
Abstract
An intrusion detection method using rough-fuzzy set and parallel quantum genetic algorithm (RFS-QGAID) is proposed in this paper. The RFS-QGAID is applied to solve the serious problems of determining the optimal antibodies subsets used to detect an anomaly. To obtain a simplified antibodies collection for high dimensional Log data sets, RFS is applied to delete the redundant antibody features and obtain the optimal antibodies features combination. Then, the optimal attitudes are entered into the QGA classifier for learning and training in the following stage. At last, the detected Log antigens are fed into RFS-QGAID, and we can classify the intrusion types. With RFS-QGAID, we give the simulations, the results on real Log data sets show that: the higher detection accuracy of RFS-QGAID is higher detection accuracy, but the false negative rate is lower for small samples sets, the adaptive performance is higher than other detection algorithms.
Introduction
As an effective network security defense tool, many Intrusion Detection Systems (IDS) based on artificial intelligence are proposed. The artificial intelligent algorithms include: deep learning (DL) [20], support vector machine (SVM) [2,11], fuzzy sets (FS) [23], outliers [18], random forest (RF) [9,10] and genetic algorithm (GA) [21]. Mohammed et al. designed an intelligent two-layer IDS for the new network Internet of Things (IoT) [14].
Alyaseen et al. designed an intrusion detection algorithm, they reduced the features with K-means and obtained higher classifying performance [2]. JooHwa et al. [10] designed an IDS, which was based on auto-encoder conditional algorithm, generatively adversarial networks and the RF algorithm (AE-CGAN-RF), auto-encoder conditional algorithm was adopted to obtain reduced features collection from high-dimensional data set.
Ren et al. applied the outliers method to calculate the attribute values and delete redundant features in a hybrid multilevel IDS [9]. These reduction algorithms can reduce partial redundant attributes, but they have shortcomings about the analysis of the characteristics of the relationship between attributes, so some redundant attributes are retained [24,25].
Because there are many redundant attributes in detected data of IDS [3,5,6,16,26], RS and FS are used in ID system. Pawlak put forward RS theory. Fortunately, RS is applied in the attributes reduction. RS has the ability to deal with incomplete and uncertain records set, get the best attributes by removing redundant. With RS and FS, we can get the memory antibodies [23].
For another, the ability of classifier directly decides the anomaly detection accuracy [12]. Yang improved the Clustering Algorithm with Modified Density Peak values (MDPCA) [23], and gave an IDS to improve the density of the peak to solve the problem of imbalance between detection rate and false detection rate. Song et al. [18] designed an anti-adversarial hidden markov model IDS (AA-HMM) to get higher classification ability. While those algorithms lack adaptivity. Orieb et al. proposed a pigeon-inspired optimization improved by a local search algorithm d (LS-PIO) [1] and applied it to an IoT network. Maya et al. gave a dual IDS with bagging and gradient boosting decision tree (GBDT) to decrease the false alarm rate [13]. Ankit and Ritika proposed an IDS based on deep neural network, they applied the fusion of statistical importance to select features [4].
The GA is applied to improve the self-adaptability in IDS. Zahra et al. gave an ID system with FS and GA, which are adopted to generate a reduced features collection, which included the fuzzy if-then antibodies classification rules, GA was applied to calculate the antibodies rule weights specification [21]. However, the initial population distribution of antibodies affect the detection performances of IDS greatly. For the fixing crossover probability values and mutation probability values of genetic operators, the global optimal solutions are unconducive to search.
In order to get higher intrusion detection performances, especially for the small samples sets, the Rough-Fuzzy Set method is proposed to delete the redundant attributes, obtain the optimum antibodies features sets and achieve effective compact features dataset after reducing all the unnecessary attributes. Then, synthesizing GA and the quantum computing, we design a MOP-AQGA algorithm. Finally, we propose an ID method based on RFS and QGA. Experiments are given on intrusion data which are collected from real network traffic records, and the results show that RFS-QGAID has better intrusion detection performances as it has higher detection, accuracy and lower false positive rate for small samples sets.
The RFS algorithm
Rough set
Combined the RS and AIS, the key definitions are given in following definitions [23].
The bonding strength is denoted as affinity between The affinity between The decision system with antibodies attributes is denoted For the collection Antibody lower approximate collection Let a decision system with antibodies attributes is Antibody attribute dependency is shown as follows.
The significance degree of antibody attributes is given as:
The theory of FS is described that all the attributes of log data are applied to generate a fuzzy matrix, at the same time, the antibodies’ classified results are calculated after analyzing the relationship of antibodies. The total number of FS and the subfunction of each subclass decide the final results [23].
We divide all the antibodies into k (
For each type of fuzzy k-division, the antibody objective function
m (
The final purpose of RFS is to generate the best classification
The goals of RFS are: we can get the diversity of antibodies, avoid the RFS-MOP-AQGAID’s local convergence. Standardized steps of the RFS are shown as Table 1.
Standardized process of the RFS
Standardized process of the RFS
In RFS, rough set algorithm is used to obtain the reduction of antibodies, while there are some attributes which are uncertain values, which are easily neglected.
Evolution process of QGA
As GA has an adaptive mechanism, with GA we can calculate the individual antibodies’ fitness and allocate certain antibody quantum rotation angle values. With GA, the IDS’ convergence rate can be accelerated. This antibody quantum rotation angle value mechanism can easily achieve diversity of antibodies in their later evolution period, so the results of intrusion detection may be obviously affected. We adopted four operators to finish the antibodies’ cooperative evolution, which include antibodies similarity calculation operator, antibody fitness calculation operator, antibody population variation correction coefficient operator, and antibodies mutation operator. So we can calculate the dynamic mutation probability of different individuals in their evolution generations, the population diversity can be increase in the late period of population evolution. Hamming distance denotes similarity of individual antibodies. With the hamming distance value decreasing, the two individuals are more similar. The operators are shown as follows:
In (11),
In equation (12),
In (13), let’s suppose that n is behalf of the antibody’s current evolution algebra, s is the largest value of its evolutionary algebra, T is a constant, which is its iterations value, while the best antibodies are invariable any more. P (
In (14),
There are three strategies in QGA, the first one is adaptive antibody correction of quantum rotation angle, which is adopted in antibody’s evolution; the second mechanism is the antibody cooperative evolution of multiple operators, with which we can obtain the optimized antibodies dynamically by modifying the mutation probability; the third one is multi-universe method, some optimal antibodies immigrant among different universes to increase the diversity the antibodies further. Therefore, antibodies quantum rotation angle is adopted to modify the antibody rotation angle step length dynamically with the antibody’s fitness. The antibody rotation angles are given in Table 2 [17].
Antibody adaptive correction strategy
Antibody adaptive correction strategy
Let us suppose that antibody x,
In (15), the antibody rotation angle step length is linearly to the antibody’s fitness, therefore, individuals with higher fitness will be allocated a larger antibody rotation angle step length for antibodies’ variety, on the contrary, antibodies that have lower fitness will be assigned a smaller one, so that the antibodies will vary more lowly.
In antibodies’ current population, we calculate the antibodies’ rotation angle step length of the ith evolution according to the antibodies rotation direction of the jth individuals, which is demonstrated as equation (16).
To decrease the extra calculation complexity, and improve the efficiency of IDS, we apply the model of 4 universes in QGA. In the 4 universes strategy, the main universe is the management center, it controls the other three auxiliary universes and translates the antibodies. In the auxiliary universe, antibodies evolve independently in their life cycles.
In some period, some part of excellent antibodies with high fitness are translated from the auxiliary universes to the main universe. In the main universe, we choose the optimal antibodies and send them to the three auxiliary universes respectively. Then certain worst antibodies with low fitness are weed out. The proposition of exchanging antibodies is 10 percent to 20 percent in all the antibodies population.
The QGA is presented in Table 3.
QGA
The RFS-QGAID includes two main steps: training initial antibodies to get memory antibodies off-line, detect the intrusions on-line. The training phase is described in following steps:
The offline log records are as the initial input resources. We get the initial memory antibodies with RFS, the final decision table is Execute the RFS, delete the redundant attributes from log records data sets with high-dimensional features. The significance between the features and different log records categories are calculated in the samples collection to generate the optimal antibodies combination. Put the best antibodies above into the QGA classifier and generate the memory antibodies. Sample from the received log records packets, get the flow log records details with the attributes in simplified Delete the unnecessary attributes and generate the d-dimensional significant attributes from the flow log records by the RFS submodule. Then, the flow log data are compared with the memory antibodies which are generated from the QGA classifier, at the same time, the accurate classified detection results are obtained, the records with results are the new antibodies which are input the QGA to update the antibodies set.
In the detection phase, the main two steps are as follows:
Simulations and results analysis
Data collection and parameters setup
To obtain the effective performances of the RFS-QGAID, we finish the experiments with the standard benchmark NS-KDD, which are offered by Lincoln laboratory for simulations of intrusion detection, the training samples collection KDDTrain+ has 125,973 records. Test sample collection contains 2 kind of sets: KDDTest−21 and KDDTest+, and each data set contains five categories of samples: Normal, Dos, the Probe, U2R and R2L.
When RFS-QGAID runs, all the log records in KDDTrain+ are used to train to obtain the initial antibodies, and KDDTest+ is used to test RFS-QGAID algorithm. The log records distribution is demonstrated in Table 4.
Log records distribution of NSL-KDD [7]
Log records distribution of NSL-KDD [7]
Because there are a small amount of U2R attacks records, U2R set belongs to a small samples collection, all the 67 U2R records are applied as the simulation data. In equation (15), we set the minimum antibodies rotation angle step length value
The RFS-QGAID is realized with C. The configuration RFS-QGAID examination environment: the type of CPU is the Intel Pentium 4, 3.20 GHz, memory is 16 GB, the OS is Windows 2016.
The detecting experiments contain 4 main steps: log records normalization, reducing the redundant attributes, training the log samples, and testing the flow log records. Some attributes may have smaller features value may be easily ignored, for the reason that there are large difference between various attributes. The log records should be transformed to a standard format, then RFS is adopted to delete the unnecessary attributes.
The log records collection includes n antibody samples, and faj[l] denotes the ith attribute value of the jth antibody. The mean value of antibody is demonstrated as equation (17), and the standard deviation value is shown as equation (18):
The evaluation standards of the detecting results are shown in following formula [15]:
TP is the total number of flow log records that are attacks, and they are accurately identified; TN is the total number of flow log records that are normal behaviors, and they are accurately identified; FP presents the total number of flow log records that are attacks, and they are falsely identified as normal behaviors; FN presents the total number of records that are normal behaviors, and they are falsely identified as attacks [19,22].
The best attributes collection based on RFS
RFS algorithm is adopted to delete the unnecessary features and generate the optimal antibodies, the detecting classifier combines these attributes with calculating their significance.
We can conclude from the experiments that when there are total 19 attributes, the deviation value of the RFS’s DR and FAR is maximal, meanwhile the DR reaches 95%. When there are 25 features, the deviation value of the DR and FAR’s between the mRMR and FRS is maximal. Therefore, the top 19 significant attributes are selected as the features of antigens and antibodies with the RFS. Similarly, in the study by Zhang and Zhang [27], the same methods are used with NMIFS and IIFS-MC algorithms, we can get 20 features.
The conclusion demonstrates that RFS owns better attribute reduction ability than mRMR, NMIFS and IIFS-MC. Table 5 gives the final attribute subsets with the two algorithms above.
The selected attributes subsets
The selected attributes subsets
From Table 5,we can conclude that the simper features collection is obtained, so the computation complexity of RFS can be used to decrease the detection time.
The K-means [2], the AE-CGAN-RF [9], AA-HMM [18], MDPCA DBN [23], GPSO [25] and FRS-QGA algorithm proposed in Section 1 are used to execute the experimental log data set. The five kinds of samples collections ROC (Receiver Operating Characteristic) curves are shown in Fig. 1.
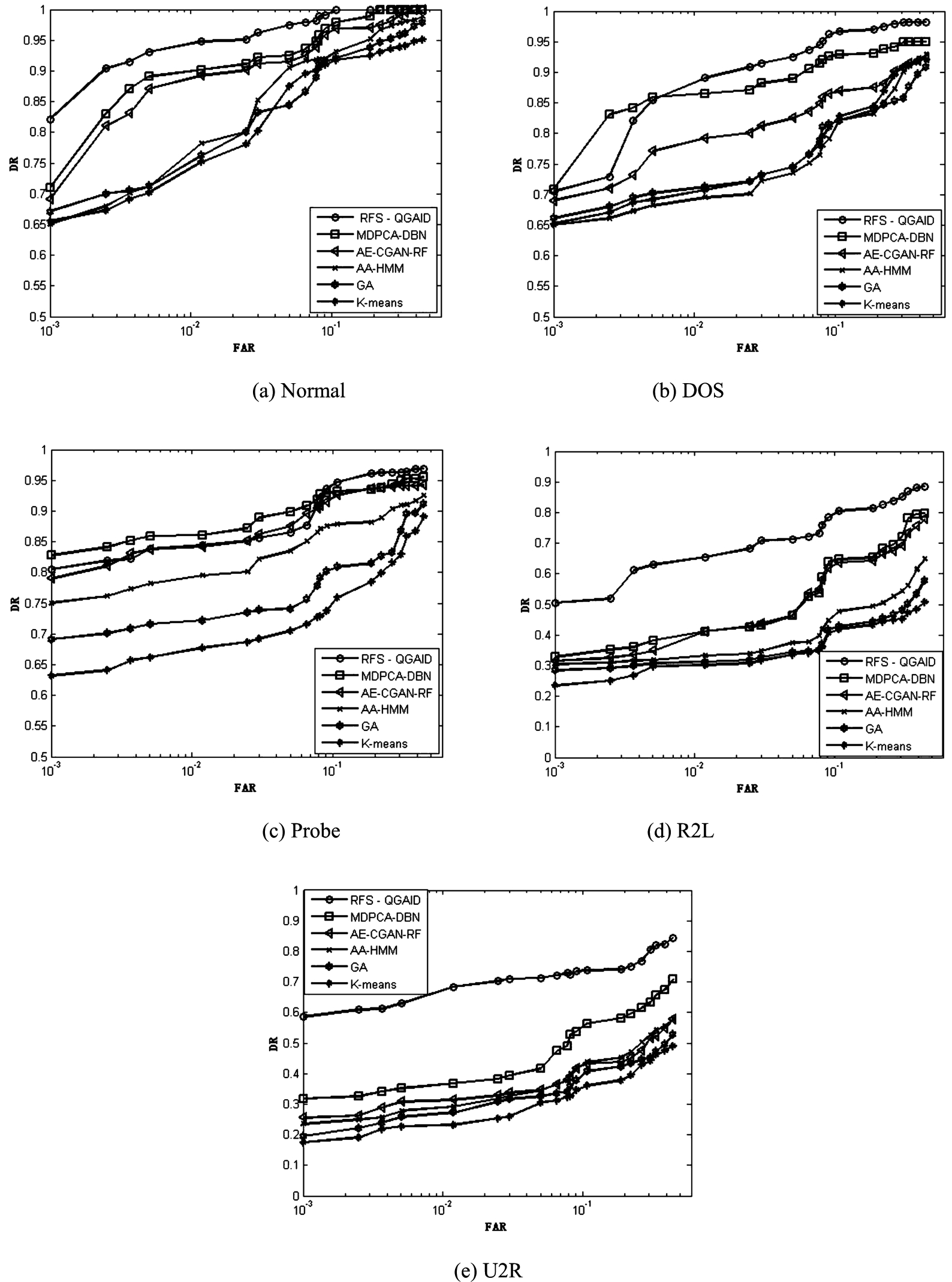
The ROC curves.
The results in Fig. 1 show that compared with the existing common detection methods, we apply FRS-QGA algorithm to detect the normal records, and the other four attacks (DOS, the Probe, R2L and U2R), and obtain a lower FAR, but a higher DR.
The RFS-QGAID algorithm is compared with the algorithms in Section 1, such as K-means [2], AE-CGAN-RF [10], AA-HMM [18], MDPCA-DBN [23], GPSO [25], LS-PIO [1], Dual-IDS [13] and DNN [4]. To execute the abnormal detection simulation, all the attacks records are settled as abnormal behaviors. In order to get the precise performance of RFS-QGAID algorithm, we run the algorithm with each records collection for 10 times to get the detection performances, such as DR, Acc, FAR, Pre and F1 score, finally calculate the average values respectively and compare them with other detection algorithms. The results are demonstrated in Table 6.
The comparisons results (/ denotes the uncharted value)
The results demonstrated in Table 6 show that the RFS-QGAID has 0.11% higher false positives and 2.91% higher detection rate than GA + Fuzzy in the study by Varzaneh and Rafsanjani [21]; the other four performance indicators are almost more excellent than other intrusion methods, meanwhile the algorithm proposed in this paper has a better balance between detection rate and the rate of false positives.
To verify the classification ability of RFS-QGAID for different types of attacks, particularly the small data sets, the results are compared, which are demonstrated in Table 7.
The first comparisons
Table 7 shows that the RFS-MOP-AQGAID owns the highest DR among all the intrusion methods according to small sample data set: Probe, U2R and R2L attacks. RFS-MOP-AQGAID has higher DR, it can improve the adaptivity of the intrusion algorithm.
Literature [23] demonstrated the algorithm’s confusion matrix, with which we calculate the DR, Pre and F1 score, and compare them with the results in this paper (Table 8).
The second comparison of different algorithms
We can conclude from Table 8 that the proposed RFS-QGAID owns higher DR, Pre, and F1 score than MDPCA-DBN in the study by Yang et al. [23]. Particularly for Probe, U2R and R2L, the proposed algorithm’s detection abilities are better for small amount of records.
This paper apply the RFS algorithm to delete the unnecessary antibodies features and generate the optimal initial antibodies from flow log sample attributes collections. From the simulation results, we obtain an effective antibodies collection of the higher dimensional attributes.
In the meantime, we design a QGA to classify the behaviors. In QGA, antibody similarity calculation operator, antibody fitness calculation operator and antibody population variation correction coefficient operator and antibodies mutation operator are used to generate individual’ mutation probability dynamically, meanwhile, adaptive parallel quantum GA was applied to guarantee the variety of antibodies. Experiment results demonstrate that, the detection accuracy, false positive rate, and better adaptivity of RFS-QGAID are all better than current IDS, especial for small samples sets. However the flaw of RFS-QGAID is that the performances for new types of attacks need to be strong. The next research is to study the zero-day attacks deploy the RFS-QGAID in the new generation network.
Conflict of interest
None to report.