
Abstract
This paper aims to explore unsupervised cross-lingual word representation learning methods with the specific task of acquiring a bilingual translation lexicon on a monolingual corpus. Specifically, an unsupervised cross-lingual word representation co-training scheme based on different word embedding models is first designed and outperforms the baseline model. In this paper, we adeptly tackles the obstacles encountered in higher education foreign language teaching and underscores the necessity for inventive teaching methods, and design and implement a linear self-encoder-based principal component acquisition scheme for the interpoint mutual information matrix obtained from a monolingual corpus. And on top of this, a collaborative training scheme based on linear self-encoder for cross-language word representation is designed to improve the learning effect of cross-language word embedding. The results of the study show that the most obvious rise in the pre and post tests of the experimental class in the practical application of the foreign language teaching model based on the method of this paper is the word sense guessing, which rose by 23.12%. Sentence meaning comprehension increased by 23.39%, main idea by 16.61%, factual details by 15.47%, and inferential judgment by 10.28%. Thus, the feasibility of the unsupervised cross-linguistic word representation learning collaborative training method is further verified.
Keywords
Introduction
In recent years, against the backdrop of globalization, postmodernism and internationalization, which are rising and profoundly influencing the direction of social development, foreign language education has become the most important social resource of a country and the invisible yardstick of cultural soft power [1, 2]. While foreign language education has rightly become a bridgehead for communication and exchange between countries, nations and peoples, and cultures, it also carries the important mission of promoting the dissemination of traditional cultural values and plays an important role in maintaining national ideology, national identity, coordinating harmonious social development, and reaching international understanding [3, 4, 5].
As an important place for cultivating foreign language talents, foreign language teaching in colleges and universities is facing new challenges and opportunities. The traditional foreign language teaching mode can no longer meet the demand for foreign language talents in modern society, so the research on the innovative mode of foreign language teaching in colleges and universities has become a hot topic in the field of education today [6, 7]. The research of innovative mode of foreign language teaching in colleges and universities not only helps to improve the quality and effect of foreign language teaching, but also helps to cultivate students’ innovative consciousness and practical ability, which will lay a solid foundation for their future development [8, 9]. Therefore, the research on the innovative mode of foreign language teaching in colleges and universities has important theoretical and practical significance.
Innovative teaching methods, with their potential impacts, encompass the introduction of novel approaches to education. These methods can significantly enhance student engagement by making learning more interactive and adaptable to various learning styles, leading to improved learning outcomes. Leveraging technology, they prepare students for the digital age and promote critical thinking and problem-solving skills. They also instill a love for lifelong learning, foster inclusivity and accessibility, and encourage ongoing teacher professional development. Furthermore, they contribute to educational research and innovation, ultimately transforming the education system to be more engaging, effective, and responsive to the evolving needs of learners in a rapidly changing world.
Jodoin studied the effects of promoting language education for sustainable development in Japanese higher education. Using an empirical case of a project, the authors explore an educational approach that integrates language learning with sustainable development goals and analyze the impact of the approach on students [10]. Ali examines how the principles of positive psychology can be applied to the language learning process to develop a more positive, optimistic, confident, and self-motivated mindset in students. The article explores the theoretical foundations of positive psychology in language education and suggests how these principles can be applied in practice to support students’ language acquisition [11]. Nagle investigated how expectancy-value theory can be used to understand motivation, persistence and achievement aspects in foreign language learning at university. The study provides valuable ideas and theoretical support for foreign language education and has some practical guidance [12]. Byram and Wagner explored how to achieve the goals of language education and intercultural dialogue in terms of intercultural education, language policy, and curriculum design. A series of theoretical frameworks and teaching strategies, such as core intercultural competencies and communicative experiences, are proposed and the important role of language teachers in this process is emphasized [13]. Tschirner their used an assessment method based on the Common European Framework of Reference for Languages to measure the listening and reading skills of German university students. By analyzing the test results and comparing them with the different levels of the Common European Framework of Reference for Languages, the authors derived the average levels of university students in listening and reading [14].
Through in-depth interviews and analysis of 12 voluntary colleges, the Bradford authors identified several major types of implementation challenges, including those of students, faculty, materials, and curriculum design. The findings of this study are of particular value to schools and institutions that are seriously thinking about and preparing for English language delivery in higher education. Not only does it provide practical evidence and recommendations, but it can also serve as a basis for future research to further improve the implementation of English language delivery globally [15]. Lyle analyzed different task types and ratings made by raters and explored the impact of these variabilities on test results. The results showed significant differences between tasks and significant variability in the ratings made by raters, and these differences may lead to uncertainty and misinterpretation of test results [16]. Huensch study aimed to reveal the influence of different cultural backgrounds and language experiences on attitudes towards learning foreign language pronunciation. Through a questionnaire survey of students from different countries and with different language backgrounds and statistical analysis of the results, the authors found some interesting findings: on the one hand, students from different cultural and linguistic backgrounds differ significantly in their approach to foreign language pronunciation problems, and on the other hand, even students from similar cultural and linguistic backgrounds differ in some aspects [17]. Jane conducted a reading and vocabulary test with 35 university learners of Russian and statistically analyzed the test results. It was found that, on the one hand, there was a significant positive correlation between vocabulary knowledge and reading ability. On the other hand, high level Russian readers excelled in vocabulary [18].
In this paper, we first improve the cross-lingual word representation learning ability of the baseline model by means of co-training. An unsupervised cross-lingual word embedding co-training scheme based on different word embedding models is designed and implemented [19]. The linear self-encoder-based principal component analysis method is then analyzed and studied, and a linear self-encoder-based principal component analysis model is implemented for the high-dimensional interpoint mutual information matrix statistically obtained on the corpus, and the scheme is optimized for the characteristics of the interpoint mutual information matrix, so that the high-dimensional principal components of the interpoint mutual information matrix are successfully obtained by the linear self-encoder [20]. Finally, an unsupervised cross-lingual word representation co-training scheme based on the former is designed to further improve the efficiency of the cross-lingual word embedding training method based on linear self-encoder and the cross-lingual performance of the resulting word embeddings.
Collaborative training method for cross-lingual word representation based on linear self-encoder
Collaborative training optimization method based on different word embedding models
Word embedding model
Word embedding is a form of distributed word representation in which the information about the distribution of words in corpus data is recorded in terms of dense vectors of expressions. The more common monolingual word embedding models include the CBOW model, the Skip-gram model, and the fastText corresponding word embedding generation model [21]. GloVe (Global Vectors for Word Representation): GloVe is an unsupervised learning algorithm for word representations. It constructs word vectors by training on global word-word co-occurrence statistics, making it effective at capturing semantic relationships between words. Word2Vec: Word2Vec, which includes the CBOW and Skip-gram models, is a popular approach for learning word embeddings from large text corpora. It excels at capturing syntactic and semantic relationships among words. ELMo (Embeddings from Language Models): ELMo is a deep contextualized word representation model. It considers the context in which a word appears to create embeddings, allowing it to capture multiple word meanings and contextual nuances. BERT (Bidirectional Encoder Representations from Transformers): BERT is a state-of-the-art language representation model that uses a transformer architecture. It captures bidirectional contextual information, making it a powerful tool for a wide range of natural language processing tasks. ULMFiT (Universal Language Model Fine-tuning): ULMFiT is a transfer learning approach for NLP tasks [22].
(1) CBOW model
CBOW is one of the specific model architectures of the word2vec tool, and its core idea is to use the surrounding word embeddings of a word to predict the probability of that central word, and to update the word embeddings of surrounding words using gradient descent accordingly [23]. Figure 1 illustrates the architecture of the CBOW model, which comprises the input layer, the projection layer, and the output layer.
Structure of CBOW and Skip-gram model.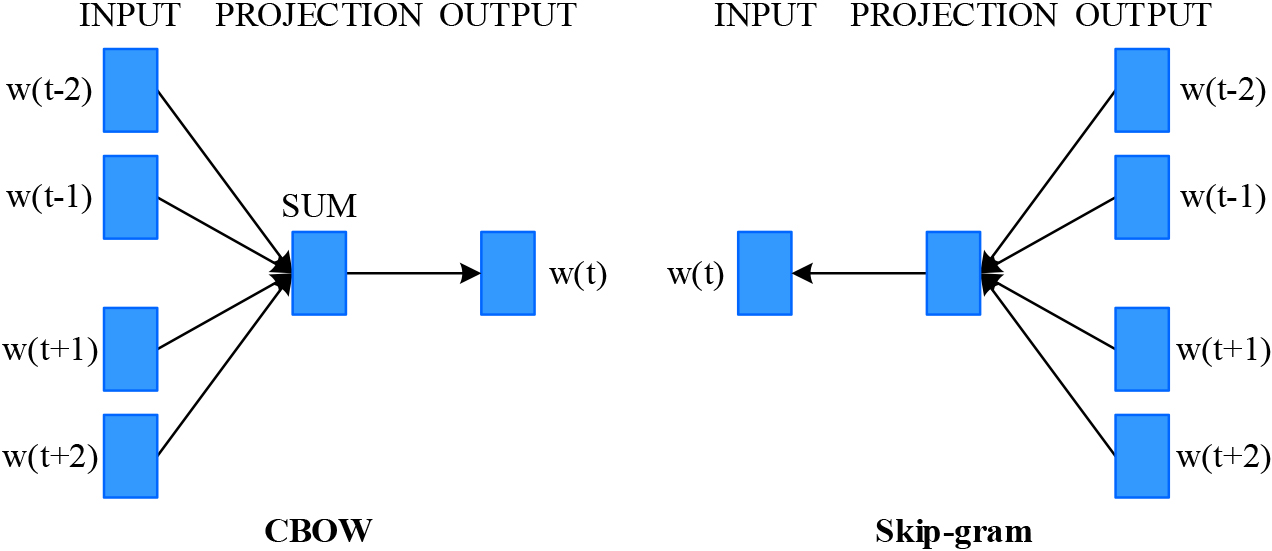
(2) Skip-gram model
In contrast to the CBOW model, the Skip-gram model uses the current word as the central word to predict its contextual word, and thus updates the central word [24]. However, the Skip-gram model requires more computations for the same corpus text data, and it is more effective in expressing the rare words.
(3) FastText model
Schematic diagram of fastText model.
Figure 2 shows the structure of the fastText model, which is similar to the three-layer structure of the CBOW model, with the unique feature that the N-gram features of words are considered along with the words. The word embeddings obtained by the fastText model can be regarded as a by-product of the classification task [25]. Since the model considers the N-gram features of words, and the N-gram features may be shared among different words, the fastText model can have a better representation of words with low frequency of occurrence. Moreover, the N-gram features can be used to construct word embeddings corresponding to words that do not appear in the training data. The implementation of fastText model is also optimized by hierarchical softmax.
Different word embedding models differ from the principle to the implementation, e.g., the CBOW model considers contextual information within a specific size window, the Skip-gram model is more expressive for rare words, and fastText incorporates subword-level information [26]. It can be seen that the word embeddings obtained by different models have different concerns and expressive power for the same original corpus text data, which is in line with the application scenario of the collaborative training framework. The co-training model that leverages distinct word embedding models is illustrated in Fig. 3. In this setup, word embeddings for both the source and target languages are derived from the same monolingual corpus data, yet two different word embedding models are employed [27]. Subsequently, the word embeddings for the source and target languages obtained from each respective model are combined and serve as the input for a cross-lingual word representation learning baseline model. The two cross-linguistic training processes operate relatively independently with the aim of projecting the source and target language word embeddings of the process they belong to into the same vector space [28, 29]. The self-learning processes of the two training processes also interact with each other to improve the confidence level of the bilingual translation dictionary D used in each process, which ultimately leads to the improvement of the cross-lingual word representation obtained by each training process.
Collaborative training model based on different word embedding models.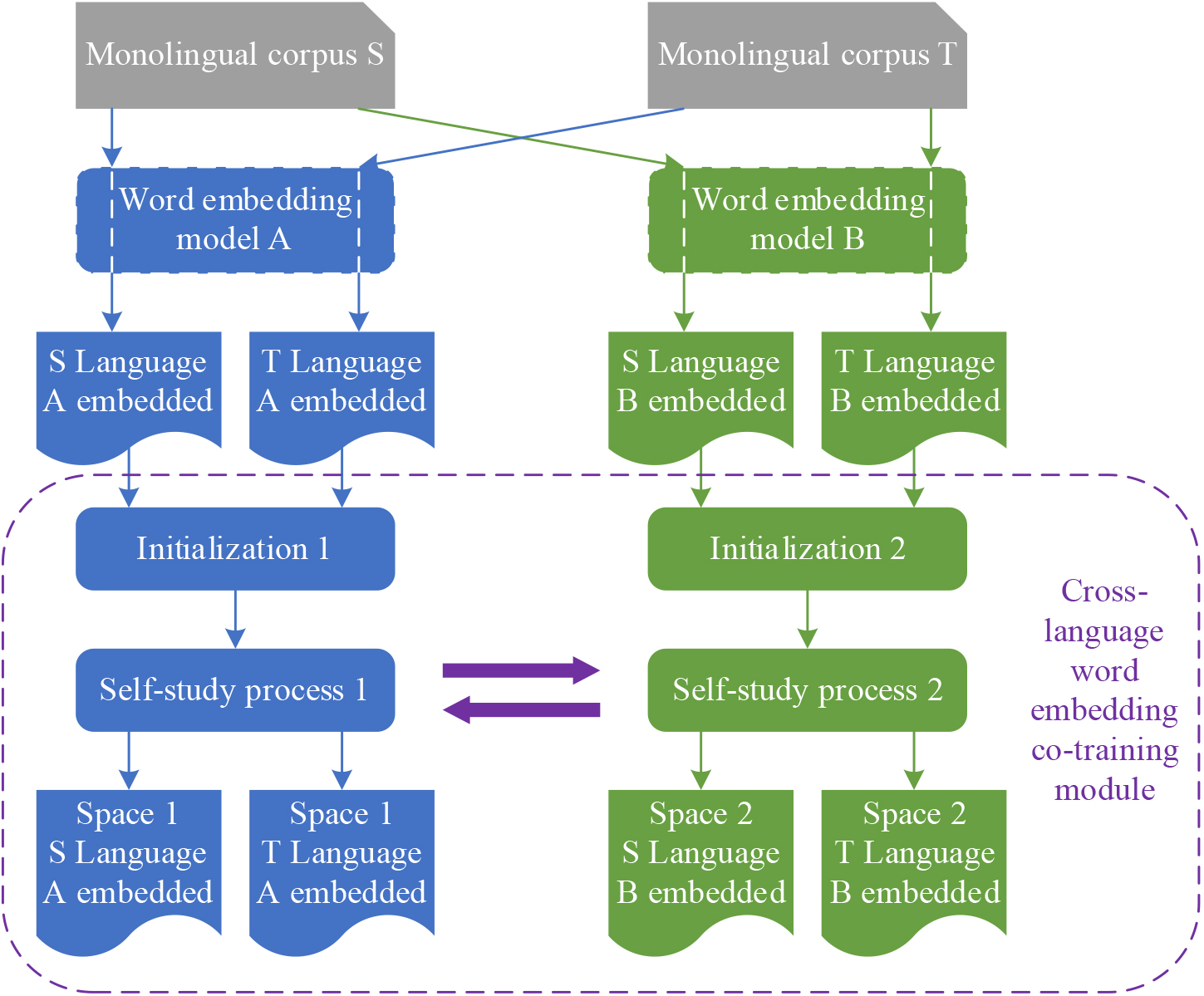
Data dimensionality reduction and self-encoder
The “cross-lingual representation training process” refers to a machine learning approach that aims to share and learn language representations or word embeddings across different languages, enabling semantic and linguistic universality between textual data in different languages [30]. This process typically involves training models using bilingual or multilingual corpora to map the vocabularies of different languages into a shared language representation space, allowing for tasks such as cross-lingual text similarity comparison, translation, and other natural language processing tasks. This helps address the issue of data scarcity between different languages and promotes cross-lingual information retrieval and understanding.
(1) Matrix of mutual information between points
The matrix that counts the co-occurrence of all words in a text data is called co-occurrence matrix, and the construction scheme of word representation based on statistical methods is generally built on the basis of co-occurrence matrix. Suppose now there is a high-dimensional sparse matrix
Instead of PMI, PPMI is used, and all negative values in MPMI are replaced by 0, i.e:
The use of PPMI matrix can better express the word-context relationship in corpus data. Usually, the word list size of the corpus is very large, thus making the size of the PMI matrix very large as well.
(2) Principal component analysis and singular value decomposition
Principal component analysis requires obtaining the covariance matrix or correlation coefficient matrix of the data matrix and decomposing the eigenvalues to obtain the eigenvalues and eigenvectors, where the eigenvector corresponding to the largest eigenvalue is the first principal component direction, so that the eigenvectors corresponding to the first few largest eigenvalues can be used to map the original high-dimensional data matrix to the low-dimensional vector space with the largest variance.
In particular, principal component analysis of a matrix can be achieved by means of singular value decomposition. Given a matrix
Where the elements on the diagonal of the diagonal matrix
Where the elements on the diagonal of
That is, each column of
(3) Self-encoder
A self-encoder is a neural network model that performs data encoding or data compression [32]. Generally, the training goal of a self-encoder model is to try to obtain an encoded representation of the original data on a large scale. Since the dimensionality of the vector representation after the action of the self-encoder is smaller than the original data size, it can be said that the goal of the self-encoder is to perform a dimensionality reduction operation on the original data.
Self-encoder structure diagram.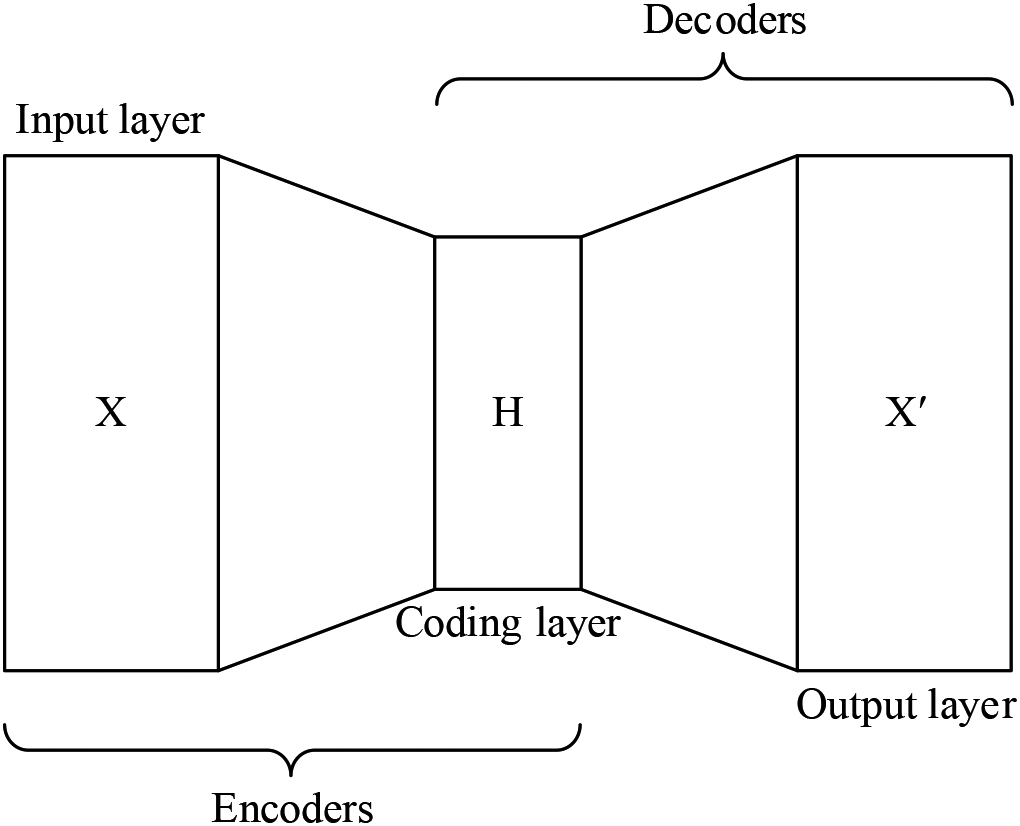
The structure of a self-encoder in its simplest form is shown in Fig. 4. Unlike a normal neural network, the learning goal of the self-encoder is to reconstruct the input data
Where
The feature vector corresponding to the largest eigenvalue captures the direction of maximum variance because it represents the direction in which the data varies the most [33]. Eigenvectors describe the primary variance directions in the data, while eigenvalues indicate the magnitude of variance in that direction. In Principal Component Analysis (PCA), our goal is to find the most significant features or principal components in the data to reduce its dimensionality while retaining as much variance as possible [34]. By selecting the eigenvector associated with the largest eigenvalue, we effectively choose the direction with the highest variance in the data, allowing us to preserve the most information.
This property is crucial in PCA because it enables us to map data from a high-dimensional space to a lower-dimensional space while maximizing the retention of data variance. This reduces data complexity, lowers computational and storage costs, and maintains the essential data structure. It facilitates dimensionality reduction, eliminating unnecessary noise and redundant information, making data analysis and visualization more efficient, and reducing the risk of overfitting [35]. Therefore, the selection of the eigenvector corresponding to the largest eigenvalue in PCA is paramount for extracting and preserving the primary directions of variation in the data.
One of the properties of principal component analysis is that the total squared error of the observations reconstructed from the principal components is the smallest among all possible linear transformations. The self-encoder is a neural network designed to minimize the reconstruction error of the observations. Therefore, a single-layer self-encoder with a linear activation function is closely related to PCA in that the weight matrix is tensed into the principal component space, i.e., the subspace tensed by the higher-order principal component vectors, but at the same time the weight matrix is not equivalent to the principal component vector matrix.
The regularized linear self-encoder can be equivalent to making PCA on the original data by modifying the loss function of the original linear self-encoder, and the proof that the vector space obtained by the regularized linear self-encoder method is the same as the principal component space of PCA is given by a rigorous mathematical derivation. The regularized linear self-encoder loss function is as follows:
Among them:
The linear self-encoder is obtained by the above loss function, and the principal component analysis of the original data is achieved by the singular value decomposition of the decoder weight matrix
There are several potential real-world applications for autoencoders, and their dimensionality reduction capabilities are crucial in practice [36]. Image Processing and Computer Vision: Autoencoders can be used for image compression, denoising, and feature extraction. By mapping high-dimensional image data to a more compact representation, they help reduce storage and computation costs while preserving essential image information, making them valuable for tasks such as image recognition, object detection, and image generation [37].
Natural Language Processing: In textual data, autoencoders can be employed for word embedding learning and text compression. They assist in reducing the dimensionality of textual data, extracting vital semantic features, and improving tasks like text classification, sentiment analysis, and machine translation.
Data Visualization: Autoencoders can be used to map high-dimensional data to a lower-dimensional space for data visualization. This is highly useful for data exploration and discovery, aiding in uncovering patterns and relationships within datasets.
Anomaly Detection: By training autoencoders to reconstruct normal data, they can be utilized for anomaly detection. Any data that cannot be reconstructed well may be considered an anomaly, which is significant in areas such as finance, network security, and manufacturing.
Recommendation Systems: In e-commerce and social media, autoencoders can be employed to learn embeddings of users and items, enhancing the performance of recommendation systems. By mapping users and items to a low-dimensional space, they help discover user interests and similar items.
How is the dimensionality reduction capability of autoencoders utilized in practice? By mapping high-dimensional data to a lower-dimensional representation, autoencoders assist in reducing storage and computation costs, improving model training efficiency, and lowering the risk of overfitting. Furthermore, they aid in removing redundant information from the data, highlighting the key features, and making the data more understandable and manageable. In the aforementioned applications, autoencoders offer more compact representations through dimensionality reduction, thereby enhancing performance in various tasks without sacrificing critical information.
Since the inception of the concept of word embedding, a series of word embedding construction tools such as Word2vec, fastText, and GloVe have emerged, and the performance of word embeddings obtained by training these tools on the corpus varies.
In the negative sampling implementation of the Word2vec tool, negative samples are collected based on a smoothed univariate grammar distribution, and this smoothing is achieved by manipulating all context counts by a factor of
Where
The word and contextual corresponding word embeddings can be obtained by performing a singular value decomposition of the PMI matrix
However, this is not the optimal way to obtain word embeddings for the word similarity task. According to Eq. (13), the context matrix
Or you can multiply neither
In this way, for a monolingual corpus of a language, the PPMI matrix can be obtained statistically, then the PPMI matrix can be optimized by contextual distribution smoothing, and finally the word embeddings can be obtained by means of Eqs (14) and (15).
Firstly, the PMI matrix is to be obtained by counting and operations on the monolingual corpus by the hyperwords tool. Then the PMI matrix is used as the input to Eq. (1) and the regularized linear self-encoder is trained until the objective function converges.
Subsequently, experiments have been structured to validate the effectiveness of the two word representations acquired through the linear self-encoder training process in the context of cross-lingual word representation training. In addition, the cross-lingual word representation co-training approach based on the linear self-encoder is outlined. Figure 5 shows the co-training process based on linear self-encoders. The linear self-encoder model in the block diagram is the self-encoder model that can output two different word embeddings as described in this section. After the PMI matrix of each language is trained by the linear self-encoder model, two different word embeddings are obtained, where the
Research on foreign language teaching model based on cross-lingual word embedding model with linear self-encoder
Analysis and conclusion of experimental pre-test results
Pre-test composite scores
Pre-test composite scores
Schematic diagram of the co-training process based on linear self-encoder.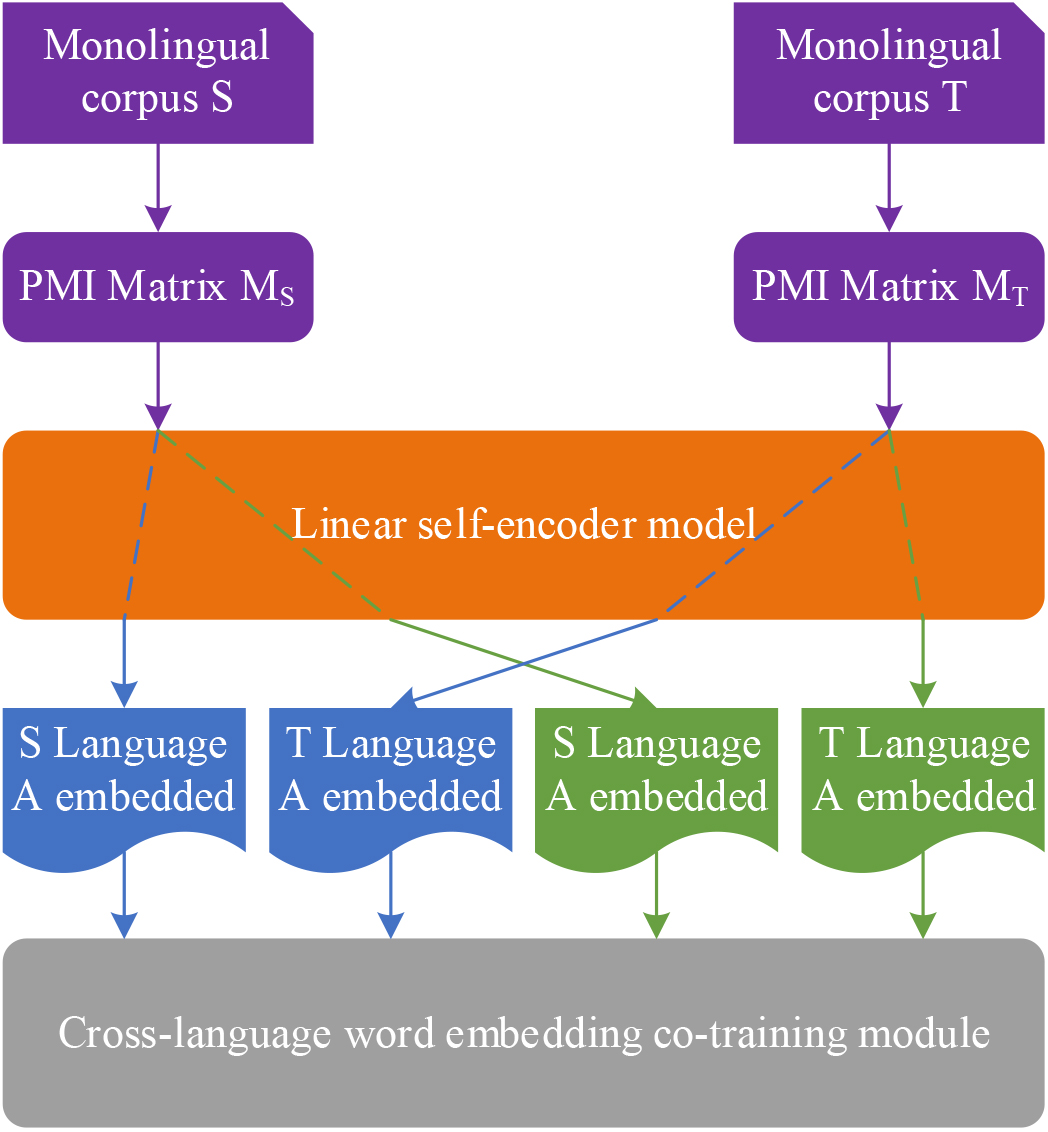
According to the statistical analysis of the pre-test scores, the overall scores of the pre-test are shown in Table 1. The difference between the overall mean scores of the two classes is about 0.82, and the difference in pass rate is 1.89% are not significant. However, whether the two classes can be used as experimental samples, further independent samples t-test is needed to test the significance of their difference levels.
Overall effect comparison
Post-test composite scores
Post-test composite scores
The overall results of the post-test are shown in Table 3. The difference between the total mean scores of the two classes in the post-test is still small, while the difference in the passing rate is larger. In contrast, the difference between the total mean scores of the two classes in the post-test was 8.39 and the difference in the passing rate was 0.75%, both of which increased compared to the difference in the pre-test, as shown in Tables 1 and 3. In order to show that there was a significant difference between the two classes’ scores, the results of the
The probability of significance of
Changes in the overall scores of the pre- and post-tests of the two classes
From the comparison results, the experimental class’ post-test scores increased significantly more than the control class, especially in the passing rate. From this point, it can be seen that after half a year of teaching experiment, the reading ability of the experimental class improved faster, and the teaching effect based on the machine translation learning model proposed in this paper is better than the traditional teaching method in teaching English reading in colleges and universities. The traditional teaching method teaching is lively for most students with weak foundation, while they themselves lose their interest in participation and confidence in reading because of their poor foundation. They always think they don’t understand and don’t read carefully, and do reading questions just by guessing randomly. The teaching method of this article at least makes them “understand” and keep their confidence in learning. The systematic explanation of grammar and the translation of the text make up for the students’ weak foundation and thus facilitate their reading comprehension of the text.
From Table 5, it seems that there is little difference in the change of the total mean score, while the difference between the control and experimental classes is larger in the increase of the passing rate. This is because the translation method is more favorable to poor students, and the classes taught with the translation method are more likely to narrow the achievement gap between students, so although there is little change in the total score, the pass rate rises significantly. In this sense, teaching based on the machine translation learning model proposed in this paper is more effective and more conducive to generally improving students’ reading performance. Therefore, the teaching method in this paper is more suitable for foreign language reading teaching.
After a six-month experiment, it can be concluded that the teaching effect of this method is better than that of traditional teaching methods in English reading teaching, and is more conducive to the improvement of reading performance. However, the results of the
Score rate of each question in the pre and post test of the experimental class.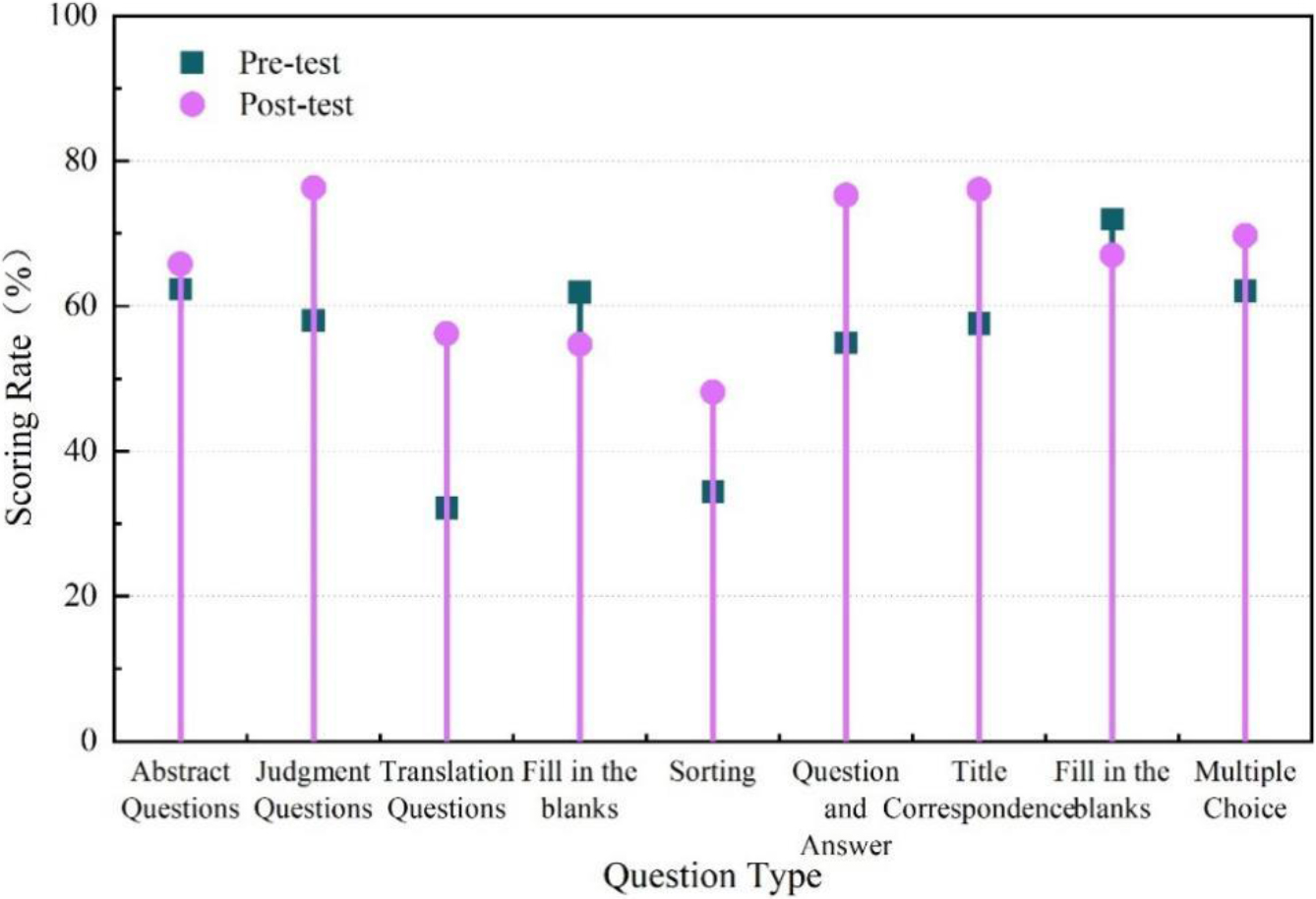
The results of the longitudinal comparison of the scores of the questions in the pre-test and post-test of the experimental class are shown in Fig. 6, which can visually compare the differences in the scores of the questions in the pre-test and post-test of the experimental class. The distinction in scores between the experimental group and the post-test was particularly pronounced in questions related to “sentence correctness assessment”, “sentence translation”, “sentence response”, and “title correspondence”. In contrast, there were no notable differences in the scores for the other types of questions. For the summary questions, the difference was only 2.14%.
Because the same type of reading comprehension can turn into many different test styles, the teaching effectiveness of a certain teaching method is not specific to which questions, but to which types of questions. To compare the specific advantages of teaching methods, it is also necessary to categorize the aforementioned questions according to their test connotations, and the results of their score rates are shown in Fig. 7.
Score rate of questions grouped by test connotation in the experimental class.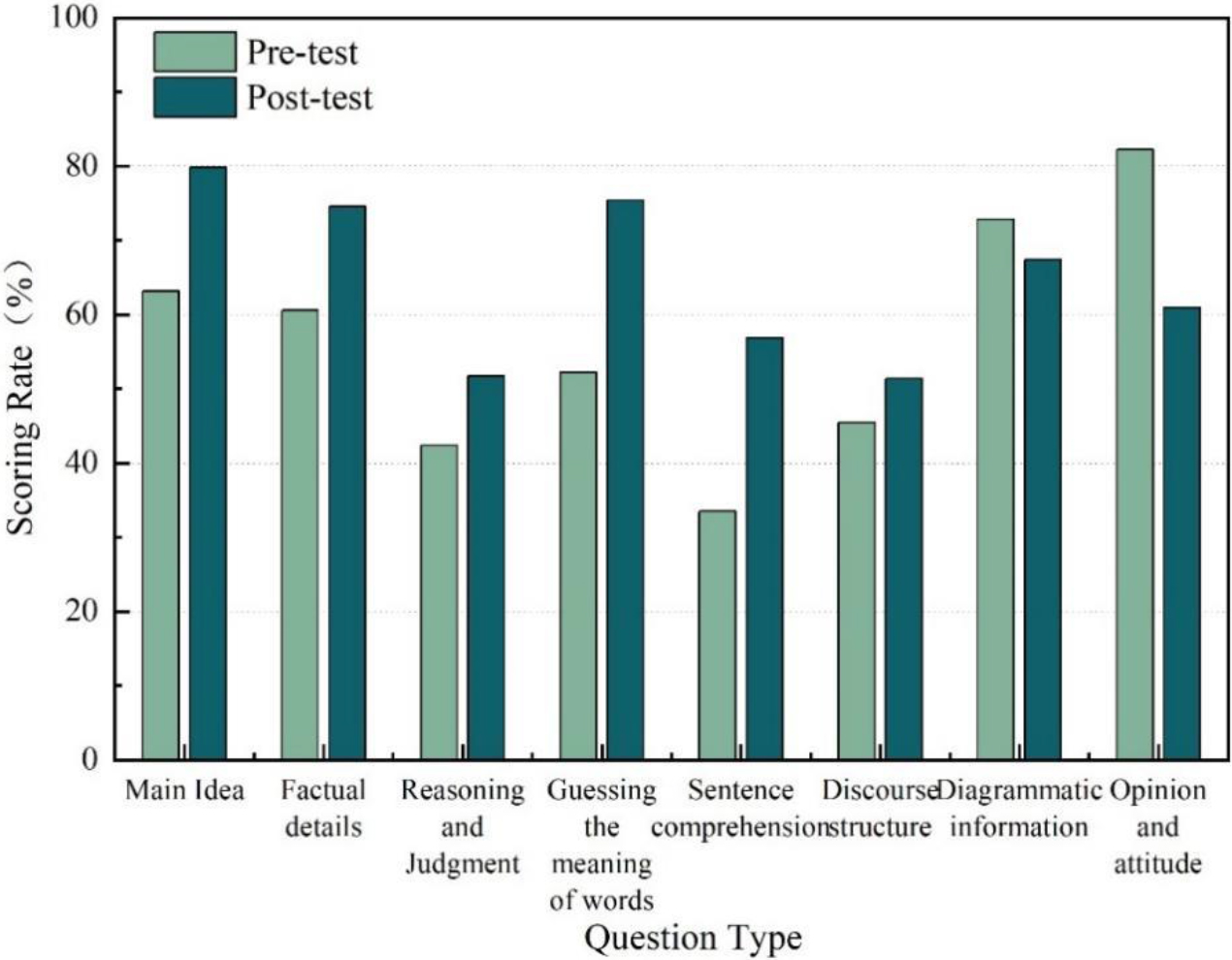
The post-test scores of the experimental class increased in different procedures for all types of questions except the graphical information and opinion-attitude questions. The most obvious increases in the pre and post-tests were word sense guessing, which rose by 23.12% and sentence comprehension, which rose by 23.39%. The main idea rose 16.61%, factual details rose 15.47%, and reasoning judgment rose 10.28%. Opinion and attitude questions dropped significantly, with a 21.94% decrease. The rise and fall of discourse structure and graphical information were less obvious.
The above results show that the performance improved in all areas except for the chart and opinion-attitude type of questions. The obvious advantages are reflected in the vocabulary aspect and sentence comprehension. This is because the teaching model proposed in this paper focuses more on grammar learning and vocabulary explanation, which has improved students’ grammar foundation and facilitated them to correctly understand the sentence structure in the text and thus correctly comprehend the meaning conveyed by the original text. The usual teaching of translation helps students to memorize vocabulary, and after a certain period of practice, students’ vocabulary improves and so does their reading comprehension ability. As a result, students’ ability to reason and judge, and to summarize the general idea has also improved. The learning model proposed in this paper showed advantages in this kind of questions, so the score rate increased more, by 20.06%.
Score rate of each question in the control class before and after the test.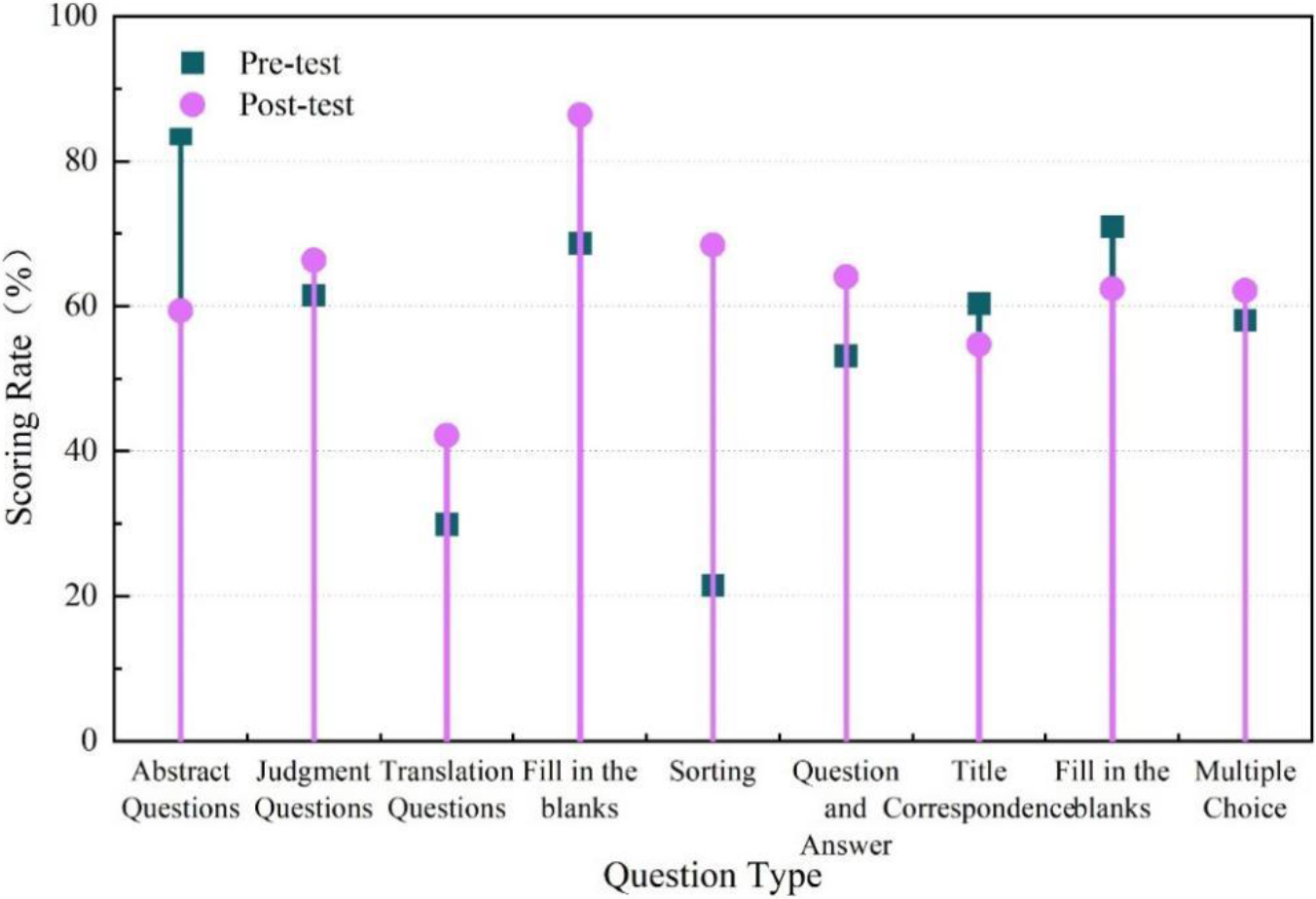
The results of the longitudinal comparison between the pre-test and post-test scores of the control class are shown in Fig. 8. The difference between the pre-test and post-test scores for each question in the control class was not significant, except for the three questions of “summary question, sentence selection, and paragraph ordering”. There was almost no change in multiple choice. The score of paragraph ordering increased significantly, by 43.37%, and the score of summary questions also decreased significantly, by 22.61%.
The preceding results solely pertain to the comparison of questions based on their surface characteristics. To provide a more detailed explanation of the specific strengths and weaknesses of traditional teaching methods across various question types, these questions were also classified and assessed based on their underlying test connotations. The scores of the pre-test and post-test questions are shown in Fig. 9.
Score rate of questions grouped by test connotation in the control class.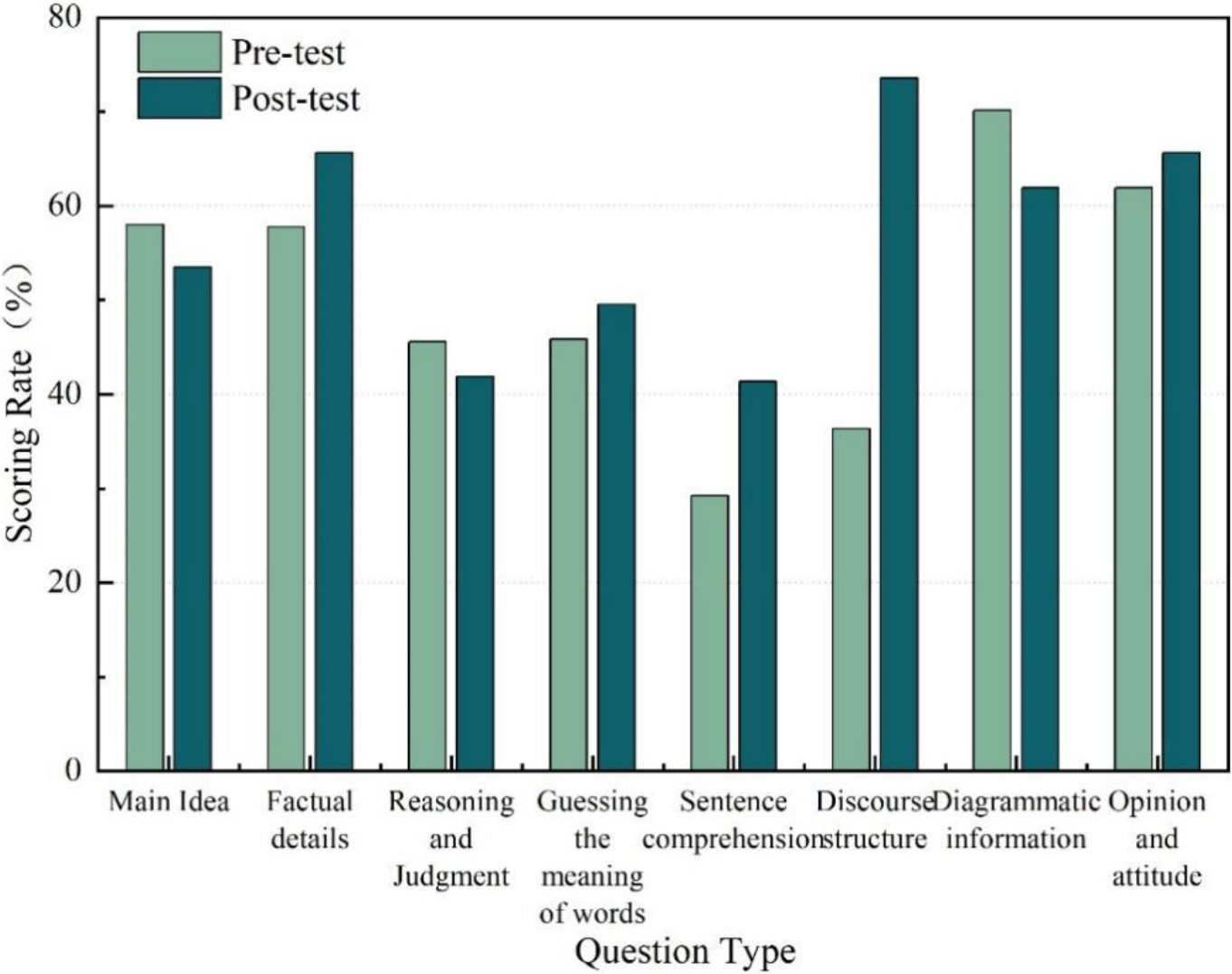
The pre and post test scores of the control class increased by 34.67% in the area of discourse structure, with less significant changes in other areas and almost no difference in word sense guessing. The post-test scores decreased by 4.94% in main idea, 5.68% in reasoning judgment and 9.41% in diagrammatic information. Combining the comparative results in Figs 8 and 9, it can be seen that the effect of the traditional teaching method in teaching English reading shows insignificant effect except for the obvious advantage in discourse structure. In reading instruction using the traditional teaching method, teachers never translate a certain sentence or paragraph, nor do they fixate on certain vocabulary phrases, nor do they focus on grammar; instead, they let students read as a whole, answer teacher questions, complete discussions or perform dialogues on their own. Traditional teaching methods focus on the whole chapter and are therefore more conducive to grasping the structural aspects of the discourse in reading instruction, so scores in this area are significantly higher. The impact on word meaning guessing was very small, because the traditional method teaches students to guess the meaning of words through the context, which is helpful in their vocabulary learning method. But on the other hand, for students with poor foundation, the actual ability to guess words is very poor, and it takes a long time to train before it may be effective, and most of the students learn by coping in class and are not interested in learning this skill or technique at all. If the vocabulary is not taught at all, they will remember very little after the lesson, which is not helpful for the vocabulary requirements necessary for reading comprehension. Therefore, the total teaching effect of the traditional teaching method in vocabulary is not obvious and inferior to the method of this paper. And the main idea, reasoning judgment, and diagram information usually require correct understanding of sentences in the original text, and the traditional teaching method usually focuses on communication rather than comprehension, and on problem solving rather than deep analysis, so it does not help students to improve their reading level in this area. The post-test scores in these areas have decreased, which precisely reflects the weakness of the traditional teaching method in teaching English reading in secondary school.
When comparing all the results of the pre-test and post-test sub-test scores of the two classes, it can be seen that the obvious advantages of this method are in the areas of vocabulary guessing and sentence meaning comprehension. In contrast, the obvious advantage of the traditional teaching method is reflected in the aspect of discourse structure, and the performance in other aspects is not obvious.
While the paper effectively underscores the challenges in foreign language teaching, a more explicit discussion on how the proposed innovative methods address and overcome these challenges would greatly enhance the overall quality and depth of the research. This study on the proposed enhancements to the baseline model, notably the co-training approach and the linear self-encoder-based principal component analysis, is thorough and maintains technical rigor. However, to enhance the manuscript’s clarity and accessibility, the inclusion of illustrative examples or figures could be advantageous. Visual depictions of the proposed methodologies and their potential implications for cross-lingual word representation learning would not only aid in better comprehending the concepts but also make the paper more engaging and informative for readers. Cross-lingual word representation is of high research interest as an important resource for a variety of natural language processing tasks such as machine translation and cross-language transfer learning, and the way it is generated. Further, since monolingual corpus data resources are more readily available than parallel texts. The current stage of research related to unsupervised cross-lingual word representation learning methods has made certain breakthroughs. In this paper, we aim to build a better cross-lingual representation training process based on the current excellent unsupervised cross-lingual word representation learning methods, combined with the idea of collaborative training. Specifically, the following research results are achieved in this paper:
After using the learning model proposed in this paper to teach foreign language to the experimental class, their scores increased in different procedures for all types except for diagrammatic information and opinion-attitude questions. The most significant increases in the pre- and post-tests were word sense guessing, which rose by 23.12% and sentence comprehension, which rose by 23.39%. The main idea rose 16.61%, factual details rose 15.47%, and reasoning judgment rose 10.28%.
Pre- and post-test scores in the control class using traditional instruction increased by 34.67% in discourse structure, but changes in other areas were less pronounced and there was almost no difference in word sense guessing. Posttest scores decreased by 4.94% in main idea, 5.68% in inferential judgment, and 9.41% in diagrammatic information.
The results of the comprehensive study, after a six-month experiment, proved that the teaching effect based on this paper’s method in English reading teaching is overall better than the traditional teaching method and more conducive to the improvement of foreign language performance.