
Abstract
BACKGROUND:
Red raspberry (Rubus idaeus L.), known as “golden fruit”, has excellent potential for immune-regulation, anti-inflammation and anti-cancer due to its health-promoting secondary metabolites. The lack of genetic information in public databases has been a constraint for the genetic improvement of red raspberry.
OBJECTIVE:
The primary aim of the work was to find the key genes relating with the secondary metabolite pathways.
METHODS:
De novo assembly transcriptome sequencing of red raspberry (‘Heritage’ variety) fruit in different development stages was performed using an Illumina Hiseq platform. Transcriptome was obtained by the de novo assembly through Trinity assembler. Coding sequences were successfully characterized using databases including non-redundant protein (NR), euKaryotic Ortholog Groups of proteins (KOG), Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG). Fragments Per Kilobase of transcript sequence per Million base pairs sequenced (FPKM) method was used to calculate the differentially expressed unigenes.
RESULTS:
In total, 205,880 unigenes with an average length of 1120 bp and an N50 of 2005 bp were obtained, of which 182,443 unigenes were annotated. Non redundant (NR) annotation showed that a majority of the best hits (58.6%) are wild strawberry (Fragaria vesca). Additionally, the unigenes were also annotated in euKaryotic Ortholog Groups of proteins database and Gene ontology database, and mapped the KEGG pathways. We predicted that 8331 TFs from the unigenes database and these TFs were classified into 94 different common families. The major families were associated with the C2H2 (9.19%), followed by the C3H (4.60%), MYB-related group (4.23%), bZIP (4.13%) and B3 (4.03%). These results were considered to be involved in the regulation of metabolic and secondary metabolic biosynthesis. Totally, 3,369, 3,461 and 441 differentially expressed genes (DEGs) were found in period 2 vs period 1, period 3 vs period 2 and period 4 vs period 3 paired comparisons, respectively. These DEGs were analyzed based on BLASTx, which were mapped to 22 KEGG pathways associating with secondary metabolites during red raspberry fruit ripening, involving anthocyanin biosynthesis, flavonoid biosynthesis, sesquiterpenoid and triterpenoid biosynthesis, etc. To validate the high-throughput sequencing results, six target genes involved in secondary metabolite pathways of red raspberry fruit were tested by qRT-PCR. The results of qRT-PCR assay were generally consistent with the results of RNA sequencing.
CONCLUSION:
The transcriptome sequencing of the red raspberry fruit at different development stage in this study enriched the genetic information resources of this variety, and will discover the genes relating with secondary metabolic pathways, benefiting to engineer high-quality plants with enhanced active ingredients.
Introduction
Natural and safe food, especially containing abundant bioactive components, is increasingly popular due to its healthy functions. Red raspberry (Rubus idaeus L.), known as ‘golden fruit’, is rich in raspberry ketone, anthocyanin, ellagitannin/ellagic acid, salicylic acid, flavonoids and other substances, and is widely distributed and cultivated in Europe, America and Asia. Its edible fruit is usually used for fresh or processed fruit [1–3], but its medicinal properties has drawn much attention recently due to the existed scientific works evidencing excellent potential for immune-regulation, anti-inflamation, anticancer and promoting stem cell differentiation into osteoblasts [4–10], mainly attributing to its health-promoting secondary metabolites. Therefore, increasing the secondary metabolites of the red raspberry fruit is much more favourable to human health.
The red raspberry fruit develpment is a genetically programmed process involving various biochemical and physiological processes. By genetic inheritance and environment regulation, the content of the secondary metabolites can be changed at different phisiological and developmental stage [11–13]. It has been proved that exogenous elicitors (e.g., methyl jasmonate, abscisic acid and pyrabactin) and modification of the nutritional status triggered the enhancement of bioactive compounds in red raspberry [14–16]. Functional genomics approaches accelerated the comprehensive research on biological systems and the gene discovery for secondary metabolite pathways [11]. Using the reverse transcriptase competitor polymerase chain reaction assay, two genes (RiPAL1 and RiPAL2) encoding L-phenylalanine ammonia-lyase (PAL) were determined in raspberry [17]. The expression of flavonoid pathway genes and developmental and environmental conditions governed the production and distribution of anthocyanin in the fruits [18, 19]. However, most of these functional genomics approaches have been limited to the sequenced plants.
Thanks to the next-generation high-throughput sequencing technologies such as Illumina HiSeq, 454 Pyrosequencing and SOLID sequencing, transcriptome sequencing has been broadly applied to get transcript sequences and gene expression data quickly and cost-effectively for non-model species without reference genomic information [20–22]. Tissue- and stage- transcriptomic profiling of woodland strawberry flower and early-stage fruit development were generated based on transcriptome analysis [23, 24], proving a wealth of genomic resources for the strawberry. Similarly, complete transcriptome data concerning mature fruit of blackberry has been obtained using the RNA-seq technology [25]. More studies by de novo assembly transcriptome sequencing on cranberry [26], blueberry [27], black raspberry [28, 29] and Salvia miltiorrhiza [30] facilitated our understanding of the molecular mechanisms of organs development of the plants and the secondary metabolic regulation mechanisms.
Despite significant progress in illuminating the molecular basis of the organ’s development and biosynthesis of active ingredients in many species, the secondary metabolic pathway genes operated in the red raspberry fruit development is not well understood. Taking advantage of the next-generation sequencing, we performed the de novo assembly transcriptome sequencing to profile the transcriptomes of red raspberry (Rubus idaeus L.) at four developmental stages. Moreover, we identified a set of putative gens involved in pathways of secondary metabolism, enriching the gene resource of Rubus idaeus L. with these data. Here, we report initial analysis of these molecular information, which is significant to discover the genes relating with secondary metabolic pathways and engineer high-quality plants with enhanced active ingredients.
Materials and methods
Plant material and tissue collection
Red raspberry (Heritage) plants used in this study were cultivated in Xingtai, Hebei province, China (36° 50′ to 37° 47′ N and 113° 52′ to 115° 49′ E). This area has a warm temperate semi-humid continental monsoon climate, with four distinctive seasons. The annual mean temperature is 12∼14°C. The fruit sampling is divided into four developmental stages (Fig. 1), the green fruit (period 1, 15 d after full bloom (DAFB)), yellow fruit (period 2, 25 DAFB), red fruit (period 3, 28 DAFB) and deep red fruit (period 4, 30 DAFB). Fruit samples at the different developmental stage were collected from at least 5 plant individuals. All the samples were immediately frozen in liquid nitrogen and stored at –80°C until RNA extraction. At least three fruits were combined to form one biological replicate and each sample has three biological replicates.
The red raspberry fruits at different development stage.
Total RNA was extracted from the 0.1 to 0.5 g of fruits tissue at different developmental stages using RNA prep pure Plant Kit (Tiangen Biotech Co., Ltd., Beijing, China) according to the manufacturer’s instructions. A total amount of 1.5 μg RNA per sample was used as input material for the RNA sample.
The quality and quantity of RNA was determined using a quadruple check, Agilent 2100 Bioanalyzer (Agilent Technologies, CA, USA), NanoPhotometer spectrophotometer (Implen, CA, USA), Qubit 2.0 Fluorometer (Life Technologies, CA, USA) and gel electrophoresis. NEBnext Ultra RNA Library Prep Kit for Illumina (NEB, USA) was used to generate the sequencing libraries on the basis of manufacturer’s recommendations according to the reported work [31]. Sequencing was carried out at Beijing Novogene Biological Information Technology Co., Ltd. (Beijing, China) employing the Illumina TruSeqTM RNA Sample Preparation Kit (Illumina, San Diego, CA, USA) according to the manufacturer’s recommendations. The library preparations were sequenced using an Illumina Hiseq platform, and paired-end reads were generated.
Transcriptome assembly
Clean reads without adaptor sequences, reads containing poly-N and low-quality sequences were obtained after processing the raw reads. Meanwhile, Q20, Q30, GC-content and sequence duplication level of the clean reads were calculated. All the downstream analyses were based on clean data with high quality. Transcriptome de novo assembly with clean reads was carried out using the assembling program Trinity (version 2.4.0) [22] with min_kmer_cov set to 2 by default and all other parameters set default [31].
Annotation and classification of gene functions
Unigene sequences were firstly aligned by Blast X to the databases including National Center for Biotechnology Information (NCBI) non-redundant protein (NR) database, Swiss-Prot, euKaryotic Ortholog Groups of proteins (KOG), NCBI nucleotide sequences (NT), Protein family (Pfam), Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG). Then we retrieved proteins owning the hightest sequence similarity with the given sequences and determined their functional annotations.
Analysis of differentially expressed genes
The expression levels of the unigenes from four samples, the green fruit (period 1), yellow fruit (period 2), red fruit (period 3) and deep red fruit (period 4), were compared and analyzed according to the reported method. RNA-Seq by Expectation Maximization (RSEM) was used to evaluate gene expression changes at different development stage of red raspberry fruit [32]. Differential expression analysis of two groups was performed using the DESeq R package (1.10.1) based on the negative binomial distribution [33]. The false discovery rate was controled by adjusting P values according to the Benjamini and Hochberg’s approach. Genes with an adjusted P-value <0.05 found by DESeq were assigned as differentially expressed. The expected number Fragments Per Kilobase of transcript sequence per Million base pairs sequenced (FPKM) method was used to calculate the differentially expressed unigenes. Gene ontology (GO) enrichment analysis of the differentially expressed genes (DEGs) was performed using the GOseq R packages based Wallenius non-central hyper-geometric distribution [34], which can adjust for gene length bias in DEGs.
KEGG enrichment of some secondary metabolic pathways
The highly integrated KEGG databases provide a reference knowledge base for linking genomes to life through the process of pathway mapping [35]. KOBAS software (version 2.0.12) was used to test the statistical enrichment of differential expression genes in KEGG pathways [36].
The genetic verification of secondary metabolism by qRT-PCR
To validate the high-throughput sequencing results, six target genes involved in secondary metabolite pathways at all four development stages of red raspberry fruit were tested by qRT-PCR. Three biological replicates per sample were performed.
The cDNA was got using the TIANScript II RT Kit (Tiangen Biotech Co., Beijing, China) according to the manufacturer’s instructions, and qRT-PCR was carried out using the ChamQ Universal SYBR qPCR Master Mix Kit (Vazyme Biotech Co., Ltd, Nanjing, China). The real-time PCR system (Applied Biosystems, Foster City, USA) with a 96-well plate was used to conduct the reaction. The conditions for the PCR amplifications were as follows: 50°C for 2 min, 95°C for 10 min, followed by 45 cycles of 95°C for 15 s, 60°C for 30 s, 95°C for 15 s, 60°C for 15 s, and 95°C for 15 s. At last, it was slowly heated from 60°C to 90°C (0.05°C/s). A gene encoding β-actin was used as a reference. Relative expression levels of genes were calculated with the 2–ΔΔCt method [37, 38].
Results and discussion
cDNA sequence generation and de novo assembly
To construct the complete transcriptome of red raspberry fruit, a total of twelve cDNA libraries were established from red raspberry fruit at different development stage, with three biological replicates. As shown in Table 1, after sequencing by Illumina paired-end sequencing technology, a total of 639,658,620 raw reads (each of the 12 libraries received more than 42 million raw reads, with the number of raw reads ranging from 42,491,226 to 66,361,300) are obtained. By getting rid of low-quality reads and adapter sequences, 528,910,176 clean reads (each of the 12 libraries received more than 41 million raw reads, with the number of raw reads ranging from 41,352,578 to 64,926,710) are remained. After a rigorous quality assessment, Q20 in each sample is greater than 95%, Q30 is greater than 93%, with GC percentage ranging from 45% to 48%. These results indicate that all the subsequent analyses based on the clean reads are high quality.
Summary of sample sequencing output statistics
Summary of sample sequencing output statistics
Due to no reference genome sequence for red raspberry, the Trinity assembler [21] is used for de novo assembly of the clean reads, and the transcripts with a total nucleotide of 323,892,215 are obtained with an average length of 1120 bp, a median length of 645 bp and an N50 of 2005 bp (Table 2). To reduce redundancy and potential assembly errors, the genes with a total nucleotide of 298,544,002 is assembled from the transcripts, with an average length of 1450 bp, a median length of 1079 bp and an N50 of 2160 bp (Table 2). This higher proportion of gene assembly results provides sufficient data for subsequent analysis of biological information.
Splice sequence length distribution of the de novo assembly
In order to get a comprehensive annotation of gene function, 205,880 unigenes were annotated using several databases. As summarized in Table 3, the number of unigenes are highly similar to entries in the NR (70.56%), NT (81.71%), Pfam (57.98%), KOG (26.72%), SwissProt (60.83%), KEGG (30.27%) or GO (58.21%). Moreover, about 88.61% of the unigenes are annotated in at least one of the above public databases, and 15.11% of the unigenes are annotated in all databases. Apart from the annotated unigenes, the rest may be untranslated areas or new genes, playing a specific role in the development of red raspberry fruit.
Success rate of genes annotated in seven official databases
Success rate of genes annotated in seven official databases
All unigenes were aligned against the NR protein database of GenBank using BLASTx. The results are shown in Fig. 2, indicating that a majority of best hits (58.6%) are wild strawberry (Fragaria vesca). Moreover, 6.8% unigenes is similarity with Prunus mume followed by 6.0% with Prunus Persica. It is noteworthy that about 21.9 % unigenes are identified with other species.
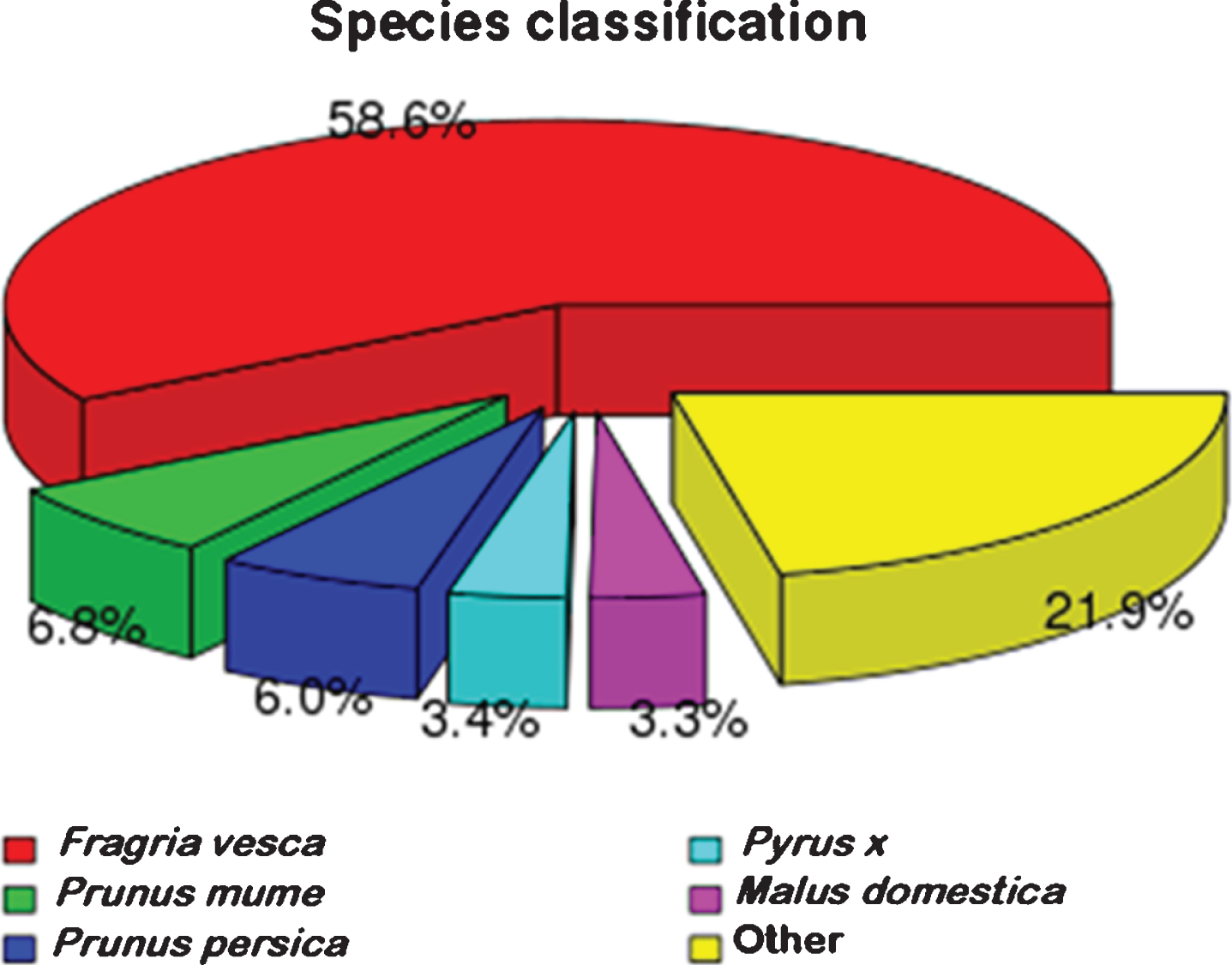
Comparison of NR protein database annotated genes with other species.
Among the annotated sequences, the species with the highest number of best hits were wild strawberry (Fragaria vesca), the similar result was found for blackberry [39] and Korean black raspberry [40]. These results are consistent since strawberry is the species closest to Rubus sp. with sequenced genomes, all belonging to the family Rosaceae, which also reflects the scientific nature of botany classification from the side. The strawberry sequence data in Fragaria×ananassa and Fragaria vesca have been presented [41, 42]. Unfortunately, the red raspberry genome has not yet been presented, and it is expected that when the raspberry genome is published, a comparison analysis with the strawberry genome will better elucidate the differences in their traits and the evolutionary relationships.
Gene ontology terms were assigned for the assembled unigenes. Based on sequence homology, 119,857 unigenes were assigned to 3 main GO categories with 57 classifications. As shown in Fig. 3, these genes are mainly associated with the categories of cellular process (68,030), metabolic process (64,124), single-organism process (52,079), biological regulation (23,456), regulation of biological process (21,723) and localization (20,583) in biological process categories, cell (37,496), cell part (37,475), organelle (26,207), macromolecular complex (24,424), membrane (21,526) and membrane part (20,077) in cellular component categories, and binding (68,985) and catalytic activity (56,297) in molecular function categories. The major volume of sequences was mapped in the biological process category with a high number of sequences associated to different metabolic processes, with similar observations for de-novo RNA-seq of Chilean red raspberry [43] and ripe blackberry [39]. For cellular component category, we observed a high number of sequences related to cell and cell part, with similar results to blackberry [39]. But a high percent of sequences associated to the cytoplasm for the cellular category was found in Chilean red raspberry [43]. Moreover, for molecular function category, de-novo RNA-seq of red raspberry in our study showed a major number of sequences associated to binding than to catalytic activity, and the similar result was determined for Chilean red raspberry [43]. But for blackberry, a similar percent of sequences associated to binding and catalytic activity for molecular function category was found [39].
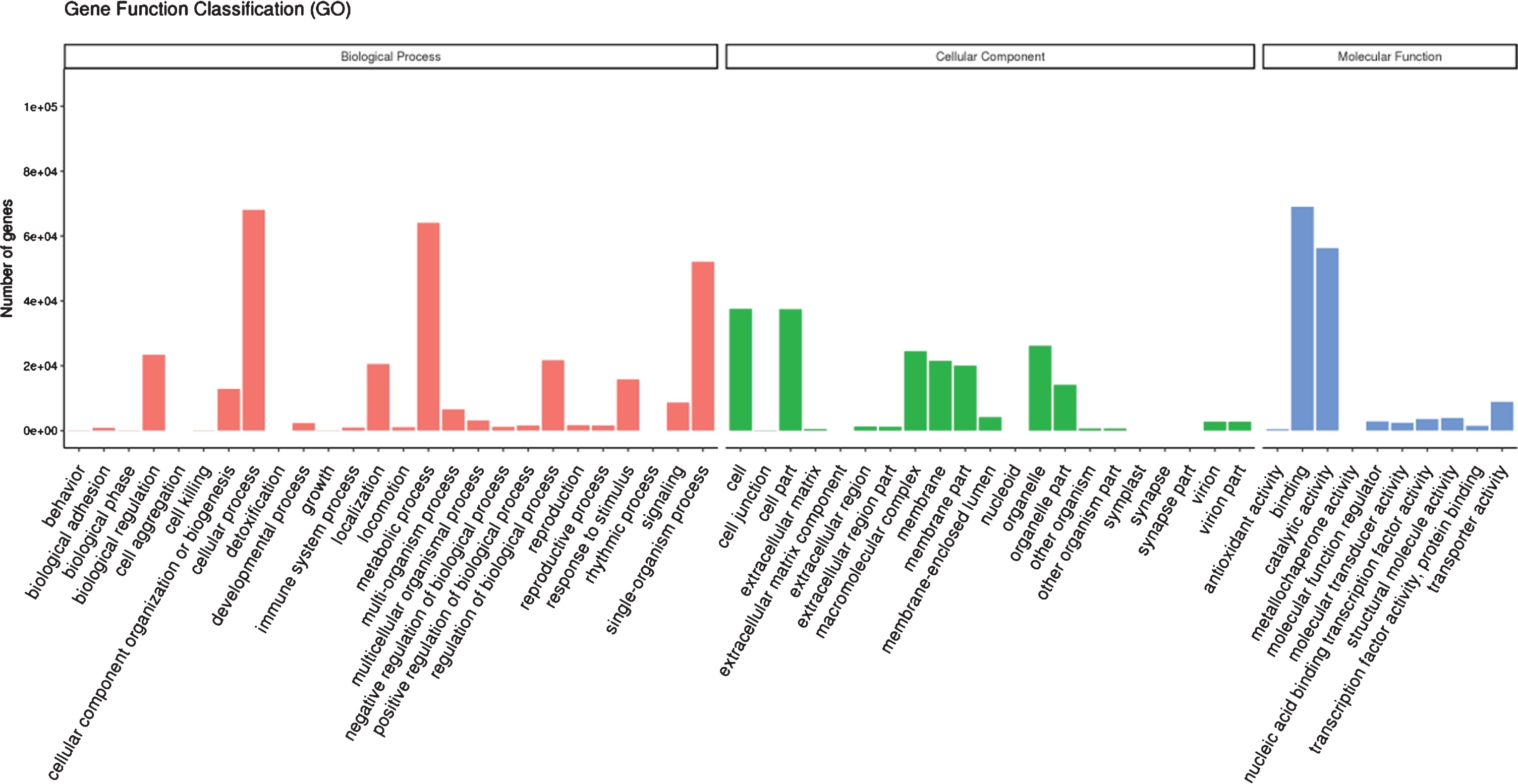
Gene ontology terms assigned for functionally annotated genes of red raspberry fruit.
By blasting against the KOG database to predict and classify function of genes, the 55,025 uingenes were assigned to 26 KOG categories, including the categories of general function prediction only (7418), protein turnover and chaperones (7225), translation, ribosomal structure and biogenesis (5250), posttranslational modification and signal transduction mechanisms (4503), RNA processing and modification (3717), and other categories (Fig. 4).
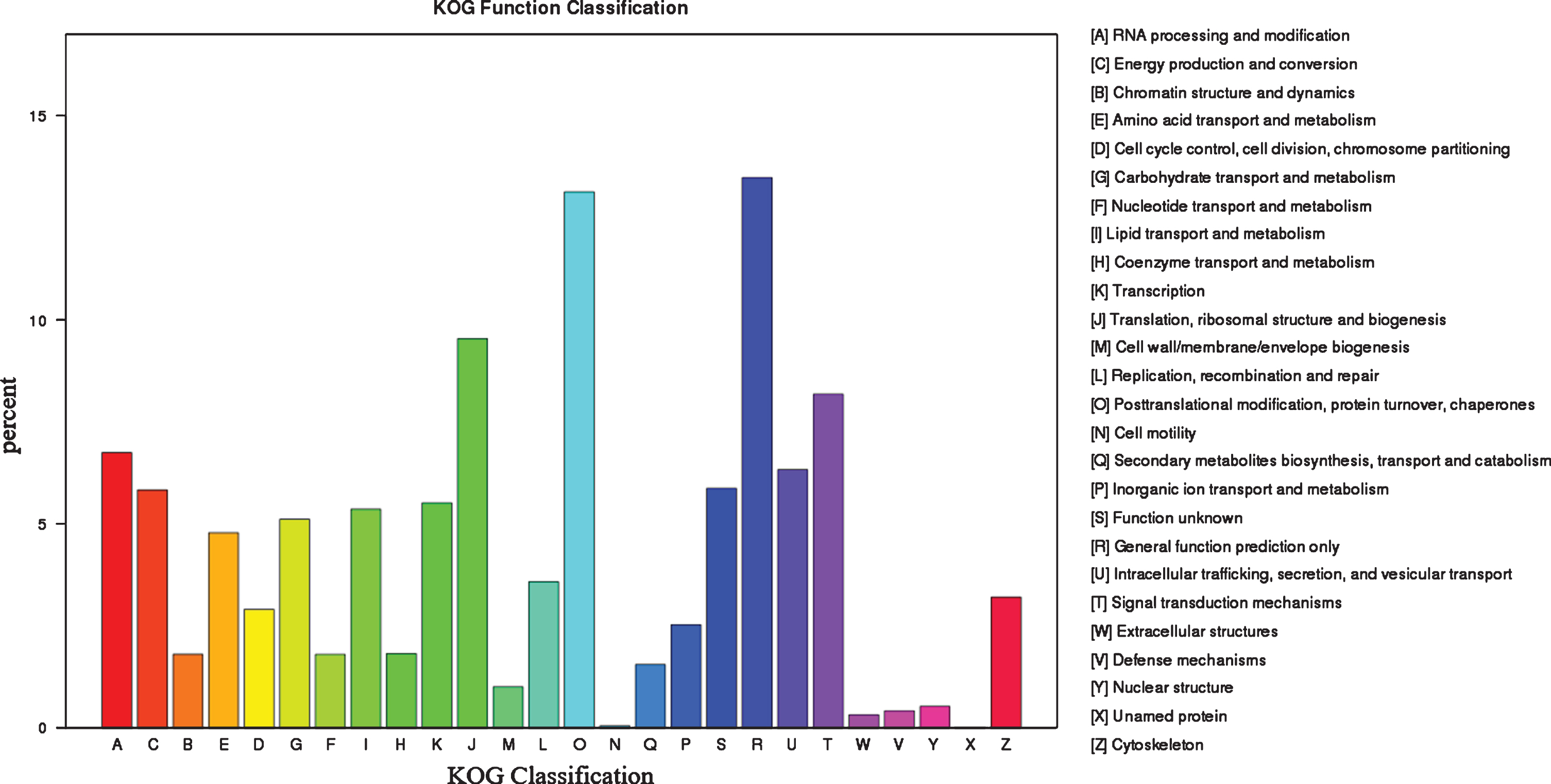
Functional annotation and classification based on KOG database.
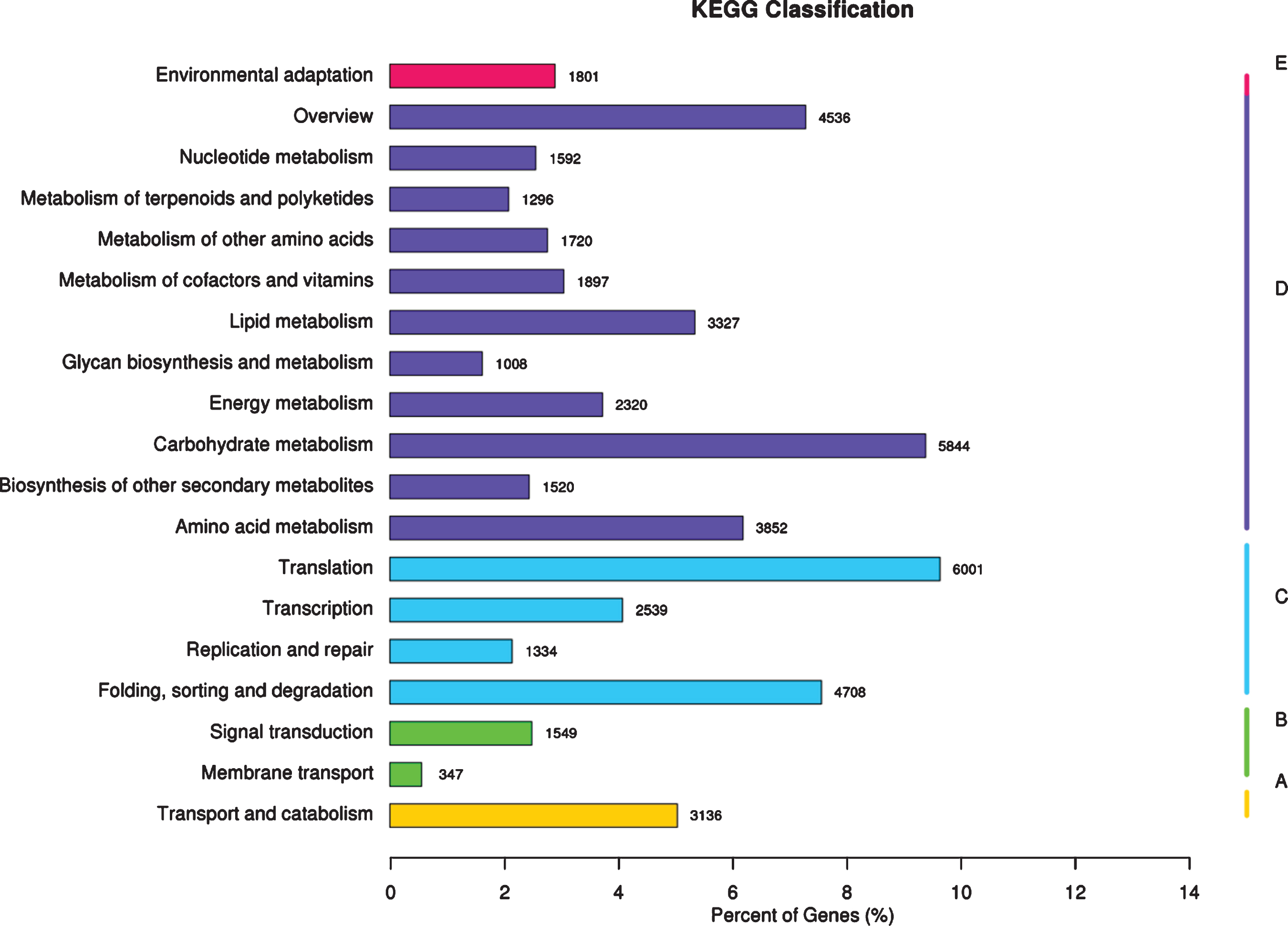
Functional annotation and classification based on KEGG database-The x-axis represents the ratio of the number of annotated genes to the total number of annotated genes, and the y-axis is the name of the KEGG metabolic pathway. According to the KEGG metabolic pathway involved in gene division, it is divided into 5 branches (A-Cellular Processes, B-Environmental Information Processing, C-Genetic Information Processing, D-Metabolism, E-Organismal Systems).
KEGG analysis system was used to assigned the unigene metabolic pathway. As illustrated in Fig. 5, the 62,321 unigenes significant matching in the database for KEGG pathway analysis are mapped to 19 pathways, mainly including translation (6,001), carbohydrate metabolism (5,844), folding, sorting and degradation (4,708), overview (4,536), amino acid metabolism (3,852), lipid metabolism (3,327), transport and catabolism (3,136), and transcription (2,539). These genes in the biosynthesis of secondary metabolites pathway expressed in red raspberry fruits will be useful for defining metabolic pathways for synthesis and turnover of active ingredients with beneficial to human health, and be modifiable by plant breeding in red raspberry.
Transcription factors (TFs) play an important role in plant growth and development [44]. We predicted that 8331 TFs from the unigenes database and their annotation was retrieved from the PlantTFDB. These TFs were classified into 94 different common families. The major families were associated with the C2H2 (9.19%), followed by the C3H (4.60%), MYB-related group (4.23%), bZIP (4.13%) and B3 (4.03%) (Fig. 6). These results were considered to be involved in the regulation of metabolic and secondary metabolic biosynthesis in the green plants [45–47]. At the same time, transcription factors (bZIP, bHLH and MYB) influencing flavonoid biosynthesis have been identified, mapped and shown to underlie QTL for quantitative and qualitative anthocyanin composition [48]. Anthocyanin accumulation during the ripening process is strongly correlated with MYB transcription factors. The production of anthocyanins is the most important indicator of maturity and quality in various fruit species [49].
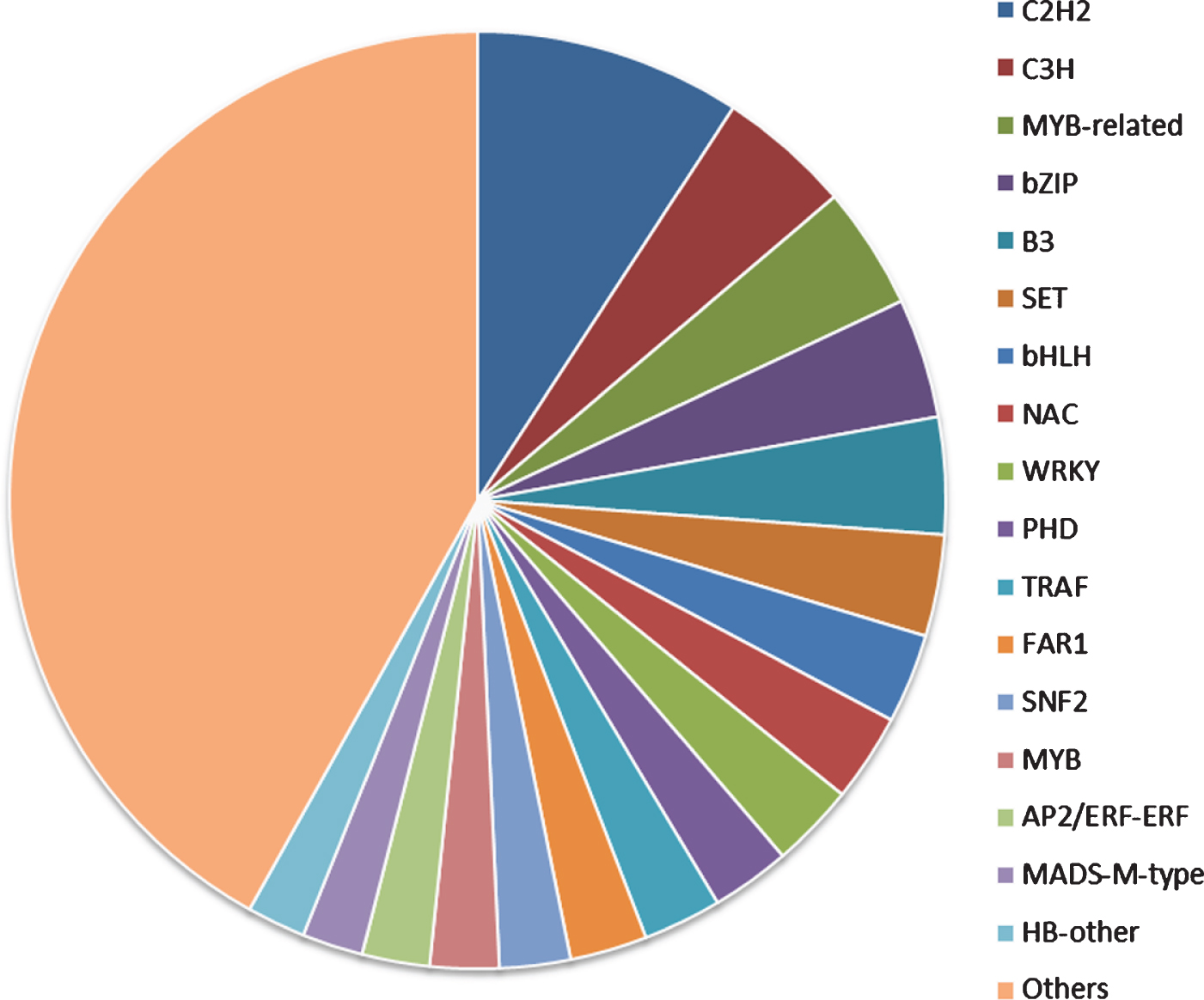
Transcription factor family classification.
To fully explore the genes expression during the red raspberry fruit development, the clean reads from each library were mapped to the reference transcriptome for profiling the expression of unigenes. The DESeq [32] provide statistical routines for determining differential expression in digital gene expression data using a model based on the negative binomial distribution. The resulting p-values were adjusted using the Benjamini and Hochberg’s approach for controlling the false discovery rate. Genes with an adjusted p-value <0.05 found by DESeq were assigned as differentially expressed.
The results are shown in Fig. 7, indicating that 3,369, 3,461 and 441 differentially expressed genes are found in period 2 vs period 1, period 3 vs period 2 and period 4 vs period 3 paired comparisons, respectively. These results suggest that a large number of specific genes are needed to coordinate the complex process at early three developmental stages.
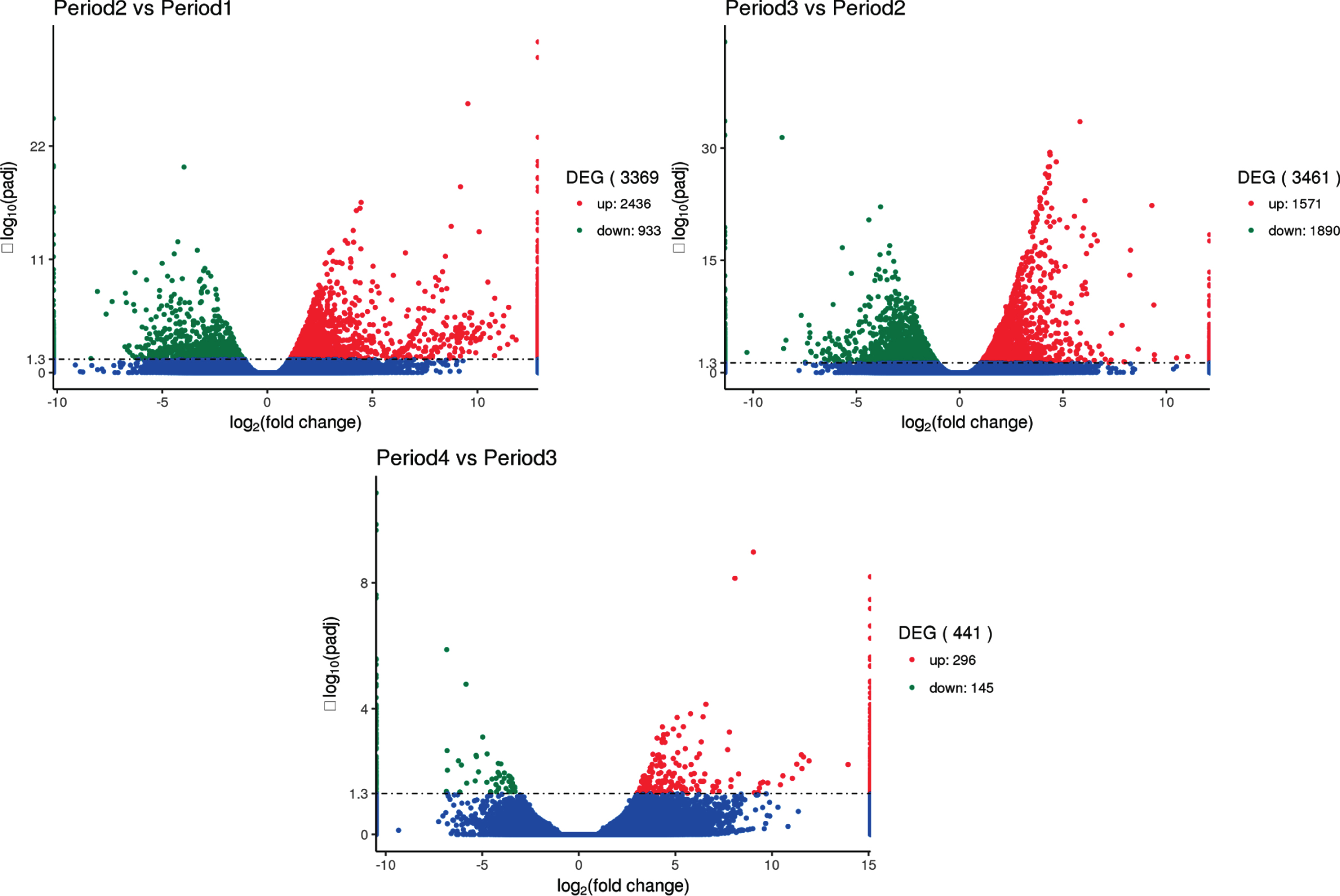
Comparison of transcriptome results to analyze the number of differential genes between groups. The x-axis represents the change in expression fold of the gene in different experimental groups/different samples, and the y-axis represents the statistically significant degree of change in gene expression. The smaller the corrected p value, the larger the -log10 (corrected p value), ie, the difference the more remarkable. The scatter points in the figure represent individual genes, the blue dots indicate genes with no significant differences, the red dots indicate up-regulated genes with significant differences, and the green dots indicate down-regulated genes with significant differences. (The screening conditions for differential genes: padj < 0.05).
Differentially expressed genes were analyzed based on BLASTx. As listed in Fig. 8, these DEGs obtained from comparative transcriptome analysis were mapped to 22 KEGG pathways associating with secondary metabolites during red raspberry development.
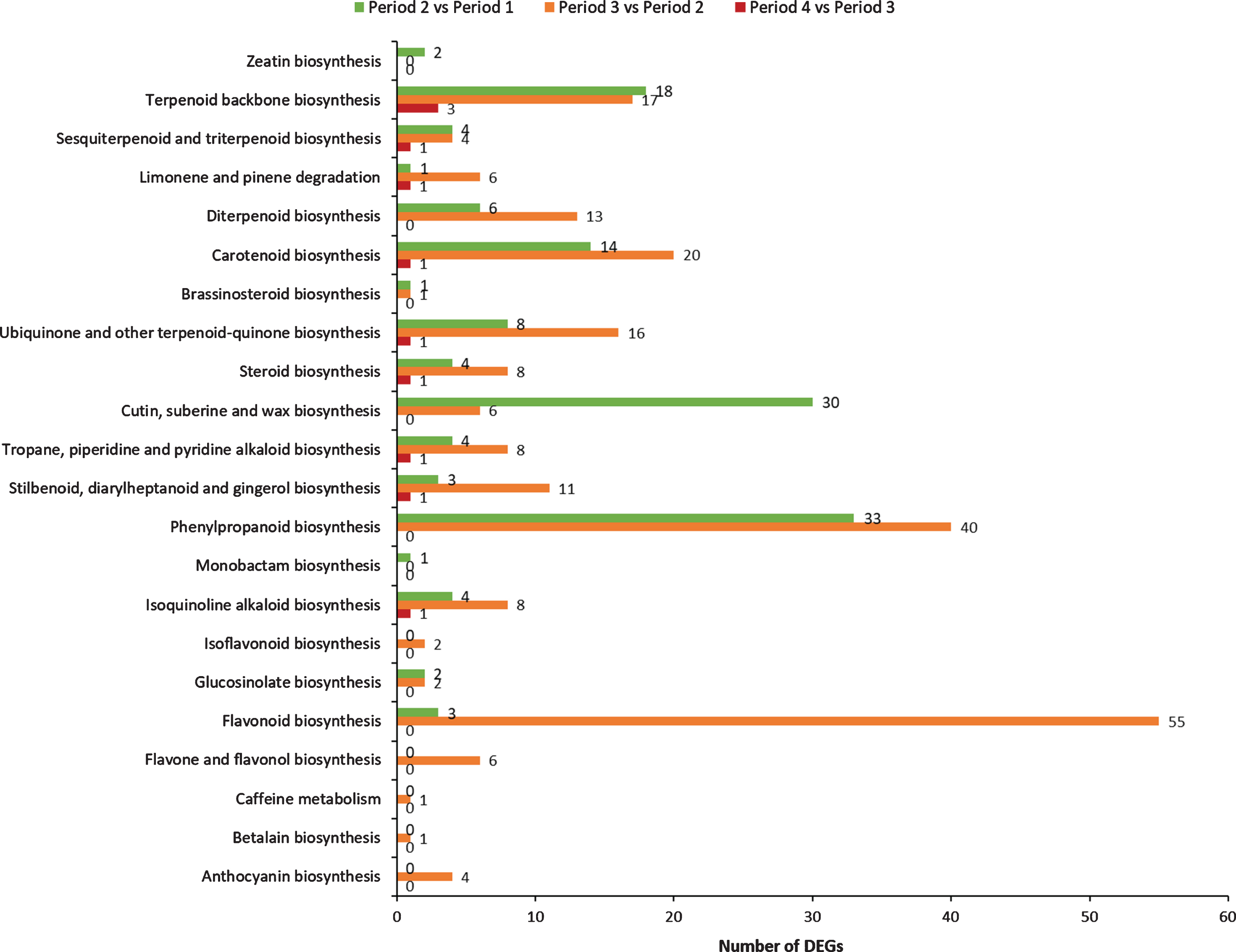
Comparison of secondary metabolic-related KEGG pathways in the preliminary screening analysis between groups.
A total of 17 pathways are identified in period 1 vs period 2 with 138 DEGs, mainly associating with phenylpropanoid biosynthesis (33 DEGs), cutin, suberine and wax biosynthesis (30 DEGs), terpenoid backbone biosynthesis (18 DEGs) and Carotenoid biosynthesis (14 DEGs). In period 2 vs period 3, 20 pathways are identified with 229 DEGs mainly involved in flavonoid biosynthesis (55 DEGs), phenylpropanoid biosynthesis (40 DEGs), carotenoid biosynthesis (20 DEGs), terpenoid backbone biosynthesis (17 DEGs), ubiquinone and other terpenoid-quinone biosynthesis (16 DEGs), diterpenoid biosynthesis (13 DEGs) and stilbenoid, diarylheptanoid and gingerol biosynthesis (11 DEGs). Only 11 DEGs are found involved in 9 pathways in period 3 vs period 4, mainly associating with terpenoid backbone biosynthesis (3 DEGs), carotenoid biosynthesis (1 DEGs), isoquinoline alkaloid biosynthesis (1 DEGs), tropane, piperidine and pyridine alkaloid biosynthesis (1 DEGs).
Obviously, more DEGs and KEGG pathways related to secondary metabolism are occurred in period 2 vs period 3. During this period, the fruit will ripen and turn red with accumulation of important compounds [50]. Modifications in fruit size and color are considered important parameters for the ripening-stage differentiation of the raspberry [51]. These results suggest that the DEGs in period 2 and period 3 play important roles in regulating the fruit development and accumulating the secondary metabolites.
The qRT-PCR experiment was performed to confirm the reliability of the RNA-Seq data using the β-action an internal control (Table 4). Six genes (PEPCK [52–54], GGPPs [55], PSY, CRTISO [56–60], ANS [61, 62] and MVK) involved in secondary metabolism were used as verification targets.
Primer sequence information verified by qRT-PCR
Primer sequence information verified by qRT-PCR
As shown in Fig. 9, the expression patterns of PEPCK (Cluster-8956.73094), GGPPs (Cluster-8956.82650), PSY(Cluster-8956.126929), CRTISO (Clueter-8956.153089), ANS (Cluster-8956.94062), and MVK (Cluster-8956.51344) are well consistent with the results of RNA sequencing, suggesting that the RNA sequencing data are reliable.
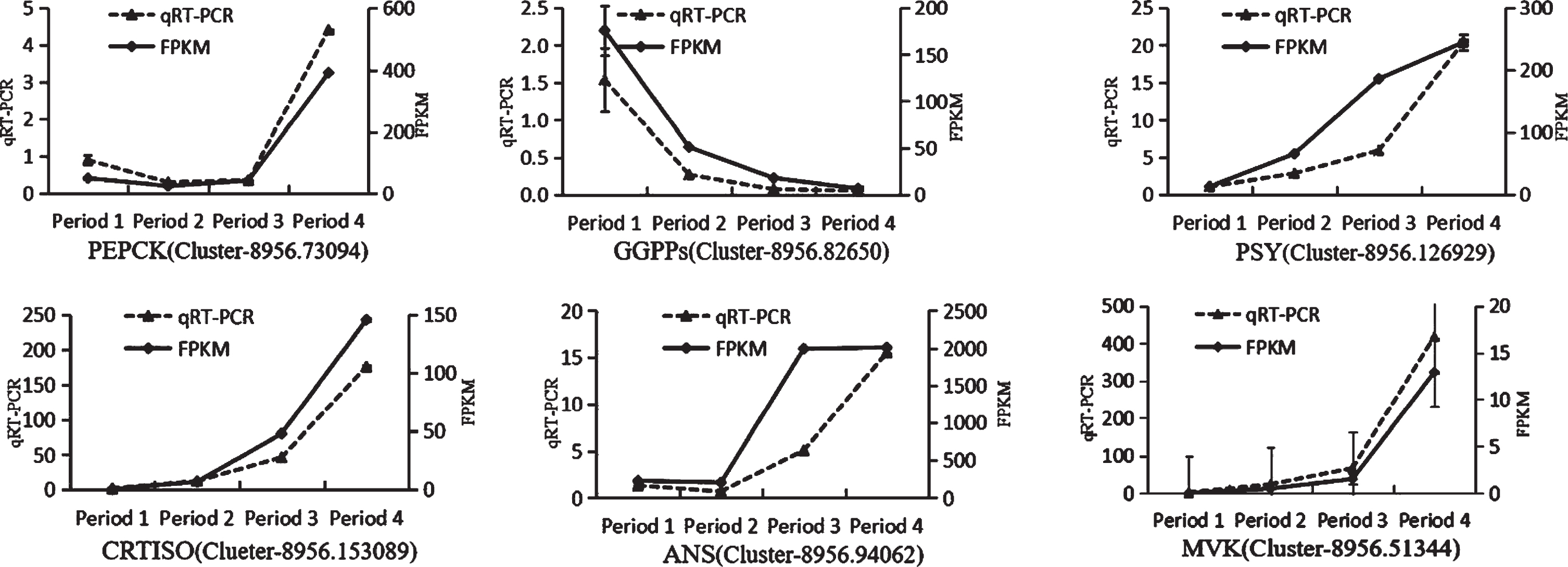
Quantitative real-time polymerase chain reaction analysis of the expression of Secondary metabolism-related genes (Analyses were completed in triplicate, and the error bars represent the standard errors).
Based on Illumina sequencing technology, the large-scale transcriptome sequencing data in red raspberry fruit are generated. The consensus unigenes were also alanalyzed against NR, GO, KOG and KEGG. The expressed genes were determined at different development stages, and these DEGs were mapped to 22 KEGG pathways including anthocyanin biosynthesis, flavonoid biosynthesis, sesquiterpenoid and triterpenoid biosynthesis. These pathways are associating with secondary metabolites during red raspberry development. We predicted that 8331 TFs from the unigenes database and these TFs were classified into 94 different common families. The major families were associated with the C2H2 (9.19%), followed by the C3H (4.60%), MYB-related group (4.23%), bZIP (4.13%) and B3 (4.03%). These results were considered to be involved in the regulation of metabolic and secondary metabolic biosynthesis. This information, together with metabolic profiling, will be of great importance for further studies to identify target genes underlying nutritional quality and engineer high-quality plants with enhanced active ingredients.
Funding
The authors report no funding.
Conflict of interest
The authors have no conflict of interest to report.
Footnotes
Acknowledgments
This work was supported by the Key R & D Plan Project of Hebei Province (19226815D).