
A classifier is utilized to produce the class label to the recommendation model on mapping clustered implicit and explicit feature space using similarity measures. In this work, hyper parameter tuned optimized Deep Neural Network [27] is considered as classifier to predict the user rating to item on processing the feature space. Class label to the feature space is represented using the matrix factorization. It computes the user and item association for the feature space distribution. Distribution of the feature in the class represents the particular user behaviour to appropriate item.
Consumer rating is unstable due to changing information of user in the data stream has been taken into consideration. It has to be extracted on exploring the data streams for new information [18]. User association to the mentioned attribute behaviour or intension to the particular item is unstable on processing of number of user- item association.
Estimation
To avoid the intrinsic error rate, voting based approach has to be implemented with respect to consumer experience. Further, it is to compute multiple classes to the feature extracted on processing the latent information of the consumer on the behaviour and experience. In order to accomplish the latent feature, latent discriminant analysis is implemented to compute the latent factor of consumer to particular item. Consumer profile is illustrated in the matrix representation as complete projection matrix. Column in the complete projection matrix illustrates latent features of the consumer on their geographical characteristics and row illustrates the behaviour characteristics or experience. matrix is processed to remove the over fitting features by computing the mean calibrated matrix [6].
Consumer Vector for individual behavioral characteristics
Consumer Vector for consolidated Characteristics
Equation 5 and Equation 6 compute the individual similar behaviour of the users and multiple similar behaviour characteristic of the user and Linear vectors on the consumer experience and behaviours is calculated and it is considered as subspace containing multiple consumer attributes. In this ‘C’ represents the characteristics or attribute, ‘r’ represents the rating. Efficient Latent feature to the product recommendation is calculated on incorporating change matrix of latent discriminant analysis. It is represented as
Change Matrix of the consumer behavior
Complete Projection Matrix representing the consumer profile is processed utilizing the consumer conversion matrix through normalization of conversion matrix on the extracted consumer cluster with associated characteristics [19]. The association of changes-adapted characteristics of the consumer feature discrimination is performed through pair wise association on their experience and behaviour aspects. Latent Feature vector is obtained as consumer cluster. In Equation 7, ‘L’ represents the latent factors of the user.
Deep Neural Network [26] is optimized using hyper- parameter to achieve current prediction architecture as customer performance-based recommendation and is represented in Fig. 3. In this architecture, prediction of the consumer for the item is predicted and recommended as multi task learning paradigm. In this section, hyper parametric tuning of the ReLU activation function to the current prediction’s objectives functions is carried out. Optimized classifier learns implicit behaviour of consumer which is considered as latent factors of the features on experience and behaviour. Model training is composed of max pooling layer which maps the latent features extracted into pair-wise features map illustration and those pair-wise feature map representations is computed in convolution layer to calculate the consumer preference to reconstruct features [20].
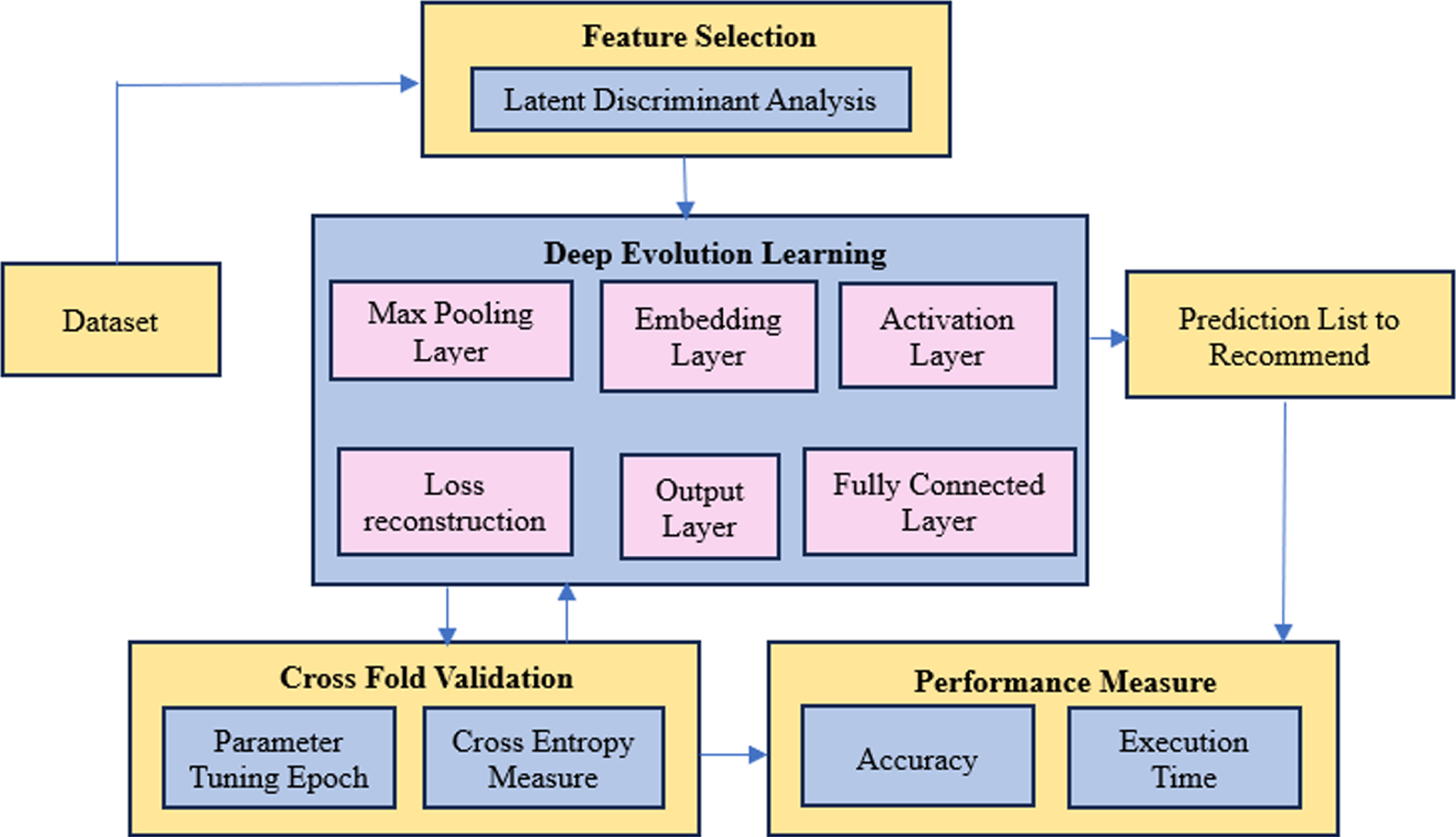
Architecture diagram of the consumer recommendation for product.
In this layer, Latent factors of the consumer features in the structure of subspace is organized in pair wise features on basis of preference pairs of consumers with bias coefficients of the model. The preference matrix is established through matrix factorization. Latent factor model is represented for predicting item to the particular consumer. The max pooling layer of the deep neural network produces the latent feature to the embedding layer of the network. Embedded layer is as follows
The pair wise feature representations of the item-user matrix will increase the difference of consumer on processing the matrix with Pearson correlation. The similarity computation of consumers on their preference is provided as resultant information. The recommendation components of the Fully Connected Neural Network for Item Prediction is represented in Table 1.
Recommendation Component for the Fully Connected Neural Network
It is to gathers the consumer preference in the feature subspace on processing the inherent features hierarchically. Those abstract features is capable of learning time varying features with reduced hyper parameters of fully connected network. Resultant feature space represented as latent attributes of the changing consumer characteristics. In this part, changing features of the consumer preference attribute is embedded in the activation function to compute the resultant consumer vector to the product.
In this part, large-dimensional pair wise consumer characteristics are linearly converted into reduced dimensional consumer vectors with sentiments.
The current model utilizes the Rectified Linear Units (ReLU) as activation method [11] to product recommendation classifier to process the changing features of consumer clusters. Consumer clusters containing the preference vector incorporating the product sentiments and pair wise product vector. Vectors is classified in the embedded layer. Activation method classifies the appropriate consumer on each product in the embedding matrix. Embedded vector is processed with transformed values to generate the suitable rating prediction to the suitable product item on updating of epoch parameter.
in this layer, hyper parameter optimized deep neural network contains prediction outcomes representing consumer recommendation to product or item. Further parametric flattening of the prediction is on basis of similarity measures is achieved in this part for consumer recommendation or product recommendation. Soft max optimization [12] is applied to the resultant set and cross entropy mechanism is employed to access the accuracy of the product prediction for consumer characteristic changes Hyper parameter tuning is made in the output layer to achieve the prediction list to be near to each feature by computing the similarity of the product or item on new consumer illustration on numerous changes.
This is to establish the prediction accuracy on recommendation system with the certain limit on fine tuning with respect to the hyper parameter of various layers of hyper-parameter optimized deep neural network to maintain the reduced reconstruction error among features of the max pooling layer and ReLu activation layer. Further cross entropy is applied as loss method to handle the prediction result to the changes of the consumer on e - commerce applications [13].
Algorithm 1: Deep consumer changes Learning architecture for multi-product Recommendation
Soft max function stimulates the embedded latent feature on feature map to generate product list to user with respect to behavioural and experience of the user in ecommerce platform as recommendation application.
Feature distributions illustrated in form of Consumer and item association on the implicit and explicit attributes is highly efficient in generating the class. Feature distribution of the attributes illustrated as vector which is capable of computing the users with similar attributes. Classifier solves the data sparsity issues. Item recommendation is predicted on basis of similarity degree between consumer to the specific item on their implicit and explicit attributes. To represent the similarity degree, two constraints has been utilized Similarity estimation of user among various perspectives. Similarity of the items among users is larger when the rating of consumer 1 and consumer 2 are much homogenous.
Item recommendation to consumer information on the multidimensional attribute set (behaviour of consumer illustrated by a vector distribution containing item) is represented as recommendation class.
Item-based recommendation is formulated on differentiating the items on user rating similarity between the users. The association of items i and j with respect to the user is determined as follows:
On calculation of the item similarity and consumer similarity on the user-Item matrix provides k similar product items to the predicted consumer. Further it generates the predicted user rating value to the selected items as follows
Where I denote the computed group of k similar items to consumer
User attribute value represents the distance between an item and k-1 item in the user-item matrix. Item rating difference calculated through Euclidean distance on the user preference to the item. Furthermore, cosine distance is calculated to determine the tolerance level of the various data samples on various item attributes to the user.
Algorithm 2: Item recommendation
The DNN model is defined as multitask learning architecture to generate the class label on considering the noticed data features of the user-item matrix with latent data samples of the evolving user characteristics. Deep learning architecture is effective on computing the consumer recommendation to the item and item recommendation to the user. Class is generated on the processing the user item matrix on evaluating its association with user and item multidimensional attributes. The observed item matrix assign label to user. Particular class of the consumer-item association is illustrated by multiple similarity on implicit and explicit feature of the user-item matrix.
Further predicted user rating of item i is represented as Ua using the implicit attribute and predicted user rating of item j is represented as Ub using the explicit attributes. The average based method produces the predicted value PIAB.Ua which is generated by the rating of Ua and Ub. The calculation is given by
where
RUa is average item rating rated by consumer a and consumer b selectively. Neighbours computed to consumer are computed on basis of similarly among the implicit based attribute and explicit-based attribute. On rating prediction to the item, item ranking is carried out according to the ratings produced and top N item is recommended to the predicted consumer.
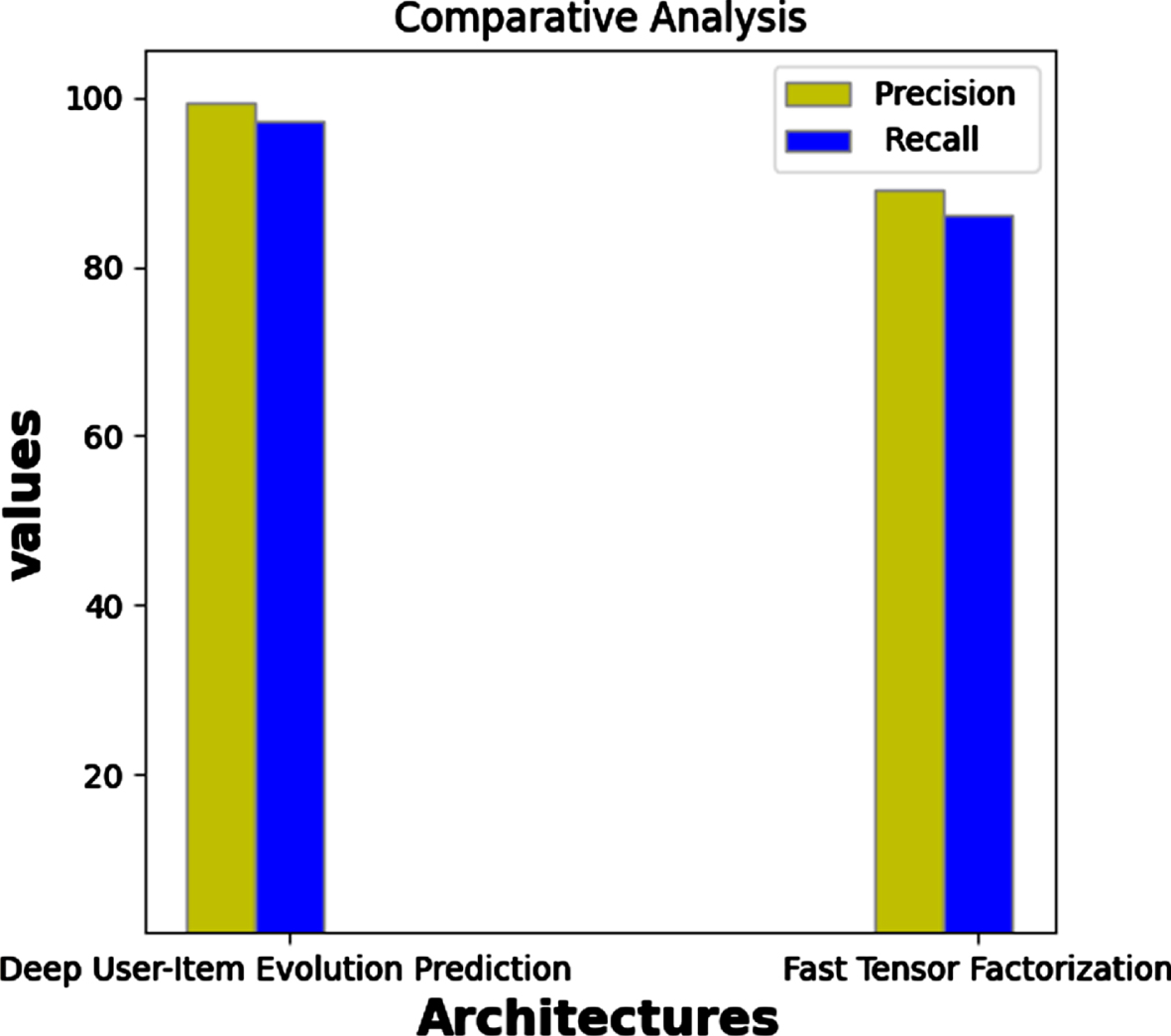
In this section, experimental outcomes of the current approach were evaluated against the traditional recommendation approaches with respect to performance measure such as Precision, Recall, f-measure and execution Time.
Dataset description
Detailed experimental analysis has been carried out on Amazon Review real dataset. Amazon Product review is largely employed dataset among the research community for generating recommendation solutions. Dataset contains 100,000 instances with ratings, comments and review for different varieties of products. The dataset which converted into matrix form is employed for experimental analysis.
Evaluation
Performance of the proposed Framework is calculated using following measures which is considered as Precision, Recall, frequency measure and Execution time. Initially, product with similar properties describe the consumer profiles and its product attributes is extracted on employing Latent Dirichlet Allocation approach in form of matrix.
Consumer profiles extracted are clustered through preference function f (ui, ek) and illustrated as feature vectors is again processed using hyper parameter optimized DNN training and testing for consumer prediction on predicted product group. Cosine similarity of the consumer features affects the prediction. The evaluation of the recommendation prediction model is assessed using performance metrics mentioned as precision and recall. The results and values of the metrics is defined in the upcoming section.
The prediction performance of the current framework and conventional framework is enabled to compute the efficiency and accuracy of the model. In this article, Amazon dataset is segmented into training data with 90% of the consumer profiles and testing data with 10% of the consumer profiles [13]. The evaluation outcomes of the precision and recall is calculated results of the consumer prediction on the predicted product and it is illustrated in the Table 2.
Performance computation of user –item context association for Entire Dataset
Performance computation of user –item context association for Entire Dataset
Predictive value of the user is the ratio of appropriate items to the retrieved items to the consumer subspace. Precision is also termed as number of selected items divided by the number of gathered items from the vector. True positive is a number of real positive predictive item occurrences in the vector space and false negative is number of real positive predictive item occurrence in the vector space. The performance of the model is evaluated with respect to Amazon dataset is illustrated in the Fig. 4.
Performance computation of prediction accuracy.
It is the ratio of appropriate item to the user to the retrieved item over the total amount of appropriate item to consumer. The recall is the ratio of appropriate occurrence of features that are classified into the exact classes. True positive is a number of real positive predictive item occurrences in the vector and false negative is number of real positive predictive item occurrence in the vector.
On recall analysis, the time-varying association among product items to consumer in the e - commerce application process defines the consumer intension or behaviour on selecting the item on basis of computation of latent pattern and preference.
Clustering approach is capable of clustering the consumers on their behaviours and its effectiveness in handling the scalability issues in large scale data explorations by associating the consumer for recommendation within smaller and highly similar clusters instead of the extracting from entire dataset.
Conventional recommendation approaches were modelled with respect to accuracy. The recommendation model results incorporate the consumer preference lists generated by model containing appropriate items. Higher similarity represents lower diversity of the result. In this process, prediction of the product item contains user intension which further enhances the recommendations quality.
It is a measure employed to compute the test’s accuracy of the recommendation result and is represented as the weighted harmonic mean of the precision and recall of the training or test data. Since increasing amount of recommendation set will result in enhancing of recall value but at the same time it leads to a reduction in precision values.
Execution time
It is represented as the time consumed to produce the item similar for various user among two attributes of user.
The performance of the execution time of the current model is calculated against conventional approach is detailed in Fig. 5 and performance values of the proposed approach is evaluated and detailed in Table 3
Performance evaluation on Execution Time. Performance evaluation of the prediction model with positive reviews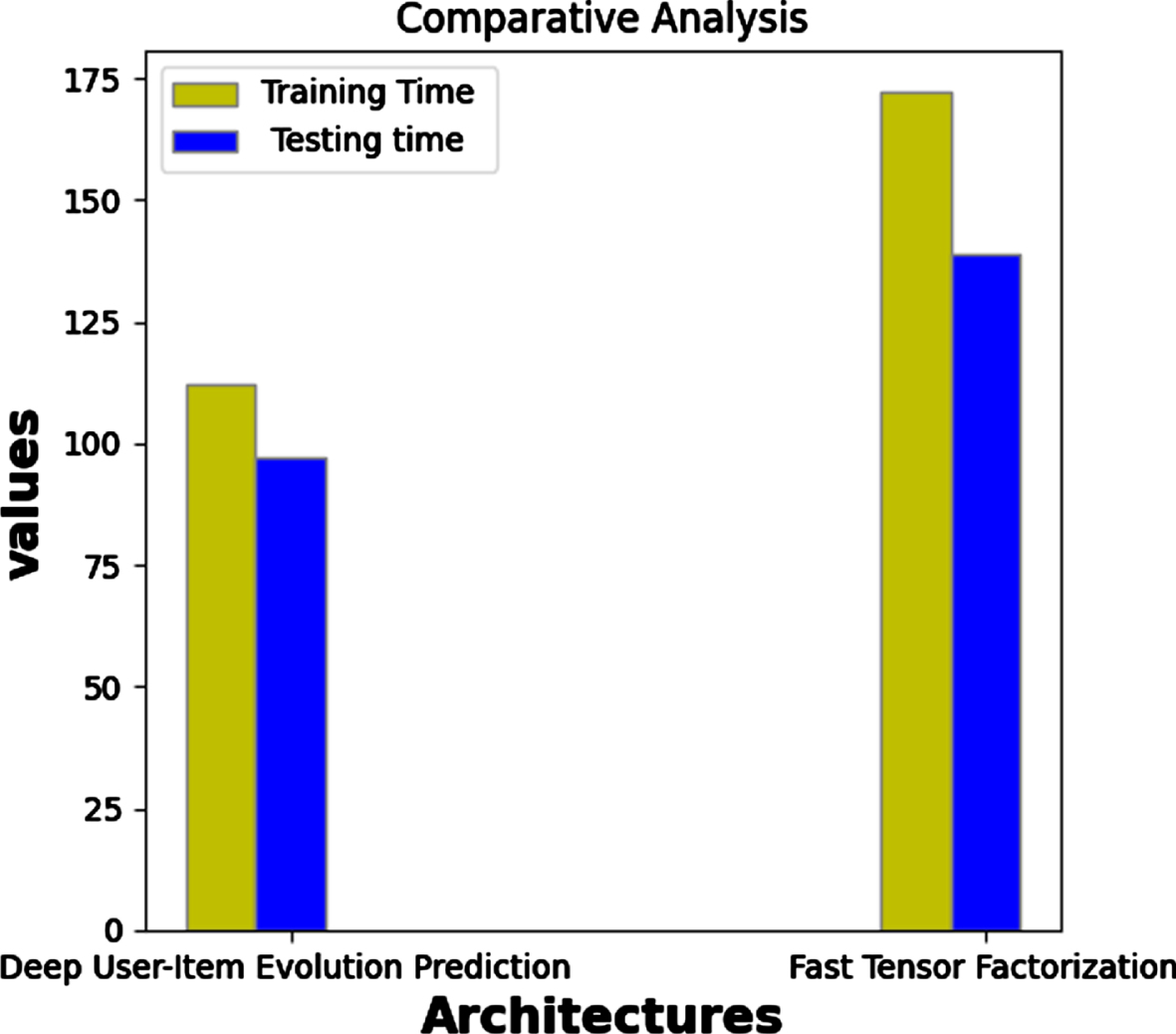
In this category, parameter sensitivity is computed as it is employed in sigmoid function towards training and testing phase of the optimized DNN. It is represented as activation function of the deep neural network [14]. Parameter of sigmoid function is termed as gradients and weights of the feature attributes of the consumer profiles. Sigmoid function is illustrated as
In this ex is the logistic function illustrating the gradient state Y.
Sigmoid function estimates the sign function bounded between 0 to 1, thus higher α is good for result approximation. The effectiveness and efficiency are calculated to generate detailed analysis. Also, the sensitiveness of the training sample proportion is discussed and is summarized. The precision and recall measure for existing and proposed architectures is measured and represented in Fig. 6 for Amazon dataset with positive reviews.
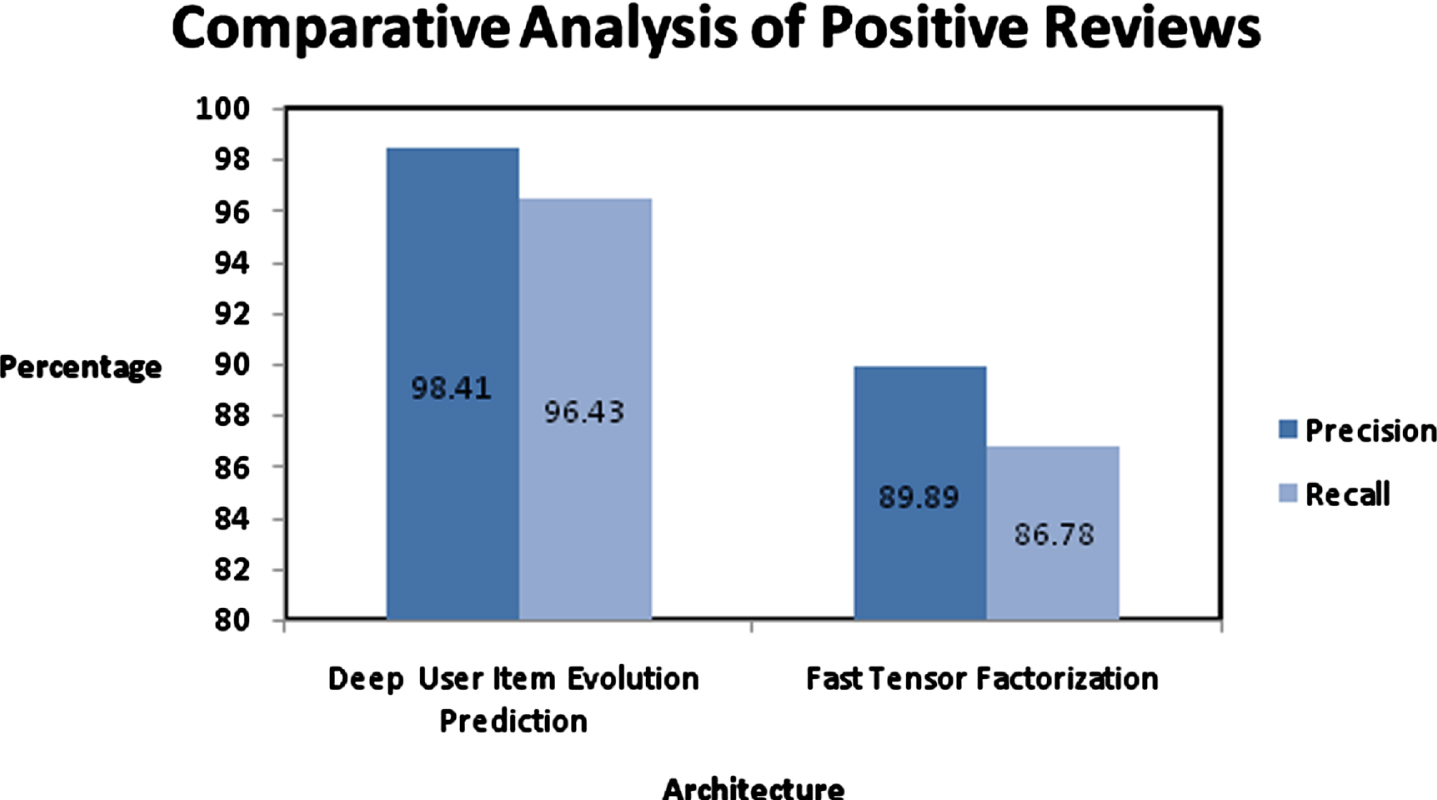
Performance evaluation of Prediction approaches with positive reviews on accuracy.
The execution time for training sample and testing sample is measured and represented in Fig. 7 for Amazon dataset with positive reviews. The performance degrades with reduced no of training samples as it represents that current architecture is sensitive personalized data evolutions.
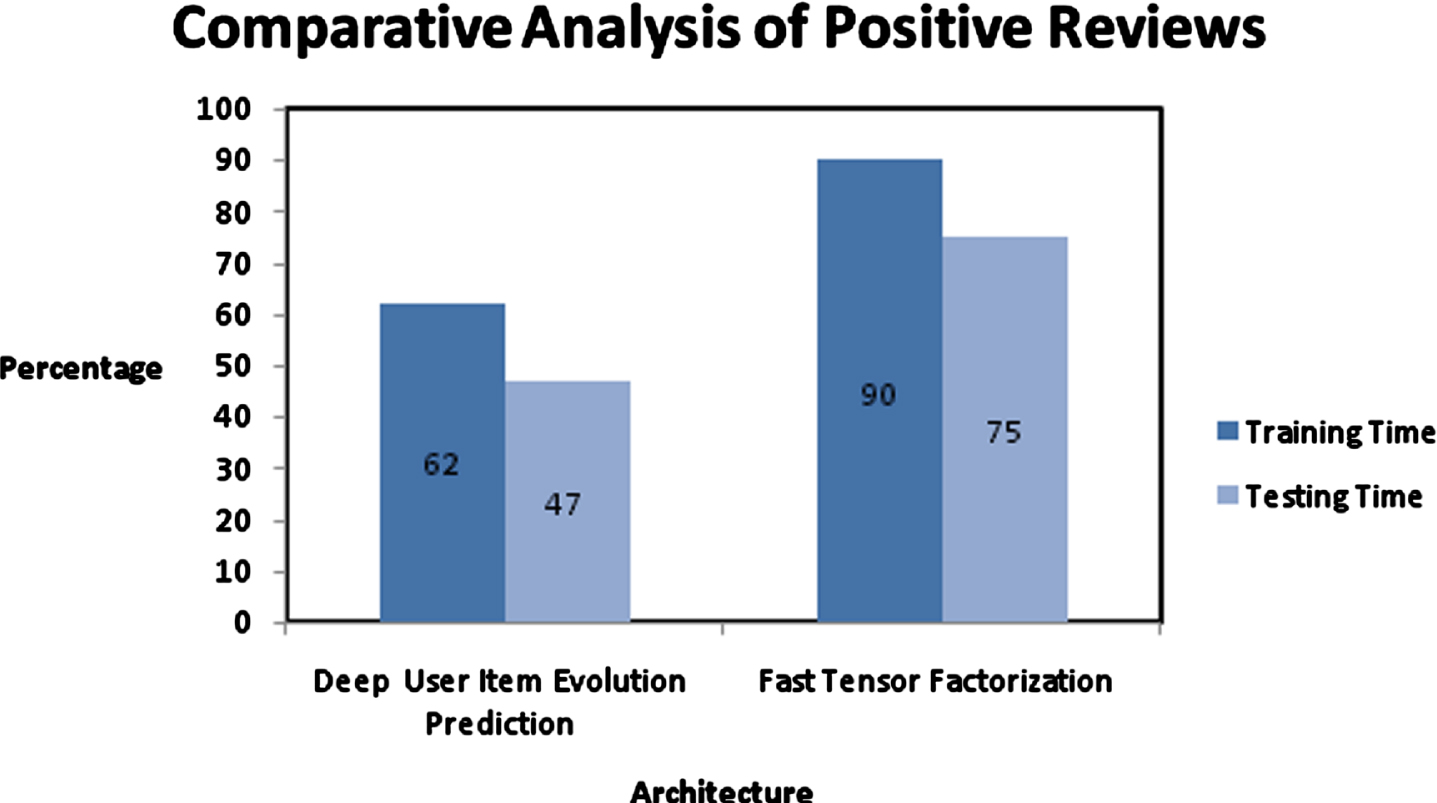
Performance evaluation of Prediction approaches with positive reviews on execution time.
Performance evaluation of the prediction model with negative reviews
Indeed, each user cluster contains more than 5items in average as classes, it achieves in few milliseconds to predict future individual for attending the review for product in the product event list. Moreover, with controlling the update frequency, the balance among prediction accuracy and update frequency has been achieved.
The precision and recall measure for existing and proposed architectures is measured and represented as performance outcome in Fig. 8 for Amazon dataset with negative reviews. The execution time for training sample and testing sample is measured and represented as performance outcome in Fig. 9 for Amazon dataset with negative reviews
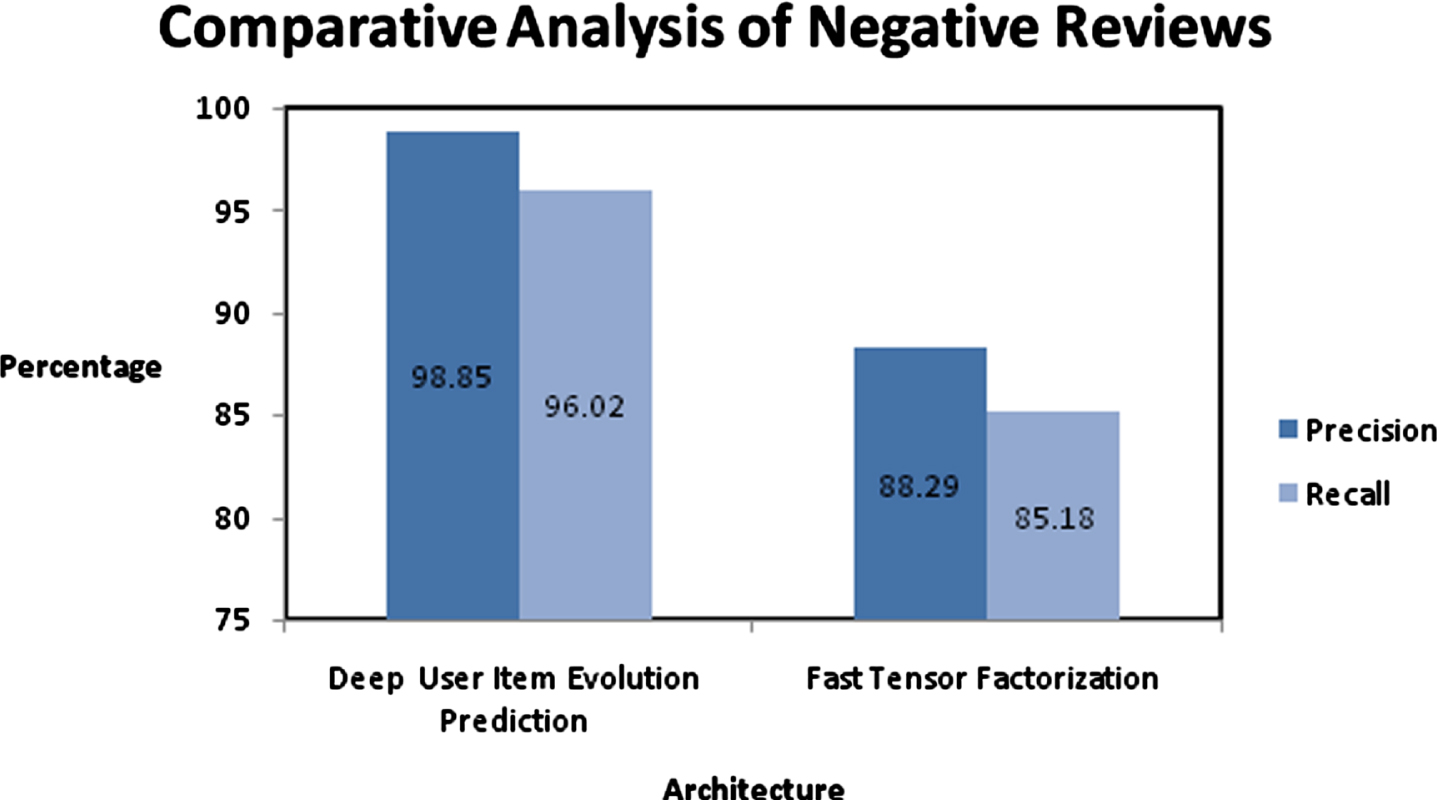
Performance Analysis of the Prediction model with negative reviews on accuracy analysis.
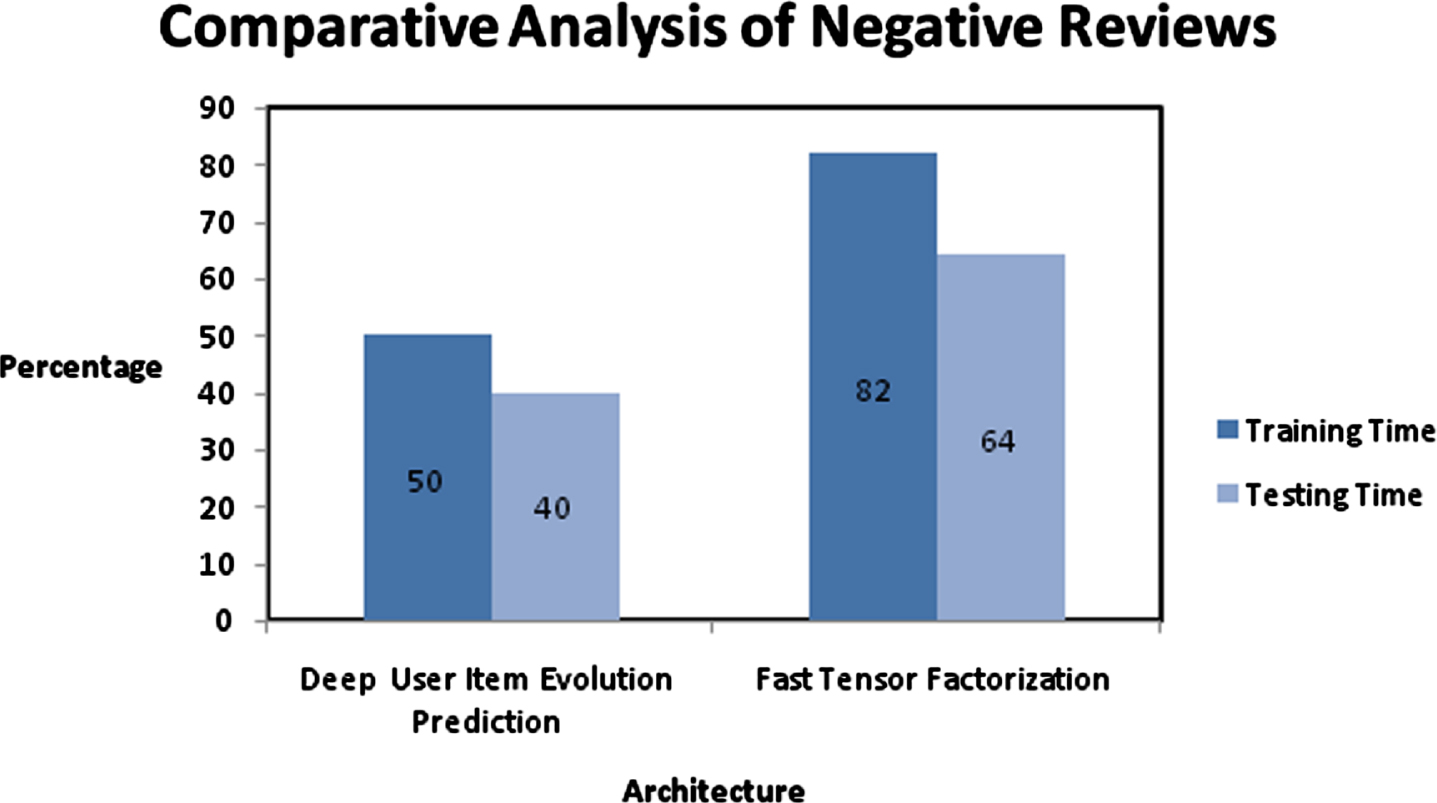
Performance evaluation of Prediction approaches with negative reviews on execution time.
The proposed framework has possibility to perform better with limited training samples and the effectiveness of “time varying” latent factors could be managed. According to the performance results, proposed framework performs better with precision as 98.85%, recall as 96.02%.
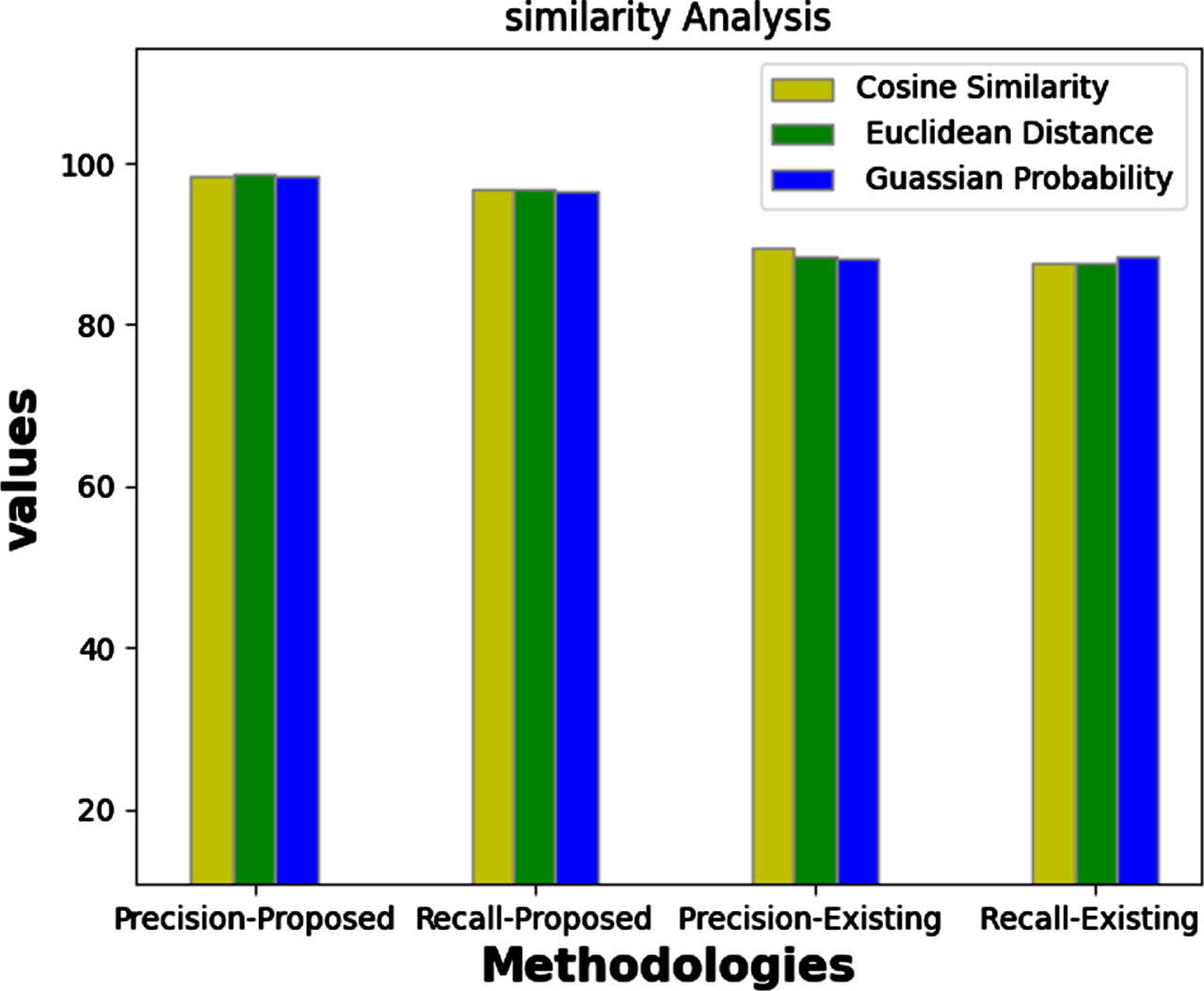
Prediction Performance analysis on various similarity metrics.
Current architecture achieves good prediction outcomes on the multifaceted interests of the consumer profiles with latent constraints. Those features processed in the various layer of the optimized DNN to enhances the prediction performance [16]. Table 5 represents the performance analysis on multiple similarity metrics. Euclidean distance could be similar with cosine (if the vector is normalized via 2-norm), their performance is quite similar and unified variance is in appropriate. Time varying factors on the connection of consumer computes the difference of the data on calculating the products. Normally each cluster contains average 20 to 30 consumer profiles which makes simple to predict the potential product with high precision and recall values.
Performance Evaluation of methodologies on Amazon dataset
The pruning validation is performed on the dataset with considering consumer influence has been summarized in Fig. 11 on measures of the precision, Recall and f measure.
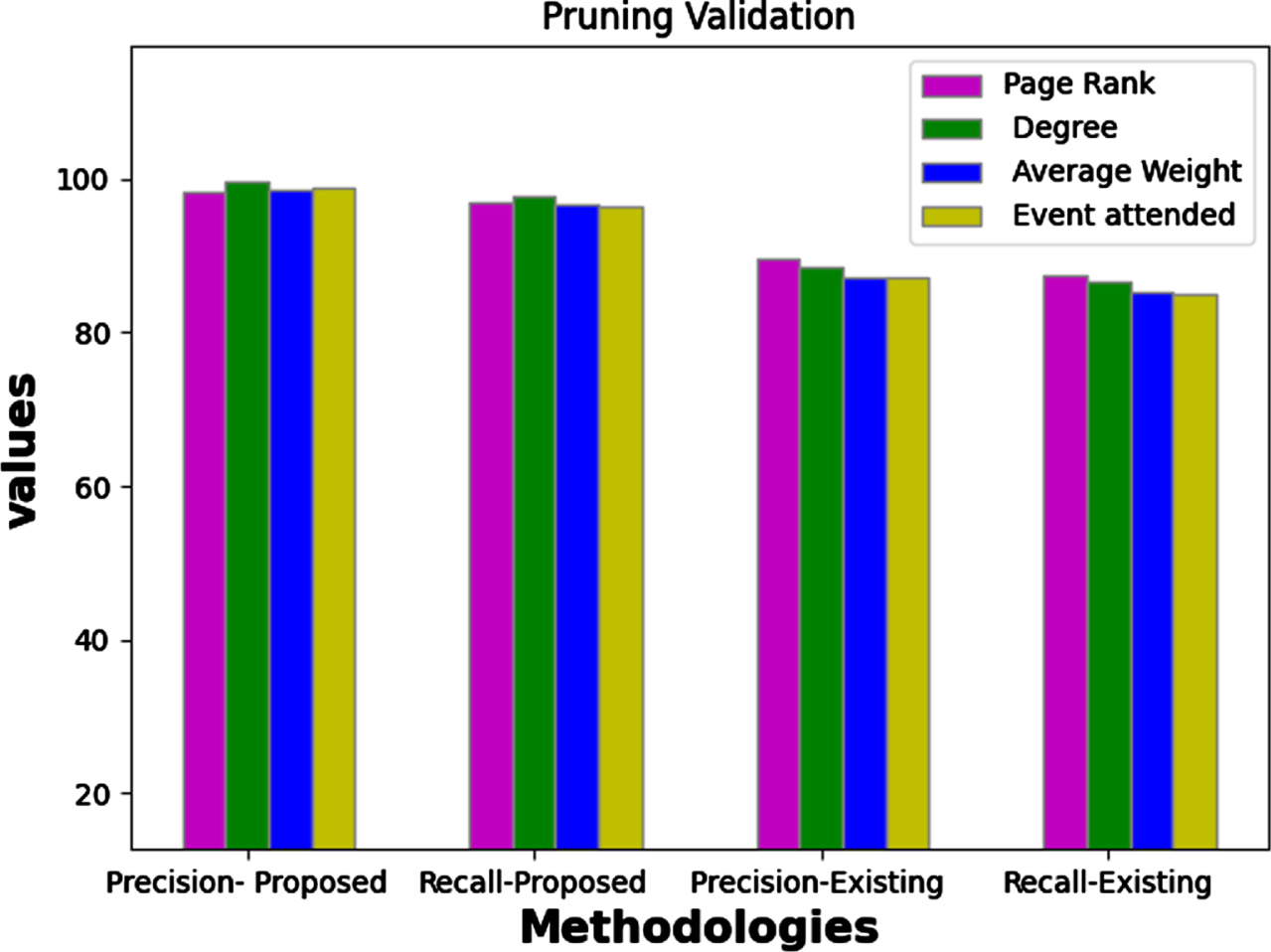
Pruning Validation against various models.
The overall performance on the pruning validation is depicted in the Table 6 which includes the performance metric such as precision, recall and execution time with respect to multiple data settings. In evaluation, the X-axis of above metric indicates the percentage of users who are rated similarly as this computation has an effect on the other consumer decisions, while for the rest users, they could only extract similar option on product buying influence, but will not influence the others. Performance of the complicate objective function is to produce latent consumer profiles and their connections to product item with provided product description with maximum expectation.
Pruning Validation on different perspectives of prediction accuracy
It is tough to conduct validation on measure of similarity. However, assuming that one predicted cluster, the most desired product must share few common attribute features. In the perspective of cluster decision-making, weighted voting based on various metrics has been employed. Specifically, PageRank, Degree, Average Weight and Event Attend are selected as metric to compute the weight of each user.
Validation on prediction
The designed products are “similar” with highly-attractive products as required to measure the prediction effectiveness. To be specific, product attribute vector to the key words (terms) has to be transferred via incorporating the multitask model. Then, users’ profiles and product description of each consumer are labelled by multiple task groups with a score 1–5, in which 5 means highest positive intentions and 1 means the lowest.
As depicted in Table 6, proposed approach for recommendation process on Amazon dataset will run 2-3 orders of magnitude quicker than conventional recommendation model on changing consumer characteristics. To evaluate the performance proposed recommendation approach, optimal solution using PSO has been analysed on the prediction process as it enhances greatly.
Conclusion
A new recommendation approach based multitask learning approach has been designed and implemented. Proposed Model computes user preference in the series of items on the consumer-item matrix incorporate the explicit attributes and implicit attributes of items and user. The explicit attribute-based recommendation incorporates the user preference approach to obtain the consumer’s multi-preferences. Proposed solution is capable of mitigating the data sparsity and cold-start issues. Further it is highly efficient in produces a diversified recommendation item list than conventional recommendation models. The underlying assumption mentioned in this model is highly effective in converting data into a series of items based on the time varying preferences of the consumers from the Amazon dataset. The proposed recommendation model is evaluated with respect to precision, Recall and f measure. Furthermore, model produces good accuracy compared with conventional approaches. Proposed model is suitable of handling increased amounts of data and it is the suitable for predicting the item recommendation on user evolution.