
Abstract
This paper proposes a sharing algorithm based on blockchain principles to address the issues of data sharing, low efficiency, and performance in traditional systems. The algorithm is integrated with the domain name system to develop a data storage system based on blockchain. The performance of the sharing algorithm is evaluated, and the data storage system is tested. This demonstrates that the sharing algorithm’s average latency is 436 ms and average throughput is 5439 tps. Furthermore, it outperforms the other comparison algorithms. Additionally, the study conducts performance experiments to compare the data storage system. The data storage system proposed in this study demonstrates a higher average throughput of 6.42*108 tps and a faster data access time of 0.15 s than the other comparison systems. The comprehensive results show that the proposed sharing algorithm and data storage system outperform the comparison algorithm and system in terms of latency, throughput, and data access performance. The constructed model exhibits good centralized and distributed storage crawling performance, which can achieve more secure, efficient, and trustworthy data sharing in distributed network data storage.
Introduction
The rapid development of the Internet and faster data generation and transmission have made distributed network data storage a crucial solution to address the challenges posed by large-scale data storage and access [1]. However, there are many problems in the traditional distributed network data storage technology. Because the data of traditional network is stored in different nodes, the read and write operation of data needs to be carried out across multiple nodes, so the data sharing efficiency is low. When the nodes are lost, it will not only lead to the problem of insufficient data security, but also lead to data inconsistency [2, 3]. Efficient and secure data sharing and storage technology is now a pressing social need to be addressed.
Blockchain is a distributed database technology with the function of recording and storing transaction data or other types of information. The core concept of blockchain is to store data in data structures called blocks, and then link these blocks together to form a chain structure. Therefore, blockchain has the characteristics of immutable, untrusted, high security and traceability, which can make it difficult for attackers to tamper with or steal data [4]. In distributed network data storage systems, the primary issue with traditional network storage models is the challenge faced in communication and collaboration between nodes. This leads to problems such as low storage efficiency and slow response speed [5]. The combination of blockchain technology with distributed network technology can collaborative work and efficient transmission between nodes, ultimately improving storage efficiency and response speed [6].
This paper proposes a Blockchain-Based Data Sharing algorithm (BBDS) with an economic incentive mechanism to encourage nodes to share and store data. Moreover, the proposed algorithm is combined with Domain Name System (DNS) to build a BBDS data storage system. The key contribution of the study is to achieve accurate data sharing while ensuring efficient data query and processing. Furthermore, the BBDS data storage system is able to effectively address the issue of inadequate defense performance and inadequate storage in the presence of large-scale malicious attacks and simultaneous access to data storage despite low defense performance and storage capacity. Moreover, this research provides both theoretical and practical foundations for the implementation of blockchain-based data sharing algorithms in distributed network data storage.
The initial section of this study provides a brief introduction to the research background and significance. The second section introduces the present scenario of data sharing algorithms and data storage. The third section creates the BBDS algorithm and the data storage system, which is based on the BBDS algorithm. The fourth section carries out the validity verification test while the fifth section concludes the study.
Related work
With the continuous development and popularity of Internet technology, the study on data sharing algorithms has been increasing. In response to the issue of traditional sharing algorithms being susceptible to external factors, Sarrafan and Zarei [7] proposed a sharing algorithm based on distributed bounded observers and conducted experiments on its effectiveness. Compared with traditional algorithms, the convergence performance and robustness of this algorithm are significantly improved. To improve the efficiency of data sharing in traditional systems, Yaghoubi and Talebi [8] proposed combining nonlinear topology algorithms with multi-agent systems to construct a clustering consistency algorithm, and conducted experiments on the proposed algorithm. This algorithm has clustering consistency and significantly improves data sharing efficiency compared to traditional algorithms. Zheng et al. [9] proposed a combination of droop control and consistency algorithm to achieve full distribution of microgrid economic scheduling, and constructed a clustering consistency algorithm. To achieve full distribution of microgrid economic scheduling, they proposed combining concavity control with consistency algorithms to construct a consistency control scheme based on concavity. A comparative analysis of the scheme found that it can effectively reduce the data sharing burden and confirm the effectiveness of the scheme. In response to the issue of insufficient accuracy in pathogen classification in gene detection systems, Favalli et al. [10] led a team to propose a gene detection classification algorithm based on the random forest algorithm. Empirical analysis shows that the data detection performance of this algorithm is superior to traditional automatic classification algorithms, addressing unmet clinical needs. To address the problem of insufficient security in the operation of energy IoT, Zhang et al. [11] proposed to fuse the consistency algorithm with the adaptive algorithm to establish a distributed adaptive control mode, and empirically analyzed the model proposed in the study. According to the results, the algorithm can recover the execution policy adaptively, thereby ensuring the secure operation of IoT, which has practical value.
The advancement of data sharing technology has resulted in a huge surge in data, leading to increased popularity in data storage research. In response to the shortcomings of traditional memory devices in terms of access speed, storage density, and energy efficiency, Cao et al. [12] proposed a non volatile polymorphic memory based on flash memory mechanism. Performance analysis found that the access performance and speed of memory have significantly improved compared to traditional models, and have practical value. Schdler et al. [13] proposed to address the issue of insufficient power demand coverage by re-measuring the storage parameters of the system, calculating its storage size, and analyzing it empirically. This improvement in the storage system size strengthens its traditional storage performance, leading to better power grid coverage. Tang et al. [14] proposed a non-contact optoelectronic control system based on bioferroelectric crystals to address the issue of insufficient performance in reading, writing, and erasing data in non-contact optoelectronic control systems. This system can successfully achieve non-contact operation of reading, writing, and erasing data. To address the issue of insufficient security and confidentiality of data stored in cloud storage systems, Deng et al. [15] proposed an attribute based encryption algorithm for cloud storage systems. This system has significantly improved security compared to traditional systems. To improve the accuracy and performance of DNA sequence storage systems, Wei and Schwartz [16] proposed a DNA sequence storage system based on new boundary code parameters. Compared with traditional systems, the classification accuracy of this system has significantly improved and has practical application value.
In summary, the development of internet technology has led to increasing attention to data sharing algorithms and data storage technologies, and many improved methods have been applied to data sharing and storage technologies. However, there is relatively little research on combining BBDS sharing algorithms with data storage systems. This paper combines the BBDS sharing algorithm with DNS to construct a BBDS data storage system. The objective is to enhance data sharing and storage performance, while also facilitating theoretical support and practical guidance for related fields.
DNS data sharing storage system based on block practice sharing algorithm
Blockchain model structure
The structure of blockchain is comparable to that of a distributed database system, including the layers of data, network, sharing, incentives, contracts, and applications. These levels collaborate to create a comprehensive blockchain system [17]. The blockchain model structure is shown in Fig. 1.
Blockchain model structure.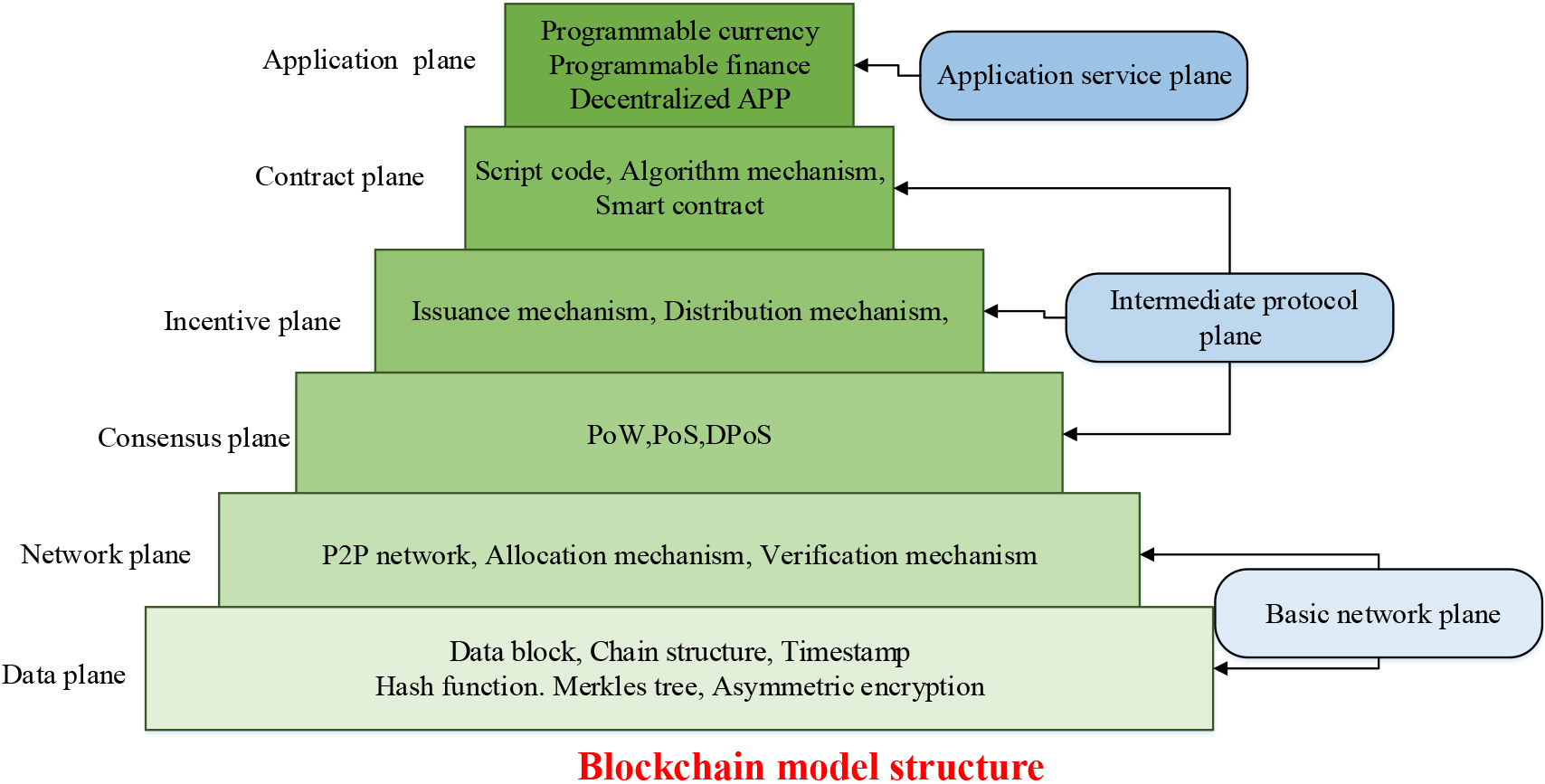
As shown in Fig. 1, the basic network layer of the blockchain model includes a data layer and a network layer. The data layer is the underlying layer of blockchain storage data, including encapsulating transaction data and other metadata into blocks, and using Merkel trees and hash functions to ensure the integrity and uniqueness of the data. The network layer serves as the infrastructure that connects each node in the blockchain network. Using a point-to-point communication protocol, nodes can transmit and receive block data and transaction data. The intermediate protocol layer consists of the shared layer, incentive layer, and contract layer. They mainly employ a shared algorithm to maintain the consistency of node data. The consensus layer is a crucial layer for ensuring data consistency within the blockchain. The consensus algorithm verifies and confirms transaction data in the blockchain, resolves disagreements between network nodes, and prevents issues such as double spending. The incentive layer is a level within the blockchain that motivates participants. Nodes are incentivized to contribute to the maintenance and security of the blockchain via the reward mechanism. Moreover, they are encouraged to participate in security verification work to ensure the system operates smoothly. The contract layer is the part of the blockchain responsible for executing smart contracts. Smart contracts are coded in a programming language and can be deployed on the blockchain for automating transactions and business logic. The topmost layer of the blockchain system is the application layer that comprises various applications and services, like digital currency, supply chain management, authentication, developed using blockchain technology. These levels interact and rely on each other to form a complete blockchain system. In the blockchain model, the block is a Merkle hash tree structure, which is a binary tree built using the hash function. This structure is created by dividing the data into blocks of a fixed size, and hashing each block. Figure 2 displays the Merkle hash tree structure.
Merkle tree structure.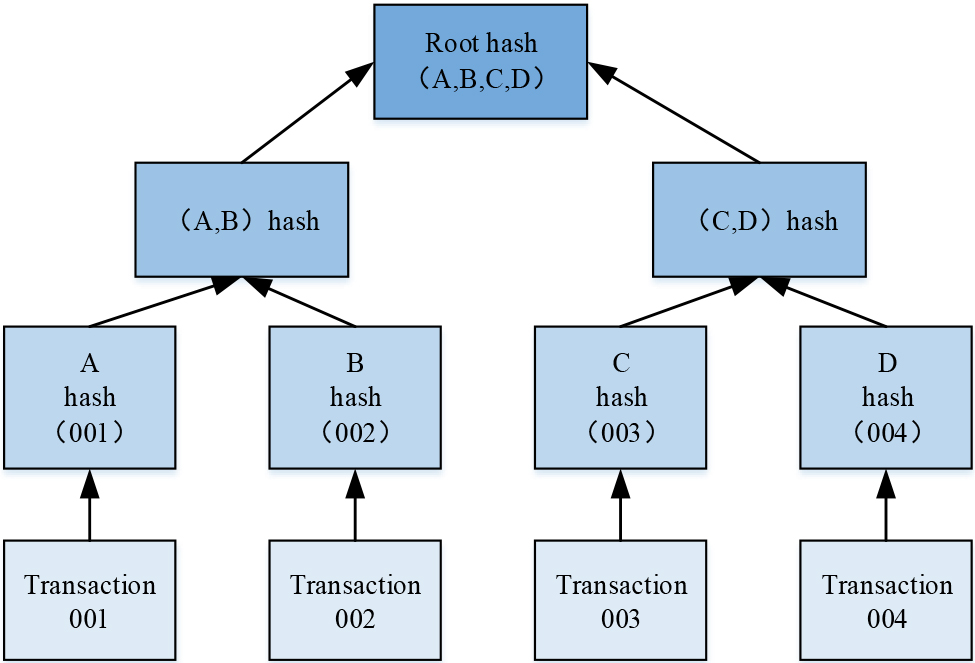
The structure of the Merkle tree comprises leaf nodes, non-leaf nodes, and root nodes, as depicted in Fig. 2. The leaf node is the lowest node of the Merkle tree, corresponding to the hash value of the data block. Every data block is computed using a hash function to produce a unique hash and is stored as a leaf node in the Merkle tree. Nodes that are non-leaf nodes: Middle-layer nodes of the tree are called non-leaf nodes and their value corresponds to a combination of hash values of their two child nodes. A new hash value is generated by combining the hash values of the two children nodes, which is then hashed again. This process continues recursively until the root node of the tree is obtained. Root Node: it is the highest level node in the tree and represents the unique hash value of the complete data set. The completeness of the entire dataset can be verified by using the hash values of the root node and comparing them to the hash values of other nodes, which allows for data manipulation. Merkle trees offer the main advantage of quickly verifying the integrity of large amounts of data without requiring the verification of each block individually. Layer by layer verification of hash values of each node beginning from the root node can determine the completeness of the data. The Merkle tree is a commonly used data structure in blockchain, particularly in transaction and block validation. In summary, the construction of a Merkle tree facilitates effective confirmation of transaction validity and block integrity, thus enhancing the security and efficiency of the blockchain.
The calculation of traditional data sharing algorithm has complex steps, high computing cost and low sharing performance [18]. To address these problems, the study constructs a BBD Salgorithm in accordance with blockchain technology. This algorithm divides the data block into multiple segments, processes and generates new blocks for each segment. The BBDS algorithm divides the original data blocks based on predetermined criteria such as data size, type, or other specific requirements. Afterward, the BBDS algorithm processes the data in each subblock. This includes operations such as encryption, compression, conversion, or other predetermined methods. The BBDS algorithm hashes the part of the processed data and combines the generated hash values with other information (such as timestamp, hash of the previous block, etc.) to form a new block. This new block comprises the processed data section along with the pertinent blockchain information. At last, the BBDS algorithm adds the newly generated blocks to the blockchain, making them a permanent part of it. This process records and shares the segmentation and processing operations performed on the data block so that other participants can verify the integrity and consistency of the blockchain before obtaining various parts of the data block. The proposed structure of the BBDS is shown in Fig. 3.
The architecture of BBDS.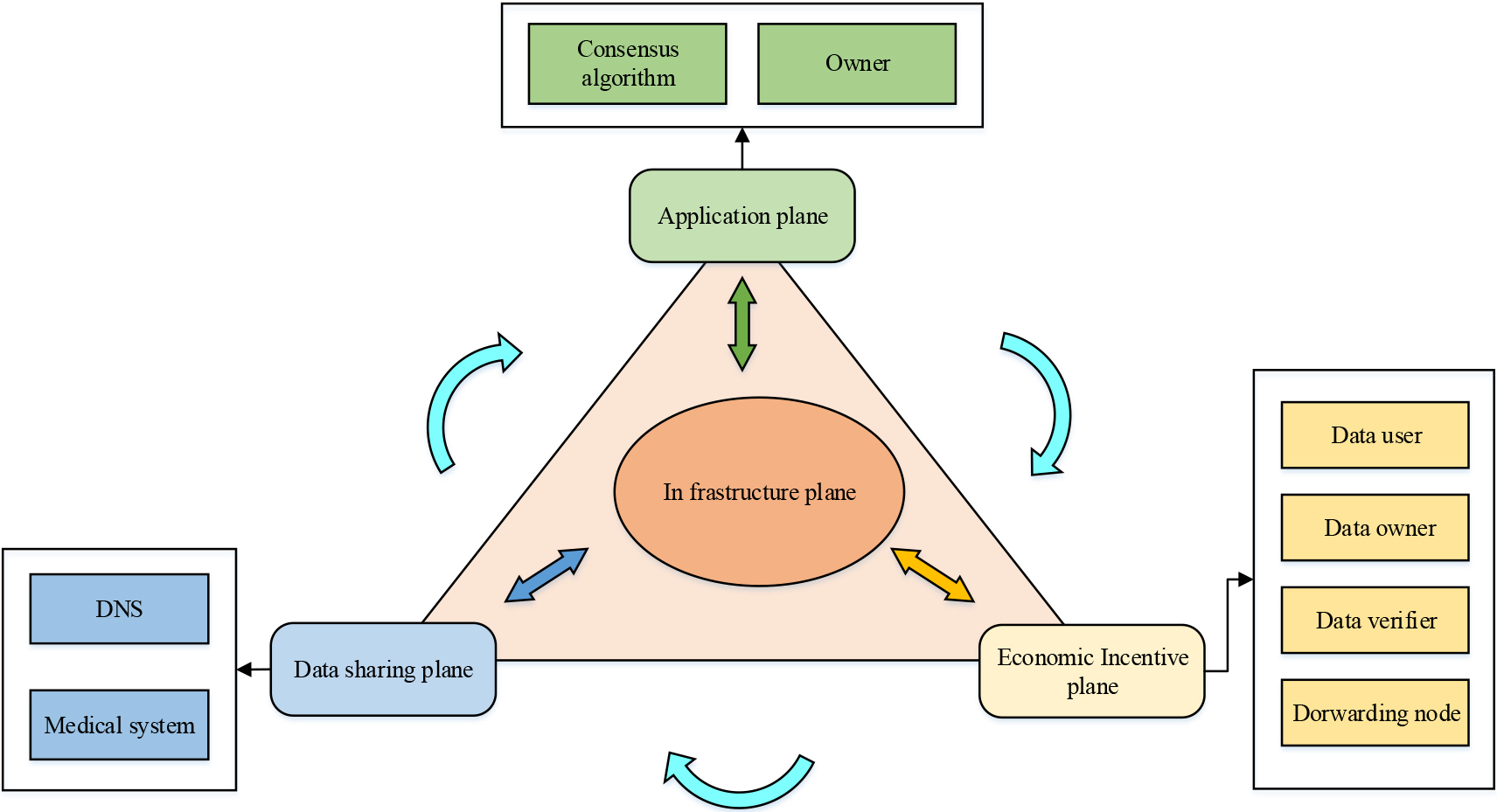
Based on traditional blockchain technology, the BBDS algorithm comprises four main components, namely the infrastructure layer, the data sharing layer, the economic incentive layer, and the service application layer, as illustrated in Fig. 3. The infrastructure layer is responsible for broadcasting the data on the data sharing layer through the network, and the specific nodes pre-selected in the broadcast data are then verified by the network. Upon successful data validation, the data sharing layer facilitates information sharing between target nodes. It also records the request and response behavior of identification information, while classifying and organizing the blocks. The rewards of the economic incentive layer will be granted according to the rules on the economic incentive layer. The shared data can be utilized by the application layer for multiple purposes. The BBDS algorithm focuses on the data sharing layer and the economic incentive layer. The structure of the BBDS blocks is illustrated in Fig. 3.
BBDS block and blockchain diagram.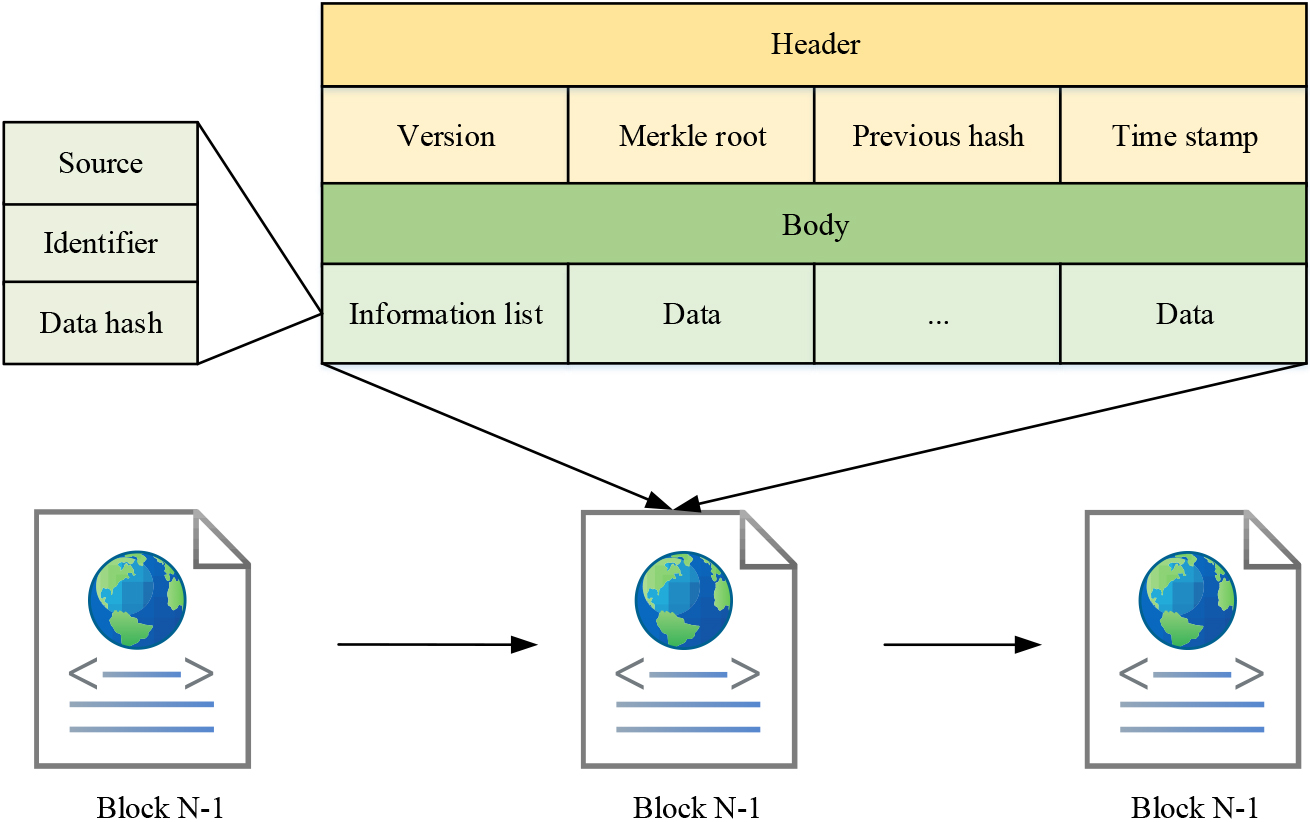
As shown in Fig. 4, the block structure includes the block header and the block body. The block header primarily comprises a timestamp, a Merkle root hash, a hash value, and a version number. The body of the block contains shared data, data source, data identifier, and hashed form data. BBDS contains many types of nodes. All node partitions are defined as
In Eq. (1),
In Eq. (2),
In Eq. (3),
In Eq. (4),
In Eq. (5),
During the iteration, the preprocessed data
The nodes in the network compose a new block of data to be validated and send it to the economic incentive layer. The economic incentive layer in BBDS contains four roles, which are data user, block creator, data validator and forwarding node. The PoD mechanism is introduced to determine the user’s account status. PoD is calculated as shown in Eq. (8).
In Eq. (8), POD denotes the proof of download;
The initial value of the reward quota is 1, and if the quota is reset to 1, the daily quota growth is reduced for inactive users with data for several days without sharing or downloading. On the other hand, users who often share data are granted an increasing daily quota that can impact the system in the future. Additionally, the formula incorporates a variable that grants a higher quota to users with greater download proof. The formula for calculating the reward gainers is shown in Eq. (10).
In Eq. (10),
In Eq. (11), the block verifier receives a tenth of the download reward, which increases the enthusiasm for verification and ensures the equity of the data owner. Moreover, the main node that produces a valid block receives a reward based on the credible information contained in the block. If they cannot suggest blocking measures due to network issues or verification failure, they will receive disciplinary action. This indicates that with a high-quality network and abundant data reserves, data owners can earn significant economic benefits. The formula for calculating the reward mechanism at this time is shown in Eq. (12).
Equation (12) ensures that the data owner receives more revenue than the master node in the section determined by the number of downloads.
Blockchain, as the underlying technology of Bitcoin, offers advantages such as large storage capacity, high sharing, and good confidentiality [19]. Therefore, in practical applications, blockchain can be used to store other data, such as domain name system data, transaction data, and medical information data. One of the DNS systems is a service system that provides domain name IP addresses for global web users [20]. Its structure is shown in Fig. 5.
DNS structure.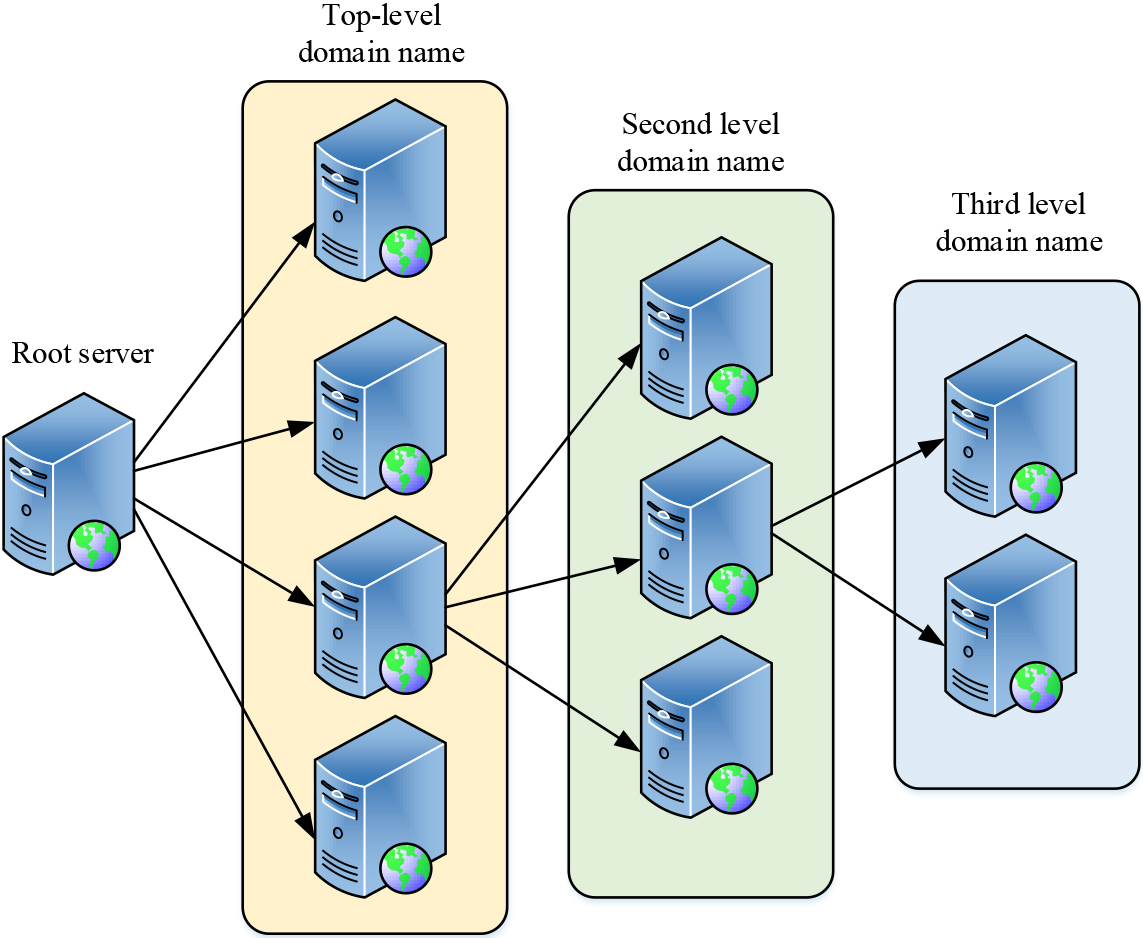
Figure 5 illustrates that the DNS structure is a cross-number structure, where the first level is the root domain name (DM) server. The second and third levels correspond to the first-level DM server and the second-level DM server, respectively. The fourth level corresponds to the third-level DM server. DNS performs iterative queries in stages to obtain the IP address corresponding to the requested DM, so the computer first sends the DM request to the public DM system. The public DM system then queries the root domain name system for the top-level DM information and returns it to the computer. Afterward, the computer searches for address information identified by the lower-level DM via the top-level DM system. Subsequently, the top-level domain name system repeatedly requests address information from the lower-level DM system until the DM resolution process is complete. Due to DNS DM resolution’s iterative nature, DNS typically stores query results in its cache to reduce resolution time. As a result, the DNS system becomes vulnerable to various threats like IP tampering, privacy information leakage, in terms of its throughput and security. The centralized architecture of DNS is responsible for the root cause of DNS security threats, as made clear by the structure and working principle of DNS. The security of blockchain is one of its most important features. The distribution of data on multiple nodes in the network by blockchain makes it harder for attackers to modify the data. As multiple nodes need to be attacked simultaneously, blockchain has high resistance to aggression and tamper-proof ability. At the same time, blockchain uses a variety of encryption technologies to ensure the confidentiality and integrity of data. Hash functions are used to verify the integrity of data, and symmetric encryption is used to protect data confidentiality. In addition, blockchain uses a consensus mechanism to achieve the consistency of data in the network. The consensus mechanism ensures that all participants agree to accept and validate new blocks and prevents malicious nodes from tampering with the data. Examples of common consensus mechanisms include proof of work and proof of equity. In addition, blockchain technology is immutable, and modifying or deleting data once it is written to the blockchain is challenging. The chain structure of the blockchain is formed by including the hash value of the previous block in each block. Tampering with the data of a block will result in the alteration of its hash value, which causes the integrity of the entire blockchain to collapse. In conclusion, the security performance of the blockchain technology is highly robust. Therefore, the study combines the BBDS sharing algorithm with the DNS system to build a BBDS data storage model to realize the decentralization of the DNS-DM system. The structure of the model is shown in Fig. 6.
BBDS data storage model.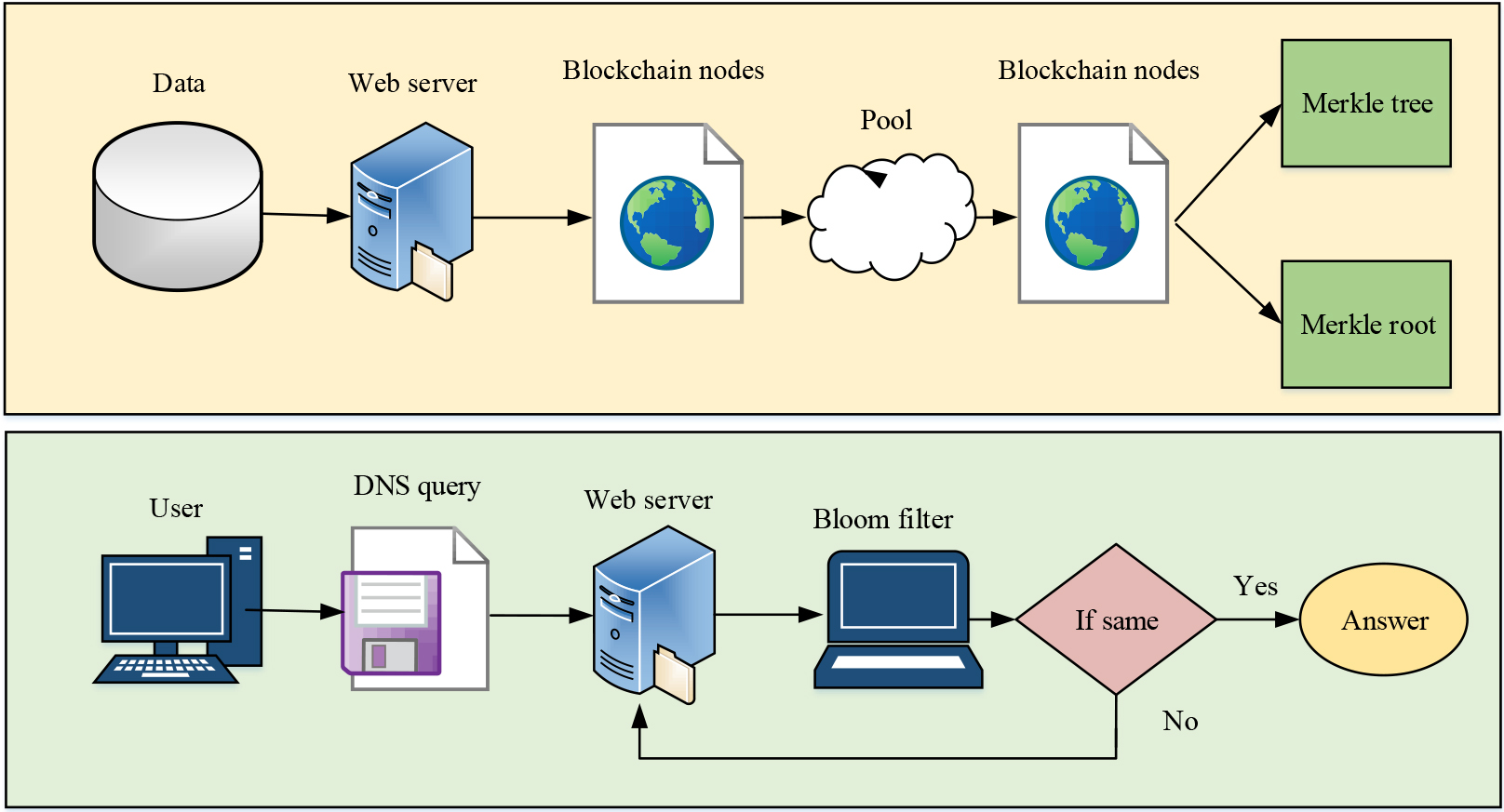
Figure 6 shows the schematic diagram of the data storage system based on BBDS. According to Fig. 6, DNS data is shared and stored through the combination of the blockchain and DNS query service. The DNS system stores data in the blockchain implementation module, which contains no input or output components. Upon arrival at the DNS system, the data is packaged into a DNS transaction object, consisting of DM-IP address, domain creation time, data operation for change, deletion, and verification, as well as the DNS data hash value. Subsequently, the data is transported to the DNS pool to create new blocks. When the next new block is constructed, the system will remove the transaction data from the pool and form a Merkle tree by recursion. After the transaction object is full, a new root hash is generated and the Merkle Root replaces the previous block header. The new block body mainly consists of DNS data objects that have been stored. During the implementation of the DNS query service, the hash value of DM is calculated upon arrival of the DNS query request. Then the Bloom filter is obtained and the Merkle leaf node is recursively traversed starting from the current block. If the hash value is the same, then the data is successfully obtained, indicating that the DNS data is in the block. If DNS data is not found within a block, the previous block is accessed through its hash, and this cycle continues until the required data is located. The Bloom filter is a smart probabilistic data structure that uses a binary vector and a series of random mapping functions to determine the presence or absence of DNS data information within a block.
Research on the effectiveness of the blockchain-based sharing algorithm
Comparison results of latency and throughput of various algorithms.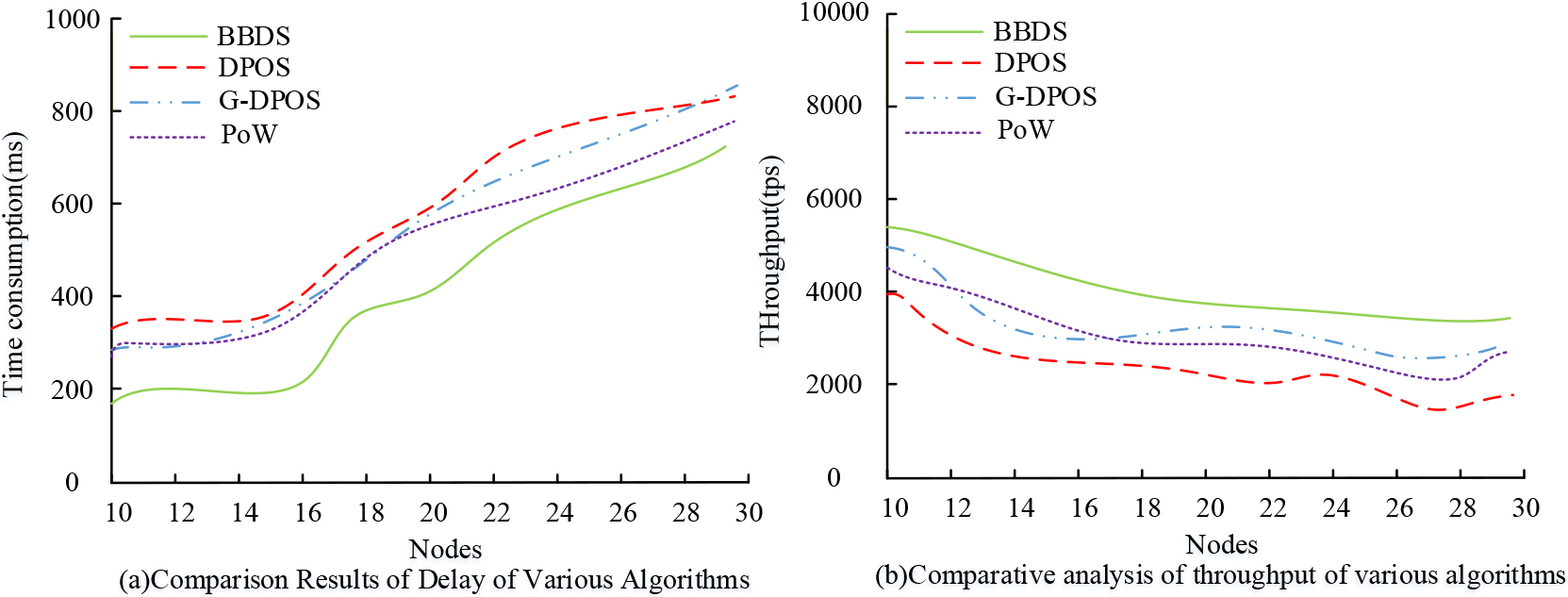
To verify the effectiveness of the proposed BBDS sharing algorithm, the BBDS sharing algorithm was compared with other algorithms. The purpose of the experimental data source is to create a regional blockchain network using the Ethereum blockchain. The duration of the experiment is 4 hours. The blockchain network in this area comprises 60 nodes, each with a storage capacity of 500 GB. The data volume is 2500 GB, and the size of each data block is 100 MB. Data sharing operations on the network include the creation, verification, broadcast, and confirmation of 45,000 transactions. The hardware configuration is an Inter Core i7-2640M processor (4 MB cache and frequency at 2.8 GHz). Meanwhile, the study uses Docker as a portable solution to solve the multi-server node problem. Sharing is achieved through the Linux kernel. The index used in the performance comparison test is the DNS query delay and throughput. Query delay is defined as the time taken by the DNS server to respond to a client’s query request, comprising the time between sending and receiving queries, processing queries, and sending and receiving results. Throughput is the average number of successful queries processed per second in a DNS system, involving operations such as sending and receiving queries, processing queries, and sending and receiving results. The comparison algorithm is one of several common shared algorithms used in the blockchain consensus layer. These include the Delegated Proof of Stake (DPOS) sharing algorithm, the improved Gain Delegated Proof of Stake (GDPOS) sharing algorithm, and the proof of workload (Proof of Work, POW) sharing algorithm. Among them, DPoS is the consensus algorithm used by EOS and other blockchain platforms. GDPO type is a modified consensus algorithm based on GDPOS algorithm. PoW is the consensus algorithm used by Bitcoin. For the performance comparison experiment of each algorithm, the results of query delay and throughput are shown in Fig. 7.
Figure 7 shows the comparison results of latency and throughput of the compared algorithms. Figure 7a shows the results of comparative analysis of latency of each algorithm, i.e., the time consumed by all nodes in the blockchain network to synchronize the same number of messages. As shown in Fig. 7a, with the increase of nodes, the latency of each algorithm shows an increasing trend, among which the overall latency curve of BBDS algorithm is lower than the curve of other algorithms. In the 10–30 nodes, the average latency of BBDS algorithm is 436 ms, and its latency performance is better than the comparison algorithm. Figure 7b shows the results of comparative throughput analysis of each algorithm, i.e., the number of messages synchronized by each algorithm in the blockchain network during the same recording time. As shown in Fig. 7b, the throughput of each algorithm shows an overall decreasing trend with the increase of nodes. The throughput curve of the BBDS algorithm gradually flattens out when the number of nodes increases to 19. Moreover, this algorithm exhibits a higher throughput curve than the others. The average throughput of the BBDS algorithm is 5439 tps which is better compared to the other algorithms. To sum up, the BBDS algorithm performs better than the other comparison algorithms.
To validate the performance of the proposed BBDS-based blockchain DNS system, the empirical analysis of the blockchain DNS system based on BBDS sharing proposed in the study is carried out by comparing five metrics. They are query latency, throughput, block generation time, query correctness rate and data storage time of the system. The comparison systems are the traditional DNS system based on Random Account Forest (RAFT) sharing algorithm, the traditional DNS system based on InterPlanetary File System (IPFS) sharing, and the traditional DNS system based on Proof of Stake (PoS) sharing. The experimental processors used are Inter Core i7-2640M (4 MB/2.8 GHz). The technologies and software used are Java, Docker, DatagramSocket and protostuff-api. The query latency and throughput of the modified decentralized DNS system based on BBDS and the traditional DNS system are shown in Fig. 8.
Comparison results of query latency and throughput among various DNS systems.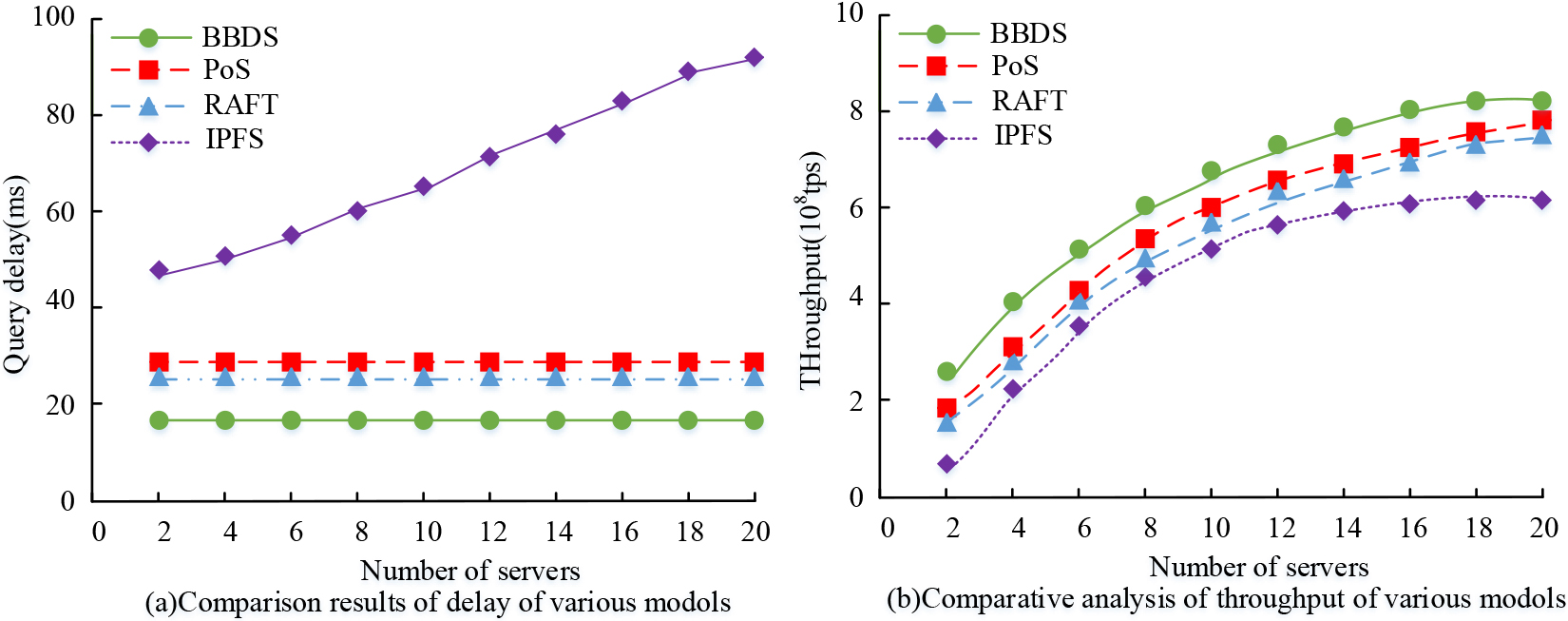
Figure 8 shows the comparison results of query latency and throughput for each DNS system. Figure 8a shows the comparison results of latency for each comparative DNS system. As depicted in Fig. 8a, the query latency of the IPFS shared DNS system increases with the number of DNS servers, whereas the query latency performance of the PoS, RAFT, and BBDS shared DNS systems proposed in this study remains stable and is not influenced by the number of servers. Notably, the BBDS shared DNS system has the lowest query latency of 18.8 ms, 2.8 ms lower than the RAFT shared DNS system. This feature makes it the optimal choice in terms of latency performance. Figure 8b shows the throughput comparison results of each comparison DNS system. As shown in Fig. 8b, the information throughput of the comparison DNS system shows an overall increasing trend with the increase of servers. The shared DNS system based on BBDS technology exhibits the highest overall throughput curve, achieving an average throughput of 6.42*108 transactions per second, which is 1.26*108 higher than the average throughput of the PoS shared DNS system and represents the best throughput performance. In conclusion, the DNS system utilizing BBDS technology presents superior latency and throughput performance. The parameters of each system are set uniformly: the number of servers is 8, and the initial data of nodes is 0. The block generation time of each comparison system is shown in Fig. 9.
Generation time of each system block.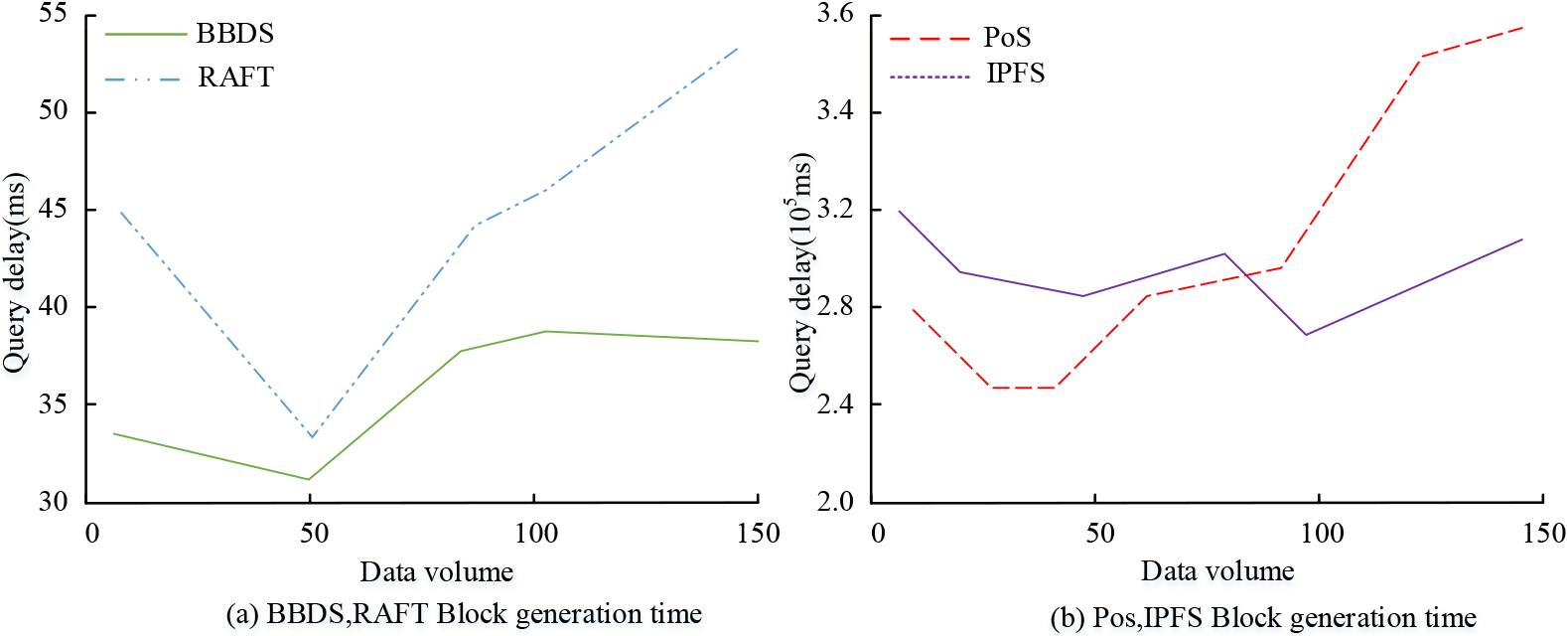
Figure 9a shows the comparison of the block generation time results of BBDS shared and RAFT shared DNS systems. Figure 9a illustrates that the block generation time of DNS systems based on BBDS and RAFT displays a trend of initially decreasing and then increasing with increasing data volume. The DNS system based on BBDS exhibits an overall block generation time curve that is lower than that of RAFT. The BBDS-based system has the lowest block generation time of 31.2 ms and the highest of 39.6 ms, indicating better performance. Figure 9a shows the comparison of the block generation time results for the PoS shared and IPFS shared DNS systems. The block generation time curves for the PoS and IPFS co-block generation in Fig. 9b are five orders of magnitude slower than the BBDS and RAFT curves. In conclusion, the BBDS algorithm has the best performance among all algorithms in terms of block generation time. BBDS block generation mode is divided into two modes: immediate generation mode refers to block generation of updated data within the time interval, and full generation refers to block generation when the data volume reaches the maximum. The study sets the time interval to [2, 12]. The block generation time of immediate generation mode and full generation mode is shown in Fig. 10.
Immediate generation method and full generation method block generation time.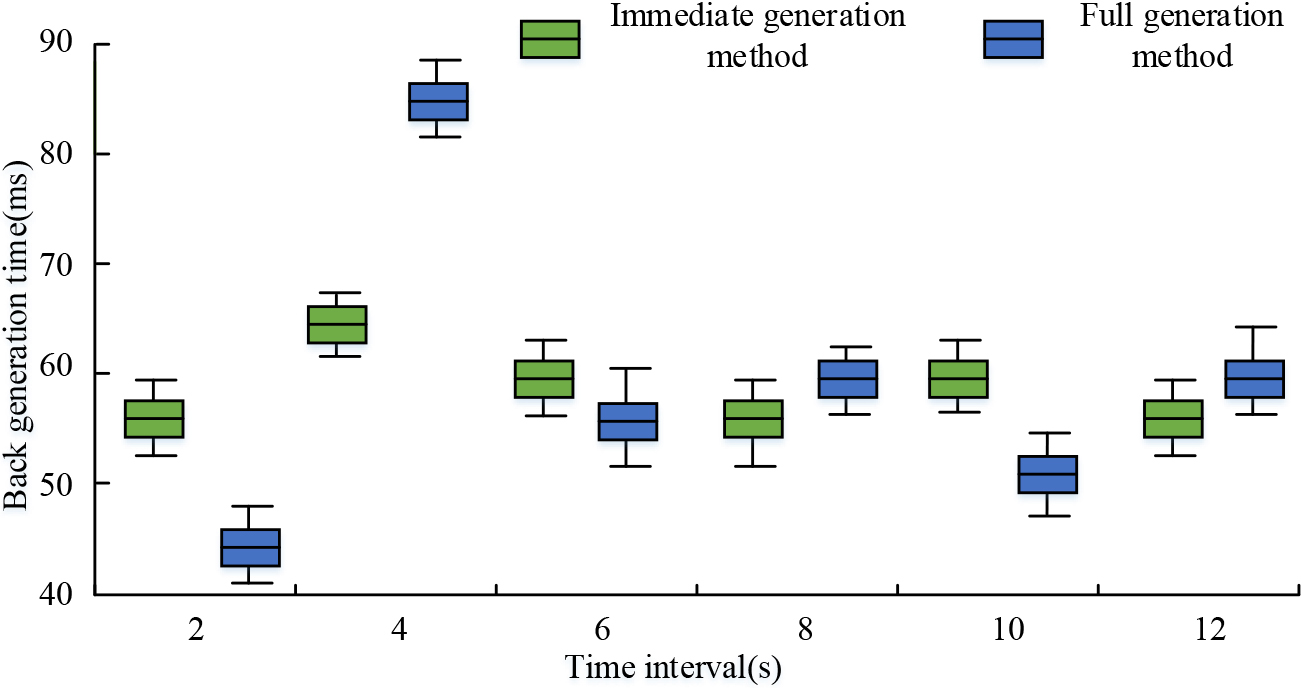
Figure 10 shows the block generation time comparison results of immediate generation mode and full generation mode. According to Fig. 10, the average block generation time (BGti) is 58.2 ms for the immediate generation mode, and 61.7 ms for the full generation mode, which is slightly longer. Moreover, the BGti is smoother in the immediate generation mode, whereas it fluctuates more in the full generation mode. In summary, the results show that the immediate generation mode is better among the DNS generation modes, and the block immediate generation mode can be selected to maximize the use of system resources.
In order to verify the performance of BBDS-based blockchain DNS system defense and data storage, the performance test of DNS system defense with distributed Denservice (Distributed Denial of Service, DDoS) attacks is studied. The study of DDoS is used to send a large number of malicious requests to the target system to consume the computing resources, network bandwidth or other system resources of the target system, so that the target system cannot process the requests of legitimate users normally. The experimental platform is the form of Omnet
System query accuracy.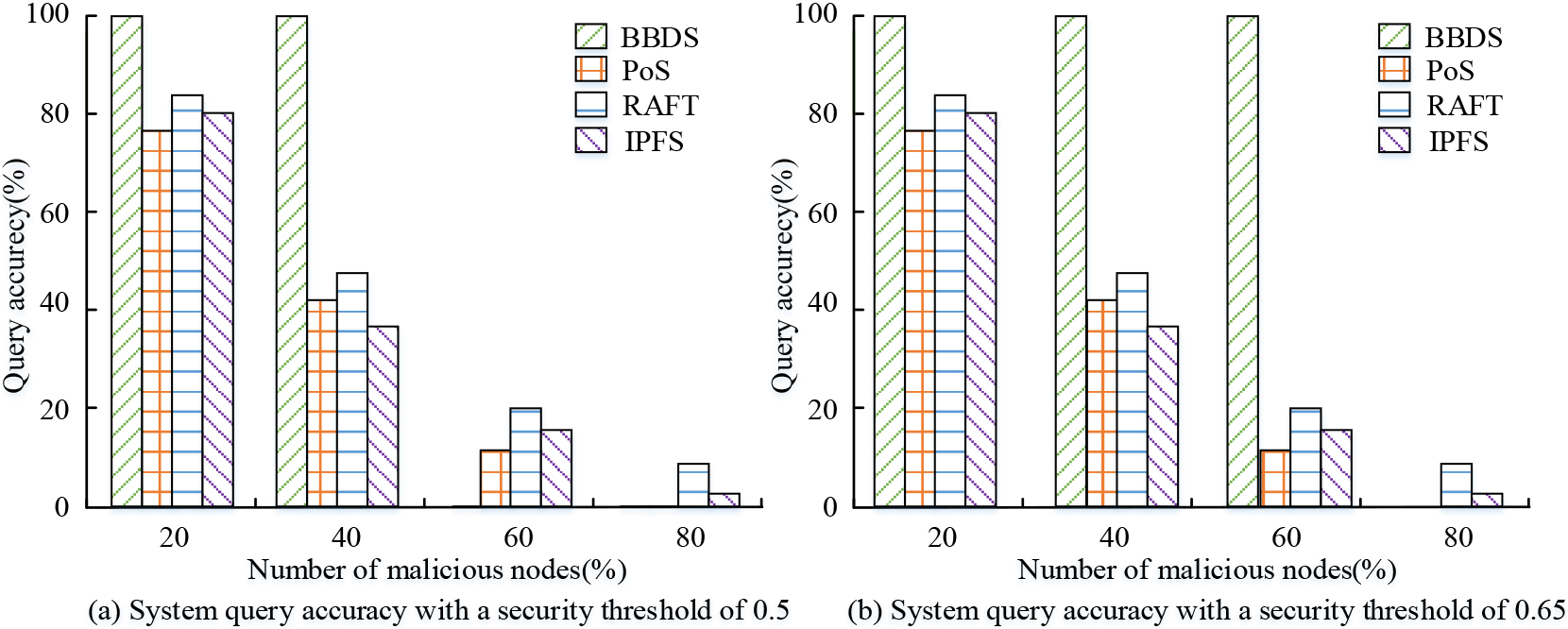
Figure 11 shows the system query accuracy with different security thresholds. Figure 11a shows the system query accuracy analysis for a security threshold value of 0.5. From Fig. 11a, the query accuracy of PoS, RAFT and IPFS shared DNS systems decreases with the increase of malicious node ratio when the security threshold is 0.5; The highest query accuracy corresponds to 71.6% for Pos, 86.4% for RAFT and 76.3% for IPFS. The query accuracy of BBDS is 100% at malicious node ratios of 20% and 40%. After the malicious node ratio exceeds 50%, the system becomes unqueryable. Figure 11b shows the query accuracy analysis of the system when the security threshold value is 0.65. From Fig. 11b, the query accuracy of PoS, RAFT and IPFS shared DNS systems decreases with the increase of malicious node ratio when the security threshold is 0.65. The query accuracy of BBDS is 100% when the malicious node ratio is 20–60%, and the system is in non-responsive query after the malicious node ratio is higher than 65%. In summary, the DNS security defense performance based on BBDS sharing is determined by the security threshold. But when the proportion of malicious nodes is lower than the security threshold, DNS is in a perfect query state; When the proportion of malicious nodes exceeds the security threshold, the DNS system will turn off the query function to prevent attacks from malicious nodes. It has better security defense performance than other DNS systems. The comparison results are shown in Fig. 12.
Comparison results of data access times among different systems.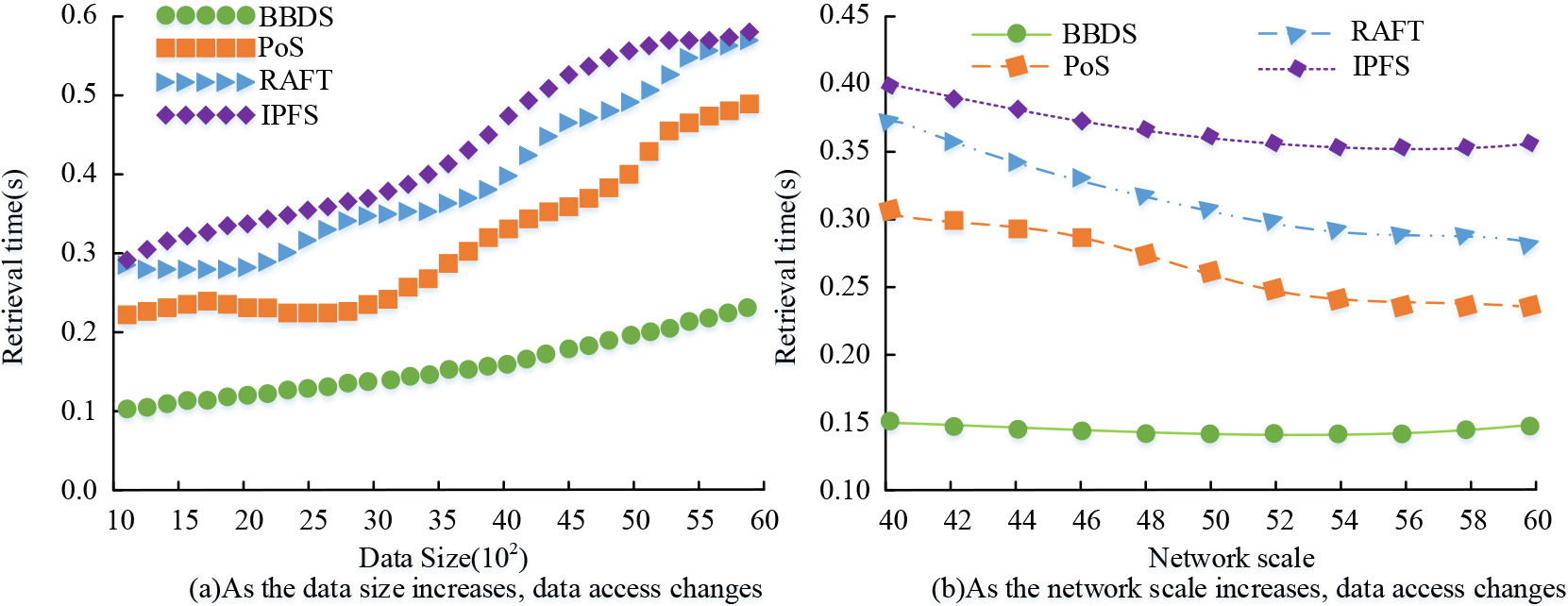
Figure 12a shows the variation of the data access time of each DNS system with the increase of data volume in a random environment. From Fig. 12a, it can be seen that the BBOS shared DNS system has the smallest data access time with the increase of data volume, and its average access time is 0.16 s. Meanwhile, the BBOS shared DNS system has the best access performance with the increase of data volume, and its data access time grows slowly. Figure 12a shows the variation of data access time of each DNS system with the increase of network size in a random environment. From Fig. 12b, the access time of DNS systems based on RAFT, IPFS, and PoS shares gradually decreases with the increase of data volume. The data access time of the DNS system based on BBOS sharing remains stable and unaffected by the network size. The DNS system based on BBOS has the lowest data access time, which is 0.15 seconds, which is 0.08 seconds lower than the average access time of PoS. In summary, the results show that the access performance of the BBOS shared-based DNS system is optimal and has practical use.
In order to explore the influencing factors of DNS system performance and experimental results, the study conducted empirical analysis on them. The performance change of the algorithm is analyzed by changing the data quantity, network bandwidth, data block size and the number of nodes. The processor used in the experiment is Inter Core i7-2640M (4 MB/2.8 GHz), and the technology and software used are Java, Docker, DatagramSocket and protostuff-api. The comparison indexes are data query delay and throughput. The data query delay and throughput results of the BBDS algorithm and DNS system under different data quantities, network bandwidth, data block size and number of network nodes are shown in Fig. 13.
Data query delay and throughput results of DNS system under different data volume, network bandwidth, data block size and number of network nodes.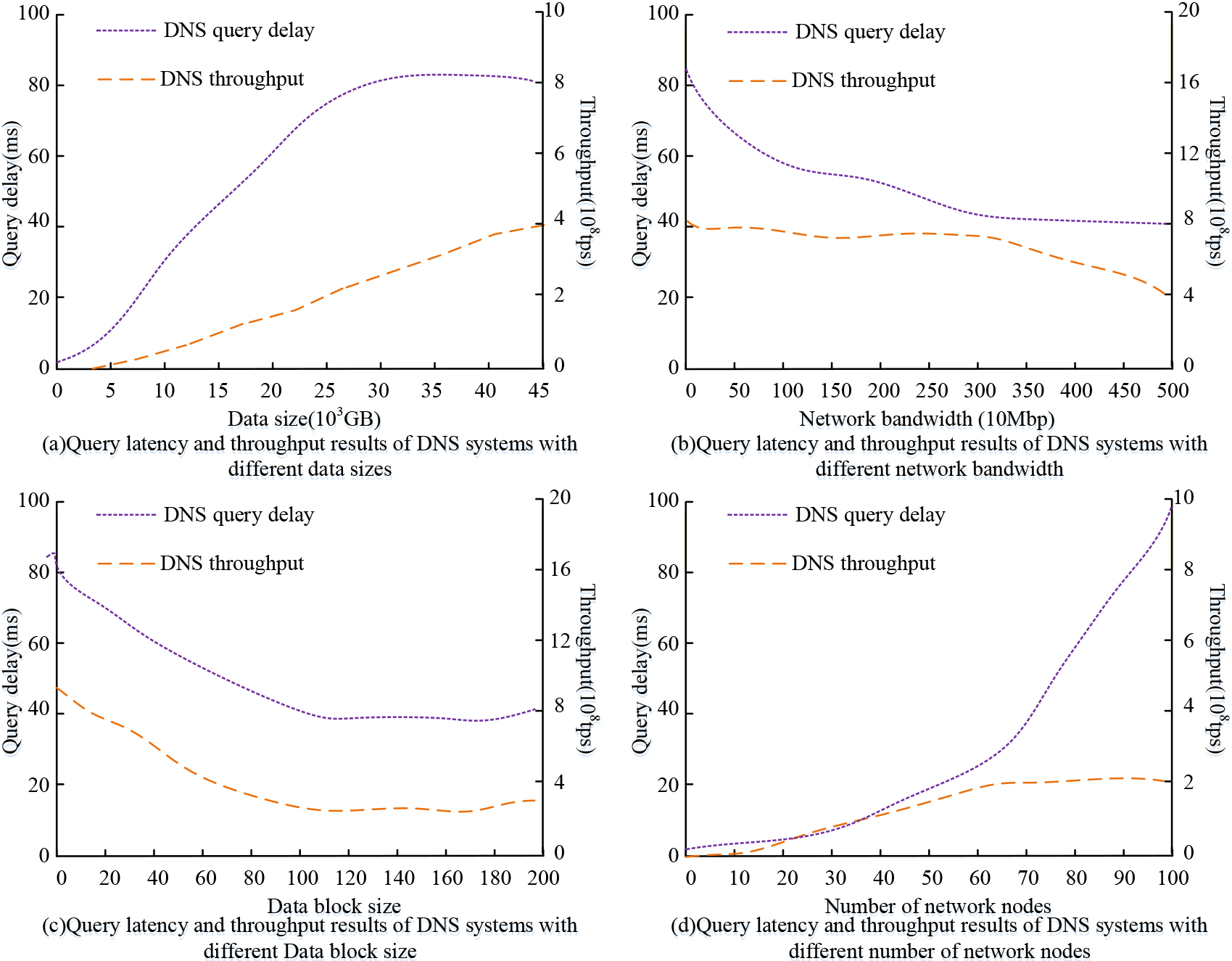
Figure 13a shows the data query delay and throughput results of the DNS system under different data sizes. As shown in Fig. 13a, with the increase of data volume, the data query delay and throughput of the DNS system also increase. Figure 13b shows the data query delay and throughput results of the DNS system under different network bandwidth sizes. As shown in Fig. 13b, with the increase of bandwidth, the data query delay and throughput of the DNS system also decrease. Figure 13c shows the data query delay and throughput results of the DNS system under different data block sizes. As shown in Fig. 13c, with the increase of the data blocks, the data query and query delay and throughput of the DNS system will also decrease. Figure 13d shows the data query delay and throughput results of the DNS system under the number of different network nodes, as shown in Fig. 13d. With the increase of the number of network nodes, the data query delay and throughput of the DNS system also increase. In conclusion, the size of the node data volume, network bandwidth, data block size and the number of network nodes of the blockchain network will affect the performance of DNS. The evaluation and optimization of the blockchain sharing algorithm’s performance requires consideration of these factors.
As the Internet is continuously developing, an improved BBDS algorithm has been developed in line with the blockchain principle to share and store data more efficiently and securely. The algorithm has been integrated with the DNS system to build the BBDS data sharing and storage system. The performance of the proposed BBDS algorithm and the BBDS data sharing and storage system has been experimentally evaluated. The study finds that the BBDS algorithm outperforms other compared algorithms in terms of latency and throughput performance, with an average latency of 436 ms and an average throughput of 5439 tps. Furthermore, the study performs experiments comparing the performance of the data sharing and storage system based on the DDBS algorithm. The results indicate that the query latency performance of ABBDS shared DNS system is stable, with a minimum latency of 18.8 ms, and an average throughput of 6.42*108 tps, which is superior to other comparable systems. Furthermore, the data access time of BBDS data sharing and storage system is found to be 0.15 s, better than other models used for comparison. The results demonstrate that the proposed BBDS algorithm and data sharing and storage system surpass both the comparative algorithm and system in terms of latency performance, throughput performance, and data access performance, thus demonstrating significant practical application value. The blockchain-based distributed data storage model, proposed by the study, has limited network nodes during the initial practical application stage, resulting in a weak anti-risk capability. In the future, it can be beneficial to investigate a consensus mechanism that isn’t influenced by computing power and external nodes in the early stages to scale up the number of nodes in the network, enhance network resilience, and ensure system stability during the early transport experiments. In BBDS data sharing and storage systems, a centralized storage management key is not required. The data owner himself generates the key for the data user and encrypts his data under the specified access policy to realize the shared access control over the data and spread the storage and service pressure from the centralized storage to each node. At the same time, in the blockchain, each node holds a copy of the entire chain, and by traversal of the blockchain, the changes of each data version can be traced and viewed in chronological order. In addition, smart contracts based on blockchain solve the problem of opaque search by traditional storage service providers. However, reviewing the work of this paper, there are still some shortcomings. In the construction of the BDS network model, only a simplified version of the study, such as data privacy of data and data query security have not been realized. The subsequent research direction of the experiment is to explore the practical application of BBDS sharing algorithm and BBDS data sharing and storage system in IPV6 environment.
Footnotes
Funding
The research is supported by: Research on Accurate Recommendation of Personalized Learning Resources for Higher Vocational Students Based on Smart Classroom, project number: ZJGB2020317.