
Abstract
Ensemble clustering helps achieve fast clustering under abundant computing resources by constructing multiple base clusterings. Compared with the standard single clustering algorithm, ensemble clustering integrates the advantages of multiple clustering algorithms and has stronger robustness and applicability. Nevertheless, most ensemble clustering algorithms treat each base clustering result equally and ignore the difference of clusters. If a cluster in a base clustering is reliable/unreliable, it should play a critical/uncritical role in the ensemble process. Fuzzy-rough sets offer a high degree of flexibility in enabling the vagueness and imprecision present in real-valued data. In this paper, a novel fuzzy-rough induced spectral ensemble approach is proposed to improve the performance of clustering. Specifically, the significance of clusters is differentiated, and the unacceptable degree and reliability of clusters formed in base clustering are induced based on fuzzy-rough lower approximation. Based on defined cluster reliability, a new co-association matrix is generated to enhance the effect of diverse base clusterings. Finally, a novel consensus spectral function is defined by the constructed adjacency matrix, which can lead to significantly better results. Experimental results confirm that the proposed approach works effectively and outperforms many state-of-the-art ensemble clustering algorithms and base clustering, which illustrates the superiority of the novel algorithm.
Introduction
Clustering is an unsupervised learning method that usually refers to dividing existing unlabeled instances into several clusters according to the similarity between objects without any prior information, making the instances in the same cluster have a higher similarity and in different clusters have a more substantial discrepancy [9, 43]. Ensemble clustering utilises a consensus function to unify multiple types of partitions of the same dataset into one clustering result. It usually constructs a base clustering pool by repeatedly running a single clustering approach or executing multiple clustering algorithms. Then, the consensus function is built through voting methods, hypergraph partitioning, or evidence accumulation to obtain more optimal clustering results [18, 25]. Many existing ensemble clustering studies have confirmed that ensemble clustering can usually improve the clustering result compared to a single clustering algorithm [1, 24].
Background
Existing established clustering algorithms are mainly based on the theories of model, grid, density, partition, and hierarchy [2, 8]. Different types of clustering algorithms are good at solving diverse types, distributions, and scales of data. In particular, with the development of deep learning [27], the performance of various clustering methods has been further improved. For example, in [28], a deep-learning feature extractor for time-series data is designed for relation extraction, and the clustering effect achieved significant improvement. Nonetheless, in view of the unknown data distribution in actual problems, it is difficult to determine which clustering algorithm can get better clustering results. Conventional solutions often try different methods and choose the algorithm that performs best. Ensemble clustering is expected to establish a general scheme to combine the advantages of multiple clustering algorithms and form the optimal clustering result. It is especially feasible under the conditions of mature distributed computing technology, so as to adapt to unknown and complex data.
The related studies to ensemble clustering are mainly divided into three categories: pair-wise co-occurrence based, graph partitioning based, and median partition based algorithms [18]. The first type refers to constructing a co-occurrence matrix by finding the times of all instances that occur in pairs (assigned as a cluster) in base clusterings. The two instances should be classified into the same cluster in the final clustering based on co-occurrence [19]. The similarity function constructed by the co-occurrence matrix can be used in any similarity matrix based clustering algorithm to acquire the final optimal clustering result, such as hierarchical clustering and spectral clustering [7, 30]. The idea of co-occurrence matrix was first proposed in [5]. Correspondingly, a method of evidence accumulation clustering (EAC) based on this theory was proposed for the ensemble clustering problem. Subsequent researches have made various improvements, such as using the technique of normalised edges and matrix completion [29, 45]. In graph partitioning, the graph model and consensus function are usually constructed to partition the graph into multiple parts representing the final cluster. The primary purpose of graph partitioning is to achieve k-way min-cut partitioning, ensuring that the similarity between subgraphs is as tiny as possible [32]. Constructing a graph model is predominantly based on instances (vertices in hypergraph) or clusters (hyperedges in hypergraph) in base clustering. For example, the cluster-based similarity partitioning algorithm (CSPA) considers the local piecewise similarity and constructs a similarity graph as well as a graph partitioning method to perform ensemble clustering [23]. Compared with CSPA, the link-based ensemble clustering constructs a dense graph with the implied similarity between each instance and individual cluster; the clustering possesses a significant effect but needs too many computations [36]. The last type (median partition based algorithms) transforms ensemble clustering into an objective optimisation problem, which finds a median partition most similar to each base clustering by solving the objective function [17]. However, the issue is NP-hard [4]. Fortunately, some deconstructions, such as using expectation maximisation (EM) [40] and weighted consensus clustering (WCC) [33], have been proposed to find approximate solutions. In addition to the common types introduced above, ensemble algorithms based on voting [21], mutual information [20], finite mixture model [3] and other theories [22, 39] are also meaningful research directions in the field of ensemble clustering.
Motivations
Ensemble clustering is mainly divided into two steps. One is to generate a base clustering pool, for example, running the same clustering algorithm multiple times with different parameters, running various clustering algorithms multiple times, and performing clustering in subspaces. The other step is to select a consensus function, mainly based on the theories such as co-occurrence matrix, graph segmentation, and information entropy. An overview of ensemble clustering algorithms is depicted in Fig. 1.
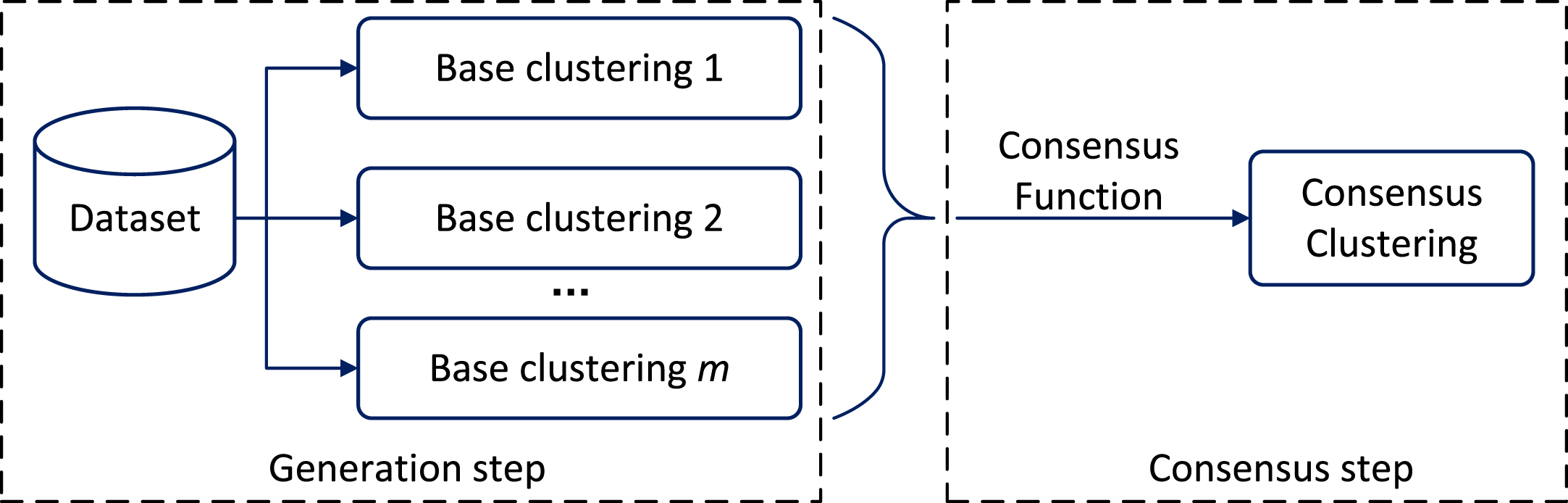
The outline of ensemble clustering.
In the numerous types of ensemble clustering solutions, the pair-wise co-occurrence based algorithms are pretty naive, easy to implement and have played a massive role in ensemble clustering fields. Nevertheless, these algorithms always treat all clusters in the base clustering equally, ignoring the difference of the clusters [35]. Some attempts have been used in cluster weighting to distinguish the effect of different clusters, such as weighting schemes of information entropy [14] and random walk [16]. The authors used related theories to distinguish different clusters and mine implicit relationships between instances. Corresponding experiments proved that it is effective to distinguish different clusters. However, these approaches always try to complete the ensemble clustering without the joining of features, but only the labels of base clusterings, which may lose some vital information implied in data features.
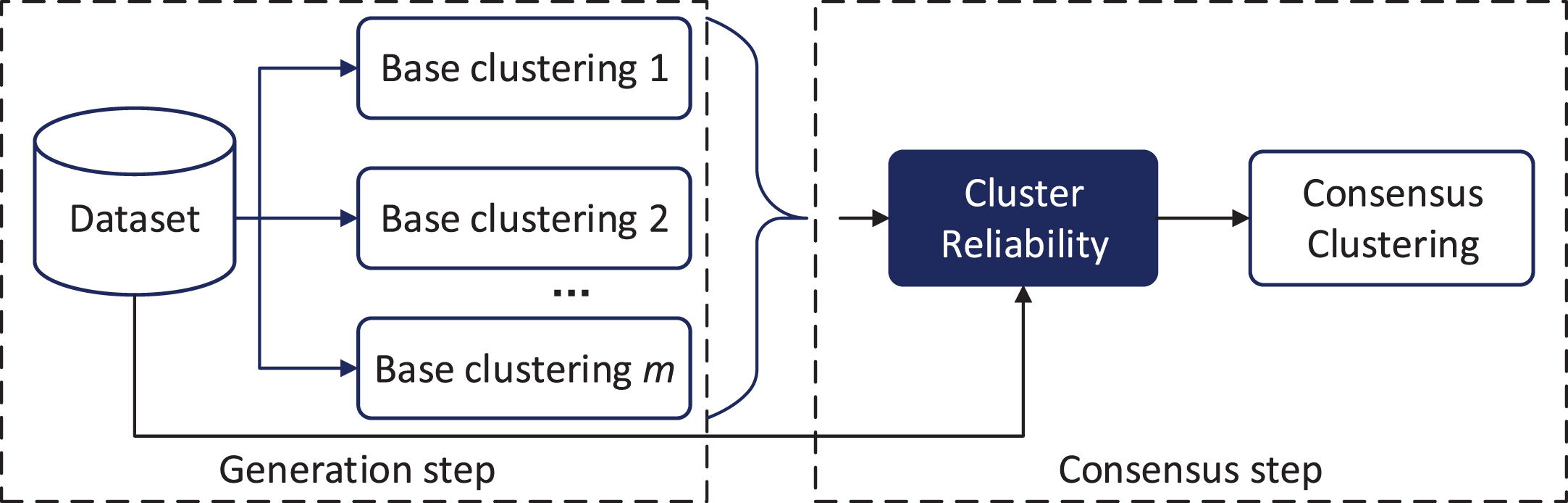
The motivation of proposed method.
Compared with the algorithms considering base clustering results only, effectively combining base clustering and original features helps further improve the performance of ensemble clustering. Fuzzy-rough sets offer a high degree of flexibility in enabling the vagueness and imprecision present in real-valued data to be simultaneously modelled effectively [12, 38]. The idea of upper and lower approximation can well depict the membership of instances to each category, which is helpful for measuring the cluster reliability in ensemble clustering. The motivation of the proposed method is described in Fig. 2, and the solid black arrow and blue box are used to illustrate the difference with similar works, which means the joining of original features while distinguishing different cluster reliability.
To distinguish the validity of different clusters and combine the role of features, in this paper, the fuzzy-rough lower approximation is used to induce cluster reliability in all base clusterings. A novel fuzzy-rough induced spectral ensemble clustering (FREC) algorithm is proposed to enhance the performance of pair-wise co-occurrence based ensemble clustering. The contribution of the paper is threefold: Proposing the novel idea of cluster reliability through the fuzzy-rough lower approximation of each instance to enable the distinction of diverse cluster significance during clustering; Developing a new adjacency matrix based on cluster reliability to effectively enhance the effect of diverse base clusterings and improve the clustering performance; Establishing a consensus function and spectral ensemble clustering algorithm with its superiority confirmed through a comparative study and analysis on various benchmark datasets.
The experiment compares eleven state-of-the-art clustering algorithms on ten benchmark datasets, as well as the parallel algorithm that ignores the difference of clusters in base clustering. The result shows that FREC achieves a significant clustering performance. As the ensemble size increases, FREC achieves a superior effect.
The remainder of the paper is structured as follows. The preliminaries of the rough set and fuzzy-rough set are introduced in Section 2. The FREC algorithm is introduced in detail in Section 3. In Section 4, the experimental results are given and analysed. Finally, a summary is presented in Section 4.
Preliminaries
This section reviews the mathematical concepts concerning rough set and fuzzy-rough set, which are relevant to the reliability of the cluster developed in this paper.
Rough set
The study on rough sets theory [13, 49] provides a methodology that can be employed to extract knowledge from a domain in a concise way: it is able to minimise information loss whilst reducing the amount of information involved. Central to rough set theory is the concept of indiscernibility. Let
Obviously, IND (P) is an equivalence relation on
where ⊗ is defined as follows for sets V and W:
For any object
Fuzzy-rough sets [6, 38] encapsulate the related but distinct concepts of vagueness (for fuzzy sets) and indiscernibility (for rough sets), both of which occur as a result of uncertainty in knowledge. Compared to rough sets, fuzzy-rough sets offer a high degree of flexibility in enabling the vagueness and imprecision present in real-valued data to be simultaneously modelled effectively. In fuzzy-rough sets, the fuzzy lower and upper approximations to approximate a fuzzy concept X can be defined as:
Here,
The unacceptable degree of clusters
The validity of a cluster can be well judged by considering the unacceptable degree (UD) of clusters in a base clustering. In multiple base clusterings, if the assignment of a cluster in one base clustering is consistently agreed by other base clusterings, this cluster should play a more critical role in the final consensus clustering. At the same time, if the assignment of a cluster is constantly negated by other base clusterings, the cluster should play a minor role.
For illustration purposes, some formalised descriptions are first introduced below. Let
Since for every fuzzy implicator
As proved in [31], if
Equation (12) implies that the lower approximation of x
i
to
For different base clusterings, the assignment of clusters is distinct, but the data location is fixed, that is, multiple base clusterings are acting on the same dataset. For a specific cluster in one base clustering, the resulting assignment has two cases: Another base clustering approves this assignment; Another base clustering denies this assignment.
In this paper, a novel concept of UD is proposed to metric the cluster reliability. Here, two exemplar artificial datasets D1 (shown in Fig. 3) and D2 (shown in Fig. 4) are employed to illustrate the UD of the two cases.
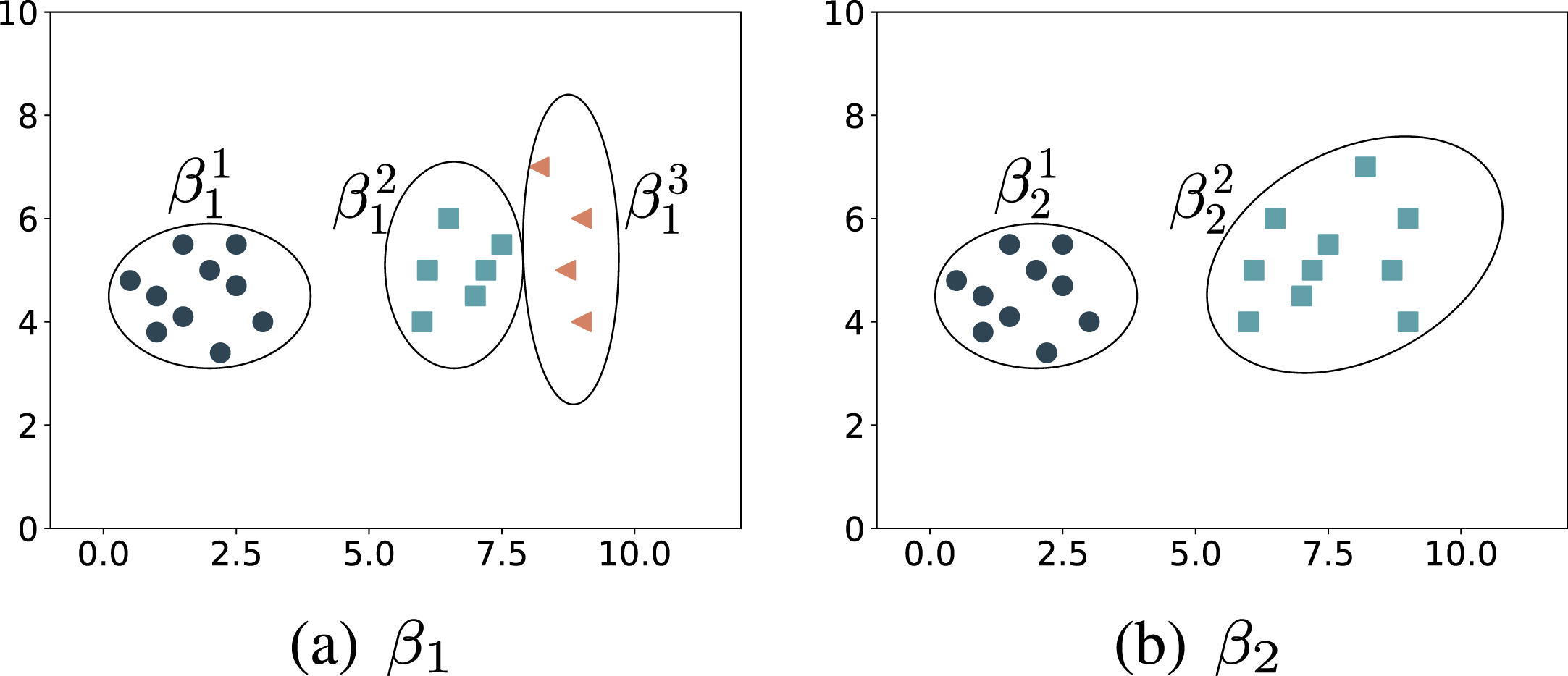
Two exemplar base clusterings β1 and β2 in dataset D1.
The first case is relatively simple, as shown in Fig. 3, including two exemplar base clusterings β1 and β2 in D1. For a specifically given cluster (e.g.,
For the three clusters (
Another situation is shown in Fig. 4. For a particular cluster in β3, if the cluster objects are split into a plurality of clusters in another base clustering β4, it can be considered that the specific cluster is not admitted or accepted by β4. Here,
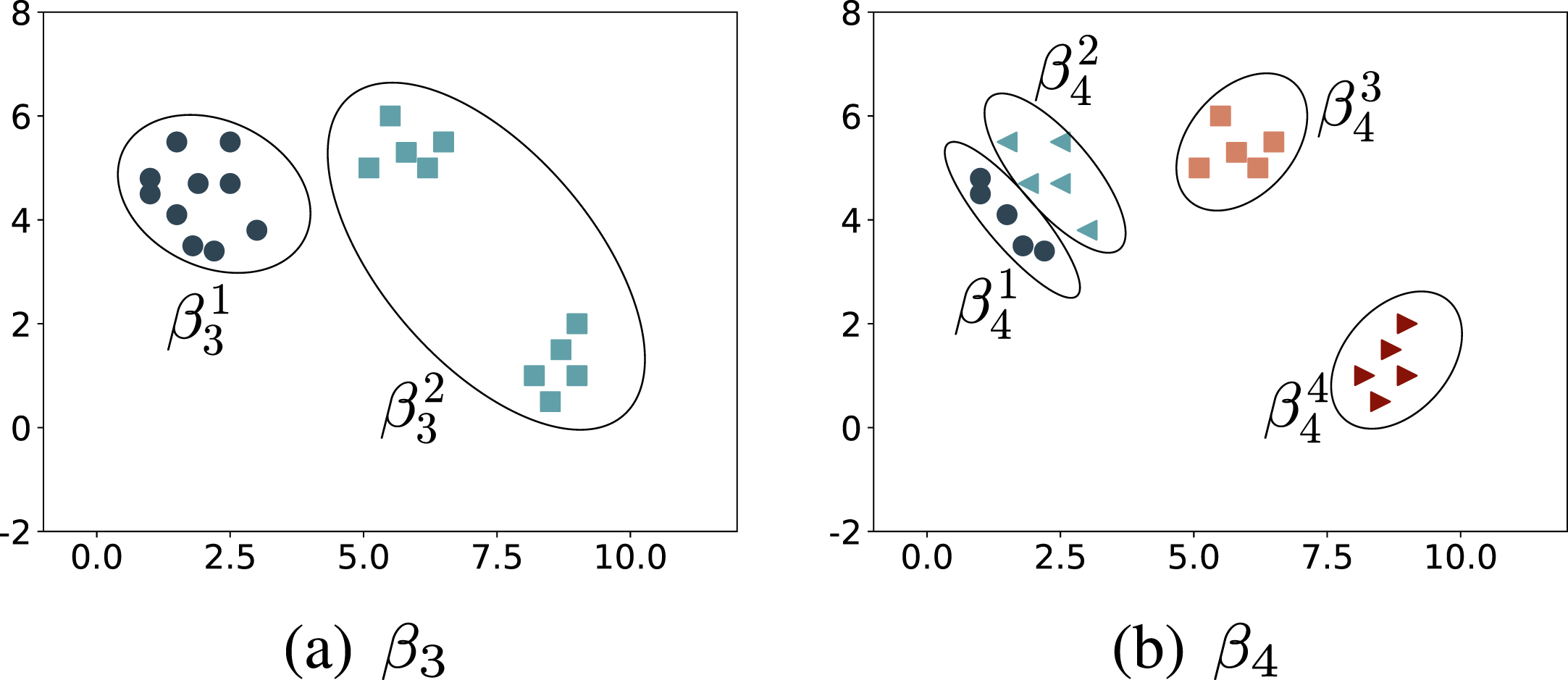
Two exemplar base clusterings β3 and β4 in dataset D2.
More specifically, for a specific cluster in a base clustering, considering its position distribution in another base clustering, if the objects of this particular cluster have a more significant lower approximation to the cluster in which the objects relocate in another base clustering, it indicates that the given cluster prefers the allocation of another base clustering. At the same time, it also means the extent of another base clustering does not accept the assignment of the given cluster.
Objects from
For the example cluster
To illustrate the concepts involved, the objects of the exemplar clusters
Two exemplar clusters in Fig. 4(a)
Relocated cluster of the objects in
Take x1, x6, x11 and x16 as an example (located in diverse clusters in β4), the respective lower approximation of the above four objects to β4 are obtained by using the Algebraic T-norm
Through further calculations, the lower approximation of all objects in β3 to the base clustering β4 are shown in Table 3.
Lower approximation of
Then, the UD of
Considering the ground distribution of
Further, the global UD
The unacceptable degree computing (UDC) algorithm is outlined in Algorithm 1. Given the inputs
Unacceptable Degree Computing (UDC)
m, number of base clusterings.
Γ, set of unacceptable degree of all clusters,
B, set of base clusterings.
1:
2: B ← Generate m base clustering.
3:
4:
5: S = ∅
6:
7:
8:
9: S = S ∪
10:
11:
12: Γ =
13:
14:
15:
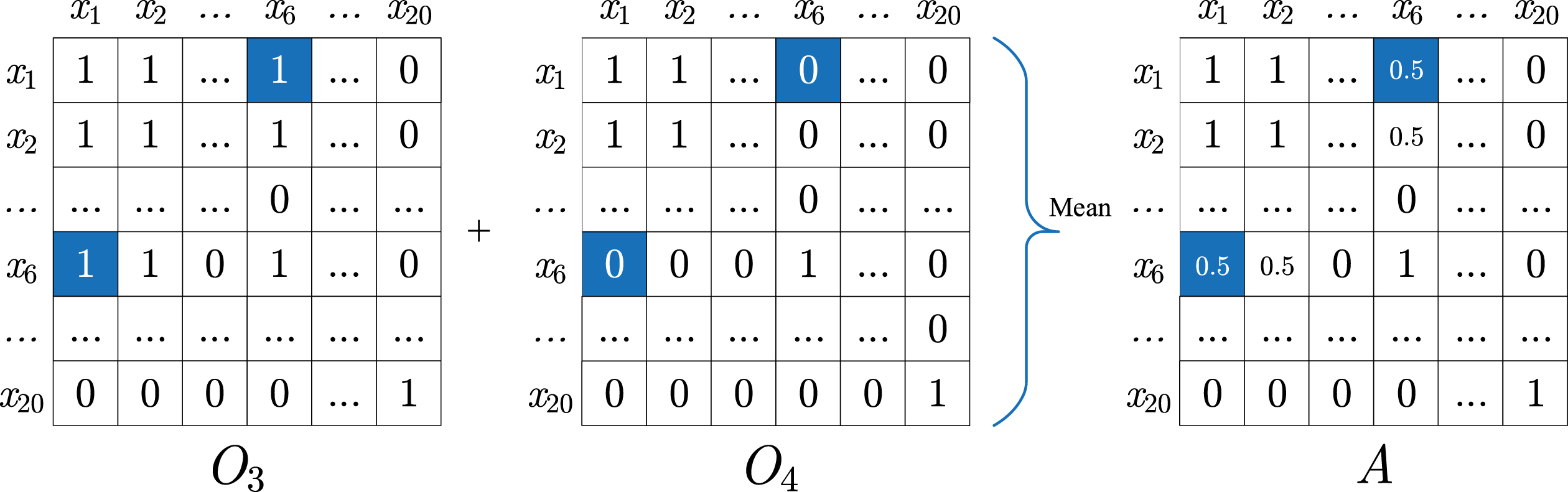
Matrices O3, O4 and A of the example in Fig. 4.
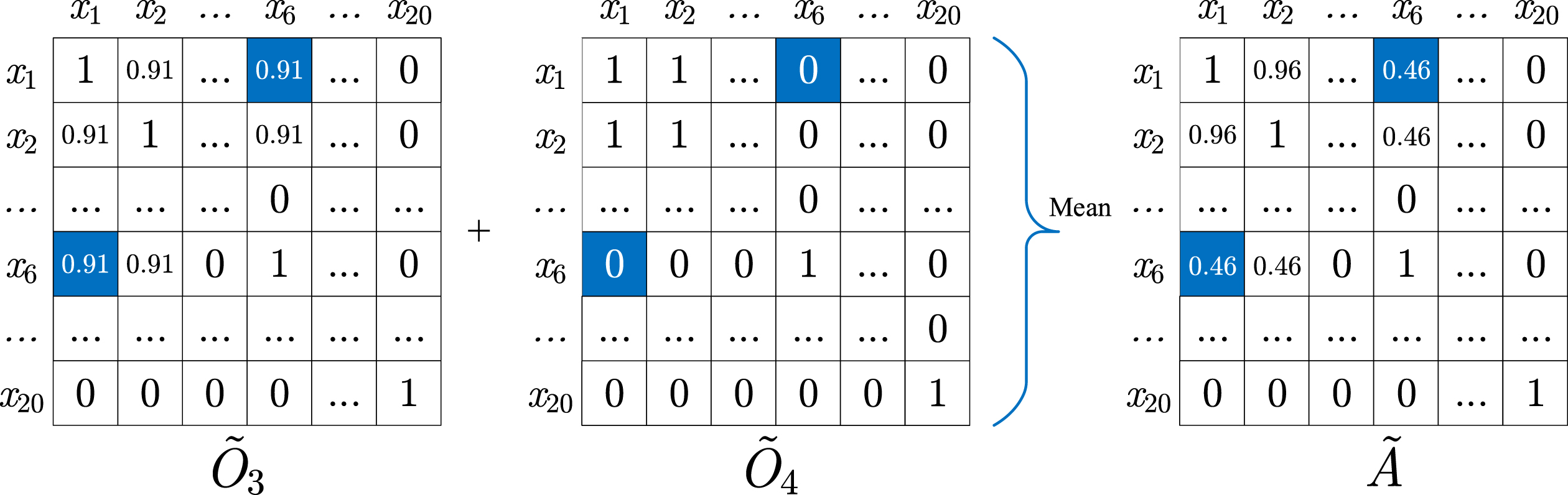
Redefined Matrices
The co-association matrix is obtained by summing and averaging a series of co-occurrence matrices, and it represents the frequency with which two objects co-occur in multiple base clusterings. Each base clustering β j produces a separate co-occurrence matrix, which can be expressed as
Given the exemplar clusters in Fig. 4 and corresponding coordinates in Table 1, the matrices O3, O4 and A are recorded in Fig. 5. Take x1 and x6 as an example (marked as a blue box):
Then, the elements a16 and a61 of A are calculated by
A higher UD for a cluster indicates that other base clusterings are more likely to disapprove of the cluster’s allocation scheme. At this point, the role of the cluster should be weakened. Otherwise, the function of the cluster should be reinforced. Therefore, the reliability of a cluster can be described as a decreasing function of the UD. In this paper, the reliability of the k-th cluster in β
j
is defined as
Similar to Equations (16), (18) and (19), the redefined co-occurrence matrix
Again, for the example of x1 and x6,
Then, the elements
The matrices
Co-Association Matrix Construction (CMC)
Γ, set of unacceptable degree of all clusters,
B, set of base clusterings.
1:
2:
3:
4: Q = ∅
5:
6:
7:
8: k = C j (x i )
9:
10:
11:
12: Q = Q ∪
13:
14:
15:
16:
17:
18:
The co-association matrix construction (CMC) algorithm is detailed in Algorithm 2. Firstly, the initialised step is performed. Lines 2 to 17 represent the overall process, including the main loop to identify the co-occurrence and co-association matrices. Note that all matrices are calculated only for upper triangular due to the symmetry. In Line 15, the lower triangular matrix of
A mapping from a set of clusterings to a single final clustering is called a consensus function. Considering the superior performance of spectral clustering in complex shapes and cross data, in this paper, the optimised co-association matrix is used in the spectral method to acquire the consensus result.
Given a graph model G = (V, L), where V indicates the vertexes set and L represents the links set. Its adjacency matrix can be constructed in various ways, such as considering the neighbours or defining the distance threshold. Let the objects in
The Laplacian matrix L of the graph G can be further defined as
Normalisation makes the diagonal entries of the Laplacian matrix to be all units and scales off-diagonal entries correspondingly. In this case, the normalised Laplacian matrix L nor is defined as
The components of the eigenvectors corresponding to the smallest eigenvalues of the graph Laplacian can be used for meaningful clustering [42]. In Equation (28), the eigenvectors corresponding to the first K smallest eigenvalues of L nor will be used in an independent clustering algorithm, generally k-means, due to its speed and efficiency.
As summarised in Algorithm 3, D and L
nor
are computed sequentially in Lines 2 to 6. EV(·) in Line 7 represents a function that generates the first K eigenvectors, and k-means(·) in Line 8 indicates a fast clustering algorithm detailed in [34]. Finally, in Line 9,
Consensus Spectral Clustering (CSC)
K, number of clusters.
1:
2:
3: d
ii
=
4:
5:
6:
7: F← EV(L nor )
8:
9:
According to the description of the above three subsections, the overall fuzzy-rough induced spectral ensemble clustering is depicted in Algorithm 4. Given a dataset
Fuzzy-Rough Induced Spectral Ensemble Clustering (FREC)
Fuzzy-Rough Induced Spectral Ensemble Clustering (FREC)
m, number of base clusterings,
K, number of clusters.
1: Γ, B =
2:
3:
4:
This section presents the experimental evaluation of FREC and other algorithms on ten popular datasets contained in UCI 1 repository. For convenience, datasets Cardiotocography, Image Segmentation, and Steel Plates Faults are represented by abbreviations Cardio, IS, and SPF, respectively. After introducing the experimental setup, the results and discussion are divided into five parts. Section 4.2 analyses the tendency of clustering effect as the number of ensembles increases. To test the impact of cluster reliability induced by fuzzy-rough lower approximation, Section 4.3 compares the effect of FREC and the original parallel algorithm EAC on all benchmark datasets. Besides, the average result of 100 base clusterings is also used to compare and validate the ensemble performance. In Sections 4.4 and 4.5, a detailed analysis of FREC and other state-of-the-art clustering algorithms is reported. Finally, the time complexity of the proposed method and running time of each algorithm are analysed in Section 4.6.
Benchmark datasets used for evaluation
Benchmark datasets used for evaluation
In the experimental investigation, all datasets are normalised first. Homogeneity score (HS) and normalised mutual info (NMI) are used to evaluate the performance of the separate clustering method [10, 15]. The base clustering pool B in Algorithm 1 is generated by running the k-means method 100 times, where the K is randomly selected from the interval [2,
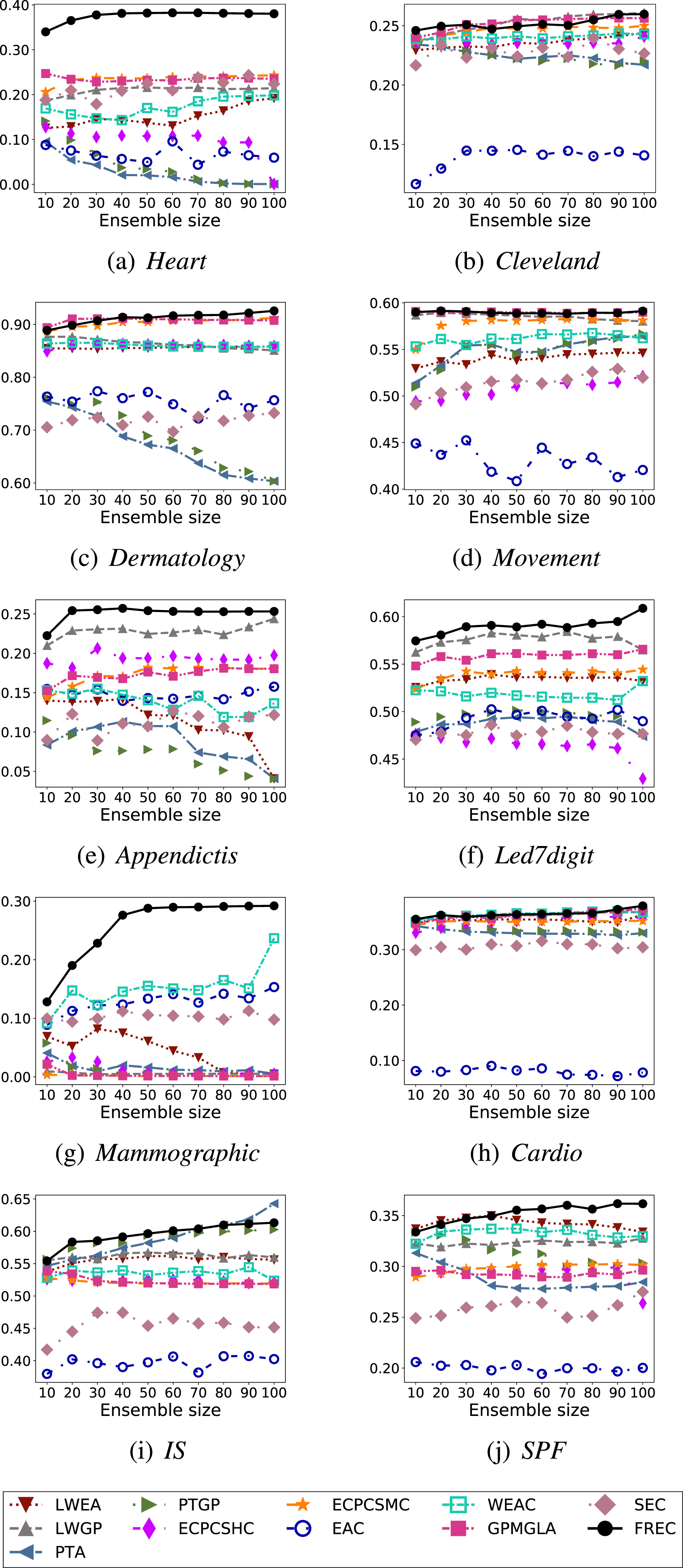
HS results with the ensemble size.
Ten state-of-the-art ensemble clustering algorithms, namely, locally weighted evidence accumulation (LWEA) [14], locally weighted graph partitioning (LWGP) [14], probability trajectory accumulation (PTA) [16], probability trajectory based graph partitioning (PTGP) [16], ensemble clustering by propagating cluster-wise similarities with hierarchical consensus function (ECPCS-HC) [18], ensemble clustering by propagating cluster-wise similarities with meta-cluster-based consensus function (ECPCS-MC) [18], evidence accumulation clustering (EAC) [5], weighted evidence accumulation clustering (WEAC) [15], graph partitioning with multi-granularity link analysis (GPMGLA) [15], and spectral ensemble clustering (SEC) [26] are selected to compare the ensemble performance of FREC. Moreover, two other non-ensemble state-of-the-art clustering methods, deep temporal clustering representation (DTCR) [37] and robust temporal feature network (RTFN) [50] are also used to compare the performance of the newly proposed method. For FREC, Łukasiewicz t-norm and Equation (9) are used to calculate the fuzzy similarity. As for other compared algorithms, there is no extra parameter for EAC, and the specific parameters of the remaining methods are set according to the recommendations or optimal values given in the corresponding papers. More specifically, the core settings are listed as follows. LWEA, LWGP: θ = 0.4; PTA, PTGP: ECPCSHC, ECPCSMC: t = 20; WEAC, GPMGLA: α = 0.5, β = 2; SEC: μ = 1; DTCR: m1 = 100, m2 = 50, m3 = 50, λ = 1e - 1, lr = 1e - 4; RTFN: CNNchannel = 128, kernelsize = 11, l
rate
(0) =0.01, d
rate
= 0.1.
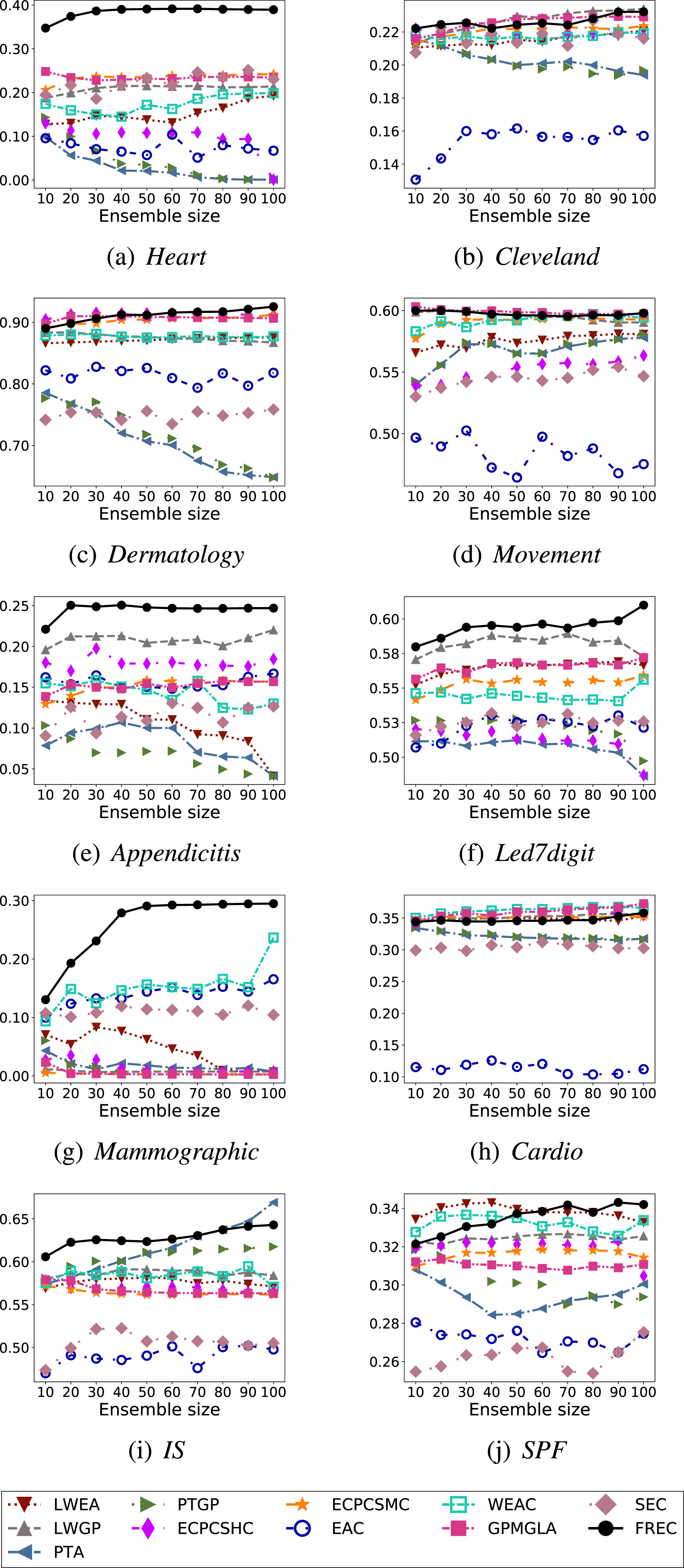
NMI results with the increased ensemble size.
NMI results of FREC versus the parallel EAC and base clustering.
Figures 7 8 show the experimental results for different ensemble sizes, including two indexes of HS and NMI on ten benchmark datasets. The various contrastive algorithms use different colours, lines and markers, as the legend details. Apparently, for the proposed FREC, as the ensemble size increases, the results on nearly all datasets deliver an upward trend regardless of the evaluation criteria, which is in line with the objective of ensemble methods. More specifically, considering HS, FREC shows significantly superior performance on datasets Heart, Appendictis, Led7digit and Mammographic, i.e. no matter how large the ensemble size is, FREC can invariably outperform the other ten ensemble techniques. For Dermatology and SPF, if the ensemble size is less than 40, the effect of FREC is slightly lower than that of GPMGLA and LWEA, respectively, but exceeds that of the other nine methods. If the ensemble size is more significant than 40, the proposed method performs superiorly, outperforming all different ways. While Cleveland, Cardio, and IS are not optimal in all ensemble sizes, FREC can always exceed most comparison approaches and always shows the best or second best performance if the ensemble size is maximum. Finally, for Movement, as the ensemble size increases, the performance of FREC tends to stabilise rapidly, and there is no apparent transformation trend. However, it can still surpass almost all contrastive algorithms.
While using the evaluation index NMI, the results are resemblance. For Heart, Appendictis, Led7digit and Mammographic, FREC can accomplish best values at any ensemble size, and the performance grows and stabilises as the ensemble size boosts. Regarding Cardio, although FREC is slightly lower than some methods if the ensemble size is less than 90, FREC still performs satisfactorily if the ensemble size is the largest, which ranks third. The curves of FREC may be slightly lower for the remaining datasets than individual algorithms at a particular ensemble size. Still, FREC can consistently achieve better results, especially at the largest ensemble size.
Comparison to the parallel EAC and base clustering
The algorithm EAC, which means the original co-association based ensemble scheme that does not consider cluster reliability, always conducts poorly in both HS and NMI. As exampled in Fig. 7(b), 7(d), 7(h) and 7(iFor the three clusters), EAC conveys the worst effect regardless of the ensemble size by comparing the other ten ensemble algorithms. To more comprehensively recognise the effect of using the cluster reliability induced by fuzzy-rough set, this part compares FREC and the parallel EAC in detail in the form of a histogram.
Since all ensemble strategies primarily achieve more satisfactory results at larger ensemble sizes, FREC and EAC use the pool containing 100 base clusterings. Moreover, both algorithms are run 100 times to acquire the average results. In addition, the algorithms in the base clustering pool (k-means) are also averaged to compare the ensemble performance.
HS results of FREC versus other ensemble algorithms
HS results of FREC versus other ensemble algorithms
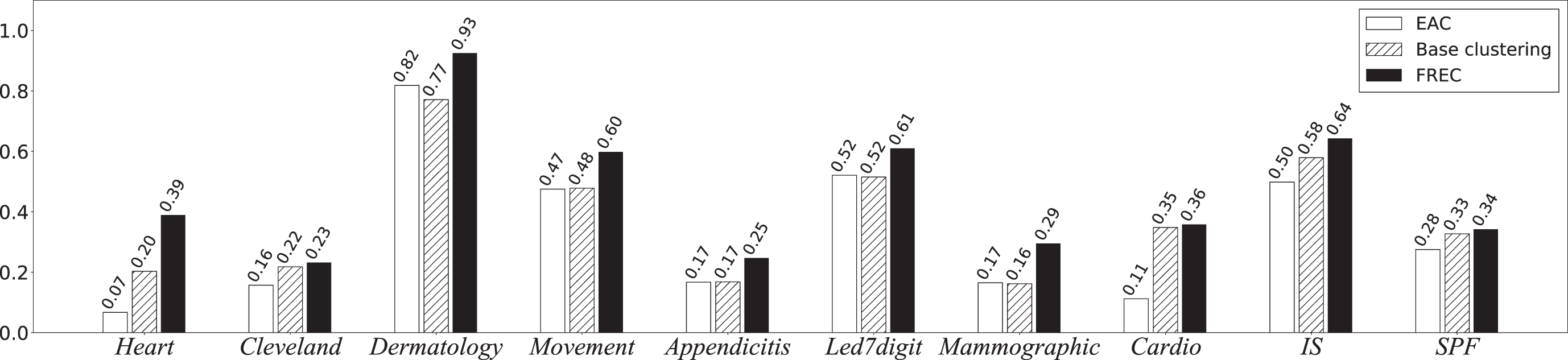
NMI results of FREC versus other ensemble algorithms
Without overloading similar results, the NMI is used to report the experiment evaluation. As shown in Fig. 9, FREC consistently achieves a better clustering effect relative to the parallel EAC and base clustering on all datasets. Especially for Heart, Dermatology, Movement and Mammographic, FREC reports the best clustering results while achieving a satisfactory improvement, illustrating the advantage which considers the cluster reliability and the superiority of FREC.
In order to comprehensively evaluate the performance of the proposed algorithm, experimental comparisons are carried out against the other eleven state-of-the-art methods. The results are summarised in Tables 5 6. Note that the results of EAC have been analysed in Section 4.3 and will not be repeated in this part.
Recall reported results, ensemble algorithms always work best using more ensemble size. Thus, all comparison ensemble methods employ the results with an ensemble size of 100, and the average and best results for each dataset are shown in columns Ave and Best, respectively. To describe the experimental results more obviously, the best results are highlighted in bold. Moreover, the second best results are highlighted with an underline to make the information in the table easier to follow.
Considering the metric HS, FREC achieves optimal average performance relative to the other eleven algorithms in most datasets, including Heart, Dermatology, Movement, Leg7digit and SPF. As for the results in column Best, although a bit inferior to one or two approaches occasionally, FREC is the best or second best in most cases. For the remaining datasets, the average performance of FREC is slightly lower than individual algorithms. Still, FREC shows a satisfactory clustering effect compared with the other techniques.
Now, take an observation of the evaluation NMI, the clustering result is highly analogous to HS. For datasets Heart, Cleveland, Dermatology, Movement, Appendicitis, Leg7digit, Mammographic and SPF, the proposed method can consistently surpass most contrasting approaches. For dataset IS, consistent with the HS, FREC is slightly inferior to PTA, ranking second in all ensemble methods. The main difference from HS is the dataset Cardio. FREC is slightly lower than WEAC and GPMLGA by 0.008 and 0.015, respectively. Nevertheless, compared with the remaining algorithms, FREC still shows excellent performance.
In general, the average and best results of FREC are equal in most cases, which means that the FREC is relatively stable and the results are less serendipitous. At the same time, regardless of the average or best results, FREC always achieves the most significant or second best effect, which illustrates the rationality of the research in this paper.
Statistical analysis
Paired t-test is used throughout the present experimental studies to show any statistically significant differences between different approaches. This helps ensure that the results are not obtained by chance. The t-test results are summarised at the end of each table, counting the number of statistically better(v), equivalent(space) or worse(*) cases for FREC in comparison to each algorithm. In all experiments reported, the threshold of significance is set to 0.05. For example, in Table 6, (11/0/0) in the column Heart indicates that the clustering performance returned by FREC performs better than other ensemble methods in eleven cases, equivalently well in no case, and worse than other approaches in no case. It can be clearly seen that whether the evaluation index is HS or NMI, the statistical results of FREC are better than other methods in most cases, especially for the HS indicator, FREC can surpass all other algorithms on more than half of the datasets. Statistical analysis experiments show that in 100 repeated experiments, the overall performance of FREC is relatively stable, which is better than most algorithms.
Time complexity analysis
As shown in Algorithm 4, the computing cost of the proposed FREC mainly includes three parts: (1) For UDC, this function mainly consists of three loops with a time complexity of O (mk (k - 1)). In particular, each instance needs to traverse to find the lower approximation when calculating UD in the inner loop, and this process will consume O (n2); (2) As for CMC, this part mainly calculates the upper triangular matrix of
Time complexity comparison of different algorithms (seconds)
Time complexity comparison of different algorithms (seconds)
To compare the running time gap with other methods, the running time (seconds) of each algorithm is reported in Table 7. The experimental CPU used is i7-12700, and the memory is 24G. It can be seen that after considering the data features, the running time of FREC is significantly higher than that of other comparison methods. Especially as the number of instances continues to increase, the time of FREC increases significantly. In comparison, methods such as LWEA, SEC, and RTFN have achieved better running time. The above implementation shows that the time efficiency of FREC is relatively poor, which requires further optimisation in subsequent work.
This paper explores the role of considering cluster reliability using fuzzy-rough set in co-occurrence based ensemble clustering, and guides a fuzzy-rough ensemble approach. The experimental results indicate that the reliability induced by fuzzy-rough lower approximation is effective and can be reasonably employed in the task of ensemble clustering. Compared with other ensemble algorithms that ignore attributes and only employ base clustering results, FREC demonstrates the advantage of viewing feature information. Meanwhile, compared with the parallel version and base clustering, FREC shows its superiority again.
Nonetheless, from the time experiment, the efficiency of FREC is relatively slow. This is mainly due to the high time complexity of the algorithm. For large sample datasets, it will take a lot of time to calculate the lower approximation for each object. In future work, the idea of KD-tree [44] can be introduced to improve the running speed of the algorithm further. In addition, in Equation (23), if the two instances do not belong to the same cluster, it may not be a better choice to assign the adjacency matrix to 0 directly. Further mining the implicit connection between instances of different clusters helps improve the clustering performance.
Whilst promising, further work remains. The performance of the ensemble strategy and multi-density cluster designs is worth further exploration. In addition, the implied relationship of the objects in the same base clustering but the different clusters is a valuable route of investigation. Moreover, a more comprehensive comparison of ensemble methods over diverse datasets from the real-world domains, such as mammographic risk assessment [46, 47] would construct the foundation for a broader series of issues for future research.